Applications d'apprentissage automatique
Les applications d'apprentissage automatique sont une représentation autonome des cas d'utilisation d'apprentissage automatique dans le service de science des données.
Les applications d'apprentissage automatique sont une nouvelle fonctionnalité du service de science des données qui offre une plate-forme MLOps robuste pour la prestation de l'intelligence artificielle et de l'apprentissage automatique. Il normalise l'ensemble et le déploiement des fonctionnalités d'intelligence artificielle et d'apprentissage automatique, ce qui vous permet de créer, de déployer et d'exploiter l'apprentissage automatique en tant que service. Avec les applications d'apprentissage automatique, vous pouvez tirer parti de Data Science pour mettre en œuvre des cas d'utilisation d'intelligence artificielle et d'apprentissage automatique et les provisionner en production pour vos applications ou vos clients. En réduisant le cycle de vie du développement de plusieurs mois à plusieurs semaines, les applications d'apprentissage automatique accélèrent le délai de mise sur le marché tout en réduisant la complexité opérationnelle et le coût total de possession. Il fournit une plate-forme de bout en bout pour le déploiement, la validation et la promotion des solutions d'apprentissage automatique à chaque étape, du développement et de l'assurance qualité à la préproduction et à la production.
Les applications d'apprentissage automatique prennent également en charge une architecture découplée en fournissant une couche d'intégration unifiée entre les capacités d'intelligence artificielle et d'apprentissage automatique et les applications clients. Cela permet le développement, les tests et l'évolution indépendants de solutions d'apprentissage automatique sans nécessiter de modifications de l'application client, ce qui permet une intégration transparente et une innovation plus rapide.
Les applications d'apprentissage automatique sont idéales pour les fournisseurs SaaS, qui doivent provisionner et tenir à jour les fonctionnalités d'apprentissage automatique dans un parc de clients tout en assurant un isolement strict des données et de la charge de travail. Il permet aux fournisseurs SaaS de fournir les mêmes fonctionnalités alimentées par l'apprentissage automatique à de nombreux locataires sans compromettre la sécurité ou l'efficacité opérationnelle. Qu'il s'agisse d'intégrer des informations basées sur l'IA, d'automatiser la prise de décision ou de permettre l'analyse prédictive, les applications d'apprentissage automatique garantissent que chaque client SaaS bénéficie d'un déploiement d'apprentissage automatique entièrement géré et isolé.
Au-delà de SaaS, les applications d'apprentissage automatique sont également idéales pour les déploiements multirégionaux et les organisations qui cherchent à créer un marché d'apprentissage automatique où les fournisseurs peuvent enregistrer, partager et monétiser les solutions d'intelligence artificielle et d'apprentissage automatique. Les clients peuvent instancier et intégrer ces capacités d'apprentissage automatique de façon transparente dans leurs flux de travail avec un minimum d'effort.
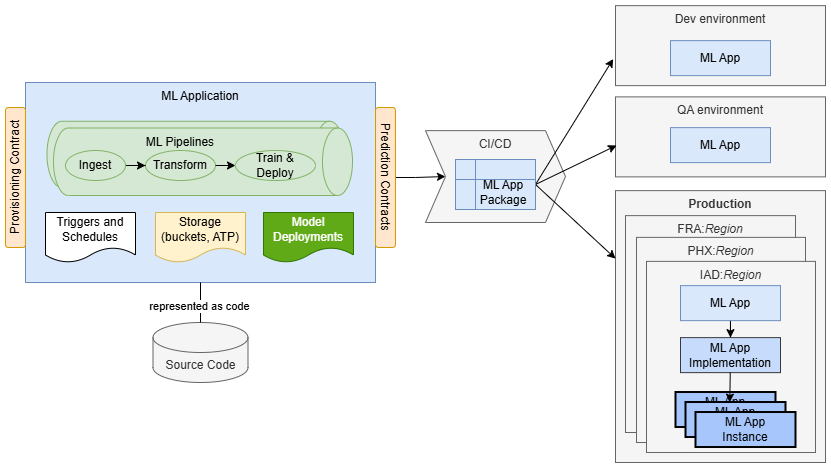
Par exemple, une application d'apprentissage automatique pour un cas d'utilisation de prédiction de perte de client peut comprendre les éléments suivants :
- Un pipeline avec l'ingestion, la transformation et les étapes d'entraînement qui préparent les données d'entraînement, entraînent un nouveau modèle et le déploient.
- un seau utilisé pour stocker les données ingérées et transformées.
- Déclencheur qui sert de point d'entrée et qui garantit l'exécution sécurisée des exécutions de pipeline dans le contexte d'un client SaaS spécifique.
- Programme qui déclenche des exécutions périodiques du pipeline d'entraînement pour maintenir le modèle à jour.
- Déploiement de modèle qui répond aux demandes de prédiction provenant des clients.
Les applications d'apprentissage automatique vous permettent de représenter l'ensemble de l'implémentation en tant que code et de la stocker et de la versionner dans un référentiel de code source. La solution est packagée en tant que package d'application ML qui contient principalement des métadonnées. Les métadonnées comprennent les informations de contrôle des versions, le contrat de provisionnement et les déclarations de dépendances de l'environnement, rendant le package indépendant de la région et de l'environnement. Une fois créé, le package peut être déployé dans n'importe quel environnement cible sans modification. Cela permet de normaliser l'emballage et la livraison de vos fonctionnalités d'apprentissage automatique.
