Configura replica bidirezionale
Dopo aver impostato una replica unidirezionale, sono disponibili solo alcuni passaggi aggiuntivi per replicare i dati nella direzione opposta. Questo esempio rapido utilizza Autonomous AI Transaction Processing e Autonomous AI Lakehouse come due database cloud.
Prima di iniziare
Per procedere con questo avvio rapido, è necessario disporre di due database esistenti nella stessa tenancy e area. Se sono necessari dati di esempio, scaricare Archive.zip, quindi seguire le istruzioni in Lab 1, Task 3: Caricare lo schema ATP
Panoramica
I passi riportati di seguito descrivono come creare un'istanza di un database di destinazione utilizzando Oracle Data Pump e impostare la replica bidirezionale (a due vie) tra due database nella stessa area.
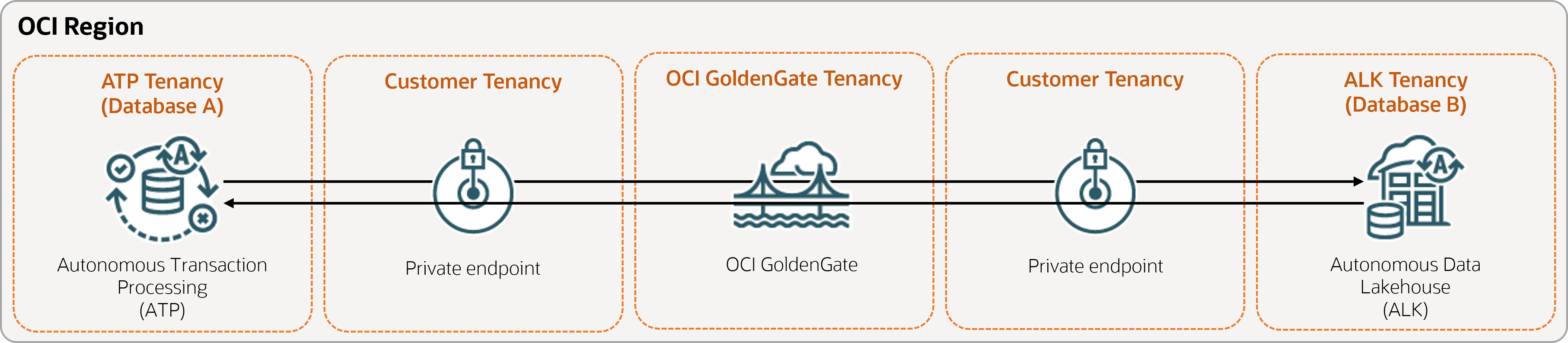
Descrizione dell'illustrazione bidirectional.png
Task 1: Impostare l'ambiente
-
Creare connessioni ai database.
-
Abilita il log supplementare:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA -
Eseguire la query seguente per assicurarsi che
support_mode=FULLper tutte le tabelle del database di origine:select * from DBA_GOLDENGATE_SUPPORT_MODE where owner = 'SRC_OCIGGLL'; -
Eseguire la query seguente sul database B per assicurarsi che
support_mode=FULLper tutte le tabelle del database:select * from DBA_GOLDENGATE_SUPPORT_MODE where owner = 'SRCMIRROR_OCIGGLL';
Task 2: Aggiungere informazioni sulle transazioni e una tabella di checkpoint per entrambi i database
Nella console di distribuzione OCI GoldenGate, andare alla schermata Configurazione per il servizio di amministrazione, quindi completare quanto riportato di seguito.
-
Aggiungere informazioni sulle transazioni nei database A e B:
-
Per il database A, immettere
SRC_OCIGGLLper il nome schema. -
Per il database B, immettere
SRCMIRROR_OCIGGLLper il nome schema.Nota: i nomi degli schemi devono essere univoci e corrispondere ai nomi degli schemi di database se si utilizza un data set diverso da questo esempio.
