Monitoraggio di Oracle NoSQL Database Cloud Service
Il servizio Oracle Cloud Infrastructure Monitoring ti consente di monitorare attivamente e passivamente le tue risorse cloud utilizzando le funzioni Metriche e Allarmi. Il servizio di monitoraggio utilizza le metriche per monitorare le risorse e gli allarmi per avvisare l'utente quando queste metriche soddisfano i trigger specificati dagli allarmi.
Una metrica è una misurazione correlata allo stato, alla capacità o alle prestazioni di una determinata risorsa. Un allarme è una regola di trigger e una query. Gli allarmi monitorano passivamente le risorse cloud utilizzando le metriche. È possibile configurare le impostazioni di notifica quando si crea un allarme.
Le metriche vengono emesse al servizio di monitoraggio come datapoint raw (una coppia indicatore orario-valore per una metrica specificata) insieme alle dimensioni (un identificativo risorsa fornito nella definizione della metrica) e ai metadati. Il servizio di monitoraggio pubblica i messaggi di allarme nelle destinazioni configurate gestite dal servizio di notifiche.
Quando si esegue una query su una metrica, il servizio di monitoraggio restituisce i dati aggregati in base ai parametri specificati. È possibile specificare un intervallo (ad esempio le ultime 24 ore), una statistica e un intervallo. Una statistica è la funzione di aggregazione applicata ai datapoint raw. La funzione di aggregazione SUM è un esempio di statistica. Un intervallo è la finestra temporale utilizzata per convertire un determinato set di datapoint raw. Ad esempio, 5 minuti.
La console visualizza un grafico di monitoraggio per metrica per le risorse selezionate. I dati aggregati in ogni grafico riflettono la statistica e l'intervallo selezionati. Le richieste API possono facoltativamente filtrare in base alla dimensione e specificare una risoluzione. Le risposte API includono il nome della metrica insieme al relativo compartimento di origine e allo spazio di nomi della metrica (indica la risorsa, il servizio o l'applicazione che emette una metrica). Lo spazio di nomi viene fornito nella definizione della metrica. Ad esempio, la definizione della metrica CpuUtilization emessa da Oracle Cloud elenca lo spazio di nomi della metrica oci_computeagent come origine della metrica.
I dati delle metriche e degli allarmi sono accessibili tramite la console, l'interfaccia CLI e l'API. Per ulteriori informazioni sui concetti relativi al servizio di monitoraggio OCI, vedere Monitoraggio dei concetti.
Questo articolo contiene i seguenti argomenti:
Metriche di Oracle NoSQL Database Cloud Service
Oracle NoSQL Database Cloud Service emette metriche utilizzando lo spazio di nomi delle metriche oci_nosql.
Le metriche per Oracle NoSQL Database Cloud Service includono le dimensioni riportate di seguito.
RESOURCEIDL'OCID della tabella NoSQL in Oracle NoSQL Database Cloud Service.
Nota: OCID è un ID univoco assegnato da Oracle e incluso come parte delle informazioni della risorsa sia nella console che nell'API.
-
TABLENAMENome della tabella NoSQL in Oracle NoSQL Database Cloud Service.
-
REPLICANome dell'area che riceve l'aggiornamento della tabella da un'altra area.
Oracle NoSQL Database Cloud Service invia le metriche a Oracle Cloud Infrastructure Monitoring Service. Puoi visualizzare o creare allarmi su queste metriche utilizzando gli SDK o l'interfaccia CLI della console di Oracle Cloud Infrastructure.
Tabella - Metriche di Oracle NoSQL Database Cloud Service
| Metrica | Nome visualizzato metrica | Unit | Descrizione | Dimensioni |
|---|---|---|---|---|
ReadUnits |
Unità di lettura | Unità | Il numero di unità di lettura utilizzate durante questo periodo. | resourceId tableName |
WriteUnits |
Unità di scrittura | Unità | Il numero di unità di scrittura utilizzate durante questo periodo. | resourceId tableName |
StorageGB |
Dimensione storage | GB | La quantità massima di storage utilizzata dalla tabella. Poiché queste informazioni vengono generate ogni ora, è possibile che i valori non siano aggiornati tra i punti di aggiornamento. | resourceId tableName |
ReadThrottleCount |
Limitazione lettura | Count | Numero di eccezioni limitazione lettura in questa tabella nel periodo di tempo. | resourceId tableName |
WriteThrottleCount |
Limitazione scrittura | Count | Numero di eccezioni limitazione scrittura in questa tabella nel periodo di tempo. | resourceId tableName |
StorageThrottleCount |
Limitazione storage | Count | Numero di eccezioni di limitazione dello storage in questa tabella nel periodo di tempo. | resourceId tableName |
MaxShardSizeUsagePercent |
Uso massimo dimensione partizione | Percentuale. | Rapporto tra lo spazio utilizzato nella partizione e lo spazio totale allocato alla partizione. Questo valore è specifico per una tabella e sarà il valore più alto in tutte le partizioni. | resourceId tableName |
Replica Lag |
Ritardo replica | Millisecondo | Ritardo di tempo durante la replica delle modifiche ai dati di una tabella attiva globale da un'area mittente a un'area ricevente. | |
Inoltre, puoi pubblicare metriche personalizzate in base alle tue esigenze. Ad esempio, è possibile impostare le metriche per acquisire la latenza delle transazioni dell'applicazione (tempo impiegato per ogni transazione completata) e quindi contabilizzare tali dati nel servizio di monitoraggio.
Metriche NDCS: spiegazione
Oracle NoSQL Database Cloud Service invia le metriche a Oracle Cloud Infrastructure Monitoring Service.
Unità di lettura:
Il numero di unità di lettura utilizzate durante questo periodo. Si tratta del throughput per un massimo di 1 KB di dati al secondo per un'operazione di lettura eventualmente coerente. Se i dati sono superiori a 1 KB, saranno necessarie più unità di lettura per leggerli. Il grafico delle metriche Unità di lettura per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
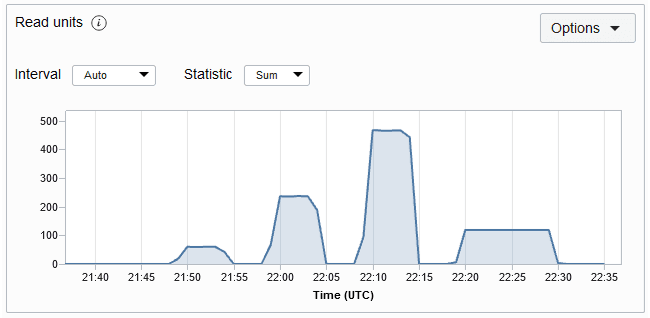
Descrizione dell'illustrazione readmetric.png
Unità di scrittura:
Il numero di unità di scrittura utilizzate durante questo periodo. È il throughput per un massimo di 1 KB di dati al secondo per un'operazione di scrittura. Le operazioni di scrittura vengono attivate durante le operazioni di inserimento, aggiornamento ed eliminazione. Se i dati sono superiori a 1 KB, per scriverli saranno necessarie più unità di lettura. Il grafico delle metriche Unità di scrittura per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
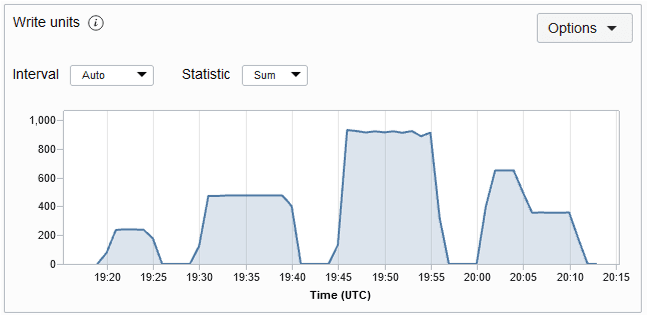
Descrizione dell'illustrazione writingemetric.png
GB di storage:
La quantità massima di storage utilizzata dalla tabella. Il grafico delle metriche di storage per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
Nota: per popolare l'inizio della registrazione delle dimensioni di storage è necessaria un'ora dopo la creazione della tabella. Dopo l'ora iniziale, le statistiche di storage vengono aggiornate ogni 5 minuti.