Lorsqu'une application ML est déployée, elle est représentée par les ressources ML Application et ML Application Implementation. À ce stade, il peut être provisionné pour utilisation. En général, une application client (telle qu'une plate-forme SaaS, un système d'entreprise ou un outil d'automatisation de flux de travail) demande au service d'application d'apprentissage automatique de provisionner une nouvelle instance de l'application d'apprentissage automatique pour un client ou une unité opérationnelle spécifique. Ce n'est qu'à ce stade que la solution est entièrement instanciée et prête à l'emploi.
En résumé, les applications d'apprentissage automatique offrent un moyen normalisé de créer, d'emballer et de fournir des fonctionnalités d'apprentissage automatique à grande échelle, réduisant ainsi la complexité et accélérant le temps de production dans divers scénarios, notamment :
- SaaS Adoption de l'IA, où les plateformes SaaS doivent intégrer des capacités d'apprentissage automatique pour des milliers de clients tout en assurant la sécurité, l'évolutivité et l'efficacité opérationnelle.
- Déploiements multirégionaux, où les fonctionnalités d'apprentissage automatique doivent être régulièrement provisionnées dans différents emplacements avec un minimum de frais généraux opérationnels.
- Adoption de l'intelligence artificielle en entreprise, où les entreprises doivent déployer des instances d'apprentissage automatique isolées entre les équipes, les unités d'affaires ou les filiales tout en assurant la gouvernance et la conformité.
- Marchés de l'apprentissage automatique, où les fournisseurs peuvent emballer et distribuer des solutions d'apprentissage automatique, ce qui permet aux clients de les découvrir, de les déployer et de les utiliser facilement en tant que service.
Au-delà de SaaS, les applications d'apprentissage automatique peuvent être utilisées dans d'autres scénarios. Ils sont bénéfiques partout où il existe souvent un besoin de provisionner une solution d'apprentissage automatique, par exemple dans différents emplacements géographiques. En outre, les applications d'apprentissage automatique peuvent être utilisées pour créer un marché où les fournisseurs peuvent enregistrer leurs applications et les offrir en tant que service aux clients, qui peuvent ensuite les instancier et les utiliser.
La fonctionnalité ML Applications elle-même est gratuite. Vous n'êtes facturé que pour l'infrastructure sous-jacente (calcul, stockage et réseau) utilisée, sans majoration supplémentaire.
Ressources d'applications d'apprentissage automatique
- Application d'apprentissage automatique
- Ressource qui représente un cas d'utilisation d'apprentissage automatique et sert de parapluie pour les mises en oeuvre et les instances d'application d'apprentissage automatique. Il définit et représente une solution d'apprentissage automatique, permettant aux fournisseurs de fournir des fonctions d'apprentissage automatique aux consommateurs.
- Mise en oeuvre de l'application d'apprentissage automatique
- Ressource qui représente une solution spécifique pour le cas d'utilisation d'apprentissage automatique défini par une application d'apprentissage automatique. Il contient tous les détails de mise en œuvre qui permettent l'instanciation de la solution pour les consommateurs. Une application d'apprentissage automatique ne peut avoir qu'une seule mise en oeuvre.
- Version de mise en oeuvre d'application d'apprentissage automatique
- Ressource en lecture seule représentant un instantané d'une implémentation d'application ML. La version est créée automatiquement lorsqu'une mise en oeuvre d'application d'apprentissage automatique atteint un nouvel état cohérent.
- Instance d'application d'apprentissage automatique
- Ressource qui représente une instance isolée unique d'une application d'apprentissage automatique permettant aux consommateurs de configurer et d'utiliser la fonctionnalité d'apprentissage automatique fournie. Les instances d'application d'apprentissage automatique jouent un rôle crucial dans la définition des limites pour l'isolement des données, des charges de travail et des modèles. Ce niveau d'isolement est essentiel pour les organisations SaaS, car cela signifie qu'elles peuvent assurer la séparation et la sécurité des ressources de leurs clients.
- Vue d'instance d'application ML
- Ressource en lecture seule, qui est une copie gérée automatiquement de l'instance d'application ML étendue avec des détails supplémentaires tels que des références aux composants d'instance. Il permet aux fournisseurs de suivre la consommation de leurs applications d'apprentissage automatique. Cela signifie que les fournisseurs peuvent observer les détails d'implémentation des instances, les surveiller et les dépanner. Lorsque les consommateurs et les fournisseurs travaillent dans différentes locations, les vues d'instance d'application d'apprentissage automatique sont le seul moyen pour les fournisseurs de recueillir des informations sur la consommation de leurs applications.
Les ressources d'application d'apprentissage automatique sont en lecture seule dans la console OCI. Pour la gestion et la création des ressources, vous pouvez utiliser l'interface de ligne de commande mlapp qui fait partie de l'exemple de projet, de l'interface de ligne de commande oci ou des API de l'application ML.
Concepts relatifs aux applications d'apprentissage automatique
- Ensemble d'applications ML
- Déclencheur d'application d'apprentissage automatique
- Ensemble d'applications ML
- Permet un emballage standardisé des fonctionnalités d'apprentissage automatique, indépendamment de l'environnement et de la région. Il contient des détails de mise en oeuvre, tels que les composants Terraform, les descripteurs et le schéma de configuration. Il s'agit d'une solution portable qui peut être utilisée dans n'importe quelle location, région ou environnement. Les dépendances d'infrastructure de la mise en oeuvre contenue (par exemple, VCN et OCID de journal) propres à une région ou à un environnement sont fournies en tant qu'arguments d'ensemble lors du processus de chargement.
