AWS Glueデータ・カタログを使用した外部データの問合せ
Autonomous AI Databaseは、Amazon AWS Glue Data Catalogインスタンスと同期するためのシステムをサポートしています。
AWS Glueデータカタログを使用したクエリーについて
Autonomous AI Databaseでは、Amazon Web Service (AWS) Glue Data Catalogメタデータと同期できます。Amazon Simple Storage Service (S3)に格納されたデータに関するAWS Glueによって収集されたすべての表に対して、Autonomous AI Databaseによってデータベース外部表が自動的に作成されます。ユーザーは、外部データ・ソースのスキーマを手動で導出して外部表を作成することなく、Autonomous AI DatabaseからS3に格納されているデータを問い合せることができます。
Amazon AWS Glue Data Catalogは、データプロフェッショナルがAWSクラウドでデータを検出し、データガバナンスをサポートするのに役立つ、一元化されたメタデータ管理サービスです。Autonomous AI Databaseインスタンスには、自動データカタログメタデータをAWS Glue Data Catalogと同期する機能があり、データベースユーザーはAutonomous AI Databaseを使用して、AWSクラウドに格納されているデータを即座にクエリできます。
AWS Glue Data Catalogとの同期には、OCI Data Catalogとの同期と同じプロパティがあります。同期は動的であり、基礎となるデータへの変更に関してデータベースを最新の状態に保ち、数百から数千の表を自動的に保持するため、管理コストを削減します。
AWS Glueデータカタログを使用したクエリーに関連する概念
Amazon Web Service (AWS) Glueデータカタログを照会するには、次の概念を理解する必要があります。
AWS Glueデータ・カタログ: データベース
AWS Glueデータベースは、論理グループに編成されたリレーショナルテーブル定義のコレクションを表します。各AWS Glueデータカタログインスタンスは、複数のデータベースを管理します。
AWS Glueデータ・カタログ: 表
AWS Glueテーブルは、AWSクラウドに格納されたデータに対するリレーショナルテーブルを表します。AWS Glueテーブルは、基になるデータのスキーマを定義し、カラム情報、パーティション情報、シリアライズ情報、ストレージ情報、統計情報、ユーザー定義メタデータ、およびその他のメタデータで構成されます。AWS Glueデータカタログ内のテーブルは、手動で作成することも、AWS Glueクローラを使用して自動的に作成することもできます。
接着剤のデータ カタログ: クローラー
クローラを使用して、AWS Glueデータカタログにテーブルを移入できます。これは、ほとんどのAWS Glueユーザーが使用する主な方法です。クローラは、1回の実行で複数のデータ・ストアをクロールできます。完了すると、クローラはデータ・カタログ内の1つ以上の表を作成または更新します。AWS Glueで定義した抽出、変換、およびロード(ETL)ジョブは、これらのデータカタログテーブルをソースおよびターゲットとして使用します。ETLジョブは、ソース・データ・カタログ表およびターゲット・データ・カタログ表に指定されているデータ・ストアに対して読取りおよび書込みを行います。
AWS Glueテーブルは、ユーザーが手動で作成することも、事前定義されたクローラまたはカスタムクローラを使用して自動的に作成することもできます。クローラは、基礎となるデータ・ストア(Amazon S3など)に接続し、データのスキーマを導出するための分類子を起動して、推測メタデータを格納するためのAWS Glue表を作成します。AWS Glueは、CSV、JSON、Parquet、AVROなどの一般的なファイルタイプの分類子を提供します。