-
-
Creare una tabella di checkpoint per i database A e B:
-
Per il database A, immettere
"SRC_OCIGGLL"."ATP_CHECKTABLE"per la tabella di checkpoint. -
Per il database B, immettere
"SRCMIRROR_OCIGGLL"."CHECKTABLE"per la tabella di checkpoint.
-
Task 3: Creazione dell'estrazione integrata
Un'estrazione integrata acquisisce le modifiche in corso al database di origine.
-
Nella pagina Dettagli distribuzione selezionare Avvia console.
-
Aggiungere ed eseguire un'estrazione integrata.
Nota: per ulteriori informazioni sui parametri che è possibile utilizzare per specificare le tabelle di origine, vedere opzioni aggiuntive dei parametri di estrazione.
-
Nella pagina Estrai parametri, aggiungere le righe seguenti in
EXTTRAIL <extract-name>:-- Capture DDL operations for listed schema tables ddl include mapped -- Add step-by-step history of -- to the report file. Very useful when troubleshooting. ddloptions report -- Write capture stats per table to the report file daily. report at 00:01 -- Rollover the report file weekly. Useful when IE runs -- without being stopped/started for long periods of time to -- keep the report files from becoming too large. reportrollover at 00:01 on Sunday -- Report total operations captured, and operations per second -- every 10 minutes. reportcount every 10 minutes, rate -- Table list for capture table SRC_OCIGGLL.*; -- Exclude changes made by GGADMIN tranlogoptions excludeuser ggadminNota:
tranlogoptions excludeuser ggadminevita di recuperare le transazioni applicate daggadminnegli scenari di replica bidirezionale.
-
-
Verifica transazioni a esecuzione prolungata:
-
Eseguire lo script seguente nel database di origine:
select start_scn, start_time from gv$transaction where start_scn < (select max(start_scn) from dba_capture);Se la query restituisce righe, è necessario individuare l'SCN della transazione e quindi eseguire il commit o il rollback della transazione.
-
Task 4: Esportare i dati utilizzando Oracle Data Pump (ExpDP)
Utilizzare Oracle Data Pump (ExpDP) per esportare i dati dal database di origine in Oracle Object Store.
-
Crea un bucket dell'area di memorizzazione degli oggetti Oracle.
Prendere nota dello spazio di nomi e del nome del bucket da utilizzare con gli script di esportazione e importazione.
-
Creare un token di autenticazione, quindi copiare e incollare la stringa di token in un editor di testo per utilizzarla in un secondo momento.
-
Creare una credenziale nel database di origine, sostituendo
<user-name>e<token>con il nome utente dell'account Oracle Cloud e la stringa di token creata nel passo precedente:BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( credential_name => 'ADB_OBJECTSTORE', username => '<user-name>', password => '<token>' ); END; -
Eseguire lo script seguente nel database di origine per creare il job Esporta dati. Assicurarsi di sostituire
<region>,<namespace>e<bucket-name>nell'URI dell'area di memorizzazione degli oggetti di conseguenza.SRC_OCIGGLL.dmpè un file che verrà creato durante l'esecuzione dello script.DECLARE ind NUMBER; -- Loop index h1 NUMBER; -- Data Pump job handle percent_done NUMBER; -- Percentage of job complete job_state VARCHAR2(30); -- To keep track of job state le ku$_LogEntry; -- For WIP and error messages js ku$_JobStatus; -- The job status from get_status jd ku$_JobDesc; -- The job description from get_status sts ku$_Status; -- The status object returned by get_status BEGIN -- Create a (user-named) Data Pump job to do a schema export. h1 := DBMS_DATAPUMP.OPEN('EXPORT','SCHEMA',NULL,'SRC_OCIGGLL_EXPORT','LATEST'); -- Specify a single dump file for the job (using the handle just returned) -- and a directory object, which must already be defined