Utiliser OKE pour améliorer la localité des données pour l'activité Cassandra et Spark
Introduction
Apache Cassandra est une base de données distribuée sans maître dans laquelle chaque noeud possède des plages de jetons. Apache Spark est un moteur de calcul distribué qui peut utiliser le connecteur Spark-Cassandra pour la lecture à partir des répliques Cassandra. Dans Kubernetes, les pods sont programmés sans savoir où vivent les données, de sorte que la localisation des données n'est pas garantie.
Ce tutoriel montre comment OKE peut améliorer la localité avec les primitives Kubernetes : StatefulSets (identité stable pour Cassandra), les étiquettes de noeud et l'affinité/anti-affinité pour colocaliser les exécuteurs Spark avec les pods Cassandra. Les lectures sont donc servies à partir du même noeud (idéal) ou, dans le pire des cas, d'un saut vers la réplique colocalisée.
Objectifs
- Déployez un cluster et un bastion OKE à 3 noeuds (ORM ou Terraform).
- Colocaliser Cassandra et Spark sur deux noeuds avec des libellés et une affinité.
- Exécutez et vérifiez un travail de lecture Spark sur Cassandra.
- Observez le trafic entre les noeuds avec les journaux de flux VCN.
Prérequis
- Location OCI avec droits d'accès pour VCN, OKE, Compute, Logging (journaux de flux) ; surveillance facultative.
- Paire de clés SSH pour l'accès au bastion.
- Connaissance de base de Kubernetes (noeuds, étiquettes, pods, etc.).
Tâche 1 : déploiement de l'environnement avec OCI Resource Manager (ORM) (recommandé).
-
Cliquez ci-dessous pour ouvrir la pile dans la console OCI :

-
Suivez le flux guidé pour :
-
Acceptez les conditions d'utilisation.
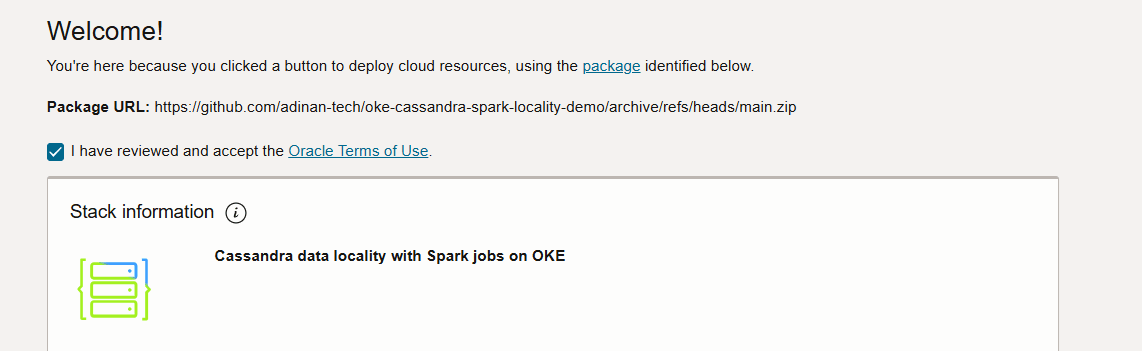
-
Insérez une clé SSH et sélectionnez le domaine de disponibilité.
