イントロダクション
HCMデータ・ローダー(HDL)では、柔軟なパイプ区切りファイル形式がサポートされており、ユースケースに必要なビジネス・オブジェクト、コンポーネントおよびコンポーネント属性のみを指定できます。データのフル・セットをロードすることも、増分変更のみを行うこともできます。この柔軟性を実現するには、各ファイルで、どのビジネス・オブジェクト・コンポーネントおよび属性をファイルに含めるかを指定する必要があります。
Oracle HCM Cloudビジネス・オブジェクトは複雑であり、通常は階層であるため、1つのビジネス・オブジェクトに対して複数の子レコードを作成できます。たとえば、1人の個人に対して複数の電話番号や1つのジョブに対して複数の有効な等級を作成できます。
各デリミタ付きファイルには、単一のビジネス・オブジェクト階層のデータが含まれます。ファイルにはビジネス・オブジェクトの名前が付けられ、.datファイル拡張子が付きます。たとえば、Worker.datにはワーカーのデータ、Job.datにはジョブのデータ、ElementEntry.datにはエレメント・エントリのデータが含まれます。
HDLによって処理されるデータを指定する場合は、ファイル内の各レコードを一意に識別する必要があります。新しいレコードでは、次の2つのメカニズムがサポートされています。
- ユーザー・キー - レコードを一意に識別するユーザー・インタフェースで見つけることができる、ユーザー・フレンドリな属性の組合せ。たとえば、ジョブの場合はJobCodeおよびSetCode、ワーカーの場合はPersonNumberです。
- ソース・キー - 2つの属性SourceSystemIdとSourceSystemOwnerの組合せを使用して、レコードを一意に識別します。SourceSystemId値には任意の値を指定できますが、多くの場合、ソース・システム上の識別子、またはアルゴリズムによって生成された値です。SourceSystemOwnerは、複数のソース・システムが存在する場合にソース・キーが一意であることを保証します。
ノート:
ソース・キーは、ユーザー・キー値が時間の経過とともに変化し、多くの場合翻訳できるため、推奨されるソリューションです。ソース・キーは、レコードの存続期間中に変更されません。ソース・キーを使用して、他のオブジェクトからレコードを参照することもできます。ソース・キーは、PersonNumberなど、ユーザー・キー属性がOracle HCM Cloudによって自動生成される場合に特に役立ちます。目的
このチュートリアルの内容:
- ユーザー・キーおよびソース・キー・ファイルを作成してロードします。
- ソース・キーで親オブジェクトと外部オブジェクトを参照します。
- 既存のレコードを更新し、新しい子レコードを既存のオブジェクトに追加します。
- 個々のレコードを削除し、オブジェクトを完了します。
- 供給レポートおよび消込情報。
前提条件
このチュートリアルを完了するには、次のものが必要です。
- HCMデータ・ローダーを使用してデータをロードするための統合スペシャリスト・アクセス。
- 参照タイプを更新するための「設定および保守」へのアクセス。
- ファイルを作成するためのテキスト・エディタ。
- ビジネス・オブジェクト・データファイルを圧縮するファイル・コンプレッサー。
ヒント :
「HCMデータ・ローダー(HDL)へのアクセスの構成およびHDLセキュリティ・オプションの理解」チュートリアルを参照してください。タスク1: 最初のファイルの作成
このステップでは、ユーザー・キーを使用して各レコードを一意に識別する新しいジョブ・ファミリをロードする簡単なファイルを作成します。
- 任意のテキスト・エディタを使用して新しいファイルを作成し、次のように入力します。
- すべてのHDLファイル行の最初の値は、常にファイル指示(この場合はMETADATA)です。
- ファイルに含める属性とその値の指定順序を定義するには、すべてのファイルに METADATA行が含まれている必要があります。
- METADATA命令の直後の文字列は、ファイル弁別子と呼ばれ、属性を使用するオブジェクト階層内のコンポーネント(この場合はJobFamily)を識別します。
