데이터 카탈로그를 사용하여 외부 데이터 질의
Oracle Cloud Infrastructure Data Catalog는 데이터를 검색하고 데이터 거버넌스를 지원하는 데 도움이 되는 Oracle Cloud의 메타데이터 관리 서비스입니다. 데이터 레이크에 대한 자산 인벤토리, 비즈니스 용어집 및 공통 메타 저장소를 제공합니다.
자율운영 AI 데이터베이스는 이 메타데이터를 활용하여 데이터 레이크의 객체 저장소에 대한 액세스를 위한 관리를 크게 간소화할 수 있습니다. 데이터 레이크에 액세스하기 위해 External Table을 수동으로 정의하는 대신 자동으로 정의되고 관리되는 External Table을 사용합니다. 이러한 테이블은 데이터 카탈로그의 변경사항으로 최신 상태로 유지되는 자율운영 AI 데이터베이스 보호 스키마에서 찾을 수 있습니다.
데이터 카탈로그를 사용한 질의 정보
자율운영 AI 데이터베이스는 데이터 카탈로그 메타데이터와 동기화하여 데이터 카탈로그에서 수집한 각 논리적 엔티티에 대해 외부 테이블을 자동으로 생성합니다. 이러한 External Table은 메타 데이터 동기화 프로세스에 의해 완전히 관리되는 데이터베이스 스키마에 정의됩니다. 사용자는 외부 데이터 소스에 대한 스키마(열 및 데이터 유형)를 수동으로 파생시키고 External Table을 수동으로 생성할 필요 없이 즉시 데이터를 query할 수 있습니다.
동기화는 동적이므로 기본 데이터 변경과 관련하여 자율운영 AI 데이터베이스를 최신 상태로 유지하여 수백에서 수천 개의 테이블을 자동으로 유지 관리하므로 관리 비용이 절감됩니다. 또한 여러 자율운영 AI 데이터베이스 인스턴스가 동일한 데이터 카탈로그를 공유할 수 있어 관리 비용이 더욱 절감되고 공통적인 비즈니스 정의 세트가 제공됩니다.
데이터 카탈로그 폴더/버킷은 Autonomous Database 스키마와 동기화되는 컨테이너입니다. 해당 폴더/버킷 내의 논리적 엔티티는 Autonomous Database 외부 테이블에 매핑됩니다. 이러한 스키마와 External Table은 동기화 프로세스를 통해 자동으로 생성되고 유지 관리됩니다.
-
폴더/버킷은 조직 용도로만 사용되는 데이터베이스 스키마에 매핑됩니다.
-
조직은 데이터 레이크와 일관성을 유지하고 다양한 경로를 통해 데이터에 액세스할 때 혼동을 최소화해야 합니다.
-
데이터 카탈로그는 스키마에 포함된 테이블에 대한 신뢰성 있는 소스입니다. 데이터 카탈로그의 변경사항은 후속 동기화 중 스키마의 테이블을 업데이트합니다.
이 기능을 사용하기 위해 데이터베이스 데이터 카탈로그 관리자는 데이터 카탈로그 인스턴스에 대한 접속을 시작하고, 동기화할 데이터 자산 및 논리적 엔티티를 선택하고, 동기화를 실행합니다. 동기화 프로세스는 선택한 데이터 카탈로그에서 수집된 데이터 자산 및 논리적 엔티티를 기반으로 스키마 및 외부 테이블을 생성합니다. External Table이 생성되자마자 Data Analysts는 External Data Source에 대한 스키마를 수동으로 파생시키고 External Table을 생성할 필요 없이 데이터 Query를 시작할 수 있습니다.
주: DBMS_DCAT 패키지는 데이터 카탈로그 객체 저장소 데이터 자산을 질의하는 데 필요한 작업을 수행하는 데 사용할 수 있습니다. DBMS_DCAT package를 참조하십시오.
데이터 카탈로그를 사용한 질의와 관련된 개념
데이터 카탈로그를 사용하여 질의하려면 다음 개념에 대한 이해가 필요합니다.
