MLアプリケーション
MLアプリケーションは、データ・サイエンスにおけるMLユース・ケースの自己完結型表現です。
MLアプリケーションは、AI/ML配信用の堅牢なMLOpsプラットフォームを提供するデータ・サイエンスの新機能です。AI/ML機能のパッケージ化と導入を標準化することで、機械学習をサービスとして構築、導入、運用できます。MLアプリケーションを使用すると、データ・サイエンスを活用してAI/MLのユース・ケースを実装し、アプリケーションや顧客の本番環境にプロビジョニングできます。開発ライフサイクルを数か月から数週間に短縮することで、ML Applicationsは、運用上の複雑さと総所有コストを削減しながら、市場投入までの時間を短縮します。開発やQAから本番や本番まで、あらゆる段階でMLソリューションをデプロイ、検証、推進するためのエンドツーエンドのプラットフォームを提供します。
MLアプリケーションは、AI/ML機能とクライアント・アプリケーション間の統合レイヤーを提供することで、分離されたアーキテクチャもサポートします。これにより、クライアント・アプリケーションを変更することなく、MLソリューションの独立した開発、テストおよび進化が可能になり、シームレスな統合と迅速なイノベーションが可能になります。
MLアプリケーションは、厳格なデータとワークロードの分離を確保しながら、顧客フリート全体でML機能をプロビジョニングおよび保守する必要があるSaaSプロバイダに最適です。SaaSベンダーは、セキュリティや運用効率を損なうことなく、多くのテナントに同じMLを活用した機能を提供できます。MLアプリケーションは、AI主導のインサイトを組み込む場合でも、意思決定を自動化する場合でも、予測分析を可能にする場合でも、SaaSのお客様一人ひとりが、完全に管理され隔離されたML導入によるメリットを享受できるようにします。
SaaS以外にも、MLアプリケーションは、プロバイダーがAI/MLソリューションを登録、共有、収益化できるMLマーケットプレイスを構築しようとしているマルチリージョン・デプロイメントや組織にも最適です。お客様は、最小限の労力でこれらのML機能をシームレスにインスタンス化し、ワークフローに統合できます。

たとえば、顧客解約予測ユース・ケースのMLアプリケーションは、次のもので構成されます。
- トレーニング・データの準備、新しいモデルのトレーニングおよびデプロイを行う取込み、変換およびトレーニング・ステップを含むパイプライン。
- 取込み済および変換済データの格納に使用されるバケット。
- トリガー: エントリ・ポイントとして機能し、特定のSaaS顧客のコンテキストでのパイプライン実行のセキュアな実行を保証します。
- スケジュール: モデルを最新の状態に保つためにトレーニング・パイプラインの定期的な実行をトリガーします。
- モデル・デプロイメント: 顧客からの予測リクエストを処理します。
MLアプリケーションを使用すると、実装全体をコードとして表現し、ソース・コード・リポジトリに格納してバージョン管理できます。このソリューションは、主にメタデータを含むMLアプリケーション・パッケージとしてパッケージ化されています。メタデータには、バージョニング情報、プロビジョニング契約および環境依存関係の宣言が含まれ、パッケージはリージョンに依存せず、環境に依存しません。ビルド時に、パッケージは変更せずに任意のターゲット環境にデプロイできます。これにより、ML機能のパッケージ化と提供を標準化できます。
MLアプリケーションがデプロイされると、MLアプリケーションおよびMLアプリケーション実装リソースによって表されます。この段階では、使用するためにプロビジョニングできます。通常、クライアント・アプリケーション(SaaSプラットフォーム、エンタープライズ・システム、ワークフロー自動化ツールなど)は、MLアプリケーション・サービスに、特定の顧客または業務ユニット用にMLアプリケーションの新しいインスタンスをプロビジョニングするようリクエストします。この時点でのみ、ソリューションが完全にインスタンス化され、すぐに使用できます。
要約すると、MLアプリケーションは、ML機能を大規模に構築、パッケージ化、提供するための標準化された方法を提供し、複雑さを軽減し、次のような様々なシナリオで生産までの時間を短縮します。
- SaaS AIの導入。SaaSプラットフォームでは、セキュリティ、スケーラビリティ、運用効率を確保しながら、数千の顧客のML機能を統合する必要があります。
- 運用上のオーバーヘッドを最小限に抑えながら、ML機能を異なる場所に一貫してプロビジョニングする必要があるマルチリージョン・デプロイメント。
