HCM 데이터 로더(HDL)는 사용 사례에 필요한 비즈니스 객체, 구성요소 및 구성요소 속성만 제공할 수 있는 유연한 파이프로 구분된 파일 형식을 지원합니다. 전체 데이터 집합은 로드하거나 Incremental 변경 사항만 로드할 수 있습니다. 이러한 유연성을 얻으려면 각 파일이 파일에 포함될 비즈니스 객체 구성요소 및 속성을 지정해야 합니다.
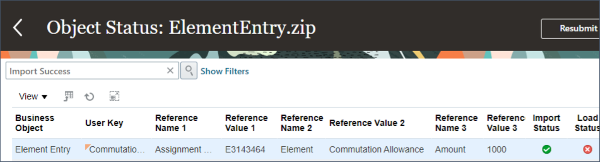
Oracle HCM Cloud 비즈니스 객체는 복잡할 수 있으며 일반적으로 계층적이므로 비즈니스 객체(예: 개인에 대한 다중 전화 번호 또는 직무에 대한 다중 적합한 등급)에 대해 다중 하위 레코드를 생성할 수 있습니다. 구분된 각 파일에는 단일 비즈니스 객체 계층에 대한 데이터가 포함됩니다. 파일 이름은 비즈니스 객체에 대해 지정되며 .dat 파일 확장자를 가집니다. 예를 들어, Worker.dat에는 근로자에 대한 데이터가 포함되고, Job.dat에는 직무에 대한 데이터가 포함되며, ElementEntry.dat에는 항목 입력에 대한 데이터가 포함됩니다.
HDL에서 처리할 데이터를 제공할 때는 파일의 각 레코드를 고유하게 식별해야 합니다. 새 레코드의 경우 다음 두 가지 방식이 지원됩니다.
사용자 키 - 레코드를 고유하게 식별하는 사용자 인터페이스에서 찾을 수 있는 사용자에게 친숙한 속성의 조합입니다. 예를 들어, 직무의 경우 JobCode 및 SetCode, 근로자의 경우 PersonNumber입니다.
소스 키 - SourceSystemId 및 SourceSystemOwner의 두 속성 조합은 레코드를 고유하게 식별하는 데 사용됩니다. SourceSystemId 값은 임의의 값일 수 있지만 소스 시스템의 식별자 또는 알고리즘에 의해 생성된 값입니다. SourceSystemOwner는 소스 시스템이 여러 개 있을 때 소스 키가 고유한지 확인합니다.
주:
사용자 키 값은 시간이 지남에 따라 변경될 수 있으며 종종 변환될 수 있으므로 소스 키는 권장되는 솔루션입니다. 레코드 수명 동안 소스 키는 변경되지 않습니다. 출처 키를 사용하여 다른 객체의 레코드를 참조할 수도 있습니다. 소스 키는 Oracle HCM Cloud(예: PersonNumber)에서 사용자 키 속성을 자동 생성하는 경우 특히 유용합니다.
목표
이 자습서에서는 다음을 수행합니다.
사용자 키 및 소스 키 파일을 만들고 로드합니다.
소스 키로 상위 및 외래 객체를 참조합니다.
기존 레코드를 업데이트하고 기존 객체에 새 하위 레코드를 추가합니다.
개별 레코드를 삭제하고 객체를 완료합니다.
공급 보고 및 조정 정보입니다.
필요 조건
이 자습서를 완료하려면 다음이 필요합니다.
HCM 데이터 로더를 사용하여 데이터를 임포트 및 로드하기 위한 통합 전문가 접근 권한입니다.
작업에는 적합한 등급이 여러 개 있을 수 있습니다. JobGrade 구성 요소는 적합한 등급을 생성하는 데 사용되며 작업 객체 계층 내에서 작업 구성 요소의 하위 항목입니다.
하위 레코드에 대한 데이터를 제공할 때는 관련된 상위 레코드의 이름을 지정해야 합니다. 이 예에서는 상위 대리 ID 속성 JobId로 이 작업을 수행합니다.
참고:
비즈니스 객체 보기 태스크를 사용하여 비즈니스 객체에 대한 상위 및 외부 대리 ID 속성을 식별합니다.
소스 키가 작업을 식별하는 데 사용되므로 JobId 속성 뒤에 (SourceSystemId) 문자열이 옵니다. 속성 이름 뒤에 괄호로 묶인 모든 항목은 힌트입니다. 이 힌트는 대리 ID 속성으로 식별된 외부(또는 상위) 객체를 참조하기 위해 출처 시스템 ID 값이 제공될 것임을 HDL에 알립니다.
