Uso dei plugin di ricerca con avvisi e notifiche OpenSearch
Utilizza i plugin di avviso e notifica integrati di OpenSearch per monitorare lo stato del cluster, le metriche delle prestazioni e i problemi operativi.
Il dimensionamento e l'ottimizzazione corretti dei cluster OpenSearch sono fondamentali per garantire prestazioni ed efficienza dei costi. Nel tempo, i modelli di utilizzo dei cluster possono cambiare, portando a sovraccarico, aumento delle latenze o errori. Il monitoraggio e gli avvisi proattivi sono essenziali per rilevare e mitigare i potenziali problemi prima che si intensifichino.
OpenSearch dispone di un plugin di avviso e monitoraggio integrato che può aiutare a creare tali avvisi. In questo argomento vengono fornite indicazioni sull'impostazione degli avvisi, sull'integrazione con Oracle Notification Service (ONS) e sulla mitigazione dei problemi più comuni.
Plugin di avviso OpenSearch
Il plugin di avviso fornisce monitoraggio e notifica per gli eventi in OpenSearch. Utilizza le API REST per creare avvisi complessi in base alle metriche cluster e nodo. Il plugin di avviso contiene le seguenti funzionalità:
- Monitoraggi garantiti: combina più condizioni da output di API REST diversi per creare avvisi complessi.
- Intervalli controllati: definisce la frequenza con cui vengono valutati gli avvisi per evitare l'affaticamento delle notifiche.
- Supporto RBAC: utilizza il controllo dell'accesso basato sui ruoli per la gestione degli avvisi.
Per ulteriori informazioni sul monitoraggio OpenSearch, vedere Monitoraggio.
Metriche e avvisi supportati
È possibile configurare il plugin di avviso per le metriche seguenti:
- Stato cluster: modifica dello stato (verde, giallo, rosso).
- Metriche nodo: uso elevato del disco, CPU, pressione JVM.
- Metriche partizioni: partizioni di grandi dimensioni, conteggi di partizioni eccessivi.
- Metriche task: task bloccati o rifiutati, numero massimo di task di scorrimento.
- Limitazione: limitazione dell'indice o della query.
Impostazione degli avvisi
È possibile impostare avvisi sugli output delle seguenti API OpenSearch:
- _cluster/stato
- _cluster/statistiche
- _cluster/impostazioni
- _nodi/statistiche
- _gatto/indici
- _cat/pending_tasks
- _gatto/recupero
- _cat/shards
- _cat/snapshot
- _cat/attività
Per ulteriori informazioni, vedere Per monitoraggi delle metriche cluster.
Plugin di notifica OpenSearch
Utilizzare il plugin di notifica per ottenere notifiche automatiche sugli avvisi configurati utilizzando il plugin di avviso. Il servizio di notifica Oracle (ONS) è integrato con il plugin di notifica. È possibile creare canali utilizzando il plugin di notifica che invia notifiche all'argomento ONS configurato. È quindi possibile collegare questi canali agli avvisi per ricevere notifiche sugli avvisi di attivazione.
Di seguito è riportato un esempio di notifica di avviso.
Monitor Test index stats just entered alert status. Please investigate the issue.
- Trigger: test
- Severity: 2
- Period start: 2025-02-06-06T08:48:45.047Z
- Period end: 2025-02-06-06T08:49:45.047ZPer ulteriori informazioni sul plugin Notifiche OpenSearch, vedere Notifiche.
Servizio di notifica Oracle (ONS)
Il servizio Oracle Cloud Infrastructure Notifications (ONS) trasmette messaggi sicuri e altamente affidabili ai componenti distribuiti tramite un pattern di pubblicazione-sottoscrizione. Puoi usarlo per le applicazioni ospitate su Oracle Cloud Infrastructure ed esternamente. Utilizzare ONS per ricevere una notifica quando le regole evento vengono attivate o gli allarmi vengono violati oppure per pubblicare direttamente un messaggio.
ONS supporta i seguenti canali per la consegna dei messaggi:
- Funzioni
- Endpoint HTTP (per applicazioni esterne)
- PagerDuty
- Slack
- SMS
Per ulteriori informazioni sul servizio di notifica OCI, vedere Notifiche.
