Panoramica di Data Flow
Scopri di più su Data Flow e su come utilizzarlo per creare, condividere, eseguire e visualizzare facilmente l'output delle applicazioni Apache Spark .
Che cos'è Oracle Cloud Infrastructure Data Flow
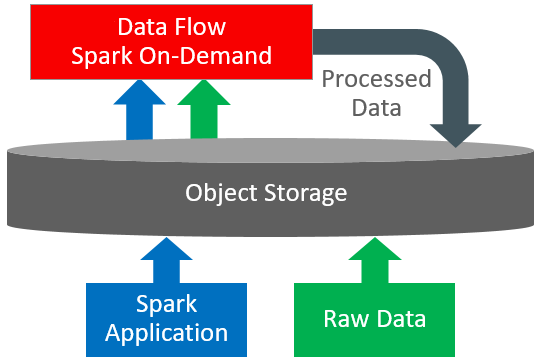
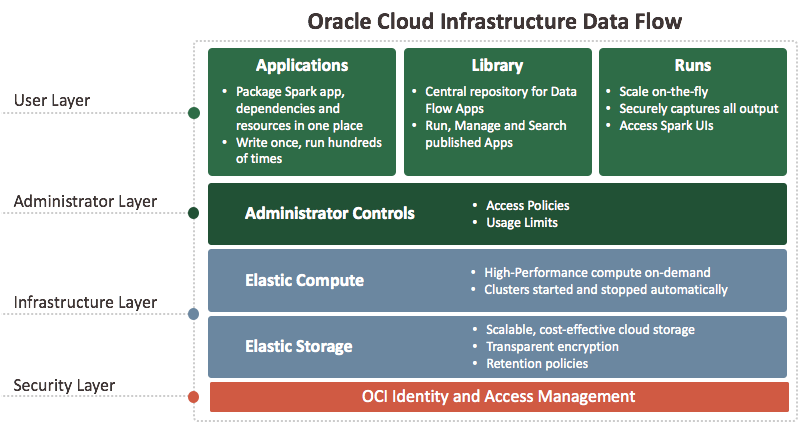
Data Flow è una piattaforma serverless basata su cloud con un'interfaccia utente avanzata. Consente agli sviluppatori e ai data scientist Spark di creare, modificare ed eseguire job Spark su qualsiasi scala senza la necessità di cluster, un team operativo o una conoscenza Spark altamente specializzata. Essere serverless significa non avere alcuna infrastruttura da distribuire o gestire. È interamente basato sulle API REST e ti offre una facile integrazione con applicazioni o flussi di lavoro. È possibile controllare il flusso dati utilizzando questa API REST. È possibile eseguire il flusso di dati dall'interfaccia CLI poiché i comandi del flusso di dati sono disponibili nell'ambito dell'interfaccia della riga di comando di Oracle Cloud Infrastructure. È possibile effettuare le seguenti operazioni.
-
Connettersi alle origini dati Apache Spark.
-
Crea applicazioni Apache Spark riutilizzabili.
-
Avvia rapidamente i job di Apache Spark.
-
Crea applicazioni Apache Spark utilizzando SQL, Python, Java, Scala o spark-submit.
-
Gestisci tutte le applicazioni Apache Spark da un'unica piattaforma.
-
Elabora i dati nel cloud o on-premise nel tuo data center.
-
Crea modelli di Big Data che puoi assemblare facilmente in applicazioni avanzate di Big Data.