데이터 카탈로그: 데이터 카탈로그는 자율운영 AI 데이터베이스로 쿼리할 객체 저장소 데이터 소스를 가리키는 데이터 자산을 수집합니다. 데이터 카탈로그에서 수집 중 데이터를 구성하는 방법을 지정하여 다양한 파일 구성 패턴을 지원할 수 있습니다. 데이터 카탈로그 수집 프로세스의 일부로 자산 내에서 관리할 버킷 및 파일을 선택할 수 있습니다. 자세한 내용은 데이터 카탈로그 개요를 참조하십시오.
객체 저장소: 객체 저장소에는 다양한 객체가 포함된 버킷이 있습니다. 이러한 버킷에서 발견되는 몇 가지 일반적인 객체 유형은 CSV, parquet, avro, json 및 ORC 파일입니다. 일반적으로 버킷에는 포함된 객체에 대한 구조 또는 설계 패턴이 있습니다. 데이터를 구조화하는 여러 가지 방법과 이러한 패턴을 해석하는 여러 가지 방법이 있습니다.
예를 들어, 일반적인 디자인 패턴은 테이블을 나타내는 최상위 폴더를 사용합니다. 지정된 폴더 내의 파일은 동일한 스키마를 공유하고 해당 테이블의 데이터를 포함합니다. 하위 폴더는 종종 테이블 분할 영역(예: 매일의 하위 폴더)을 나타내는 데 사용됩니다. 데이터 카탈로그는 각 최상위 레벨 폴더를 논리적 엔티티로 참조하며, 이 논리적 엔티티는 자율운영 AI 데이터베이스 외부 테이블에 매핑됩니다.
접속: 접속은 데이터 카탈로그 인스턴스에 대한 자율운영 AI 데이터베이스 접속입니다. 각 자율운영 AI 데이터베이스 인스턴스에 대해 여러 데이터 카탈로그 인스턴스에 대한 접속이 있을 수 있습니다. 자율운영 AI 데이터베이스 인증서는 객체 스토리지에서 수집된 데이터 카탈로그 자산에 액세스할 수 있는 권한이 있어야 합니다.
수확: 객체 스토리지를 스캔하고 데이터 세트에서 논리적 엔티티를 생성하는 데이터 카탈로그 프로세스입니다.
데이터 자산: 데이터 카탈로그의 데이터 자산은 데이터베이스, Oracle Object Storage, Kafka 등을 포함하는 데이터 소스를 나타냅니다. 자율운영 AI 데이터베이스는 메타데이터 동기화를 위해 Oracle Object Storage 자산을 활용합니다.
데이터 엔티티: 데이터 카탈로그의 데이터 엔티티는 데이터베이스 테이블 또는 뷰와 같은 데이터 모음이거나 단일 파일이며 일반적으로 해당 데이터를 설명하는 많은 속성을 가집니다.
논리적 엔티티: 데이터 레이크에서 많은 파일은 일반적으로 단일 논리적 엔티티로 구성됩니다. 예를 들어, 매일 클릭스트림 파일이 있을 수 있으며 이러한 파일은 동일한 스키마 및 파일 유형을 공유합니다.
데이터 카탈로그 논리적 엔티티는 데이터 자산에 생성되고 지정된 파일 이름 패턴을 적용하여 수집 중 파생된 오브젝트 스토리지 파일 그룹입니다.
데이터 객체: 데이터 카탈로그의 데이터 객체는 데이터 자산 및 데이터 엔티티를 참조합니다.
파일 이름 패턴: 데이터 레이크에서 데이터는 다양한 방식으로 구성될 수 있습니다. 일반적으로 폴더는 동일한 스키마 및 유형의 파일을 캡처합니다. 데이터 카탈로그에 데이터 구성 방법을 등록해야 합니다. 파일 이름 패턴은 데이터가 구성되는 방식을 식별하는 데 사용됩니다. 데이터 카탈로그에서 정규식을 사용하여 파일 이름 패턴을 정의할 수 있습니다. 데이터 카탈로그가 지정된 파일 이름 패턴으로 데이터 자산을 수집할 때 파일 이름 패턴을 기반으로 논리적 엔티티가 생성됩니다. 이러한 패턴을 정의하고 데이터 자산에 지정하면 파일 이름 패턴을 기반으로 여러 파일을 논리적 엔티티로 그룹화할 수 있습니다.
