OKEを使用したCassandraおよびSparkアクティビティのデータ・ローカリティの改善
はじめに
Apache Cassandraは、各ノードがトークン範囲を所有する分散マスターレス・データベースです。Apache Sparkは、Spark-Cassandraコネクタを使用してCassandraレプリカから読み取れる分散コンピュート・エンジンです。Kubernetesでは、ポッドはデータが存在する場所を知らずにスケジュールされるため、データのローカリティは保証されません。
このチュートリアルでは、OKEがKubernetesプリミティブ(StatefulSets (Cassandraの安定したアイデンティティ)、ノード・ラベル、およびSparkエグゼキュータをCassandraポッドとコロケーションするためのアフィニティ/アンチアフィニティ)を使用して、どのようにローカリティを改善できるかを示します。そのため、読取りは同じノード(理想)または最悪の場合は、同じロケーション・レプリカへの1ホップから提供されます。
目的
- 3ノードのOKEクラスタおよび要塞(ORMまたはTerraform)をデプロイします。
- ラベル+アフィニティを持つ2つのノードでCassandraとSparkを同時に配置します。
- Cassandraに対してSpark読取りジョブを実行して確認します。
- VCNフロー・ログとのノード間トラフィックを監視します。
前提条件
- VCN、OKE、Compute、Logging (Flow Logs)の権限を持つOCIテナンシ。オプションのMonitoring。
- 要塞アクセス用のSSHキー・ペア。
- Kubernetesに関する基本的な知識(ノード、ラベル、ポッドなど)。
タスク1: OCI Resource Manager (ORM)を使用した環境のデプロイ(推奨)。
-
OCIコンソールでスタックを開くには、次をクリックします:

-
ガイド付きフローに従って、次の操作を行います。
-
利用規約に同意します。
-
SSHキーを挿入し、可用性ドメインを選択します。
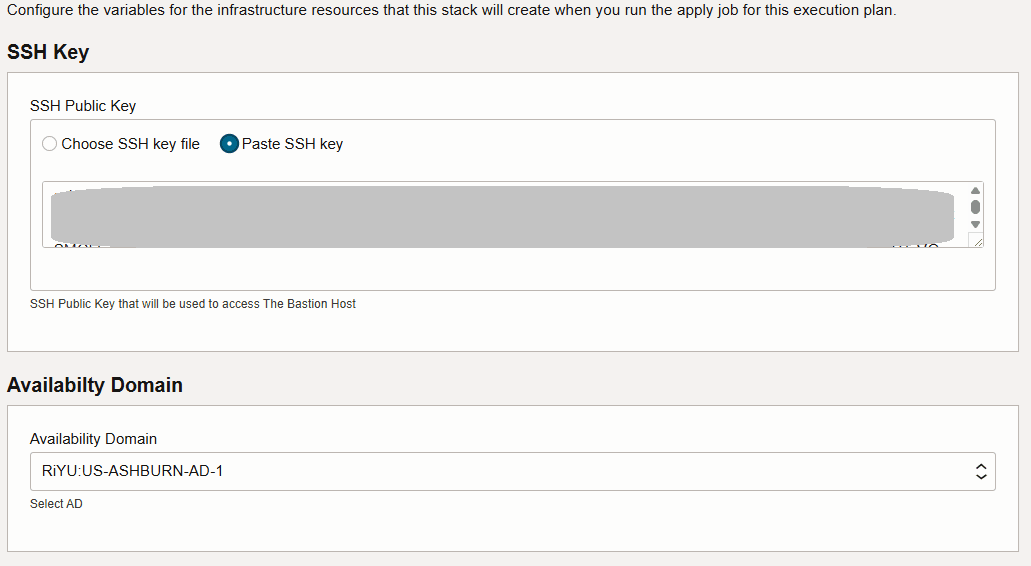
-
VCN、OKEクラスタおよび要塞をデプロイするために、値のリストをデフォルトのままにできます。
