Configuration d'Apache Hue pour utiliser différents composants Hadoop
-
Sur le noeud maître ou utilitaire, dans le répertoire suivant, utilisez les fichiers JAR liés à Spark et ajoutez-les en tant que dépendances à votre projet Spark. Par exemple, copiez les fichiers JAR spark-core et spark-sql dans lib/ pour le projet SBT.
/usr/lib/oozie/share/lib/spark/spark-sql_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar /usr/lib/oozie/share/lib/spark/spark-core_2.12-3.0.2.odh.1.0.ce4f70b73b6.jarVoici un exemple de code de décompte de mots. Assemblez le code dans le fichier JAR :
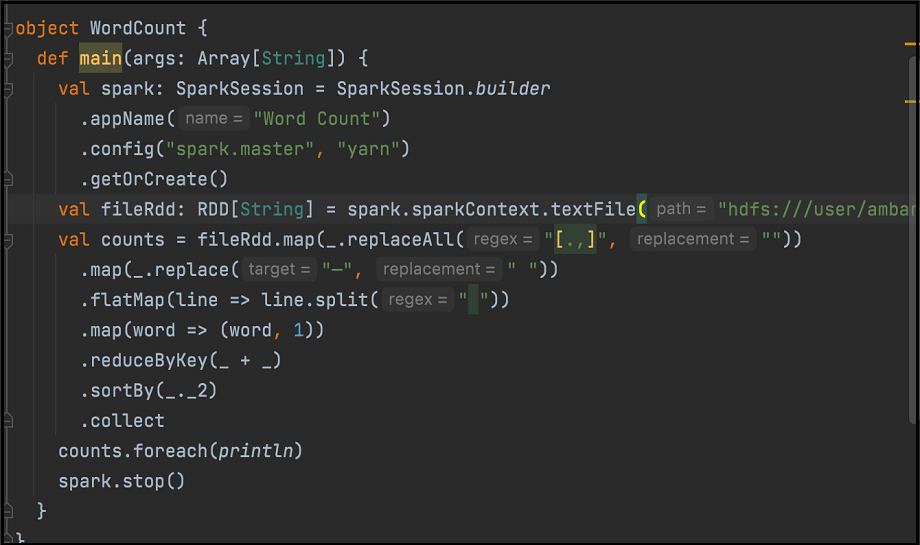
Sur l'interface Hue Spark, utilisez les fichiers JAR appropriés pour exécuter le travail Spark.
-
Pour exécuter MapReduce via Oozie, procédez comme suit :
- Copiez
oozie-sharelib-oozie-5.2.0.jar(contient la classe OozieActionConfigurator) dans votre exemple de code. - Définissez les classes de correspondance et de réduction comme dans n'importe quel exemple standard de nombre de mots MapReduce.
- Créez une autre classe comme indiqué ici :
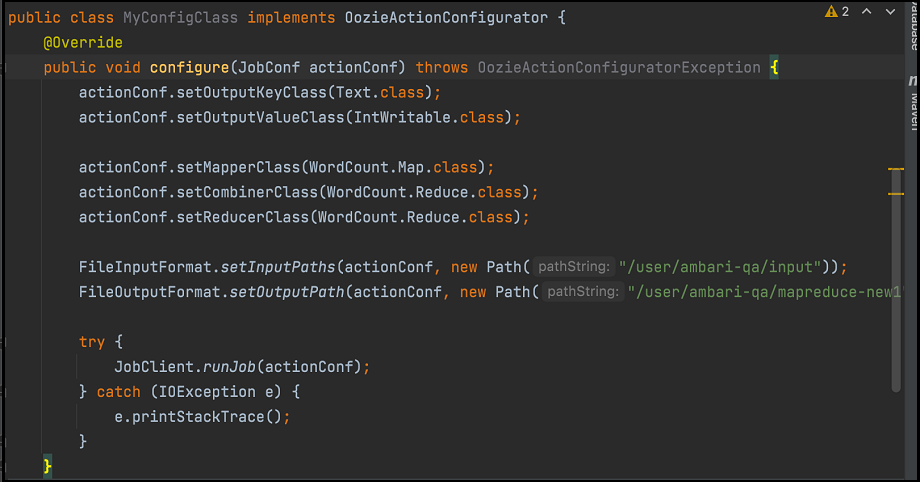 Packagez le code comme dans l'image précédente, ainsi que les classes de correspondance et de réduction dans un fichier JAR, et procédez comme suit :
Packagez le code comme dans l'image précédente, ainsi que les classes de correspondance et de réduction dans un fichier JAR, et procédez comme suit :- Téléchargez-le vers HDFS via le navigateur de fichiers Hue.
- Indiquez ce qui suit pour exécuter le programme MapReduce, où
oozie.action.config.classpointe vers le nom de classe qualifié complet dans le fragment de code, comme le montre l'image précédente.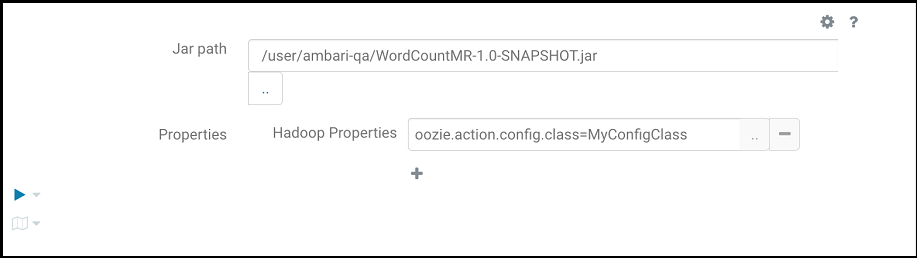
- Copiez
-
Configurez HBase.