and accessible -- to the user running this procedure. DBMS_DATAPUMP.ADD_FILE(h1,'https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket-name>/o/SRC_OCIGGLL.dmp','ADB_OBJECTSTORE','100MB',DBMS_DATAPUMP.KU$_FILE_TYPE_URIDUMP_FILE,1); -- A metadata filter is used to specify the schema that will be exported. DBMS_DATAPUMP.METADATA_FILTER(h1,'SCHEMA_EXPR','IN (''SRC_OCIGGLL'')'); -- Start the job. An exception will be generated if something is not set up properly. DBMS_DATAPUMP.START_JOB(h1); -- The export job should now be running. In the following loop, the job -- is monitored until it completes. In the meantime, progress information is displayed. percent_done := 0; job_state := 'UNDEFINED'; while (job_state != 'COMPLETED') and (job_state != 'STOPPED') loop dbms_datapump.get_status(h1,dbms_datapump.ku$_status_job_error + dbms_datapump.ku$_status_job_status + dbms_datapump.ku$_status_wip,-1,job_state,sts); js := sts.job_status; -- If the percentage done changed, display the new value. if js.percent_done != percent_done then dbms_output.put_line('*** Job percent done = ' \|\| to_char(js.percent_done)); percent_done := js.percent_done; end if; -- If any work-in-progress (WIP) or error messages were received for the job, display them. if (bitand(sts.mask,dbms_datapump.ku$_status_wip) != 0) then le := sts.wip; else if (bitand(sts.mask,dbms_datapump.ku$_status_job_error) != 0) then le := sts.error; else le := null; end if; end if; if le is not null then ind := le.FIRST; while ind is not null loop dbms_output.put_line(le(ind).LogText); ind := le.NEXT(ind); end loop; end if; end loop; -- Indicate that the job finished and detach from it. dbms_output.put_line('Job has completed'); dbms_output.put_line('Final job state = ' \|\| job_state); dbms_datapump.detach(h1); END;
Task 5: creare un'istanza del database di destinazione utilizzando Oracle Data Pump (ImpDP)
Utilizzare Oracle Data Pump (ImpDP) per importare i dati nel database di destinazione dal file SRC_OCIGGLL.dmp esportato dal database di origine.
-
Creare una credenziale nel database di destinazione per accedere all'area di memorizzazione degli oggetti Oracle (utilizzando le stesse informazioni nella sezione precedente).
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( credential_name => 'ADB_OBJECTSTORE', username => '<user-name>', password => '<token>' ); END; -
Eseguire lo script seguente nel database di destinazione per importare i dati da
SRC_OCIGGLL.dmp. Assicurarsi di sostituire<region>,<namespace>e<bucket-name>nell'URI dell'area di memorizzazione degli oggetti di conseguenza:DECLARE ind NUMBER; -- Loop index h1 NUMBER; -- Data Pump job handle percent_done NUMBER; -- Percentage of job complete job_state VARCHAR2(30); -- To keep track of job state le ku$_LogEntry; -- For WIP and error messages js ku$_JobStatus; -- The job status from get_status jd ku$_JobDesc; -- The job description from get_status sts ku$_Status; -- The status object returned by get_status BEGIN -- Create a (user-named) Data Pump job to do a "full" import (everything -- in the dump file without filtering). h1 := DBMS_DATAPUMP.OPEN('IMPORT','FULL',NULL,'SRCMIRROR_OCIGGLL_IMPORT'); -- Specify the single dump file for the job (using the handle just returned) -- and directory object, which must already be defined and accessible -- to the user running this procedure. This is the dump file created by -- the export operation in the first example. DBMS_DATAPUMP.ADD_FILE(h1,'https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket-name>/o/SRC_OCIGGLL.dmp','ADB_OBJECTSTORE',null,DBMS_DATAPUMP.KU$_FILE_TYPE_URIDUMP_FILE); -- A metadata remap will map all schema objects from SRC_OCIGGLL to