-
スタックを起動します。
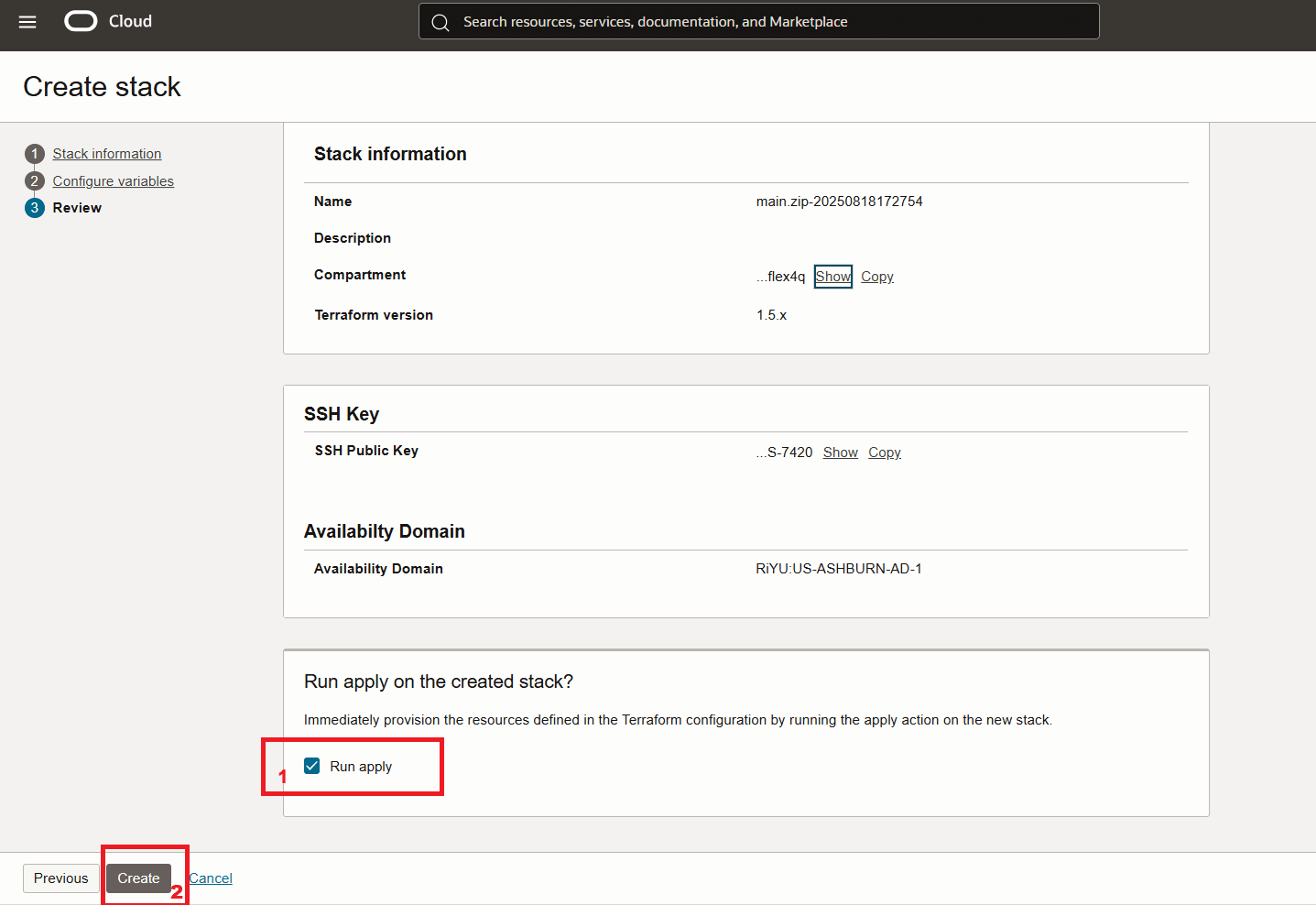
-
スタックが完了すると、出力セクションに要塞のIPが表示されます。
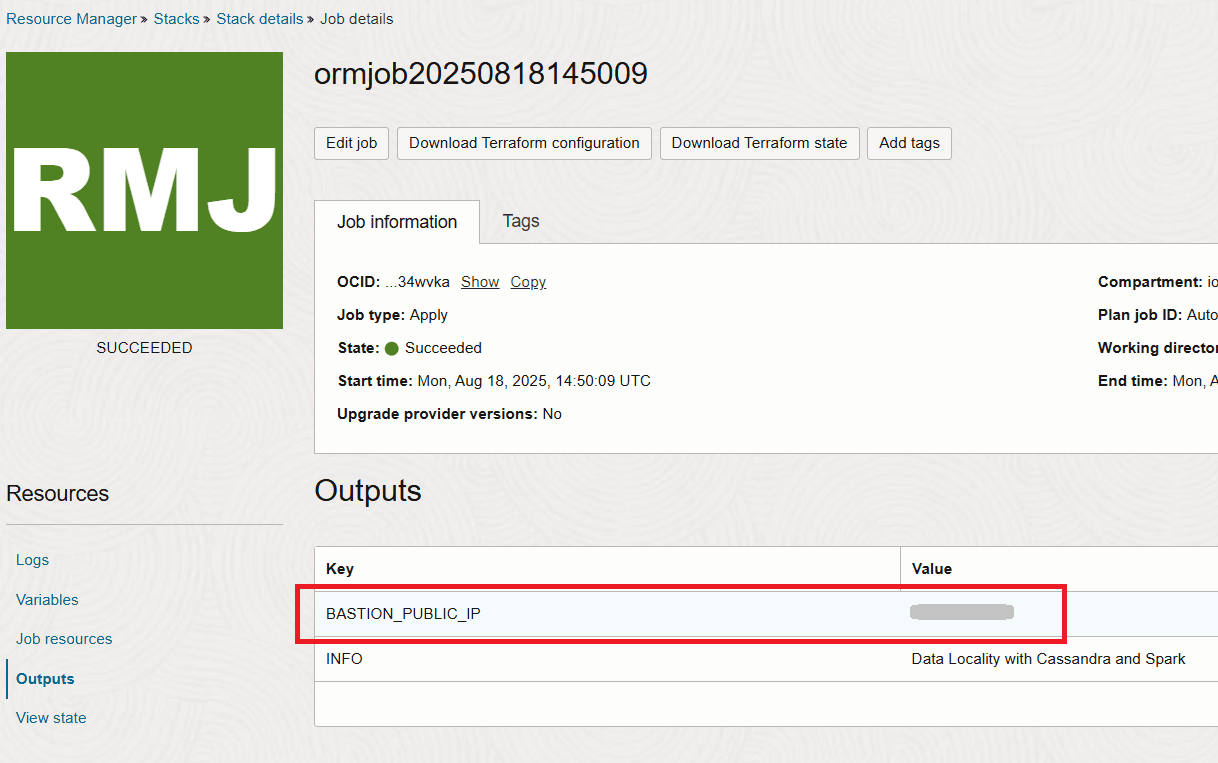
タスク2: 要塞への接続とデプロイメントの検証
初期インフラストラクチャ・プロビジョニングは約15分以内に完了しますが、フル・セットアップ(要塞のcloud-init経由)では、Helmのインストール、CassandraとSparkのデプロイ、および読取りジョブの実行に約20分かかります。
-
プロセスを監視するには、要塞にSSHを実行します。
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
次のコマンドを実行して、cloudinitスクリプトの進行状況を監視します。
tail -f /var/log/oke-automation.log -
3つのシードCassandra値が読み取られ、Cloud-init completeメッセージが表示されると、スタックは完了します。
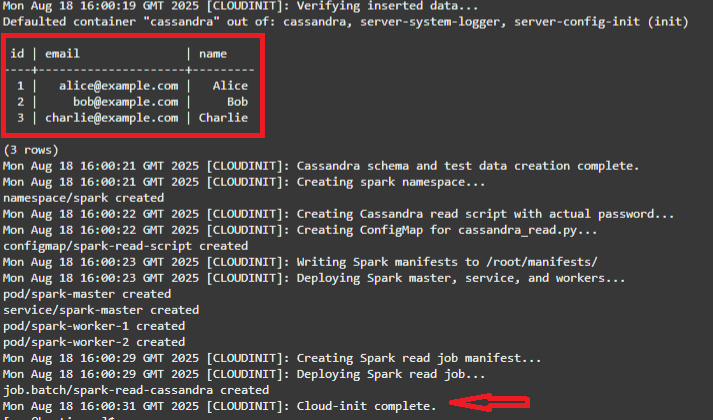
注意: cloudinitスクリプトの実行内容は次のとおりです。
- kubectl、Helm、OCI CLI (インスタンス・プリンシパル)をインストールし、kubeconfigをフェッチします。
- 就業者の待機
- 最初の2つのノードに
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-bというラベルを付けます。 - cert-managerとk8ssandra-operator (CRD)をインストールします。
- K8ssandraClusterの適用
- Cassandraの待機
- testks.usersを作成し、3行を挿入します
- スパーク・ネームスペースを作成します。/scripts/cassandra_read.pyを使用してConfigMapを構築します(testks.usersを読み込みます)
- Sparkマスター、サービスおよび2人のワーカーをデプロイします(nodeSelector spark-locality: "true"、ワーカー・アンチアフィニティ)
