Référence Oracle NoSQL Database Cloud Service
Découvrez les types de données pris en charge, les instructions DDL, les paramètres et mesures d'Oracle NoSQL Database Cloud Service.
Cet article comprend les rubriques suivantes :
Types de données pris en charge
Oracle NoSQL Database Cloud Service prend en charge de nombreux types d'informations courants.
| Type de données | Description |
|---|---|
BINARY |
Séquence d'aucun octet ou de plusieurs octets. La taille de stockage est le nombre d'octets plus un codage de la taille de la baie d'octets, qui est une variable, en fonction de la taille de la baie. |
FIXED_BINARY |
Tableau d'octets à taille fixe. Il n'y a pas de surcharge de codage supplémentaire pour ce type de données. |
BOOLEAN |
Type de données avec l'une des deux valeurs possibles : TRUE ou FALSE. La taille de stockage de l'objet boolean est de 1 octet. |
DOUBLE |
Nombre long à virgule flottante, codé en utilisant 8 octets de stockage pour les clés d'index. S'il s'agit d'une clé primaire, elle utilise 10 octets de stockage. |
FLOAT |
Nombre long à virgule flottante, codé à l'aide de 4 octets de stockage pour les clés d'index. S'il s'agit d'une clé primaire, elle utilise 5 octets de stockage. |
LONG |
Un nombre entier long a un codage de longueur variable qui utilise de 1 à 8 octets de stockage en fonction de la valeur. S'il s'agit d'une clé primaire, elle utilise 10 octets de stockage. |
INTEGER |
Un nombre entier long a un codage de longueur variable qui utilise 1 à 4 octets de stockage en fonction de la valeur. S'il s'agit d'une clé primaire, elle utilise 5 octets de stockage. |
STRING |
Séquence de zéro ou plusieurs caractères Unicode. Le type String est codé en UTF-8 et stocké dans ce codage. La taille de stockage est le nombre d'octets UTF-8 plus la longueur, qui peut être de 1 à 4 octets en fonction du nombre d'octets dans l'encodage. Lorsqu'elle est stockée dans une clé d'index, la taille de stockage est le nombre d'octets UTF-8 plus un seul octet de terminaison NULL. |
NUMBER |
Nombre décimal signé de précision arbitraire. Il est sérialisé dans un format de tableau d'octets qui peut être utilisé pour les comparaisons ordonnées. Le format comporte 2 parties : 1. Le signe et l'exposant plus un seul chiffre. Cela prend de 1 à 6 octets mais est normalement de 2, sauf si l'exposant est assez grand 2. Le mantissa de la valeur qui est d'environ un octet pour tous les 2 chiffres Exemples : 12.345678 sérialise en 6 octets 1.234E+102 sérialise en 5 octets Remarque : Lorsque vous devez utiliser des valeurs numériques dans votre schéma, il Il est recommandé de décider des types de données dans l'ordre indiqué ci-dessous : INTEGER, LONG, FLOAT, DOUBLE, NUMÉRO Évitez NUMÉRO sauf si vous en avez vraiment besoin pour votre cas d'utilisation car NUMÉRO est coûteux en termes de puissance de stockage et de traitement utilisée. |
TIMESTAMP |
Point dans le temps avec une précision. La précision a une incidence sur la taille et l'utilisation du stockage. L'horodatage est stocké et géré au format UTC (Temps universel coordonné). Le type de données Timestamp nécessite de 3 à 9 octets selon la précision utilisée. La ventilation suivante illustre le stockage utilisé par ce type de données : - bit[0~13] année - 14 bits - bit[14~17] mois - 4 bits - bit[18~22] jour - 5 bits - bit[23~27] heure - 5 bits [facultatif] - bit[28~33] minute - 6 bits [facultatif] - bit[34~39] seconde - 6 bits [facultatif] - bit[40~71] seconde fractionnaire [facultatif avec longueur variable] |
UUID |
