Applicazioni ML
ML Applications è una rappresentazione autonoma dei casi d'uso di ML in Data Science.
ML Applications è una nuova funzionalità di Data Science che offre una solida piattaforma MLOps per la distribuzione AI/ML. Standardizza il packaging e la distribuzione delle funzionalità AI/ML, consentendoti di creare, distribuire e gestire il machine learning as a service. Con le applicazioni ML, puoi sfruttare Data Science per implementare casi d'uso AI/ML ed eseguirne il provisioning in produzione per le tue applicazioni o i tuoi clienti. Riducendo il ciclo di vita dello sviluppo da mesi a settimane, le applicazioni ML velocizzano il time-to-market riducendo al contempo la complessità operativa e il total cost of ownership. Fornisce una piattaforma end-to-end per implementare, convalidare e promuovere soluzioni ML in ogni fase, dallo sviluppo e dal controllo della qualità alla preproduzione e alla produzione.
ML Applications supporta anche un'architettura disaccoppiata fornendo un livello di integrazione unificato tra le funzionalità AI/ML e le applicazioni client. Ciò consente lo sviluppo, il test e l'evoluzione indipendenti delle soluzioni ML senza richiedere modifiche all'applicazione client, consentendo un'integrazione perfetta e un'innovazione più rapida.
Le applicazioni ML sono ideali per i provider SaaS, che devono eseguire il provisioning e gestire le funzionalità ML in una flotta di clienti, garantendo al contempo un rigoroso isolamento dei dati e dei carichi di lavoro. Consente ai fornitori SaaS di offrire le stesse funzionalità basate su ML a molti tenant senza compromettere la sicurezza o l'efficienza operativa. Che si tratti di integrare insight basati sull'intelligenza artificiale, automatizzare il processo decisionale o abilitare l'analisi predittiva, le applicazioni ML garantiscono che ogni cliente SaaS tragga vantaggio da una distribuzione ML completamente gestita e isolata.
Oltre a SaaS, le applicazioni ML sono ideali anche per implementazioni e organizzazioni multiregion che desiderano creare un mercato ML in cui i provider possono registrare, condividere e monetizzare le soluzioni AI/ML. I clienti possono creare e integrare senza problemi queste funzionalità di ML nei propri flussi di lavoro con il minimo sforzo.
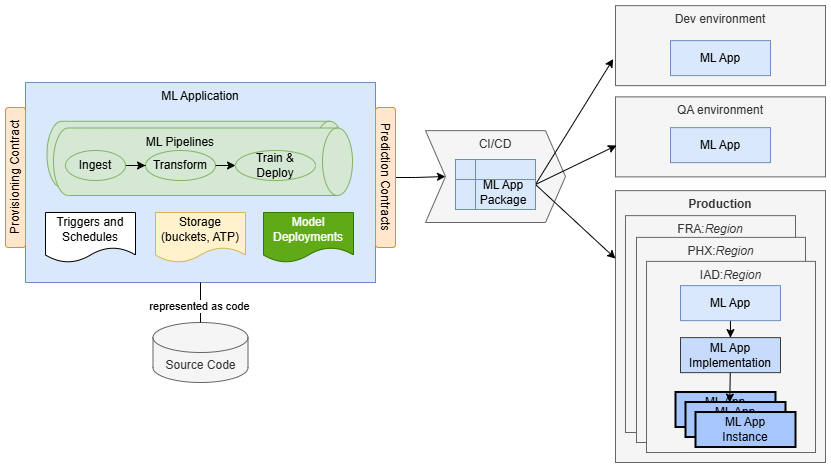
Ad esempio, un'applicazione ML per un caso d'uso di previsione del churn del cliente potrebbe essere costituita da:
- una pipeline con passi di inclusione, trasformazione e formazione che preparano i dati di formazione, addestrano un nuovo modello e lo distribuiscono.
- un bucket utilizzato per memorizzare i dati inclusi e trasformati.
- un trigger che funge da punto di accesso e garantisce l'esecuzione sicura delle esecuzioni della pipeline nel contesto di un cliente SaaS specifico.
- una pianificazione che attiva le esecuzioni periodiche della pipeline di formazione per mantenere aggiornato il modello.
- una distribuzione di modelli che soddisfa le richieste di previsione provenienti dai clienti.
ML Applications ti consente di rappresentare l'intera implementazione come codice e memorizzarla e distribuirla in un repository di codici sorgente. La soluzione è confezionata come pacchetto di applicazioni ML che contiene principalmente metadati. I metadati includono informazioni sul controllo delle versioni, il contratto di provisioning e le dichiarazioni di dipendenze dell'ambiente, rendendo il package indipendente dall'area e dall'ambiente. Una volta creato, il pacchetto può essere distribuito in qualsiasi ambiente di destinazione senza modifiche. Ciò consente di standardizzare l'imballaggio e la consegna della funzionalità ML.
