Exécution d'une application avec l'éditeur de code
Dans la console, vous pouvez utiliser l'éditeur de code pour exécuter une application Data Flow.
Vous devez avoir créé le fichier
configpour l'authentification utilisateur, comme décrit dans Utilisation de l'éditeur de code.-
Sélectionnez le logo Oracle O.
La liste des modules d'extension disponibles s'affiche.
-
Cliquez avec le bouton droit de la souris sur le projet à exécuter et sélectionnez Exécuter localement.
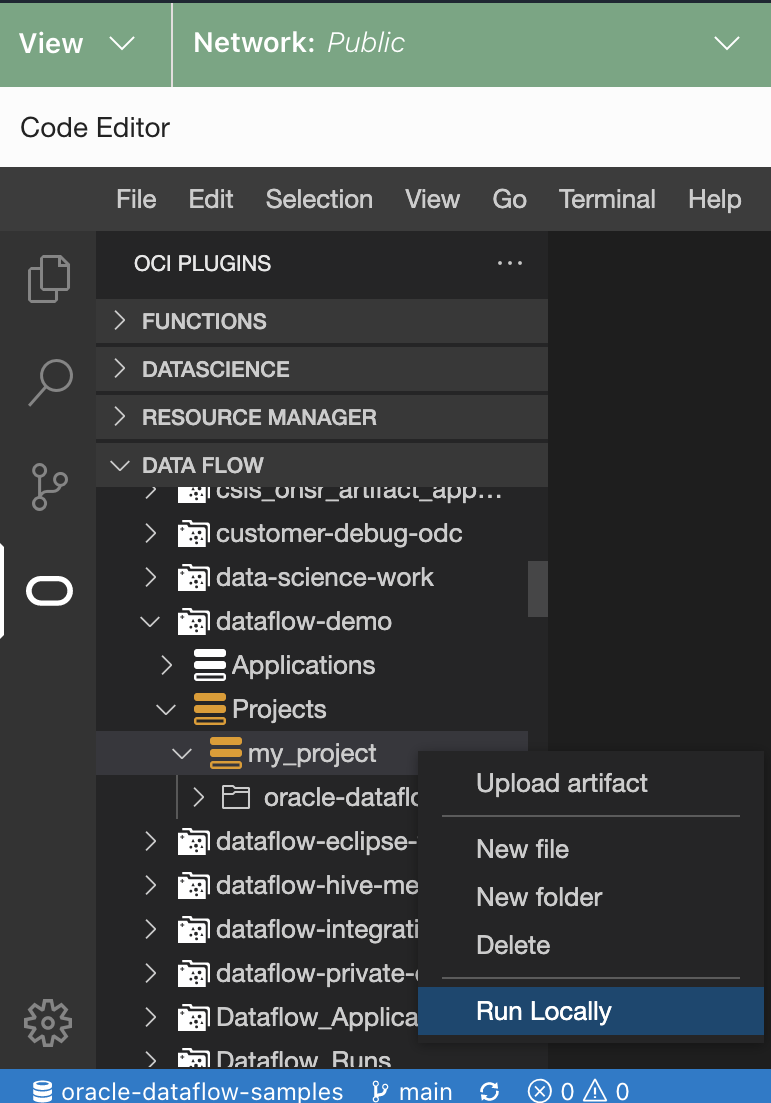 La fenêtre Run Application (Exécuter l'application) s'ouvre.