- Déclencheur d'application d'apprentissage automatique
- Les déclencheurs permettent aux fournisseurs d'applications d'apprentissage automatique de spécifier le mécanisme de déclenchement de leurs tâches ou pipelines d'apprentissage automatique, facilitant ainsi la mise en oeuvre de MLOps entièrement automatisé. Les déclencheurs sont les points d'entrée pour les exécutions de vos flux de travail d'apprentissage automatique. Ils sont définis par des fichiers YAML dans le package ML Applications en tant que composants d'instance. Les déclencheurs sont créés automatiquement lorsqu'une nouvelle instance d'application d'apprentissage automatique est créée, mais uniquement lorsque tous les autres composants d'instance sont créés. Ainsi, lorsqu'un déclencheur est créé, il peut faire référence à d'autres composants d'instance créés précédemment.
Rôles d'application d'apprentissage automatique
- Fournisseurs
- Consommateurs
- Fournisseur
- Les fournisseurs sont des clients OCI qui créent, déploient et exécutent des fonctions d'apprentissage automatique. Ils regroupent et déploient des fonctions d'apprentissage automatique en tant qu'applications et mises en oeuvre d'apprentissage automatique. Ils utilisent des applications d'apprentissage automatique pour fournir des services de prédiction de manière as-a-service aux consommateurs. Ils s'assurent que les services de prédiction fournis respectent les contrats de niveau de service (CNS) convenus.
- Client
- Les consommateurs sont des clients OCI qui créent des instances d'application d'apprentissage automatique et utilisent les services de prédiction offerts par ces instances. En général, les consommateurs sont des applications SaaS telles que Fusion. Ils utilisent des applications d'apprentissage automatique pour intégrer les fonctionnalités d'apprentissage automatique et les offrir à leurs clients.
Gestion du cycle de vie
Les applications d'apprentissage automatique couvrent tout le cycle de vie des solutions d'apprentissage automatique.
Cela commence par les premières étapes de conception, où les équipes peuvent s'entendre sur des contrats et peuvent commencer à travailler de manière indépendante. Il comprend le déploiement en production, la gestion du parc et le déploiement de nouvelles versions.
Compilation
- Représentation en tant que code
- L'ensemble de la solution, y compris tous ses composants et flux de travail, est représenté sous forme de code. Cela favorise les meilleures pratiques de développement logiciel telles que la cohérence et la reproductibilité.
- Automatisation
- Avec les applications d'apprentissage automatique, l'automatisation est simple. Vous pouvez vous concentrer sur l'automatisation des flux de travail au sein de la solution à l'aide du programmateur de science des données, des pipelines d'apprentissage automatique et des déclencheurs d'application d'apprentissage automatique. L'automatisation des flux de provisionnement et de configuration est gérée par le service d'application d'apprentissage automatique.
- Emballage standardisé
- Les applications ML fournissent un ensemble indépendant de l'environnement et de la région, notamment des métadonnées pour le contrôle des versions, les dépendances et les configurations de provisionnement.
Déployer
- Déploiement géré par le service
- Vous pouvez déployer et gérer vos solutions d'apprentissage automatique en tant que ressources d'application d'apprentissage automatique. Lorsque vous créez votre ressource de mise en oeuvre d'application d'apprentissage automatique, vous pouvez déployer votre mise en oeuvre en tant qu'ensemble d'application d'apprentissage automatique. Le service d'application d'apprentissage automatique orchestre le déploiement pour vous, en validant votre mise en oeuvre et en créant les ressources OCI correspondantes.
- Environnements
- Les applications d'apprentissage automatique permettent aux fournisseurs de se déployer dans divers environnements de cycle de vie, comme le développement, l'assurance de la qualité et la préproduction, ce qui permet un déploiement contrôlé des applications d'apprentissage automatique vers la production. En production, certaines organisations offrent aux clients plusieurs environnements, tels que "production" et "production". Avec les applications d'apprentissage automatique, de nouvelles versions peuvent être déployées, évaluées et testées dans une " phase intermédiaire " avant d'être promues en " production ". Cela donne aux clients un grand contrôle sur l'adoption des nouvelles versions, y compris les fonctionnalités d'apprentissage automatique.
- Déploiement inter-régions
- Déployer des solutions dans différentes régions, y compris des régions non commerciales telles que les régions gouvernementales.
Exploiter
- Livraison en tant que service
- Les fournisseurs fournissent des services de prédiction " en tant que service " pour l'ensemble de la maintenance et des opérations. Les clients utilisent les services de prédiction, sans voir les détails de mise en oeuvre.
- Surveillance et dépannage
- Surveillance simplifiée, dépannage et analyse des causes fondamentales grâce à un contrôle des versions détaillé, à la traçabilité et à des renseignements contextuels.
- Évolvabilité
- Offrez des itérations, des mises à niveau et des correctifs rapides sans temps d'arrêt, assurant ainsi une amélioration continue et une adaptation aux besoins des clients.
