2 Implement the HDR Platform
Implementation Overview
This section describes the implementation process for the Oracle Healthcare Data Repository development platform, including the implementation task sequence.
Implementation Process Description
Oracle Healthcare Data Repository provides an API call interface to implement its core services. Some implementation procedures incidentally employ a command-line interface as well.
Implementation Tasks
The following chart provides an overview of the implementation process for the HDR Platform; the table that follows it lists all implementation tasks:
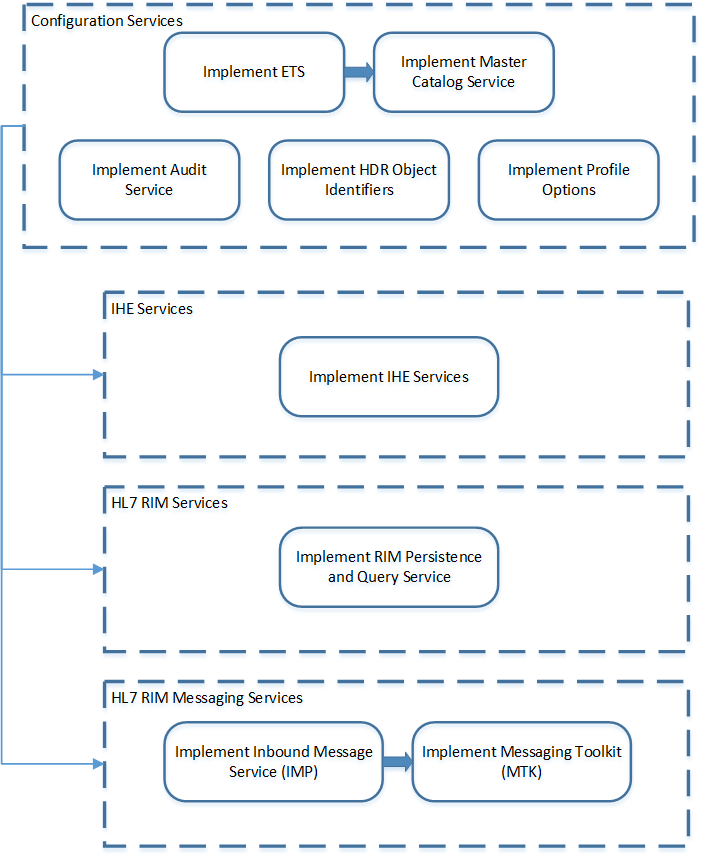
Implementation Tables
Table 2-1 HDR Implementation Tasks Summarized (HDR Platform)
|
Task |
Description |
Optional? |
|
1 |
Implementing Enterprise Terminology Services (ETS) |
No |
|
2 |
Implementing Security |
No |
|
3 |
Implementing Audit Services |
Yes |
|
4 |
Implementing HDR Object Identifiers |
No |
|
5 |
Implementing Profile Option Services |
Yes |
|
6 |
Implementing Master Catalog |
No |
|
7 |
Implementing Inbound Messaging Services |
Yes |
|
8 |
Implementing the Healthcare Enterprise Cross-Enterprise Document Sharing-b Web Service |
Yes |
|
9 |
Implementing Clinical Document Architecture Persistence or Clinical Document Ingest Web Service |
Yes |
Enterprise Terminology Services
Enterprise Terminology Services (ETS) is a core component of HDR that incorporates a range of terminology systems and provides extensive terminology services to HDR applications, including the following principal features:
-
Consistent and real-time access to all terminology content - whether standards-based or user-defined.
-
Support for standard-based terminologies:
-
SNOMED, LOINC, and FDB terminologies through a specialized model (referred as Core terminologies in ETS).
-
Other terminologies like ICD9, CPT4, and HCPCS through a generic model.
-
-
Support for user-defined terminologies.
-
High level of terminology integration - between different terminologies and between different versions of the same terminology.
-
Support for user-defined containers of terminology content such as Concept Lists and Classifications. These containers can be used for building application interfaces, constraining and validating attribute values, and generating context-sensitive reports.
-
Multi language support (MLS) on concept descriptions (except Classifications and editable terminologies).
ETS is based on the following core concepts:
Generic and Core Terminologies
ETS uses a generic terminology model that captures the essential features of disparate terminology systems. The generic terminology model provides:
-
Real-time access to terminology content.
-
A generic API that provides basic terminology services for all terminologies.
-
A data model for custom terminologies.
Terminologies are represented in ETS as Coding Schemes. A Coding Scheme is a generic structure that contains terminology meta-data, such as name, description, and active versions. Actual terminology content is loaded and stored in a Coding Scheme Version. Names of Coding Scheme Versions are decided by the user and are specified when the version is loaded. You can load new Coding Scheme Versions as required. For Coding Schemes that have multiple versions, exactly one version can be designated as default. Note that editable terminologies have only one version; Concepts in an editable terminology can be modified without loading a new version.
A Coding Scheme Version contains a definite set of Concepts, Descriptions, Attributes, and Relationships. A concept is the basic unit of information in a coding scheme version: It corresponds to a specific unit of meaning in the native terminology. Every concept has a Concept Code, which is the code given to it by the terminology. ETS identifies concepts and other ETS components (Descriptions and Relationships) using a system-generated identifier called ETS ID. Concepts (and other components) from different versions of a terminology have different ETS IDs, as the concept code may not correctly identify a concept in a different version.
A concept may have one or more textual descriptions. ETS supports multiple descriptions for a concept in the languages supported by that coding scheme version – whether defined by the terminology, or added later by the user. For concepts that have multiple descriptions, exactly one description must be designated as the preferred description for every language supported by the Coding Scheme Version. All other descriptions of a given language, associated with that concept are designated as synonyms. An application may use specific descriptions for designated contexts. This is done by defining Usage Contexts and associating local descriptions to those contexts.
A Relationship represents a directed relation between two concepts: from a source concept to a target concept. Relationships can be defined between concepts in the same Coding Scheme Version. These are usually provided as part of the terminology itself.
The generic terminology model serves as the base for a number of standard-based terminologies for which ETS provides special support. These terminologies are referred to as core terminologies in HDR. The following terminologies are referred to as core terminologies in ETS:
-
FDB4
-
HL7 v3 Code Systems (Seeded)
-
LOINC
-
IHTSDO
Special support for core terminologies is in the form of:
-
Terminology-specific APIs (in addition to the generic APIs).
-
Specific loaders (and associated integrity checking) for loading the terminologies into ETS.
As core terminologies are based on the generic terminology model, they support all features of generic terminologies, such as local descriptions, usage contexts, equivalence, attributes, and cross maps. However, core terminologies are not editable: new Coding Scheme Versions have to be loaded and activated to update the terminology content.
Equivalence is a symmetric, reflexive, and transitive relationship between two concepts. Two concepts—from the same or different terminologies—that have the same meaning, are considered equivalent in ETS. Equivalent concepts can be used interchangeably, without any loss of meaning. ETS provides APIs for identifying and retrieving equivalent concepts for a given concept.
Note: ETS does not support authoring of equivalence information. Equivalence must be provided to ETS in one of the specified ETS file formats.
Equivalence may be Intra-terminology or Inter-terminology. Intra-terminology equivalence is defined between concepts from the same terminology. For example, the concept Cholera is represented in ICD-9-CM 2002 and in ICD-9-CM 2003 by the same concept code [001_CHOLERA]. Because both concepts have the same meaning, they can be treated as equivalents---ETS treats them as equivalent by default, as they belong to the same coding scheme and have the same concept code.
Intra-terminology equivalence information is provided to ETS as a ”change file”, when loading a new version of a terminology. Change files identify reuse of codes (codes that represent different meanings than the previous version), and reassignment of codes (meanings that are now represented with different codes).
Oracle provides Intra-terminology equivalence information only for core terminologies. You must author and load change files for new versions of custom terminologies not supported by HDR and generic terminologies supported by HDR.
Note: ETS does not support the authoring of change files.
ETS allows concepts from two different terminologies to be defined as semantic equivalents. Equivalence between concepts from different terminologies, or Inter-terminology equivalence, is defined using cross maps. For example, the concept for the disease Cholera in the ICD-10 terminology (2016 version), and the concept representing the same disease in the IHTSDO terminology (2017 version), can be defined as equivalents using a cross map.
Inter-terminology Mapping provides support for any type of relationship, including equivalence, between two different terminologies. Relationships that can be defined include (but not restricted to) broader-than, narrower-than, and clinical-to-administrative relationships.
Inter-terminology Mapping is implemented using Cross Maps. A Cross Map defines the relationship between a source concept and a target concept. A number of Cross Maps are aggregated into a Map Set. ETS specifies file formats for Map Sets and Cross Maps. The HDR Loader job loads these files into ETS tables.
Concept lists are arbitrary lists of ETS concepts that can be used for a variety of purposes, including validation of attribute values and populating user interface controls. Concept lists are used by all types of HDR solutions including HDR Messaging applications.
ETS Classifications are containers for grouping existing ETS concepts from different coding schemes and versions. Classifications are intended for large categorizations of concepts, while concept lists are intended for smaller sets for the purposes of validation or display. ETS Classifications provide the following features:
-
Classifications can be arranged in a hierarchy.
-
Tests for containment in a classification search down the levels of the hierarchy.
-
Classifications can be created and populated through an API or through creating and loading text files.
-
Classification contents incorporate equivalence.
-
Concepts added to an ETS Classification retain their equivalence information and characteristics.
-
ETS Classifications are themselves ETS Concepts--components of a special, predefined editable terminology called ETSClassifications. Accordingly the following applies:
-
A classification has a concept identifier.
-
A classification can have multiple descriptions, including local descriptions.
-
A classification's local descriptions can be associated with usage contexts.
-
-
ETS Classifications can be defined using the API or using the HDR Loader job and HDR Importer job.
ETS provides Multi Language Support (MLS) on:
-
Terminology-specified concept descriptions of non-editable terminologies.
-
Locally-specified concept descriptions of terminologies (editable and non-editable) and Classifications.
MLS in ETS lets you load Coding Scheme versions with Concept descriptions in multiple languages. Each Coding Scheme version can support Concept descriptions in multiple languages, but every Concept in a Coding Scheme version must be supplied with a terminology-preferred description in the languages supported by that version.
You can create local descriptions in multiple languages. Concept descriptions (both terminology-specified and local) based on a language can be obtained by calling methods that accept a language.
Note:
-
The terminology-specified Concept descriptions of editable terminologies and Classifications are created in the base language of the HDR installation.
-
ETS will not translate terminology content - whether seeded or loaded.
-
ETS does not perform any validation to ascertain whether a description is actually in the language that it claims to be in. You can load pseudo translated text as concept descriptions for a supported language along with the real description text. For example, you can load the data given in the following table as Concept descriptions into ETS without getting any errors:
Table 2-2 Sample Concept Descriptions
|
Version ID |
Concept ID |
Description Text |
Language |
|
v20070101 |
A25.66 |
Fracture of Femur |
American English |
|
v20070101 |
A25.66 |
Fracture of Femur |
Korean |
|
v20070101 |
A25.66 |
Fracture of Femur |
Spanish |
|
v20070101 |
A25.66 |
Fracture of Femur |
Japanese |
|
v20070101 |
A25.66 |
Fracture of Femur |
German |
See Also:
-
HDR Concept Lists Index, Oracle Healthcare Data Repository Javadoc (click HDR Concept Lists link at bottom of Javadoc pages), for seeded concept lists and values.
Prerequisites
-
Implementing Security Services: User accounts must exist.
ETS Implementation Procedure
The following chart provides an overview of the implementation process:
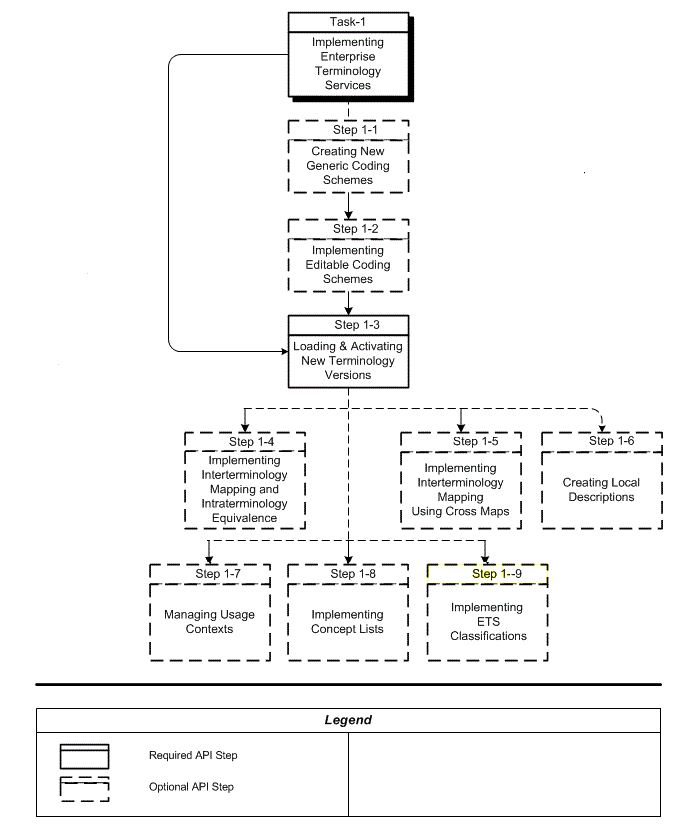
To implement ETS, refer to the following procedure table:
All optional steps are done via the API. Loading and activating coding scheme versions is done using the API and scripts.
Creating New Generic Coding Schemes
ETS lets users define and implement custom terminologies for specific needs. Custom terminologies must be based on the generic ETS terminology model. Coding schemes that implement the generic terminology model are known as generic coding schemes.
Caution: Do not attempt to create coding schemes for the following core and generic terminologies supported by ETS; they are created by default when ETS is installed:
-
CPT4
-
FDB4
-
HCPCS-2
-
HL7 v3 Code Systems (Seeded)
-
ICD-10
-
ICD-9-CM-DRG
-
ICD-9-CM-MDC
-
ICD-9-CM-V1
-
ICD-9-CM-V3
-
LOINC
-
IHTSDO
Create and implement new generic coding schemes:
-
Create the terminology files based on the specified file structure. ETS expects the terminology content to be available as a control file and a set of three terminology files. For information about the file structure, refer the /ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip folder.
-
Create a coding scheme by using the HDR API.
-
Load, import, and activate the coding scheme version.
The terminology content can now be loaded using the HDR Terminology Jobs.
See Also:
-
Loading and Activating Coding Scheme Versions
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip for information about the formats required for loading ETS generic terminologies.
Implementing Editable Coding Schemes
Because user-defined terminologies frequently change, ETS lets you edit generic coding schemes in place, without loading a new version. You can define generic coding schemes as editable when they are being created.
Note: The following terminologies supported by ETS cannot be designated as editable. They are created as non-editable by default when ETS is installed:
-
CPT4
-
FDB4
-
HCPCS-2
-
HL7 v3 Code Systems (Seeded)
-
ICD-10
-
ICD-9-CM-DRG
-
ICD-9-CM-MDC
-
ICD-9-CM-V1
-
ICD-9-CM-V3
-
LOINC
-
IHTSDO
Although editable coding schemes can be updated using ETS APIs, editable coding schemes cannot be updated by loading a new version, because they can have only one version.
Caution: Do not attempt to load new versions for an editable coding scheme, other than the original version.
Creating an Editable Coding Scheme
Using the HDR API, you can create an editable coding scheme by creating a new generic coding scheme with the editable attribute set to true. After the coding scheme is created, you can edit the original version, but a new version is not permitted.
Loading an Editable Terminology
An initial version of the editable coding scheme must be created and loaded before it is used. Use the generic terminology loader to load an editable coding scheme version.
Editing an Editable Coding Scheme
Editing concepts, descriptions, and relationships is limited to addition and removal of attributes, changing status, and changing a description's preferred status. Other changes are made by retiring a component and adding a new component in its place. For example, a description's text cannot be changed, but the description can be retired and a new description added to replace it. The new description can optionally be designated preferred.