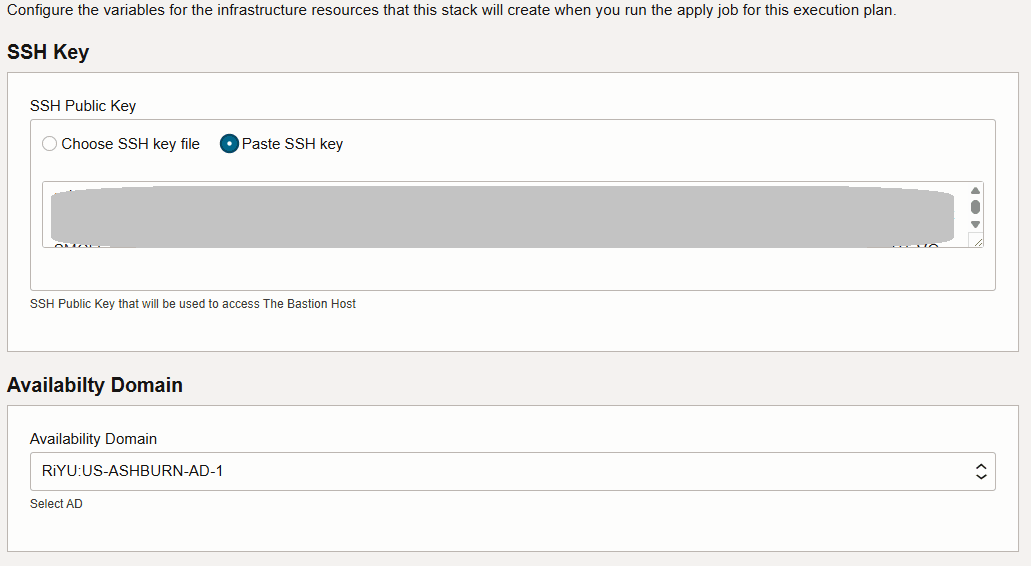
-
Vous pouvez laisser le reste des valeurs par défaut afin d'obtenir un VCN, un cluster OKE et un bastion déployés.
-
Lancez la pile.
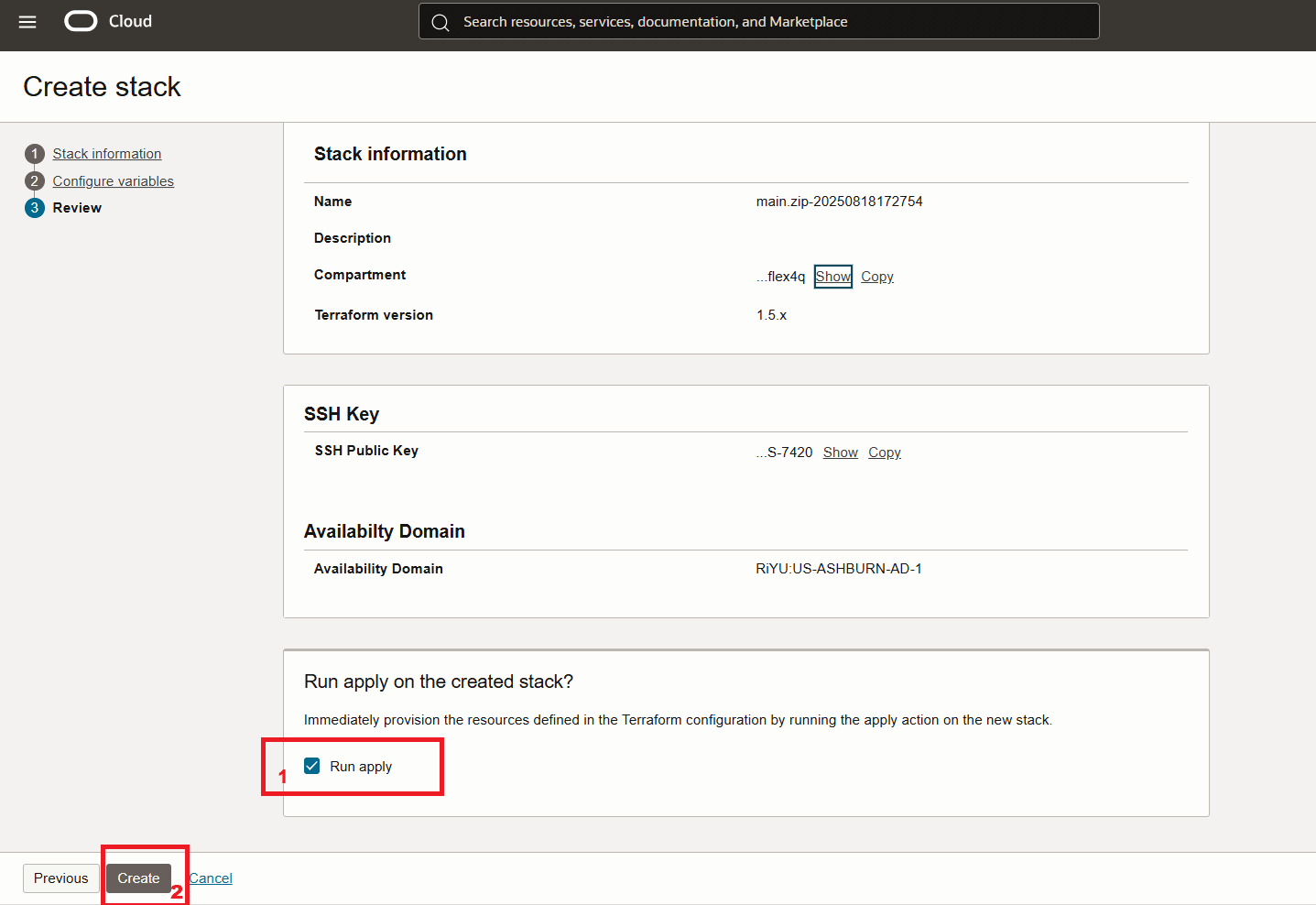
-
Une fois la pile terminée, vous obtenez l'adresse IP du bastion dans la section de sortie.
