이 사용지침서에서는 고객 및 파트너가 주요 비즈니스 동인을 고려하여 보다 정확한 예측을 생성할 수 있는 ML 기능을 사용하여 고급 예측을 구성할 수 있도록 지원합니다. 이 사용지침서에서는 고급 예측을 구성하는 방법을 보여주고 비즈니스 고려 사항 및 IPM의 솔루션 기능을 기반으로 구현 권장 사항을 제공합니다. 이 사용지침서에서는 볼륨 예측과 관련된 특정 비즈니스 사용 사례와 ML 모델을 교육하고 보다 정확한 예측을 생성하기 위한 몇 가지 주요 입력 동인을 중점적으로 다룹니다. 섹션은 상호 연결되어 구축되었으며 순차적으로 완료해야 합니다.
배경
고급 예측 또는 ML 예측은 머신 러닝 모델을 사용하여 입력 기능을 기반으로 데이터를 예측하는 프로세스를 의미합니다.
고급 예측의 주요 이점:
제공된 다른 데이터 포인트와 상관하여 보다 강력한 예측을 수행할 수 있습니다.
Oracle EPM에 내장되어 있어 다차원 계획 및 예측 사용 사례에 최적화된 데이터 과학을 통해 재무 및 운영 사용자의 역량을 강화할 수 있습니다.
보다 정교한 알고리즘을 활용하고 정확성을 개선합니다.
단계별 구성 마법사를 사용하여 더 쉽게 구성할 수 있습니다.
고급 예측의 장점:
EPM 데이터 및 컨텍스트에 기반: 사용자는 외부 데이터 과학 플랫폼 또는 ML 도구로 이동할 필요가 없습니다. 고급 예측 기능은 EPM 데이터 및 컨텍스트에 내장되어 있어 재무 및 운영 사용자의 역량을 강화합니다.
OCI AI 인프라 기반: EPM 시스템 내에서 머신러닝 모델을 구축, 교육, 배포할 수 있습니다.
예측 정확도 향상: 고급 예측은 예측을 실행하기 전에 데이터에 대해 기능 엔지니어링 및 기능 선택을 수행할 수 있으므로 예측 정확도가 향상됩니다.
향상된 의사 결정: 예측에 가장 큰 영향을 미치는 비즈니스 동인을 파악하고 각 동인의 상대적 기여도를 기능 중요도 차트와 비교합니다.
모든 계층의 개인정보 보호 및 보안: 고급 예측은 EPM 보안 계층을 준수합니다. 즉, ML 모델에 의해 생성된 예측 데이터에 대한 액세스는 EPM 시스템의 다른 영역을 관리하는 동일한 강력한 보안 프레임워크에 의해 제어됩니다.
추가 비용 없이 내장: 추가 비용 없이 Oracle EPM Enterprise 라이센스와 함께 사용할 수 있습니다.
확장 가능한 프레임워크: 외부 데이터가 포함된 파이프라인을 사용하는 확장 가능한 프레임워크를 통해 데이터 처리 및 사전 처리를 지원하고, API, BYOML을 사용하여 여러 플랫폼에서 예측을 지원합니다.
고급 예측의 주요 고려 사항:
Enterprise EPM 라이센스에서만 사용 가능
Redwood 테마를 통해서만 접근
옵트인 전용 기능 - 애플리케이션 설정에서 옵트인 사용 가능
OCI Data Science를 사용하여 EPM에 내장되어 있으므로 OCI Data Science 배포에 추가 비용이 발생하지 않습니다.
모듈, 사용자정의, FreeForm, 영업 계획, 전략적 Workforce Planning, 예측 현금 예측 등 다양한 Planning 애플리케이션에서 사용 가능
BSO 및 ASO 큐브 둘 다 사용
볼륨 예측 사용 사례
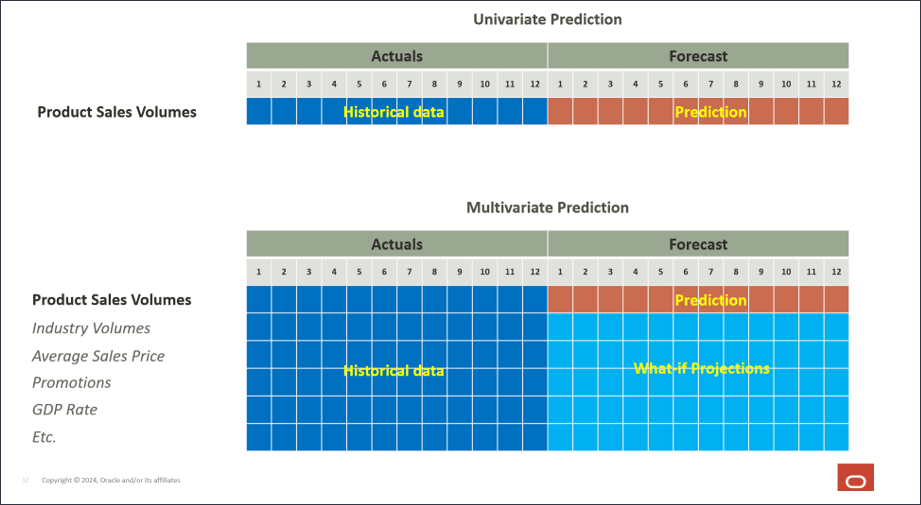
1월 FY22부터 6월 FY24까지의 과거 판매량을 기반으로 제품별 판매량을 예측하려는 사용 사례를 고려해 보십시오. 과거 판매량 외에도 산업 거래량, 평균 판매 가격, 광고 및 마케팅 프로모션, 할인율과 같은 입력 동인(미래 거래량 예측에 영향을 줄 수 있는 모든 내부 요인)을 사용합니다. 또한 GDP 성장률과 같은 경제 지표와 미래의 볼륨 예측에 영향을 줄 수있는 개인 소비 지출과 같은 몇 가지 외부 동인을 사용합니다.
과거 입력 드라이버는 대부분 데이터 소스에서 임포트되며, 미래 입력 드라이버 값은 드라이버 또는 추세 기반과 같은 기존 메소드를 사용하여 계획할 수도 있고, 고급 예측 작업 자체의 일부로 사용할 수 있는 단변량 예측(변량 기능)을 사용할 수도 있습니다.
필요 조건
Cloud EPM 실습 자습서에서는 Cloud EPM Enterprise Service 인스턴스로 스냅샷을 임포트해야 할 수 있습니다. 자습서 스냅샷을 임포트하려면 먼저 다른 Cloud EPM Enterprise Service 인스턴스를 요청하거나 현재 애플리케이션 및 비즈니스 프로세스를 제거해야 합니다. 자습서 스냅샷은 기존 애플리케이션 또는 비즈니스 프로세스로 가져오지 않으며 현재 작업 중인 애플리케이션 또는 비즈니스 프로세스를 자동으로 바꾸거나 복원하지 않습니다.
이 자습서를 시작하기 전에 다음을 수행해야 합니다.
Cloud EPM Enterprise Service 인스턴스에 대한 서비스 관리자에게 접근 권한을 부여합니다. 인스턴스에는 비즈니스 프로세스가 생성되지 않아야 합니다.
고급 예측 및 AI 기능 사용을 시작하려면 먼저 애플리케이션 설정 페이지로 이동하여 사용으로 설정해야 합니다.
홈 페이지에서 애플리케이션, 설정, 순으로 누릅니다.
설정에서 아래로 스크롤하고 오른쪽 아래 섹션의 AI 사용에서 고급 예측을 선택하여 고급 다변량 예측에 대한 AI 데이터 분석을 사용으로 설정합니다.
정보 메시지에서 확인을 누릅니다.
위로 이동하여 Save를 누릅니다.
정보 메시지에서 확인을 누릅니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
응용 프로그램 준비
이 자습서의 단계를 수행하기 전에 응용 프로그램을 준비해야 합니다. 제공된 애플리케이션에는 그룹, 역할 또는 보안이 포함되지 않으므로 EPM 그룹을 생성한 다음 EPM Cloud 네비게이션 플로우에 지정해야 합니다. EPM Cloud 네비게이션 플로우를 사용하여 고급 예측을 사용하여 생성된 예측을 검토합니다.
EPM 그룹 생성
홈 페이지에서 툴, 액세스 제어 순으로 누릅니다.
그룹 관리에서 생성을 누릅니다.
그룹 생성에서 이름에 EPM을 입력합니다.
그룹이 선택된 상태에서 사용 가능한 그룹 옆에 있는 (검색)을 누릅니다.
사용 가능한 그룹이 나열됩니다.
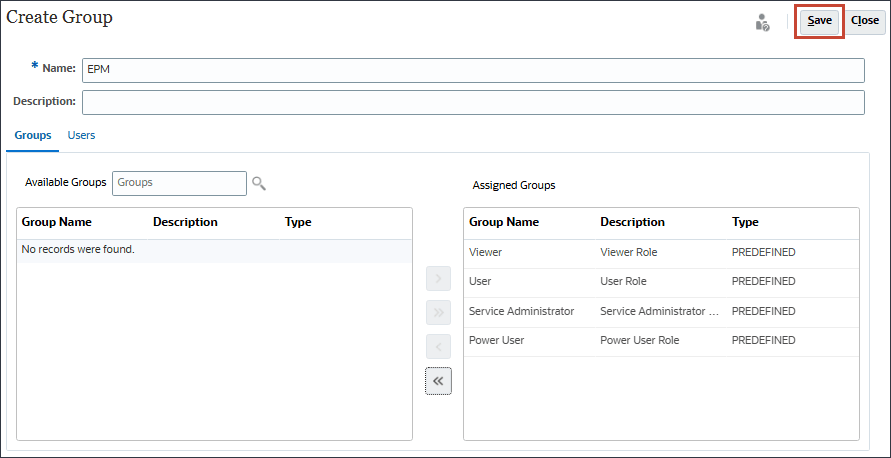
사전 정의된 역할을 모두 이동하려면 (모두 이동)을 누릅니다.
Save를 누릅니다.
정보 메시지에서 확인을 누릅니다.
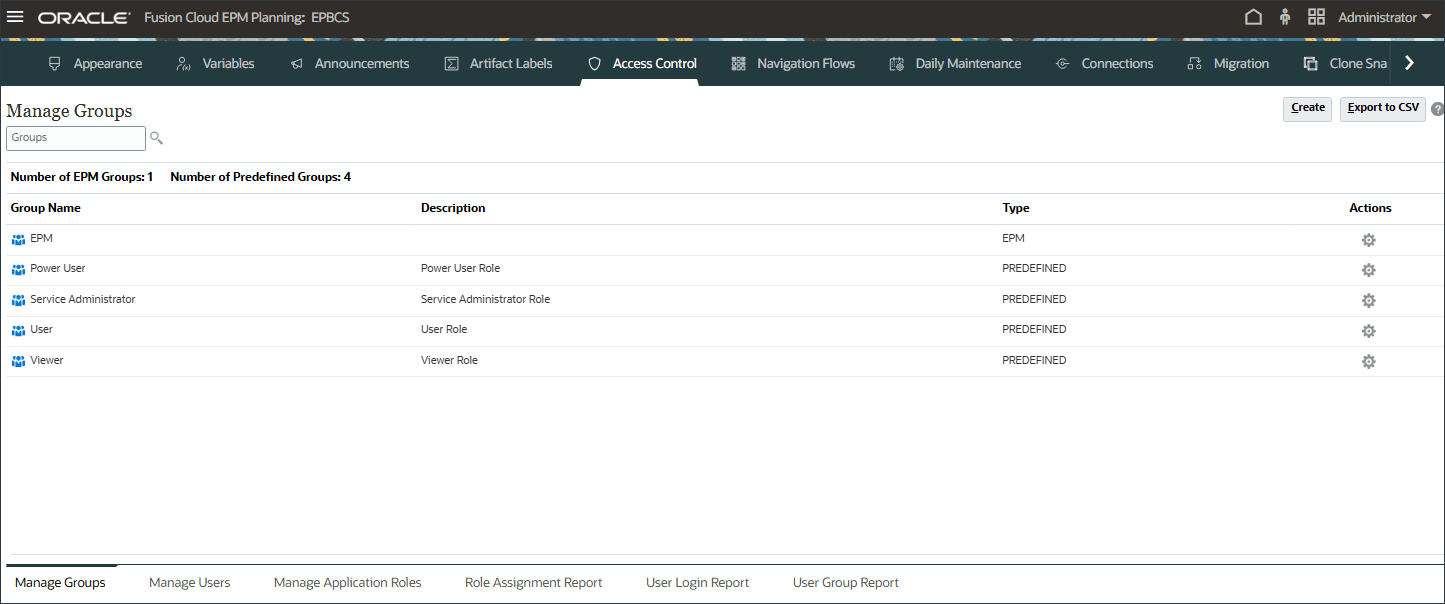
EPM이 그룹 관리에 나열되어 있는지 확인합니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
EPM Cloud 네비게이션 플로우에 EPM 그룹 지정
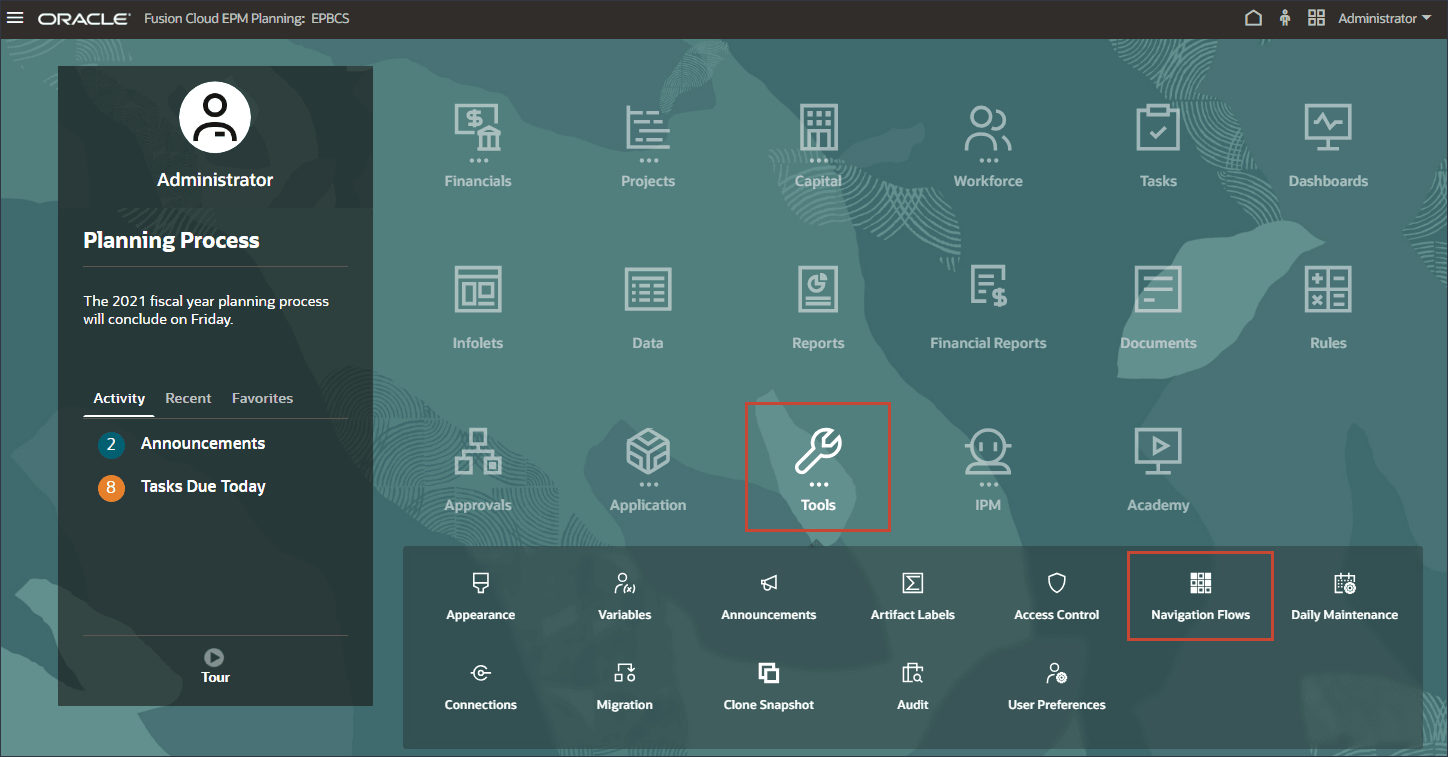
홈 페이지에서 툴, 네비게이션 플로우 순으로 누릅니다.
네비게이션 플로우에서 EPM Cloud가 비활성으로 설정되어 있는지 확인한 다음 EPM Cloud를 누릅니다.
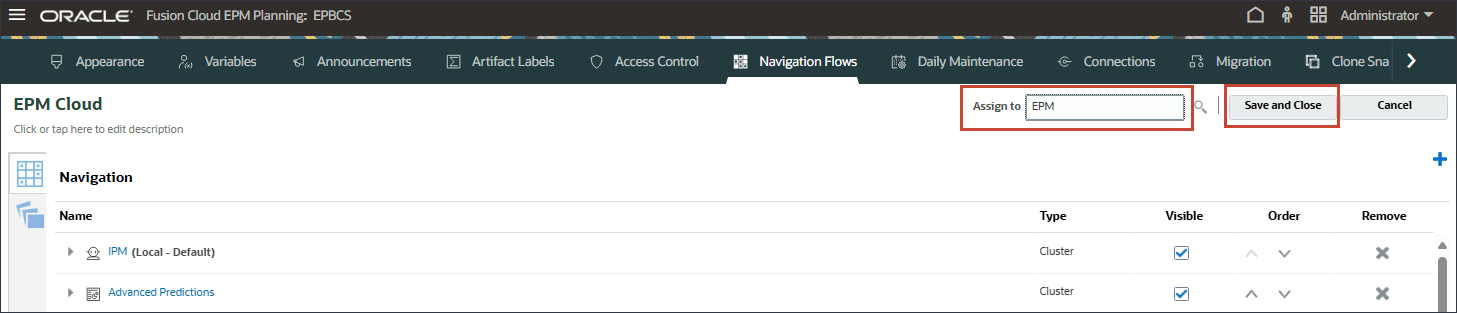
EPM Cloud에서 지정 대상에 대해 EPM을 입력하고 저장 후 닫기를 누릅니다.
EPM Cloud의 경우 비활성을 눌러 EPM Cloud 네비게이션 플로우를 활성화합니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
고급 예측 준비
이 섹션에서는 고급 예측을 구성하기 전에 일반 사용자 단계를 완료합니다. 사용자 변수가 설정되었는지 확인하고 EPM Cloud 네비게이션 플로우를 선택합니다. 볼륨 분석 대시보드도 검토합니다. 입력 드라이버를 검토하고 편집합니다. 미래 기간에 대해 누락된 입력 드라이버 값을 검토하고 예측 양식을 검토합니다.
사용자 변수 설정
양식 및 대시보드에서 데이터를 볼 수 있도록 사용자 변수를 설정합니다.
홈 페이지에서 툴, 사용자 환경설정 순으로 누릅니다.
사용자 변수를 누릅니다.
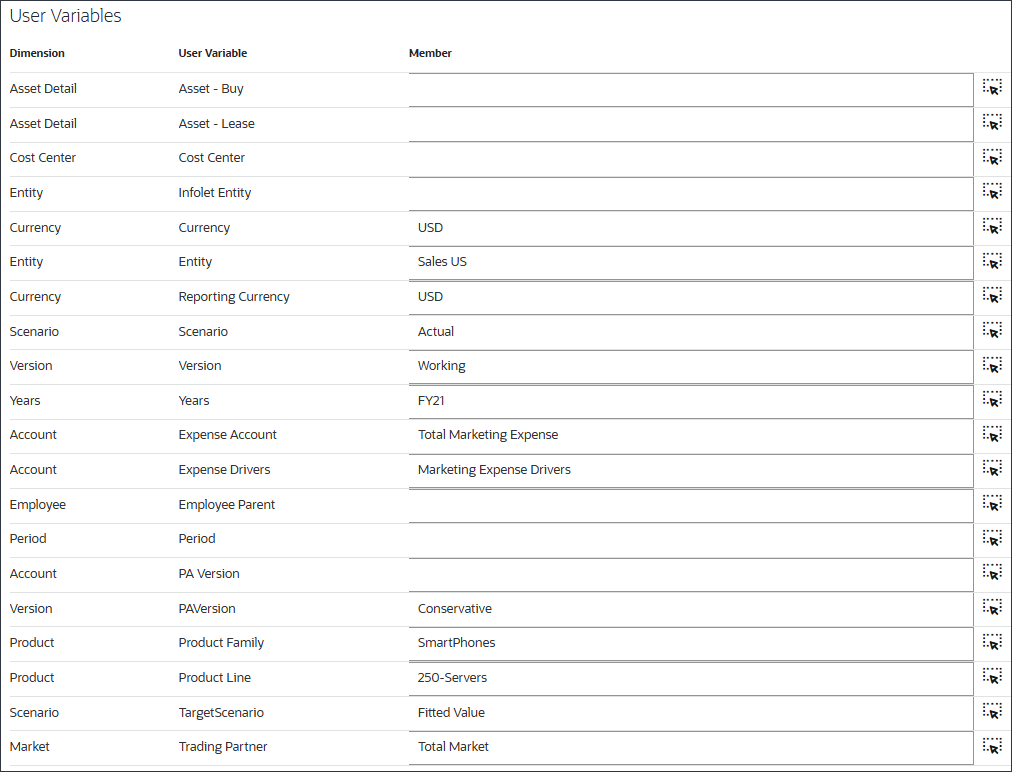
사용자 변수의 경우 다음을 입력하거나 선택하고 저장을 누릅니다.
차원
사용자 변수
멤버
통화
통화
USD
엔티티
엔티티
미국 판매
통화
신고 통화
USD
Scenario
Scenario
실제
Version
Version
작업 중
년
년
FY21
계정
경비 계정
총 마케팅 비용
계정
비용 동인
마케팅 비용 동인
Version
PA 버전
보수적
제품
제품군
SmartPhones
제품
제품 라인
250-Servers
Scenario
TargetScenario
적합 값
Market
거래 파트너
총 시장
사용자 변수가 선택됩니다.
정보 메시지에서 확인을 누릅니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
네비게이션 플로우 선택
볼륨 예측을 검토할 수 있도록 고급 예측용 카드가 포함된 EPM Cloud 네비게이션 플로우를 선택합니다.
홈 페이지에서 (기본값)을 누르고 EPM Cloud를 선택합니다.
EPM Cloud 네비게이션 플로우가 표시됩니다.
EPM Cloud 네비게이션 플로우에서 고급 예측 카드를 확인합니다.
고급 예측을 누릅니다.
고급 예측을 사용하여 생성된 예측을 검토할 수 있는 네비게이션 플로우입니다.