동기화(동기화): 자율운영 AI 데이터베이스는 데이터 카탈로그와의 동기화를 수행하여 기본 데이터의 변경 사항에 따라 데이터베이스를 최신 상태로 자동 유지합니다. 수동으로 또는 일정에 따라 동기화를 수행할 수 있습니다.
동기화 프로세스는 데이터 카탈로그 데이터 자산 및 논리적 엔티티를 기반으로 스키마 및 외부 테이블을 생성합니다. 이러한 스키마는 보호됩니다. 즉, 해당 메타 데이터는 데이터 카탈로그에 의해 관리됩니다. 메타데이터를 변경하려면 데이터 카탈로그에서 변경해야 합니다. 자율운영 AI 데이터베이스 스키마는 다음 동기화가 실행된 후의 모든 변경사항을 반영합니다. 자세한 내용은 동기화 매핑을 참조하십시오.
동기화 매핑
동기화 프로세스는 데이터 카탈로그 데이터 자산, 폴더, 논리적 엔티티, 속성 및 관련 사용자정의 무효화를 기반으로 자율운영 AI 데이터베이스 스키마 및 외부 테이블을 생성하고 업데이트합니다.
| Data Catalog | 자율운영 AI 데이터베이스 | 매핑 설명 |
|---|---|---|
| 데이터 자산 및 폴더(객체 스토리지 버킷) | 스키마 이름 | 기본값: 기본적으로 자율운영 AI 데이터베이스에서 생성된 스키마 이름의 형식은 다음과 같습니다.
사용자 정의: 사용자정의 속성, 비즈니스 이름 및 표시 이름을 정의하여 기본data-asset-name 및 folder-name를 사용자정의하여 해당 기본 이름을 무효화할 수 있습니다.
예를 들면 다음과 같습니다.
|
| 논리적 개체 | 외부 테이블 | 논리적 엔티티는 External Table에 매핑됩니다. 논리적 엔티티에 분할된 속성이 있는 경우 분할된 외부 테이블에 매핑됩니다. 외부 테이블 이름은 해당 논리적 엔티티의 표시 이름 또는 업무 이름에서 파생됩니다.
예를 들어 엔티티에 대한 |
| 논리적 엔티티의 속성 | 외부 테이블 컬럼 | 열 이름: 외부 테이블 열 이름은 해당 논리적 엔티티의 속성 표시 이름 또는 업무 이름에서 파생됩니다. Parquet, Avro 및 ORC 파일에서 파생된 논리적 엔티티의 경우 열 이름은 소스 파일에서 파생된 필드 이름을 나타내므로 항상 속성의 표시 이름입니다. CSV 파일에서 파생된 논리적 엔티티에 해당하는 속성의 경우 다음 속성 필드가 열 이름 생성을 위한 우선 순위로 사용됩니다.
열 유형:
열 길이: 열 소수점 이하 자릿수:
열 눈금: |
데이터 카탈로그가 있는 일반적인 워크플로우
데이터 카탈로그를 사용하여 질의하려는 사용자가 수행하는 일반적인 작업 워크플로우가 있습니다.
데이터베이스 데이터 카탈로그 관리자는 자율운영 AI 데이터베이스 인스턴스와 데이터 카탈로그 인스턴스 간에 접속을 생성한 다음 데이터 카탈로그와 자율운영 AI 데이터베이스 간에 동기화를 구성하고 실행합니다. 동기화는 동기화된 데이터 카탈로그 콘텐츠를 기반으로 자율운영 AI 데이터베이스 인스턴스에 외부 테이블 및 스키마를 생성합니다.
데이터베이스 데이터 카탈로그 질의 관리자 또는 데이터베이스 관리자는 데이터 분석가 및 기타 데이터베이스 사용자가 외부 테이블을 찾아보고 질의할 수 있도록 생성된 외부 테이블에 대한 READ 액세스 권한을 부여합니다.
