イントロダクション
このチュートリアルでは、主要なビジネス推進要因を考慮して、より正確な予測を生成するためのML機能を使用した高度な予測の構成において、お客様とパートナーをサポートします。このチュートリアルでは、高度な予測を構成する方法を示し、ビジネス上の考慮事項およびIPMのソリューション機能に基づく実装の推奨事項を示します。このチュートリアルでは、ボリューム予測に関する特定のビジネス・ユース・ケースに焦点を当て、MLモデルをトレーニングし、より正確な予測を生成するための主要な入力ドライバを検討します。各項は互いの上に構築され、順番に完了する必要があります。
バックグラウンド
高度な予測またはML予測とは、機械学習モデルを使用して入力機能に基づいてデータを予測するプロセスを指します。
高度な予測の主な利点:
- 提供された他のデータ・ポイントと相関させることで、より強力な予測が可能になります。
- Oracle EPMに組み込まれているため、多次元の計画および予測のユース・ケース用に最適化されたデータ・サイエンスにより、財務および業務ユーザーを強化できます。
- より高度なアルゴリズムを活用し、精度を向上させます。
- ステップ・バイ・ステップ構成ウィザードを使用して、より簡単に構成できます。
高度な予測の利点:
- EPMデータとコンテキストに縛られる: ユーザーは、外部のデータ・サイエンス・プラットフォームやMLツールにアクセスする必要はありません。EPMデータおよびコンテキストに高度な予測機能が組み込まれており、財務および業務ユーザーを支援します。
- OCI AIインフラストラクチャを搭載: EPMシステム内で機械学習モデルを構築、トレーニング、導入します。
- 予測精度の向上: 高度な予測では、予測を実行する前にデータに対して機能エンジニアリングと機能選択を実行できるため、予測精度が向上します。
- 意思決定の強化: どのビジネス・ドライバが予測に最も影響を与えるかを理解し、各ドライバの相対的な貢献度を機能の重要度チャートと比較します。
- すべてのレイヤーのプライバシーとセキュリティ: 高度な予測はEPMセキュリティ・レイヤーを採用しています。つまり、MLモデルによって生成された予測データへのアクセスは、EPMシステムの他の領域を管理する同じ堅牢なセキュリティ・フレームワークによって制御されます。
- 追加コストなしで埋め込み: Oracle EPM Enterpriseライセンスで追加コストなしで利用できます。
- 拡張可能フレームワーク: 外部データを含むパイプラインを使用する拡張可能フレームワークを使用したデータの処理および前処理をサポートし、API、BYOMLを使用する複数のプラットフォームでの予測をサポートします。
高度な予測に関する主な考慮事項:
- Enterprise EPMライセンスでのみ使用可能
- Redwoodテーマからのみアクセス
- オプトインのみの機能- 「アプリケーション設定」でオプトインを使用可能
- OCI Data ScienceでEPMに組み込まれているため、OCI Data Scienceを導入するための追加コストはありません
- モジュール、カスタム、FreeForm、Sales Planning、Strategic Workforce Planning、Predictive Cash Forecastingなど、様々なPlanningアプリケーションで利用できます。
- BSOキューブとASOキューブの両方で機能します。
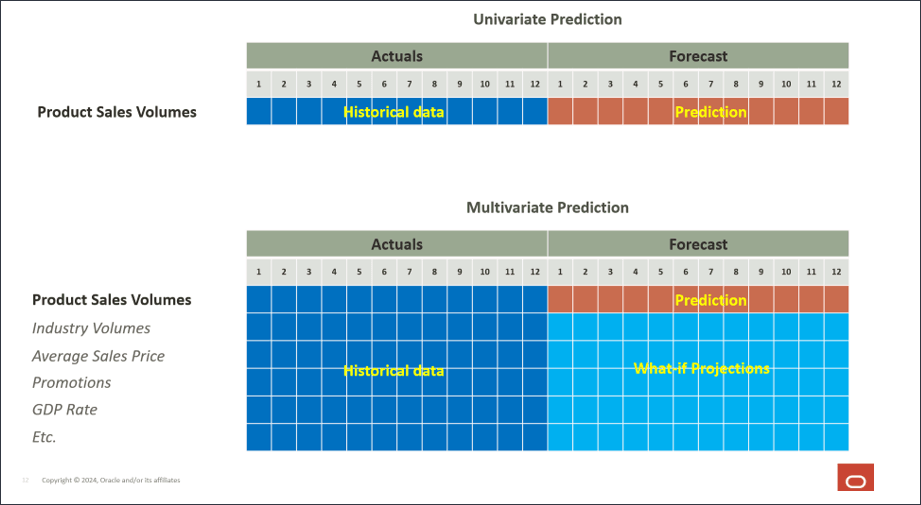
ボリューム予測のユースケース

1月FY22から6月FY24までの過去の販売量に基づいて製品別の販売量を予測するユース・ケースを考えてみます。過去の販売量に加えて、業界のボリューム、平均販売価格、広告およびマーケティングのプロモーション、割引率などの入力ドライバも使用します。これは、将来のボリューム予測に影響を与える可能性のあるすべての内部要因です。また、GDP成長率などの経済指標や、将来のボリューム予測に影響を与える可能性のある個人消費支出など、いくつかの外部ドライバを使用します。
履歴入力ドライバは主にデータ・ソースからインポートされ、将来の入力ドライバ値は、ドライバやトレンド・ベースなどの従来の方法を使用して計画することも、拡張予測ジョブ自体の一部として使用できる単変量予測(計算機能)を使用することもできます。
前提条件
Cloud EPMのハンズオン・チュートリアルでは、Cloud EPM Enterprise Serviceインスタンスにスナップショットをインポートする必要がある場合があります。チュートリアル・スナップショットをインポートする前に、別のCloud EPM Enterprise Serviceインスタンスをリクエストするか、現在のアプリケーションおよびビジネス・プロセスを削除する必要があります。チュートリアル・スナップショットは、既存のアプリケーションまたはビジネス・プロセスにはインポートされません。また、現在作業中のアプリケーションまたはビジネス・プロセスを自動的に置換または復元することもありません。
このチュートリアルを始める前に次の準備をする必要があります。
- サービス管理者にCloud EPM Enterprise Serviceインスタンスへのアクセス権を付与します。インスタンスにビジネス・プロセスを作成しないでください。
- このスナップショットをPlanningビジネス・プロセスにアップロードおよびインポートします。
- この日付マッピングをローカル・マシンにダウンロードします。
ヒント :
ファイルをローカルに保存するには、右クリックして「リンクに名前を付けて保存」を選択します。ファイルは必ず.csvファイルとして保存します。 - この販売量予測レポートをローカル・マシンにダウンロードします。
ヒント :
ファイルをローカルに保存するには、右クリックして「リンクに名前を付けて保存」を選択します。
ノート:
スナップショットのインポート中に移行エラーが発生した場合は、HSS-Shared Servicesコンポーネントを除く移行、およびコア・コンポーネントのセキュリティ・アーティファクトとユーザー・プリファレンス・アーティファクトを再実行します。スナップショットのアップロードおよびインポートの詳細は、Oracle Enterprise Performance Management Cloud移行の管理のドキュメントを参照してください。高度な予測のためのオプトイン
拡張予測およびAI機能の使用を開始する場合は、まず「アプリケーション設定」ページに移動して有効にする必要があります。
- ホーム・ページで、「アプリケーション」をクリックし、次に「設定」をクリックします。
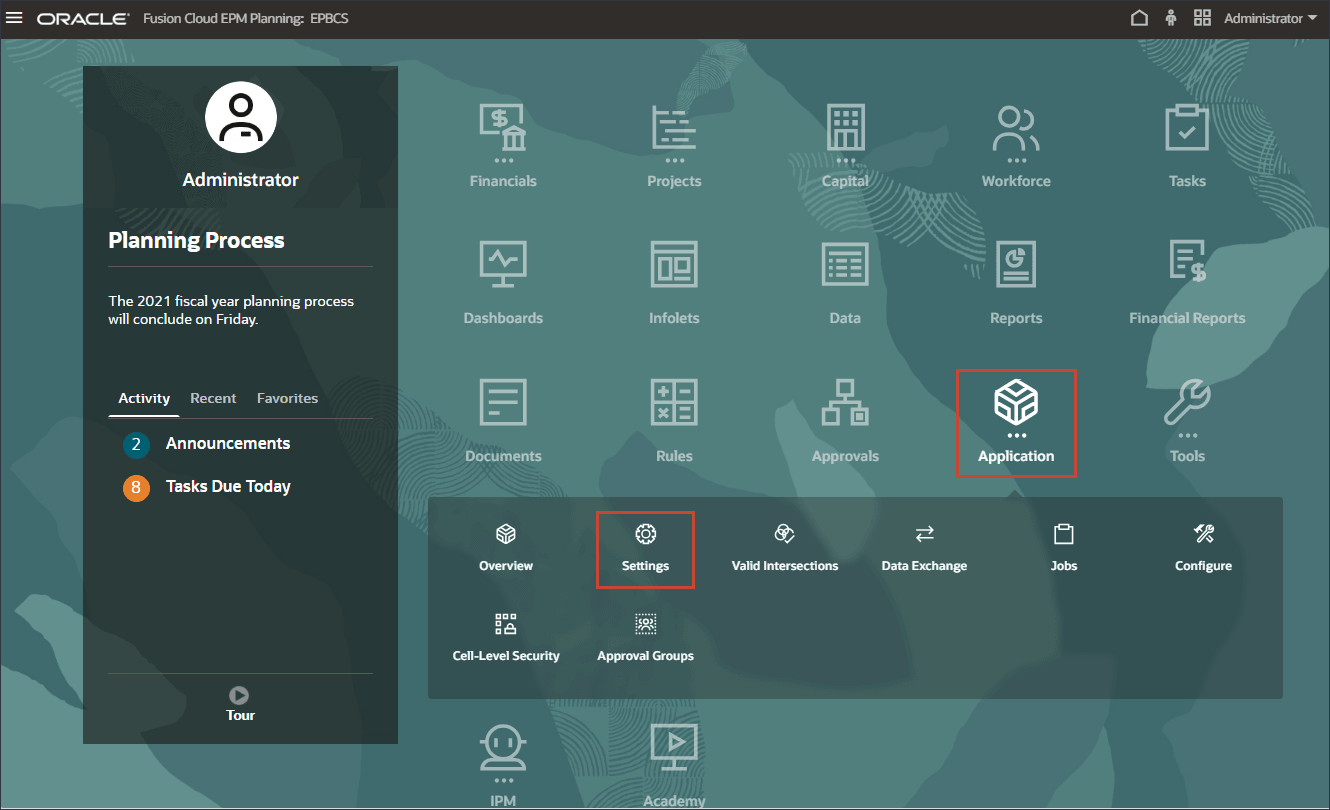
- 「設定」で、スクロール・ダウンして右下のセクションの「AIの有効化」で、「拡張予測」を選択して、高度な多変量予測のAIデータ分析を有効にします。

- 情報メッセージから、「OK」をクリックします。

- 上にスクロールし、「保存」をクリックします。
- 「情報」メッセージの「OK」をクリックします。
![[Home]](images/icon-home.png) (ホーム)をクリックして、ホーム・ページに戻ります。
(ホーム)をクリックして、ホーム・ページに戻ります。
アプリケーションの準備
このチュートリアルのステップを実行する前に、アプリケーションを準備する必要があります。提供されているアプリケーションにはグループ、ロールまたはセキュリティが含まれていないため、EPMグループを作成し、EPM Cloudナビゲーション・フローに割り当てる必要があります。EPM Cloudのナビゲーション・フローを使用して、拡張予測を使用して生成された予測をレビューします。
EPMグループの作成
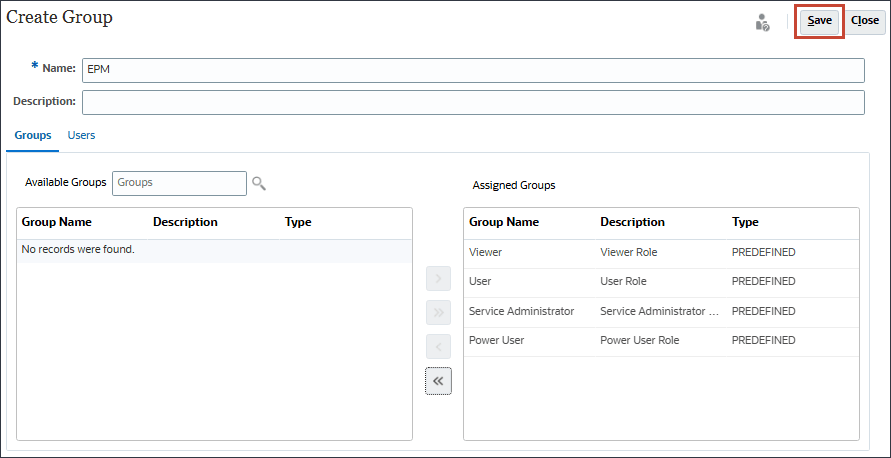
- ホーム・ページで、「ツール」、「アクセス制御」の順にクリックします。
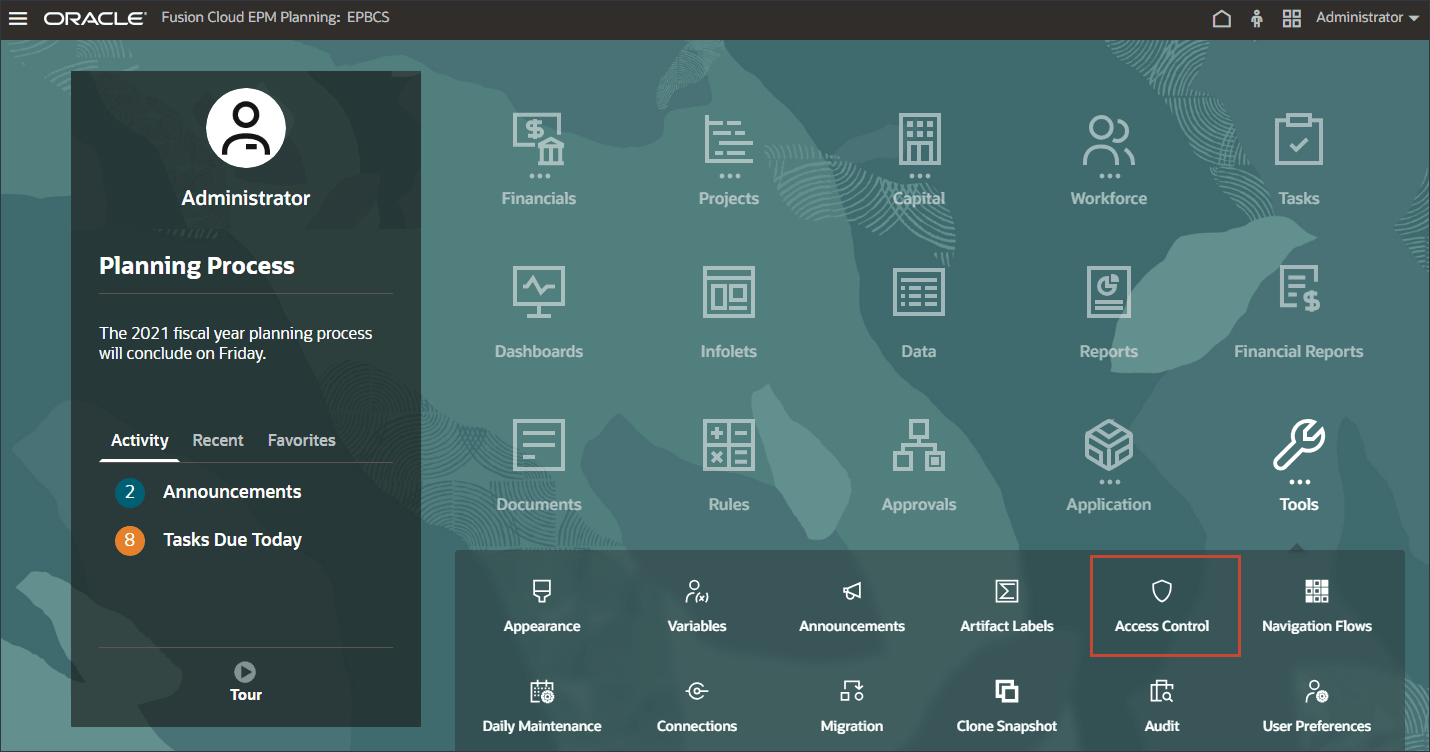
- 「グループの管理」で、「作成」をクリックします。
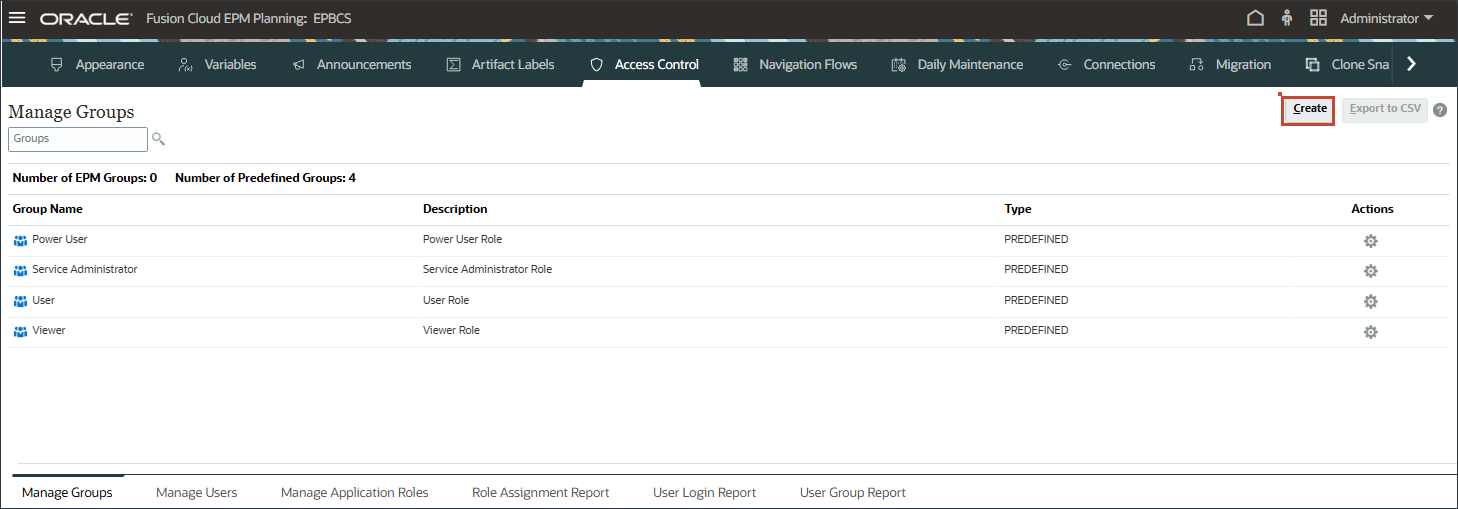
- 「グループの作成」で、「名前」にEPMと入力します。
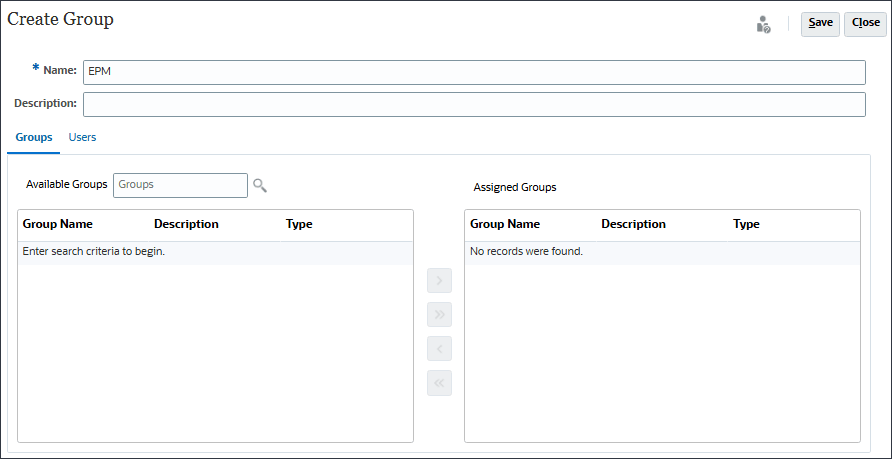
- 「グループ」が選択された状態で、「使用可能なグループ」の横にある
 (検索)をクリックします。
(検索)をクリックします。
使用可能なグループがリストされます。
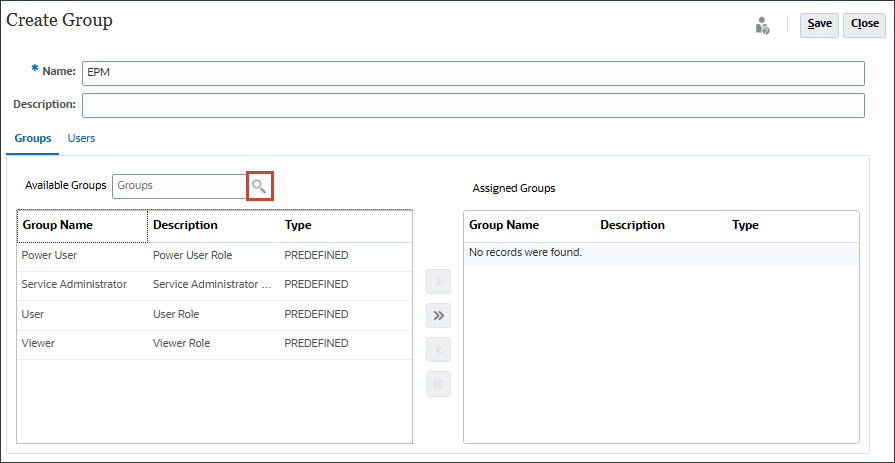
- すべての事前定義済ロールを移動するには、
 (「すべて移動」)をクリックします。
(「すべて移動」)をクリックします。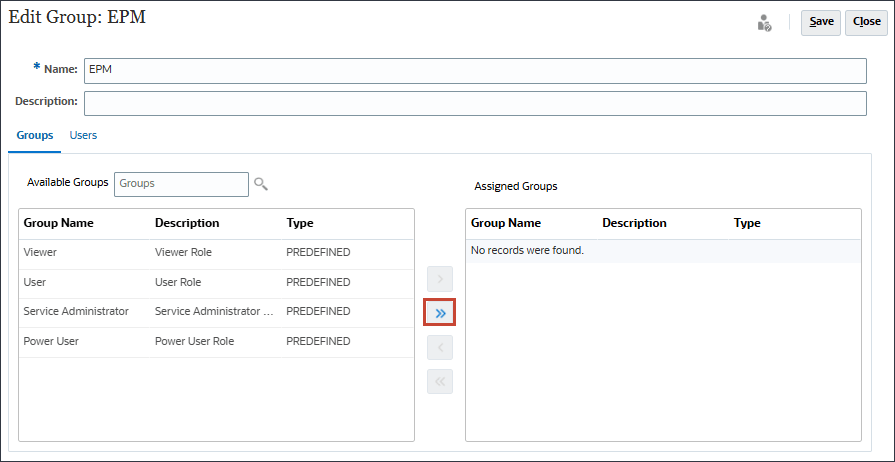
- 「保存」をクリックします。
- 情報メッセージで、「OK」をクリックします。

- EPMが「グループの管理」にリストされていることを確認します。
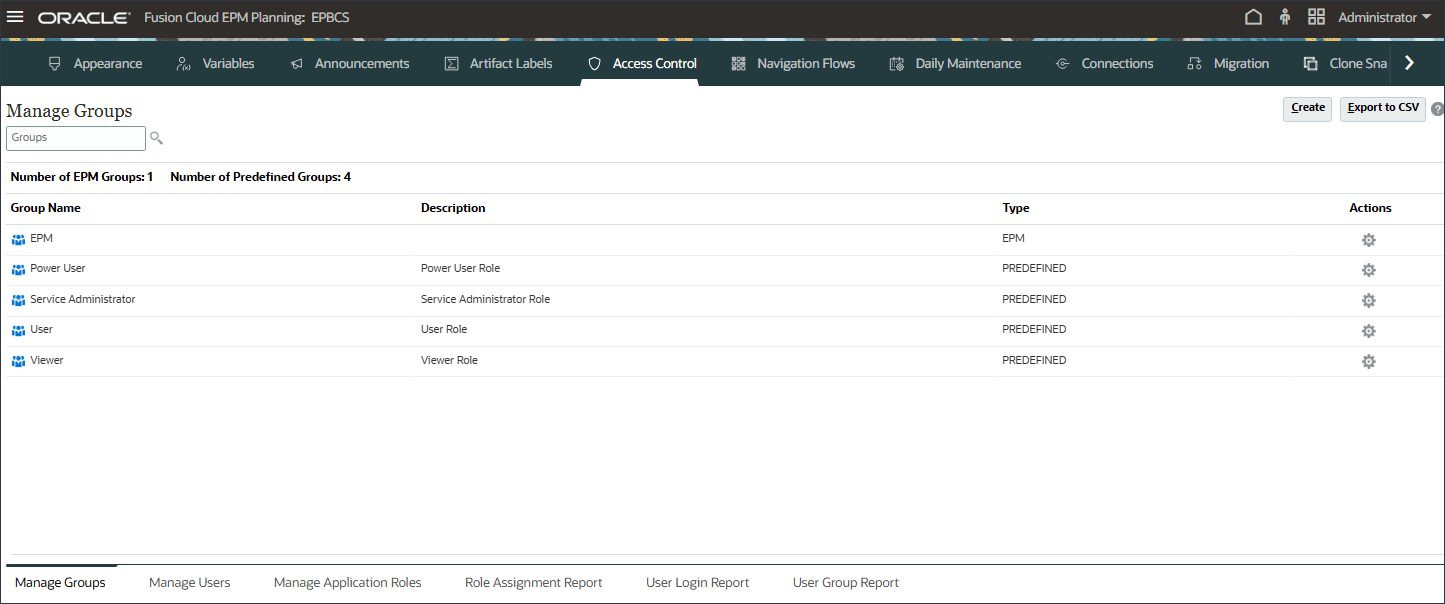
- (ホーム)をクリックして、ホーム・ページに戻ります。
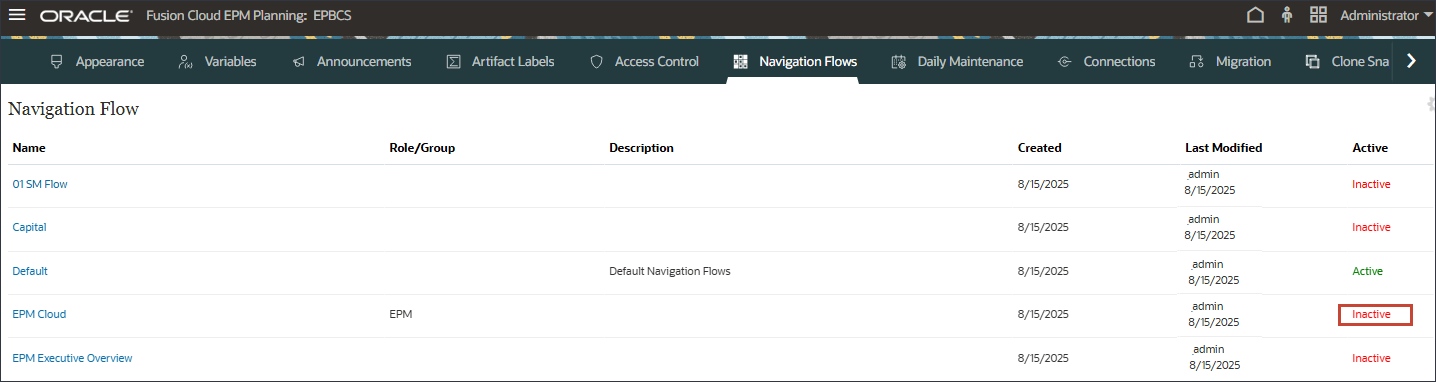
- ホーム・ページで「ツール」をクリックし、「ナビゲーション・フロー」をクリックします。
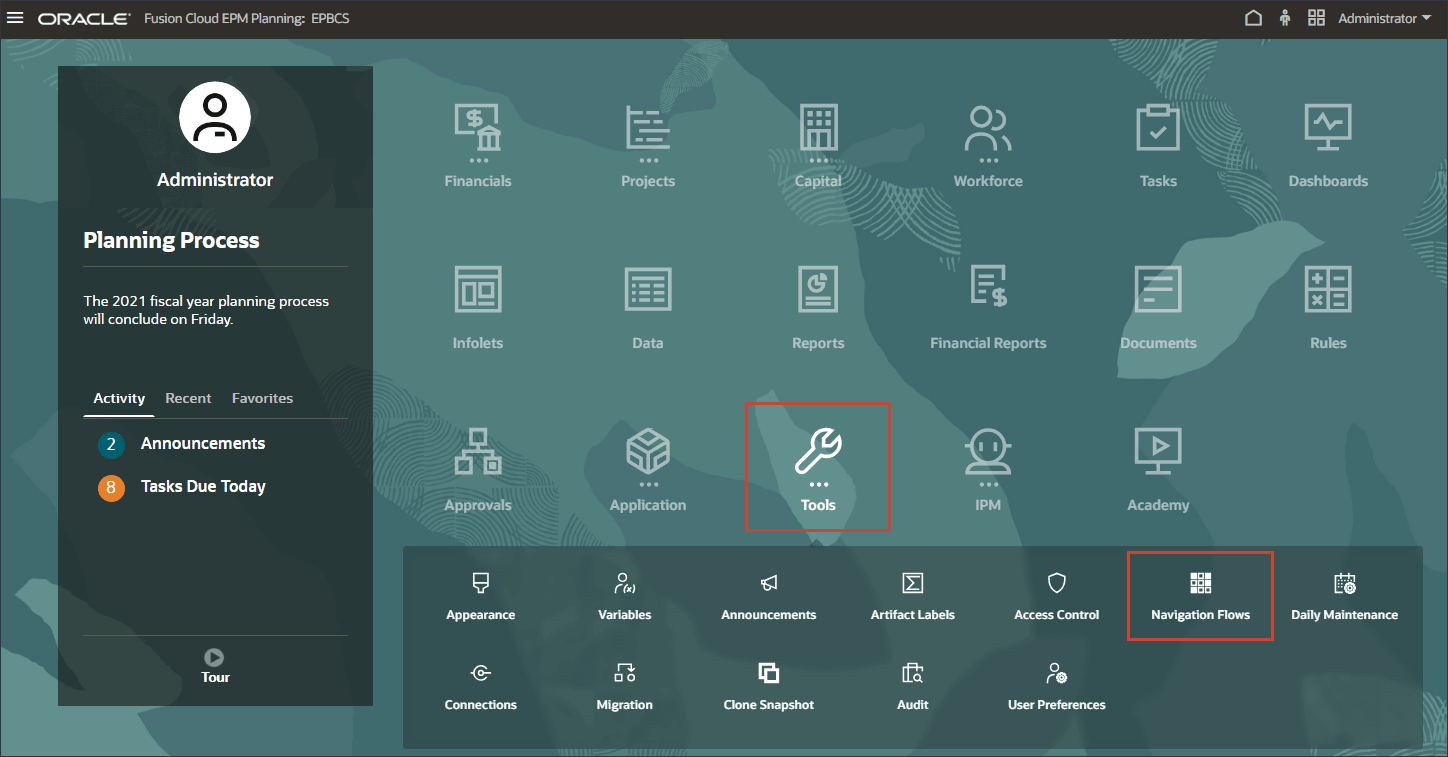
- ナビゲーション・フローで、EPM Cloudが「非アクティブ」に設定されていることを確認し、「EPM Cloud」をクリックします。
- EPM Cloudで、「割当て先」にEPMと入力し、「保存してクローズ」をクリックします。
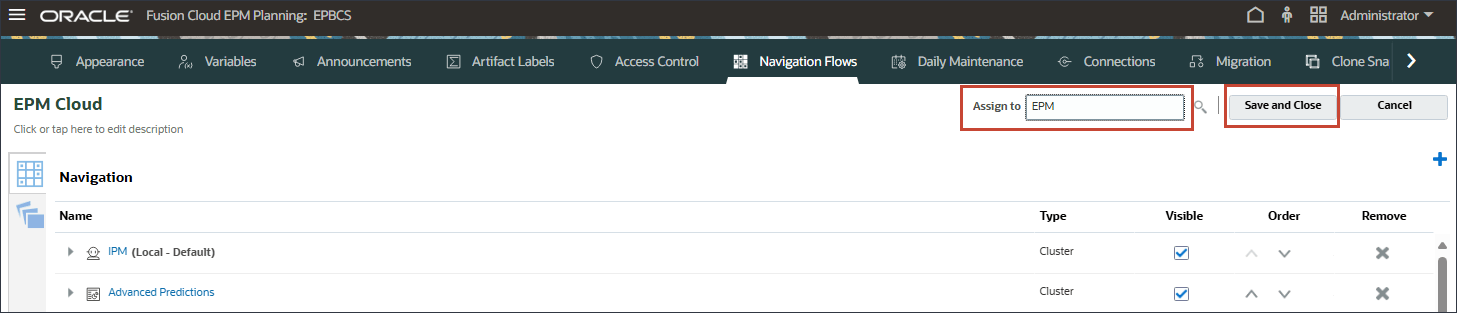
- EPM Cloudで、「非アクティブ」をクリックしてEPM Cloudナビゲーション・フローをアクティブ化します。
- (ホーム)をクリックして、ホーム・ページに戻ります。
EPM Cloudナビゲーション・フローへのEPMグループの割当て
高度な予測の準備
この項では、拡張予測を構成する前にエンド・ユーザーのステップを完了します。ユーザー変数が設定されていることを確認し、EPM Cloudナビゲーション・フローを選択します。ボリューム分析ダッシュボードも確認します。入力ドライバを確認および編集します。将来期間の入力ドライバの欠落値をレビューし、予測フォームをレビューします。
ユーザー変数の設定
フォームおよびダッシュボードでデータを表示できるように、ユーザー変数を設定します。
- ホーム・ページで、「ツール」をクリックし、「ユーザー・プリファレンス」をクリックします。
- 「ユーザー変数」をクリックします。
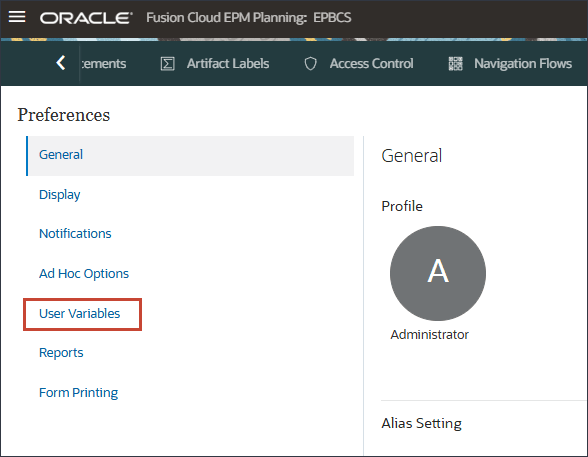
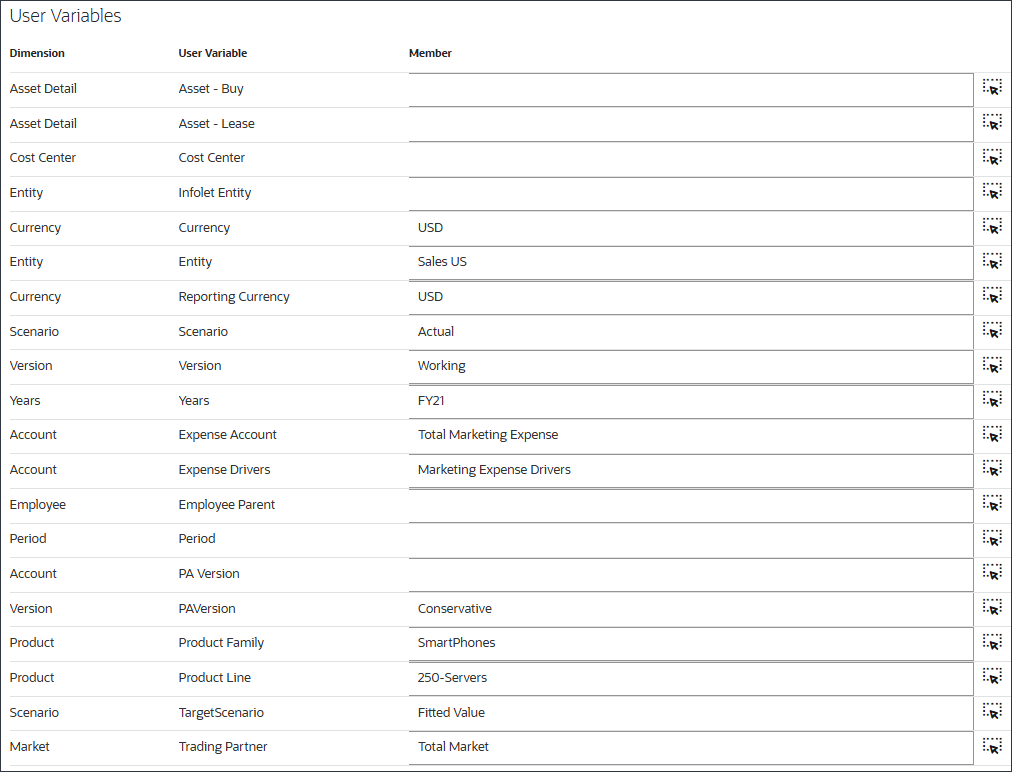
- ユーザー変数の場合は、次を入力または選択し、「保存」をクリックします。
Dimension ユーザー変数 メンバー 通貨 通貨 USD エンティティ エンティティ 米国営業 通貨 レポート通貨 USD Scenario Scenario 実績 Version Version 作業中 年 年 FY21 勘定科目 費用勘定 マーケティング費用合計 勘定科目 費用ドライバ マーケティング費用ドライバ Version PAバージョン 保守的 製品 製品ファミリ SmartPhones 製品 製品ライン 250-Servers Scenario TargetScenario 適合値 Market 取引パートナ 市場合計 ユーザー変数が選択されます。
- 情報メッセージで、「OK」をクリックします。
- (ホーム)をクリックして、ホーム・ページに戻ります。
ナビゲーション・フローの選択
ボリューム予測をレビューできるように、拡張予測のカードを含むEPM Cloudナビゲーション・フローを選択します。
- ホーム・ページで、
 (デフォルト)をクリックし、「EPM Cloud」を選択します。
(デフォルト)をクリックし、「EPM Cloud」を選択します。
EPM Cloudのナビゲーション・フローが表示されます。