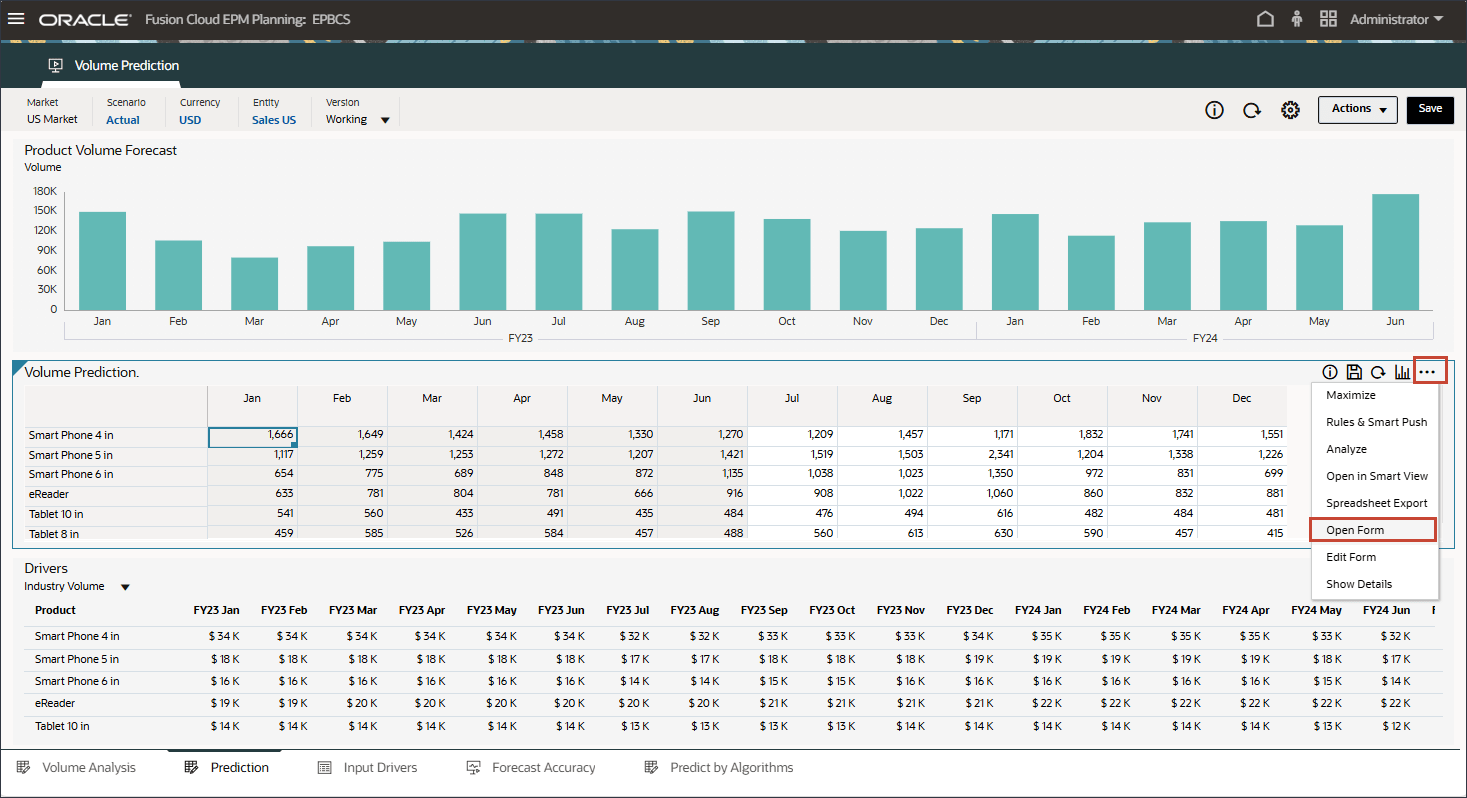
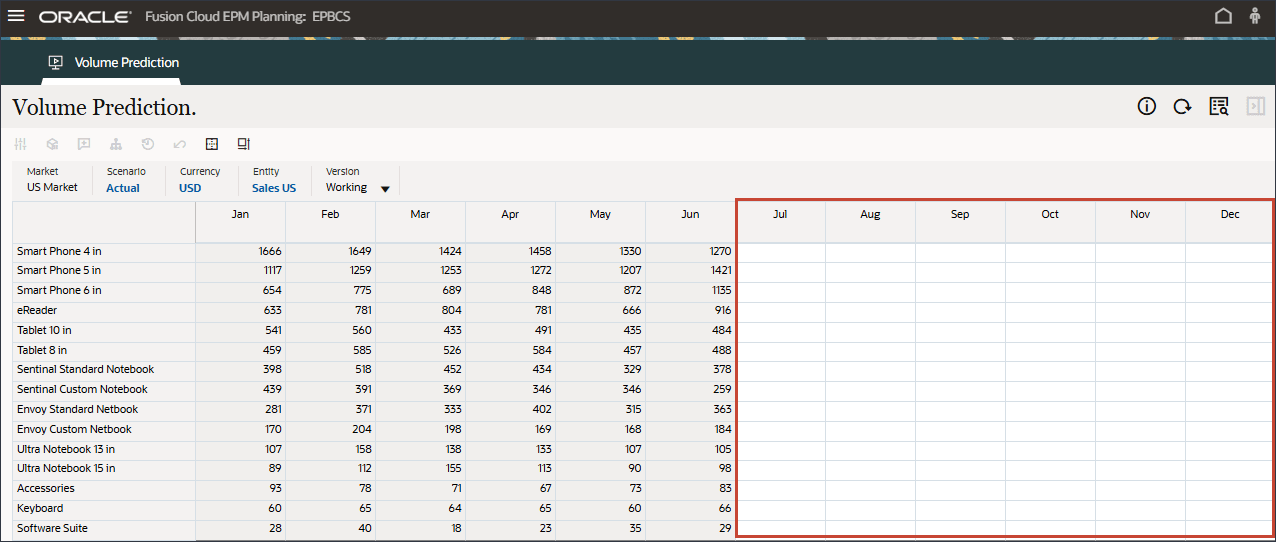
볼륨 예측 검토
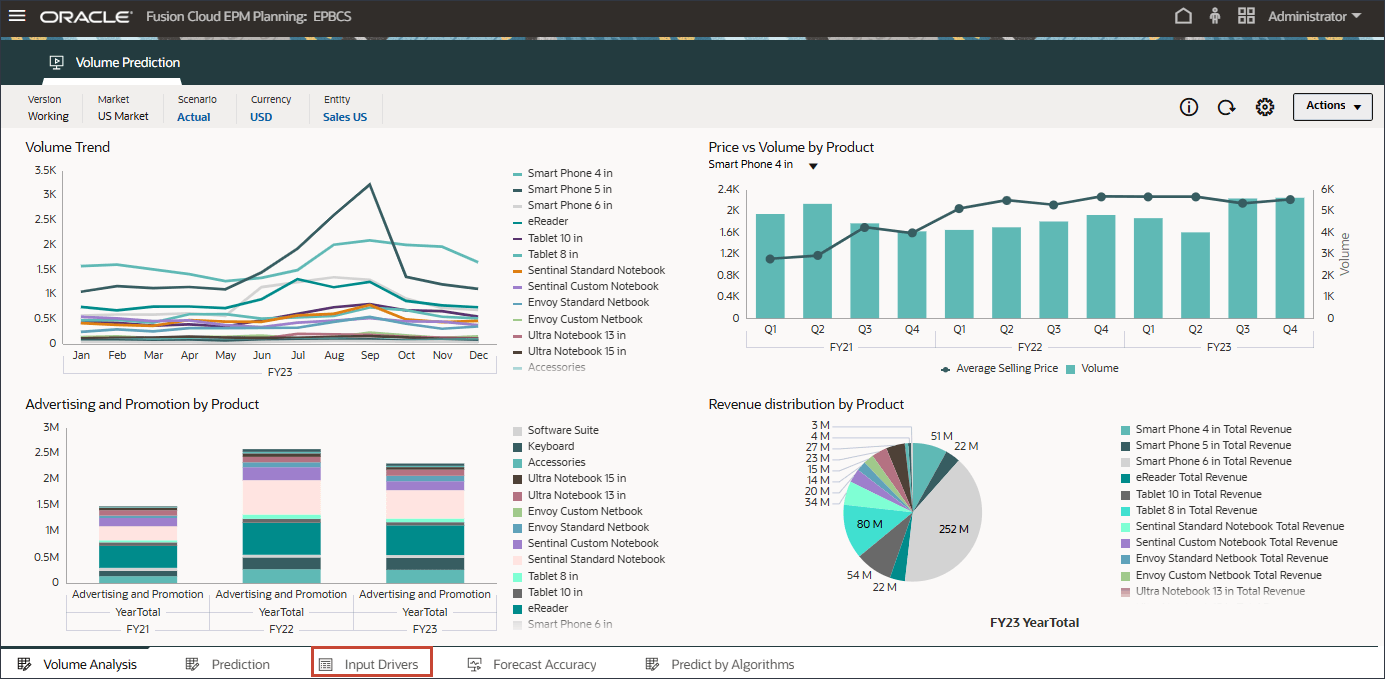
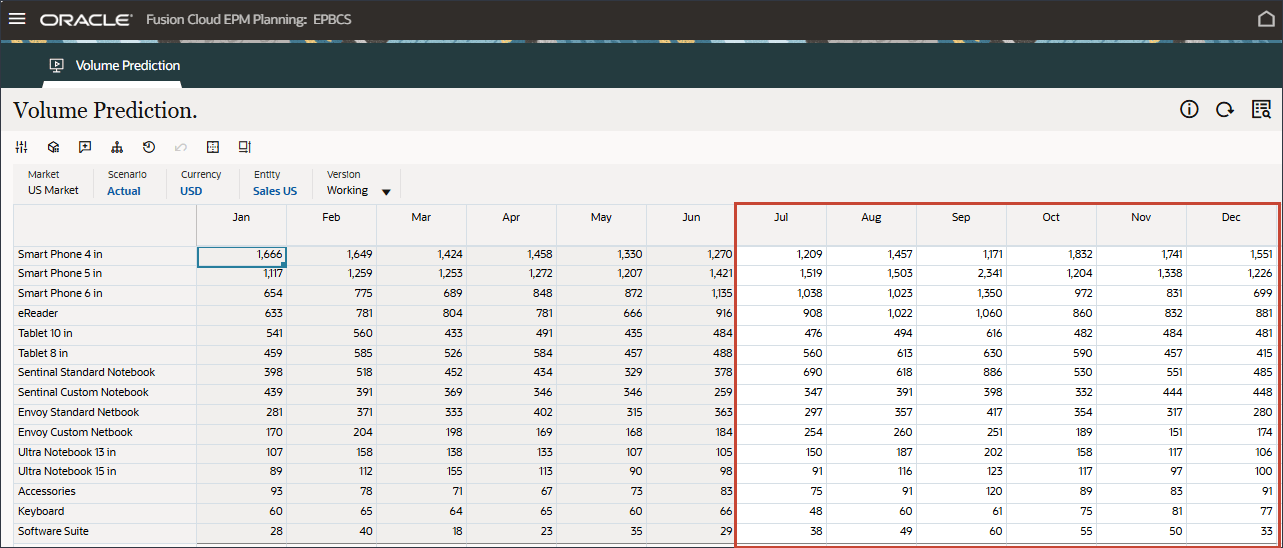
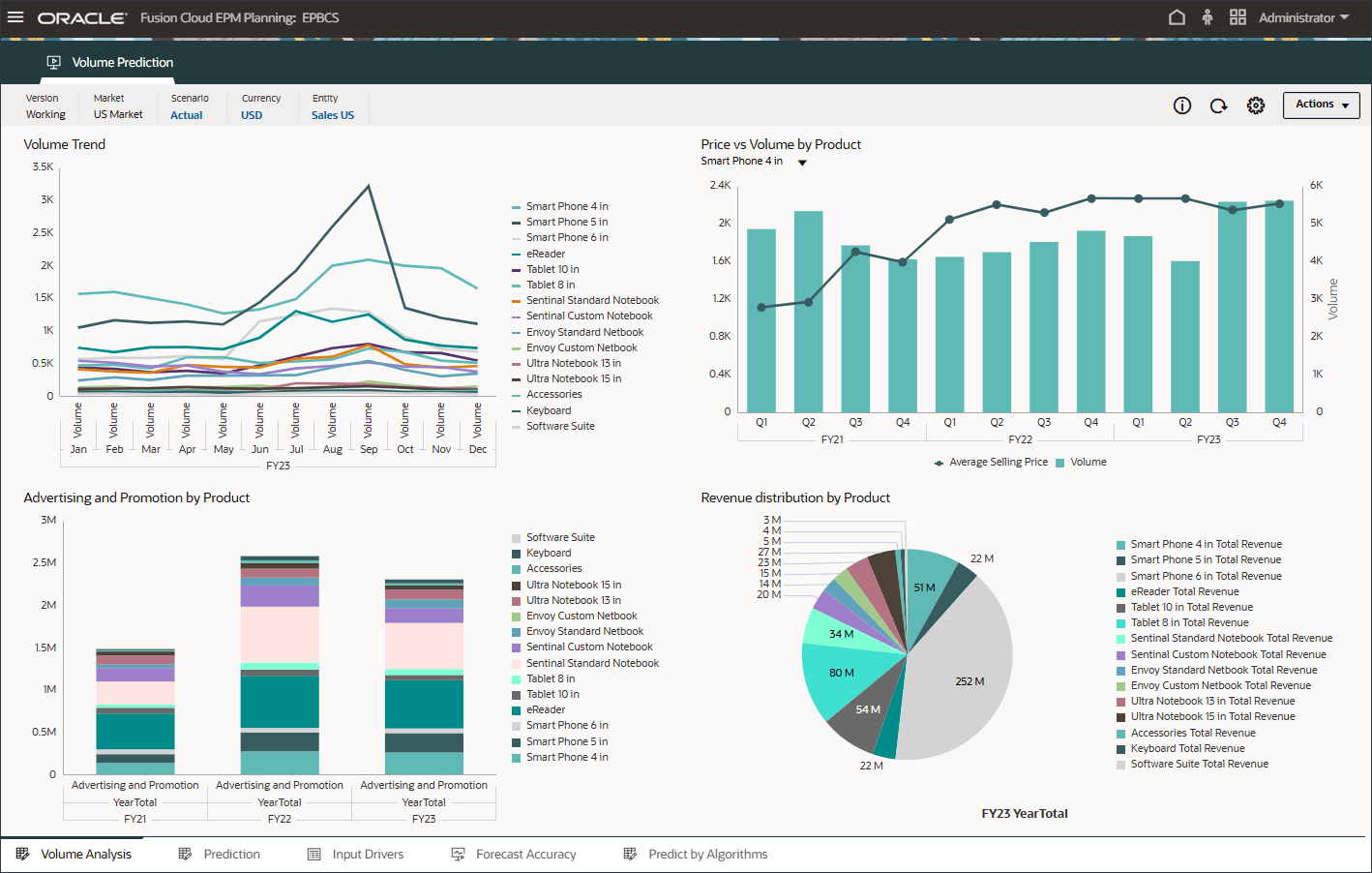
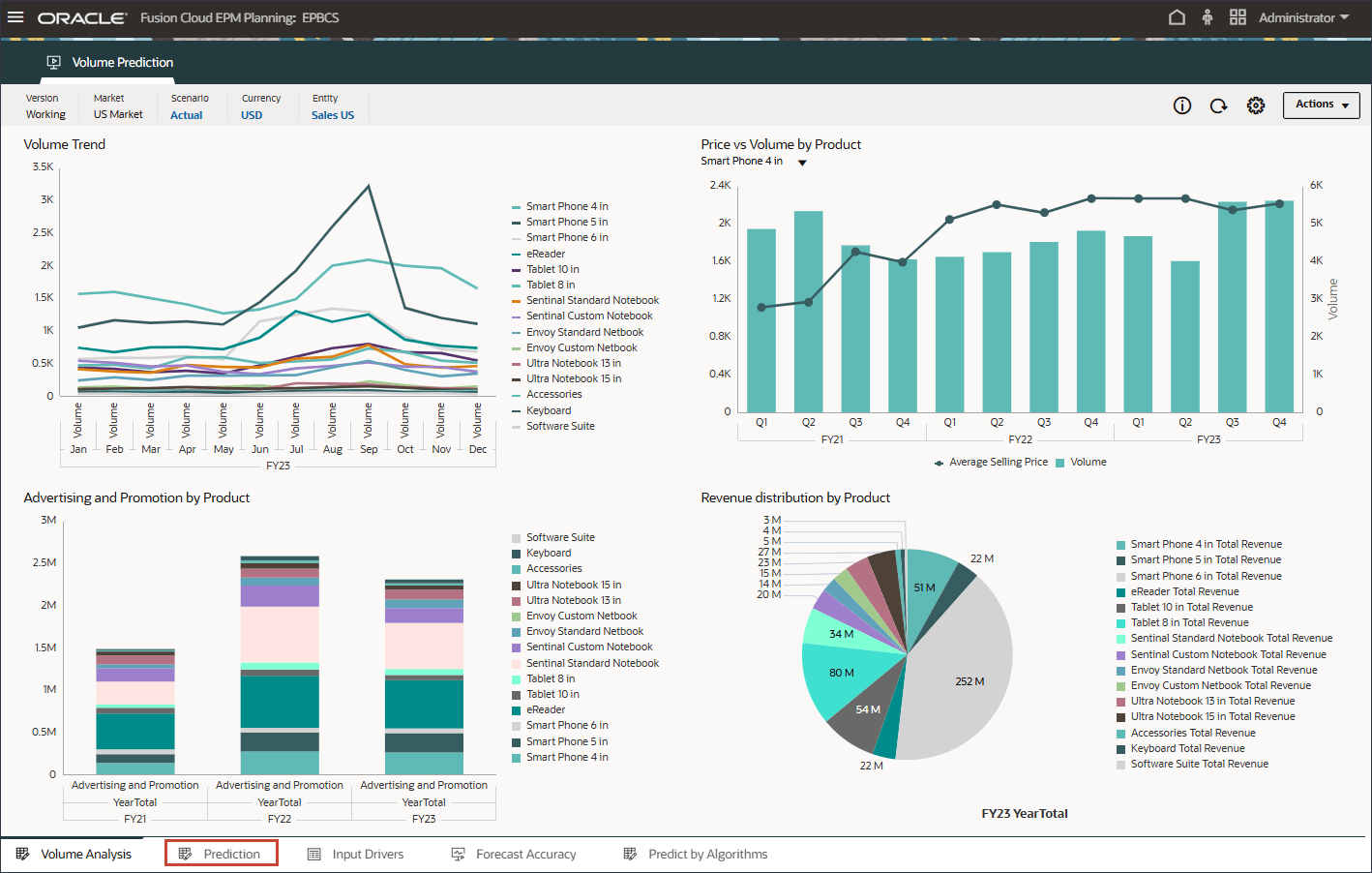
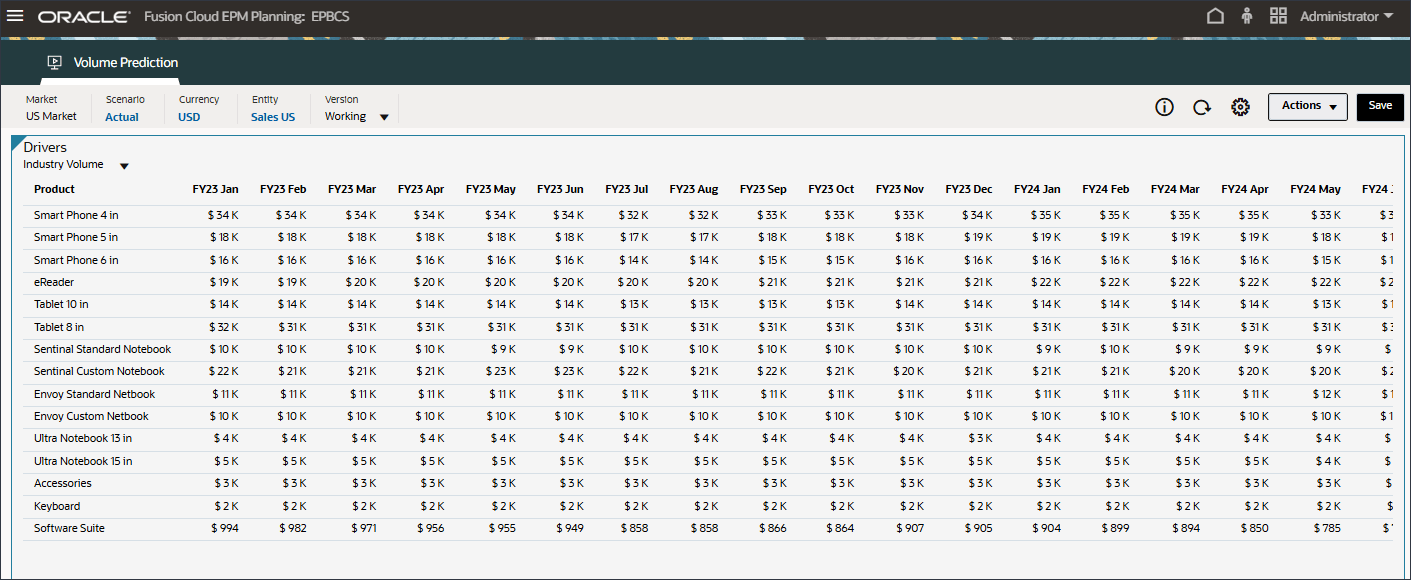
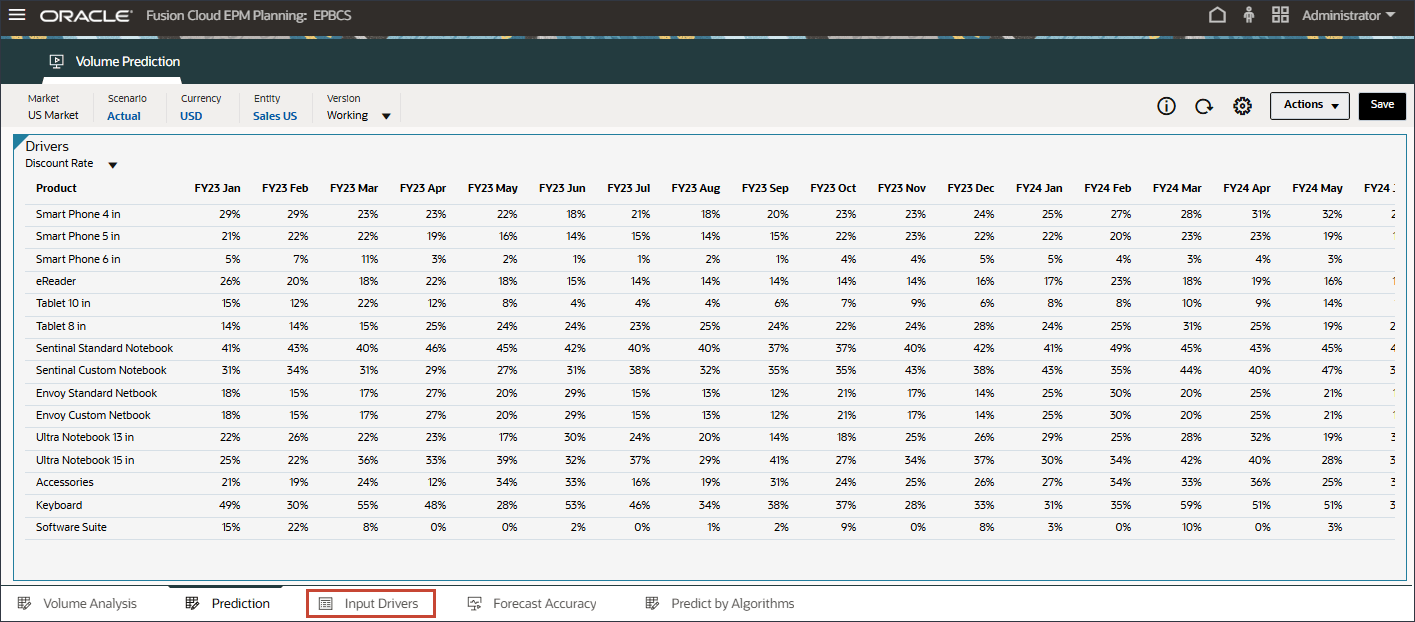
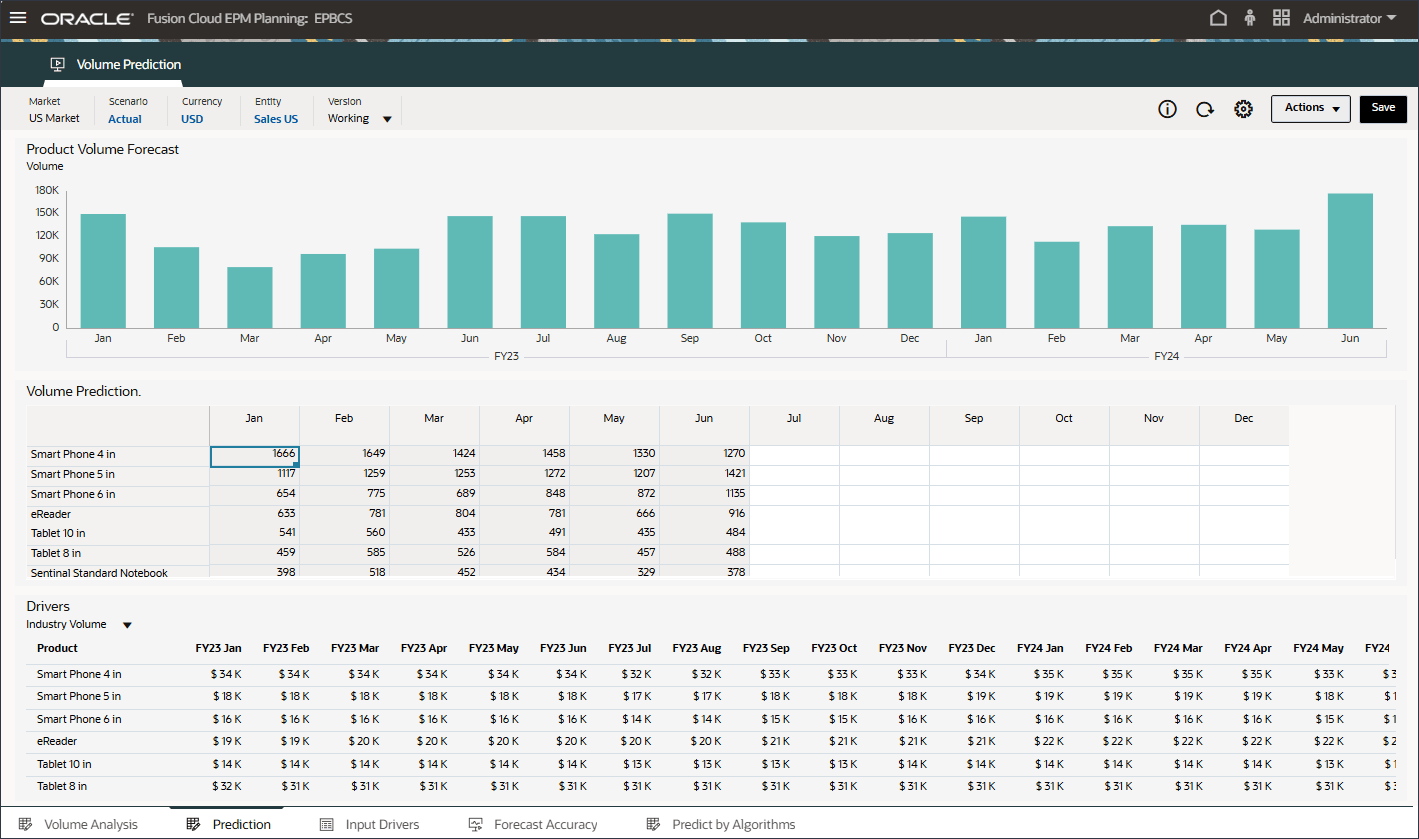
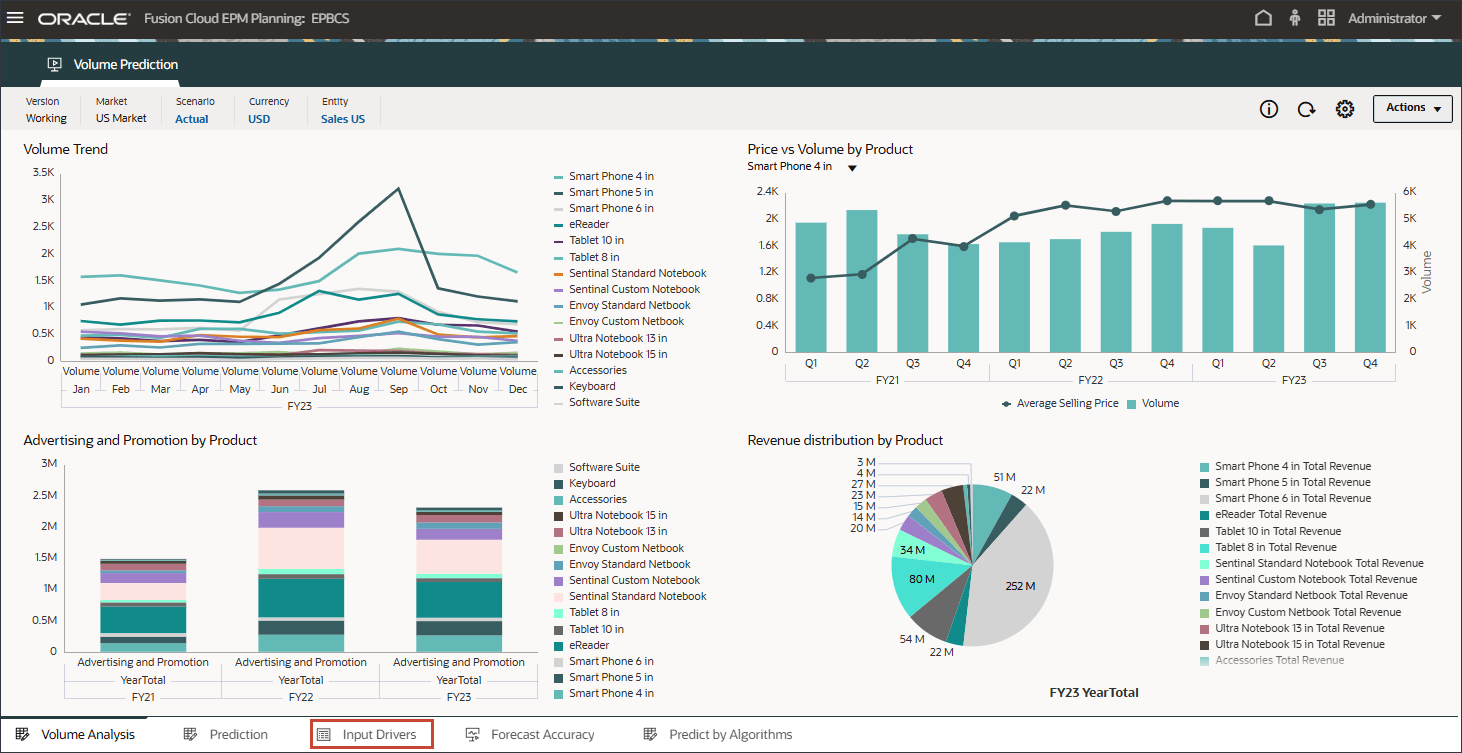
볼륨 예측을 생성하고 실행하기 전에 이 사용 사례에 대해 준비된 과거 데이터와 함께 볼륨 예측 대시보드를 검토합니다. 기간별 볼륨 분석 및 기타 드라이버를 표시하도록 설정된 볼륨 예측 카드를 사용합니다. 이 카드에는 드라이버 값 및 예측 결과를 표시하도록 설정된 탭도 포함되어 있습니다.