Quando un'applicazione ML viene distribuita, è rappresentata dalle risorse dell'applicazione ML e dell'implementazione dell'applicazione ML. In questa fase è possibile eseguire il provisioning per l'uso. In genere, un'applicazione client (ad esempio una piattaforma SaaS, un sistema aziendale o uno strumento di automazione del flusso di lavoro) richiede al servizio ML Application di eseguire il provisioning di una nuova istanza dell'applicazione ML per un cliente o un'unità operativa specifica. Solo a questo punto la soluzione è completamente istanziata e pronta per l'uso.
In sintesi, le applicazioni ML offrono un modo standardizzato per creare, creare pacchetti e fornire funzionalità ML su larga scala, riducendo la complessità e accelerando il time-to-production in vari scenari, tra cui:
- SaaS Adozione dell'AI, in cui le piattaforme SaaS devono integrare funzionalità ML per migliaia di clienti, garantendo al contempo sicurezza, scalabilità ed efficienza operativa.
- Implementazioni multiregionali, in cui il provisioning della funzionalità ML deve essere eseguito in modo coerente in diverse sedi con un sovraccarico operativo minimo.
- Adozione dell'AI aziendale, in cui le organizzazioni devono distribuire istanze ML isolate tra team, business unit o società controllate, mantenendo al contempo governance e compliance.
- I marketplace ML, dove i fornitori possono creare pacchetti e distribuire soluzioni ML, consentendo ai clienti di scoprire, distribuire e utilizzare facilmente le soluzioni come servizio.
Oltre a SaaS, le applicazioni ML possono essere utilizzate in vari altri scenari. Sono utili ovunque esista la necessità di fornire una soluzione ML molte volte, ad esempio in diverse posizioni geografiche. Inoltre, le applicazioni ML possono essere utilizzate per creare un marketplace in cui i provider possono registrare le proprie applicazioni e offrirle come servizio ai clienti, che possono quindi creare un'istanza e utilizzarle.
La stessa funzionalità delle applicazioni ML è gratuita. Ti viene addebitato solo il costo dell'infrastruttura di base (computazione, storage e rete) utilizzata, senza alcun markup aggiuntivo.
Risorse sulle applicazioni ML
- Applicazione ML
- Una risorsa che rappresenta un caso d'uso ML e funge da ombrello per le implementazioni e le istanze dell'applicazione ML. Definisce e rappresenta una soluzione ML, consentendo ai provider di fornire funzionalità ML ai consumatori.
- Implementazione dell'applicazione ML
- Risorsa che rappresenta una soluzione specifica per lo use case ML definito da un'applicazione ML. Contiene tutti i dettagli di implementazione che consentono di creare un'istanza della soluzione per i consumatori. Un'applicazione ML può avere una sola implementazione.
- Versione implementazione dell'applicazione ML
- Risorsa di sola lettura che rappresenta un'istantanea di un'implementazione dell'applicazione ML. La versione viene creata automaticamente quando un'implementazione dell'applicazione ML raggiunge un nuovo stato coerente.
- Istanza dell'applicazione ML
- Risorsa che rappresenta una singola istanza isolata di un'applicazione ML che consente ai consumer di configurare e utilizzare la funzionalità ML fornita. Le istanze delle applicazioni ML svolgono un ruolo fondamentale nella definizione dei limiti per l'isolamento di dati, carichi di lavoro e modelli. Questo livello di isolamento è essenziale per le organizzazioni SaaS in quanto consente loro di garantire la segregazione e la sicurezza delle risorse dei propri clienti.
- Vista dell'istanza dell'applicazione ML
- Una risorsa di sola lettura, ovvero una copia gestita automaticamente dell'istanza dell'applicazione ML estesa con dettagli aggiuntivi, ad esempio riferimenti ai componenti dell'istanza. Consente ai provider di monitorare il consumo delle proprie applicazioni ML. Ciò significa che i provider possono osservare i dettagli di implementazione delle istanze, monitorarle e risolverle. Quando consumatori e provider lavorano in tenancy diverse, le visualizzazioni dell'istanza dell'applicazione ML sono l'unico modo per i provider di raccogliere informazioni sul consumo delle proprie applicazioni.
Le risorse dell'applicazione ML sono di sola lettura nella console OCI. Per la gestione e la creazione delle risorse, è possibile utilizzare l'interfaccia CLI mlapp che fa parte del progetto di esempio, dell'interfaccia CLI oci o delle API dell'applicazione ML.
Concetti dell'applicazione ML
- Package dell'applicazione ML
- Trigger dell'applicazione ML
- Package dell'applicazione ML
- Consente un packaging standardizzato di funzionalità ML indipendenti dall'ambiente e dall'area geografica. Contiene dettagli sull'implementazione, come componenti, descrittori e schema di configurazione Terraform, ed è una soluzione portatile che può essere utilizzata in qualsiasi tenancy, area o ambiente. Le dipendenze dell'infrastruttura dell'implementazione contenuta (ad esempio, VCN e OCID di log) specifiche di un'area o di un ambiente vengono fornite come argomenti del package durante il processo di caricamento.