- EPM Cloudのナビゲーション・フローで、「拡張予測」カードを確認します。
- 「拡張予測」をクリックします。
これは、拡張予測を使用して生成された予測をレビューできるナビゲーション・フローです。
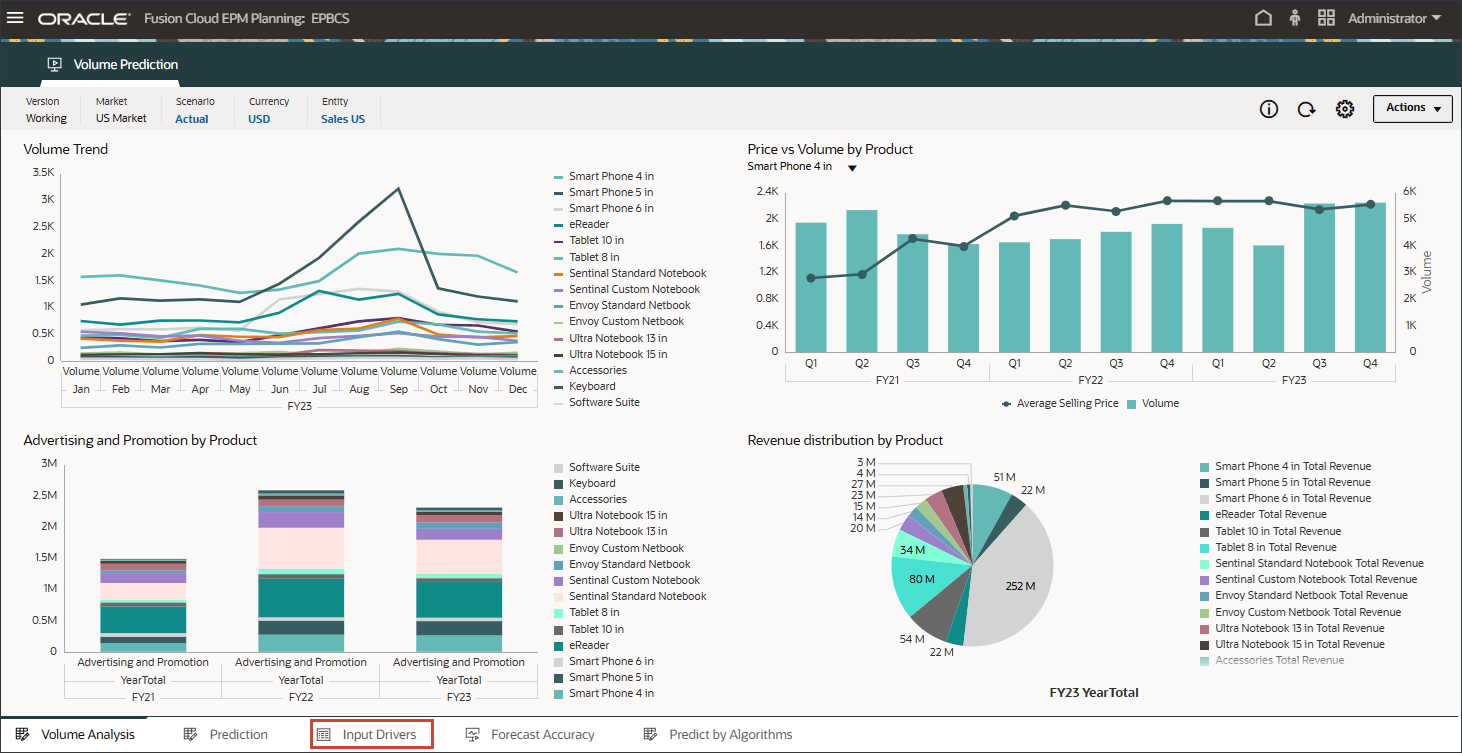
ボリューム予測の確認
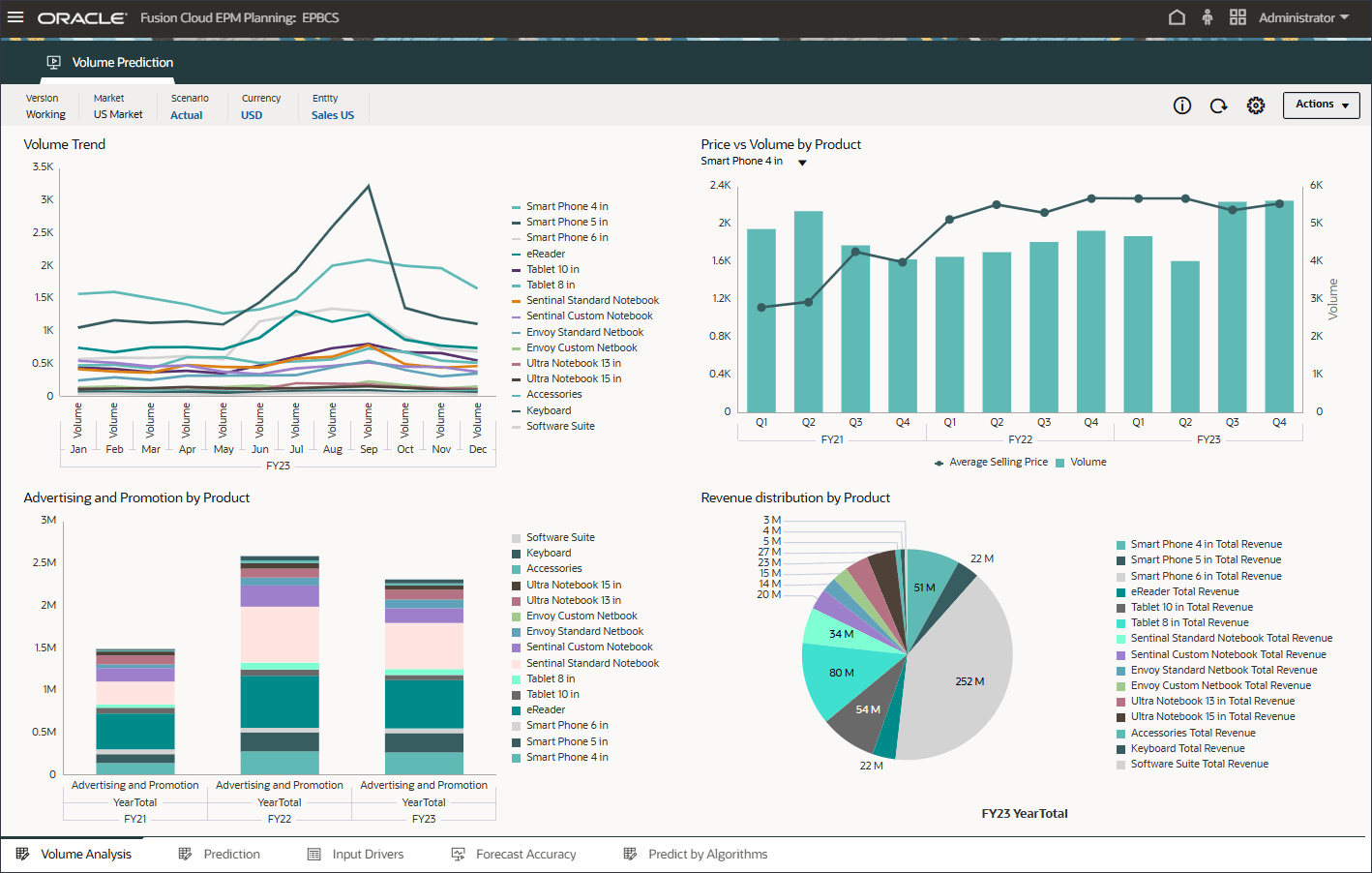
ボリューム予測を作成して実行する前に、このユース・ケース用に準備された履歴データとともにボリューム予測ダッシュボードを確認します。期間別のボリューム分析およびその他のドライバを表示するように設定されているボリューム予測カードを使用します。このカードには、ドライバ値および予測結果を表示するように設定されているタブも含まれています。
- ホーム・ページで、「拡張予測」、「ボリューム予測」の順にクリックします。
- ボリューム・トレンド、製品別価格vsボリューム、製品別広告およびプロモーション、製品別収益配分などのボリューム予測をレビューします。
- 下部の「予測」タブをクリックします。
- 上部の棒グラフで、履歴ボリューム予測を確認します。
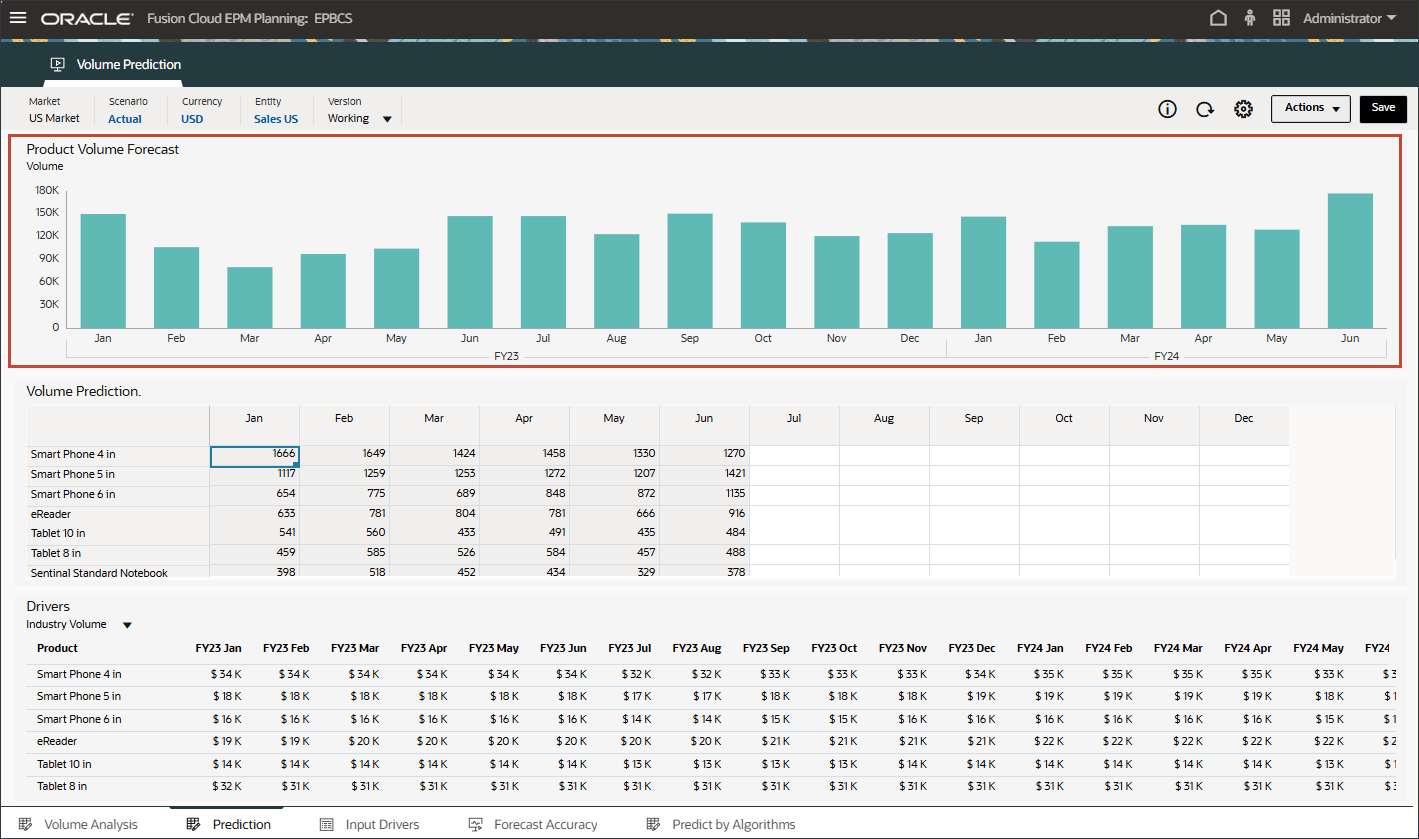
- 下部の「ドライバ」グリッドで、高度な予測で使用されるドライバ・データを確認します。これには、履歴および将来のドライバ・データの両方が含まれます。
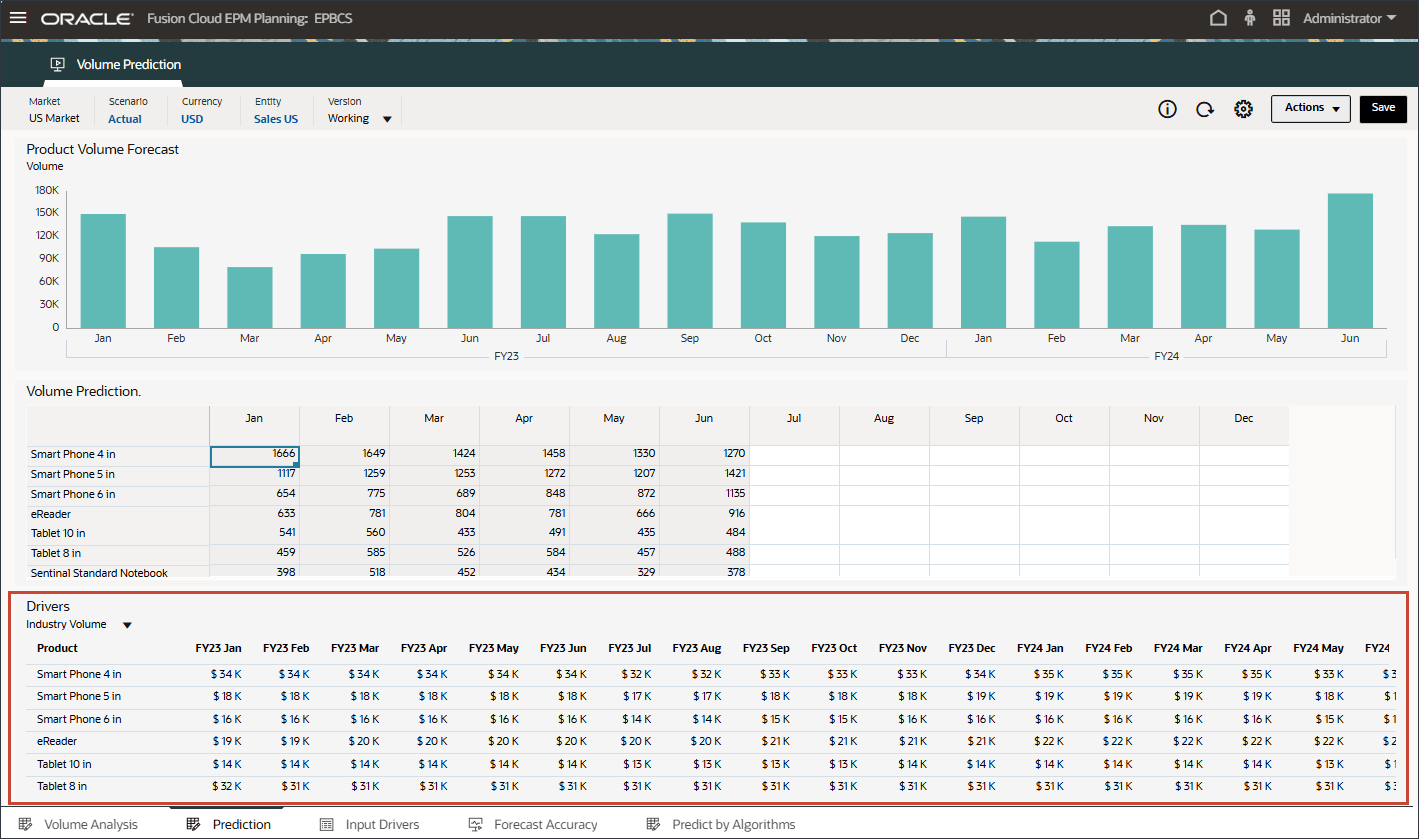
ドライバの実績データの履歴は、統合によって異なるシステムから取得できますが、将来のドライバ・データは、ドライバ/トレンド/手動ベースなどの従来の予測方法で導出することも、拡張予測ジョブの設定に基づいて、単変量予測(統計的方法)を使用して入力ドライバ・データを自動的に生成することもできます。
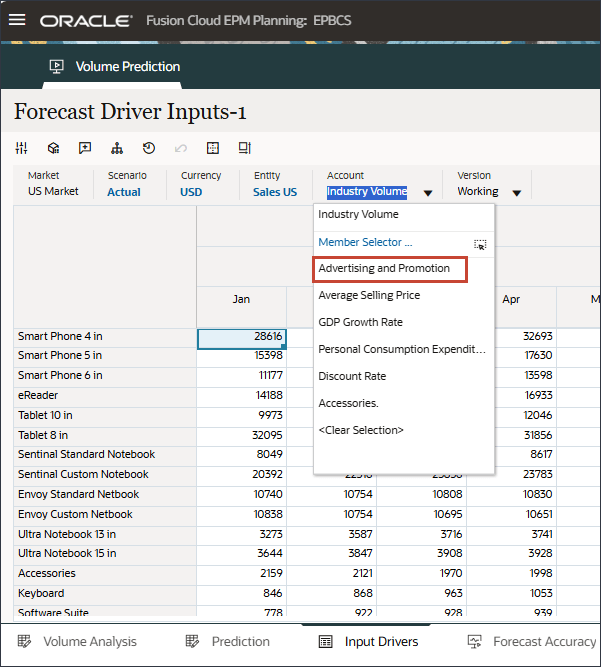
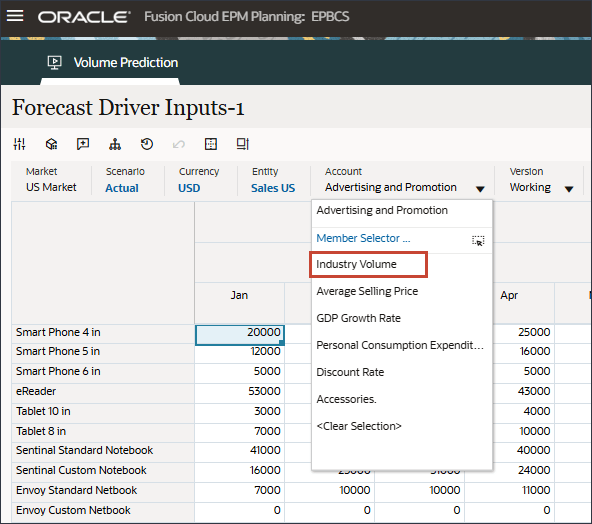
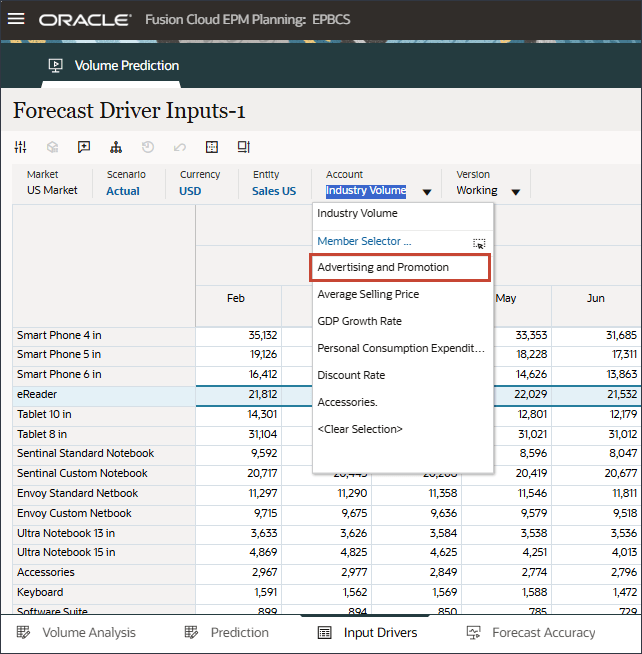
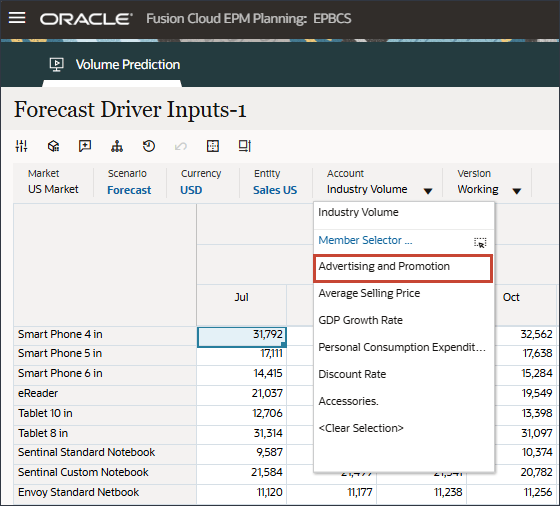
- ドライバで、「Industry Volume」をクリックしてドライバを確認します。次に、ドライバを確認した後、「Industry Volume」を再度クリックしてリストを閉じます。
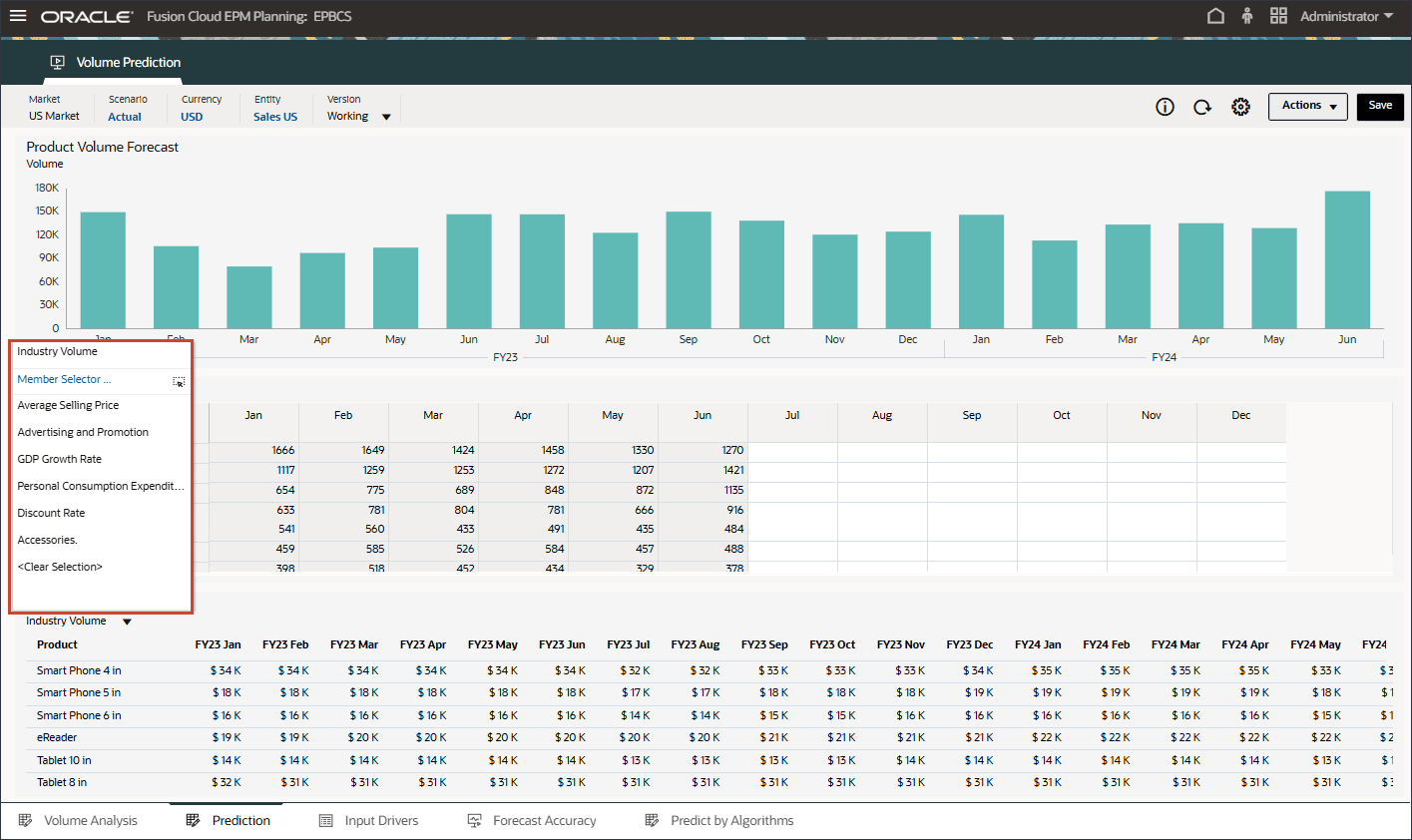
平均販売価格、広告およびプロモーション、割引率など、いくつかのドライバのいずれかを選択できます。
- 「ドライバ」グリッドで、
 (アクション)をクリックし、「最大化」を選択します。
(アクション)をクリックし、「最大化」を選択します。
- Industry Volumeの過去と将来の両方のデータの入力ドライバを確認します。
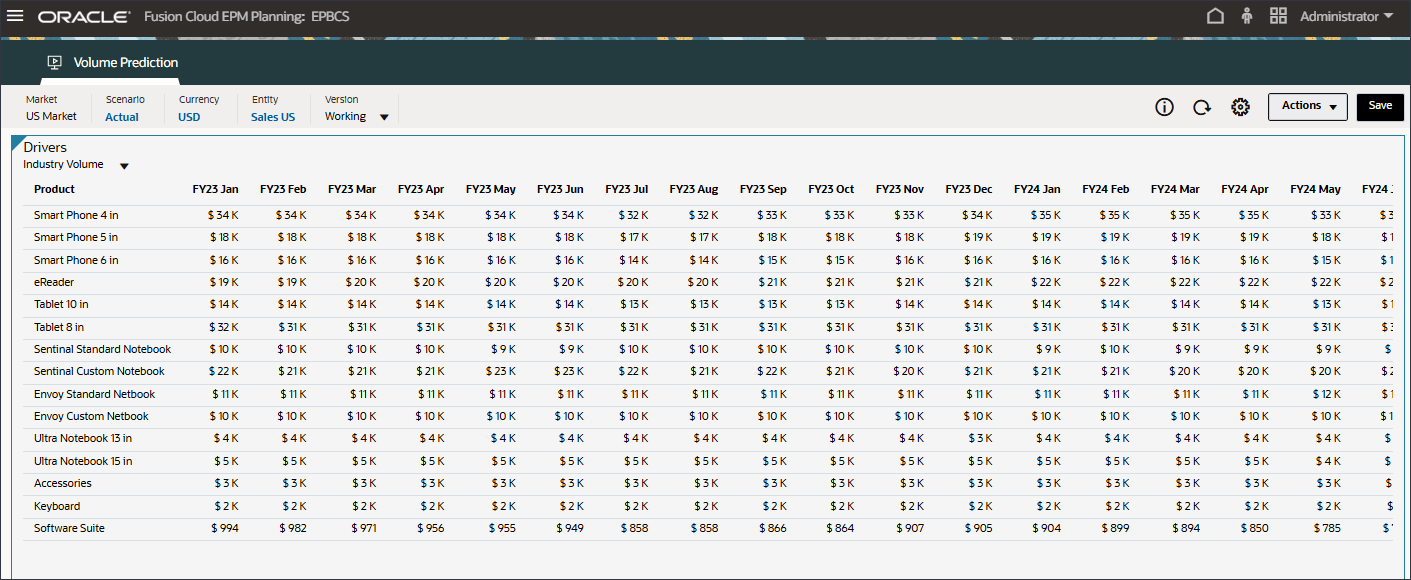
- 将来の値を確認するには、右にスクロールします。
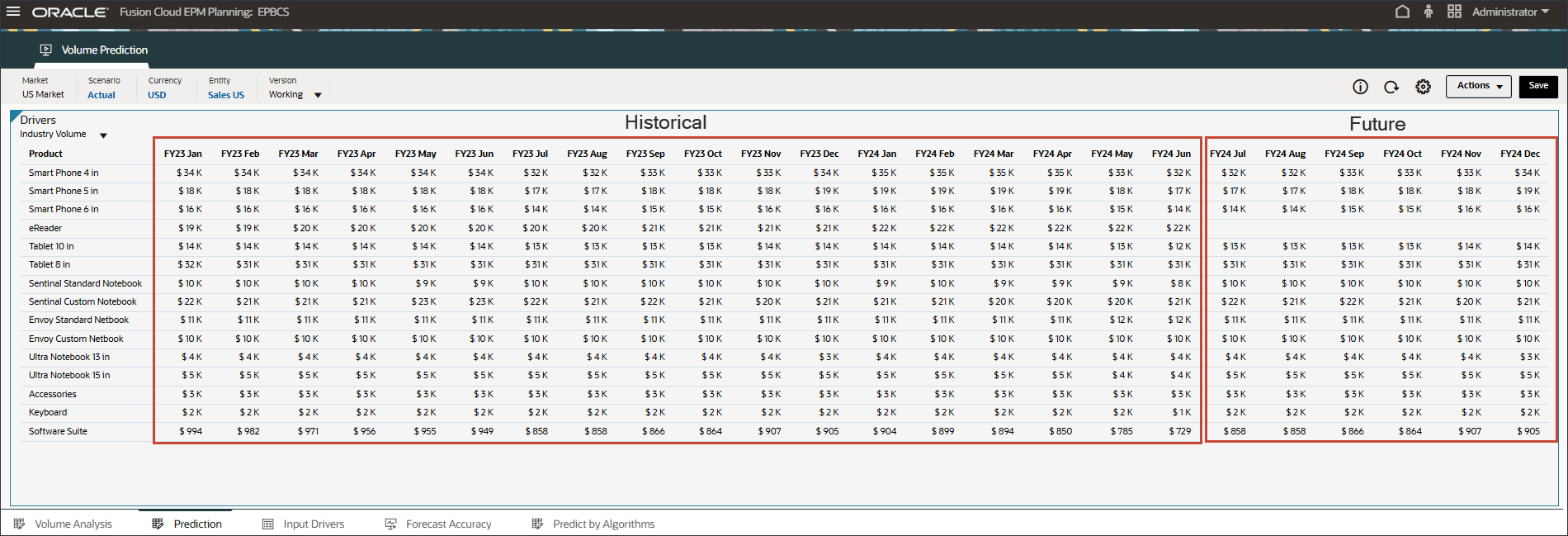
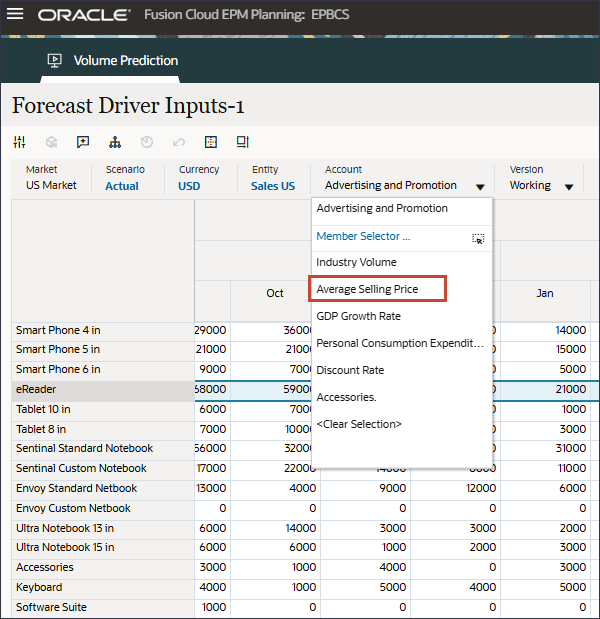
- 「ドライバ」ドロップダウンで、「業種ボリューム」をクリックし、「平均販売価格」を選択します。
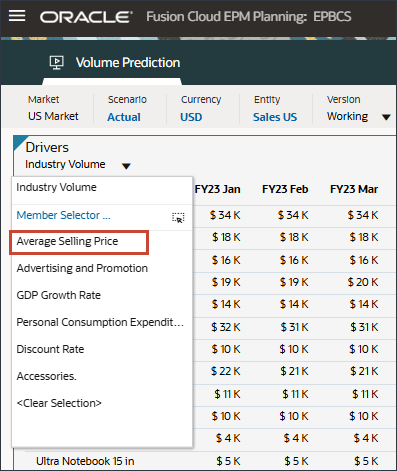
平均販売価格のデータが表示されます。
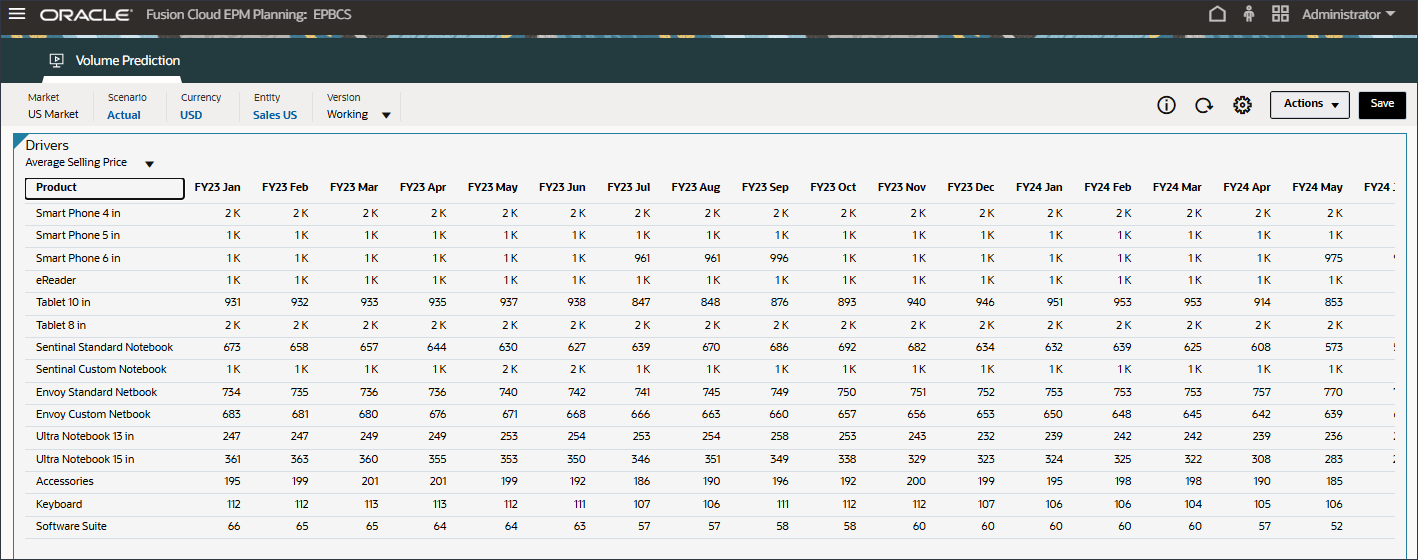
- 「ドライバ」ドロップダウンで、「平均販売価格」をクリックし、「広告およびプロモーション」を選択します。
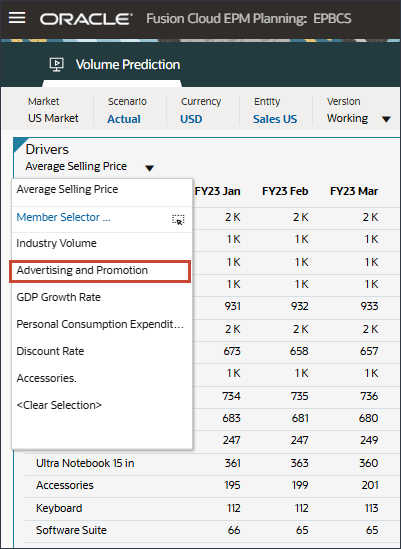
広告およびプロモーションのデータが表示されます。
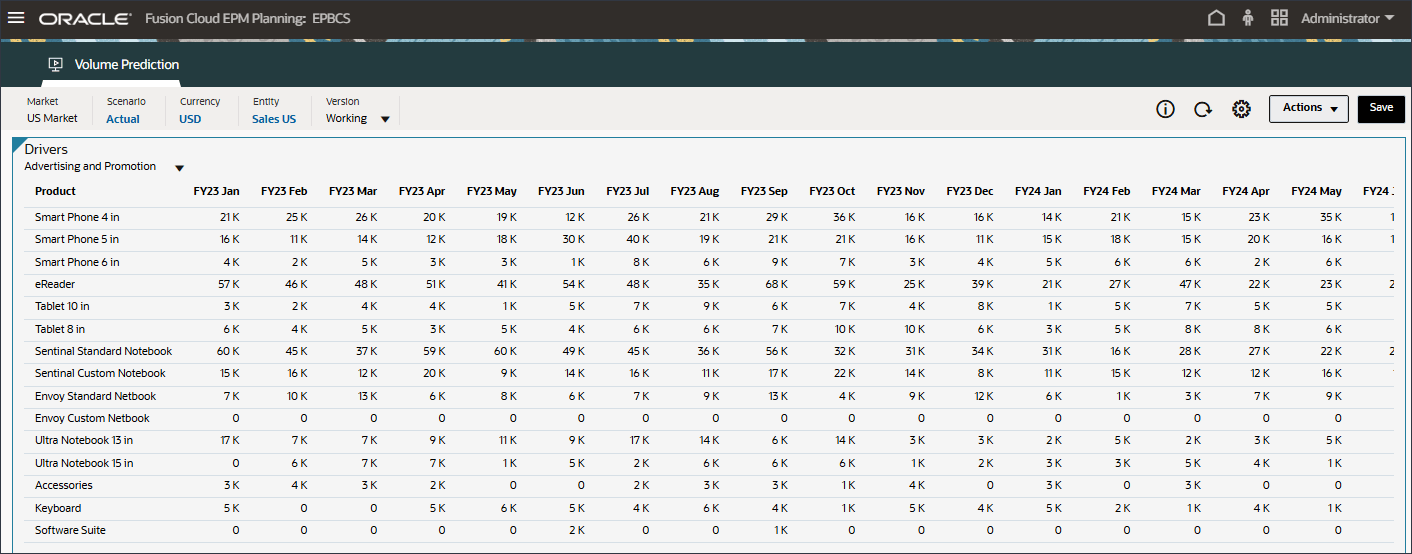
- 「ドライバ」ドロップダウンで、「広告およびプロモーション」をクリックし、「GDP成長率」を選択します。
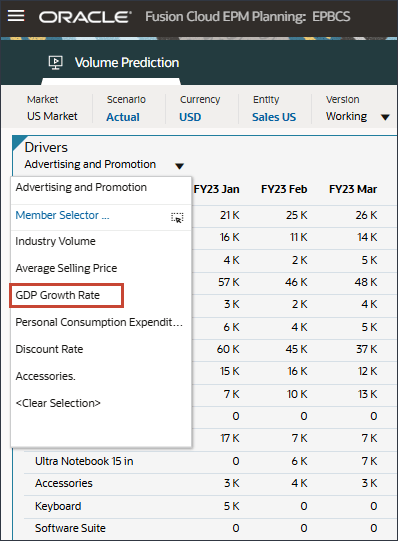
GDP成長率のデータが表示されます。
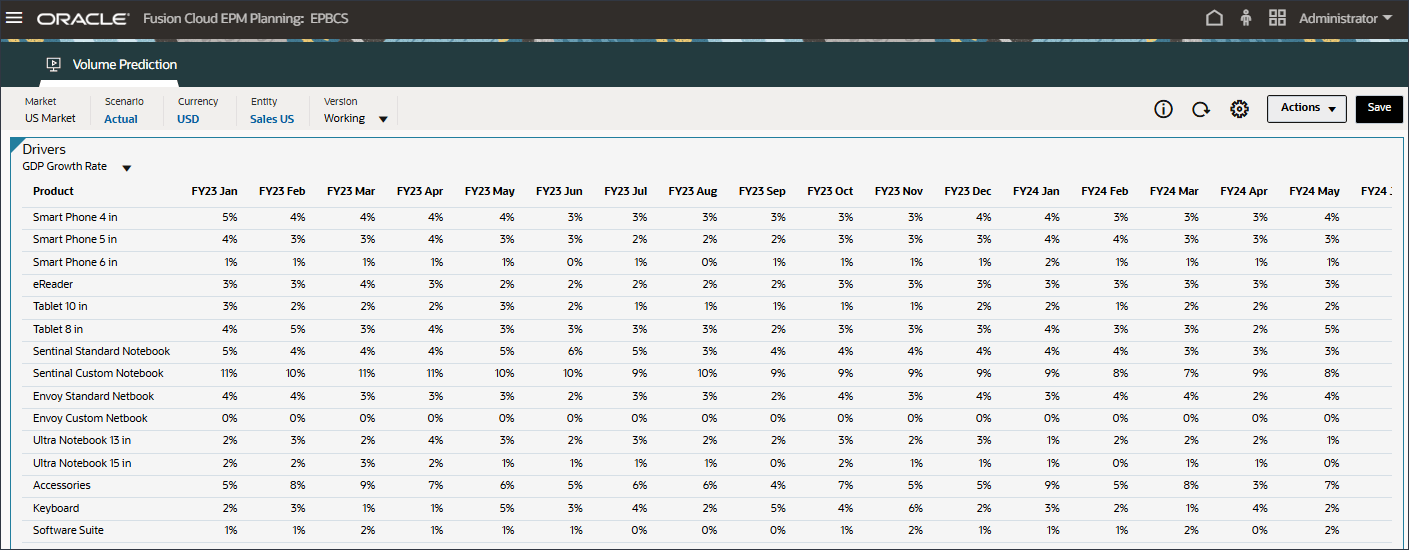
- 「ドライバ」ドロップダウンで、「GDP成長率」をクリックし、「個人消費支出(耐久消費財)」を選択します。
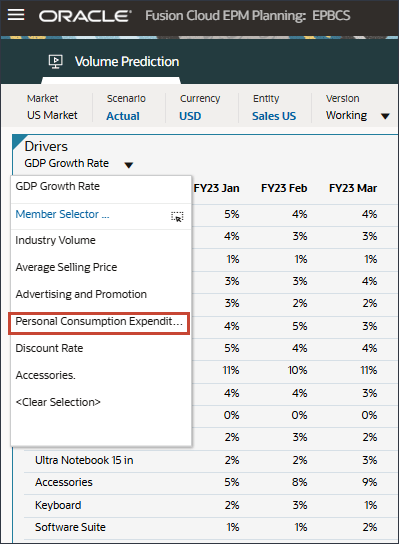
個人消費支出(Durable Goods)のデータが表示されます。
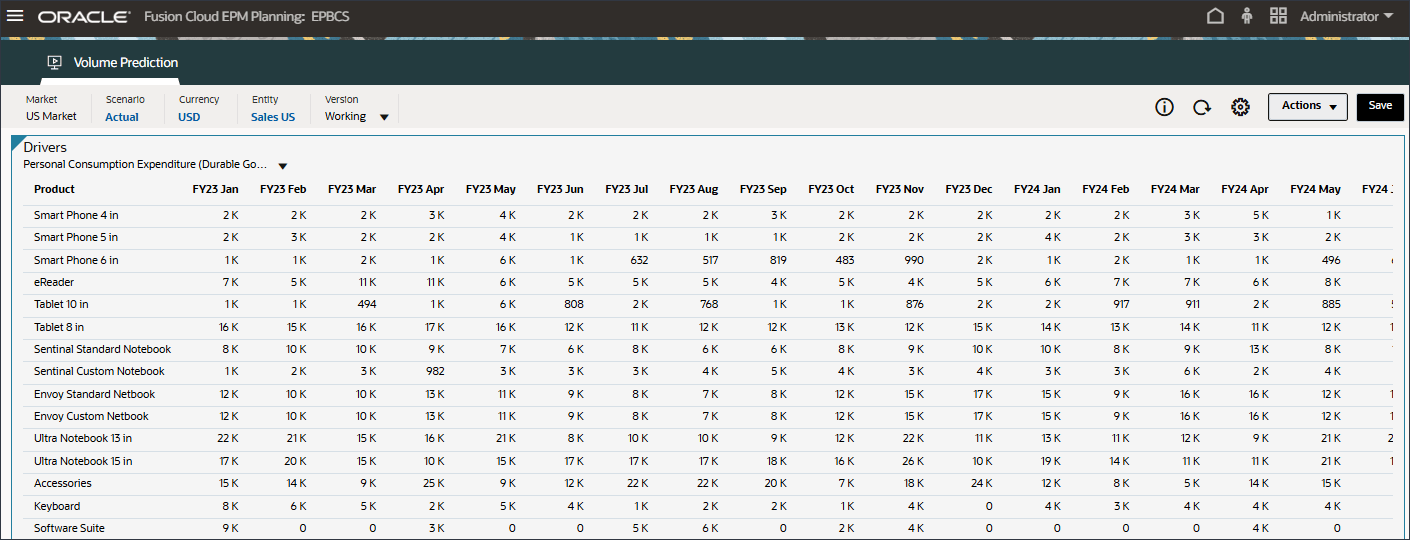
- 「ドライバ」ドロップダウンで、「個人消費支出(耐久消費財)」をクリックし、「割引率」を選択します。
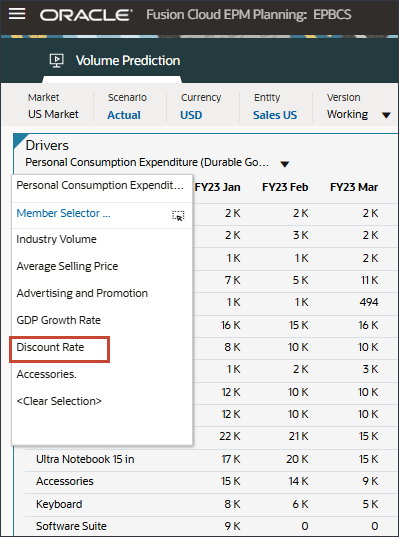
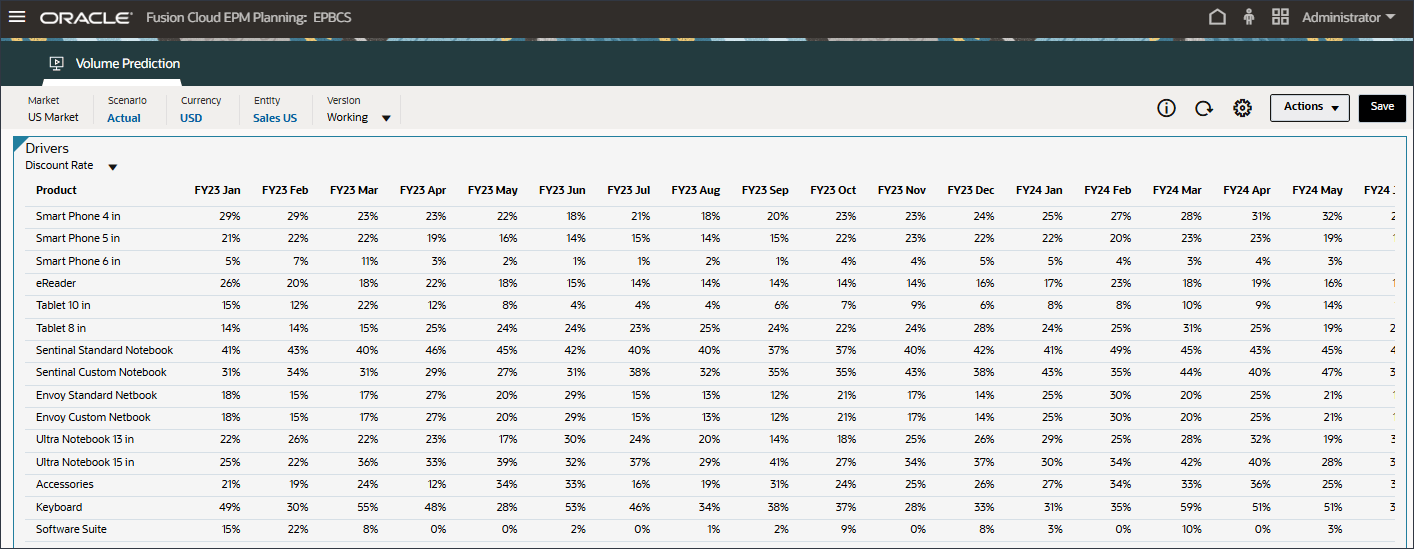
割引率のデータが表示されます。
- ページの下部で、「入力ドライバ」タブをクリックします。
予測ドライバ入力が表示されます。
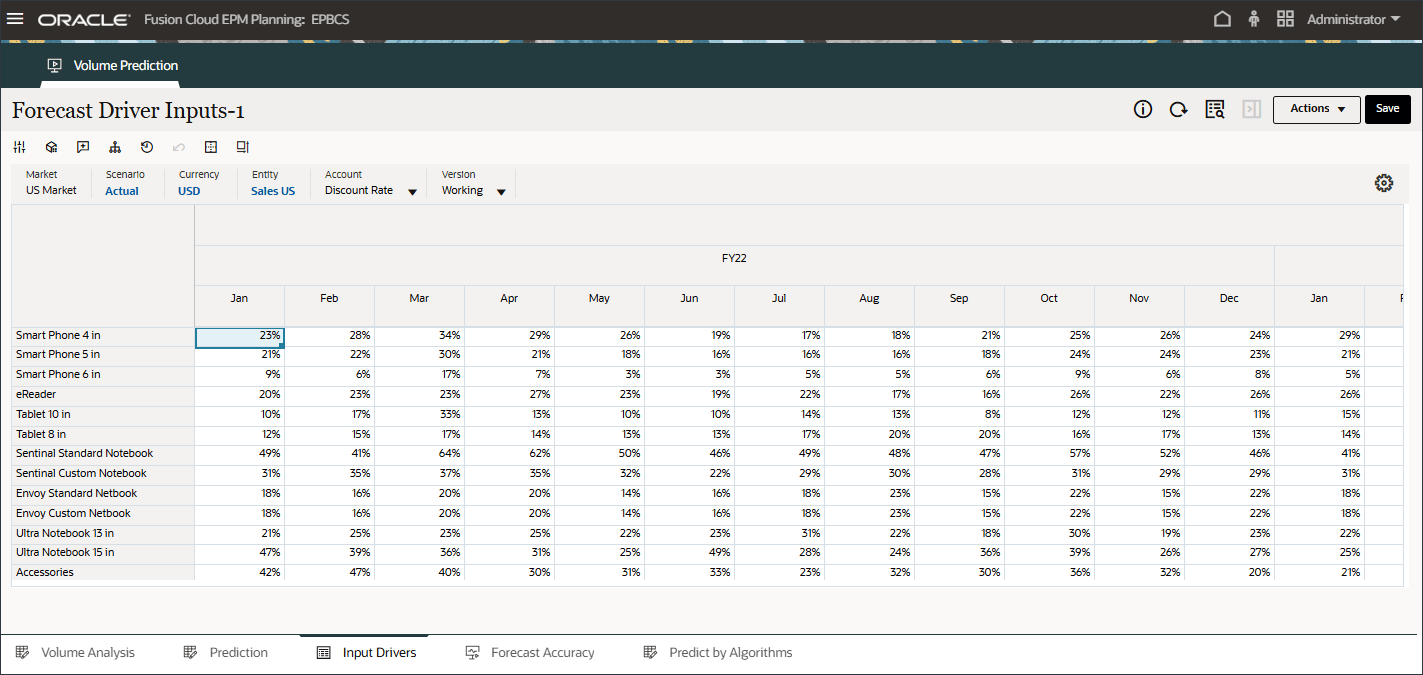
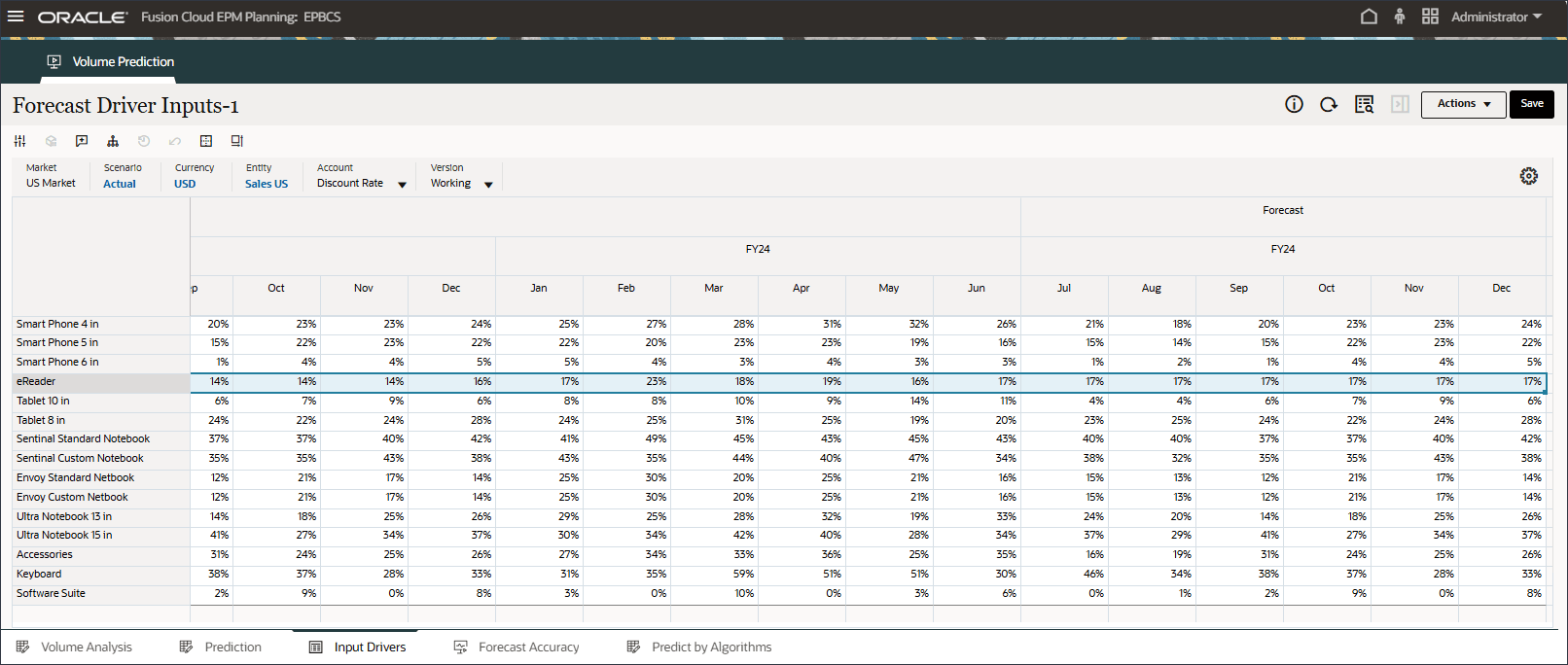
- 「アカウント」で、「割引率」をクリックし、「業種ボリューム」を選択します。
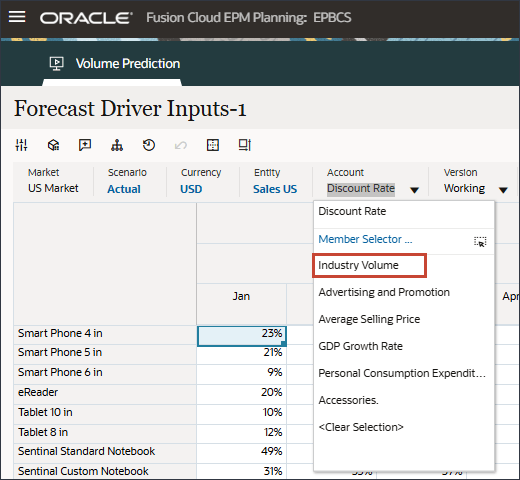
変更を加えた場合は、「保存」をクリックして変更を保存します。
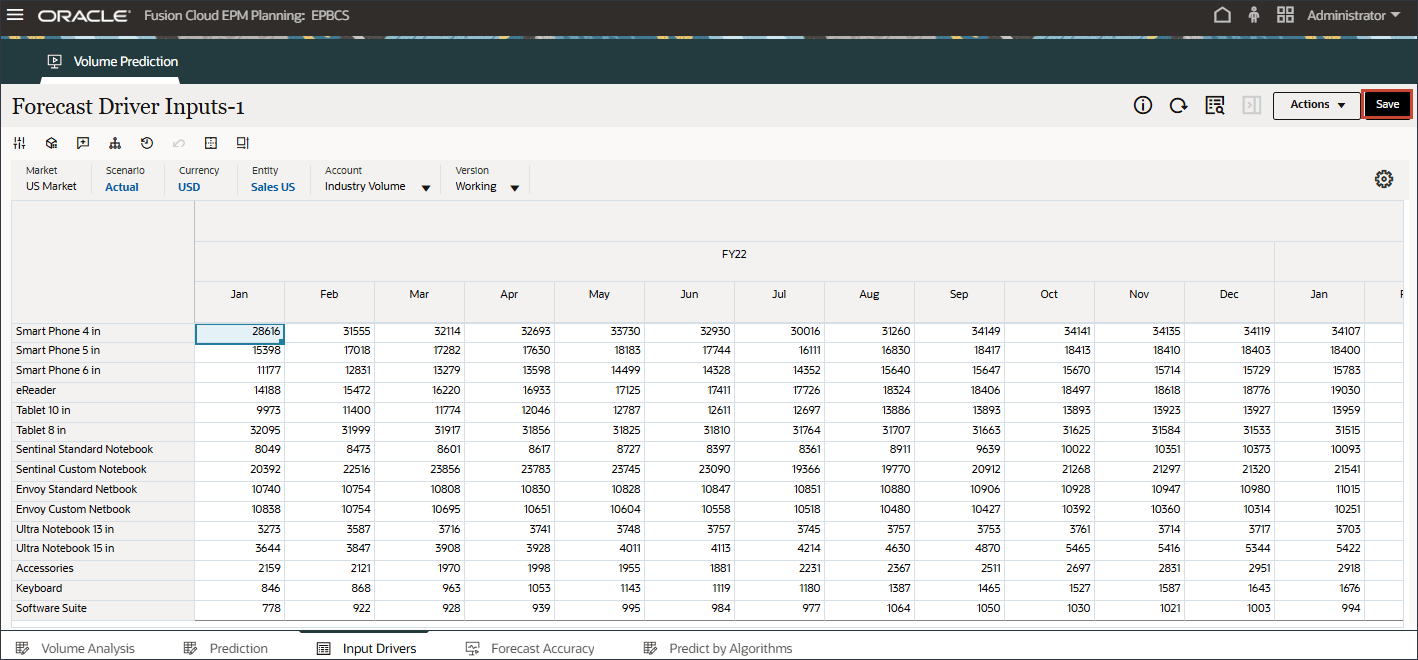
同様に、任意のドライバを選択して編集できます。
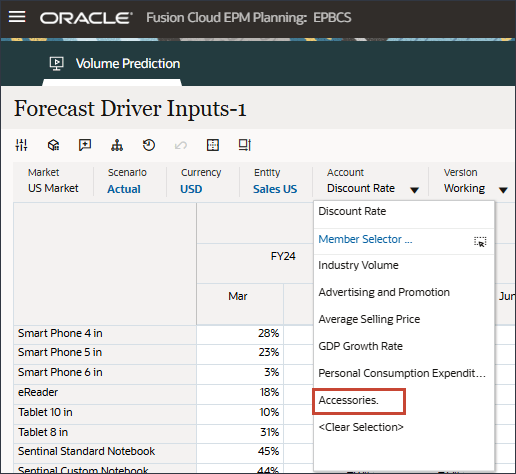
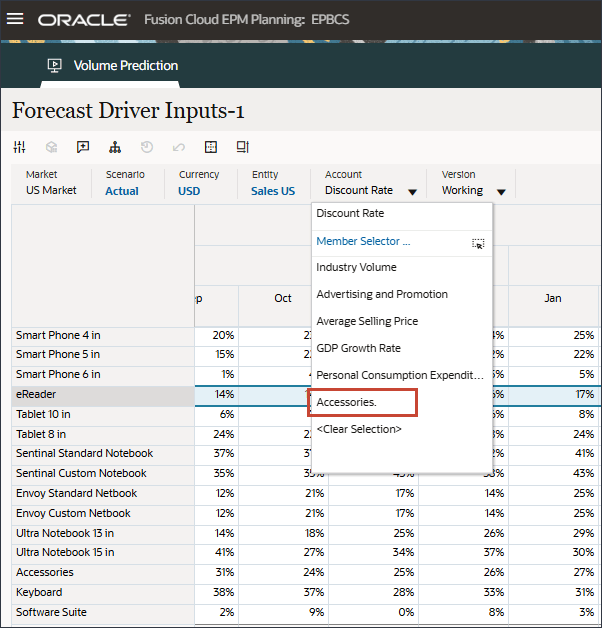
- アカウントで、「インダストリ・ボリューム」をクリックし、「アクセサリ」を選択します。
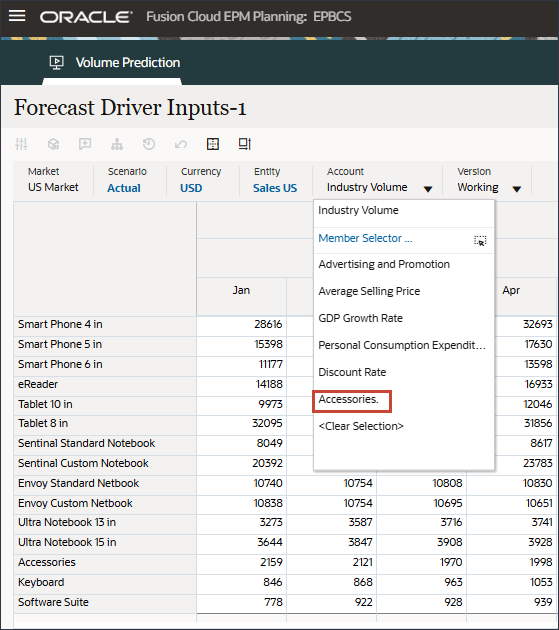
Accessoriesドライバはスマート・リストを使用します。データ・サイエンスでは、これはカテゴリ変数と呼ばれます。将来の販売量を計算するには、数値またはスマート・リスト値を使用できます。この場合、選択したスマート・リスト値(アクセサリの有無にかかわらず)に応じて、将来の販売量の予測に影響を与える可能性があります。
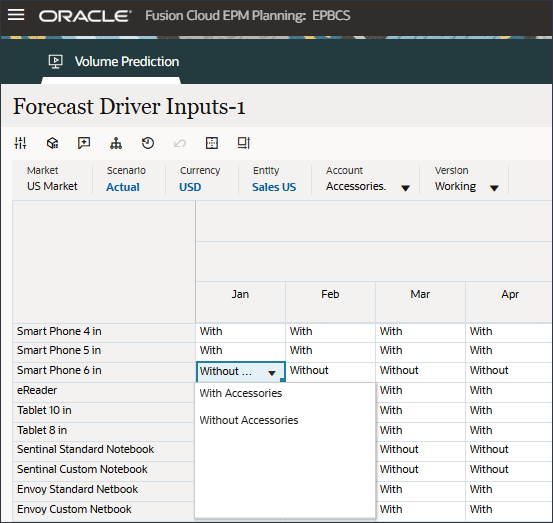
- アカウントで、「アクセサリ」をクリックし、「インダストリ・ボリューム」を選択します。
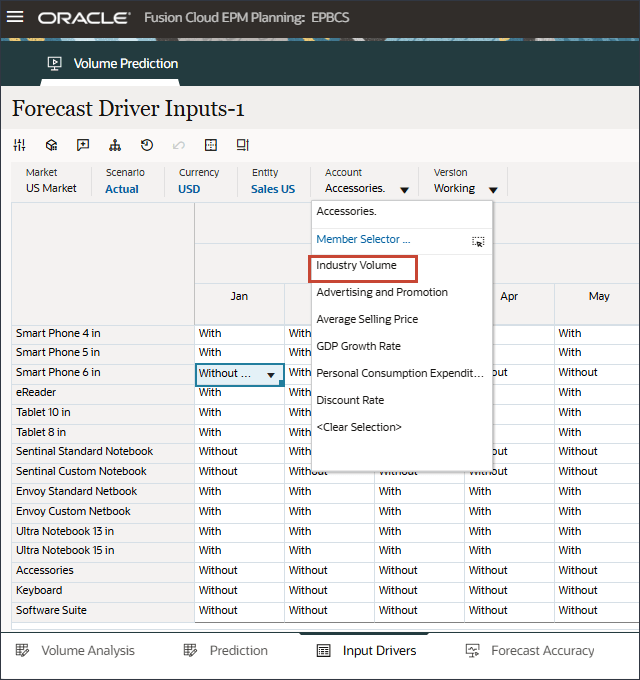
- 右にスクロールし、eReaderの「Forecast」で、7月から12月までの業界ボリュームの値が欠落していることを確認します。FY24
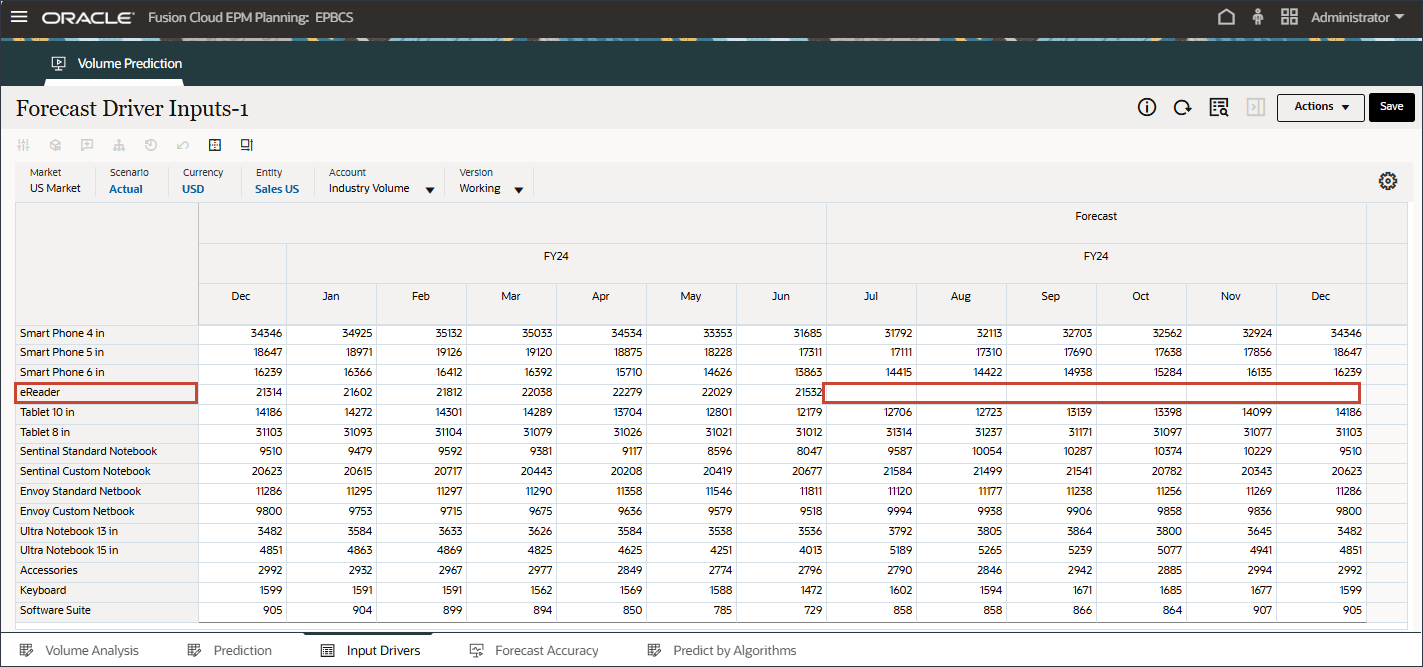
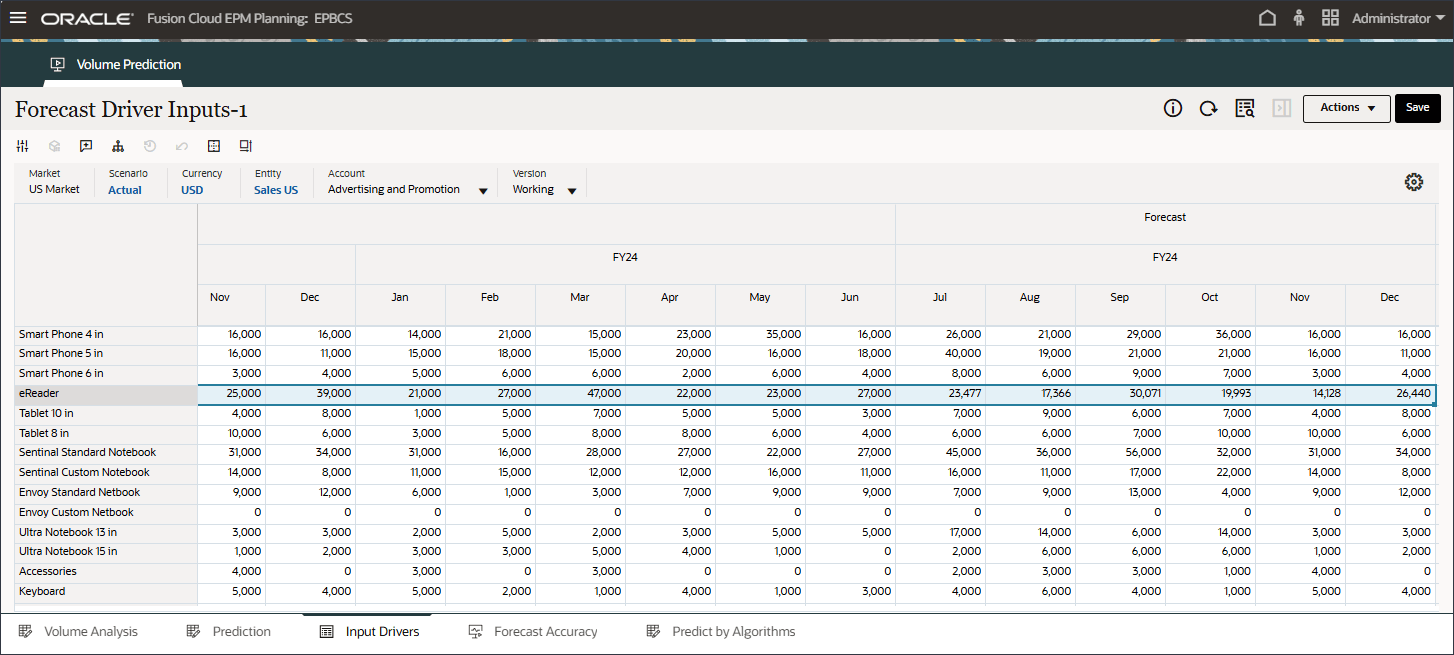
- 「アカウント」で、「業種ボリューム」をクリックし、「広告およびプロモーション」を選択します。
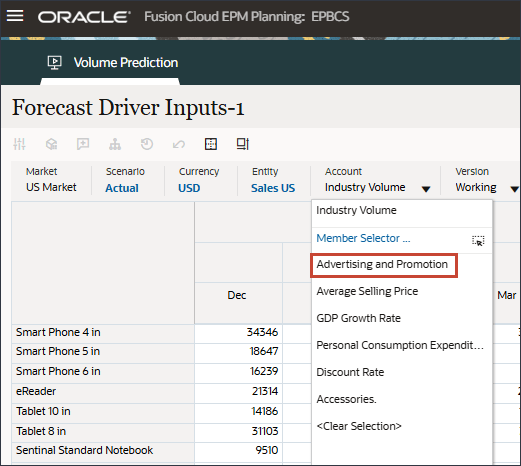
- 右にスクロールし、eReaderの「Forecast」で、7月から12月までのAdvertising and Promotionの値が欠落していることを確認します。FY24
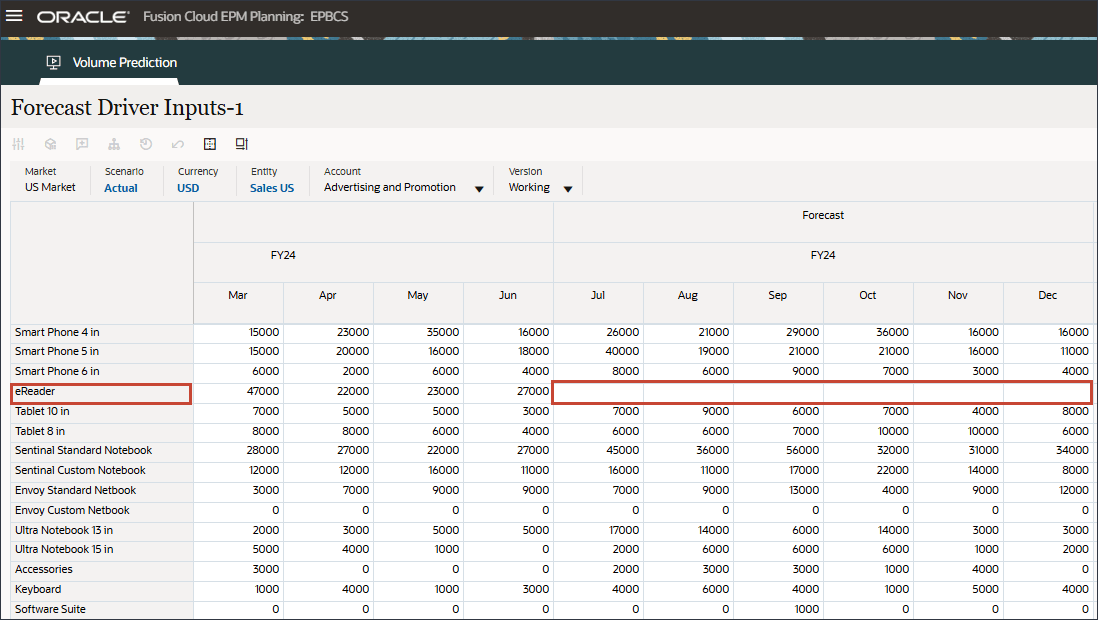
- 「アカウント」で、「広告およびプロモーション」をクリックし、「平均販売価格」を選択します。
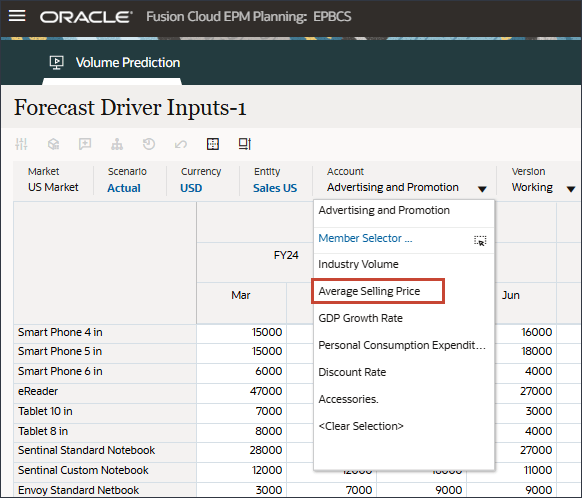
- 右にスクロールし、eReaderの「Forecast」で、7月から12月までの平均販売価格の値が欠落していることを確認します。FY24
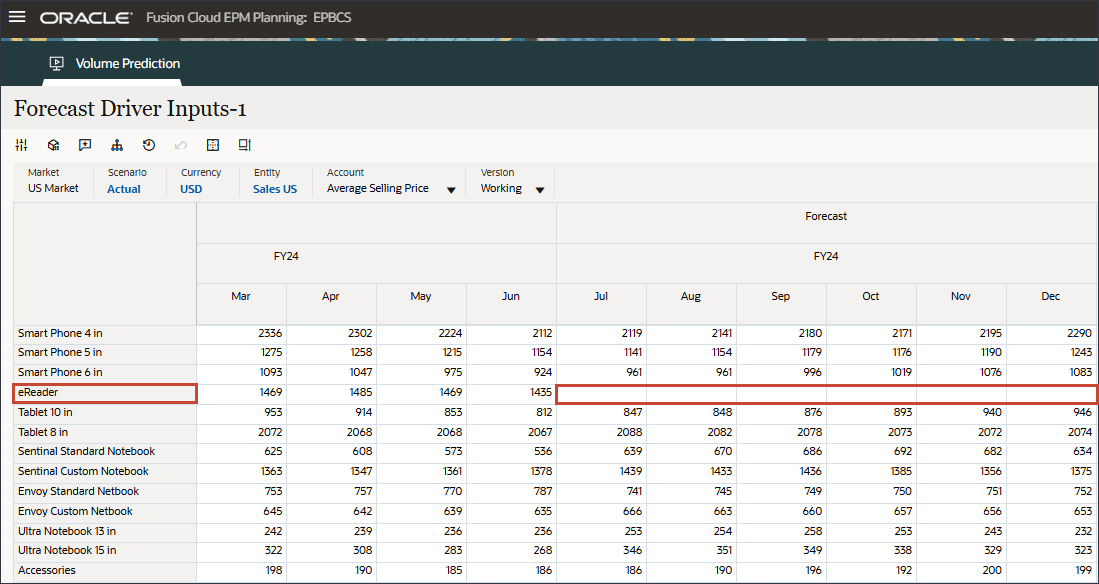
- 「勘定科目」で、「平均販売価格」をクリックし、「個人消費支出(耐久消費財)」を選択します。
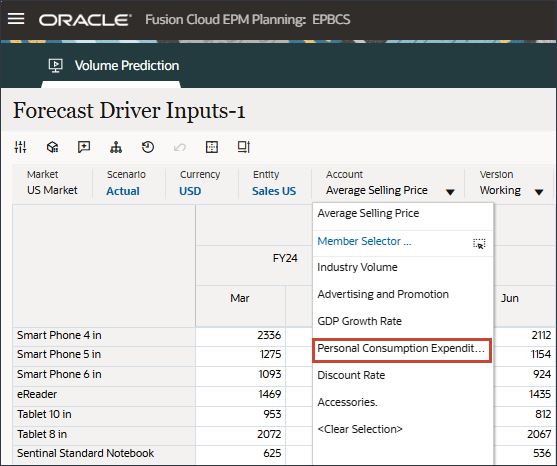
- 右にスクロールし、eReaderの「Forecast」で、7月から12月までの「Personal Consumption Expenditure (Durable Goods)」の値が欠落していることを確認します。FY24
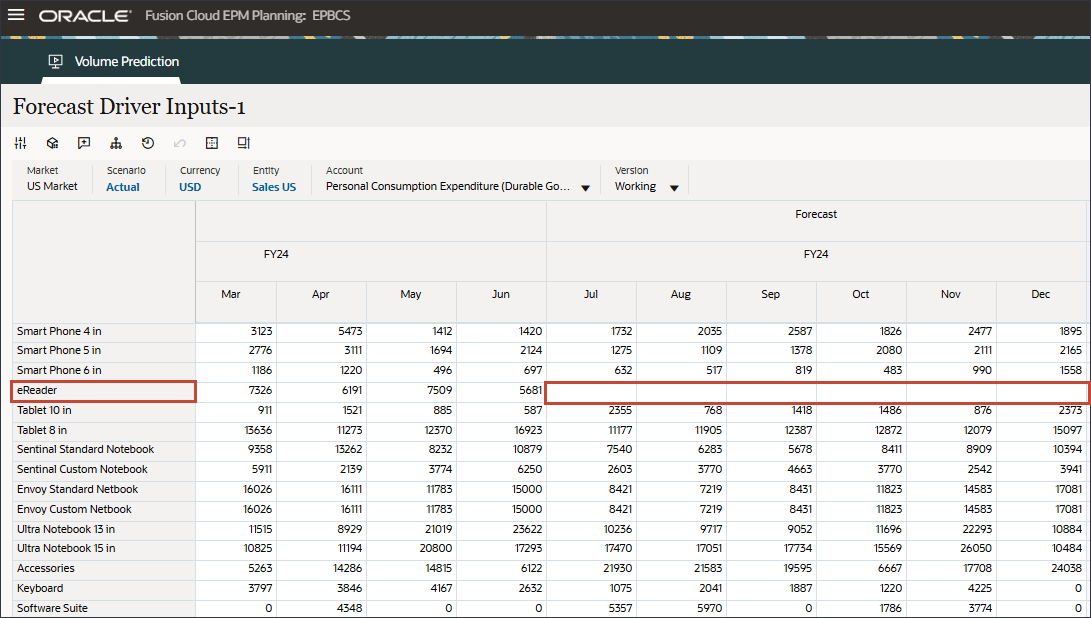
- 「勘定科目」で、「個人消費支出(耐久消費財)」をクリックし、「割引率」を選択します。
- 右にスクロールし、eReaderの「Forecast」で、7月から12月までの割引率の値が欠落していることを確認します。FY24
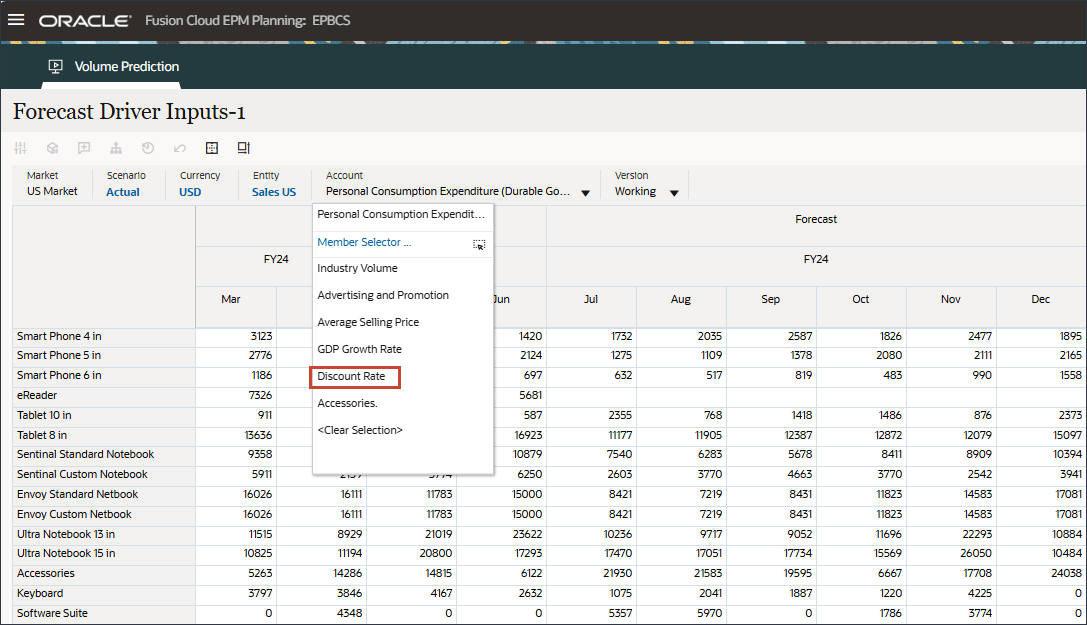
- 「アカウント」で、「割引率」をクリックし、「アクセサリ」を選択します。
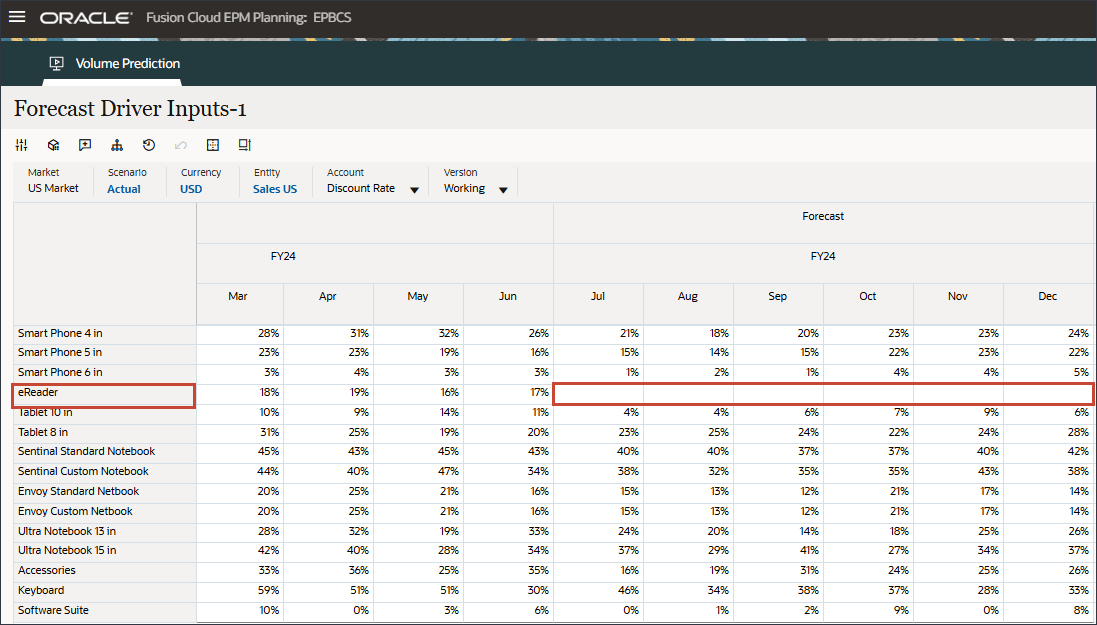
- 右にスクロールし、eReaderの「Forecast」で、7月と12月FY24の間のアクセサリの値が欠落していることを確認します。
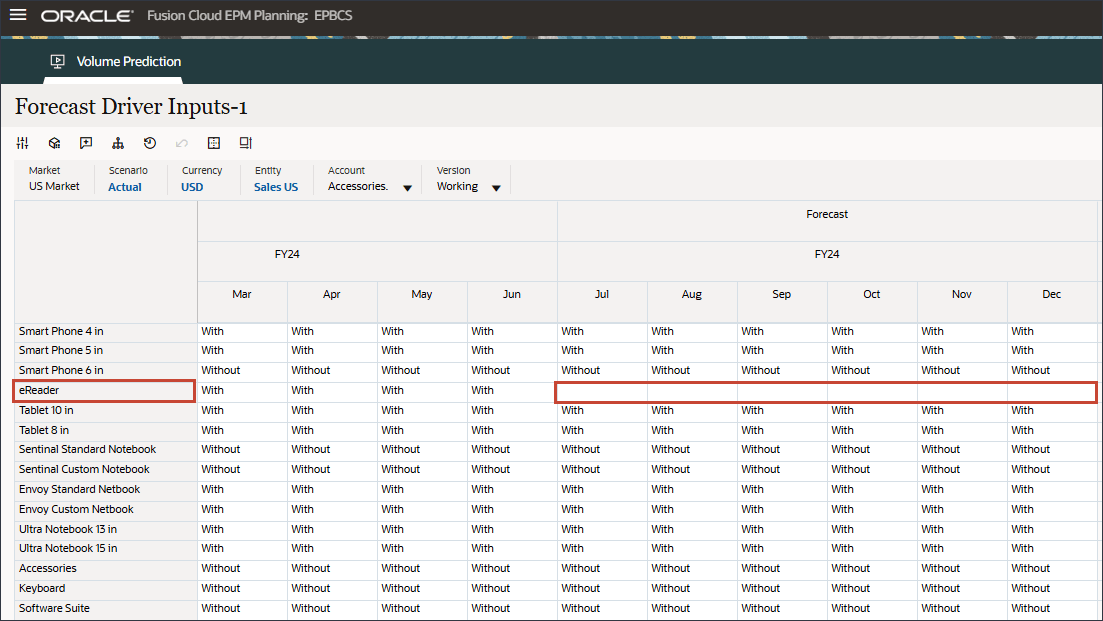
拡張予測では、欠落している入力ドライバ値を予測できます。このチュートリアルの後半の項では、eReaderの今後の入力ドライバ値が予測されるように、拡張予測ジョブを構成します。
- 下部の「予測」タブをクリックします。
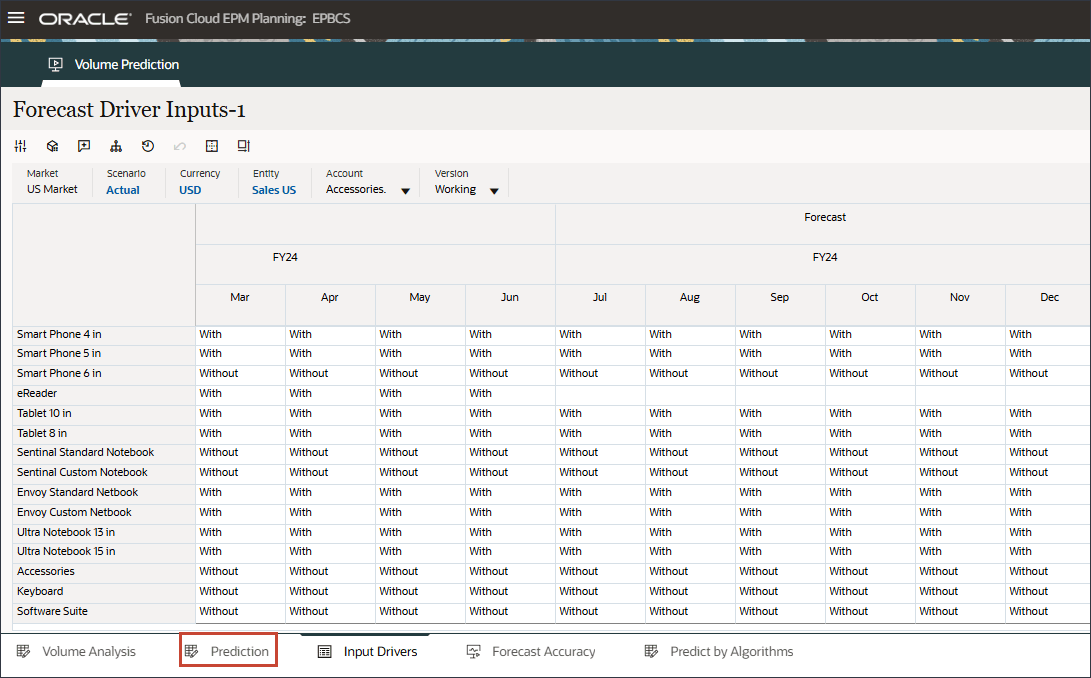
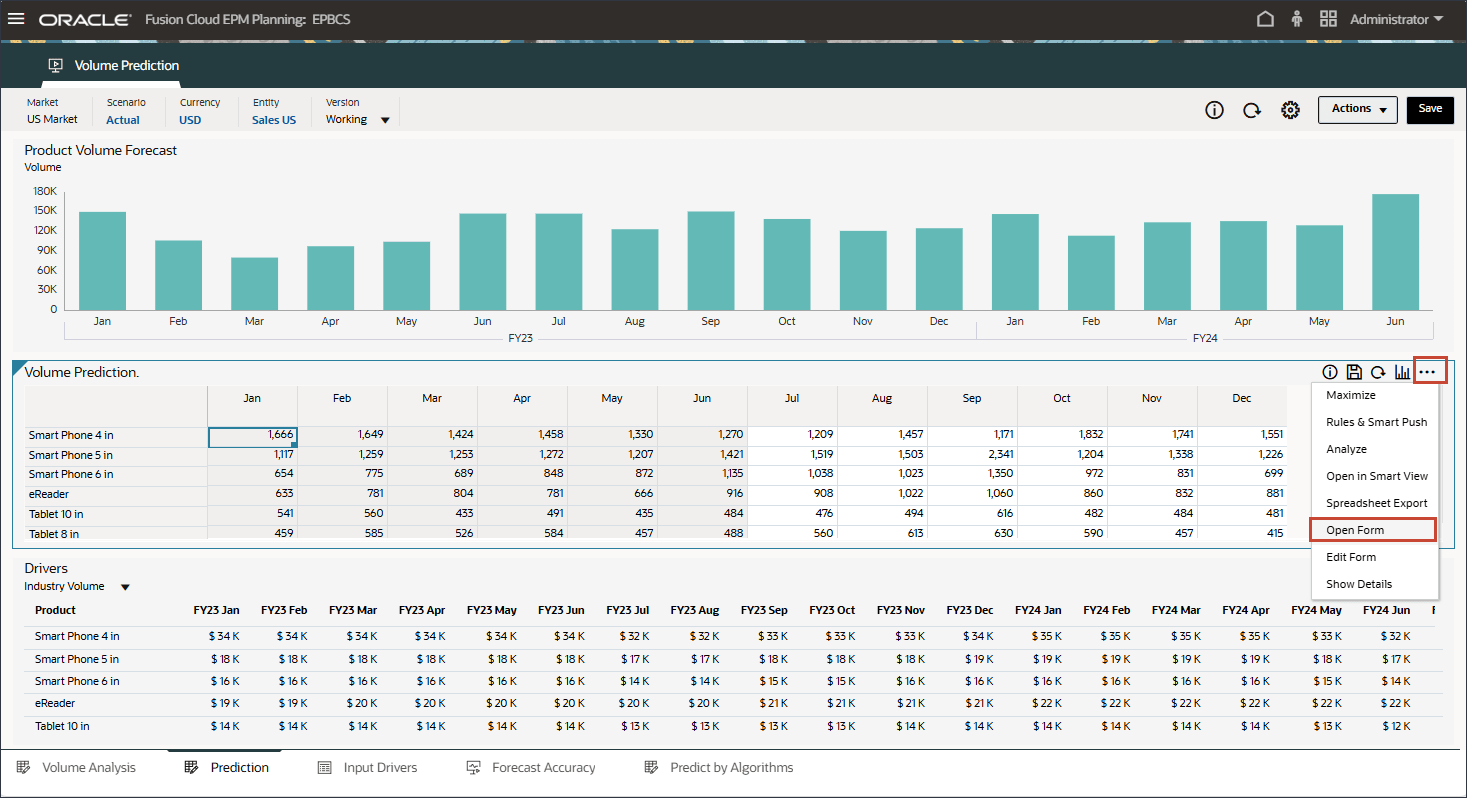
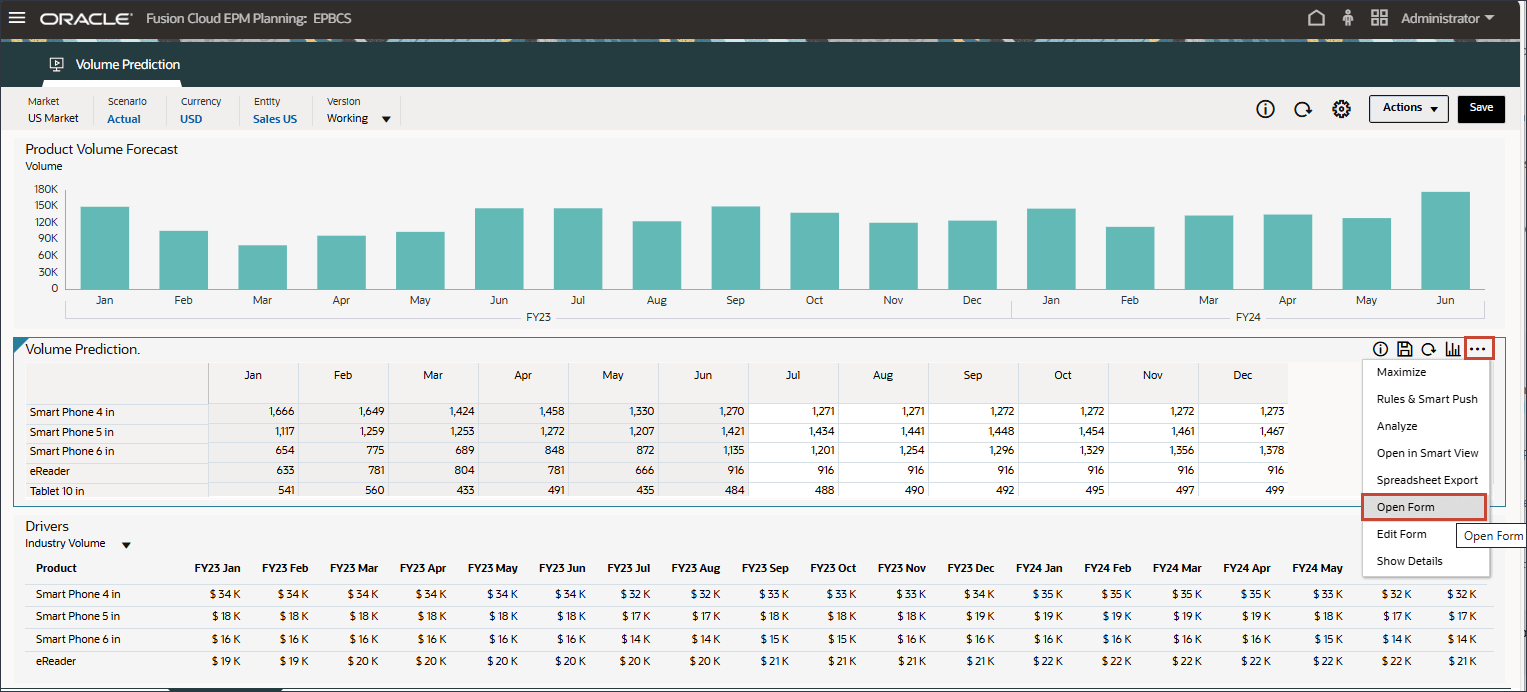
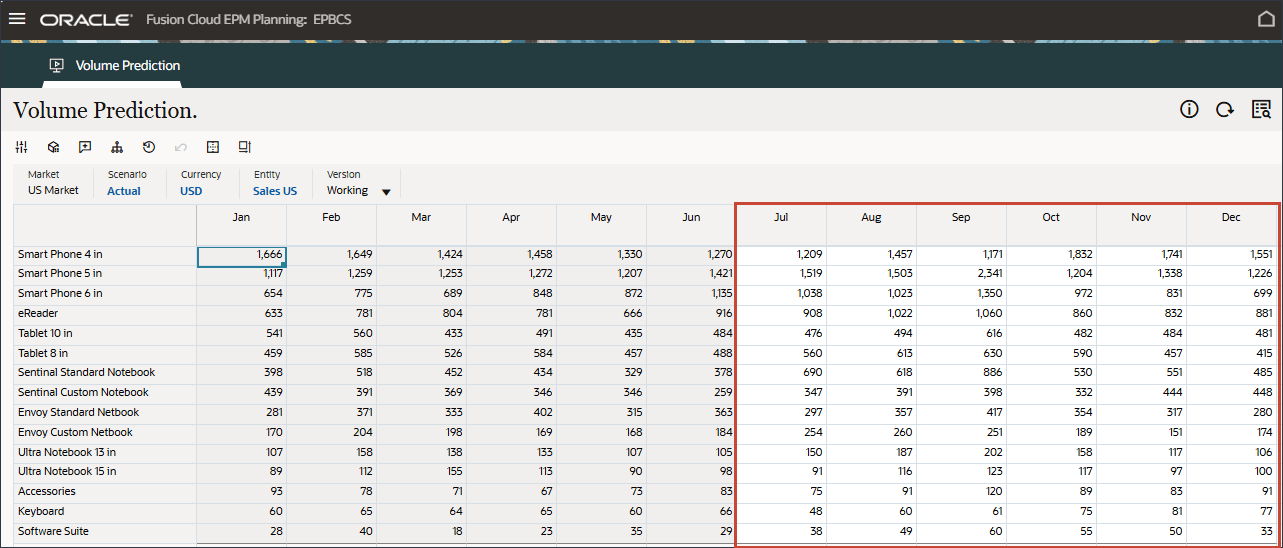
- 「ボリューム予測」フォームで、右側の(アクション)をクリックし、「フォームを開く」を選択します。
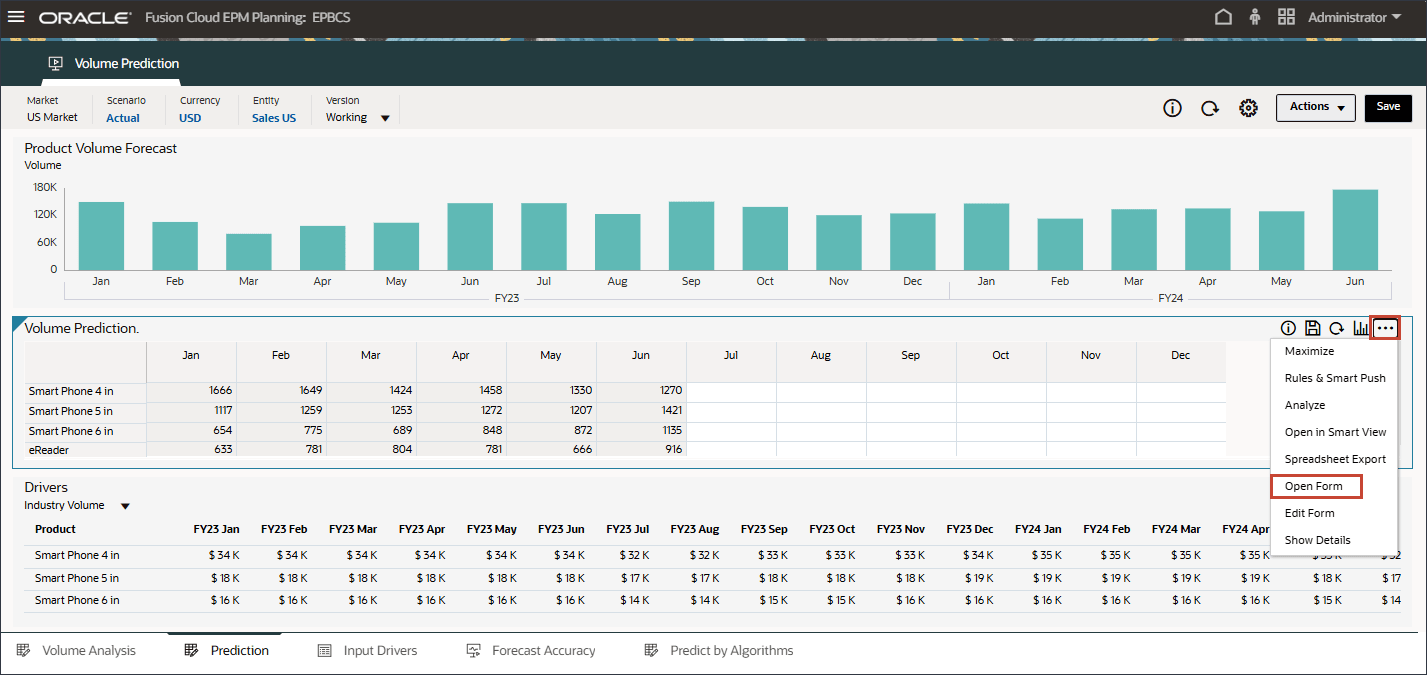
- 7月から12月までの期間の予測結果が欠落していることに注意してください。FY24.
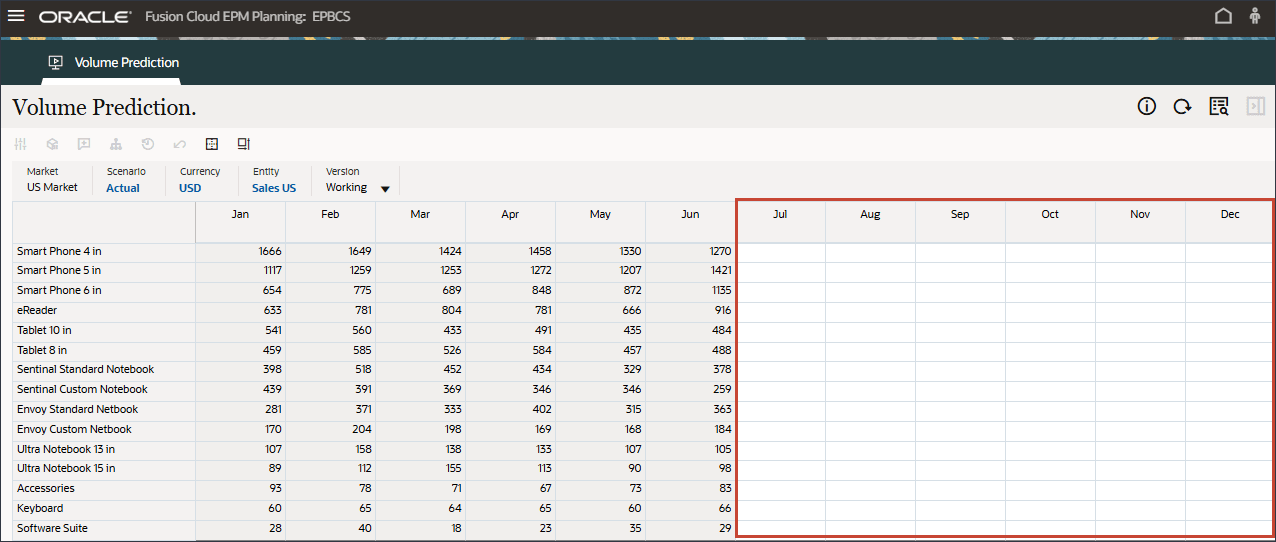
これらは、高度な予測機能を使用して、すべての製品について予測する期間です。
- (ホーム)をクリックして、ホーム・ページに戻ります。
「予測」タブには、予測されるボリュームを含むダッシュボードが表示され、ボリュームの予測に使用されるすべてのドライバを含む表も含まれます。
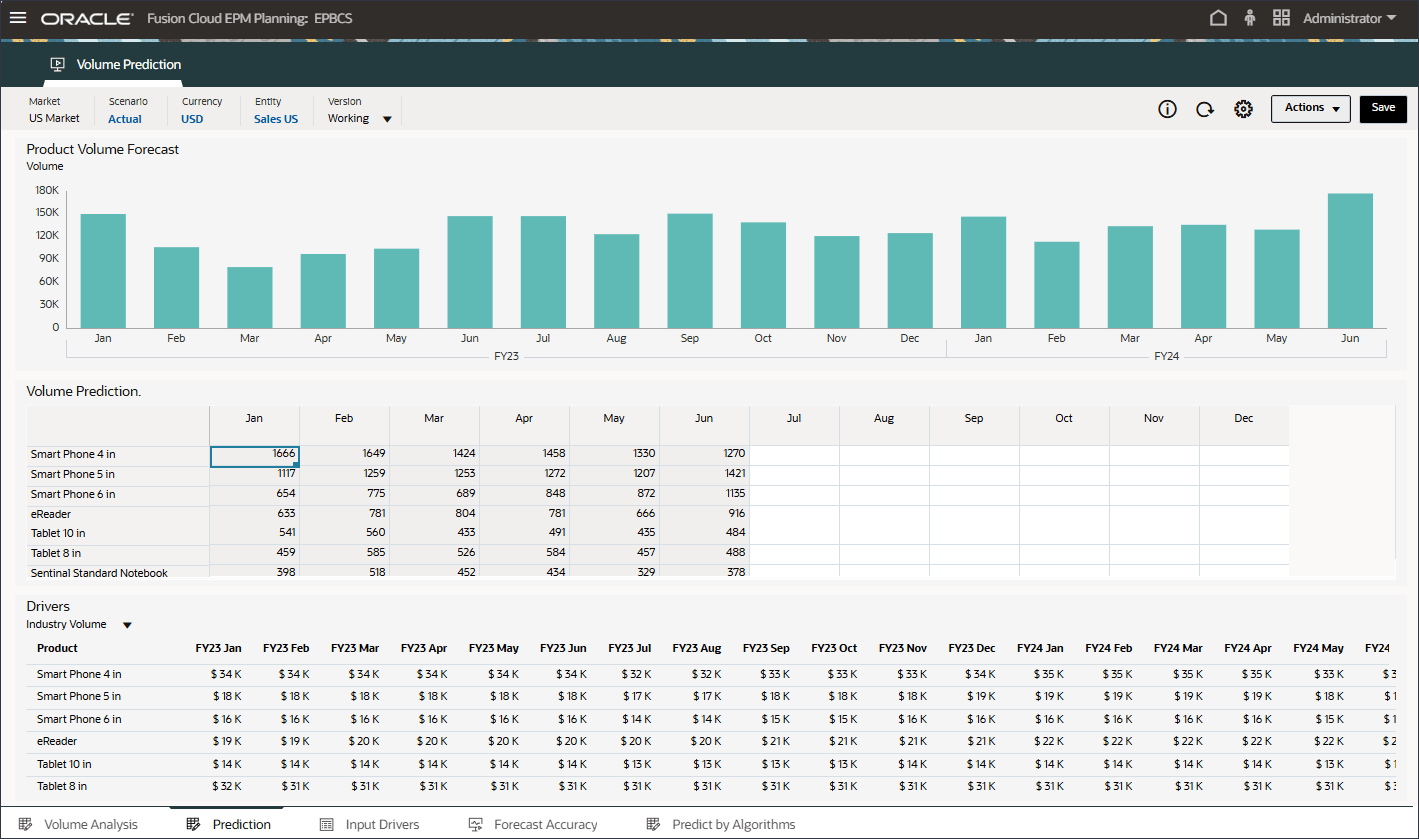
これらの入力ドライバは、高度な予測アルゴリズムを使用してボリューム予測を正確に導出するのに役立ちます。
入力ドライバの編集
任意の入力ドライバを編集できます。履歴データと将来データの両方を編集できます。
将来期間の欠落入力ドライバ値のレビュー
この項では、欠落している入力ドライバを確認します。
予測フォームの確認
この項では、「ボリューム予測」フォームで欠落値を確認します。
拡張予測の構成
この項では、将来の製品量を予測するための拡張予測を構成します。
IPM構成ウィザードのステップを実行して、拡張予測を構成します。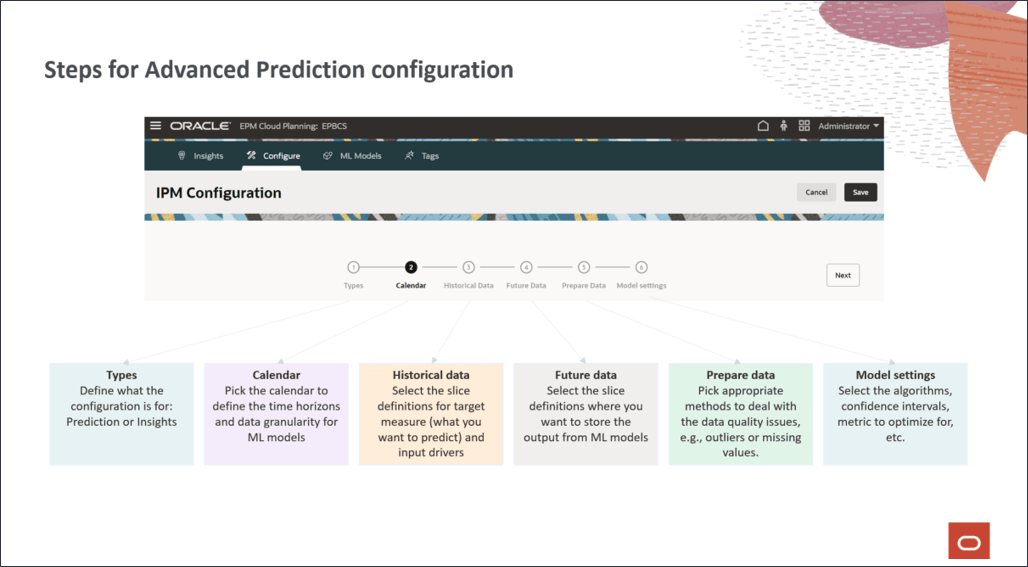
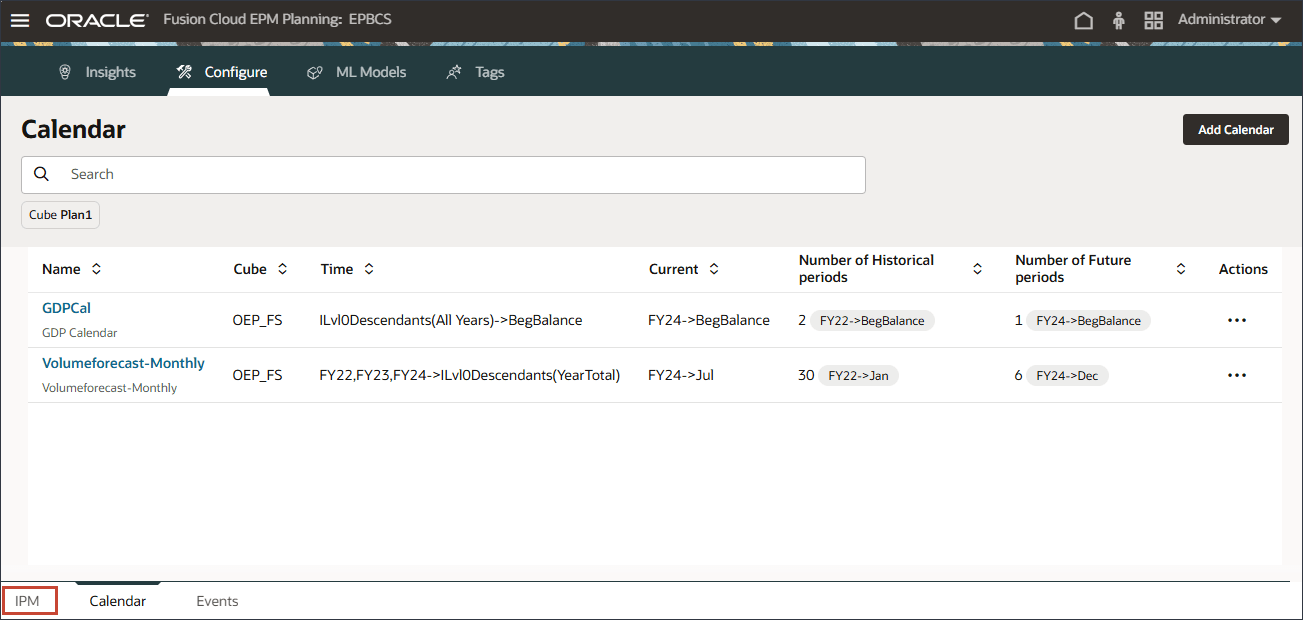
拡張予測カレンダの設定
拡張予測を構成する前に、履歴期間と将来期間の両方を含むカレンダを定義する必要があります。
- ホーム・ページで、「IPM」→「構成」をクリックします。
- 下部の「カレンダ」タブをクリックします。
- 「カレンダの追加」をクリックします。
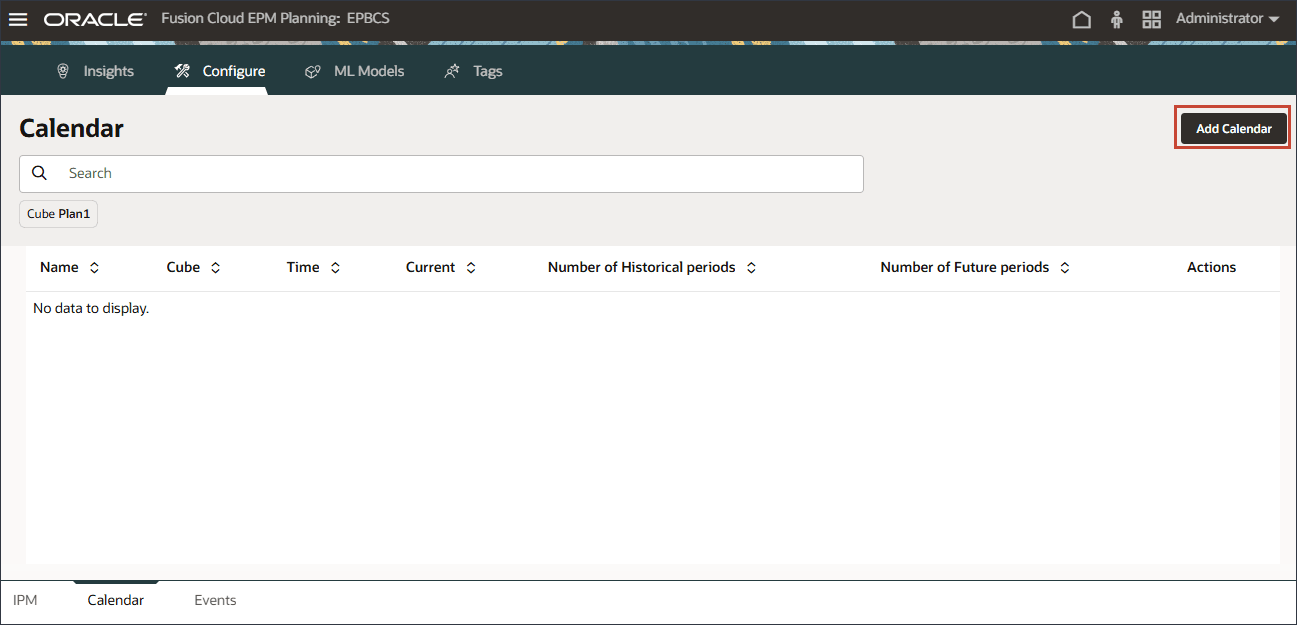
- 「名前と説明」に、Volumeforecast-Monthlyと入力します。
新しいカレンダの名前と説明が入力されます。
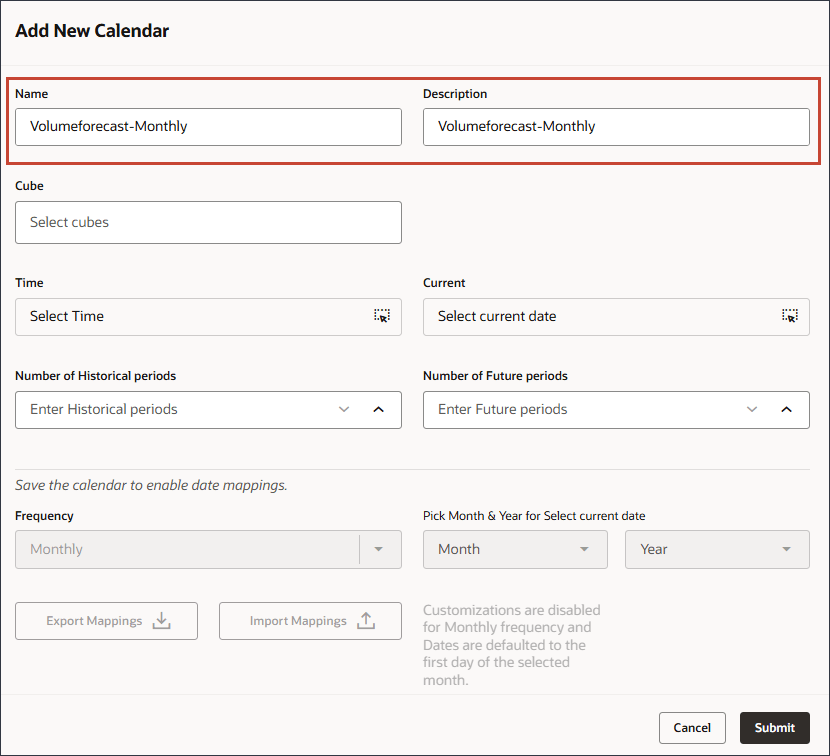
- 「キューブ」で、「OEP_FS」を選択します。
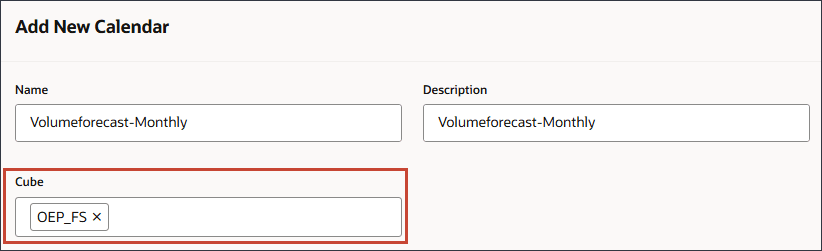
- 時間については、
 (時間の選択)をクリックします。
(時間の選択)をクリックします。
- 「メンバーの選択」で、「年」で「すべての年」を選択し、FY22、FY23およびFY24を選択します。
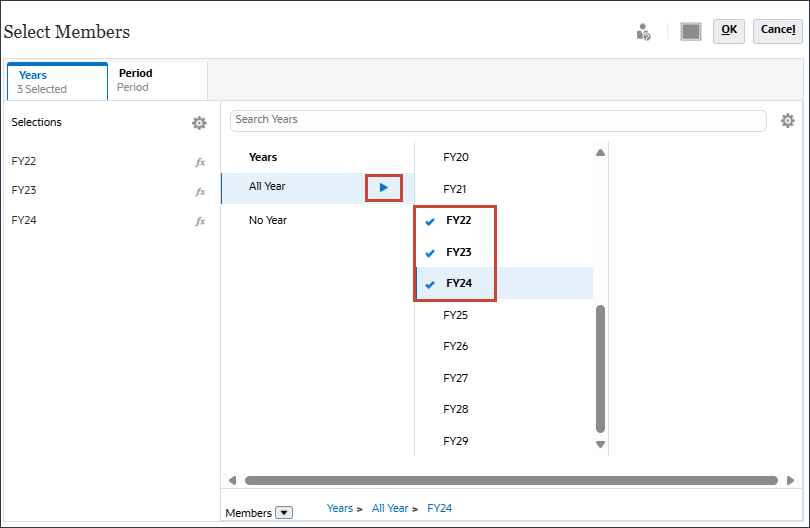
時間については、予測に必要な履歴期間と将来期間の範囲全体を含めます。
- 「Period」をクリックします。
- YearTotalで、
 (関数セレクタ)を選択し、「レベル0の子孫」を選択します。
(関数セレクタ)を選択し、「レベル0の子孫」を選択します。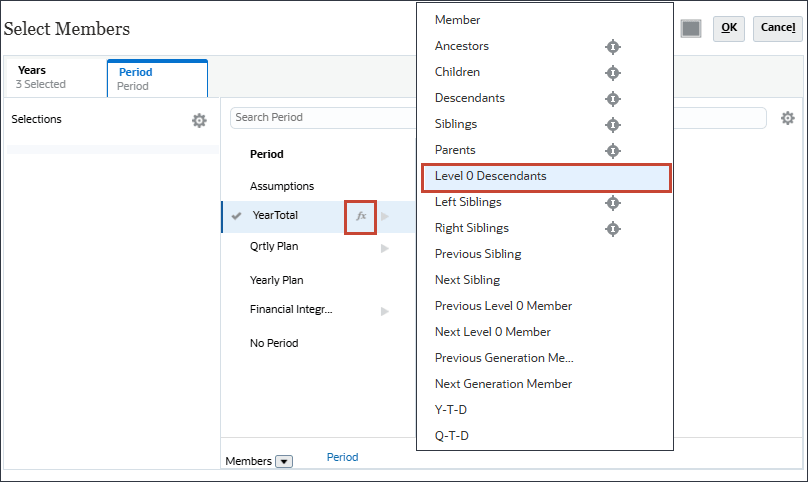
選択内容が表示されます。
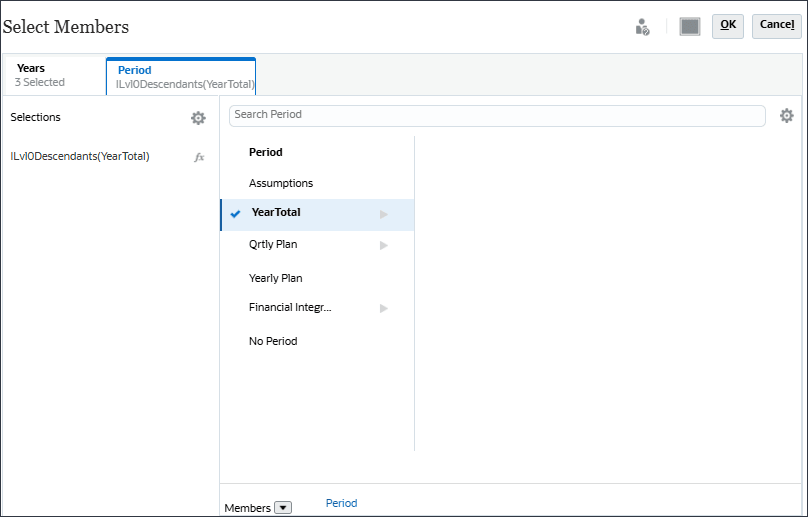
期間には、データを使用する時期の履歴期間を含めることができます。予測する将来のために、予測する将来のデータに何年も含めることができます。この例では、年(FY22、FY23、FY24およびピリオド)を選択し、YearTotalのすべてのレベル0の子孫(すべての月)を選択します。
- 「OK」をクリックします。
年および期間の選択は、カレンダーに含まれます。
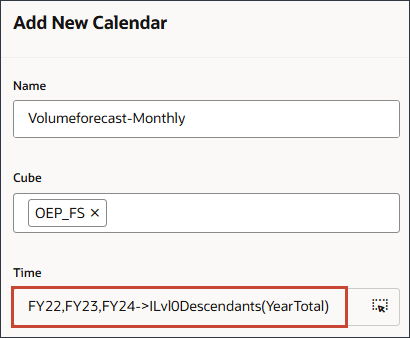
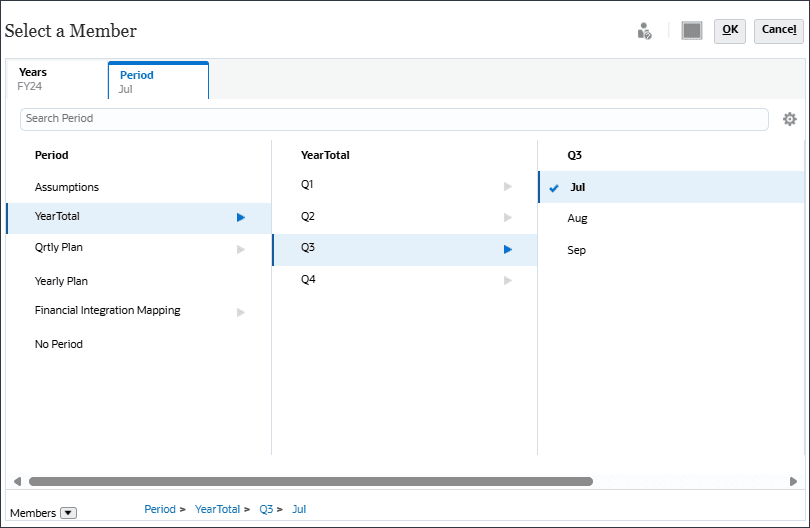
- 「現行」で、 (現在の日付を選択)をクリックします。
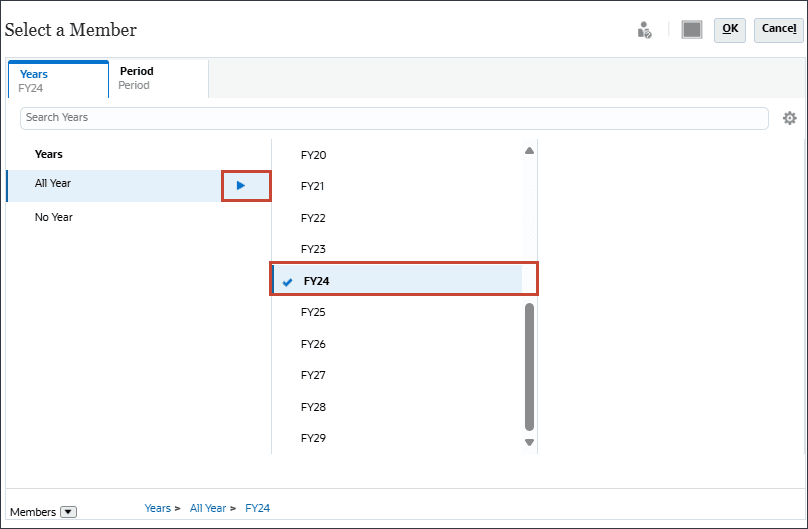
- 「年」で、FY24を選択します。
- 「Period」をクリックします。
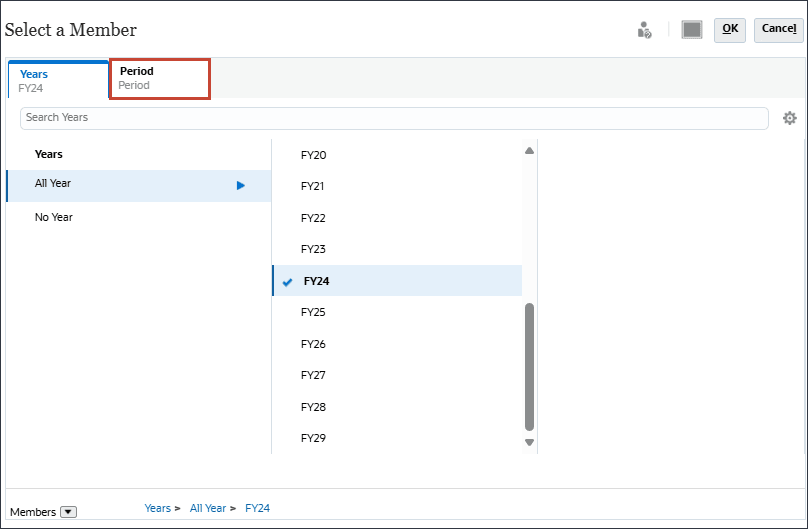
- YearTotalおよびQ3で、「Jul」を選択し、「OK」をクリックします。
ノート:
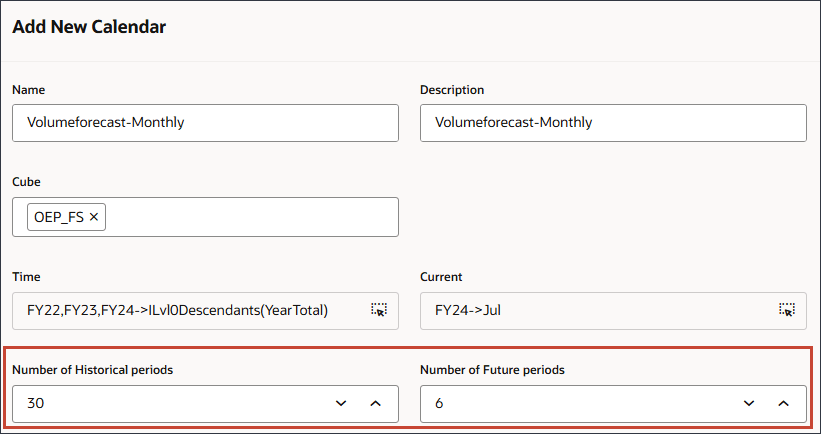
現在の年は、代替変数を使用して設定できます。 - 「履歴期間数」に30と入力し、「将来期間数」に6と入力します。
- 「発行」をクリックします。
確認メッセージが表示されます。