- エンタープライズAIの導入。組織では、ガバナンスとコンプライアンスを維持しながら、チーム、ビジネスユニット、子会社に隔離されたMLインスタンスを導入する必要があります。
- MLマーケットプレイスでは、プロバイダーがMLソリューションをパッケージ化して配布できるため、顧客はそれらをサービスとして簡単に検出、導入、使用できます。
SaaS以外にも、MLアプリケーションは様々な他のシナリオで使用できます。MLソリューションを何度もプロビジョニングする必要がある場合(地理的に異なる場所など)に有益です。また、MLアプリケーションは、プロバイダがアプリケーションを登録し、顧客にサービスとして提供できるマーケットプレイスを構築するために使用でき、顧客はそれをインスタンス化して使用できます。
MLアプリケーション機能自体は無料です。使用されている基礎となるインフラストラクチャ(コンピュート、ストレージおよびネットワーク)に対してのみ課金され、追加のマークアップは行われません。
MLアプリケーション・リソース
- MLアプリケーション
- MLのユース・ケースを表し、MLアプリケーションの実装およびインスタンスの包括的な役割を果たすリソース。MLソリューションを定義し、表すことで、プロバイダはML機能を消費者に提供できます。
- MLアプリケーションの実装
- MLアプリケーションによって定義されたMLユース・ケースの特定のソリューションを表すリソース。これには、コンシューマ向けのソリューションのインスタンス化を可能にするすべての実装の詳細が含まれます。MLアプリケーションに設定できる実装は1つのみです。
- MLアプリケーション実装のバージョン
- MLアプリケーション実装のスナップショットを表す読取り専用リソース。このバージョンは、MLアプリケーション実装が新しい一貫性のある状態になると自動的に作成されます。
- MLアプリケーション・ インスタンス
- 提供されたML機能の構成および使用を可能にする、MLアプリケーションの単一の分離されたインスタンスを表すリソース。MLアプリケーション・インスタンスは、データ、ワークロードおよびモデルを分離するための境界を定義する際に重要な役割を果たします。SaaS組織は、顧客のリソースの分離とセキュリティを確保できるため、このレベルの分離が不可欠です。
- MLアプリケーションインスタンスビュー
- 読取り専用リソース。MLアプリケーション・インスタンスの自動管理コピーで、インスタンス・コンポーネントへの参照などの追加の詳細とともに拡張されます。これにより、プロバイダはMLアプリケーションの消費を追跡できます。つまり、プロバイダはインスタンスの実装の詳細を監視し、監視およびトラブルシューティングできます。コンシューマとプロバイダが異なるテナンシで作業する場合、MLアプリケーション・インスタンス・ビューは、プロバイダがアプリケーションの消費に関する情報を収集する唯一の方法です。
MLアプリケーション・リソースは、OCIコンソールで読取り専用です。リソースの管理およびオーサリングには、MLアプリケーションのサンプル・プロジェクト、oci CLIまたはAPIの一部であるmlapp CLIを使用できます。
MLアプリケーションの概念
- MLアプリケーション・パッケージ
- MLアプリケーション・トリガー
- MLアプリケーション・パッケージ
- 環境および地域に依存しないML機能の標準化されたパッケージ化を可能にします。これには、Terraformコンポーネント、ディスクリプタ、構成スキーマなどの実装の詳細が含まれ、任意のテナンシ、リージョンまたは環境で使用できる移植可能なソリューションです。リージョンまたは環境に固有の、含まれている実装(VCNやログOCIDsなど)のインフラストラクチャ依存関係は、アップロード・プロセス中にパッケージ引数として提供されます。
- MLアプリケーション・トリガー
- トリガーを使用すると、MLアプリケーション・プロバイダはMLジョブまたはパイプラインのトリガー・メカニズムを指定できるため、完全に自動化されたMLOpsの実装が容易になります。トリガーは、MLワークフローの実行のエントリ・ポイントです。これらは、ML Applicationsパッケージ内のYAMLファイルでインスタンス・コンポーネントとして定義されます。トリガーは、新しいMLアプリケーション・インスタンスの作成時に自動的に作成されますが、他のすべてのインスタンス・コンポーネントが作成された場合にのみ作成されます。したがって、トリガーが作成されると、以前に作成された他のインスタンス・コンポーネントを参照できます。
MLアプリケーション・ロール
- プロバイダ
- コンシューマ