- Trigger dell'applicazione ML
- I trigger consentono ai provider di applicazioni ML di specificare il meccanismo di attivazione per i propri job o pipeline ML, semplificando l'implementazione di MLOps completamente automatizzato. I trigger sono i punti di accesso per le esecuzioni dei flussi di lavoro ML. Sono definiti dai file YAML all'interno del package ML Applications come componenti dell'istanza. I trigger vengono creati automaticamente quando viene creata una nuova istanza dell'applicazione ML, ma solo quando vengono creati tutti gli altri componenti dell'istanza. Pertanto, quando viene creato un trigger, può fare riferimento ad altri componenti dell'istanza creati in precedenza.
Ruoli applicazione ML
- Provider
- Consumer
- Provider
- I provider sono clienti OCI che creano, distribuiscono e gestiscono funzioni ML. Offrono pacchetti e implementano funzionalità ML come applicazioni e implementazioni ML. Usano le applicazioni ML per fornire ai consumatori servizi di previsione in modo as-a-Service. Garantiscono che i servizi di previsione forniti soddisfino i loro accordi sul livello di servizio concordati (SLA).
- Consumer
- I consumatori sono clienti OCI che creano istanze di applicazioni ML e utilizzano i servizi di previsione offerti da queste istanze. In genere, i consumatori sono applicazioni SaaS come Fusion. Le applicazioni ML vengono utilizzate per integrare la funzionalità ML e distribuirla ai propri clienti.
Gestione del ciclo di vita
Le applicazioni ML coprono l'intero ciclo di vita delle soluzioni ML.
Questo inizia con le prime fasi di progettazione, in cui i team possono concordare i contratti e iniziare a lavorare in modo indipendente. Include l'implementazione della produzione, la gestione della flotta e il lancio di nuove versioni.
Creazione
- Rappresentazione come codice
- L'intera soluzione, inclusi tutti i suoi componenti e flussi di lavoro, è rappresentata come codice. Ciò promuove le migliori pratiche di sviluppo software come la coerenza e la riproducibilità.
- Automazione
- Con le applicazioni ML, l'automazione è semplice. Puoi concentrarti sull'automazione dei flussi di lavoro all'interno della soluzione utilizzando Data Science Scheduler, ML Pipelines e trigger dell'applicazione ML. L'automazione dei flussi di provisioning e configurazione è gestita dal servizio dell'applicazione ML.
- Imballaggio standardizzato
- Le applicazioni ML offrono pacchetti indipendenti dall'ambiente e dall'area, inclusi metadati per il controllo delle versioni, le dipendenze e le configurazioni di provisioning.
Distribuzione
- Distribuzione gestita dal servizio
- Puoi distribuire e gestire le tue soluzioni ML come risorse dell'applicazione ML. Quando crei la risorsa di implementazione dell'applicazione ML, puoi distribuire l'implementazione in package come package dell'applicazione ML. Il servizio applicazioni ML orchestra automaticamente la distribuzione, convalidando l'implementazione e creando le risorse OCI corrispondenti.
- Ambienti
- Le applicazioni ML consentono ai provider di distribuire attraverso vari ambienti del ciclo di vita come sviluppo, QA e preproduzione, offrendo così un'implementazione controllata delle applicazioni ML alla produzione. In produzione, alcune organizzazioni offrono ai clienti diversi ambienti, come "staging" e "produzione". Con le applicazioni ML, le nuove versioni possono essere distribuite, valutate e testate in "staging" prima di essere promosse in "produzione". Ciò offre ai clienti un grande controllo sull'adozione di nuove versioni, incluse le funzionalità ML.
- Distribuzione tra più aree
- Implementa soluzioni in varie aree, incluse quelle non commerciali come le region governative.
Operatività
- Consegna as-a-service
- I provider forniscono servizi di previsione "as-a-service", che gestiscono tutte le attività di manutenzione e le operazioni. I clienti utilizzano i servizi di previsione, senza visualizzare i dettagli dell'implementazione.
- Monitoraggio e risoluzione dei problemi
- Monitoraggio, risoluzione dei problemi e analisi delle cause principali semplificate con controllo delle versioni dettagliato, tracciabilità e insight contestuali.
- Evoluzione
- Aiuta a fornire iterazioni, aggiornamenti e patch rapidi senza tempi di inattività, garantendo miglioramenti e adattamenti continui alle esigenze dei clienti.
Caratteristiche principali
Alcune caratteristiche chiave delle applicazioni ML sono:
- Consegna as-a-service
- ML Applications consente ai team di creare e fornire servizi di previsione come SaaS (software-as-a-service). Ciò significa che i provider possono gestire ed evolvere le soluzioni senza influire sui clienti. Le applicazioni ML fungono da meta-servizio, facilitando la creazione di nuovi servizi di previsione che possono essere utilizzati e ridimensionati come offerte SaaS.
- Nativo OCI
- La perfetta integrazione con le risorse OCI garantisce coerenza e semplifica l'implementazione in ambienti e aree.