L'immagine seguente mostra come le notifiche vengono trasmesse utilizzando ONS:
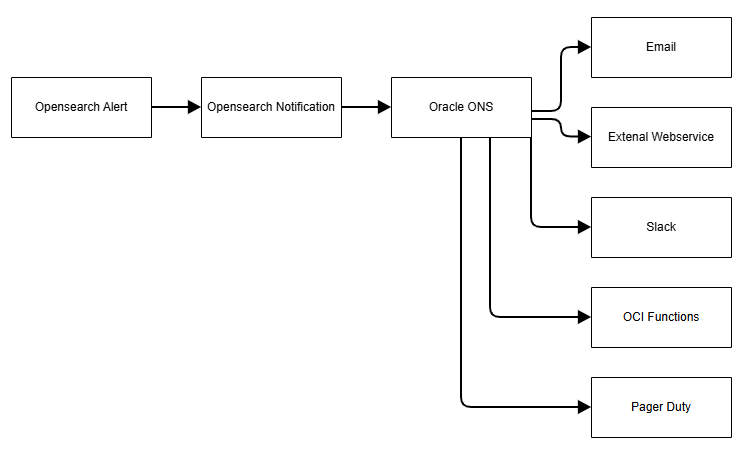
Avvisi di esempio con notifiche
È possibile creare avvisi per monitorare la maggior parte delle aree importanti di OpenSearch che possono influire sulle prestazioni del cluster OpenSearch. Le procedure ottimali consentono di impostare avvisi a livello di avvertenza che indicano che alcuni parametri diventano problematici, in modo che sia possibile intraprendere un'azione correttiva prima che il cluster OpenSearch entri in uno stato non valido.
Nelle sezioni riportate di seguito vengono forniti avvisi a livello di avvertenza e di errore che possono essere impostati nel cluster OpenSearch.
Canale di notifica
Prima di creare avvisi, si consiglia di impostare un canale di notifica. Puoi utilizzare la tua sottoscrizione al canale ONS per ottenere notifiche automatiche attraverso vari metodi di comunicazione, tra cui e-mail, Slack, funzioni OCI, flussi e altri.
L'esempio seguente mostra come creare un canale di notifica.
{
"config_id": "sample-id",
"name": "test-ons1",
"config": {
"name": "test-ons1",
"description": "send notifications",
"config_type": "ons",
"is_enabled": true,
"ons": {
"topic_id": "ocid1.onstopic.oc1.iad.amaaaaaawtpq47yar24xitgso2wble2a5shal52r6zoc6eyth3jzsmbvxspa"
}
}
}Cluster stato
Il cluster OpenSearch dispone dei seguenti stati di integrità:
- Verde: tutte le partizioni disponibili.
- Giallo: alcune partizioni di replica non sono disponibili. Le prestazioni potrebbero essere compromesse a causa della disponibilità di meno repliche.
- Rosso: alcune partizioni primarie non sono disponibili. Il rosso indica l'indisponibilità dei dati, con conseguente errore delle query sulle partizioni non disponibili.
Configurazione degli avvisi cluster gialli
Utilizzare la configurazione seguente per impostare gli avvisi gialli per il cluster:
POST: {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthYellow",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"yellow\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Configurazione degli avvisi cluster gialli
Utilizzare la configurazione seguente per impostare gli avvisi rossi per il cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthRed",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"red\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Numero di nodi
Utilizzare la configurazione seguente per specificare il numero di nodi per il cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterNodesUnavailable",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check all nodes available",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].number_of_nodes< 8",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Risoluzione dei problemi
Lo stato del cluster può diventare Giallo o Rosso a causa di vari motivi, ad esempio un ripristino non riuscito, la disconnessione temporanea dei nodi e il completamento del disco. Sebbene alcuni problemi debbano essere risolti dal team OCI OpenSearch, puoi risolvere autonomamente altri problemi.
Per risolvere i problemi personalmente, effettuare le operazioni indicate di seguito.
- Ottieni una lista di tutte le partizioni utilizzando l'API delle partizioni di categoria per avere un'idea delle partizioni non assegnate.
- Se il cluster OpenSearch è rosso:
- Controllare il motivo dell'allocazione per le partizioni non allocate utilizzando l'API di allocazione CAT.
- Utilizzare l'API di reindirizzamento forza per provare a riallocare le partizioni, se il problema era temporaneo e viene mitigato.
- Se la spiegazione dell'allocazione delle partizioni menziona un tentativo di ripristino non riuscito, ripristinare il cluster a uno stato valido noto precedente.
- Se il problema persiste, contattare il team OCI OpenSearch.
- Se il cluster OpenSearch è giallo:
- Controllare se il numero di nodi è uguale o maggiore del numero massimo di repliche per un indice.
- Controllare il motivo dell'allocazione per le partizioni non allocate utilizzando l'API di allocazione CAT.
- Se il problema sembra essere temporaneo, utilizzare l'API force reroute per riallocare le partizioni.