Remarque : Le type de données UUID est considéré comme un sous-type du type de données STRING. La taille de stockage est de 16 octets en tant que clé d'index. Si elle est utilisée en tant que clé primaire, la taille de stockage est de 19 octets. |
ENUM |
Une énumération est représentée sous forme de tableau de chaînes. Les valeurs ENUM sont des identificateurs symboliques (jetons) stockés sous forme de petites valeur entières représentant une position ordonnée dans l'énumération. |
ARRAY |
Collection triée de zéro élément ou de plusieurs éléments saisis. Les tableaux qui ne sont pas définis comme JSON ne peuvent pas contenir de valeurs NULL. Les tableaux déclarés en tant que JSON peuvent contenir n'importe quel JSON valide, y compris la valeur spéciale NULL, appropriée à JSON. |
MAP |
Ensemble non trié de zéro paire ou plusieurs paires clé-élément, où toutes les clés sont des chaînes et tous les éléments sont du même type. Toutes les clés doivent être uniques. Les paires clé-élément sont appelées des champs, les clés sont desnoms du champ et les éléments associés sont desvaleurs du champ. Les valeurs de champ peuvent avoir des types différents, mais les correspondances ne peuvent pas contenir de valeurs de champ NULL. |
RECORD |
Ensemble fixe d'une ou de plusieurs paires clé-élément, où toutes les clés sont des chaînes. Toutes les clés d'un enregistrement doivent être uniques. |
JSON |
Toutes les données JSON valides. |
Cycles de vie et états de table
Découvrez les différents états de table et leur signification (processus de cycle de vie des tables).
Chaque table passe par une série d'états différents de sa création à sa suppression. Par exemple, une table avec l'état DROPPING ne peut pas passer à l'état ACTIVE, tandis qu'une table à l'état ACTIVE peut passer à l'état UPDATING. Vous pouvez suivre les différents états d'une table en surveillant son cycle de vie. Cette section décrit les différents états d'une table.
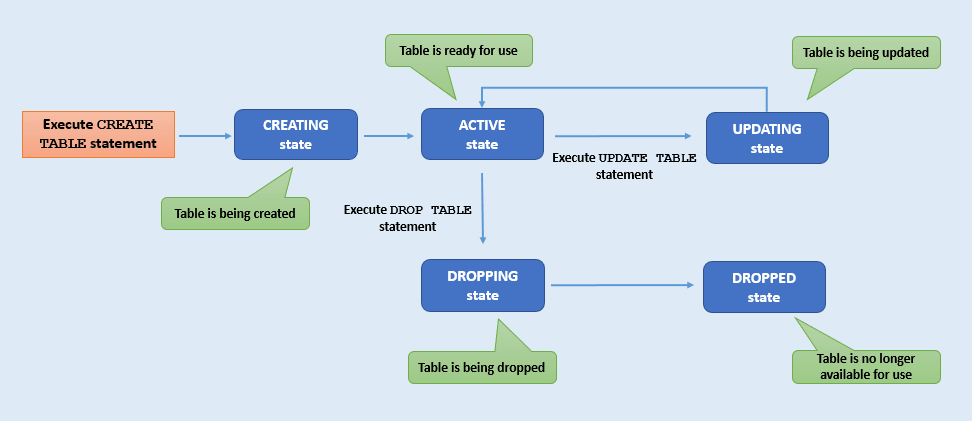
Description de l'image table-state.png
| Etat de la table | Description |
|---|---|
CREATING |
La table est en cours de création. Elle n'est pas encore prête à l'emploi. |
UPDATING |
La mise à niveau de la table est en cours. D'autres modifications de table ne sont pas possibles tant que la table est dans cet état. Une table présente l'état UPDATING lorsque :- Les limites de table sont en cours de modification - Le schéma de table évolue - Ajout ou suppression d'un index de table |
ACTIVE |
La table peut être utilisée lorsqu'elle est dans cet état. La table a peut-être été récemment créée ou modifiée, mais son état est désormais stable. |
DROPPING |
La table est en cours de suppression et n'est pas accessible. |
DROPPED |
La table a été supprimée et n'existe plus pour les activités de lecture, d'écriture ou de requête. Remarque : Une fois supprimée, une table portant le même nom peut être créée à nouveau. |
Débogage des erreurs d'instruction SQL dans la console OCI
Lorsque vous utilisez la console OCI pour créer une table à l'aide d'une instruction LDD ou d'une instruction LMD pour insérer ou mettre à jour des données, ou à l'aide d'une requête SELECT pour extraire des données, vous pouvez obtenir une erreur indiquant que votre instruction est incomplète ou défectueuse dans l'un des scénarios courants suivants :
- Si vous avez un point-virgule à la fin de l'instruction SQL,
- S'il y a une erreur de syntaxe dans votre instruction SQL comme la mauvaise utilisation des virgules, l'utilisation de tout caractère inutile dans l'instruction, etc.