- 「Volumeforecast-Monthly」で、 (アクション)をクリックし、「編集」を選択します。

- 「頻度」で、「月次」が選択されていることを確認します。
頻度および日付書式を定義する日付マッピングは、データ・サイエンス・エンジンに期間データを送信するための重要なステップです。
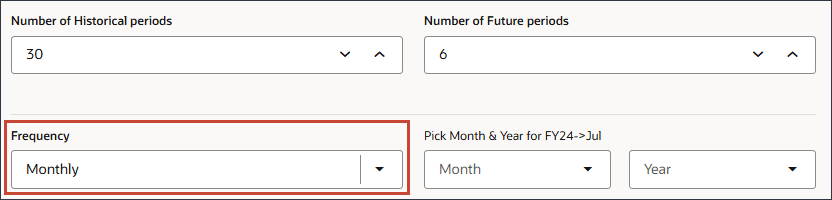
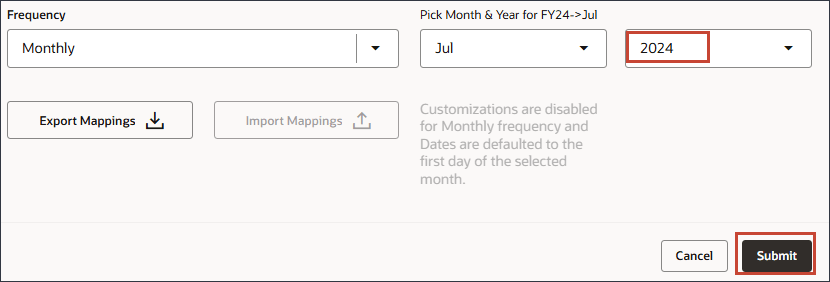
- 「Pick Month、 & Year for FY24 -> Jul」で、「Month」が選択されていることを確認し、「Month」で「July」を選択します。

- 「Year」をクリックし、「Year」で「2024」を選択し、「Submit」をクリックします。
- マッピングを確認するには、VolumeForecast-Monthlyカレンダで、 (アクション)をクリックし、「編集」を選択します。

- 「マッピングのエクスポート」をクリックします。
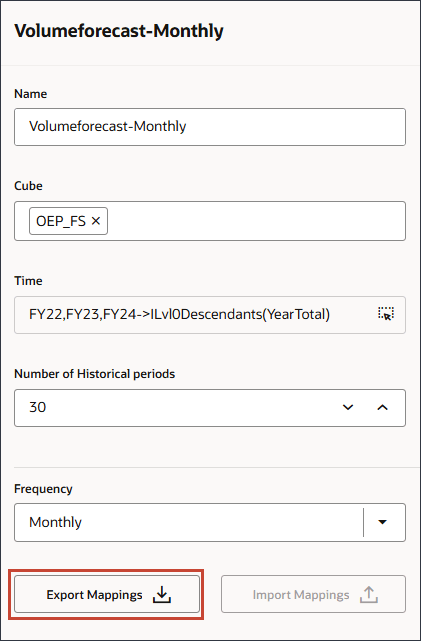
ファイルを開いてマッピングを確認できます。メモ帳で.csvファイルを開いてください。
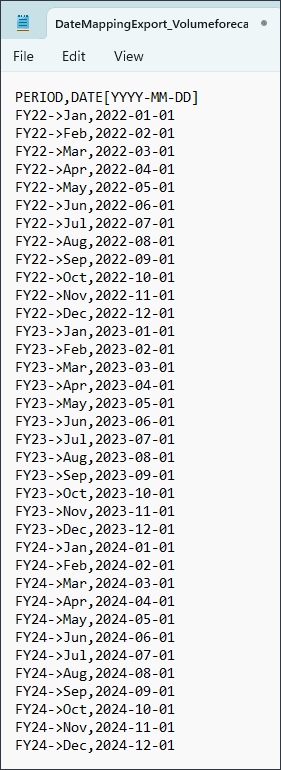
- メモ帳ファイルを閉じて、「取消」をクリックします。
注意:
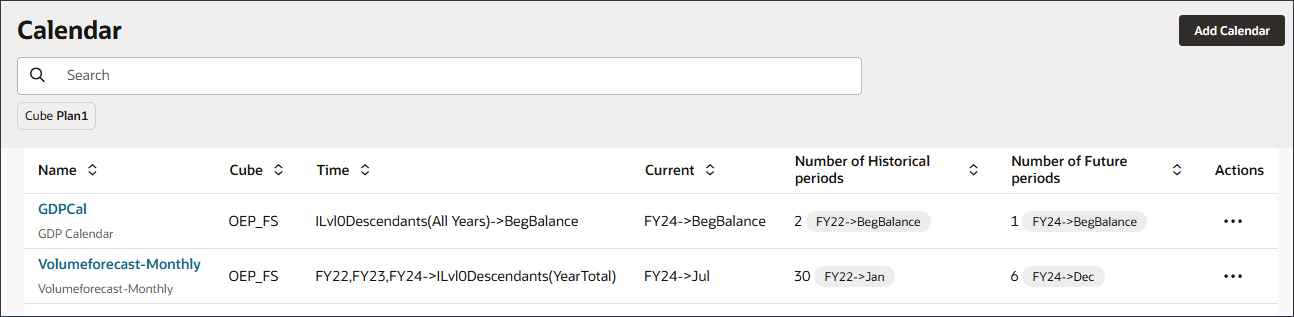
「送信」をクリックして日付マッピングを設定する前に、カレンダを保存してください。カスタム・カレンダの作成
FY22、FY23およびFY24のGDP成長率はBegBalanceに格納されるため、拡張予測にBegBalance期間の入力を含めることができるようにカスタム・カレンダを作成します。
- カスタムカレンダーを作成する前に、メモ帳の DateMappingExport_GDPCal.csvファイルを開いて内容を確認します。
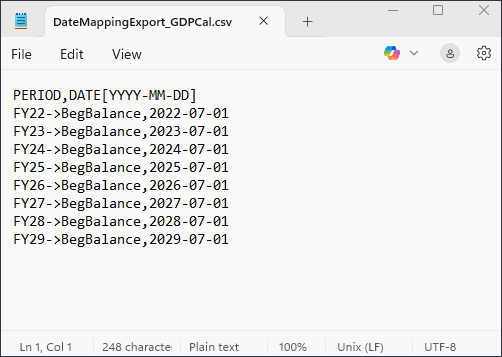
このファイルには、7月初日のFY22からFY29までの各年のBegBalanceが含まれています。
- ノートパッドを閉じます。
- 「カレンダの追加」をクリックします。
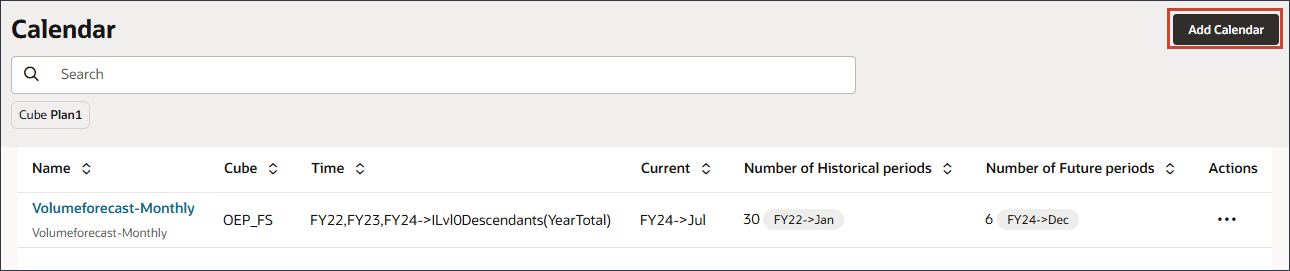
- 「名前」に、GDPCalと入力します。
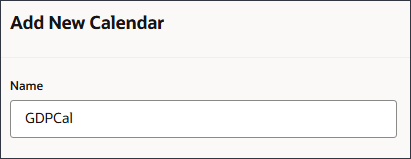
- 「説明」に、GDP Calendarと入力します。