Se uno o più nodi nel cluster non sono disponibili per un periodo di tempo prolungato, contattare il team OCI OpenSearch. Questi sintomi indicano che qualcosa potrebbe essere sbagliato con l'infrastruttura sottostante.
Statistiche a livello di nodo
Tutti i nodi OpenSearch dovrebbero avere un buon buffer in termini di tutte le metriche di base, come CPU, RAM e spazio su disco, affinché funzionino in modo ottimale. Raggiungere i livelli critici di queste metriche può portare a una riduzione delle latenze, a un aumento dei ritardi e, infine, a bloccare o lasciare il cluster.
È possibile impostare due livelli di alert su queste metriche: uno per un livello di avvertenza e l'altro per un livello critico.
High Disk/CPU/JVM
Livello di avvertenza
Utilizzare la configurazione riportata di seguito per specificare un avviso a livello di avvertenza per i nodi OpenSearch.
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 70) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Livello critico
Utilizzare la configurazione seguente per specificare un avviso di livello critico per i nodi OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 85) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Risoluzione dei problemi
Per un uso elevato del disco, provare ad aumentare la dimensione del disco o a impostare criteri ISM per rimuovere i dati precedenti.
Esaminare il traffico e le configurazioni dei nodi, se il cluster è in stato di stress a causa dei parametri dei nodi per un lungo periodo di tempo, in genere indica un cluster non configurato.
Task in sospeso
La lista dei task in sospeso specifica quali task OpenSearch vengono eseguiti sui nodi. La maggior parte dei task OpenSearch, diversi da alcuni come l'operazione di reindicizzazione, sono piccoli task che OpenSearch ha diviso da sforzi più grandi.
Utilizzare la configurazione seguente per elencare i task in sospeso per i nodi OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "pending_tasks",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"enabled_time": 1746584774661,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_TASKS",
"path": "_cat/tasks",
"path_params": "",
"url": "http://localhost:9200/_cat/tasks",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "jUOQqJYBQxJTy-1pqNIF",
"name": "test",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].tasks){\n\nif(item.running_time_in_nanos> 300000000000) return true;\n}\nreturn false\n",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false
}Risoluzione dei problemi
I task in sospeso possono indicare un sovraccarico sul nodo, uno stato errato del nodo o parametri errati per il task. Utilizzare le istruzioni riportate di seguito per risolvere i problemi relativi ai nodi in sospeso.
- Se il cluster esegue più unioni di tipo o indici di massa, eseguire un'unione forzata per risolvere il problema durante l'unione di tutto in un'unica azione.
- Se il cluster subisce il blocco delle impostazioni di aggiornamento del cluster, potrebbe indicare un problema con lo stato del nodo o con le code del nodo. Provare a eliminare i task bloccati o a riavviare il nodo per risolvere il problema.
- Se il cluster sperimenta il blocco degli snapshot del tipo, potrebbe indicare un problema con il repository. Controllare le impostazioni del repository. Contattare il team OCI OpenSearch se l'errore è correlato ai backup automatici.
Task e thread rifiutati
I thread rifiutati indicano un livello elevato di limitazione tra i task. Ad esempio, potrebbe essere quando c'è così tanta attività, molte richieste di indicizzazione e ricerca che non possono essere servite vengono invece limitate.
Utilizzare la configurazione seguente per elencare i task e i thread rifiutati:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Rejected threads",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "1kNRrpYBQxJTy-1pGtJ9",
"name": "rejected thread pool",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{\n for (e in entry.getValue().thread_pool.entrySet()) {\n if(e.getValue().rejected>10){\n return true;\n}\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Risoluzione dei problemi
I task rifiutati possono indicare un sovraccarico nel sistema. Esaminare il tipo di task rifiutati. Verificare se il traffico di queste attività può essere ridotto o se le impostazioni/struttura del task sono state modificate.
Se la funzione di ricerca è in fase di limitazione, verificare se la query di ricerca può essere ottimizzata.
Se la funzione di indicizzazione è in fase di limitazione, verificare se è possibile aggiornare la velocità di indicizzazione o le impostazioni di massa oppure se è possibile suddividere l'indice e le partizioni in task più piccoli.