- ファイル弁別子に続く値は、JobFamilyコンポーネントで使用可能な属性の名前で、このファイルに値を含めます。
- ファイル・インストラクション、ファイル・デリミタおよびすべての属性名は、デフォルトでパイプ'|'文字で区切られます。
- このMERGE行をMETADATA行の下にあるファイルに追加します。
- MERGE命令は、レコードが存在しない場合は作成するか、存在する場合は更新するようにHDLに指示します。
- MERGE命令が識別した直後のファイル弁別子は、JobFamilyレコードです。後続の値は、対応するMETADATA行で指定された属性の値です。
- ファイル指示、ファイル・デリミタおよびすべての属性値は、デフォルトでパイプ'|'文字で区切られます。
- 属性値は、対応するMETADATA行で定義された順序で指定する必要があります。
- 日付を書式YYYY/MM/DDを使用して入力します。
- 有効終了日はオプションで、この値は4712年12月31日にデフォルト設定されます。これは、このレコードに終了日がないことを意味します。
- 次の追加のMERGE行をファイルに追加します。
MERGE|JobFamily|CLERICAL|Clerical and Administration|2000/01/01|4712/12/31 MERGE|JobFamily|MANAGERIAL|Managerial|2000/01/01|4712/12/31
各レコードを一意に識別する必要があります。ジョブ・ファミリ・レコードの場合、ユーザー・キーは単一の属性JobFamilyCode (CLERICALおよびMANAGERIAL)です。
ヒント :
このファイルをロードする前に、イニシャルをジョブ・ファミリ・コード値に追加して、それらが一意であり、データベースにまだ作成されていないことを確認できます。 - ファイルを保存し、JobFamily.datという名前を付けます。または、JobFamily.datファイルをダウンロードして編集することもできます。
ヒント :
ロードするオブジェクト階層のデータファイルに名前を付けます。.datファイル拡張子が必要です。ビジネス・オブジェクト・ファイル名では大文字小文字が区別されます。 - JobFamily.datを任意のファイル名に圧縮(zip)しますが、拡張子は.zipである必要があります。
METADATA|JobFamily|JobFamilyCode|JobFamilyName|EffectiveStartDate|EffectiveEndDate
ノート:
同じファイル内のオブジェクト階層の各コンポーネントに対して指定できるMETADATA行は1つのみです。つまり、オブジェクト階層内のコンポーネントに対して含める属性の定義のみを指定できます。ヒント :
テキスト・エディタがUTF-8エンコーディングを使用していることを確認します。MERGE|JobFamily|SALES|Sales|2000/01/01|4712/12/31
このMERGE行では、ジョブ・ファミリ・コードSALESで識別されるジョブ・ファミリが作成されます。ジョブ・ファミリ・コードはSALESという名前で、2000年1月1日に始まります。
ノート:
ジョブ・ファミリ名は翻訳できるため、環境の基本言語(通常はUS)で指定する必要があります。HCMデータ・ローダーは、セッション言語が基本言語であり、セッション・ユーザーのものとは異なる可能性がある昇格されたユーザーを使用してデータをロードします。
ヒント :
「ビジネス・オブジェクトの表示」タスクを使用して、データをロードするオブジェクト階層のファイル名およびファイル識別子を指定します。タスク2: ファイルのインポートおよびロード
- アプリケーションのホームページで、「自分のクライアント・グループ」→「データ交換」をクリックします
- 「データのインポートおよびロード」
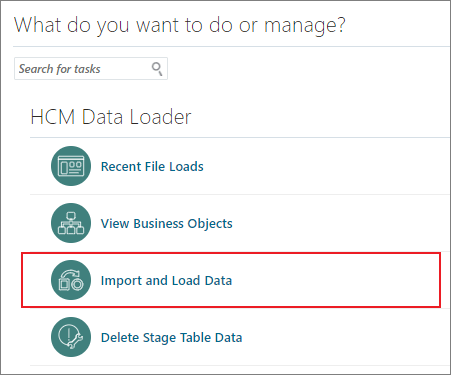
- 表ツールバーの「ファイルのインポート」→「ローカル・ファイルのインポート」をクリックします。
