Conception d'une table dans Oracle NoSQL Database Cloud Service
Découvrez comment concevoir et configurer des tables dans Oracle NoSQL Database Cloud Service.
Cet article comprend les rubriques suivantes :
Champs de table
Découvrez comment concevoir et configurer des données à l'aide de champs de table.
Une application est en mesure de choisir d'utiliser des tables sans schéma, dans lesquelles une ligne se compose de champs de clés et d'un champ JSON unique. Une table sans schéma offre une flexibilité quant aux éléments pouvant être stockés dans une ligne.
L'application peut également choisir d'utiliser des tables de schéma fixes dans lesquelles tous les champs de table sont définis en tant que types spécifiques.
Les tables de schéma fixe contenant des données saisies sont plus sûres du point de vue de l'application et l'efficacité du stockage. Bien que le schéma de ces tables puisse être modifié, la structure des tables ne peut pas être facilement modifiée. Une table sans schéma est flexible et la structure de la table peut être facilement modifiée.
Enfin, l'application peut également utiliser une approche de modèle de données hybride dans laquelle une table peut disposer de champs de données JSON et de données saisies.
Les exemples suivants illustrent la conception et la configuration des données pour les trois approches.
Exemple 1 : Conception d'une table sans schéma
Vous disposez de plusieurs options pour stocker des informations à propos des modèles de navigation dans votre table. L'une des options consiste à définir une table qui utilise un ID de cookie en tant que clé et qui conserve les données de segmentation de l'audience sous la forme d'un seul champ JSON.
// schema less, data is stored in a JSON field
CREATE TABLE audience_info (
cookie_id LONG,
audience_data JSON,
PRIMARY KEY(cookie_id))Dans ce cas, la table audience_info peut contenir un objet JSON tel que :
{
"cookie_id": "",
"audience_data": {
"ipaddr" : "
10.0.00.xxx",
"audience_segment: {
"sports_lover" : "2018-11-30",
"book_reader" : "2018-12-01"
}
}
}Votre application disposera d'un champ de clé et d'un champ de données pour cette table. Les éléments que vous choisissez de stocker en tant qu'informations dans le champ audience_data sont flexibles. Vous pouvez donc facilement modifier les types d'informations disponibles.
Exemple 2 : Conception d'une table de schéma fixe
Vous pouvez stocker des informations sur les modèles de navigation en créant une table avec des champs déclarés plus explicitement :
// fixed schema, data is stored in typed fields.
CREATE TABLE audience_info(
cookie_id LONG,
ipaddr STRING,
audience_segment RECORD(sports_lover TIMESTAMP(9),
book_reader TIMESTAMP(9)),
PRIMARY KEY(cookie_id))Dans cet exemple, votre table comporte un champ de clé et deux champs de données. Vos données sont plus compactes et vous pouvez vous assurer que tous les champs de données sont exacts.
Exemple 3 : Conception d'une table hybride
Vous pouvez stocker des informations sur les modèles de navigation à l'aide des champs de données saisis et des champs de données JSON dans la table.
// mixed, data is stored in both typed and JSON fields.
CREATE TABLE audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Clés primaires et clés de shard
Découvrez l'objectif des clés primaires et des clés de shard pendant la conception de l'application.
Les clés primaires et les clés de shard sont des éléments importants dans le schéma. Elles vous aident à accéder aux données et à les distribuer efficacement. Vous créez des clés primaires et des clés de shard uniquement lorsque vous créez une table. Elles sont conservées pendant toute la durée de vie de la table et ne peuvent être ni modifiées ni supprimées.
Clés primaires
Vous devez désigner des colonnes de clé primaire lors de la création de la table. Une clé primaire identifie chaque ligne de la table de façon unique. Pour l'opération CRUD simple, Oracle NoSQL Database Cloud Service utilise la clé primaire pour extraire une ligne spécifique à lire ou modifier. Par exemple, supposons qu'une table comporte les champs suivants :
-
productName -
productType -
productLine
D'expérience, vous savez que le nom du produit est important et qu'il est unique pour chaque ligne. Vous devez donc définir productName comme clé primaire. Ensuite, vous extrayez les lignes qui vous intéressent en fonction de productName. Dans un tel cas, utilisez une instruction semblable à celle-ci pour définir la table.
/* Create a new table called users. */
CREATE TABLE if not exists myProducts
(
productName STRING,
productType STRING,
productLine INTEGER,
PRIMARY KEY (productName)
)"Clés de shard
Le principal objectif des clés de shard est de distribuer des données dans le cluster Oracle NoSQL Database Cloud Service pour améliorer l' efficacité, et d'installer des enregistrements qui partagent la clé de shard localement pour faciliter l' accès et la référencement. Les enregistrements partageant la clé de shard sont stockés dans le même emplacement physique, et vous pouvez y accéder de façon atomique et efficace.
