자율운영 AI 데이터베이스의 데이터 파이프라인 정보
자율운영 AI 데이터베이스 데이터 파이프라인은 로드 파이프라인이거나 익스포트 파이프라인입니다.
로드 파이프라인은 외부 소스에서 데이터를 지속적으로 증분 로드하는 기능을 제공합니다(데이터가 객체 저장소에 도착하면 데이터베이스 테이블로 로드됨). 엑스포트 파이프라인은 객체 저장소로 엑스포트되는 데이터베이스 테이블에 새 데이터가 나타나므로 객체 저장소로 엑스포트되는 연속 증분 데이터를 제공합니다. 파이프라인은 데이터베이스 스케줄러를 사용하여 증분 데이터를 지속적으로 로드하거나 내보냅니다.
자율운영 AI 데이터베이스 데이터 파이프라인은 다음을 제공합니다.
-
통합 작업: 파이프라인을 사용하면 빠르고 쉽게 데이터를 로드 또는 익스포트하고 새 데이터에 대해 정기적으로 이러한 작업을 반복할 수 있습니다.
DBMS_CLOUD_PIPELINE패키지는 파이프라인 구성과 로드 또는 엑스포트 작업에 대해 일정이 잡힌 작업을 생성 및 시작하기 위한 통합 PL/SQL 프로시저 집합을 제공합니다. -
일정이 잡힌 데이터 처리: 파이프라인은 데이터 소스를 모니터하고 새 데이터가 도착할 때 정기적으로 데이터를 로드하거나 내보냅니다.
-
고성능: 자율운영 AI 데이터베이스에서 사용 가능한 리소스로 데이터 전송 작업을 확장하는 파이프라인입니다. 파이프라인은 기본적으로 모든 로드 또는 익스포트 작업에 병렬화를 사용하며 자율운영 AI 데이터베이스에서 사용 가능한 CPU 리소스 또는 구성 가능한 우선 순위 속성에 따라 확장됩니다.
-
원자성 및 복구: 파이프라인은 객체 저장소의 파일이 로드 파이프라인에 대해 정확히 한 번 로드되도록 원자를 보장합니다.
-
모니터링 및 문제 해결: 파이프라인은 파이프라인 작업을 모니터하고 디버깅할 수 있는 자세한 로그 및 상태 테이블을 제공합니다.
-
멀티클라우드 호환: 자율운영 AI 데이터베이스의 파이프라인은 애플리케이션 변경 없이 클라우드 제공업체 간의 간편한 전환을 지원합니다. 파이프라인은 자율운영 AI 데이터베이스가 지원하는 모든 인증서 및 객체 저장소 URI 형식(Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage, Google Cloud Storage 및 Amazon S3 호환 객체 저장소)을 지원합니다.
데이터 파이프라인 수명 주기
DBMS_CLOUD_PIPELINE 패키지는 파이프라인을 생성, 구성, 테스트 및 시작하는 프로시저를 제공합니다. 파이프라인 수명 주기와 프로시저는 로드 및 익스포트 파이프라인에 대해 동일합니다.
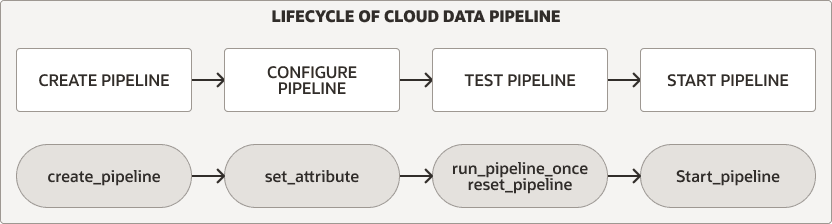
그림 pipeline_lifecycle.png에 대한 설명
두 파이프라인 유형에 대해 다음 단계를 수행하여 파이프라인을 생성하고 사용합니다.
-
파이프라인을 생성하고 구성합니다. 자세한 내용은 파이프라인 생성 및 구성을 참조하십시오.
-
새 파이프라인을 테스트합니다. 자세한 내용은 테스트 파이프라인을 참조하십시오.
-
파이프라인을 시작합니다. 자세한 내용은 파이프라인 시작을 참조하십시오.
또한 파이프라인을 모니터, 정지 또는 삭제할 수 있습니다.
-
파이프라인이 실행되는 동안, 테스트 중 또는 파이프라인을 시작한 후 정기적으로 사용하는 동안 파이프라인을 모니터링할 수 있습니다. 자세한 내용은 파이프라인 모니터링 및 문제 해결을 참조하십시오.
-
파이프라인을 중지한 후 나중에 다시 시작하거나 파이프라인 사용을 마쳤을 때 파이프라인을 삭제할 수 있습니다. 자세한 내용은 파이프라인 중지 및 파이프라인 삭제를 참조하십시오.
파이프라인 로드
객체 저장소의 외부 파일에서 데이터베이스 테이블로 연속 증분 데이터 로드를 수행하려면 로드 파이프라인을 사용합니다. 로드 파이프라인은 객체 저장소의 새 파일을 주기적으로 식별하고 새 데이터를 데이터베이스 테이블로 로드합니다.
로드 파이프라인은 다음과 같이 작동합니다. 이러한 기능 중 일부는 파이프라인 속성을 사용하여 구성할 수 있습니다.
-
객체 저장소 파일은 데이터베이스 테이블에 병렬로 로드됩니다.
-
로드 파이프라인은 객체 저장소 파일 이름을 사용하여 최신 파일을 고유하게 식별하고 로드합니다.
-
객체 저장소의 파일이 데이터베이스 테이블에 로드되고 나면 객체 저장소의 파일 콘텐츠가 변경되면 다시 로드되지 않습니다.