- Imballaggio standard
- Il packaging indipendente dall'ambiente e dall'area geografica standardizza l'implementazione, semplificando la distribuzione delle applicazioni ML a livello globale.
- Isolamento del tenant
- Garantisce l'isolamento completo di dati e carichi di lavoro per ogni cliente, migliorando sicurezza e compliance.
- Controllo versioni
- Supporta implementazioni in evoluzione con processi di rilascio indipendenti, consentendo aggiornamenti e miglioramenti rapidi.
- Aggiornamenti senza tempi di inattività
- Gli aggiornamenti automatici delle istanze garantiscono un servizio continuo senza interruzioni.
- Provisioning cross-tenancy
- Supporta l'osservabilità cross-tenancy e il consumo del mercato, ampliando le possibilità di implementazione.
ML Applications introduce le seguenti risorse:
- Applicazione ML
- Implementazione dell'applicazione ML
- Versione implementazione dell'applicazione ML
- Istanza dell'applicazione ML
- Vista dell'istanza dell'applicazione ML
Valore aggiunto
Le applicazioni ML fungono da platform-as-a-service (PaaS), fornendo alle organizzazioni il framework e i servizi di base necessari per creare, distribuire e gestire le funzioni ML su larga scala.
Ciò fornisce ai team una piattaforma predefinita per la modellazione e la distribuzione di casi d'uso di ML, eliminando la necessità di sviluppare framework e strumenti personalizzati. Pertanto, i team possono dedicare i loro sforzi alla creazione di soluzioni AI innovative, riducendo sia il time-to-market che il costo totale di proprietà per le funzionalità ML.
ML Applications offre alle organizzazioni API e abstract per supervisionare l'intero ciclo di vita dei casi d'uso di ML. Le implementazioni sono rappresentate come codice, inserite in pacchetti di applicazioni ML e distribuite nelle risorse di implementazione delle applicazioni ML. Le versioni cronologiche delle implementazioni vengono tracciate come risorse della versione di implementazione dell'applicazione ML. ML Applications è la colla che stabilisce la tracciabilità tra tutti i componenti utilizzati dalle implementazioni, dal controllo delle versioni e dalle informazioni sull'ambiente e dai dati di consumo dei clienti. Attraverso le applicazioni ML, le organizzazioni ottengono insight precisi su quali implementazioni ML vengono distribuite in ambienti e aree, quali clienti utilizzano applicazioni specifiche e lo stato generale della flotta ML. Inoltre, ML Applications offre funzionalità di ripristino delle istanze, consentendo un facile ripristino da errori di infrastruttura e configurazione.
Con confini ben definiti, le applicazioni ML aiutano a stabilire contratti di provisioning e previsione, consentendo ai team di dividere e conquistare le attività in modo più efficiente. Ad esempio, i team che lavorano sul codice dell'applicazione client (ad esempio una piattaforma SaaS o un sistema aziendale) possono collaborare senza problemi con i team ML concordando contratti di previsione, consentendo a entrambi i team di lavorare in modo indipendente. Allo stesso modo, i team ML possono definire contratti di provisioning, consentendo ai team di gestire autonomamente le attività di provisioning e configurazione. Questo disaccoppiamento elimina le dipendenze e velocizza i tempi di consegna.
ML Applications semplifica l'evoluzione delle soluzioni ML automatizzando il processo di upgrade della versione. Gli aggiornamenti vengono orchestrati interamente dalle applicazioni ML, mitigando gli errori e consentendo il ridimensionamento delle soluzioni a molte istanze (clienti). Gli implementatori possono promuovere e verificare i cambiamenti in una catena di ambienti del ciclo di vita (ad esempio, sviluppo, QA, pre-prod, produzione), mantenendo il controllo sul rilascio delle modifiche ai clienti.
L'isolamento dei tenant si distingue come un vantaggio chiave delle applicazioni ML, garantendo la completa separazione di dati e carichi di lavoro per ogni cliente, migliorando così sicurezza e compliance. A differenza dei metodi tradizionali che si basano sull'isolamento basato su processi, le applicazioni ML consentono ai clienti di implementare limitazioni basate sui privilegi, salvaguardando l'isolamento dei tenant anche in caso di difetti.
Progettato pensando alla scalabilità, ML Applications significa che le grandi organizzazioni, in particolare le organizzazioni SaaS, possono adottare una piattaforma standardizzata per lo sviluppo del ML, garantendo coerenza tra molti team. Centinaia di soluzioni ML possono essere sviluppate senza che l'intera iniziativa ML scenda nel caos. Grazie all'automazione che abbraccia l'implementazione di pipeline ML, l'implementazione di modelli e il provisioning, le organizzazioni SaaS possono industrializzare lo sviluppo di funzionalità ML per SaaS e gestire in modo efficiente milioni di pipeline e modelli in esecuzione autonoma nella produzione.
TTM
- Implementazione standardizzata
- Rimuove la necessità di framework personalizzati, consentendo ai team di concentrarsi sui casi d'uso aziendali.