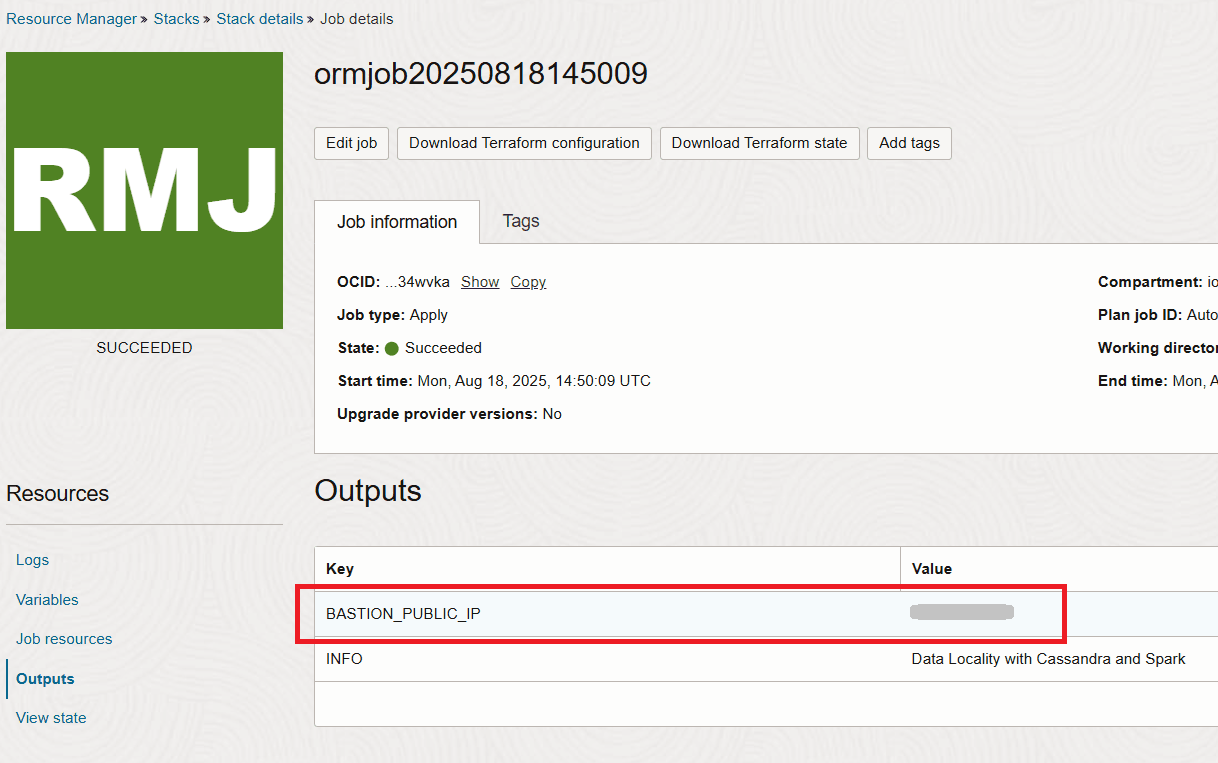
Tâche 2 : se connecter au bastion et vérifier le déploiement
Le provisionnement initial de l'infrastructure se termine en 15 minutes environ, mais la configuration complète (via cloud-init sur le bastion) prend environ 20 minutes supplémentaires pour installer Helm, déployer Cassandra et Spark, et exécuter le travail de lecture.