Equivalence
As an editable terminology has only a single version, equivalence in an editable terminology must be intraversion – in other words, equivalence may only be declared between concepts in the same version. In the initial version load, equivalence may be declared using a change file, just as for any terminology being loaded with intraversion equivalence information. After the initial load, reassignments (introduction of a new concept that has the same meaning as an existing concept but has a different concept code than the existing concept) may be declared when a new concept is added. The new concept's code may be declared, using the relevant API, to be a reassignment from an existing concept's code.
No reuse of codes (introduction of a concept whose concept code is the same as an existing code, but where the concept has a different meaning than the existing code represents) is permitted in an editable terminology.
See Also:
-
Implementing Interterminology and Intraterminology Equivalence
-
Implementing Interterminology Mapping Using Cross Maps
Reference
Oracle Healthcare Data Repository API Documentation
The following table provided information about the ETSAuthoringService interface used to implement editable terminologies:
Oracle Healthcare Data Repository Javadoc
Table 2-3 Service and Methods: Editable Terminologies
|
Level |
Detail |
|
Package |
oracle.hsgbu.ets.authoring |
|
Interface |
ETSAuthoringService |
|
Methods |
|
Refer to the following sections to edit the components of an Editable Coding Scheme:
-
Adding Components
-
Changing Component Status
-
Adding and Removing Component Attributes
Note: These changes are exclusive; any other changes to concepts, descriptions, and relationships can only be made by retiring the component and adding a new one.
Adding Components
Use the addConcepts, addConceptDescriptions, and addRelationships methods to add concepts, descriptions, relationships and attributes to an editable coding scheme. Candidate components are created first and passed to the add methods.
Changing Component Status
Components such as concepts, relationships and descriptions of an editable coding scheme cannot be edited or removed directly. To modify a component, it must be retired and replaced. A component can be retired or made active by changing the status flag associated with the component. Use the changeStatus method to change component status.
Loading and Activating Coding Scheme Versions
Terminologies have to be loaded into ETS (as coding scheme versions), imported, and activated before they are used. This includes initial versions of core terminologies, which have to be loaded, imported and activated at implementation.
ETS provides terminology loader and importer jobs that load and import a terminology after performing required validations. ETS provides custom loader and importer jobs for core terminologies, and generic loader and importer jobs for generic and custom terminologies.
Note:
New versions of the following terminologies can be loaded if required; HDR does not seed versions of these terminologies (they are available from Apelon, Inc.):
-
IETF RFC 1766
-
ISO 3166-1 alpha-2
-
NUBC-UB92
New versions of the following terminologies can be loaded if required; HDR does not seed versions of these terminologies (they are available from Apelon, Inc.):
Caution:Do not load versions of terminologies that are seeded in HDR. These include:
-
HL7
-
HDR Supplemental
If you have already loaded such versions, mark them as retired and non-default.
The procedure for implementing a new coding scheme version is the same for both generic and core terminologies. To load and activate coding scheme versions, perform the following steps:
Steps:
-
Prepare the terminology files.
-
Load the terminology into ETS as a coding scheme version.
-
Publish the coding scheme version.
-
Activate the coding scheme version.
You can use HDR Terminology Jobs to load and publish coding scheme versions.
See Also
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip for additional information about loading.
The notes can be categorized into DBA, General, and Terminology related notes.
-
DBA Notes: Gives a brief description of some common database management issues related to ETS, such as sizing issues, rollback adjustments for loads and imports, intermedia text indexes, and load/import performance, as well as a general description of database access patterns of ETS.
-
General Notes: Gives the basic principals common to all terminology file formats. This section must be read before moving on to the details of specific loader file formats.
-
Terminology Notes: Gives additional information relating to the core terminologies supported in ETS. Each of the core terminologies have a separate notes file. These files are to be referenced for information relating to the respective loader file formats.
-
Preparing Terminology Content and Control Files
To create the terminology files and move them into the correct folder, perform the following steps:
Steps
-
If the terminology is a generic terminology, create the terminology files in the format expected by the ETS generic loader. Otherwise, ensure that the files are in the format expected by the appropriate terminology loader. (If the terminology is supported by Apelon, this step is not required.)
See Also
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip, for details regarding file formats required by ETS terminology loaders.
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme/Change_File_Formats_General.txt from hdr-1.0.0-8.0.0.zip, for details about change files.
Note:
-
To load equivalence information for the terminology version being loaded, the change file must be specified while loading the version-ETS does not support retrospective loading of change information.
-
For equivalence processing to be performed correctly, versions must be loaded in order. Equivalence processing assumes that the codes referenced in the change file are from the version currently being loaded and its immediate predecessor.
-
-
Move the terminology files to a directory in the same file system as the Applications instance-a directory that is accessible by the Oracle Database Scheduler (DBMS_SCHEDULER).
-
Create a control file that reflects the locations of the terminology files and move it to a directory in the same file system as the Applications instance-a directory that is accessible by the Oracle Database Scheduler (DBMS_SCHEDULER).
Loading a Coding Scheme Version
To load a new coding scheme version, use the Oracle Database Scheduler (DBMS_SCHEDULER).
See Also:
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip, for information about control files.
Using Oracle Database Scheduler (DBMS_SCHEDULER)
Select the HDR Loader Job, and enter values for the Control File (absolute path), Coding Scheme Name, and Coding Scheme Version Name parameters. For more information, refer to Appendix D: Running HDR Terminology Jobs.
Publishing a Coding Scheme Version
A loaded terminology is staged for importation into ETS. Use HDR Importer Job directly for publishing a coding scheme version. For more information refer Appendix D: Running HDR Terminology Jobs.
The published coding scheme version is in the quarantined state by default. The coding scheme version must be activated before it can be used.
Note: In order to support concept equivalence, the HDR Importer job process does not publish a second quarantined version of a coding scheme if one already exists. This facilitates verification of equivalence between the quarantined version and the previous version of the terminology before the quarantined version is published.
Using Oracle Database Scheduler (DBMS_SCHEDULER)
For publishing a staged coding scheme version, select the HDR Importer job, and enter values for the Load Sequence Number and Dry Run Mode parameters. You can get the Load Sequence Number from the log file of the HDR Loader job that has successfully loaded the data (coding scheme versions, classifications, and cross maps).
See Also:
-
Oracle Applications System Administrator's Guide
Note: In order to support concept equivalence, the HDR Importer job does not publish a second quarantined version of a terminology if one already exists. This facilitates verification of equivalence between the quarantined version and the previous version of the terminology before the quarantined version is published.
See Also:
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme, for details regarding file formats for ETS terminologies and loaders.
Implementing Interterminology and Intraterminology Equivalence
Over a period of time, ETS can use different concepts to record the same meaning. This happens either because of changes to the terminology or because different terminologies are used to record the same meaning. The Concept Equivalence service lets HDR solutions find data recorded using different concepts.
With Concept Equivalence, concepts from the same or different terminologies—that have the same meaning— are considered equivalent. Concept Equivalence facilitates specification and query of concepts that are equivalent.
Concept equivalence is also used by HDR solutions that implement the HDR messaging services.
Concept equivalence services include:
-
Intraterminology Equivalence
-
Interterminology Equivalence
Intraterminology Equivalence
Intraterminology equivalence deals with identical concepts (those with the same meaning) within a single terminology. When a new version of a terminology is released, there may be several changes to the representation and meaning of concepts when compared to the previous version. Because there is no way for ETS to automatically determine these changes, by default it treats concepts from the previous and new versions as distinct and unrelated. However, it is possible to explicitly indicate the changes that have occurred between a prior version and a new version in a change file that is loaded with the new version. Using this information, Intraterminology equivalence services can determine whether two concepts from the previous version and the new version have the same meaning.
Given a concept from a version of a terminology, ETS can retrieve equivalent concepts from all contiguous versions that have change files loaded. Given two concepts from different versions of a terminology, ETS can verify if they are equivalent, provided that the more recent version and all the intermediate versions have change files loaded.
Interterminology Equivalence
Interterminology equivalence deals with identical concepts (those with the same meaning) from different terminologies. Concepts from two different terminologies can vary widely in their granularity and coverage of a domain. Because there is no way for ETS to automatically determine these differences, by default it treats concepts from the two terminologies as distinct and unrelated. However, it is possible to explicitly indicate equivalence between concepts from two versions of different terminologies in the form of an Interterminology Mapping. Using this information, Interterminology equivalence services can determine whether two concepts from different terminologies have the same meaning.
Combining Intraterminology and Interterminology Equivalence
Equivalence between concepts is a transitive relationship. In the following chart, if Concept A1 is equivalent to Concept A2, and Concept A2 is equivalent to Concept A3, it can be inferred that Concept A1 is equivalent to Concept A3. Consistent with this logic, Concept Equivalence services in ETS can determine if concepts from two terminologies are equivalent—provided that an inter terminology mapping exists between versions of the two terminologies, and, change files have been loaded for all versions.
Concept Equivalence Model
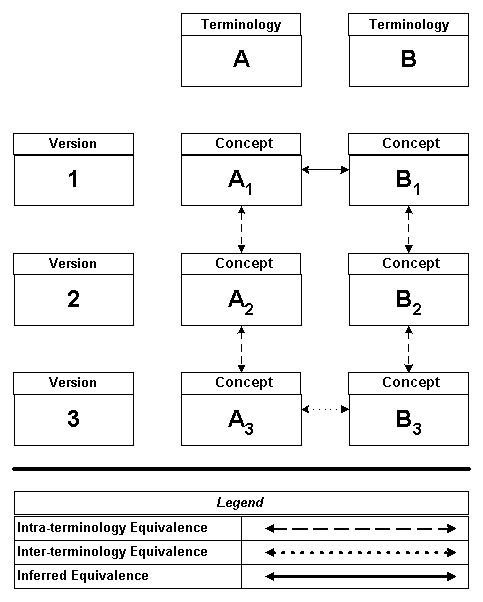
In this chart, ETS transitively combines intraterminology equivalence and interterminology equivalence information to infer that Concept A1 is equivalent to Concept B1.
Implementing Intraterminology Equivalence Using Change Files
Change files are used to document the differences between successive versions of a terminology that are loaded into ETS, in a format that is acceptable for loading purposes. Change files are loaded at the same time as the terminology version data using the same loader and importer. Change files contain the following types of information:
-
Reassignment: The meaning of one concept is occasionally reassigned to another concept represented by a different concept code. Following are some of the situations in which reassignment occurs:
-
Duplicate concepts are detected. One of them is elected to continue representing the meaning while the other is retired or deleted and reassigned to the retained concept.
-
A concept is detected to be erroneous. The erroneous concept is retired or deleted and reassigned to a correct concept.
-
The classification of a concept is changed. If the concept codes are hierarchical (as in ICD-9-CM), the change in classification translates to a change in concept code, necessitating reassignment.
-
A reassignment is indicated in a change file by a row containing an entry of type S (semantic reassignment), followed by a source concept code (the concept whose meaning is being reassigned to another code), and a target concept code (the concept whose code now captures the meaning).
See Also
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme/Change_File_Formats_General.txt from hdr-1.0.0-8.0.08.0.0.zip for more information about the format of the change file.
If both the source and target concepts of a reassignment are from the new version, the reassignment is said to be intra-version. For example, in SNOMED-CT, if a duplicate or erroneous concept is detected, the new version carries forward the duplicate or erroneous concept in an inactive status. The reassignment in this case is from the inactive concept in the new version to an active concept in the new version.
If the source of a reassignment is from the previous version and the target is from the new version, the reassignment is said to be inter-version. For example, in ICD-9-CM, if an erroneous concept is detected, it is deleted and excluded from the new version. A correct concept is provided in the new version and a reassignment is created between the concepts in the previous version and the new version. To process an inter-version reassignment contained in a change file, the ETS importer looks for the source code in the non-quarantined version (of the terminology in question) that has the latest load date. The non-quarantined version can be either active or retired.
-
-
Reuse: Occasionally, a concept code used in the previous version is reused to represent a concept with a different meaning in the new version. Note that this is considered bad terminology practice and should only be used to account for inadvertent errors. Unless a reuse is explicitly called out in the change file, a concept in the previous version is always considered equivalent to a concept with the same concept code in the new version.
Change files are preseeded for the following terminologies (no further implementation steps are required):
-
HL7
-
HDR Supplemental
For each of the following terminologies, new versions and their change files are available to customers, possessing licenses, from the vendor of the terminology:
-
IETF RFC 1766
-
ISO 3166-1 alpha2
-
NUBC-UB92
-
CPT-4
-
FDB
-
HCPCS-2
-
ICD-10
-
ICD-9-CM-DRG
-
ICD-9-CM-MDC
-
ICD-9-CM-V1
-
ICD-9-CM-V3
-
LOINC
-
SNOMED-CT
For all other terminologies that are loaded into ETS, change files must be created separately and loaded for each new version as described in the implementation steps.
Note that change files must be loaded concurrently with the new version of a terminology. It is not possible to load a change file for a version of a terminology after both versions have been loaded.
Note also that a change file can only equivalence concepts between two consecutively imported versions of a terminology. Hence the order in which versions are imported is significant if change files are being used. The following scenarios illustrate this constraint:
-
A concept (concept code X) exists in version 1 of a coding scheme. The concept neither appears in version 2 nor is reassigned to an equivalent version 2 concept. A concept with code X reappears in version 3 with the same meaning as in version 1. It is not possible to indicate to ETS that concept X from version 1 is equivalent to concept X from version 3-because it spans a version.
-
A concept (concept code X) exists in version 1 of a coding scheme. The concept neither appears in version 2 nor is reassigned to an equivalent version 2 concept. In version 3, another concept (concept code Y) is created that is equivalent to concept X from version 1. It is not possible to indicate to ETS that concept X from version 1 is equivalent to concept Y from version 3.
Note: To support concept equivalence, the ETS importer does not import a second quarantined version of a terminology if one already exists. This facilitates verification of equivalence between the quarantined version and the previous version of the terminology before the quarantined version is published.
Steps:
-
Determine if the reassignment information for the terminology is inter-version or intra-version. Use the following rules to make this determination:
-
Intra-version reassignment is used by terminologies that carry forward the duplicate or erroneous concept into the new version, albeit with a retired status, and reassign it to an active concept with a different concept code in the new version.
-
Inter-version equivalence should be used for terminologies that do not carry over the concept to be reassigned into the new version. Such terminologies will instead reassign directly from the concept in the previous version to a concept in the new version.
-
-
Create the change file with the appropriate Reassignment and Reuse entries. See /ets/hdr-ets-1.0.0-8.0.0/db/execute/readme/Change_File_Formats_General.txt from hdr-1.0.0-8.0.0.zip for details about the format of the change file. Note that the S ENTRY_TYPE is called Reassignment in this guide.
-
Set the HISTORY_TYPE property of the terminology loader control file to INTRAVERSION or INTERVERSION based on the determination made in Step 1. If the HISTORY_TYPE is set to INTRAVERSION, both the SOURCE_CONCEPT_CODE and TARGET_CONCEPT_CODE of a reassignment are assumed to be from the version being loaded. If the HISTORY_TYPE is INTERVERSION, the SOURCE_CONCEPT_CODE is assumed to be from the previous version, and the TARGET_CONCEPT_CODE is assumed to be from the new version.
Note: If no HISTORY_TYPE is present, the value defaults to NONE and no equivalence information is processed. If the HISTORY_TYPE is INTERVERSION or INTRAVERSION, a change file must be specified using the CHANGE_FILE property. Even if no reassignment or reuse has occurred, an empty change file with the header line must be provided.
-
Specify the location of the change file using the CHANGE_FILE property of the terminology loader control file.
-
Perform the steps described in Loading and Activating New Terminology Versions to load and activate the terminology version along with the change file.
See Also:
Implementing Interterminology Equivalence Using Interterminology Mapping
Interterminology equivalence is implemented by creating cross maps. Cross maps that implement equivalence constitute a special case of interterminology mapping. Note that interterminology mapping can also be used to map source and target concepts where the source is semantically broader than or narrower than the target, or where the source and target are related in some other manner.
Cross maps can be used to implement equivalence by specifying that the source and target are equivalent in the EQUIVALENCECONTEXT field of the Cross Maps file.
