Utilisation de votre propre conteneur
Créer et utiliser un conteneur personnalisé (Utiliser son propre conteneur ou BYOC) en tant que dépendance d'exécution lors de la création d'un déploiement de modèle.
Avec des conteneurs personnalisés, vous pouvez regrouper les dépendances du système et de la langue, installer et configurer des serveurs d'inférence et configurer différents temps d'exécution de la langue. Le tout dans les limites définies d'une interface avec une ressource de déploiement de modèle pour exécuter les conteneurs.
BYOC permet le transfert de conteneurs entre différents environnements afin que vous puissiez migrer et déployer des applications vers le nuage OCI.
Pour exécuter la tâche, vous devez créer un fichier Dockerfile, puis créer une image. Vous commencez par un fichier Dockerfile qui utilise une image Python. Le fichier Dockerfile permet de créer des sous-versions locales et distantes. Utilisez la sous-version locale pour tester localement votre code. Lors du développement local, vous n'avez pas besoin de créer de nouvelle image à chaque modification de code.
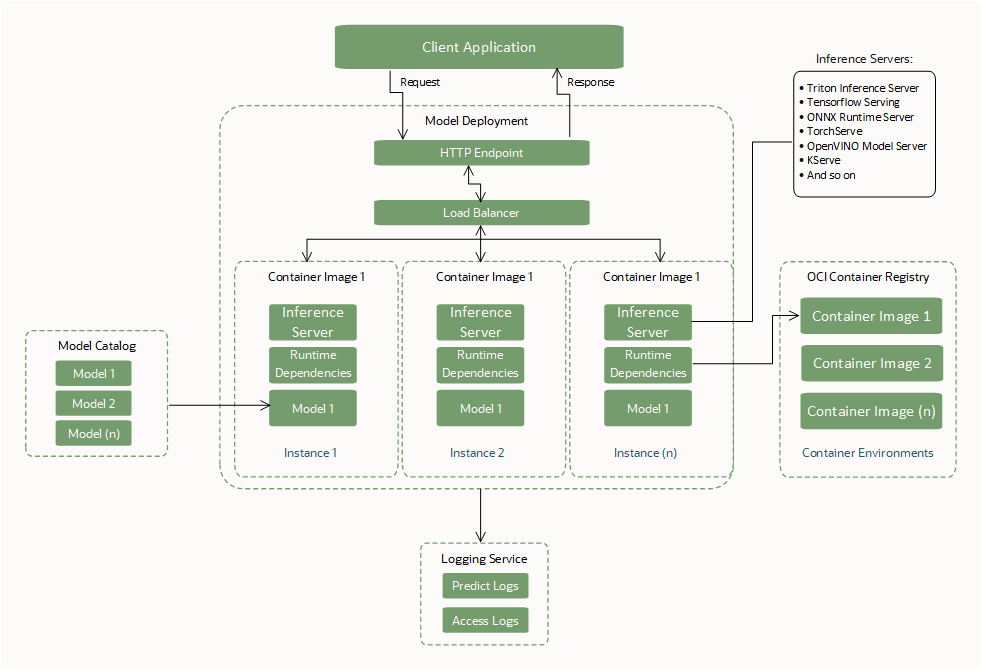
Interfaces requises BYOC
Créez ou spécifiez les interfaces requises pour utiliser un déploiement de modèle.
Artefact de modèle
| Interface | Description |
|---|---|
| Charger les artefacts de modèle dans le catalogue de modèles du service de science des données. | Les artefacts de modèle, tels que la logique de notation, le modèle d'apprentissage automatique et les fichiers dépendants, doivent être chargés dans le catalogue de modèles du service de science des données avant d'être utilisés par une ressource de déploiement de modèle. |
| Aucun fichier obligatoire. |
Aucun fichier n'est obligatoire pour créer un déploiement de modèle BYOC.