![[ファイルのインポート]をクリックします。](images/import_file.png)
- ファイル・エクスプローラからファイル・セレクタに.zipファイルをドラッグ・アンド・ドロップします。または、ファイル・セレクタをクリックして、ファイルを検索および選択します。
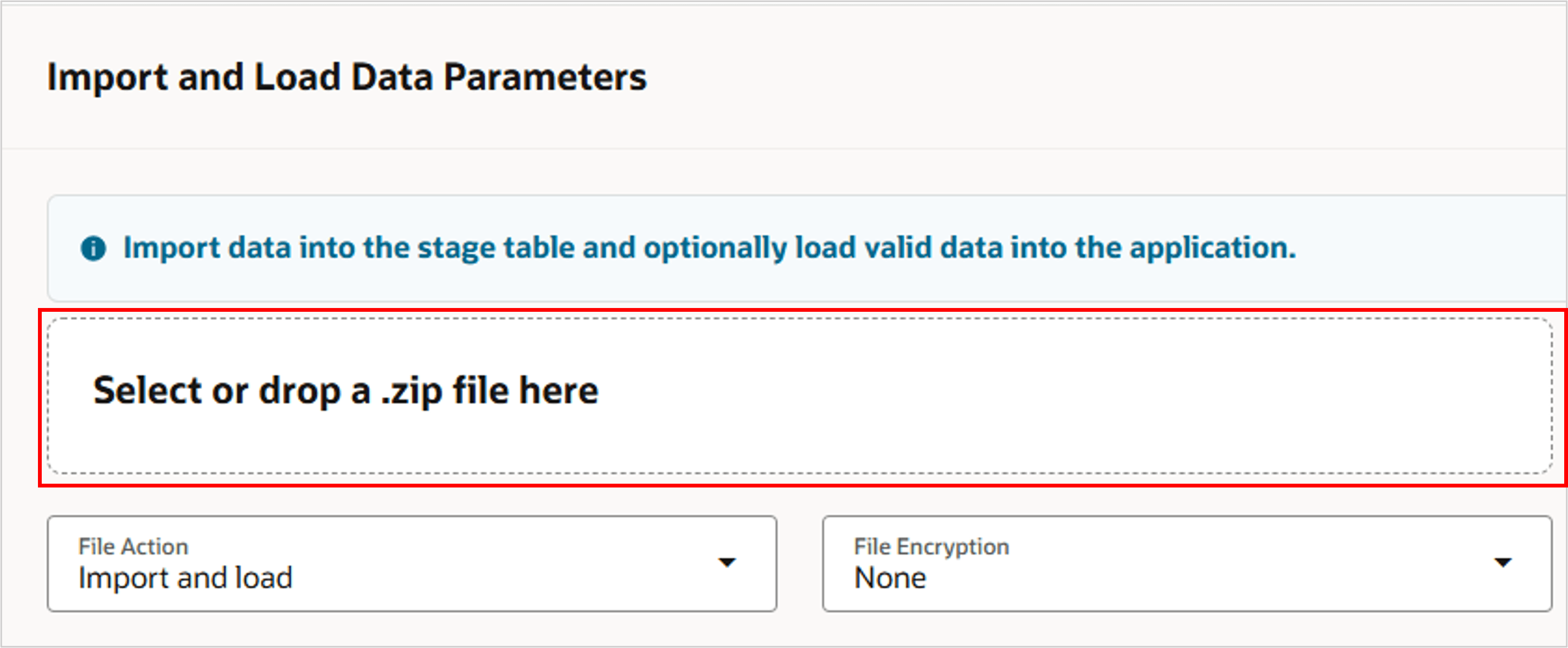
- 「送信」をクリックします。デフォルトのパラメータ値を変更する必要はありません。
- データ・セット情報を表示するには、「リフレッシュ」をクリックします。
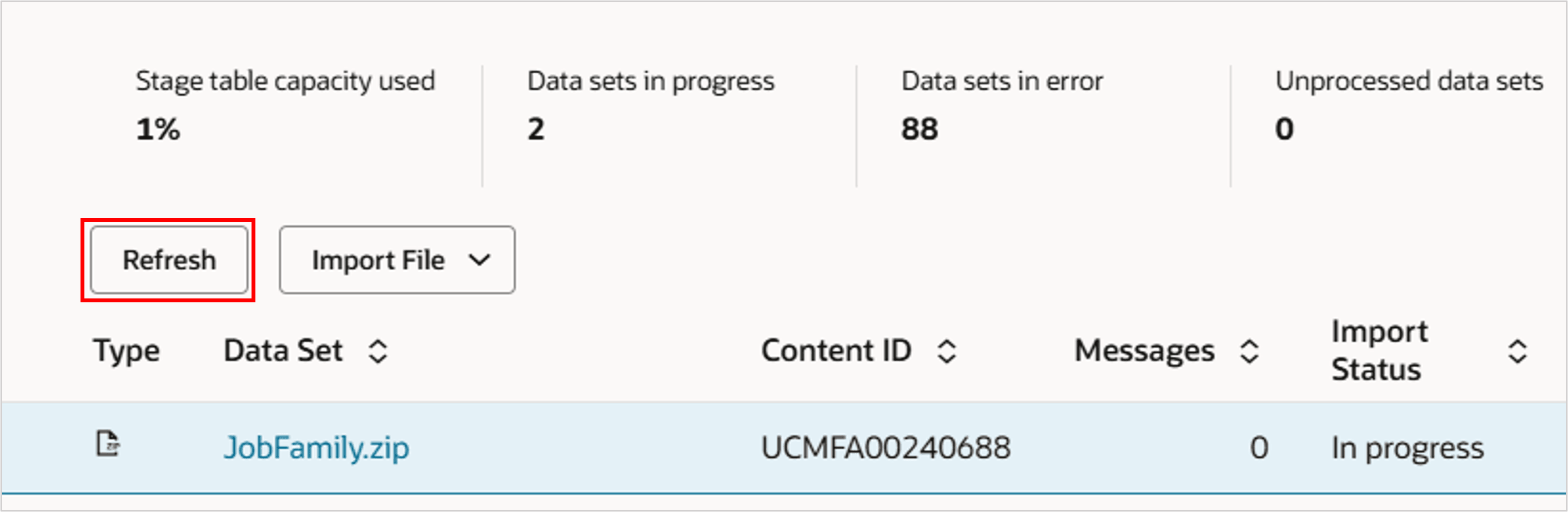
ヒント :
データ・セットはzipファイルと同じ名前になります。- 「インポート・ステータス」は、ファイル内のデータがステージング表にインポートされるかどうかを示します。
- 「ロード・ステータス」は、データがOracle HCM Cloudアプリケーション表に正常にロードされたかどうかを示します。
- 様々なカウントがあります:
- 「ファイル行」は、ファイル内のデータ行の数を示します。ファイルには3つのMERGE行がありました。
- 「オブジェクト」は、ファイル内のオブジェクト数を示します。この単純なファイルでは、3行で3つのジョブ・ファミリ・オブジェクトが作成されるため、「オブジェクト合計」も3になります。
- 「失敗オブジェクト」は、正常にロードされなかったオブジェクトの数を示します。これはファイルに対してゼロである必要があります。
ヒント :
ほとんどのオブジェクトには複雑な階層があり、1つのオブジェクトを作成するには複数のファイル行を指定する必要があります。これらのオブジェクトの場合、ファイル行数はオブジェクト数よりはるかに大きくなります。
- データ・セットのロードが完了するまで、「リフレッシュ」を再度クリックします。
ヒント :
この表で使用可能なその他の列があります。表ツールバーの最後にある「列のカスタマイズ」ボタンをクリックし、表の列を選択して並べ替えます。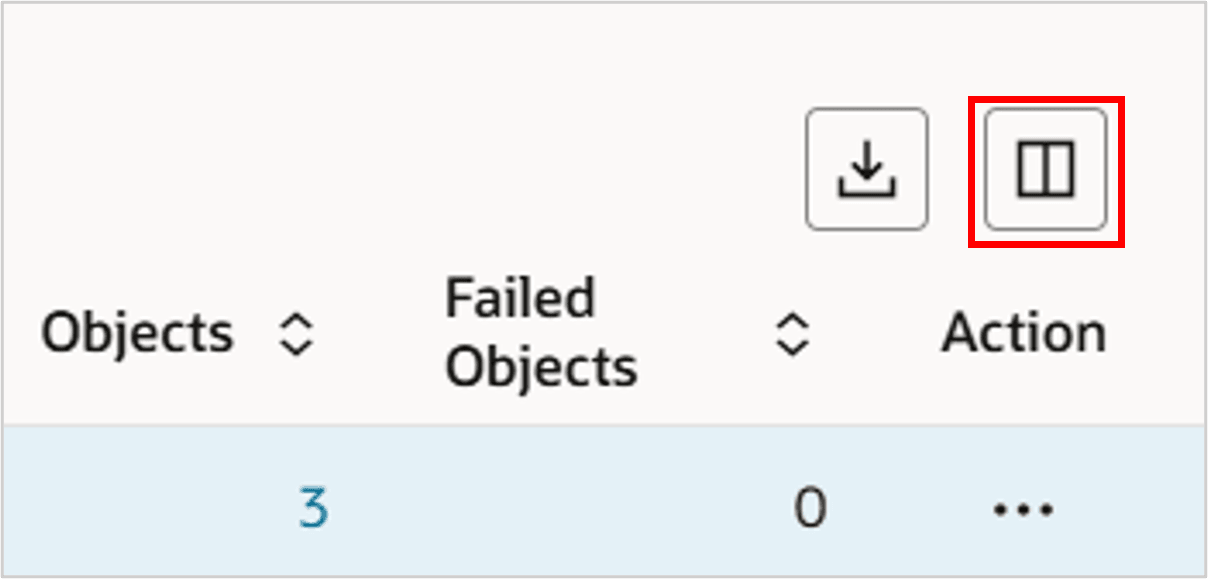
タスク3: ソース・キーを使用した単純なファイルの作成
レコードを一意に識別するために、常にソース・キーを指定することをお薦めします。
ソース・システム所有者の定義
ソース・キーを使用するファイルをロードする前に、まずソース・システムの所有者値を登録する必要があります。
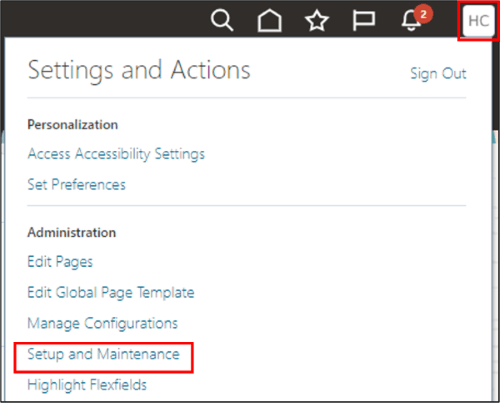
- 「設定および保守」にアクセスできるユーザーでアプリケーションにログインします。
- 「自分の企業」→「設定および保守」に移動します。
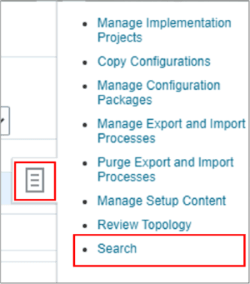
- サイド・ドロワー・アイコンをクリックし、「検索」をクリックします。
- 「共通参照の管理」タスクを検索して選択します。
- 参照タイプの検索 HRC_SOURCE_SYSTEM_OWNER
- 参照コード表の「追加」アイコンをクリックします。
- 参照コードと意味でVISIONを指定し、「開始日」に01/01/2000を指定します。
- 「保存」をクリックします。


単純なソース・キー・ファイルの作成
このステップでは、等級をロードするための単純なソース・キー・ファイルを作成します。
- 新しいファイルを作成し、次のMETADATA行を入力します。
- 次のMERGE行をファイルに追加します。
- ファイルを保存し、Grade.datという名前を付けます。または、Grade.datファイルをダウンロードして編集します。
- このファイルをアップロードしないでください。これは、次のステップで作成したファイルとともにロードされます。
METADATA|Grade|SourceSystemOwner|SourceSystemId|GradeCode|SetCode|GradeName|EffectiveStartDate|ActiveStatus
SourceSytemOwnerおよびSourceSystemId属性は、Gradeオブジェクトに固有の属性とともにMETADATA行に含まれます。
