異なるHadoopコンポーネントを使用するためのApache Hueの設定。
-
Hue UIで、クラスタの作成中に使用したパスワードを使用して管理者ユーザーを作成します
-
「Administer users」に移動して次を実行します:
- Hueユーザーを選択します。
- パスワードを更新します。
- 後続のログインでHueユーザーとしてサインインすることをユーザーに許可します。
要件に応じて、さらにユーザーを作成できます。
ノート
セキュアなクラスタの場合は、必ず「Create home directory」チェック・ボックスを選択し、sudo useradd <new_user>コマンドを使用してユーティリティ・ノードにユーザーを作成して、Rangerを使用してアクセス・ポリシーを管理します。
-
DistCpおよびMapReduceアプリケーションを実行するには、MapReduceライブラリをYARNクラスパスに追加します。ライブラリを追加するには、次のステップに従います:
- Ambari UIの「YARN」で、「Configs」を選択します。
yarn.application.classpathを検索します。- 次の構成をコピーし、
yarn.application.classpath値に貼り付けます:$HADOOP_CONF_DIR,/usr/lib/hadoop-mapreduce/*,/usr/lib/hadoop/*,/usr/lib/hadoop/lib/*,/usr/lib/hadoop-hdfs/*,/usr/lib/hadoop-hdfs/lib/*,/usr/lib/hadoop-yarn/*,/usr/lib/hadoop-yarn/lib/*
- YARN、OozieおよびMapReduceサービスを保存して再起動します。
-
Sqoopを構成します。構成するには、次のステップに従います:
- mysql-connectorをoozieクラスパスにコピーします。
sudo cp /usr/lib/oozie/embedded-oozie-server/webapp/WEB-INF/lib/mysql-connector-java.jar /usr/lib/oozie/share/lib/sqoop/
sudo su oozie -c "hdfs dfs -put /usr/lib/oozie/share/lib/sqoop/mysql-connector-java.jar /user/oozie/share/lib/sqoop"
- Ambariを使用してOozieサービスを再起動します。
- Sqoopジョブはワーカー・ノードから実行されます。
ビッグ・データ・サービス・クラスタ(バージョン3.0.7以降)では、すべてのワーカー・ノードからhue mysqlユーザーにアクセスできます。