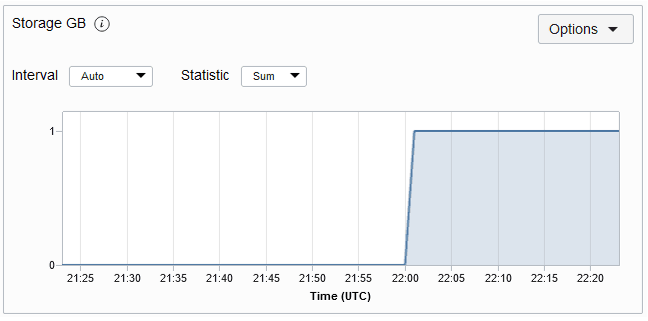
Descrizione dell'illustrazione storagemetric.png
Nota: la metrica GB di storage viene troncata. Pertanto, l'uso dello storage inferiore a 1 GB verrà visualizzato come 0. Il grafico inizierà a visualizzare lo storage quando l'uso è maggiore di 1 GB.
ReadThrottleCount:
Fornisce un conteggio del numero di eccezioni di limitazione di lettura nella tabella specificata nel periodo di tempo. Un'eccezione di limitazione indica in genere che il throughput di lettura di cui è stato eseguito il provisioning è stato superato. Se li ricevi frequentemente, dovresti considerare di aumentare le Unità di lettura sul tuo tavolo. Il grafico delle metriche del conteggio limitazioni di lettura per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
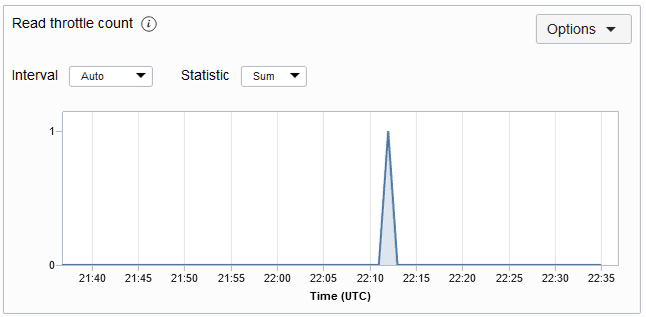
Descrizione dell'illustrazione readthrottlemetric.png
WriteThrottleCount:
Fornisce un conteggio del numero di eccezioni di limitazione della scrittura nella tabella specificata nel periodo di tempo. Un'eccezione di limitazione indica in genere che il throughput di scrittura di cui è stato eseguito il provisioning è stato superato. Se si ottengono questi spesso, allora si dovrebbe prendere in considerazione l'aumento delle unità di scrittura sul tavolo. Il grafico delle metriche del conteggio limitazioni di scrittura per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
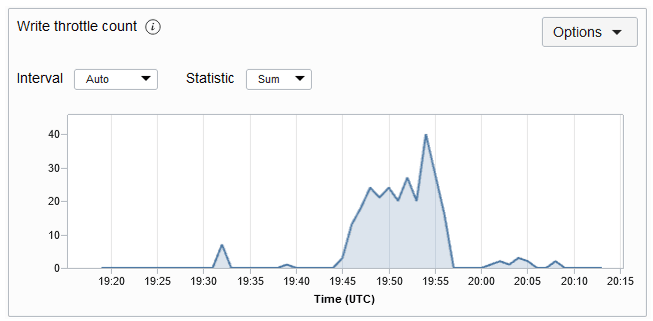
Descrizione dell'illustrazione writeethrottlemetric.png
StorageThrottleCount:
Fornisce un conteggio del numero di eccezioni di limitazione dello storage nella tabella specificata nel periodo di tempo. Un'eccezione di limitazione indica in genere che la capacità di storage di cui è stato eseguito il provisioning è stata superata. Se li ricevi frequentemente, dovresti considerare di aumentare la capacità di storage della tua tabella. Il grafico delle metriche del conteggio limitazioni di storage per una tabella è mostrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
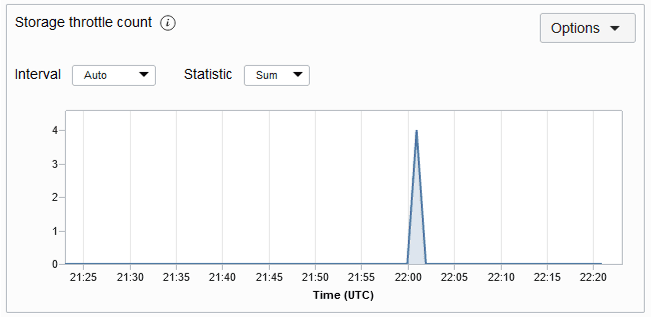
Descrizione dell'illustrazione storagethrottlemetric.png
MaxShardSizeUsagePercentuale
Uso massimo dello spazio in una partizione per una tabella specifica, come percentuale dello spazio utilizzato in tale partizione.
Nota: Oracle NoSQL Database Cloud Service esegue l'hashing delle chiavi delle partizioni per fornire la distribuzione su una raccolta di nodi di storage che forniscono storage per le tabelle. Sebbene non siano visibili direttamente all'utente, le tabelle di Oracle NoSQL Database Cloud Service vengono partizionate e replicate per garantire disponibilità e prestazioni. Una chiave della partizione corrisponde al 100% alla chiave primaria oppure è un subset della chiave primaria. Tutti i record che condividono una chiave partizione vengono collocati insieme per raggiungere la località dei dati.
Quando maxShardSizeUsagepercent raggiunge 100, non è più possibile eseguire un'operazione di scrittura nella tabella. È necessario aumentare la capacità di storage per eseguire una scrittura nella tabella. Questa metrica consente di determinare se esiste un hotspot di storage per la tabella NoSQL.
