Utilizzare OKE per migliorare la localizzazione dei dati per l'attività Cassandra e Spark
Introduzione
Apache Cassandra è un database masterless distribuito in cui ogni nodo possiede intervalli di token. Apache Spark è un motore di calcolo distribuito che può utilizzare il connettore Spark-Cassandra per leggere dalle repliche Cassandra. In Kubernetes, i pod vengono pianificati senza sapere dove si trovano i dati, quindi la località dei dati non è garantita.
Questo tutorial mostra come OKE può migliorare la località con le primitive Kubernetes: StatefulSets (identità stabile per Cassandra), le etichette dei nodi e l'affinità/anti-affinità per co-locare gli esecutori Spark con i pod Cassandra, quindi le letture vengono servite dallo stesso nodo (ideale) o, nel peggiore dei casi, un salto alla replica in co-ubicazione.
Obiettivi
- Distribuire un cluster e un bastion OKE a 3 nodi (ORM o Terraform).
- Co-localizza Cassandra e Spark su due nodi con etichette + affinità.
- Esegui e verifica un job di lettura Spark su Cassandra.
- Osservare il traffico tra nodi con i log di flusso della VCN.
Prerequisiti
- Tenancy OCI con autorizzazioni per VCN, OKE, Compute, Log (log dei flussi); monitoraggio facoltativo.
- Coppia di chiavi SSH per l'accesso al bastion.
- Familiarità di base di Kubernetes (nodi, etichette, pod e così via).
Task 1: Distribuire l'ambiente con OCI Resource Manager (ORM) (consigliato).
-
Fare clic di seguito per aprire lo stack nella console OCI:

-
Segui il flusso guidato per:
-
Accetto le condizioni d'uso.
-
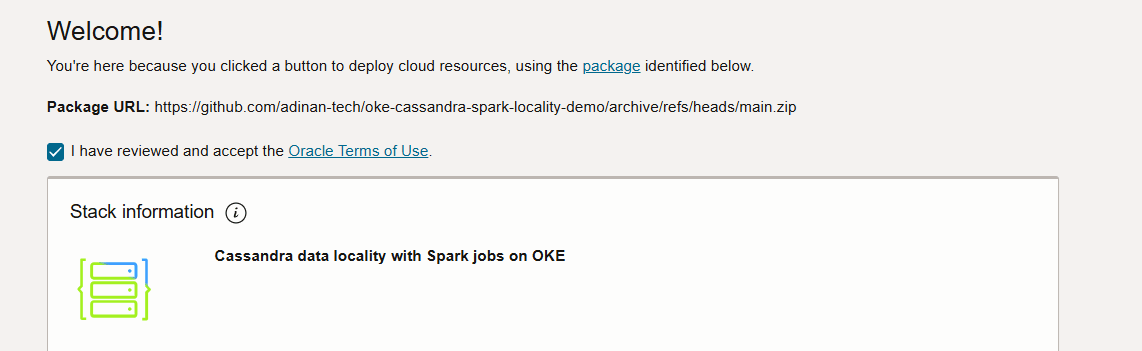
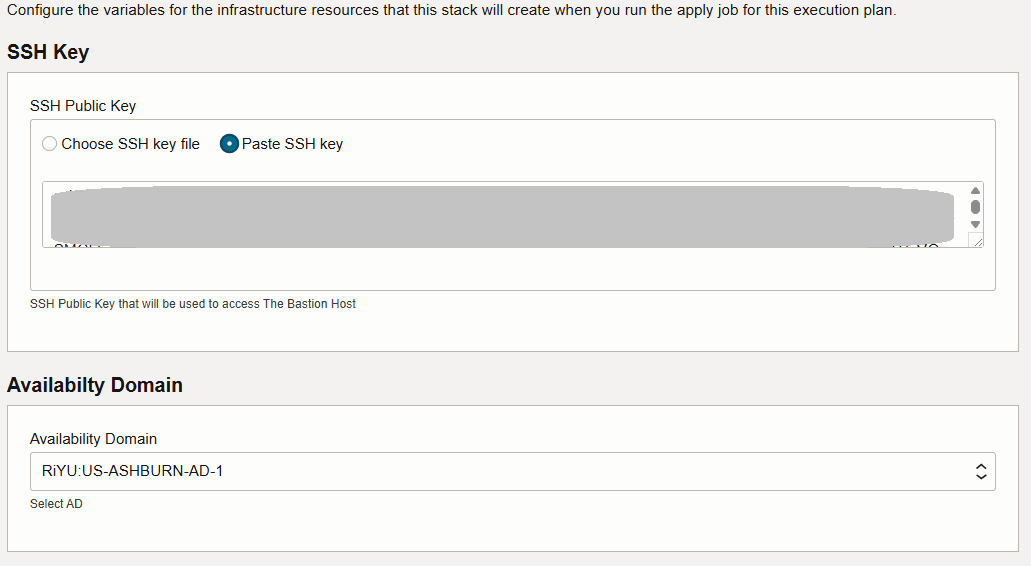
Inserire una chiave SSH e selezionare il dominio di disponibilità.