- En cas d'erreur d'orthographe dans votre instruction SQL dans l'un des mots-clés SQL ou dans votre définition de type de données.
- Si vous avez défini la colonne comme NOT NULL, mais que vous ne lui avez pas affecté de valeur par défaut.
- Si vous avez défini la colonne comme NOT NULL, mais que vous ne lui avez pas affecté de valeur par défaut.
Comment gérer certaines erreurs incomplètes ou défectueuses lors de l'utilisation de la console OCI pour créer ou gérer des données :
- Enlevez le point-virgule (le cas échéant) à la fin de l'instruction SQL.
- Vérifiez s'il existe un caractère indésirable ou une ponctuation incorrecte dans votre instruction SQL.
- Recherchez les erreurs d'orthographe dans votre instruction SQL.
- Vérifiez si toutes les définitions de colonne sont complètes et correctes.
- Vérifiez si vous avez défini une clé primaire pour votre table.
Si vous obtenez toujours une erreur après avoir éliminé certaines des situations possibles décrites ci-dessus, vous pouvez utiliser Cloud Shell pour exécuter la requête et capturer l'erreur exacte, comme indiqué dans l'exemple ci-dessous.
Exemple : obtention du message d'erreur pour une instruction SELECT à partir du cloud shell
La commande summarize vérifie la syntaxe et renvoie un bref résumé d'une instruction SQL.
-
Dans la console OCI, ouvrez Cloud Shell dans le menu supérieur droit.
-
Copiez l'instruction SQL SELECT (par exemple,
query1.sql) dans une variable (SQL_SELECTSTMT).Par exemple :
SQL_SELECTSTMT=$(cat ~/query1.sql | tr '\n' ' ') -
Appelez la commande oci ci-dessous pour vérifier la syntaxe de l'instruction SQL SELECT.
Remarque : vous devez indiquer
compartment_idpour cette instruction SELECT.oci raw-request --http-method GET --target-uri https://nosql.${OCI_REGION}.oci.oraclecloud.com/20190828/query/summarize?compartmentId=$NOSQL_COMPID\ &statement="$SQL_SELECTSTMT" | jq '.data'
Vous obtenez ainsi l'erreur exacte dans votre instruction SQL.
Référence de langage DDL (Data Definition Language)
Découvrez comment utiliser le langage DDL dans Oracle NoSQL Database Cloud Service.
Utilisez le script DDL Oracle NoSQL Database Cloud Service pour créer, modifier et supprimer des tables et des index.
Pour plus d'informations sur la syntaxe du langage DDL, reportez-vous au guide DDL (Data Definition Language) de table. Ce guide présente le langage DDL pris en charge par le produit Oracle NoSQL Database sur site. Oracle NoSQL Database Cloud Service prend en charge un sous-ensemble de cette fonctionnalité et les différences sont documentées dans la section Différences de langage DDL dans le cloud.
En outre, chaque pilote NoSQL Langage fournit une API permettant d'exécuter une instruction DDL. Pour écrire votre application, reportez-vous à Utilisation d'API pour créer des tables et des index dans Oracle NoSQL Database Cloud Service.