Principales fonctions
Voici quelques caractéristiques clés des applications d'apprentissage automatique :
- Prestation en tant que service
- Les applications ML permettent aux équipes de créer et de fournir des services de prédiction sous la forme SaaS (logiciel-service). Cela signifie que les fournisseurs peuvent gérer et faire évoluer les solutions sans affecter les clients. Les applications ML servent de méta-service, facilitant la création de nouveaux services de prédiction pouvant être consommés et mis à l'échelle en tant qu'offres SaaS.
- OCI natif
- L'intégration transparente aux ressources OCI assure la cohérence et simplifie le déploiement dans les environnements et les régions.
- Emballage standard
- L'emballage indépendant de l'environnement et de la région normalise la mise en œuvre, ce qui facilite le déploiement des applications d'apprentissage automatique à l'échelle mondiale.
- Isolation du locataire
- Assure une isolation complète des données et des charges de travail pour chaque client, améliorant ainsi la sécurité et la conformité.
- Contrôle des versions
- Prend en charge l'évolution des mises en oeuvre avec des processus de version indépendants, ce qui permet des mises à jour et des améliorations rapides.
- Mises à niveau sans temps d'arrêt
- Les mises à niveau d'instance automatisées garantissent un service continu sans interruption.
- Provisionnement interlocation
- Prend en charge l'observabilité interlocation et la consommation sur le marché, élargissant les possibilités de déploiement.
Les applications ML présentent les ressources suivantes :
- Application d'apprentissage automatique
- Mise en oeuvre de l'application d'apprentissage automatique
- Version de mise en oeuvre d'application d'apprentissage automatique
- Instance d'application d'apprentissage automatique
- Vue d'instance d'application ML
Valeur ajoutée
Les applications d'apprentissage automatique servent de plateforme-service (PaaS) et fournissent aux organisations le cadre de base et les services nécessaires pour créer, déployer et gérer des fonctions d'apprentissage automatique à grande échelle.
Cela fournit aux équipes une plate-forme prédéfinie pour la modélisation et le déploiement de cas d'utilisation d'apprentissage automatique, éliminant ainsi le besoin de développer des cadres et des outils personnalisés. Ainsi, les équipes peuvent consacrer leurs efforts à concevoir des solutions d'IA innovantes, réduisant ainsi à la fois le temps de mise sur le marché et le coût total de possession des fonctionnalités d'apprentissage automatique.
Les applications ML offrent aux organisations des API et des abstractions pour superviser l'ensemble du cycle de vie des cas d'utilisation ML. Les mises en oeuvre sont représentées sous forme de code, intégrées dans des ensembles d'applications ML et déployées dans les ressources de mise en oeuvre d'applications ML. Les versions historiques des mises en oeuvre sont suivies en tant que ressources de la version de mise en oeuvre d'application d'apprentissage automatique. Les applications ML sont la colle qui établit la traçabilité entre tous les composants utilisés par les mises en œuvre, le contrôle des versions et les informations sur l'environnement, ainsi que les données de consommation des clients. Grâce aux applications d'apprentissage automatique, les organisations obtiennent des informations précises sur les mises en œuvre d'apprentissage automatique déployées dans tous les environnements et régions, sur les clients qui utilisent des applications spécifiques et sur l'état général du parc d'apprentissage automatique. De plus, les applications ML offrent des capacités de récupération d'instance, permettant une récupération facile à partir des erreurs d'infrastructure et de configuration.
Avec des limites bien définies, les applications d'apprentissage automatique aident à établir des contrats de provisionnement et de prévision, ce qui permet aux équipes de diviser et de conquérir les tâches plus efficacement. Par exemple, les équipes qui travaillent sur le code d'application client (par exemple, une plate-forme SaaS ou un système d'entreprise) peuvent collaborer en toute transparence avec les équipes d'apprentissage automatique en convenant de contrats de prédiction, ce qui permet aux deux équipes de travailler de manière indépendante. De même, les équipes d'apprentissage automatique peuvent définir des contrats d'approvisionnement, ce qui permet aux équipes de gérer les tâches d'approvisionnement et de configuration de manière autonome. Ce découplage élimine les dépendances et accélère les délais de livraison.
Les applications d'apprentissage automatique rationalisent l'évolution des solutions d'apprentissage automatique en automatisant le processus de mise à niveau des versions. Les mises à jour sont entièrement orchestrées par les applications d'apprentissage automatique, ce qui permet d'atténuer les erreurs et d'étendre les solutions à de nombreuses instances (clients). Les responsables de la mise en oeuvre peuvent promouvoir et vérifier les modifications dans une chaîne d'environnements de cycle de vie (par exemple, développement, assurance qualité, préproduction, production), tout en gardant le contrôle sur la transmission des modifications aux clients.
L'isolement des locataires est un avantage clé des applications d'apprentissage automatique, qui assure une séparation complète des données et des charges de travail pour chaque client, améliorant ainsi la sécurité et la conformité. Contrairement aux méthodes traditionnelles basées sur l'isolement basé sur les processus, les applications d'apprentissage automatique permettent aux clients de mettre en oeuvre des restrictions basées sur des privilèges, protégeant l'isolement des locataires même en cas de défectuosité.