Note : Lorsque BYOC n'est pas utilisé pour un déploiement de modèle, les fichiers |
| Emplacement des artefacts de modèle montés. |
Lors des déploiements de modèle d'amorçage, décompressez l'artefact de modèle et montez les fichiers dans le répertoire Zip d'un jeu de fichiers (y compris le modèle d'apprentissage automatique et la logique de notation) ou d'un dossier contenant un jeu de fichiers ont un chemin d'accès différent au modèle d'apprentissage automatique dans le conteneur. Assurez-vous que le chemin correct est utilisé lors du chargement du modèle dans la logique de notation. |
Image de conteneur
| Interface | Description |
|---|---|
| Dépendances d'exécution d'ensemble. | Programmez l'image de conteneur avec les dépendances d'exécution nécessaires pour charger et exécuter le fichier binaire du modèle d'apprentissage automatique. |
| Packagez un serveur Web pour exposer les points d'extrémité. |
Encapsulez l'image de conteneur avec un serveur Web sans état basé sur HTTP (FastAPI, Flask, Triton, service TensorFlow, service PyTorch, etc.). Exposez un point d'extrémité
Note : Les noeuds Si le point d'extrémité de votre serveur d'inférence ne peut pas être personnalisé pour répondre à l'interface de point d'extrémité du service de science des données, utilisez un mandataire (par exemple, NGINX) pour mapper les points d'extrémité requis par le service aux points d'extrémité fournis par votre cadre. |
| Ports exposés. |
Les ports à utiliser pour les points d'extrémité Les ports sont limités entre 1024 et 65535. Les ports 24224, 8446 et 8447 sont exclus. Les ports fournis sont exposés dans le conteneur par le service. Il n'est donc pas nécessaire de les exposer de nouveau dans le fichier Docker. |
| Taille de l'image. | La taille de l'image du conteneur est limitée à 16 Go sous forme non compressée. |
| Accès à l'image. | L'opérateur qui crée le déploiement de modèle doit avoir accès à l'image de conteneur à utiliser. |
| Ensemble Curl. | L'ensemble curl doit être installé dans l'image de conteneur pour que la politique HEALTHCHECK Docker réussisse. Installez la dernière commande curl stable qui n'a aucune vulnérabilité ouverte. |
CMD, Entrypoint
|
Le docker CMD ou Entrypoint doit être fourni au moyen de l'API ou du fichier Docker qui démarre le serveur Web. |
CMD, taille Entrypoint. |
La taille combinée de CMD et Entrypoint ne peut pas être supérieure à 2048 octets. Si la taille est supérieure à 2048 octets, spécifiez les arguments d'application à l'aide de l'artefact de modèle ou utilisez le stockage d'objets pour extraire les données. |
Recommandations générales
| Recommandation | Description |
|---|---|
| Encapsulez le modèle d'apprentissage automatique dans les artefacts de modèle. |
Encapsulez le modèle d'apprentissage automatique en tant qu'artefact et chargez-le dans le catalogue de modèles du service de science des données pour utiliser les fonctions de gouvernance et de contrôle des versions de modèle, bien qu'il existe une option pour encapsuler le modèle d'apprentissage automatique dans l'image de conteneur. Enregistrer le modèle dans le catalogue de modèles. Une fois le modèle chargé dans le catalogue de modèles et référencé lors de la création du déploiement de modèle, le service de science des données télécharge une copie de l'artefact et le décompose dans le répertoire |
| Fournir un condensé d'image et d'image pour toutes les opérations | Nous vous recommandons de fournir l'image et le condensé d'image pour créer, mettre à jour et activer les opérations de déploiement de modèle afin de maintenir la cohérence dans l'utilisation de l'image. Lors d'une opération de mise à jour vers une image différente, l'image et le condensé d'image sont essentiels pour mettre à jour l'image attendue. |
| Balayage de vulnérabilités | Nous recommandons d'utiliser le service de balayage de vulnérabilités OCI pour balayer les vulnérabilités de l'image. |
| Champ d'API nul | Si un champ d'API est vide, ne transmettez pas une chaîne vide, un objet vide ou une liste vide. Transmettez le champ comme nul ou ne le transmettez pas du tout, sauf si vous voulez explicitement le transmettre comme objet vide. |
Meilleures pratiques BYOC
- Le déploiement de modèle prend uniquement en charge l'image de conteneur résidant dans le registre OCI.
