Bring Your Own Container
Crea e utilizza un contenitore personalizzato (Bring Your Own Container o BYOC) come dipendenza di runtime quando crei una distribuzione del modello.
Con i container personalizzati, puoi creare un package delle dipendenze di sistema e lingua, installare e configurare i server di inferenza e impostare tempi di esecuzione di lingue diverse. Il tutto entro i limiti definiti di un'interfaccia con una risorsa di distribuzione del modello per eseguire i container.
BYOC consente il trasferimento di container tra ambienti diversi in modo da poter eseguire la migrazione e distribuire le applicazioni nel cloud OCI.
Per eseguire il job, è necessario creare un file Dockerfile, quindi creare un'immagine. Si inizia con un Dockerfile che utilizza un'immagine Python. Dockerfile è progettato per consentire la creazione di build locali e remote. Utilizzare la build locale quando si esegue il test a livello locale in base al codice. Durante lo sviluppo locale, non è necessario creare una nuova immagine per ogni modifica del codice.
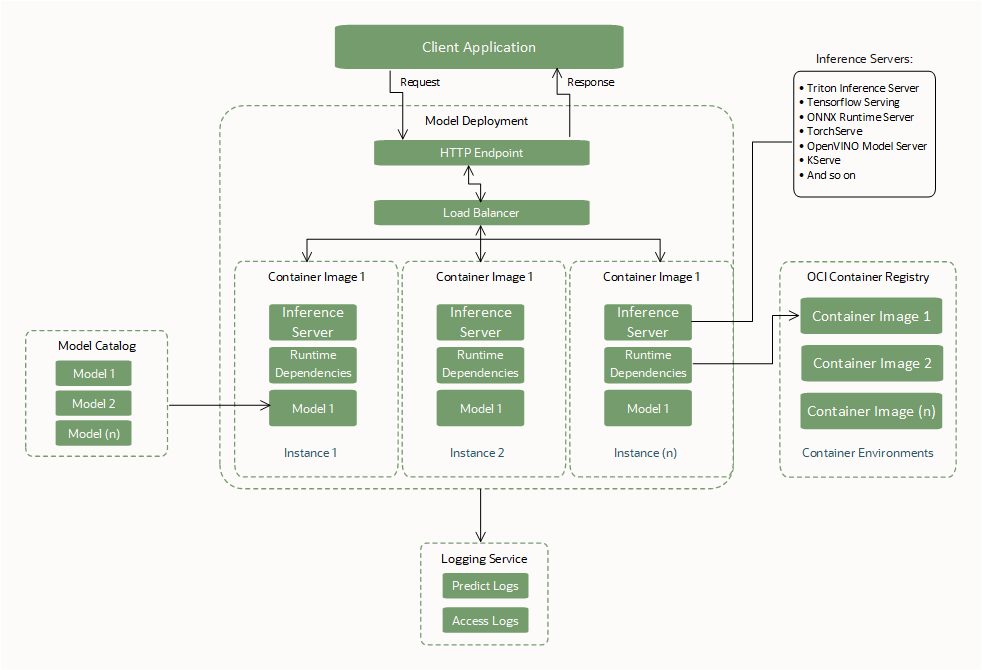
Interfacce richieste BYOC
Creare o specificare queste interfacce necessarie per utilizzare una distribuzione modello.
Artifact modello
| Interfaccia | descrizione; |
|---|---|
| Caricare gli artifact del modello nel catalogo dei modelli Data Science. | Gli artifact del modello, ad esempio la logica di assegnazione punteggio, il modello ML e i file dipendenti, devono essere caricati nel catalogo dei modelli di Data Science prima di essere utilizzati da una risorsa di distribuzione del modello. |
| Nessun file obbligatorio. |
Nessun file obbligatorio per la creazione di una distribuzione modello BYOC.