- プロバイダ
- プロバイダとは、ML機能を構築、導入、運用するOCIのお客様です。ML機能をMLアプリケーションおよび実装としてパッケージ化およびデプロイします。MLアプリケーションを使用して、消費者にサービスとしての方法で予測サービスを提供します。提供されている予測サービスが、合意されたサービス・レベル合意(SLA)を満たしていることを確認します。
- コンシューマ
- コンシューマとは、MLアプリケーション・インスタンスを作成し、これらのインスタンスによって提供される予測サービスを使用するOCIのお客様です。通常、コンシューマはFusionなどのSaaSアプリケーションです。MLアプリケーションを使用してML機能を統合し、顧客に提供しています。
ライフサイクル管理
MLアプリケーションは、MLソリューションのライフサイクル全体をカバーしています。
これは、チームが契約に同意し、独立して作業を開始できる初期の設計段階から始まります。これには、本番デプロイメント、フリート管理、および新しいバージョンのロールアウトが含まれます。
構築
- コードとしての表現
- すべてのコンポーネントとワークフローを含むソリューション全体がコードとして表されます。これにより、一貫性や再現性などのソフトウェア開発のベストプラクティスが促進されます。
- 自動化
- MLアプリケーションを使用すると、自動化は簡単です。データ・サイエンス・スケジューラ、MLパイプラインおよびMLアプリケーションのトリガーを使用して、ソリューション内のワークフローの自動化に集中できます。プロビジョニング・フローおよび構成フローの自動化は、MLアプリケーション・サービスによって管理されます。
- 標準化された包装
- MLアプリケーションは、バージョニング、依存性、プロビジョニング構成のメタデータなど、環境に依存しないリージョンに依存しないパッケージを提供します。
デプロイ
- サービス管理デプロイメント
- MLソリューションをMLアプリケーション・リソースとしてデプロイおよび管理できます。MLアプリケーション実装リソースを作成するときに、MLアプリケーション・パッケージとしてパッケージ化された実装をデプロイできます。ML Application Serviceは、実装を検証し、対応するOCIリソースを作成して、デプロイメントを調整します。
- 環境
- MLアプリケーションを使用すると、プロバイダは開発、QA、本番前などの様々なライフサイクル環境を通じてデプロイできるため、MLアプリケーションから本番への制御されたロールアウトが可能になります。本番環境では、「ステージング」や「本番」など、複数の環境を顧客に提供する組織もあります。MLアプリケーションを使用すると、「本番」に昇格する前に、新しいバージョンを「ステージング」でデプロイ、評価およびテストできます。これにより、ML機能など、新しいバージョンの導入を大幅に制御できます。
- リージョン間のデプロイメント
- 政府リージョンなどの非商用リージョンを含む様々なリージョンにソリューションをデプロイします。
操作
- サービスとしての提供
- プロバイダは、すべてのメンテナンスと操作を処理する予測サービスを「サービスとして」提供します。顧客は、実装の詳細を表示せずに予測サービスを利用します。
- モニターおよびトラブルシューティング
- 詳細なバージョニング、トレーサビリティおよびコンテキスト・インサイトにより、モニタリング、トラブルシューティングおよび根本原因分析を簡素化します。
- 展開
- ダウンタイムを発生させずに、迅速な反復、アップグレード、パッチの提供を支援し、継続的な改善と顧客のニーズへの適応を実現します。
主な機能
MLアプリケーションの主な機能は次のとおりです。
- サービスとして提供
- MLアプリケーションを使用すると、チームはSaaS (Software-as-a-Service)として予測サービスを作成および提供できます。つまり、プロバイダは顧客に影響を与えずにソリューションを管理および進化させることができます。MLアプリケーションは、メタサービスとして機能し、SaaS製品として消費およびスケーリングできる新しい予測サービスの作成を容易にします。
- OCIネイティブ
- OCIリソースとのシームレスな統合により、一貫性が確保され、環境とリージョン間のデプロイメントが簡素化されます。
- Standardの包装
- 環境に依存しないリージョンに依存しないパッケージングにより、実装が標準化され、MLアプリケーションをグローバルに簡単にデプロイできます。
- テナント分離
- お客様ごとにデータとワークロードを完全に分離し、セキュリティとコンプライアンスを強化します。