La fenêtre Run Application (Exécuter l'application) s'ouvre. -
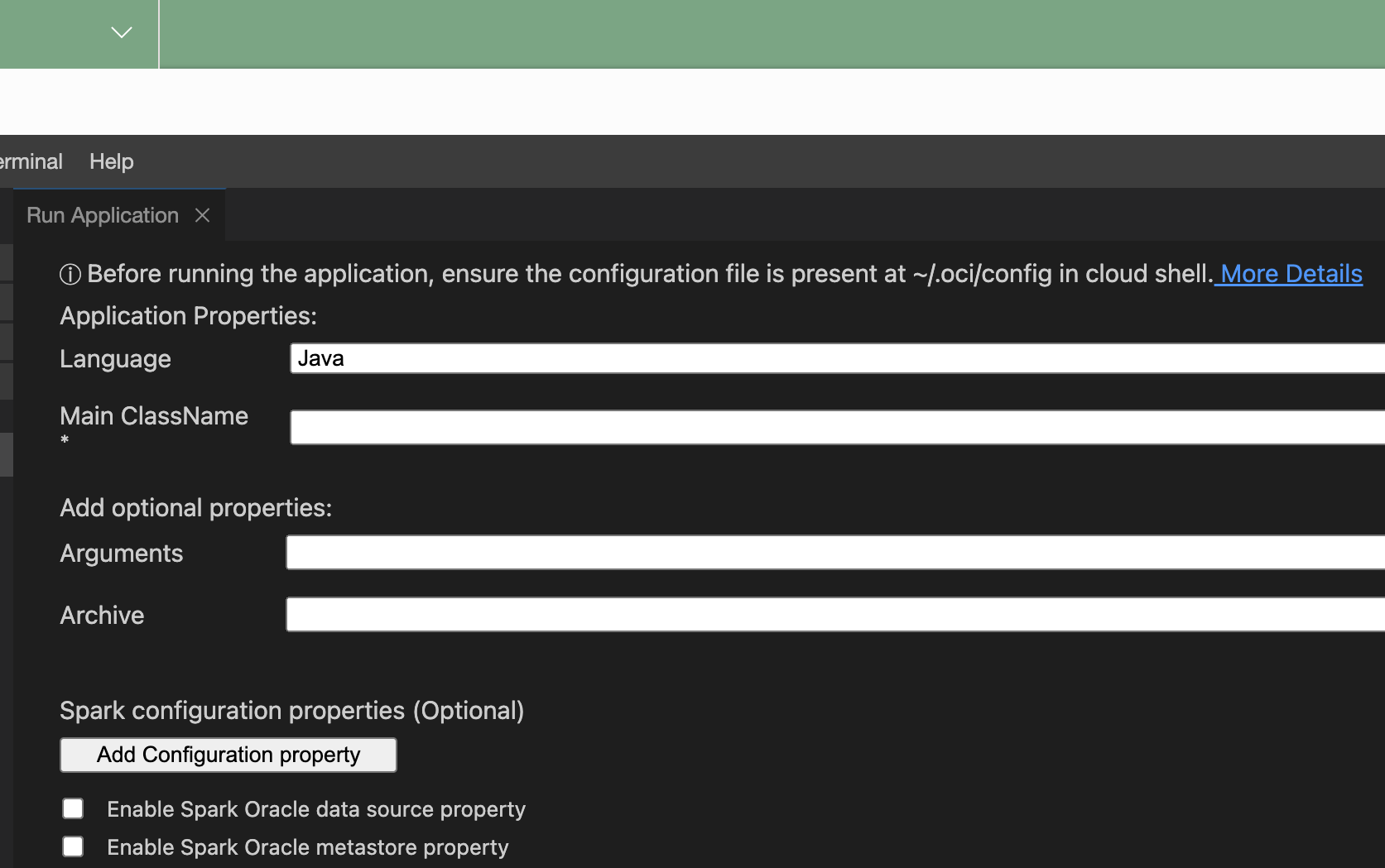
Fournissez les propriétés d'application suivantes :
- Language : langage Java, Python ou Scala.
- ClassName principal : nom de la classe principale exécutée dans le projet. Pour Python, il s'agit de Nom de fichier principal.
- Arguments : arguments de ligne de commande attendus par l'application Spark.
- conf : toute configuration supplémentaire pour l'exécution de l'application.
- jars : fichier JAR tiers requis par l'application.
- Cochez Activer la propriété de source de données Oracle Spark pour utiliser la source de données Oracle Spark.
- Cochez Activer la propriété de metastore Oracle Spark pour utiliser un metastore.
- Sélectionnez un compartiment.
- Sélectionnez un métasore.

- (Facultatif) Vérifiez le statut de l'application à partir de la barre de notification. La sélection de l'onglet Notifications fournit des informations de statut plus détaillées.

