Pipelines
Un pipeline d'apprentissage automatique (ML) du service de science des données est une ressource qui définit un flux de travail de tâches, appelé étapes.
L'apprentissage automatique est souvent un processus complexe, impliquant plusieurs étapes de travail ensemble dans un flux de travail, pour créer et servir un modèle d'apprentissage automatique. Ces étapes comprennent généralement l'acquisition et l'extraction de données, la préparation des données pour l'apprentissage automatique, la featurisation, l'entraînement d'un modèle (y compris la sélection d'algorithmes et le réglage des hyperparamètres), l'évaluation du modèle et le déploiement du modèle.
Les étapes de pipeline peuvent avoir des dépendances avec d'autres étapes pour créer le flux de travail. Chaque étape est discrète, ce qui vous donne la flexibilité de mélanger différents environnements et même différents langages de codage dans le même pipeline.
Un pipeline typique (flux de travail) comprend les étapes suivantes :
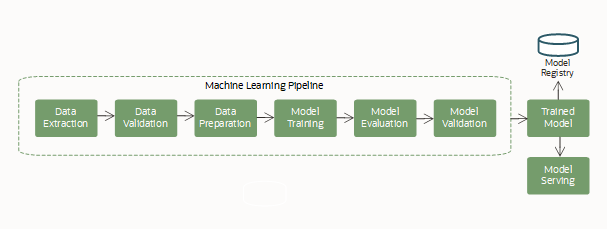
Ce cycle de vie d'apprentissage automatique s'exécute en tant que pipeline d'apprentissage automatique reproductible et continu.
Concepts relatifs aux opportunités
Un pipeline peut ressembler au flux de travail suivant :
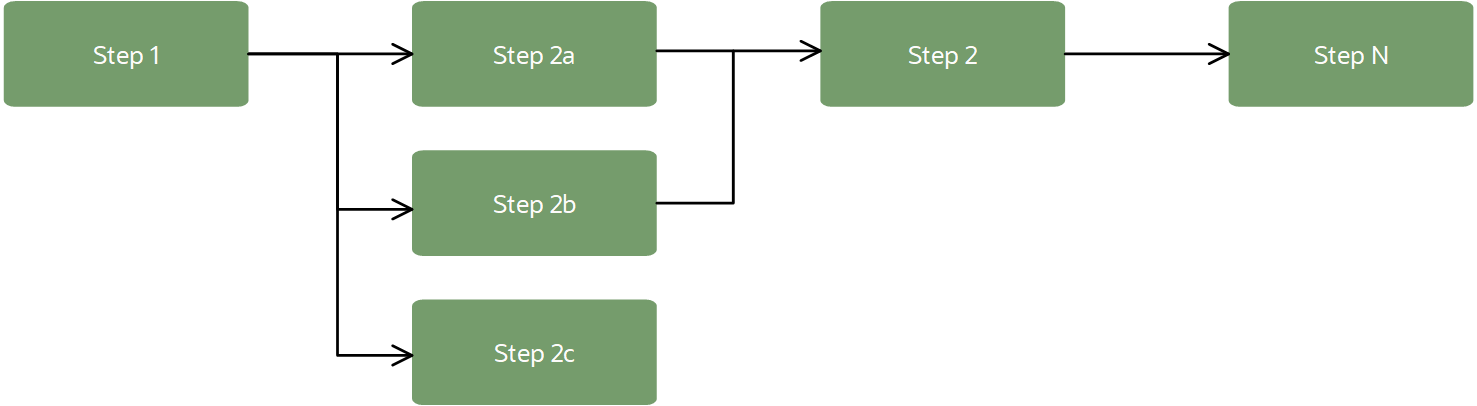
Dans un contexte d'apprentissage automatique, les pipelines fournissent généralement un flux de travail pour l'importation de données, la transformation de données, l'entraînement de modèle et l'évaluation de modèle. Les étapes du pipeline peuvent être exécutées en séquence ou en parallèle, à condition qu'elles créent un graphe acyclique dirigé (DAG).
- Pipeline
-
Ressource qui contient toutes les étapes et leurs dépendances (flux de travail DAG). Vous pouvez définir des configurations par défaut pour l'infrastructure, les journaux et d'autres paramètres à utiliser dans les ressources de pipeline. Ces paramètres par défaut sont utilisés lorsqu'ils ne sont pas définis dans les étapes du pipeline.
Vous pouvez également modifier une partie de la configuration du pipeline après sa création, par exemple le nom, le journal et les variables d'environnement personnalisées.
- Étape de pipeline
-
Tâche à exécuter dans un pipeline. L'étape contient l'artefact d'étape, l'infrastructure (forme de calcul, volume par blocs) à utiliser lors de l'exécution, les paramètres de journal, les variables d'environnement, etc.
Une étape de pipeline peut être de l'un des types suivants :
- Un script (fichiers de code). Python, Bash et Java sont pris en charge et une configuration pour l'exécuter.
-
Tâche existante du service de science des données identifiée par son OCID.
- Artificiel d'étape
-
Obligatoire lors de l'utilisation d'un type d'étape de script. Un artefact est tout le code à utiliser pour exécuter l'étape. L'artefact lui-même doit être un seul fichier. Cependant, il peut s'agir d'un fichier compressé (zip) qui inclut plusieurs fichiers. Vous pouvez définir le fichier spécifique à exécuter lors de l'exécution de l'étape.
Toutes les étapes de script d'un pipeline doivent avoir un artefact pour que le pipeline soit à l'état ACTIF afin qu'il puisse être exécuté.
- DAG
-
Flux de travail des étapes, défini par les dépendances de chaque étape sur les autres étapes du pipeline. Les dépendances créent un flux de travail logique ou un graphique (doit être acyclique). Le pipeline s'efforce d'exécuter des étapes en parallèle pour optimiser le temps d'achèvement du pipeline, sauf si les dépendances forcent les étapes à s'exécuter séquentiellement. Par exemple, l'entraînement doit être terminé avant d'évaluer le modèle, mais plusieurs modèles peuvent être entraînés en parallèle pour rivaliser avec le meilleur modèle.
- Exécution de pipeline
-
Instance d'exécution d'un pipeline. Chaque exécution de pipeline comprend ses exécutions d'étape. Une exécution de pipeline peut être configurée pour remplacer certaines des valeurs par défaut du pipeline avant de démarrer l'exécution.
- Exécution d'étape de pipeline
-
Instance d'exécution d'une étape de pipeline. La configuration de l'exécution d'étape provient de l'exécution du pipeline en premier lorsqu'elle est définie, ou de la définition du pipeline en second lieu.
- État du cycle de vie de l'ensemble d'opportunités
-
Au fur et à mesure que le pipeline est créé, construit et même supprimé, il peut se trouver dans différents états. Après la création du pipeline, celui-ci est à l'état Création et ne peut pas être exécuté tant que toutes les étapes n'ont pas un artefact ou une tâche à exécuter, puis le pipeline passe à l'état Actif.
- Accès aux ressources OCI
-
Les étapes de pipeline peuvent accéder à toutes les ressources OCI d'une location, à condition qu'une politique l'autorise. Vous pouvez exécuter des pipelines sur des données dans ADW ou dans le service de stockage d'objets. Vous pouvez également utiliser des chambres fortes pour fournir un moyen d'authentification sécurisé auprès de ressources tierces. Les étapes de pipeline peuvent accéder à des sources externes si vous avez configuré le VCN approprié.