아래 표에서는 각 작업에 대해 자세히 설명합니다. 이 표에 포함된 여러 사용자 유형에 대한 설명은 데이터 카탈로그 사용자 및 역할을 참조하십시오.
주: DBMS_DCAT 패키지는 데이터 카탈로그 객체 저장소 데이터 자산을 질의하는 데 필요한 작업을 수행하는 데 사용할 수 있습니다. DBMS_DCAT Package를 참조하십시오.
| 작업 | 사용자의 사용자 | 설명 |
|---|---|---|
| 정책 생성 | 데이터베이스 데이터 카탈로그 관리자 | 자율운영 AI 데이터베이스 사용자 인증서에는 데이터 카탈로그를 관리하고 객체 스토리지에서 읽을 수 있는 적절한 권한이 있어야 합니다. 자세한 내용은 필수 인증서 및 IAM 정책을 참조하십시오. |
| 인증서 생성 | 데이터베이스 데이터 카탈로그 관리자 | 데이터 카탈로그에 액세스하고 객체 저장소를 질의하려면 데이터베이스 인증서가 준비되어 있는지 확인하십시오. 사용자가 자세한 내용은 DBMS_CLOUD CREATE_CREDENTIAL Procedure를 참조하십시오. |
| 데이터 카탈로그에 대한 접속 생성 | 데이터베이스 데이터 카탈로그 관리자 | 자율운영 AI 데이터베이스 인스턴스와 데이터 카탈로그 인스턴스 간 접속을 시작하기 위해 사용자가 데이터 카탈로그 인스턴스에 접속하려면 충분한 OCI(Oracle Cloud Infrastructure) 권한이 있는 사용자 인증서를 사용해야 합니다. 접속이 완료되면 데이터 카탈로그 인스턴스가 자세한 내용은 SET_DATA_CATALOG_CONN 프로시저, UNSET_DATA_CATALOG_CONN 프로시저를 참조하십시오. |
| 선택적 동기화 생성 | 데이터베이스 데이터 카탈로그 관리자 | 동기화할 데이터 카탈로그 객체를 선택하여 동기화 작업을 생성합니다. 사용자는 다음을 수행할 수 있습니다.
자세한 내용은 CREATE_SYNC_JOB 프로시저, DROP_SYNC_JOB 프로시저, 동기화 매핑을 참조하십시오. |
| 데이터 카탈로그와 동기화 | 데이터베이스 데이터 카탈로그 관리자 | 사용자가 동기화 작업을 시작합니다. 동기화는 동기화 작업은 데이터 카탈로그 내용에 따라 외부 테이블 및 스키마를 생성, 수정 및 삭제하고 선택 항목을 동기화합니다. 데이터 카탈로그 사용자정의 속성을 사용하여 수동 구성이 적용됩니다. 자세한 내용은 DBMS_DCAT RUN_SYNC 프로시저, CREATE_SYNC_JOB 프로시저, 동기화 매핑을 참조하십시오. |
| 동기화 모니터링 및 로그 보기 | 데이터베이스 데이터 카탈로그 관리자 | 사용자는 USER_LOAD_OPERATIONS 뷰를 질의하여 동기화 상태를 볼 수 있습니다. 동기화 프로세스가 완료되면 사용자는 논리적 엔티티와 External Table 간의 매핑에 대한 세부 정보를 포함하여 동기화 결과 로그를 볼 수 있습니다. |
| 권한 부여 | 데이터베이스 데이터 카탈로그 질의 관리자, 데이터베이스 관리자 | 데이터베이스 데이터 카탈로그 질의 관리자 또는 데이터베이스 관리자는 데이터 분석가 사용자에게 생성된 외부 테이블에 대한 READ를 부여해야 합니다. 이렇게 하면 데이터 분석가가 생성된 External Table을 query할 수 있습니다. |