- 「キューブ」で、「OEP_FS」を選択します。
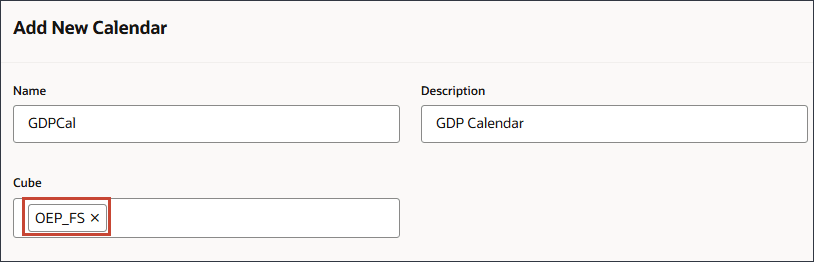
- 「時間」で、 (「時間の選択」)をクリックします。
- 「メンバーの選択」の「年」で、「すべての年」の(関数セレクタ)をクリックし、Level0Descendantsを選択します。
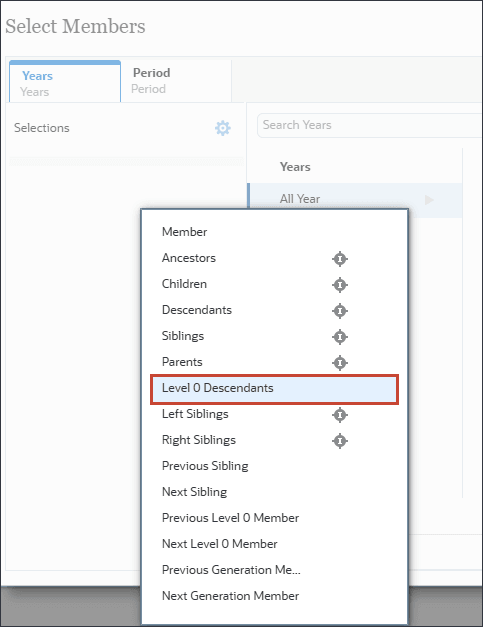
時間については、予測に必要な履歴期間と将来期間の範囲全体を含めます。
- 「Period」をクリックします。
- 「期間」で、「仮定」を選択し、「OK」をクリックします。
- 「現行」で、 (現在の日付を選択)をクリックします。
- 現在の日付については、「年」でFY24を選択し、「期間」で「仮定」を選択して「OK」をクリックします。
- 「履歴期間数」に2と入力し、「将来期間数」に1と入力して「発行」をクリックします。
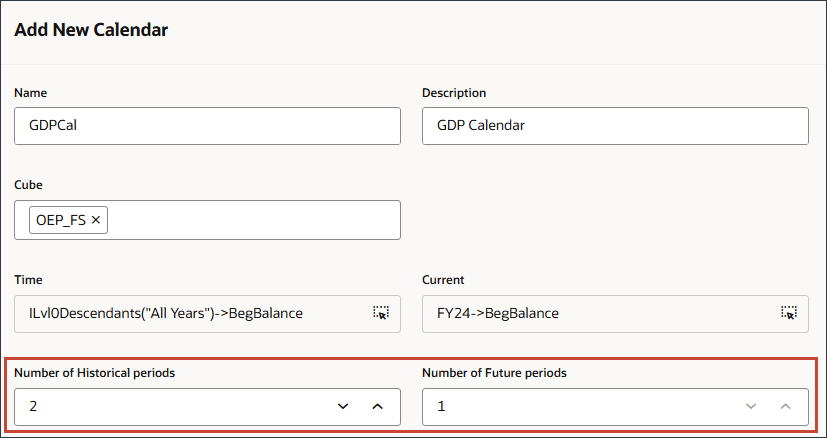
確認メッセージが表示されます。

確認メッセージはクローズできます。
-
GDPCal行で、 (アクション)をクリックし、「編集」を選択します。
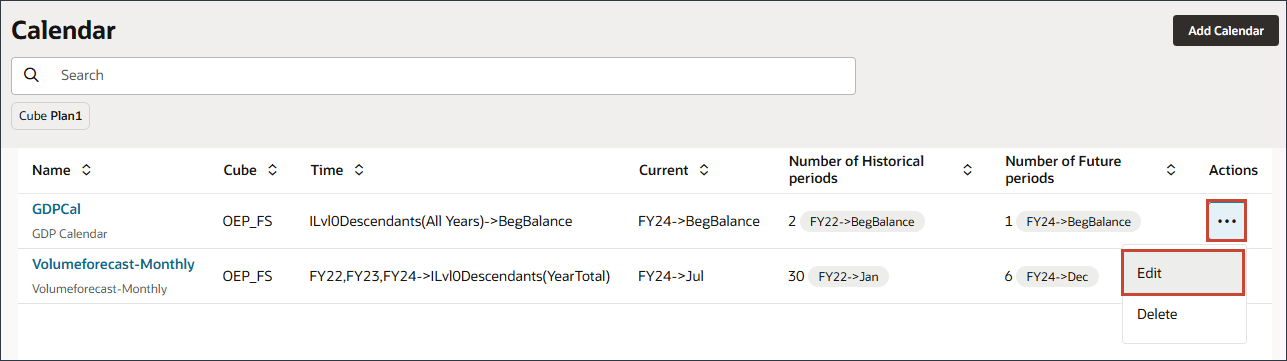
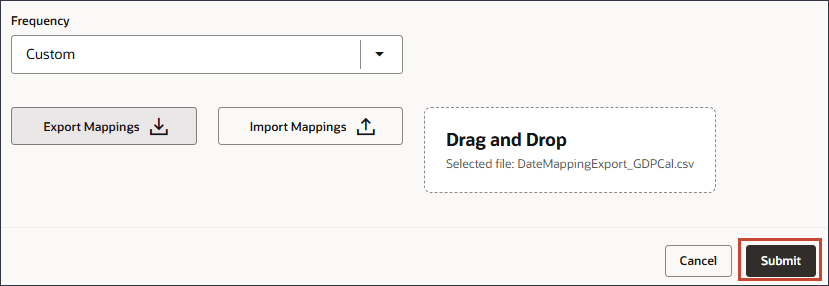
- 「頻度」で、「カスタム」を選択します。
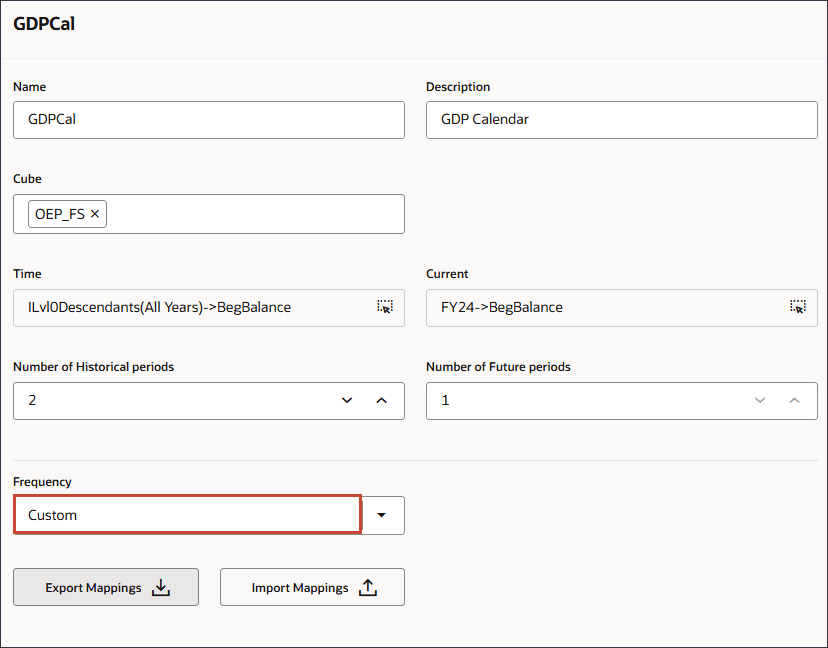
- 「マッピングのインポート」をクリックします。
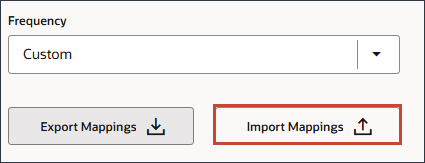
- 「DateMappingExport_GDPCal.csv」を見つけて選択し、「開く」をクリックします。
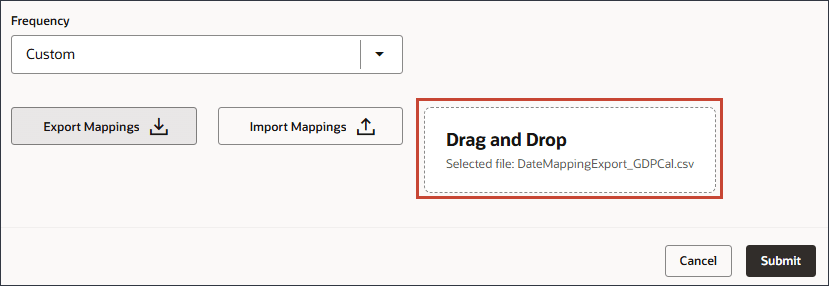
- 「送信」をクリックします。
GDPカレンダーが追加されました。
- (ホーム)をクリックして、ホーム・ページに戻ります。
注意:
「送信」をクリックして日付マッピングを設定する前に、必ずGDPCalを保存してください。IPMジョブでの高度な予測の構成
- ホーム・ページで、「IPM」、「構成」の順にクリックします。
- 「IPM」タブをクリックします。
- 「IPM」ページで、「作成」をクリックします。
- 「詳細」で、「名前」にSales volume forecastと入力し、「摘要」にForecast sales volume based on input driverと入力します。
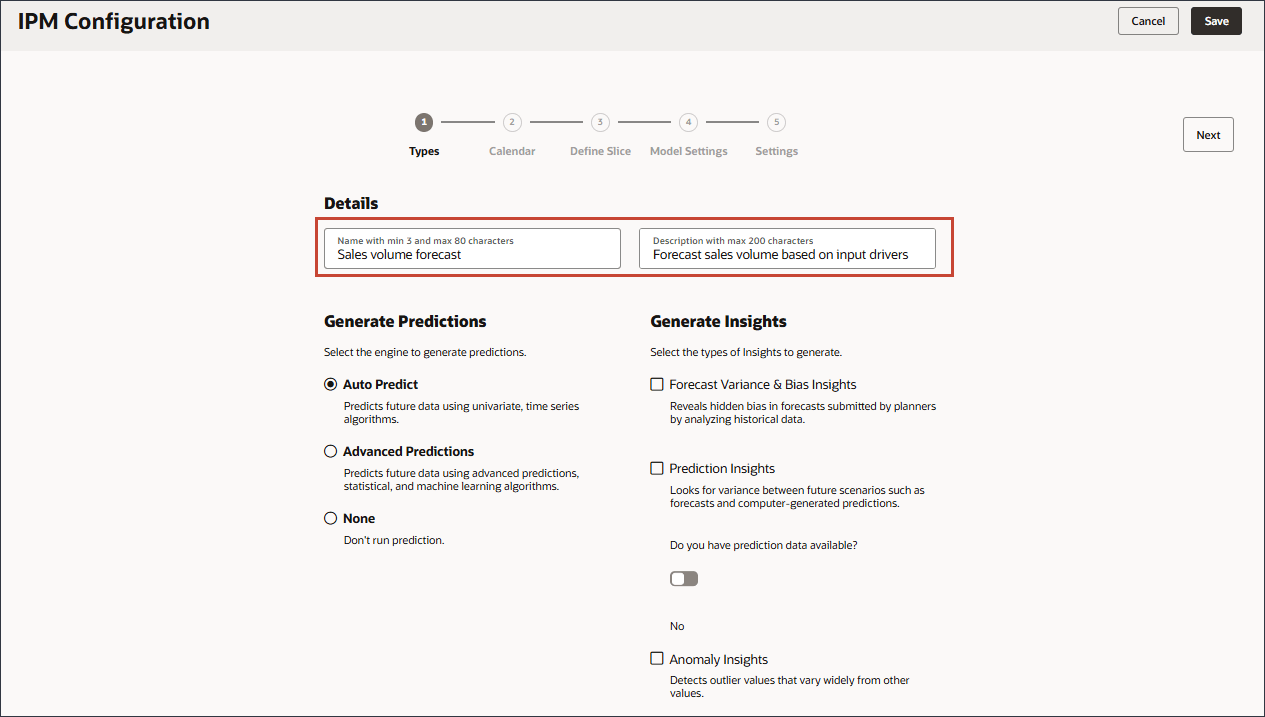
- 多変量、統計および機械学習アルゴリズムを使用して将来のデータを予測するには、「拡張予測」を選択し、「次」をクリックします。
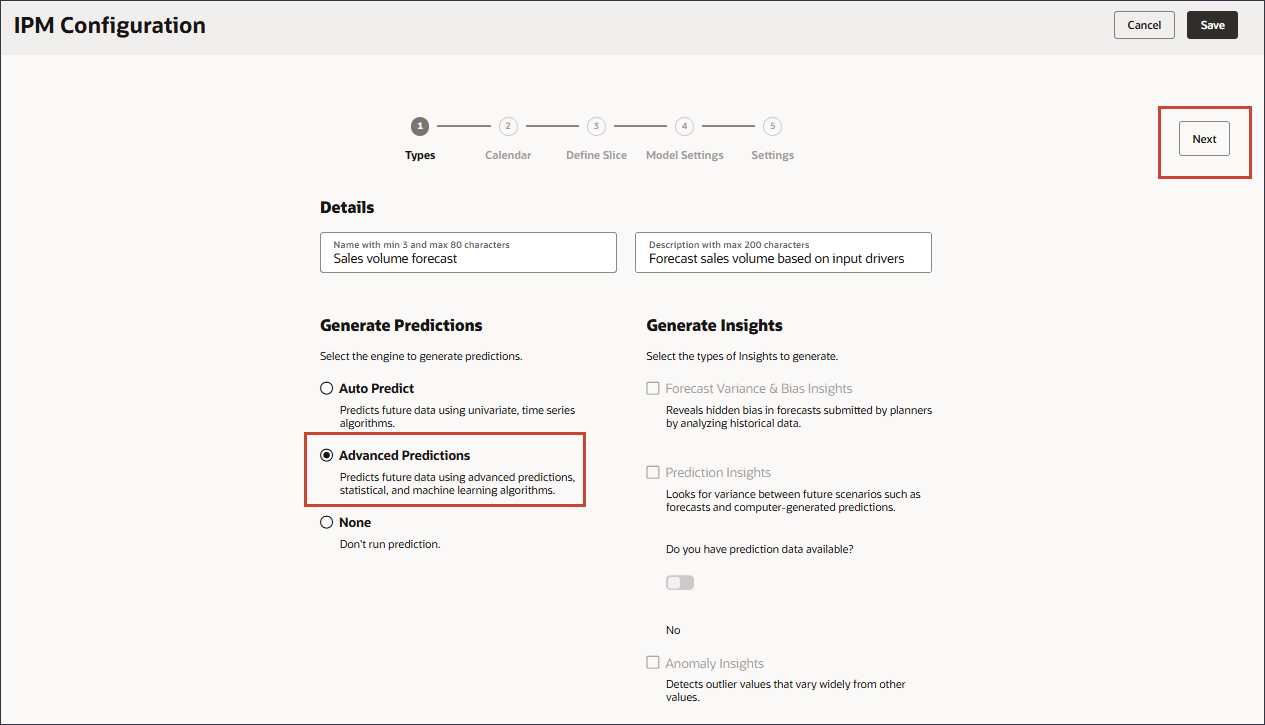
カレンダの選択
履歴期間と将来期間の時間範囲は、カレンダを選択するか、期間範囲を手動で指定することによって定義できます。
- カレンダを選択するには、「カレンダ」をクリックし、「Volumeforecast-Monthly」を選択します。
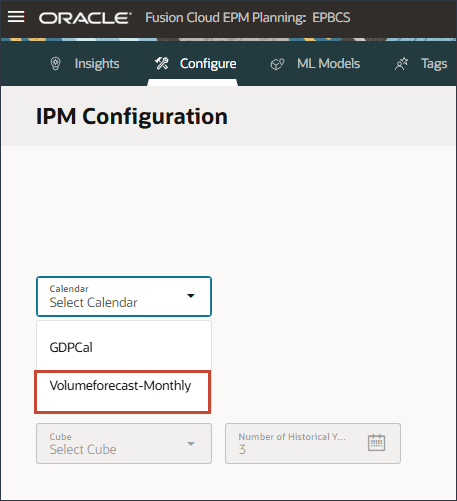
カレンダを選択すると、履歴期間と将来期間の範囲が自動的に入力されます。
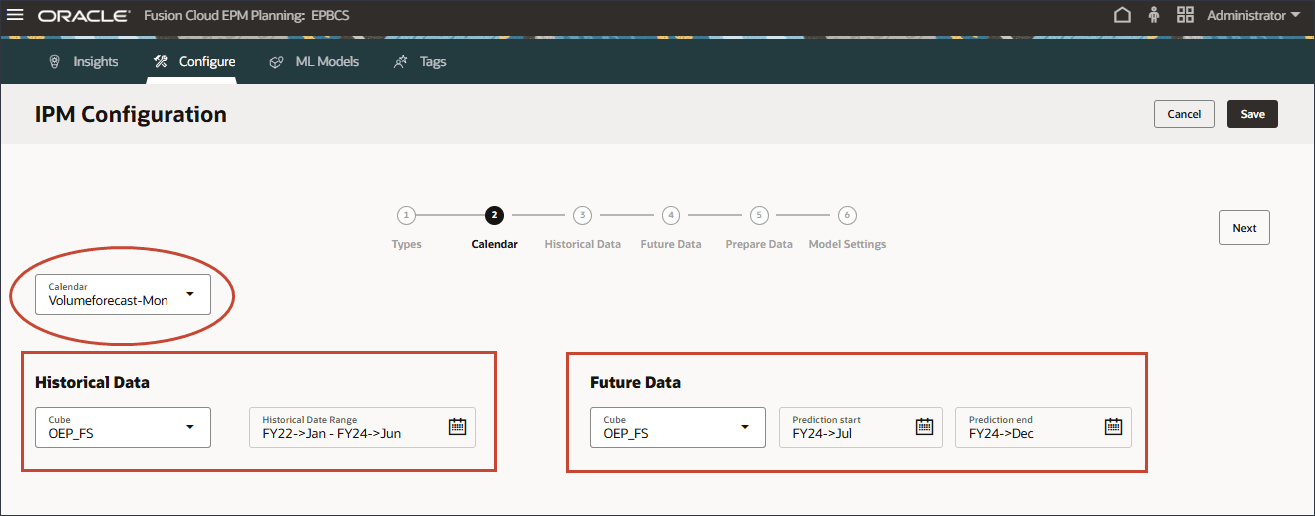
キューブの選択は、カレンダ定義から自動的に入力されます。
カレンダを選択した場合は、期間範囲定義がカレンダ定義から移入されているため、期間範囲を変更できません。期間を変更する場合は、カレンダ設定に戻り、そこで変更を行う必要があります。
- 「次へ」をクリックします。
ノート:
拡張予測の場合、IPM構成で履歴データまたは将来データを手動で選択することはできません。カレンダを事前に定義する必要があります。履歴データのスライス定義の選択
この項では、予測する内容と使用する入力ドライバを定義します。入力ドライバを定義し、キューブ内のデータにマップします。これらの出力メジャーおよび入力ドライバは、EPMキューブにすでに定義されている必要があります。チュートリアルで前述したように、様々なアカウント(ターゲット・ドライバと入力ドライバの両方)に必要なアカウント・メンバーとデータがあります。
この構成では、勘定科目ディメンションに出力ドライバと入力ドライバの両方に必要なメジャーおよび勘定科目が含まれているため、勘定科目ディメンションを構成定義の行に含める必要があります。
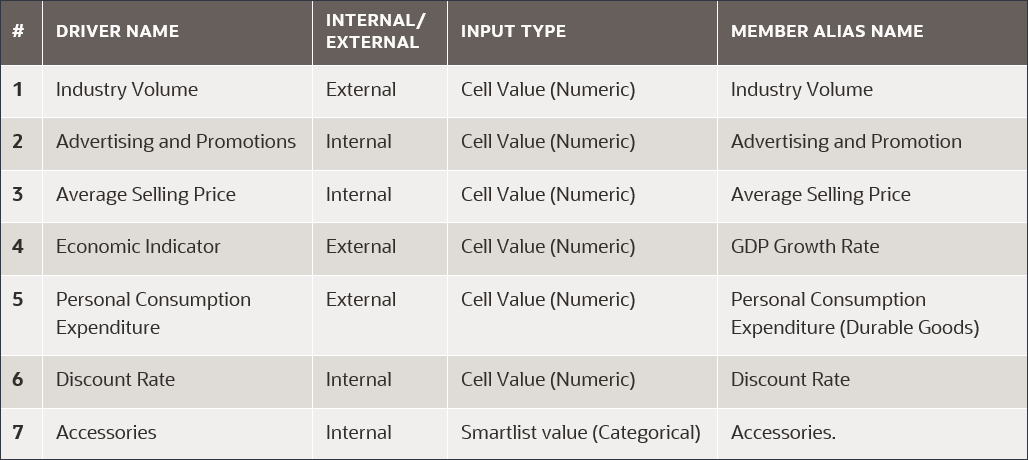
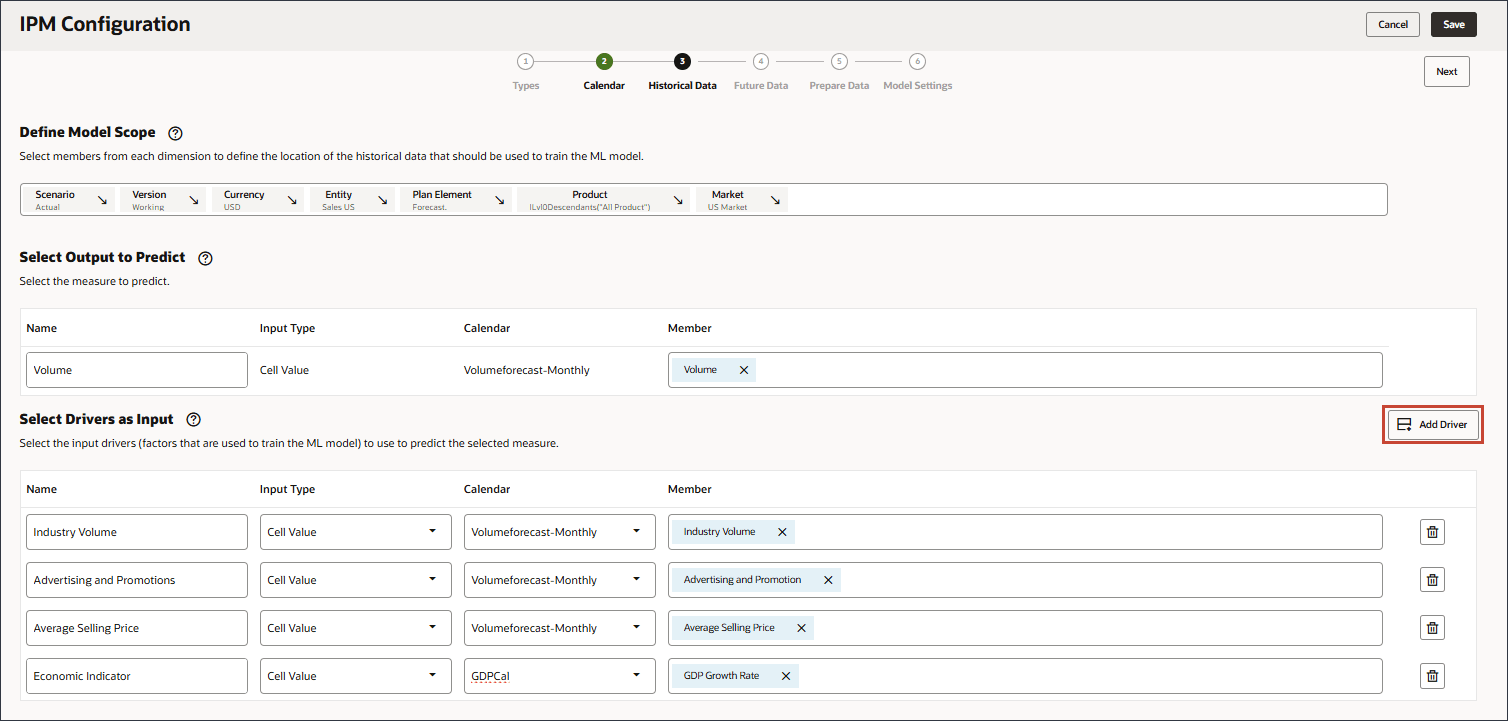
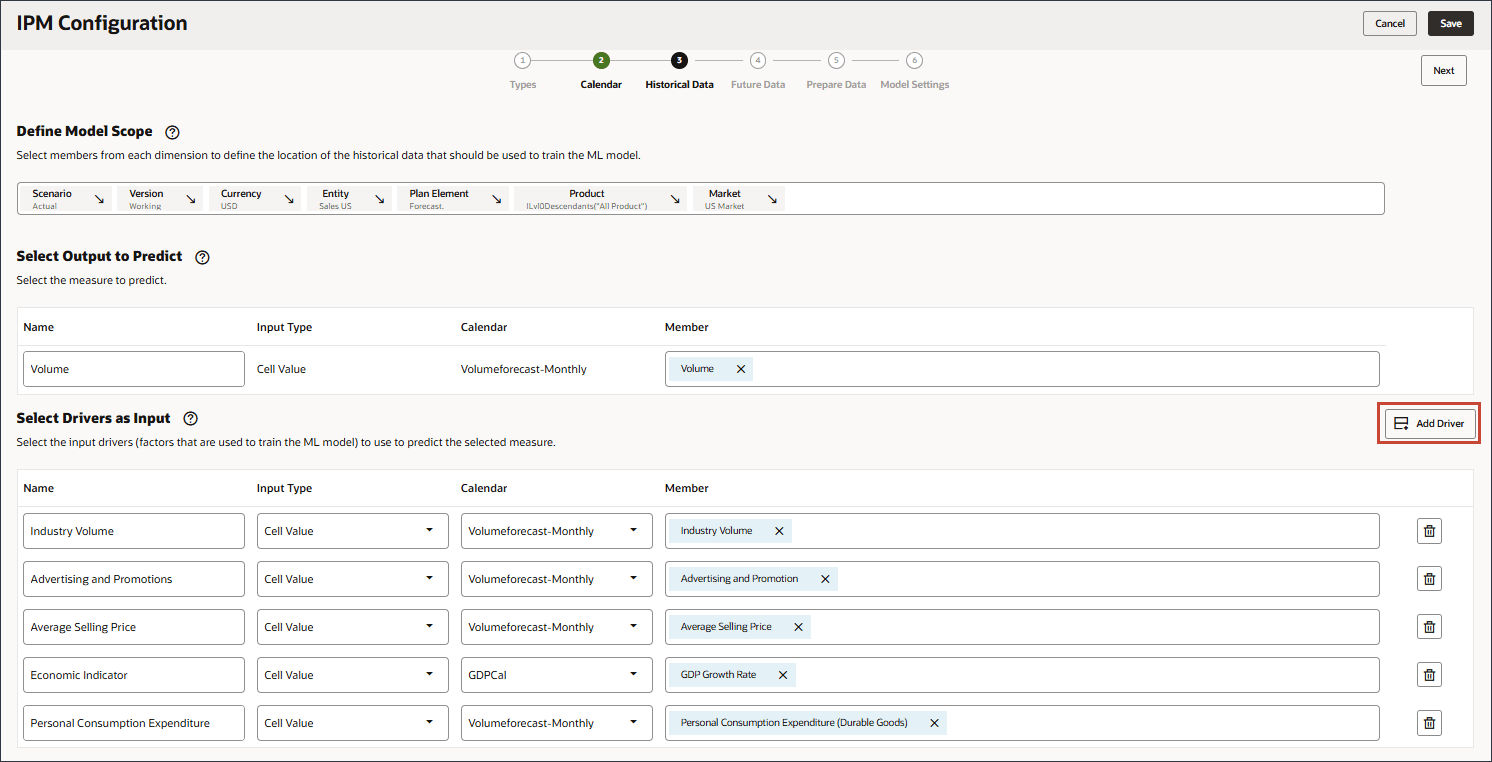
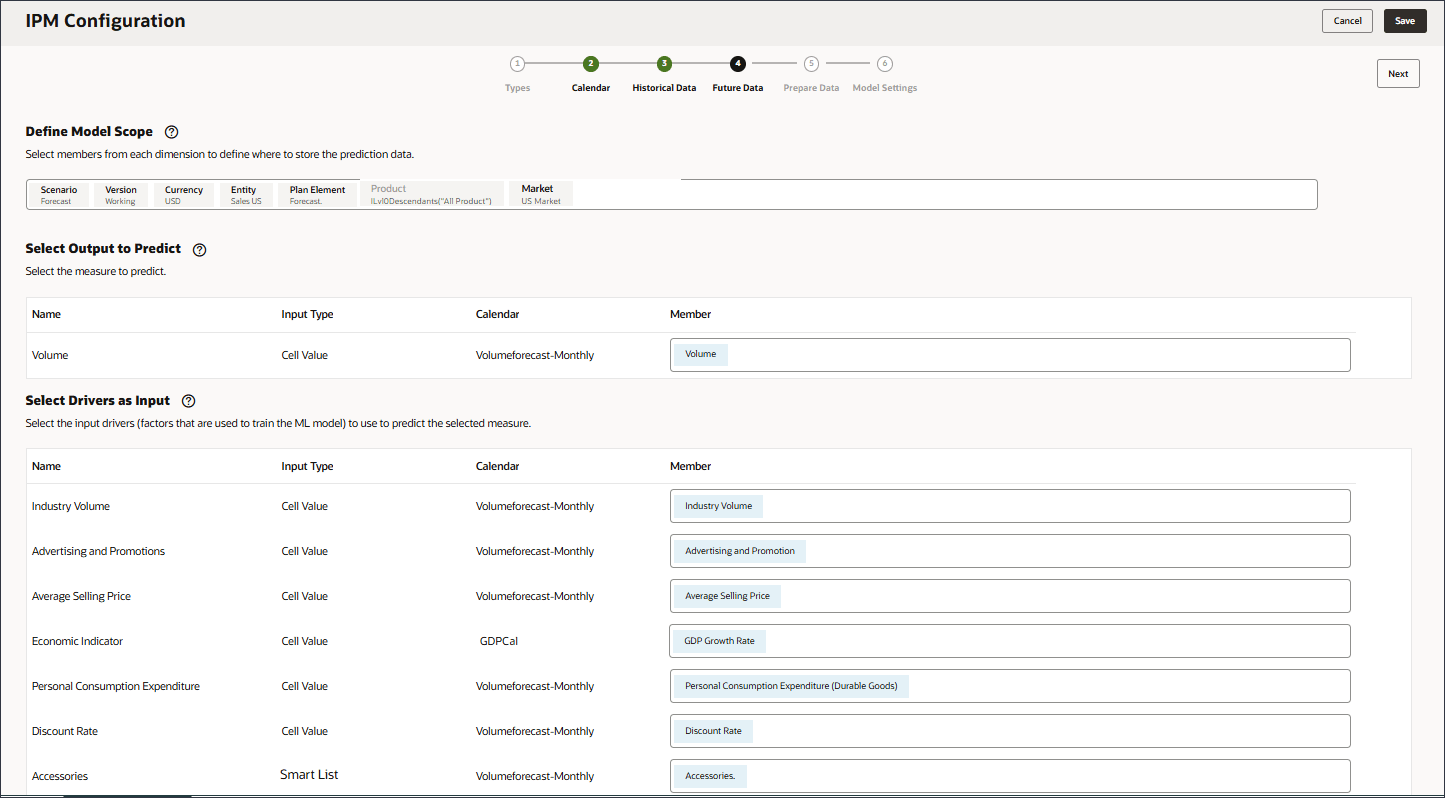
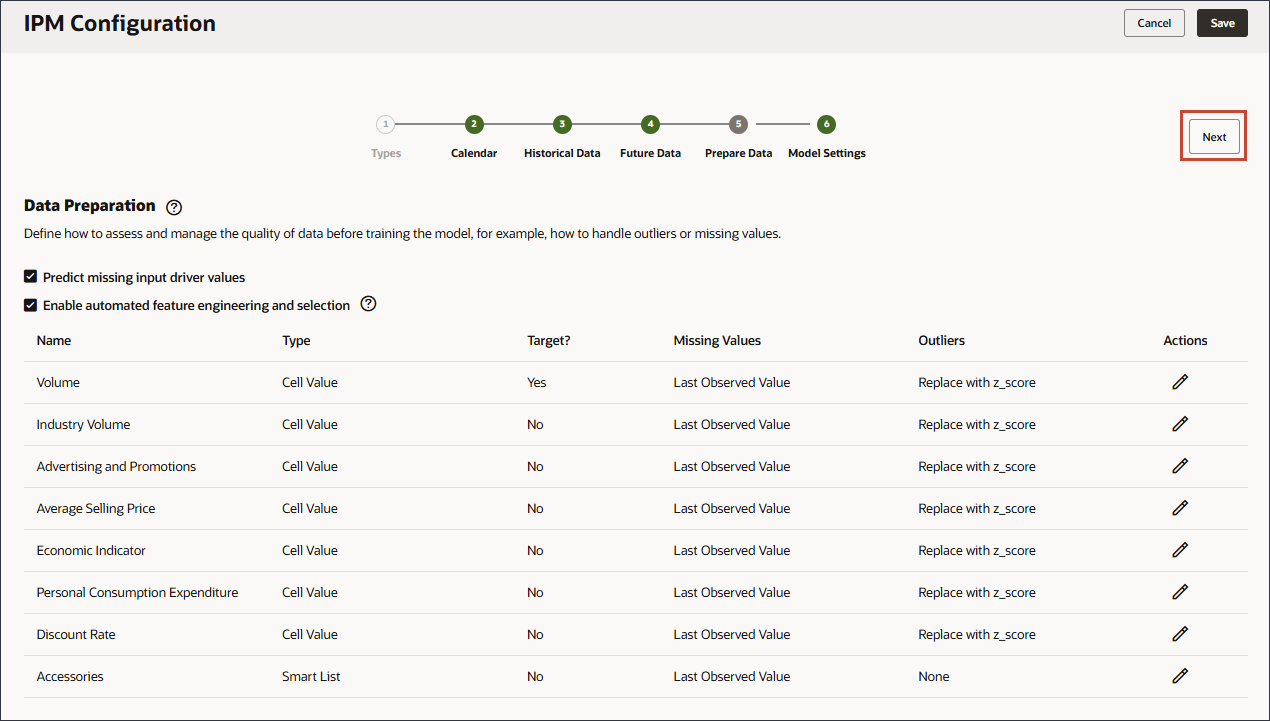
選択したメジャーを予測するための予測モデルのトレーニングに使用されるファクタである入力ドライバを定義します。7つの入力ドライバがあります。
- 「アカウント」の右側にある矢印をクリックします。
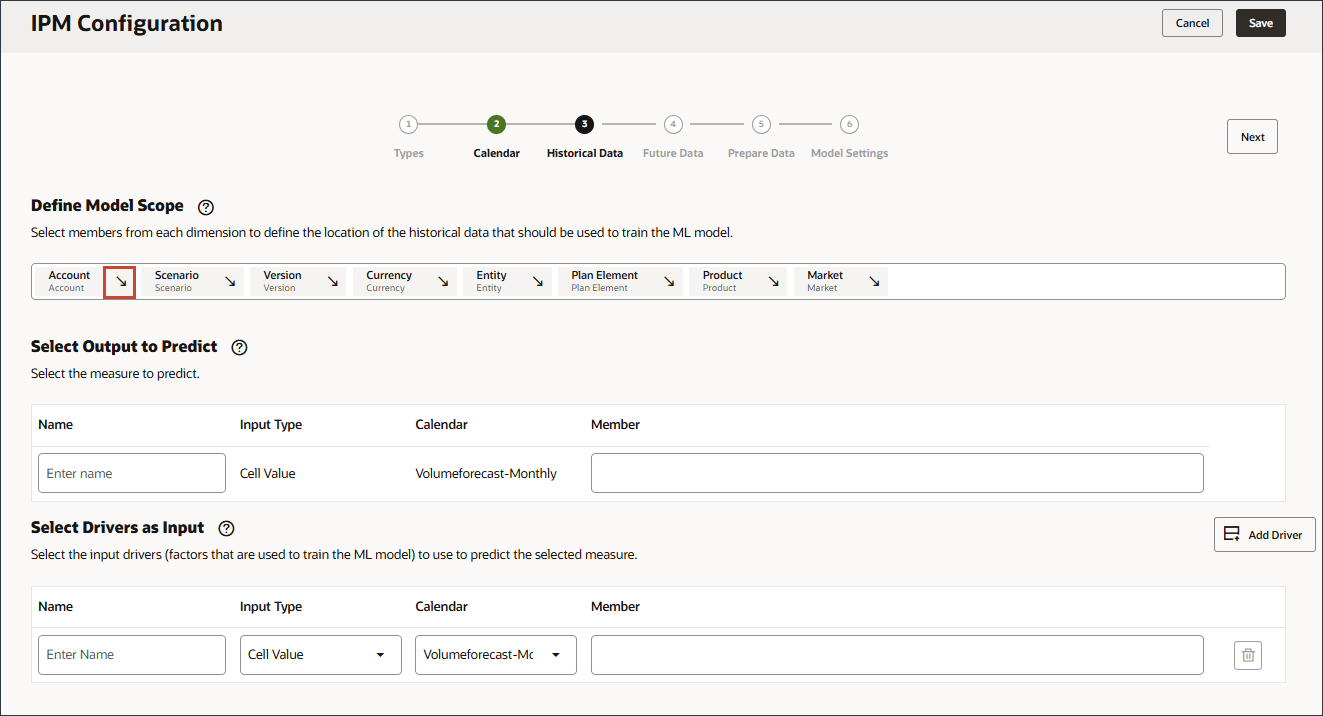
勘定科目が行に追加されます。
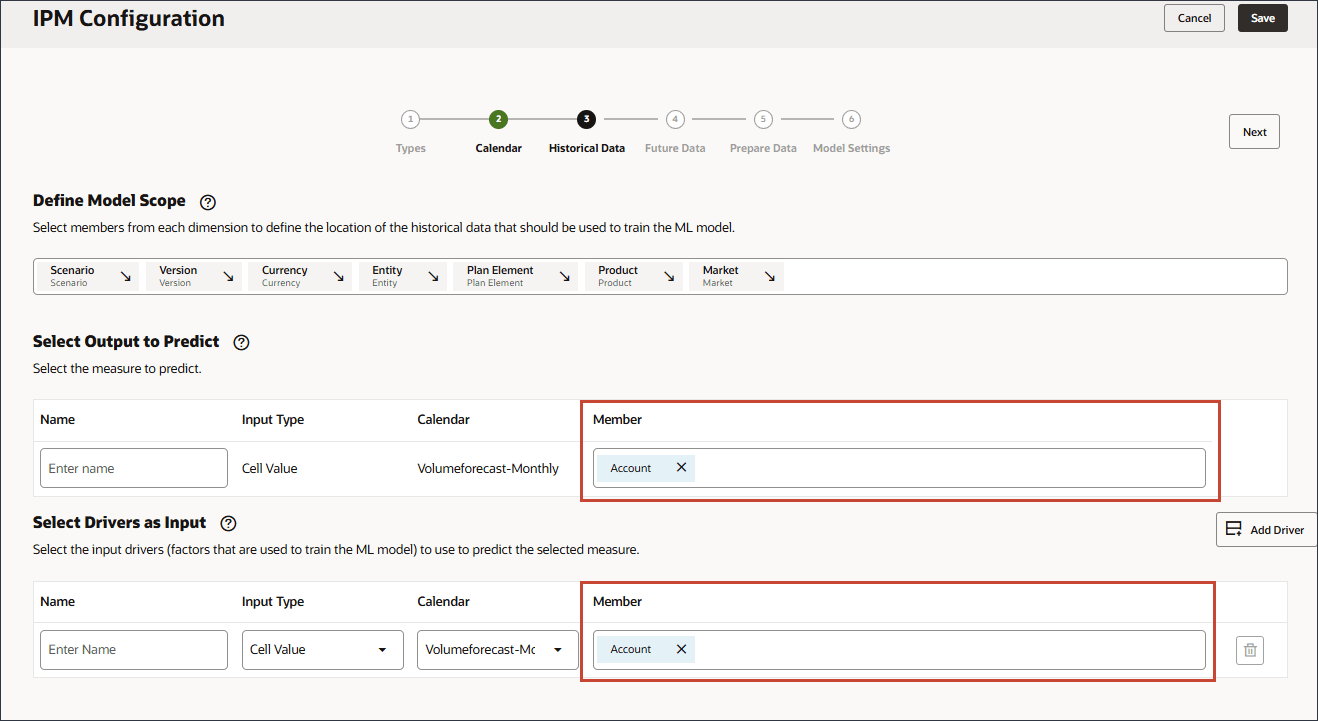
- シナリオの場合、「シナリオ」をクリックしてメンバー・セレクタを開きます。