Implementing Interterminology Mapping Using Cross Maps
Interterminology mapping provide a mechanism by which concepts from a source version in one terminology can be mapped to concepts from a target version in another terminology. Mappings are typically tailored for a specific application. For example, a data-aggregating or reporting application may require a mapping between specialized SNOMED-CT codes and coarse ICD-9-CM codes. A data retrieval application may use mappings with the opposite semantics (from less granular classifier codes to more detailed codes). These examples serve to illustrate that mappings serve multiple purposes, and not all cross maps indicate equivalence. Those cross maps that truly do indicate equivalence must be explicitly flagged by the author of the cross maps. This section describes the steps you should follow to indicate equivalence between concepts from two different terminologies using interterminology mapping files.
Perform the following steps to define interterminology mapping using cross maps:
Steps:
-
Create Map Set Loader files.
-
Perform the following steps on the file referenced by the CROSS_MAP_FILE property of the Map Set Loader Control File
-
The eighth column of the cross maps file is called EQUIVALENCECONTEXT. The Map Set Loader inspects this column in each row to determine if the cross map in that row can be used for equivalence. If this column in a particular row is left empty or set to null, the cross map in that row will not be used by ETS Concept Equivalence Services.
-
If the EQUIVALENCECONTEXT column is populated, the cross map is interpreted as indicating equivalence between the concepts represented by the MAPCONCEPTID and the MAPTARGETID.
-
Because determining similarity of meaning between concepts from different terminologies is often subjective, it may not be appropriate to use the same set of cross maps for interterminology equivalence on all occasions. For example, the requirements of a reporting application may be satisfied by a looser definition of equivalence than a clinical order entry application. The EQUIVALENCECONTEXT parameter lets each cross map be associated with the context in which its use is appropriate. At runtime, the EQUIVALENCECONTEXT can be provided as a parameter to ETS Equivalence Services to selectively use only those cross maps that are associated with that context.
-
The default EQUIVALENCECONTEXT is SYSTEM. Cross maps that are flagged with this context will be used by IMP and OMP to determine equivalents in concept lists and the master catalog. If a context is not specified in an equivalence query at runtime, this context is assumed by default.
-
If the same cross map is deemed suitable for multiple contexts, it may be repeated several times in the cross maps file, each time with a different EQUIVALENCECONTEXT.
See Also
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme/Terminology_File_Formats_MapSet.txt from hdr-1.0.0-8.0.0.zip for Map Set Loader file formats.
-
-
Load the Map Set files.
Loading the Map Set Files
Perform the following steps to load the map set files:
-
Create a cross map file and a control file in ETS format, and move them into a directory located in the same file system as the Applications instance-a directory that is accessible by the Oracle Database Scheduler (DBMS_SCHEDULER).
See Also:
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip, for details about Cross Map file formats.
-
Use Oracle Database Scheduler (DBMS_SCHEDULER) to load the map set files.
Select the HDR Loader Job. Select the coding scheme name called Map Set Loader, and enter values for the control file and coding scheme version name.
See Also:
-
Oracle Applications System Administrator's Guide
-
-
After completion of the load, use the HDR Importer Job to import the loaded terminology.
Enter the load sequence number. You can get this value from the log file of the HDR Loader Job that has successfully loaded the data (coding scheme versions, classifications, and cross maps).
Select Off as the value of dry run mode.
See Also:
-
Oracle Applications System Administrator's Guide
-
Guidelines: Cross Maps
The ETS Cross mapping model is based on the SNOMED CT cross mapping model. Cross-mapping mechanisms provide support for the following:
-
Mapping a single concept to a target code (a one-to-one mapping).
-
Mapping to a set of Target codes (a one-to-many mapping).
The current structure does not support:
-
Mapping a set of Concepts to a Target.
The relationship between these tables is shown by the following chart:
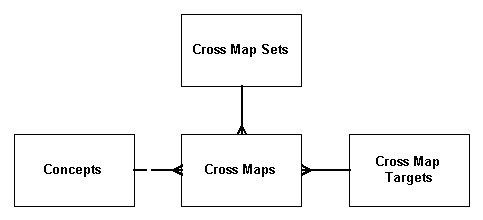
A map set defines a mapping between two coding scheme versions, such as Terminology A version 2003 and Terminology B version 2.01. Each map set is composed of multiple cross maps. Each cross map consists of a source concept and one or more target concepts, such as a source concept from Terminology A and one or more target concepts from Terminology B—to which it maps.
Loading Cross Maps Provided by the College of American Pathologists
The principal difference between cross map files distributed by the College of American Pathologists (with SNOMED CT) and those expected by ETS loaders is that the SNOMED CT files could contain data regarding multiple map sets in a single file. The map set file may contain multiple rows, each pertaining to a different map set. The cross map file may contain cross maps relating to multiple map sets, and the map targets file may contain targets used by multiple map sets (targets related to multiple coding schemes).
To make the SNOMED CT files suitable for ETS loading, split the files into map sets. The map set file should contain only one row, representing one map set. The cross maps file should contain only rows containing the map set ID of the chosen map set. The map targets file should contain only targets related to the target coding scheme specific to the map set.
See Also:
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme from hdr-1.0.0-8.0.0.zip for the cross-map table structures.
Creating Local Descriptions
You can specify local descriptions for any ETS concept. These descriptions can be used in place of terminology-specified descriptions for display purposes. You can assign a single usage context to each local description.
The usage context for each local description must be unique; no two local concept descriptions share the same usage context.
Note: Local descriptions of a concept can be created for any language, not just for languages loaded with the coding scheme version.
Use ETS API to create local description. You can create local descriptions for retired or active concepts, but the typical procedure is to create a description for concepts in the active default version of the terminology.
Managing Usage Contexts
Usage Contexts let an HDR solution specify and determine which concept list or local description (of a specific ETS concept) should be used in a given application context. Usage contexts are an attribute of concept lists and local descriptions. A user may specify a usage context when a concept list or a local description is created or later.
When accessing a concept list or local description, HDR solutions may specify a usage context. Based on the specified usage context, HDR retrieves a matching concept list or local description. For example, a Utilization Review department may require diagnoses to be displayed as short names or abbreviations. For this to be implemented in HDR, first a usage context with a name such as Utilization Review must be created. Then, the required local descriptions (short names or abbreviations) with the Utilization Review usage context can be created for the appropriate concepts. Subsequently, applications developed for the department can use ETS APIs with the Utilization Review usage context to display the required local descriptions.
Each local description of a concept must have a single usage context that is unique for that concept. If a local description is assigned a usage context and a local description for that concept already exists with the same usage context, the operation succeeds—but the usage context is removed from the first local description.
A usage context can similarly be used by a concept list. associated with an organization can by an application. For example, a healthcare enterprise might have a concept list of medical services called ENT_MED_SERVICES. A hospital owned by the enterprise may require a specialization of that concept list that contains a subset of the original values. For this to be implemented in HDR, first create a usage context with a name such as Fair Oaks, and associate it with a hospital unit. Then, a specialization of the ENT_MED_SERVICES concept list can be created, with a name such as FAIR_OAKS_MED_SERVICES, and associated with the Fair Oaks usage context.
Use ETS API to manage usage context.
Implementing Concept Lists
Concept lists group ETS concepts for a variety of purposes, such as displaying certain concepts in user interface drop-down lists and other controls, or constraining values of an attribute to certain concepts.
Concept list member concepts possess activation and retirement dates; and have active, retired, or pending status within a list. Each member concept in a concept list has a code by which it is known in the list (a membership code). The membership code is unique among active or pending members of the concept list, and it can be used by HDR solutions to identify the member concept.
HDR is shipped with a set of pre-defined concept lists. These concept lists are used within HDR to validate attributes that must have coded values, and to process inbound messages. These concept lists have predefined concept names that start with either CTB_ (prior releases) or CL_ (current release).
ETS treats concept lists as of three types based on whether the concept list can be extended or not:
-
SYSTEM: HDR is shipped with a set of pre-defined concept lists. These concept lists are used within HDR to validate attributes that must have coded values, and to process inbound and messages. These concept lists have predefined concept names that start with either CTB_ (prior releases) or CL_ (current release).
-
Do not use predefined concept lists for any other purpose (other than the defined purpose).
-
Do not use the CTB_ and CL_ prefix for concept lists you create.
-
-
EXTENSIBLE: Certain concept lists have been seeded empty-the concept lists are created in the system, but no concepts are added to them. They must be filled by concepts during implementation. Predefined lists that are empty are necessarily extensible. Other predefined lists that have concepts may be extensible also: content may be added to them as required.
-
USER:
You can create specializations of concept lists that are defined as EXTENSIBLE. Specializations are child concept lists that initially inherit parent concepts, but may be modified by adding or removing member concepts.
A Specialization can be associated with a usage context, which may in turn be associated with a particular HDR organization.
You can also subset seeded lists, if only a subset of the seeded values are applicable. Because HDR seeded lists are of the type SYSTEM or EXTENSIBLE, and only lists designated USER can be subsetted directly, you must employ indirect methods to subset seeded lists.
Creating and Updating a Concept List
Use ETS API to create a concept list. For more information on Concept Lists API, refer to the Oracle Healthcare Data Repository Javadoc.
Adding Concepts to a Concept List
Concepts can be added to extensible concept lists. Concepts to be added to a concept list must be contained in a coding scheme version that has already been loaded into ETS. Determine if the concept exists in ETS and the coding scheme version in which it is contained.
Perform the steps described in this section to add concepts to a concept list.
Caution: Certain extensible concept lists are empty and must be populated with concepts before using their respective functionality.
Adding Concepts to a Concept List
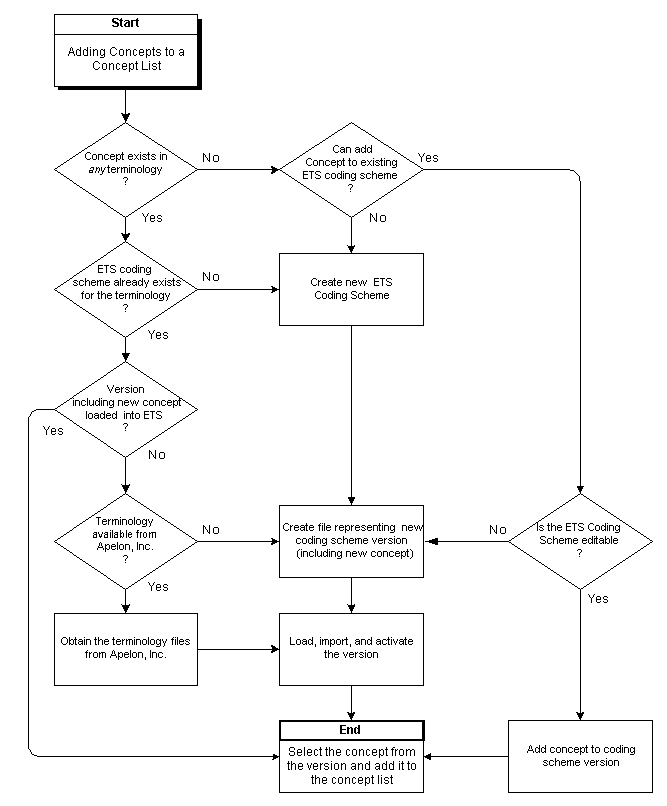
Note:
A concept cannot be added under the following conditions: the concept is already active or pending in the selected list; the selected list is the parent of an additive child specialization and the concept is already active or pending on the child; the selected list is a SYSTEM list; or the selected list is a restricted child specialization and the concept is not active or pending on the parent lists.
If any (but not all) concepts chosen for addition are not addable, a warning diagnostic lists the concepts that will not be added. You can elect to continue or return to list selection.
If all concepts selected for addition are not addable, the List Selection window is reloaded with an information box listing these concepts. To continue, select another list.
If any of these conditions exist, select a new membership code or activation date as appropriate, and click Next. You can alternatively click Back to return to the List Selection page, or click Cancel to exit the addition process.
Note: If the concept is being added to a restricted specialization, and the selected activation date would cause the concept's active period to exceed that of the corresponding concept in the parent list, an exception occurs; a dialog warns you that the concept has not been added.
See Also:
Oracle Healthcare Data Repository Javadoc
Caution: We strongly recommend that wherever possible, you only add concepts from the same terminology to a single concept list. Concept meanings can be sensitive to the context in which they are included in a terminology; mixing them with concepts from other terminologies may distort those meanings.
Specializing a Concept List
Concept lists can be specialized. A specialization of a concept list is a child concept list that initially inherits the active members of the parent list. It is a separate concept list, distinct from the parent list. Subsequent behavior of the specialization (a child concept list) with respect to the parent concept list depends upon the setting of its inheritance type:
-
Addition Inheritance: Any concept added to the parent list is added to the child list.
-
Deletion Inheritance: Any concept retired from the parent list is retired from the child list.
-
Restricted Inheritance: A child list cannot contain any concept not contained in its parent list; before a concept is added to the child list it must first either exist in the parent list or be added to the parent list. A concept in a restricted child list also inherits certain changes to the activation and retirement dates of the corresponding concept in the parent list.
The inheritance types are not mutually exclusive. A restrictive list must also exhibit deletion inheritance. You can update a list's addition inheritance and deletion inheritance by turning them on or off, but you cannot update its restricted inheritance.
A specialization can be associated with a usage context, as can a concept local description. A usage context can in turn be associated with an organization. Accordingly, a concept list can have multiple specializations, each associated with a particular organization.
A concept list specialization is created in the same manner as any other concept list (Steps).
Values in a concept list specialization can be added or retired as for any concept list.
Subsetting a Concept List
It may be desirable to subset a concept list—using only a subset of a concept list's members, for UI display purposes, or for validating data to be stored by an application. The following sections describe how to subset a concept list:
Subsetting a User Concept List
A concept list of extensibility type User can be subsetted by retiring unwanted members from the list. A member is retired by updating its retirement date and time.
Note: This subsetting procedure does not apply to System or System extensible concept lists.
Subsetting a Concept List of any Extensibility Type
A concept list of any extensibility type (including user) can be subsetted using either of two additional procedures. These procedures are especially useful if the list to be subsetted is a System or System Extensible list, from which members cannot be retired (two methods):
Method 1: Using the Core Member Setting of List Members
The core set of members in the list can then be retrieved using the method:
getCoreSet
Checks of individual members of the list can be performed using the method:
isCoreMember
Method 2: Using a Specialization of the Concept List and Retiring Members
Reference:
Oracle Healthcare Data Repository Javadoc
Table 2-4 Service and Methods: Specializing Concept Lists
|
Level |
Detail |
|
Package |
oracle.hsgbu.ets.base |
|
Class |
ConceptList |
|
Methods |
getChildConceptList |
To subset a concept list of any extensibility type using Procedure-2, do the following:
Create a specialization of the concept list, and specify a usage context for the child list. You can then subset the child concept list, and you can use the subsetted list as required by your application.
Access the specialization using the method:
getChildconceptList
Implement Security
HDR EJB (Enterprise Java Beans) services require all callers of the service be authenticated by the application server.
WebLogic admin user can access the HDR services. But still it is recommended to create a HDR specific WebLogic user called hdradmin.
WebLogic users can be maintained in the default security provider or any WebLogic server supported providers such as LDAP, that can be configured and used with HDR.
HDR does not require user authorization to access the services. Any authenticated user in any role can access HDR services.
Reference
Implementing ETS Classifications
Large amounts of healthcare data are difficult to use unless they are well organized. Creating classifications is the most common means of organizing healthcare data. As institutions generally use a combination of (standard and local) terminologies, classifications need to incorporate concepts from different coding schemes and versions.
The following table summarizes the principal interfaces referenced by this section:
Table 2-5 Service and Methods: ETS Classifications
|
Level |
Detail |
|
Package |
oracle.hsgbu.ets.base |
|
Class |
ETSAdministrationService |
|
Methods |
|
|
Class |
ETSService |
|
Methods |
|
|
Class |
Classification |
|
Methods |
|
ETS Classifications provide a mechanism for grouping concepts from different coding schemes and versions, and arranging the groups in hierarchies navigable by the ETS API. ETS Classifications facilitate:
-
Viewing a large number of concepts
-
Selection of concepts
-
Class-based query of information
For example, a classification called cardiovascular diseases could be created and populated with concepts that represent different cardiovascular diseases from different terminologies. The following chart shows this classification:
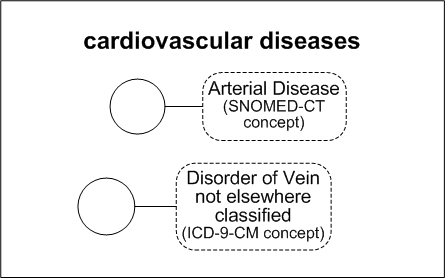
ETS Classifications are internally represented as concepts in an editable generic coding scheme called ETSClassification. In this example, the classification, cardiovascular diseases is stored as a concept in the coding scheme ETSClassification.