홈 페이지에서 고급 예측, 볼륨 예측 순으로 누릅니다.
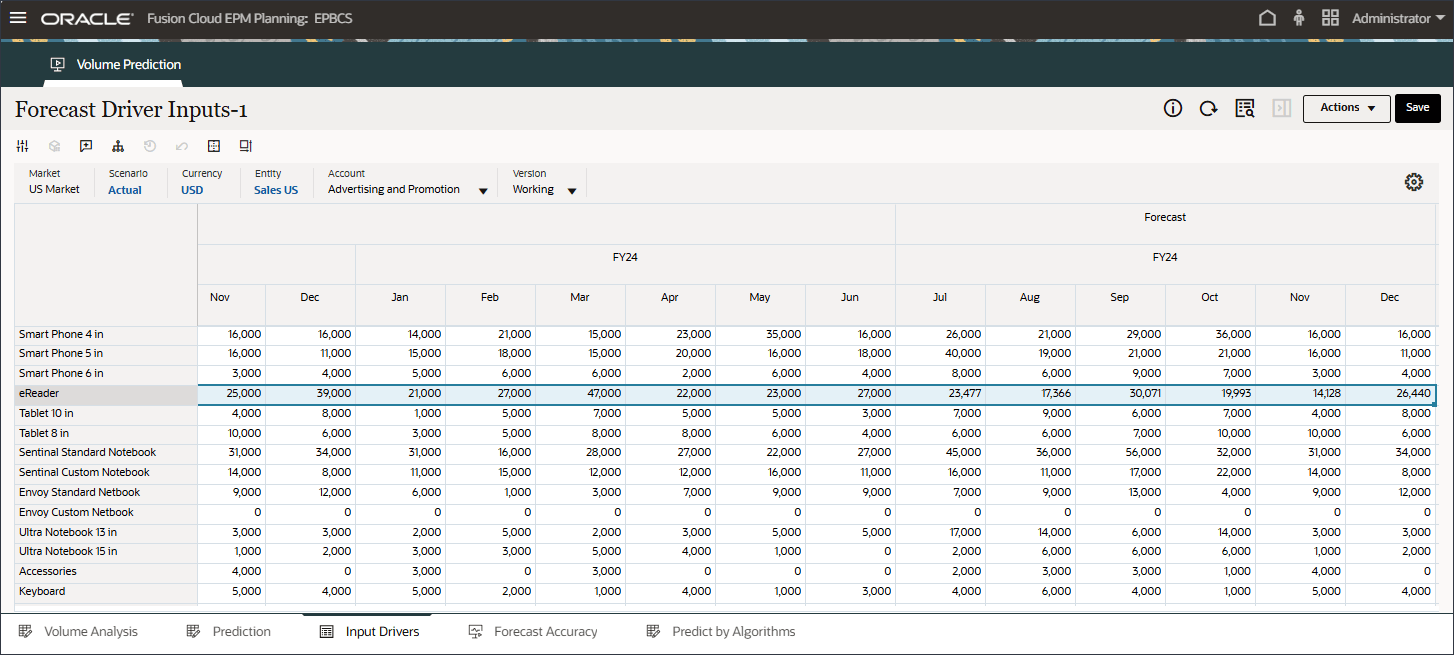
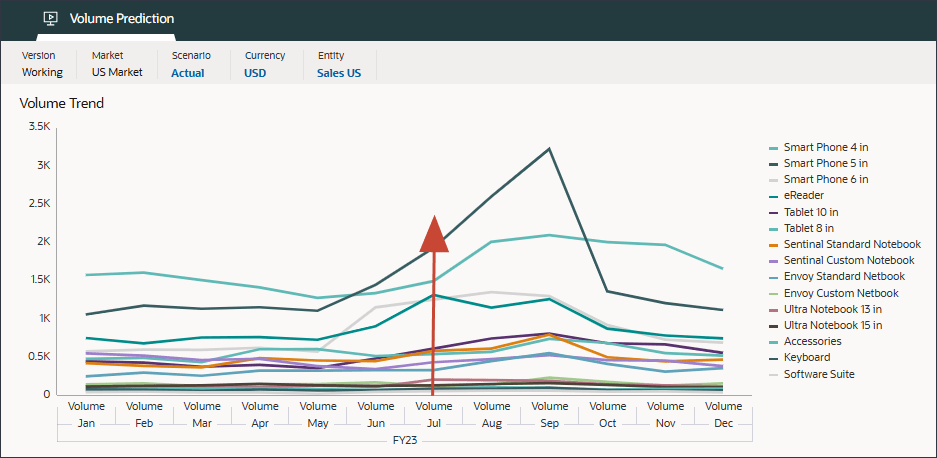
제품별 거래량 추세, 제품별 가격 대 거래량, 제품별 광고 및 판촉, 제품별 매출 분포를 비롯한 거래량 예측을 검토합니다.
하단에서 예측 탭을 누릅니다.
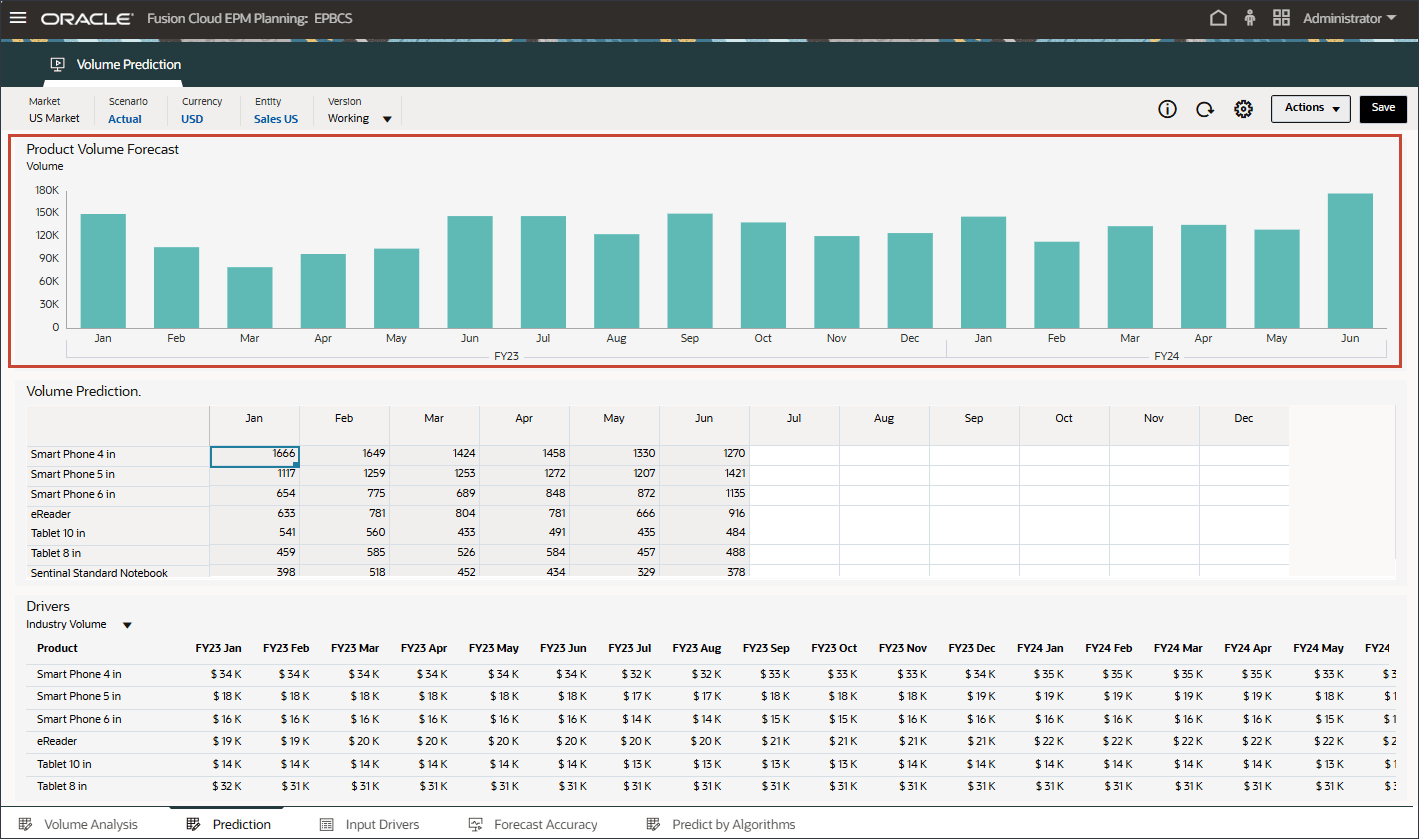
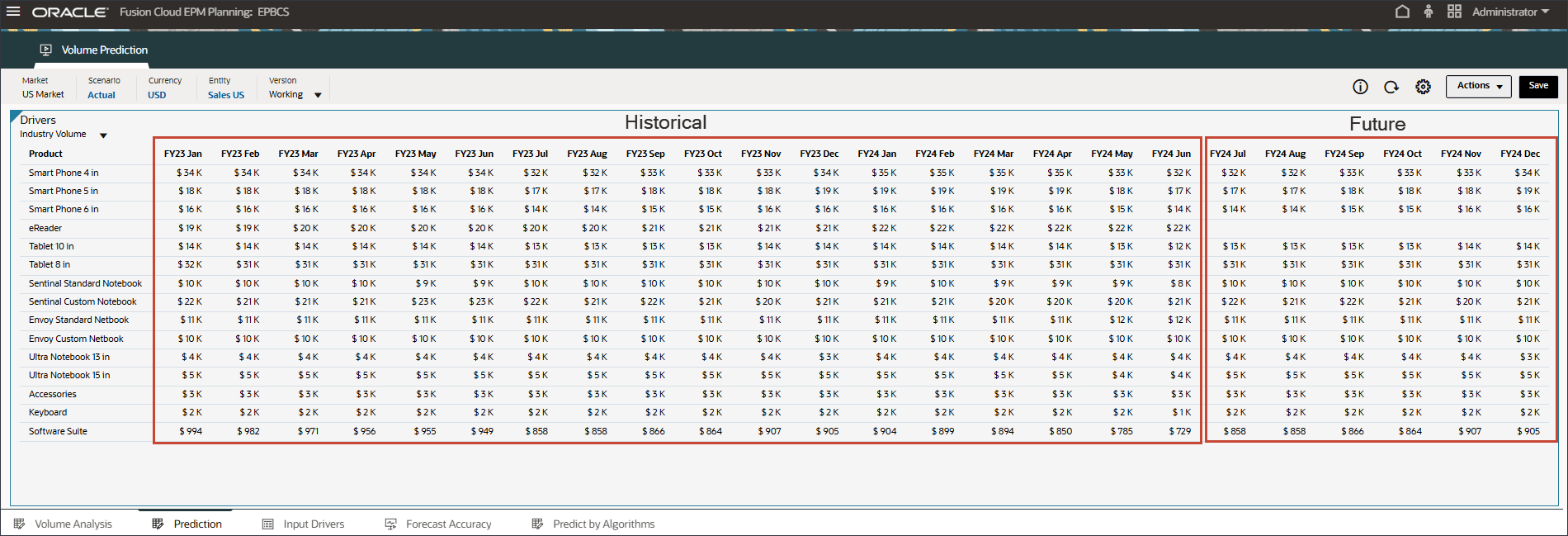
예측 탭에는 예측할 볼륨이 있는 대시보드가 표시되며 볼륨 예측에 사용할 모든 드라이버가 있는 테이블도 포함됩니다.
상단의 막대 차트에서 과거 거래량 예측을 검토합니다.
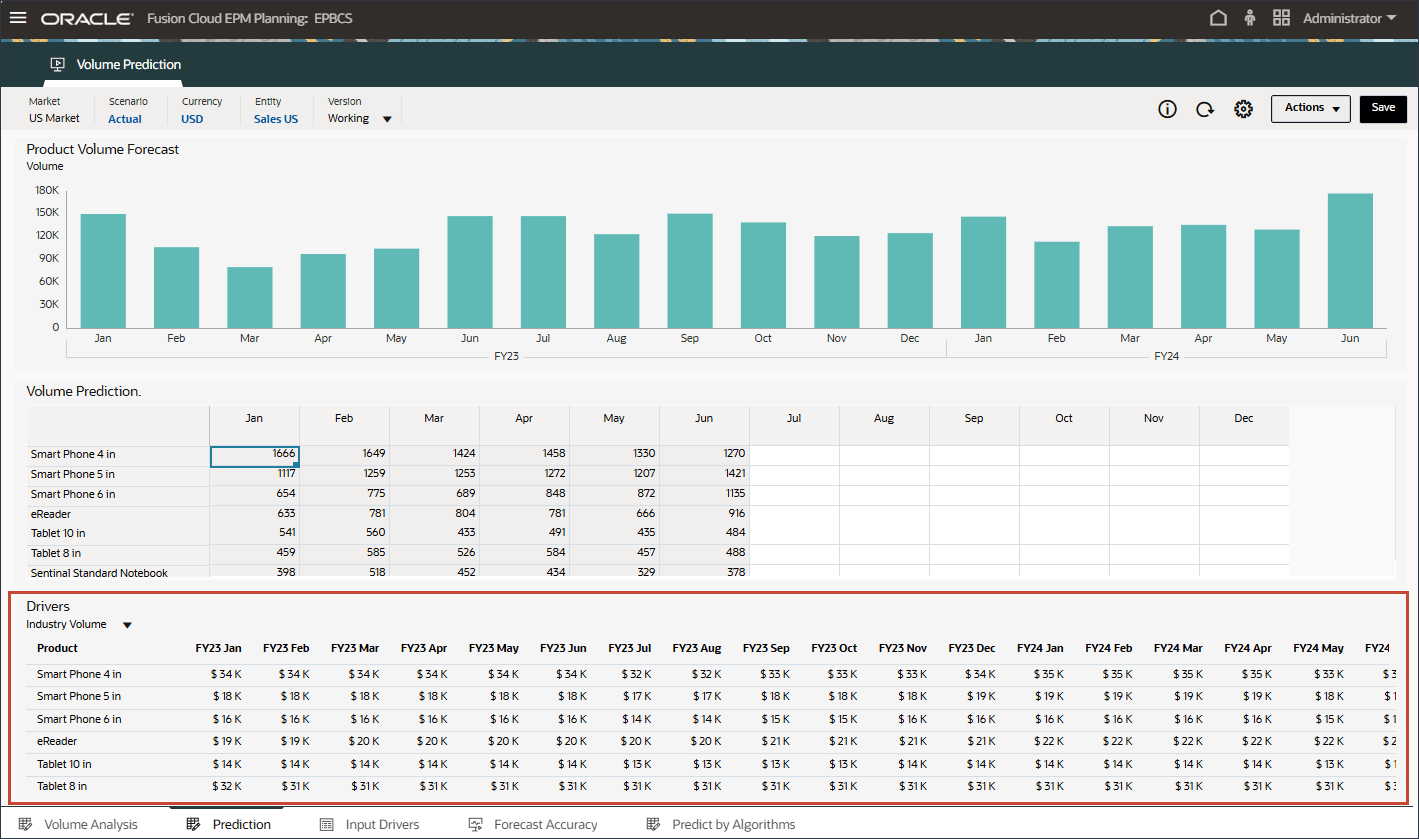
하단의 드라이버 그리드에서 고급 예측에 사용된 드라이버 데이터를 검토합니다. 여기에는 과거 및 미래 드라이버 데이터가 모두 포함됩니다.
드라이버에 대한 과거 실제 데이터를 통합을 통해 여러 시스템에서 가져올 수 있지만, 향후 드라이버 데이터는 동인/추세/수동 기반과 같은 기존 예측 방법을 통해 파생될 수도 있고, 고급 예측 작업의 설정을 기반으로 단변량 예측(통계 방법)을 사용하여 입력 드라이버 데이터를 자동으로 생성할 수도 있습니다.