| External Table 찾아보기 및 query | 데이터 분석가 | 데이터 분석가는 Oracle SQL을 지원하는 툴이나 응용 프로그램을 통해 External Table을 query할 수 있습니다. 데이터 분석가는 DCAT$\* 스키마의 동기화된 스키마 및 테이블을 검토하고 Oracle SQL을 사용하여 테이블을 질의할 수 있습니다. 추가 정보: 동기화 매핑 |
| 데이터 카탈로그에 대한 접속 종료 | 데이터베이스 데이터 카탈로그 관리자 | 기존 데이터 카탈로그 연관을 제거하려면 사용자가 이 작업은 더 이상 데이터 카탈로그 및 카탈로그에서 파생된 외부 테이블을 사용할 계획이 없는 경우에만 수행됩니다. 데이터 카탈로그 메타데이터를 삭제하고 자율운영 AI 데이터베이스 인스턴스에서 동기화된 외부 테이블을 삭제합니다. 데이터 카탈로그 및 OCI 정책의 사용자정의 속성은 영향을 받지 않습니다. 자세한 내용: UNSET_DATA_CATALOG_CONN 프로시저 |
예: MovieStream 시나리오
이 시나리오에서 Moviestream은 오브젝트 스토리지의 랜딩 존에 있는 데이터를 캡처합니다. 그런 다음 이러한 데이터의 대부분이 자율운영 AI 데이터베이스에 공급하는 데 사용되지만 전부는 아닙니다. 자율운영 AI 데이터베이스에 공급하기 전에 데이터는 변환, 정리 및 "골드" 영역에 저장됩니다.
데이터 카탈로그는 이러한 소스를 수집한 다음 데이터에 대한 비즈니스 컨텍스트를 제공하는 데 사용됩니다. 데이터 카탈로그 메타데이터는 자율운영 AI 데이터베이스와 공유되므로 자율운영 AI 데이터베이스 사용자가 Oracle SQL을 사용하여 해당 데이터 소스를 쿼리할 수 있습니다. 이 데이터는 자율운영 AI 데이터베이스로 로드되거나 외부 테이블을 사용하여 동적으로 질의할 수 있습니다.
데이터 카탈로그 사용에 대한 자세한 내용은 데이터 카탈로그 설명서를 참조하십시오.
-
객체 저장소 - 버킷, 폴더 및 파일 검토
-
객체 저장소의 버킷을 검토합니다.
예를 들어 오브젝트 스토리지의 랜딩(
moviestream_landing) 및 골드 영역(moviestream_gold) 버킷은 다음과 같습니다. -
객체 저장소 버킷의 폴더 및 파일을 검토합니다.
예를 들어 다음은 오브젝트 스토리지의 랜딩 버킷(
moviestream_landing)에 있는 폴더입니다.
-
-
데이터 카탈로그 - 파일 이름 패턴 생성
-
데이터 카탈로그에 파일 이름 패턴을 사용하여 데이터를 구성하는 방법을 알립니다. 파일 분류에 사용되는 정규 표현식입니다. 파일 이름 패턴은 데이터 카탈로그 수집기에서 논리적 엔티티를 파생시키는 데 사용됩니다. 다음 두 개의 파일 이름 패턴은 MovieStream 예제에서 버킷을 수집하는 데 사용됩니다. 파일 이름 패턴 생성에 대한 자세한 내용은 객체 스토리지 파일을 논리적 데이터 엔티티로 수집을 참조하십시오.
Hive 스타일 폴더 스타일 {bucketName:.*}/{logicalEntity:[^/]+}.db/{logicalEntity:[^/]+}/.*{bucketName:[\w]+}/{logicalEntity:[^/]+}(?<!.db)/.*$- 객체 이름의 첫번째 부분으로 ".db"를 포함하는 소스에 대한 논리적 엔티티를 생성합니다.
- 버킷 내에서 고유성을 보장하기 위해 결과 이름은 (db-name).(폴더 이름)입니다.
- 루트 외부의 폴더 이름을 기반으로 논리적 엔티티를 생성합니다.
- Hive와의 중복을 방지하기 위해 ".db"가 있는 객체 이름을 건너뜁니다.