ヒント :
レコードを一意に識別するユーザー・キー属性は、ソース・キーが指定されている場合でも、新しいレコードの作成時に必要になることがよくあります。ただし、ソース・キーとユーザー・キーの両方を指定する場合は、ソース・キーを使用して各レコードを一意に識別します。MERGE|Grade|VISION|IC1|IND_CON_1|COMMON|Individual Contributor 1|2000/01/01|A MERGE|Grade|VISION|IC2|IND_CON_2|COMMON|Individual Contributor 2|2000/01/01|A MERGE|Grade|VISION|IC3|IND_CON_3|COMMON|Individual Contributor 3|2000/01/01|A MERGE|Grade|VISION|MG1|MANAGER_1|COMMON|Manager 1|2000/01/01|A MERGE|Grade|VISION|MG2|MANAGER_2|COMMON|Manager 2|2000/01/01|A
これらのファイル行では、5つの等級が作成され、それぞれがソース・キーで識別されます。
| ソース・システム所有者 | ソース・システムID | 成績コード | 等級名 |
|---|---|---|---|
| ビジョン | IC1 | IND_COND_1 | 個人貢献者1 |
| ビジョン | IC2 | IND_COND_2 | 個人貢献者2 |
| ビジョン | IC3 | IND_COND_3 | 個人貢献者3 |
| ビジョン | MG1 | MANAGER_1 | 管理者1 |
| ビジョン | MG2 | MANAGER_2 | 管理者2 |
ヒント :
SourceSystemId値は任意です。この例では、GradeCodeと異なる値を使用して、次のタスクで指定される値をクリアします。SourceSystemId値にイニシャルを追加して、一意にすることができます。タスク4: ソース・キーを使用した外部オブジェクトの参照
このステップでは、ソース・キー・ファイルを作成して、ユーザー・キーでジョブ・ファミリを参照し、ソース・キーで等級を参照するジョブをアップロードします。
- 新しいファイルを作成し、次のMETADATA行を入力します。
- 次のMERGE行をファイルに追加します。
- 次のMETADATA行を追加します。
- 子レコードのデータを指定する場合は、関連する親レコードに名前を付ける必要があります。この例では、親サロゲートID属性JobIdを使用してこれを実現しています。
- ソース・キーを使用してジョブを識別すると、JobId属性の後に文字列(SourceSystemId)が続きます。属性名の後のカッコ内のすべてがヒントです。このヒントは、サロゲートID属性で識別される外部(または親)オブジェクトを参照するためにソース・システムID値が指定されることをHDLに通知します。
- 等級への参照ではソース・キーも使用され、ソース・システムID値は等級を参照する外部サロゲートID属性に指定され、GradeIdは(SourceSystemId)ヒントを追加する必要があります。
- この例では、等級ソース・キーのソース・システム所有者は、SourceSystemOwner属性から継承されます。ただし、ソース・システムの所有者値が異なる場合は、外部オブジェクトのサロゲートID属性に(SourceSystemOwner)ヒントを指定して、これを指定できます。たとえば、GradeId(SourceSystemOwner)です。
- 次のMERGE行をファイルに追加します。
- 属性SourceSystemOwnerおよびSourceSystemIdを持つソース・キーを定義することで、一意の識別子を提供します。
- 親サロゲートID属性JobId(SourceSystemId)を使用して親ジョブを識別し、親ジョブ・レコードに指定されたSourceSystemId値を指定します。たとえば、SCNは営業コンサルタント・ジョブのSourceSystemIdであるため、営業コンサルタント・ジョブの有効な等級のJobId(SourceSystemId)属性もSCNである必要があります。