Questo scenario si verifica a causa di uno squilibrio nel modo in cui i dati della tabella vengono memorizzati nelle partizioni. Uno squilibrio può verificarsi quando la maggior parte dei dati della tabella viene memorizzata in un sottoinsieme delle partizioni. Lo storage in un database NoSQL viene partizionato e la chiave partizione fa parte della definizione della tabella. Nelle tabelle gerarchiche, le tabelle padre e figlio condividono la stessa chiave partizione. Se si dispone di una tabella padre con tabelle figlio, tutti i record condividono la stessa chiave partizione. Quindi tutti questi dati saranno archiviati insieme. Se una tabella padre ha meno figli, occupa meno spazio di archiviazione in una singola partizione. A causa di questo squilibrio, alcune partizioni possono contenere molti più dati rispetto ad altre partizioni.
A un certo punto, una partizione avrà il massimo utilizzo di spazio per una tabella specifica e la percentuale utilizzata in tale partizione è MaxShardSizeUsagePercent. Il grafico delle metriche maxShardSizeUsagepercent per una tabella è illustrato di seguito. Per impostazione predefinita, la metrica viene eseguita ogni minuto e i grafici delle metriche vengono rappresentati per un intervallo di 5 minuti.
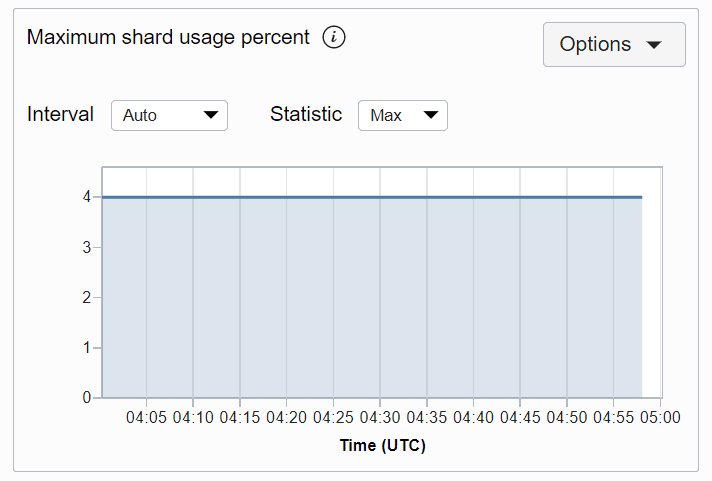
Descrizione dell'illustrazione maxshardusageprct.png
Oltre a visualizzare il grafico per una metrica, sono disponibili le opzioni riportate di seguito.
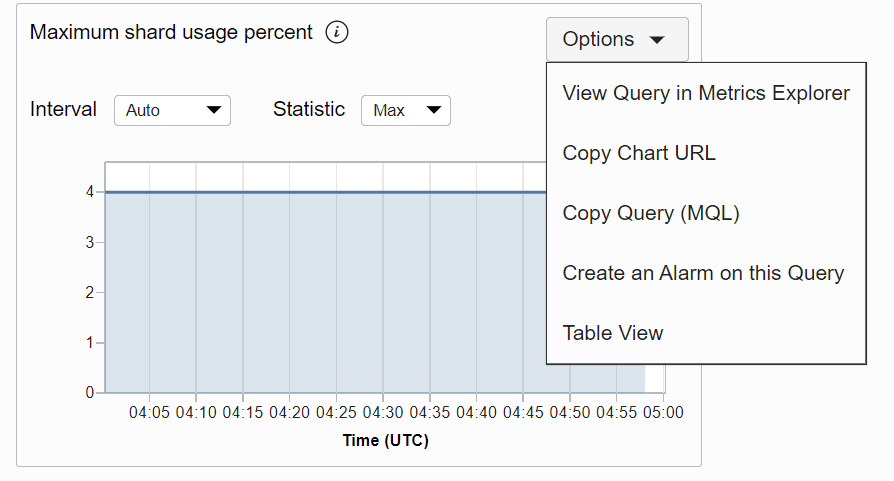
Descrizione dell'illustrazione metrico-options.png
È possibile ottenere la vista tabella per controllare il valore di una metrica in un determinato momento.
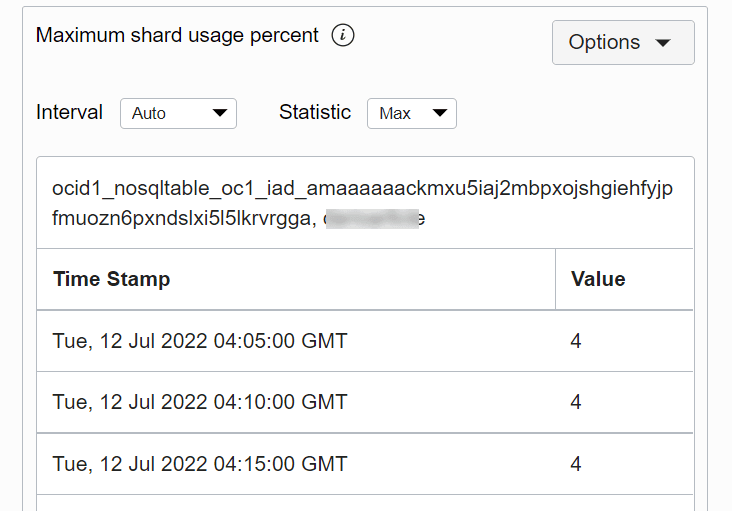
Descrizione dell'illustrazione tableview.png
Monitoraggio della metrica MaxShardSizeUsagePercent
È necessario monitorare periodicamente questo grafico per sapere se il maxShardSizeUsagepercent viene raggiunto o meno. In modo proattivo è possibile creare un allarme per questa metrica.
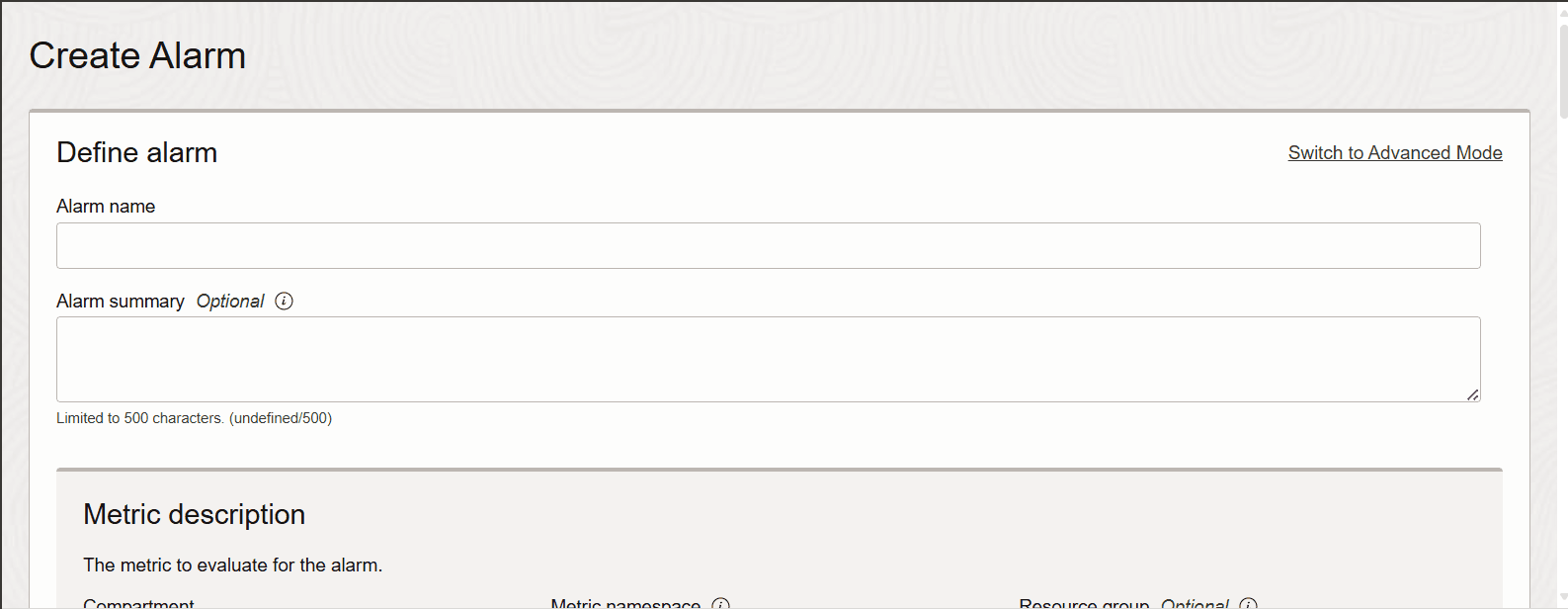
Descrizione dell'illustrazione new-alarm-crt-1.png
In altre parole, è necessario attivare un allarme quando la metrica raggiunge un determinato valore, ad esempio il 90%.
