Configuration de Data Flow
Pour pouvoir créer, gérer et exécuter des applications dans Data Flow, l'administrateur de locataire (ou tout utilisateur disposant de privilèges élevés permettant de créer des buckets et de modifier des stratégies dans IAM) doit créer des groupes, un compartiment, un stockage et les stratégies associées dans IAM.
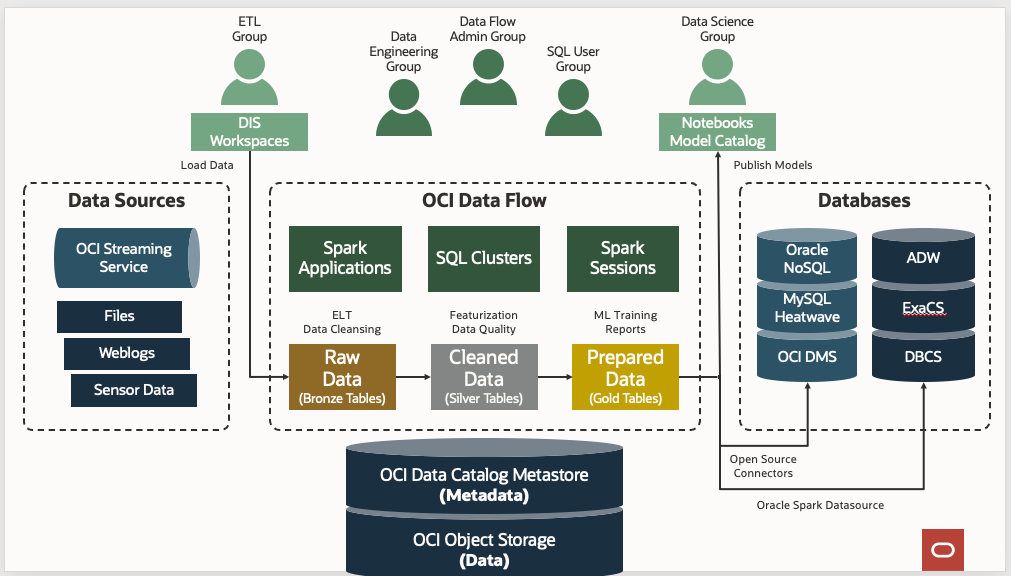 Voici les étapes de configuration de Data Flow :
Voici les étapes de configuration de Data Flow :- Configuration des groupes d'identités.
- Configuration des buckets de compartiment et de stockage d'objets.
- Configuration de stratégies Identity and Access Management
Configurer des groupes d'identités
En règle générale, classez les utilisateurs Data Flow en trois groupes pour une séparation claire de leurs cas d'emploi et de leur niveau de privilège.
Créez les trois groupes suivants dans votre service d'identité et ajoutez des utilisateurs à chaque groupe :
- administrateurs de flux de données
- dataflow-data-engineers
- dataflow-sql-users
- administrateurs de flux de données
- Les utilisateurs de ce groupe sont des administrateurs ou des superutilisateurs de Data Flow. Ils disposent des privilèges nécessaires pour effectuer une action sur Data Flow ou pour configurer et gérer différentes ressources liées à Data Flow. Ils gèrent les applications appartenant à d'autres utilisateurs et les exécutions démarrées par n'importe quel utilisateur de leur location. Les administrateurs de flux de données n'ont pas besoin d'un accès d'administration aux clusters Spark provisionnés à la demande par Data Flow, car ces clusters sont entièrement gérés par Data Flow.
- dataflow-data-engineers
- Les utilisateurs de ce groupe disposent des privilèges nécessaires pour gérer et exécuter les applications et exécutions Data Flow pour leurs travaux d'ingénierie des données. Par exemple, l'exécution de travaux ETL (extraction, transformation, chargement) dans les clusters Spark sans serveur à la demande de Data Flow. Les utilisateurs de ce groupe ne disposent pas et n'ont pas besoin d'un accès d'administration aux clusters Spark provisionnés à la demande par Data Flow, car ces clusters sont entièrement gérés par Data Flow.
- dataflow-sql-users
- Les utilisateurs de ce groupe sont autorisés à exécuter des requêtes SQL interactives en se connectant aux clusters SQL interactifs Data Flow via JDBC ou ODBC.
Configuration du compartiment et des buckets Object Storage
Suivez ces étapes pour créer un compartiment et des buckets Object Storage pour Data Flow.