- 外部サロゲートID属性GradeId(SourceSystemId)を使用して等級を識別します。
ヒント :
等級ファイルのSourceSystemId値にイニシャルを追加した場合は、ここでも同様です。 - ファイルを保存し、Job.datという名前を付けます。または、Job.datファイルをダウンロードして編集します。
- 任意のファイル名を使用してGrade.datファイルとJob.datファイルを圧縮(zip)し、拡張子が.zipであることを確認します。
- 「ファイルのインポートおよびロード」で説明されているステップを使用して、等級およびジョブをアップロードします。
- データ・セット名をクリックして、「ビジネス・オブジェクト詳細」ページにナビゲートします。
- データ・セットにリストされているビジネス・オブジェクトをレビューします。zipファイルに含まれるビジネス・オブジェクト・ファイルごとにエントリが存在します。
METADATA|Job|SourceSystemOwner|SourceSystemId|EffectiveStartDate|SetCode|JobCode|Name|JobFamilyCode|ActiveStatus|FullPartTime|RegularTemporary
SourceSytemOwnerおよびSourceSystemId属性は、各ジョブを一意に識別します。ジョブ・ファミリへの参照では、JobFamilyCodeユーザー・キー属性が使用されます。
MERGE|Job|VISION|SCN|2000/01/01|COMMON|SALES_CONS|Sales Consultant|SALES|A|FULL_TIME|R MERGE|Job|VISION|ADM|2000/01/01|COMMON|ADMIN|Administrator|CLERICAL|A|FULL_TIME|R MERGE|Job|VISION|MGR|2000/01/01|COMMON|MANAGER|Manager|MANAGERIAL|A|FULL_TIME|R
ヒント :
最初のファイルで職務系列コードを変更した場合は、このファイルに対して同じ更新を行う必要があります。この3つのファイル行によって、3つのジョブが作成されます。タスク1で作成した異なるジョブ・ファミリに属する各ジョブ。
| ジョブ名 | ジョブ・ファミリ |
|---|---|
| セールスコンサルタント | セールス(セールス) |
| Administrator | CLERICAL(事務・行政) |
| 管理者 | MANAGERIAL(管理職) |
METADATA|JobGrade|SourceSystemOwner|SourceSystemId|JobId(SourceSystemId)|GradeId(SourceSystemId)|EffectiveStartDate
ジョブには複数の有効な等級を指定できます。JobGradeコンポーネントは、有効な等級を作成するために使用され、ジョブ・オブジェクト階層内のJobコンポーネントの子です。
ヒント :
「ビジネス・オブジェクトの表示」タスクを使用して、ビジネス・オブジェクトの親および外部サロゲートID属性を識別します。MERGE|JobGrade|VISION|SCN_IC1|SCN|IC1|2000/01/01 MERGE|JobGrade|VISION|SCN_IC2|SCN|IC2|2000/01/01 MERGE|JobGrade|VISION|SCN_IC3|SCN|IC3|2000/01/01 MERGE|JobGrade|VISION|ADM_IC1|ADM|IC1|2000/01/01 MERGE|JobGrade|VISION|ADM_IC2|ADM|IC2|2000/01/01 MERGE|JobGrade|VISION|ADM_IC3|ADM|IC3|2000/01/01 MERGE|JobGrade|VISION|MGR_MG1|MGR|MG1|2000/01/01 MERGE|JobGrade|VISION|MGR_MG2|MGR|MG2|2000/01/01
