Développement d'applications Data Flow
Apprenez-en davantage sur la bibliothèque , y compris sur les modèles d'application Spark réutilisables et la sécurité des applications. Découvrez également comment créer des applications, les visualiser, les modifier, les supprimer, et comment appliquer des arguments ou des paramètres.
- Lors de la création d'applications à l'aide de la console
- Sous Options avancées, indiquez la durée en Durée d'exécution maximale en minutes.
- Lors de la création d'applications à l'aide de la CLI
- Option de ligne de commande Pass de
--max-duration-in-minutes <number> - Lors de la création d'applications à l'aide du kit SDK
- Indiquez l'argument facultatif
max_duration_in_minutes - Lors de la création d'applications à l'aide de l'API
- Définissez l'argument facultatif
maxDurationInMinutes.
Modèles d'application Spark réutilisables
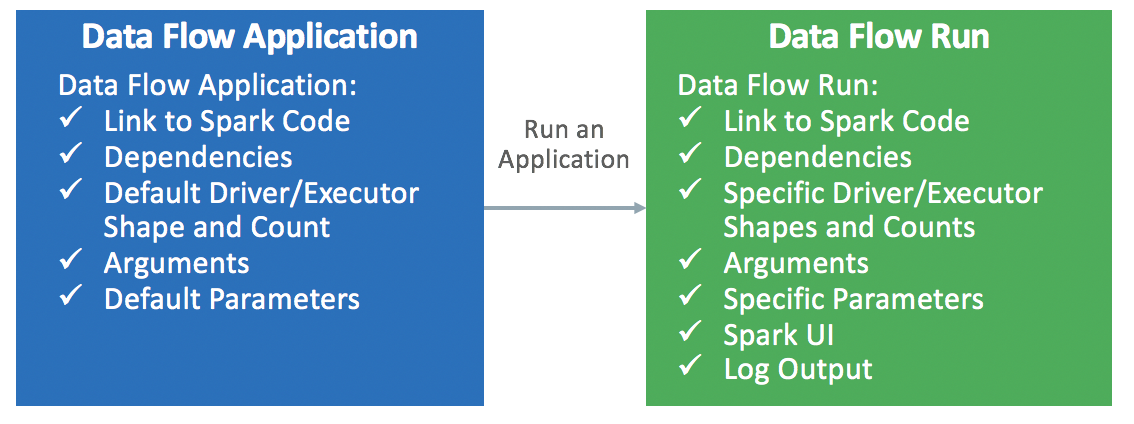
Une application est un modèle d'application Spark réutilisable à l'infini.
Les applications Data Flow se composent d'une application Spark, de ses dépendances, des paramètres par défaut et d'une spécification de ressource d'exécution par défaut. Une fois qu'un développeur Spark a créé une application Data Flow, tout utilisateur peut s'en servir sans s'inquiéter de la complexité de son déploiement, de sa configuration ou de son exécution. Vous pouvez l'utiliser via les analyses Spark dans des rapports, des scripts, des tableaux de bord personnalisés ou des appels d'API REST. 
Chaque fois que vous appelez l'application Data Flow, vous créez une exécution Run . Elle renseigne les détails du modèle d'application et démarre sur un ensemble spécifique de ressources IaaS.