Nota: quando BYOC non viene utilizzato per una distribuzione modello, i file |
| Posizione degli artifact del modello con MOUNT eseguito. |
Durante le distribuzioni del modello di bootstrap estrarre l'artifact del modello ed eseguire il MOUNT dei file nella directory Zipping di un set di file (incluso il modello ML e la logica di scoring) o di una cartella contenente un set di file ha un percorso di posizione diverso per il modello ML all'interno del contenitore. Assicurarsi che venga utilizzato il percorso corretto durante il caricamento del modello nella logica di assegnazione punteggio. |
Immagine contenitore
| Interfaccia | descrizione; |
|---|---|
| Dipendenze runtime dei package. | Crea un package dell'immagine contenitore con le dipendenze di runtime necessarie per caricare ed eseguire il file binario del modello ML. |
| Creare un package di un server Web per esporre gli endpoint. |
Creare un package dell'immagine contenitore con un server Web senza conservazione dello stato basato su http (FastAPI, Flask, Triton, TensorFlow, PyTorch e così via). Esporre un endpoint
Nota: Se l'endpoint del server inferenza non può essere personalizzato per soddisfare l'interfaccia endpoint di Data Science, utilizzare un proxy (ad esempio, NGINX) per mappare gli endpoint obbligatori per il servizio agli endpoint forniti dal framework. |
| Porti esposti. |
Le porte da utilizzare per gli endpoint Le porte sono limitate a tra 1024 e 65535. Sono escluse le porte 24224, 8446 e 8447. Le porte fornite vengono esposte nel container dal servizio, pertanto non è necessario esporle nuovamente nel file Docker. |
| Dimensione dell'immagine. | La dimensione dell'immagine del contenitore è limitata a 16 GB in formato non compresso. |
| Accesso all'immagine. | L'operatore che crea la distribuzione del modello deve avere accesso all'immagine del contenitore da utilizzare. |
| Pacchetto Curl. | Affinché il criterio HEALTHCHECK Docker riesca, il pacchetto curl deve essere installato nell'immagine del contenitore. Installare l'ultimo comando curl stabile, che non presenta vulnerabilità aperte. |
CMD, Entrypoint
|
Il docker CMD o Entrypoint deve essere fornito tramite il file API o Docker che esegue il bootstrap del server Web. |
CMD, dimensione Entrypoint. |
La dimensione combinata di CMD e Entrypoint non può superare i 2048 byte. Se la dimensione supera i 2048 byte, specificare gli argomenti dell'applicazione che utilizzano l'artifact modello oppure utilizzare lo storage degli oggetti per recuperare i dati. |
Raccomandazioni generali
| Suggerimento | descrizione; |
|---|---|
| Package del modello ML negli artifact del modello. |
Crea il package del modello ML come artifact e caricalo nel catalogo del modello Data Science per utilizzare le funzioni di governance e controllo delle versioni del modello, anche se esiste un'opzione per creare il package del modello ML nell'immagine del contenitore. Salva modello nel catalogo modelli. Dopo che il modello viene caricato nel catalogo modelli e vi viene fatto riferimento durante la creazione della distribuzione del modello, Data Science scarica una copia dell'artifact ed estrae l'artifact nella directory |
| Fornisci digest di immagini e immagini per tutte le operazioni | Si consiglia di fornire il digest di immagini e immagini per creare, aggiornare e attivare le operazioni di distribuzione dei modelli per mantenere la coerenza nell'uso dell'immagine. Durante un'operazione di aggiornamento a un'immagine diversa, sia l'immagine che il digest dell'immagine sono essenziali per l'aggiornamento all'immagine prevista. |
| Analisi delle vulnerabilità | Si consiglia di utilizzare il servizio OCI Vulnerability Scanning per rilevare le vulnerabilità nell'immagine. |
| Campo API nullo | Se un campo API è vuoto, non passare una stringa vuota, un oggetto vuoto o una lista vuota. Passare il campo come nullo o non passare affatto a meno che non si desideri passare esplicitamente come oggetto vuoto. |
Best practice BYOC
- La distribuzione del modello supporta solo l'immagine del contenitore presente nel registro OCI.
- Assicurarsi che l'immagine del contenitore esista nel registro OCI durante tutto il ciclo di vita della distribuzione del modello. L'immagine deve esistere per garantire la disponibilità nel caso in cui un'istanza venga riavviata automaticamente o il team del servizio esegua l'applicazione delle patch.
- Con BYOC sono supportati solo i container docker.
- Data Science utilizza l'artifact modello compresso per portare la logica di punteggio del modello ML e prevede che sia disponibile nel catalogo dei modelli Data Science.
- La dimensione dell'immagine del contenitore è limitata a 16 GB in formato non compresso.
-
Data Science aggiunge un task
HEALTHCHECKprima di avviare il contenitore, in modo che il criterioHEALTHCHECKnon debba essere aggiunto in modo esplicito nel file Docker perché viene sostituito. Il controllo dello stato inizia a essere eseguito 10 minuti dopo l'avvio del contenitore, quindi controlla/healthogni 30 secondi, con un timeout di tre secondi e tre nuovi tentativi per controllo. - Affinché il criterio
HEALTHCHECKDocker riesca, è necessario installare un package curl nell'immagine del contenitore. - L'utente che crea la risorsa di distribuzione del modello deve avere accesso all'immagine del contenitore in OCI Registry per utilizzarla. In caso contrario, creare un criterio IAM di accesso utente prima di creare una distribuzione modello.