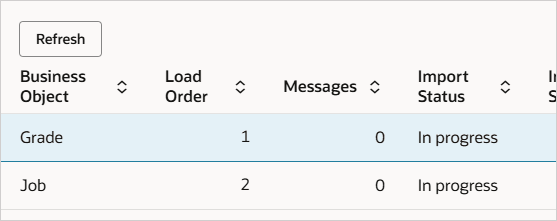
これらのファイル行によって、3つの各職務に対して有効な等級が作成されます。有効な各等級レコード:
ヒント :
複数のビジネス・オブジェクトの.datファイルを同じzipファイルに指定できます。HCMデータ・ローダーはそれらをパラレルにインポートしますが、順次ロードします。参照データが後続のビジネス・オブジェクト・ファイルで参照される前に、Oracle HCM Cloudにロードされるようにします。タスク5: レコードの更新
このステップでは、個々のレコードを更新し、新しい子レコードを追加する方法を学習します。
ヒント :
「ビジネス・オブジェクトの表示」タスクを使用して、オブジェクトが更新をサポートしているかどうかを確認します。更新および削除するオブジェクトの作成
このステップでは、回答を含む質問を作成します。この質問は、後続のタスクで更新および削除されます。
- 次の行を含むファイルを作成します。
- ファイルを保存し、Question.datという名前を付けます。または、Question.datファイルをダウンロードして編集します。
- 任意のファイル名を使用してQuestion.datファイルを圧縮(zip)し、拡張子が.zipであることを確認します。
- このファイルをロードする前に、カテゴリ・コードを作成する必要があります。
- 「自分のクライアント・グループ」にナビゲートし、「クイック処理」で「詳細の表示」をクリックします。
- 「質問」クイック処理を検索してクリックします。
- 「サブスクライバ」を「採用」に変更します。
- 「追加」アイコンをクリックし、「フィードバック」のフォルダを指定します。
- 「OK」をクリックします。
- 「ファイルのインポートおよびロード」で説明されているステップを使用して、質問をアップロードします。
- 「質問」タスクを使用して、質問とその回答をレビューします。
METADATA|Question|SubscriberName|QuestionCode|QstnVersionNum|QuestionText|Status|QuestionType|PrivacyFlag|ResponseTypeName|CategoryName MERGE|Question|Recruiting|FEEDBACK_1|1|How satisfied are you with the training?|A|MULTCHOICE|N|Check Multiple Choices|Feedback METADATA|Answer|SubscriberName|QuestionCode|QstnVersionNum|AnswerCode|LongText|SequenceNumber|Score MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS11|Yes, I'm satisfied.|5|151 MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS21|No, I'm not satisfied.|3|151 MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS31|I have no opinion on this.|2|151
オブジェクトの更新
- 次の行を含むファイルを作成します。
- ファイルを保存し、Question.datという名前を付けます。
- Question.datファイルを圧縮(zip)し、インポートしてロードします。
- 「質問」タスクを使用して質問テキストをレビューします。
METADATA|Question|SubscriberName|QuestionCode|QstnVersionNum|QuestionText MERGE|Question|Recruiting|FEEDBACK_1|1|Are you satisfied with the training?