La conception de votre clé primaire et shard a des conséquences sur l'ajustement et l'atteinte du débit provisionné. Par exemple, lorsque des enregistrements partagent des clés de shard, vous pouvez supprimer plusieurs lignes de table en une opération atomique, ou extraire un sous-ensemble de lignes dans votre table en une seule opération atomique. En plus de permettre l'évolutivité, des clés de shard bien conçues peuvent améliorer les performances car elles exigent moins de cycles pour mettre en place des données ou obtenir des données à partir d'un seul shard.
Par exemple, supposons que vous désignez trois champs de clé primaire :
PRIMARY KEY (productName, productType, productLine)Comme vous savez que votre application effectue fréquemment des requêtes à l'aide des colonnes productName et productType, vous pouvez donc indiquer ces champs comme clés du shard. La désignation de clé de shard garantit que toutes les lignes de ces deux colonnes sont stockées sur le même shard. Si ces deux champs ne sont pas des clés du shard, les colonnes les plus fréquemment interrogées peuvent être stockées sur n'importe quel shard. Ensuite, la localisation de toutes les lignes pour les deux champs nécessite l'analyse de l'ensemble du stockage de données, plutôt que d'un seul shard.
Les clés de shard désignent le stockage sur le même shard afin de faciliter l'efficacité des requêtes pour les valeurs de clé. Toutefois, comme vous voulez que vos données soient distribuées sur les shards pour de meilleures performances, évitez les clés de shard ayant peu de valeurs uniques.
Remarque : si vous ne désignez pas d'unités de shard lors de la création d'une table, Oracle NoSQL Database Cloud Service utilise les clés primaires pour l'organisation de shard.
Facteurs importants à prendre en compte lors du choix d'une clé de shard
-
Cardinalité : des champs de cardinalité faible, tels qu'un pays d'accueil d'utilisateur, regroupent les enregistrements sur quelques shards. A leur tour, ces shards nécessitent un rééquilibrage fréquent des données, ce qui augmente la probabilité des problèmes de shard à chaud. En revanche, chaque clé de shard doit avoir une cardinalité élevée, où la clé de shard peut exprimer une tranche égale d'enregistrements dans l'ensemble de données. Par exemple, les numéros d'identité comme
customerID,userIDouproductIDsont de bons candidats pour une clé de shard. -
Atomicité : seuls les objets partageant la clé de shard peuvent participer à une transaction. Si vous avez besoin de transactions ACID qui couvrent plusieurs enregistrements, choisissez une clé de shard qui vous permet de répondre à cette exigence.
Quelles sont les meilleures pratiques à suivre ?
-
Distribution uniforme d'éléments de shard : lorsque les éléments de shard sont distribués uniformément, aucun shard unique n'affecte la capacité du système.
-
Isolement de requête : les requêtes doivent être ciblées sur un shard spécifique afin d'augmenter l'efficacité et les performances. Si les requêtes ne sont pas isolées sur un seul shard, la requête est appliquée à tous les shards, ce qui les rend moins efficaces et augmente leur latence.
Reportez-vous à Création d'une table pour découvrir comment affecter des clé primaires et des clés de shard en utilisant l'objet TableRequest.
Durée de vie
Découvrez comment indiquer un délai d'expiration pour les tables et les lignes à l'aide de la fonctionnalité Durée de vie.
De nombreuses applications gèrent des données qui ont une durée de vie utile limitée. La durée de vie est un mécanisme qui vous permet de définir sur les lignes de la table une période après laquelle les lignes expirent automatiquement et ne sont plus disponibles. Il s'agit de la durée d'autorisation des données à rester dans Oracle NoSQL Database Cloud Service. Les données qui atteignent le délai d'expiration ne peuvent plus être extraites et n'apparaissent dans aucune statistique de stockage.
Par défaut, la valeur de durée de vie de chaque table que vous créez est zéro, ce qui indique l'absence de délai d'expiration. Vous pouvez déclarer une valeur de durée de vie lorsque vous créez une table, en indiquant un nombre, suivi de HOURS ou DAYS. Les lignes de la table héritent la valeur TTL de la table dans laquelle elles résident, sauf si vous définissez explicitement une valeur TTL pour les lignes de la table. La définition de la valeur de durée de vie d'une ligne remplace la valeur de durée de vie de la table. Si vous modifiez la valeur des durées de vie d'une table après que la rangée a une valeur des durées de vie, la valeur des durées de vie de cette dernière est conservée.