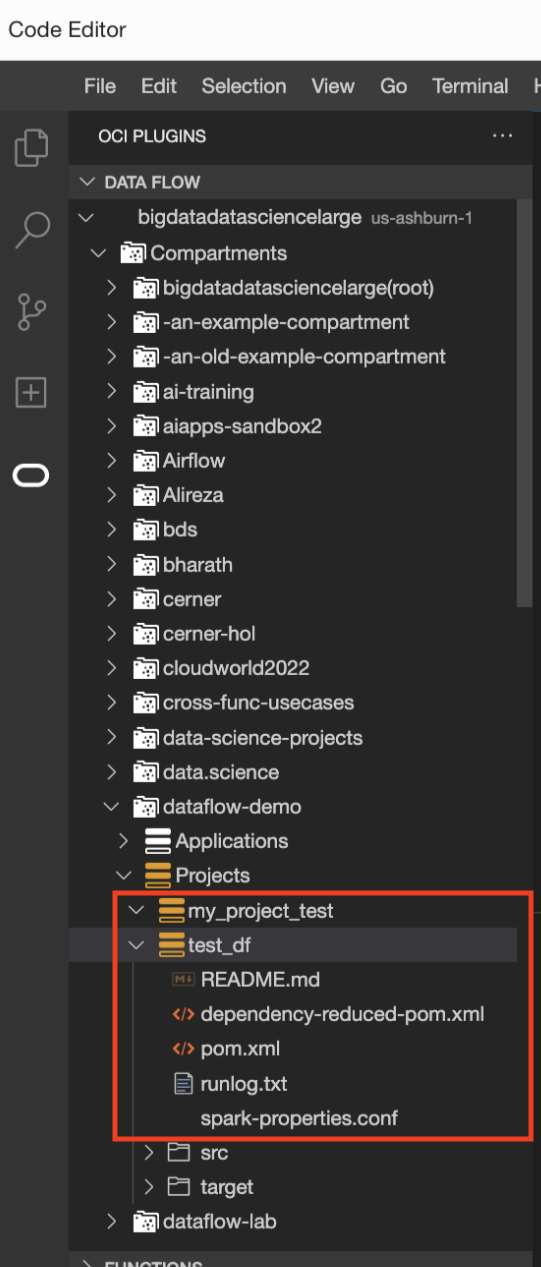
- (Facultatif) Sélectionnez runlog.txt pour consulter les fichiers journaux.
- (Facultatif) Téléchargez l'artefact vers Data Flow.
- Cliquez avec le bouton droit de la souris sur le projet en question.
- Sélectionnez Télécharger l'artefact vers le serveur.
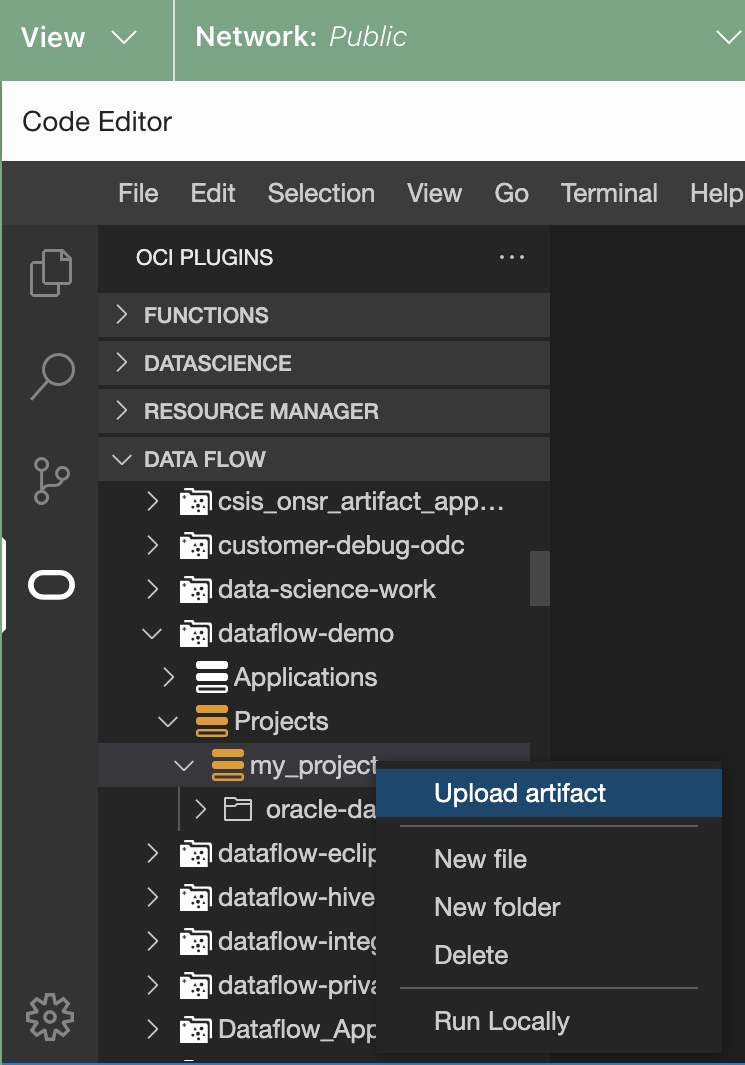
- Sélectionnez la langue.
- Entrez l'espace de noms Object Storage.
- Saisissez le nom du bucket.
-
Sélectionnez le logo Oracle O.
Cette tâche ne peut pas être effectuée à l'aide de l'interface de ligne de commande.
Cette tâche ne peut pas être effectuée à l'aide de l'API.