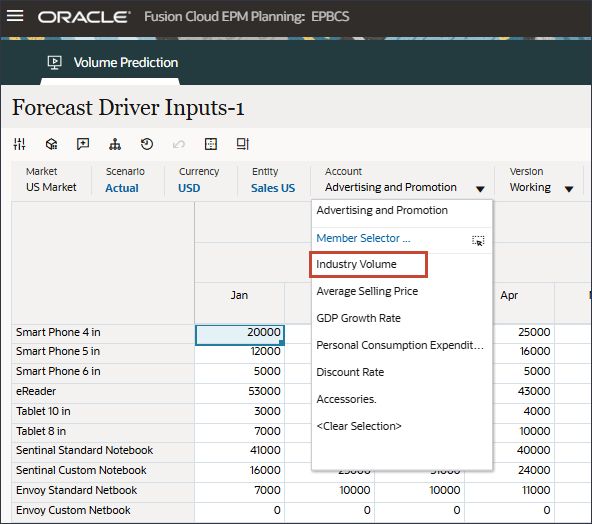
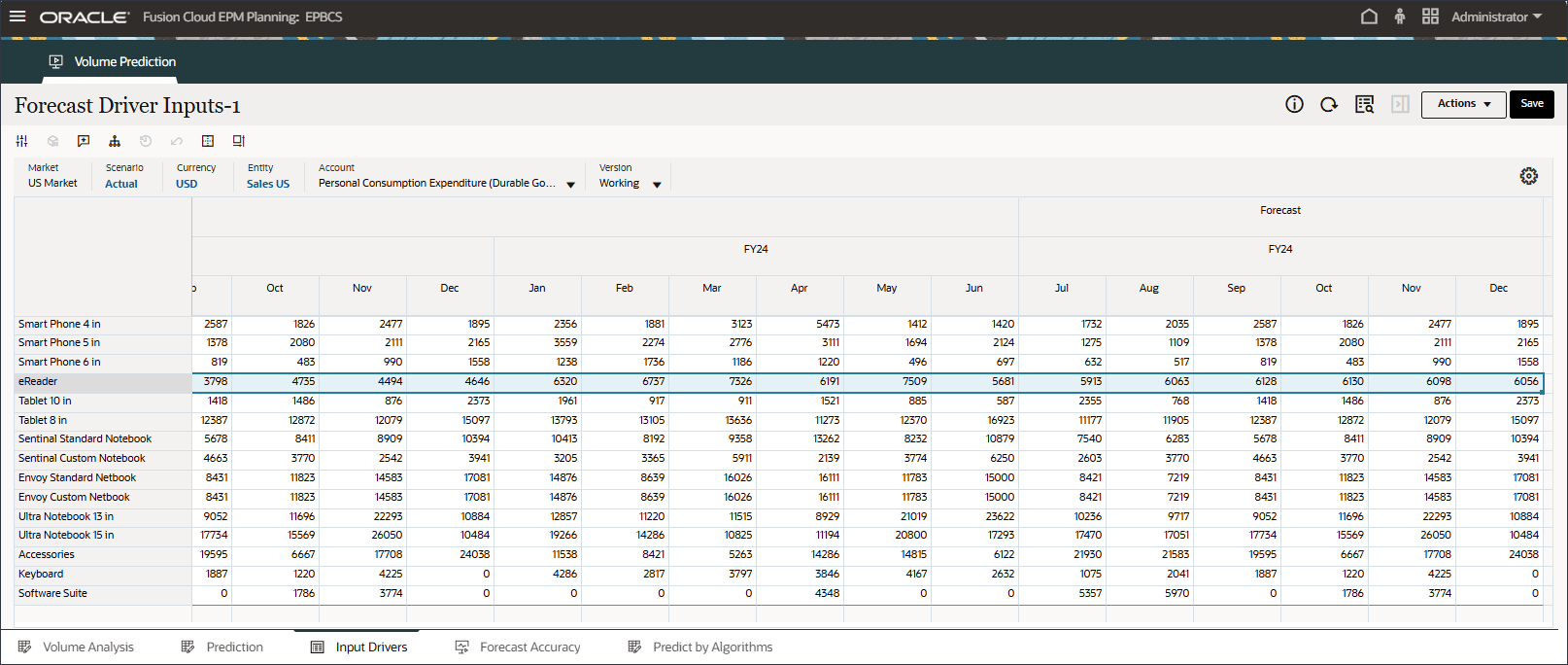
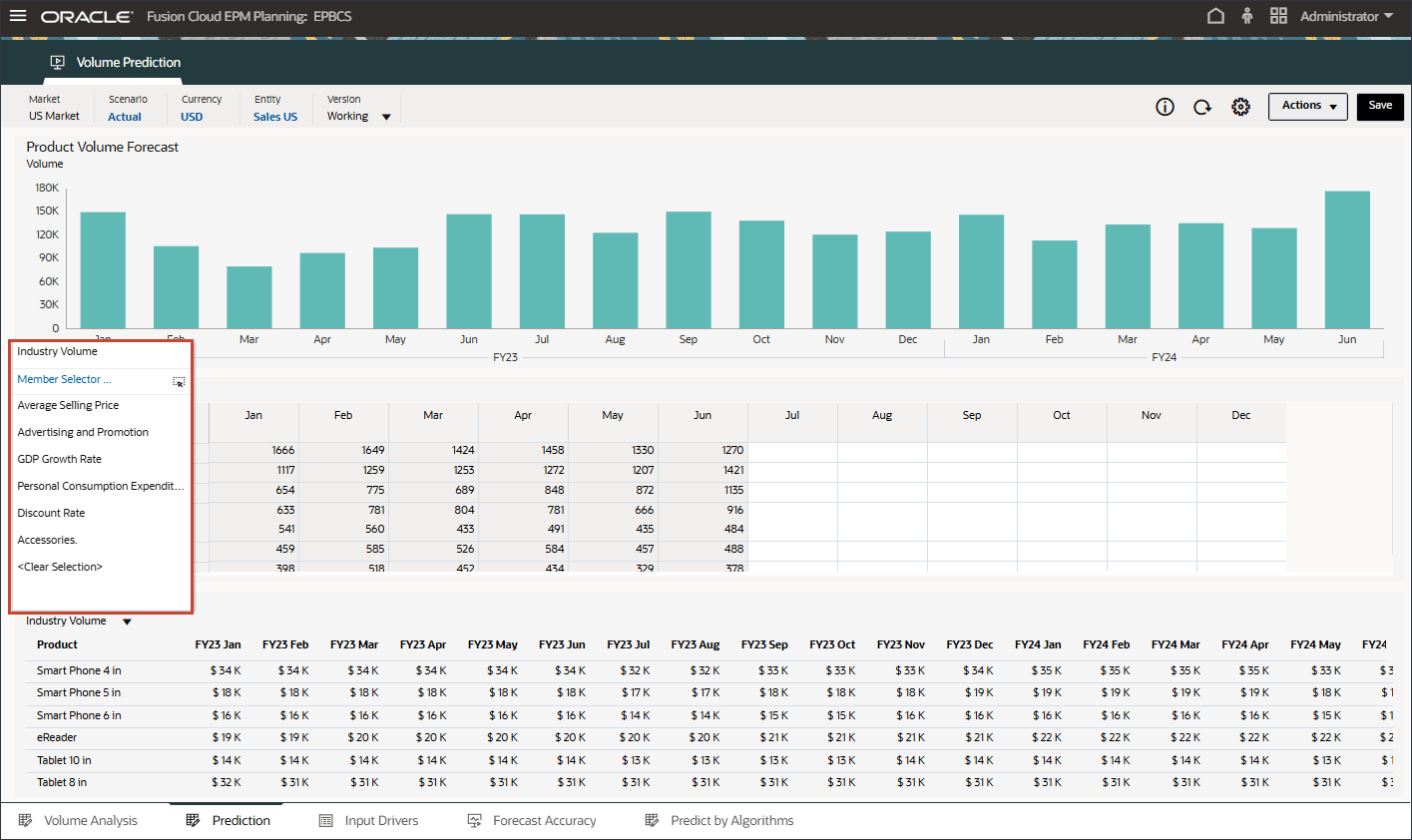
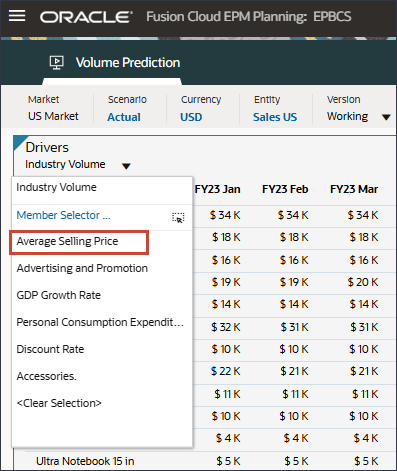
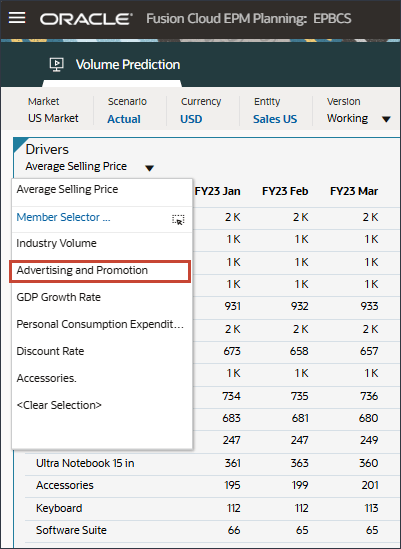
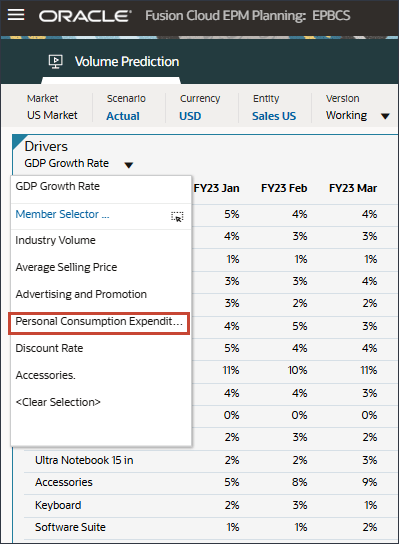
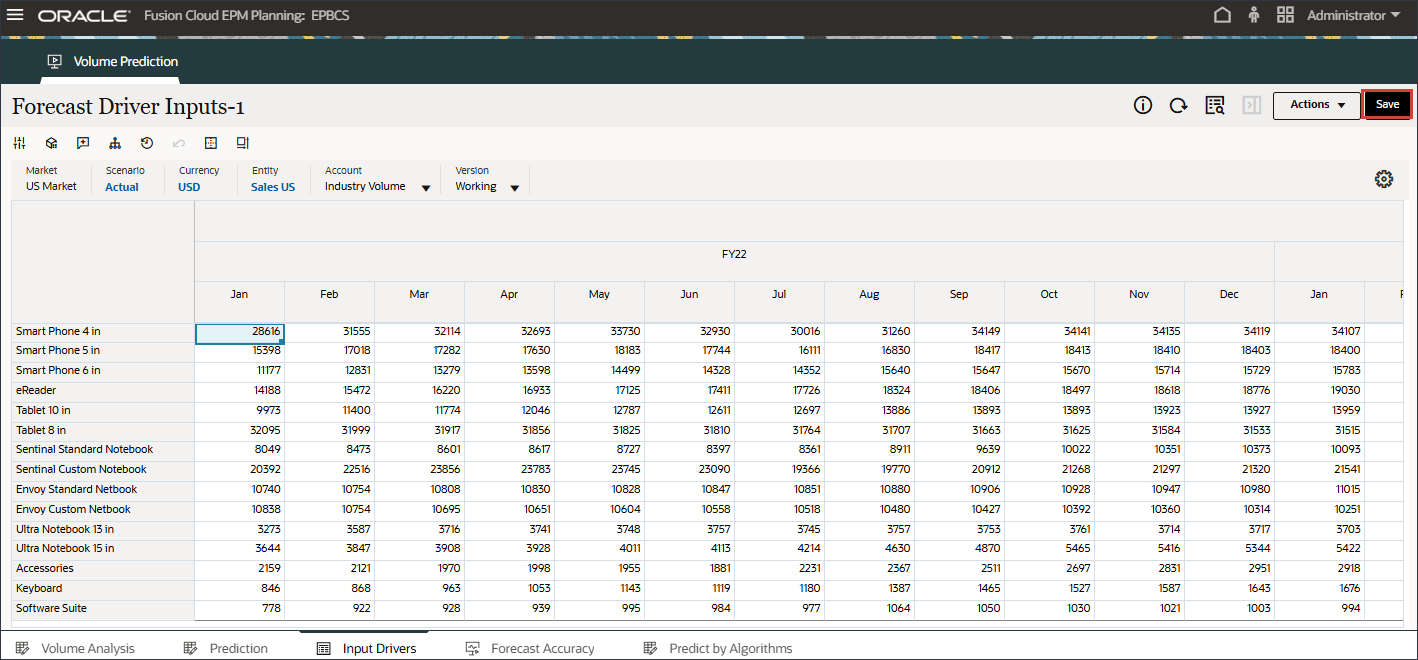
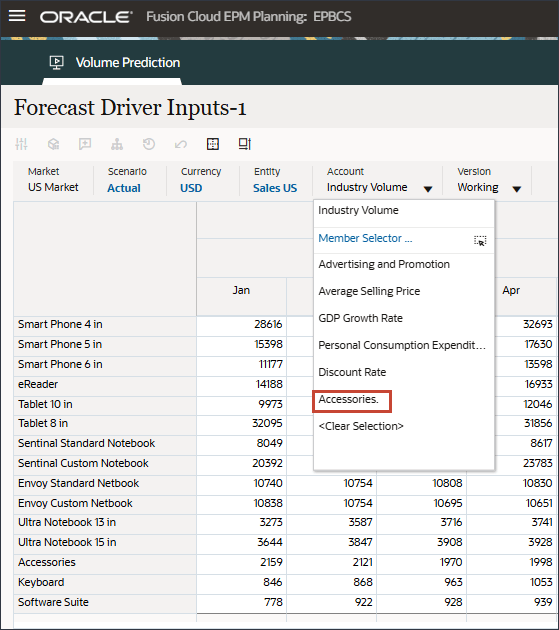
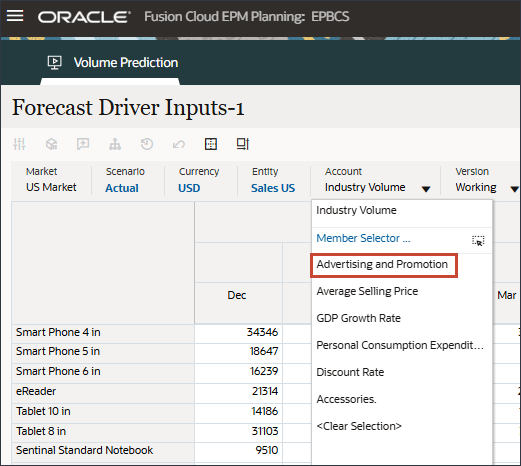
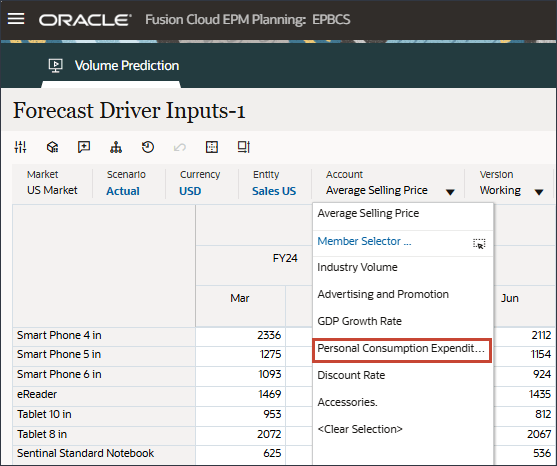
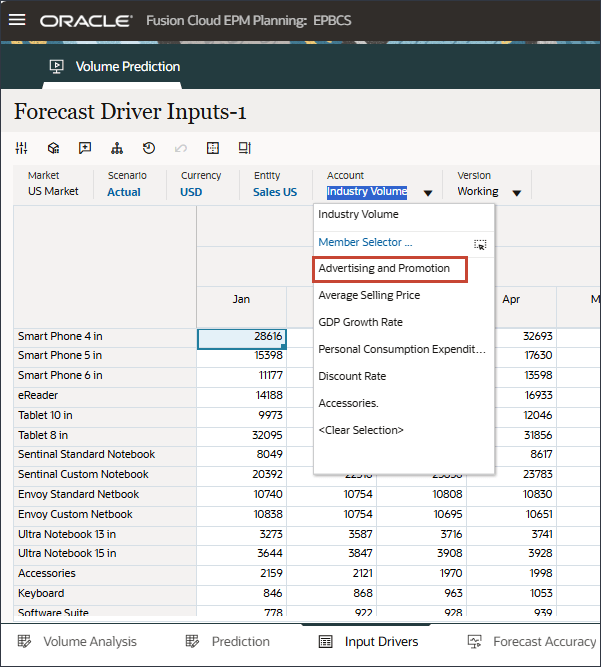
드라이버에서 산업 볼륨을 눌러 드라이버를 검토합니다. 그런 다음 드라이버를 검토한 후 산업 볼륨을 다시 눌러 목록을 닫습니다.
평균 판매 가격, 광고 및 프로모션, 할인율을 비롯한 여러 드라이버 중 하나를 선택할 수 있습니다.
드라이버 그리드에서 (작업)을 누르고 최대화를 선택합니다.
이러한 입력 드라이버는 고급 예측 알고리즘을 통해 볼륨 예측을 정확하게 도출하는 데 유용합니다.
산업 볼륨에 대한 과거 및 미래 데이터의 입력 드라이버를 검토합니다.
오른쪽으로 스크롤하여 미래 값을 검토합니다.
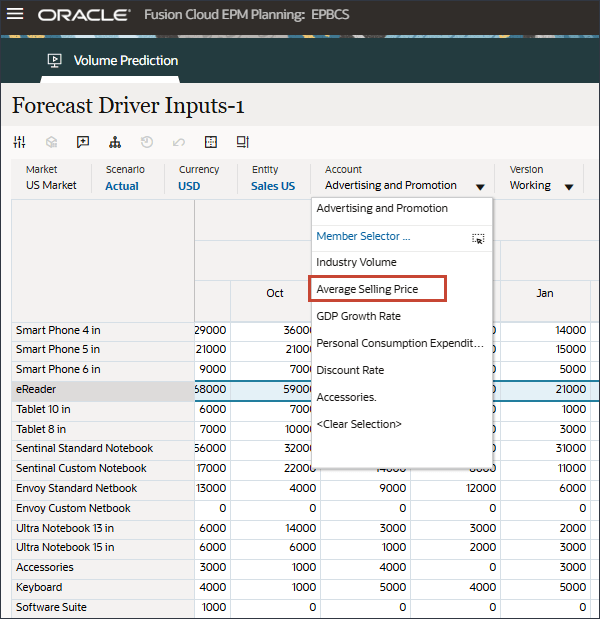
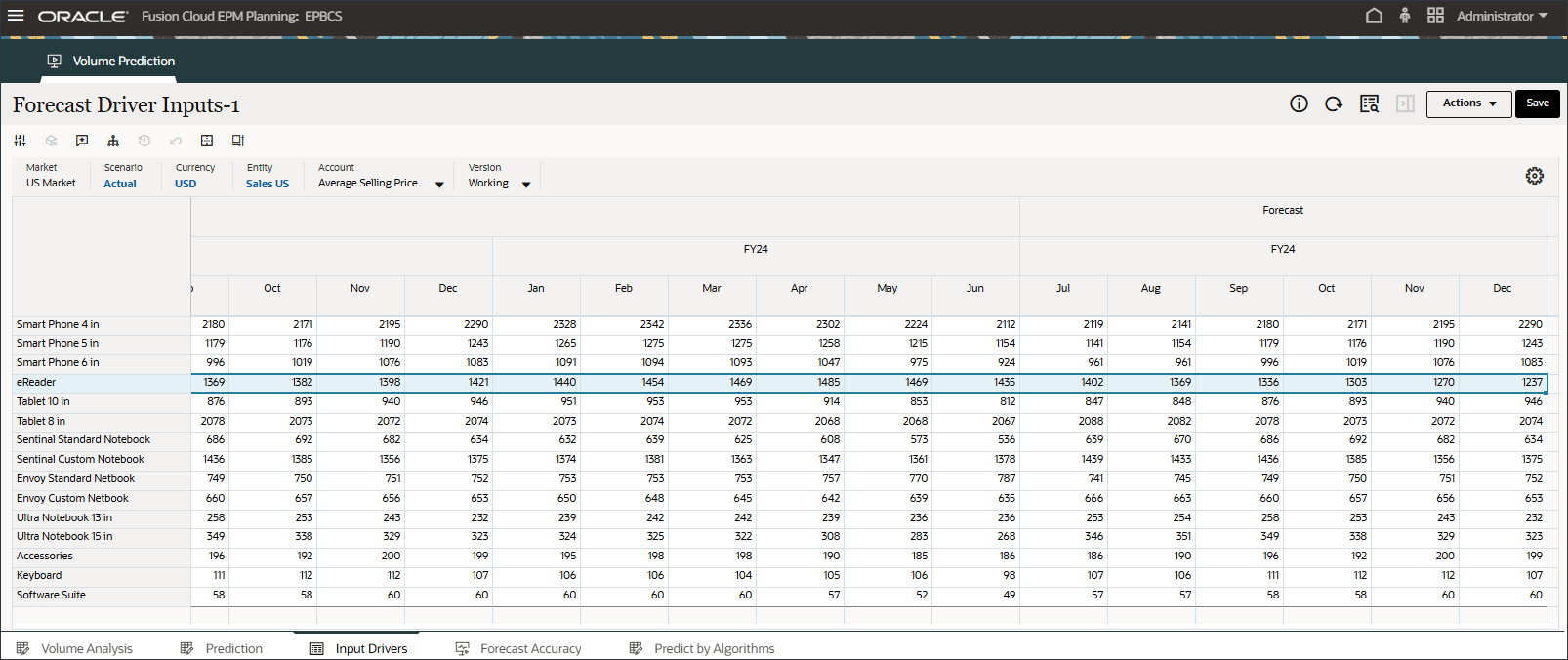
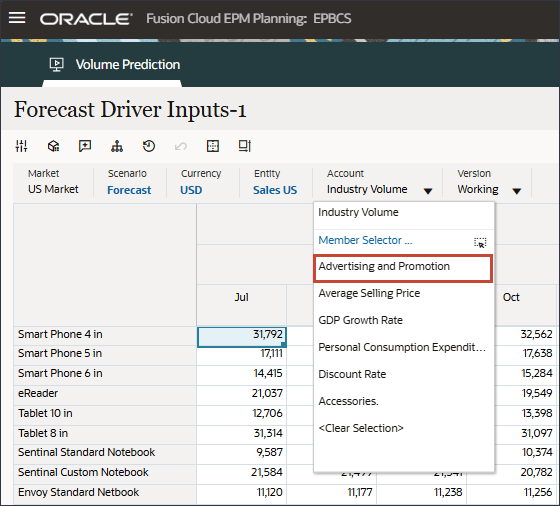
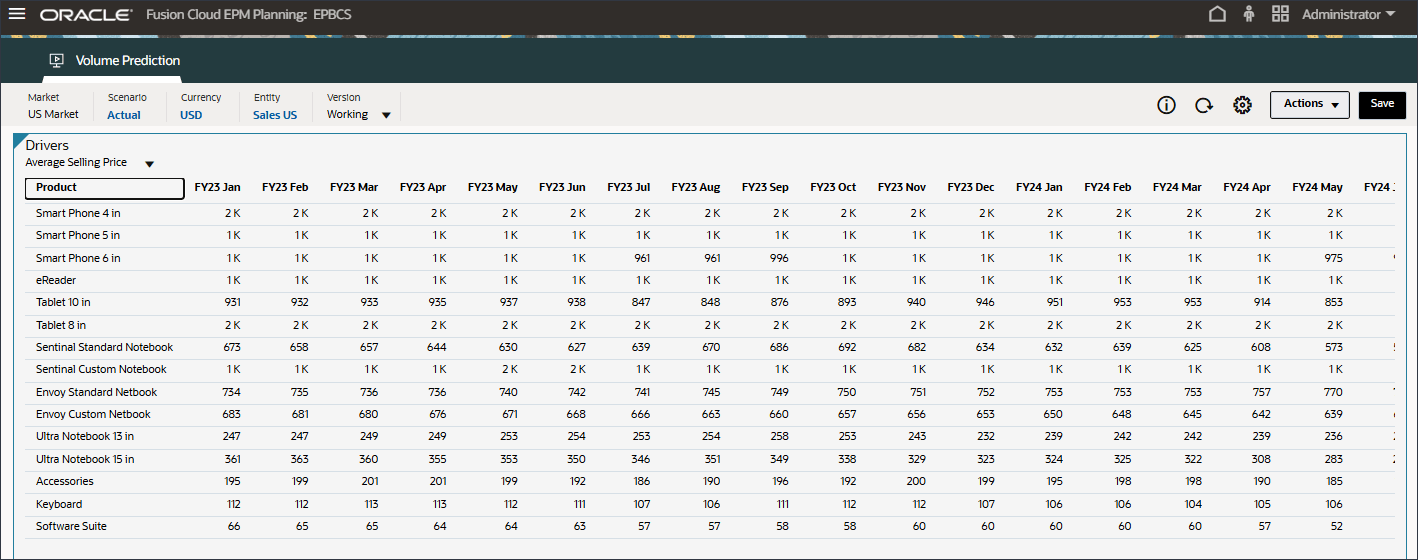
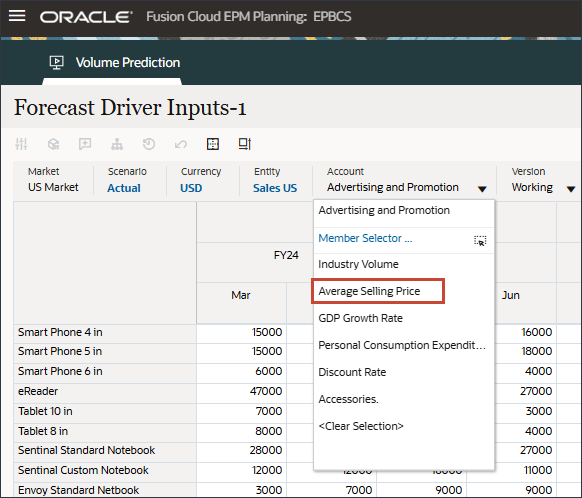
드라이버 드롭다운에서 산업 거래량을 누르고 평균 판매 가격을 선택합니다.
평균 판매 가격에 대한 데이터가 표시됩니다.
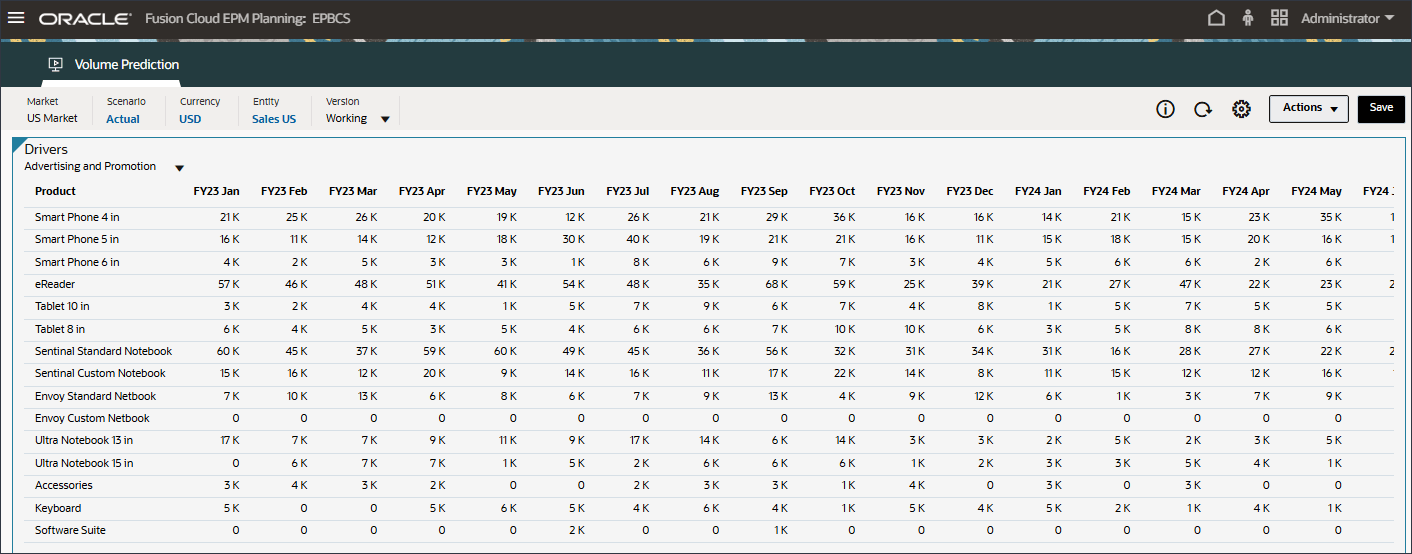
드라이버 드롭다운에서 평균 판매 가격을 누르고 광고 및 프로모션을 선택합니다.
광고 및 홍보용 데이터가 표시됩니다.
