Oracle Autonomous Databaseおよびプロパティ・グラフ問合せ言語を使用したナレッジ・グラフの作成
はじめに
このチュートリアルでは、グラフ理論、ナレッジ・グラフの概念、およびOracle Autonomous Database with Property Graph Query Language (PGQL)を使用した実装方法について説明します。また、LLMを使用してドキュメントから関係を抽出し、それらをOracleのグラフ構造として格納するために使用されるPython実装についても説明します。
グラフとは
グラフは、オブジェクト間のモデリング関係に焦点を当てた数学とコンピュータサイエンスの分野です。グラフは次のもので構成されます。
-
行(ノード):エンティティを表します。
-
エッジ(リンク):エンティティ間の関係を表します。
グラフは、ソーシャル・ネットワーク、セマンティック・ネットワーク、ナレッジ・グラフなどのデータ構造を表すために広く使用されています。
ナレッジ・グラフとは
ナレッジ・グラフは、現実世界のナレッジのグラフベースの表現です。ここでは:
-
ノードは、個人、場所、製品などのエンティティを表します。
-
エッジはセマンティック関係を表します。たとえば、作業場所、一部など。
ナレッジ・グラフは、セマンティック検索、推奨システムおよび質問回答アプリケーションを強化します。
PGQLでOracle Autonomous Databaseを使用する理由
Oracleは、プロパティ・グラフを格納および問合せするための完全管理環境を提供します。
-
PGQLはSQLに似ており、複雑なグラフ・パターンの問合せ用に設計されています。
-
Oracle Autonomous Databaseでは、作成、問合せ、可視化などのプロパティ・グラフ機能を使用して、グラフ問合せをネイティブに実行できます。
-
LLMとの統合により、非構造化データ(PDFなど)からグラフ構造を自動的に抽出できます。
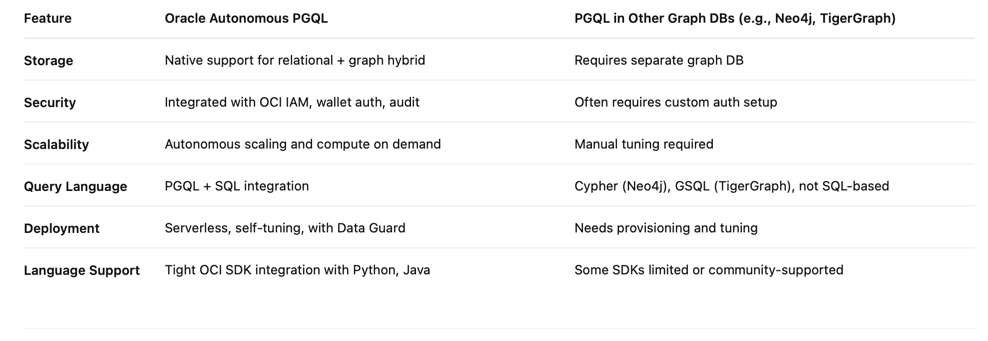
他のグラフ問合せ言語との比較

PGQLを使用したOracle Autonomous Databaseと従来のグラフ・データベースのメリット
目的
- Oracle Autonomous DatabaseおよびPGQLを使用してナレッジ・グラフを作成します。
前提条件
- Python
version 3.10以上およびOracle Cloud Infrastructureコマンドライン・インタフェース(OCI CLI)をインストールします。
タスク1: Pythonパッケージのインストール
Pythonコードには、Oracle Cloud Infrastructure(OCI)生成AIを使用するための特定のライブラリが必要です。必要なPythonパッケージをインストールするには、次のコマンドを実行します。このファイルは、requirements.txtからダウンロードできます。
pip install -r requirements.txt
タスク2: Oracle Database 23aiの作成(Always Free)
このタスクでは、Oracle Database 23aiをAlways Freeモードでプロビジョニングする方法を学習します。このバージョンは、追加コストなしで開発、テスト、学習に最適なフルマネージド環境を提供します。
-
OCIコンソールにログインし、「Oracle Database」、「Autonomous Database」に移動して、「Autonomous Databaseインスタンスの作成」をクリックします。
-
次の情報を入力します
- データベース名:インスタンスの識別名を入力します。
- ワークロード・タイプ:必要に応じて、「データ・ウェアハウス」または「トランザクション処理」を選択します。
- コンパートメント:リソースを編成する適切なコンパートメントを選択します。
-
「Always Free」を選択して、インスタンスが無償でプロビジョニングされていることを確認します。
-
データベースへのアクセスに使用される
ADMINユーザーのセキュアなパスワードを作成します。 -
設定を確認し、「Autonomous Databaseの作成」をクリックします。インスタンスがプロビジョニングされ、使用可能になるまで数分待ちます。
Oracle Autonomous Databaseへの接続プロセスに慣れていない場合は、次のリンクに従ってコードを理解し、適切に構成してください。
ノート: Walletメソッドを使用して、Pythonコード内のデータベースに接続する必要があります。
タスク3: コードのダウンロードと理解
Graphの非常に一般的なユース・ケースは、LLMおよびPDFファイルなどのナレッジ・ベースと連携するコンポーネントの1つとして使用することです。
前述のすべてのコンポーネントを使用する基盤として、OCI生成AIを使用した自然言語でのPDFドキュメントの分析というチュートリアルを使用します。ただし、このドキュメントでは、Oracle Database 23aiとGraphの併用に焦点を当てます。基本的に、ベース・マテリアルのPythonコード(main.py)は、Oracle Database 23aiを使用するパートでのみ変更されます。
このサービスで実行されるプロセスは次のとおりです。
-
グラフ・スキーマを作成します。
-
LLMを使用してエンティティおよび関係を抽出します。
-
Oracleにデータを挿入します。
-
プロパティ・グラフを作成します。
Oracle Database 23aiと互換性のある更新済Pythonグラフ・コードをmain.pyからダウンロードします。
-