-
파일 이름 패턴을 생성하려면 데이터 카탈로그에 대한 파일 이름 패턴 탭으로 이동하여 파일 이름 패턴 생성을 누릅니다. 예를 들어, 다음은
moviestream데이터 카탈로그에 대한 파일 이름 패턴 생성 탭입니다.
-
-
데이터 카탈로그 - 데이터 자산 생성
-
객체 저장소에서 데이터를 수집하는 데 사용되는 데이터 자산을 생성합니다.
예를 들어,
phoenixObjStore이라는 데이터 자산이moviestream데이터 카탈로그에 생성됩니다. -
데이터 자산에 접속을 추가합니다.
이 예에서 데이터 자산은
moviestream오브젝트 스토리지 리소스의 컴파트먼트에 연결됩니다. -
이제 파일 이름 패턴을 데이터 자산과 연관시킵니다. 파일 이름 패턴 지정을 선택하고 원하는 패턴을 확인한 다음 지정을 누릅니다.
예를 들어, 다음은
phoenixObjStore데이터 자산에 지정된 패턴입니다.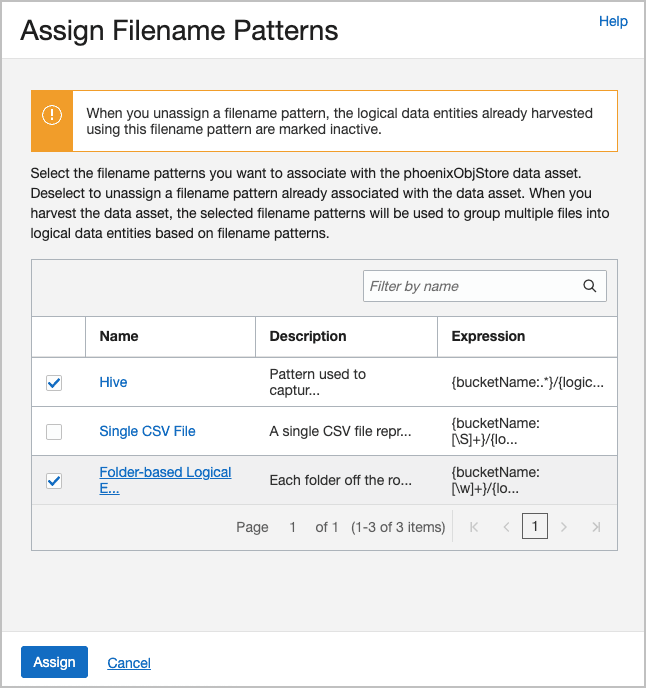
-
데이터 카탈로그 - 객체 저장소에서 데이터 수집
a. 데이터 카탈로그 데이터 자산을 수집합니다. 소스 데이터가 포함된 객체 저장소 버킷을 선택합니다.
이 예에서는 객체 저장소의
moviestream_gold및 ` moviestream_landing` 버킷이 수집하도록 선택됩니다.b. 작업을 실행한 후 논리적 엔티티가 표시됩니다. 데이터 자산 찾아보기를 사용하여 검토합니다.
이 예에서는
customer-extension논리적 엔티티 및 해당 속성을 살펴봅니다.용어집이 있는 경우 데이터 카탈로그는 개체 및 해당 속성과 연계할 범주 및 용어를 권장합니다. 품목에 대한 비즈니스 컨텍스트를 제공합니다. 스키마, 테이블 및 열은 종종 자체적으로 설명되지 않습니다.
예제에서는 다양한 유형의 버킷과 해당 컨텐트의 의미를 구별하려고 합니다.
-
착륙 지역이란 무엇입니까?
-
데이터가 얼마나 정확합니까?
-
마지막으로 업데이트된 시간은 언제입니까?
