Riferimento di Oracle NoSQL Database Cloud Service
Informazioni sui tipi di dati supportati, sulle istruzioni DDL, sui parametri e sulle metriche di Oracle NoSQL Database Cloud Service Service.
Questo articolo contiene i seguenti argomenti:
Tipi di dati supportati
Oracle NoSQL Database Cloud Service supporta molti tipi di dati comuni.
| Tipo di dati | Descrizione |
|---|---|
BINARY |
Sequenza di zero o più byte. La dimensione di archiviazione è il numero di byte più una codifica della dimensione dell'array di byte, che è una variabile, a seconda della dimensione dell'array. |
FIXED_BINARY |
Array di byte a dimensione fissa. Nessun overhead di codifica aggiuntivo per questo tipo di dati. |
BOOLEAN |
Tipo di dati con uno dei due valori possibili: TRUE o FALSE. La dimensione di memorizzazione del valore booleano è di 1 byte. |
DOUBLE |
Numero a virgola mobile lungo, codificato utilizzando 8 byte di storage per le chiavi di indice. Se si tratta di una chiave primaria, utilizza 10 byte di storage. |
FLOAT |
Numero a virgola mobile lungo, codificato utilizzando 4 byte di storage per le chiavi di indice. Se si tratta di una chiave primaria, utilizza 5 byte di storage. |
LONG |
Un numero intero lungo ha una codifica a lunghezza variabile che utilizza 1-8 byte di storage a seconda del valore. Se si tratta di una chiave primaria, utilizza 10 byte di storage. |
INTEGER |
Un numero intero lungo ha una codifica a lunghezza variabile che utilizza 1-4 byte di storage a seconda del valore. Se si tratta di una chiave primaria, utilizza 5 byte di storage. |
STRING |
Sequenza di zero o più caratteri Unicode. Il tipo di stringa è codificato come UTF-8 e memorizzato in tale codifica. La dimensione di storage è il numero di byte UTF-8 più la lunghezza, che può essere compresa tra 1 e 4 byte a seconda del numero di byte presenti nella codifica. Quando memorizzato in una chiave di indice, la dimensione dello storage è il numero di byte UTF-8 più un singolo byte di terminazione nullo. |
NUMBER |
Numero decimale con segno di precisione arbitrario. È serializzato in un formato di array di byte che può essere utilizzato per i confronti ordinati. Il formato ha 2 parti: 1. Il segno e l'esponente più una singola cifra. Ciò richiede 1-6 byte, ma normalmente è 2 a meno che l'esponente non sia abbastanza grande 2. La mantissa del valore che è di circa un byte per ogni 2 cifre Esempi: 12.345678 serializza in 6 byte 1.234E+102 serializza in 5 byte Nota: quando è necessario utilizzare valori numerici nello schema, viene Si consiglia di decidere i tipi di dati nell'ordine indicato di seguito: INTEGER, LONG, FLOAT, DOUBLE, NUMBER Evitare NUMBER a meno che non ne abbiate davvero bisogno per il vostro caso d'uso in quanto NUMBER è costoso sia in termini di capacità di archiviazione che di elaborazione utilizzata. |
TIMESTAMP |
Un punto nel tempo con precisione. La precisione influisce sulle dimensioni e sull'utilizzo dello storage. L'indicatore orario viene memorizzato e gestito in UTC (Coordinated Universal Time). Il tipo di dati Timestamp richiede da 3 a 9 byte a seconda della precisione utilizzata. La seguente analisi illustra lo storage utilizzato da questo tipo di dati: - bit[0~13] anno - 14 bit - bit[14~17] mese - 4 bit - bit[18~22] giorno - 5 bit - bit[23~27] ora - 5 bit [opzionale] - bit[28~33] minuto - 6 bit [opzionale] - bit[34~39] secondo - 6 bit [opzionale] - bit[40~71] secondo frazionario [opzionale con lunghezza variabile] |
UUID |
Nota: il tipo di dati UUID è considerato un sottotipo del tipo di dati STRING. La dimensione di storage è di 16 byte come chiave di indice. Se utilizzata come chiave primaria, la dimensione dello storage è di 19 byte. |
ENUM |
Un'enumerazione è rappresentata come un array di stringhe. I valori ENUM sono identificatori simbolici (token) e vengono memorizzati come un piccolo valore intero che rappresenta una posizione ordinata nell'enumerazione. |
ARRAY |
Raccolta ordinata di zero di più articoli con tipi diversi. Gli array non definiti come JSON non possono contenere valori NULL. Gli array dichiarati come JSON possono contenere qualsiasi JSON valido, incluso il valore speciale, nullo, rilevante per JSON. |
MAP |
Una raccolta non ordinata di zero o più coppie di elementi chiave, in cui tutte le chiavi sono stringhe e tutti gli elementi sono dello stesso tipo. Tutte le chiavi devono essere univoche. Le coppie chiave-elemento sono denominate campi, le chiavi sono nomi di campo e gli elementi associati sono valori di campo. I valori dei campi possono avere tipi diversi, ma le mappe non possono contenere valori di campo NULL. |
RECORD |
Raccolta fissa di una o più coppie di elementi chiave-chiave, in cui tutte le chiavi sono stringhe. Tutte le chiavi in un record devono essere univoche. |
JSON |
Qualsiasi dato JSON valido. |
Stati tabella e cicli di vita
Scopri i diversi stati delle tabelle e il loro significato (processo del ciclo di vita delle tabelle).