create_knowledge_graph:def create_knowledge_graph(chunks): cursor = oracle_conn.cursor() # Creates graph if it does not exist try: cursor.execute(f""" BEGIN EXECUTE IMMEDIATE ' CREATE PROPERTY GRAPH {GRAPH_NAME} VERTEX TABLES (ENTITIES KEY (ID) LABEL ENTITIES PROPERTIES (NAME)) EDGE TABLES (RELATIONS KEY (ID) SOURCE KEY (SOURCE_ID) REFERENCES ENTITIES(ID) DESTINATION KEY (TARGET_ID) REFERENCES ENTITIES(ID) LABEL RELATIONS PROPERTIES (RELATION_TYPE, SOURCE_TEXT)) '; EXCEPTION WHEN OTHERS THEN IF SQLCODE != -55358 THEN -- ORA-55358: Graph already exists RAISE; END IF; END; """) print(f"🧠 Graph '{GRAPH_NAME}' created or already exists.") except Exception as e: print(f"[GRAPH ERROR] Failed to create graph: {e}") # Inserting vertices and edges into the tables for doc in chunks: text = doc.page_content source = doc.metadata.get("source", "unknown") if not text.strip(): continue prompt = f""" You are an expert in knowledge extraction. Given the following technical text: {text} Extract key entities and relationships in the format: - Entity1 -[RELATION]-> Entity2 Use UPPERCASE for RELATION types. Return 'NONE' if nothing found. """ try: response = llm_for_rag.invoke(prompt) result = response.content.strip() except Exception as e: print(f"[ERROR] Gen AI call error: {e}") continue if result.upper() == "NONE": continue triples = result.splitlines() for triple in triples: parts = triple.split("-[") if len(parts) != 2: continue right_part = parts[1].split("]->") if len(right_part) != 2: continue raw_relation, entity2 = right_part relation = re.sub(r'\W+', '_', raw_relation.strip().upper()) entity1 = parts[0].strip() entity2 = entity2.strip() try: # Insertion of entities (with existence check) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity1, entity1]) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity2, entity2]) # Retrieve the IDs cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity1]) source_id = cursor.fetchone()[0] cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity2]) target_id = cursor.fetchone()[0] # Create relations cursor.execute(""" INSERT INTO RELATIONS (SOURCE_ID, TARGET_ID, RELATION_TYPE, SOURCE_TEXT) VALUES (:src, :tgt, :rel, :txt) """, [source_id, target_id, relation, source]) print(f"✅ {entity1} -[{relation}]-> {entity2}") except Exception as e: print(f"[INSERT ERROR] {e}") oracle_conn.commit() cursor.close() print("💾 Knowledge graph updated.")-
グラフ・スキーマは、
CREATE PROPERTY GRAPHを使用して作成され、ENTITIES(頂点)およびRELATIONS(エッジ)がリンクされます。 -
MERGE INTOを使用して、新しいエンティティが存在しない場合のみ(一意性を保証)挿入します。 -
LLM (Oracle Generative AI)は、
Entity1 -[RELATION]-> Entity2.形式のトリプルを抽出するために使用されます。 -
Oracleとのすべての相互作用は、
oracledbおよびPL/SQL無名ブロックを介して行われます。
これで、次のことができます。
-
PGQLを使用して、グラフ関係を探索および問い合せます。
-
ビジュアライゼーションのためにGraph Studioに接続します。
-
API RESTまたはLangChainエージェントを介してグラフを公開します。
-
-
グラフ問合せサポート関数
ナレッジ・グラフに対するセマンティック検索および推論を可能にする2つの必須関数(
extract_graph_keywordsおよびquery_knowledge_graph)があります。これらのコンポーネントを使用すると、質問をOracle Autonomous DatabaseでPGQLを使用して意味のあるグラフ問合せに解釈できます。-