以前のバージョンのクラスタでは、Apache Hue構成のセキュアなクラスタとセキュアでないクラスタ項にあるステップ2の説明に従って、grant文を実行します。コマンドの実行時に、ローカル・ホストをワーカー・ホスト名に置き換えて、クラスタ内のワーカー・ノードごとにこれを繰り返します。例:
grant all privileges on *.* to 'hue'@'wn_host_name ';
grant all on hue.* to 'hue'@'wn_host_name';
alter user 'hue'@'wn_host_name' identified by 'secretpassword';
flush privileges;
-
マスター・ノードまたはユーティリティ・ノードで、次のディレクトリから、spark関連のjarを使用してsparkプロジェクトへの依存関係として追加します。たとえば、sbtプロジェクトのlib/にspark-coreおよびspark-sqlのjarをコピーします。
/usr/lib/oozie/share/lib/spark/spark-sql_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
/usr/lib/oozie/share/lib/spark/spark-core_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
次に、ワード・カウント・コードの例を示します。コードをJARに構成します:
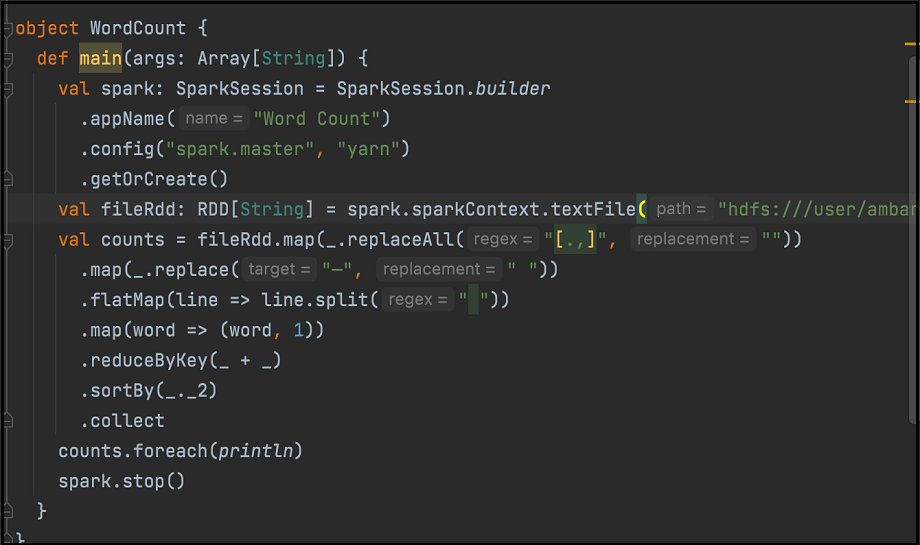
Hue Sparkインタフェースで、関連するjarを使用してSparkジョブを実行します。
-
Oozieを使用してMapReduceを実行するには、次を実行します:
oozie-sharelib-oozie-5.2.0.jar (OozieActionConfiguratorクラスを含む)をサンプル・コードにコピーします。- 標準のワード・カウントMapReduceの例に指定されているように、マッパー・クラスとレデューサ・クラスを定義します。
- 次に示すように、別のクラスを作成します:
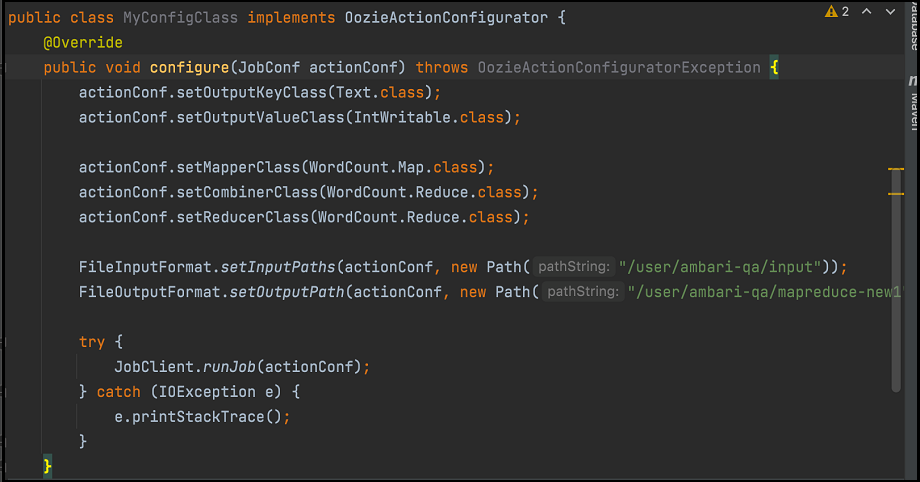
前の図に示されているコードを、マッパー・クラスおよびレデューサ・クラスとともにjarにパッケージ化し、次を実行します:
- Hueファイル・ブラウザを使用してそれをHDFSにアップロードします。
- 次のように指定してMapReduceプログラムを実行します。
oozie.action.config.classは、前の図に示すように、スニペットの完全修飾クラス名を指します。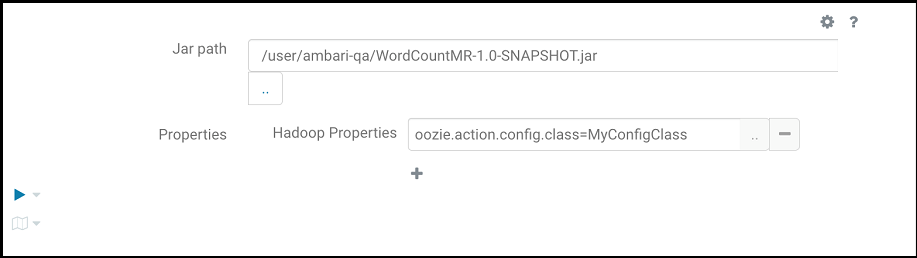