Statistiche livello indice
Dimensionamento partizione
I dati di indice vengono memorizzati in strutture indipendenti, note come partizioni. Ogni partizione è costituita da segmenti, che vengono caricati nella memoria OpenSearch per facilitare la funzione di ricerca. Le partizioni nell'intervallo di 30-50 GB o più grandi portano a segmenti più grandi, che portano a un maggiore utilizzo della memoria. Il dimensionamento corretto delle partizioni è importante per le prestazioni del cluster. In genere, le dimensioni delle partizioni possono essere controllate dai criteri ILM (Indice Lifecycle Management). Per gli indici che non dispongono di ILM, è possibile impostare avvisi sulle dimensioni delle partizioni per evitare che gli indici diventino troppo grandi.
Utilizzare la configurazione seguente per elencare le partizioni e le relative dimensioni:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Big shard size",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_SHARDS",
"path": "_cat/shards",
"path_params": "",
"url": "http://localhost:9200/_cat/shards",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "pkOWqJYBQxJTy-1pO9Im",
"name": "big shards",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].shards)\nif((item.store != null)&&(item.store.contains(\"gb\"))&&(item.store.length()>4)\n&&(Double.parseDouble(item.store.substring(0,item.store.length()-3))>30)) return true\n",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false
}Risoluzione dei problemi
Impostare il criterio ILM del cluster per eseguire il rollback degli indici quando raggiungono una determinata dimensione.
Aumentare il numero di partizioni per gli indici esistenti cresciuti utilizzando la funzione di reindicizzazione. Per indici di grandi dimensioni superiori a 100 GB, attenersi alle procedure ottimali riportate di seguito.
- Dividere il task in parti più piccole utilizzando l'API di query.
- Impostare la dimensione batch appropriata e il numero di richieste al secondo.
Indicizzazione in ritardo
Quando i dati vengono indicizzati nel cluster, OpenSearch lo scrive inizialmente in un file translog. Il processo OpenSearch preleva quindi le voci da questo file a intervalli regolari per includere i dati nelle sue strutture Apache Lucene, creando segmenti appropriati con oggetti interni obbligatori come tokenizer, dati di campo e così via. Elevati tassi di ingestione o un cluster non configurato possono portare a un ritardo nel processo di ingestione. Qui, la dimensione del file translog aumenta insieme al ritardo nell'indicizzazione dei documenti. È possibile monitorare questo comportamento utilizzando le statistiche di indicizzazione.
Utilizzare la configurazione riportata di seguito per monitorare l'esecuzione ritardata degli indici.
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "UncommittedSize large",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Uncommited size",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.translog.uncommitted_size_in_bytes>1000000000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Risoluzione dei problemi
Durante la risoluzione dei problemi relativi all'indicizzazione in ritardo, eseguire i task riportati di seguito.
- Rivedere la pressione di indicizzazione.
- Esaminare le altre statistiche sui nodi, ad esempio le statistiche di CPU, memoria e I/O su disco.
Considerare le opzioni riportate di seguito in base ai risultati dei task precedenti.
- Ridurre la pressione di indicizzazione.
- Aumentare la configurazione dei nodi.
- Aumentare refresh_interval, se il translog non è troppo alto.
Limitazione
OpenSearch memorizza i dati sotto forma di segmenti Lucene. I segmenti sono condensati e fusi insieme continuamente per raccogliere molte operazioni sugli stessi documenti. Quando la velocità di indicizzazione richiesta è maggiore di quella consentita dal cluster OpenSearch, queste unioni vengono limitate. È possibile monitorare la limitazione utilizzando le statistiche di indicizzazione e aggiornare la soglia di limitazione per soddisfare i requisiti.
Utilizzare la configurazione seguente per impostare la limitazione:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Merge Throttling",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "Merge Throttling",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.merges.total_throttled_time_in_millis>300000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}
Risoluzione dei problemi
Durante la risoluzione dei problemi di limitazione, eseguire i task riportati di seguito.
- Rivedere la pressione di indicizzazione.
- Esaminare le altre statistiche sui nodi, ad esempio le statistiche di CPU, memoria e I/O su disco.
Considerare le opzioni riportate di seguito in base ai risultati dei task precedenti.
- Ridurre la pressione di indicizzazione.
- Aumentare la configurazione dei nodi.
- Aumentare refresh_interval, se il translog non è troppo alto.
Cerca
Scorri
La ricerca con scorrimento viene utilizzata quando sono previsti molti risultati. Tuttavia, l'utilizzo di troppi scroll richiede memoria in OpenSearch perché deve mantenere il contesto, portando a prestazioni scadenti. L'avviso f può essere utilizzato per mantenere una scheda sul numero di rotoli costantemente aperti.
Utilizzare la configurazione seguente per tenere traccia del numero di scorrimento aperti in modo coerente.
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Large Number of Open Scrolls",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Open Scrolls",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.search.scroll_current>200) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}