- バージョニング
- 独立したリリース・プロセスによる進化する実装をサポートし、迅速な更新と拡張を可能にします。
- 停止時間ゼロのアップグレード
- インスタンス・アップグレードの自動化により、中断することなく継続的なサービスを保証します。
- クロステナンシ・プロビジョニング
- クロステナンシの可観測性とマーケットプレイスの消費をサポートし、展開の可能性を拡大します。
MLアプリケーションには、次のリソースが導入されています。
- MLアプリケーション
- MLアプリケーションの実装
- MLアプリケーション実装のバージョン
- MLアプリケーション・ インスタンス
- MLアプリケーションインスタンスビュー
追加された値
MLアプリケーションはPlatform-as-a-Service (PaaS)として機能し、ML機能を大規模に構築、デプロイおよび管理するために必要な基本的なフレームワークおよびサービスを組織に提供します。
これにより、MLのユース・ケースをモデル化およびデプロイするための事前構築済みプラットフォームがチームに提供されるため、カスタム・フレームワークやツールを開発する必要がなくなります。そのため、チームは革新的なAIソリューションを作成することに専念できるため、市場投入までの時間とML機能の総所有コストの両方を削減できます。
MLアプリケーションは、MLユース・ケースのライフサイクル全体を監督するための組織のAPIと抽象化を提供します。実装はコードとして表され、MLアプリケーション・パッケージにパッケージ化され、MLアプリケーション実装リソースにデプロイされます。実装の履歴バージョンは、MLアプリケーション実装バージョンのリソースとして追跡されます。MLアプリケーションは、実装、バージョニングと環境情報、顧客消費データによって使用されるすべてのコンポーネント間のトレーサビリティを確立する接着剤です。MLアプリケーションを通じて、組織は、環境や地域にまたがってどのML実装が導入されているか、お客様が特定のアプリケーションを使用しているか、MLフリートの全体的な状態について、正確なインサイトを得ることができます。さらに、MLアプリケーションはインスタンス・リカバリ機能を提供し、インフラストラクチャおよび構成エラーからの簡単なリカバリを可能にします。
MLアプリケーションは、明確に定義された境界により、プロビジョニング契約と予測契約の確立を支援し、チームがタスクをより効率的に分割して征服できるようにします。たとえば、クライアント・アプリケーション・コード(SaaSプラットフォームやエンタープライズ・システムなど)に取り組んでいるチームは、予測契約に同意することでMLチームとシームレスにコラボレーションできるため、両方のチームが独立して作業できます。同様に、MLチームはプロビジョニング契約を定義できるため、チームはプロビジョニング・タスクと構成タスクを自律的に処理できます。この分離により、依存関係が排除され、配送スケジュールが短縮されます。
ML Applicationsは、バージョン・アップグレード・プロセスを自動化することで、MLソリューションの進化を合理化します。更新はMLアプリケーションによって完全に調整され、エラーを軽減し、多数のインスタンス(顧客)に対するソリューションのスケーリングを可能にします。実装者は、一連のライフサイクル環境(開発、QA、本番前、本番など)にわたって変更をプロモートおよび検証し、顧客に対する変更のリリースを管理できます。
テナント分離は、MLアプリケーションの重要な利点として際立っており、各顧客のデータとワークロードを完全に分離することで、セキュリティとコンプライアンスを強化します。プロセスベースの分離に依存する従来の方法とは異なり、MLアプリケーションを使用すると、お客様は特権に基づいて制限を実装でき、欠陥が発生した場合でもテナントの分離を保護できます。
スケーラビリティを考慮して設計されたMLアプリケーションは、大規模な組織(特にSaaS組織)がML開発用の標準化されたプラットフォームを採用し、多くのチーム間で一貫性を確保できることを意味します。MLイニシアチブ全体が混乱に陥ることなく、数百のMLソリューションを開発できます。SaaS組織は、MLパイプラインの実装、モデルの導入、プロビジョニングにわたる自動化により、SaaSのML機能の開発を工業化し、本番環境で自律的に実行されている数百万のパイプラインとモデルを効率的に管理できます。
市場投入までの時間
- 標準化された実装
- カスタム・フレームワークの必要性がなくなり、チームはビジネス・ユース・ケースに集中できます。
- 自動化