But you could also create another classification such as heart diseases and make it a child classification of the cardiovascular diseases classification. Thereafter, any concept in the heart diseases classification, such as congestive heart failure, would be considered by the Classifications interface to be implicitly contained in the cardiovascular diseases classification.
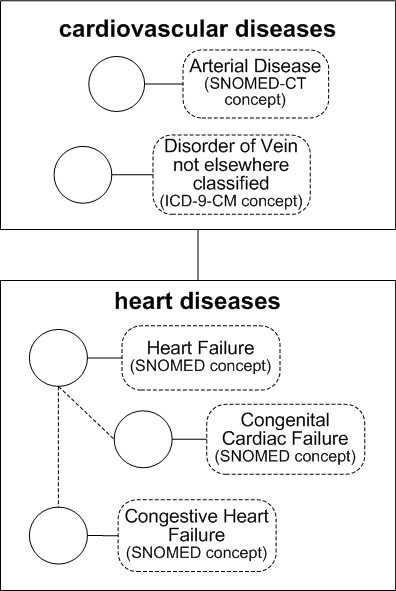
ETS Classifications are basically containers of ETS concepts. In this chart, the concepts in each classification node could derive from different coding schemes.
ETS classification interfaces are oblivious to relationships between the classification concepts in their native terminologies. For example, in this chart, congestive heart failure and congenital cardiac failure are children of heart failure in their native terminology, but the heart disease ETS Classification views its contents as a flat list of concepts. There is no classification interface that is aware of relationships between the classification concepts in their native terminologies. However, those relationships can be navigated by querying the individual concepts, using the ETS generic terminology interface or a terminology-specific interface.
Classifications are themselves ETS Concepts – components of a special, pre-defined editable terminology called ETSClassifications. Creating a new classification actually is creating a new concept in the ETSClassifications terminology. Since classifications are concepts:
-
A classification may have multiple descriptions, one of which is designated preferred
-
Local descriptions may be associated with usage contexts
-
A classification has an ETS ID
Classifications can be Linked Hierarchically
Classifications may be linked in strict or multiple hierarchies (a classification may have multiple parent classifications) to form a network of linked classifications forming an acyclic graph.
Testing Containment
ETS classifications support testing of containment across levels of a hierarchy. For example, given the hierarchy in the chart Sample ETS Classification, if the concept congestive heart failure is in the heart disease classification, and the heart disease classification is a child of the cardiovascular diseases classification, you can test if congestive heart failure is a cardiovascular disease, and the answer will be Yes.
Equivalence is incorporated into Classifications.
The concepts contained in an ETS Classification retain their equivalence information. For example, what is actually considered as included in cardiovascular diseases are groups of concepts that are equivalent to heart failure, congenital cardiac failure, congestive heart failure, and arterial anuerysm. Consequently, if concept X is equivalent to congestive heart failure, and the question ”Does ’cardiovascular diseases' contain X?” is asked, the answer will be ”yes”.
Creating and Populating Classifications
Classifications are created by generating a hierarchical network of classification nodes and populating those nodes with individual ETS concepts. An individual classification node may contain concepts from multiple terminologies.
A single concept can be used in multiple classifications, including multiple sub-classifications of the same parent classification, but it cannot appear more than once in the same sub-classification. However, equivalent concepts can be inserted into the same sub-classification. As for all ETS concepts, concepts in a classification can have multiple text representations.
Classifications may be created and populated by two methods:
-
Specifying classification data in files, and loading the files using HDR Terminology Jobs
-
Using ETS APIs directly
A new classification will have a pending state when it is created and loaded. It will become effective only when the HDR Maintenance job is run. Until then, the new classification will be unusable. This enables new classifications to be created and readied for use without requiring a downtime.
Whenever changes are made that could affect classification contents (declarations are added or removed, a version of a terminology that contains classification concepts is loaded, or a mapping involving a version that contains classification concepts is loaded), the classification moves from the active state to a dirty state. In this state the classification in its former active state is still usable. The effects of the changes that placed the classification into the dirty state will not be usable until the classification is moved from the dirty state to the active state. Classifications are moved from the dirty state to the active state by running the HDR Maintenance Job.
See Also:
Classification contents are defined declaratively. This enables a short-cut for adding concepts declared a terminology to be children of another concept. For example, the concepts heart failure, congenital cardiac failure, and congestive heart failure could have been added to heart diseases by a single statement(add heart failure and its descendents to heart diseases). This adds heart failure and its children as defined within its native terminology. A declaration can also add a concept and only those concepts deemed to be direct children in its native terminology, add a concept's descendents but not the concept itself, or add a concept's direct children but not the concept itself. The various insertion choices are called insert options.
See Also
Oracle Healthcare Data Repository Javadoc
A declaration with an insert option of concept only adds a single concept ((the concept with none of its children). The contents of a classification amount to a series of declarations. Classification contents are augmented or reduced by adding or removing declarations.
To retrieve a concept's children when implementing a declaration, the ETS classification build process must know which relationships in the concept's native terminology represent parent-child relationships. Accordingly, for each core terminology, HDR has identified certain relationships as defining parent-child associations. The ETS classification build process queries for such relationships when called upon to find a concept's children. For generic terminologies, the build process queries for relationships in which the relationship type concept is identified as type IS_PARENT_OF or IS_CHILD_OF.
See Also
-
Documentation at the Apelon, Inc. web site for descriptions of the treatment of specific terminologies.
-
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme /Terminology_File_Formats_Generic.txt from hdr-1.0.0-8.0.0.zip
Note:
Each ETS concept defined in a generic terminology must be identified as being valid or invalid for use as a relationship type, and is indicated by the RELATIONSHIPTYPEFLAG column in the Concepts fie. This flag can contain one of the following values (Table):
Table 2-6 Concept File: RELATIONSHIPTYPEFLAG Legal Values
|
Value |
Description |
|
N |
The concept cannot be used as a relationship type. |
|
Y |
The concept can be used as a relationship type. |
|
IS_PARENT_OF |
The concept can be used as a relationship type, and the type indicates that the source concept is the parent of the target. |
|
IS_CHILD_OF |
The concept can be used as a relationship type, and the type indicates that the source concept is the child of the target. |
Those concepts designated as valid relationship types in the concepts file can subsequently be used in the relationships file in the RELATIONSHIPTYPECONCEPTCODE column.
Use the following HDR interfaces to define and use ETS classifications:
-
ETSAdministrationService
-
ETSService
-
Classification
Creating a Classification
To create and populate a classification via the loader, perform the following steps:
Steps:
-
Create a Classifications file. This file lists the classifications to be created and their properties.
-
Create a Classifications descriptions file: This file lists the descriptions to be associated with the classifications and their properties. Just as multiple descriptions for a concept can be listed in a terminology descriptions file, multiple descriptions can be created for a classification.
See Also:
-
Create a Classifications declarations file. This file lists the declarations (each declaration consisting of a concept and an insert option) that will be added to classifications. The classifications referenced in this file can be new classifications listed in the classifications file, or pre-existing classifications.
Note: Declarations must be removed through an API call; they cannot be removed through the loader.
-
Create a control file specifying the Classifications, Classification Descriptions, and Classification Declarations files.
See Also:
/ets/hdr-ets-1.0.0-8.0.0/db/execute/readme/Terminology_File_Formats_Classifications.txt from hdr-1.0.0-8.0.0.zip for file formats.
-
Load the classification. The procedure for loading a classification is the same as that for loading a Coding Scheme Version. Enter ETSClassifications in the Coding Scheme Name field on the Parameters page. Enter any text for the Coding Scheme Version Name (this field must contain text, but the actual text is ignored by the loader).
See Also:
-
Import the classification. The procedure for importing a classification is the same that for importing a Coding Scheme Version.
See Also
-
Run the Healthcare HDR Maintenance Job to build the classification.
Building a Classification with the HDR Maintenance Job
To build a classification run the HDR Maintenance Job with CLASSIFICATIONS in run mode.
Note: Run the HDR Maintenance job in the full mode whenever a significant amount of new classification data is created (including the first time classifications are created and populated in ETS.
Updating Published Coding Scheme Versions
After a coding scheme version is imported (published), you can update its properties (description, status, and default status) through the ETS API.
Running the HDR Maintenance Job
The HDR maintenance Job performs several database tasks. These tasks include:
-
Maintaining the ETS stage tables. For example, cleanup of incomplete or obsolete data in the staged tables.
-
Maintaining the ETS data in the active tables. For example, cleanup of failed imports in the active tables.
-
Building classifications by processing data for classifications in the pending or dirty state.
-
Building and synchronizing intermedia indexes.
-
Gathering statistics for the Cost-based Optimizer.
-
Ensuring that there is an entry in the language mapping table for each combination of coding scheme version and installed languages.
The maintenance job must be run in either FULL mode or CLASSIFICATIONS mode to move a classification from the 'dirty' or pending state to the active state. In general, it is a good idea to run the maintenance job periodically to keep ETS running optimally.
Note: You should run the HDR Maintenance Job in the FULL mode:
-
Each time you apply a patch to ETS.
-
Whenever a significant amount of new classification data is created (including the first time classifications are created and populated in ETS).
Scheduling the Maintenance Job
Steps
Refer to Running HDR maintenance Job from Appendix D: Running HDR Terminology Jobs
Note: In job arguments, select the desired Run Mode. The available choices are:
-
CLASSIFICATIONS: Builds classifications by matching definitions of classifications in the pending or dirty state. Classifications that have been created since the last time the maintenance job was run in CLASSIFICATIONS or FULL mode will be in the pending state. Classifications that have been modified since the last time the maintenance job was run in CLASSIFICATIONS or FULL mode will be in the dirty state. Successfully processed classifications obtain the active state.
-
CLEAN_ACTIVE: Performs maintenance on the ETS data in the active tables. Removes data from failed imports in the active tables, and rebuilds the intermedia indexes, if necessary. Ensures that there is an entry in the language mapping table for each combination of coding scheme version and installed languages.
-
CLEAN_STAGE: Performs maintenance on ETS stage tables. Removes incomplete or obsolete data from the staged tables, and rebuilds the intermedia indexes, if necessary.
-
DEFAULT: Performs maintenance on ETS stage, active, and language mapping tables, but does not build classifications. This mode is composed of CLEAN_ACTIVE and CLEAN_STAGE modes of the maintenance job.
-
FULL: Performs all operations, including maintenance of stage, active and language mapping tables, and building of classifications. This mode is composed of CLEAN_ACTIVE, CLEAN_STAGE, and CLASSIFICATION modes of the maintenance job.
-
TRUNCATE_STAGE: Removes all staged contents, regardless of their status. This mode is faster than CLEAN_STAGE for large datasets.
Caution: The TRUNCATE_STAGE option can cause data that could have been used by the importer to be lost.
See Also:
-
Oracle Applications System Administrator's Guide
Implement Audit Services
HDR Auditing Services lets you log and monitor all HDR activities, to monitor security policy and regulation compliance-by recording actions taken by users during sessions. Such actions could include invoking an API, performing a custom function, or other defined events.
HDR Configuration Manager, a GUI tool, lets security administrators define auditing policies. Implementation of HDR Audit Services includes the following steps:
-
Enabling HDR Audit Services
-
Initializing existing audit event types
-
Creating new audit event types
-
Invoking HDR Audit Services
-
Implementing Enterprise Terminology Services
The following chart provides an overview of the implementation process for Audit Services:
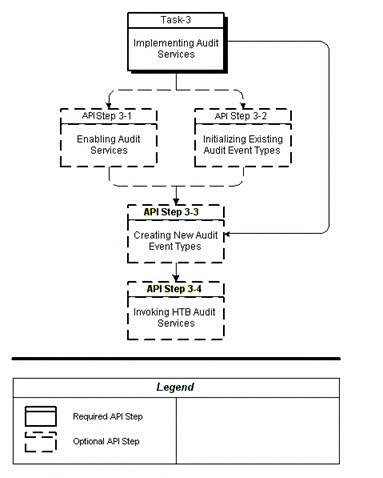
To implement Audit Services, refer to the following procedure table:
| Task-Step | Description | Optional? |
|---|---|---|
| 3-1 | Enabling Audit Services | Yes |
| 3-2 | Initializing Existing Audit Event Types | Yes |
| 3-3 | Creating New Audit Event Types | Yes |
| 3-4 | Invoking HDR Audit Services | Yes |
Enabling Audit Services
HDR Audit Services can be enabled (turned on) or disabled (turned off) globally. When enabled, audit events of all seeded and user-defined audit event types can be audited. When disabled, Audit Services is not operative.
Auditing is turned on or off by setting the profile option CTB: Auditing ON to Y or N respectively. By default, CTB: Auditing ON is set to Y on install. Use the ProfileOptionService to update this value. The profile option service API to update this profile option is:
ProfileOptionService.setProfileOptionValue
Initializing Existing Audit Event Types
Audit event types can selectively be turned on or off. When both the global auditing flag and a particular audit event type are turned on, events of this particular type are audited by HDR Audit Service.
Following is the list of HDR audit event types is seeded for HDR use. By default, these event types are turned on.
-
CTB: Audit Receive Message
-
CTB: Audit Update OID
-
CTB: Audit Query on Personal Health Information
-
CTB: Audit Insert/Update of Personal Health Information
Creating New Audit Event Types
Applications developed on the HDR Platform can define business audit event types in addition to the seeded event types.
For example, an Admitting application might define an audit event type asAdmit Patient, and monitor events of this type.
Note: Although HDR provides the mechanism to audit business events, it is your responsibility to implement the appropriate audit calls to log such events.
To create a new audit event type, use ProfileOptionService.createProfileOption to create a new profile option with the new audit event type as the profile option code.
Invoking HDR Audit Services
After defining new audit event types, applications can log audit events of these types by calling the Audit Services interface.
Reference
Oracle Healthcare Data Repository Javadoc
Table 2-7 Service and Methods: Audit Services
|
Level |
Detail |
|
Package |
oracle.hsgbu.hdr.auditing |
|
Class |
AuditService |
|
Methods |
createEventLog |
Prerequisite
Creating New Audit Event Types
Login
This is an API-based implementation procedure.
Responsibility
Any responsibility.
Navigation
This is an API-based implementation procedure.
Steps
-
Turn on HDR Audit Services and the audit event type.
-
Enabling Audit Services
-
Initializing Existing Audit Event Types
-
-
In the application code, call the createEventLog method with the new event type as the value of the EventType attribute. This can be found in Oracle Healthcare Data Repository Javadoc.
Implement HDR Object Identifiers
HDR generates a unique identifier for each Act, Entity, and Role persisted through RIMServices. Each identifier is an Instance Identifier data type, consisting of a root that uniquely identifies the HDR instance and an extension that is unique within the HDR instance. Together, they uniquely identify the HDR act, entity, or role. The value used for the root is configured during the setup of HDR and needs to be unique to a given HDR instance to support the sending of HL7 messages between different HDR instances and other systems. If an organization has multiple HDR instances, each instance must have a separate OID. The root is considered the namespace for the HDR instance's identifiers and guarantees the uniqueness of the identifier among all HL7 compliant systems. That is, two objects created in two different systems may have the same extension but can be uniquely identified due to different roots.
Note: User-defined or externally-supplied instance identifiers may also be persisted for an object. These are in addition to the system generated identifier. The system generated identifier guarantees that each object has at least one unique identifier.
This section describes how to configure the root object identifiers (OIDs) used for the various identifiers created by HDR.
A set of root OIDs must be configured during implementation to enable HDR to generate identifiers. Use the HDR Object Identifiers window to configure the root OID values for various identifier types. The various root OIDs defined using this window are used by HDR as a default root for the identifier, for the object being persisted.
Root OID values are not seeded because they are unique to each HDR installation. They are owned by the organization implementing HDR; they are not Oracle registered OIDs. Accordingly, the organization must obtain the OIDs from an appropriate issuing authority, such as HL7 or the standards authority relevant to their country. Alternatively, if the organization already owns an OID, they can use it or define a sub-OID to represent the instance of HDR. In order to enable interoperability with external systems, the root OID values must uniquely identify the HDR instance. Oracle will not supply the OIDs.