Conçues en tenant compte de l'évolutivité, les applications d'apprentissage automatique signifient que les grandes organisations, en particulier les organisations SaaS, peuvent adopter une plateforme normalisée pour le développement de l'apprentissage automatique, assurant ainsi la cohérence entre de nombreuses équipes. Des centaines de solutions de ML peuvent être développées sans que toute l'initiative de ML ne descende dans le chaos. Grâce à l'automatisation couvrant la mise en œuvre de pipelines d'apprentissage automatique, le déploiement de modèles et le provisionnement, les organisations SaaS peuvent industrialiser le développement de fonctions d'apprentissage automatique pour SaaS et gérer efficacement des millions de pipelines et de modèles s'exécutant de manière autonome en production.
Délai de mise sur le marché
- Mise en œuvre normalisée
- Élimine le besoin de cadres personnalisés, permettant aux équipes de se concentrer sur les cas d'utilisation commerciale.
- Automatisation
- Améliore la vitesse et réduit les interventions manuelles, essentielles à la mise à l'échelle des solutions SaaS.
- Séparation des préoccupations
- Éliminer les frontières, les contrats et les API permettent à différentes équipes de travailler de manière indépendante tout en rationalisant le développement et le déploiement.
Coûts de développement et d'exploitation
- Réduction des coûts de développement
- L'utilisation de services prédéfinis réduit le besoin de travail de base.
- Évolvabilité
- Les itérations rapides et les mises à niveau indépendantes sans temps d'arrêt assurent une amélioration continue.
- Traçabilité
- Des informations détaillées sur les environnements, les composants et les révisions de code facilitent la compréhension et la gestion des solutions d'apprentissage automatique.
- Provisionnement et observabilité automatisés
- Simplifie la gestion et la surveillance des solutions d'apprentissage automatique, réduisant ainsi les frais généraux opérationnels.
- Gestion de parc
- Gérer le cycle de vie complet des instances d'application d'apprentissage automatique à grande échelle. Les applications d'apprentissage automatique offrent une visibilité sur toutes les instances provisionnées, prennent en charge les mises à jour et les mises à niveau à l'échelle du parc, et permettent le provisionnement et le déprovisionnement, si nécessaire. En outre, les solutions d'apprentissage automatique conçues avec des applications d'apprentissage automatique peuvent être surveillées à l'aide du service de surveillance OCI pour suivre la performance et l'état.
Sécurité et fiabilité
- Isolement des données et de la charge de travail
- Assure l'isolement sécurisé des données et des charges de travail de chaque client.
- Fiabilité
- Des mises à jour automatisées et une surveillance robuste éliminent les erreurs et assurent des opérations stables.
- Aucun problème de voisin bruyant
- Garantit que les charges de travail n'interfèrent pas entre elles, en maintenant la performance et la stabilité.
Flux de travail de création et de déploiement
Le développement d'applications ML ressemble au développement de logiciels standard.
Les ingénieurs et les spécialistes des données gèrent leur mise en oeuvre dans un référentiel de code source, à l'aide de la documentation des applications d'apprentissage automatique et des référentiels pour obtenir des conseils. Ils commencent généralement par cloner un exemple de projet fourni par l'équipe ML Applications, qui fait la promotion des meilleures pratiques et aide les équipes SaaS à commencer rapidement le développement tout en évitant une courbe d'apprentissage abrupte.
En commençant par un exemple entièrement fonctionnel de bout en bout, les équipes peuvent rapidement créer, déployer et provisionner l'exemple et se familiariser rapidement avec les applications d'apprentissage automatique. Ils peuvent ensuite modifier le code pour ajouter une logique métier spécifique, par exemple ajouter une étape de prétraitement au pipeline d'entraînement ou un code d'entraînement personnalisé.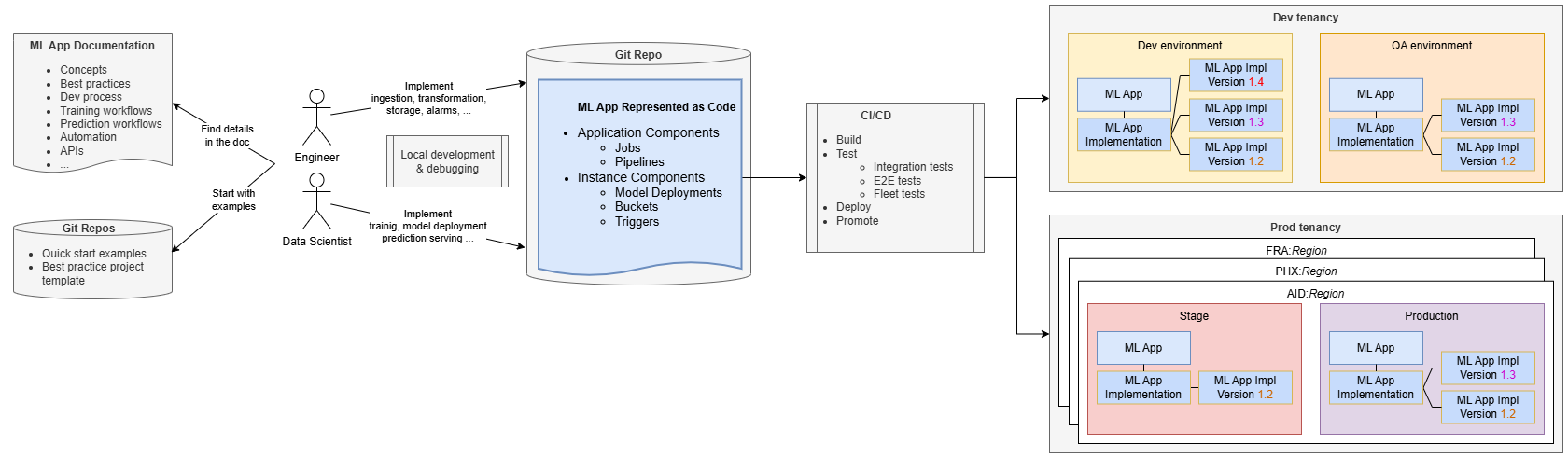
Le développement et les tests peuvent être effectués localement sur leurs ordinateurs, mais la configuration de l'intégration et de la livraison continues (CI/CD) est essentielle pour accélérer les cycles de sortie, améliorer la collaboration et la cohérence. Les équipes peuvent utiliser les exemples et les outils fournis par l'équipe d'application d'apprentissage automatique pour mettre en oeuvre des pipelines d'intégration et de développement en continu.