- Automazione
- Migliora la velocità e riduce gli interventi manuali, fondamentali per la scalabilità delle soluzioni SaaS.
- Separazione delle preoccupazioni
- Limiti chiari, contratti e API consentono a diversi team di lavorare in modo indipendente, semplificando lo sviluppo e la distribuzione.
Costi operativi e di sviluppo
- Riduzione dei costi di sviluppo
- L'utilizzo di servizi predefiniti riduce la necessità di un lavoro di base.
- Evoluzione
- Le iterazioni rapide e gli aggiornamenti indipendenti senza tempi di inattività garantiscono un miglioramento continuo.
- Tracciabilità
- Insight dettagliati su ambienti, componenti e revisioni del codice aiutano a comprendere e gestire le soluzioni ML.
- Provisioning e osservabilità automatizzati
- Semplifica la gestione e il monitoraggio delle soluzioni ML, riducendo il sovraccarico operativo.
- Fleet Management
- Gestisci l'intero ciclo di vita delle istanze dell'applicazione ML su larga scala. ML Applications offre visibilità su tutte le istanze di cui è stato eseguito il provisioning, supporta aggiornamenti e upgrade a livello di flotta e abilita il provisioning e il deprovisioning in base alle esigenze. Inoltre, le soluzioni ML create con applicazioni ML possono essere monitorate utilizzando OCI Monitoring per monitorare prestazioni e stato.
Sicurezza e affidabilità
- Isolamento dei dati e dei carichi di lavoro
- Garantisce l'isolamento sicuro dei dati e dei carichi di lavoro di ciascun cliente.
- Affidabilità
- Gli aggiornamenti automatizzati e il monitoraggio efficace eliminano gli errori e garantiscono operations stabili.
- Nessun problema di vicino rumoroso
- Garantisce che i carichi di lavoro non interferiscano tra loro, mantenendo prestazioni e stabilità.
Workflow di creazione e distribuzione
Lo sviluppo di applicazioni ML assomiglia allo sviluppo di software standard.
Ingegneri e data scientist gestiscono la loro implementazione in un repository di codice sorgente, utilizzando la documentazione e i repository delle applicazioni ML per ricevere istruzioni. In genere iniziano clonando un progetto di esempio fornito dal team ML Applications, che promuove le best practice e aiuta i team SaaS a iniziare rapidamente lo sviluppo evitando al contempo una curva di apprendimento ripida.
A partire da un esempio end-to-end completamente funzionale, i team possono creare, distribuire ed eseguire il provisioning dell'esempio in tempi rapidi, acquisendo familiarità con le applicazioni ML. Possono quindi modificare il codice per aggiungere una logica aziendale specifica, ad esempio aggiungere un passo di pre-elaborazione alla pipeline di formazione o un codice di formazione personalizzato.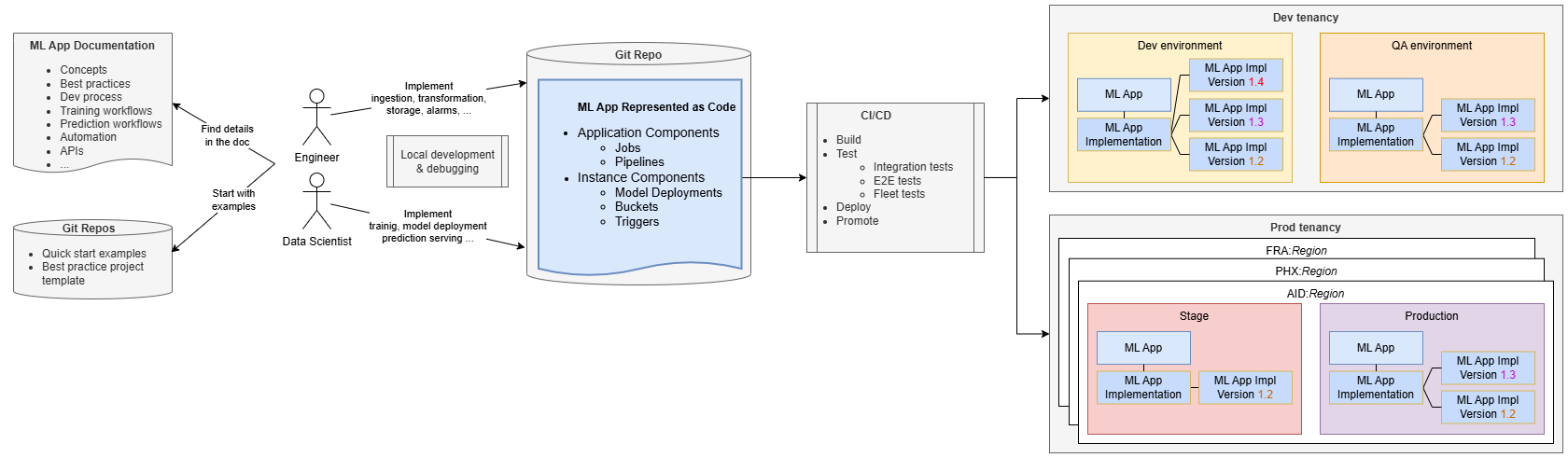
Lo sviluppo e i test possono essere condotti localmente sui loro computer, ma l'impostazione dell'integrazione continua / distribuzione continua (CI / CD) è essenziale per cicli di rilascio più rapidi, maggiore collaborazione e coerenza. I team possono utilizzare esempi e strumenti forniti dal team di applicazioni ML per implementare pipeline CI/CD.