-
논리적 엔티티 또는 해당 속성의 정의
-
-
자율운영 AI 데이터베이스 - 데이터 카탈로그에 접속
자율운영 AI 데이터베이스를 데이터 카탈로그에 연결합니다. 연결에 사용되는 인증서가 데이터 카탈로그 자산에 액세스할 수 있는 권한이 부여된 OCI 주체를 사용하고 있는지 확인해야 합니다. 자세한 내용은 데이터 카탈로그 정책을 참조하십시오.
a. 데이터 카탈로그에 접속
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.iad.aaaaaaaardp66bg....twiq' define dcat_region='us-ashburn-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections;b. 데이터 카탈로그를 자율운영 AI 데이터베이스와 동기화합니다. 여기서는 모든 오브젝트 스토리지 자산을 동기화합니다.
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes;c. 자율운영 AI 데이터베이스 - 이제 객체 저장소에 대해 질의 실행을 시작합니다.
-- Query the Data ! select *from dcat$phoenixobjstore_moviestream_gold.genre; -
객체에 대한 스키마 변경
기본 스키마 이름은 다소 복잡합니다 데이터 카탈로그에 자산과 폴더의
Oracle-Db-Schema사용자정의 속성을 모두 지정하여 단순화해 보겠습니다. 데이터 자산을PHX로 변경하고 폴더를 각각landing및gold로 변경합니다. 이 스키마는 두 스키마가 연결되어 있습니다.a. 데이터 카탈로그에서
moviestream_landing버킷으로 이동하고 자산을 각각landing및gold로 변경합니다.변경하기 전:
변경 이후:
b. 다른 동기화를 실행합니다.
-
예제: 분할된 데이터 시나리오
이 시나리오에서는 객체 저장소의 분할된 데이터에서 수집된 데이터 카탈로그 논리적 엔티티를 기반으로 자율운영 AI 데이터베이스에 외부 테이블을 생성하는 방법을 보여줍니다.
다음 예제는 Example: MovieStream Scenario를 기반으로 하며 분할된 데이터와의 통합을 보여주도록 조정되었습니다. 데이터 카탈로그는 이러한 소스를 수집한 다음 데이터에 대한 비즈니스 컨텍스트를 제공하는 데 사용됩니다. 이 예제에 대한 자세한 내용은 예제: MovieStream 시나리오를 참조하십시오.
데이터 카탈로그 사용에 대한 자세한 내용은 데이터 카탈로그 설명서를 참조하십시오.
-
객체 저장소 - 버킷, 폴더 및 파일 검토
-
객체 저장소의 버킷을 검토합니다.
예를 들어 오브젝트 스토리지의 랜딩(
moviestream_landing) 및 골드 영역(moviestream_gold) 버킷은 다음과 같습니다. -
객체 저장소 버킷의 폴더 및 파일을 검토합니다.
예를 들어 다음은 오브젝트 스토리지의 랜딩 버킷(
moviestream_landing)에 있는 폴더입니다.
-
-
데이터 카탈로그 - 파일 이름 패턴 생성
-
데이터 카탈로그에 파일 이름 패턴을 사용하여 데이터를 구성하는 방법을 알립니다. 파일 분류에 사용되는 폴더 접두어 또는 정규 표현식입니다. 파일 이름 패턴은 데이터 카탈로그 수집기에서 논리적 엔티티를 파생시키는 데 사용됩니다. 폴더 접두어가 지정되면 데이터 카탈로그는 객체 저장소의 지정된 폴더 접두어에서 논리적 엔티티를 자동으로 생성합니다. 다음 파일 이름 패턴은 MovieStream 예제에서 버킷을 수집하는 데 사용됩니다. 파일 이름 패턴 생성에 대한 자세한 내용은 객체 스토리지 파일을 논리적 데이터 엔티티로 수집을 참조하십시오.
폴더 접두어 설명 workshop.db/객체 저장소에 "workshop.db" 경로가 포함된 소스에 대한 논리적 엔티티를 생성합니다. -
파일 이름 패턴을 생성하려면 데이터 카탈로그에 대한 파일 이름 패턴 탭으로 이동하여 파일 이름 패턴 생성을 누릅니다. 예를 들어, 다음은
moviestream데이터 카탈로그에 대한 파일 이름 패턴 생성 탭입니다.
-
-
데이터 카탈로그 - 데이터 자산 생성
-
객체 저장소에서 데이터를 수집하는 데 사용되는 데이터 자산을 생성합니다.