Les pipelines d'intégration et de développement en continu déploient l'application d'apprentissage automatique dans l'environnement requis (par exemple, Développement) et effectuent des tests d'intégration pour s'assurer que la solution d'apprentissage automatique est correcte indépendamment de l'application SaaS. Ces tests peuvent déployer l'application et son implémentation, créer des instances de test, déclencher le flux d'entraînement et tester le modèle déployé. Les tests de bout en bout garantissent une intégration appropriée à l'application SaaS.
Lorsque votre application d'apprentissage automatique est déployée, elle est représentée en tant que ressource d'application d'apprentissage automatique avec une mise en oeuvre d'application d'apprentissage automatique. La ressource Version de mise en oeuvre de l'application d'apprentissage automatique permet de suivre les informations sur les différentes versions que vous avez déployées. Par exemple, la version 1.3 est la dernière version déployée, qui met à jour la version précédente 1.2.
Les pipelines d'intégration et de développement en continu doivent promouvoir la solution dans les environnements de cycle de vie jusqu'à la production. En production, il est souvent nécessaire de déployer l'application d'apprentissage automatique dans plusieurs régions pour l'aligner sur le déploiement de l'application client. Lorsque les clients disposent de plusieurs environnements de production (par exemple, environnements de préparation et de production), les pipelines d'intégration et de développement en continu doivent promouvoir l'application d'apprentissage automatique dans tous ces environnements.
Vous pouvez utiliser des pipelines d'apprentissage automatique en tant que composants d'application dans vos applications d'apprentissage automatique pour mettre en oeuvre un flux de travail à plusieurs étapes. Les pipelines d'apprentissage automatique peuvent alors orchestrer des étapes ou des tâches arbitraires que vous devez mettre en oeuvre.
Opération de déploiement
L'opération de déploiement implique plusieurs étapes clés pour s'assurer que les applications d'apprentissage automatique sont correctement mises en œuvre et mises à jour dans tous les environnements.
Tout d'abord, il est nécessaire de s'assurer que l'application d'apprentissage automatique et les ressources d'implémentation d'application d'apprentissage automatique existent. Sinon, ils sont créés. S'ils existent déjà, ils sont mis à jour :
- Créez ou mettez à jour la ressource d'application ML. Cela représente l'ensemble du cas d'utilisation de l'apprentissage automatique et toutes les ressources et informations connexes.
- Créez ou mettez à jour la ressource Mise en oeuvre d'application ML. Il existe sous les ressources de l'application d'apprentissage automatique et représente la mise en oeuvre, ce qui vous permet de la gérer. Vous avez besoin de l'implémentation de l'application ML pour déployer votre package d'implémentation.
- Chargez l'ensemble d'applications ML. Cet ensemble contient la mise en oeuvre de votre application d'apprentissage automatique ainsi que d'autres métadonnées, regroupées sous forme d'archive zip avec une structure spécifique.
Lorsqu'un ensemble est chargé dans une ressource de mise en oeuvre d'application d'apprentissage automatique, le service d'application d'apprentissage automatique le valide, puis effectue le déploiement. En le simplifiant, les étapes clés du déploiement du package sont les suivantes :
- Les composants d'application (composants multilocataires) sont instanciés.
- Toutes les ressources existantes d'instance d'application d'apprentissage automatique déjà provisionnées pour les clients SaaS sont mises à jour. Les composants d'instance de chaque instance sont mis à jour pour correspondre aux définitions nouvellement chargées.
Flux de provisionnement
Pour que les instances d'application d'apprentissage automatique puissent être provisionnées, l'application d'apprentissage automatique doit être déployée et enregistrée dans l'application client.
- 1. Vérification de l'abonnement client et de l'application d'apprentissage automatique
- Le flux de provisionnement commence lorsqu'un client s'abonne à l'application client. L'application client vérifie si des applications d'apprentissage automatique sont provisionnées pour le client.
- 2. Demande de provisionnement
- Si des applications d'apprentissage automatique sont nécessaires, l'application client contacte le service d'application d'apprentissage automatique et demande de provisionner une instance, y compris les détails de configuration propres au locataire.