Le pipeline CI/CD distribuiscono l'applicazione ML nell'ambiente richiesto (ad esempio, Sviluppo) ed eseguono test di integrazione per garantire la correttezza della soluzione ML indipendentemente dall'applicazione SaaS. Questi test possono distribuire l'applicazione e la relativa implementazione, creare istanze di test, attivare il flusso di formazione ed eseguire il test del modello distribuito. I test end-to-end garantiscono la corretta integrazione con l'applicazione SaaS.
Quando l'applicazione ML viene distribuita, viene rappresentata come risorsa dell'applicazione ML insieme a un'implementazione dell'applicazione ML. La risorsa Versione implementazione applicazione ML consente di tenere traccia delle informazioni sulle diverse versioni distribuite. Ad esempio, la versione 1.3 è l'ultima versione distribuita, che aggiorna la versione precedente 1.2.
Le pipeline CI/CD devono promuovere la soluzione attraverso ambienti del ciclo di vita fino alla produzione. In produzione, è spesso necessario distribuire l'applicazione ML in diverse aree geografiche per allinearsi alla distribuzione dell'applicazione client. Quando i clienti hanno diversi ambienti di produzione (ad esempio, staging e produzione), le pipeline CI/CD devono promuovere l'applicazione ML attraverso tutti questi ambienti.
È possibile utilizzare le pipeline ML come componenti dell'applicazione all'interno delle applicazioni ML per implementare un flusso di lavoro in più fasi. Le pipeline ML possono quindi orchestrare passi o job arbitrari da implementare.
Operazione di distribuzione
L'operazione di distribuzione prevede diversi passi chiave per garantire che le applicazioni ML siano implementate e aggiornate correttamente in tutti gli ambienti.
In primo luogo, è necessario assicurarsi che esistano le risorse dell'applicazione ML e dell'implementazione dell'applicazione ML. In caso contrario, vengono creati. Se esistono già, vengono aggiornati:
- Creare o aggiornare la risorsa Applicazione ML. Questo rappresenta l'intero caso d'uso di ML e tutte le risorse e le informazioni correlate.
- Creare o aggiornare la risorsa Implementazione applicazione ML. Questa funzionalità è disponibile nelle risorse dell'applicazione ML e rappresenta l'implementazione, consentendo di gestirla. Per distribuire il package di implementazione, è necessario disporre dell'implementazione dell'applicazione ML.
- Caricare il pacchetto applicazione ML. Questo package contiene l'implementazione dell'applicazione ML insieme ad altri metadati, inseriti in un package come archivio zip con una struttura specifica.
Quando un package viene caricato in una risorsa di implementazione applicazione ML, il servizio applicazione ML la convalida e quindi esegue la distribuzione. Semplificandolo, i passaggi chiave durante l'implementazione del pacchetto sono:
- Viene creata un'istanza dei componenti dell'applicazione (componenti multi-tenant).
- Tutte le risorse esistenti dell'istanza dell'applicazione ML di cui è già stato eseguito il provisioning per i clienti SaaS vengono aggiornate. I componenti di istanza di ogni istanza vengono aggiornati in modo che corrispondano alle definizioni appena caricate.
Flusso di provisioning
Prima di poter eseguire il provisioning delle istanze dell'applicazione ML, è necessario distribuire e registrare l'applicazione ML nell'applicazione client.
- 1. Sottoscrizione dei clienti e verifica dell'applicazione ML
- Il flusso di provisioning viene avviato quando un cliente esegue la sottoscrizione all'applicazione client. L'applicazione client controlla se viene eseguito il provisioning di applicazioni ML per il cliente.
- 2. Richiesta di provisioning
- Se sono necessarie applicazioni ML, l'applicazione client contatta il servizio applicazione ML e richiede di eseguire il provisioning di un'istanza, inclusi i dettagli di configurazione specifici del tenant.
- 3. Creazione e configurazione di un'istanza dell'applicazione ML
- Il servizio Applicazione ML crea la risorsa Istanza applicazione ML con la configurazione specifica. Questa risorsa è gestita dall'applicazione client, che può attivare, disattivare, riconfigurare o eliminare l'istanza. Inoltre, il servizio Applicazione ML crea una risorsa Vista istanza applicazione ML che consente ai provider di informarli sul consumo e sui componenti dell'istanza dell'applicazione ML. Il servizio applicazione ML crea inoltre tutti i componenti dell'istanza definiti nell'implementazione, ad esempio trigger, bucket, esecuzioni di pipeline, esecuzioni di job e distribuzioni di modelli.