Ogni tabella passa attraverso una serie di stati diversi dalla creazione della tabella all'eliminazione (drop). Ad esempio, una tabella nello stato DROPPING non può passare allo stato ACTIVE, mentre una tabella nello stato ACTIVE può passare allo stato UPDATING. È possibile tenere traccia dei diversi stati delle tabelle monitorando il ciclo di vita delle tabelle. Questa sezione descrive i vari stati delle tabelle.
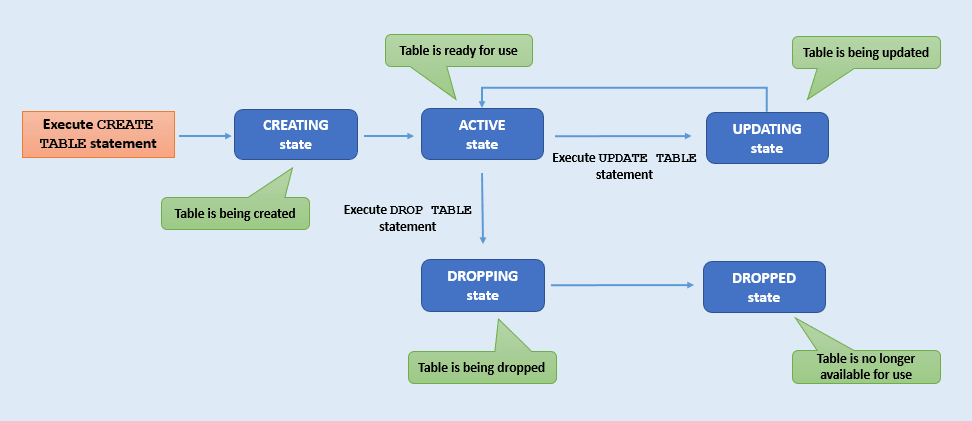
Descrizione dell'illustrazione table-state.png
| Stato tabella | Descrizione |
|---|---|
CREATING |
La tabella è in fase di creazione. Non è pronto per l'uso. |
UPDATING |
Aggiornamento della tabella in corso. Ulteriori modifiche alla tabella non sono possibili mentre la tabella si trova in questo stato. Una tabella si trova nello stato UPDATING quando:- I limiti della tabella vengono modificati - Lo schema della tabella è in evoluzione - Aggiunta o eliminazione di un indice della tabella |
ACTIVE |
La tabella può essere utilizzata nello stato corrente. La tabella potrebbe essere stata creata o modificata di recente, ma lo stato della tabella è ora stabile. |
DROPPING |
La tabella è in fase di eliminazione e non è possibile accedervi per alcuno scopo. |
DROPPED |
La tabella è stata eliminata e non esiste più per le attività di lettura, scrittura o query. Nota: una volta eliminata, è possibile creare di nuovo una tabella con lo stesso nome. |
Debug degli errori delle istruzioni SQL nella console OCI
Quando si utilizza la console OCI per creare una tabella utilizzando un'istruzione DDL o un'istruzione DML per inserire o aggiornare i dati o utilizzando una query SELECT per recuperare i dati, è possibile che si verifichi un errore che indica che l'istruzione è Incompleta o difettosa in uno degli scenari comuni riportati di seguito.
