5 Configuring the Flat File Adapter
This chapter explains how to configure the Oracle GoldenGate Adapter for writing flat files by setting user exit parameters and file writer properties.
This chapter includes the following sections:
5.1 Configuring the Adapter for Writing Flat Files
Figure Section 5.1, "Typical Configuration For Writing Flat Files," shows a typical configuration for an Oracle GoldenGate Application Adapters that is writing flat files. Transactions are captured from the source database by a Primary Extract process that writes the data to an Oracle GoldenGate trail. A Data Pump Extract is then used to send the transactions to a trail that will be read by the Adapter Extract. The user exit library that is associated with the Adapter Extract writes the data to flat files that have been formatted for a third party application.
To configure the source database system:
GGSCI > ADD EXTRACT pump, EXTTRAILSOURCE dirdat/aa GGSCI > ADD RMTTRAIL dirdat/bb, EXTRACT pump, MEGABYTES 20
To configure the data integration:
GGSCI > ADD EXTRACT ffwriter, EXTTRAILSOURCE dirdat/bb
The sample process names and trail names used above can be replaced with any valid name. Process names must be 8 characters or less, trail names must be two characters.
Figure 5-1 Typical Configuration For Writing Flat Files
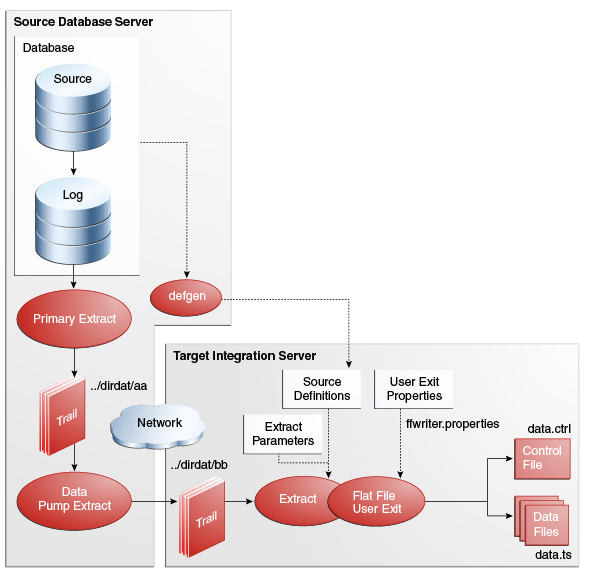
Description of "Figure 5-1 Typical Configuration For Writing Flat Files"
5.1.1 User Exit Extract Parameters
The user exit Extract parameters (ffwriter.prm) are as follows:
| Parameter | Description |
|---|---|
EXTRACT FFWRITER |
All Extract parameter files start with the Extract name. In this case it is the user exit's file writer name. |
SOURCEDEFS dirdef/hr_ora.def |
A source definitions file to determine trail contents. |
CUSEREXIT flatfilewriter.dll CUSEREXIT PASSTHRU, INCLUDEUPDATEBEFORES, PARAMS ffwriter.properties |
The CUSEREXIT parameter options:
|
TABLE HR.*; |
Specifies a list of tables to process. |
5.1.2 User Exit Properties
The user exit reads properties from the file identified in CUSEREXIT PARAMS. The default is to read from ffwriter.properties.
The properties file contains details of how the user exit should operate. For more information on individual properties see Chapter 8, "Flat File Properties."
5.2 Recommended Data Integration Approach
To take best advantage of the micro-batch capabilities, customers should do the following in their data integration tool:
-
Wait on the control file
-
Read list of files to process from the control file
-
Rename the control file
-
Iterate over the comma-delimited list of files read from the control file
-
Process each data file, deleting the data file when complete
-
Delete the renamed control file
On startup, the data integration tool should check for the renamed control file to see if it needs to recover from previously failed processing
When the control file is renamed, the user exit will write a new one on the first file rollover, which will contain the list of files for the next batch.
If the user exit has been configured to also output a summary file, the data integration tool can optionally also read that summary file and cross-check the number of operations it has processed with the data in the summary file for each processed data file.
5.3 Producing Data Files
Data files are produced by configuring a writer in the user exit properties. A single user exit properties file can have multiple writers, which allows for the generation of multiple differently formatted output data files for the same input data.
Writers are added by name to the goldengate.flatfilewriter.writers property. For example:
goldengate.flatfilewriter.writers=dsvwriter,diffswriter,binarywriter
The remainder of the properties file contains detailed properties for each of the named writers where the properties are prefixed by the writers name. For example:
dsvwriter.files.onepertable=true binarywriter.files.onepertable=false binarywriter.files.oneperopcode=true
Each writer can output all the data to a single (rolling) data file, or produce one (rolling) data file per input table or operation type. This is controlled by the files.onepertable and files.oneperopcode properties as shown in the example above.
The data written by each writer can be in one of two output formats controlled by the mode property. This can either be:
-
DSV – Delimiter Separated Values
-
LDV – Length Delimited Values
For example:
dsvwriter.mode=dsv binarywriter.mode=ldv
When data files are first written to disk, they have a temporary extension. Once the file meets rollover criteria, the extension is switched to the rolled extension. If control files are used, the final file name is added to the list in the control file, creating the control file if necessary. Also, if a file level statistics summary is being generated, it will be created upon rollover of the file.
The output directory (for data files and control files separately), temporary extension, rolled extension, control extension and statistical summary extension can all be configured through properties. For output configuration details see Section 8.2.2, "Output File Properties."
Each data file that is written follows a naming convention which depends on the output style. For files written one per table, the name includes the table name, for example:
MY.TABLE_2013-08-03_11:30:00_data.dsv
For files written with all data in one file, the name does not include the table name, for example:
output_2013-08-03_11:30:00_data.dsv
In addition to the basic data contents, additional metadata columns can be added to the output data to aid in data consumption. This includes the schema (owner) and table information, source commit timestamp, Oracle GoldenGate read position and more. For a detailed description of metadata columns see Section 8.2.4.8, "Metadata Columns."
The contents of the data file depend on the mode, the input data, and the various properties determining which (if any) metadata columns are added, whether column names are included, whether before images are included etc. For full details of all properties governing the output data see section Section 8.2.4, "Data Content Properties."