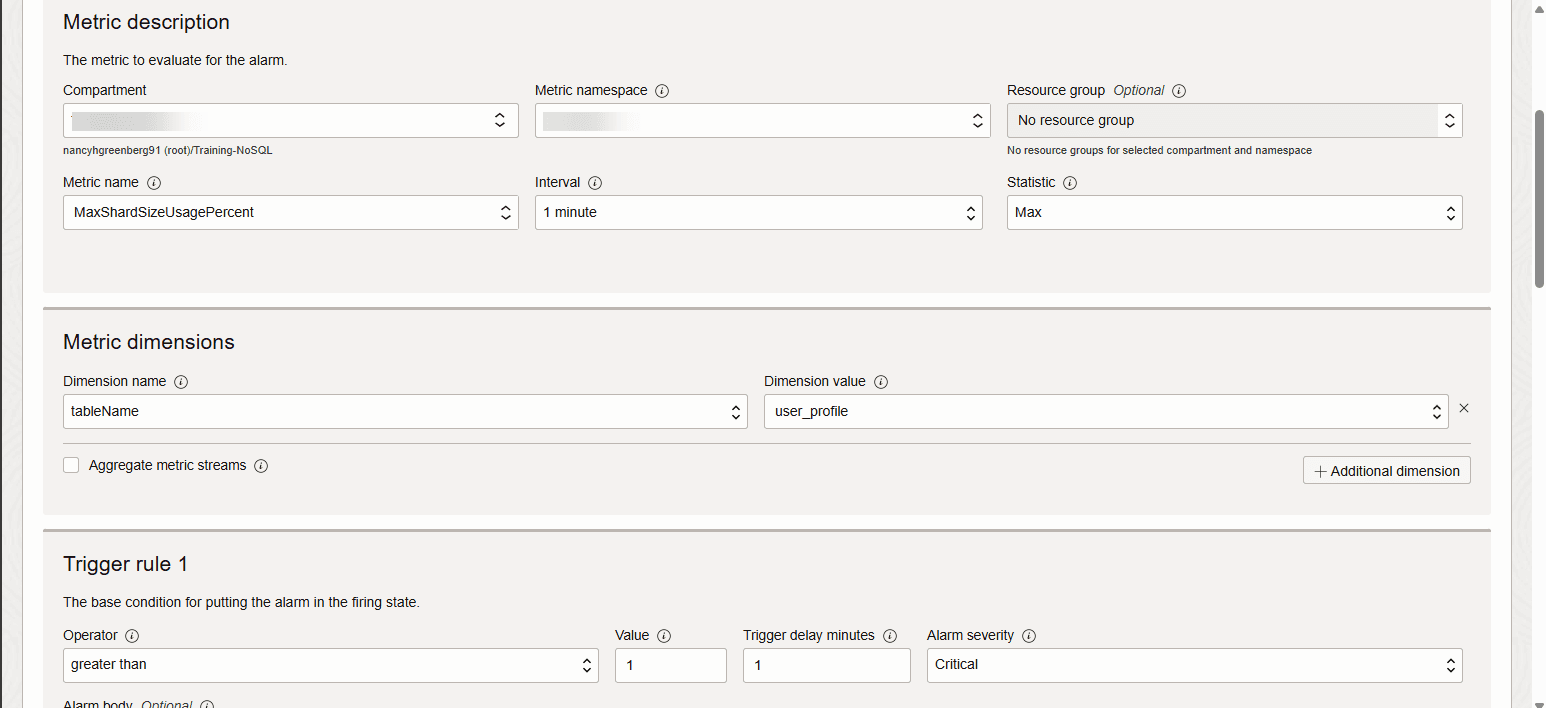
Descrizione dell'illustrazione new-alarm-crt-2.png
L'allarme OCI utilizza il servizio di notifica OCI per inviare notifiche. Di solito, l'allarme verrà configurato per inviare notifiche tramite e-mail configurate. Quando maxShardSizeUsagepercent raggiunge il 90%, viene inviata una notifica e-mail.
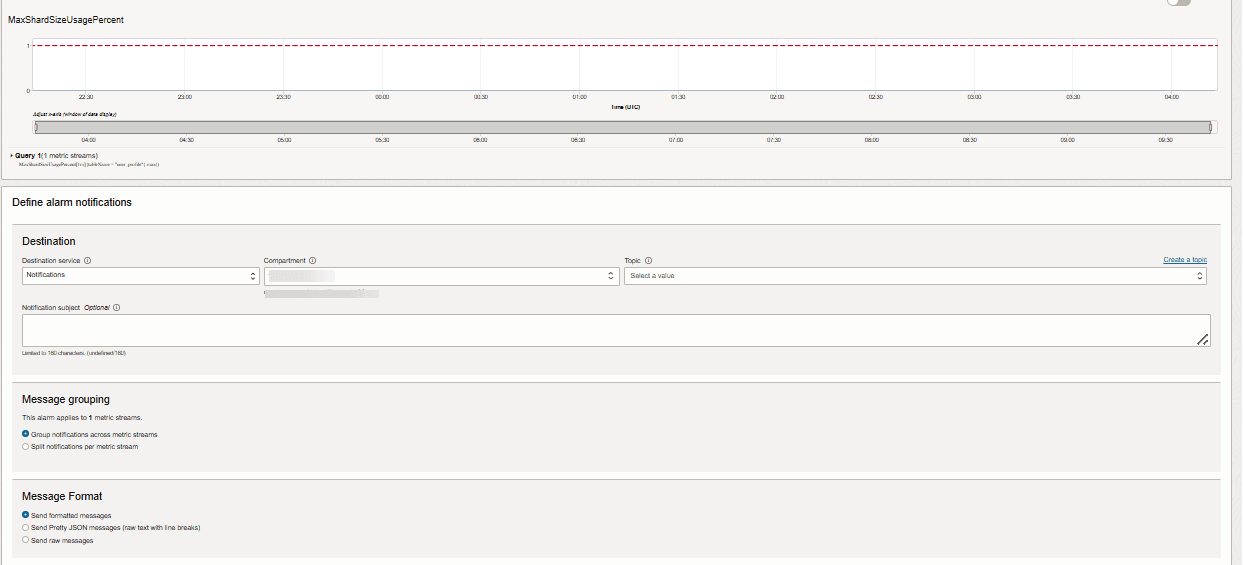
Descrizione dell'illustrazione new-alarm-crt-3.png
Per ulteriori dettagli, vedere Gestione di allarmi e notifiche.