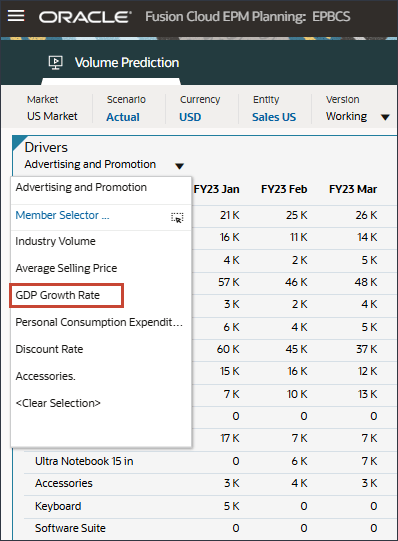
드라이버 드롭다운에서 광고 및 프로모션을 누르고 GDP 성장률을 선택합니다.
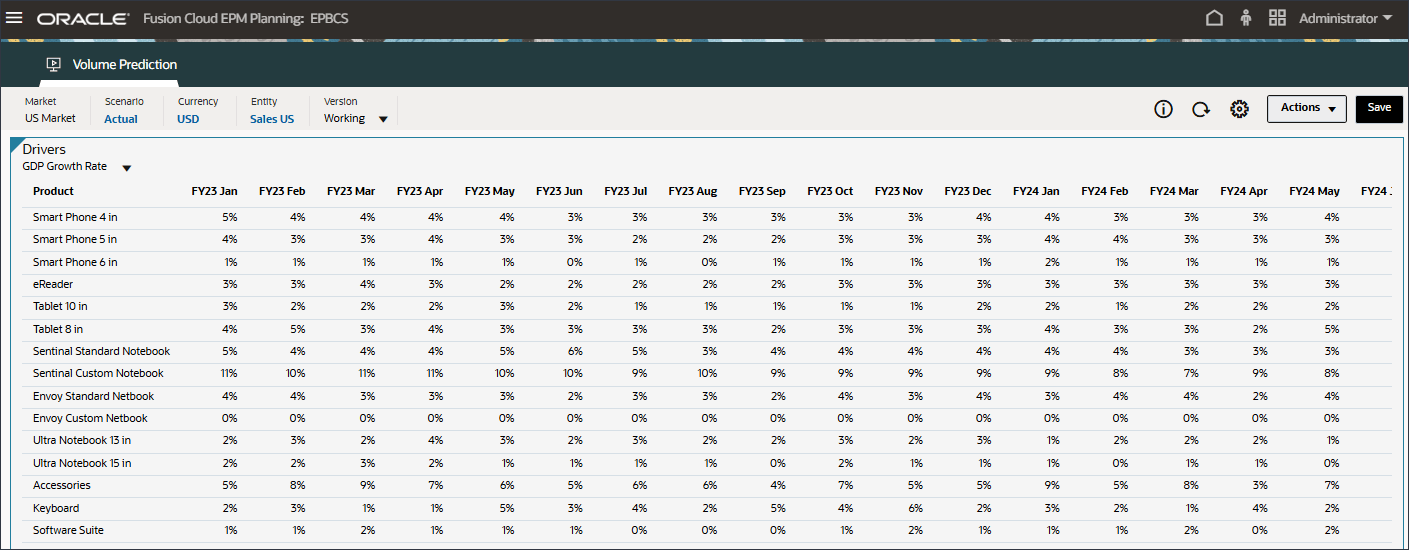
GDP 성장률에 대한 데이터가 표시됩니다.
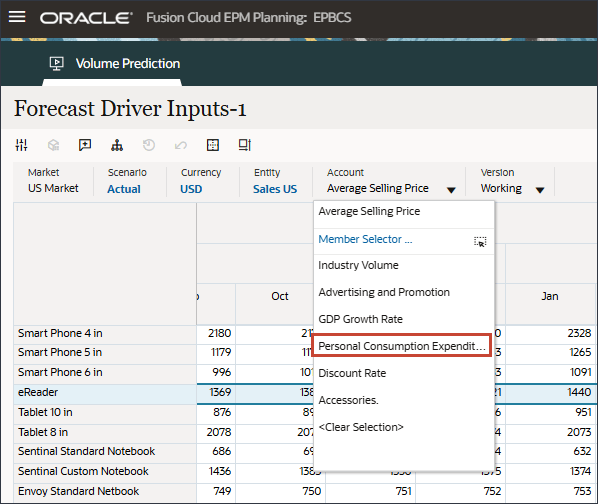
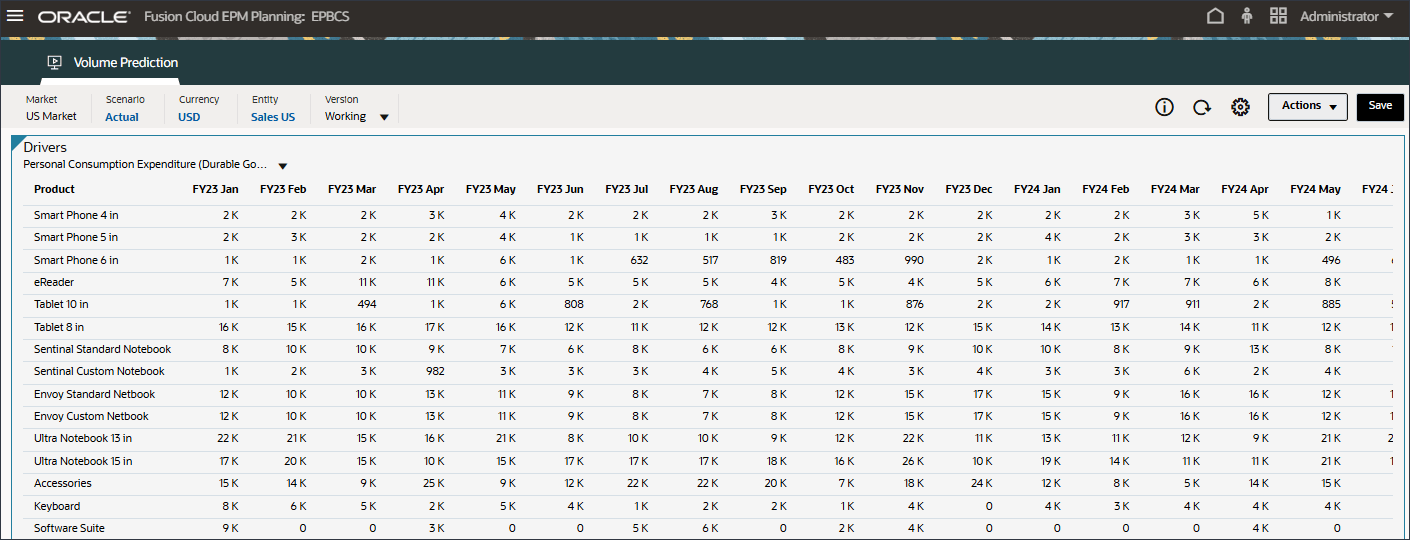
드라이버 드롭다운에서 GDP 증가율을 누르고 개인 소비 지출(내구재)을 선택합니다.
개인 소비 지출(내구재)에 대한 데이터가 표시됩니다.
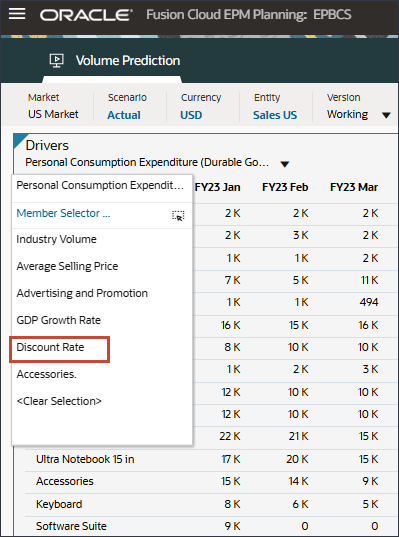
드라이버 드롭다운에서 개인 소비 비용(내구재)을 누르고 할인율을 선택합니다.
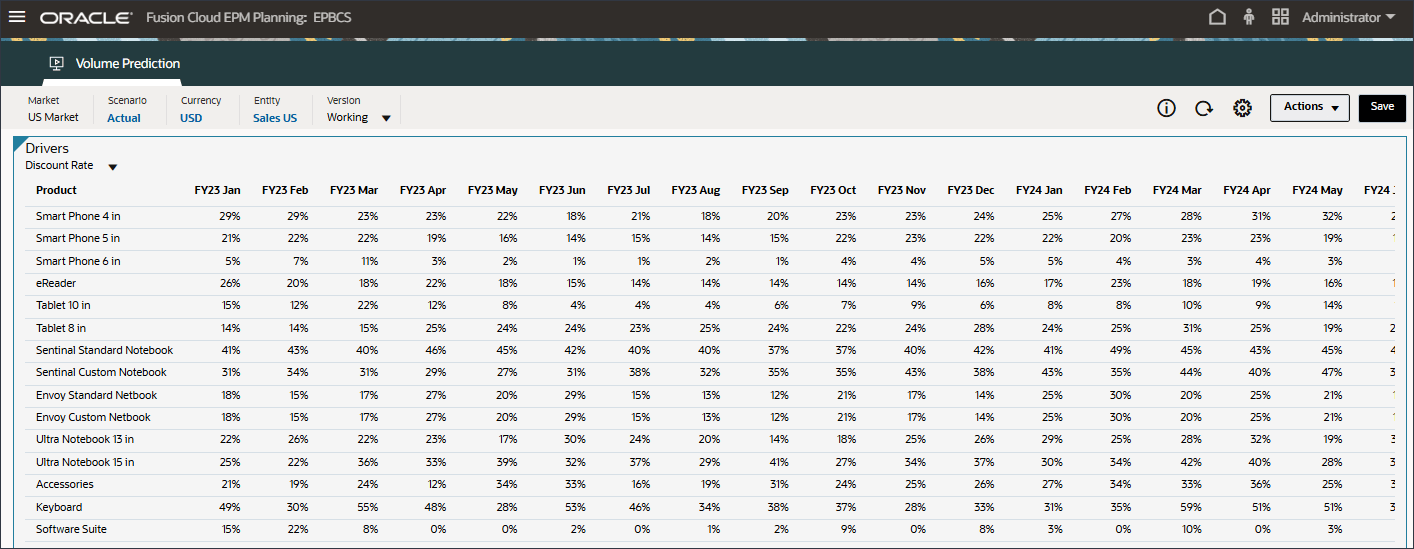
할인율 데이터가 표시됩니다.
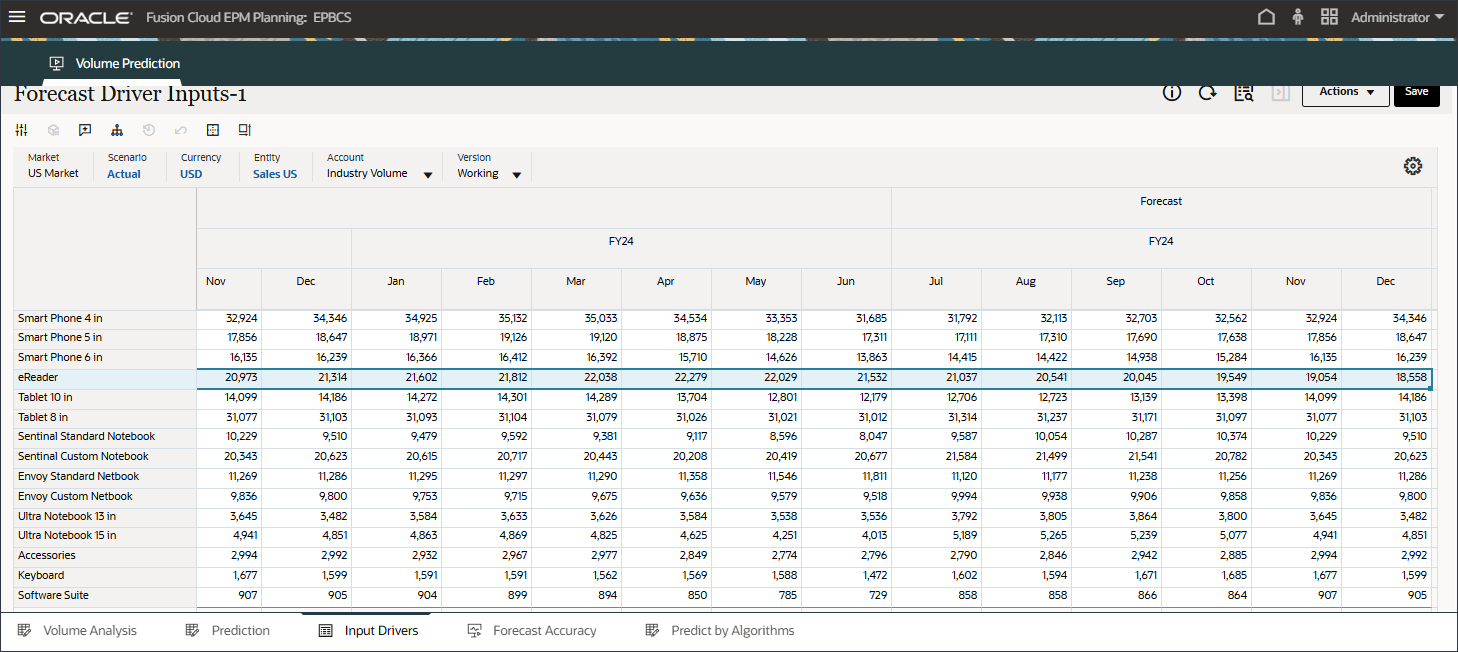
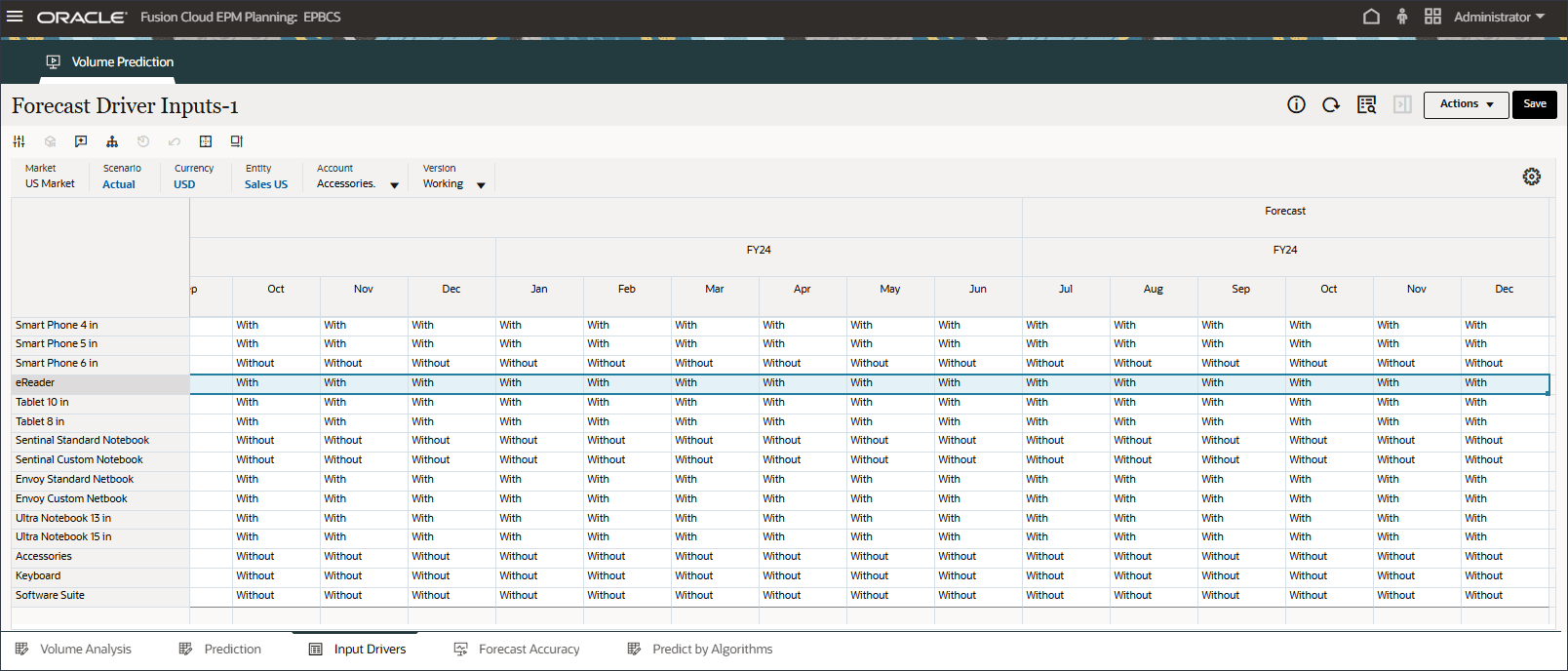
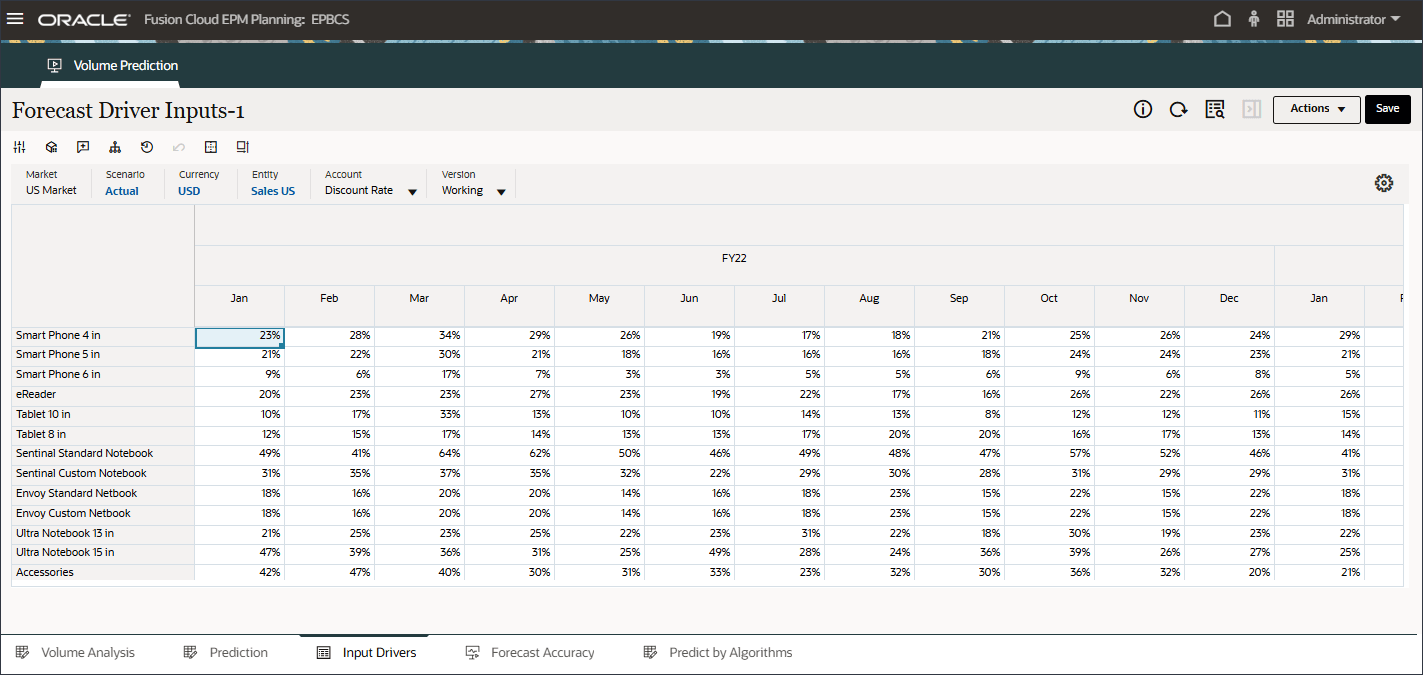
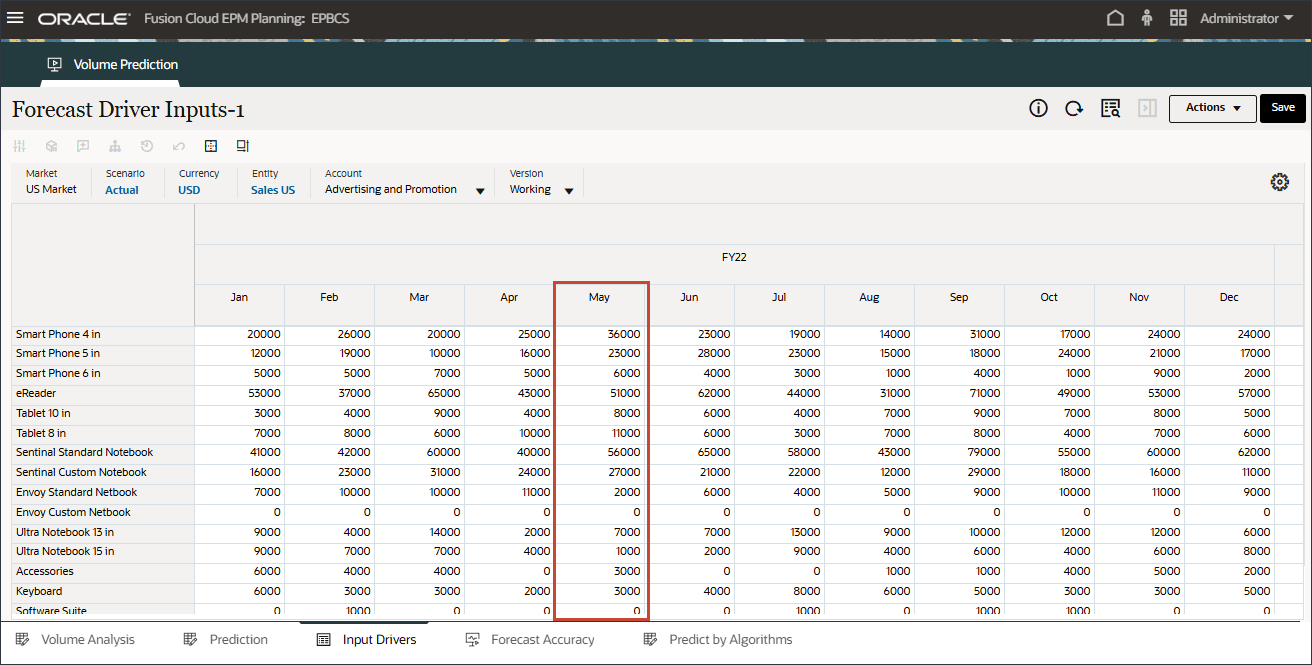
입력 드라이버 편집
입력 드라이버를 편집할 수 있습니다. 과거 데이터와 미래 데이터를 모두 편집할 수 있습니다.
페이지 하단에서 입력 드라이버 탭을 누릅니다.
예측 드라이버 입력이 표시됩니다.
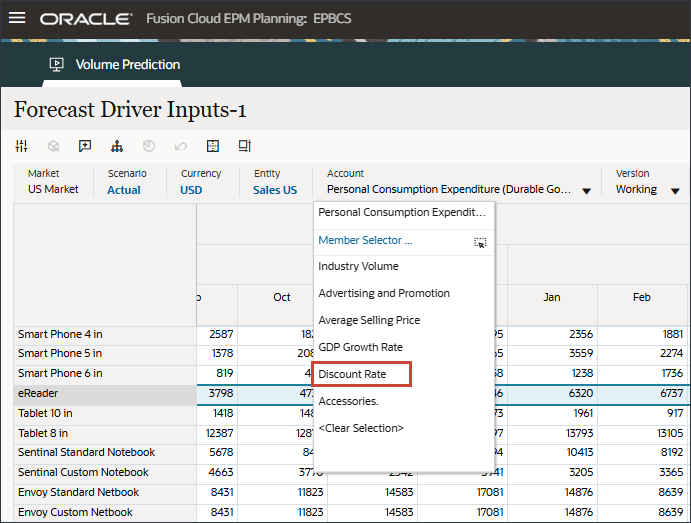
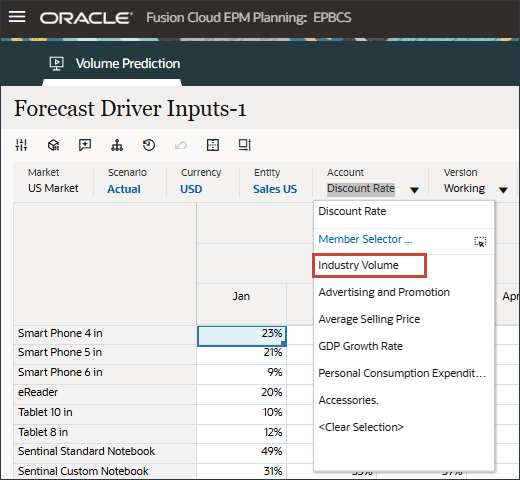
계정에서 할인율을 누르고 산업 볼륨을 선택합니다.
변경한 경우 저장을 눌러 변경 사항을 저장합니다.
마찬가지로 드라이버를 선택하여 편집할 수 있습니다.