- OEP_Scenariosを展開し、「実際」を選択します。
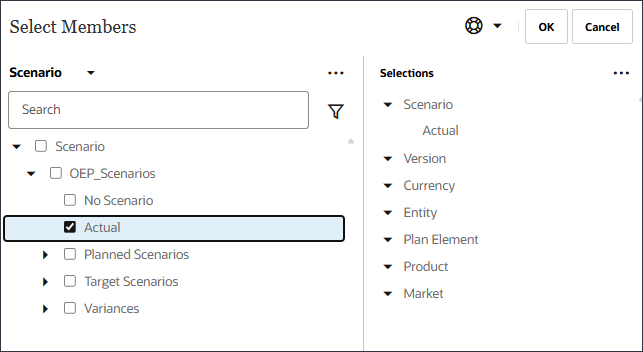
- 「シナリオ」をクリックし、「バージョン」を選択します。
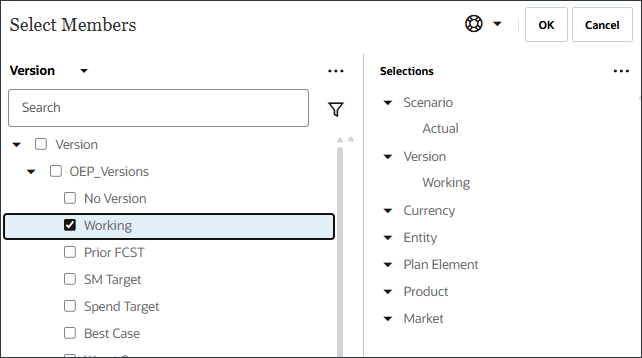
- OEP_Versionsを展開し、「Working」を選択します。
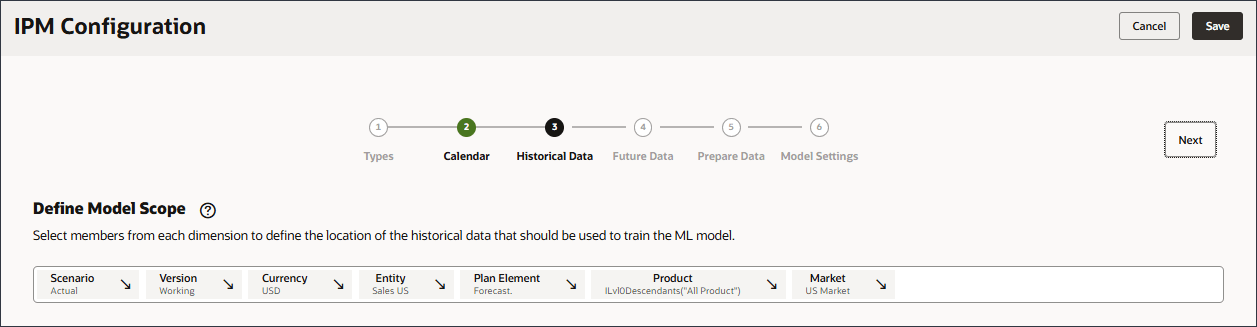
- メンバー・セレクタを使用してモデル・スコープを定義し、次のPOVディメンション・メンバーを選択します。すべてのメンバーを選択したら、「OK」をクリックします。
ヒント :
POV (モデル・スコープ)を定義するには、各ディメンションを選択し、「メンバーの選択」ダイアログで関数を含むメンバーを選択します。メンバーを検索できます。Dimension メンバー Scenario 実績 Version 作業中 通貨 USD エンティティ 米国営業部 プラン要素 予測です。 製品 Ilvl0Descendants("全製品") Market 米国市場 ヒント :
計画要素の場合は、「計画要素」の下にある「予測」、「計画合計」を選択します。"Forecast."は、OFS_Loadメンバーの別名です。別名「予測」には、名前にピリオドが含まれます。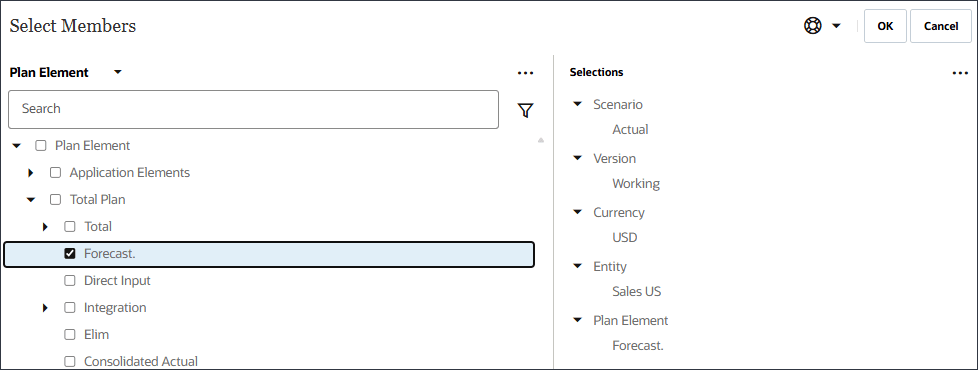
ヒント :
「Product」で、「All Product」の「Lev 0 Descendents」を選択します。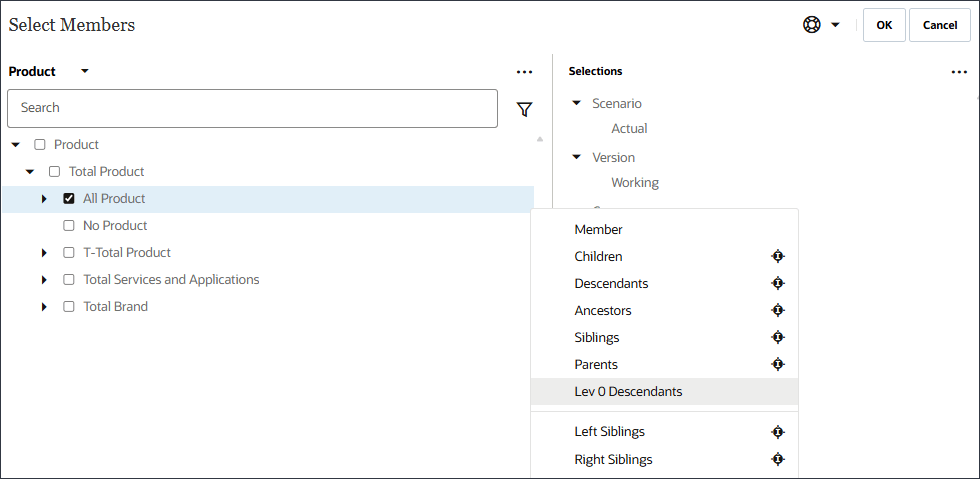
各ディメンションからPOVメンバーを選択して、拡張予測モデルのトレーニングに使用する必要がある履歴データの場所を定義します。たとえば、拡張予測モデルをトレーニングして、Ilvl0Descendants("All Product")のすべてのメンバーのボリュームを予測し、実績シナリオおよび作業バージョンの履歴データを使用し、USD通貨を使用し、Sales USエンティティを使用します。
- 選択内容を確認します。
- 「予測する出力の選択」で、「名前」に「ボリューム」と入力します。
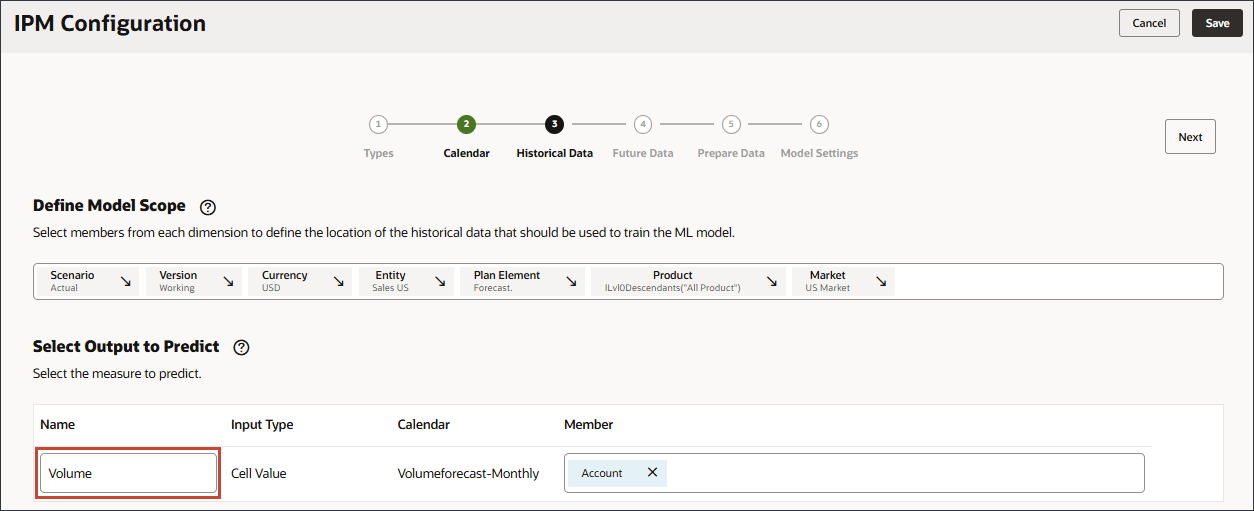
- 「予測する出力の選択」で、「アカウント」をクリックします。
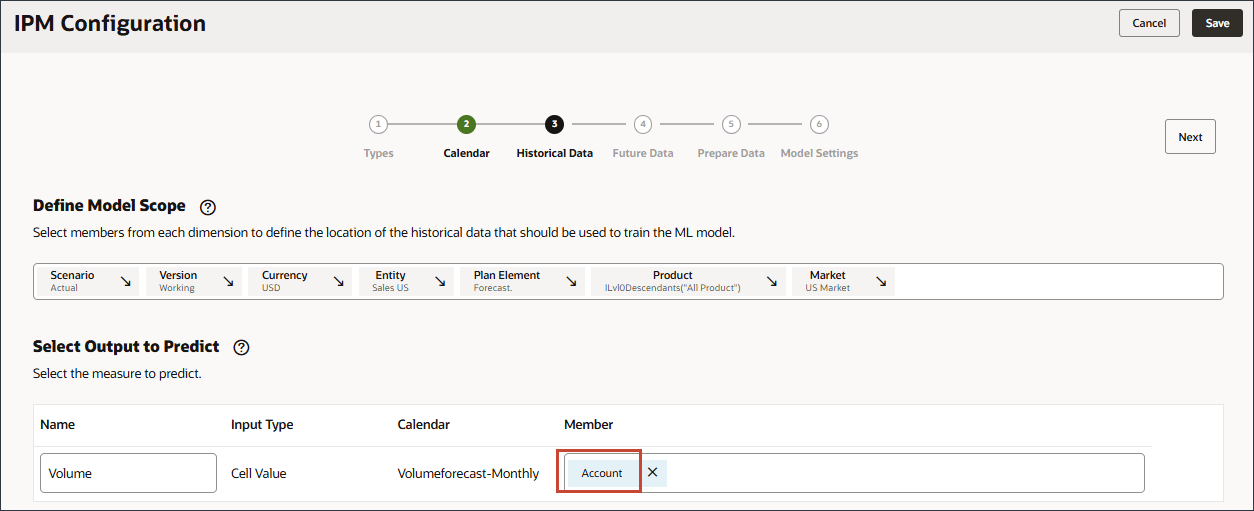
- メンバー・セレクタを使用して、「ボリューム」を選択し、「OK」をクリックします。
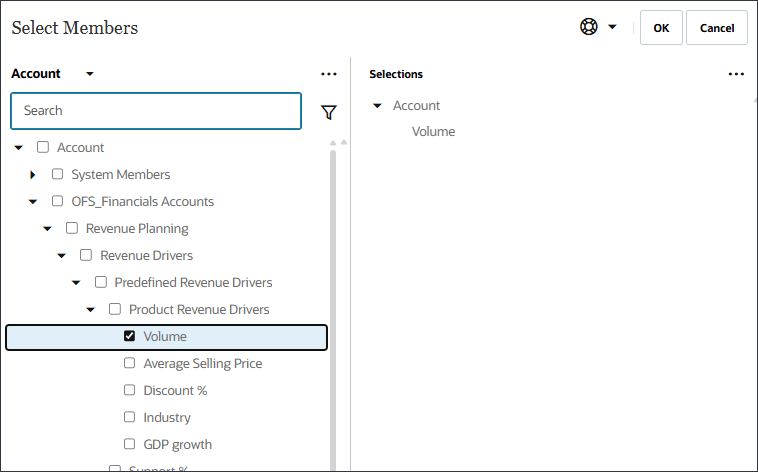
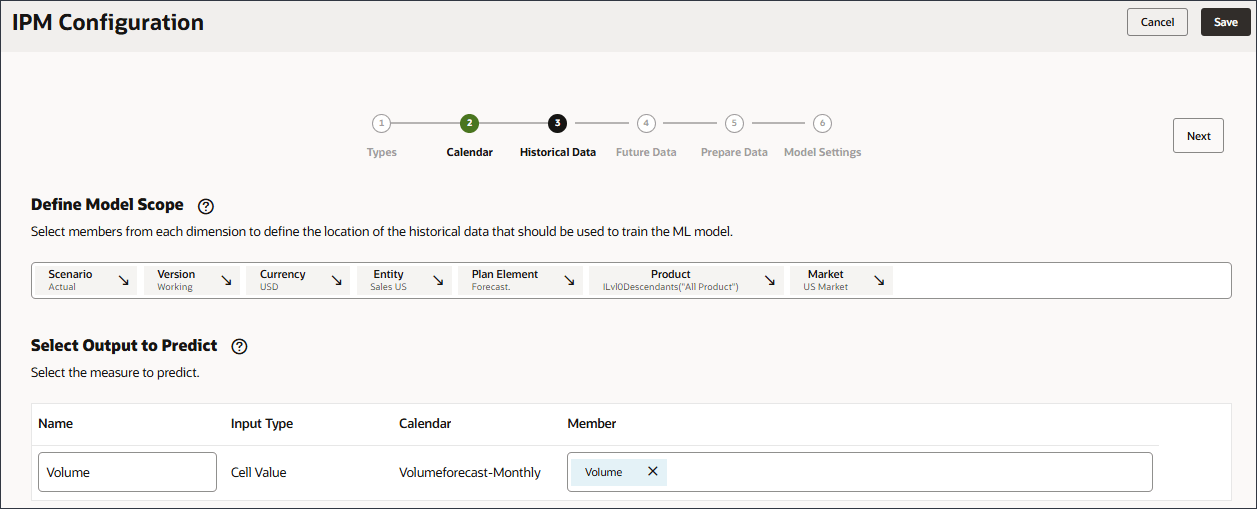
注意:
正しいボリューム・アカウントを選択してください。このアカウントのメンバー名はOFS_Volumeで、別名はVolumeです。ボリュームが選択されています。
- 「ドライバを入力として選択」で、「名前」に「業種ボリューム」と入力し、「アカウント」をクリックします。
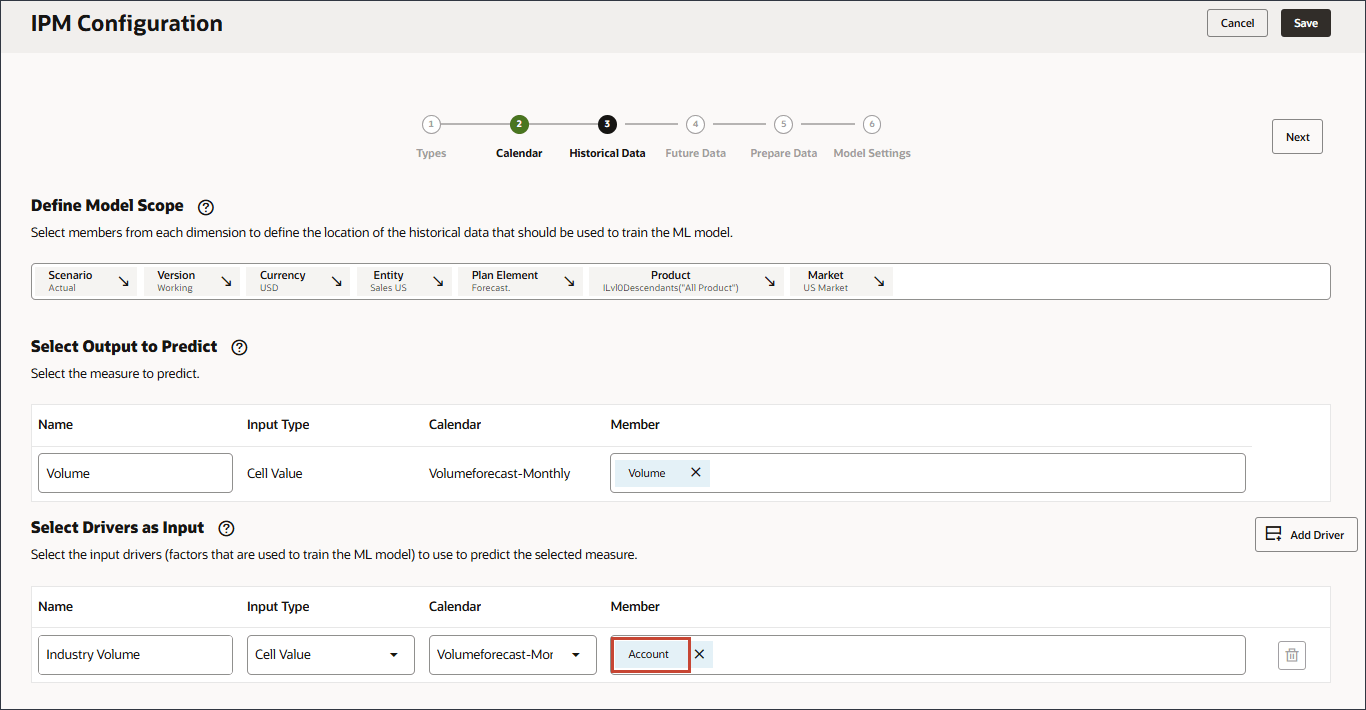
- 「Industry Volume」を選択し、「OK」をクリックします。
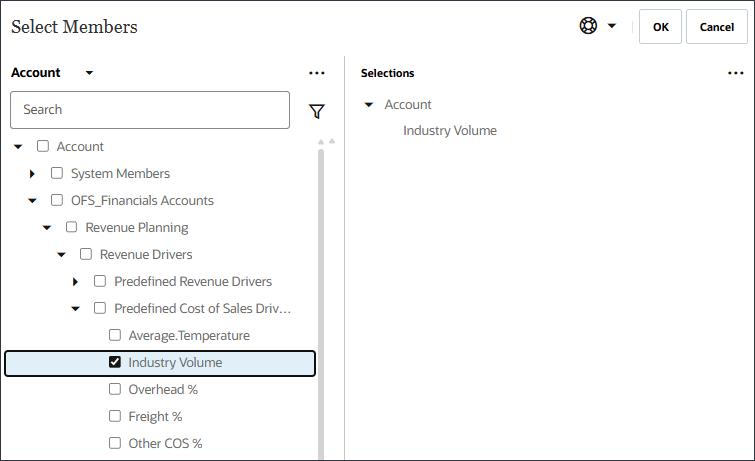
注意:
階層の「販売ドライバの事前定義済コスト」の下にある正しい産業ボリューム・アカウントを選択してください。 - 「ドライバの追加」をクリックします。
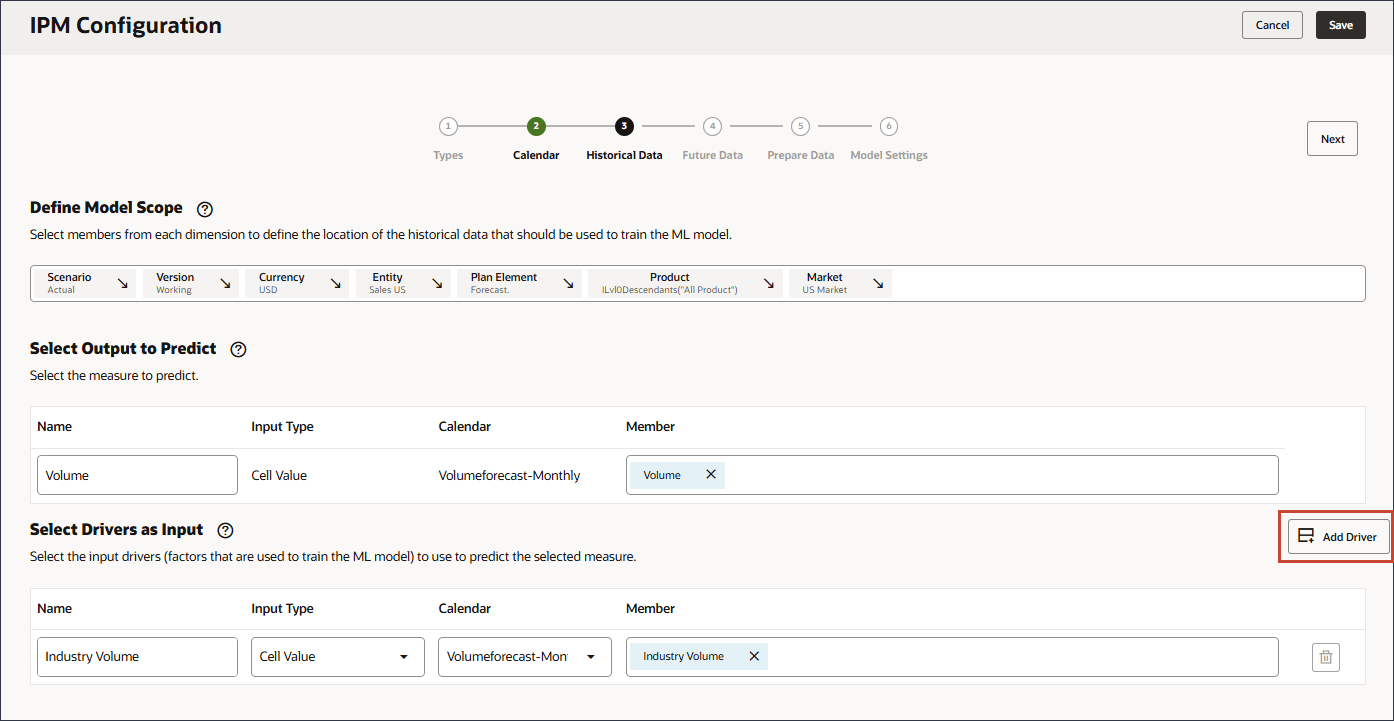
- 「名前」にAdvertising and Promotionsと入力し、「メンバー」にAdvertising and Promotionsの「業種別」をクリックします。
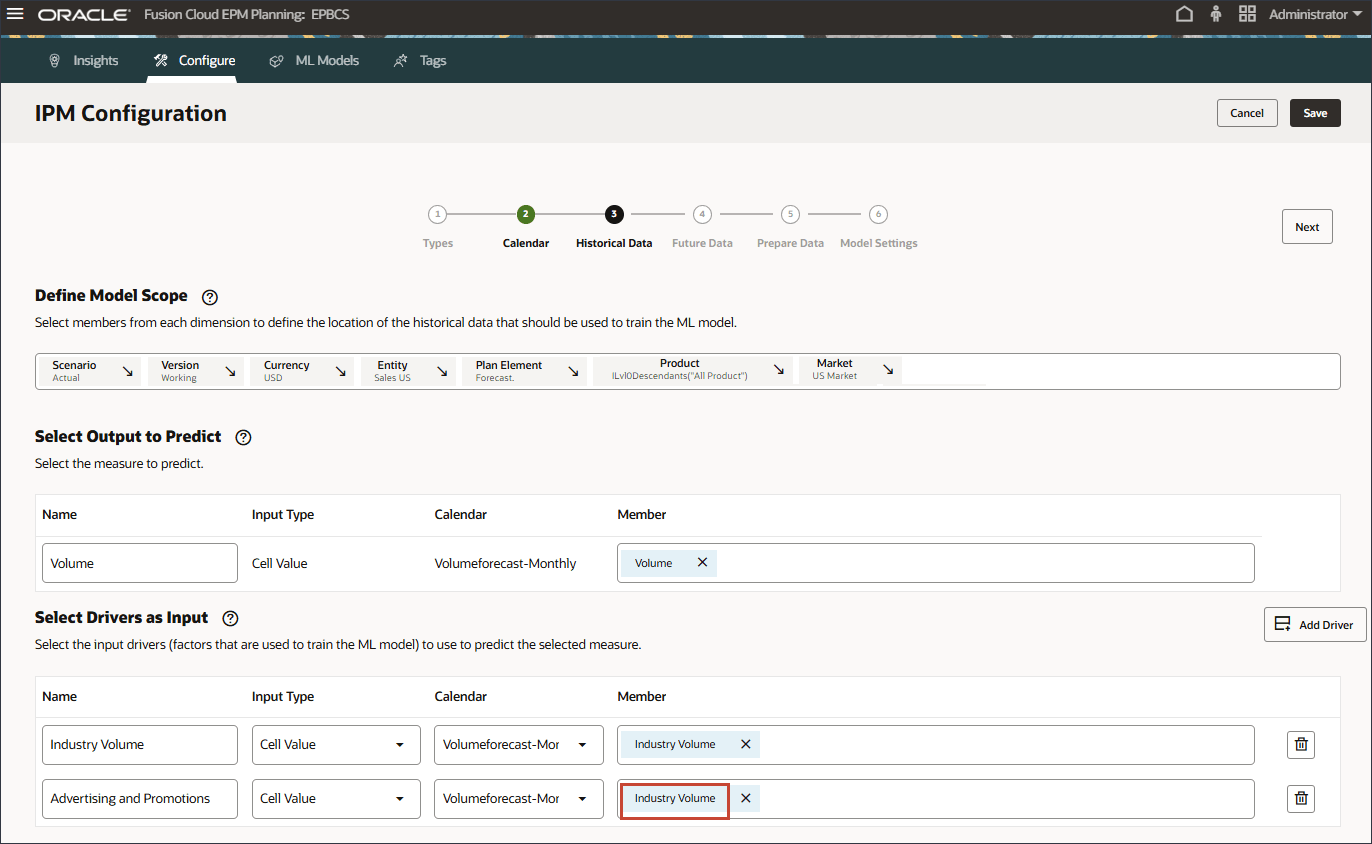
- 「広告と宣伝」を選択し、「OK」をクリックします。
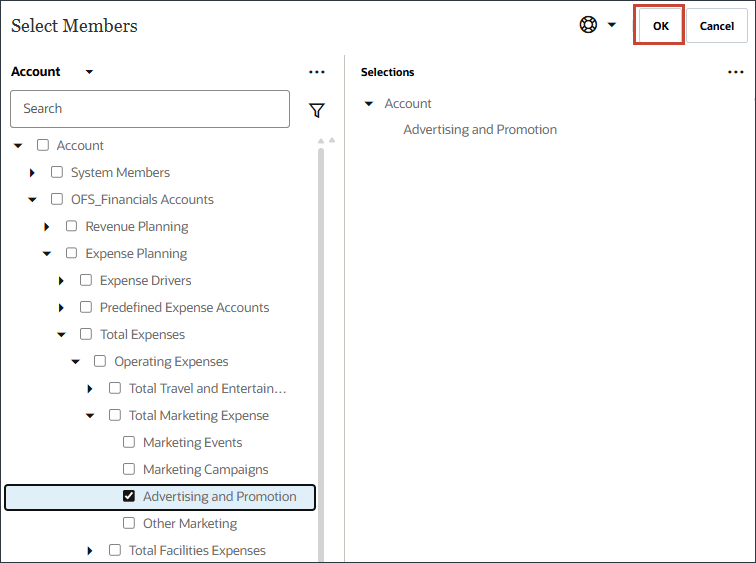
ヒント :
メンバー名が「OFS_Advertising and Promotion」のメンバーを選択してください。別名は「広告およびプロモーション」です。 - 「ドライバの追加」をクリックします。
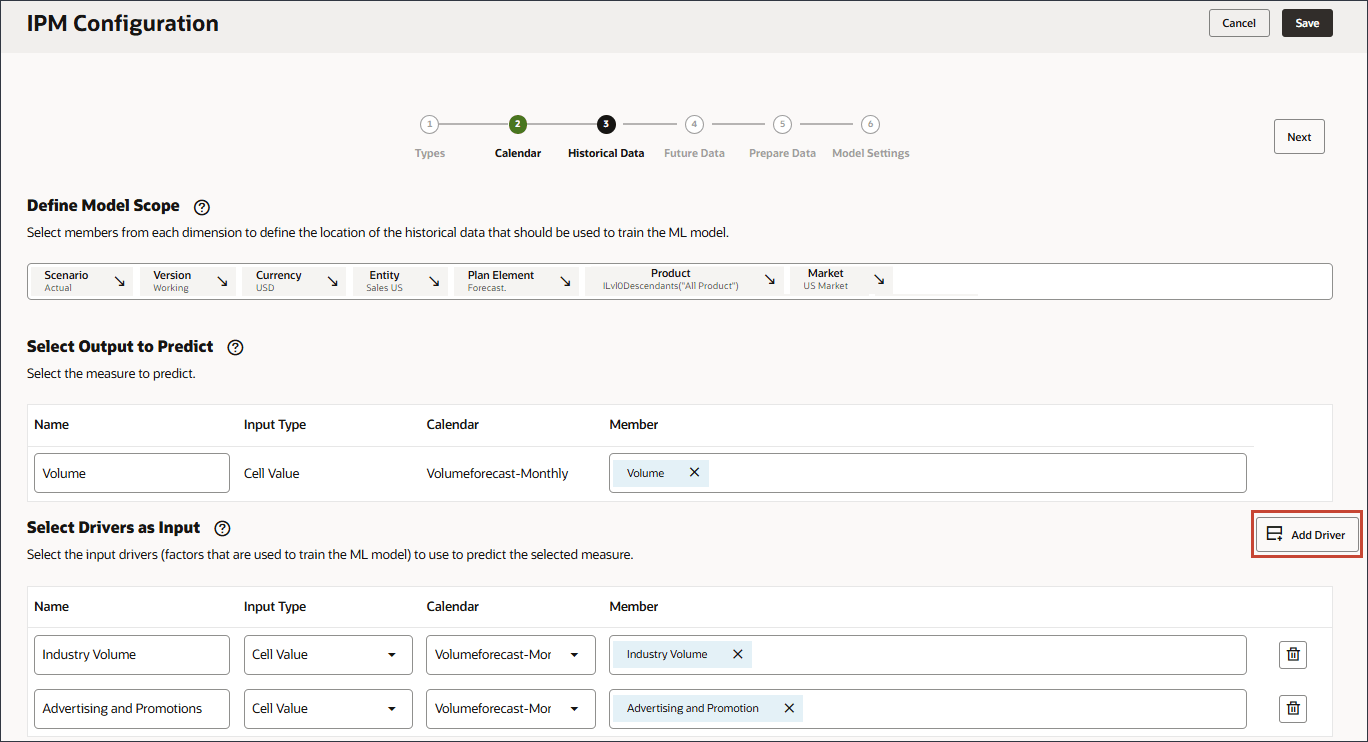
- 「名前」に「平均販売価格」と入力し、「メンバー」に「平均販売価格」で「業種別価格」をクリックします。
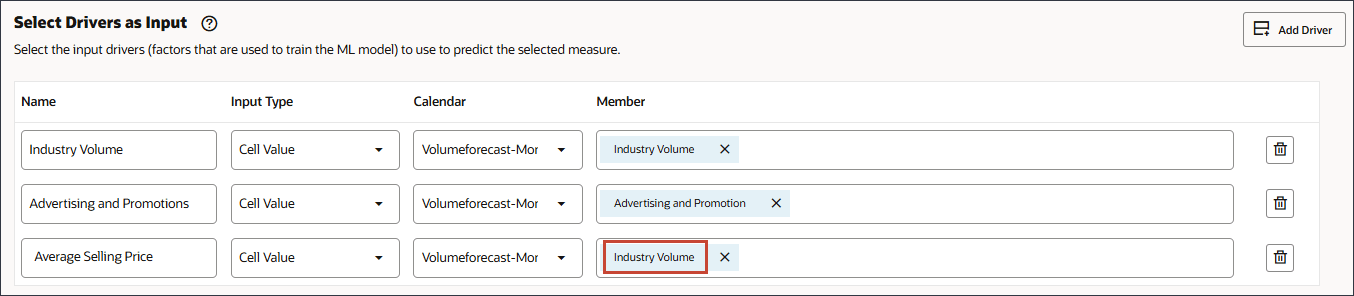
- 「平均販売価格」を選択し、「OK」をクリックします。
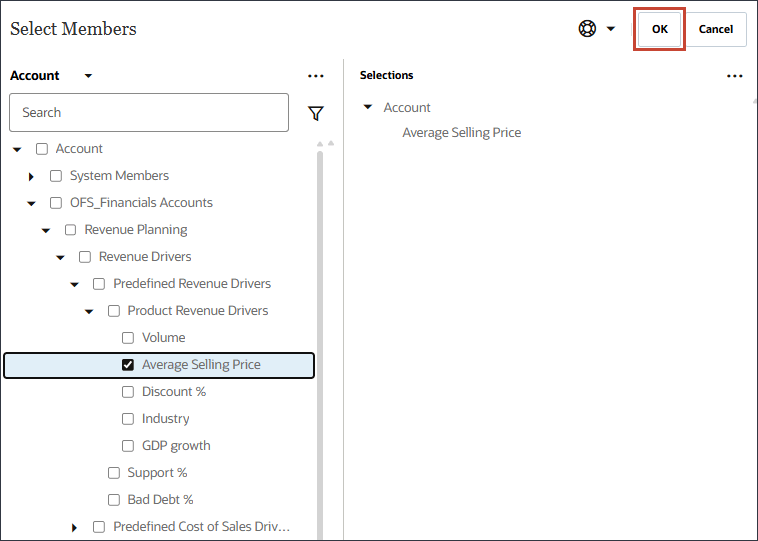
ヒント :
メンバー名が「OFS_Ave Selling Price」のメンバーを選択してください。別名は平均販売価格です。 - 「ドライバの追加」をクリックします。

- 「名前」に「経済指数」と入力し、「メンバー」に「産業量」をクリックします。
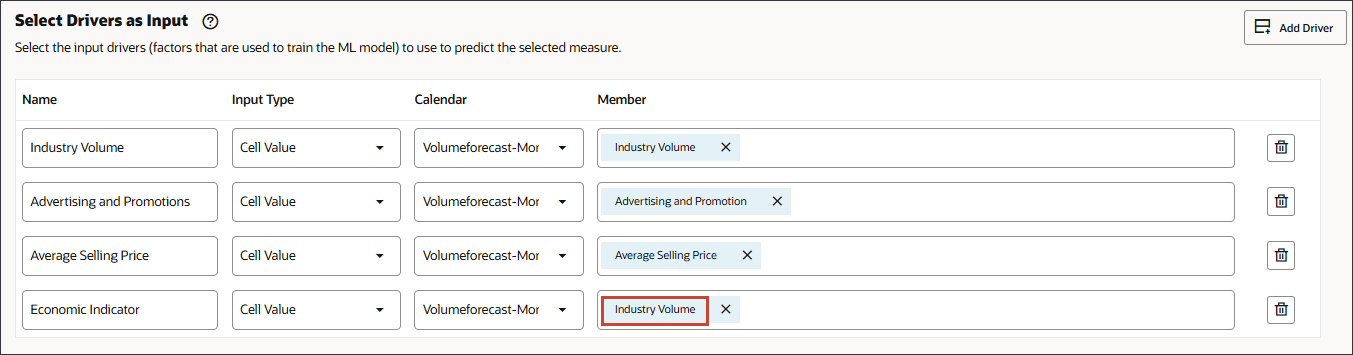
- 「GDP成長率」を選択し、「OK」をクリックします。
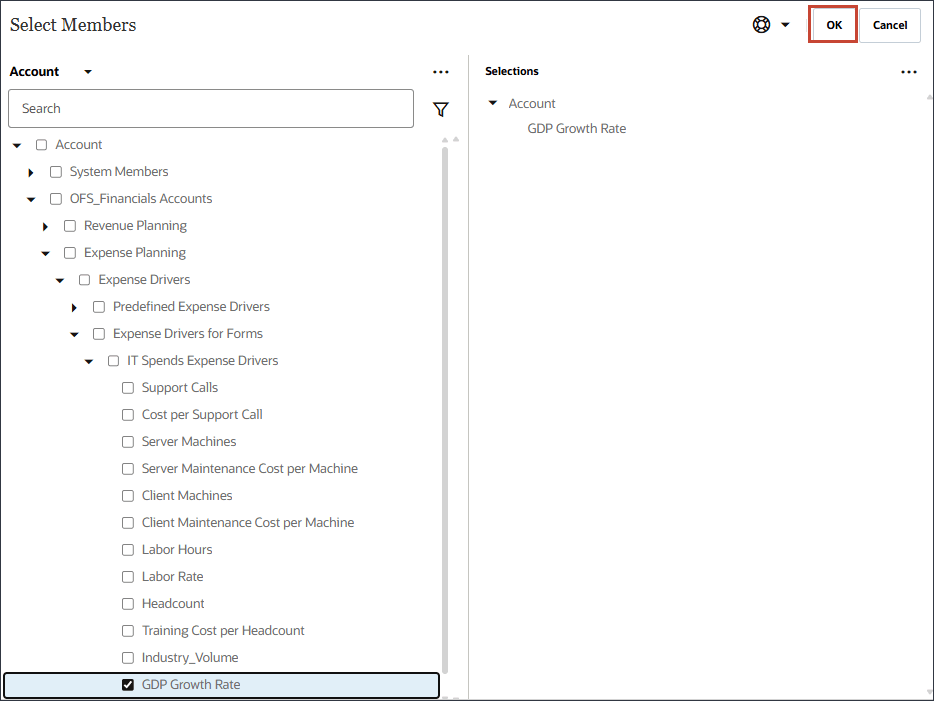
注意:
正しいアカウントを選択していることを確認します。この勘定科目のメンバー名は「経済指数」で、別名は「GDP成長率」です。メンバーの経済指標はGDP成長率にマップされます。
- 「経済指数」の「カレンダ」で、「Volumeforecast-Monthly」をクリックし、GDPCalを選択します。
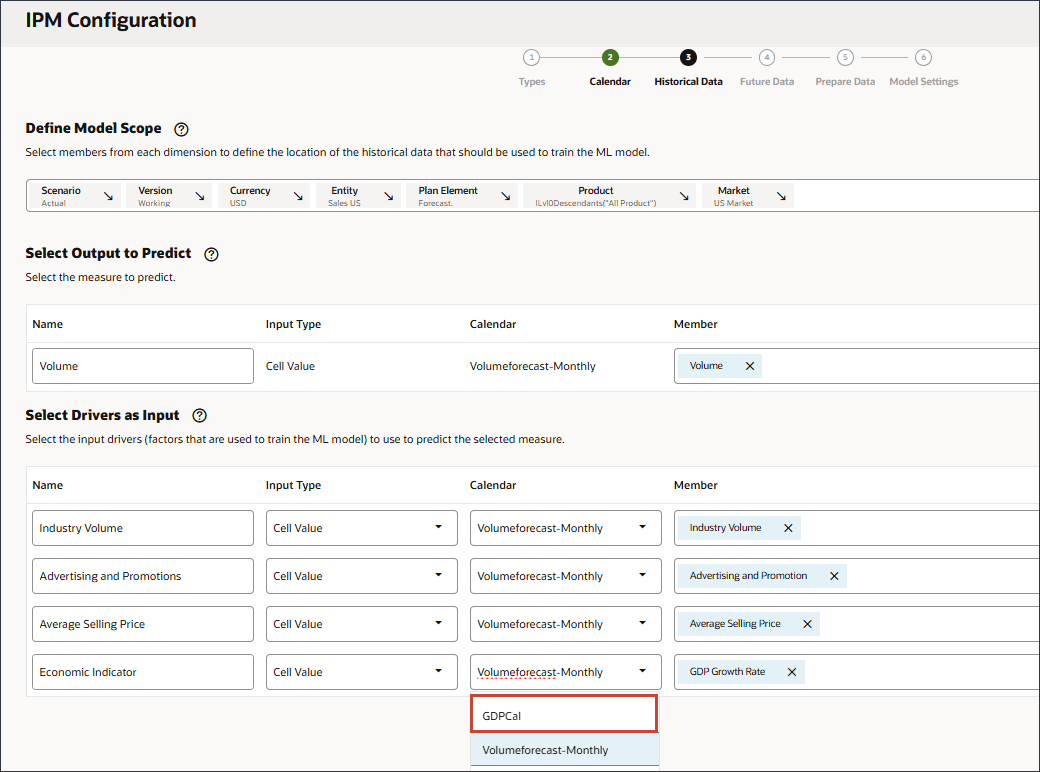
- 「ドライバの追加」をクリックします。
- 「名前」に「個人消費支出」と入力し、「個人消費支出」の「メンバー」で「業種ボリューム」をクリックします。
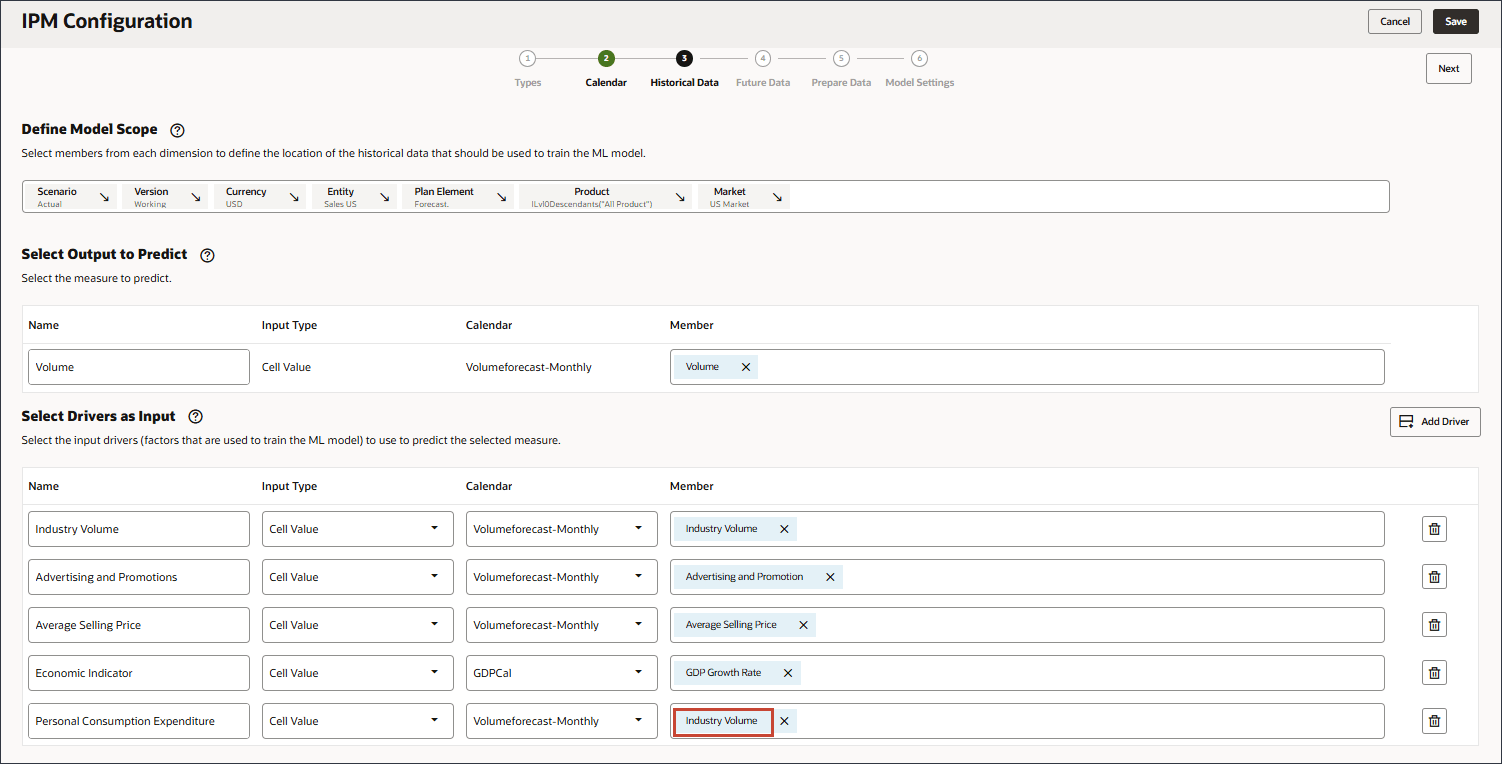
- 「個人消費支出(耐久消費財)」を選択し、「OK」をクリックします。
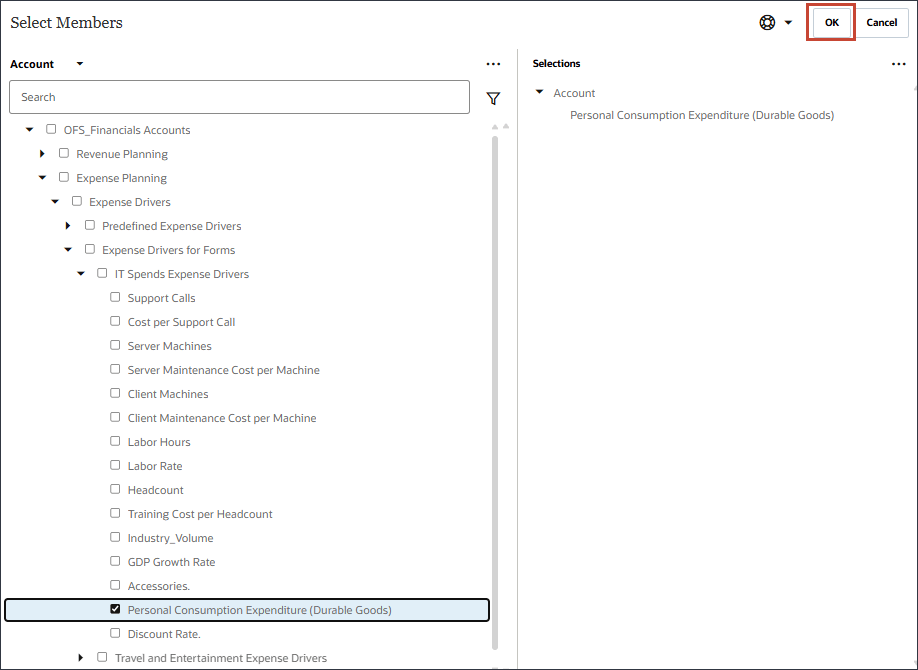
ヒント :
メンバー名が「個人消費支出(耐久消費財)」のメンバーを選択してください。このメンバーの別名は「個人消費支出(耐久財)」でもあります。 - 「ドライバの追加」をクリックします。
- 「名前」に「割引率」と入力し、「メンバー」に「業種別価格」をクリックします。
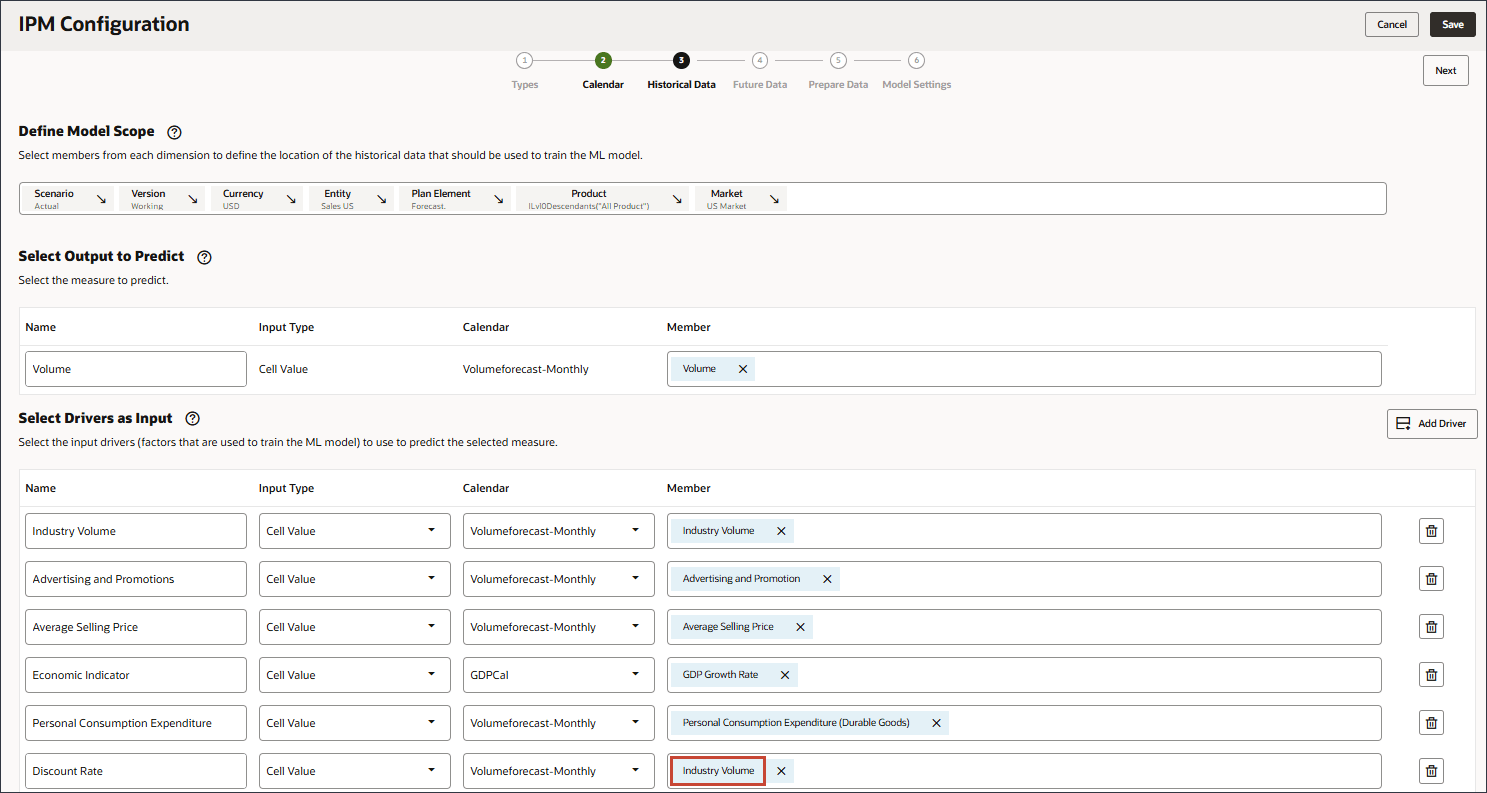
- 「割引率」を選択し、「OK」をクリックします。
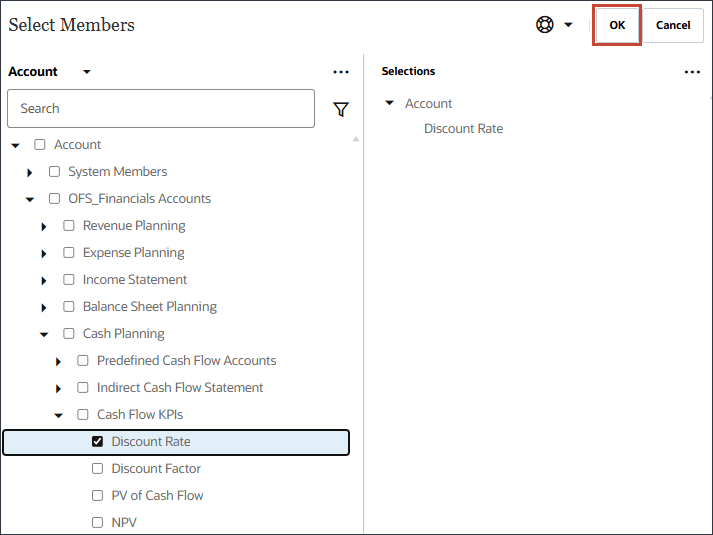
ヒント :
メンバー名が「OFS_Discount Rate」のメンバーを選択してください。このメンバーの別名は「割引率」で、名前に期間はありません。 - 「ドライバの追加」をクリックします。
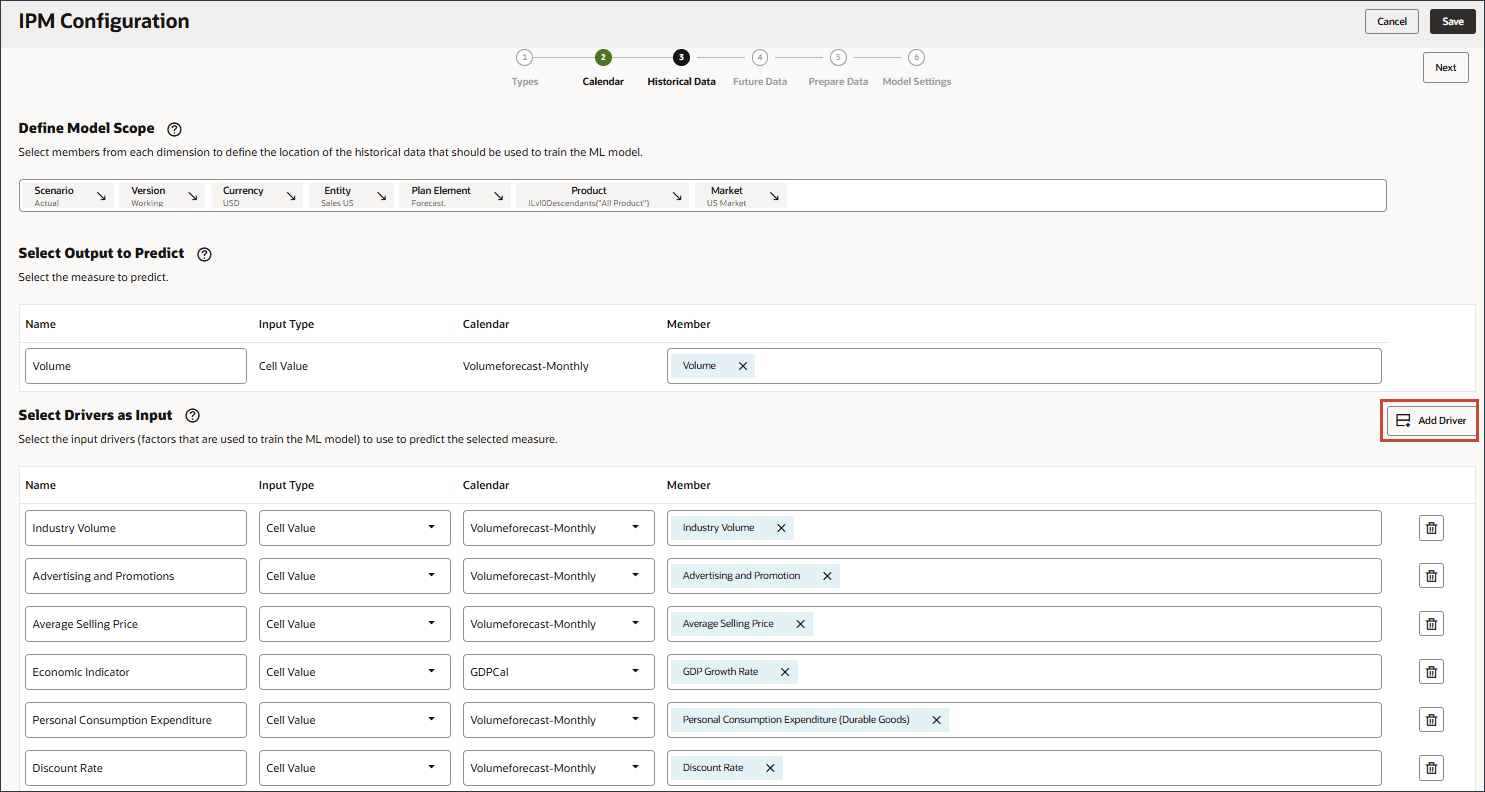
- 「名前」に「アクセサリ」と入力し、「入力タイプ」に「セル値」をクリックして、「スマート・リスト」を選択します。
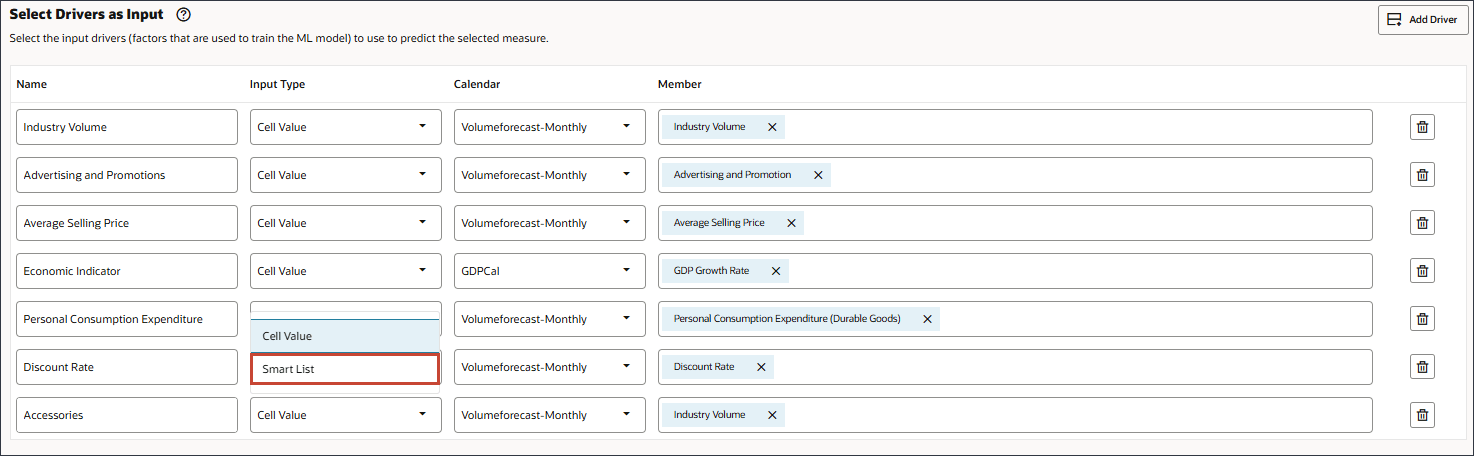
- 「アクセサリ」で、「メンバー」で「インダストリ・ボリューム」をクリックします。
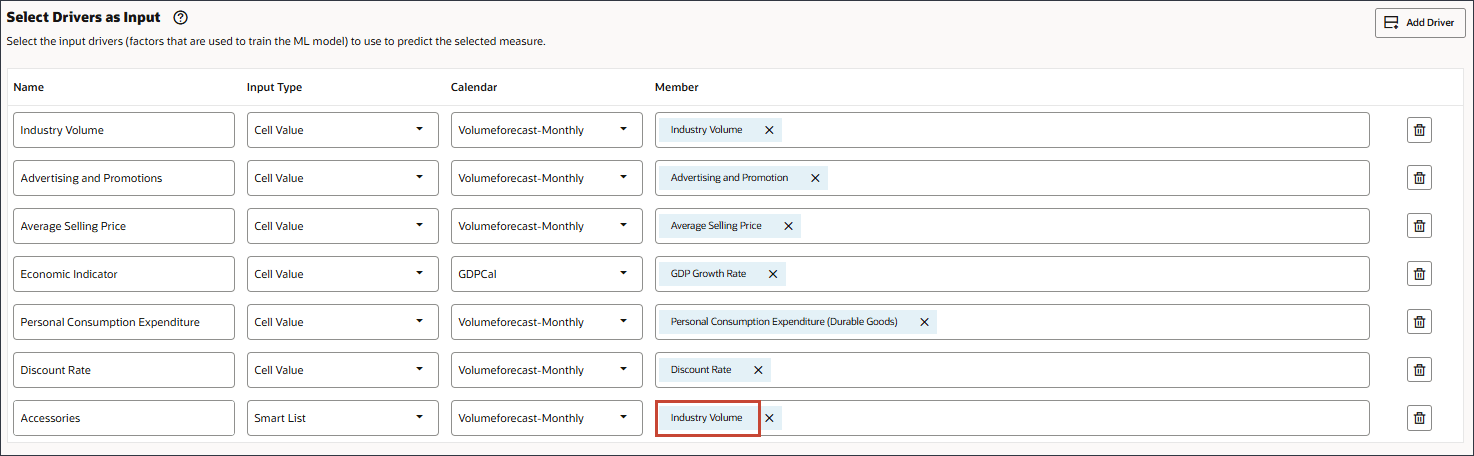
- 「アクセサリ」を選択し、「OK」をクリックします。
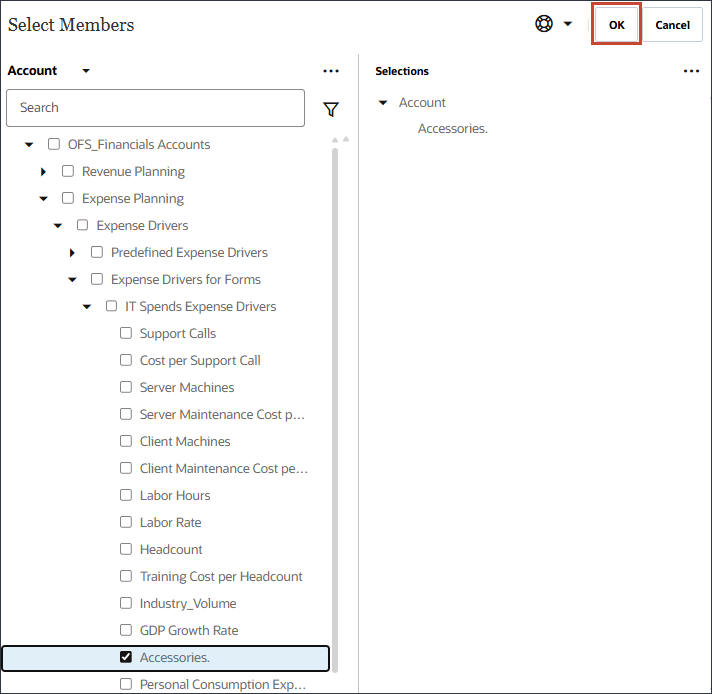
ヒント :
メンバー名が「アクセサリ」のメンバーを選択してください。メンバー名と別名は両方とも同じで、両方の名前にはピリオドが含まれます。 - 上にスクロールし、「次へ」をクリックします。
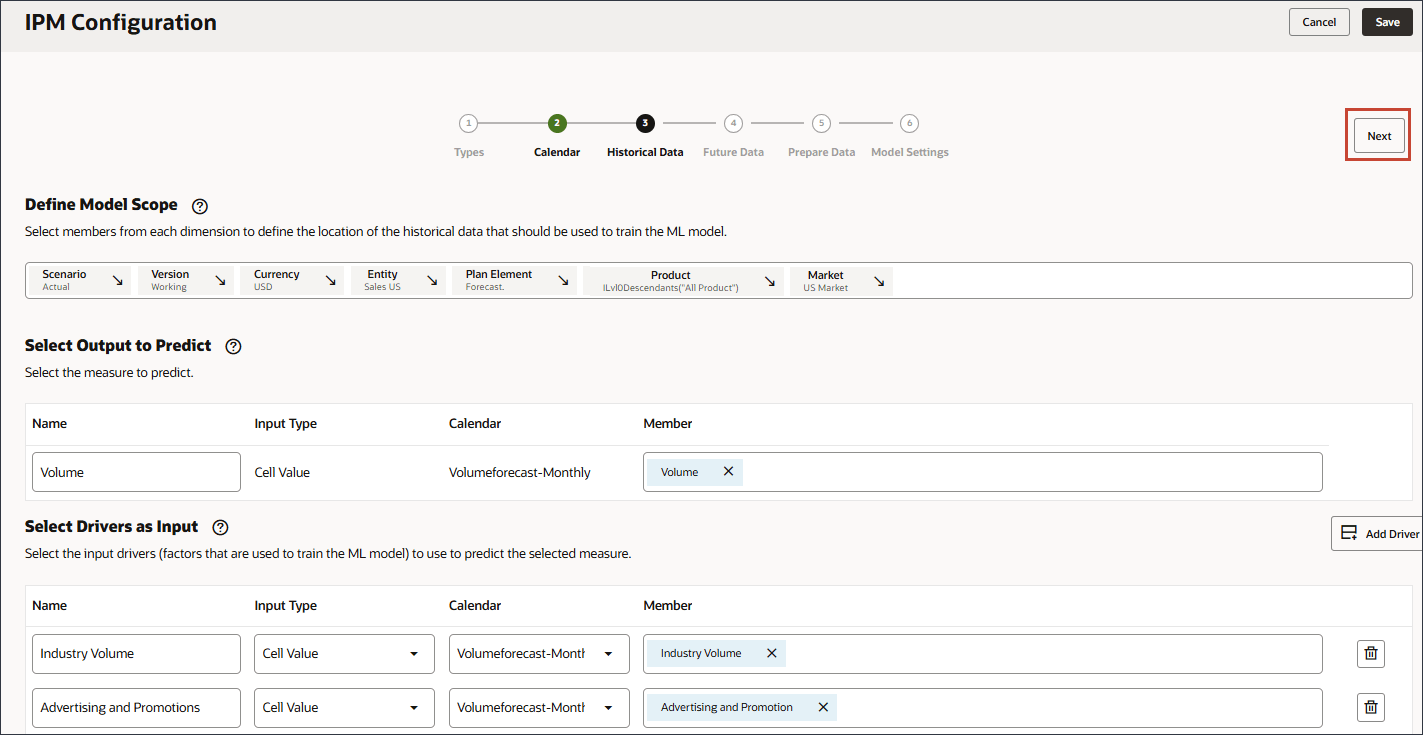
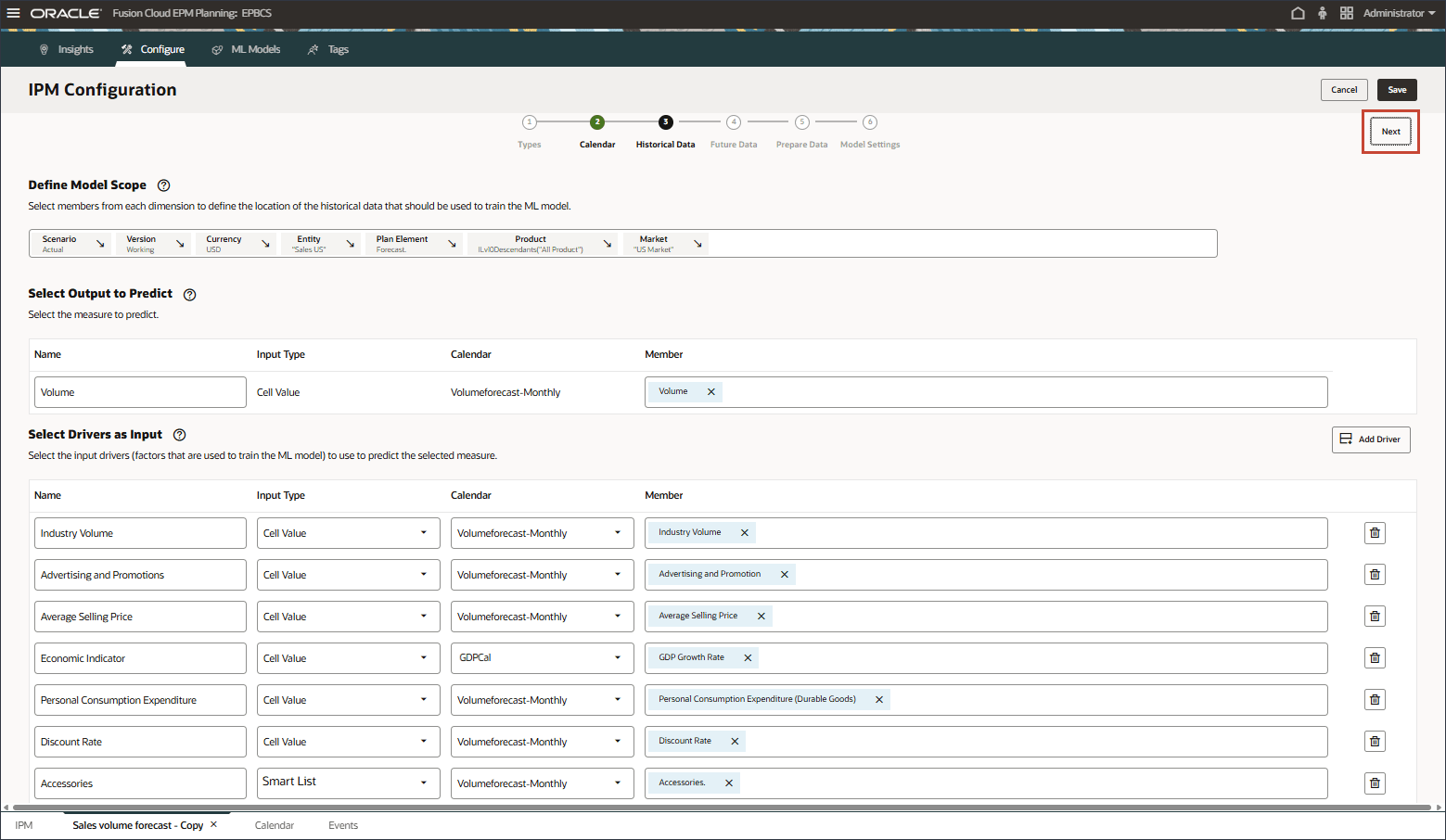
将来のデータのスライス定義の選択
この項では、予測からの出力を格納するスライス定義を選択します。デフォルトでは、履歴データに設定した設定が将来のデータ ページに繰り越されます。特定のメンバーを変更して、将来のデータが存在する場所や予測が格納される場所を定義できます。
- POVで、「シナリオ」をクリックします。
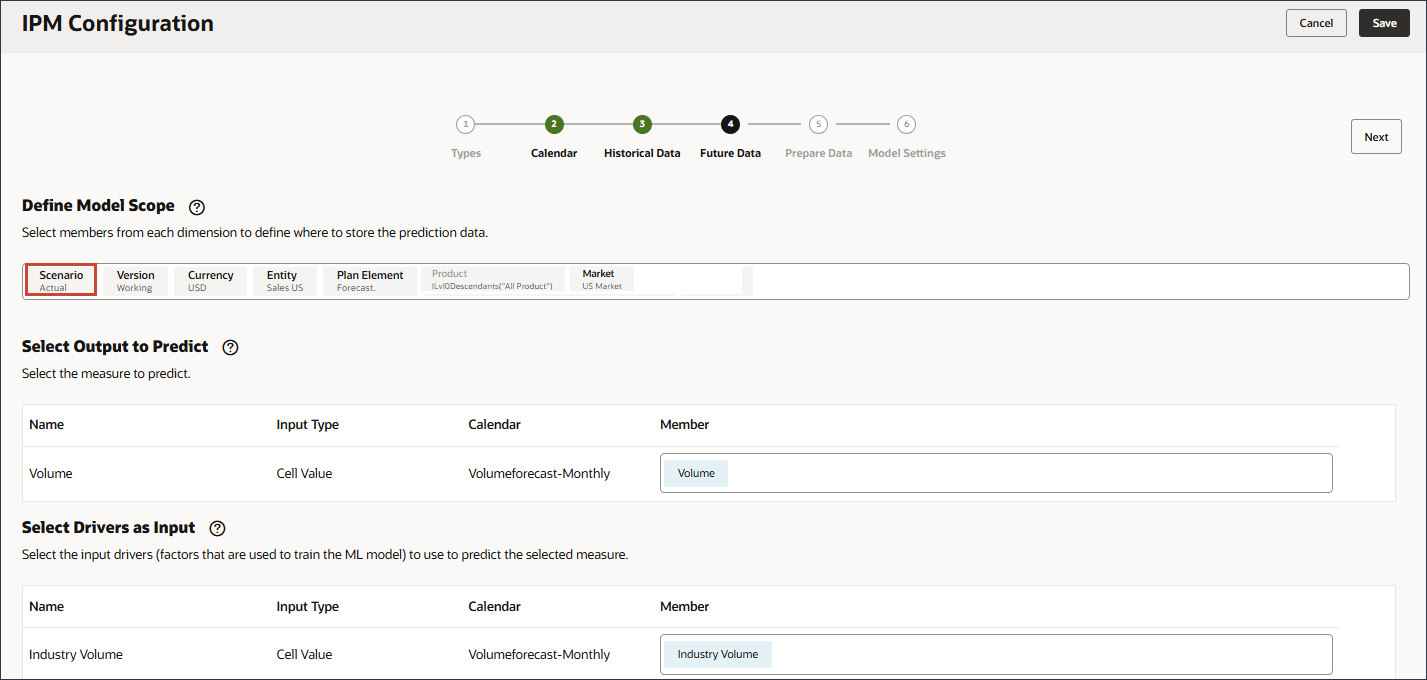
- 「予測」を選択し、「OK」をクリックします。
その他の変更は必要ありません。入力ドライバと出力ドライバが同じである
予測出力は、予測シナリオまたは予測を格納する任意のシナリオに移動できます。
- 「次へ」をクリックします。
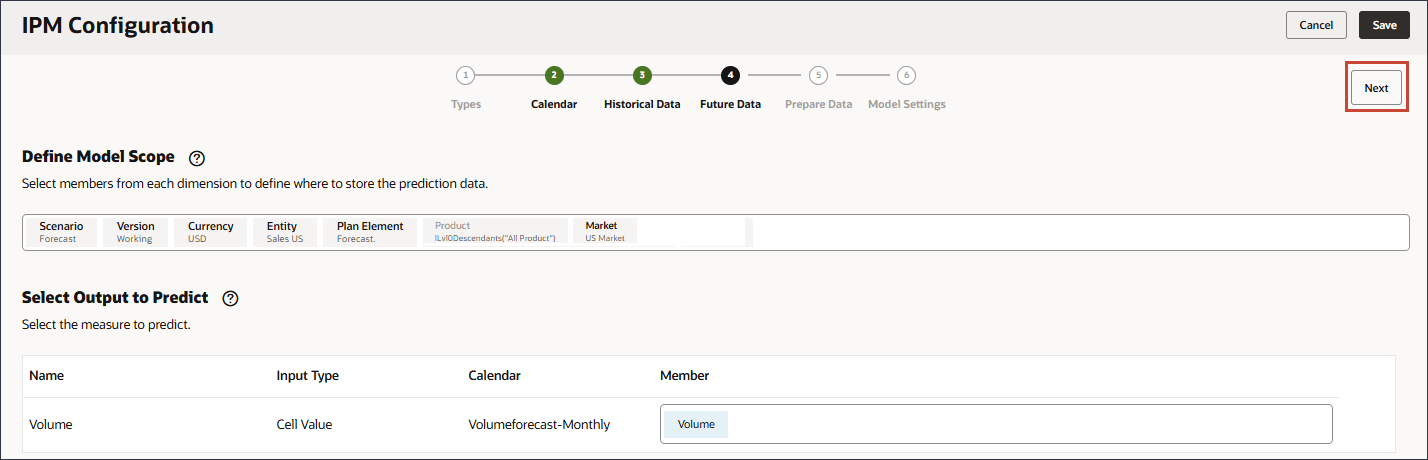
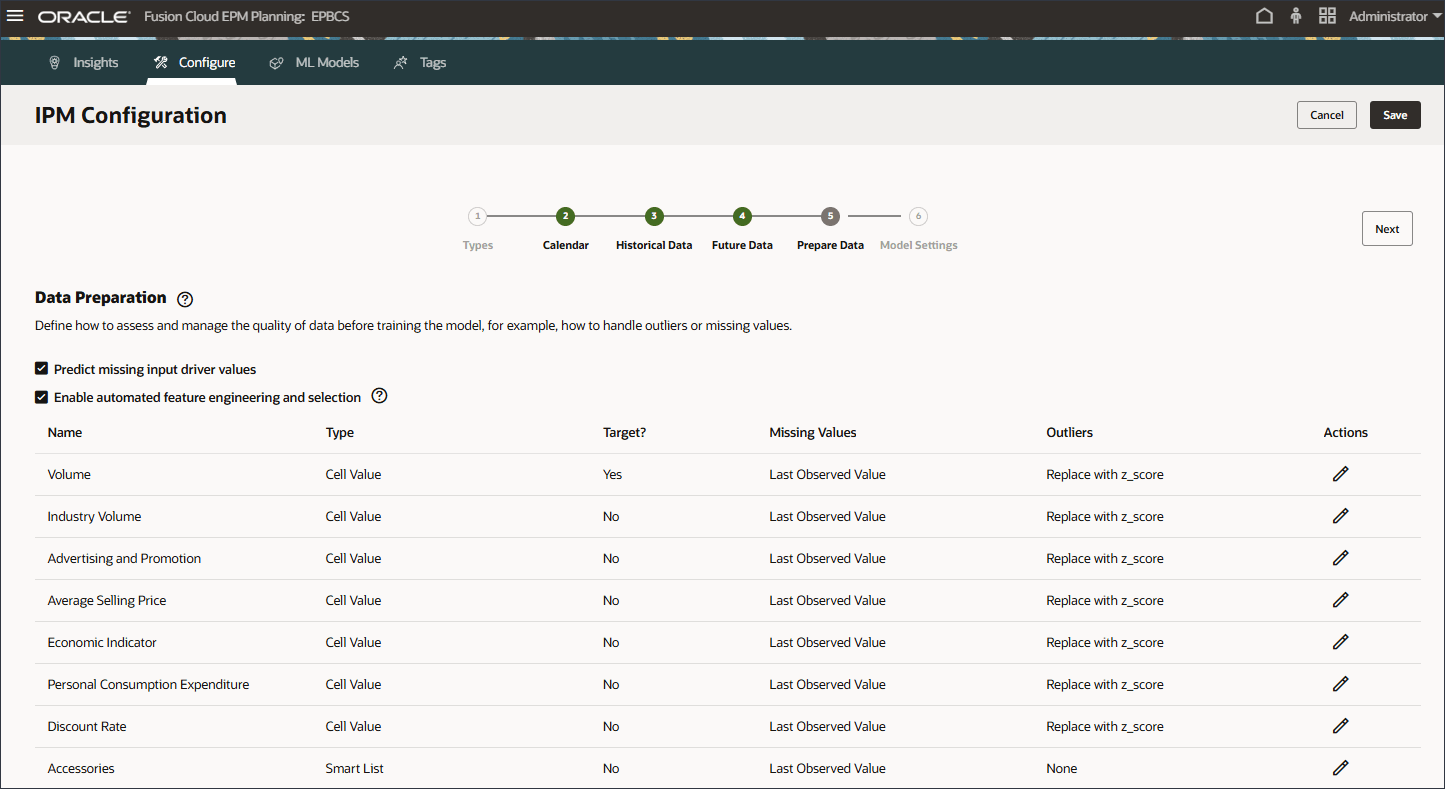
データ品質問題の処理方法の定義
データ準備段階では、欠落している入力ドライバ値の処理方法を選択できます。前に、入力ドライバを確認して、製品'eReader'に将来のドライバ・データ値がないことに気付きました。
データ準備には、ドライバ名、タイプ、ターゲット、欠落値、外れ値およびアクションの列が含まれます。
モデルをトレーニングする前に、データの品質を評価および管理する方法を定義します(例、外れ値または欠損値の処理方法)。
値の予測に使用される履歴データでは、値が欠落していることがよくあります。測定の失敗、書式設定の問題、ヒューマン・エラー、記録する情報の不足など、いくつかの理由でデータが欠落している可能性があります。ターゲット予測および関連データセット内の欠落値を処理するための、提供されている様々な充填オプションがあります。入力とは、データセット内の不足しているエントリに標準化された値を追加するプロセスです。
次のオプションから選択して、欠落している値を置換できます。
- なし: 実行するアクションはありません(データをそのまま送信します)。
- ゼロ: 欠落している列の値をゼロで置換します。
- 平均で置換(数値データ): 履歴系列全体で平均で置換します。
- 中央値(数値データ)で置換: 履歴系列の中央値で置換します。
- モード(数値および質的データ)で置換: 履歴データの最も一般的な値で置換します。
- 次の観察された値で置換: 欠落した値を次の期間に観察された値または表示された値で置換します。
- 最後の観測値で置換: 欠落した値を前の期間に観測された値で置換します。
外れ値の場合、ゼロ、平均、zスコアまたはなしのいずれで置換するかを定義します。
外れ値を置換するには、次のオプションを選択できます。
- なし: 実行する外れ値処理はありません。
- 0で置換: 0で置換します。
- 平均で置換: Kに最も近い値の平均で置換します。
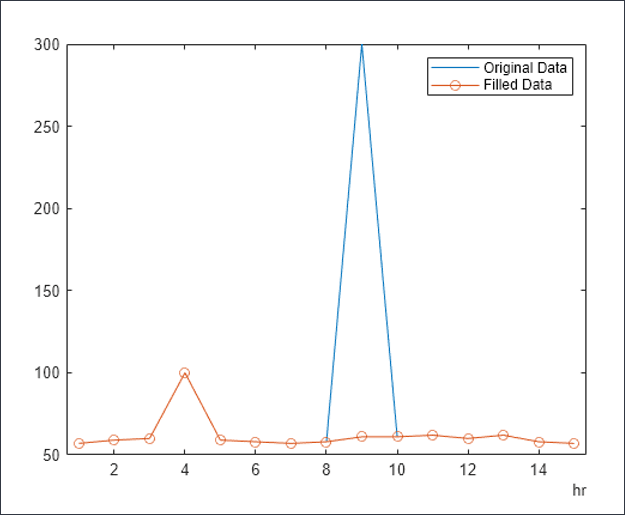
- Zスコアで置換: 任意の数値列について、平均+/- 3*標準偏差(標準偏差)から除外される値は外れ値として扱われます。'mean - 3*std dev'より小さい値は'mean -3*std dev'に置き換えられます。同様に、'mean + 3*std dev'より大きい値は'mean + 3*std dev'に置き換えられます。
次のグラフは、正規化された値で識別されて置換される外れ値の例です。
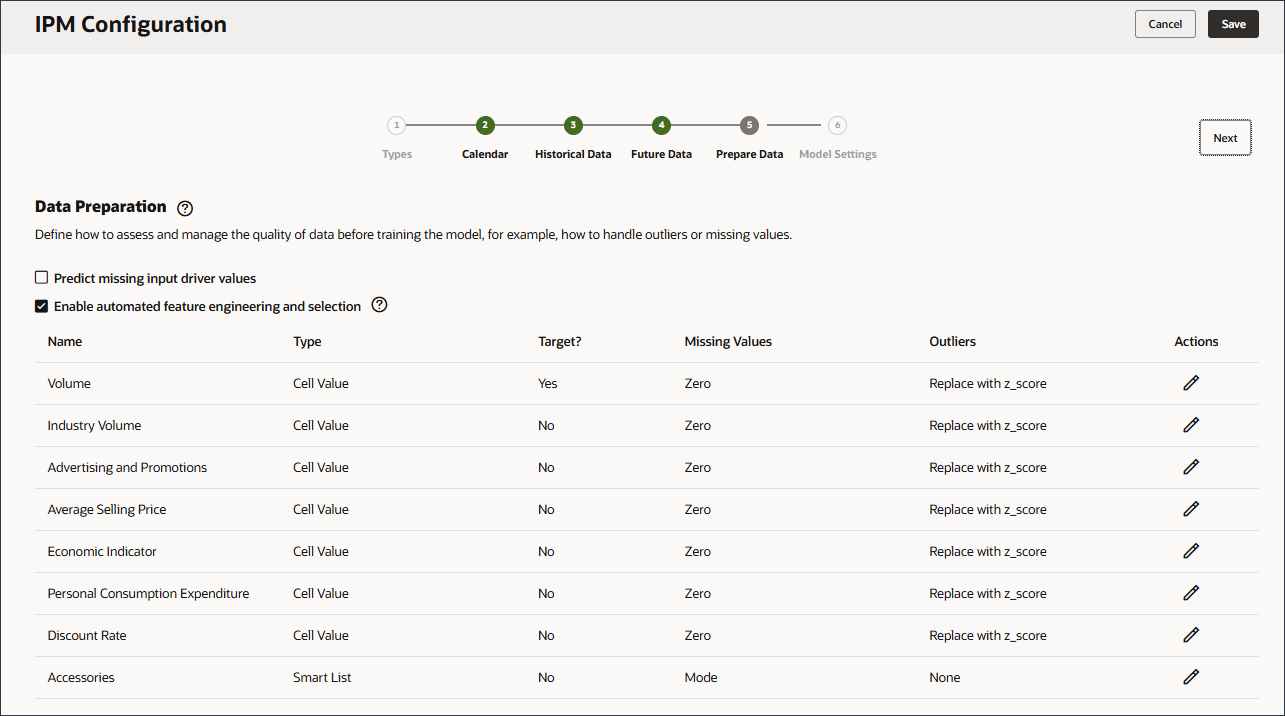
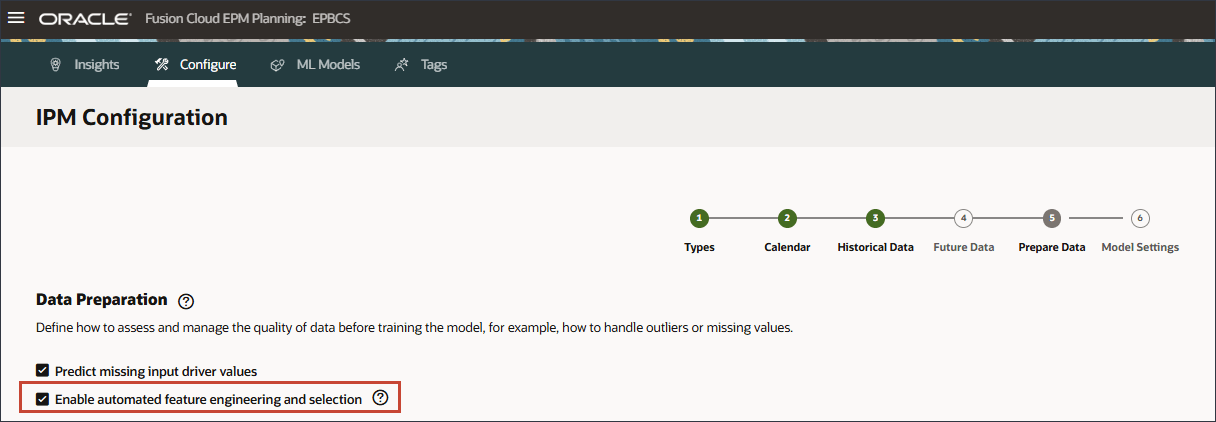
- 「欠落した入力ドライバ値のプレディクト」を有効にします。
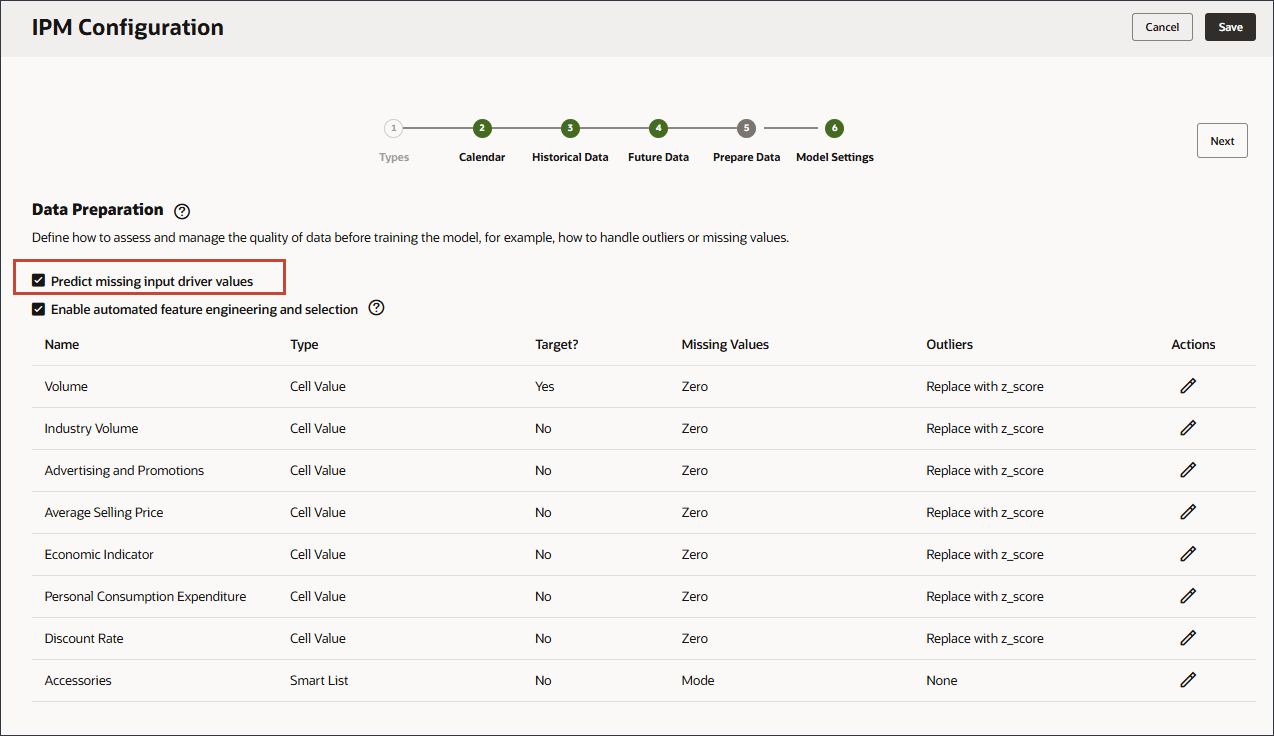
Predictの欠落している入力ドライバ値を有効にすると、統計予測を使用して値が予測されます。つまり、これらのメジャーにデータが存在しない場合の単変量予測です。
- 「欠損値」の場合は、オプションのリストを確認します。
欠落値の選択を変更する場合は、ドライバ行の「アクション」列で、
 (「アクション」)をクリックします。
(「アクション」)をクリックします。 - ドライバの各行について、「アクション」で(「アクション」)をクリックし、オプション・リストで「最終監視値」を選択します。
- 外れ値については、オプションのリストを確認してください。
ドライバ行の「アクション」列で外れ値の選択を変更する場合は、
(「アクション」)をクリックします。
ヒント :
各行の「欠落値」オプションを変更した後、すべてのドライバの欠落値は、「最終観察値」に設定されます。
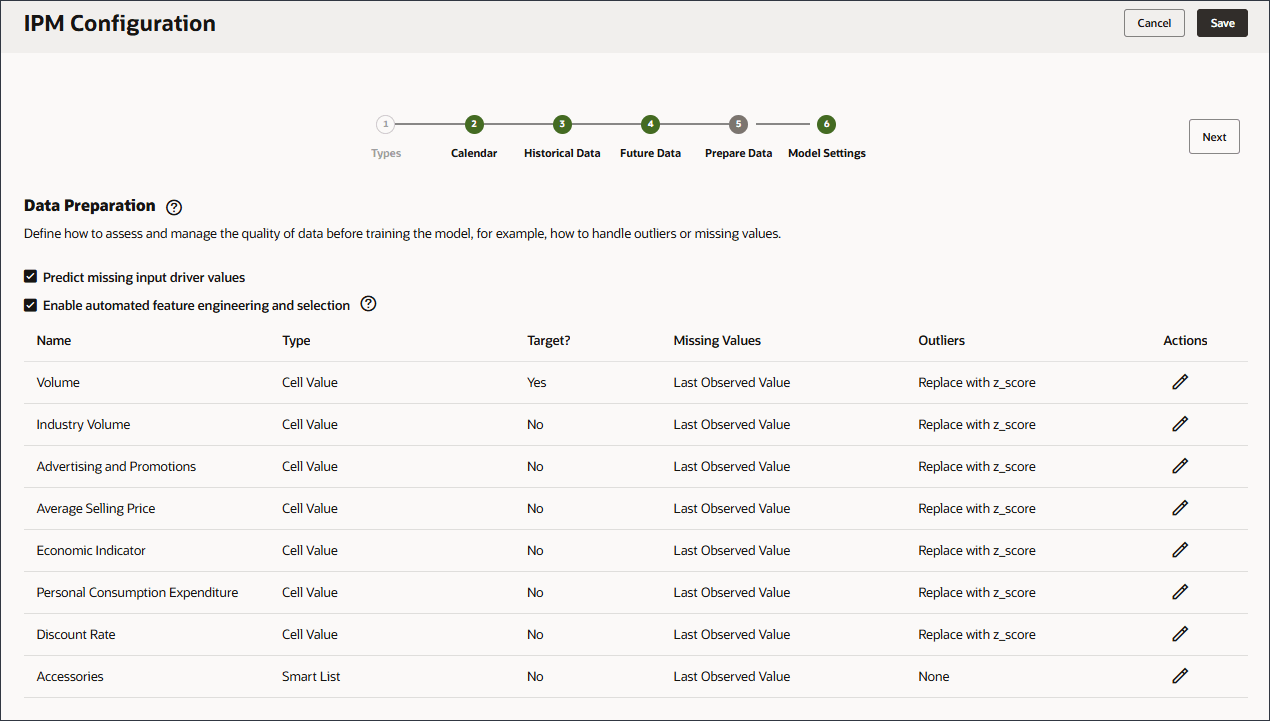
機能エンジニアリングの有効化
この項では、機能エンジニアリングが有効になっていることを確認します。
拡張予測内で、機能エンジニアリングを使用して、入力ドライバと予測出力の間の非表示の関係を見つけます。予測ジョブによって適切に設計された機能が自動的に作成され、モデルがより関連性の高い情報を取得できるようになり、モデルのパフォーマンスが向上し、予測が改善されます。
フィーチャー・エンジニアリングとは、既存の機能を変換したり、モデル・パフォーマンスを向上させるための新しい機能を作成することで、機械学習用のデータを準備するプロセスです。
インテリジェントな機能エンジニアリングは、定義されたドライバに基づいて機能を作成します。
機能エンジニアリングでは、より正確な予測につながる追加情報が導出されます。
適用される変換には次のものがあります。
- 時間ベースの機能。特定の曜日には、より多くの影響がありますか?
- ラグ効果。5月のマーケティング支出が7月の販売量に及ぼす影響など、ターゲットに対するビジネス・ドライバのラグ効果は何ですか。
- 集計変換。たとえば、1つのデータ・ポイントではなく、ビジネス・ドライバにローリング平均値が与える影響は何ですか。
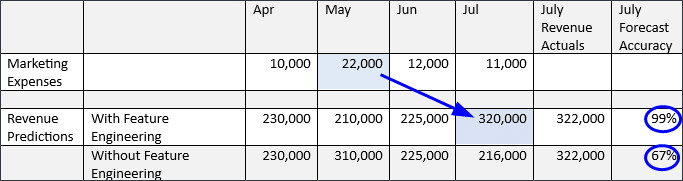
次の例では、ターゲットに対するビジネス・ドライバのラグ効果を確認できます。5月のマーケティング支出は、7月の販売量に影響します。機能エンジニアリングがないと、7月の収益予測の精度は67%になりますが、機能エンジニアリングにより、7月の収益は99%の精度で予測されます。
ラグ効果
機能エンジニアリングはデフォルトで有効になっています。
- 機能エンジニアリングが有効になっていることを確認します。
- 「次へ」をクリックします。
モデル設定のアルゴリズムの選択
この項では、モデル設定のアルゴリズムを選択します。
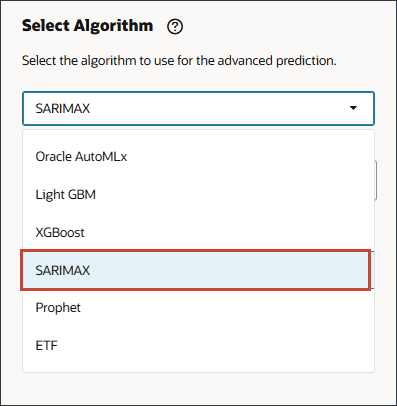
Oracle AutoML、またはLight GBM、XGBoost、Prophet、SARIMAXなどの特定のアルゴリズムを選択できます。
Oracle AutoMLxは、次のことを実行する独自のフレームワークです。
- 様々な統計モデルと機械学習アルゴリズムをデータ上で実行します
- モデルのチューニングと検証
- データに最適なモデルを見つける
- データを最適なモデルに適合