-
È possibile lasciare i restanti valori come predefiniti per ottenere una VCN, un cluster OKE e un bastion distribuiti.
-
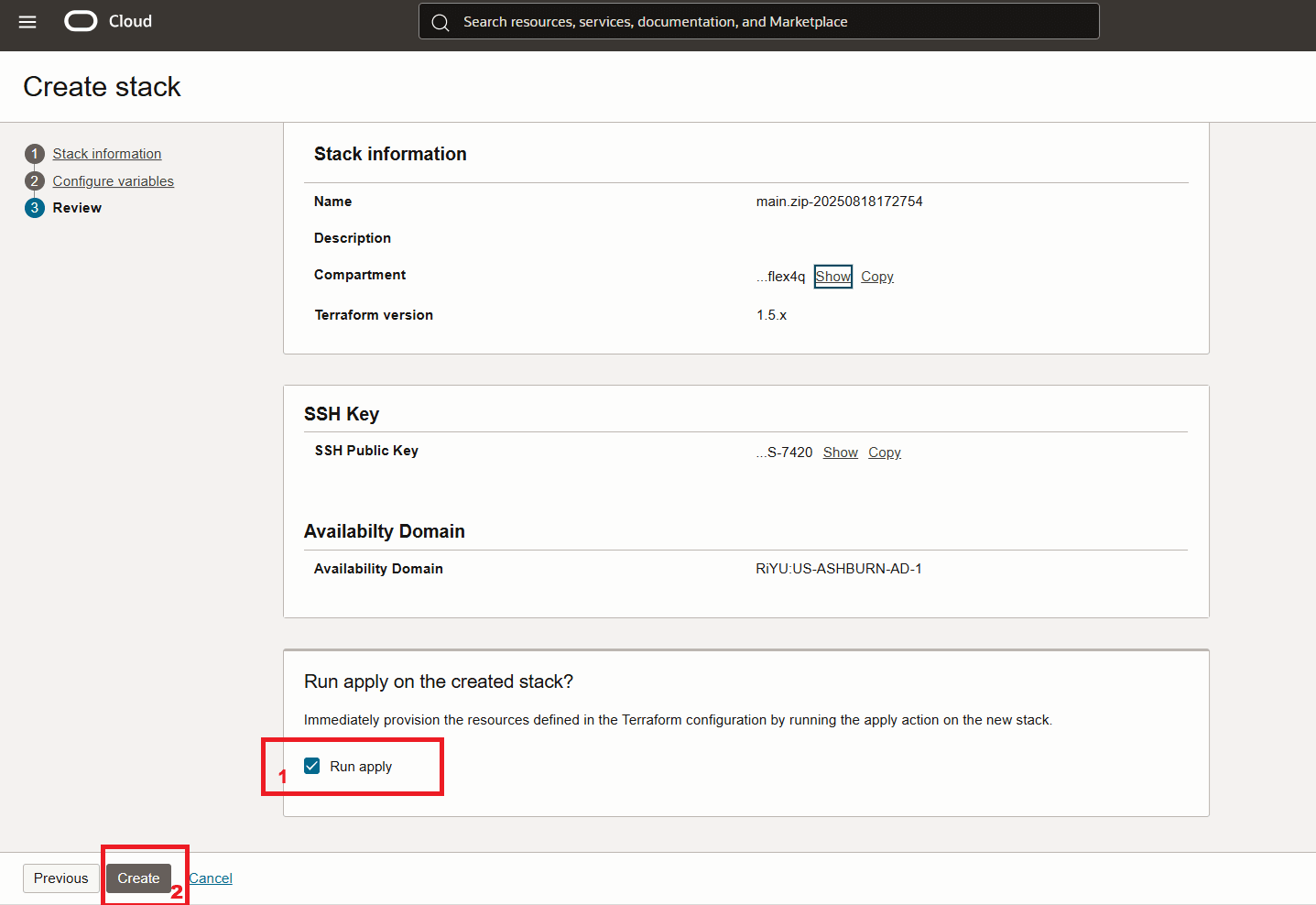
Avviare lo stack.