- ジョブspark-read-cassandraの発行
-
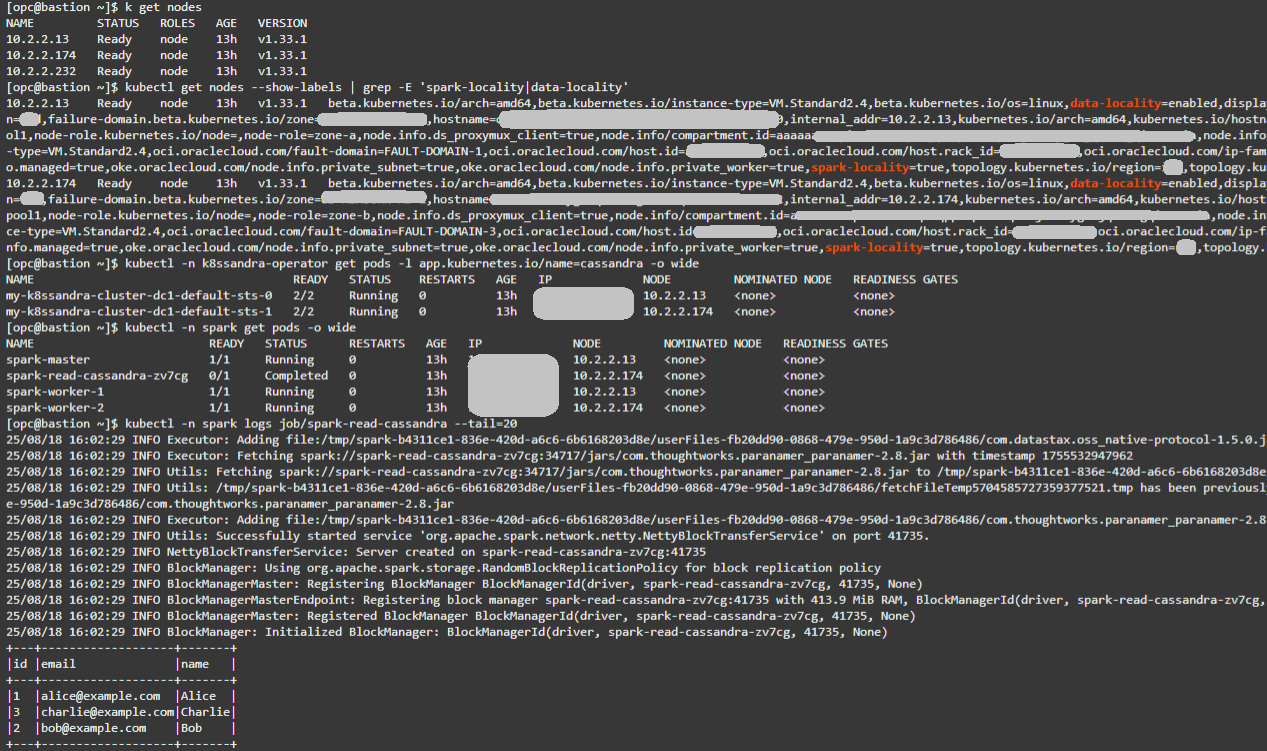
要塞VMから、既存のノードを確認します:
kubectl get nodes -
納税地ラベルを確認します。spark-locality=trueおよび data-locality=enabledの2つのノードが必要です。
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Cassandra配置の検証:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Sparkの配置を確認します。
kubectl -n spark get pods -o wide -
Spark読取りジョブ・ログを確認します。testks.usersの3つのレコードと正常な実行が表示されます。
kubectl -n spark logs job/spark-read-cassandra --tail=20
ヒント: CassandraポッドとSparkポッド間でNODE値を一致させると、ローカリティの共存条件と理想的な条件が確認されます。より詳細なフロー・ログ結果を得るには、cqlshを使用して追加の行をtestks.usersに挿入します。データセットが大きいほど、より多くの読み取りトラフィックが生成され、近傍性効果と非近傍性効果が観察しやすくなります。
以下に、上記のコマンドの出力例を示します。
タスク3: VCNフロー・ログによるネットワーク効果の監視
VCNフロー・ログを使用して、Spark読取り中にCassandraトラフィックがフローする場所を理解します。現在の自動化ではFlannel (VXLAN)が使用され、フロー・ログで表示できる内容に影響します。
CNIの変化
- Flannel (VXLAN、このラボ):
- 同一ノード・ポッド・トラフィックはホスト・ブリッジにとどまるため、VCNフロー・ログ・エントリはありません。
- ノード間ポッド・トラフィックは、UDP
(VXLAN)としてカプセル化されます。デフォルトでは、Flannelはポート8472を使用しますが、そのポートが使用できない場合は、別の高い UDPポートを選択できます。正確なポートはデプロイメントごとに異なる場合があります。