- SaaSソリューションのスケーリングに不可欠な、スピードを高め、手動介入を削減します。
- 関心の分離
- 明確な境界、契約およびAPIにより、様々なチームが独立して作業できるようになり、開発とデプロイメントが合理化されます。
開発および運用コスト
- 開発コストの削減
- 事前構築済みのサービスを使用することで、基本的な作業の必要性が軽減されます。
- 展開
- 迅速な反復とダウンタイムなしの独立したアップグレードにより、継続的な改善が保証されます。
- トレース可能性
- 環境、コンポーネント、コード・リビジョンに関する詳細なインサイトが、MLソリューションの理解と管理に役立ちます。
- プロビジョニングと可観測性の自動化
- MLソリューションの管理と監視を簡素化し、運用上のオーバーヘッドを削減します。
- フリート管理
- MLアプリケーション・インスタンスのライフサイクル全体を大規模に管理します。MLアプリケーションは、プロビジョニングされたすべてのインスタンスを可視化し、フリート全体の更新とアップグレードをサポートし、必要に応じてプロビジョニングとプロビジョニング解除を可能にします。また、MLアプリケーションで構築されたMLソリューションは、OCI Monitoringを使用して監視し、パフォーマンスと健全性を追跡できます。
セキュリティと信頼性
- データとワークロードの分離
- 各顧客のデータとワークロードが安全に分離されるようにします。
- 信頼性
- 自動更新と堅牢な監視により、エラーを排除し、安定した運用を実現します。
- ノイジーネイバー問題なし
- ワークロードが相互に干渉しないようにし、パフォーマンスと安定性を維持します。
ビルドおよびデプロイメント・ワークフロー
MLアプリケーションの開発は、標準のソフトウェア開発に似ています。
エンジニアとデータ・サイエンティストは、MLアプリケーションのドキュメントとリポジトリを使用してガイダンスを行い、ソース・コード・リポジトリでの実装を管理します。通常は、MLアプリケーション・チームが提供するサンプル・プロジェクトをクローニングすることから始めます。これにより、ベスト・プラクティスが促進され、SaaSチームが急激な学習曲線を回避しながら迅速に開発を開始できます。
完全に機能するエンドツーエンドの例から始めて、チームはこの例を迅速に構築、導入、プロビジョニングし、MLアプリケーションにすぐに慣れることができます。その後、コードを変更して、トレーニング・パイプラインやカスタム・トレーニング・コードへの前処理ステップの追加など、特定のビジネス・ロジックを追加できます。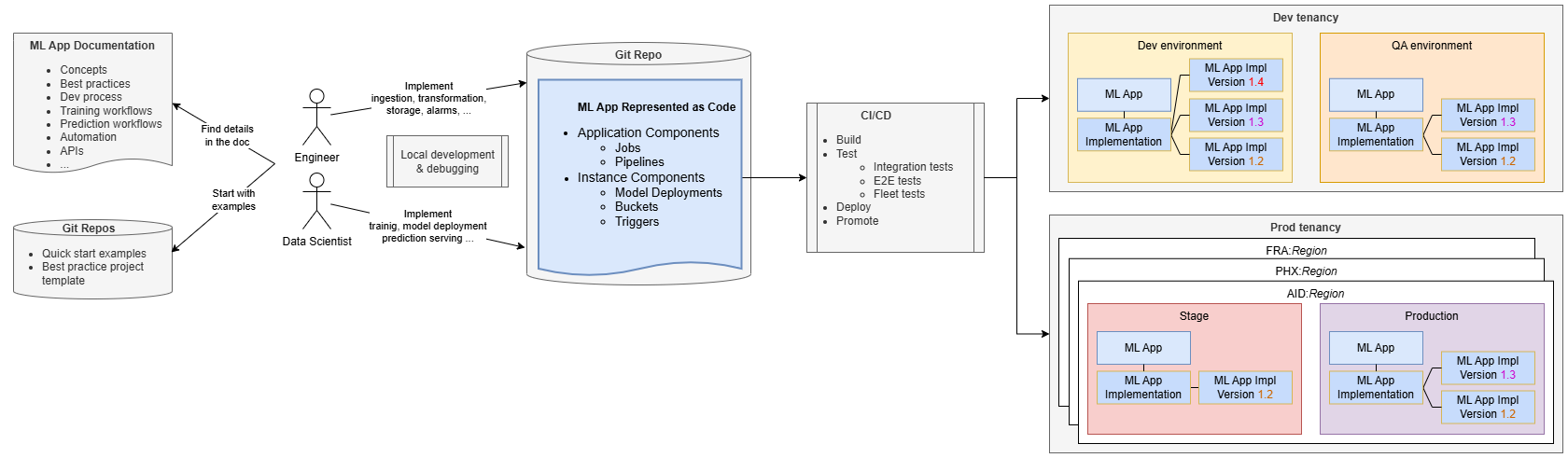
開発とテストはコンピュータ上でローカルで実行できますが、リリース・サイクルの短縮、コラボレーションの強化、一貫性の向上には継続的インテグレーション/継続的デリバリ(CI/CD)の設定が不可欠です。チームは、MLアプリケーション・チームが提供する例とツールを使用して、CI/CDパイプラインを実装できます。
CI/CDパイプラインは、MLアプリケーションを必要な環境(開発など)にデプロイし、統合テストを実行して、SaaSアプリケーションとは独立してMLソリューションの正確性を確保します。これらのテストでは、アプリケーションとその実装のデプロイ、テスト・インスタンスの作成、トレーニング・フローのトリガー、デプロイ済モデルのテストを実行できます。エンドツーエンドのテストにより、SaaSアプリケーションとの適切な統合が保証されます。
MLアプリケーションがデプロイされると、MLアプリケーション実装とともにMLアプリケーション・リソースとして表されます。MLアプリケーション実装バージョン・リソースは、デプロイした様々なバージョンに関する情報を追跡するのに役立ちます。たとえば、バージョン1.3は、以前のバージョン1.2を更新する最新のデプロイ済バージョンです。
CI/CDパイプラインは、ライフサイクル環境を通じて本番環境までソリューションを促進する必要があります。本番環境では、多くの場合、MLアプリケーションを複数のリージョンにデプロイして、クライアント・アプリケーション・デプロイメントと一致させる必要があります。お客様が複数の本番環境(ステージング環境や本番環境など)を持っている場合、CI/CDパイプラインは、これらすべての環境を通じてMLアプリケーションをプロモートする必要があります。
MLパイプラインをMLアプリケーション内のアプリケーション・コンポーネントとして使用して、マルチステップ・ワークフローを実装できます。MLパイプラインは、実装する必要がある任意のステップまたはジョブを編成できます。
デプロイ操作