-
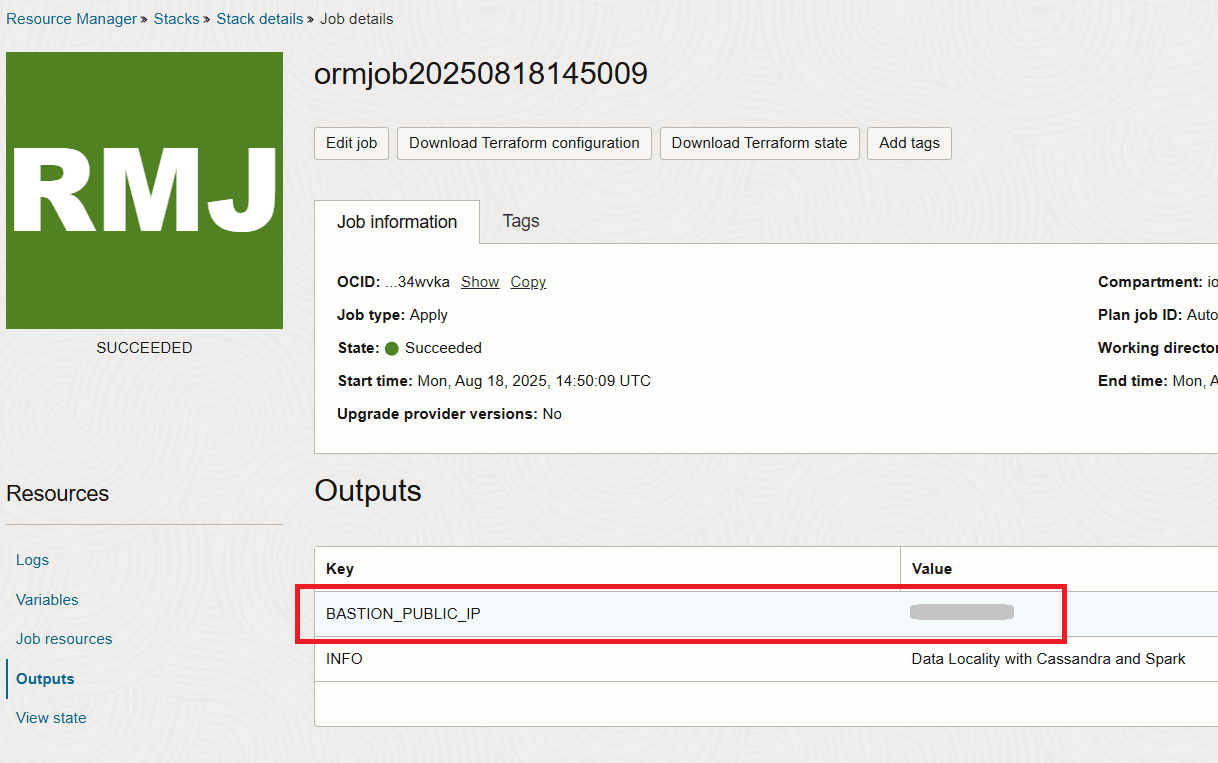
Una volta completato lo stack, si otterrà l'IP del bastion nella sezione di output.