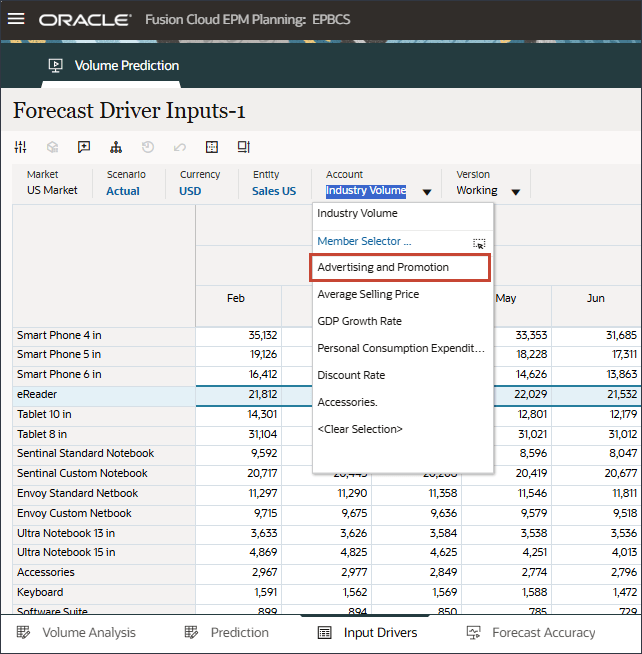
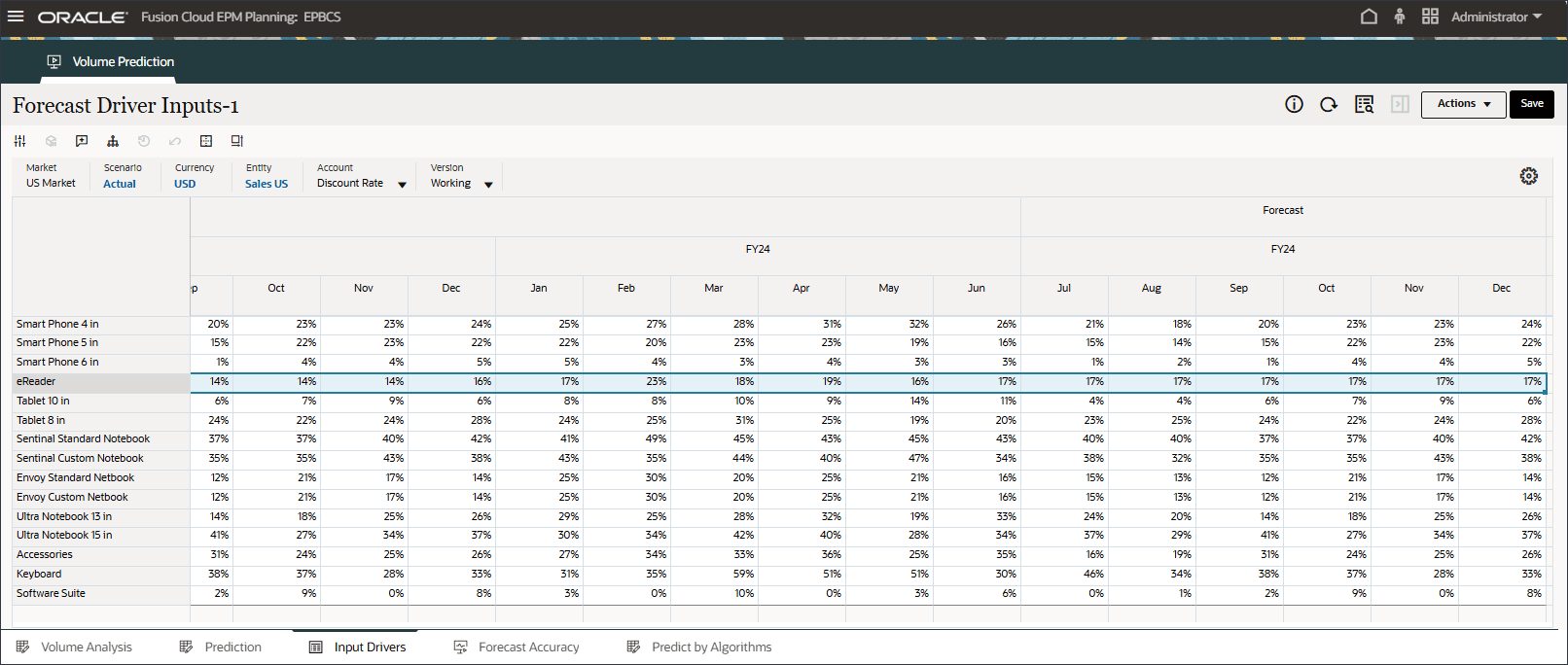
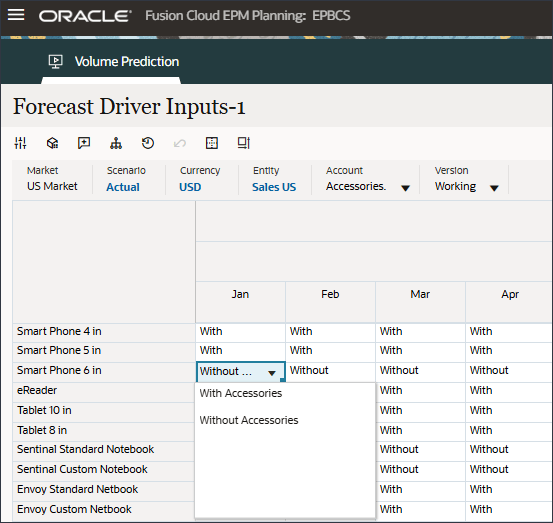
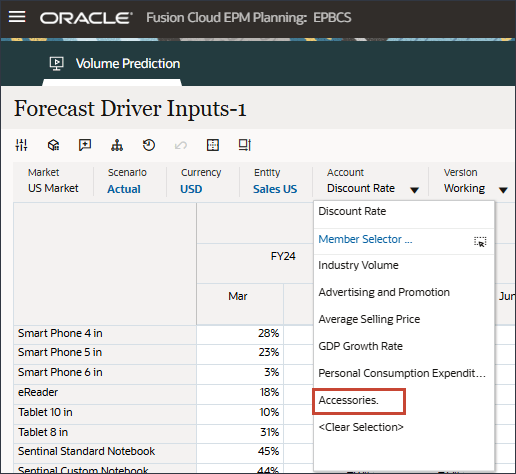
계정에서 산업 볼륨을 누르고 부속품을 선택합니다.
액세서리 드라이버는 스마트 목록을 사용합니다. 데이터 과학에서는 이것을 범주 변수라고 합니다. 미래 판매량을 계산하려면 숫자 값 또는 스마트 목록 값을 사용할 수 있습니다. 이 경우 선택한 스마트 목록 값(부속품 포함 또는 제외)에 따라 향후 판매량 예측에 영향을 줄 수 있습니다.
미래 기간에 대한 누락된 입력 드라이버 값 검토
이 섹션에서는 누락된 입력 드라이버가 있는지 확인합니다.
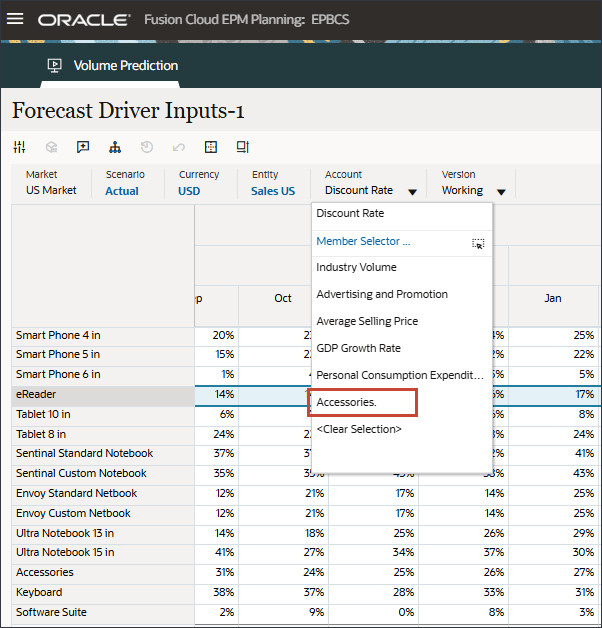
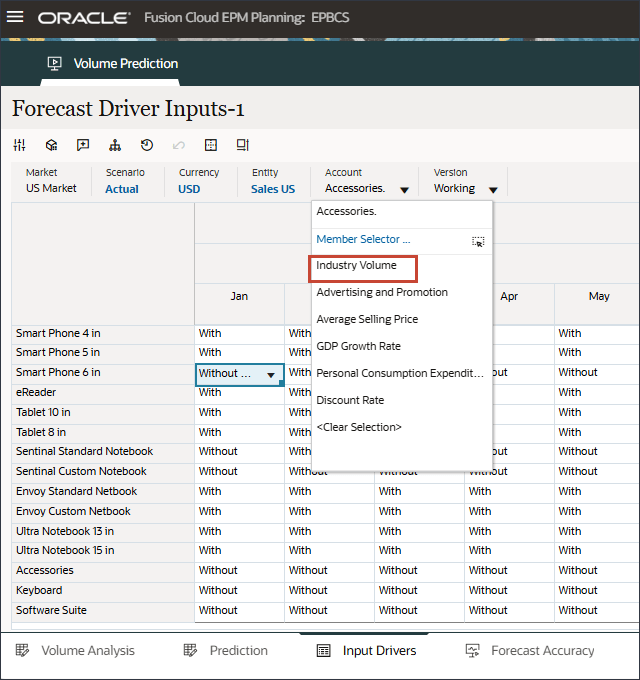
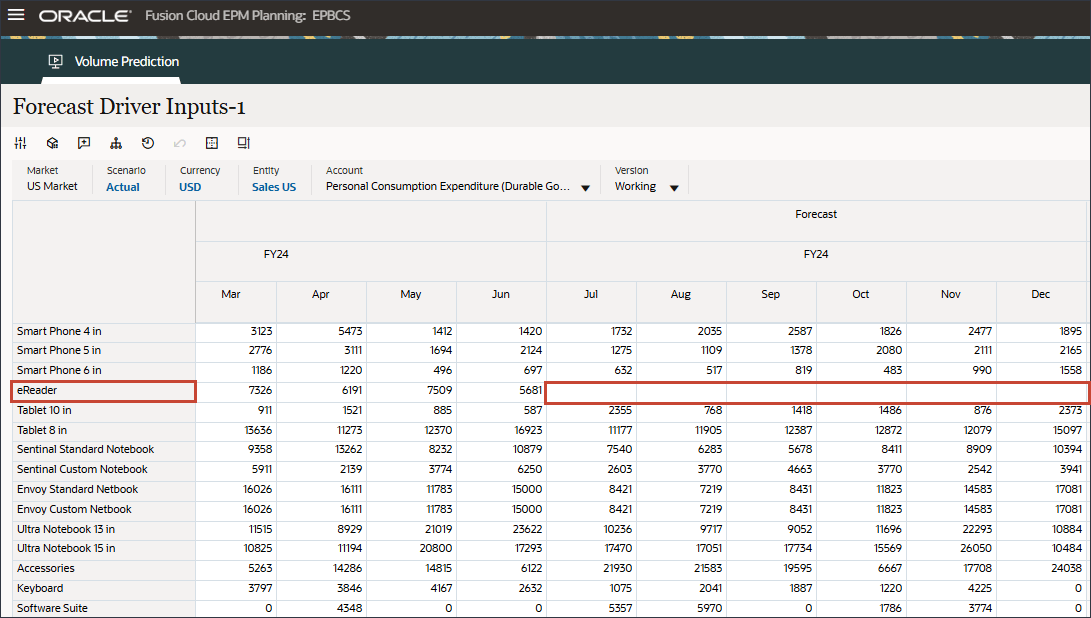
계정에서 액세서리를 누르고 산업 볼륨을 선택합니다.
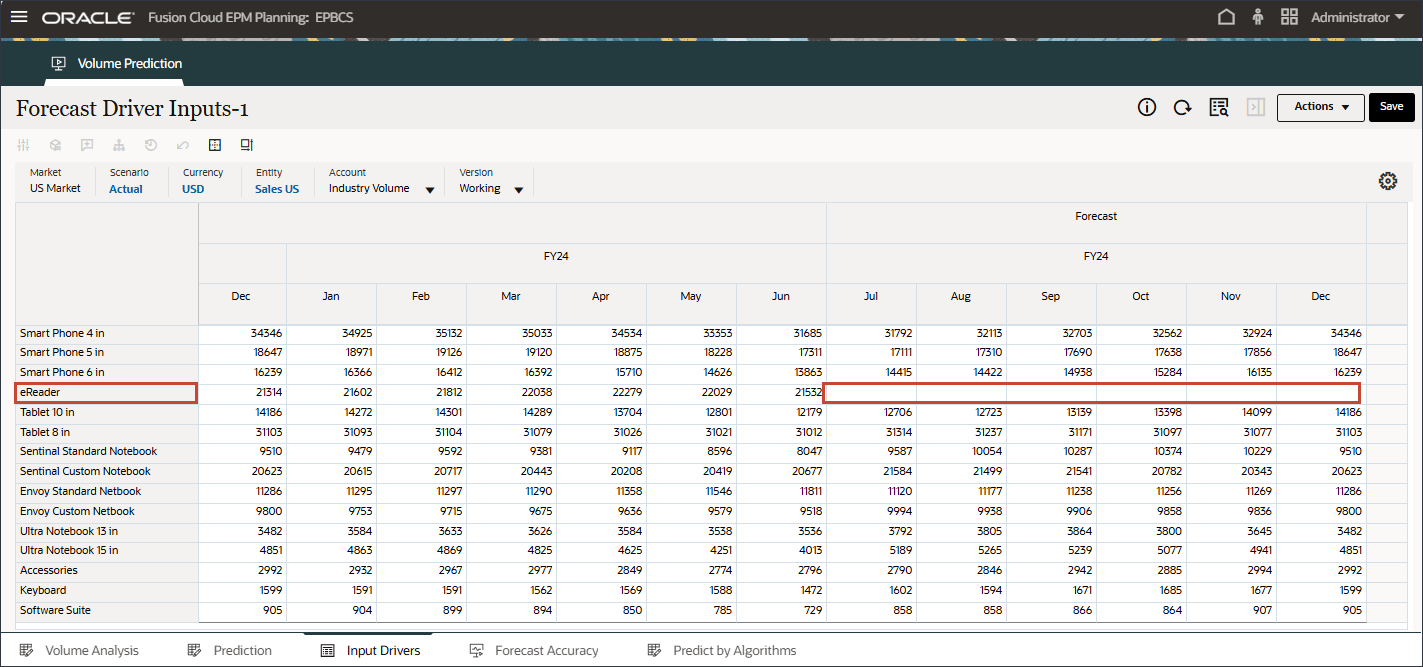
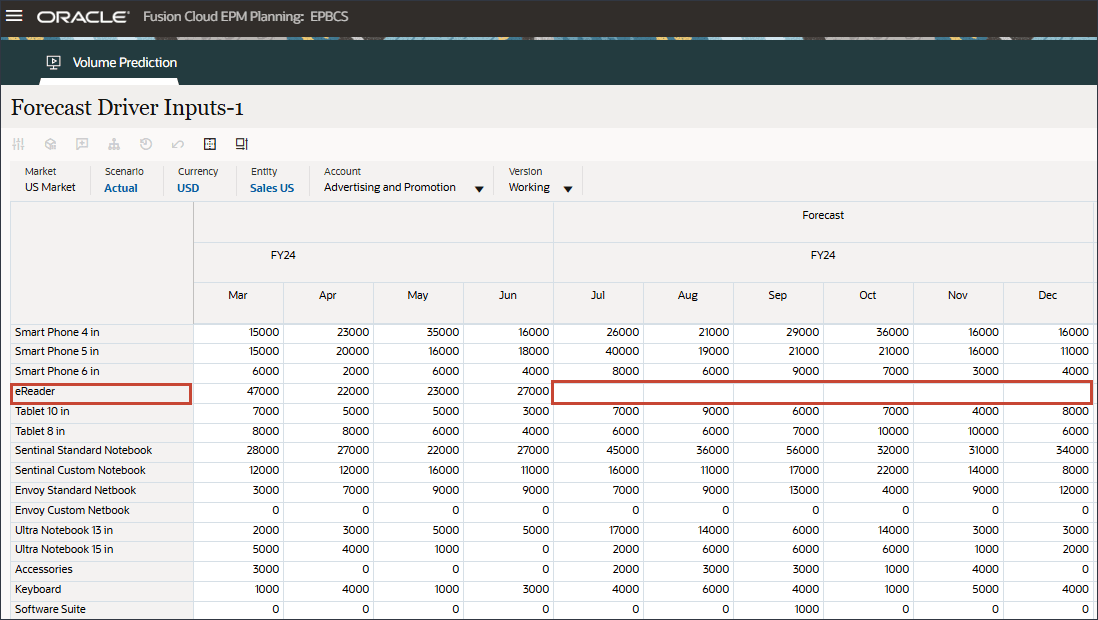
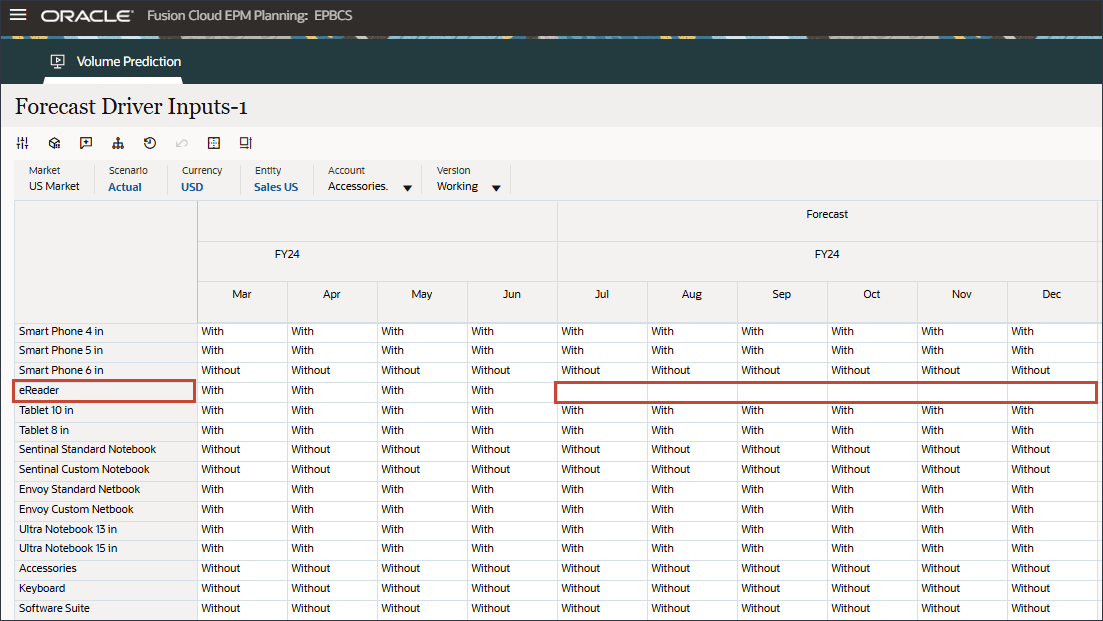
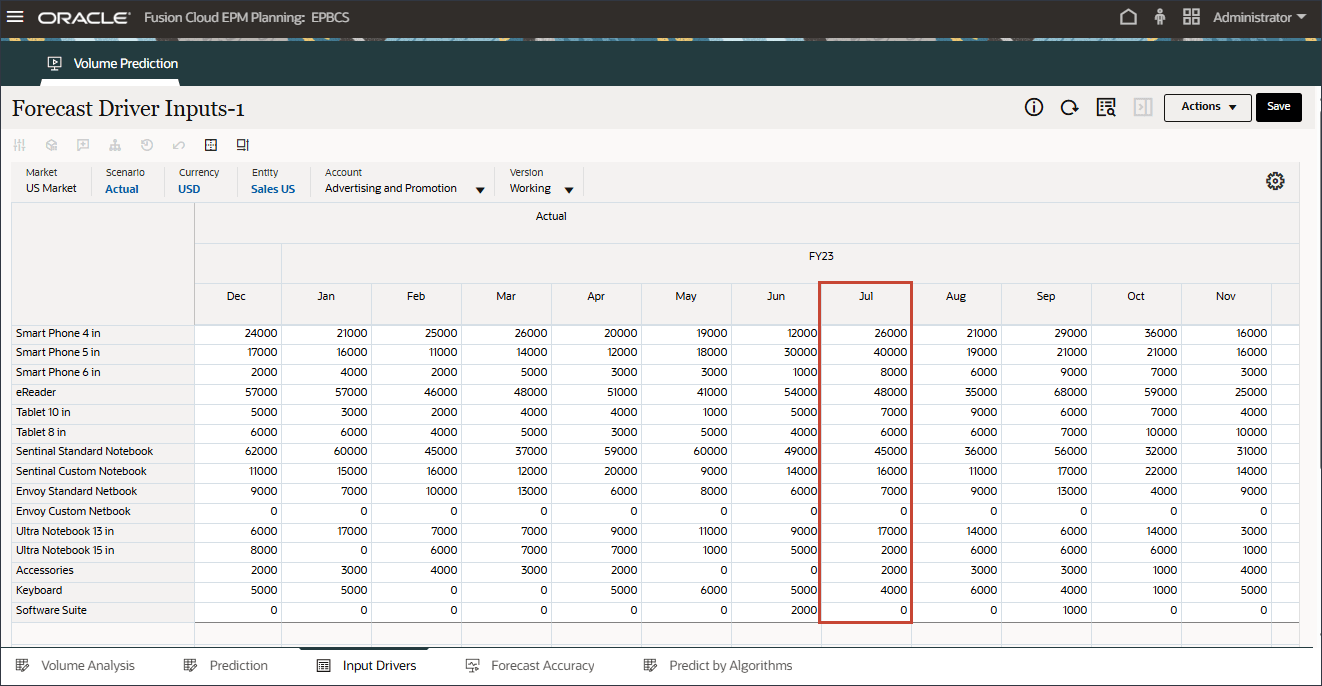
오른쪽으로 스크롤하고 eReader의 경우 예측에 대해 7월에서 12월 FY24 사이의 업종 볼륨에 대한 누락된 값을 확인합니다.
계정에서 산업 거래량을 누르고 광고 및 프로모션을 선택합니다.
오른쪽으로 스크롤하고 eReader의 경우 Forecast에서 7월과 12월 FY24 사이에 Advertising and Promotion의 누락된 값을 확인합니다.
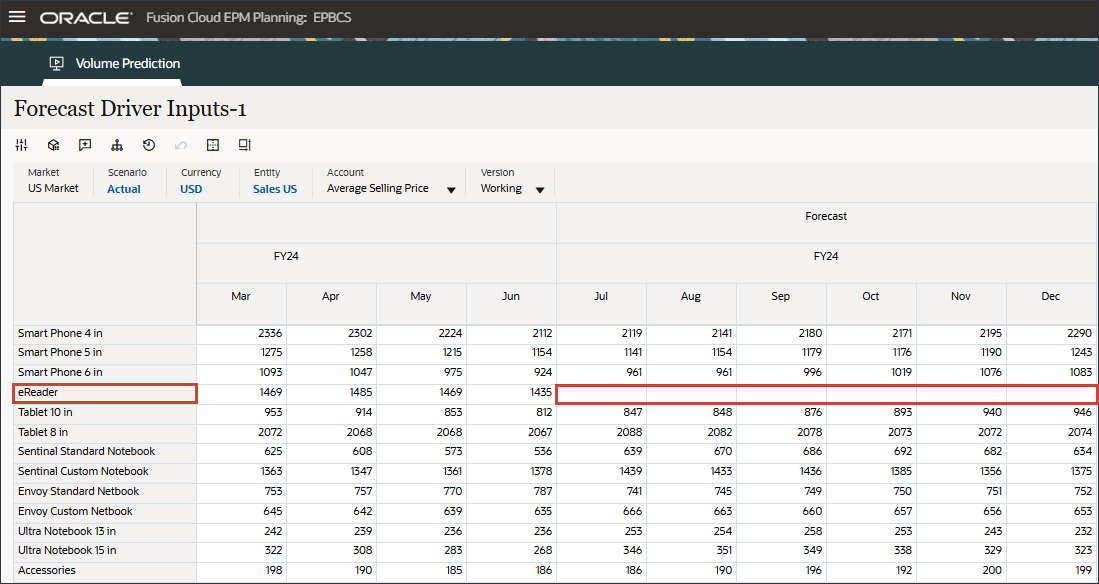
계정에서 광고 및 프로모션을 누르고 평균 판매 가격을 선택합니다.
오른쪽으로 스크롤하고 eReader의 경우 예측에 대해 7월과 12월 사이의 평균 판매 가격에 대해 누락된 값을 확인합니다. FY24.
계정에서 평균 판매 가격을 누르고 개인 소비 지출(내구재)을 선택합니다.