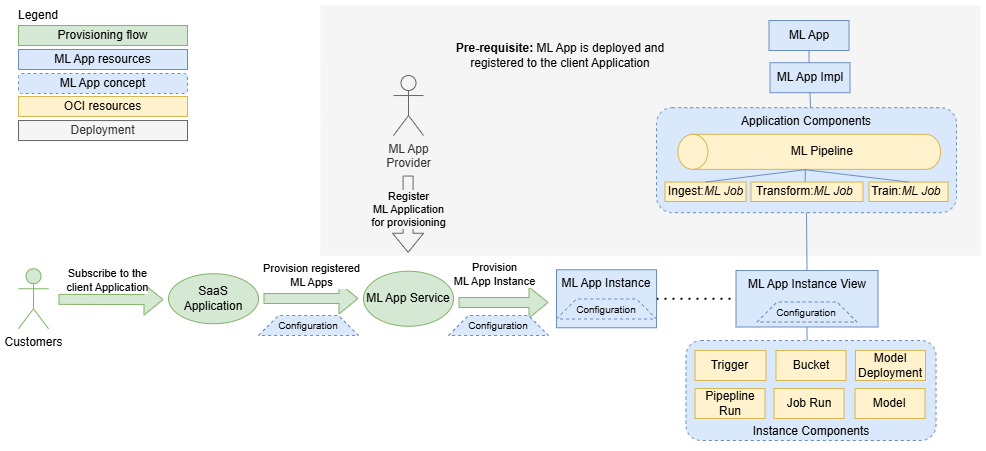
Quando un nuovo package dell'applicazione ML viene distribuito dopo la creazione delle istanze, il servizio dell'applicazione ML garantisce che tutte le istanze vengano aggiornate con le definizioni di implementazione più recenti.
Flusso runtime
Quando viene eseguito il provisioning dell'applicazione ML per un cliente, viene creata un'istanza completa dell'intera implementazione.
- Componenti multi-tenant
- Creazione di un'istanza una sola volta all'interno di un'applicazione ML, a supporto di tutti i clienti (ad esempio, pipeline ML). Queste vengono definite come componenti dell'applicazione.
- Componenti tenant singoli
- Creazione di un'istanza per ogni cliente, in esecuzione solo nel contesto di un determinato cliente. Queste vengono definite come componenti di istanza.
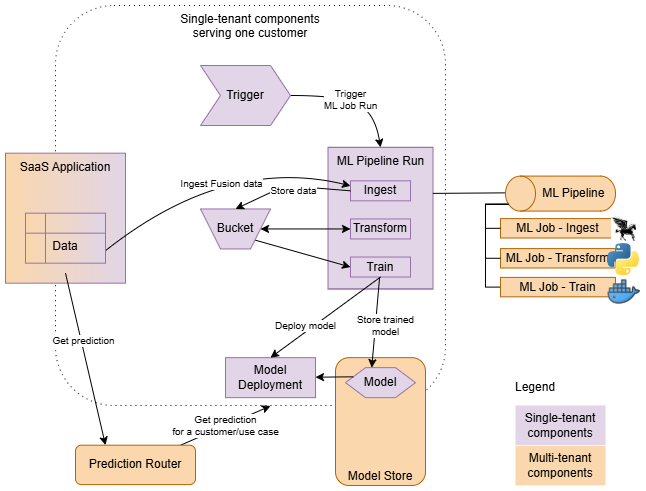
Le pipeline o i job nell'implementazione vengono avviati dai trigger. I trigger creano pipeline ed esecuzioni di job nel contesto di ogni cliente, passando i parametri (contesto) appropriati alle esecuzioni create. Inoltre, i trigger sono essenziali per garantire l'isolamento dei tenant. Garantiscono che il principal risorsa (identità) delle risorse dell'istanza dell'applicazione ML sia ereditato da tutti i carichi di lavoro avviati. Ciò consente di creare criteri che stabiliscono una sandbox di sicurezza per ogni istanza di cui è stato eseguito il provisioning.
Le pipeline consentono di definire un set di passi e di orchestrarli. Ad esempio, un flusso tipico potrebbe comportare l'inclusione dei dati dall'applicazione client, la trasformazione in un formato adatto per la formazione e quindi la formazione e la distribuzione di nuovi modelli.
La distribuzione del modello viene utilizzata come backend di previsione, ma l'applicazione client non vi accede direttamente. L'applicazione client, che può essere single-tenant (di cui è stato eseguito il provisioning per ogni cliente) o multi-tenant (di cui servono molti clienti), ottiene previsioni contattando il router di previsione dell'applicazione ML. Prediction Router trova il backend di previsione corretto in base all'istanza utilizzata e al caso d'uso di previsione implementato dall'applicazione.
Esempio di rischio fetale
Di seguito sono riportati i dettagli di implementazione di un'applicazione ML di esempio per capire come implementarne una.