Quando si verifica uno squilibrio nel modo in cui i dati della tabella vengono distribuiti tra partizioni, non sarà possibile utilizzare la capacità di storage allocata alla tabella al massimo. In questo scenario, maxShardSizeUsagepercent raggiunge il valore di 100 anche senza utilizzare l'intero storage allocato alla tabella. È ora necessario aggiungere ulteriore spazio di archiviazione per continuare a scrivere sulla tabella. Questo scenario può essere evitato seguendo alcune linee guida durante la progettazione della tabella.
-
Decidere la chiave di partizione corretta per la tabella. Gli attributi con cardinalità elevata sono una buona scelta per le chiavi di partizione.
-
Limitare il numero di tabelle figlio per evitare una potenziale situazione di squilibrio nello storage delle partizioni.
Ritardo replica
Ritardo di tempo durante la replica delle modifiche ai dati (INSERT/UPDATE o DELETE) di una tabella attiva globale da un'area mittente a un'area ricevente. L'operazione di scrittura eseguita nell'area mittente di una tabella attiva globale viene riflessa nell'area ricevente dopo un intervallo di tempo. Le informazioni sul ritardo temporale sono espresse come metrica denominata Ritardo replica. Il ritardo della replica è una misura della corrente dei dati della tabella nell'area di replica del ricevente rispetto ai dati nella tabella dell'area del mittente. Il ritardo di replica indica che la tabella nell'area ricevente non ha ancora ricevuto aggiornamenti dall'area mittente che si sono verificati durante il periodo di ritardo. Se non è stata eseguita alcuna scrittura dell'applicazione per la tabella nell'area del mittente, il servizio utilizza i meccanismi di ping per calcolare un'approssimazione del ritardo e la statistica del ritardo sarà ancora disponibile nell'area del ricevente.
Ottenere informazioni sul ritardo della replica:
Nell'area ricevente, fare clic sulla tabella Attivo globale e visualizzare le informazioni sulla tabella. In Risorse, fare clic su Metriche. Viene visualizzata una metrica, Ritardo replica, che visualizza il ritardo di replica in millisecondi. Nel grafico di esempio qui sotto, si vede che la metrica Replica Lag è presa nella regione sud-est del Canada (Toronto), che è la regione ricevente. Questa tabella Global Active contiene due repliche di tabella regionali, una per ciascuna nell'area Canada Sud-Est (Montreal) e Stati Uniti Est (Ashburn). Si vede che il grafico ha due linee una ciascuna per queste repliche di tabelle regionali a Montreal e Ashburn.
Nel grafico seguente, l'intervallo indica la finestra temporale utilizzata per rappresentare il grafico. Le varie opzioni di intervallo disponibili sono 1 minuto, 5 minuti, 1 ora e 1 giorno. Per impostazione predefinita, il ritardo di replica viene monitorato ogni 1 minuto e il grafico viene tracciato ogni 5 minuti. È possibile selezionare statistiche diverse per la metrica Ritardo replica.
Esempio 1: lag di replica con Canada sud-est (Toronto) come area ricevente e Canada sud-est (Montreal) e Stati Uniti est (Ashburn) come aree mittente.
La seguente tabella è tracciata per la statistica Media per un intervallo di 5 minuti.
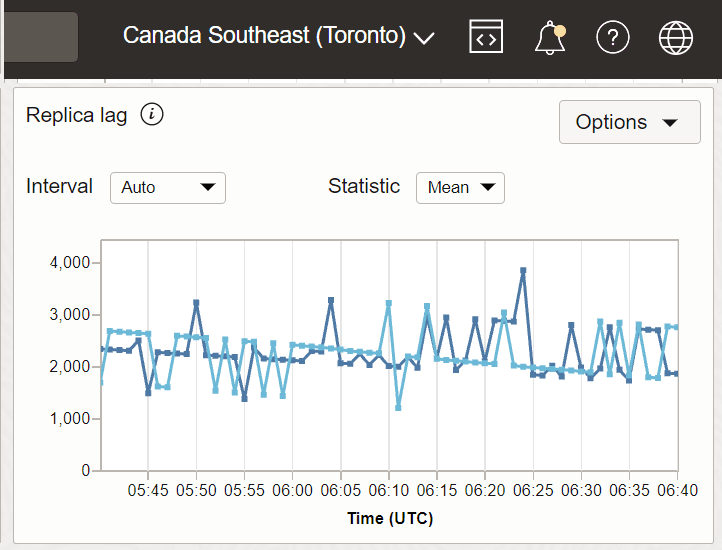
Descrizione dell'illustrazione metriche_replica2.png
In questo esempio, Montreal e Ashburn sono due regioni mittente e Toronto è la regione ricevente in cui viene acquisita la metrica. Considera il valore di Replica Lag alle 12:25 UTC per Montreal. Sono 2020 millisecondi. Ciò significa che la regione ricevente Canada sud-est (Toronto) non ha ricevuto aggiornamenti che si sono verificati nella regione del mittente Canada sud-est (Montreal) negli ultimi 2020 millisecondi. Allo stesso modo, considera il valore del ritardo di replica alle 12:25 UTC per Ashburn. Sono 2954 millisecondi. Ciò significa che la regione ricevente Canada Sud-Est (Toronto) non ha ricevuto aggiornamenti che si sono verificati nella regione del mittente Stati Uniti Est (Ashburn) negli ultimi 2954 millisecondi.
Esempio 2: ritardo della replica con US East (Ashburn) come area ricevente e Canada Southeast (Montreal) e Canada Southeast Toronto come aree mittenti.
In questo esempio, Montreal e Toronto sono due regioni mittente e Ashburn è la regione ricevente in cui viene acquisita la metrica.
