Informazioni su Data Pipelines nell'Autonomous AI Database
Le pipeline di dati di Autonomous AI Database sono pipeline di caricamento o di esportazione.
Le pipeline di caricamento forniscono un caricamento continuo dei dati incrementale da origini esterne (poiché i dati arrivano nell'area di memorizzazione degli oggetti, vengono caricati in una tabella di database). Le pipeline di esportazione forniscono un'esportazione continua di dati incrementali nell'area di memorizzazione degli oggetti (poiché i nuovi dati vengono visualizzati in una tabella di database, vengono esportati nell'area di memorizzazione degli oggetti). Le pipeline utilizzano lo scheduler del database per caricare o esportare continuamente dati incrementali.
Le pipeline di dati di Autonomous AI Database forniscono quanto segue:
-
Operazioni unificate: le pipeline consentono di caricare o esportare dati in modo rapido e semplice e di ripetere queste operazioni a intervalli regolari per nuovi dati. Il package
DBMS_CLOUD_PIPELINEfornisce un set unificato di procedure PL/SQL per la configurazione della pipeline e per la creazione e l'avvio di un job pianificato per le operazioni di caricamento o esportazione. -
Elaborazione dei dati pianificata: le pipeline monitorano la propria origine dati e caricano o esportano periodicamente i dati all'arrivo di nuovi dati.
-
Performance elevate: le pipeline ridimensionano le operazioni di trasferimento dati con le risorse disponibili su Autonomous AI Database. Per impostazione predefinita, le pipeline utilizzano il parallelismo per tutte le operazioni di caricamento o esportazione e la scalabilità in base alle risorse CPU disponibili nell'Autonomous AI Database o in base a un attributo di priorità configurabile.
-
Atomicità e recupero: le pipeline garantiscono l'atomicità in modo che i file nell'area di memorizzazione degli oggetti vengano caricati esattamente una volta per una pipeline di caricamento.
-
Monitoraggio e risoluzione dei problemi: le pipeline forniscono tabelle di log e di stato dettagliate che consentono di monitorare ed eseguire il debug delle operazioni della pipeline.
-
Compatibile con il multicloud: le pipeline su Autonomous AI Database supportano un passaggio semplice tra provider cloud senza modifiche alle applicazioni. Le pipeline supportano tutti i formati URI delle credenziali e dell'area di memorizzazione degli oggetti supportati da Autonomous AI Database (Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage, Google Cloud Storage e le aree di memorizzazione degli oggetti compatibili con Amazon S3).
Ciclo di vita pipeline dati
Il pacchetto DBMS_CLOUD_PIPELINE fornisce procedure per la creazione, la configurazione, il test e l'avvio di una pipeline. Il ciclo di vita e le procedure della pipeline sono uguali sia per le pipeline di caricamento che per quelle di esportazione.
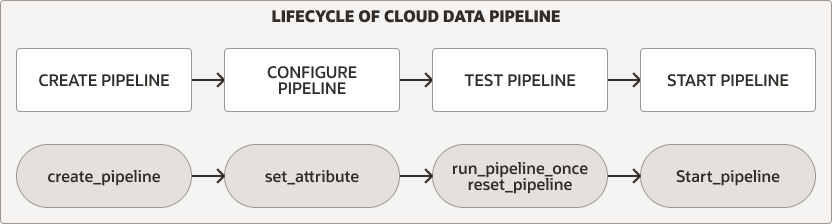
Descrizione dell'immagine pipeline_lifecycle.png
Per uno dei tipi di pipeline, eseguire i passi riportati di seguito per creare e utilizzare una pipeline.
-
Creare e configurare la pipeline. Per ulteriori informazioni, vedere Crea e configura pipeline.
-
Eseguire il test di una nuova pipeline. Per ulteriori informazioni, vedere Test delle pipeline.
-
Avvia una pipeline. Per ulteriori informazioni, vedere Avvio di una pipeline.
Inoltre, è possibile monitorare, arrestare o eliminare le pipeline:
-
Durante l'esecuzione di una pipeline, durante i test o durante l'uso regolare dopo l'avvio della pipeline, è possibile monitorare la pipeline. Per ulteriori informazioni, vedere Monitoraggio e risoluzione dei problemi delle pipeline.
-
È possibile arrestare una pipeline e avviarla di nuovo in seguito oppure eliminare una pipeline al termine dell'utilizzo della pipeline. Per ulteriori informazioni, vedere Arrestare una pipeline e Eliminare una pipeline.
Carica pipeline
Utilizzare una pipeline di caricamento per il caricamento continuo dei dati incrementali da file esterni nell'area di memorizzazione degli oggetti in una tabella di database. Una pipeline di caricamento identifica periodicamente nuovi file nell'area di memorizzazione degli oggetti e carica i nuovi dati nella tabella del database.
Una pipeline di caricamento opera nel modo seguente (alcune di queste funzioni sono configurabili utilizzando gli attributi della pipeline):
-
I file dell'area di memorizzazione degli oggetti vengono caricati in parallelo in una tabella di database.
-
Una pipeline di caricamento utilizza il nome file dell'area di memorizzazione degli oggetti per identificare e caricare in modo univoco i file più recenti.
-
Una volta caricato un file nell'area di memorizzazione degli oggetti nella tabella del database, se il contenuto del file cambia nell'area di memorizzazione degli oggetti, non verrà caricato di nuovo.
