Autonomous AI Database上のデータ・パイプラインについて
Autonomous AI Databaseのデータ・パイプラインは、ロード・パイプラインまたはエクスポート・パイプラインです。
ロード・パイプラインは、外部ソースからの継続的な増分データ・ロードを提供します(データはオブジェクト・ストアに到着すると、データベース表にロードされます)。エクスポート・パイプラインは、オブジェクト・ストアへの継続的な増分データ・エクスポートを提供します(新しいデータはデータベース表に表示されるため、オブジェクト・ストアにエクスポートされます)。パイプラインでは、データベース・スケジューラを使用して、増分データを継続的にロードまたはエクスポートします。
Autonomous AI Databaseのデータ・パイプラインは、次のものを提供します。
-
統合操作: パイプラインを使用すると、データを迅速かつ簡単にロードまたはエクスポートし、新しいデータに対して定期的にこれらの操作を繰り返すことができます。
DBMS_CLOUD_PIPELINEパッケージは、パイプライン構成およびロードまたはエクスポート操作のためのスケジュール済ジョブの作成および開始のためのPL/SQLプロシージャの統合セットを提供します。 -
スケジュール済データ処理: パイプラインは、データ・ソースを監視し、新しいデータが到着するとデータを定期的にロードまたはエクスポートします。
-
High Performance: パイプラインは、自律型AIデータベースで使用可能なリソースを使用して、データ転送操作を拡張します。パイプラインは、デフォルトでは、すべてのロード操作またはエクスポート操作に並列性を使用し、Autonomous AI Databaseで使用可能なCPUリソース、または構成可能な優先度属性に基づいてスケーリングします。
-
アトミック性およびリカバリ: パイプラインは、オブジェクト・ストア内のファイルがロード・パイプラインに対して1回のみロードされるようにアトミック性を保証します。
-
モニタリングおよびトラブルシューティング: パイプラインには、パイプライン操作をモニターおよびデバッグできる詳細なログおよびステータス表が用意されています。
-
マルチクラウド互換: 自律型AIデータベースのパイプラインは、アプリケーションを変更することなく、クラウドプロバイダー間の容易な切り替えをサポートします。パイプラインは、Autonomous AI Databaseがサポートするすべての資格証明およびオブジェクト・ストアURI形式(Oracle Cloud Infrastructure Object Storage、Amazon S3、Azure Blob Storage、Google Cloud StorageおよびAmazon S3互換オブジェクト・ストア)をサポートします。
データ・パイプラインのライフサイクル
DBMS_CLOUD_PIPELINEパッケージには、パイプラインを作成、構成、テストおよび起動するためのプロシージャが用意されています。パイプラインのライフサイクルとプロシージャは、ロード・パイプラインとエクスポート・パイプラインの両方で同じです。
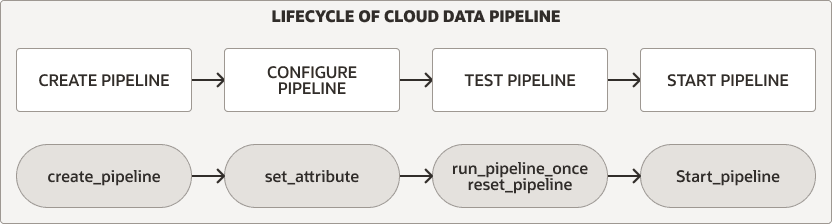
いずれかのパイプライン・タイプについて、次のステップを実行してパイプラインを作成および使用します。
-
パイプラインを作成して構成します。詳細は、パイプラインの作成および構成を参照してください。
-
新しいパイプラインをテストします。詳細は、テスト・パイプラインを参照してください。
-
パイプラインを開始します。詳細は、パイプラインの開始を参照してください。
さらに、パイプラインをモニター、停止または削除できます。
-
パイプラインの実行中、テスト中またはパイプライン起動後の通常の使用中に、パイプラインをモニターできます。詳細は、パイプラインのモニターおよびトラブルシューティングを参照してください。
-
パイプラインを停止して後で再度起動するか、パイプラインの使用が終了したらパイプラインを削除できます。詳細は、パイプラインの停止およびパイプラインの削除を参照してください。
パイプラインのロード
ロード・パイプラインを使用して、オブジェクト・ストアの外部ファイルからデータベース表に継続的に増分データをロードします。ロード・パイプラインは、オブジェクト・ストア内の新しいファイルを定期的に識別し、新しいデータをデータベース表にロードします。
ロード・パイプラインは次のように動作します(これらの機能の一部は、パイプライン属性を使用して構成できます)。
-
オブジェクト・ストア・ファイルは、データベース表にパラレルにロードされます。
-
ロード・パイプラインは、オブジェクト・ストア・ファイル名を使用して、より新しいファイルを一意に識別およびロードします。
-
オブジェクト・ストア内のファイルがデータベース表にロードされると、ファイル・コンテンツがオブジェクト・ストアで変更された場合、そのファイルは再度ロードされません。
-
オブジェクト・ストア・ファイルを削除しても、データベース表のデータには影響しません。
-
-
障害が発生した場合、ロード・パイプラインは自動的に操作を再試行します。再試行は、パイプラインのスケジュール済ジョブの後続の実行のたびに試行されます。
-
ファイル内のデータがデータベース表に準拠していない場合は、
FAILEDとしてマークされ、問題をデバッグおよびトラブルシューティングするために確認できます。- いずれかのファイルのロードに失敗した場合、パイプラインは停止せず、他のファイルのロードを続行します。
-