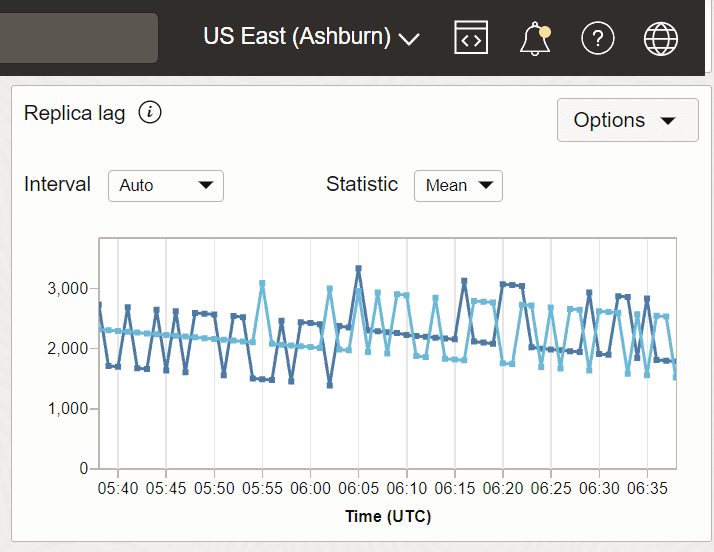
Descrizione dell'illustrazione metriche_replica3.png
Esempio 3: ritardo della replica con Canada sud-est (Montreal) come area ricevente e Stati Uniti est (Ashburn) e Canada sud-est di Toronto come aree mittenti.
In questo esempio, Ashburn e Toronto sono due regioni mittente e Montreal è la regione ricevente in cui viene acquisita la metrica.
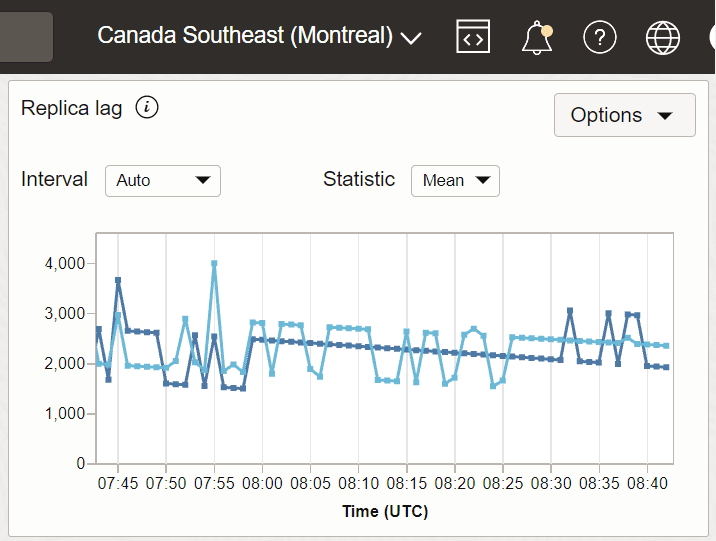
Descrizione dell'immagine Metric_replica1.png
Oltre a visualizzare il grafico per il ritardo della replica, sono disponibili le seguenti opzioni.
Descrizione dell'immagine metriche_options.png
È possibile ottenere la vista tabella per controllare il valore del ritardo della replica in un determinato momento.
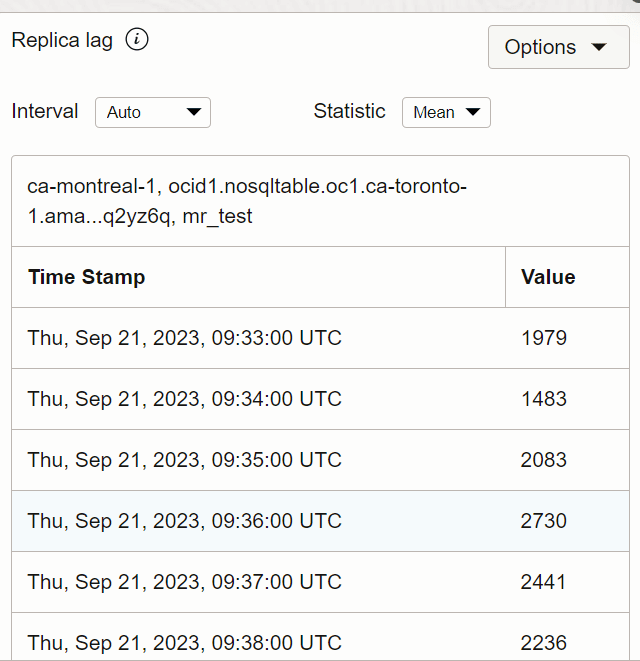
Descrizione dell'immagine tabview_toronto.png
Visualizzazione o elenco delle metriche di Oracle NoSQL Database Cloud Service
È possibile visualizzare le metriche disponibili per Oracle NoSQL Database Cloud Service dalla console. Inoltre, puoi ottenere la lista delle metriche disponibili per Oracle NoSQL Database Cloud Service utilizzando i comandi CLI OCI.
-
Aprire il menu di navigazione e fare clic su Observability & Management. In Monitoraggio, fare clic su Metriche servizio.
-
Selezionare il compartimento e lo spazio di nomi delle metriche (oci_nosql).
Da Cloud Shell eseguire il comando seguente. Restituisce le definizioni delle metriche che corrispondono ai criteri specificati nella richiesta. OCID compartimento richiesto. Per ulteriori informazioni sulle OPZIONI disponibili con il comando list, vedere Metriche list.
oci monitoring metric list --compartment-id <Compartment_OCID> --namespace oci_nosql
Ad esempio:
oci monitoring metric list --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya --namespace oci_nosqlRisposta di esempio:
{
"data": [
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageGB",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteUnits",
"namespace": "oci_nosql",
"resource-group": null
}
]
}Come raccogliere le metriche di Oracle NoSQL Database Cloud Service?
Puoi creare query sulle metriche per la raccolta di set specifici di metriche (dati aggregati). Una query metrica contiene l'espressione MQL (Monitoring Query Language) da valutare per la restituzione di dati aggregati. La query deve specificare una metrica, una statistica e un intervallo.
Puoi utilizzare le query sulle metriche per monitorare attivamente e passivamente le tue risorse cloud. Monitora attivamente con query metriche che generi spontaneamente, on-demand. Nella console aggiornare un grafico per visualizzare i dati di più query. Memorizza le query che si desidera riutilizzare. Monitorare passivamente con allarmi che aggiungono una condizione o una regola trigger a una query di metrica.
Sintassi query metrica:
metric[interval] {dimensionname=dimensionvalue}.groupingfunction.statisticSintassi query allarme soglia:
metric[interval]{dimensionname=dimensionvalue}.groupingfunction.statistic alarmoperator alarmvaluePer i valori dei parametri supportati, vedere Riferimento MQL (Monitoring Query Language).
Query di esempio Query di metrica semplice
Somma dei conteggi dei limiti di storage per tutte le tabelle in un compartimento a un intervallo di un minuto.
Numero di righe visualizzate nel grafico delle metriche (console): 1 per tabella.
StorageThrottleCount[1m].sum()Query metrica filtrata
Somma dei conteggi dei limiti di storage in un compartimento a un intervallo di un minuto, filtrata in una singola tabella.
Numero di righe visualizzate nel grafico delle metriche (console): 1 per tabella.
StorageThrottleCount[1m]{tableName = "demoKeyVal"}.sum()Query metrica aggregata
Media aggregata dell'operazione di lettura a un intervallo di sessanta minuti, filtrata in un compartimento, aggregata per la media.
Numero di righe visualizzate nel grafico delle metriche (console): 1 per tabella.