- Assurez-vous que l'image de conteneur existe dans le registre OCI tout au long du cycle de vie du déploiement de modèle. L'image doit exister pour garantir la disponibilité si une instance redémarre automatiquement ou si l'équipe de service applique des correctifs.
- Seuls les conteneurs docker sont pris en charge par BYOC.
- Le service de science des données utilise l'artefact de modèle compressé pour apporter la logique de notation du modèle d'apprentissage automatique et s'attend à ce qu'il soit disponible dans le catalogue de modèles du service de science des données.
- La taille de l'image du conteneur est limitée à 16 Go sous forme non compressée.
-
Le service de science des données ajoute une tâche
HEALTHCHECKavant de démarrer le conteneur afin que la politiqueHEALTHCHECKn'ait pas à être ajoutée explicitement dans le fichier Docker, car elle est remplacée. La vérification de l'état commence à s'exécuter 10 minutes après le démarrage du conteneur, puis vérifie/healthtoutes les 30 secondes, avec une temporisation de trois secondes et trois nouvelles tentatives par vérification. - Un ensemble curl doit être installé dans l'image de conteneur pour que la politique
HEALTHCHECKDocker réussisse. - L'utilisateur qui crée la ressource de déploiement de modèle doit avoir accès à l'image de conteneur dans le registre OCI pour pouvoir l'utiliser. Dans le cas contraire, créez une politique IAM d'accès utilisateur avant de créer un déploiement de modèle.
- Le docker
CMDouEntrypointdoit être fourni au moyen de l'API ou du fichier Dockerfile, qui démarre le serveur Web. - La temporisation définie par le service pour l'exécution du conteneur est de 10 minutes. Assurez-vous donc que le conteneur de service d'inférence démarre (est sain) dans cette période.
- Testez toujours le conteneur localement avant de le déployer dans le nuage à l'aide d'un déploiement de modèle.
Condensé d'image Docker
Les images dans un registre Docker sont identifiées par un référentiel, un nom et un marqueur. En outre, Docker attribue un condensé alphanumérique unique à chaque version d'une image. Lors de la transmission d'une image Docker mise à jour, nous recommandons d'affecter un nouveau marqueur à l'image mise à jour pour l'identifier, plutôt que de réutiliser un marqueur existant. Cependant, même si vous poussez une image mise à jour et que vous lui donnez le même nom et le même marqueur que ceux d'une version précédente, la nouvelle version poussée a un condensé différent de la version précédente.
Lorsque vous créez une ressource de déploiement de modèle, spécifiez le nom et le marqueur d'une version particulière d'une image sur laquelle baser le déploiement de modèle. Pour éviter les incohérences, le déploiement de modèle enregistre le condensé unique de cette version de l'image. Vous pouvez également fournir le condensé de l'image lors de la création d'un déploiement de modèle.
Par défaut, lorsque vous poussez une version mise à jour d'une image vers le registre Docker avec le même nom et le même marqueur que la version initiale de l'image sur laquelle le déploiement du modèle est basé, il continue d'utiliser le condensé initial pour extraire la version initiale de l'image. Si vous voulez que le déploiement de modèle utilise la version ultérieure de l'image, modifiez explicitement le nom de l'image avec un marqueur et condensé que le déploiement de modèle utilise pour identifier la version de l'image à extraire.
Pour assurer l'intégrité des images lorsque vous utilisez des condensés, envisagez de signer des images de conteneur. Pour plus d'informations, voir Signature d'images à des fins de sécurité.
Préparer l'artefact de modèle
Créez un fichier zip d'artefact et enregistrez-le avec le modèle dans le catalogue de modèles. L'artefact inclut le code permettant de faire fonctionner le conteneur et d'exécuter les demandes d'inférence.