- VCNネイティブ・ポッド・ネットワーキング(NPN):
- ポッドはVCN IPを取得し、トラフィックはオーバーレイなしでL3にルーティングされます。
- フロー・ログには、実際のアプリケーション・ポートが表示されます(Cassandraの場合: TCP 9042)。
-
ワーカー・サブネットでフロー・ログを有効にします。
OCIコンソールで、OKEワーカー・サブネットのフロー・ログを有効にします。Spark読取りジョブを再実行(または待機)してトラフィックを生成します。
-
問合せフロー・ログ(クラスタに一致するパスを選択)
この自動化(Flannel/VXLAN)を使用する場合:次のような拡張問合せを使用します:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
- ポッド間トラフィックは、
ワーカー・ノードのIP間(Cassandraポート9042ではなく)のUDPにカプセル化されます。 - 同一ノード読取り: VCNフロー・ログ・エントリがありません(トラフィックはローカルに残ります)。
- クロスノード読取り: 次の図で、ワーカー・ノードのIP間のUDP 14789フローとして表示されます。
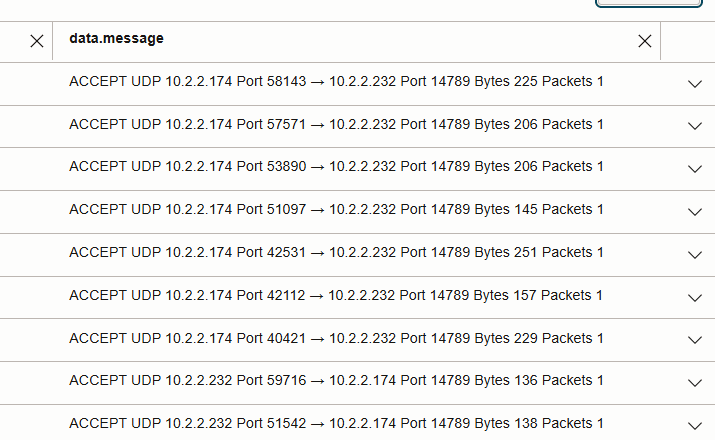
- UDP 14789でパケット数を比較すると、データ近傍性と非近傍性の効果が強調されます。
クラスタでNPNを使用している場合:
- ポッド/ワーカーIP間のTCP dstPort = 9042を直接フィルタします。
- Cassandra CQLの読取り/書込みが9042フローとして表示されるはずです。(特にごくわずか)
ノート: フロー・ログは、新しいエントリの収集に数分かかる場合があります。
主な考慮事項
-
ノード数が3個を超えるクラスタ:
ローカリティは、クラスタ・サイズが大きくなるにつれて重要になります。配置ルールがない場合、Sparkエグゼキュータはローカル・レプリカのないノードで実行され、多数のリモート読取りが発生する可能性があります。共存により、読取りがローカルであるか、最悪の場合は別のレプリカへの単一ホップであることが保証されます。