Note: See Also
-
HL7 Web site: http://www.hl7.org/. Refer to the current version 3 ballot documentation for details on the OID and II data types.
-
ISO/IEC 8824 standard: http://www.iso.org/iso/en/ISOOnline.frontpage. Refer to the ISO standard for further details on OIDs.
The set of root OIDs requiring configuration at implementation apply to specific HDR features and need not be configured if the associated features are not required. However, all parts of HDR make use of the RIM Services feature and therefore, the INTERNAL_ROOT must be configured in order to persist HDR objects. It is the root for any HDR internal identifier, which is essentially the primary key of an object. The other root OIDs must be configured if certain EMPI, TCA, Messaging, Financials, Identification, or Migration features are to be used. See the table Optional Root Object Identifiers for further information about how each OID is used.
The user-defined or externally-supplied instance identifiers are not pre-configured in HDR. The root and extension for these external OIDs are sent from external systems or created via an application built on HDR.
Prerequisites
Obtain the relevant OIDs from the appropriate issuing authority, such as HL7 or the relevant standards authority. Alternatively, if the organization already owns an appropriate root OID (that represents the organization), they can use this OID or issue a sub-OID to represent the instance of HDR.
Procedures
The following chart provides an overview of the implementation process for HDR Object Identifiers:
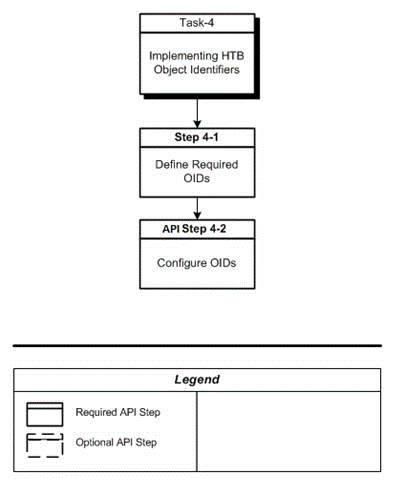
Use the OIDService.registerOID API to register new OIDs in HDR.
Implement Profile Option Services
Profile options are configurable preferences that affect the way an Oracle application looks and behaves. System administrators can control HDR behavior by setting profile option values. Application developers can control application behavior by programming their applications to perform in accordance with customized profile option values.
Examples of typical profile options include the following:
-
Language: Determines the language in which the application is displayed to users.
-
Date Format: Determines the format (mmddyyyy, ddmmyy...) for date displays.
System administrators can set profile options at the following levels:
-
User (highest level)
-
Org
-
Site (lowest level)
The profile option values set at each level define runtime values for each user's profile options. An option's runtime value is the highest level setting for that option.
A profile option can be set at more than one level. When a profile option is set to more than one level, an order of precedence applies: Site has the lower priority, superseded by Org, which is further superseded by User. A profile option value entered at the Site level can thus be overridden by value entered at the Org level, and value entered at the Org level can thus be overridden by the value entered at the User level.
Prerequisites
User Accounts must exist before setting profile options.
Procedures
The following chart provides an overview of the implementation process for Profile Option Services:
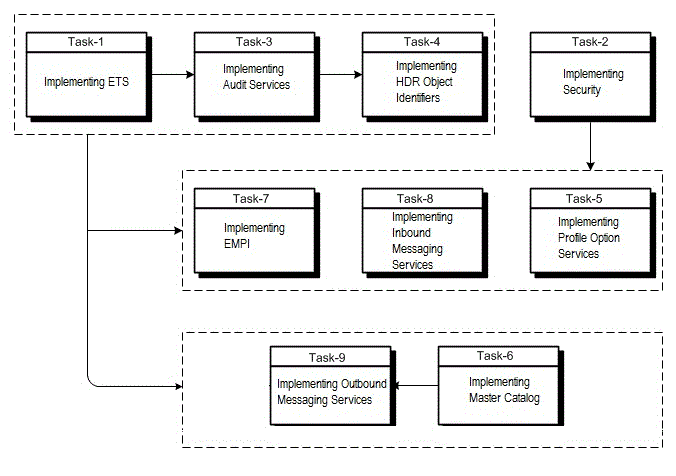
Implement Profile Options
The HDR ProfileOptionService enables users to manager profile options and its associated values at various profile levels.
Implement Master Catalog and Focal Class State Transitions
The Healthcare Data Repository (HDR) incorporates two configuration components that provide a repository of Act, Entity, and Role metadata. These two configuration components are the Master Catalog and the Focal Class State Transitions.
You can use a MasterCatalogService APIs to create, update, and search for Master Catalog and Focal Class State Transition entries.
Master Catalog
The Master Catalog defines specific combinations of the principal attributes on the Act, Entity, and Role classes.
These principal attributes are sometimes referred to as the structural attributes. For acts, the principal attributes are classCode, moodCode, and code. For entities, the principal attributes are the classCode, determinerCode, and code. For roles, the principal attributes are classCode and code, and the principal attributes of the player and scoper entities.
The following are the three main reasons for creating a Master Catalog entry:
-
Defining which types of Acts, Entities, and Roles can be persisted to the HDR repository by the Reference Information Model (RIM) Service interfaces. The Enterprise Terminology Services (ETS) repository defines the valid concepts allowed for the coded attributes on the Act, Entity, and Role classes (for example, classCode, moodCode, determinerCode, and code). The Master Catalog provides additional validation, beyond that provided by ETS, by defining the valid combination of the Act, Entity, and Role classCode, with the other principal attributes on the object.
See Also
-
Implementing Enterprise Terminology Services
-
Oracle Healthcare Data Repository Programmer's Guide (RIM Services > HDR RIM Services > Using Master Catalog API)
-
-
Distinguishing between multiple similar Acts, Entities, or Roles to provide a unique Master Catalog Id based on the unique concept assigned to the code attribute of the Act, Entity, or Role. The unique Master Catalog Id is referenced by the Act Concept Configuration.
See Also
-
Defining the specific combinations of the principal attributes of the Acts, Entities, or Roles to enable definition of the side effect processing rules for each unique combination. The unique Master Catalog Id is referenced by the Side Effect Configuration, used in Inbound Message Processing (IMP).
See Also
Oracle Healthcare Data Repository Programmer's Guide (HDR Messaging > HDR Inbound Message Processor > IMP Configuration API Usage > Sender Side Effect Configuration Attributes)
The Master Catalog is a required HDR component and must be installed and configured before the use of the HDR RIM Services, IMP, and OMP interfaces. Each combination of the principal attributes for the Acts, Entities, and Roles required by an HDR solution must have a corresponding entry in the Master Catalog.
Master Catalog is supplied with seeded entries that address a wide range of Act, Entity, and Role requirements. HDR solutions can use the seeded Master Catalog entries, and you can also define new Master Catalog entries that allow additional Acts, Entities, and Roles to be used.
There are three types of Master Catalog entries that are described in the following sections
-
Master Catalog Acts
-
Master Catalog Entities
-
Master Catalog Roles
Master Catalog Acts
In RIM, the Class Code, Mood Code, and Code attributes on an Act specify the type of Act that instance represents. As in the RIM, these attributes in the Master Catalog specify the types of Acts that are used in HDR. Act Master Catalog entries define the specific combinations of the Class Code, Mood Code and Code, which are required by the HDR solution.
The following table describes the Master Catalog metadata that can be defined for Acts:
Table 2-8 Act Master Catalog Attributes
|
Attribute |
Content |
Description |
Mandatory |
|
Master Catalog Id |
Internal identifier generated by the system. |
Uniquely identifies each Master Catalog entry. This attribute is not displayed on the Master Catalog - Act, Entity, or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Entry Type Code |
Defaulted to ACT for all Act Master Catalog entries. |
Specifies which type of class-Act, Entity, or Role-this Master Catalog entry relates to. This attribute is defaulted for the Master Catalog entry, depending on which screen is used to create the entry. This attribute is not displayed on the Master Catalog - Act, Entity, or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Class Code |
A valid ETS concept from the ActClass code system. |
Specifies the value for the Act.classCode attribute. |
Yes |
|
Mood Code |
A valid ETS concept from the ActMood code system |
Specifies the value for the Act.moodCode attribute. |
Yes |
|
Active Flag |
Valid values are:
|
Determines if this Master Catalog entry is active or inactive. |
Yes |
|
Code Type |
Valid values are:
|
Indicates how the Code attribute of the Master Catalog entry is used.
|
Yes |
|
Code System Name, Version Name, Code |
A valid ETS code, version, and code system if the Code Type is ID, or null if the Code Type is NULL or ANY. |
Specifies the value for the Act.code attribute. The value defined for the Act.code includes the specific code system, version, and code that have been defined, and any equivalence defined for that code system/version/code. |
Yes, if Code Type is ID. Should be null if Code Type is NULL or ANY. |
|
Confidentiality Code |
A valid ETS concept or concepts from the Confidentiality code system. |
Allows you to assign one or more confidentiality codes to a Master Catalog entry, to specify the type of confidentiality associated with these types of Acts. The Confidentiality Code may be used when querying the HDR repository, to mask specific information on the act. Note: The Master Catalog Confidentiality Code attribute is independent of the Act.confidentialityCode attribute. Both attributes can be used to store the same or different confidentiality codes. Both attributes can be used when querying the HDR repository, to mask specific information on the act. |
No |
See Also
Oracle Healthcare Data Repository Javadoc, MasterCatalog interface
Sample Act Master Catalog entries (from the seeded data supplied with HDR) are given in the Sample Act Entries table.
Concept Equivalence Support
The Master Catalog incorporates concept equivalence. Concept equivalence considers all concepts that are equivalent to the concept used in the Master Catalog entry, as also being covered by that Master Catalog entry. For example, an OBS.EVN Master Catalog entry is defined with the Code attribute valued with 364075005 (SNOMED-CT, Version 0607CORE) for heart rate. Subsequently, a new version of SNOMED-CT is released with a different concept representing heart rate. When using concept equivalence, it is not necessary to modify or append the existing Master Catalog entry. If the concept equivalence defines the equivalence between the two concepts for heart rate, Master Catalog will consider as valid any OBS.EVN with either of the two concepts, though the Master Catalog entry itself only contains the Version 0607CORE concept. This approach eliminates the need to update the Master Catalog when a new coding scheme or version is loaded in ETS, provided equivalence information is also loaded with the new coding scheme or version.
Using the Code Type Attribute for Acts
The Code Type attribute in the Master Catalog specifies the values permitted for the Code attribute on the Act instance. You can choose to do any one of the following:
-
Allow a specific Code value for a given Class Code and Determiner Code (Code Type ID)
-
Allow any Code value for a given Class Code and Determiner Code (Code Type ANY)
-
Constrain the Code attribute so it must be null (Code Type NULL)
Code Type ID
If the Code Type attribute of the Act Master Catalog entry is ID, the Class Code, Mood Code, and Code attributes of the entry specify which Acts are covered by this Master Catalog entry. The Code attribute of the Act (Act.code) must have the specified value, or its equivalent.
The following table displays a sample Act entry with Code Type attribute as ID:
Table 2-9 Sample Act Entry with Code Type ID
|
Class Code |
Mood Code |
Code Type |
Code/Code System |
Code Description |
|
PCPR |
EVN |
ID |
000928/HDR Supplemental |
PCP Assignment |
This Act Master Catalog entry encompasses Acts representing a patient care provision event, specifically a primary care provider (PCP) assignment. That is, any Act whose Class Code attribute is PCPR, Mood Code attribute is EVN, and Code attribute is 000928 or an equivalent ETS Concept.
Code Type NULL
If the Code Type attribute of the Act Master Catalog entry is NULL, the Class Code, Mood Code, and Code attributes of the entry specify which Acts are covered by this Master Catalog entry. The Code attribute of the allowed Act (Act.code) must be null.
The following table displays a sample Act entry with Code Type attribute as NULL:
Table 2-10 Sample Act Entry With Code Type NULL
|
Class Code |
Mood Code |
Code Type |
Code/Code System |
Code Description |
|
PCPR |
RQO |
NULL |
- |
- |
This Act Master Catalog entry encompasses Acts representing a request for patient care provision, with no further specification. That is, any Act whose Class Code attribute is PCPR, Mood Code attribute is RQO, and Code attribute is null.
Code Type ANY
If the Code Type attribute of the Act Master Catalog entry is ANY, the Class Code, Mood Code, and Code attributes of the entry specify which Acts are covered by this Master Catalog entry. The Code attribute of the allowed Act (Act.code) can have any value except null.
The following table displays a sample Act entry with Code Type attribute as ANY:
Table 2-11 Sample Act Entry With Code Type ANY
|
Class Code |
Mood Code |
Code Type |
Code/Code System |
Code Description |
|
PCPR |
RQO |
ANY |
- |
- |
This Act Master Catalog entry encompasses Acts representing a request for patient care provision, with further specification. That is, any Act whose Class Code attribute is PCPR, Mood Code attribute is RQO, and Code attribute is any valid ETS concept. Acts that have a null Act.code are not covered by this Master Catalog entry.
The following table displays sample Act Master Catalog entries from the HDR seed data:
|
Class Code |
Mood Code |
Code Type |
Code/Code System |
Code Description |
|
PCPR |
RQO |
ANY |
- |
- |
|
PCPR |
RQO |
NULL |
- |
- |
|
PCPR |
EVN.CRT |
NULL |
- |
- |
|
PCPR |
EVN.CRT |
ANY |
- |
- |
|
PCPR |
EVN |
NULL |
- |
- |
|
PCPR |
EVN |
ANY |
- |
- |
|
PCPR |
EVN |
ID |
000928/HDR Supplemental |
PCP Assignment |
|
INC |
EVN |
NULL |
- |
- |
|
INC |
EVN |
ANY |
- |
- |
Note: The Confidentiality Code column has not been displayed as no data is seeded for this attribute
Master Catalog Entities
In the RIM, the Class Code, Determiner Code, and Code attributes on an Entity specify the type of Entity that instance represents. As in the RIM, these attributes in the Master Catalog specify the types of Entities that are used in HDR. Entity Master Catalog entries define the specific combinations of the Class Code, Determiner Code and Code, which are required by the HDR solution.
The following table describes the Master Catalog metadata that can be defined for Entities:
Table 2-13 Entity Master Catalog Attributes
|
Attribute |
Content |
Description |
Mandatory |
|
Master Catalog Id |
Internal identifier generated by the system. |
Uniquely identifies each Master Catalog entry. This attribute is not displayed on the Master Catalog - Act, Entity or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Entry Type Code |
Defaulted to ENTITY for all Entity Master Catalog entries. |
Specifies which type of class-Act, Entity, or Role-this Master Catalog entry relates to. This attribute is defaulted for the Master Catalog entry, depending on which screen is used to create the entry. This attribute is not displayed on the Master Catalog - Act, Entity, or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Class Code |
A valid ETS concept from the EntityClass code system. |
Specifies the value for the Entity.classCode attribute. |
Yes |
|
Determiner Code |
A valid ETS concept from the EntityDeterminer code system |
Specifies the value for the Entity.determinerCode attribute. |
Yes |
|
Active Flag |
Valid values are:
|
Determines if this Master Catalog entry is active or inactive. |
Yes |
|
Code Type |
Valid values are:
|
Indicates how the Code attribute of the Master Catalog entry is used.
|
Yes |
|
Code System Name, Version Name, Code |
A valid ETS code, version, and code system if the Code Type is ID, or null if the Code Type is NULL or ANY. |
Specifies the value for the Entity.code attribute. The value defined for the Entity.code includes the specific code system, version, and code that have been defined, and any equivalence defined for that code system/version/code. |
Yes, if code type is ID. Should be null if Code Type is NULL or ANY. |
See Also
Oracle Healthcare Data Repository API Documentation, MasterCatalog interface
Sample Entity Master Catalog entries (from the seeded data supplied with HDR) are given in the Sample Entity Entries table.