Le conteneur doit exposer un point d'extrémité /health pour retourner l'état du serveur d'inférence et un point d'extrémité /predict pour l'inférence.
Le fichier Python suivant dans l'artefact de modèle définit ces points d'extrémité à l'aide d'un serveur Flask avec le port 5000 :
# We now need the json library so we can load and export json data
import json
import os
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neural_network import MLPClassifier
import pandas as pd
from joblib import load
from sklearn import preprocessing
import logging
from flask import Flask, request
# Set environnment variables
WORK_DIRECTORY = os.environ["WORK_DIRECTORY"]
TEST_DATA = os.path.join(WORK_DIRECTORY, "test.json")
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE_LDA = os.environ["MODEL_FILE_LDA"]
MODEL_PATH_LDA = os.path.join(MODEL_DIR, MODEL_FILE_LDA)
# Loading LDA model
print("Loading model from: {}".format(MODEL_PATH_LDA))
inference_lda = load(MODEL_PATH_LDA)
# Creation of the Flask app
app = Flask(__name__)
# API 1
# Flask route so that we can serve HTTP traffic on that route
@app.route('/health')
# Get data from json and return the requested row defined by the variable Line
def health():
# We can then find the data for the requested row and send it back as json
return {"status": "success"}
# API 2
# Flask route so that we can serve HTTP traffic on that route
@app.route('/predict',methods=['POST'])
# Return prediction for both Neural Network and LDA inference model with the requested row as input
def prediction():
data = pd.read_json(TEST_DATA)
request_data = request.get_data()
print(request_data)
print(type(request_data))
if isinstance(request_data, bytes):
print("Data is of type bytes")
request_data = request_data.decode("utf-8")
print(request_data)
line = json.loads(request_data)['line']
data_test = data.transpose()
X = data_test.drop(data_test.loc[:, 'Line':'# Letter'].columns, axis = 1)
X_test = X.iloc[int(line),:].values.reshape(1, -1)
clf_lda = load(MODEL_PATH_LDA)
prediction_lda = clf_lda.predict(X_test)
return {'prediction LDA': int(prediction_lda)}
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port = 5000)
Créer le conteneur
Vous pouvez utiliser n'importe quelle image du registre de conteneurs pour OCI. Voici un exemple de fichier Dockerfile qui utilise le serveur Flask :
FROM jupyter/scipy-notebook
USER root
RUN \
apt-get update && \
apt-get -y install curl
ENV WORK_DIRECTORY=/opt/ds/model/deployed_model
ENV MODEL_DIR=$WORK_DIRECTORY/models
RUN mkdir -p $MODEL_DIR
ENV MODEL_FILE_LDA=clf_lda.joblib
COPY requirements.txt /opt/requirements.txt
RUN pip install -r /opt/requirements.txtL'ensemble Curl doit être installé dans l'image de conteneur pour que la politique docker HEALTHCHECK fonctionne.
Créez un fichier requirements.txt avec les ensembles suivants dans le même répertoire que Dockerfile :
flask
flask-restful
joblibExécutez la commande docker build :
docker build -t ml_flask_app_demo:1.0.0 -f Dockerfile .La taille maximale d'une image de conteneur décompressée que vous pouvez utiliser avec les déploiements de modèle est de 16 Go. N'oubliez pas que la taille de l'image de conteneur ralentit le temps de provisionnement pour le déploiement de modèle, car elle est extraite du registre de conteneurs. Nous vous recommandons d'utiliser les plus petites images de conteneur possibles.