Utilizziamo un'applicazione di previsione del rischio fetale che sfrutta i dati della cardiotocografia (CTG) per classificare lo stato di salute di un feto. Questa applicazione mira ad aiutare gli operatori sanitari prevedendo se la condizione fetale è normale, rischiosa o anormale in base ai record degli esami CTG.
Dettagli di implementazione
L'implementazione segue il pattern di previsione online standard ed è costituita da una pipeline con passi di inclusione, trasformazione e addestramento e distribuzione dei modelli.
-
Ingestione: questo passo prepara il data set raw e lo memorizza nel bucket dell'istanza.
-
Trasformazione: la preparazione dei dati viene eseguita utilizzando la libreria ADS. Questa operazione prevede quanto riportato di seguito.
- Upsampling: il set di dati è inclinato verso i casi normali, pertanto viene eseguito l'upsampling per bilanciare le classi.
- Ridimensionamento delle funzioni: le funzioni vengono ridimensionate utilizzando QuantileTransformer.
- Il data set preparato viene quindi memorizzato di nuovo nel bucket dell'istanza.
-
Formazione e distribuzione dei modelli: l'algoritmo XGBoost viene utilizzato per l'addestramento dei modelli a causa della sua precisione superiore rispetto ad altri algoritmi (ad esempio, Random Forest, KNN, SVM). Per questo processo viene utilizzata la libreria ADS e il modello addestrato viene distribuito alla distribuzione del modello di istanza.
L'attuazione consiste in:
-
Componenti applicazione: il componente principale è la pipeline che orchestra tre job:
- Job di inclusione
- Job di trasformazione
- Lavoro di formazione
-
Componenti istanza: qui sono definiti quattro componenti istanza:
- Bucket istanza
- Modello predefinito
- Distribuzione modello
- Trigger pipeline
- descriptor.yaml: contiene i metadati che descrivono l'implementazione (il pacchetto).
-
Componenti applicazione: il componente principale è la pipeline che orchestra tre job:
Il codice sorgente è disponibile in questo progetto.
descriptor.yaml :descriptorSchemaVersion: 1.0
mlApplicationVersion: 1.0
implementationVersion: 1.2
# Package arguments allow you to resolve dependencies of your implementation that are environment-specific.
# Typically, OCIDs of infrastructure resources like subnets, data science projects, logs, etc., are passed as package arguments.
# For illustration purposes, only 2 package arguments are listed here.
packageArguments:
# The implementation needs a subnet, and it is environment-specific. It is provided as a package argument.
subnet_id:
type: ocid
mandatory: true
description: "Subnet OCID for ML Job"
# similarly for the ID of a data science project
data_science_project_id:
type: ocid
mandatory: true
description: "Project OCID for ML Job"
# Configuration schema allows you to define the schema for your instance configuration.
# It will be used during provisioning, and the initial configuration provided must conform to the schema.
configurationSchema:
# The implementation needs to know the name of the external bucket (not managed by ML Apps) where the raw dataset is available.
external_data_source:
type: string
mandatory: true
description: "External Data Source (OCI Object Storage Service URI in form of <a target="_blank" href="oci://">oci://</a><bucket_name>@<namespace>/<object_name>"
sampleValue: "<a target="_blank" href="oci://test_data_fetalrisk@mynamespace/test_data.csv">oci://test_data_fetalrisk@mynamespace/test_data.csv</a>"
# This application provides 1 prediction use case (1 prediction service).
onlinePredictionUseCases:
- name: "fetalrisk"Tutte le risorse OCI utilizzate nell'implementazione vengono definite utilizzando Terraform. Terraform consente di specificare in modo dichiarativo i componenti necessari per l'implementazione.
# For illustration purposes, only a partial definition is listed here.
resource oci_datascience_job ingestion_job {
compartment_id = var.app_impl.compartment_id
display_name = "Ingestion_ML_Job"
delete_related_job_runs = true
job_infrastructure_configuration_details {
block_storage_size_in_gbs = local.ingestion_job_block_storage_size
job_infrastructure_type = "STANDALONE"
shape_name = local.ingestion_job_shape_name
job_shape_config_details {
memory_in_gbs = 16
ocpus = 4
}
subnet_id = var.app_impl.package_arguments.subnet_id
}
job_artifact = "./src/01-ingestion_job.py"
}resource "oci_objectstorage_bucket" "data_storage_bucket" {
compartment_id = var.compartment_ocid
namespace = var.bucket_namespace
name = "ml-app-fetal-risk-bucket-${var.instance_id}"
access_type = "NoPublicAccess"
}I componenti dell'istanza in genere fanno riferimento a variabili specifiche dell'istanza, ad esempio l'ID istanza. È possibile fare affidamento su variabili implicite definite dal servizio dell'applicazione ML. Quando è necessario, ad esempio, il nome dell'applicazione, è possibile fare riferimento ad esso con ${var.ml_app_name}.
In conclusione, l'implementazione delle applicazioni ML richiede alcuni componenti chiave: un descrittore di pacchetto e un paio di definizioni Terraform. Seguendo la documentazione fornita, puoi scoprire i dettagli su come creare le tue applicazioni ML.