Using the Code Type Attribute for Entities
The Code Type attribute in the Master Catalog specifies the values permitted for the Code attribute on the Entity instance. You can choose to do any one of the following:
-
Allow a specific Code value for a given Class Code and Determiner Code (Code Type ID)
-
Allow any Code value for a given Class Code and Determiner Code (Code Type ANY)
-
Constrain the Code attribute so it must be null (Code Type NULL)
Code Type ID
If the Code Type attribute of the Entity Master Catalog entry is ID, the Class Code, Determiner Code, and Code attributes of the entry specify which Entities are covered by this Master Catalog entry. The Code attribute of the Entity (Entity.code) must have the specified value or its equivalent.
The following table displays a sample Entity entry with Code Type attribute as ID:
Table 2-14 Sample Entity Entry with Code Type ID
|
Class Code |
Determiner Code |
Code Type |
Code/Code System |
Code Description |
|
ORG |
INSTANCE |
ID |
RELIG/EntityCode |
Religious Institution |
This Entity Master Catalog entry encompasses Entities representing an organization instance, where the organization is specifically a religious organization. That is, any Entity whose Class Code attribute is ORG, Determiner Code attribute is INSTANCE, and Code attribute is RELIG or an equivalent ETS Concept.
Code Type NULL
If the Code Type attribute of the Entity Master Catalog entry is ANY, the Class Code, Determiner Code, and Code attributes of the entry specify which Entities are covered by the entry. The Code attribute of the allowed Entity (Entity.code) can have any value except null.
The following table displays a sample Entity entry with Code Type attribute as NULL:
Table 2-15 Sample Entity Entry with Code Type NULL
|
Class Code |
Determiner Code |
Code Type |
Code/Code System |
Code Description |
|
ORG |
INSTANCE |
NULL |
- |
- |
This Entity Master Catalog entry encompasses Entities representing an organization instance, with no further specification. That is, any Entity whose Class Code attribute is ORG, Determiner Code attribute is INSTANCE, and Code attribute is null.
Code Type ANY
If the Code Type attribute of the Entity Master Catalog entry is ANY, the Class Code, Determiner Code, and Code attributes of the entry specify which Entities are covered by the entry. The Code attribute of the allowed Entity (Entity.code) can have any value except null.
The following table displays a sample Act entry with Code Type attribute as ANY:
Table 2-16 Sample Entity Entry with Code Type ANY
|
Class Code |
Determiner Code |
Code Type |
Code/Code System |
Code Description |
|
ORG |
INSTANCE |
ANY |
- |
- |
This Entity Master Catalog entry encompasses Entities representing an instance of an organization, with further specification. That is, any Entity whose Class Code attribute is ORG, Determiner Code attribute is INSTANCE, and Code attribute is any valid ETS Concept. Entities that have a null Entity.code are not allowed by this entry.
The following table displays sample Master Catalog Entity entries from the HDR seed data:
Table 2-17 Sample Entity Entries
|
Class Code |
Determiner Code |
Code Type |
Code/Code System |
Code Description |
|
PLC |
INSTANCE |
ANY |
- |
- |
|
PLC |
INSTANCE |
NULL |
- |
- |
|
PSN |
INSTANCE |
ANY |
- |
- |
|
PSN |
INSTANCE |
NULL |
- |
- |
|
ORG |
INSTANCE |
ANY |
- |
- |
|
ORG |
INSTANCE |
NULL |
- |
- |
|
ORG |
INSTANCE |
ID |
RELIG/EntityCode |
Religious Institution |
|
CONT |
INSTANCE |
ANY |
- |
- |
|
CONT |
INSTANCE |
NULL |
- |
- |
|
CONT |
KIND |
ANY |
- |
- |
|
CONT |
KIND |
NULL |
- |
- |
Master Catalog Roles
In the RIM, the Class Code and Code attributes on a Role, and the Class Code, Determiner Code, and Code attributes on the player and scoper Entity, specify the type of Role that instance represents. As in the RIM, these attributes in the Master Catalog specify the types of Roles that are used in HDR. Role Master Catalog entries define the specific combinations of the Class Code and Code, and Entity Class Code, Determiner Code, and Code, which are required by the HDR solution.
The following table describes the Master Catalog metadata that can be defined for Roles:
Table 2-18 Role Master Catalog Attributes
|
Attribute |
Content |
Description |
Mandatory |
|
Master Catalog Id |
Internal identifier generated by the system. |
Uniquely identifies each Master Catalog entry. This attribute is not displayed on the Master Catalog - Act, Entity, or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Entry Type Code |
Defaulted to ROLE for all Entity Master Catalog entries. |
Specifies which type of class-Act, Entity, or Role-this Master Catalog entry relates to. This attribute is defaulted for the Master Catalog entry, depending on which screen is used to create the entry. This attribute is not displayed on the Master Catalog - Act, Entity, or Role screens on the user interface. |
Not Applicable (This is a system-generated attribute.) |
|
Class Code |
A valid ETS concept from the RoleClass code system. |
Specifies the value for the Role.classCode attribute. |
Yes |
|
Role Owner Code |
Valid values:
|
Specifies if the Role is owned by an Entity, and if so, whether that owning Entity is the player Entity or the scoper Entity.
Note: It is valid to specify the Player Entity and/or the Scoper Entity, even if Role Owner Code is NULL. NULL indicates that there is no owning Entity. |
No |
|
Active Flag |
Valid values are:
|
Determines if this Master Catalog entry is active or inactive. |
Yes |
|
Code Type |
Valid values are:
|
Indicates how the Code attribute of the Master Catalog entry is used.
|
Yes |
|
Code System Name, Version Name, Code |
A valid ETS code, version, and code system if the Code Type is ID, or null if the Code Type is NULL or ANY. |
Specifies the value for the Role.code attribute. The value defined for the Role.code includes the specific code system, version, and code that have been defined, and any equivalence defined for that code system/version/code. |
Yes, if code type is ID. Should be null if Code Type is NULL or ANY. |
|
Player Master Catalog |
A valid Master Catalog Entity classCode, determinerCode, codeType, and code. |
Specifies the player Entity for Roles allowed by this Master Catalog entry. The value must identify an Entity entry in the Master Catalog. If this attribute is null, the Role must not have a player Entity. |
Yes, if Role Owner Code is 'Player' |
|
Scoper Master Catalog |
A valid Master Catalog Entity classCode, determinerCode, codeType, and code. |
Specifies the scoper Entity for Roles allowed by this Master Catalog entry. The value must identify an Entity entry in the Master Catalog. If this attribute is null, then the Role must not have a scoper Entity. |
Yes, if Role Owner Code is 'Scoper' |
|
Confidentiality Code |
A valid ETS concept or concepts from the Confidentiality code system. |
Allows you to assign one or more confidentiality codes to a Master Catalog entry, to specify the type of confidentiality associated with these types of Roles. The Confidentiality Code may be used when querying the HDR repository, to mask specific information on the Role. Note: The Master Catalog Confidentiality Code attribute is independent of the Role.confidentialityCode attribute. Both attributes can be used to store the same or different confidentiality codes. Both attributes can be used when querying the HDR repository, to mask specific information on the Role. |
No |
See Also
Oracle Healthcare Data Repository Javadoc, MasterCatalog interface
Using the Code Type Attribute for Roles
The Code Type attribute in the Master Catalog specifies the values permitted for the Code attribute on the Role instance. You can choose to do any one of the following:
-
Allow a specific Code value for a given Class Code, player, and scoper Entity (Code Type ID)
-
Allow any Code value for a given Class Code, player, and scoper Entity (Code Type ANY)
-
Constrain the Code attribute so it must be null (Code Type NULL)
Code Type ID
If the Code Type attribute of the Role Master Catalog entry is ID, the Class Code and Code attributes of the Role entry, and the Class Code, Determiner Code, and Code attributes of the player Entity and scoper Entity, specify which Roles are covered by this Master Catalog entry. The Code attribute of the Role (Role.code) must have the specified value or its equivalent.
The following table displays a sample Role entry with Code Type attribute as ID:
Table 2-19 Sample Role Entry with Code Type ID
|
Class Code |
Code Type |
Code/Code System |
Code Description |
Role Owner |
Player Master Catalog Scoper Master Catalog |
|
GUAR |
ID |
001899/HDR Supplemental |
Worker's Compensation Guarantor |
Scoper |
ORG.INSTANCE.ANY PSN.INSTANCE.ANY |
This Role Master Catalog entry encompasses Roles representing a guarantor, specifically a workers compensation guarantor, with a playing organization Entity and a scoping person Entity, where the scoping person Entity owns the role. That is, any Role whose Class Code attribute is GUAR and Code attribute is 001899 or an equivalent ETS Concept, which is played by an ORG.INSTANCE with any valid Entity.code, and scoped by a PSN.INSTANCE with a NULL Entity.code, where the PSN.INSTANCE is the owning Entity.
Code Type NULL
If the Code Type attribute of the Role Master Catalog entry is NULL, the Class Code and Code attributes of the Role entry, and the Class Code, Determiner Code, and Code attributes of the player Entity and scoper Entity, specify which Roles are covered by this Master Catalog entry. The Code attribute of the allowed Role (Role.code) must be null.
The following table displays a sample Role entry with Code Type attribute as NULL:
Table 2-20 Sample Role Entry with Code Type NULL
|
Class Code |
Code Type |
Code/Code System |
Code Description |
Role Owner |
Player Master Catalog Scoper Master Catalog |
|
BIRTHPL |
NULL |
- |
- |
Scoper |
PLC.INSTANCE.ANY - |
This Role Master Catalog entry encompasses Roles representing a birthplace, with a playing place Entity and a scoping person Entity, where the scoping person Entity owns the role. That is, any Role whose Class Code attribute is BIRTHPLC and Code attribute is null, which is played by a PLC.INSTANCE with any valid Entity.code and scoped by a PSN.INSTANCE with a null Entity.code, where the PSN.INSTANCE is the owning Entity.
Code Type ANY
If the Code Type attribute of the Entity Master Catalog entry is ANY, the Class Code and Code attribute of the Role entry, and the Class Code, Determiner Code, and Code attributes of the player Entity and scoper Entity, specify which Roles are covered by this Master Catalog entry. The Code attribute of the allowed Role (Role.code) may have any value except null.
The following table displays a sample Role entry with Code Type attribute as ANY:
Table 2-21 Sample Role Entries with Code Type ANY
|
Class Code |
Code Type |
Code/Code System |
Code Description |
Role Owner |
Player Master Catalog Scoper Master Catalog |
|
COVPTY |
ANY |
- |
- |
- |
PLC.INSTANCE.NULL - |
This Role Master Catalog entry encompasses Roles representing a covered party, with a playing person Entity and a null scoping Entity, where the role is not owned. That is, any Role whose Class Code attribute is COVPTY and Code attribute is any valid ETS Concept, which is played by a PSN.INSTANCE with a null Entity.code, with no scoper entity and no owning entity.
The following table displays sample Master Catalog Role entries from the HDR seed data:
Table 2-22 Sample Role Entries
|
Class Code |
Code Type |
Code/Code System |
Code Description |
Role Owner |
Player Master Catalog Scoper Master Catalog |
|
BIRTHPL |
NULL |
- |
- |
Scoper |
PLC.INSTANCE.ANY PSN.INSTANCE.NULL |
|
BIRTHPL |
NULL |
- |
- |
Scoper |
PLC.INSTANCE.NULL PSN.INSTANCE.NULL |
|
BIRTHPL |
NULL |
- |
- |
Scoper |
- PSN.INSTANCE.NULL |
|
COVPTY |
ANY |
- |
- |
- |
PSN.INSTANCE.NULL - |
|
COVPTY |
NULL |
- |
- |
- |
- - |
|
CRINV |
NULL |
- |
- |
- |
PSN.INSTANCE.NULL - |
|
CRINV |
NULL |
- |
- |
- |
- - |
|
GUAR |
ID |
001899/HDR Supplemental |
Worker's Compensation Guarantor |
Scoper |
ORG.INSTANCE.ANY PSN.INSTANCE.NULL |
|
GUAR |
ID |
001899/HDR Supplemental |
Worker's Compensation Guarantor |
Scoper |
ORG.INSTANCE.NULL PSN.INSTANCE.NULL |
|
GUAR |
ANY |
- |
- |
Scoper |
ORG.INSTANCE.ANY PSN.INSTANCE.NULL |
|
GUAR |
ANY |
- |
- |
Scoper |
ORG.INSTANCE.NULL PSN.INSTANCE.NULL |
|
NOK |
NULL |
- |
- |
Player |
PSN.INSTANCE.NULL PSN.INSTANCE.NULL |
|
NOK |
ANY |
- |
- |
Player |
PSN.INSTANCE.NULL PSN.INSTANCE.NULL |
Note: The Confidentiality Code column has not been displayed as no data is seeded for this attribute.
Focal Class State Transitions
The Focal Class State Transitions is a repository of state transitions for the Acts, Entities, and Roles defined in the Master Catalog. The following are the main purposes of the Focal Class State Transitions:
-
To define which state transitions can be applied to the HDR repository by the RIM Service interfaces. A state transition is a change in the statusCode (from a beginning state to an ending state) of an Act, Entity, or Role. The ETS repository defines the valid concepts allowed for Act, Entity, and Role statusCode. The HDR Generic State Transitions define the valid transitions for Act, Entity, and Role statusCode. The Focal Class State Transitions provides additional validation, beyond that provided by ETS and the Generic State Transitions, by defining the valid combination of the start state and end state for the specific combination of the Master Catalog Act, Entity, or Role and the specific Control Act.
See Also
-
Oracle Healthcare Data Repository Javadoc, for more information on Act, Entity, and Role.
Oracle Healthcare Data Repository Programmer's Guide (RIM Services > HDR RIM Services > Using Master Catalog)
-
-
To define any business events that should be initiated in the event of that unique state transition.
The repository of Focal Class State Transitions is a required HDR component and must be installed and configured before the use of the HDR RIM Services, IMP, and OMP interfaces. Each unique combination of Control Act, Focal Class, begin state, and end state required for HDR processing must have a corresponding entry in the Focal Class State Transition table. The Focal Class State Transition entries required for Inbound Messaging and other solution areas are supplied as seed data as part of the base HDR platform. You can add entries to this table to meet additional requirements.
Note: As HDR conforms to the RIM standard, all entries in the Focal Class State Transition table must be a subset of the state transitions prescribed by the RIM.
Each record in the Focal Class State Transition table references the relevant Master Catalog Control Act and Master Catalog Focal Class. Therefore, the relevant Act, Entity, and Role entries must exist in the Master Catalog before the Focal Class State Transition entries are defined for them.
Note: The Focal Class State Transition table is dependent upon the Master Catalog as it contains references to Master Catalog entries.
See Also
Business Events
In the Focal Class State Transition table there is a Business Event attribute, which refers to a process that will be raised or initiated in the event of that state transition. (This attribute is named TriggerEventCode in the HDR API). HDR Applications can use these business events to initiate processes that are dependent on specific focal class state transitions.
For example, an encounter discharge may be defined in the Focal Class State Transition table with the relevant Control Act and Focal Class, and begin state active and end state completed. The business event code for the discharge business event will then be populated in the Focal Class State Transition table to cross reference the state transition to the business event details.
No default values for the business events are seeded with the base HDR platform data. You must add your own business event codes if you wish to utilize this functionality.