Tester le conteneur
Assurez-vous que l'artefact de modèle et le code d'inférence se trouvent dans le même répertoire que le fichier Dockerfile. Exécutez le conteneur sur votre machine locale. Vous devez faire référence aux fichiers stockés sur votre machine locale en montant le répertoire de modèle local sur /opt/ds/model/deployed_model :
docker run -p 5000:5000 \
--health-cmd='curl -f http://localhost:5000/health || exit 1' \
--health-interval=30s \
--health-retries=3 \
--health-timeout=3s \
--health-start-period=1m \
--mount type=bind,src=$(pwd),dst=/opt/ds/model/deployed_model \
ml_flask_app_demo:1.0.0 python /opt/ds/model/deployed_model/api.pyEnvoyez une demande d'état pour vérifier que le conteneur est en cours d'exécution dans les 10 minutes définies par le service :
curl -vf http://localhost:5000/healthTester en envoyant une demande de prédiction :
curl -H "Content-type: application/json" -X POST http://localhost:5000/predict --data '{"line" : "12"}'Pousser le conteneur vers le registre de conteneurs pour OCI
Avant de pouvoir pousser des images vers et depuis Oracle Cloud Infrastructure Registry (également appelé Registre de conteneurs), vous devez avoir un jeton d'autorisation Oracle Cloud Infrastructure. Vous voyez uniquement la chaîne du jeton d'authentification lors de sa création. Copiez-la immédiatement dans un emplacement sécurisé.
- Pour voir les détails dans la console : Dans la barre de navigation, sélectionnez le menu Profil, puis Paramètres de l'utilisateur ou Mon profil, selon l'option que vous voyez.
- Dans la page Jetons d'authentification, sélectionnez Générer un jeton.
- Entrez une description conviviale pour le jeton d'authentification. Évitez d'entrer des informations confidentielles.
- Sélectionnez Générer un jeton. Le nouveau jeton d'authentification s'affiche.
- Copiez immédiatement le jeton d'authentification vers un emplacement sécurisé où vous pourrez l'extraire plus tard. Vous ne verrez plus le jeton d'authentification dans la console.
- Fermez la boîte de dialogue Générer un jeton.
- Ouvrez une fenêtre de terminal sur votre ordinateur local.
- Connectez-vous au registre de conteneurs pour pouvoir créer, exécuter, tester, marquer et pousser l'image du conteneur.
docker login -u '<tenant-namespace>/<username>' <region>.ocir.io -
Marquez l'image de conteneur local :
docker tag <local_image_name>:<local_version> <region>.ocir.io/<tenancy_ocir_namespace>/<repository>:<version> -
Poussez l'image de conteneur :
docker push <region>.ocir.io/<tenancy>/byoc:1.0Note
Assurez-vous que la ressource de déploiement de modèle comporte une politique pour le principal de ressource afin qu'elle puisse lire l'image à partir du registre OCI à partir du compartiment dans lequel vous avez stocké l'image. Pour plus d'informations, voir Accéder au déploiement de modèle à un conteneur personnalisé à l'aide d'un principal de ressource
Note
(Signature d'image) : Avant le déploiement, suivez le processus de signature d'image et enregistrez l'OCID de la signature d'image pour la vérification et la vérification. Pour plus de détails, voir la section Signature de l'image sous Diffusions d'images Docker.Note
(Exigence d'accès à la chambre forte) : L'utilisateur qui crée le déploiement de modèle doit avoir au moins un accès de niveauUSEaux clés de chambre forte et aux ressources de la famille de clés secrètes dans le service de chambre forte. Pour plus d'informations, voir Informations détaillées sur le service de chambre forte.
Vous êtes prêt à utiliser cette image de conteneur avec l'option BYOC lorsque vous créez un déploiement de modèle.
Les déploiements de modèle BYOC ne prennent pas en charge l'extraction d'image de conteneur inter-région. Par exemple, lors de l'exécution d'un déploiement de modèle BYOC dans une région IAD (Ashburn), vous ne pouvez pas extraire des images de conteneur de l'OCIR (Oracle Cloud Container Registry) de la région PHX (Phoenix).
Comportement de l'opération de mise à jour BYOC
Les opérations de mise à jour BYOC sont des mises à jour partielles de type fusion superficielles.