Oracle AutoMLx、Light GBM、XGBoost、Prophet、SARIMAXなどの様々なアルゴリズムの1つを選択できます。これらは、モデル・トレーニングでグローバルに使用できるベスト・プラクティスの拡張予測アルゴリズムです。AutoMLxアルゴリズムには、次の詳細に従って複数のアルゴリズムがあります。
AutoMLx pythonパッケージは、機械学習パイプラインとモデルを自動的に作成、最適化、説明しています。AutoMLパイプラインは、特定のトレーニング・データセットと予測タスクに最適なモデルを見つけるチューニングされたMLパイプラインを提供します。AutoMLには、正確にチューニングされたモデルを使用してデータ・サイエンス・プロセスを迅速に開始する単純なパイプライン・レベルのPython APIがあります。AutoMLでは、次のいずれかのタスクがサポートされます。
- AutoClassifier: 表形式データセットを使用した監視付き分類または回帰予測。ターゲットは、それぞれ表の単純なバイナリ値、マルチクラス値または実値列です。
- AutoRegressor: イメージおよびテキスト・データセットの監視あり分類。
- AutoAnomalyDetector: ターゲットまたはラベルが指定されていない、教師なし異常検出。
- AutoForecaster: 単変量および多変量時系列予測タスク。
AutoMLパイプラインは、MLパイプラインの5つの主要なステージ(前処理、アルゴリズム選択、適応サンプリング、機能選択およびモデル・チューニング)で構成されます。これらのピースは単純なAutoMLパイプラインに簡単に結合され、限られたユーザー入力/インタラクションでパイプライン全体を自動的に最適化します。
EPMの高度な予測では、AutoMLのAutoForecasterパッケージを内部で活用します。
AutoForecasterのアルゴリズムのリスト:
- NaiveForecaster
- ThetaForecaster
- ExpSmoothForecaster
- ETSForecaster
- STLwESForecaster
- STLwARIMAForecaster
- SARIMAXForecaster– 多変量
- ExtraTreesForecaster - 多変量
- XGBForecaster (XG Boost)– 多変量
- LGBMForecaster (軽量グラデーションブーストマシン)– 多変量
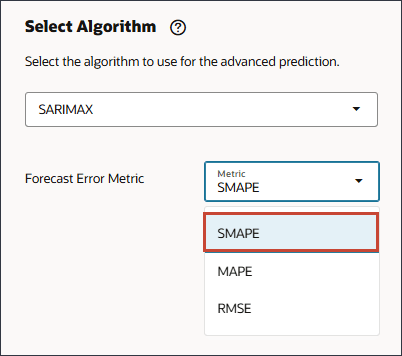
予測エラー・メトリックの選択では、次のエラー・メジャーを選択します。
- RMSE: 2乗の平均平方根誤差
- MAPE: 平均絶対パーセント誤差
- MAD: 平均絶対偏差
予測エラー・メトリックは、エラーが最も少ないモデルを最適なモデルとして選択します。
最適なモデル:
- 入力系列に対応する継手シリーズを生成します。
- 範囲の予測を生成します。
- 「アルゴリズムの選択」で、ドロップダウン・リストをクリックして選択を表示し、「SARIMAX」を選択します。
- 「予測エラー・メトリック」で、「メトリック」に「SMAPE」を選択します。
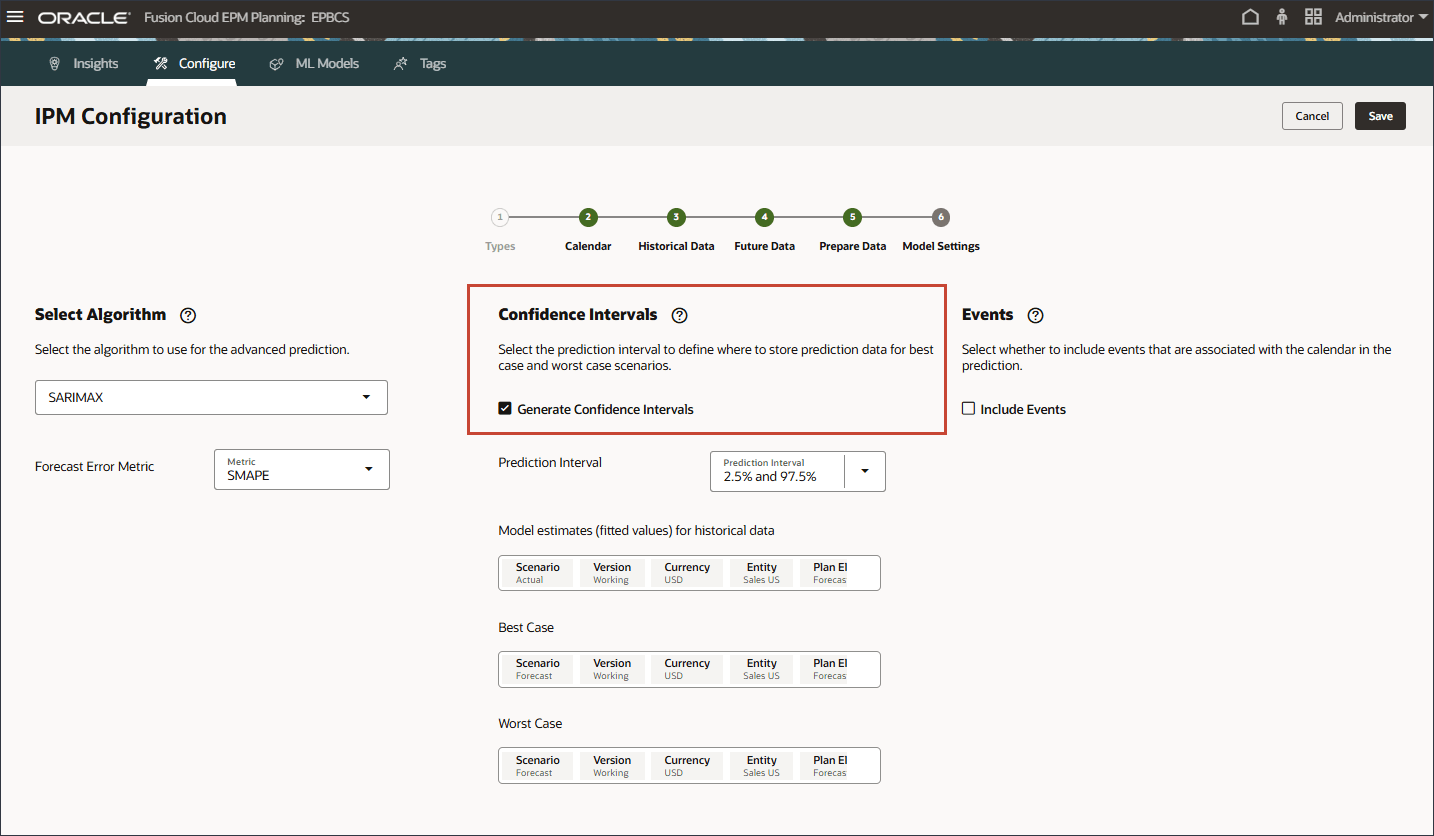
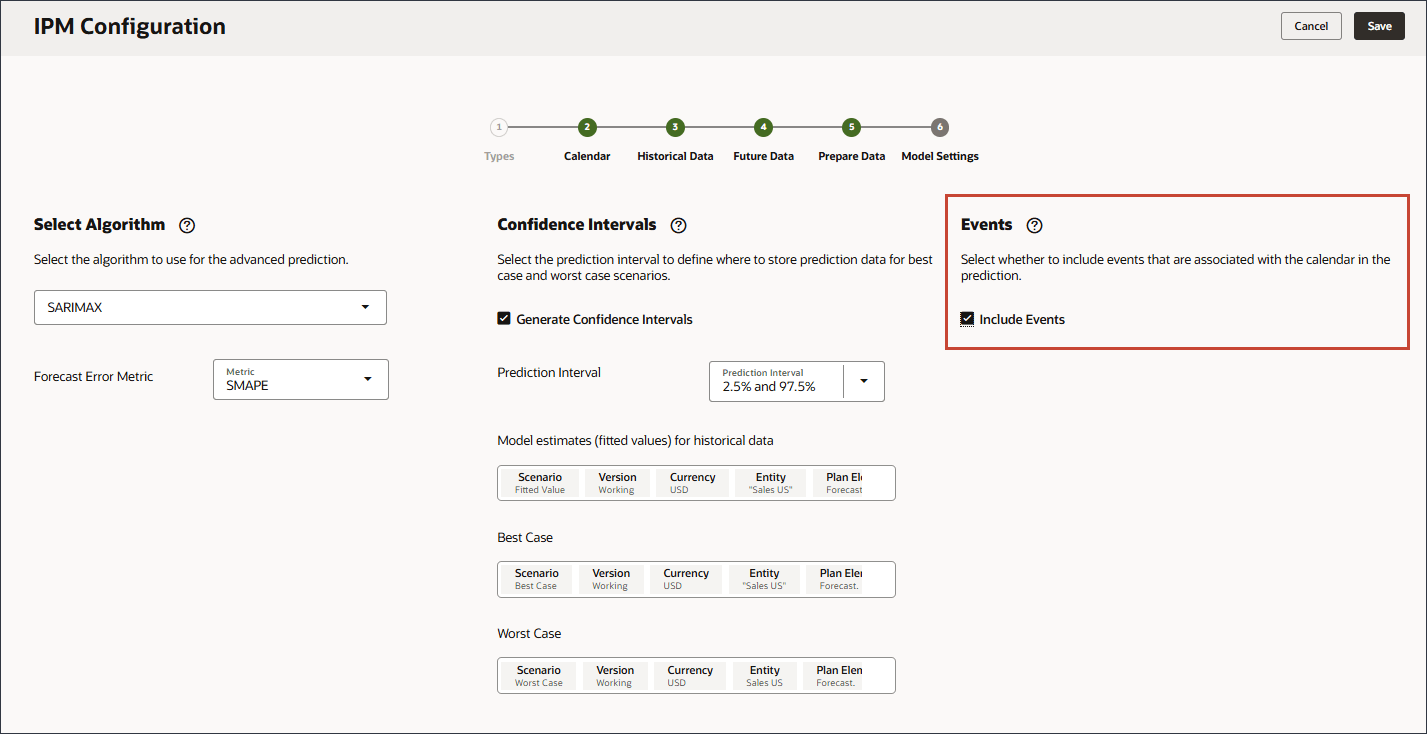
モデル設定の信頼区間の選択
この項では、信頼区間および最適化するメトリックを選択します。
信頼区間設定に基づいて、拡張予測の複数のシナリオが生成され、このモデル設定で指定されたシナリオに従って結果が格納されます。
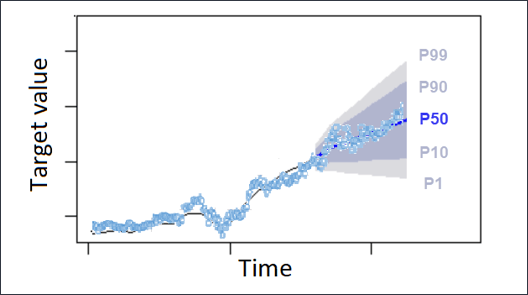
- 予測の信頼区間は、予測出力値の上限と下限を提供できます。
- たとえば、10% (P10)および90% (P90)の信頼区間を使用すると、80%の信頼区間と呼ばれる値の範囲が提供されます。観測された値はP10値の10%より低く、P90値は観測された値の90%より大きくなることが予想されます。
- P10およびP90で予測を生成すると、実際の値が時間の80%の範囲に収まることが予想されます。この値の範囲は、図のP10とP90の間の網掛けリージョンで表されます。
- 「モデル設定」ページの「信頼区間」で、「信頼区間の生成」を選択します。
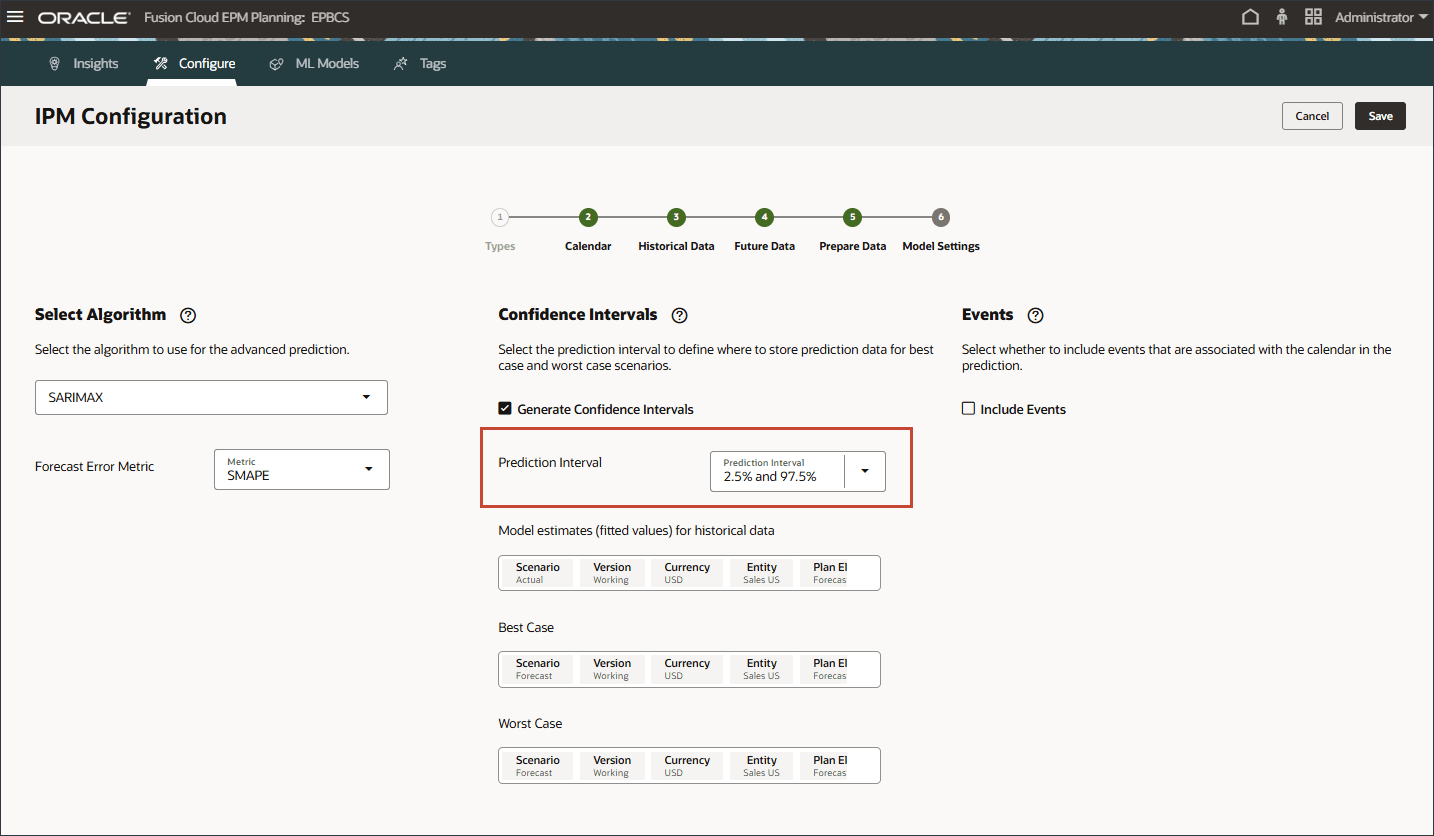
- 「予測間隔」では、「最良ケース」、「最悪ケース」および「適合」の値予測のデフォルト設定を保持します。
- 履歴データのモデル見積り(適合値)で、「シナリオ」をクリックします。
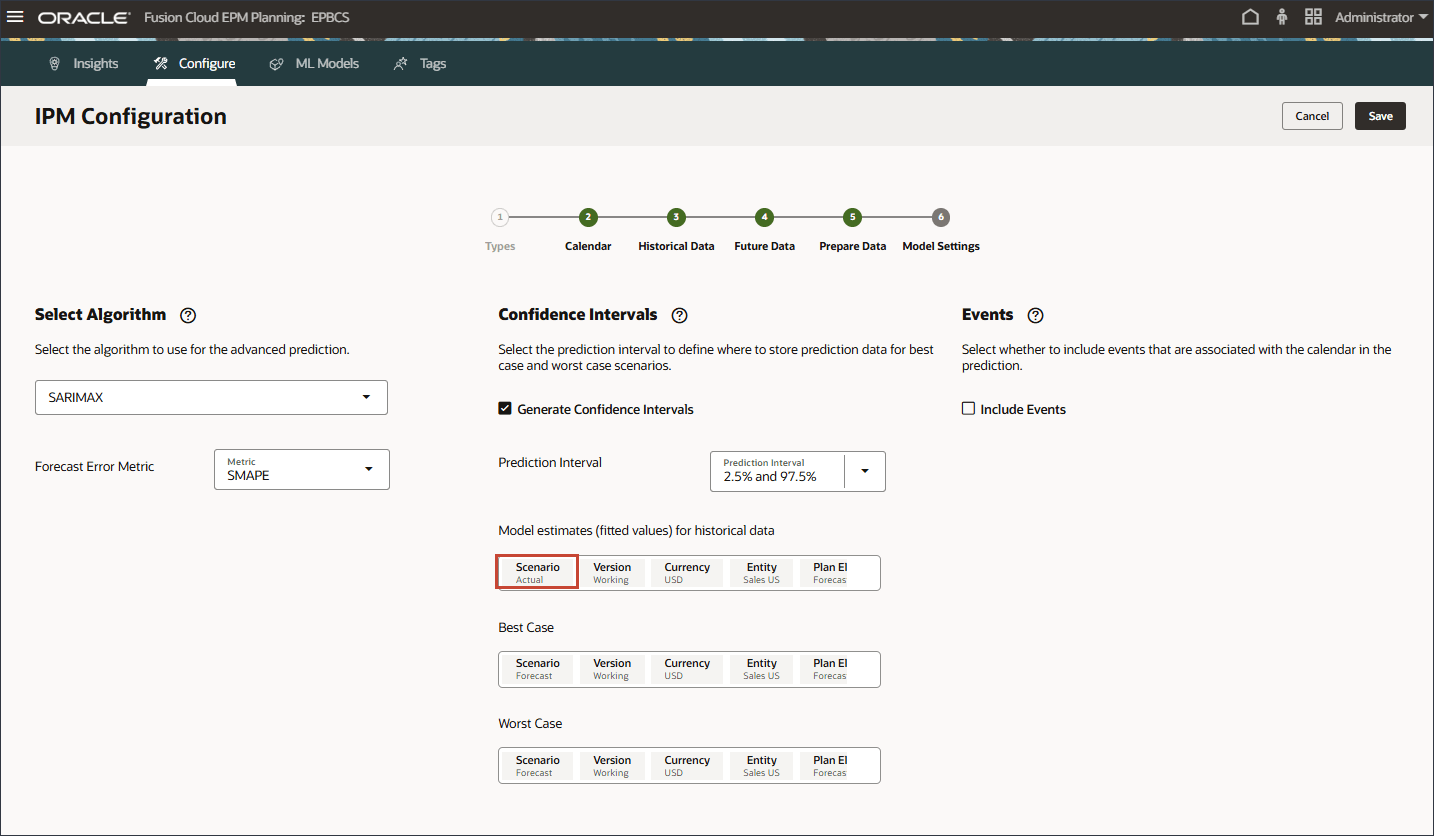
- シナリオの場合は、「適合値」を選択し、「OK」をクリックします。
- ベスト・ケースで、「シナリオ」をクリックします。
- シナリオの場合は、「ベスト・ケース」を選択し、「OK」をクリックします。
- 「最悪の場合」で、「シナリオ」をクリックします。
- 「シナリオ」で、「最悪ケース」を選択し、「OK」をクリックします。
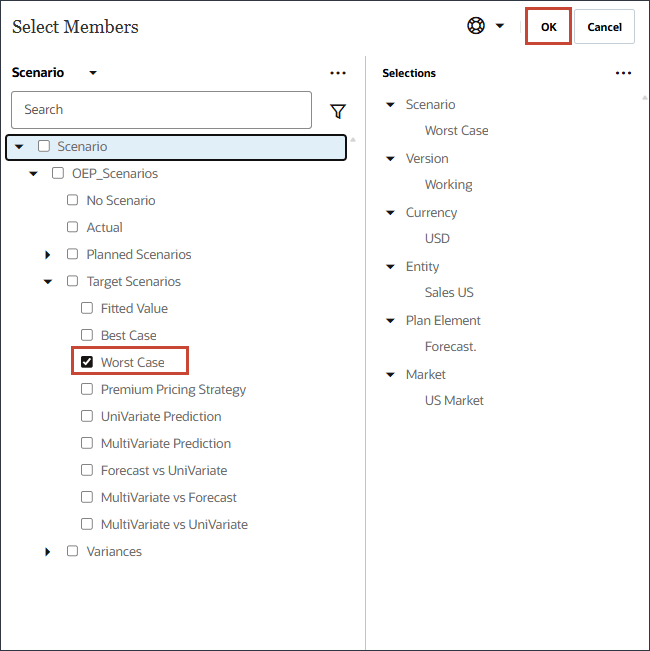
イベントを選択しています
この項では、予測にイベントを含めるかどうかを選択します。
予測にイベントを含めることができます。イベントは、特定のイベントが発生し、過去のデータに影響する予測を考慮する場合に、高度なチューニングや精度の向上に使用できます。次のイベントが含まれます。
- クリスマスなど、同じ期間の繰返しイベント
- ラマダンのような様々な期間での繰返しイベント
- ハリケーンなどの単発イベント
- パンデミックなどのイベントをスキップ
- 右側の「イベント」で、「イベントを含める」を選択します。
- 「保存」をクリックします。
情報メッセージが表示されます。

- 「取消」をクリックします。
新しい拡張予測ジョブが表示されます。
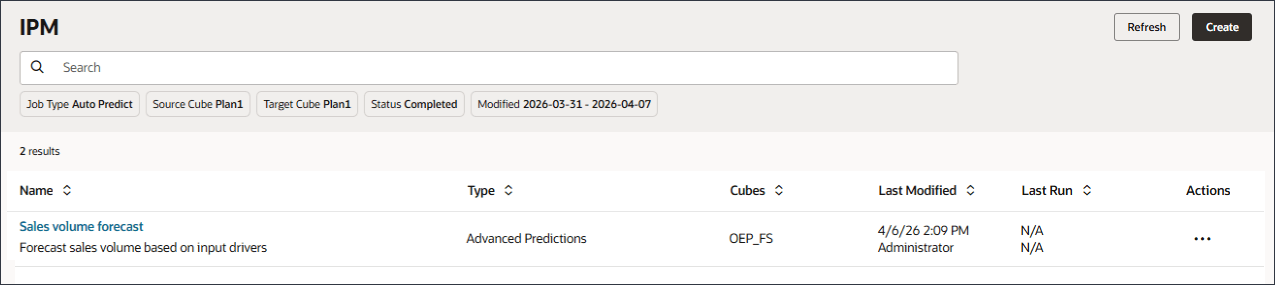
イベントの追加
この項では、5月22日、7月23日および9月24日の期間について、新しいマーケティング・キャンペーン・イベントを追加します。May-22とJul-23は実際の期間ですが、Sep-24はマーケティング・キャンペーンが行われる予定の将来の予測期間です。イベントは基本的に、前年の5月と7月に発生した同じイベントも、将来の年に9月に行われる予定であることを示しています。
- 「イベント」タブをクリックします。
- 「イベントの追加」をクリックします。
- 新しいイベントについては、次の情報を指定または選択します。
列 Value 名前 マーケティング活動 説明 マーケティング活動 入力してください 繰返し カレンダ ボルミエキャスト- 月次 時間 1 マーケティング・キャンペーン・イベントのタイプは「繰返し」で、Volumeforecast-Monthlyカレンダに基づきます。

- 「発生」で、
 (イベント発生)をクリックします。
(イベント発生)をクリックします。 
- 「カスタム」を選択し、「期間の選択」をクリックします。
- 期間については、「5月FY22」を選択し、選択した期間に移動します。
- 左側の期間領域をクリックし、FY23と入力します。
検索ボックスが表示されます。
- 「Jul FY23」を選択します。
- 「使用可能な期間」領域をクリックし、FY24と入力して、「9月FY24」を選択します。
- すべての期間を選択した期間に移動します。
- 「適用」をクリックします。
- 新しいイベントの行の右側で、
 (保存)をクリックします。
(保存)をクリックします。
- (ホーム)をクリックして、ホーム・ページに戻ります。
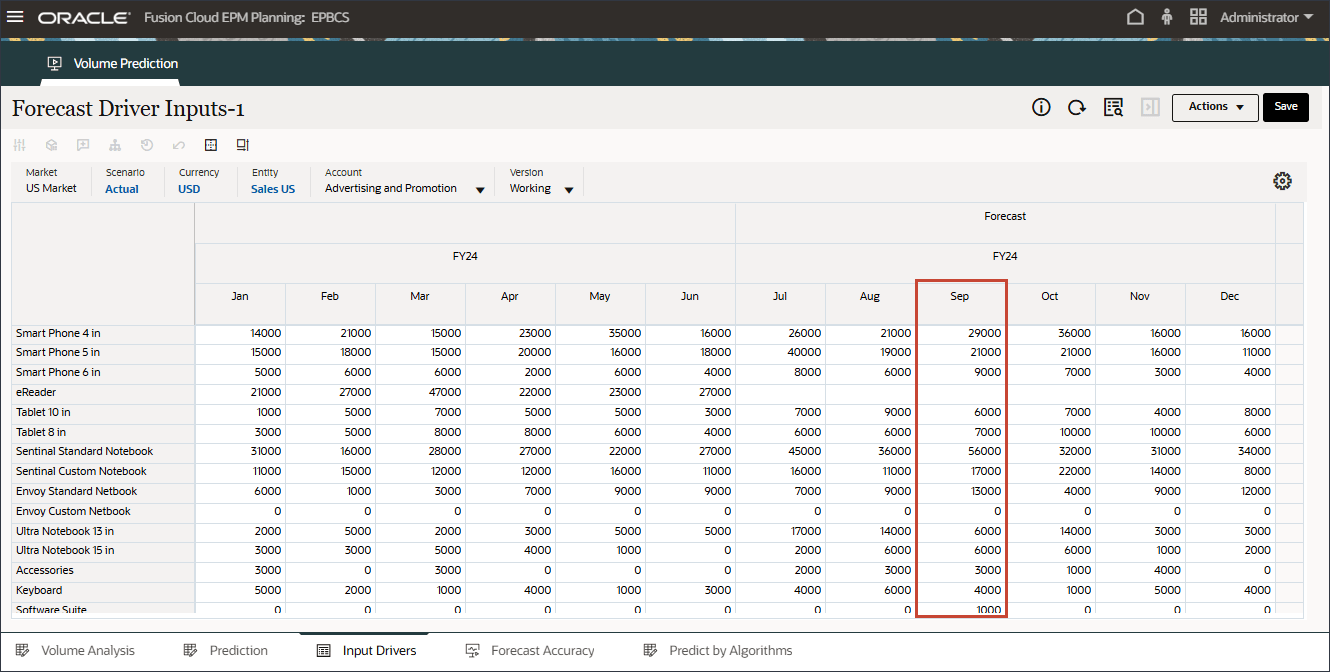
広告およびプロモーション費用および販売量の確認
この項では、2022年5月と2023年7月のAdvertising and Promotionの原価および販売量の実績データをレビューし、ドライバと出力の相関関係を理解します。また、将来の2024年9月のドライバ・データも確認します。
- ホーム・ページで、「拡張予測」、「ボリューム予測」の順にクリックします。
- 「入力ドライバ」タブを選択します。
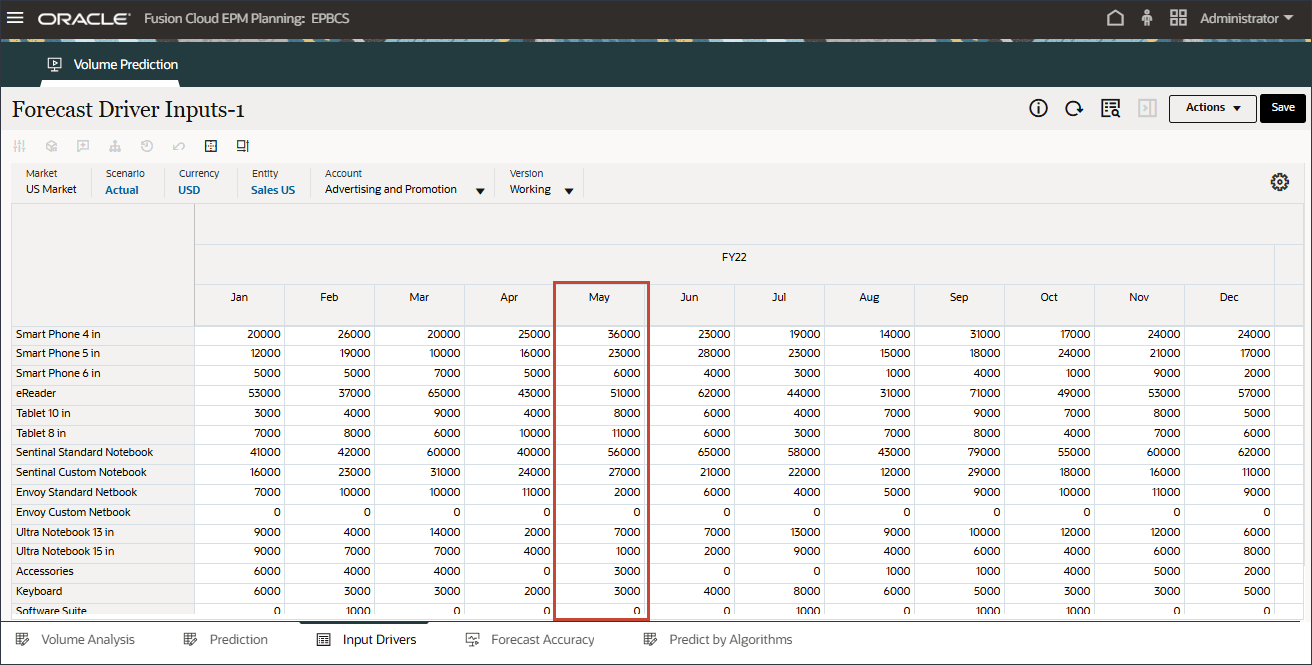
- POVで、「アカウント」をクリックし、「広告およびプロモーション」を選択します。
- 5月22日と7月23日について、データはその月の間バンプアップされます。
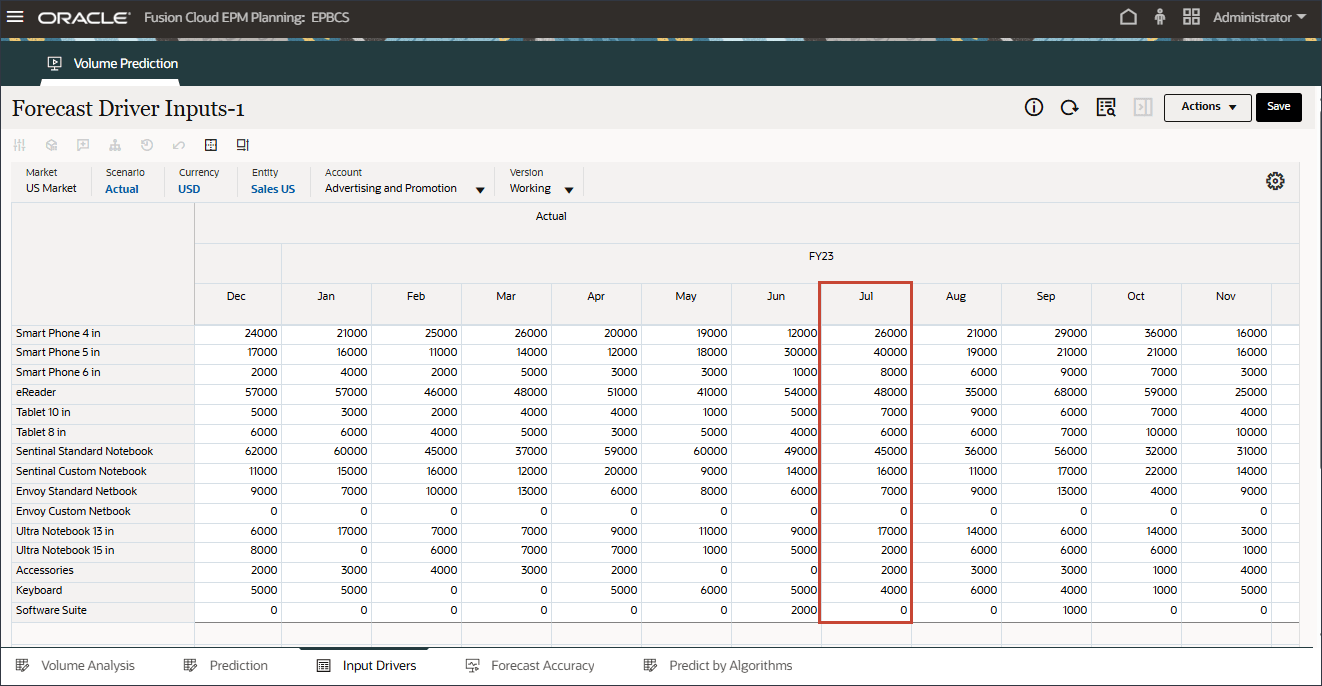
2024年9月の将来のデータでは、構成ジョブでイベントが有効になっているため、予測結果が自動的にバンプアップされます。
- ページの下部で、「ボリューム分析」タブをクリックします。
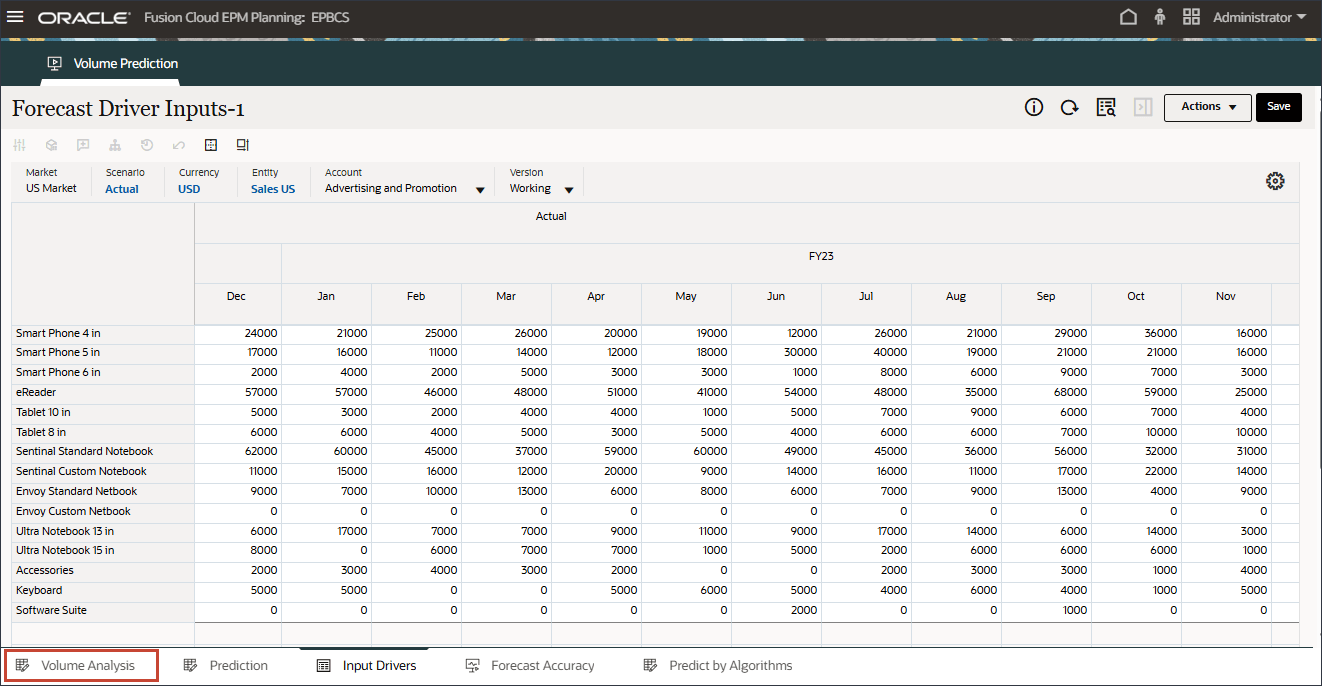
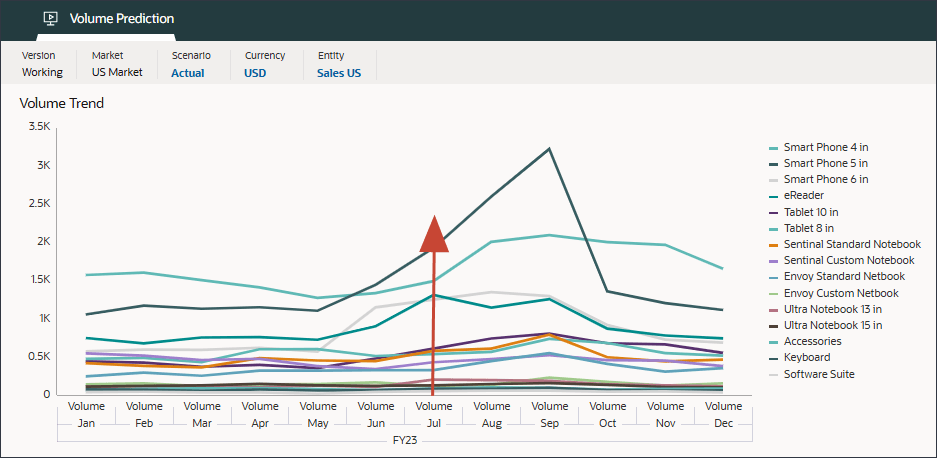
ボリューム分析チャートには、マーケティング・キャンペーン・イベントのために2023年7月のボリューム・データがバンプアップされていることが示されています。
- (ホーム)をクリックして、ホーム・ページに戻ります。
拡張予測ジョブの実行
この項では、拡張予測ジョブを実行して予測を生成します。
- ホーム・ページで、「IPM」をクリックし、「構成」を選択します。
- 下部で、「IPM」タブを選択します。
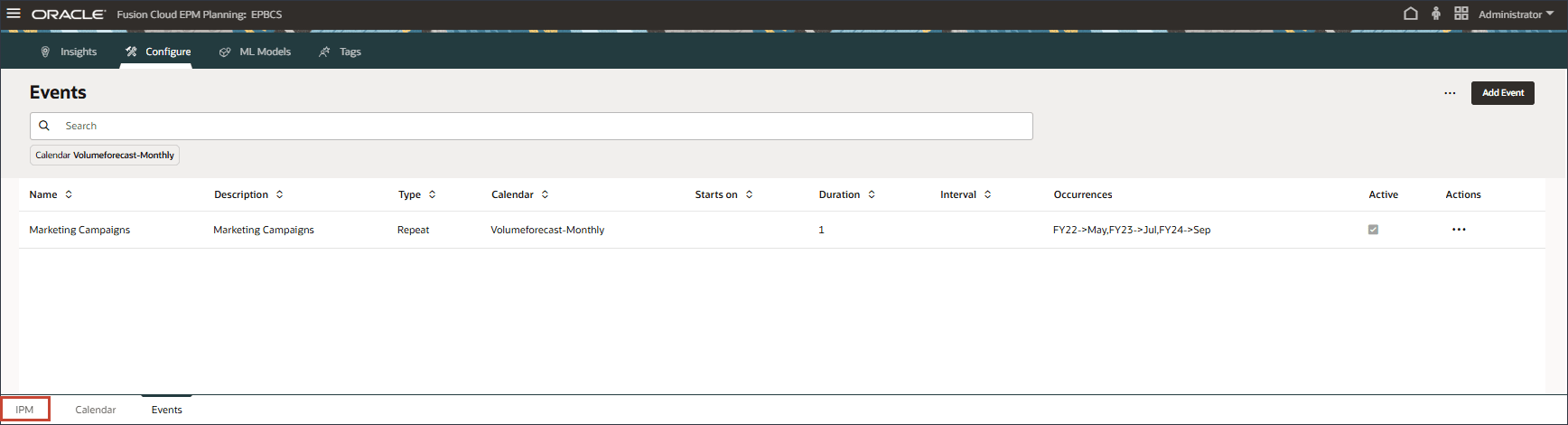
- 販売量予測の場合は、右側で (アクション)をクリックし、「実行」を選択します。
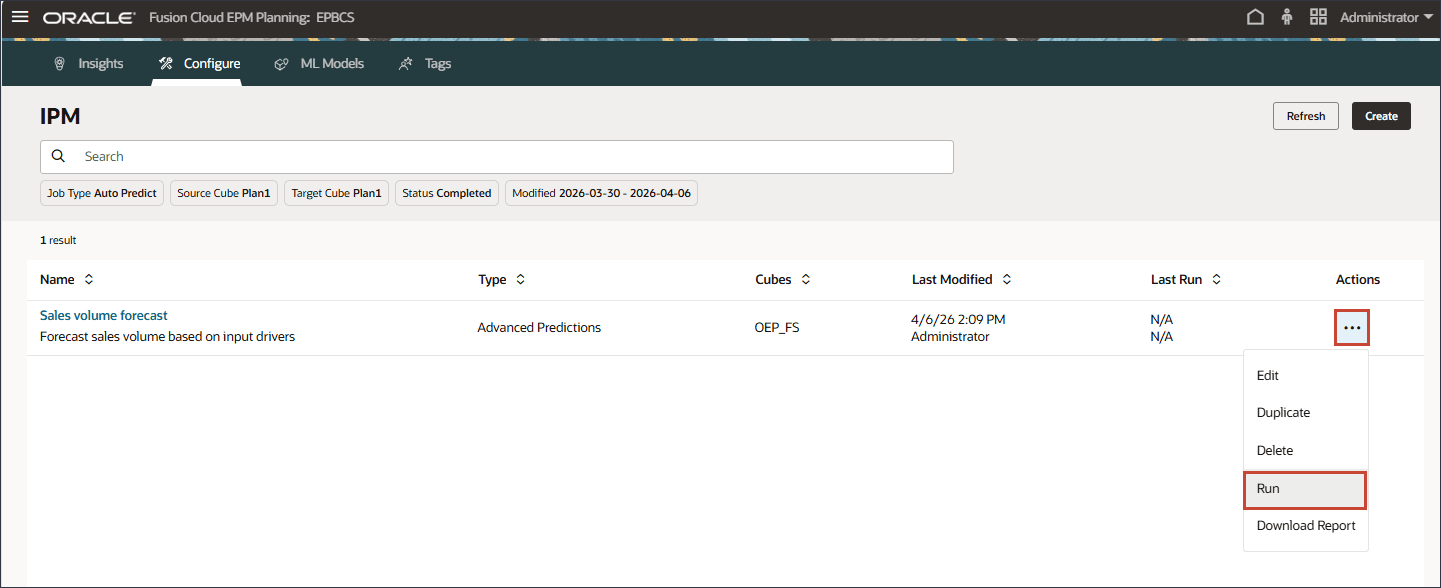
IPMページでは、拡張予測ジョブを実行し、ジョブのステータスを監視し、エラー・ログを確認して、必要に応じて構成を変更できます。
- ジョブを実行すると、ジョブが正常に開始されたことを知らせる情報メッセージが表示されます。