See Also
-
Oracle Workflow
-
Oracle BPEL Server
The following table describes the metadata that can be defined for Focal Class State Transitions:
Table 2-23 Focal Class State Transition Attributes
|
Attribute |
Content |
Description |
Mandatory |
|
Focal Class |
Defaulted to the relevant Act, Entity, or Role Master Catalog entry. |
Specifies which focal class - Act, Entity or Role - this Focal Class State Transition applies to. This attribute is defaulted for the Focal Class State Transition, depending upon the Master Catalog entry being updated. |
Yes |
|
Control Act Code Type and Code |
A valid Code and Code Type for a Master Catalog control act. ETS code, version, and code system if the Code Type is ID or null if the Code Type is NULL or ANY. |
The Focal Class State Transition must be linked to an existing Master Catalog control act. A control act is represented in the Master Catalog by Class Code CACT and Mood Code EVN. You must identify the unique control act by defining the Code Type and Code attributes of the control act. |
Yes |
|
Start State |
A valid ETS concept from the ActStatus, EntityStatus, or RoleStatus code systems (depending on the Entry Type of the Master Catalog entry). |
The object status at the beginning of the create or update process. Valid inputs for this attribute are specific RIM-defined states (such as 'active', 'completed', and 'suspended'), or generic values of 'null' or 'any'. |
Yes |
|
End State |
A valid ETS concept from the ActStatus, EntityStatus, or RoleStatus code systems (depending on the Entry Type of the Master Catalog entry). |
The object status at the end of the create or update process. Valid inputs for this attribute are specific RIM-defined states (such as 'active', 'completed', and 'suspended'), or generic values of 'null' or 'any'. |
Yes |
|
Business Event Code System Name and Code |
A valid ETS concept from the defined code system used for business events. |
The unique code that is used to define the business event associated with this state transition. This attribute informs HDR to raise a specific business event. |
No |
|
Active Flag |
Valid values are:
|
Determines if this Focal Class State Transition is active or inactive. |
Yes |
See Also
Oracle Workflow
Start State and End State
The start state and end state of the Focal Class State Transitions can be defined with specific values (RIM-defined states, such as active and completed) or generic values (null or any). This allows you to define which state transitions are allowed. For example, an entry can allow a start state of active and an end state of completed for a given control act and focal class. Alternatively, an entry can broadly define the state transitions allowed for a given control act and focal class. For example, from any start state to any end state, or from a null start state to a specific end state of active.
The following combinations of start state and end state are valid:
-
any to any
-
null to null
-
specific state to specific state
-
null to specific state
The following combinations of start state and end state are invalid:
-
specific state to any
-
specific state to null
-
any to specific state
The following table displays sample Focal Class State Transitions from the HDR seed data:
| Control Act Details | Focal Class Details | Start State | End State |
| CACT.EVN.ID. REPC_TE002001 | Act: PCPR.RQO.ANY | null | active |
| CACT.EVN.ID. REPC_TE002002 | Act: PCPR.RQO.ANY | null | completed |
| CACT.EVN.ID. REPC_TE002002 | Act: PCPR.RQO.ANY | active | completed |
| CACT.EVN.ID. REPC_TE002003 | Act: PCPR.RQO.ANY | active | aborted |
| CACT.EVN.ID. REPC_TE002003 | Act: PCPR.RQO.ANY | suspended | aborted |
| CACT.EVN.ID. PRPA_TE000001 | Entity: PSN.INSTANCE.NULL | null | active |
| CACT.EVN.ID. PRPA_TE000002 | Entity: PSN.INSTANCE.NULL | active | active |
| CACT.EVN.ID. PRPA_TE000003 | Entity: PSN.INSTANCE.NULL | active | inactive |
| CACT.EVN.ID. PRPA_TE000004 | Entity: PSN.INSTANCE.NULL | active | inactive |
| CACT.EVN.ID. MFFI_TE000101 | Role: EMP.ID.001895 Player PSN.INSTANCE.NULL Scoper ORG.INSTANCE.ANY | null | active |
| CACT.EVN.ID. MFFI_TE000102 | Role: EMP.ID.001895 Player PSN.INSTANCE.NULL Scoper ORG.INSTANCE.ANY | active | active |
| CACT.EVN.ID. MFFI_TE000103 | Role: EMP.ID.001895 Player PSN.INSTANCE.NULL Scoper ORG.INSTANCE.ANY | active | nullified |
| CACT.EVN.ID. MFFI_TE000103 | Role: EMP.ID.001895 Player PSN.INSTANCE.NULL Scoper ORG.INSTANCE.ANY | terminated | nullified |
| CACT.EVN.ID. MFFI_TE000104 | Role: EMP.ID.001895 Player PSN.INSTANCE.NULL Scoper ORG.INSTANCE.ANY | active | terminated |
Creating Master Catalog Entries
Prerequisites
-
Implementing HDR Object Identifiers: The following seeded object identifier must be configured:
-
INTERNAL_ROOT
-
-
Implementing Enterprise Terminology Services
Procedure
The following chart provides an overview of the implementation process for Master Catalog:
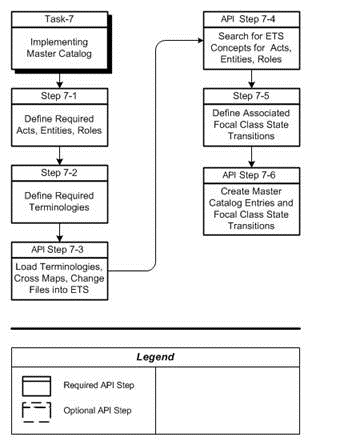
To implement Master Catalog, refer to the following procedure table:
Table 2-24 HDR Implementation Procedures: Master Catalog
|
Task-Step |
Description |
Optional? |
Responsibility |
Interface |
|
7-1 |
Define Required Acts, Entities, Roles |
No |
NA |
Analytical Step |
|
7-2 |
Define Required Terminologies |
No |
NA |
Analytical Step |
|
7-3 |
Load Terminologies, Cross Maps, Change Files into ETS |
No |
NA |
HDR Terminology Jobs |
|
7-4 |
Search for ETS Concepts for Acts, Entities, Roles |
Yes |
NA |
ETSService APIs |
|
7-5 |
Define Associated Focal Class State Transitions |
No |
NA |
Analytical Step |
|
7-6 |
Create Master Catalog Entries and Focal Class State Transitions |
No |
NA |
MasterCatalogService |
Setting Up Master Catalog
Perform the following steps to make entries into the Master Catalog:
Steps
For a new implementation of HDR, perform the following steps:
-
Create a comprehensive list of all Acts, Entities, and Roles required by the entire healthcare enterprise.
This may include Acts, Entities, and Roles that will need to be persisted by RIM Services, and any required to support Act Concept Configuration and Side Effect Configuration.
Many generic Act, Entity, and Role entries are provided in the Master Catalog as seed data. These can be a starting point for this analysis. Identify any required Act, Role, and Entity classes that are not provided as seed data.
See Also
-
Oracle Healthcare Data Repository, Seeded Master Catalog Entries for Version 5, an Oracle White Paper available on My Oracle Support
-
Oracle Healthcare Data Repository Programmer's Guide (HDR Messaging > HDR Inbound Message Processor > IMP Configuration > Side Effect Configuration)
-
-
Analyze the identified acts, roles and entities to determine which terminology best meets enterprise requirements.
-
In some cases, a single standard terminology may be sufficient for a logical group. For example, the LOINC terminology can be used for all laboratory results.
-
In other cases, you may have to extend a standard terminology. For example, LOINC and a local vocabulary could be used for laboratory orders.
-
Less frequently, an unmapped local vocabulary scheme may be required or created for unique needs, such as patient education.
-
-
Load the core, standard, and local terminologies into ETS that are required for creating the enterprise Master Catalog. Also load the relevant Cross Maps and Change files (which contain the equivalence data).
See Also
-
Implementing Enterprise Terminology Services
-
Implementing Interterminology and Intraterminology Equivalence
-
-
Search for the ETS Concepts that are to be used for specific Act, Entity, and Role Master Catalog entries with a Code Type ID and identify their Concept Code, Code System, and Version. For example, to create a Master Catalog Act entry for a specific observation (Code Type is ID) with Act.code defined as SNOMED-CT concept 364075005 (heart rate), you must determine the Concept Code, Code System, and Version for this concept.
-
Determine the Master Catalog attribute values for each Act, Entity, and Role.
See Also
Act, Entity, and Role Master Catalog Attribute tables for information about Act, Role, and Entity attributes
-
Identify focal class state transitions (clinical, administrative and core) relevant to the defined Act, Entity, and Role Master Catalog entries. All focal class state transitions required to support the HDR messaging solutions are provided as seed data. These can be used as a starting point. Identify any additionally required focal class state transitions, which are not already provided as seed data.
To identify the focal class state transitions do the following:
-
Identify the focal class object, which must be an Act, an Entity, or a Role from the Master Catalog.
-
Identify the appropriate Control Act from the Master Catalog.
-
Identify the required state transitions.
Caution: These state transitions must be a complete set or subset of the valid state transitions defined by HL7. You cannot extend the valid state transitions defined by HL7.
-
-
Create the Master Catalog (Act, Entity, and Role) entries and Focal Class State Transition entries using the MasterCatalogService API.
See Also
-
Act Master Catalog Attributes table, for information about Act attributes.
-
Entity Master Catalog Attributes table, for information about Entity attributes.
-
Role Master Catalog Attributes table, for information about Role attributes.
-
Master Catalog Object Factory
The Master Catalog object factory provides methods for creating two types of objects:
-
Master Catalog entries
-
Master Catalog focal class state transition entries
Both object types are intended to be passed to the MasterCatalogService.
Implement Inbound Messaging Services
Healthcare enterprises typically operate a number of departmental systems such as ADT, diagnostic departments, pharmacy, and others that may be acquired from multiple vendors. Such systems require messaging services to communicate events and request actions from applications throughout the enterprise.
The two principal components of system messaging are Inbound Messaging Services, described by this section. Note that you can elect to implement inbound messaging services separately or jointly.
To route the message from the source system, an external interface engine that handles HL7 message translation and routing must be implemented for IMP (Inbound Message Processor) to function. Although a single interface engine is typically required, multiple interface engines can be implemented. An interface engine is not included with HDR. However, Oracle B2B/BPEL can be used as an Interface Engine.
In the following chart, the ADT system registers and admits patients. After updating its own database, ADT sends an HL7 message to an interface engine that in turn routes the message to HDR and to other systems within the enterprise. HDR maintains this patient data in a clinical data repository, available to HDR-based applications.
The Inbound Message Processor (IMP) provides message interpretation, persistence, and acknowledgement services to HDR applications for processing inbound messages from external systems. IMP supports XML formatted inbound messages that conform to the HL7 version 3 messaging standard and compliant with messaging schemas of HDR supported message types.
HDR includes messaging schemas for all supported message types. Messaging schema includes the following for each message type:
-
Schema (XSD Files) for the Payload of the Message Type
-
Composite Message Schema (XSD File) for each Interaction ID of the Message Type
-
Model Interchange Files (MIF files) for the Payload of the Message Type
In addition, messaging schema contains a common Vocabulary schema and data type schema for all message types.
The Composite Message Schema (CMS) has three parts: Message Wrapper, Control Act Wrapper, and Payload Reference. If there are three Interaction IDs seeded for the same Payload, there will be three composite message schemas; one for each Interaction ID and all of them will refer to the same Payload.
For samples, refer to the schemas for Lab Result available at the following locations:
-
Payload Schema for a Message Type (Lab Result)
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/schemas/POLB_MT004000HT01.xsd
-
Composite Message Schema for Interaction Ids POLB_IN004003, POLB_IN004004 (Lab Result)
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/schemas/POLB_IN004003.xsd
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/schemas/POLB_IN004004.xsd
-
Common Data Type Schemas
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/coreschemas/datatypes.xsd
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/coreschemas/datatypes-base.xsd
-
Common Vocabulary Schemas
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/coreschemas/datatypes.xsd
$JAVA_TOP/oracle/apps/ctb/message/defs/rim214101/coreschemas/datatypes-base.xsd
For more information on message types supported, refer to the Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification.
Acknowledgement Processing
Upon receipt of a message from the sending application (the source of the message), IMP synchronously processes the message into HDR, and returns an Application Acknowledgment (AA), an Application Error (AE), or an Application Reject (AR).
-
Application Acknowledgement (AA): An AA response indicates that the message was successfully processed and persisted in HDR.
-
Application Error (AE): An AE response indicates an error reported by HDR, including error information in message content or format (error type code, error detail code, free text). It is the responsibility of the interface engine to determine if the acknowledgement message is returned to the sending system or if the message should be resent to HDR or skipped (abandoning the message). IMP does not support sequence number protocol--the interface engine is responsible for assuring that messages are delivered in order.
-
Application Reject (AR):An AR response indicates that the message is rejected, for reasons unrelated to its content or format (system or network down, network transmission errors). For most such problems, the receiving system may be able to accept the message at a later time. The sending system or interface engine must decide on an application-specific basis whether the message should be sent again. Ultimately, the AR is resolved to either an AA (upon successful retransmission) or an AE--which thence generates a call to error processing.
The acknowledgement message contains the following XML segments:
Table 2-25 XML Segments in an Acknowledgement Message
|
Components |
XPATH |
Sample values |
|
Acknowledgement Type |
MCCI_MT002300HT01.Message/ acknowledgement/typeCode/@code |
<typeCode code="AA"/> , <typeCode code="AE"/>, <typeCode code="AR"/> |
|
Acknowledgement Detail Code |
MCCI_MT002300HT01.Message/acknowledgement/ acknowledgementDetail/ code/@code |
<code code="NS250" codeSystemName="AcknowledgementDetailCode"/> |
|
Acknowledgement Error Text |
MCCI_MT002300HT01.Message/acknowledgement/ acknowledgementDetail/ text |
<text mediaType="text/plain" encoding="TXT"> Application: CTB, Message Name: CTB_MS_INVALID_PROCESS_MD_CD. Tokens: PROCESSING_MODE_CODE = T1; </text> |
|
Acknowledgement Error Location |
MCCI_MT002300HT01.Message/acknowledgement/ acknowledgementDetail/location |
<location> CTB_MS_IMP_EXCEPTION_LOCATION2 :Error occurred while processing XML data located at line 6, column 30. XPATH: /PRPA_IN400000[1] COMPLEX_TYPE: MCCI_MT000100HT04.Message</location> |
|
HDR Error Code |
MCCI_MT002300HT01.Message/acknowledgement/ acknowledgementDetail/text |
CTB_MS_INVALID_PROCESS_MD_CD |
|
Responder Information |
MCCI_MT002300HT01.Message/sender/device/id |
<sender type="CommunicationFunction"> <typeCode code="SND"/> <device type="Device" classCode="DEV" determinerCode="INSTANCE"> <id root="9.989898.5.100" extension="ORG1000"/> <asAgent type="RoleHeir" classCode="AGNT"> <representedOrganization type="Organization" classCode="ORG" determinerCode="INSTANCE"> <id root="9.989898.5.100" extension="ORG1000"/> </representedOrganization> </asAgent> </device> </sender> |
Before processing a message, the message type must be configured for the sender. IMP extracts Sender, Receiver, and Interaction Id available in the message, and picks up the associated side-effect configuration. If Interaction ID is not configured for the Sender and Receiver, IMP rejects the message.
Based on the side-effect configuration, IMP sets the reference modifier on RIM objects available in the message. If a particular RIM object is not configured for side-effect, IMP defaults the value of reference modifier for the RIM object to MUST_EXIST. There are certain side-effect rules in IMP that influences the value of reference modifier of a RIM Object. These rules are illustrated in Oracle Healthcare Data Repository Programmer's Guide.
In addition to being compliant with messaging schema, IMP imposes certain validations on messages before processing the message. Major validations that affect messages are described in this section.
Identified Object Processing
All RIM objects containing ids are identified objects. If a message instance contains repeating objects with same ids, IMP merges the information of repeating objects and persists union of data from different instances into HDR Repository. This is called Identified Object Processing. If the repeating objects in the message contain inconsistent information, IMP rejects the message. For example, if the age of a particular person (having same II) has different values at different segments of the message, IMP rejects the message. For information on complete set of rules to merge information of repeating objects, refer to the Oracle Healthcare Data Repository Programmer's Guide and Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification.
Media Type and MIME Type Validation for CDA Messages
For CDA Message Types, IMP supports only certain Media Type and MIME Type. Refer to the CDA Message Type section of the Oracle Healthcare Data Repository Message Conformance Specification V6.1.
Master Catalog Validation
Master Catalog entries must exist in HDR Repository for all Acts, Entities, and Roles submitted to HDR for persistence.
Vocabulary Validation
Code System Names used in the message must be loaded into ETS and the Codes used should be part of Coding Scheme.
State Transition Validation
All Acts, Entities, and Roles submitted to HDR for persistence is subjected to Generic State Transition validation. The Focal object in the message is subjected to focal class state transition.
Immutable Attributes Validation
An update message cannot modify values of structural attributes and code (example, act.ClassCode) of an already persisted object.
RIM Service Validation
Every message is persisted as a control act graph in HDR Repository and subjected to the validations done by RIM Persistence Service.
To process a message, IMP needs the following RMIM schematic information about the message elements:
-
Name of RIM Foundation Class of the RIM Object available in the message element.
-
Type of RIM Association.
-
Constrained RMIM Data Type of the attribute.