예를 들어,
amsterdamObjStore라는 데이터 자산이moviestream데이터 카탈로그에 생성됩니다. -
데이터 자산에 접속을 추가합니다.
이 예에서 데이터 자산은
moviestream오브젝트 스토리지 리소스의 컴파트먼트에 연결됩니다. -
이제 파일 이름 패턴을 데이터 자산과 연관시킵니다. 파일 이름 패턴 지정을 선택하고 원하는 패턴을 확인한 다음 지정을 누릅니다.
예를 들어, 다음은
amsterdamObjStore데이터 자산에 지정된 패턴입니다.
-
-
데이터 카탈로그 - 객체 저장소에서 데이터 수집
-
데이터 카탈로그 데이터 자산을 수집합니다. 소스 데이터가 포함된 객체 저장소 버킷을 선택합니다.
이 예에서는 객체 저장소의
moviestream_gold및 ` moviestream_landing` 버킷이 수집하도록 선택됩니다. -
작업을 실행한 후 논리적 엔티티가 표시됩니다. 데이터 자산 찾아보기를 사용하여 검토합니다.
이 예에서는
sales_sample_parquet논리적 엔티티 및 해당 속성을 살펴봅니다. 데이터 카탈로그는month속성을 분할된 것으로 식별했습니다.
-
-
자율운영 AI 데이터베이스 - 데이터 카탈로그에 접속
자율운영 AI 데이터베이스를 데이터 카탈로그에 연결합니다. 연결에 사용되는 인증서가 데이터 카탈로그 자산에 액세스할 수 있는 권한이 부여된 OCI 주체를 사용하고 있는지 확인해야 합니다. 자세한 내용은 데이터 카탈로그 정책을 참조하십시오.
-
데이터 카탈로그에 접속
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.eu-amsterdam-1....leguurn3dmqa' define dcat_region='eu-amsterdam-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections; -
데이터 카탈로그를 자율운영 AI 데이터베이스와 동기화합니다. 여기서는 모든 오브젝트 스토리지 자산을 동기화합니다.
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes; -
자율운영 AI 데이터베이스 - 이제 객체 저장소에 대해 질의 실행을 시작합니다.
-- Query the Data ! select count(*) from DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING.SALES_SAMPLE_PARQUET; -- Examine the generated partitioned table select dbms_metadata.get_ddl('TABLE','SALES_SAMPLE_PARQUET','DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING') from dual; CREATE TABLE "DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING"."SALES_SAMPLE_PARQUET" ( "MONTH" VARCHAR2(4000) COLLATE "USING_NLS_COMP", "DAY_ID" TIMESTAMP (6), "GENRE_ID" NUMBER(20,0), "MOVIE_ID" NUMBER(20,0), "CUST_ID" NUMBER(20,0), ... ) DEFAULT COLLATION "USING_NLS_COMP" ORGANIZATION EXTERNAL ( TYPE ORACLE_BIGDATA ACCESS PARAMETERS ( com.oracle.bigdata.fileformat=parquet com.oracle.bigdata.filename.columns=["MONTH"] com.oracle.bigdata.file_uri_list="https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/*" ... ) ) REJECT LIMIT 0 PARTITION BY LIST ("MONTH") (PARTITION "P1" VALUES (('2019-01')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-01/*'), PARTITION "P2" VALUES (('2019-02')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-02/*'), ...PARTITION "P24" VALUES (('2020-12')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2020-12/*')) PARALLEL
-
-
객체에 대한 스키마 변경
기본 스키마 이름은 다소 복잡합니다 데이터 카탈로그에 자산과 폴더의
Oracle-Db-Schema사용자정의 속성을 모두 지정하여 단순화해 보겠습니다. 데이터 자산을PHX로 변경하고 폴더를 각각landing및gold로 변경합니다. 이 스키마는 두 스키마가 연결되어 있습니다.-
데이터 카탈로그에서
moviestream_landing버킷으로 이동하고 자산을 각각landing및gold로 변경합니다.변경하기 전에:
변경 이후:
-
다른 동기화를 실행합니다.
-