更新するレコードを一意に識別する必要があります。この例では、ユーザー・キー属性SubscriberName、QuestionCodeおよびQstnVersionNumを使用します。
ヒント :
「ビジネス・オブジェクトの表示」タスクを使用して、各コンポーネントを一意に識別するために使用されるユーザー・キー属性を決定します。ヒント :
ソース・キーを使用してレコードを識別する場合は、かわりにこれらの属性(SourceSystemIdおよびSourceSystemOwner)を使用します。このファイルは質問テキストのみを更新するため、ファイルに含まれるその他の属性はQuestionTextのみです。
子レコードの更新および追加
- 次の行を含むファイルを作成します。
- 質問レコードは更新されないため、回答の対象となる質問の識別に使用される属性のみが含まれます。
- ファイル内の最初の回答は、既存のレコードの更新です。
- ファイルの2つ目の回答は、この質問の新しい回答です。
- ファイルを保存し、Question.datという名前を付けます。
- Question.datファイルを圧縮(zip)し、インポートしてロードします。
- 「質問」タスクを使用して回答を確認します。
METADATA|Question|SubscriberName|QuestionCode|QstnVersionNum MERGE|Question|Recruiting|FEEDBACK_1|1 METADATA|Answer|SubscriberName|QuestionCode|QstnVersionNum|AnswerCode|LongText|SequenceNumber|Score MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS11|Yes, I'm very satisfied.|5|151 MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS41|Yes, I'm somewhat satisfied.|4|151
質問は、関連する回答をグループ化するためにファイルに含まれ、一緒に処理されるようにします。
ヒント :
新しいレコードの作成と既存のレコードの更新の両方にMERGE指示を使用します。レコードがすでに存在するかどうかを知る必要はありません。HDLはデータを作成または更新するかどうかを決定します。ヒント :
子レコードを指定する場合は、作成または更新されるレコードを一意に識別するだけでなく、常に親レコードの一意の参照を指定することを忘れないでください。タスク6: レコードの削除
このステップでは、個々のレコードを削除してオブジェクトを完了する方法を学習します。
このステップで削除される質問を作成するタスク5を完了したと想定しています。
ヒント :
「ビジネス・オブジェクトの表示」タスクを使用して、オブジェクトが削除をサポートするかどうかを決定します。個別の子レコードの削除
- 次の行を含むファイルを作成します。
- DELETE命令は、レコードを削除するようにHDLに指示します。
- 削除するレコードを識別する属性のみを指定します。
- ファイルを保存し、Question.datという名前を付けます。
- 任意のファイル名を使用してQuestion.datファイルを圧縮(zip)し、拡張子が.zipであることを確認します。
- ファイルをインポートしてロードします。
- 「質問」タスクを使用して質問をレビューし、回答が3つしかないことを確認します。
METADATA|Question|QuestionCode|QstnVersionNum|SubscriberName MERGE|Question|FEEDBACK_1|1|Recruiting METADATA|Answer|QuestionCode|QstnVersionNum|SubscriberName|AnswerCode DELETE|Answer|FEEDBACK_1|1|Recruiting|FEEDBACK_1ANS31
このファイルは、AnswerCode FEEDBACK_1ANS31で識別される回答を削除します。
ヒント :
MERGE命令を使用して、ファイルに親を含めることをお薦めします。これにより、すべての関連レコードがグループ化され、まとめて処理されます。「質問」など、いくつかのオブジェクト階層では、子レコードを更新または削除するときに、ファイルに最上位のレコードを含めます。完全なオブジェクトの削除
- 次の行を含むファイルを作成します。
- ファイルを保存し、Question.datという名前を付けます。
- 任意のファイル名を使用してQuestion.datファイルを圧縮(zip)し、拡張子が.zipであることを確認します。
- ファイルをインポートしてロードします。
- 「質問」タスクを使用して、質問が存在しないことを確認します。
