Utilizzo dei notebook per connettersi a Data Flow
È possibile connettersi a Data Flow ed eseguire un'applicazione Apache Spark da una sessione notebook di Data Science. Queste sessioni ti consentono di eseguire carichi di lavoro Spark interattivi su un cluster Data Flow di lunga durata tramite un'integrazione Apache Livy.
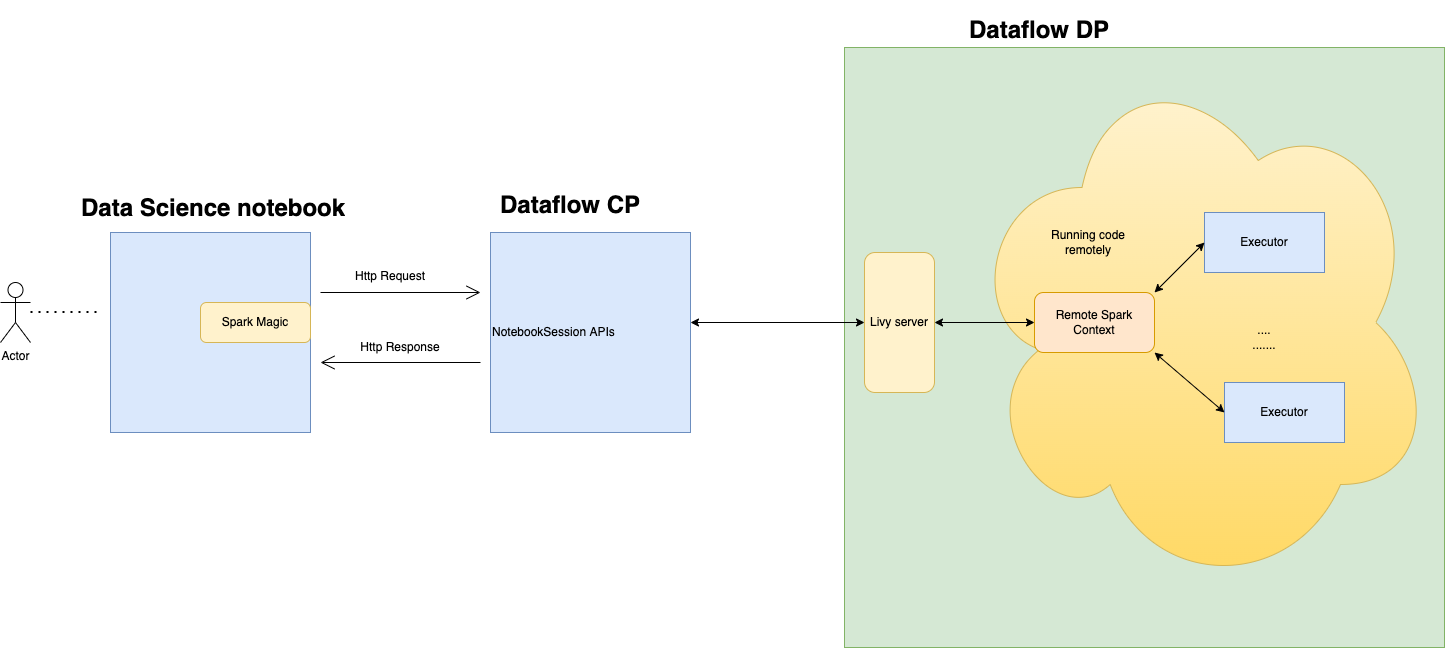
Data Flow utilizza i notebook Jupyter completamente gestiti per consentire ai data scientist e ai data engineer di creare, visualizzare, collaborare ed eseguire il debug delle applicazioni di data engineering e data science. È possibile scrivere queste applicazioni in Python, Scala e PySpark. È inoltre possibile connettere una sessione notebook Data Science a Data Flow per eseguire le applicazioni. I kernel e le applicazioni Data Flow vengono eseguiti su Oracle Cloud Infrastructure Data Flow. Data Flow è un servizio Apache Spark completamente gestito che esegue task di elaborazione su data set estremamente grandi, senza la necessità di distribuire o gestire l'infrastruttura. Per ulteriori informazioni, consulta la documentazione di Data Flow.
Apache Spark è un sistema di calcolo distribuito progettato per elaborare i dati su larga scala. Supporta l'elaborazione SQL, batch e stream su larga scala e task di Machine Learning. Spark SQL fornisce supporto di tipo database. Per eseguire query sui dati strutturati, utilizzare Spark SQL. Si tratta di un'implementazione SQL standard ANSI.
Flusso di dati è un servizio Apache Spark completamente gestito che esegue task di elaborazione su data set estremamente grandi, senza infrastruttura da distribuire o gestire. Puoi utilizzare Spark Streaming per eseguire ETL cloud sui tuoi dati di streaming prodotti in modo continuo. Consente una rapida distribuzione delle applicazioni perché è possibile concentrarsi sullo sviluppo delle applicazioni e non sulla gestione dell'infrastruttura.
Apache Livy è un'interfaccia REST per Spark. Invia job Spark con tolleranza degli errori dal notebook utilizzando metodi sincroni e asincroni per recuperare l'output.
SparkMagic consente la comunicazione interattiva con Spark utilizzando Livy. Utilizzo della direttiva magic `%%spark` all'interno di una cella di codice JupyterLab. I comandi SparkMagic sono disponibili per Spark 3.2.1 e per l'ambiente Conda di Data Flow.
Le sessioni del flusso di dati supportano la scala automatica delle funzionalità del cluster del flusso di dati. Per ulteriori informazioni, vedere Ridimensionamento automatico nella documentazione relativa al flusso di dati. Le sessioni di flusso di dati supportano l'uso di ambienti conda come ambienti runtime Spark personalizzabili.
- Limitazioni
-
-
Le sessioni di flusso dati durano fino a 7 giorni o 10.080 minuti (maxDurationInMinutes).
- Le sessioni di flusso dati hanno un valore di timeout inattività predefinito di 480 minuti (8 ore) (idleTimeoutInMinutes). È possibile configurare un valore diverso.
- La sessione di flusso dati è disponibile solo tramite una sessione notebook di Data Science.
- È supportato solo Spark versione 3.2.1.
-
Guarda il video dell'esercitazione sull'utilizzo di Data Science con Data Flow. Per ulteriori informazioni sull'integrazione di Data Science e Data Flow, consulta anche la documentazione di Oracle Accelerated Data Science SDK.