Instructions DDL standard
Voici quelques exemples d'instructions DDL communes :
Créer une table
CREATE TABLE [IF NOT EXISTS] (
field-definition, field-definition-2 ...,
PRIMARY KEY (field-name, field-name-2...),
) [USING TTL ttl]Exemple :
CREATE TABLE IF NOT EXISTS audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Modifier la table
ALTER TABLE table-name (ADD field-definition)
ALTER TABLE table-name (DROP field-name)
ALTER TABLE table-name USING TTL ttlExemple :
ALTER TABLE audience_info USING TTL 7 daysCréer un index
CREATE INDEX [IF NOT EXISTS] index-name ON table-name (path_list)Exemple :
CREATE INDEX segmentIdx ON audience_info
(audience_segment.sports_lover AS STRING)Supprimer une table
DROP TABLE [IF EXISTS] table-nameExemple :
DROP TABLE audience_infoPour obtenir une liste complète, reportez-vous aux guides de référence :
Différences de langage DDL dans le cloud
Le langage DDL du service cloud diffère de la description contenue dans le guide de référence comme suit :
Noms de table
- Ils sont limités à 256 caractères, caractères alphanumériques et traits de soulignement.
- Doit commencer par une lettre
- Ils ne peuvent pas contenir de caractères spéciaux.
- Les tables enfant ne sont pas prises en charge.
Concepts non pris en charge
- Instructions
DESCRIBEetSHOW TABLE - Index de texte intégral
- Gestion des utilisateurs et des rôle
- Régions sur site
Référence de langage de requête
Découvrez comment utiliser des instructions SQL pour mettre à jour et interroger des données dans Oracle NoSQL Database Cloud Service.
Oracle NoSQL Database utilise le langage de requête SQL pour mettre à jour et interroger les données dans les tables NoSQL. Pour connaître la syntaxe du langage de requête, reportez-vous à Référence SQL pour Oracle NoSQL Database.
Requêtes standard
SELECT <expression>
FROM <table name>
[WHERE <expression>]
[GROUP BY <expression>]
[ORDER BY <expression> [<sort order>]]
[LIMIT <number>]
[OFFSET <number>];Exemple :
SELECT * FROM Users;
SELECT id, firstname, lastname FROM Users WHERE firstname = "Taylor";UPDATE <table_name> [AS <table_alias>]
<update_clause>[, <update_clause>]*
WHERE <expr>[<returning_clause>];Exemple :
UPDATE JSONPersons $j
SET TTL 1 DAYS
WHERE id = 6
RETURNING remaining_days($j) AS Expires;Différences de langage de requête dans le cloud
La prise en charge d'une requête du service cloud diffère de la description contenu dans le manuel de référence du langage de requête comme suit :
Restrictions relatives aux expressions utilisées dans la clause SELECT
Oracle NoSQL Database Cloud Service prend en charge des expressions d'agrégation ou des expressions arithmétiques entre les fonctions d'agrégation. Aucun autre type d'expression n'est autorisé dans la clause SELECT. Par exemple, les expressions CASE ne sont pas autorisées dans la clause SELECT.
Chaque pilote NoSQL Database fournit une API permettant d'exécuter une instruction de requête.
Référence du plan de requête
Un plan d'exécution de requête est la séquence d'opérations qu'Oracle NoSQL Database effectue pour exécuter une requête.
Un plan d'exécution de requête est une arborescence d'itérateurs de plan. Chaque type d'itérateur évalue un type d'expression différent qui peut apparaître dans une requête. En général, le choix de l'index et le type de prédicat d'index associé peuvent avoir un effet drastique sur les performances des requêtes. Par conséquent, en tant qu'utilisateur, vous voulez souvent voir quel index est utilisé par une requête et quels prédicats y ont été propagés. En fonction de ces informations, vous pouvez forcer l'utilisation d'un autre index via des conseils d'index. Ces informations sont contenues dans le plan d'exécution de la requête. Tous les pilotes Oracle NoSQL fournissent des API permettant d'afficher le plan d'exécution d'une requête.
Certains des itérateurs les plus courants et les plus importants utilisés dans les requêtes sont :
Itérateur de TABLE : un itérateur de TABLE est responsable des éléments suivants :
- Analyse de l'index utilisé par l'interrogation (qui peut être l'index principal).
- Application des prédicats de filtrage transmis à l'index
- Extrayez les lignes désignées par les entrées d'index qualifiantes si nécessaire. Si l'index est couvert, l'ensemble de résultats de l'itérateur TABLE est un ensemble d'entrées d'index, sinon il s'agit d'un ensemble de lignes de TABLE.
Remarque : Un index est appelé index de couverture par rapport à une requête si celle-ci peut être évaluée en utilisant uniquement les entrées de cet index, c'est-à-dire sans avoir à extraire les lignes associées.