ロード・パイプラインでは、JSON、CSV、XML、Avro、ORC、Parquetなどの複数の入力ファイル形式がサポートされています。

Oracle以外のデータベースからの移行は、ロード・パイプラインの考えられるユースケースの1つです。Oracle以外のデータベースからOracle Autonomous AI Database on Dedicated Exadata Infrastructureにデータを移行する必要がある場合は、データを抽出してAutonomous AI Databaseにロードできます(Oracle Data Pump形式は、Oracle以外のデータベースからの移行には使用できません)。CSVなどの汎用ファイル形式を使用してOracle以外のデータベースからデータをエクスポートすることで、データをファイルに保存し、ファイルをオブジェクト・ストアにアップロードできます。次に、Autonomous AI Databaseにデータをロードするパイプラインを作成します。ロード・パイプラインを使用して大量のCSVファイルをロードすると、フォルト・トレランス、再開および再試行操作などの重要な利点が得られます。大規模なデータ・セットを使用する移行では、Oracle以外のデータベース・ファイル用に1つの表に1つずつ複数のパイプラインを作成して、Autonomous AI Databaseにデータをロードできます。
パイプラインのエクスポート
エクスポート・パイプラインを使用して、データベースからオブジェクト・ストアにデータを継続的に増分エクスポートします。エクスポート・パイプラインは、候補データを定期的に識別し、データをオブジェクト・ストアにアップロードします。
次の3つのエクスポート・パイプライン・オプションがあります(エクスポート・オプションはパイプライン属性を使用して構成できます)。
-
新しいデータを追跡するためのキーとして日付列またはタイムスタンプ列を使用して、問合せの増分結果をオブジェクト・ストアにエクスポートします。
-
新しいデータを追跡するためのキーとして日付列またはタイムスタンプ列を使用して、表の増分データをオブジェクト・ストアにエクスポートします。
-
日付列またはタイムスタンプ列を参照せずにデータを選択する問合せを使用して、表のデータをオブジェクト・ストアにエクスポートします(これにより、各スケジューラの実行に対して問合せによって選択されたすべてのデータがパイプラインによってエクスポートされます)。
エクスポート・パイプラインには次の機能があります(これらの一部はパイプライン属性を使用して構成できます)。
-
結果はオブジェクト・ストアにパラレルにエクスポートされます。
-
障害が発生した場合、後続のパイプライン・ジョブはエクスポート操作を繰り返します。
-
エクスポート・パイプラインでは、CSV、JSON、ParquetまたはXMLなど、複数のエクスポート・ファイル形式がサポートされています。
Oracle管理パイプライン
Autonomous AI Database on Dedicated Exadata Infrastructureには、特定のログをJSON形式でオブジェクト・ストアにエクスポートするための組込みパイプラインが用意されています。これらのパイプラインは事前構成されており、ADMINユーザーが起動および所有します。
Oracle管理パイプラインは次のとおりです。
-
ORA$AUDIT_EXPORT: このパイプラインは、データベース監査ログをJSON形式でオブジェクト・ストアにエクスポートし、パイプラインの起動後15分ごとに(interval属性値に基づいて)実行します。 -
ORA$APEX_ACTIVITY_EXPORT: このパイプラインは、Oracle APEXワークスペース・アクティビティ・ログをJSON形式のオブジェクト・ストアにエクスポートします。このパイプラインには、APEXアクティビティ・レコードを取得するためのSQL問合せが事前構成されており、パイプラインの起動後15分ごとに(interval属性値に基づいて)実行されます。
Oracle管理対象パイプラインを構成および起動するには:
-
使用するOracle Managed Pipeline:
ORA$AUDIT_EXPORTまたはORA$APEX_ACTIVITY_EXPORTを決定します。 -
credential_nameおよびlocation属性を設定します。ノート:
credential_nameは、Autonomous AI Database on Dedicated Exadata Infrastructureの必須値です。たとえば:
BEGIN DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'credential_name', attribute_value => 'DEF_CRED_OBJ_STORE' ); DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'location', attribute_value => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/' ); END; /データベースのログ・データは、指定したオブジェクト・ストアの場所にエクスポートされます。
詳細は、SET_ATTRIBUTEを参照してください。
-
オプションで、
interval、formatまたはpriority属性を設定します。詳細は、SET_ATTRIBUTEを参照してください。
-
パイプラインを開始します。
詳細は、START_PIPELINEを参照してください。