Autonomous AI DatabaseとAWS Glue間のマッピング
同期プロセス中に、AWS Glue Data CatalogデータベースおよびAmazon S3上の表から導出されたAutonomous AI Databaseに外部表が作成されます。
AWS Glueは、データベースとテーブルに収集されたメタデータを整理します。AWS Glueデータベースは、リレーショナルテーブル定義のコレクションです。表に関連付けられたファイルの共通スキーマおよびプロパティを説明するAWS Glue表。
AWS Glueは、属性を表すリレーショナルモデルに従います。階層スキーマをリレーショナル・スキーマにマッピングする場合、AWS Glueは半構造化データのスキーマを推測し、ETLプロセスを使用してリレーショナル・スキーマにデータをフラット化します。
次の表に、OCIデータ・カタログの概念とAWS Glueデータ・カタログの概念との間のマッピングを示します。
| OCIデータ・カタログ | AWS Glueデータ・カタログ | Oracle Database |
|---|---|---|
| データ・アセット | データベース | スキーマ |
| フォルダ | (バケット) | スキーマ |
| 論理的なエンティティ | 表 | 表 |
AWS Glueデータカタログを使用したクエリのためのユーザーワークフロー
AWS S3データをAWS Glue Data Catalogでクエリするための基本的なユーザーワークフローでは、AWS Glue Data Catalogに接続し、Autonomous AI Databaseと同期して外部テーブルを自動的に作成してから、S3データをクエリします。
データベース・データ・カタログ管理者は、Autonomous AI DatabaseインスタンスとAWS Glue Data Catalogインスタンス間の接続を作成し、AWS Glue Data CatalogとAutonomous AI Databaseの間の同期(同期)を構成して実行します。Autonomous AI Databaseは、S3に格納されたデータに関するAWS Glueによって収集された表の外部表を自動的に作成します。
データベース・データ・カタログ問合せ管理者またはデータベース管理者は、生成された外部表へのREADアクセス権を付与します。これにより、データ・アナリストや他のデータベース・ユーザーは、外部データ・ソースのスキーマを手動で導出して外部表を作成することなく、Autonomous AI Databaseを参照および問合せできます。
ユーザー
次の表では、ユーザーワークフローアクションを実行するさまざまなタイプのユーザーについて説明します。
| ユーザー | 説明 |
|---|---|
| データベース・データ・カタログ管理者 | DCAT_SYNCロールを持つデータベース・ユーザー。 |
| データベース・データ・カタログ問合せ管理者 | データベース・ユーザーは、自動的に作成された外部表に対するアクセス権を他のユーザーに付与できます。 |
| データ・アナリスト | Autonomous AI Database上のデータベース・ユーザーは、自動作成された外部表を問い合せるか、AWS Glue Data Catalogと直接対話することで、AWS S3のデータを問い合せます。 |
| AWS Glueデータ・カタログ・ユーザー | AWS Glue Data CatalogにアクセスできるAWSユーザー。 |
| AWS S3 Object Storageユーザー | AWS S3に保存されたデータにアクセスできるAWSユーザー |
ユーザー・ワークフロー
ノート: DBMS_DCATパッケージは、AWS Glue Data Catalogを使用してAWS S3オブジェクト・ストレージを問い合せるために必要なタスクを実行するために使用できます。「DBMS_DCATパッケージ」を参照してください。
| アクション | ユーザーがだれであるか | 説明 |
|---|---|---|