- Se si dispone di un punto e virgola alla fine dell'istruzione SQL.
- Se si verifica un errore di sintassi nell'istruzione SQL, ad esempio l'uso errato di virgole, l'uso di qualsiasi carattere non necessario nell'istruzione e così via.
- Se si verifica un errore di ortografia nell'istruzione SQL in una delle parole chiave SQL o nella definizione del tipo di dati.
- Se la colonna è stata definita come NOT NULL ma non è stato assegnato un valore DEFAULT.
- Se la colonna è stata definita come NOT NULL ma non è stato assegnato un valore DEFAULT.
Come gestire alcuni errori non completi o errati durante l'utilizzo della console OCI per creare o gestire i dati:
- Rimuovere il punto e virgola (se presente) alla fine dell'istruzione SQL.
- Verificare se nell'istruzione SQL sono presenti caratteri indesiderati o punteggiatura errata.
- Verificare la presenza di errori di ortografia nell'istruzione SQL.
- Verificare che tutte le definizioni di colonna siano complete e corrette.
- Verificare se è stata definita una chiave primaria per la tabella.
Se si riceve ancora un errore dopo aver eliminato alcune delle possibili situazioni descritte in precedenza, è possibile utilizzare Cloud Shell per eseguire la query e acquisire l'errore esatto come mostrato nell'esempio riportato di seguito.
Esempio: recupero del messaggio di errore per un'istruzione SELECT dalla cloud shell
Il comando summarize controlla la sintassi e restituisce un breve riepilogo di un'istruzione SQL.
-
Nella console OCI, aprire Cloud Shell dal menu in alto a destra.
-
Copiare l'istruzione SQL SELECT (ad esempio,
query1.sql) in una variabile (SQL_SELECTSTMT).Esempio:
SQL_SELECTSTMT=$(cat ~/query1.sql | tr '\n' ' ') -
Richiamare il comando oci riportato di seguito per controllare la sintassi dell'istruzione SQL SELECT.
Nota: è necessario fornire il valore
compartment_idper questa istruzione SELECT.oci raw-request --http-method GET --target-uri https://nosql.${OCI_REGION}.oci.oraclecloud.com/20190828/query/summarize?compartmentId=$NOSQL_COMPID\ &statement="$SQL_SELECTSTMT" | jq '.data'
In questo modo verrà visualizzato l'errore esatto nell'istruzione SQL.
Riferimento per il linguaggio di definizione dei dati
Scopri come utilizzare DDL in Oracle NoSQL Database Cloud Service.
Utilizzare Oracle NoSQL Database Cloud Service DDL per creare, modificare ed eliminare tabelle e indici.
Per informazioni sulla sintassi del linguaggio DDL, consultare il manuale Table Data Definition Language Guide. Questa guida documenta il linguaggio DDL supportato dal prodotto Oracle NoSQL Database on-premise. Oracle NoSQL Database Cloud Service supporta un sottoinsieme di questa funzionalità e le differenze sono documentate nelle differenze DDL nella sezione Cloud.
Inoltre, ogni driver del linguaggio NoSQL fornisce un'API per eseguire un'istruzione DDL. Per scrivere l'applicazione, vedere Uso delle interfacce API per creare tabelle e indici in Oracle NoSQL Database Cloud Service.
