専用Exadataインフラストラクチャ上のAutonomous AI Databaseを使用したApache Iceberg表の問合せ
Autonomous AI Databaseは、Apache Icebergテーブルのクエリをサポートしています。
ノート: Apache Iceberg表の問合せのサポートは、Oracle Database 19c (バージョン19.28以降)およびOracle Database 26ai (バージョン23.9以降)で使用できます。
サポートされる構成
次の特定の構成がサポートされています。
-
Amazon Web Services AWSのIcebergテーブル:
-
AWS Glue Data Catalogに登録されたIcebergテーブルは、SparkまたはAthenaで作成されます。
詳細は、AWS Glueコネクタを使用したACIDトランザクションを含むApache Iceberg表の読取りおよび書込みおよびタイム・トラベルの実行およびIceberg表の使用を参照してください。
-
ルートメタデータファイルのURLを直接指定することで、AWS S3に保存されたIcebergテーブル。
-
-
Oracle Cloud Infrastructure (OCI)オブジェクト・ストレージ上のIcebergテーブル:
-
Hadoopカタログを使用してOCIデータ・フローで生成されたIceberg表。
詳細は、Oracle Data Flowの例およびHadoopカタログの使用を参照してください。
-
ルート・メタデータ・ファイルのURLを直接指定することで、OCIオブジェクト・ストレージに格納されるIceberg表。
-
制限
-
パーティション化されたIceberg表
Oracleでは、Icebergパーティション表はサポートされません。
-
Icebergテーブルの行レベルの更新
Oracleでは、Iceberg表更新の読取りマージはサポートされていません。Icebergメタデータで削除されたファイルに遭遇するクエリーは失敗します。読取り中のマージの詳細は、列挙RowLevelOperationModeを参照してください。
-
スキーマの展開
Oracle外部表のスキーマは固定されており、外部表作成時のIcebergスキーマ・バージョンを反映しています。IcebergメタデータがIceberg表の作成に使用したものと比較して異なるスキーマ・バージョンを指している場合、問合せは失敗します。外部表の作成後にIcebergスキーマが変更された場合は、外部表を再作成することをお薦めします。
Apache Iceberg表の問合せに関連する概念
次の概念を理解することは、Apache Iceberg表の問合せに役立ちます。
Icebergカタログ
Icebergカタログは、表スナップショット、表スキーマおよびパーティション化情報などの表メタデータを管理するサービスです。Icebergテーブルの最新のスナップショットをクエリーするには、クエリーエンジンはまずカタログにアクセスし、最新のメタデータファイルの場所を取得する必要があります。AWS Glue、Hive、Nessie、Hadoopなど、使用可能なカタログ実装が多数あります。Autonomous AI Databaseは、Sparkで使用されるAWS GlueカタログおよびHadoopCatalog実装をサポートしています。
詳細は、「Optimistic Concurrency」を参照してください。
メタデータ・ファイル
メタデータ・ファイルは、表スナップショット、パーティション化スキームおよびスキーマ情報を追跡するJSONドキュメントです。メタデータ・ファイルは、マニフェスト・リストおよびマニフェスト・ファイルの階層へのエントリ・ポイントです。マニフェストは、パーティショニングやカラム統計などの情報とともに、テーブルのデータファイルを追跡します。詳細は、Iceberg Table Specificationを参照してください。
トランザクション
Icebergは、copy-on-writeまたはmerge-on-readのいずれかを使用して、表に対する行レベルの更新をサポートしています。Copy-on-writeは、更新された行を反映する新しいデータファイルを生成しますが、merge-on-readは、読取り中にデータファイルとマージする必要がある新しい削除ファイルを生成します。Oracleはcopy-on-writeをサポートしています。削除ファイルが見つかった場合、氷山表に対する問合せは失敗します。詳細は、RowLevelOperationModeを参照してください。