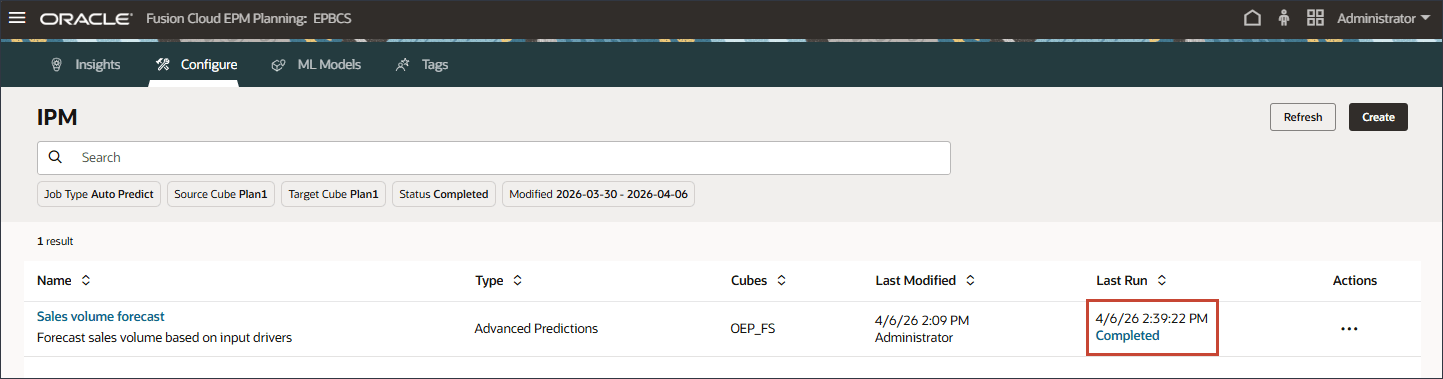
日時がある「最終実行」列で、現在のステータスを表示できます。ジョブの送信後、「処理中」のステータスが表示されます。
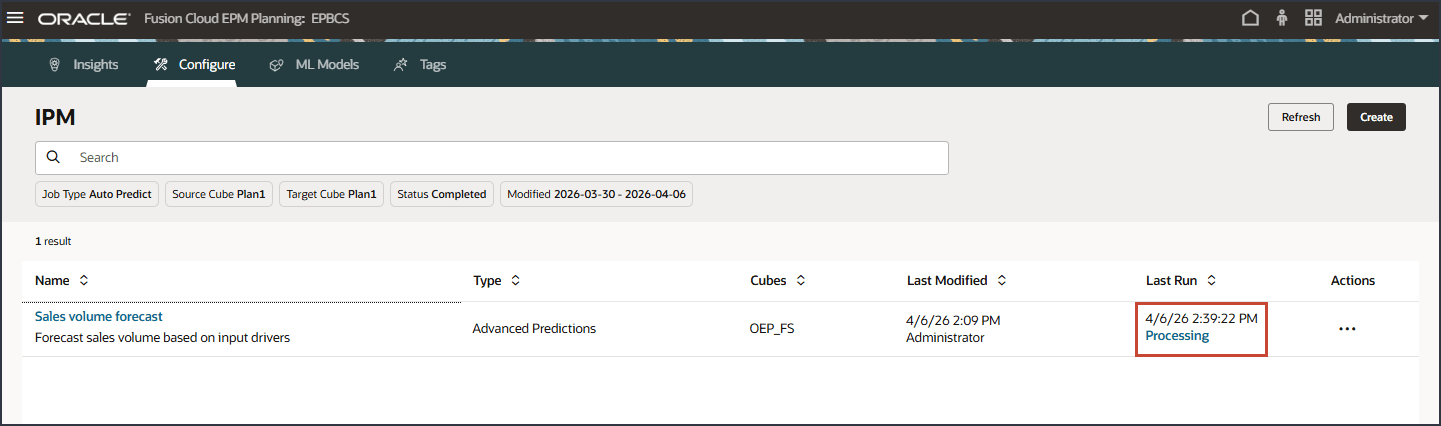
- IPMページで、「リフレッシュ」をクリックしてジョブ・ステータスを更新します。

 (ナビゲータ)をクリックし、「アプリケーション」で「ジョブ」をクリックします。
(ナビゲータ)をクリックし、「アプリケーション」で「ジョブ」をクリックします。
- 「ジョブ」ページで、「販売量予測」をクリックします。

予測を生成するために、複数のジョブが内部でトリガーされました。
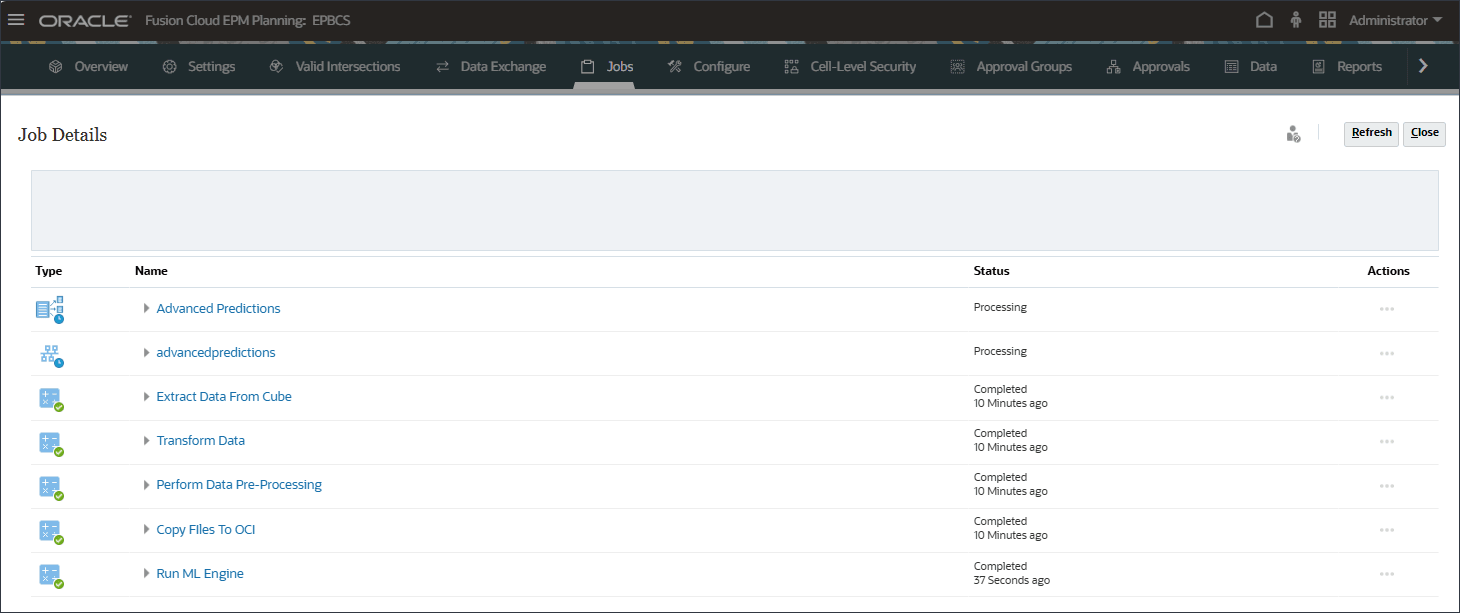
1回のクリックで、指数平滑法、ARIMA、回帰モデルなど、複数のアルゴリズムをテストし、最も統計的に正確な予測を表示します。これにより、計画担当者は、手作業による分析時間を置き換え、数秒でデータ主導型の予測を作成できるようになります。
- すべての拡張予測ジョブが正常に完了するまで待機し、「閉じる」をクリックします。
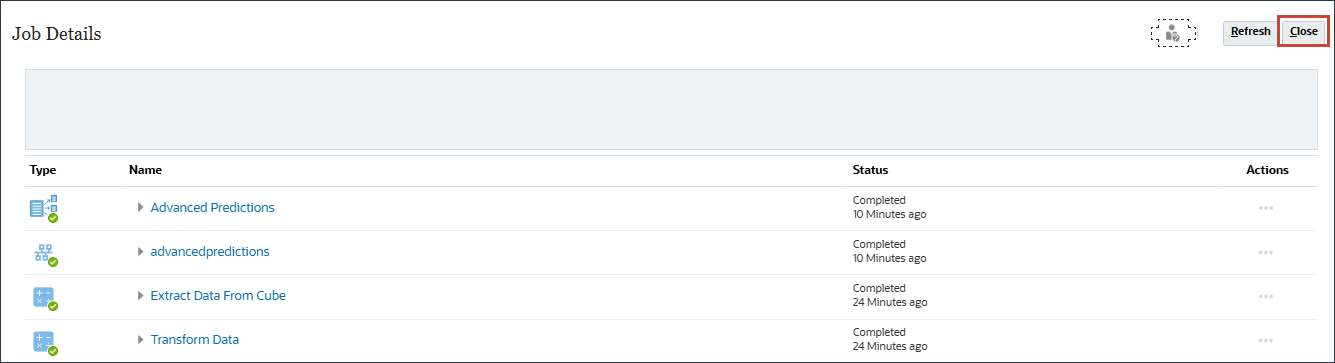
- 「リフレッシュ」をクリックします。
- (ナビゲータ)をクリックし、「IPM」で「構成」をクリックします。
販売量予測が正常に完了しました。
- ジョブが正常に完了したら、レポートをダウンロードして予測結果を確認できます。販売量予測の場合、右側で (アクション)をクリックし、「レポートのダウンロード」を選択します。
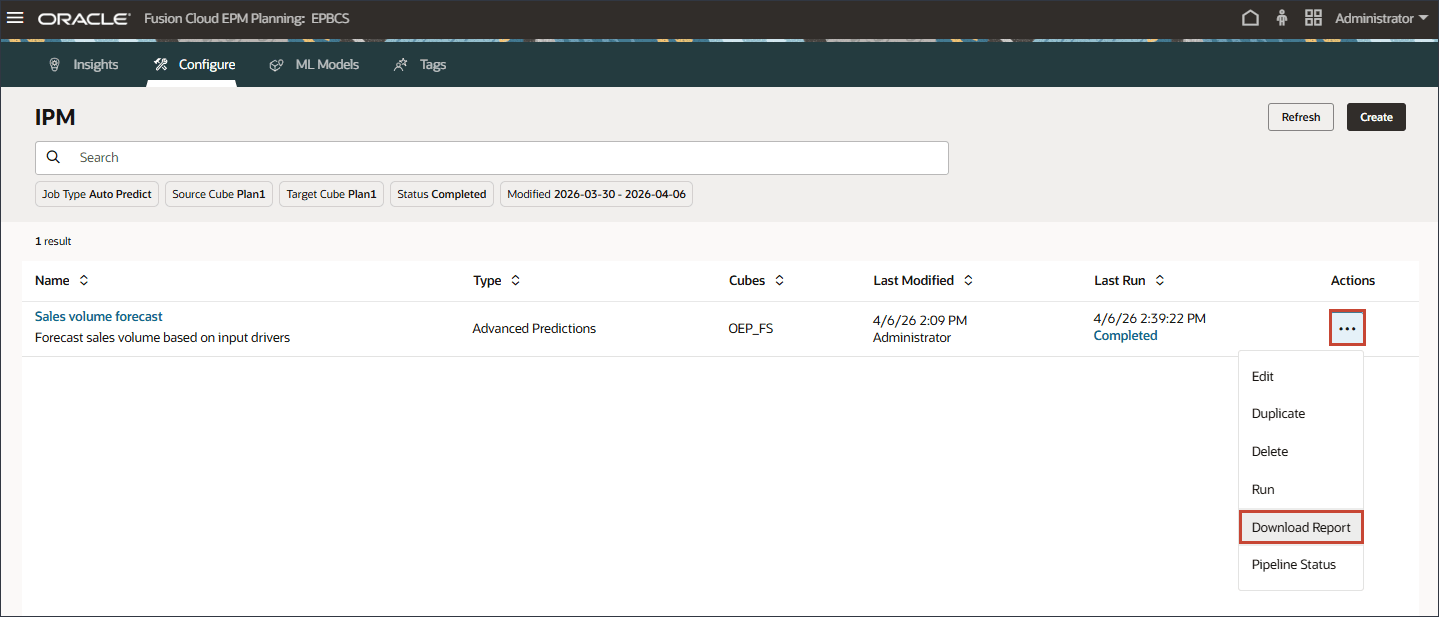
ダウンロード・レポートは、拡張予測ジョブに関連するすべての詳細を含む.csvファイルを含むzipファイルです。このサンプルの販売量予測レポートを確認できます。
以下はレポートのサンプルです。
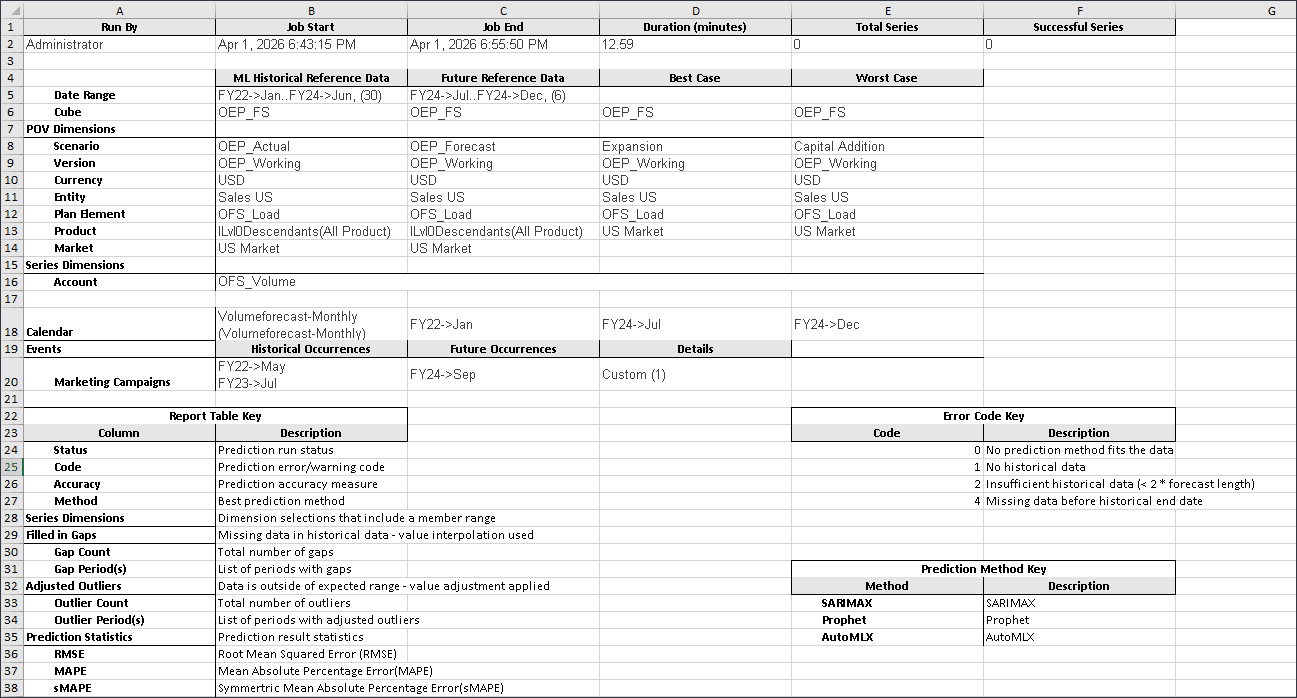
- (ホーム)をクリックして、ホーム・ページに戻ります。
ノート:
ジョブの完了には少し時間がかかります。ノート:
ジョブの完了には少し時間がかかります。メイン・ジョブが正常に完了しました。
高度な予測結果の確認
ボリューム予測結果のレビュー
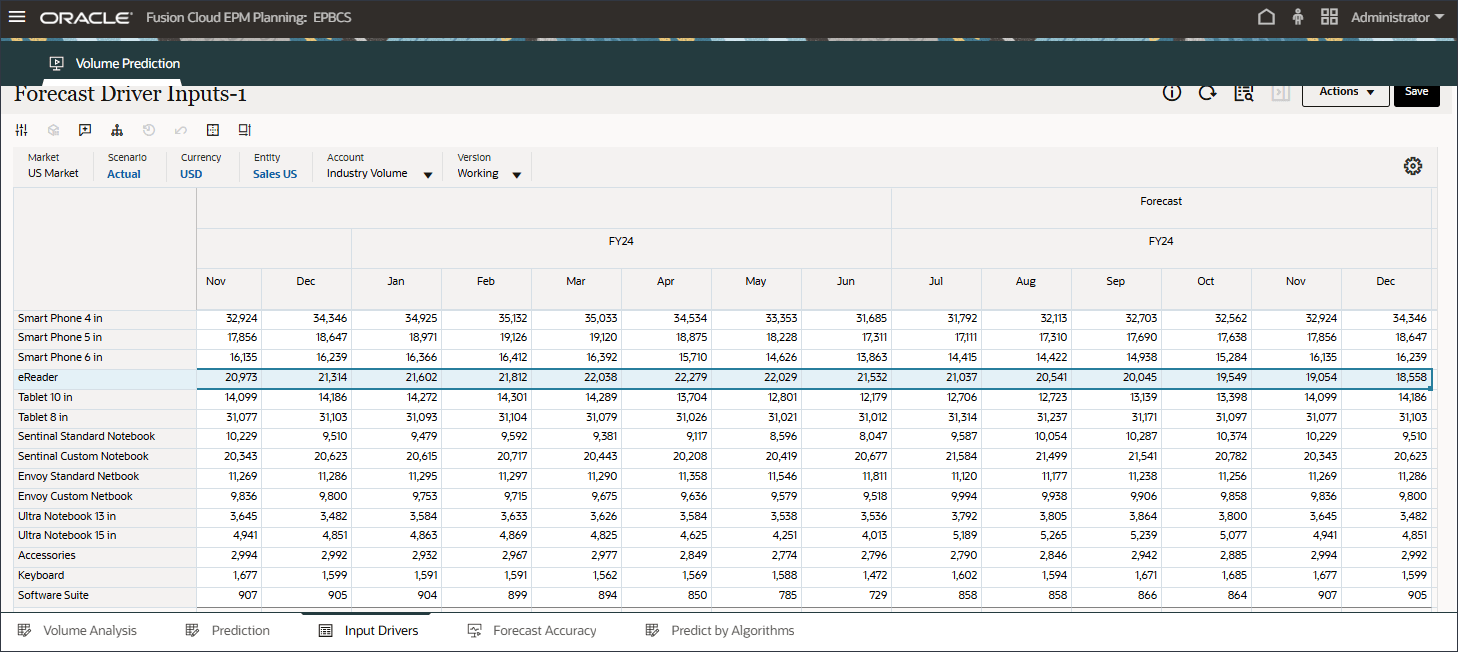
この項では、ボリューム予測の予測結果を確認します。あなたは、eReader製品カテゴリの将来の値が、すべての入力ドライバ・アカウントの「入力ドライバ値の欠落の予測」インピュテーション機能を使用して予測されるようにしようと考えています。
- ホーム・ページで、「拡張予測」をクリックし、「ボリューム予測」を選択します。
- 下部の「入力ドライバ」タブをクリックします。
- POVの「Account」で、「Industry Volume」を選択します。
- 右にスクロール
業界ボリュームの将来データ(7月から12月、FY24)は、拡張予測ジョブのインピュテーション機能(「入力ドライバ値の欠落の予測」)を使用して予測されました。
- POVの「勘定科目」で、「広告およびプロモーション」を選択します。
アドバタイズおよびプロモーション・データ(7月から12月、FY24)は、アドバンスト予測ジョブのインピュテーション機能(「入力ドライバ値の欠落の予測」)を使用して予測されました。
- POVの「勘定科目」で、「平均販売価格」を選択します。
平均販売価格(7月から12月、FY24)は、拡張予測ジョブのインピュテーション機能(「入力ドライバ値の欠落の予測」)を使用して予測されました。
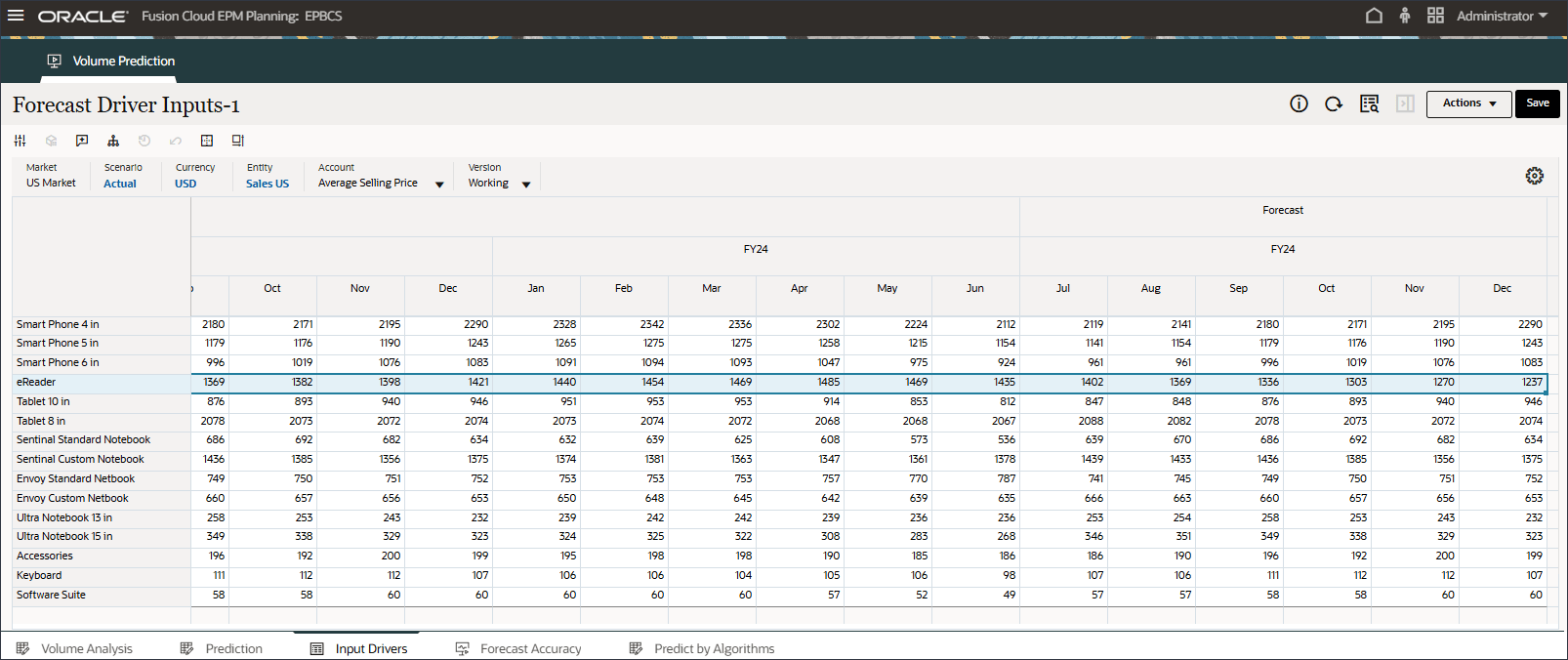
- POVの「勘定科目」で、「個人消費支出(耐久消費財)」を選択します。
個人消費支出(耐久消費財)(7月から12月、FY24)は、拡張予測ジョブのインピュテーション機能("入力ドライバ値の欠落の予測")を使用して予測されました。
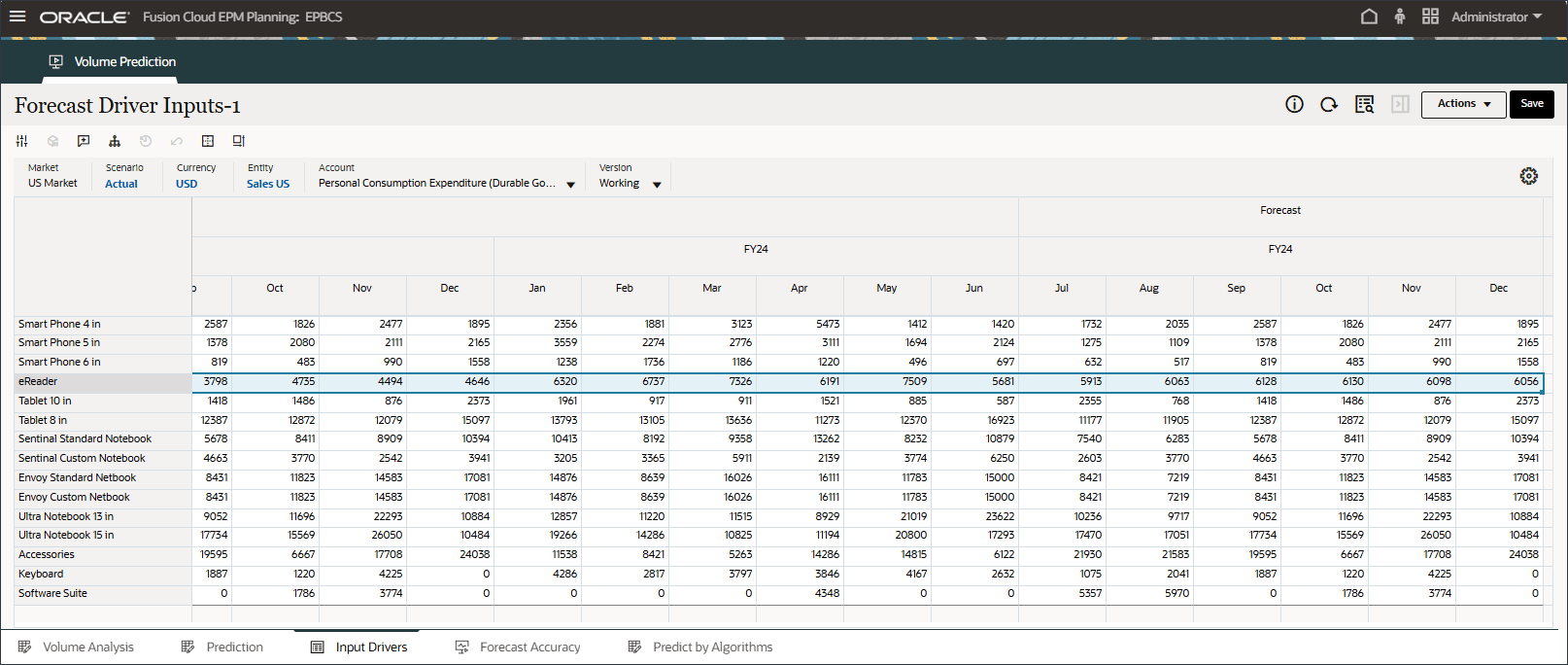
- POVの「勘定科目」で、「割引率」を選択します。
割引率(7月から12月、FY24)は、拡張予測ジョブのインピュテーション機能(「入力ドライバ値の欠落の予測」)を使用して予測されました。
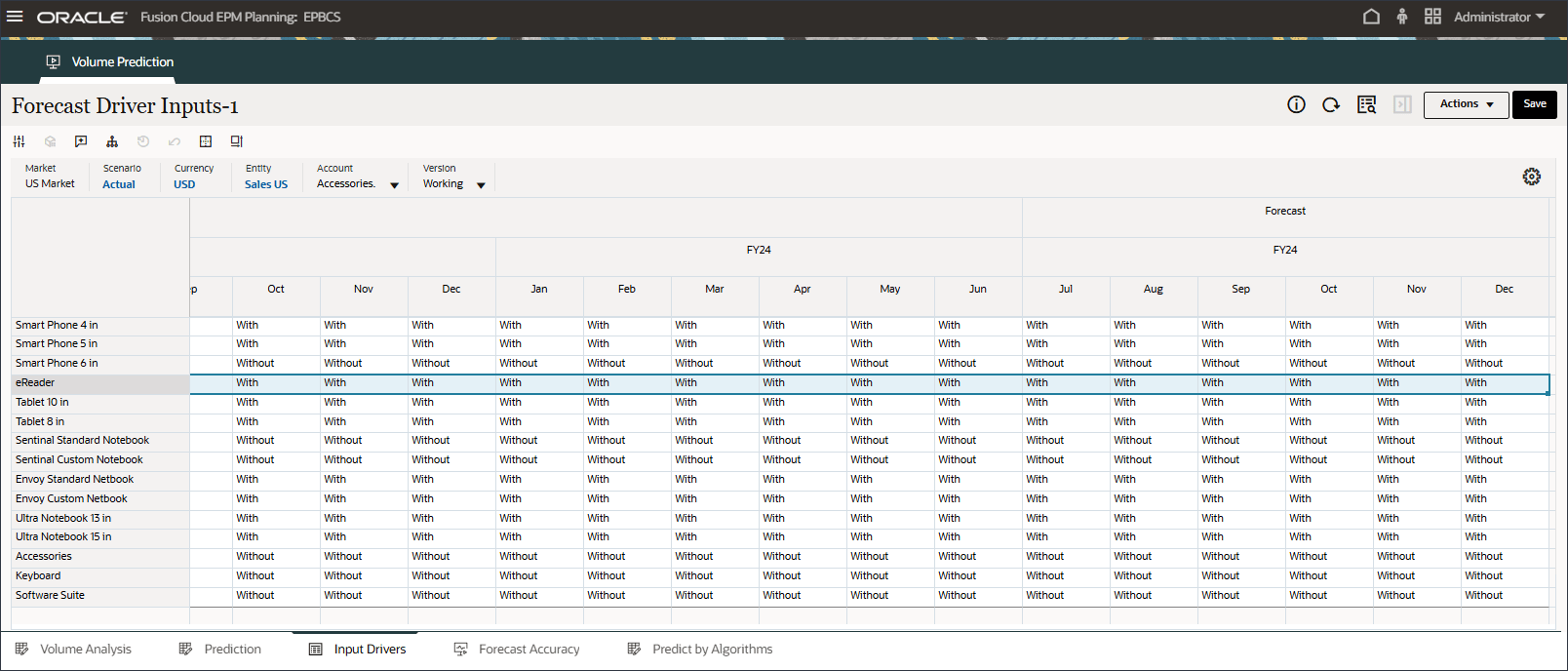
- POVの「勘定科目」で、「アクセサリ」を選択します。
アクセサリ(7月から12月まで、FY24)は、拡張予測ジョブのインピュテーション機能("入力ドライバ値の欠落を予測")を使用して予測されました。
ターゲット変数の予測結果の確認
この項では、Product Salesボリュームであるターゲット変数の予測結果を確認します。また、説明可能性をレビューし、機能の重要性を確認します。