Istruzioni DDL tipiche
Pochi esempi di istruzioni DDL comuni sono i seguenti:
Crea tabella
CREATE TABLE [IF NOT EXISTS] (
field-definition, field-definition-2 ...,
PRIMARY KEY (field-name, field-name-2...),
) [USING TTL ttl]Ad esempio:
CREATE TABLE IF NOT EXISTS audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Altera tabella
ALTER TABLE table-name (ADD field-definition)
ALTER TABLE table-name (DROP field-name)
ALTER TABLE table-name USING TTL ttlAd esempio:
ALTER TABLE audience_info USING TTL 7 daysCrea indice
CREATE INDEX [IF NOT EXISTS] index-name ON table-name (path_list)Ad esempio:
CREATE INDEX segmentIdx ON audience_info
(audience_segment.sports_lover AS STRING)Elimina tabella
DROP TABLE [IF EXISTS] table-nameAd esempio:
DROP TABLE audience_infoVedere le guide di riferimento per un elenco completo:
- Guida per il linguaggio di definizione dei dati della tabella
- Riferimento SQL per Oracle NoSQL Database
Differenze DDL nel cloud
Il linguaggio DDL del servizio cloud differisce da quanto descritto nella guida di riferimento nel modo seguente:
Nomi di tabelle
- Limitato a 256 caratteri e limitato a caratteri alfanumerici e caratteri di sottolineatura
- Deve iniziare con una lettera
- Impossibile includere caratteri speciali
- Le tabelle figlio non sono supportate
Concetti non supportati
- Istruzioni
DESCRIBEeSHOW TABLE. - Indici di testo completo
- Gestione degli utenti e dei ruoli
- Region on-premise
Riferimento linguaggio query
Scopri come utilizzare le istruzioni SQL per aggiornare ed eseguire query sui dati in Oracle NoSQL Database Cloud Service.
Oracle NoSQL Database utilizza il linguaggio di query SQL per aggiornare ed eseguire query sui dati nelle tabelle NoSQL. Per informazioni sulla sintassi del linguaggio di query, vedere SQL Reference for Oracle NoSQL Database.
Query tipiche
SELECT <expression>
FROM <table name>
[WHERE <expression>]
[GROUP BY <expression>]
[ORDER BY <expression> [<sort order>]]
[LIMIT <number>]
[OFFSET <number>];Ad esempio:
SELECT * FROM Users;
SELECT id, firstname, lastname FROM Users WHERE firstname = "Taylor";UPDATE <table_name> [AS <table_alias>]
<update_clause>[, <update_clause>]*
WHERE <expr>[<returning_clause>];Ad esempio:
UPDATE JSONPersons $j
SET TTL 1 DAYS
WHERE id = 6
RETURNING remaining_days($j) AS Expires;Differenze di linguaggio delle query nel cloud
Il supporto delle query del servizio cloud è diverso da quello descritto nella guida di riferimento al linguaggio di query nel modo seguente:
Restrizioni sulle espressioni utilizzate nella clausola SELECT
Oracle NoSQL Database Cloud Service supporta il raggruppamento di espressioni o espressioni aritmetiche tra funzioni di aggregazione. Nella clausola SELECT non sono consentiti altri tipi di espressioni. Ad esempio, le espressioni CASE non sono consentite nella clausola SELECT.
Ogni driver NoSQL Database fornisce un'API per eseguire un'istruzione di query.
Riferimento piano query
Un piano di esecuzione delle query è la sequenza di operazioni eseguite da Oracle NoSQL Database per eseguire una query.
Un piano di esecuzione delle query è una struttura di iteratori del piano. Ogni tipo di iteratore valuta un tipo diverso di espressione che può apparire in una query. In generale, la scelta dell'indice e il tipo di predicati di indice associati possono avere un effetto drastico sulle prestazioni delle query. Di conseguenza, l'utente spesso desidera vedere quale indice viene utilizzato da una query e quali predicati sono stati spostati verso il basso. Sulla base di queste informazioni, è possibile forzare l'uso di un indice diverso tramite suggerimenti di indice. Queste informazioni sono contenute nel piano di esecuzione delle query. Tutti i driver Oracle NoSQL forniscono API per visualizzare il piano di esecuzione di una query.
Alcuni degli iteratori più comuni e importanti utilizzati nelle query sono:
Iteratore di tabella: un iteratore di tabella è responsabile di:
- Scansione dell'indice utilizzato dalla query (che può essere l'indice primario).
- Applicazione di eventuali predicati di filtro sottoposti a push nell'indice
- Se necessario, recuperare le righe a cui fanno riferimento le voci dell'indice qualificante. Se l'indice è coperto, il set di risultati dell'iteratore TABLE è un set di voci di indice, altrimenti è un set di righe di tabella.
Nota: un indice viene definito indice di copertura rispetto a una query se la query può essere valutata utilizzando solo le voci di tale indice, ovvero senza la necessità di recuperare le righe associate.