- 3. Création et configuration d'une instance d'application d'apprentissage automatique
- Le service d'application d'apprentissage automatique crée la ressource d'instance d'application d'apprentissage automatique avec la configuration spécifique. Cette ressource est gérée par l'application client, qui peut activer, désactiver, reconfigurer ou supprimer l'instance. En outre, le service d'application d'apprentissage automatique crée une ressource de vue d'instance d'application d'apprentissage automatique pour les fournisseurs afin de les informer de la consommation de l'application d'apprentissage automatique et des composants d'instance. Le service d'application d'apprentissage automatique crée également tous les composants d'instance définis dans la mise en oeuvre, tels que les déclencheurs, les seaux, les exécutions de pipeline, les exécutions de travail et les déploiements de modèle.
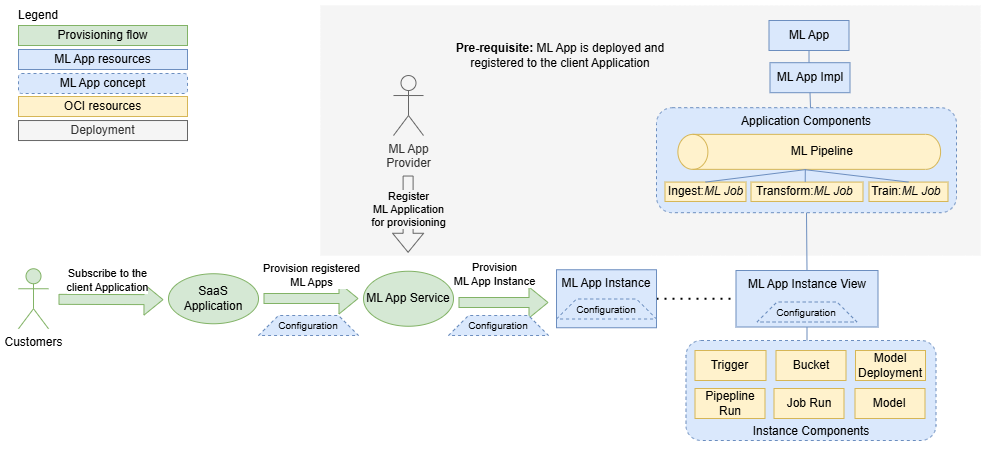
Lorsqu'un nouvel ensemble d'applications d'apprentissage automatique est déployé après la création d'instances, le service d'application d'apprentissage automatique veille à ce que toutes les instances soient mises à jour avec les dernières définitions de mise en oeuvre.
Flux d'exécution
Lorsque votre application d'apprentissage automatique est provisionnée pour un client, toute la mise en oeuvre est entièrement instanciée.
- Composants multilocataires
- Instancié une seule fois au sein d'une application d'apprentissage automatique, prenant en charge tous les clients (par exemple, pipelines d'apprentissage automatique). Ils sont définis en tant que composants d'application.
- Composants à locataire unique
- Instancié pour chaque client, exécuté uniquement dans le contexte d'un client particulier. Ils sont définis en tant que composants d'instance.
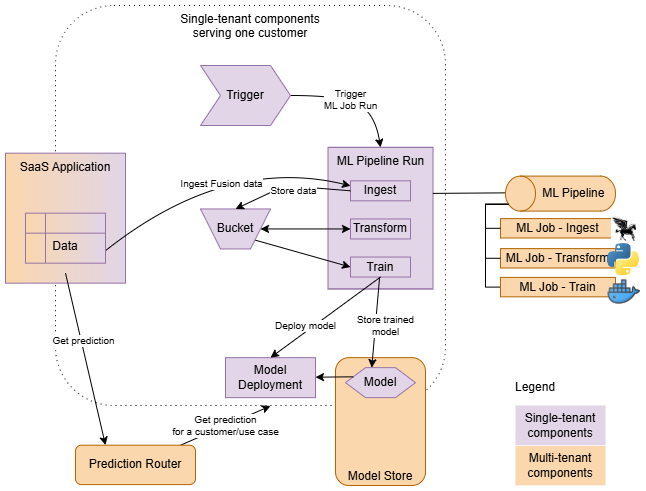
Les pipelines ou les tâches de votre mise en oeuvre sont démarrés par des déclencheurs. Les déclencheurs créent des exécutions de pipeline et de travail dans le contexte de chaque client, en transmettant les paramètres appropriés (contexte) aux exécutions créées. En outre, les déclencheurs sont essentiels pour assurer l'isolement du locataire. Ils s'assurent que le principal de ressource (identité) des ressources d'instance d'application d'apprentissage automatique est hérité par toutes les charges de travail qu'ils démarrent. Vous pouvez ainsi créer des politiques qui établissent un bac à sable de sécurité pour chaque instance provisionnée.
Les pipelines vous permettent de définir un jeu d'étapes et de les orchestrer. Par exemple, un flux type peut impliquer l'ingestion de données à partir de l'application client, leur transformation dans un format adapté à l'entraînement, puis l'entraînement et le déploiement de nouveaux modèles.
Le déploiement de modèle est utilisé comme dorsale de prédiction, mais n'est pas accessible directement par l'application client. L'application client, qui peut être un locataire unique (provisionnée pour chaque client) ou multilocataire (au service de nombreux clients), obtient des prévisions en communiquant avec le routeur de prédiction d'application d'apprentissage automatique. Le routeur de prédiction trouve le serveur dorsal de prédiction correct en fonction de l'instance utilisée et du cas d'utilisation de prédiction mis en oeuvre par votre application.