| ポリシーの作成 | データベース・データ・カタログ管理者 | Autonomous AI Databaseのユーザー資格証明には、AWS Glue Data Catalogにアクセスし、S3オブジェクト・ストレージから読み取るための適切な権限が必要です。 詳細情報: 必要な資格証明およびIAMポリシー。 |
| 資格証明の作成 | データベース・データ・カタログ管理者 | {::nomarkdown} <p>AWS Glue Data Catalogにアクセスし、S3オブジェクト・ストレージを問い合せるために、データベース資格証明が設定されていることを確認します。ユーザーは、DBMS_CLOUD.CREATE_CREDENTIALをコールしてユーザー資格証明を作成します。</p><p>ノート: Amazon Web Services (AWS)資格証明のみがサポートされています。AWS Amazonリソース名(ARN)資格証明はサポートされていません。</p><p>詳細情報: DBMS_CLOUD CREATE_CREDENTIALプロシージャ</p> |
| CONNECT | データベース・データ・カタログ管理者 | Autonomous AI DatabaseインスタンスとAWS Glue Data Catalogインスタンス間の接続を確立します。接続は、AWS Glue Data Catalog Userの権限を使用します。Autonomous AI Databaseインスタンスから複数のAWS Glue Data Catalogインスタンスへの接続がサポートされています。 Autonomous AI DatabaseインスタンスとAWS Glue Data Catalogインスタンス間の接続を開始するには:
接続が行われると、Autonomous AI Databaseには、AWS GlueカタログID、リージョン、エンドポイント、資格証明オブジェクトなどの関連メタデータが格納されます。 詳細は、SET_DATA_CATALOG_CONNプロシージャ、UNSET_DATA_CATALOG_CONNプロシージャおよびDBMS_DCATを参照してください。SET_DATA_CATALOG_CREDENTIAL、DBMS_DCAT.SET_OBJECT_STORE_CREDENTIAL。 |
| 同期 | データベース・データ・カタログ管理者 | ユーザーは、 同期では次の処理が実行されます。
|
| 同期の監視 | データベース・データ・カタログ管理者 | ユーザーは、USER_LOAD_OPERATIONSビューを問い合せることで同期ステータスを表示できます。同期プロセスが完了すると、ユーザーは、外部表へのマッピングの詳細など、同期結果のログを表示できます。 |
| 権限を付与します | データベース・データ・カタログ問合せ管理者、データベース管理者 | データベース・データ・カタログ問合せ管理者またはデータベース管理者は、生成された外部表に対するREAD権限をデータ・アナリスト・ユーザーに付与する必要があります。これにより、データ・アナリストは生成された外部表を問い合せることができます。 |
| 問合せ | データ・アナリスト | データ・アナリストは、GLUE$*スキーマ内の同期スキーマおよび表を確認し、Oracle SQLをサポートする任意のツールまたはアプリケーションを介して外部表を問い合せることができます。 S3のデータには、AWS S3オブジェクト・ストレージ・ユーザーの権限を使用してアクセスします。 |
| 接続の終了 | データベース・データ・カタログ管理者 | 既存のデータ・カタログ・アソシエーションを削除するには、ユーザーが このアクションは、接続されたAWS Glue Data Catalogおよびカタログから導出された外部テーブルを使用する予定がなくなった場合にのみ実行されます。このアクションは、AWS Glue Data Catalogメタデータを削除し、同期された外部表をAutonomous AI Databaseインスタンスから削除します。 |
例: AWS Glueデータカタログを使用したクエリ
この例では、AWS Glue Data Catalogを使用して、Amazon Simple Storage Service (Amazon S3)に保存されているデータセットに対してクエリーを実行するプロセスを順を追って説明します。