Vous pouvez mettre à jour la valeur de durée de vie d'une ligne de table à tout moment avant que la ligne n'atteigne le délai d'expiration. Les données arrivées à expiration ne sont plus accessibles. Par conséquent, l'utilisation de valeurs de durée de vie est plus efficace que la suppression manuelle de lignes, car le temps système de l'écriture d'une entrée de journal de base de données pour la suppression de données est évité. Les données arrivées à expiration sont purgées du disque après la date d'expiration.
Cycles de vie et états de table
Découvrez les différents états de table et leur signification (processus de cycle de vie des tables).
Chaque table passe par une série d'états différents de sa création à sa suppression. Par exemple, une table avec l'état DROPPING ne peut pas passer à l'état ACTIVE, tandis qu'une table à l'état ACTIVE peut passer à l'état UPDATING. Vous pouvez suivre les différents états d'une table en surveillant son cycle de vie. Cette section décrit les différents états d'une table.
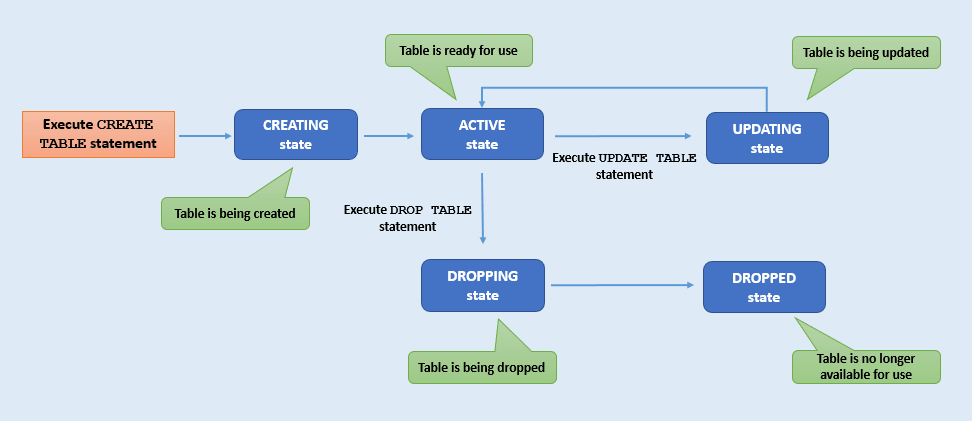
Description de l'image table-state.png
| Etat de la table | Description |
|---|---|
CREATING |
La table est en cours de création. Elle n'est pas encore prête à l'emploi. |
UPDATING |
La mise à niveau de la table est en cours. Vous ne pouvez pas apporter d'autres modifications à la table tant qu'elle est dans cet état. Une table a l'état
|
ACTIVE |
La table peut être utilisée lorsqu'elle est dans cet état. La table a peut-être été récemment créée ou modifiée, mais son état est désormais stable. |
DROPPING |
La table est en cours de suppression et n'est pas accessible. |
DROPPED |
La table a été supprimée et n'existe plus pour les activités de lecture, d'écriture ou de requête. Remarque : une fois supprimée, vous pouvez recréer une table du même nom. |
Hiérarchies de table
Oracle NoSQL Database permet aux tables d'exister dans une relation parent-enfant. Il s'agit des hiérarchies de table.
L'instruction create table permet de créer une table en tant qu'enfant d'une autre table, qui devient alors le parent de la nouvelle table. Pour ce faire, utilisez un nom de composite (name_path) pour la table enfant. Un nom composite est constitué d'un nombre N (N > 1) d'identificateurs séparés par des points. Le dernier identificateur est le nom local de la table enfant et les premiers identificateurs N-1 pointent vers le nom du parent.
Caractéristiques des tables parent-enfant :
-
Une table enfant hérite des colonnes de clé primaire de sa table parent.
-
Toutes les tables de la hiérarchie ont les mêmes colonnes de clé de shard, qui sont indiquées dans l'instruction de création de table de la table racine.
-
Une table parent ne peut pas être supprimée avant que ses enfants ne soient supprimés.
-
Une contrainte d'intégrité référentielle n'est pas appliquée dans une table parent-enfant.
Vous devez envisager d'utiliser des tables enfant lorsqu'une certaine forme de normalisation des données est requise. Les tables enfant peuvent également être un bon choix lors de la modélisation de relations 1 à N et fournissent également une sémantique de transaction ACID lors de l'écriture de plusieurs enregistrements dans une hiérarchie parent-enfant.