- 下部の「予測」タブをクリックします。
ボリューム予測ダッシュボードが表示されます。
- 「ボリューム予測」フォームの中央で、 (アクション)をクリックし、「フォームを開く」を選択します。
高度な予測結果は、IPMジョブで構成されたSARIMAXアルゴリズムを使用して、FY24の7月から12月に生成されます。
- POVで、「実績」をクリックします。
- 「OEP_Scenarios」および「Planned Scenarios」の下で、「Forecast」を選択し、「OK」をクリックします。
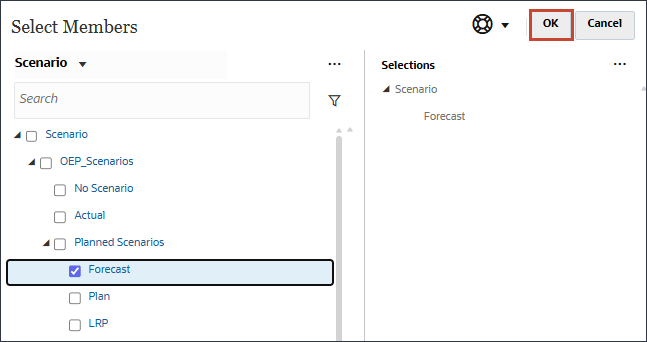
予測データが表示されます。
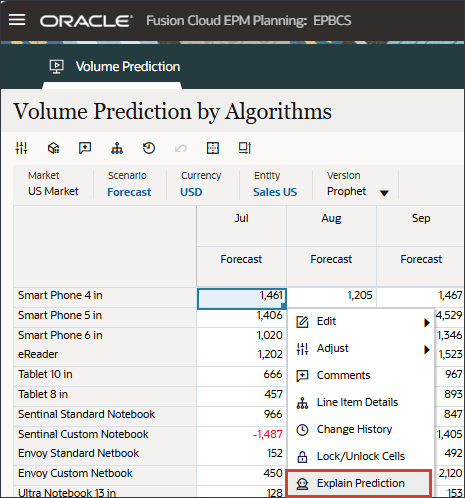
- 詳細を確認し、予測結果の説明を参照するには、7月などの任意の期間でSmart Phone 5で右クリックし、「予測の説明」
「予測の説明」を選択すると、2つのタブに情報がある説明可能性を確認できます。
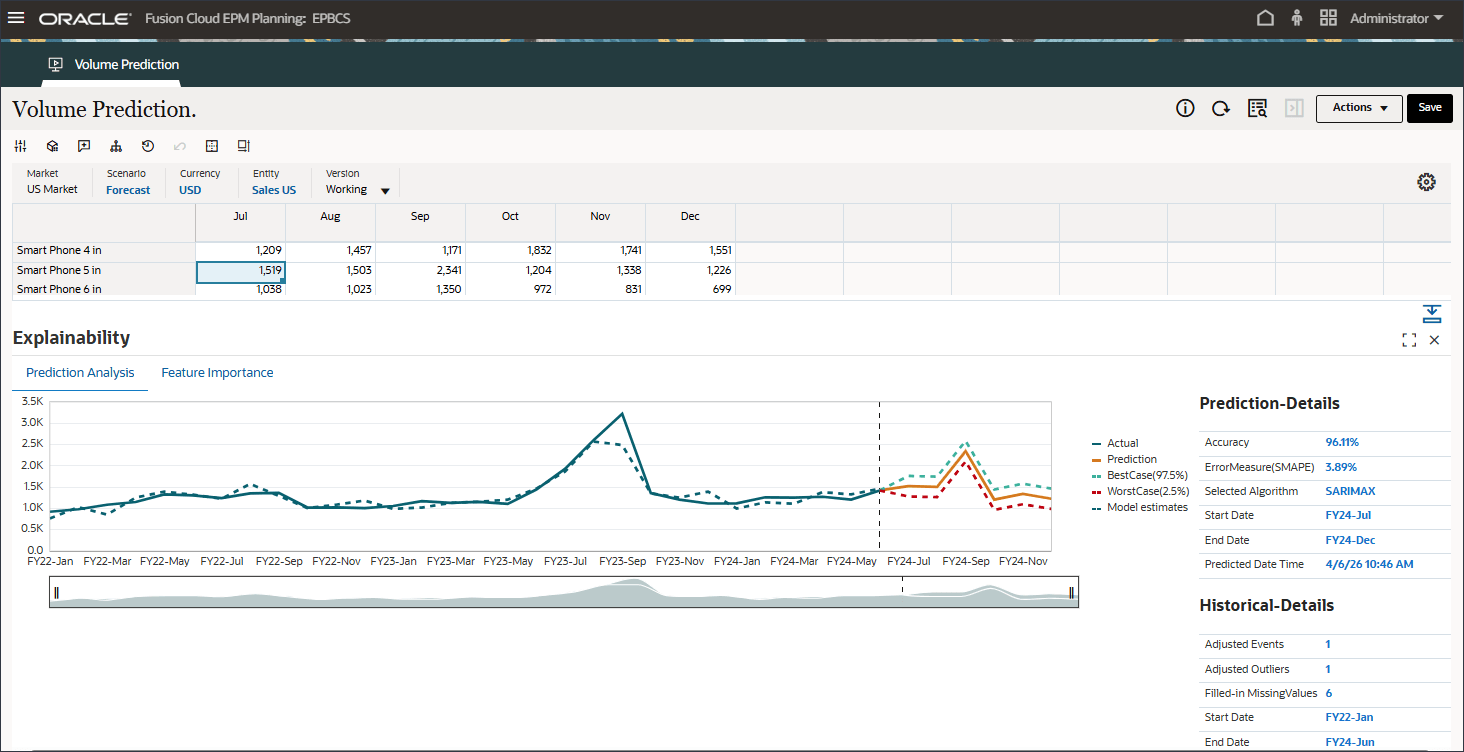
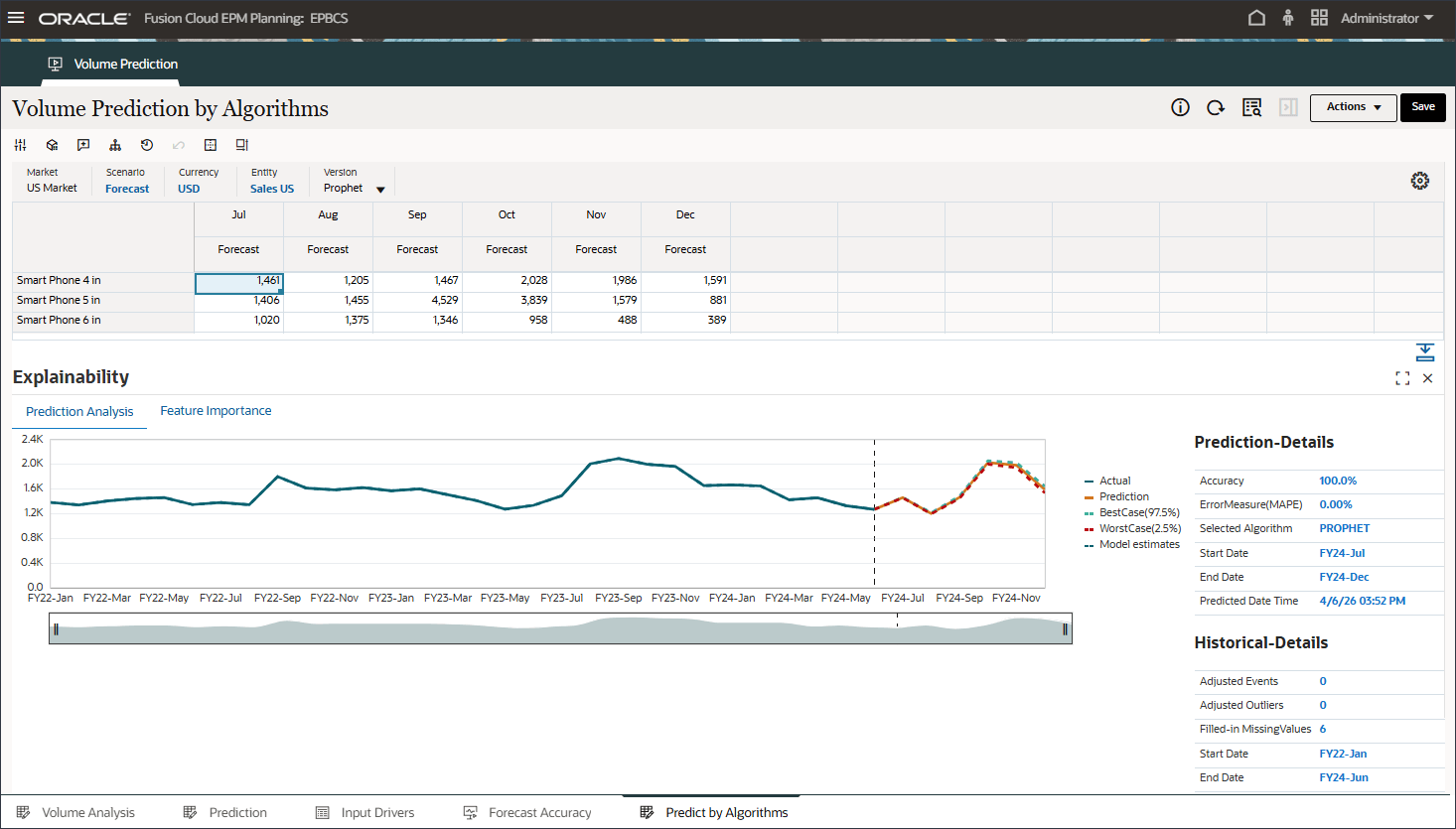
「予測分析」タブには、ベスト・ケース、ワースト・ケース、可能性が最も高いシナリオを考慮した履歴トレンドおよび予測結果を含む折れ線グラフが表示されます。また、精度、エラー・メジャー(SMAPE)、予測結果の生成に使用されるアルゴリズム、予測開始日および終了日など、追加の予測詳細も提供されます。
- スマートフォン6インチの場合は、9月などの別の選択を行います。
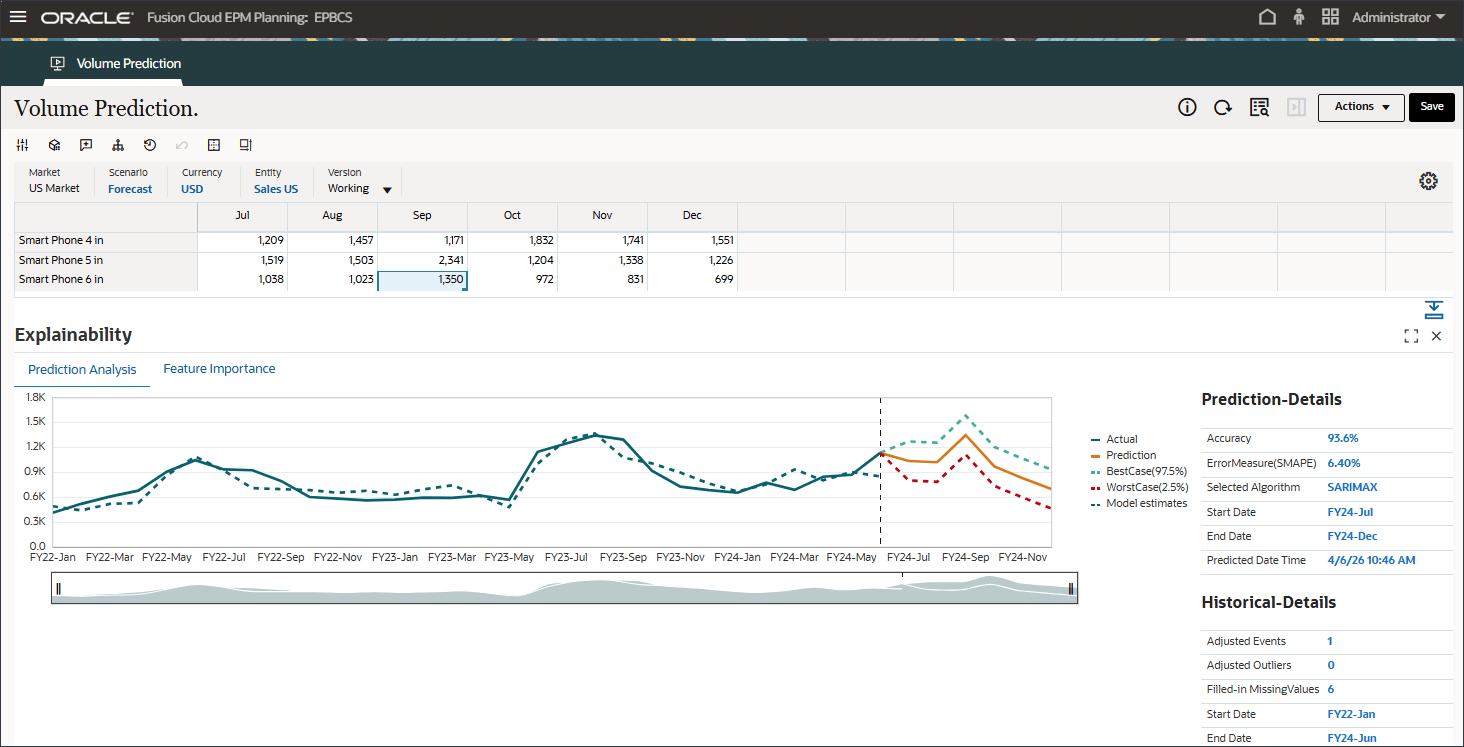
FY22-May、FY23-JulおよびFY24-Sep予測結果に表示されるイベントの影響に注意してください。
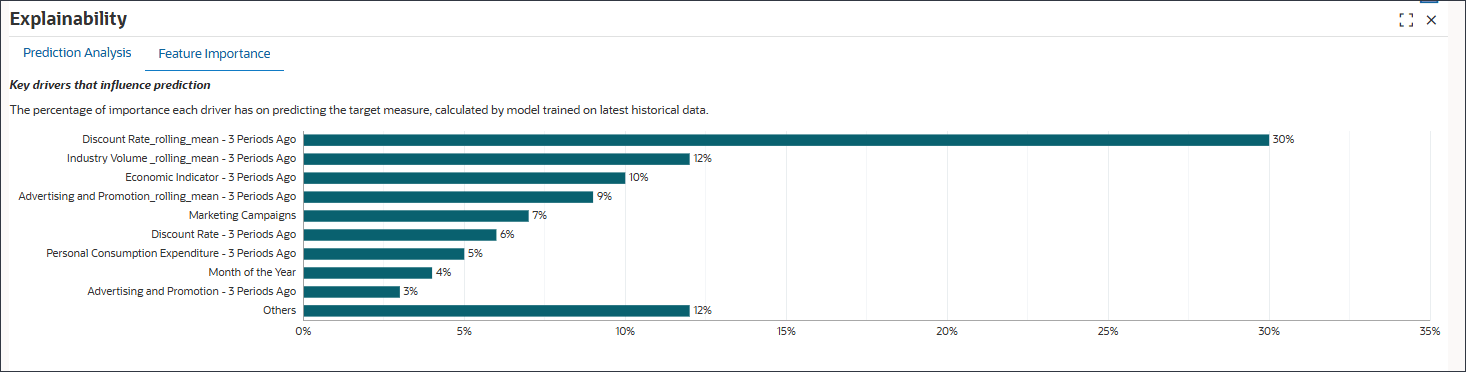
- 「機能の重要度」タブを選択します。
- 遅延フィーチャーの特定
Laggingの特徴:
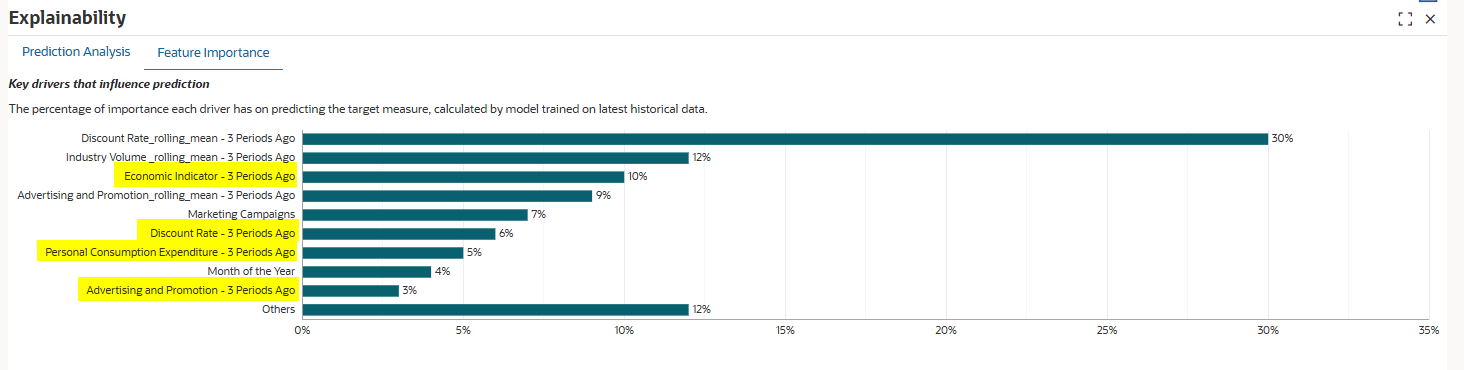
経済インジケータ- 3期間前、割引率- 3期間前、個人消費支出- 3期間前、および広告および販促- 3期間前は遅延機能です。
この例では、「Discount Rate - 3 Periods Ago」が重要な機能としてチャートの上部に表示されます。これは、3か月前に行われた価格決定は、ボリュームに遅延するが重大な影響を与えることを示唆しています。これは、機能エンジニアリングが自動的に明らかになったビジネス・インサイトです。機能エンジニアリングがなければ、現在の期間の割引率のみが考慮されます。
ローリング平均:
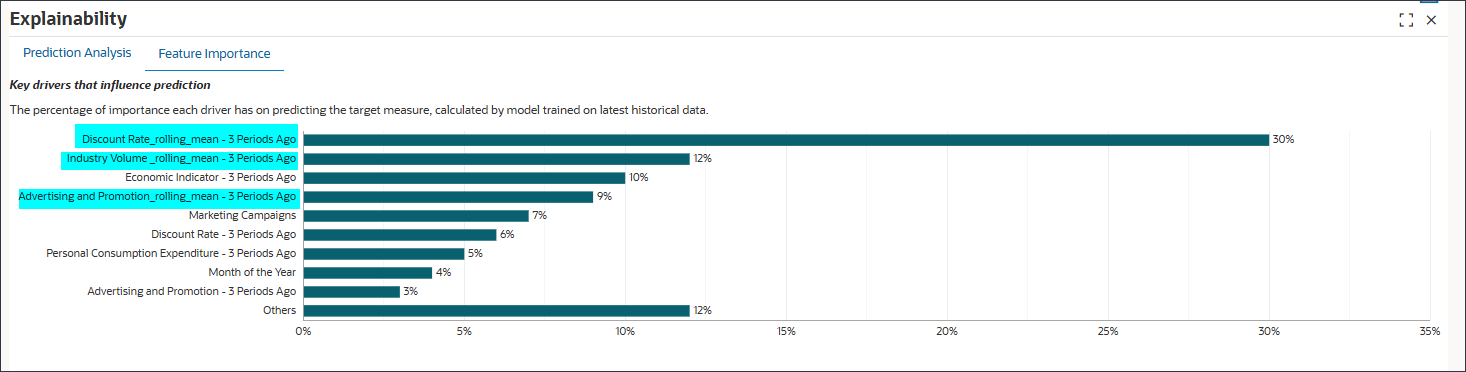
Discount Rate_rolling_mean - 3期間前、Industry Volume_rolling_mean - 3期間前、Advertising and Promotions_rolling_mean 3期間前はローリング平均です。
ローリング平均は、数期間にわたってドライバの値を平均することによって短期的な変動を平滑化します。たとえば、Discount Rate_rolling_mean - 3 Periods Agoは、前回のウィンドウの平均割引率を反映します。これは、基礎となるトレンドが単一月の値より多く表される場合があります。
- 機能重要性の確認
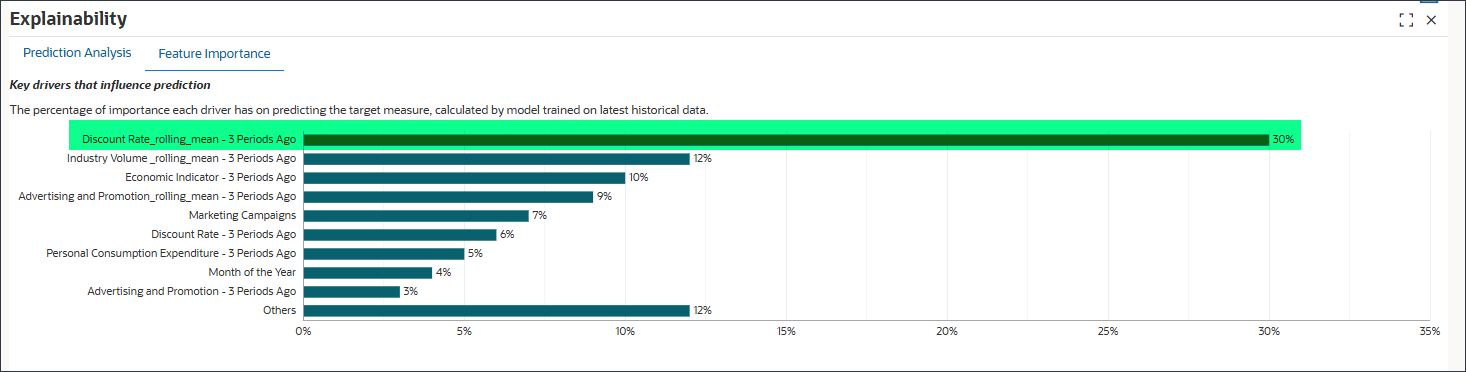
30%のDiscount Rate_rolling_mean - 3 Periods Agoは、ターゲット・メジャーの予測に最も重要です。産業Volume_rolling_mean - 前3期間は12%、経済インジケータ- 前3期間は10%です。
- 入力ドライバを絞り込んで拡張予測ジョブを再実行する場合は、「入力ドライバ」タブに移動してドライバの値を編集できます。
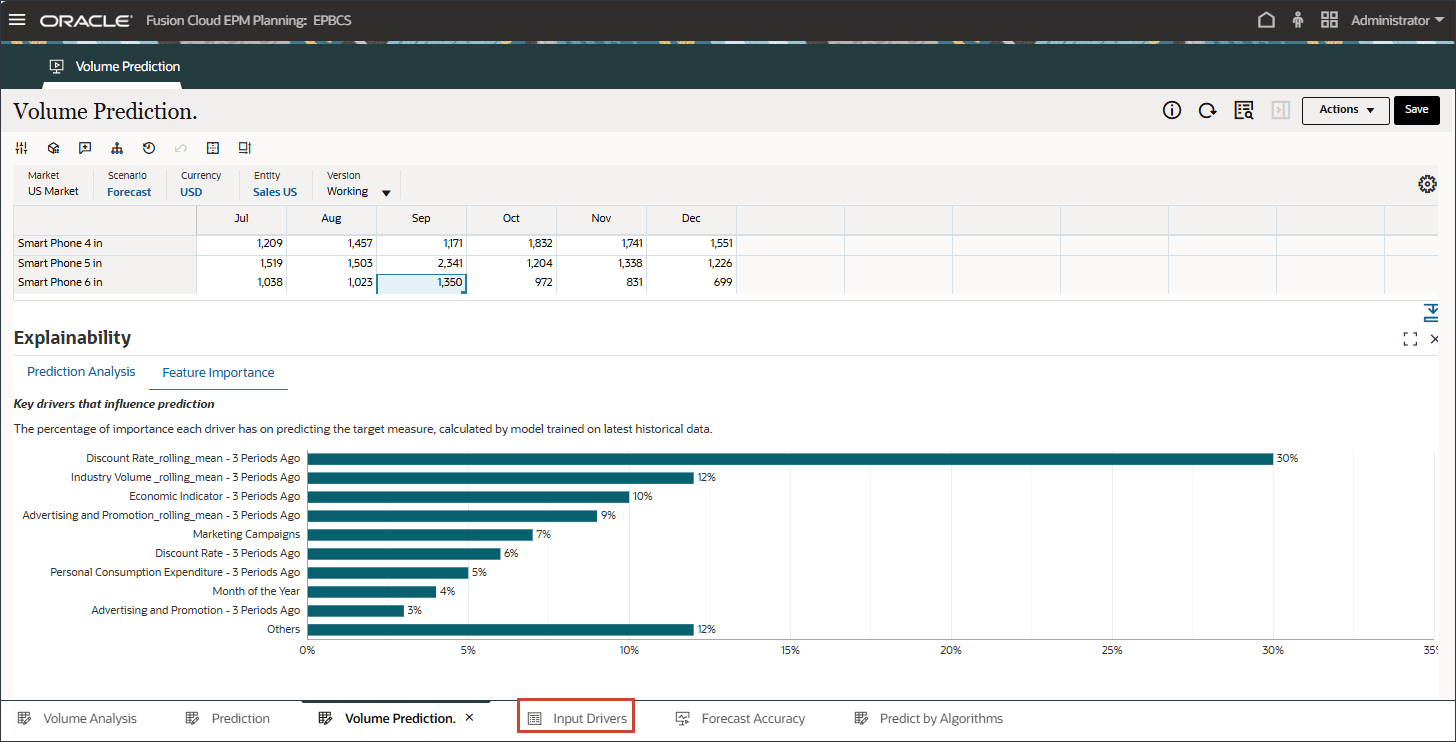
- 「アカウント」をクリックし、Advertising and Promotionなどのドライバを選択します。次に、拡張予測ジョブを再度実行する前に、更新された値を入力して保存します。
- 拡張予測ジョブを実行するには、このチュートリアルの「拡張予測ジョブの実行」の項のステップに従います。
- (ホーム)をクリックして、ホーム・ページに戻ります。
適合した値と実績履歴データを比較して、予測モデルが提供されたデータの変動をどの程度把握できたかを確認できます。予測は、履歴データの適合値を使用して将来のトレンドを使用して行われました。
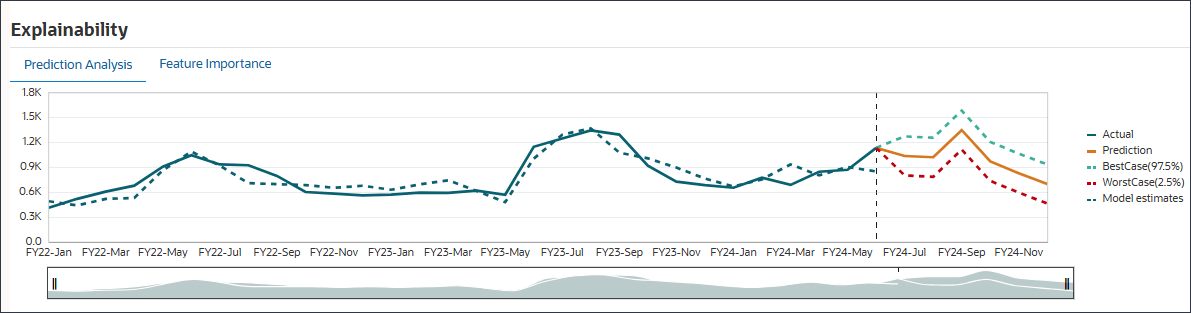
点線/曲線は、基礎となるロジック/トレンドの学習に基づく履歴データに対するモデルの見積りなど、適合線を表します。適合した値と実績履歴データを比較すると、提供されたデータのバリエーションをモデルがどの程度取得できたかを確認できます。
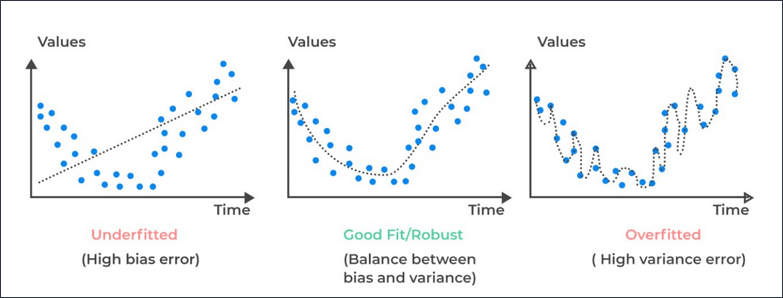
「機能選択」は、予測の精度に影響を与える最も関連性の高いビジネス推進要因を特定し、「ノイジー」または「影響の少ない変数」を除外して過剰な適合を回避します。また、複雑さと処理時間を短縮することでパフォーマンスも向上します。予測能力に基づいて機能をランク付けすることで、説明可能性をサポートします。
チャートには、上位9つの機能が表示されます。残りの機能は、そのパーセンテージ値で集計され、「その他」という見出しの下にグループ化されます。
予測アルゴリズムの変更
この項では、予測の生成に使用するアルゴリズムを変更します。拡張予測ジョブのコピーを作成し、別の予測方法を選択するように詳細を変更します。
- ホーム・ページで、「IPM」、「構成」の順にクリックします。
- Salesボリューム予測行で、 (アクション)をクリックし、「複製」を選択します。
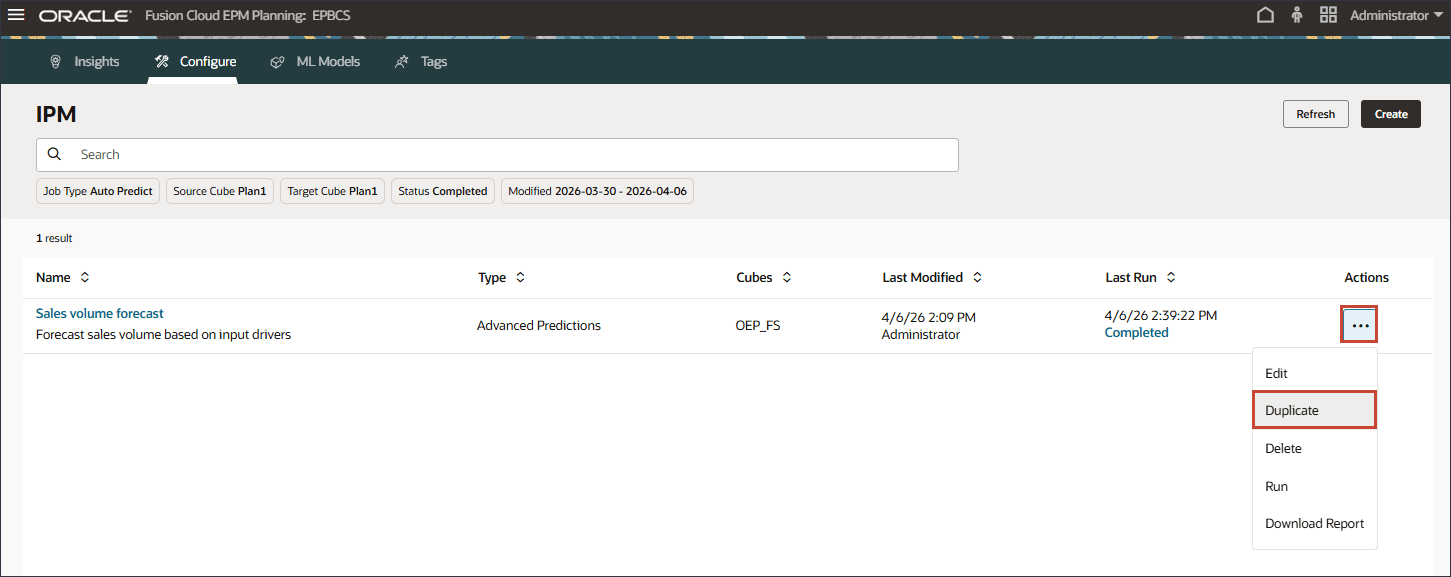
- 複製ジョブの設定を変更するには、「販売量予測- コピー」をクリックします。
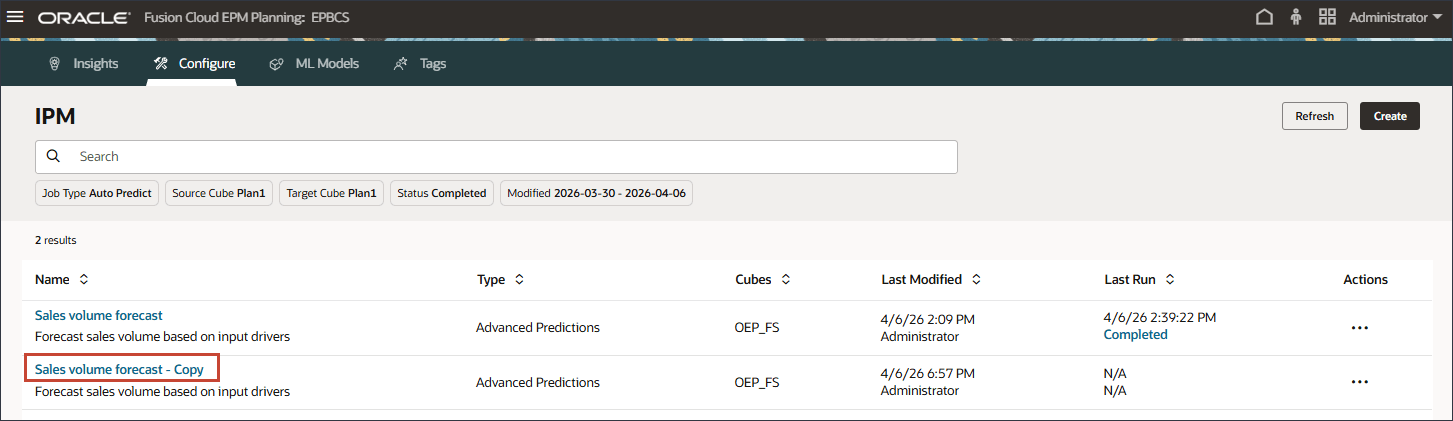
- 「詳細」で、名前を「販売量予測- 預言者」に更新し、説明を「預言者メソッドを使用した販売量予測分析」に更新して、「次へ」をクリックします。
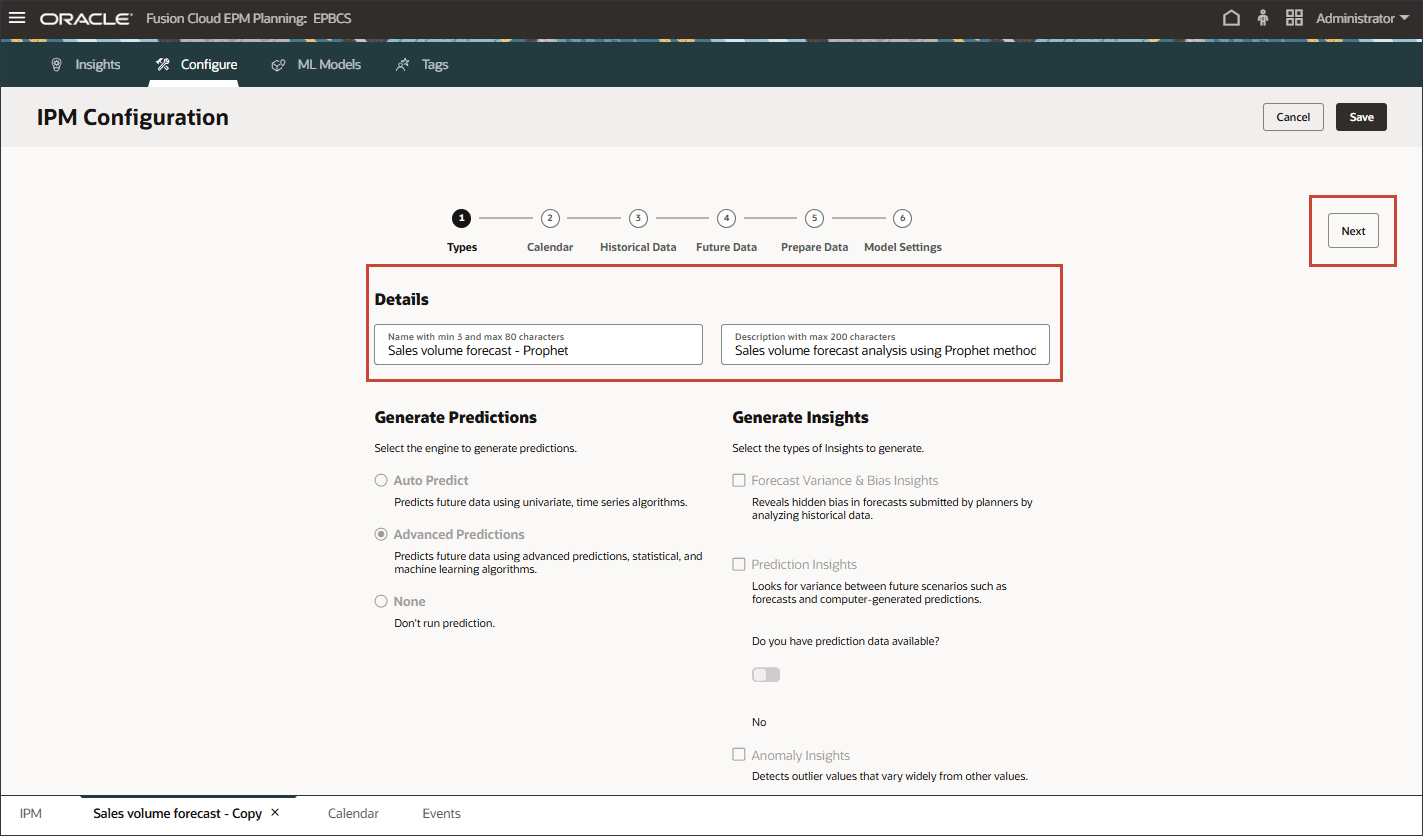
- カレンダを同じままにして、「次へ」をクリックします。
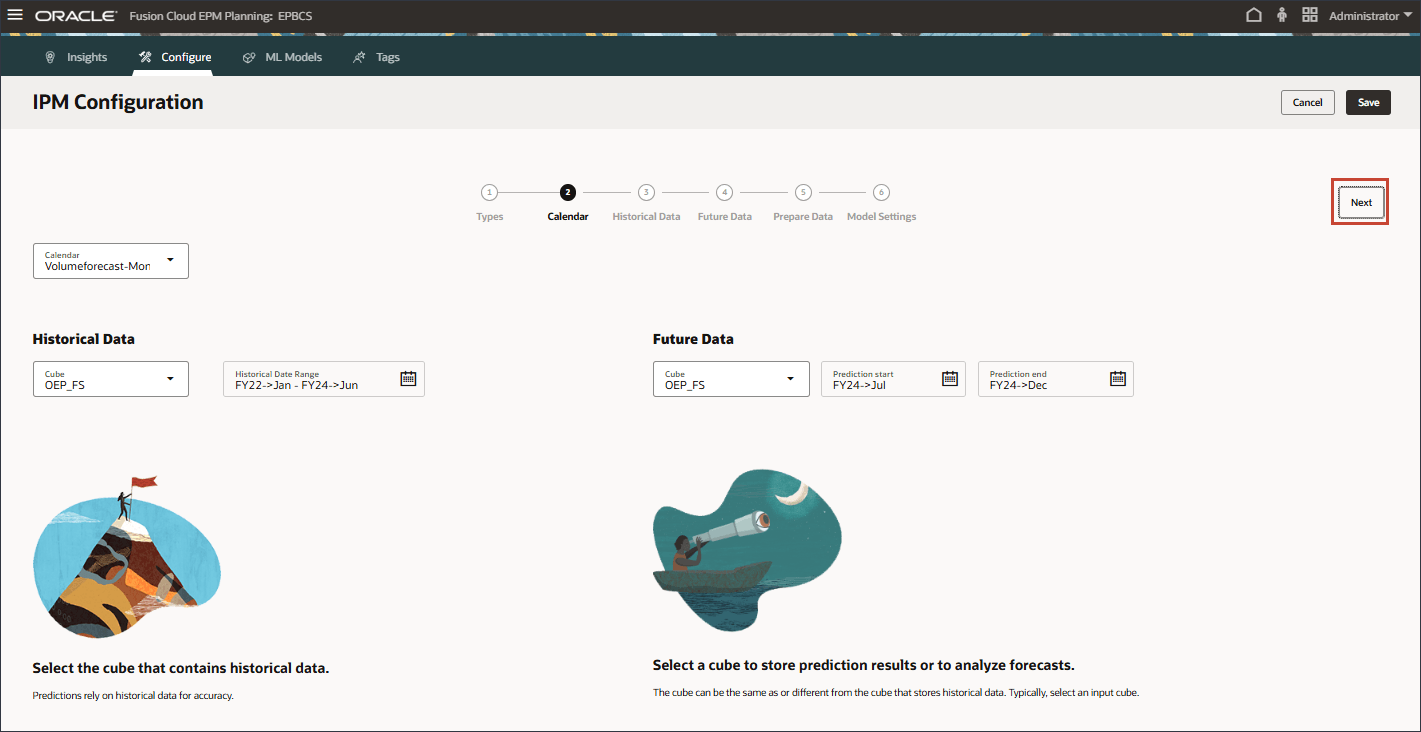
- 履歴データ・スライスを同じままにして、「次へ」をクリックします。
- 「将来データ」の「モデル範囲の定義」で、「バージョン」をクリックします。
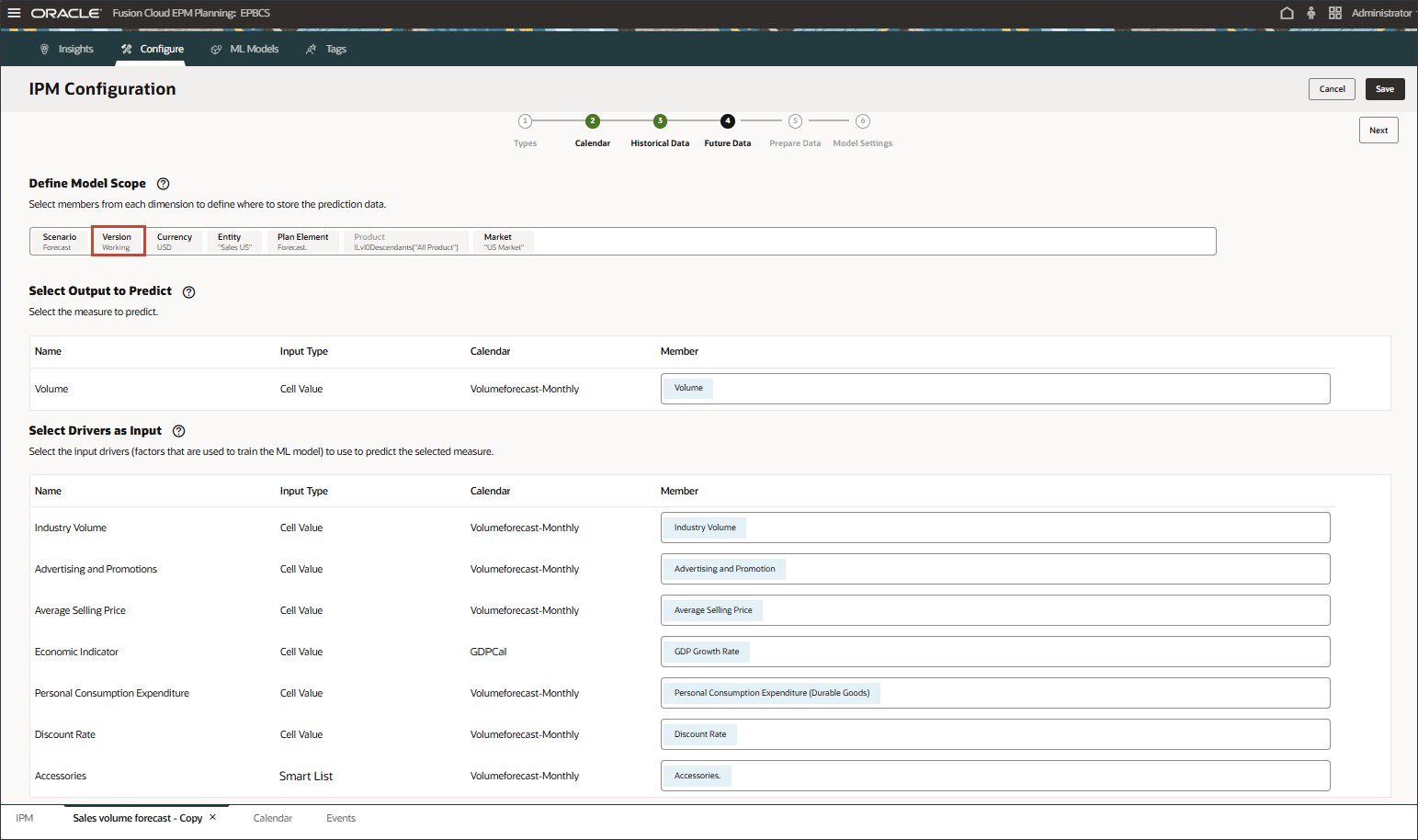
- 「Prophet」を選択し、「OK」をクリックします。
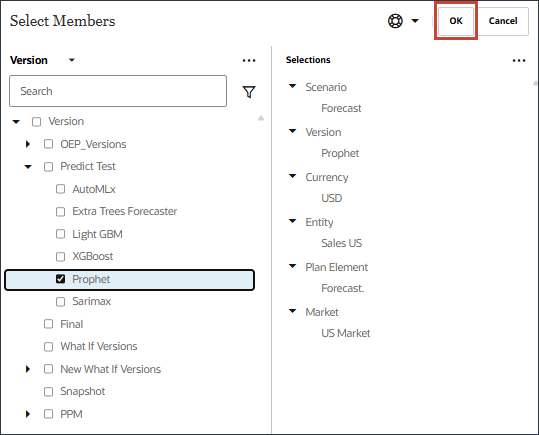
- 更新されたモデル・スコープを確認して、「次へ」をクリックします。

- 「データの準備」ステップでは、変更は必要ありません。「次へ」をクリックします。
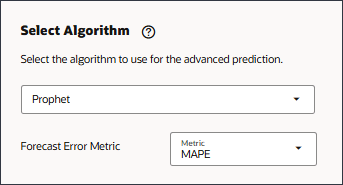
- モデル設定ステップの「アルゴリズムの選択」で、「預言者」を選択します。
- 「予測エラー・メトリック」で、「MAPE」を選択します。
- モデル見積り、最良ケースおよび最悪ケースの場合は、バージョンをProphetに変更します。
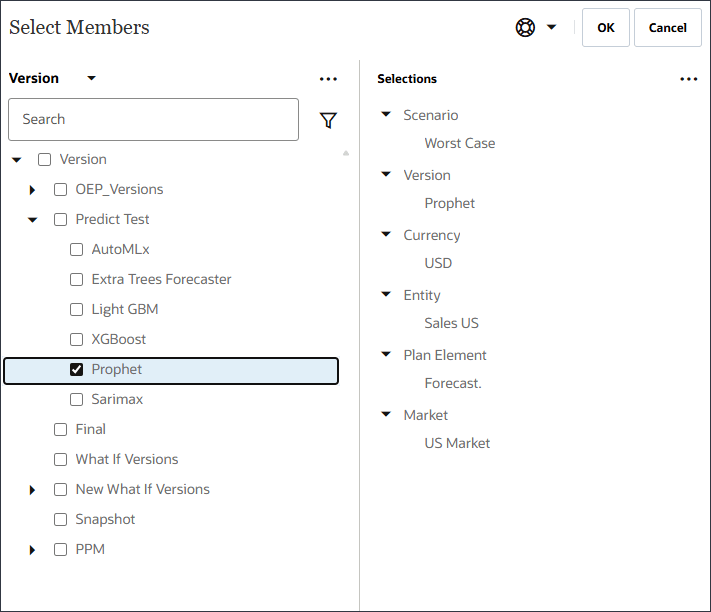
モデル見積りのバージョン、最良ケース、最悪ケースがProphetに変更されます。
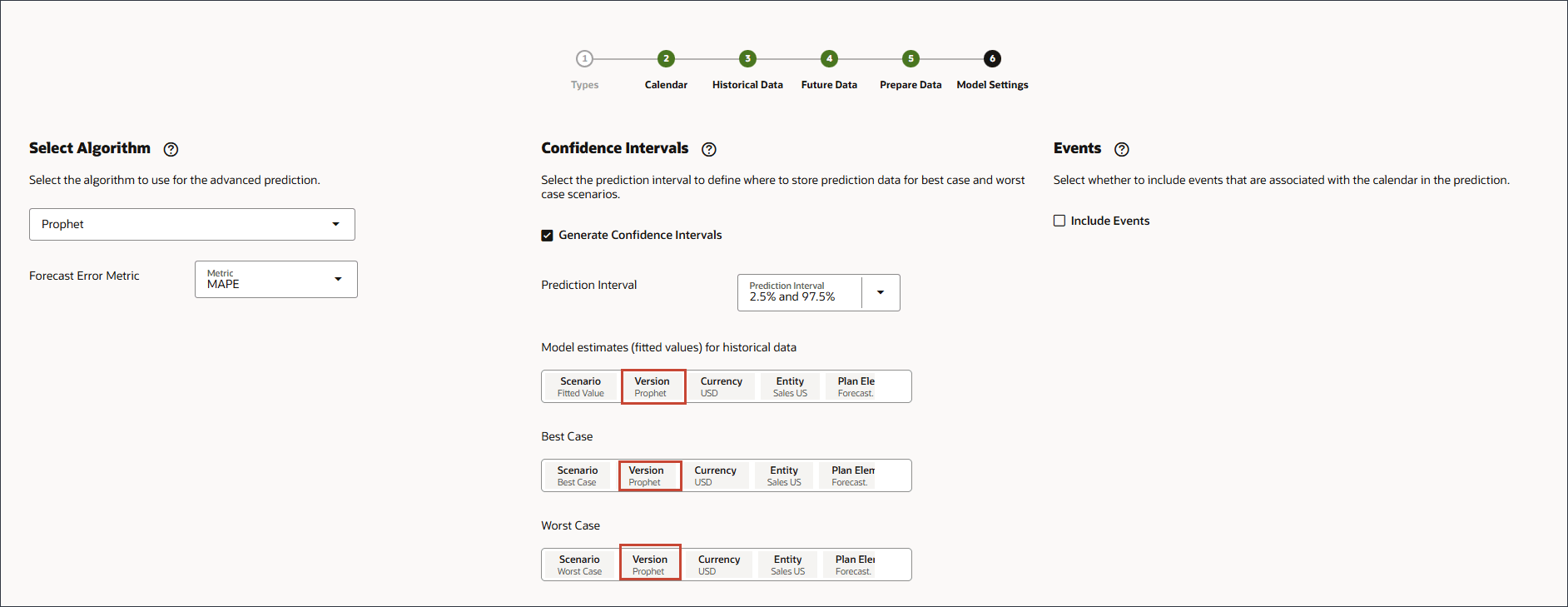
- 「イベント」で、「イベントを含める」が選択されていることを確認し、「保存」をクリックします。
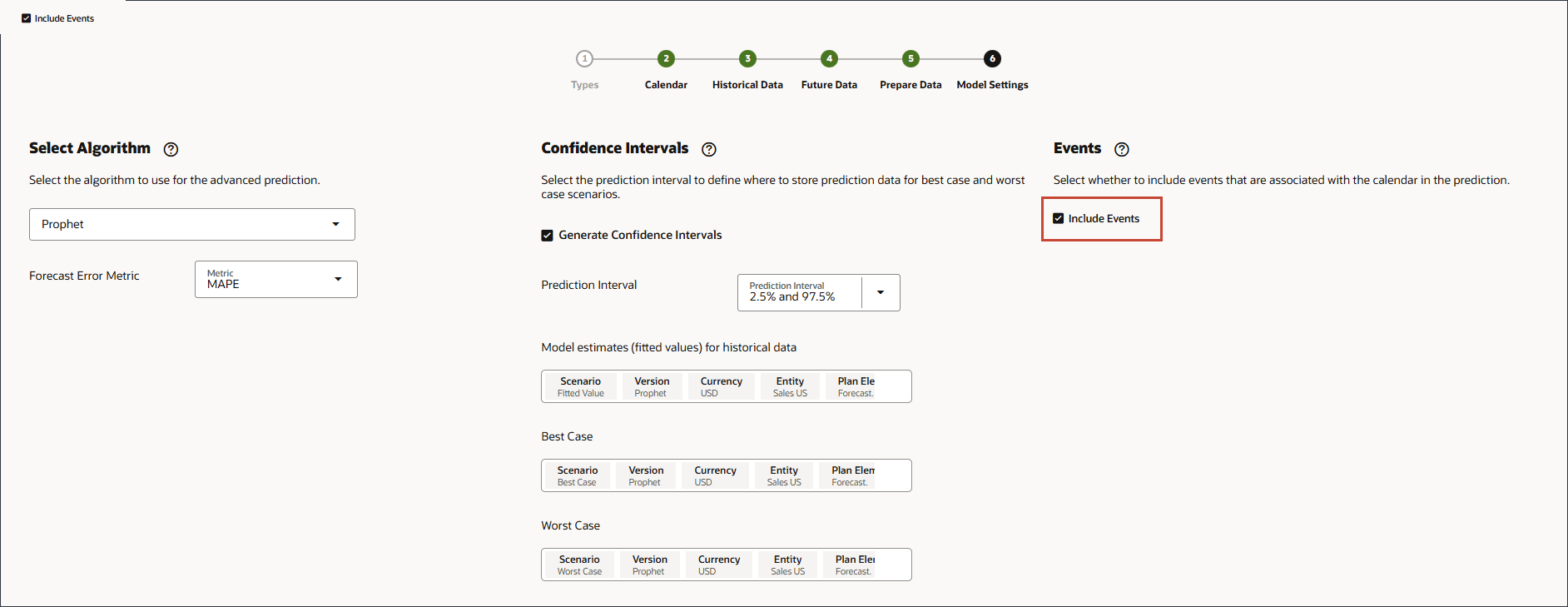
- 「取消」をクリックします。
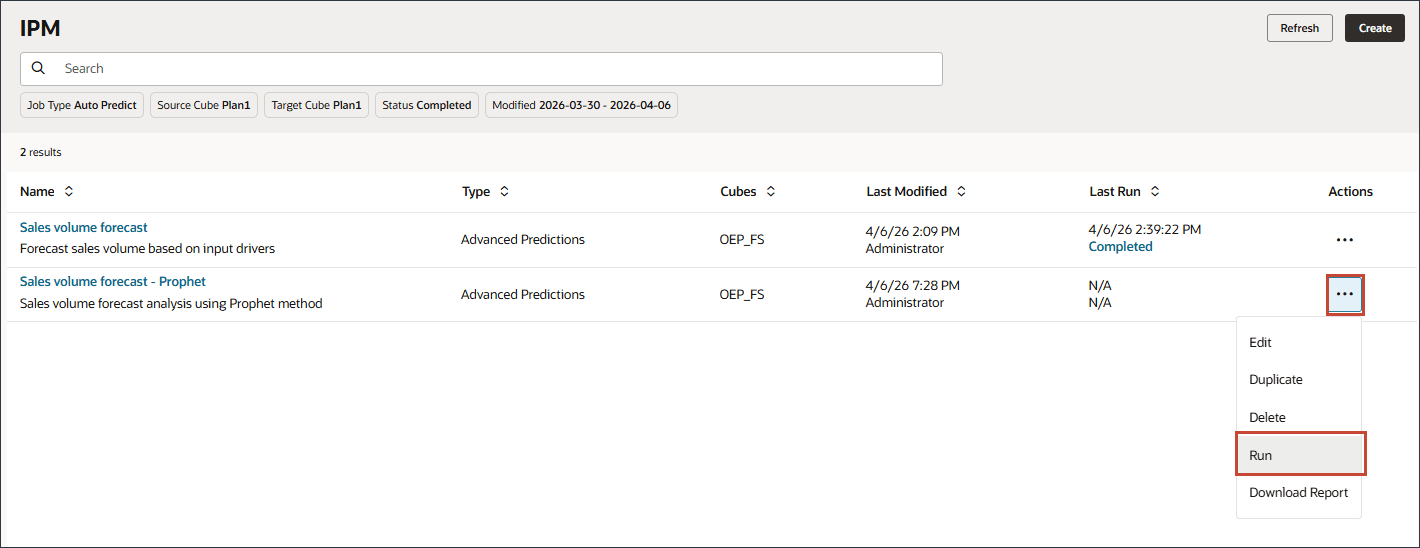
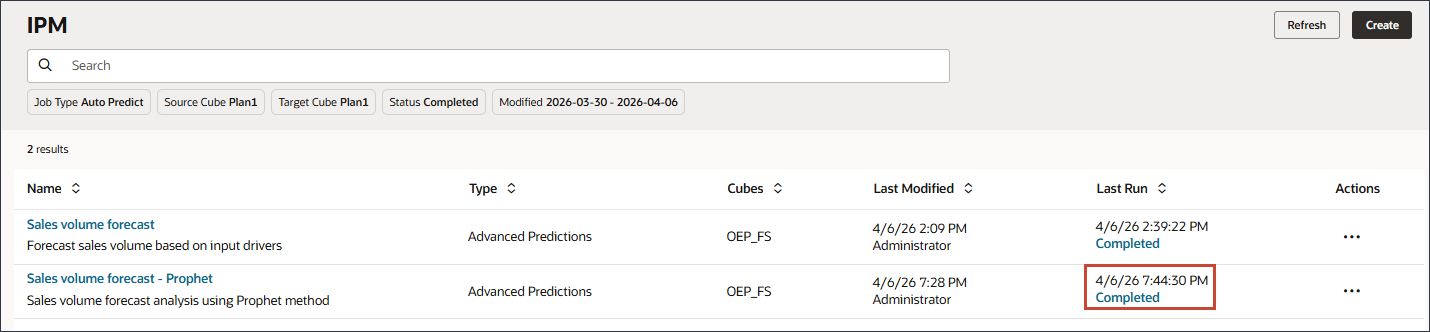
- 販売量予測- Prophetジョブで、 (アクション)をクリックし、「実行」を選択します。
- ジョブが完了したことが示されるまで、「リフレッシュ」をクリックします。
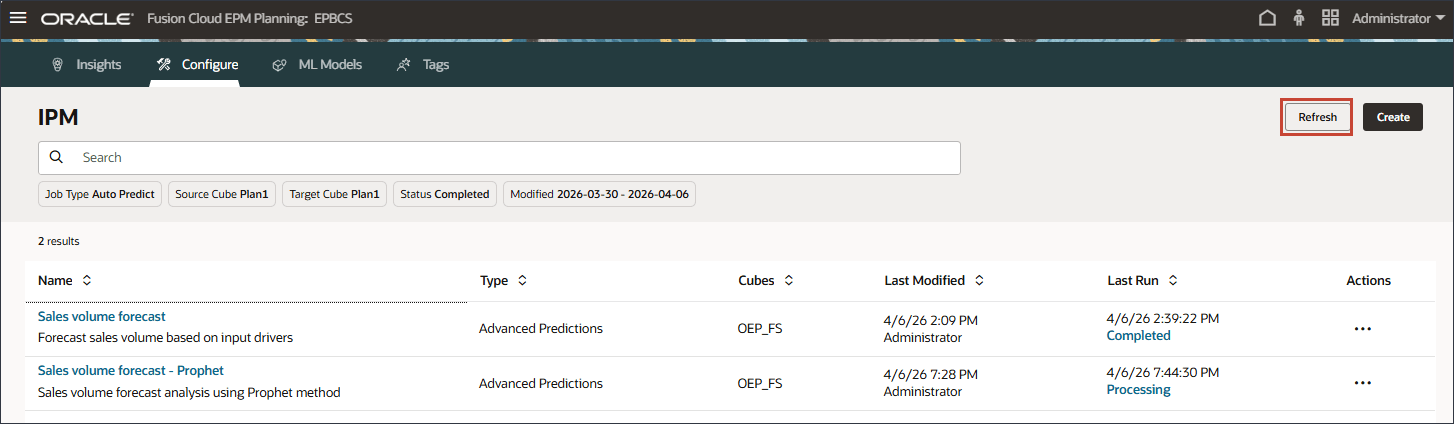
ノート:
ジョブの完了には少し時間がかかります。ジョブは完了済です。
- (ホーム)をクリックして、ホーム・ページに戻ります。
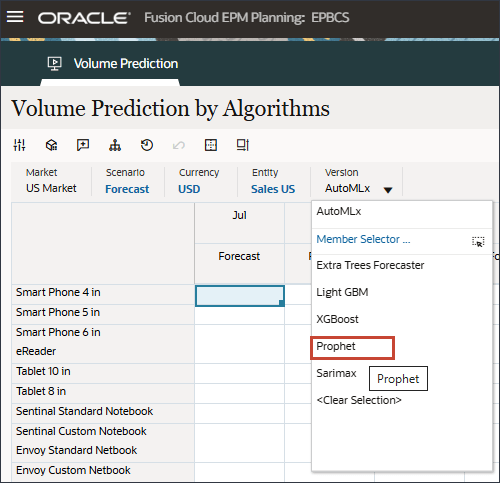
- ホーム・ページで、「拡張予測」、「ボリューム予測」の順にクリックします。
- 下部の「アルゴリズムによる予測」タブを選択します。
- 「バージョン」で、「預言者」を選択します。
- 「予測の説明」をクリックして、予測を確認します。「Smart Phone 4 in」の「Jul」などの値を右クリックし、「予測の説明」を選択します。
説明可能性を確認します。一部の製品シリーズでは、Prophetの精度が向上します。
予測値追加
予測値追加(FVA)は、予測方法の変更による精度の向上(または低下)を測定することによって、予測プロセスの有効性を評価するために予測で使用されるメトリックです。FVAは、予測プロセスの各ステップがベースライン(前回の予測バージョンなど)と比較して値を加算するかどうかを決定するのに役立ちます。
- 下部で、「予測精度」タブをクリックします。
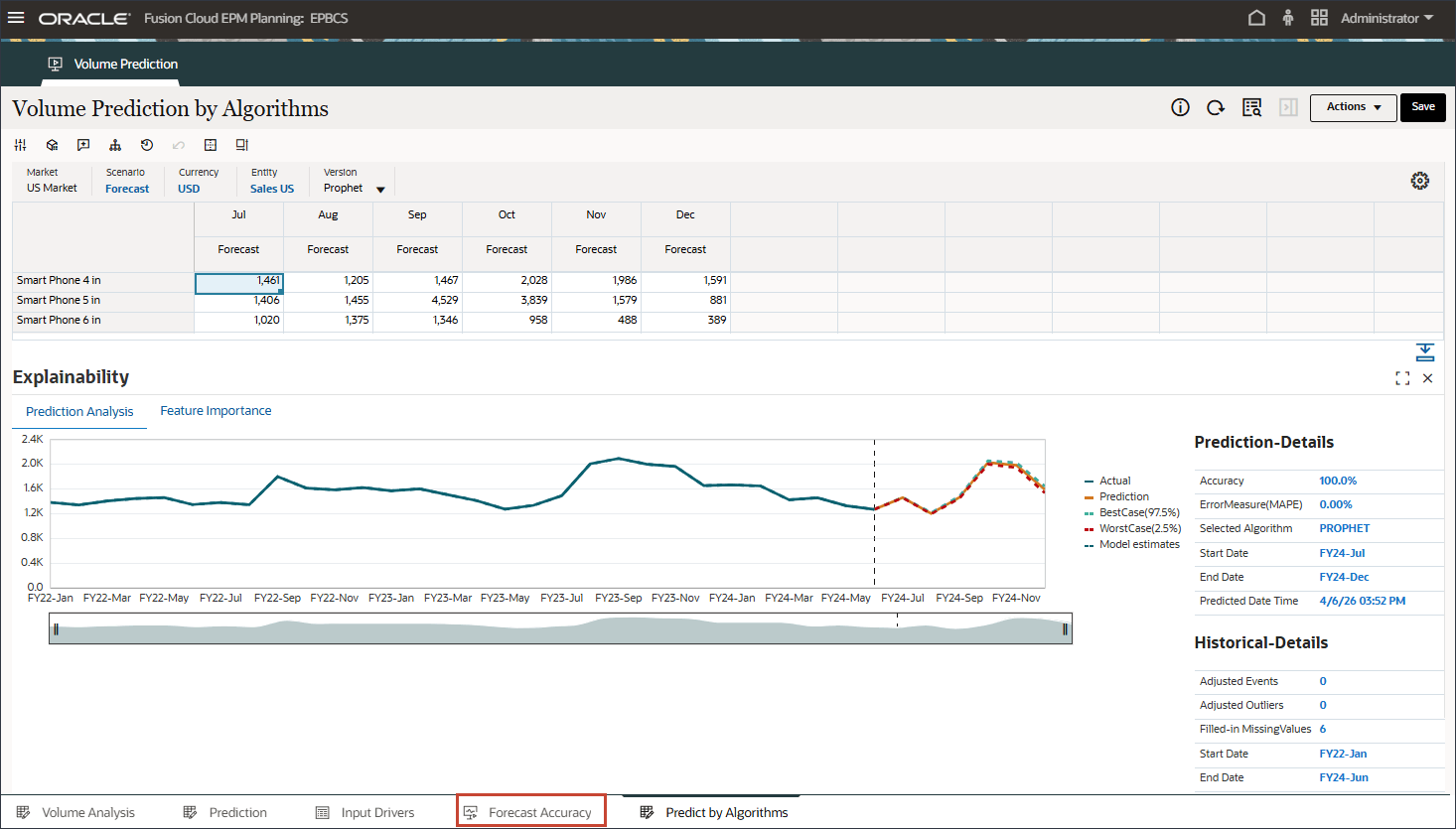
テストは、1月24日から6月24日までの期間(実際のデータがすでに使用可能)の予測精度を測定するために行われます。高度な予測結果(多変量予測)、単変量予測および予測と実際の値を比較して、予測の精度を測定できます。
FVAを計算するために、調整済予測の精度がベースラインの精度と比較されます。調整済予測でベースラインと比較してエラーが減少した場合、FVAは正の値になり、エラーが増加した場合、FVAは負の値になります。この指標は、予測担当者が、精度を向上させ、予測プロセスにおける付加価値以外の活動を排除するステップに集中するのに役立ちます。
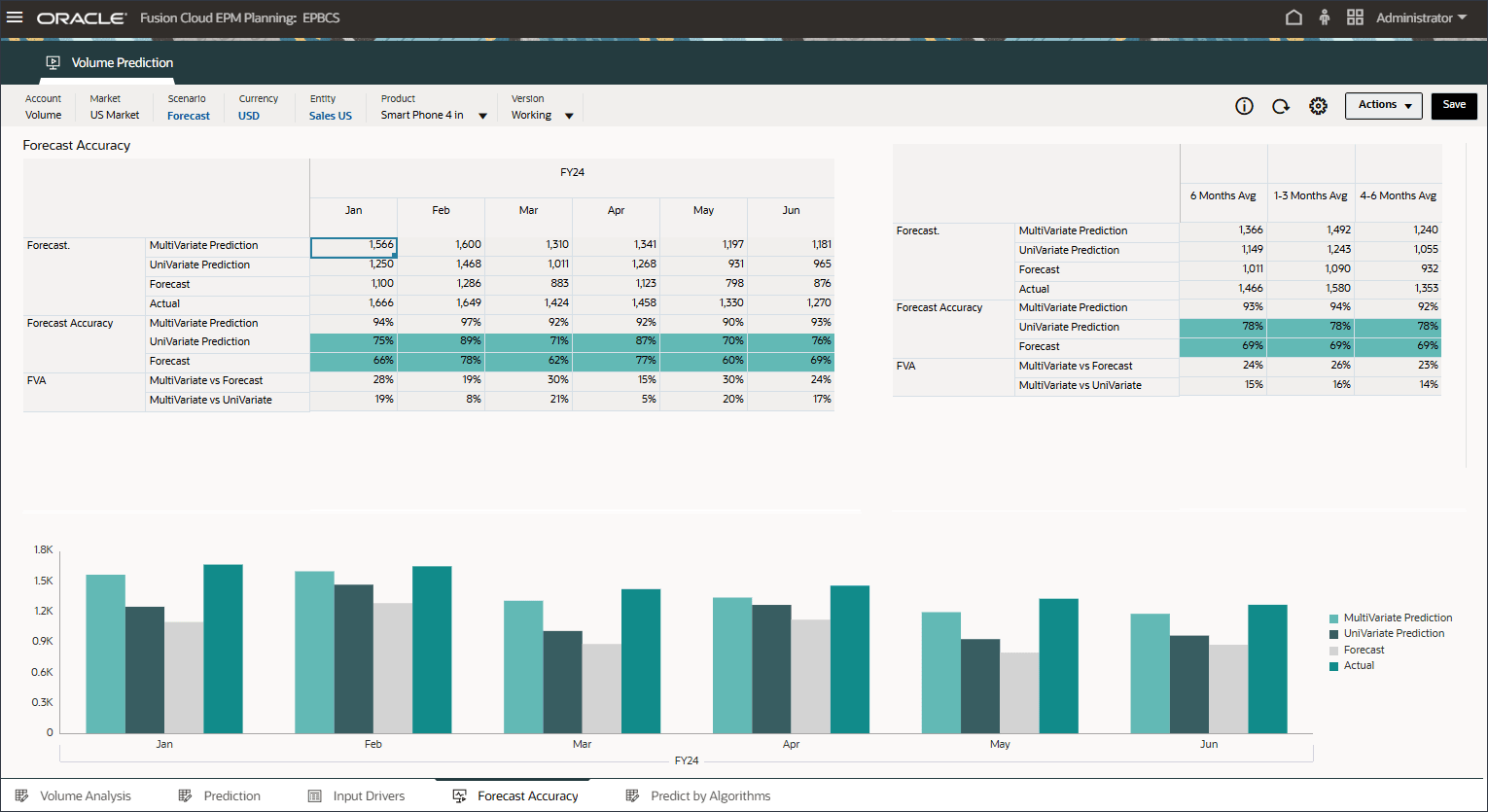
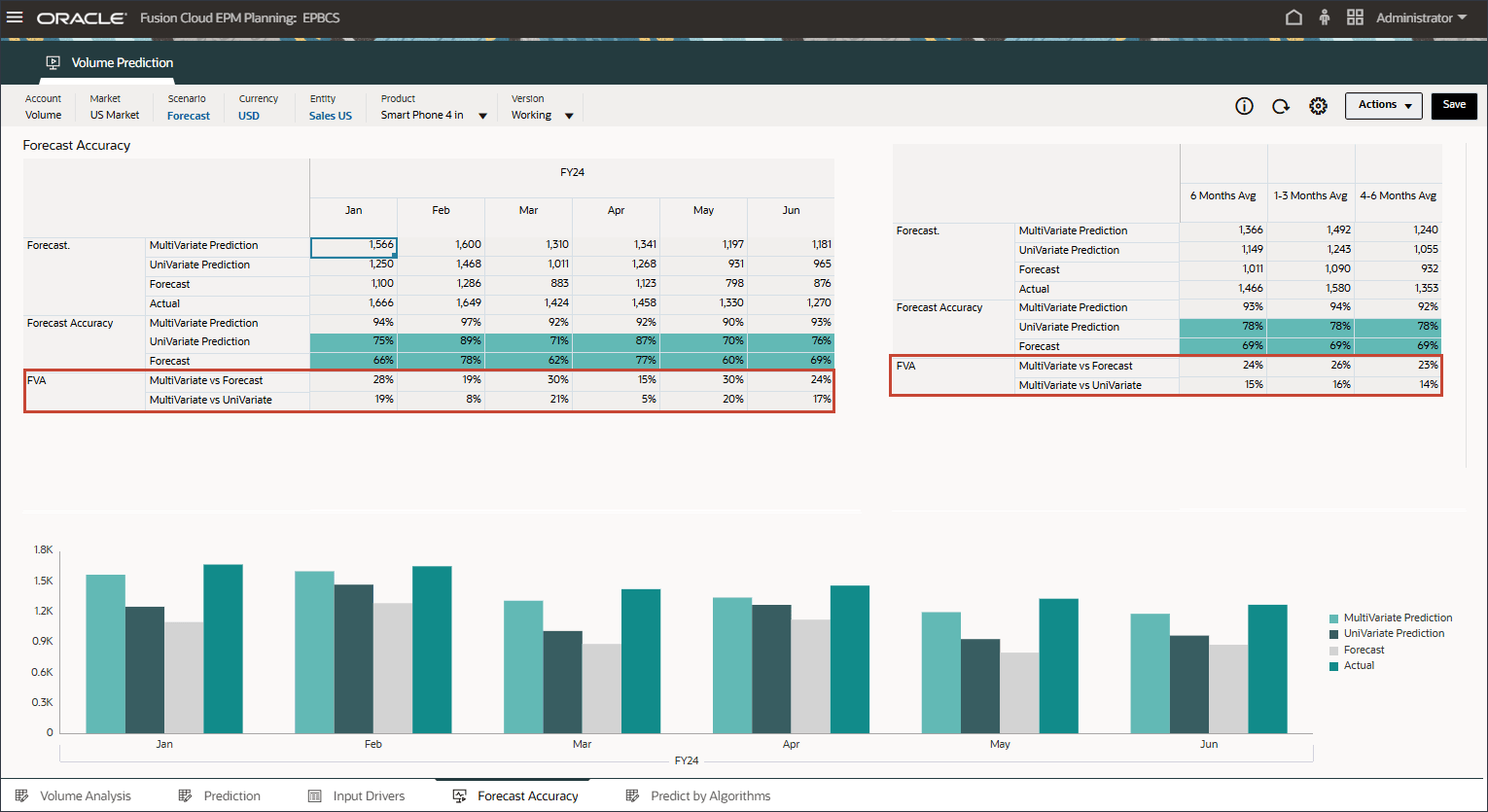
- 拡張予測(ML)の予測値追加をレビューして、予測および単変量予測結果と比較してはるかに優れていることを確認します。
- 拡張予測結果と単変量予測および予測シナリオを比較する棒グラフを確認します。
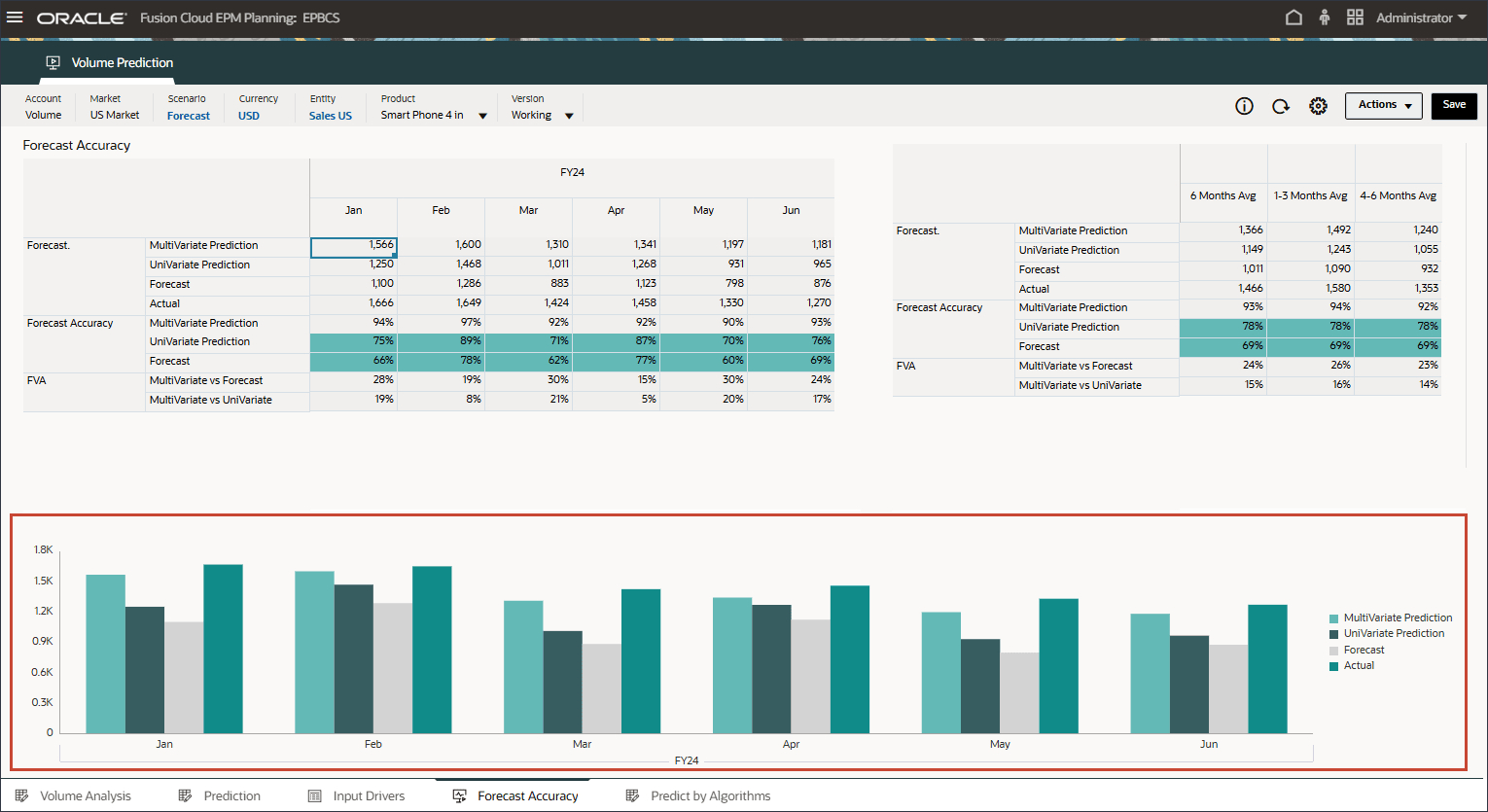
MLを使用した高度な予測は、実際の結果に近いため、計画担当者が将来の計画および予測に高度な予測方法を使用できる信頼度レベルが向上します。
関連リンク
その他の学習リソース
docs.oracle.com/learnで他のラボを確認するか、Oracle Learning YouTubeチャネルで無料のラーニング・コンテンツにアクセスしてください。さらに、Oracle Universityにアクセスして、利用可能なトレーニング・リソースを確認してください。
製品ドキュメントについては、Oracle Help Centerを参照してください。