ReadUnits[60m]{compartmentId="ocid1.compartment.oc1.phx..exampleuniqueID"}.grouping().mean()Query metrica aggregata a gruppo
Media aggregata del conteggio dei limiti di lettura per unità di lettura a un intervallo di sessanta minuti, filtrata in una singola tabella in un compartimento.
Numero di righe visualizzate nel grafico delle metriche (console): 1 per unità di lettura.
ReadThrottleCount[60m]{tableName = "demoKeyVal"}.groupBy(ReadUnits).mean()Creazione di una query metrica
Esistono due modi per creare una query metrica. È possibile creare una query utilizzando il comando Console o OCI CLI.
-
Aprire il menu di navigazione e fare clic su Observability & Management. In Monitoraggio, fare clic su Metrics Explorer.
Nella pagina Explorer metriche viene visualizzato un grafico vuoto con i campi per creare una query.
-
Compilare i campi per una nuova interrogazione.
-
Compartimento: compartimento contenente le tabelle di Oracle NoSQL Database Cloud Service che si desidera monitorare. Per impostazione predefinita, viene selezionato il primo compartimento accessibile.
-
Spazio di nomi delle metriche: Oracle NoSQL Database Cloud Service emette metriche per le tabelle che si desidera monitorare. Esempio: oci_nosql.
-
Gruppo di risorse (facoltativo): il gruppo a cui appartiene la metrica. Un gruppo di risorse è una stringa personalizzata fornita con una metrica personalizzata. Non applicabile alle metriche del servizio.
-
Nome metrica: il nome della metrica. È possibile specificare solo una metrica. Le selezioni delle metriche dipendono dal compartimento e dallo spazio di nomi delle metriche selezionati. Esempio: ReadUnits
-
Intervallo: finestra di aggregazione.
-
Statistica: funzione di aggregazione.
-
Dimensioni metrica: filtri facoltativi per limitare i dati delle metriche valutati.
- Campi dimensione: per le metriche di Oracle NoSQL Database Cloud Service è possibile selezionare resourceId o tableName come coppia nome dimensione e valore dimensione.
-
Aggrega flussi di metriche: rappresenta una singola riga nel grafico delle metriche per rappresentare il valore combinato di tutti i flussi di metriche per la statistica selezionata.
-
-
Fare clic su Aggiorna grafico.
Il grafico mostra i risultati della nuova query. I valori molto piccoli o grandi sono indicati dal Sistema Internazionale di Unità (unità SI), come M per mega (da 10 a sesta potenza). Le unità corrispondono alla metrica selezionata e non cambiano in base alla statistica.
-
Per visualizzare la query come espressione MQL (Monitoring Query Language), selezionare Modalità avanzata.
-
La modalità avanzata si trova a destra, sotto il grafico.
Utilizzare la modalità Avanzate per modificare la query utilizzando la sintassi MQL per aggregare i risultati per gruppo. La sintassi MQL supporta anche valori di parametro aggiuntivi. Per ulteriori informazioni sui parametri delle query nelle modalità Basic e Advanced, vedere Monitoring Query Language (MQL) Reference.
-
Da Cloud Shell eseguire il comando seguente. Restituisce i dati aggregati che corrispondono ai criteri specificati nella richiesta. OCID compartimento richiesto.
oci monitoring metric-data summarize-metrics-data --compartment-id<Compartment_OCID> --namespace oci_nosql --query-text [text]
--query-text è l'espressione MQL (Monitoring Query Language) da utilizzare durante la ricerca dei datapoint delle metriche da aggregare. La query deve specificare una metrica, una statistica e un intervallo. Valori supportati per l'intervallo: 1m-60m (anche 1h). Facoltativamente, è possibile specificare dimensioni e funzioni di raggruppamento. Funzioni di raggruppamento supportate: grouping(), groupBy(). Per ulteriori informazioni sulle OPZIONI disponibili con il comando summary-metrics-data, vedere Riepilogo dei dati delle metriche. Nell'esempio riportato di seguito, stiamo creando una query metrica filtrata per ottenere la somma delle unità di lettura in un compartimento a un intervallo di un minuto, filtrata in una singola tabella.
Ad esempio:
oci monitoring metric-data summarize-metrics-data --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'ReadUnits[1m]{tableName="articles"}.sum()'Risposta di esempio:
{
"data": [
{
"aggregated-datapoints": [
{
"timestamp": "2022-02-17T11:03:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:04:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:05:00+00:00",
"value": 0.0
},
...
...
...
{
"timestamp": "2022-02-17T13:59:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:00:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:01:00+00:00",
"value": 0.0
}
],
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyav7f67yuj3t2q6rk7lp2a2obfdxa6hg2ho2ea7qabin4q",
"tableName": "demo"
},
"metadata": {},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resolution": null,
"resource-group": null
}
]
}Creazione degli allarmi
È possibile creare un allarme che valuti la query di allarme e invii una notifica quando l'allarme è in stato di attivazione, insieme ad altre proprietà di allarme. Quando attivato, un allarme invia un messaggio di allarme all'argomento configurato (in Notifiche), che quindi invia il messaggio a tutte le sottoscrizioni dell'argomento. Slack, Email, SMS e PagerDuty sono alcuni degli esempi di argomenti configurati nelle notifiche.
Quando sono configurate, le notifiche ripetute ricordano uno stato di attivazione continua all'intervallo di ripetizione configurato. Viene inoltre inviata una notifica quando un allarme torna allo stato OK o quando viene reimpostato.
Una query di allarme contiene l'espressione MQL (Monitoring Query Language) da valutare per la restituzione di dati aggregati. La query deve specificare una metrica, una statistica e un intervallo.
Ci sono due modi per creare un allarme. È possibile creare una query utilizzando la console o l'interfaccia CLI OCI.
-
Aprire il menu di navigazione e fare clic su Observability & Management. In Monitoraggio, fare clic su Definizioni degli avvisi.
-
Fare clic su Crea allarme.
Nota: è inoltre possibile creare un allarme da un'interrogazione predefinita nella pagina Metriche servizio. Espandere Opzioni e fare clic su Crea un allarme in questa interrogazione. Per ulteriori informazioni sulle metriche del servizio, vedere Visualizzazione o elenco delle metriche di Oracle NoSQL Database Cloud Service.
-
Nella pagina Crea allarme, in Definisci allarme, immettere o aggiornare le impostazioni dell'allarme. Per passare dalla modalità base alla modalità avanzata, fare clic su Passa alla modalità avanzata o su Passa alla modalità base (a destra di Definisci allarme):
-
Nome allarme: nome riconoscibile dall'utente per il nuovo allarme. Questo nome viene inviato come titolo per le notifiche correlate a questo allarme. Evitare di fornire informazioni riservate.
-
Riepilogo allarme: immettere un riepilogo intuitivo per il nuovo allarme. Questo campo è facoltativo.
-
Tag (facoltativo): se si dispone dell'autorizzazione per creare una risorsa, si dispone anche dell'autorizzazione per applicare tag in formato libero a tale risorsa. Per applicare una tag definita, è necessario disporre dell'autorizzazione per utilizzare lo spazio di nomi tag. Per ulteriori informazioni sull'applicazione di tag, vedere Tag risorsa. Se non si è certi di applicare i tag, saltare questa opzione (è possibile applicare i tag in seguito) o chiedere all'amministratore.
