Imposta flusso dati
Prima di poter creare, gestire ed eseguire applicazioni in Data Flow, l'amministratore del tenant (o qualsiasi utente con privilegi elevati per creare bucket e modificare criteri in IAM) deve creare gruppi, un compartimento, uno storage e i criteri associati in IAM.
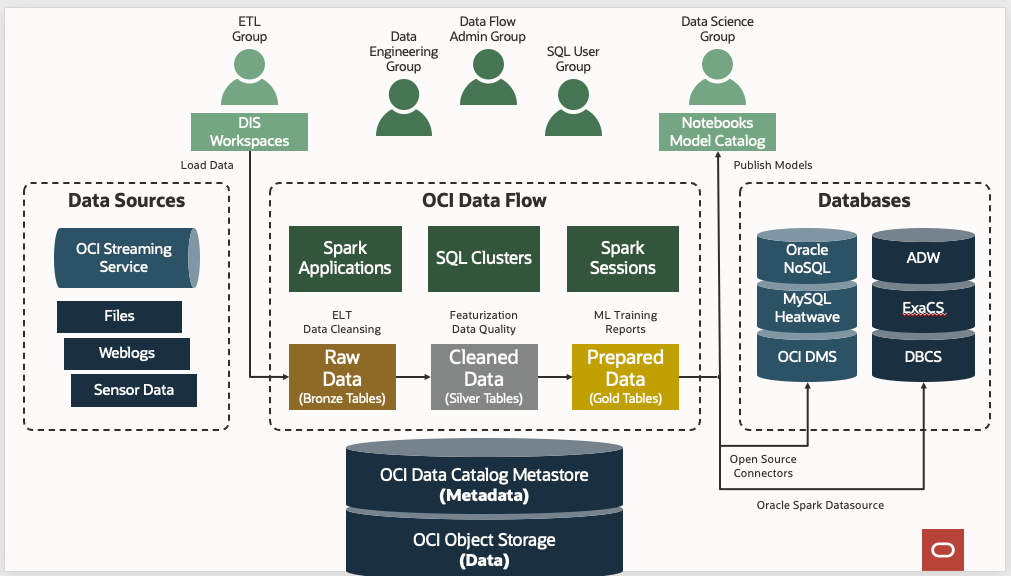 I passaggi di impostazione del flusso dati riportati di seguito sono riportati.
I passaggi di impostazione del flusso dati riportati di seguito sono riportati.- Impostazione dei gruppi di identità.
- Impostazione dei bucket del compartimento e dello storage degli oggetti.
- Impostazione dei criteri di gestione delle identità e degli accessi
Imposta gruppi di identità
Come procedura generale, suddividere gli utenti di Data Flow in tre gruppi per una chiara separazione dei casi d'uso e del livello di privilegi.
Creare i tre gruppi seguenti nel servizio Identity e aggiungere utenti a ciascun gruppo:
- amministratori del flusso di dati
- dataflow-data-engineers
- dataflow-sql-users
- amministratori del flusso di dati
- Gli utenti di questo gruppo sono amministratori o superutenti del flusso dati. Dispongono dei privilegi per eseguire qualsiasi azione su Data Flow o per impostare e gestire diverse risorse correlate a Data Flow. Gestiscono le applicazioni di proprietà di altri utenti e le esecuzioni avviate da qualsiasi utente all'interno della propria tenancy. Gli amministratori del flusso di dati non devono disporre dell'accesso amministrativo ai cluster Spark di cui è stato eseguito il provisioning su richiesta da parte di Data Flow, poiché tali cluster sono completamente gestiti da Data Flow.
- dataflow-data-engineers
- Gli utenti di questo gruppo dispongono del privilegio per gestire ed eseguire le applicazioni e le esecuzioni di Data Flow per i propri job di progettazione dati. Ad esempio, l'esecuzione di job ETL (Extract Transform Load) nei cluster Spark serverless su richiesta di Data Flow. Gli utenti di questo gruppo non dispongono né hanno bisogno dell'accesso di amministrazione ai cluster Spark di cui è stato eseguito il provisioning su richiesta da parte di Data Flow, poiché tali cluster sono completamente gestiti da Data Flow.
- dataflow-sql-users
- Gli utenti di questo gruppo dispongono del privilegio per eseguire query SQL interattive mediante la connessione ai cluster SQL interattivi di Data Flow su JDBC o ODBC.
Impostazione dei bucket del compartimento e dello storage degli oggetti
Attenersi alla procedura riportata di seguito per creare un compartimento e bucket di storage degli oggetti per il flusso di dati.