Itérateur SELECT : il est responsable de l'exécution de l'expression SELECT.
Chaque requête contient une clause SELECT. Chaque plan de requête aura donc un itérateur SELECT. Un itérateur SELECT présente la structure suivante :
"iterator kind" : "SELECT",
"FROM" :
{
},
"FROM variable" : "...",
"SELECT expressions" :
[
{
}
]L'itérateur SELECT comporte des champs tels que "FROM", "WHERE", "variable FROM" et "Expressions SELECT". "FROM" et "FROM variable" représentent la clause FROM de l'expression SELECT, WHERE représente la clause filter et SELECT expression représente la clause SELECT.
itérateur RECEIVE : il s'agit d'un itérateur interne spécial qui sépare le plan de requête en 2 parties :
-
L'itérateur RECEIVE lui-même et tous les itérateurs qui sont au-dessus de lui dans l'arborescence d'itérateurs sont exécutés au niveau du pilote.
-
Tous les itérateurs situés sous l'itérateur RECEIVE sont exécutés sur les noeuds de réplication (RN) ; ces itérateurs forment une sous-arborescence enracinée dans l'enfant unique de l'itérateur RECEIVE.
En général, l'itérateur RECEIVE agit en tant que coordonnateur de requêtes. Il envoie son sous-plan aux numéros RN appropriés pour exécution et collecte les résultats. Il peut effectuer des opérations supplémentaires telles que le tri et l'élimination des doublons et propager les résultats à ses itérateurs ancêtres (le cas échéant) pour un traitement ultérieur.
Types de distribution :
Un type de distribution indique la façon dont la requête sera distribuée pour exécution entre les noms régionaux participant à une base de données Oracle NoSQL (emplacement de stockage). Le type de distribution est une propriété de l'itérateur RECEIVE.
Différents choix de types de distribution sont :
- SINGLE_PARTITION : une requête SINGLE_PARTITION indique une clé de shard complète dans sa clause WHERE. Par conséquent, son ensemble de résultats complet est contenu dans une seule partition, et l'itérateur RECEIVE enverra son sous-plan à un seul RN qui stocke cette partition. Une requête SINGLE_PARTITION peut utiliser l'index de clé primaire ou un index secondaire.
- ALL_PARTITIONS : les requêtes utilisent l'index de clé primaire ici et n'indiquent pas de clé de shard complète. Par conséquent, si le magasin a M partitions, l'itérateur RECEIVE enverra M copies de son sous-plan à exécuter sur l'une des M partitions chacune.
- ALL_SHARDS : les requêtes utilisent un index secondaire ici et n'indiquent pas de clé de shard complète. Par conséquent, si le magasin a N shards, l'itérateur RECEIVE enverra N copies de son sous-plan à exécuter sur l'un des N shards chacun.
Caractéristiques d'un plan d'exécution d'interrogation :
L'exécution de la requête s'effectue par lots. Lorsqu'un sous-plan de requête est envoyé à une partition ou à un shard pour exécution, il s'exécute là jusqu'à ce qu'une limite de batch soit atteinte. La limite de batch est un nombre d'unités de lecture consommées localement par la requête. La valeur par défaut est de 2000 unités de lecture (environ 2 Mo de données), et elle ne peut être diminuée que via une option de niveau requête.
Lorsque la limite de lots est atteinte, tous les résultats locaux générés sont renvoyés à l'itérateur RECEIVE pour traitement ultérieur, ainsi qu'un indicateur booléen indiquant si d'autres résultats locaux peuvent être disponibles. Si l'indicateur est défini sur Vrai, la réponse inclut les informations de reprise. Si l'itérateur RECEIVE décide de renvoyer la requête vers la même partition/le même shard, il inclura ces informations de reprise dans sa demande, de sorte que l'exécution de la requête redémarre au point où elle s'est arrêtée au cours du batch précédent. En effet, aucun état de requête n'est maintenu au niveau de l'IPR après la fin d'un batch. Le lot suivant pour la même partition/le même shard peut avoir lieu au même RN que le lot précédent ou à un autre RN qui stocke également la même partition/le même shard.