-
객체 저장소 파일이 삭제된 경우 데이터베이스 테이블의 데이터에 영향을 주지 않습니다.
-
-
실패가 발생하면 로드 파이프라인이 자동으로 작업을 재시도합니다. 파이프라인 일정이 잡힌 작업의 모든 후속 실행에 대해 재시도가 시도됩니다.
-
파일의 데이터가 데이터베이스 테이블을 준수하지 않는 경우
FAILED로 표시되며 문제를 디버그하고 해결하기 위해 검토할 수 있습니다.- 파일 로드에 실패하면 파이프라인이 중지되지 않고 계속해서 다른 파일을 로드합니다.
-
로드 파이프라인은 JSON, CSV, XML, Avro, ORC, Parquet 등 여러 입력 파일 형식을 지원합니다.

비Oracle 데이터베이스로부터의 마이그레이션은 로드 파이프라인의 사용 사례 중 하나입니다. When you need to migrate your data from a non-Oracle database to Oracle Autonomous AI Database on Dedicated Exadata Infrastructure, you can extract the data and load it into Autonomous AI Database (Oracle Data Pump format cannot be used for migrations from non-Oracle databases). CSV와 같은 일반 파일 형식을 사용하여 비Oracle 데이터베이스에서 데이터를 익스포트하면 데이터를 파일에 저장하고 파일을 객체 저장소에 업로드할 수 있습니다. 그런 다음 자율운영 AI 데이터베이스로 데이터를 로드하는 파이프라인을 생성합니다. 로드 파이프라인을 사용하여 많은 CSV 파일 집합을 로드하면 내결함성, 재개 및 재시도 작업과 같은 중요한 이점이 있습니다. 큰 데이터 세트를 사용한 마이그레이션의 경우 비Oracle 데이터베이스 파일에 대해 테이블당 하나씩 여러 개의 파이프라인을 생성하여 자율운영 AI 데이터베이스로 데이터를 로드할 수 있습니다.
파이프라인 익스포트
익스포트 파이프라인을 사용하여 데이터베이스에서 객체 저장소로 데이터를 지속적으로 증분 익스포트할 수 있습니다. 익스포트 파이프라인은 주기적으로 후보자 데이터를 식별하고 데이터를 객체 저장소에 업로드합니다.
내보내기 파이프라인 옵션에는 다음 세 가지가 있습니다. 내보내기 옵션은 파이프라인 속성을 사용하여 구성할 수 있습니다.
-
최신 데이터를 추적하기 위한 키로 날짜 또는 시간 기록 열을 사용하여 쿼리의 증분 결과를 객체 저장소로 내보냅니다.
-
날짜 또는 시간 기록 열을 최신 데이터 추적을 위한 키로 사용하여 테이블의 증분 데이터를 객체 저장소로 익스포트합니다.
-
쿼리를 사용하여 테이블 데이터를 객체 저장소로 내보내 날짜 또는 시간 기록 열을 참조하지 않고 데이터를 선택합니다(파이프라인이 각 스케줄러 실행에 대해 질의가 선택하는 모든 데이터를 익스포트하도록 함).
내보내기 파이프라인에는 다음과 같은 기능이 있습니다. 이들 중 일부는 파이프라인 속성을 사용하여 구성할 수 있습니다.
-
결과는 객체 저장소에 병렬로 익스포트됩니다.
-
실패할 경우 후속 파이프라인 작업이 익스포트 작업을 반복합니다.
-
익스포트 파이프라인은 CSV, JSON, Parquet 또는 XML과 같은 여러 익스포트 파일 형식을 지원합니다.
Oracle 유지 관리 파이프라인
전용 Exadata 인프라의 자율운영 AI 데이터베이스는 특정 로그를 JSON 형식의 객체 저장소로 익스포트할 수 있는 내장 파이프라인을 제공합니다. 이러한 파이프라인은 미리 구성되어 있으며 ADMIN 사용자가 시작하고 소유합니다.
Oracle 유지 관리 파이프라인은 다음과 같습니다.
-
ORA$AUDIT_EXPORT: 이 파이프라인은 데이터베이스 감사 로그를 JSON 형식의 객체 저장소로 익스포트하고 파이프라인을 시작한 후 15분마다 실행됩니다(interval속성 값 기준). -
ORA$APEX_ACTIVITY_EXPORT: 이 파이프라인은 Oracle APEX 작업영역 작업 로그를 JSON 형식의 객체 저장소로 익스포트합니다. 이 파이프라인은 APEX 작업 레코드를 검색하기 위해 SQL 질의로 미리 구성되어 있으며 파이프라인 시작 후 15분마다 실행됩니다(interval속성 값 기준).
Oracle 관리 파이프라인을 구성하고 시작하려면 다음과 같이 하십시오.
-
사용할 Oracle 관리 파이프라인(
ORA$AUDIT_EXPORT또는ORA$APEX_ACTIVITY_EXPORT)을 결정합니다. -
credential_name및location속성을 설정합니다.참고:
credential_name은 전용 Exadata 인프라의 자율운영 AI 데이터베이스에서 필수 값입니다.예:
BEGIN DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'credential_name', attribute_value => 'DEF_CRED_OBJ_STORE' ); DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'location', attribute_value => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/' ); END; /데이터베이스의 로그 데이터가 지정한 객체 저장소 위치로 익스포트됩니다.
자세한 내용은 SET_ATTRIBUTE를 참조하십시오.
-
선택적으로
interval,format또는priority속성을 설정합니다.자세한 내용은 SET_ATTRIBUTE를 참조하십시오.
-
파이프라인을 시작합니다.
자세한 내용은 START_PIPELINE을 참조하십시오.