Iteratore SELECT: è responsabile dell'esecuzione dell'espressione SELECT.
Ogni query contiene una clausola SELECT. Quindi ogni piano di query avrà un iteratore SELECT. Un iteratore SELECT ha la seguente struttura:
"iterator kind" : "SELECT",
"FROM" :
{
},
"FROM variable" : "...",
"SELECT expressions" :
[
{
}
]L'iteratore SELECT dispone di campi quali "FROM", "WHERE", "FROM variable" e "SELECT expression". "FROM" e "FROM variable" rappresentano la clausola FROM dell'espressione SELECT, WHERE rappresenta la clausola filter e "SELECT expression" rappresenta la clausola SELECT.
iteratore RECEIVE: si tratta di un iteratore interno speciale che separa il piano di query in 2 parti:
-
L'iteratore RECEIVE stesso e tutti gli iteratori che sono al di sopra di esso nell'albero dell'iteratore vengono eseguiti al driver.
-
Tutti gli iteratori al di sotto dell'iteratore RECEIVE vengono eseguiti nei nodi di replica (RN); questi iteratori formano una struttura secondaria radicata nel figlio univoco dell'iteratore RECEIVE.
In generale, l'iteratore RECEIVE funge da coordinatore query. Invia il suo piano secondario agli RN appropriati per l'esecuzione e raccoglie i risultati. Può eseguire operazioni aggiuntive come l'ordinamento e l'eliminazione dei duplicati e propagare i risultati ai relativi iteratori predecessori (se presenti) per un'ulteriore elaborazione.
Tipi di distribuzione:
Un tipo di distribuzione specifica la modalità di distribuzione della query per l'esecuzione tra gli RN che partecipano a un database Oracle NoSQL (un'area di memorizzazione). Il tipo di distribuzione è una proprietà dell'iteratore RECEIVE.
Diverse scelte dei tipi di distribuzione sono:
- SINGLE_PARTITION: una query SINGLE_PARTITION specifica una chiave di partizione completa nella clausola WHERE. Di conseguenza, il suo set di risultati completo è contenuto in una singola partizione e l'iteratore RECEIVE invierà il suo piano secondario a un singolo RN che memorizza tale partizione. Una query SINGLE_PARTITION può utilizzare l'indice della chiave primaria o un indice secondario.
- ALL_PARTITIONS: le query utilizzano l'indice delle chiavi primarie qui e non specificano una chiave partizione completa. Di conseguenza, se il negozio ha partizioni M, l'iteratore RECEIVE invierà M copie del suo piano secondario da eseguire su una delle partizioni M ciascuna.
- ALL_SHARDS: le query utilizzano qui un indice secondario e non specificano una chiave di partizione completa. Di conseguenza, se il negozio ha N partizioni, l'iteratore RECEIVE invierà N copie del suo piano secondario da eseguire su una delle partizioni N ciascuna.
Anatomia di un piano di esecuzione delle query:
L'esecuzione delle query viene eseguita in batch. Quando un piano secondario di query viene inviato a una partizione o a una partizione per l'esecuzione, verrà eseguito lì fino al raggiungimento di un limite batch. Il limite batch è un numero di unità di lettura consumate localmente dalla query. Il valore predefinito è 2000 unità di lettura (circa 2 MB di dati) e può essere ridotto solo tramite un'opzione a livello di query.
Quando viene raggiunto il limite batch, tutti i risultati locali prodotti vengono restituiti all'iteratore RECEIVE per un'ulteriore elaborazione insieme a un flag booleano che indica se potrebbero essere disponibili ulteriori risultati locali. Se il flag è true, la risposta include le informazioni di ripresa. Se l'iteratore RECEIVE decide di inviare di nuovo la query alla stessa partizione o partizione, includerà queste informazioni di ripresa nella richiesta, in modo che l'esecuzione della query venga riavviata nel punto in cui è stata arrestata durante il batch precedente. Questo perché non viene mantenuto alcuno stato di query in RN al termine di un batch. Il batch successivo per la stessa partizione o partizione può essere eseguito allo stesso RN del batch precedente o in un RN diverso che memorizza anche la stessa partizione o partizione.