등급에 대한 참조는 출처 키도 사용하며, 출처 시스템 ID 값은 등급을 참조하는 외래 대리 ID 속성에 제공되어야 합니다. GradeId는 (SourceSystemId) 힌트를 추가합니다.
이 예에서는 등급 소스 키에 대한 소스 시스템 소유자가 SourceSystemOwner 속성에서 상속됩니다. 그러나 소스 시스템 소유자 값이 다른 경우 (SourceSystemOwner) 힌트와 함께 외부 객체의 대리 ID 속성을 사용하여 이 값을 제공할 수 있습니다. 예를 들어, GradeId(SourceSystemOwner)입니다.
이러한 파일 라인은 세 작업 각각에 대해 적합한 등급을 생성합니다. 유효한 각 등급 기록:
SourceSystemOwner 및 SourceSystemId 속성으로 소스 키를 정의하여 고유 식별자를 제공합니다.
상위 대리 ID 속성 JobId(SourceSystemId)을 사용하여 상위 작업을 식별하고 상위 작업 레코드에 제공된 SourceSystemId 값을 제공합니다. 예를 들어, SCN은 영업 컨설턴트 작업의 SourceSystemId이므로 영업 컨설턴트 작업의 적합한 등급에 대한 JobId(SourceSystemId) 속성도 SCN이어야 합니다.
외래 대리 ID 속성 GradeId(SourceSystemId)을 사용하여 등급을 식별합니다.
참고:
등급 파일의 SourceSystemId 값에 이니셜을 추가한 경우 여기서도 마찬가지입니다.
Job.dat의 이름을 지정하여 파일을 저장합니다. 또는 Job.dat 파일을 다운로드하고 편집합니다.
선택한 파일 이름을 사용하여 Grade.dat 및 Job.dat 파일을 함께 압축(zip)하여 확장자가 .zip인지 확인합니다.
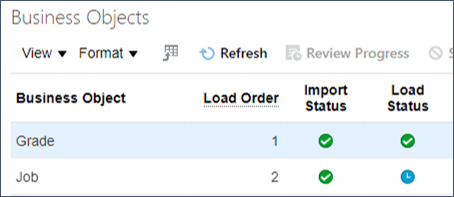
데이터 세트에 대한 비즈니스 객체 테이블을 검토합니다. zip 파일에 포함된 각 비즈니스 객체 파일에 대한 항목이 있습니다.
참고:
동일한 zip 파일에 여러 비즈니스 객체 .dat 파일을 제공할 수 있습니다. HCM 데이터 로더는 병렬로 임포트하지만 순차적으로 로드합니다. 참조된 데이터가 후속 비즈니스 객체 파일에서 참조되기 전에 Oracle HCM Cloud로 로드되도록 합니다.
태스크 5: 레코드 갱신
이 단계에서는 개별 레코드를 갱신하고 새 하위 레코드를 추가하는 방법을 배웁니다.
참고:
비즈니스 객체 보기 태스크를 사용하여 객체가 업데이트를 지원하는지 여부를 결정합니다.
업데이트 및 삭제할 객체 생성
이 단계에서는 답변이 포함된 질문을 생성합니다. 그러면 다음 태스크에서 이 질문이 업데이트되고 삭제됩니다.
다음 행으로 파일을 만듭니다.
METADATA|Question|SubscriberName|QuestionCode|QstnVersionNum|QuestionText|Status|QuestionType|PrivacyFlag|ResponseTypeName|CategoryName
MERGE|Question|Recruiting|FEEDBACK_1|1|How satisfied are you with the training?|A|MULTCHOICE|N|Check Multiple Choices|Feedback
METADATA|Answer|SubscriberName|QuestionCode|QstnVersionNum|AnswerCode|LongText|SequenceNumber|Score
MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS11|Yes, I'm satisfied.|5|151
MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS21|No, I'm not satisfied.|3|151
MERGE|Answer|Recruiting|FEEDBACK_1|1|FEEDBACK_1ANS31|I have no opinion on this.|2|151
Question.dat의 이름을 지정하여 파일을 저장합니다. 또는 Question.dat 파일을 다운로드하고 편집합니다.
선택한 파일 이름을 사용하여 Question.dat 파일을 압축(zip)하여 확장자가 .zip인지 확인합니다.



![[검색]을 누릅니다.](images/search.png)