スキーマ展開
Icebergはスキーマの進化をサポートしています。スキーマの変更は、IcebergメタデータにスキーマIDを使用して反映されます。Oracle外部表には固定スキーマがあり、表の作成時に最新のスキーマ・バージョンによって決定されます。問合せ対象のメタデータが、表作成時に使用したものと比較して異なるスキーマ・バージョンを指している場合、Iceberg問合せは失敗します。詳細は、Schema Evolutionを参照してください。
パーティション化
Icebergは、隠れたパーティション化や、コストのかかるデータ・レイアウトの変更なしに表のメタデータの処理/変更に依存するパーティションの進化などの高度なパーティション化オプションをサポートしています。
例: Apache Iceberg表の問合せ
これらの例は、データ・カタログを使用して、ルート・マニフェスト・ファイルに直接URLを使用して、Amazon Web Services (AWS)およびOracle Cloud Infrastructure (OCI)でApache Iceberg表を問い合せる方法を示しています。
Apache Icebergの外部表の作成の詳細は、「Apache IcebergのCREATE_EXTERNAL_TABLEプロシージャ」を参照してください。
Glueデータ・カタログを使用したAWS上のIceberg表の問合せ
この例では、Iceberg表iceberg_parquet_time_dimを問い合せます。 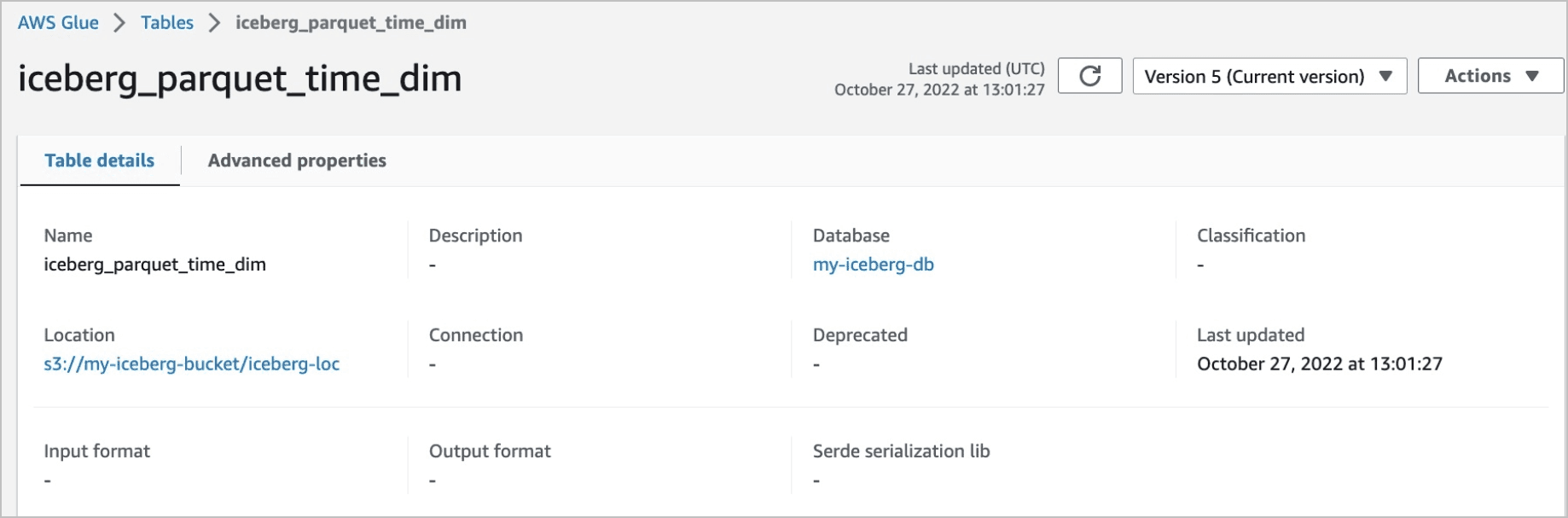
表はGlueデータベースmy-iceberg-dbに属し、フォルダs3://my-iceberg-bucket/iceberg-locに格納されます。
iceberg_parquet_time_dimの表の詳細を次に示します。
iceberg_parquet_time_dimの外部表は、次のように作成できます。
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim',
credential_name => 'AWS_CRED',
file_uri_list => '',
format =>
'{"access_protocol":
{
"protocol_type": "iceberg",
"protocol_config":
{
"iceberg_catalog_type": "aws_glue",
"iceberg_glue_region": "us-west-1",
"iceberg_table_path": "my-iceberg-db.iceberg_parquet_time_dim"
}
}
}'
);
END;
/protocol_configセクションで、表がカタログ・タイプとしてAWS Glueを使用するように指定し、カタログのリージョンをus-west-1に設定します。
資格証明AWS_CREDは、AWS APIキーとともにdbms_cloud.create_credentialを使用して作成されます。Glueデータ・カタログ・インスタンスは、各アカウントに単一のGlueデータ・カタログ・リージョンがあるため、リージョンus-west-1のAWS_CREDに関連付けられたアカウントIDによって決定されます。protocol_configセクションのiceberg_table_path要素は、$database_name.$table_nameパスを使用して、Glue表名およびデータベース名を指定します。最後に、表のスキーマはIcebergメタデータから自動的に導出されるため、column_list およびfield_listパラメータはNULLのままです。
この資格証明の作成の詳細は、CREATE_CREDENTIALプロシージャに関する項を参照してください。
AWS Glueリソースの詳細は、「AWS GlueリソースARNの指定」を参照してください。
ルート・メタデータ・ファイルの場所を使用して、AWSでIceberg表を問い合せます。
Icebergテーブルのメタデータファイルの場所がわかっている場合は、次のようにカタログを指定せずに外部テーブルを作成できます。
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim',
credential_name => 'AWS_CRED',