-
HBaseを構成します。
バージョン3.0.7以降のビッグ・データ・サービス・クラスタでは、Apache Ambariを使用してHue HBaseモジュールを有効にする必要があります。 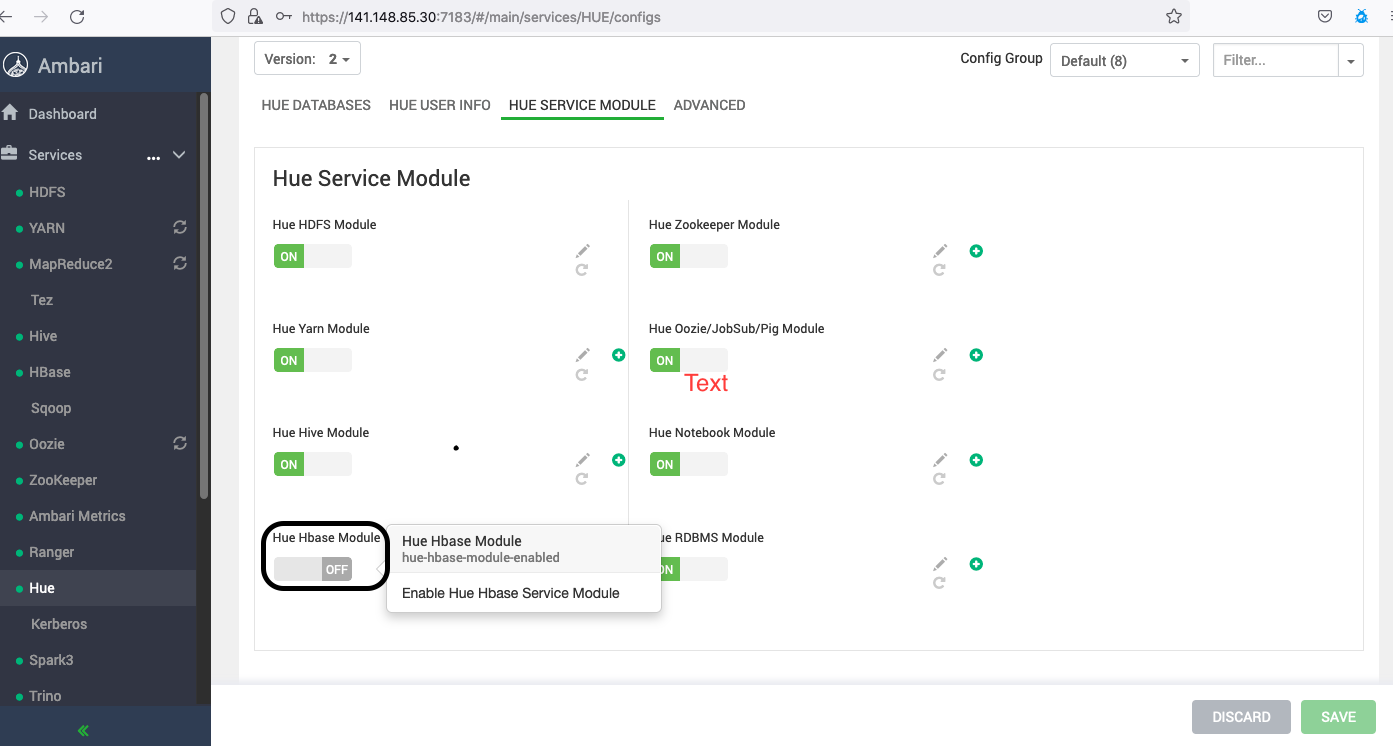
Hueは、HBase Thriftサーバーと対話します。したがって、HBaseにアクセスするには、Thriftサーバーを起動する必要があります。次のステップを実行します:
- AmbariページでHBaseサービスを追加した後、「Custom Hbase-Site.xml」に移動します(HBaseから「Configs」に移動し、「Advanced」で「Custom Hbase-Site.xml」を選択します)。
- keytabまたはプリンシパルを置き換えて、次のパラメータを追加します。
hbase.thrift.support.proxyuser=true
hbase.regionserver.thrift.http=true
##Skip the below configs if this is a non-secure cluster
hbase.thrift.security.qop=auth
hbase.thrift.keytab.file=/etc/security/keytabs/hbase.service.keytab
hbase.thrift.kerberos.principal=hbase/_HOST@BDSCLOUDSERVICE.ORACLE.COM
hbase.security.authentication.spnego.kerberos.keytab=/etc/security/keytabs/spnego.service.keytab
hbase.security.authentication.spnego.kerberos.principal=HTTP/_HOST@BDSCLOUDSERVICE.ORACLE.COM
- マスター・ノード端末で次のコマンドを実行します。
# sudo su hbase
//skip kinit command if this is a non-secure cluster
# kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/<master_node_host>@BDSCLOUDSERVICE.ORACLE.COM
# hbase thrift start
- Hueがインストールされているユーティリティ・ノードにサインインします。
sudo vim /etc/hue//conf/pseudo-distributed.iniファイルを開き、app_blacklistからhbaseを削除します。