デプロイメント操作には、MLアプリケーションが環境全体で正しく実装および更新されるようにするためのいくつかの重要なステップが含まれます。
まず、MLアプリケーションおよびMLアプリケーション実装リソースが存在することを確認する必要があります。そうでない場合は、作成されます。すでに存在する場合は、次のように更新されます。
- MLアプリケーション・リソースを作成または更新します。これは、MLのユース・ケース全体と、関連するすべてのリソースおよび情報を表します。
- MLアプリケーション実装リソースを作成または更新します。これはMLアプリケーション・リソースの下に存在し、実装を表すため、管理できます。実装パッケージをデプロイするには、MLアプリケーション実装が必要です。
- MLアプリケーション・パッケージをアップロードします。このパッケージには、MLアプリケーションの実装が他のメタデータとともに含まれており、特定の構造を持つzipアーカイブとしてパッケージ化されています。
パッケージがMLアプリケーション実装リソースにアップロードされると、MLアプリケーション・サービスによって検証され、デプロイメントが実行されます。簡略化すると、パッケージのデプロイ時の主なステップは次のとおりです。
- アプリケーション・コンポーネント(マルチテナント・コンポーネント)がインスタンス化されます。
- SaaS顧客に対してすでにプロビジョニングされている既存のMLアプリケーション・インスタンス・リソースが更新されます。各インスタンスのインスタンス・コンポーネントは、新しくアップロードされた定義と一致するように更新されます。
プロビジョニング・フロー
MLアプリケーション・インスタンスをプロビジョニングする前に、MLアプリケーションをデプロイし、クライアント・アプリケーションに登録する必要があります。
- 1. 顧客サブスクリプションとMLアプリケーションのチェック
- プロビジョニング・フローは、顧客がクライアント・アプリケーションをサブスクライブしたときに開始されます。クライアント・アプリケーションは、顧客に対してMLアプリケーションがプロビジョニングされているかどうかを確認します。
- 2. プロビジョニング・リクエスト
- MLアプリケーションが必要な場合、クライアント・アプリケーションはMLアプリケーション・サービスに接続し、テナント固有の構成の詳細を含むインスタンスをプロビジョニングするようにリクエストします。
- 3.MLアプリケーション・インスタンスの作成と構成
- MLアプリケーション・サービスは、特定の構成でMLアプリケーション・インスタンス・リソースを作成します。このリソースは、インスタンスをアクティブ化、非アクティブ化、再構成または削除できるクライアント・アプリケーションによって管理されます。また、MLアプリケーション・サービスは、MLアプリケーションの消費およびインスタンス・コンポーネントについてプロバイダに通知するために、MLアプリケーション・インスタンス・ビュー・リソースを作成します。MLアプリケーション・サービスでは、トリガー、バケット、パイプライン実行、ジョブ実行、モデル・デプロイメントなど、実装に定義されているすべてのインスタンス・コンポーネントも作成されます。

インスタンスの作成後に新しいMLアプリケーション・パッケージをデプロイすると、MLアプリケーション・サービスによって、すべてのインスタンスが最新の実装定義で確実に更新されます。
ランタイム・フロー
MLアプリケーションが顧客用にプロビジョニングされると、実装全体が完全にインスタンス化されます。
- マルチテナント・コンポーネント
- MLアプリケーション内で1回のみインスタンス化し、すべての顧客(MLパイプラインなど)をサポートします。これらはアプリケーション・コンポーネントとして定義されます。
- 単一のテナント・コンポーネント
- 顧客ごとにインスタンス化され、特定の顧客のコンテキスト内でのみ実行されます。これらは、インスタンス・コンポーネントとして定義されます。
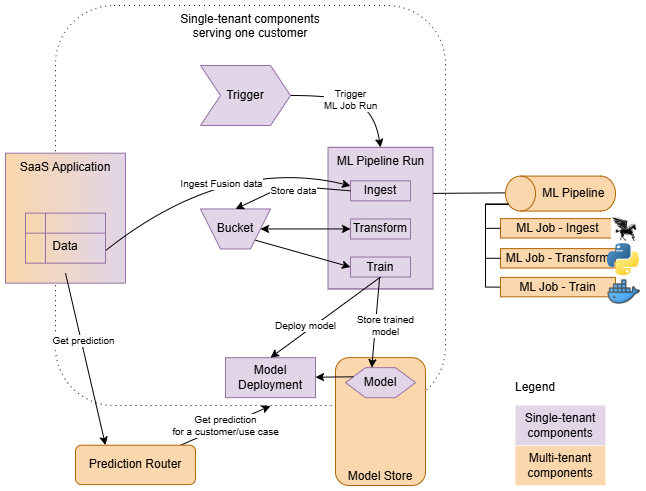
実装のパイプラインまたはジョブはトリガーによって開始されます。トリガーは、各顧客のコンテキストでパイプラインおよびジョブ実行を作成し、作成された実行に適切なパラメータ(コンテキスト)を渡します。また、テナントの分離を確保するためにトリガーが不可欠です。これにより、MLアプリケーション・インスタンス・リソースのリソース・プリンシパル(アイデンティティ)が、起動するすべてのワークロードに継承されます。これにより、プロビジョニングされたインスタンスごとにセキュリティ・サンドボックスを確立するポリシーを作成できます。