-
Se il file dell'area di memorizzazione degli oggetti viene eliminato, non influisce sui dati nella tabella del database.
-
-
Se si verificano errori, una pipeline di caricamento prova automaticamente l'operazione. Vengono tentati nuovi tentativi in ogni esecuzione successiva del job pianificato della pipeline.
-
Nei casi in cui i dati di un file non sono conformi alla tabella del database, vengono contrassegnati come
FAILEDe possono essere rivisti per eseguire il debug e risolvere il problema.- Se il caricamento di un file non riesce, la pipeline non si arresta e continua a caricare gli altri file.
-
Le pipeline di caricamento supportano più formati di file di input, tra cui: JSON, CSV, XML, Avro, ORC e Parquet.

Descrizione dell'illustrazione load-pipeline.svg
La migrazione da database non Oracle è un possibile caso d'uso per una pipeline di caricamento. Quando devi eseguire la migrazione dei tuoi dati da un database non Oracle a Oracle Autonomous AI Database on Dedicated Exadata Infrastructure, puoi estrarre i dati e caricarli in Autonomous AI Database (il formato Oracle Data Pump non può essere utilizzato per le migrazioni da database non Oracle). Utilizzando un formato di file generico, ad esempio CSV, per esportare i dati da un database non Oracle, è possibile salvare i dati in file e caricare i file nell'area di memorizzazione degli oggetti. Successivamente, crea una pipeline per caricare i dati in Autonomous AI Database. L'utilizzo di una pipeline di caricamento per caricare un ampio set di file CSV fornisce benefit importanti quali la tolleranza agli errori e le operazioni di ripresa e nuovo tentativo. Per una migrazione con un data set di grandi dimensioni puoi creare più pipeline, una per tabella per i file di database non Oracle, per caricare i dati in Autonomous AI Database.
Esporta pipeline
Utilizza una pipeline di esportazione per l'esportazione incrementale continua dei dati dal database all'area di memorizzazione degli oggetti. Una pipeline di esportazione identifica periodicamente i dati dei candidati e carica i dati nell'area di memorizzazione degli oggetti.
Sono disponibili tre opzioni della pipeline di esportazione (le opzioni di esportazione sono configurabili utilizzando gli attributi della pipeline):
-
Esporta i risultati incrementali di una query nell'area di memorizzazione degli oggetti utilizzando una colonna data o indicatore orario come chiave per tenere traccia dei dati più recenti.
-
Esportare i dati incrementali di una tabella nell'area di memorizzazione degli oggetti utilizzando una colonna data o indicatore orario come chiave per la registrazione dei dati più recenti.
-
Esportare i dati di una tabella nell'area di memorizzazione degli oggetti utilizzando una query per selezionare i dati senza un riferimento a una colonna data o indicatore orario (in modo che la pipeline esporta tutti i dati selezionati dalla query per ogni esecuzione dello scheduler).
Le pipeline di esportazione dispongono delle funzioni seguenti (alcune di queste sono configurabili utilizzando gli attributi della pipeline):
-
I risultati vengono esportati in parallelo nell'area di memorizzazione degli oggetti.
-
In caso di errori, un job pipeline successivo ripete l'operazione di esportazione.
-
Le pipeline di esportazione supportano più formati di file di esportazione, tra cui CSV, JSON, Parquet o XML.
Pipeline gestite da Oracle
Autonomous AI Database on Dedicated Exadata Infrastructure fornisce pipeline integrate per esportare log specifici in un'area di memorizzazione degli oggetti in formato JSON. Queste pipeline sono preconfigurate e vengono avviate e di proprietà dell'utente ADMIN.
Le pipeline gestite da Oracle sono le seguenti:
-
ORA$AUDIT_EXPORT: questa pipeline esporta i log di audit del database nell'area di memorizzazione degli oggetti in formato JSON ed viene eseguita ogni 15 minuti dopo l'avvio della pipeline (in base al valore dell'attributointerval). -
ORA$APEX_ACTIVITY_EXPORT: questa pipeline esporta il log delle attività dell'area di lavoro di Oracle APEX nell'area di memorizzazione degli oggetti in formato JSON. Questa pipeline è preconfigurata con la query SQL per il recupero dei record di attività APEX ed viene eseguita ogni 15 minuti dopo l'avvio della pipeline (in base al valore dell'attributointerval).
Per configurare e avviare una pipeline gestita da Oracle:
-
Determinare la pipeline gestita Oracle che si desidera utilizzare:
ORA$AUDIT_EXPORToORA$APEX_ACTIVITY_EXPORT. -
Impostare gli attributi
credential_nameelocation.Nota:
credential_nameè un valore obbligatorio in Autonomous AI Database on Dedicated Exadata Infrastructure.Ad esempio:
BEGIN DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'credential_name', attribute_value => 'DEF_CRED_OBJ_STORE' ); DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'location', attribute_value => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/' ); END; /I dati di log del database vengono esportati nella posizione dell'area di memorizzazione degli oggetti specificata.
Per ulteriori informazioni, vedere SET_ATTRIBUTE.
-
Facoltativamente, impostare gli attributi
interval,formatopriority.Per ulteriori informazioni, vedere SET_ATTRIBUTE.
-
Avviare la pipeline.
Per ulteriori informazioni, vedere START_PIPELINE.