SRCMIRROR_OCIGGLL. DBMS_DATAPUMP.METADATA_REMAP(h1,'REMAP_SCHEMA','SRC_OCIGGLL','SRCMIRROR_OCIGGLL'); -- If a table already exists in the destination schema, skip it (leave -- the preexisting table alone). This is the default, but it does not hurt -- to specify it explicitly. DBMS_DATAPUMP.SET_PARAMETER(h1,'TABLE_EXISTS_ACTION','SKIP'); -- Start the job. An exception is returned if something is not set up properly. DBMS_DATAPUMP.START_JOB(h1); -- The import job should now be running. In the following loop, the job is -- monitored until it completes. In the meantime, progress information is -- displayed. Note: this is identical to the export example. percent_done := 0; job_state := 'UNDEFINED'; while (job_state != 'COMPLETED') and (job_state != 'STOPPED') loop dbms_datapump.get_status(h1, dbms_datapump.ku$_status_job_error + dbms_datapump.ku$_status_job_status + dbms_datapump.ku$_status_wip,-1,job_state,sts); js := sts.job_status; -- If the percentage done changed, display the new value. if js.percent_done != percent_done then dbms_output.put_line('*** Job percent done = ' \|\| to_char(js.percent_done)); percent_done := js.percent_done; end if; -- If any work-in-progress (WIP) or Error messages were received for the job, display them. if (bitand(sts.mask,dbms_datapump.ku$_status_wip) != 0) then le := sts.wip; else if (bitand(sts.mask,dbms_datapump.ku$_status_job_error) != 0) then le := sts.error; else le := null; end if; end if; if le is not null then ind := le.FIRST; while ind is not null loop dbms_output.put_line(le(ind).LogText); ind := le.NEXT(ind); end loop; end if; end loop; -- Indicate that the job finished and gracefully detach from it. dbms_output.put_line('Job has completed'); dbms_output.put_line('Final job state = ' \|\| job_state); dbms_datapump.detach(h1); END;
Task 6: Aggiunta ed esecuzione di un Replicat non integrato
-
Aggiungere ed eseguire Replicat.
-
Nella schermata File dei parametri sostituire
MAP *.*, TARGET *.*;con lo script seguente:-- Capture DDL operations for listed schema tables ddl include mapped -- Add step-by-step history of ddl operations captured -- to the report file. Very useful when troubleshooting. ddloptions report -- Write capture stats per table to the report file daily. report at 00:01 -- Rollover the report file weekly. Useful when PR runs -- without being stopped/started for long periods of time to -- keep the report files from becoming too large. reportrollover at 00:01 on Sunday -- Report total operations captured, and operations per second -- every 10 minutes. reportcount every 10 minutes, rate -- Table map list for apply DBOPTIONS ENABLE_INSTANTIATION_FILTERING; MAP SRC_OCIGGLL.*, TARGET SRCMIRROR_OCIGGLL.*;Nota:
DBOPTIONS ENABLE_INSTATIATION_FILTERINGabilita il filtro CSN sulle tabelle importate utilizzando Oracle Data Pump. Per ulteriori informazioni, vedere Riferimento DBOPTIONS.
-
-
Eseguire alcune modifiche al database A per visualizzarle replicate nel database B.
Task 7: Configurare la replica dal database B al database A
Task da 1 a 6 Replica stabilita dal database A al database B. I passi riportati di seguito consentono di impostare la replica dal database B al database A.
-
Aggiungere ed eseguire un'estrazione nel database B. Nella pagina dei parametri di estrazione dopo EXTRAIL <extract-name>, assicurarsi di includere quanto segue.
-- Table list for capture table SRCMIRROR_OCIGGLL.*; -- Exclude changes made by GGADMIN tranlogoptions excludeuser ggadmin -
Aggiungere ed eseguire un Replicat al database A. Nella pagina Parametri, sostituire
MAP *.*, TARGET *.*;con:MAP SRCMIRROR_OCIGGLL.*, TARGET SRC_OCIGGLL.*; -
Eseguire alcune modifiche al database B per visualizzarle replicate nel database A.