extract_graph_keywords:def extract_graph_keywords(question: str) -> str: prompt = f""" Based on the question below, extract relevant keywords (1 to 2 words per term) that can be used to search for entities and relationships in a technical knowledge graph. Question: "{question}" Rules: - Split compound terms (e.g., "API Gateway" → "API", "Gateway") - Remove duplicates - Do not include generic words such as: "what", "how", "the", "of", "in the document", etc. - Return only the keywords, separated by commas. No explanations. Result: """ try: resp = llm_for_rag.invoke(prompt) keywords_raw = resp.content.strip() # Additional post-processing: remove duplicates, normalize keywords = {kw.strip().lower() for kw in re.split(r'[,\n]+', keywords_raw)} keywords = [kw for kw in keywords if kw] # remove empty strings return ", ".join(sorted(keywords)) except Exception as e: print(f"[KEYWORD EXTRACTION ERROR] {e}") return ""処理の内容:
-
LLM (
llm_for_rag)を使用して、自然言語の質問をグラフに適したキーワードのリストに変換します。 -
プロンプトは、グラフの検索に関連するエンティティおよび用語をクリーンに抽出するように設計されています。
重要な理由:
-
非構造化質問と構造化問合せのギャップを埋めます。
-
PGQL問合せでの照合に特定のドメイン関連用語のみが使用されるようにします。
LLM拡張動作:
-
複合技術用語を破棄します。
-
ストップワード(what、howなど)を削除します。
-
用語を小文字にして複製解除することにより、テキストを正規化します。
例:
-
入力:
"What are the main components of an API Gateway architecture?" -
出力キーワード:
api, gateway, architecture, components
-
-
query_knowledge_graph:def query_knowledge_graph(query_text): cursor = oracle_conn.cursor() sanitized_text = query_text.lower() pgql = f""" SELECT from_entity, relation_type, to_entity FROM GRAPH_TABLE( {GRAPH_NAME} MATCH (e1 is ENTITIES)-[r is RELATIONS]->(e2 is ENTITIES) WHERE CONTAINS(e1.name, '{sanitized_text}') > 0 OR CONTAINS(e2.name, '{sanitized_text}') > 0 OR CONTAINS(r.RELATION_TYPE, '{sanitized_text}') > 0 COLUMNS ( e1.name AS from_entity, r.RELATION_TYPE AS relation_type, e2.name AS to_entity ) ) FETCH FIRST 20 ROWS ONLY """ print(pgql) try: cursor.execute(pgql) rows = cursor.fetchall() if not rows: return "⚠️ No relationships found in the graph." return "\n".join(f"{r[0]} -[{r[1]}]-> {r[2]}" for r in rows) except Exception as e: return f"[PGQL ERROR] {e}" finally: cursor.close()処理の内容:
- キーワードベースの文字列(多くの場合、
extract_graph_keywordsによって生成されます)を受け入れ、ナレッジ・グラフから関係を取得するPGQL問合せを構築します。
主な仕組み:
-
GRAPH_TABLE句では、MATCHを使用して、ソース・ノードからターゲット・ノードにグラフを移動します。 -
CONTAINS()を使用して、ノード/エッジ属性(e1.name、e2.name、r.RELATION_TYPE)で部分検索およびファジー検索を許可します。 -
出力のフラッディングを回避するために、結果を20に制限します。
PGQLを使用する理由:
-
PGQLはSQLに似ていますが、グラフ・トラバーサル用に設計されています。
-
Oracle Autonomous Databaseは、リレーショナル・ワールドとグラフ・ワールドをシームレスに統合できるプロパティ・グラフをサポートしています。
-
エンタープライズ対応の索引付け、最適化およびネイティブ・グラフ検索機能を提供します。
Oracle固有のノート:
-
GRAPH_TABLE()はOracle PGQLに固有であり、リレーショナル表で定義されたグラフの論理ビューに対する問合せが可能です。 -
Cypher (Neo4j)とは異なり、PGQLはSQL拡張を使用して構造化データを処理するため、RDBMSの負荷が高い環境ではより使いやすくなります。
- キーワードベースの文字列(多くの場合、
-
タスク4: チャットボットの実行
次のコマンドを実行してチャットボットを実行します。
python main.py
関連リンク
確認
- 著者 - 星川クリスティアーノ(Oracle LAD A、チーム・ソリューション・エンジニア)
その他の学習リソース
docs.oracle.com/learnで他のラボを確認するか、Oracle Learning YouTubeチャネルで無料のラーニング・コンテンツにアクセスしてください。また、education.oracle.com/learning-explorerにアクセスして、Oracle Learning Explorerになります。
製品ドキュメントについては、Oracle Help Centerを参照してください。
Create a Knowledge Graph with Oracle Autonomous Database and Property Graph Query Language
G38836-02
Copyright ©2025, Oracle and/or its affiliates.