-
Pour surveiller le processus, accédez au bastion via SSH :
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
Exécutez la commande ci-dessous pour surveiller la progression du script cloudinit.
tail -f /var/log/oke-automation.log -
La pile se termine lorsque vous voyez les 3 valeurs Cassandra prédéfinies en cours de lecture et le message Cloud-init complete.
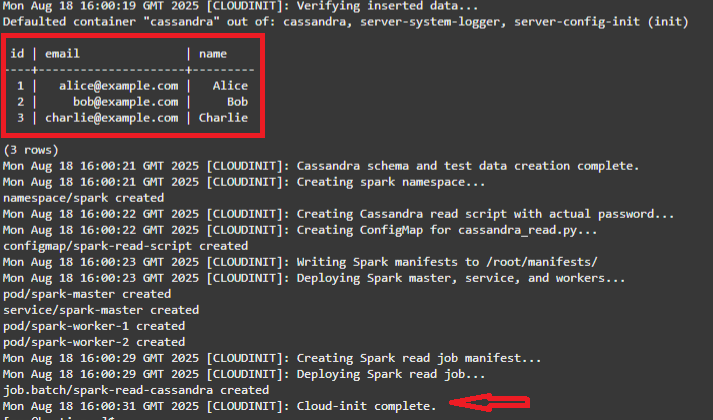
Remarque : le script cloudinit a effectué les opérations suivantes :
- Installez kubectl, Helm, l'interface de ligne de commande OCI (principaux d'instance), extrayez kubeconfig.
- Attendre les salariés
- Nommez les deux premiers noeuds comme suit :
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - Installer le gestionnaire de certificats et l'opérateur k8ssandra (CRD)
- Appliquer K8ssandraCluster
- Attendre Cassandra
- Créer testks.users et insérer 3 lignes
- Créer un espace de noms spark ; créez ConfigMap avec /scripts/cassandra_read.py (lire testks.users)
- Déployer le maître Spark, le service et deux processus actifs (nodeSelector spark-locality : "true", worker anti-affinity)
- Soumettre le travail spark-read-cassandra
-
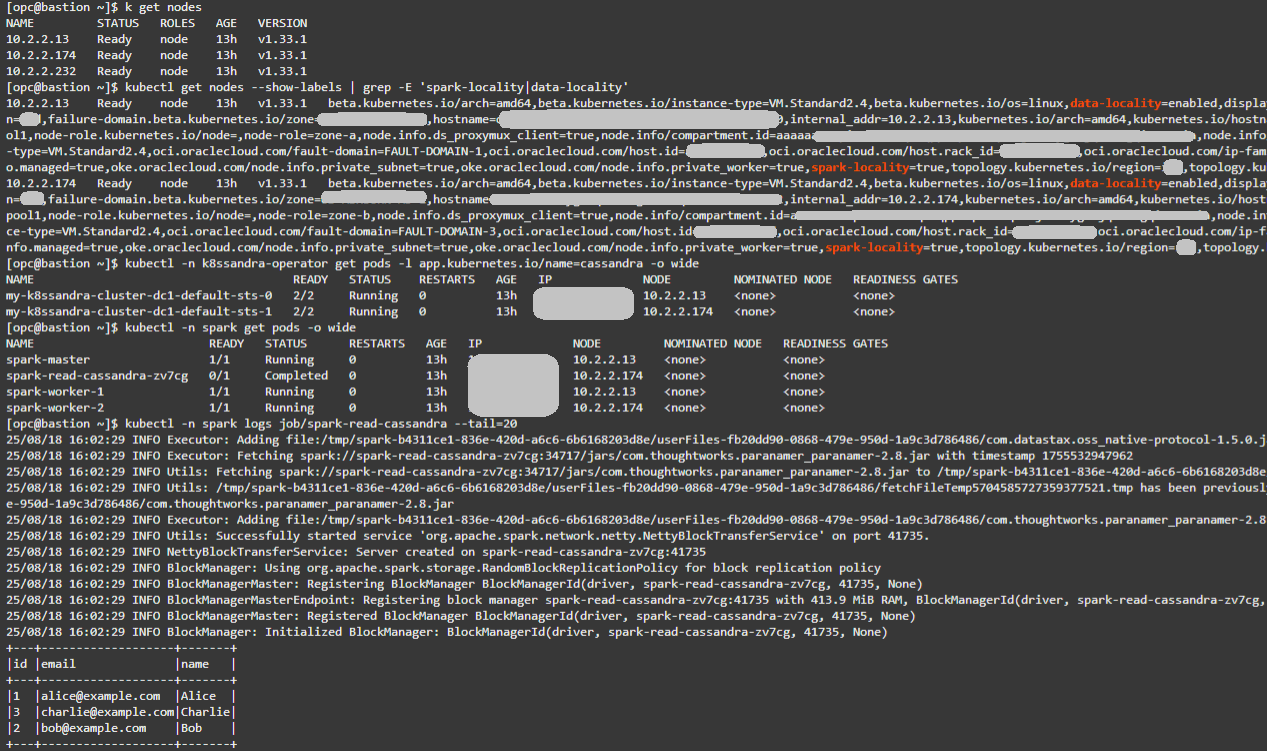
A partir de la machine virtuelle du bastion, vérifiez les noeuds existants :
kubectl get nodes -
Confirmer les étiquettes de localité. Attendez-vous à deux noeuds avec spark-locality=true et data-locality=enabled.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Vérifier le placement Cassandra :
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Vérifiez le placement Spark :
kubectl -n spark get pods -o wide -
Consultez les journaux de travail de lecture Spark. Vous devez voir les 3 enregistrements de testks.users et une exécution réussie.