# Comma separated list of apps to not load at startup.
# e.g.: pig, zookeeper
app_blacklist=search, security, impala, hbase, pig
- AmbariからHueを再起動します。
- Rangerは、HBaseサービスへのアクセスを管理します。したがって、Hueを使用してセキュア・クラスタ上のHBase表にアクセスするには、RangerからHBaseサービスにアクセスできる必要があります。
-
スクリプト・アクション・ワークフローを構成します。
- Hueにサインインします。
- スクリプト・ファイルを作成し、Hueにアップロードします。
- 色相にサインインし、左端のナビゲーション・メニューで「スケジューラ」を選択します。
- 「ワークフロー」を選択し、「自分のワークフロー」を選択してワークフローを作成します。
- シェル・アイコンを選択して、スクリプト・アクションを「ここにアクションをドロップ」領域にドラッグします。
- 「シェル・コマンド」ドロップダウンからスクリプトを選択します。
- 「FILES」ドロップダウンからワークフローを選択します。
- 保存アイコンを選択します。
- フォルダ構造からワークフローを選択し、送信アイコンを選択します。
ノート Hueワークフローでシェル・アクションを実行する際に、ジョブがスタックしているか、
Permission Denied or Exit code[1]などのエラーのために失敗した場合は、次の手順を実行して問題を解決してください。
- 必要なすべてのファイル(スクリプト・ファイルおよびその他の関連ファイル)が、ワークフローの実行ユーザー(ログイン・ユーザー)に必要な権限とともに、指定された場所で使用可能であることを確認します。
- spark-submitなどの場合、特定のユーザーなしでSparkジョブを発行すると、デフォルトでは、ジョブはコンテナ・プロセス所有者(yarn)で実行されます。この場合、ユーザーyarnにジョブの実行に必要なすべての権限があることを確認してください。
例:
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --deploy-mode client --queue default --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
// Application throws exception if yarn user doesn't have read permission to access spark-examples_2.12-3.2.1.jar.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=yarn, access=READ, inode="/workflow/lib/spark-examples_2.12-3.2.1.jar":hue:hdfs:---------x
この場合、ユーザーyarnには含めるために必要な権限が必要です
spark-examples_2.12-3.2.1.jar
Sparkジョブ内。
- 特定のユーザー(--proxy-user spark)でSparkジョブを発行する場合は、Yarnユーザーがその指定したユーザーを偽装できることを確認してください。Yarnユーザーが指定したユーザーに偽装できず、(
User: Yarn is not allowed to impersonate Spark)などのエラーを受信した場合は、次の構成を追加します。
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --proxy-user spark --deploy-mode client --queue default --class
org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
この場合、ジョブはSparkユーザーを使用して実行されます。Sparkユーザーは、すべての関連ファイル(spark-examples_2.12-3.2.1.jar)にアクセスできる必要があります。また、YarnユーザーがSparkユーザーを偽装できることを確認してください。yarnユーザーが他のユーザーを偽装するように、次の構成を追加します。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「サービス」で、「HDFS」を選択します。
- 「詳細」タブを選択し、「カスタム・コアサイト」の下に次のパラメータを追加します。
- hadoop.proxyuser.yarn.groups = *
- hadoop.proxyuser.yarn.hosts = *
- 「保存」を選択し、必要なすべてのサービスを再起動します。
-
OozieからHiveワークフローを実行します。
- Hueにサインインします。
- スクリプト・ファイルを作成し、Hueにアップロードします。
- 色相にサインインし、左端のナビゲーション・メニューで「スケジューラ」を選択します。
- ワークフロー。
- HiveServer2の3番目のアイコンを「アクションをここにドロップ」領域にドラッグします。
- HDFSからHive問合せスクリプトを選択するには、スクリプト・メニューを選択します。問合せスクリプトは、サインインしているユーザーがアクセスできるHDFSパスに格納されます。
- ワークフローを保存するには、「保存」アイコンを選択します。
- 「実行」アイコン。