表抽出
表抽出を使用して、ドキュメント内の表を識別し、その内容を抽出できます。たとえば、PDF領収書に税金と合計金額を含む表が含まれている場合、Document Understandingはその表を識別し、表構造を抽出します。
Document Understandingは、表の行数と列数、および各表のセルの内容を提供します。各セルには信頼度スコアがあります。信頼度スコアは10進数です。スコアが1に近いと、抽出されたテキストの信頼性が高いことを示しますが、スコアが小さいと信頼度スコアが低くなります。各ラベルの信頼度スコアの範囲は0から1です。
サポートされている機能は次のとおりです。
- 枠線の有無にかかわらず表の抽出
- 境界ポリゴン
- 信頼度スコア
- 単一リクエスト
- バッチ要求
- 英語のみ
表抽出の例
Document Understandingでの表抽出の使用例。
- 入力ドキュメント
-
表抽出入力
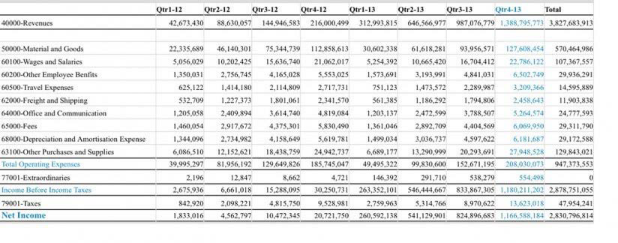 APIリクエスト:
APIリクエスト:{ "processorConfig": { "processorType": "GENERAL", "features": [ { "featureType": "TABLE_EXTRACTION" } ] }, "inputLocation": { "sourceType": "OBJECT_STORAGE_LOCATIONS", "objectLocations": [ { "source": "OBJECT_STORAGE", "namespaceName": "", "bucketName": "", "objectName": "" } ] }, "compartmentId": "", "outputLocation": { "namespaceName": "", "bucketName": "", "prefix": "" } } - 出力:
-
表抽出出力
 APIレスポンス:
APIレスポンス:{ "documentMetadata": { "pageCount": 1, "mimeType": "application/pdf" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 2575, "height": 1013, "unit": "PIXEL" }, ... "tables": [ { "rowCount": 15, "columnCount": 9, "bodyRows": [ { "cells": [ { "text": "Qtr1-12", "rowIndex": 0, "columnIndex": 1, "confidence": 0.92011595, "boundingPolygon": { "normalizedVertices": [ { "x": 0.2532038834951456, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.05330700888450148 }, { "x": 0.2532038834951456, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 0 ] }, { "text": "Qtr2-12", "rowIndex": 0, "columnIndex": 2, "confidence": 0.919653, "boundingPolygon": { "normalizedVertices": [ { "x": 0.33048543689320387, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.05330700888450148 }, { "x": 0.33048543689320387, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 1 ] }, ...