kubectl -n spark logs job/spark-read-cassandra --tail=20
A savoir : La mise en correspondance des valeurs NODE entre les pods Cassandra et Spark confirme la co-implantation et les conditions idéales pour la localité. Pour obtenir des résultats de journal de flux plus concluants, insérez des lignes supplémentaires dans testks.users à l'aide de cqlsh. Des jeux de données plus volumineux généreront plus de trafic de lecture, ce qui facilitera l'observation des effets de localité et de non-localité.
Vous trouverez ci-dessous un exemple de sortie pour les commandes ci-dessus :
Tâche 3 : observer les effets réseau avec les journaux de flux VCN
Utilisez les journaux de flux VCN pour comprendre où circule le trafic Cassandra pendant les lectures Spark. L'automatisation actuelle utilise Flannel (VXLAN), ce qui affecte ce que les journaux de flux peuvent voir.
Ce qui change avec le CNI
- Flannel (VXLAN, ce laboratoire) :
- Le trafic de pod sur le même noeud reste sur le pont hôte → aucune entrée de journal de flux VCN.
- Le trafic de pod entre noeuds est encapsulé en tant que UDP
(VXLAN). Par défaut, Flannel utilise le port 8472, mais si ce port n'est pas disponible, il peut sélectionner un autre port UDP élevé. Le port exact peut varier selon le déploiement.
- Réseau de pod natif VCN (NPN) :
- Les pods obtiennent des adresses IP VCN et le trafic est acheminé sur L3 sans superposition.
- Les journaux de flux affichent les ports d'application réels (pour Cassandra : TCP 9042).
-
Activez les journaux de flux sur le sous-réseau de processus actif.
Dans la console OCI, activez les journaux de flux pour le sous-réseau de processus actif OKE. Réexécutez (ou attendez) le travail de lecture Spark pour générer du trafic.