Dans les clusters Big Data Service avec la version 3.0.7 ou ultérieure, vous devez activer le module Hue HBase à l'aide d'Apache Ambari.
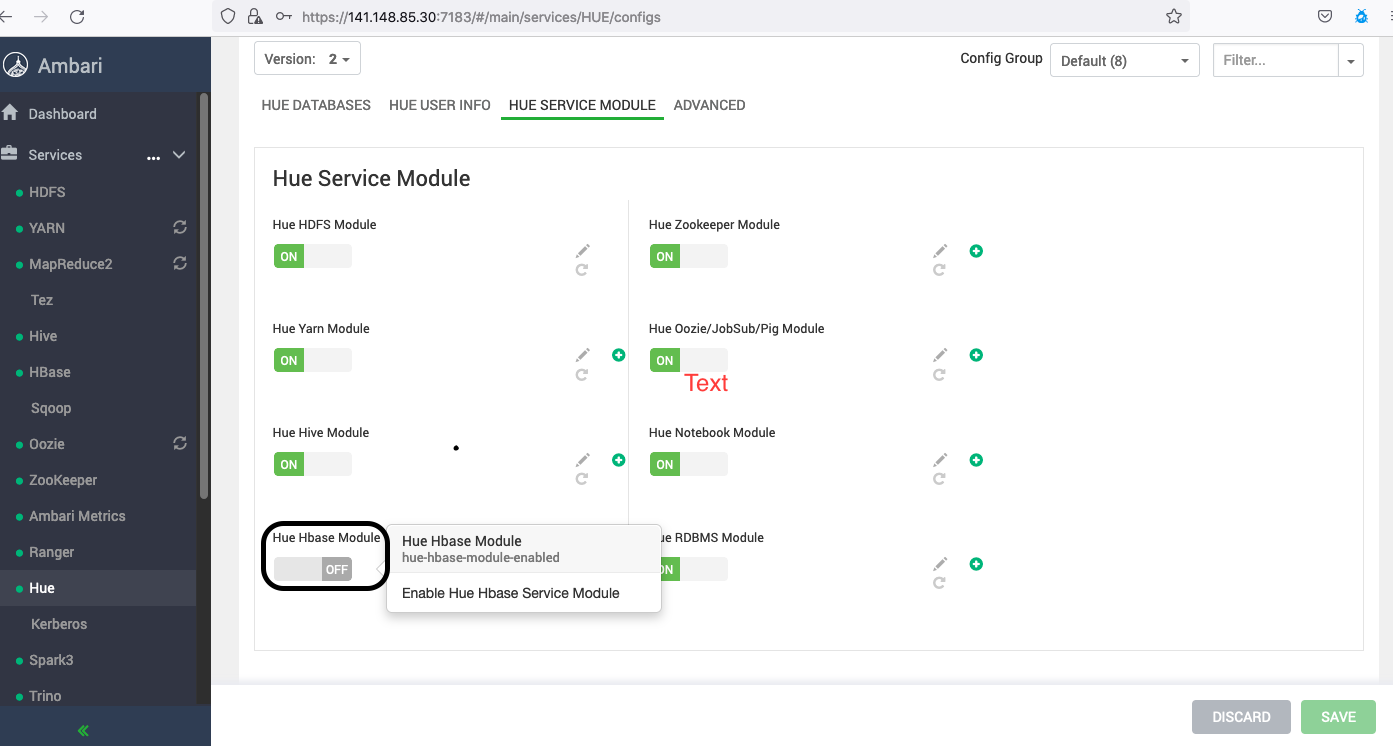
Hue interagit avec le serveur Thrift HBase. Par conséquent, pour accéder à HBase, vous devez démarrer le serveur Thrift. Suivez les étapes suivantes :
- Une fois le service HBase ajouté sur la page Ambari, accédez à Custom Hbase-Site.xml (dans HBase, accédez à Configurations et, sous Avancé, sélectionnez Custom Hbase-Site.xml).
- Ajoutez les paramètres suivants en remplaçant le fichier keytab ou le principal.
hbase.thrift.support.proxyuser=true hbase.regionserver.thrift.http=true ##Skip the below configs if this is a non-secure cluster hbase.thrift.security.qop=auth hbase.thrift.keytab.file=/etc/security/keytabs/hbase.service.keytab hbase.thrift.kerberos.principal=hbase/_HOST@BDSCLOUDSERVICE.ORACLE.COM hbase.security.authentication.spnego.kerberos.keytab=/etc/security/keytabs/spnego.service.keytab hbase.security.authentication.spnego.kerberos.principal=HTTP/_HOST@BDSCLOUDSERVICE.ORACLE.COM - Exécutez les commandes suivantes sur le terminal des noeuds maîtres :
# sudo su hbase //skip kinit command if this is a non-secure cluster # kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/<master_node_host>@BDSCLOUDSERVICE.ORACLE.COM # hbase thrift start - Connectez-vous au noeud de l'utilitaire sur lequel Hue est installé.
- Ouvrez le fichier
sudo vim /etc/hue//conf/pseudo-distributed.iniet enlevez hbase deapp_blacklist.# Comma separated list of apps to not load at startup. # e.g.: pig, zookeeper app_blacklist=search, security, impala, hbase, pig - Redémarrez Hue depuis Ambari.
- Ranger régit l'accès au service HBase. Par conséquent, pour utiliser Hue et accéder aux tables HBase sur un cluster sécurisé, vous devez avoir accès au service HBase à partir de Ranger.