오른쪽으로 스크롤하고 eReader의 경우 예측에 대해 7월에서 12월 FY24 사이의 개인 소비 지출(내구재)에 대한 누락된 값을 확인합니다.
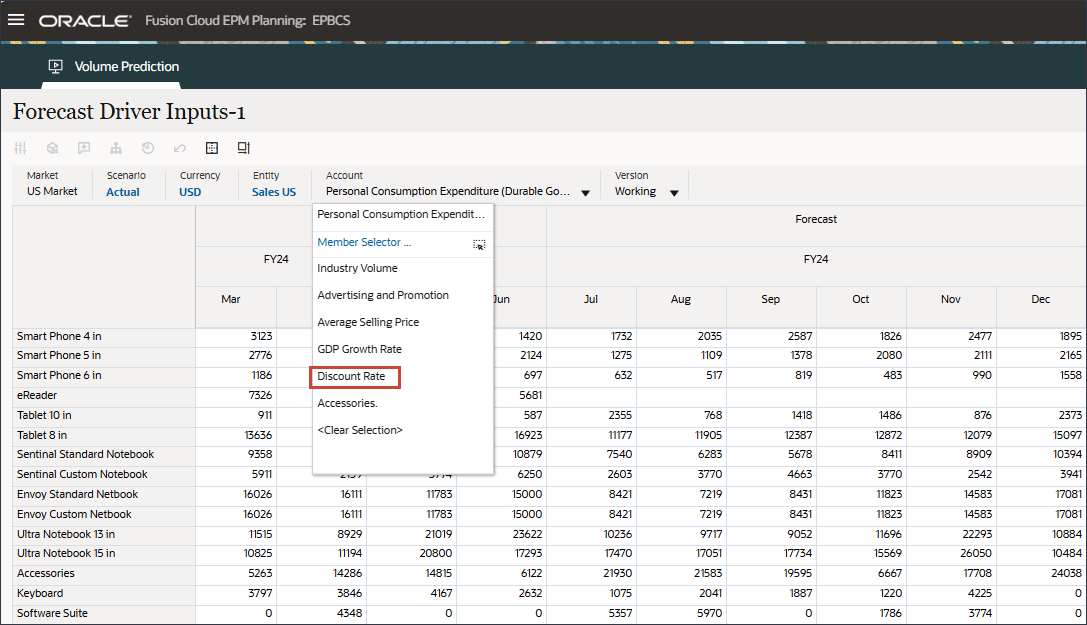
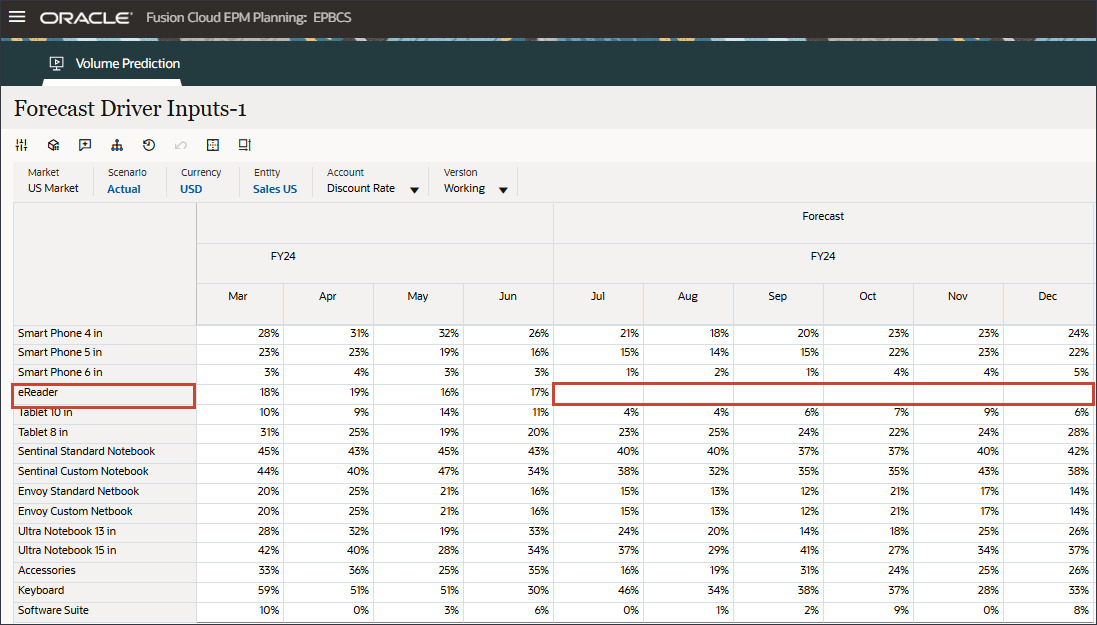
계정에서 개인 소비 비용(내구재)을 누르고 할인율을 선택합니다.
오른쪽으로 스크롤하고 eReader의 경우 Forecast에서 FY24 7월과 12월 사이의 할인율에 대한 누락된 값을 확인합니다.
계정에서 할인율을 누르고 부속품을 선택합니다.
오른쪽으로 스크롤하고 eReader의 경우 Forecast에서 FY24 7월과 12월 사이의 Accessories 값이 누락된 것을 확인합니다.
고급 예측은 누락된 입력 동인 값을 예측할 수 있습니다. 이 자습서의 이후 섹션에서는 eReader에 대한 미래 입력 드라이버 값이 예측되도록 고급 예측 작업을 구성합니다.
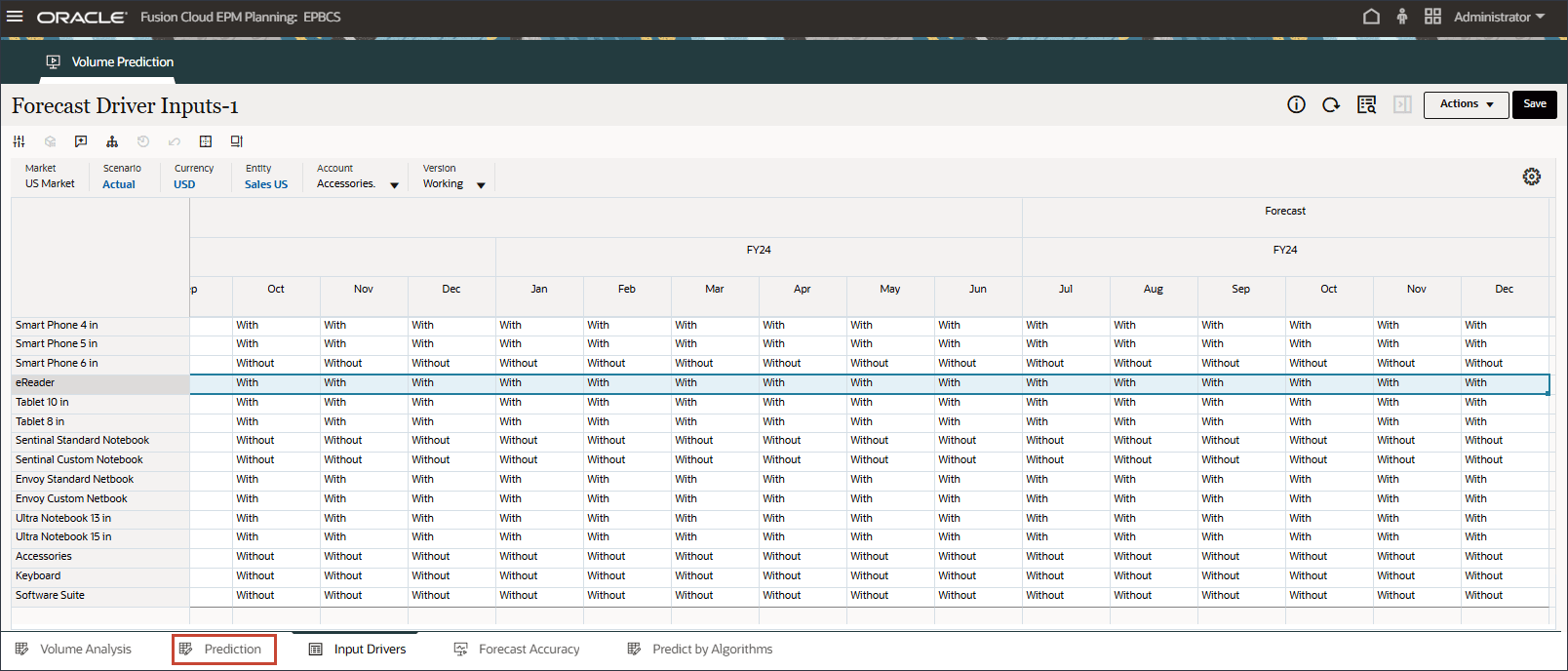
예측 Form 검토
이 섹션에서는 볼륨 예측 양식에서 누락된 값을 검토합니다.
하단에서 예측 탭을 누릅니다.
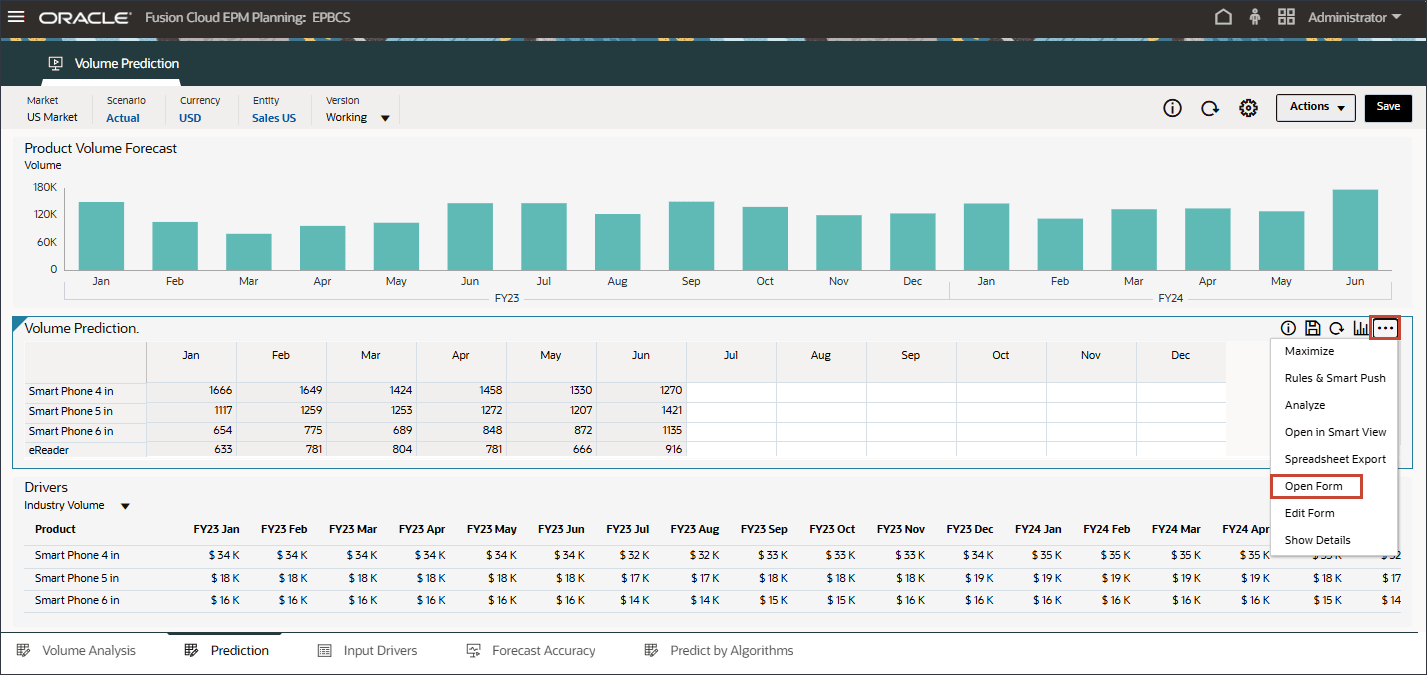
볼륨 예측 양식의 오른쪽에서 (작업)을 누르고 양식 열기를 선택합니다.
7월 ~ 12월 FY24 기간 동안 예측 결과가 누락되었습니다.
이러한 기간은 고급 예측 기능을 사용하여 모든 제품에 대해 예측하고자 하는 기간입니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
고급 예측 구성
이 섹션에서는 향후 제품 수량을 예측하도록 고급 예측을 구성합니다.
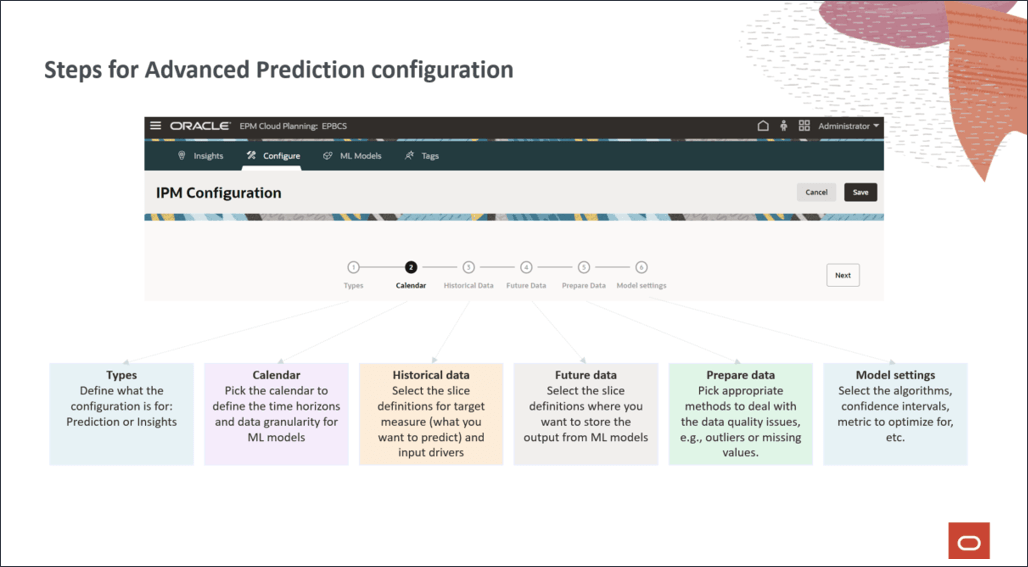
IPM 구성 마법사의 단계를 완료하여 고급 예측을 구성합니다.
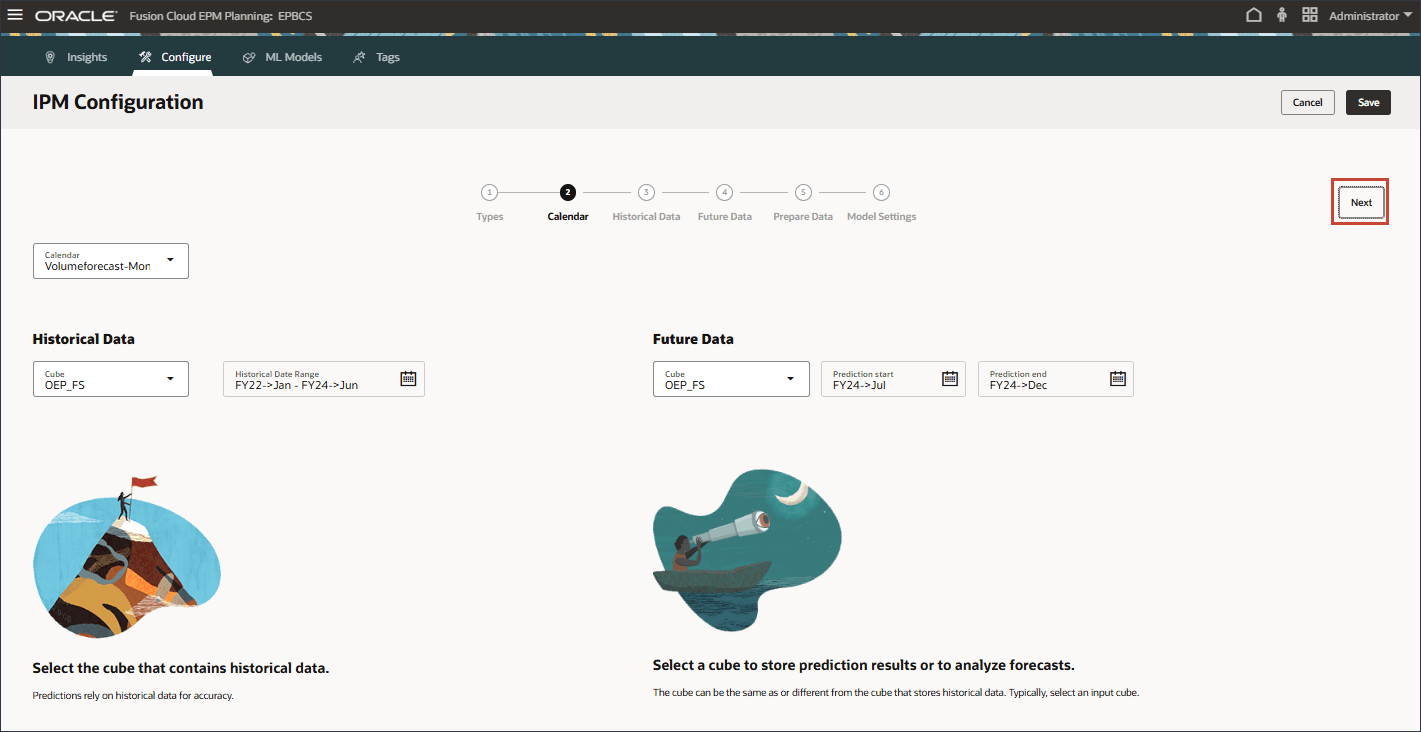
고급 예측 달력 설정
고급 예측을 구성하려면 먼저 과거 및 미래 기간을 모두 포함하는 캘린더를 정의해야 합니다.
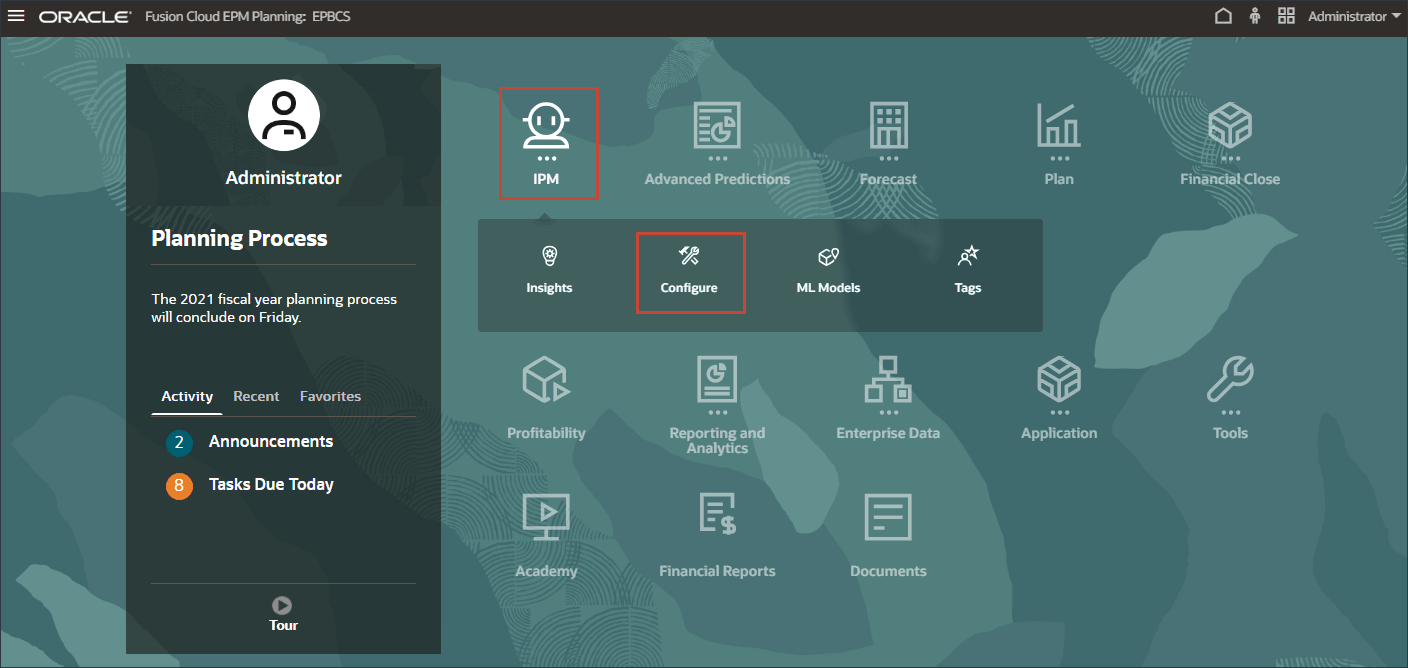
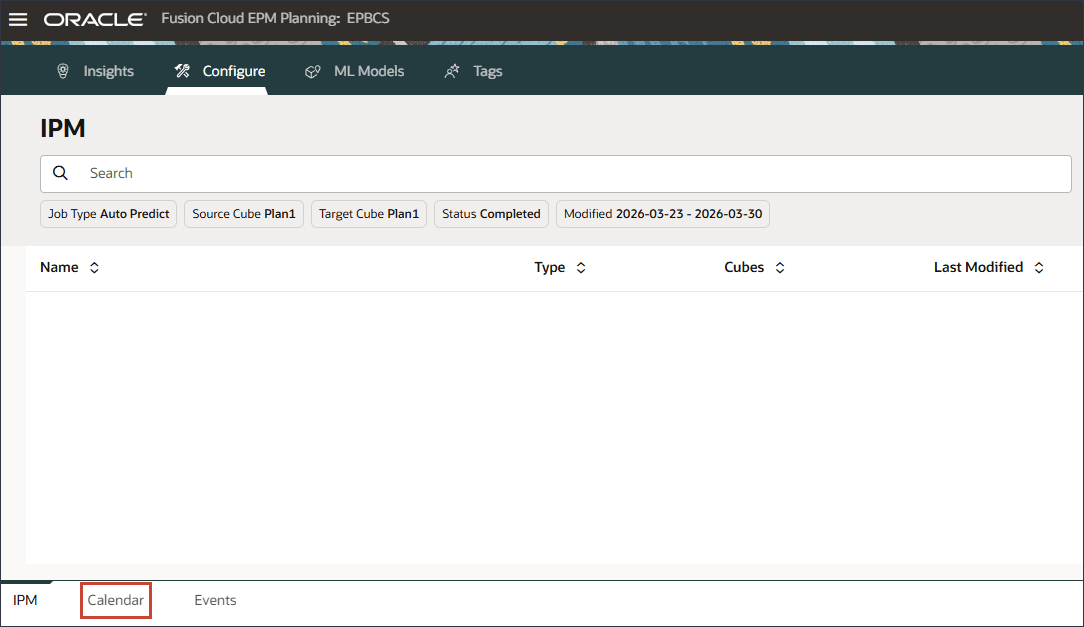
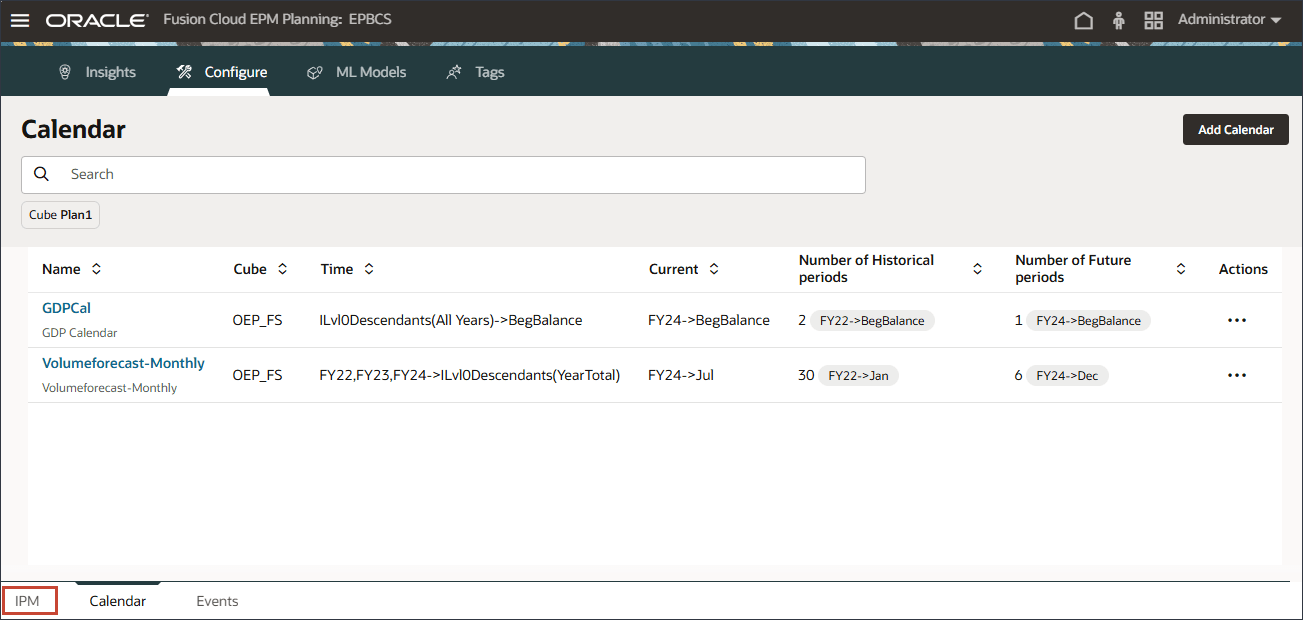
홈 페이지에서 IPM, 구성 순으로 누릅니다.