-
Journaux de flux de requête (choisissez le chemin correspondant à votre cluster)
Si vous utilisez cette automatisation (Flannel/VXLAN) : utilisez une requête avancée semblable à la suivante :
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
Remplacez
- Le trafic pod-to-pod est encapsulé dans UDP
entre les adresses IP de noeud de processus actif (au lieu du port Cassandra 9042). - Lectures sur le même noeud : aucune entrée du journal de flux VCN (le trafic reste local).
- Lectures entre noeuds : visibles au fur et à mesure que UDP 14789 circule entre les adresses IP de noeud de processus actif dans l'image ci-dessous.
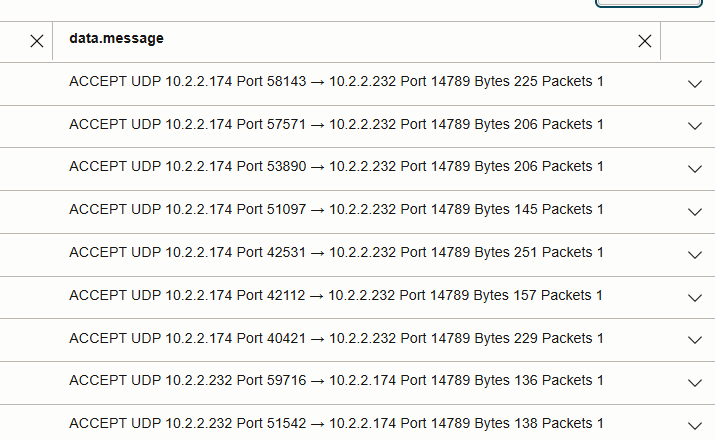
- La comparaison du nombre de paquets sur UDP 14789 met en évidence l'effet de la localisation des données par rapport à la non-localité.
Si votre cluster utilise NPN :
- Filtrez directement pour TCP dstPort = 9042 entre les adresses IP de pod/processeur.
- Vous devriez voir Cassandra CQL lire / écrire comme 9042 coule. (idéalement très peu)
Remarque : l'inclusion de nouvelles entrées dans les journaux de flux peut prendre quelques minutes.
Remarques importantes
-
Clusters avec >3 noeuds :
La localité est plus importante à mesure que la taille du cluster augmente. Sans règles de placement, les exécuteurs Spark peuvent s'exécuter sur des noeuds sans réplique locale, ce qui entraîne de nombreuses lectures distantes. La colocalisation garantit que les lectures sont locales ou, au pire, un seul saut vers une autre réplique.
- Gains de performance de la co-implantation :
- Lectures locales sans saut → latence la plus faible.
- Moins de lectures entre noeuds → utilisation réduite de la bande passante et contention réduite.
- Débit plus élevé pour les travaux Spark qui lisent Cassandra en parallèle.
- Mécanismes utilisés dans cette automatisation :
- StatefulSets → identités de pod Cassandra stables.
- Libellés de noeud (
spark-locality,data-locality) → désignent des noeuds pour le colocalisation. - Affinité/anti-affinité de pod → Exécuteurs Spark programmés sur les noeuds Cassandra, équilibrés sur eux.
- K8ssandra Opérateur → Déploiement et gestion déclaratifs de Cassandra.
- ConfigMap + travail Spark → valide les lectures Cassandra et génère le trafic.
- Journaux de flux VCN → observer et confirmer les effets de localité.
- Hors du champ d'application d'OKE (facteurs de niveau application) :
- Planification des tâches Spark et affectation de partition.
- Facteur de réplication Cassandra et niveau de cohérence.
- Logique de connecteur Spark-Cassandra pour la sélection de répliques.
Liens connexes
Fournissez des liens vers des ressources supplémentaires. Cette section est facultative ; supprimez-la si nécessaire.
Accusés de réception
- Auteurs - Adina Nicolescu (architecte cloud principale)
Ressources de formation supplémentaires
Explorez d'autres ateliers sur le site docs.oracle.com/learn ou accédez à d'autres contenus d'apprentissage gratuits sur le canal Oracle Learning YouTube. En outre, visitez le site education.oracle.com/learning-explorer pour devenir un explorateur Oracle Learning.
Pour obtenir de la documentation sur le produit, consultez Oracle Help Center.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53299-01