file_uri_list => 'https://my-iceberg-bucket.s3.us-west-1.amazonaws.com/iceberg-loc/metadata/00004-1758ee2d-a204-4fd9-8d52-d17e5371a5ce.metadata.json',
format =>'{"access_protocol":{"protocol_type":"iceberg"}}');
END;
/file_uri_listパラメータを使用して、メタデータ・ファイルの場所をAWS S3仮想ホスト形式のURL形式で指定します。この形式の詳細は、AWS S3バケットにアクセスする方法を参照してください。
この例では、データベースはメタデータ・ファイルに直接アクセスするため、formatパラメータにprotocol_configセクションを指定する必要はありません。メタデータ・ファイルの場所を使用して外部表を作成する場合、データベースはメタデータ・ファイルによって参照される最新のスナップショットを問い合せます。新しいスナップショットおよび新しいメタデータ・ファイルを作成するIceberg表の以降の更新は、データベースに表示されません。
OCIでHadoopカタログを使用するIceberg表の問合せ
この例では、SparkがIcebergカタログのHadoopCatalog実装を使用するOCIデータ・フローを使用して作成されたIceberg表icebergTablePyを問い合せます。HadoopCatalogは、warehouseディレクトリを使用し、Icebergメタデータをこのディレクトリの下の$database_name/$table_nameサブフォルダに配置します。また、最新のメタデータ・ファイル・バージョンのバージョン番号を含むversion-hint.textファイルも使用します。Githubの例は、OCIデータ・フローでのIcebergサポートを参照してください。
サンプル表db.icebergTablePyは、icebergという名前のwarehouseフォルダを使用して、OCIバケットmy-iceberg-bucketに作成されました。表icebergTablePyのOCIの記憶域レイアウトを次に示します。

表db.icebergTablePyの外部表を次のように作成します。
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim3',
credential_name => 'OCI_CRED',
file_uri_list => '',
format =>'{"access_protocol":{"protocol_type":"iceberg",
"protocol_config":{"iceberg_catalog_type": "hadoop",
"iceberg_warehouse":"https://objectstorage.uk-cardiff-1.oraclecloud.com/n/my-tenancy/b/my-iceberg-bucket/o/iceberg",
"iceberg_table_path": "db.icebergTablePy"}}}');
END;
/ルート・メタデータ・ファイルの場所を使用して、OCI上のIceberg表を問い合せます
次のように、メタデータ・ファイルのURLを直接使用して、前の項で説明したIceberg表を問い合せることができます。
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim4',
credential_name => 'OCI_CRED',
file_uri_list => 'https://objectstorage.uk-cardiff-1.oraclecloud.com/n/my-tenancy/b/my-iceberg-bucket/o/iceberg/db/icebergTablePy/metadata/v2.metadata.json',
format =>'{"access_protocol":{"protocol_type":"iceberg"}}'
);
END;
/この例では、file_uri_listパラメータを使用して、ネイティブOCI URI形式を使用してメタデータ・ファイルのURIを指定します。メタデータ・ファイルURIを使用する場合、外部表は常に、特定のファイルに格納されている最新のスナップショットを問い合せます。新しいスナップショットおよび新しいメタデータ・ファイルを生成する後続の更新には、問合せからアクセスできません。
ネイティブOCI URI形式の詳細は、クラウド・オブジェクト・ストレージのURI形式を参照してください。