- コロケーションによるパフォーマンス向上:
- ゼロホップローカル読み取り→最小待機時間。
- クロスノード読み取りの削減→帯域幅の使用の削減と競合の低減
- Cassandraを並行して読み取るSparkジョブのスループットが向上します。
- この自動化で使用されるメカニズム:
- StatefulSets→ 安定したCassandraポッドID。
- ノード・ラベル(
spark-locality、data-locality)→共存するノードを指定します。 - Pod affinity/anti-affinity→ SparkエグゼキュータがCassandraノード上にスケジュールされ、それらのノード間でバランスがとれています。
- K8ssandraオペレータ → 宣言的Cassandraデプロイメントと管理。
- ConfigMap + Spark job→Cassandraの読み取りとトラフィックの生成を検証します。
- VCNフロー・ログ → 近傍性効果を確認および確認します。
- OKEの範囲外(アプリケーション・レベルの要因):
- Sparkタスクのスケジューリングおよびパーティション割当て。
- Cassandraレプリケーション・ファクタと一貫性レベル。
- レプリカを選択するためのSpark-Cassandraコネクタ・ロジック。
関連リンク
追加リソースへのリンクを提供します。このセクションはオプションです。必要ない場合は削除してください。
確認
- 作成者 - Adina Nicolescu (Principal Cloud Architect)
その他の学習リソース
docs.oracle.com/learnの他のラボを調べるか、Oracle Learning YouTubeチャネルで無料のラーニング・コンテンツにアクセスしてください。また、Oracle Learning Explorerになるには、education.oracle.com/learning-explorerにアクセスしてください。
製品ドキュメントについては、Oracle Help Centerを参照してください。
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53301-01