Task 2: Connettersi al bastion e verificare la distribuzione
Il provisioning dell'infrastruttura iniziale viene completato in circa 15 minuti, ma l'impostazione completa (tramite l'inizializzazione del cloud nel bastion) richiede circa altri 20 minuti per installare Helm, distribuire Cassandra e Spark ed eseguire il job di lettura.
-
Per monitorare il processo, SSH nel bastion:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
Eseguire il comando riportato di seguito per monitorare l'avanzamento dello script cloudinit.
tail -f /var/log/oke-automation.log -
Lo stack viene completato quando vengono visualizzati i 3 valori predefiniti di Cassandra in fase di lettura e il messaggio Cloud-init complete.
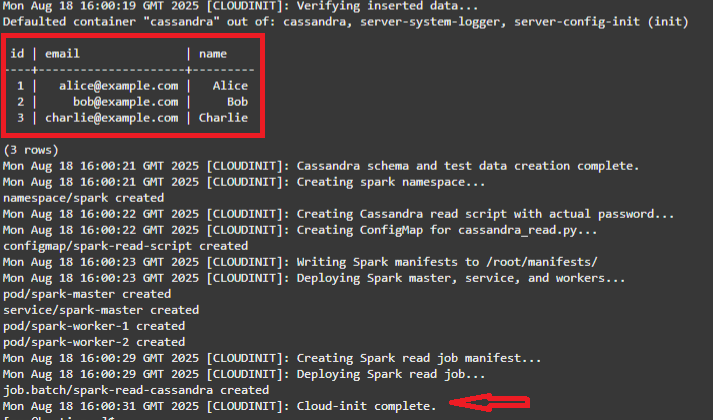
Nota: lo script cloudinit ha eseguito le operazioni riportate di seguito.
- Installare kubectl, Helm, OCI CLI (principali istanza), recuperare kubeconfig.
- Attendi lavoratori
- Etichetta i primi due nodi con:
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - Installare cert-manager e k8ssandra-operator (CRD)
- Applica K8ssandraCluster
- Aspetta Cassandra
- Creare testks.users e inserire 3 righe
- Creare uno spazio di nomi spark; creare ConfigMap con /scripts/cassandra_read.py (leggi testks.users)
- Distribuisci master, servizio e due lavoratori Spark (nodeSelector spark-locality: "true", worker anti-affinity)
- Sottometti spark-read-cassandra job
-
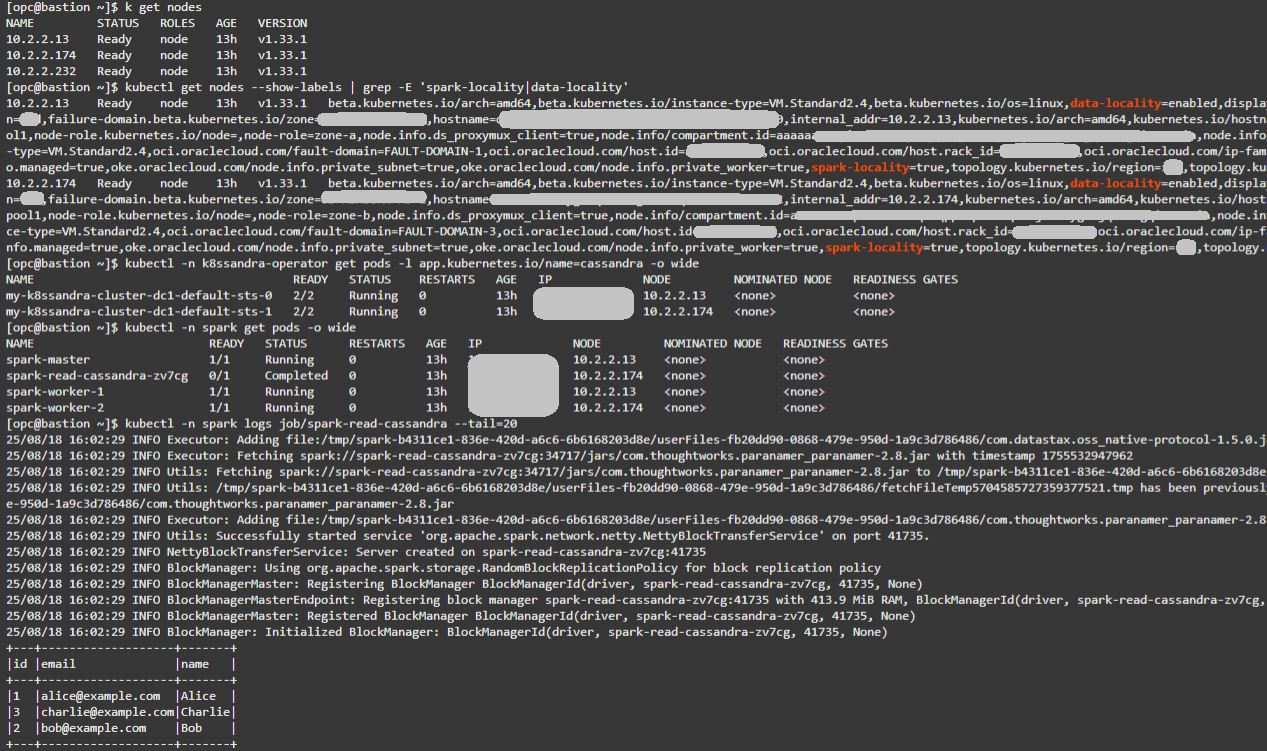
Dalla VM bastion confermare i nodi esistenti:
kubectl get nodes -
Confermare le etichette di località. Prevedono due nodi con spark-locality=true e data-locality=enabled.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Verificare il posizionamento di Cassandra:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Verificare il posizionamento di Spark:
kubectl -n spark get pods -o wide -
Controllare i log dei job di lettura Spark. Si consiglia di visualizzare i 3 record di testks.users e un'esecuzione riuscita.
kubectl -n spark logs job/spark-read-cassandra --tail=20
Suggerimento: la corrispondenza dei valori NODE nei pod Cassandra e Spark conferma la co-ubicazione e le condizioni ideali per la località. Per risultati più conclusivi del log di flusso, inserire righe aggiuntive in testks.users utilizzando cqlsh. I set di dati più grandi genereranno più traffico di lettura, rendendo più facili da osservare gli effetti di località e non di località.
Di seguito è riportato un esempio di output per i comandi sopra riportati:
Task 3: Osservare gli effetti di rete con i log di flusso della VCN
Utilizza i log di flusso della VCN per capire dove scorre il traffico Cassandra durante le letture della Spark. L'automazione attuale utilizza Flannel (VXLAN), che influisce sui log di flusso.
Cosa cambia con il CNI
- Flanella (VXLAN, questo laboratorio):
- Il traffico pod dello stesso nodo rimane sul bridge host → nessuna voce del log di flusso VCN.
- Il traffico pod cross-node è incapsulato come UDP
(VXLAN). Per impostazione predefinita, Flannel utilizza la porta 8472, ma se tale porta non è disponibile, potrebbe selezionare un'altra porta UDP alta. La porta esatta può variare in base alla distribuzione.
- Rete pod VCN nativo (NPN):
- I pod ottengono gli IP VCN e il traffico viene instradato all'indirizzo L3 senza overlay.
- I log di flusso mostrano le porte delle applicazioni reali (per Cassandra: TCP 9042).
-
Abilita i log di flusso nella subnet del lavoratore.
Nella console OCI abilitare i log di flusso per la subnet del worker OKE. Rieseguire (o attendere) il job di lettura Spark per generare traffico.