Exemple de risque fœtal
Examinons les détails de mise en oeuvre d'un exemple d'application d'apprentissage automatique pour comprendre comment en mettre en oeuvre un.
Nous utilisons une application de prédiction du risque foetal qui exploite les données de cardiotocographie (CTG) pour classer l'état de santé d'un fœtus. Cette application vise à aider les professionnels de la santé en prédisant si l'état fœtal est normal, risqué ou anormal sur la base des dossiers d'examen CTG.
Détails de la mise en oeuvre
La mise en oeuvre suit le modèle de prédiction en ligne standard et se compose d'un pipeline avec des étapes d'ingestion, de transformation et d'entraînement et de déploiement de modèle.
-
Ingestion : Cette étape prépare le jeu de données brut et le stocke dans le seau d'instance.
-
Transformation : La préparation des données est effectuée à l'aide de la bibliothèque ADS. Cela implique :
- Upsampling (Upsampling) : Le jeu de données est asymétrique par rapport aux cas normaux. L'échantillonnage ascendant est donc effectué pour équilibrer les classes.
- Ajustement des fonctions : Les fonctions sont mises à l'échelle à l'aide de QuantileTransformer.
- Le jeu de données préparé est ensuite stocké de nouveau dans le seau d'instance.
-
Entraînement et déploiement de modèles : L'algorithme XGBoost est utilisé pour entraîner les modèles en raison de sa précision supérieure par rapport aux autres algorithmes (par exemple, Random Forest, KNN, SVM). La bibliothèque ADS est utilisée pour ce processus et le modèle entraîné est déployé dans le déploiement du modèle d'instance.
La mise en œuvre consiste à :
-
Composants d'application : Le composant principal est le pipeline qui orchestre trois tâches :
- Travail d'ingestion
- Tâche de transformation
- Travail de formation
-
Composants d'instance : Quatre composants d'instance sont définis ici :
- Seau d'instance
- Modèle par défaut
- Modèle de déploiement
- Déclencheur de pipeline
- descriptor.yaml : Contient les métadonnées décrivant la mise en oeuvre (l'ensemble).
-
Composants d'application : Le composant principal est le pipeline qui orchestre trois tâches :
Le code source est disponible dans ce projet.
descriptor.yaml :descriptorSchemaVersion: 1.0
mlApplicationVersion: 1.0
implementationVersion: 1.2
# Package arguments allow you to resolve dependencies of your implementation that are environment-specific.
# Typically, OCIDs of infrastructure resources like subnets, data science projects, logs, etc., are passed as package arguments.
# For illustration purposes, only 2 package arguments are listed here.
packageArguments:
# The implementation needs a subnet, and it is environment-specific. It is provided as a package argument.
subnet_id:
type: ocid
mandatory: true
description: "Subnet OCID for ML Job"
# similarly for the ID of a data science project
data_science_project_id:
type: ocid
mandatory: true
description: "Project OCID for ML Job"
# Configuration schema allows you to define the schema for your instance configuration.
# It will be used during provisioning, and the initial configuration provided must conform to the schema.
configurationSchema:
# The implementation needs to know the name of the external bucket (not managed by ML Apps) where the raw dataset is available.
external_data_source:
type: string
mandatory: true
description: "External Data Source (OCI Object Storage Service URI in form of <a target="_blank" href="oci://">oci://</a><bucket_name>@<namespace>/<object_name>"
sampleValue: "<a target="_blank" href="oci://test_data_fetalrisk@mynamespace/test_data.csv">oci://test_data_fetalrisk@mynamespace/test_data.csv</a>"
# This application provides 1 prediction use case (1 prediction service).
onlinePredictionUseCases:
- name: "fetalrisk"Toutes les ressources OCI utilisées dans votre mise en oeuvre sont définies à l'aide de Terraform. Terraform vous permet de spécifier de manière déclarative les composants nécessaires à votre mise en oeuvre.
# For illustration purposes, only a partial definition is listed here.
resource oci_datascience_job ingestion_job {
compartment_id = var.app_impl.compartment_id
display_name = "Ingestion_ML_Job"
delete_related_job_runs = true
job_infrastructure_configuration_details {
block_storage_size_in_gbs = local.ingestion_job_block_storage_size
job_infrastructure_type = "STANDALONE"
shape_name = local.ingestion_job_shape_name
job_shape_config_details {
memory_in_gbs = 16
ocpus = 4
}
subnet_id = var.app_impl.package_arguments.subnet_id
}
job_artifact = "./src/01-ingestion_job.py"
}resource "oci_objectstorage_bucket" "data_storage_bucket" {
compartment_id = var.compartment_ocid
namespace = var.bucket_namespace
name = "ml-app-fetal-risk-bucket-${var.instance_id}"
access_type = "NoPublicAccess"
}Les composants d'instance font généralement référence à des variables propres à l'instance, telles que l'ID instance. Vous pouvez vous fier aux variables implicites définies par le service d'application ML. Lorsque vous avez besoin, par exemple, du nom de l'application, vous pouvez y faire référence avec ${var.ml_app_name}.
En conclusion, la mise en oeuvre d'applications d'apprentissage automatique nécessite quelques composants clés : un descripteur d'ensemble et quelques définitions Terraform. En suivant la documentation fournie, vous pouvez apprendre comment créer vos propres applications d'apprentissage automatique.