Nota: fare clic su Mostra opzioni avanzate nella parte inferiore della pagina per accedere alle opzioni Tag.
-
Descrizione della metrica: la metrica da valutare per la condizione di allarme.
-
Compartimento: compartimento contenente le tabelle di Oracle NoSQL Database Cloud Service che si desidera monitorare. Per impostazione predefinita, viene selezionato il primo compartimento accessibile.
-
Spazio di nomi delle metriche: Oracle NoSQL Database Cloud Service emette metriche per le tabelle che si desidera monitorare. Esempio: oci_nosql.
-
Gruppo di risorse (facoltativo): il gruppo a cui appartiene la metrica. Un gruppo di risorse è una stringa personalizzata fornita con una metrica personalizzata. Non applicabile alle metriche del servizio.
-
Nome metrica: il nome della metrica. È possibile specificare solo una metrica. Le selezioni delle metriche dipendono dal compartimento e dallo spazio di nomi delle metriche selezionati. Esempio: ReadUnits
-
Intervallo: finestra di aggregazione.
-
Statistica: funzione di aggregazione.
-
Dimensioni metrica: filtri facoltativi per limitare i dati delle metriche valutati.
- Campi dimensione: per le metriche di Oracle NoSQL Database Cloud Service è possibile selezionare resourceId o tableName come coppia nome dimensione e valore dimensione.
-
-
Aggrega flussi di metriche: rappresenta una singola riga nel grafico delle metriche per rappresentare il valore combinato di tutti i flussi di metriche per la statistica selezionata.
-
Regola trigger: la condizione che deve essere soddisfatta affinché l'allarme sia in stato di attivazione. La condizione può specificare una soglia, ad esempio il 90% per StorageGB.
-
Operatore: l'operatore utilizzato nella soglia della condizione.
-
Valore: il valore da utilizzare per la soglia della condizione.
-
Minuti di ritardo trigger: il numero di minuti durante i quali la condizione deve essere gestita prima dell'impostazione dello stato di attivazione dell'allarme.
-
Severità dell'allarme: il tipo di risposta percepito richiesto quando l'allarme è in stato di attivazione.
-
Corpo dell'allarme: il contenuto leggibile dalla persona della notifica consegnata. Oracle consiglia di fornire agli operatori linee guida per la risoluzione della condizione di allarme. Esempio: "Conteggio limitazione lettura elevata".
-
-
-
Per modificare la vista dei risultati della query, fare clic sull'opzione appropriata sopra i risultati, a destra:
-
Mostra tabella dati: elenca i datapoint, indicando l'indicatore orario e i byte per ciascuno di essi.
-
Mostra grafico (predefinito): consente di tracciare i datapoint in un grafico.
-
-
Impostare le notifiche: in Notifiche, compilare i campi.
-
Destinazioni: argomento da utilizzare per le notifiche.
-
Ripeti notifica?: quando l'allarme è in stato di attivazione, rinvia le notifiche in base all'intervallo specificato.
-
Frequenza di notifica: il periodo di tempo di attesa prima di inviare di nuovo la notifica.
-
Sopprimi notifiche: impostare una finestra temporale di eliminazione durante la quale sospendere le valutazioni e le notifiche. Utile per evitare notifiche di allarme durante i periodi di manutenzione del sistema.
-
-
Se si desidera disabilitare il nuovo allarme, deselezionare Abilitare questo allarme?
-
Fare clic su Salva allarme.
Da Cloud Shell, eseguire il comando seguente per creare un nuovo allarme nel compartimento specificato. OCID compartimento richiesto.
oci monitoring alarm create --compartment-id <Compartment_OCID> --namespace oci_nosql --query-text [text] --destinations [complex type] --display-name [text] --is-enabled [boolean] --metric-compartment-id [text] --severity [text]
--query-text è l'espressione MQL (Monitoring Query Language) da utilizzare durante la ricerca dei datapoint delle metriche da aggregare. La query deve specificare una metrica, una statistica e un intervallo. Valori supportati per l'intervallo: 1m-60m (anche 1h). Facoltativamente, è possibile specificare dimensioni e funzioni di raggruppamento. Funzioni di raggruppamento supportate: grouping(), groupBy(). Per ulteriori informazioni sulle OPZIONI disponibili con il comando di creazione allarme, vedere create - allarme. Nell'esempio riportato di seguito, stiamo creando un allarme con query di allarme quando 90il percentile di StorageGB è maggiore di 85 in un compartimento a un intervallo di un minuto, filtrato in una singola tabella.
Esempio di allarme soglia:
oci monitoring alarm create --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'StorageGB[1m]{tableName="demo"}.groupBy(WriteUnits).percentile(0.9) > 85'
--display-name HighStorageConsumption --metric-compartment-id demonosql --severity Critical --is-enabled trueGestione degli allarmamenti
È possibile seguire queste linee guida su come gestire gli allarmi.
-
Creare un set di allarmi per ogni metrica. Per ogni metrica emessa dalla tabella Oracle NoSQL Database Cloud Service, creare allarmi che definiscono i comportamenti delle risorse riportati di seguito.
-
A rischio: Oracle NoSQL Database Cloud Service rischia di diventare inutilizzabile, come indicato dai valori delle metriche. Ad esempio, la dimensione dello storage per una tabella è a rischio di un utilizzo elevato.
-
Non ottimale: Oracle NoSQL Database Cloud Service esegue prestazioni a livelli non ottimali, come indicato dai valori delle metriche. Ad esempio, ReadUnits o Write Unit hanno una latenza elevata.
-
Risorsa attiva o inattiva: Oracle NoSQL Database Cloud Service non è raggiungibile o non è operativo. Ad esempio, Numero massimo per ReadThrottleCount o WriteThrottleCount.
-
-
Impostare un processo per la risposta agli allarmi. In base alla gravità dell'allarme, è possibile scegliere di rispondere agli allarmi nei seguenti modi:
-
Per gli allarmi critici a rischio, è possibile decidere di avvisare immediatamente il team operativo perché è necessaria una riparazione per riportare le istanze a livelli operativi ottimali. È possibile configurare le notifiche di allarme per il team responsabile sia tramite PagerDuty che tramite posta elettronica, richiedendo un'indagine e le correzioni appropriate prima che le istanze diventino inutilizzabili. Le notifiche di ripetizione vengono impostate ogni minuto. Quando qualcuno risponde alle notifiche di allarme, interrompi temporaneamente le notifiche sopprimendo l'allarme. Una volta che le metriche tornano ai valori ottimali, si rimuove l'eliminazione.
-
Per gli allarmi avvertenza o non ottimali, è possibile decidere di notificare alla persona o al team appropriato che la tabella Oracle NoSQL Database Cloud Service utilizza una dimensione di storage superiore al solito. È possibile configurare un allarme di soglia per notificare i contatti appropriati in quanto non sono necessarie azioni immediate per analizzare e ridurre le dimensioni dello storage. È possibile impostare la notifica solo via e-mail, indirizzata allo sviluppatore o al team appropriato, con notifiche ripetute ogni 24 ore per ridurre il rumore delle notifiche e-mail.
-