- Il docker
CMDoEntrypointdeve essere fornito tramite l'API o il Dockerfile, che esegue il bootstrap del server Web. - Il timeout definito dal servizio per l'esecuzione del contenitore è di 10 minuti, quindi assicurarsi che il contenitore di servizio di inferenza inizi (in buono stato) entro questo intervallo di tempo.
- Eseguire sempre il test del contenitore a livello locale prima di eseguire la distribuzione nel cloud utilizzando una distribuzione modello.
Digest immagine Docker
Le immagini in un registro Docker sono identificate da un repository, un nome e una tag. Inoltre, Docker offre a ogni versione di un'immagine un digest alfanumerico univoco. Quando si esegue il push di un'immagine Docker aggiornata, si consiglia di assegnare all'immagine aggiornata un nuovo tag per identificarla, anziché riutilizzare un tag esistente. Tuttavia, anche se si esegue il PUSH di un'immagine aggiornata e si assegna lo stesso nome e lo stesso tag di una versione precedente, la nuova versione sottoposta a PUSH ha un digest diverso rispetto alla versione precedente.
Quando si crea una risorsa di distribuzione del modello, specificare il nome e la tag di una versione particolare di un'immagine su cui basare la distribuzione del modello. Per evitare incongruenze, la distribuzione del modello registra il digest univoco di tale versione dell'immagine. È inoltre possibile fornire il digest dell'immagine quando si crea una distribuzione del modello.
Per impostazione predefinita, quando si invia una versione aggiornata di un'immagine al registro Docker con lo stesso nome e la stessa tag della versione originale dell'immagine su cui si basa la distribuzione del modello, continua a utilizzare il digest originale per estrarre la versione originale dell'immagine. Se si desidera che la distribuzione del modello utilizzi la versione successiva dell'immagine, modificare in modo esplicito il nome dell'immagine con una tag e un digest utilizzati dalla distribuzione del modello per identificare la versione dell'immagine da estrarre.
Per garantire l'integrità dell'immagine quando si utilizzano i digest, considerare la possibilità di firmare le immagini dei contenitori. Per ulteriori informazioni, vedere Firma di immagini per la sicurezza.
Prepara artifact modello
Creare un file zip artifact e salvarlo con il modello nel catalogo modelli. L'artifact include il codice per utilizzare il contenitore ed eseguire le richieste di inferenza.
Il contenitore deve esporre un endpoint /health per restituire lo stato del server di inferenza e un endpoint /predict per l'inferenza.
Il seguente file Python nell'artifact modello definisce questi endpoint utilizzando un server Flask con porta 5000:
# We now need the json library so we can load and export json data
import json
import os
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neural_network import MLPClassifier
import pandas as pd
from joblib import load
from sklearn import preprocessing
import logging
from flask import Flask, request
# Set environnment variables
WORK_DIRECTORY = os.environ["WORK_DIRECTORY"]
TEST_DATA = os.path.join(WORK_DIRECTORY, "test.json")
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE_LDA = os.environ["MODEL_FILE_LDA"]
MODEL_PATH_LDA = os.path.join(MODEL_DIR, MODEL_FILE_LDA)
# Loading LDA model
print("Loading model from: {}".format(MODEL_PATH_LDA))
inference_lda = load(MODEL_PATH_LDA)
# Creation of the Flask app
app = Flask(__name__)
# API 1
# Flask route so that we can serve HTTP traffic on that route
@app.route('/health')
# Get data from json and return the requested row defined by the variable Line
def health():
# We can then find the data for the requested row and send it back as json
return {"status": "success"}
# API 2
# Flask route so that we can serve HTTP traffic on that route
@app.route('/predict',methods=['POST'])
# Return prediction for both Neural Network and LDA inference model with the requested row as input
def prediction():
data = pd.read_json(TEST_DATA)
request_data = request.get_data()
print(request_data)
print(type(request_data))
if isinstance(request_data, bytes):
print("Data is of type bytes")
request_data = request_data.decode("utf-8")
print(request_data)
line = json.loads(request_data)['line']
data_test = data.transpose()
X = data_test.drop(data_test.loc[:, 'Line':'# Letter'].columns, axis = 1)
X_test = X.iloc[int(line),:].values.reshape(1, -1)
clf_lda = load(MODEL_PATH_LDA)
prediction_lda = clf_lda.predict(X_test)
return {'prediction LDA': int(prediction_lda)}
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port = 5000)
Crea il container
Puoi utilizzare qualsiasi immagine da OCI Container Registry. Di seguito è riportato un dockerfile di esempio che utilizza il server Flask:
FROM jupyter/scipy-notebook
USER root
RUN \
apt-get update && \
apt-get -y install curl
ENV WORK_DIRECTORY=/opt/ds/model/deployed_model
ENV MODEL_DIR=$WORK_DIRECTORY/models
RUN mkdir -p $MODEL_DIR
ENV MODEL_FILE_LDA=clf_lda.joblib
COPY requirements.txt /opt/requirements.txt
RUN pip install -r /opt/requirements.txtIl pacchetto Curl deve essere installato nell'immagine del contenitore affinché il criterio HEALTHCHECK docker funzioni.