-
If the association is a choice.
The RMIM schematic information is not available in the schemas for message types, but present in the MIF files for the same message type. The information is extracted from the MIF file and loaded into the database after installing HDR. This information is known as Messaging Metadata.
To load Messaging Metadata, use ConcurrentProgService.loadMessagingMetadata() API.
Profile Options and System Properties
Use the CTB: Store Incoming Message profile option to indicate whether the incoming message has to be stored or not. The valid values are Y and N. If the value is Y, the incoming message is stored in the submission unit table. If the value is N, the incoming message is not stored.
The following system properties impacts behavior of the IMP engine:
Table 2-26 IMP System Properties
|
Property Name |
Valid Values |
Description |
|
IgnoreUnrecognizedElements |
Y or N |
With value 'N' throws an exception when an unrecognized RIM attribute is encountered. With 'Y', just skips it. If N, IMP throws an exception when an unrecognized RIM attribute is encounters. If Y, IMP skips the validation. The default value is N. |
|
IMP_NONDESTRUCTIVE_MODE |
Y or N |
If Y, IMP rollbacks all transactions and does not update the audit log. The default value is N. |
|
IMP_BUNDLED_MODE |
Y or N |
If Y, IMP collects all non-runtime exceptions, and continues processing. If N, each exception aborts processing immediately. The default value is N. |
See Also
-
Oracle Healthcare Data Repository Programmer's Guide
-
Oracle Healthcare Data Repository Javadoc
-
Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification
Prerequisites
-
Implement HDR Object Identifiers: The following HDR Object Identifiers must be configured:
-
INTERNAL_ROOT
-
CDA_MMID
-
-
Implement Master Catalog and Focal Class State Transitions: Master Catalog must be implemented before assigning them in Sender and Receiver configuration, and every act, role and entity referenced in an incoming message must have a pre-existing entry in a Master Catalog table.
-
Enterprise Terminology Services: Terminologies used in messages should be loaded.
Inbound messages can contain coded data types that include a codeSystemName, and code but no codeSystemVersion. In the absence of a version, IMP searches for the code in the default version of the terminology as configured in ETS. If no default version is found the message is rejected. Configuring default versions is critical because some terminologies may reuse codes across versions. To use the concept with the intended meaning, ETS must know explicitly which version to use for a certain terminology.
Procedures:
The following chart provides an overview of the implementation process for Inbound Messaging Services:
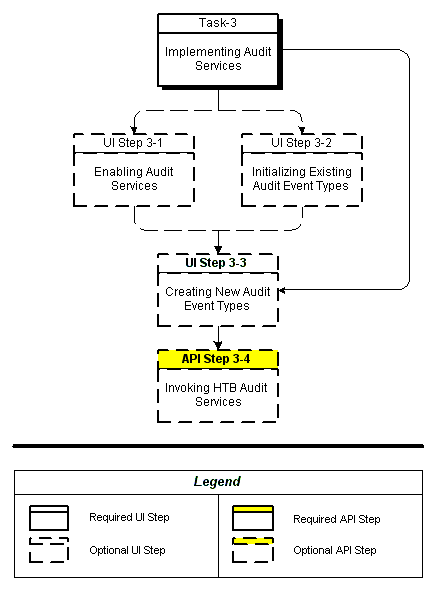
To implement Inbound Messaging Services, refer to the following procedure table:
Table 2-27 HDR Implementation Procedures: Inbound Messaging Services
|
Task-Step |
Description |
Optional? |
Interface |
|
9-1 |
Yes |
API |
|
|
9-2 |
No |
API |
|
|
9-3 |
Yes |
API |
Configuring Interactions
IMP extracts Interaction Id and Trigger Event Code from the incoming message and checks whether it is configured or not. The following table lists the location of the parameters in the message
Table 2-28 Location of the Parameters in the Message
|
Parameter |
XPath |
|
Interaction Id |
Top Level Element in the message. Example, PRPA_IN400000 |
|
Trigger Event Code |
PRPA_IN400000/controlActProcess/code/@code |
Interaction Ids for all supported message types are seeded. Refer to the Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification for the list of seeded interaction ids. You can also configure new Interactions Id for supported messages. Use the Interactions window to configure new Interaction Id. For more information on the Interactions window, refer to Oracle Healthcare Data Repository User Interface Guide.
When you configure a new Interaction Id, an Interaction schema is generated by the Healthcare Data Repository User Interface and stored at the following location with the name of {InteractionId}.xsd::
$JAVA_TOP/oracle/apps/ctb/message/defs/customSchema/newMessageType/interaction.
Configuring Sender, Sender Interaction, and Side Effect
IMP extracts the following information (in the table) from the message and validates them for the configuration:
Table 2-29 Information Extracted and Validated by IMP
|
Parameter |
XPath |
|
Interaction Id |
Top Level Element in the message. Example, PRPA_IN400000 |
|
Sender Root |
PRPA_IN400000/sender/device/ id/@root |
|
Sender Extension |
PRPA_IN400000/sender/device/id/@extension |
|
Receiver Root |
PRPA_IN400000/receiver/device/asAgent/representedOrganization /id/@root |
|
Receiver Extension |
PRPA_IN400000/receiver/device/as Agent/representedOrganization/id/@extension |
|
Trigger Event Code |
PRPA_IN400000/controlActProcess/code/@code |
If the Sender Root and Extension and Receiver Root and Extension is not configured, IMP rejects the message. This configuration thus controls a valid sender and HDR enterprises authorized to send messages. This is called the Sender Configuration.
Important: You must only use Organization's external II while creating sender configuration. You must not use any of the Internal IIs that are automatically generated in HDR.
Upon validation of the Sender Configuration, IMP uses its configuration to determine if the Interaction Id is valid for the Sender Configuration. If it is not configured for that Sender Configuration, IMP rejects the message. This configuration thus controls which types of Interaction Id a sender is permitted to send to a receiver. This is called the Sender Interaction Configuration.
Upon validation of the Sender Configuration and Sender Interaction Configuration combination, IMP processes the message payload. The focal object is created or updated in the HDR Repository. However, for non-focal objects, IMP inspects its side effect configuration to determine its behavior. You can configure IMP to let each non-focal object type create or not create the object if it is not present in the repository, and to update or overlay or not update or overlay the object if it is present in the repository. This configuration of side effects is called the Side Effect Configuration.
Use the IMPConfigAdminIntrService to configure sender and side effects.
See Also
-
Oracle Healthcare Data Repository Programmer's Guide, for more information on Side Effect Processing Rules.
-
Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification for a list of side effect configuration records required for each message type.
Invoke Inbound Messaging Services
Reference
-
Oracle Healthcare Data Repository Javadoc
-
Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification
The following table lists the principal IMP service and methods:
Table 2-30 Service and Methods: IMP
|
Level |
Detail |
|
Package |
oracle.hsgbu.hdr.message.improcessor |
|
Class |
IMPService |
|
Methods |
|
|
Class |
RawIMPService |
|
Methods |
|
|
Class |
Result |
|
Methods |
|
Login
This is an API-based implementation procedure.
Navigation
This is an API-based implementation procedure.
Steps
-
Use the Service Locator to access the IMP Service.
Note:
RawIMPServiceis implemented as a container-managed transactions (CMT) bean, and does not createSubmissionUnit. UseRawIMPServiceif you want to use the Java Transaction API (JTA) support of IMP. -
Use the processMessage method with an HDR-compliant message (see following Note) as a parameter to invoke message processing services; a Result object is returned.
-
Use the following methods to inspect the result of processing the message:
-
getResponseXML
-
getStatus
-
Note:
IMP supports XML formatted inbound messages that conform to the HL7 version 3 messaging standard. The messages must conform to the messaging schema for the message types supported in HDR. The schemas for all supported message type is available at the following location:
$JAVA_TOP/oracle/apps/ctb/messge/defs/rim214101/schemas
The list of supported message types is provided in Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification. Using Messaging Tool Kit, additional message types can be supported. For more information, refer to Oracle Healthcare Data Repository Messaging Tool Kit User Guide.
See Also
-
Oracle Healthcare Data Repository HL7 Version 3 Conformance Specification, for information about message types supported by IMP.
-
Oracle Healthcare Data Repository Messaging Tool Kit User Guide.
-
Oracle Healthcare Data Repository Programmer's Guide.
Implement Concurrent Program Service
HDR provides a JMS queue based job scheduler service called ConcurrentProgramService, which is exposed on ServiceLocator as a stateless session bean. ConcurrentProgramService is used to schedule the following jobs.
Messaging metadata load can be scheduled as a background job using the ConcurrentProgramService.loadMessagingMetadata() API call. The API returns a request ID that can be used to monitor the job status using the ConcurrentProgramService.getJobStatus() API.
Loading MTK Schema to HDR Server
MTK schemas from a local directory specified in the profile option value for profile code CTB_MTK_SCHEMA_DIR_PATH, can be loaded to HDR server location using the ConcurrentProgramService.loadMTKCustomSchema() API.
Loading MTK Interaction Schema to HDR Server
Composite message schema can be created using the MTK custom interaction schemas using the ConcurrentProgramService.loadMTKCustomInteractionSchema() API.
Implement RIM Service
The RIMService is the main persistence and query service for persistence and retrieval of HL7 V3 RIM data. The HDR RIM Java APIs allows customers to build any HL7 V3 RIM object model to represent any clinical information model and persist clinical data based on the RIM clinical models into HDR.
The Java APIs include implementation of the standard HL7 RIM standard classes, associations and data types based on RIM version 2.14.1.01.
HDR RIM Service supports generic object models constructed using the supported RIM standard and does not constrain implementations to use any specific RIM models.
All RIM objects to be updated must follow the allowed state transitions specified in the supported RIM standard.
Before implementing the RIM Service, the following must be implemented before data can be successfully persisted using the RIM Service APIs:
-
Load terminologies using ETS: All coded terminologies to be used in the data to be persisted must be first loaded into the ETS. Please refer to Implementing "Enterprise Terminology Services" section to learn how to load terminologies into ETS.
See also:Programmer's Guide for more details about the ETS Services.
-
Master Catalog Configuration: All of the RIM Act/Role/Entity objects must resolve to a valid master catalog id to be successfully persisted in HDR. This master catalog configuration allows implementers to have a fine grained control over what type of clinical data can be persisted in HDR. For example, users can allow only Lab and Medication data to be persisted into HDR and disallow any radiology reports to be persisted in HDR. For example, this will be helpful in building solutions where HDR is one component that is designed to store only Lab and Medication data whereas Radiology reports are designed to be processed by another non-HDR component. Similar master catalog configuration also permits configuring allowed state transitions on focal classes. For more on master catalog configuration, please refer to "Implement Master Catalog and Focal Class State Transitions".
There are several types of update behaviors that can be configured when persisting RIM objects. RIM objects can be configured only to be created OR only updated OR created or updated OR only referenced with no updates. Please refer to ReferenceModifier.java in Javadoc for more details on the update behaviors supported and their usage.
RIM Service APIs provide a fine grained query API where the users can define their queries in terms of the RIM model and retrieve data out of HDR. The query results will be returned in the RIM Java object models. For more on the RIM Service API usage please refer to the HDR Javadoc (link). The query API supports querying any part of the persisted model, and also supports querying aggregated clinical data based on the query filter criteria, like patient identifier.
There are several types of update behaviors that can be configured when persisting RIM objects. RIM objects can be configured only to be created OR only updated OR created or updated OR only referenced with no updates. Please refer to ReferenceModifier.java in Javadoc for more details on the update behaviors supported and their usage.
RIM Service APIs provide a fine grained query API where the users can define their queries in terms of the RIM model and retrieve data out of HDR. The query results will be returned in the RIM Java object models. For more on the RIM Service API usage please refer to the HDR Javadoc (link). The query API supports querying any part of the persisted model and also support querying aggregated clinical data based on the query filter criteria like patient identifier.
Generate SQL Queries
The SQL queries generated by the RIM query API can be optimized in three different ways. By default, in all nested select sub queries, the where conditions will be generated as a SQL IN condition. This can be modified by configuring the HDR managed server start-up JVM argument CTB_SUBQRY_OPT_METHOD with one of the values NONE, EXISTS, or JOIN. Based on the database version and configuration, you can choose an option that results in the best database SQL execution plans for the HDR generated SQL queries.
-DCTB_SUBQRY_OPT_METHOD=NONE
This is the default behavior where all nested select sub queries in the where condition will be generated as the SQL IN condition.
For example, SELECT CtbCoreRolesEO.ROLE_ID, CtbCoreRolesEO.ROLE_VERSION_NUM FROM CTB_CORE_ROLES CtbCoreRolesEO WHERE CtbCoreRolesEO.CLASS_CODE = 'PAT' AND(CtbCoreRolesEO.PLAYER_ID, CtbCoreRolesEO.PLAYER_VERSION_NUM) IN ( SELECT CtbCoreEntitiesEO.ENTITY_ID, CtbCoreEntitiesEO.ENTITY_VERSION_NUM FROM CTB_CORE_ENTITIES CtbCoreEntitiesEO WHERE CtbCoreEntitiesEO.CLASS_CODE = 'PSN' AND CtbCoreEntitiesEO.DETERMINER_CODE = 'INSTANCE' AND CtbCoreEntitiesEO.ENTITY_ID IN ( SELECT CtbCoreEntyIIEO.ENTITY_ID FROM CTB_CORE_ENTY_II CtbCoreEntyIIEO WHERE CtbCoreEntyIIEO.ROOT_ID = '1.2.3' AND CtbCoreEntyIIEO.EXTENSION_TXT = 'Person1' ) ) ;
-DCTB_SUBQRY_OPT_METHOD=EXISTS
By setting sub-query optimization method to EXISTS, all nested select sub queries in the where condition will be generated as the SQL EXISTS condition.
For example, SELECT CtbCoreRolesEO.ROLE_ID, CtbCoreRolesEO.ROLE_VERSION_NUM FROM CTB_CORE_ROLES CtbCoreRolesEO WHERE CtbCoreRolesEO.CLASS_CODE = 'PAT' AND EXISTS ( SELECT 1 FROM CTB_CORE_ENTITIES CtbCoreEntitiesEO WHERE CtbCoreEntitiesEO.CLASS_CODE = 'PSN' AND CtbCoreEntitiesEO.DETERMINER_CODE = 'INSTANCE' AND CtbCoreEntitiesEO.ENTITY_ID = CtbCoreRolesEO.PLAYER_ID AND CtbCoreEntitiesEO.ENTITY_VERSION_NUM = CtbCoreRolesEO.PLAYER_VERSION_NUM AND EXISTS ( SELECT 1 FROM CTB_CORE_ENTY_II CtbCoreEntyIIEO WHERE CtbCoreEntyIIEO.ROOT_ID = '1.2.3' AND CtbCoreEntyIIEO.EXTENSION_TXT = 'Person1' AND CtbCoreEntyIIEO.ENTITY_ID = CtbCoreEntitiesEO.ENTITY_ID ) ) ;
-DCTB_SUBQRY_OPT_METHOD=JOIN
By setting sub-query optimization method to JOIN, all nested select sub queries in the where condition will be converted to the SQL JOIN condition.
For example, SELECT CtbCoreRolesEO1.ROLE_ID, CtbCoreRolesEO1.ROLE_VERSION_NUM FROM CTB_CORE_ROLES CtbCoreRolesEO1, CTB_CORE_ENTITIES CtbCoreEntitiesEO1, CTB_CORE_ENTY_II CtbCoreEntyIIEO1 WHERE CtbCoreRolesEO1.CLASS_CODE = 'PAT' AND CtbCoreEntitiesEO1.CLASS_CODE = 'PSN' AND CtbCoreEntitiesEO1.DETERMINER_CODE = 'INSTANCE' AND CtbCoreEntitiesEO1.ENTITY_ID = CtbCoreRolesEO1.PLAYER_ID AND CtbCoreEntitiesEO1.ENTITY_VERSION_NUM = CtbCoreRolesEO1.PLAYER_VERSION_NUM AND CtbCoreEntyIIEO1.ROOT_ID = '1.2.3' AND CtbCoreEntyIIEO1.EXTENSION_TXT = 'Person1' AND CtbCoreEntyIIEO1.ENTITY_ID = CtbCoreEntitiesEO1.ENTITY_ID;