この例では、AWS Glueデータカタログのメタデータを検査して、以前にクロールされ、データカタログ内に存在している Amazon S3オブジェクトを確認します。Autonomous AI Databaseは、AWS Glue Data CatalogとAmazon S3に関連付けられます。データカタログはAutonomous AI Databaseと同期され、Amazon S3に格納されているデータセット上に外部テーブルが作成されます。外部テーブルは、Amazon S3のデータセットをクエリーするために使用されます。
-
AWS Glue Data Catalogでメタデータを検査します。
-
AWS Glueコンソールを起動します。
-
データ・カタログ、データベースおよび表にナビゲートして、既存のオブジェクトを検索します。
この例では、AWS Glueが以前クロールしてテーブルを作成したオブジェクトの一部が Amazon S3に存在します。次に例を示します。
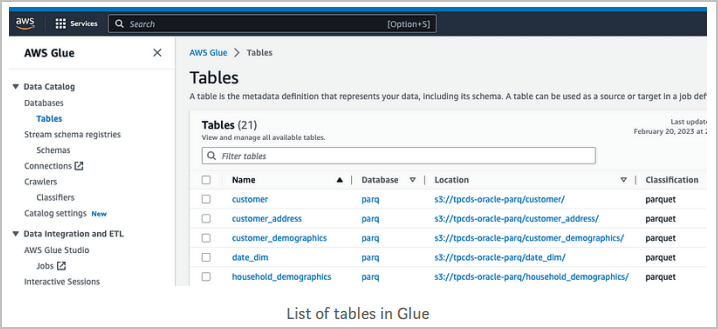
-
-
AWS GlueをAutonomous AI Databaseに関連付けます。
-
Autonomous AI Databaseで資格証明を作成します。
次のプロシージャ・コールには、Autonomous AI DatabaseがAmazon S3の基礎となるデータにアクセスできるようにするためのアクセスIDおよび秘密キーが含まれています。
exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>'); -
資格証明をAWS Glue Data CatalogおよびAmazon S3オブジェクト・ストレージに関連付けます。
これらのプロシージャ・コールは、データ・カタログとオブジェクト・ストレージをそれぞれ資格証明に関連付けます。
exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS'); -
Glueが実行されているAWSリージョンを設定します。
exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');
-
-
メタデータを同期して、AWS Glueデータベースおよび表から導出されたAutonomous AI Databaseに外部表を作成します。
-
アソシエーションが完了したので、
all_glue_databasesビューを使用して、AWS Glueデータ・カタログ内のデータベースを検索します。select * from all_glue_databases order by name; -
all_glue_tablesビューを使用して、同期可能な表のリストを取得します。select * from all_glue_tables order by database_name, name;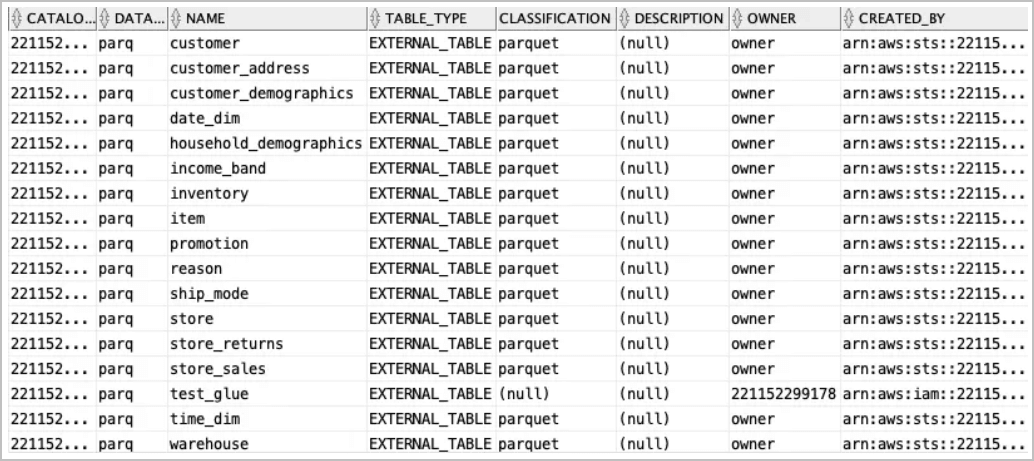
-
Autonomous AI Databaseを、
parqデータベースにある2つの表storeおよびitemと同期します。begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /
-
-
Autonomous AI Databaseで新しいオブジェクトを検査し、S3上でクエリを実行します。
-
SQL Developerを使用して、前の同期操作で作成された新しいオブジェクトを表示します。
GLUE$PARQ_TPCDS_ORACLE_PARQスキーマは、dbms_dcat.run_syncプロシージャ・コールによって自動的に生成および名前が付けられました。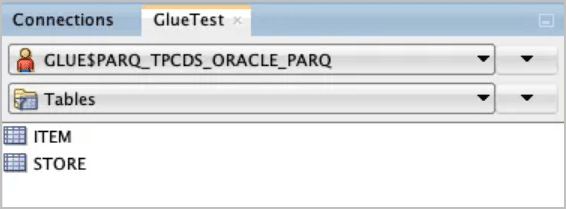
-
Amazon S3のデータセット・ストアに対してSQL問合せを実行します。
SELECT * FROM glue$parq_tpcds_oracle_parq.store;
-