Creare un file requirements.txt con i seguenti pacchetti nella stessa directory di Dockerfile:
flask
flask-restful
joblibEseguire il comando docker build:
docker build -t ml_flask_app_demo:1.0.0 -f Dockerfile .La dimensione massima di un'immagine contenitore decompressa che è possibile utilizzare con le distribuzioni di modelli è di 16 GB. Tenere presente che la dimensione dell'immagine del contenitore rallenta il tempo di provisioning per la distribuzione del modello perché viene estratta dal Container Registry. Si consiglia di utilizzare le immagini del contenitore più piccole possibili.
Test del contenitore
Assicurarsi che l'artifact modello e il codice inferenza si trovino nella stessa directory del Dockerfile. Eseguire il contenitore sul computer locale. È necessario fare riferimento ai file memorizzati sul computer locale attivando la directory del modello locale su /opt/ds/model/deployed_model:
docker run -p 5000:5000 \
--health-cmd='curl -f http://localhost:5000/health || exit 1' \
--health-interval=30s \
--health-retries=3 \
--health-timeout=3s \
--health-start-period=1m \
--mount type=bind,src=$(pwd),dst=/opt/ds/model/deployed_model \
ml_flask_app_demo:1.0.0 python /opt/ds/model/deployed_model/api.pyInviare una richiesta di integrità per verificare che il contenitore sia in esecuzione entro i 10 minuti definiti dal servizio:
curl -vf http://localhost:5000/healthEseguire il test inviando una richiesta di previsione:
curl -H "Content-type: application/json" -X POST http://localhost:5000/predict --data '{"line" : "12"}'Esegui il push del container in OCI Container Registry
Prima di poter eseguire il push e il pull delle immagini in e da Oracle Cloud Infrastructure Registry (noto anche come Container Registry), è necessario disporre di un token di autorizzazione per Oracle Cloud Infrastructure. La stringa del token di autenticazione viene visualizzata solo quando viene creata, quindi assicurarsi di copiare immediatamente il token di autenticazione in una posizione sicura.
- Per visualizzare i dettagli nella console: nella barra di navigazione, selezionare il menu Profilo, quindi selezionare Impostazioni utente o Profilo personale, a seconda dell'opzione visualizzata.
- Nella pagina Token di autenticazione selezionare Genera token.
- Immettere una descrizione descrittiva per il token di autenticazione. Evitare di fornire informazioni riservate.
- Selezionare Genera token. Viene visualizzato il nuovo token di autenticazione.
- Copiare immediatamente il token di autenticazione in una posizione sicura in cui è possibile recuperarlo in seguito. Il token di autenticazione non verrà più visualizzato nella console.
- Chiudere la finestra di dialogo Genera token.
- Aprire una finestra di terminale sul computer locale.
- Accedi a Container Registry in modo da poter creare, eseguire, testare, etichettare e inviare l'immagine del contenitore.
docker login -u '<tenant-namespace>/<username>' <region>.ocir.io -
Tagare l'immagine del contenitore locale:
docker tag <local_image_name>:<local_version> <region>.ocir.io/<tenancy_ocir_namespace>/<repository>:<version> -
Push dell'immagine del contenitore:
docker push <region>.ocir.io/<tenancy>/byoc:1.0Nota
Assicurarsi che la risorsa di distribuzione modello disponga di un criterio per il principal risorsa in modo che possa leggere l'immagine dal registro OCI dal compartimento in cui è stata memorizzata l'immagine. Per ulteriori informazioni, vedere Dare l'accesso alla distribuzione del modello a un contenitore personalizzato utilizzando il principal risorsa
Nota
(firma dell'immagine): prima di eseguire la distribuzione, seguire il processo di firma dell'immagine e registrare l'OCID della firma dell'immagine per l'audit e la verifica. Per informazioni dettagliate, vedere la sezione sulla firma delle immagini in Docker Image Digests.Nota
(requisiti di accesso ai vault): l'utente che crea la distribuzione del modello deve disporre almeno dell'accesso di livelloUSEalle chiavi vault e alle risorse della famiglia di segreti nel servizio vault. Per ulteriori informazioni, vedere Dettagli per il servizio Vault.