METADATA|Question|QuestionCode|QstnVersionNum|SubscriberName DELETE|Question|FEEDBACK_1|1|Recruiting
ヒント :
ほとんどのオブジェクトでは、最初に子レコードを削除する必要はありません。最上位レベルのレコードを削除すると、削除がカスケードされ、すべての子レコードも削除されます。タスク7: 供給消込データ
HCMデータ・ローダーによってロードされたデータは汎用ステージング表に保持され、ビジネス・オブジェクトに指定された値が常に同じデータベース列に格納されるとはかぎりません。
警告:
HDLステージング表からデータを直接読み取ろうとしないでください。かわりに、ソース参照属性にレポート、合計または突合せする属性値を指定します。「ソース参照」属性は、「データのインポートおよびロード」ユーザー・インタフェースの「オブジェクト・ステータス」ページに表示され、HCM抽出およびOTBIレポートを使用して抽出できます。
METADATA行では、次の形式を使用して、各ソース参照列のプロンプトを指定します。
SourceRef001={source-column-001}|SourceRef002={source-column-002}|SourceRef003={source-column-003}
たとえば次のようにします。
METADATA|ElementEntry|...|SourceRef001=PersonNumber|SourceRef002=ElementName|SourceRef003=Amount MERGE|ElementEntry|...|892334|Travel Allowance|200
ヒント :
最大10個のソース参照値を指定できます。- 次の行を含むファイルを作成します。
- ElementEntry.datという名前のファイルを保存します。または、ElementEntry.datファイルをダウンロードして編集します。
- ElementEntry.datファイルを圧縮します。
- HCMデータ・ローダーを使用した圧縮ファイルのアップロード
- データ・セットの処理が完了するまで、「リフレッシュ」をクリックします。ロード・エラーが発生します。
- 「オブジェクト」の数をクリックします。
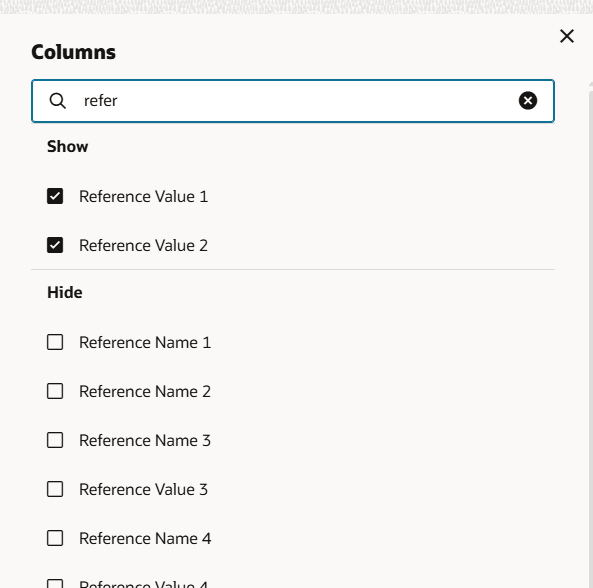
- デフォルトでは、最初の2つの参照値が表示されます。
- 「列のカスタマイズ」ボタンを使用して、表に表示する参照属性の名前と値を構成します。
METADATA|ElementEntry|LegislativeDataGroupName|AssignmentNumber|ElementName|EffectiveStartDate|MultipleEntryCount|EntryType|CreatorType|SourceRef001=Assignment Number|SourceRef002=Element|SourceRef003=Amount MERGE|ElementEntry|Vision Corp|E3143464|Commutation Allowance|2019/04/01|1|E|H|E3143464|Commutation Allowance|1000 METADATA|ElementEntryValue|LegislativeDataGroupName|AssignmentNumber|ElementName|EffectiveStartDate|MultipleEntryCount|EntryType|InputValueName|ScreenEntryValue MERGE|ElementEntryValue|Vision Corp|E3143464|Commutation Allowance|2019/04/01|1|E|Periodicity|Periodically MERGE|ElementEntryValue|Vision Corp|E3143464|Commutation Allowance|2019/04/01|1|E|Amount|1000


次のステップ
次のチュートリアルでは、HCMデータ・ローダーに関する知識をさらに深めます。
関連リンク
HDLおよびHSDLの最新のチュートリアルは、Cloud Customer Connectのこのトピックで公開されています。
詳細は、ヘルプ・ガイドを参照してください。
謝辞
- 著者 - Ema Johnson (シニア・プリンシパル・プロダクト・マネージャー)
その他の学習リソース
docs.oracle.com/learnで他のラボを確認するか、Oracle Learning YouTubeチャネルで無料のラーニング・コンテンツにアクセスしてください。また、education.oracle.com/learning-explorerにアクセスして、Oracle Learning Explorerになります。
製品ドキュメントについては、Oracle Help Centerを参照してください。