パイプラインを使用すると、一連のステップを定義して調整できます。たとえば、一般的なフローには、クライアント・アプリケーションからのデータの取込み、トレーニングに適した形式への変換、新しいモデルのトレーニングとデプロイが含まれます。
モデル・デプロイメントは予測バックエンドとして使用されますが、クライアント・アプリケーションでは直接アクセスされません。クライアント・アプリケーションは、シングルテナント(顧客ごとにプロビジョニング)またはマルチテナント(多くの顧客にサービスを提供)のいずれかで、MLアプリケーション予測ルーターに連絡して予測を取得します。予測ルーターは、使用されたインスタンスとアプリケーションによって実装された予測ユース・ケースに基づいて、正しい予測バックエンドを検索します。
胎児リスクの例
サンプルMLアプリケーションの実装の詳細を見て、実装方法を理解しましょう。
心電図(CTG)データを活用して胎児の健康状態を分類する胎児リスク予測アプリケーションを使用しています。このアプリケーションは、CTG試験記録に基づいて胎児の状態が正常、危険、または異常であるかどうかを予測することで、医療専門家を支援することを目的としています。
実装の詳細
実装は、標準のオンライン予測パターンに従い、取込み、変換、モデルのトレーニングおよびデプロイメント・ステップを含むパイプラインで構成されます。
-
収集: このステップでは、RAWデータセットが準備され、インスタンス・バケットに格納されます。
-
変換: データ準備はADSライブラリを使用して実行されます。これには、次の操作が含まれます。
- アップサンプリング: データセットは通常のケースに偏っているため、クラスのバランスを調整するためにアップサンプリングが実行されます。
- 機能のスケーリング: 機能は、QuantileTransformerを使用してスケーリングされます。
- その後、準備されたデータセットがインスタンス・バケットに格納されます。
-
モデルのトレーニングおよびデプロイメント: XGBoostアルゴリズムは、他のアルゴリズム(ランダム・フォレスト、KNN、SVMなど)と比較して高い精度でモデルのトレーニングに使用されます。ADSライブラリがこのプロセスに使用され、トレーニング済モデルがインスタンス・モデル・デプロイメントにデプロイされます。
この実装は、次のものから構成されます。
-
アプリケーション・コンポーネント: 主要なコンポーネントは、次の3つのジョブを編成するパイプラインです。
- 取込みジョブ
- 変換ジョブ
- トレーニング・ジョブ
-
インスタンス・コンポーネント: ここでは、4つのインスタンス・コンポーネントが定義されています:
- インスタンス・バケット
- デフォルトのモデル
- モデルのデプロイメント
- パイプライン・トリガー
- descriptor.yaml: 実装(パッケージ)を記述するメタデータが含まれます。
-
アプリケーション・コンポーネント: 主要なコンポーネントは、次の3つのジョブを編成するパイプラインです。
ソースコードは このプロジェクトで使用できます。
descriptor.yaml ファイルを確認します。descriptorSchemaVersion: 1.0
mlApplicationVersion: 1.0
implementationVersion: 1.2
# Package arguments allow you to resolve dependencies of your implementation that are environment-specific.
# Typically, OCIDs of infrastructure resources like subnets, data science projects, logs, etc., are passed as package arguments.
# For illustration purposes, only 2 package arguments are listed here.
packageArguments:
# The implementation needs a subnet, and it is environment-specific. It is provided as a package argument.
subnet_id:
type: ocid
mandatory: true
description: "Subnet OCID for ML Job"
# similarly for the ID of a data science project
data_science_project_id:
type: ocid
mandatory: true
description: "Project OCID for ML Job"
# Configuration schema allows you to define the schema for your instance configuration.
# It will be used during provisioning, and the initial configuration provided must conform to the schema.
configurationSchema:
# The implementation needs to know the name of the external bucket (not managed by ML Apps) where the raw dataset is available.
external_data_source:
type: string
mandatory: true
description: "External Data Source (OCI Object Storage Service URI in form of <a target="_blank" href="oci://">oci://</a><bucket_name>@<namespace>/<object_name>"
sampleValue: "<a target="_blank" href="oci://test_data_fetalrisk@mynamespace/test_data.csv">oci://test_data_fetalrisk@mynamespace/test_data.csv</a>"
# This application provides 1 prediction use case (1 prediction service).
onlinePredictionUseCases:
- name: "fetalrisk"実装で使用されるすべてのOCIリソースは、Terraformを使用して定義されます。Terraformでは、実装に必要なコンポーネントを宣言的に指定できます。
# For illustration purposes, only a partial definition is listed here.
resource oci_datascience_job ingestion_job {
compartment_id = var.app_impl.compartment_id
display_name = "Ingestion_ML_Job"
delete_related_job_runs = true
job_infrastructure_configuration_details {
block_storage_size_in_gbs = local.ingestion_job_block_storage_size
job_infrastructure_type = "STANDALONE"
shape_name = local.ingestion_job_shape_name
job_shape_config_details {
memory_in_gbs = 16
ocpus = 4
}
subnet_id = var.app_impl.package_arguments.subnet_id
}
job_artifact = "./src/01-ingestion_job.py"
}resource "oci_objectstorage_bucket" "data_storage_bucket" {
compartment_id = var.compartment_ocid
namespace = var.bucket_namespace
name = "ml-app-fetal-risk-bucket-${var.instance_id}"
access_type = "NoPublicAccess"
}通常、インスタンス・コンポーネントはインスタンスIDなどのインスタンス固有の変数を参照します。MLアプリケーション・サービスによって定義された暗黙的な変数に依存できます。たとえば、アプリケーションの名前が必要な場合は、${var.ml_app_name}を使用して参照できます。
結論として、MLアプリケーションの実装には、いくつかの重要なコンポーネント(パッケージ記述子といくつかのTerraform定義)が必要です。提供されているドキュメントに従って、独自のMLアプリケーションの構築方法の詳細を学習できます。