È possibile utilizzare questa immagine contenitore con l'opzione BYOC quando si crea una distribuzione modello.
Le distribuzioni del modello BYOC non supportano l'estrazione dell'immagine del contenitore tra più aree. Ad esempio, quando si esegue una distribuzione modello BYOC in un'area IAD (Ashburn), non è possibile estrarre le immagini dei container da OCIR (Oracle Cloud Container Registry) nell'area PHX (Phoenix).
Funzionamento dell'operazione di aggiornamento BYOC
Le operazioni di aggiornamento BYOC sono aggiornamenti parziali di tipo unione superficiale.
Un campo di livello superiore scrivibile deve essere sostituito completamente quando viene visualizzato nel contenuto della richiesta e conservato invariato. Ad esempio, per una risorsa come la seguente:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 5454,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {
"a": "b",
"c": "d",
"e": "f"
},
"entrypoint": [ "python", "-m", "uvicorn", "a/model/server:app", "--port", "5000","--host","0.0.0.0"]
"cmd": ["param1"]
}Aggiornamento riuscito con i seguenti elementi:
{
"environmentConfigurationDetails": {
"serverPort": 2000,
"environmentVariables": {"x":"y"},
"entrypoint": []
}
}Consente di ottenere uno stato in cui serverPort e environmentVariables vengono sovrascritti dal contenuto dell'aggiornamento (inclusa la distruzione dei dati presenti in precedenza nei campi profondi non presenti nel contenuto dell'aggiornamento). image viene mantenuto invariato perché non è stato visualizzato nel contenuto dell'aggiornamento e entrypoint viene cancellato da un elenco vuoto esplicito:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 2000,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {"x": "y"},
"entrypoint": []
"cmd": ["param1"]
}Il campo
imageSignatureId è facoltativo.Un aggiornamento riuscito con { "environmentConfigurationDetails": null or {} } non comporta la sovrascrittura di alcun elemento. Una sostituzione completa al livello superiore cancella tutti i valori che non sono presenti nel contenuto della richiesta in modo da evitare che. Tutti i campi sono facoltativi nell'oggetto di aggiornamento, pertanto se non si fornisce l'immagine non è necessario annullare l'impostazione dell'immagine nella distribuzione. Data Science sostituisce i campi di secondo livello solo se non sono nulli.
Se non si imposta un campo nell'oggetto richiesta (passando un valore nullo), Data Science non considererà tale campo per trovare la differenza e sostituirlo con il valore di campo esistente.
Per reimpostare un valore di qualsiasi campo, passare un oggetto vuoto. Per i campi elenco e tipo di mappa, Data Science può accettare un elenco vuoto ([]) o un mapping ({}) come indicazione per cancellare i valori. In ogni caso, null non significa cancellare i valori. Tuttavia, è sempre possibile modificare il valore in qualcos'altro. Per utilizzare una porta predefinita e annullare l'impostazione del valore del campo relativo, impostare in modo esplicito la porta predefinita.
L'aggiornamento ai campi elenco e mappa è una sostituzione completa. Data Science non guarda all'interno degli oggetti per i singoli valori.
Per immagine e digest, Data Science non consente di cancellare il valore.
Distribuisci con un contenitore server di inferenza Triton
NVIDIA Triton Inference Server semplifica e standardizza l'inferenza AI consentendo AI team di distribuire, eseguire e ridimensionare modelli AI formati da qualsiasi framework su qualsiasi infrastruttura basata su GPU o CPU.
Alcune caratteristiche chiave di Triton sono:
- Esecuzione di modelli concorrenti: la possibilità di servire più modelli ML contemporaneamente. Questa funzione è utile quando più modelli devono essere distribuiti e gestiti insieme in un unico sistema.
- Batching dinamico: consente al server di raggruppare le richieste in batch in modo dinamico in base al carico di lavoro per migliorare le prestazioni.
La distribuzione del modello prevede un supporto speciale per NVIDIA Triton Inference Server. È possibile distribuire un'immagine Triton esistente dal catalogo container di NVIDIA e la distribuzione dei modelli garantisce la corrispondenza delle interfacce Triton senza dover modificare alcun elemento nel contenitore utilizzando la variabile di ambiente riportata di seguito durante la creazione della distribuzione del modello.
CONTAINER_TYPE = TRITONUn esempio completo e documentato di come distribuire i modelli ONNX in Triton è disponibile nella distribuzione del modello Data Science GitHub repository.