Un champ de niveau supérieur accessible en écriture doit être complètement remplacé lorsqu'il apparaît défini dans le contenu de la demande et conservé autrement inchangé. Par exemple, pour une ressource telle que :
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 5454,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {
"a": "b",
"c": "d",
"e": "f"
},
"entrypoint": [ "python", "-m", "uvicorn", "a/model/server:app", "--port", "5000","--host","0.0.0.0"]
"cmd": ["param1"]
}Mise à jour réussie avec les éléments suivants :
{
"environmentConfigurationDetails": {
"serverPort": 2000,
"environmentVariables": {"x":"y"},
"entrypoint": []
}
}Résultats dans un état où serverPort et environmentVariables sont remplacés par le contenu de la mise à jour (y compris la destruction des données précédemment présentes dans des champs profonds absents du contenu de la mise à jour). La valeur image est conservée inchangée car elle n'apparaissait pas dans le contenu de la mise à jour et la valeur entrypoint est effacée par une liste vide explicite :
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 2000,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {"x": "y"},
"entrypoint": []
"cmd": ["param1"]
}Le champ
imageSignatureId est facultatif.Une mise à jour réussie à l'aide de { "environmentConfigurationDetails": null or {} } n'entraîne aucun remplacement. Un remplacement complet au niveau supérieur efface toutes les valeurs qui ne sont pas présentes dans le contenu de la demande afin d'éviter cela. Tous les champs sont facultatifs dans l'objet de mise à jour, de sorte que si vous ne fournissez pas l'image, elle ne doit pas annuler la définition de l'image dans le déploiement. Le service de science des données ne remplace les champs de deuxième niveau que s'ils ne sont pas nuls.
Ne pas définir de champ dans l'objet de demande (transmission d'une valeur nulle) signifie que le service de science des données ne tiendra pas compte de ce champ pour rechercher la différence et le remplacer par la valeur de champ existante.
Pour réinitialiser une valeur d'un champ, transmettez un objet vide. Pour les champs de type liste et mappage, le service de science des données peut accepter une liste vide ([]) ou un mappage ({}) comme indication pour effacer les valeurs. Dans tous les cas, null ne signifie pas effacer les valeurs. Cependant, vous pouvez toujours changer la valeur pour quelque chose d'autre. Pour utiliser un port par défaut et annuler la définition de la valeur du champ, définissez explicitement le port par défaut.
La mise à jour de la liste et des champs de mappage est un remplacement complet. Le service de science des données ne recherche pas les valeurs individuelles dans les objets.
Pour l'image et le condensé, le service de science des données ne vous permet pas d'effacer la valeur.
Déployer avec un conteneur de serveur d'inférence Triton
Le serveur d'inférence Triton de NVIDIA rationalise et normalise l'inférence d'IA en permettant aux équipes de déployer, d'exécuter et d'adapter des modèles d'IA formés à partir de n'importe quel cadre sur n'importe quel processeur graphique ou infrastructure basée sur l'UC.
Quelques caractéristiques clés de Triton sont :
- Exécution simultanée de modèles : Possibilité de servir plusieurs modèles d'apprentissage automatique simultanément. Cette fonctionnalité est utile lorsque plusieurs modèles doivent être déployés et gérés ensemble dans un seul système.
- Lotage dynamique : Activation du serveur pour regrouper dynamiquement les demandes en fonction de la charge de travail afin d'améliorer la performance.
Le déploiement de modèle prend en charge le serveur d'inférence Triton NVIDIA. Vous pouvez déployer une image Triton existante à partir du catalogue de conteneurs de NVIDIA et le déploiement de modèle garantit que les interfaces Triton correspondent sans avoir à modifier quoi que ce soit dans le conteneur à l'aide de la variable d'environnement suivante lors de la création du déploiement de modèle :
CONTAINER_TYPE = TRITONUn exemple complet documenté sur le déploiement des modèles ONNX dans Triton est disponible dans le référentiel GitHub du déploiement des modèles du service de science des données.