-
Esegui query sui log di flusso (scegliere il percorso che corrisponde al cluster)
Se si utilizza questa automazione (Flannel/VXLAN): utilizzare una query avanzata simile a:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
Sostituire
- Il traffico pod-to-pod è incapsulato in UDP
tra gli IP dei nodi di lavoro (anziché la porta Cassandra 9042). - Letture dello stesso nodo: nessuna voce del log di flusso VCN (il traffico rimane locale).
- Lettura cross-node: visibile come UDP 14789 scorre tra gli IP dei nodi di lavoro nell'immagine seguente.
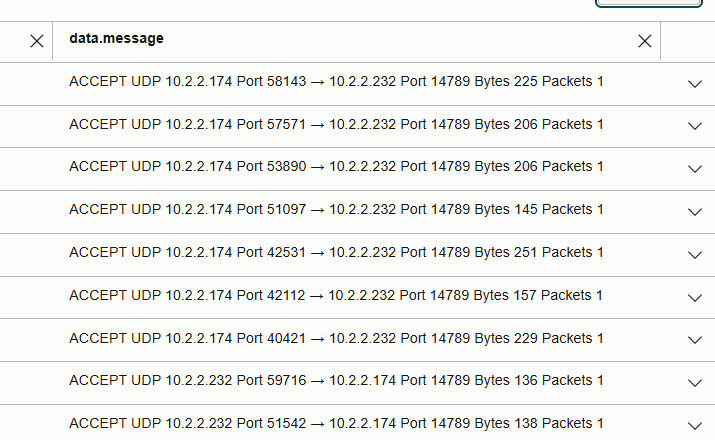
- Il confronto dei conteggi dei pacchetti su UDP 14789 evidenzia l'effetto della località dei dati rispetto alla non località.
Se il cluster utilizza NPN:
- Filtra direttamente per TCP dstPort = 9042 tra IP pod/worker.
- Si dovrebbe vedere Cassandra CQL leggere / scrivere come 9042 flussi. (idealmente molto poco)
Nota: i log di flusso possono richiedere alcuni minuti per includere nuove voci.
Considerazioni chiave
-
Cluster con nodi >3:
La località è più importante man mano che la dimensione del cluster aumenta. Senza regole di posizionamento, gli esecutori Spark possono essere eseguiti su nodi senza repliche locali, causando molte letture remote. La co-ubicazione garantisce che le letture siano locali o, nel peggiore dei casi, un singolo hop a un'altra replica.
- Incrementi delle prestazioni derivanti dalla co-locazione:
- Letture locali zero-hop → latenza più bassa.
- Meno letture cross-node → uso ridotto della larghezza di banda e minore conflitto.
- Throughput più elevato per i job Spark che leggono Cassandra in parallelo.
- Meccanismi utilizzati in questa automazione:
- StatefulSets → identità pod Cassandra stabili.
- Le etichette dei nodi (
spark-locality,data-locality) → designano i nodi per la co-ubicazione. - Affinità pod/anti-affinità → Esecutori Spark pianificati sui nodi Cassandra, bilanciati tra loro.
- K8ssandra Operatore → distribuzione e gestione dichiarativa di Cassandra.
- ConfigMap + Spark → convalida Cassandra legge e genera traffico.
- I log di flusso VCN → osservano e confermano gli effetti della località.
- Fuori dall'ambito di OKE (fattori a livello di applicazione):
- Pianificazione dei task Spark e assegnazione della partizione.
- Fattore di replica Cassandra e livello di coerenza.
- Logica del connettore Spark-Cassandra per la selezione delle repliche.
Collegamenti correlati
Fornire collegamenti a risorse aggiuntive. Questa sezione è facoltativa; eliminare se non necessario.
Conferme
- Autori - Adina Nicolescu (Principal Cloud Architect)
Altre risorse di apprendimento
Esplora altri laboratori su docs.oracle.com/learn o accedi a più contenuti di formazione gratuiti sul canale YouTube di Oracle Learning. Inoltre, visitare education.oracle.com/learning-explorer per diventare Oracle Learning Explorer.
Per la documentazione del prodotto, visitare Oracle Help Center.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53300-01