아래쪽에서 달력 탭을 누릅니다.
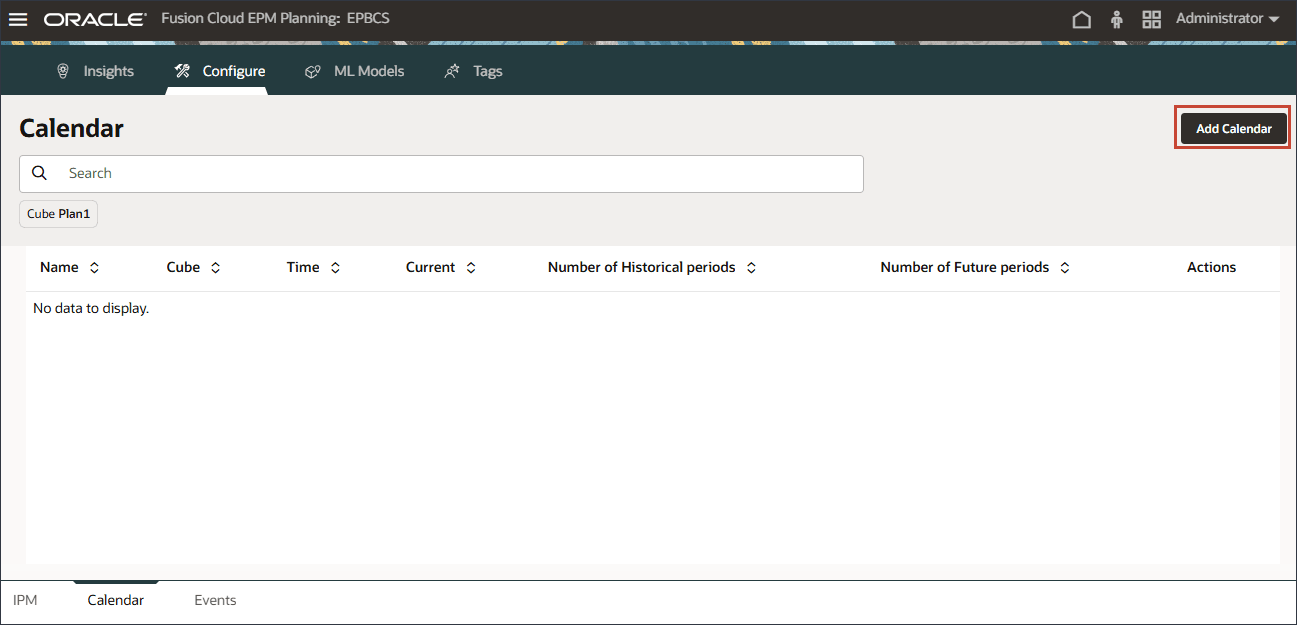
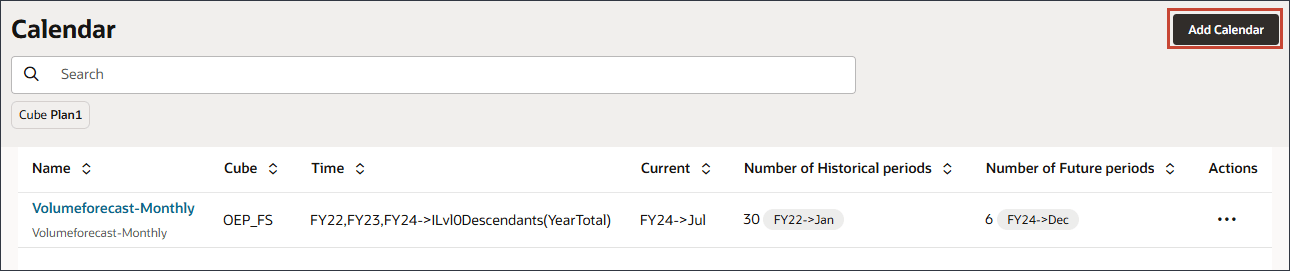
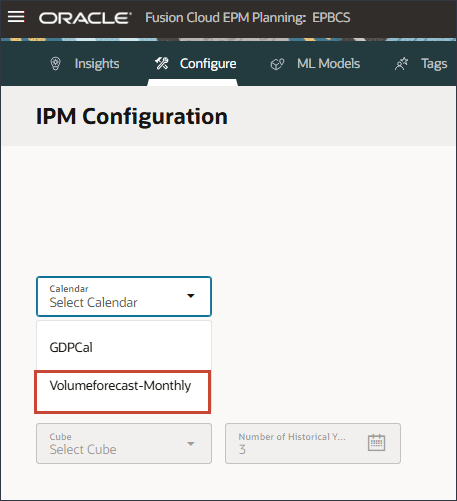
달력 추가를 누릅니다.
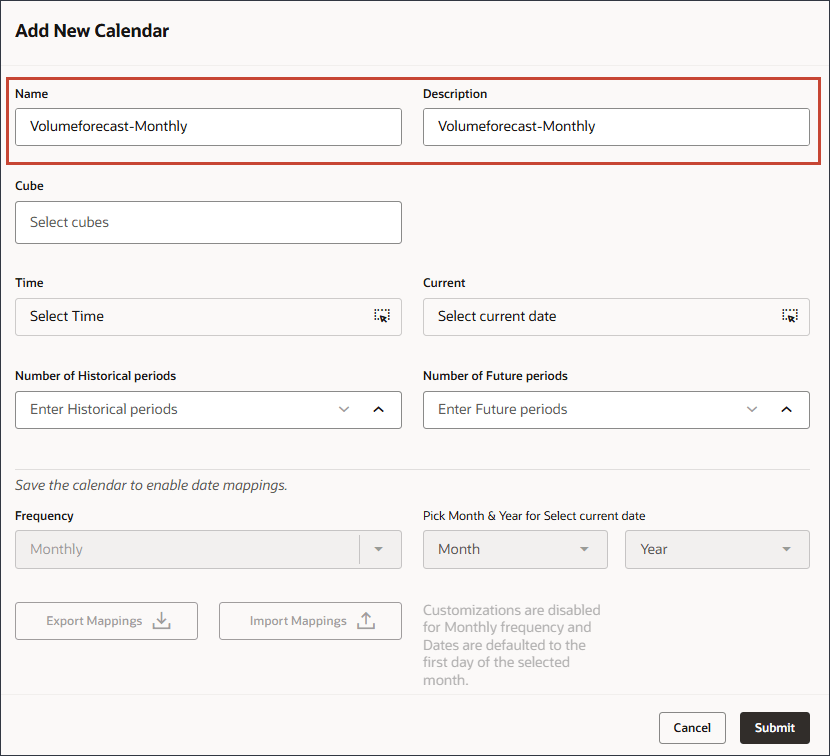
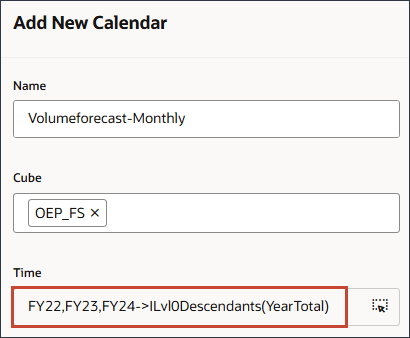
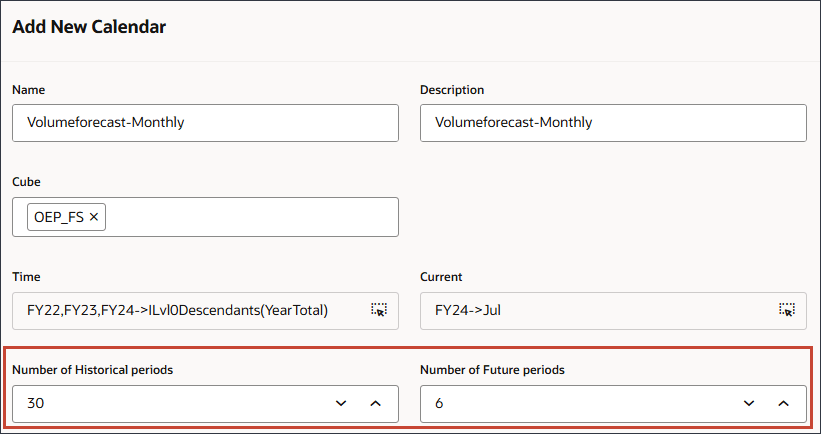
이름 및 설명에 Volumeforecast-Monthly를 입력합니다.
새 달력에 대한 이름과 설명이 입력됩니다.
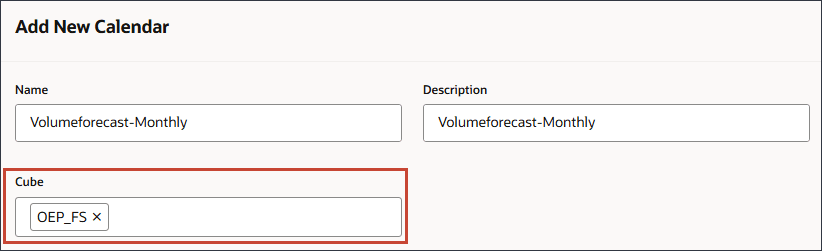
큐브의 경우 OEP_FS를 선택합니다.
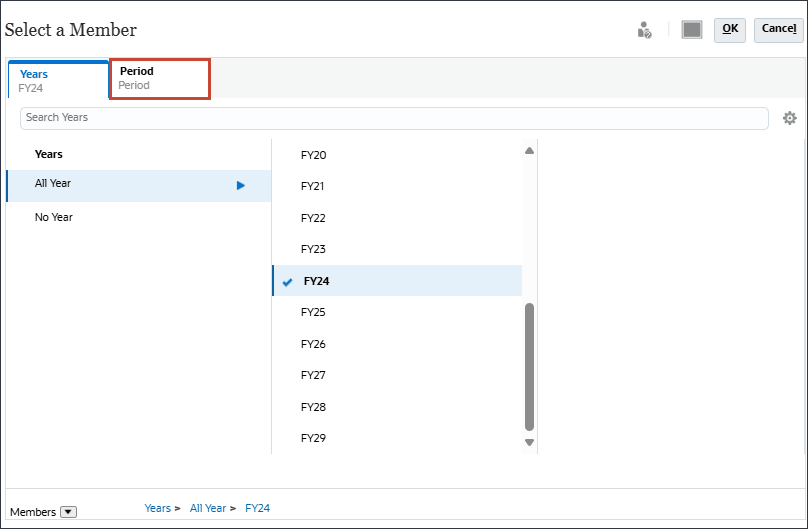
시간상 (시간 선택)을 누릅니다.
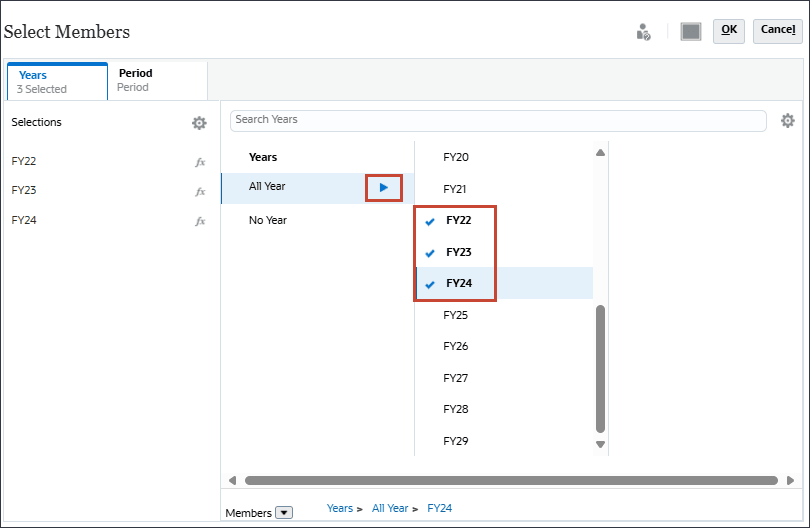
멤버 선택에서 연도에 대해 모든 연도에 대해 FY22, FY23 및 FY24를 선택합니다.
시간의 경우 예측에 필요한 과거 및 미래 기간의 전체 범위를 포함합니다.
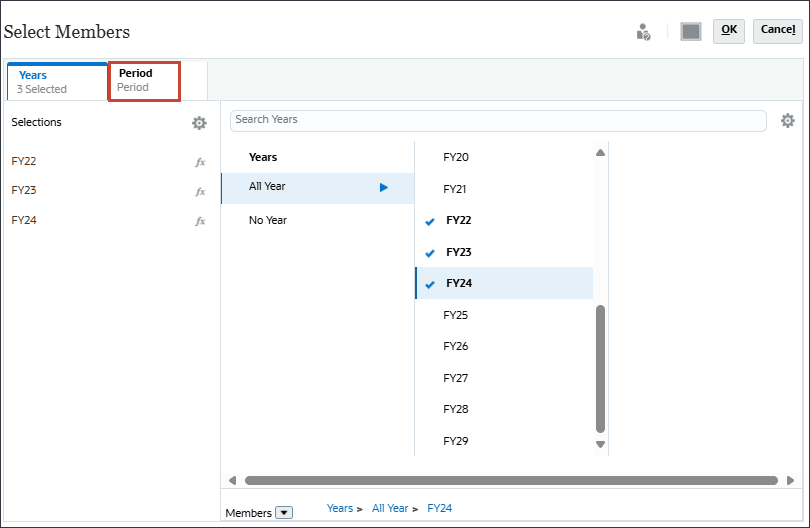
기간을 누릅니다.
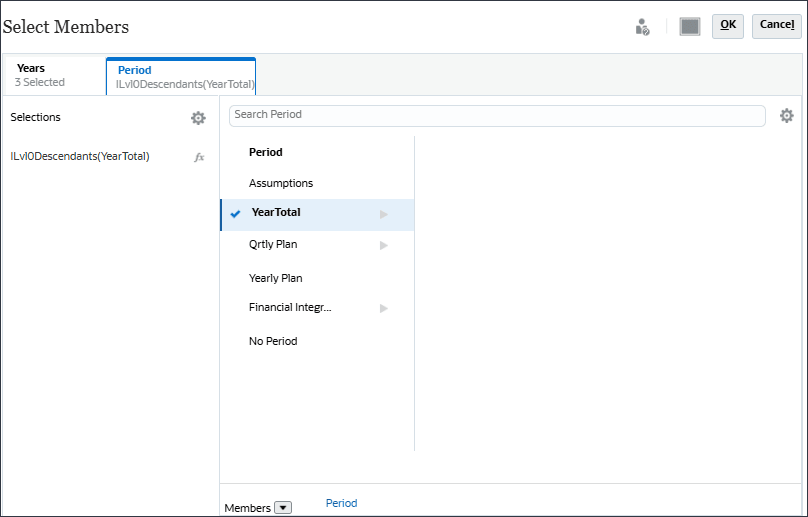
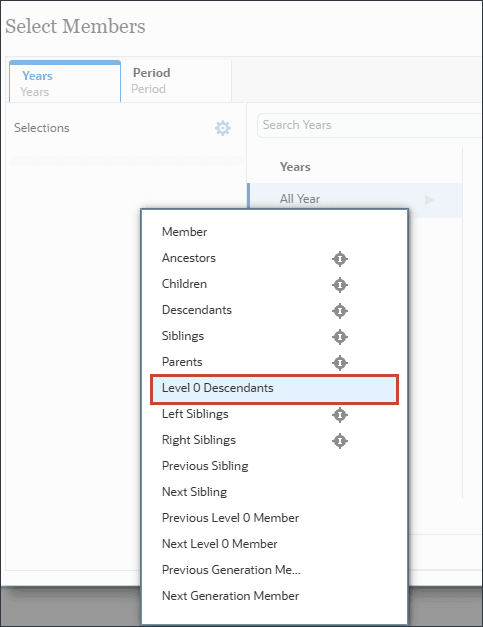
YearTotal의 경우 (함수 선택기)을 선택하고 레벨 0 하위 멤버를 선택합니다.
선택 항목이 표시됩니다.
기간의 경우 데이터를 사용할 과거 기간을 포함할 수 있습니다. 미래 예측을 위해 예측할 미래 데이터에 연도를 포함할 수 있습니다. 이 예에서는 연도(FY22, FY23, FY24) 및 기간(YearTotal(모든 월)의 모든 레벨 0 하위)을 선택했습니다.
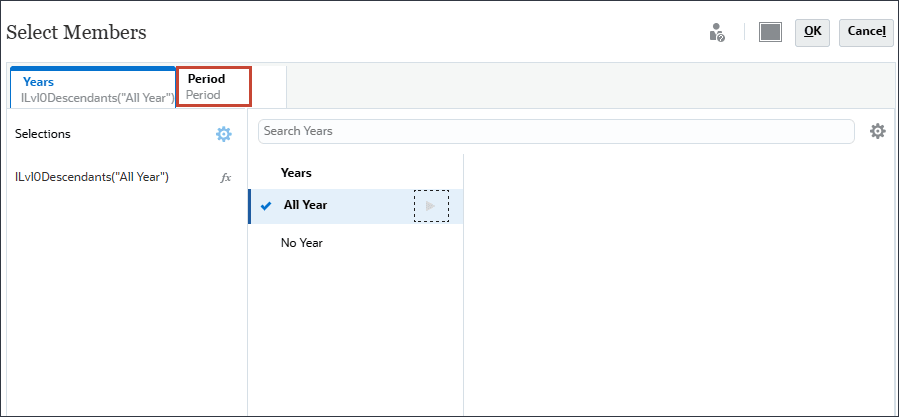
확인을 누릅니다.
연도 및 기간 선택이 캘린더에 포함됩니다.
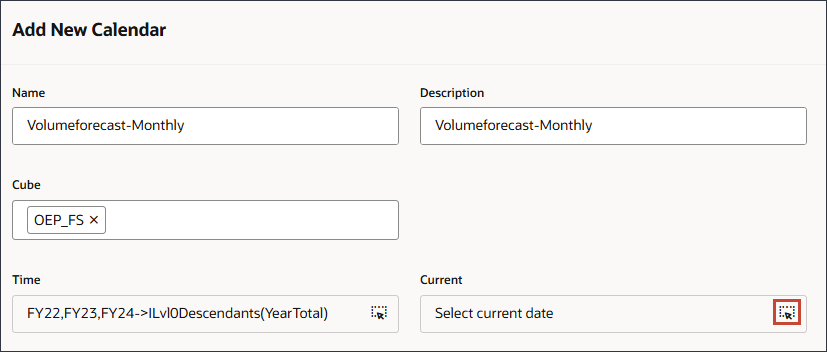
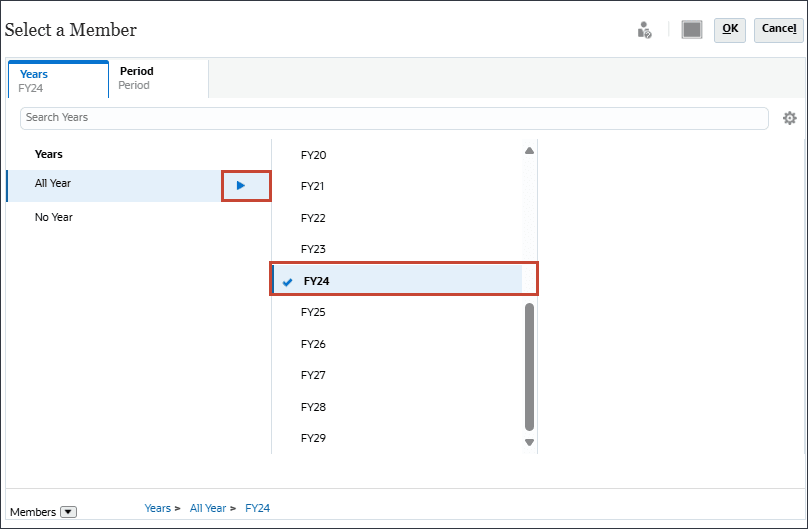
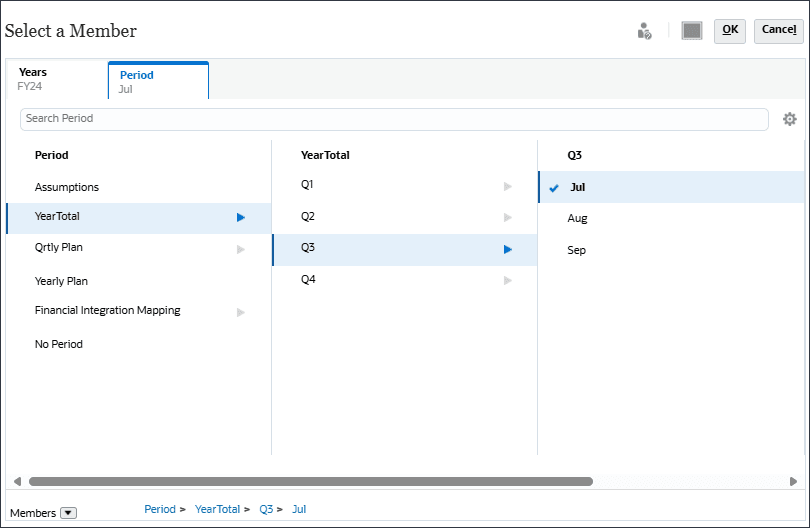
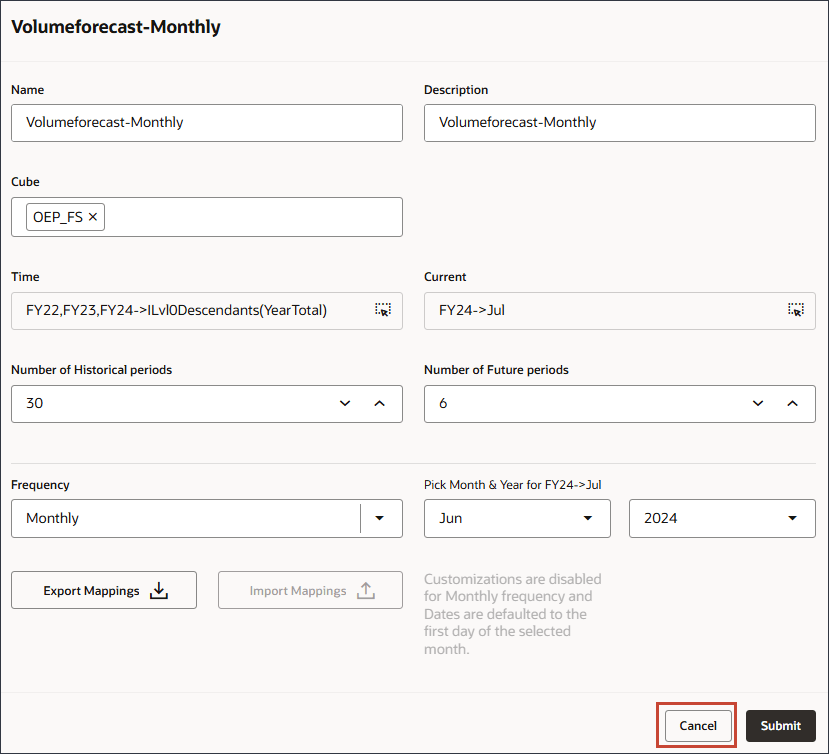
현재에서 (현재 일자 선택)을 누릅니다.
연도의 경우 FY24을 선택합니다.
기간을 누릅니다.
YearTotal 및 Q3에서 7월을 선택하고 확인을 누릅니다.
주:
대체 변수를 사용하여 현재 연도를 설정할 수 있습니다.
내역 기간 수에 30을 입력하고 미래 기간 수에 6을 입력합니다.
제출을 누릅니다.
확인 메시지가 표시됩니다.
주의:
제출을 눌러 일자 매핑을 설정하기 전에 캘린더를 저장했는지 확인하십시오.
Volumeforecast-Monthly의 경우 (작업)을 누르고 편집을 선택합니다.
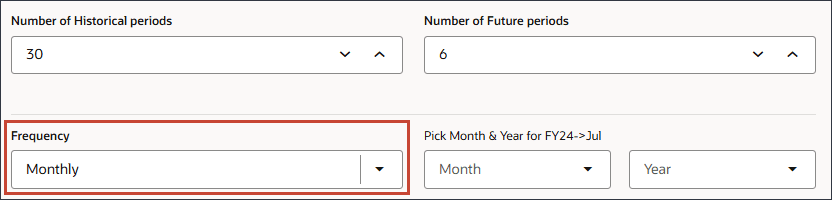
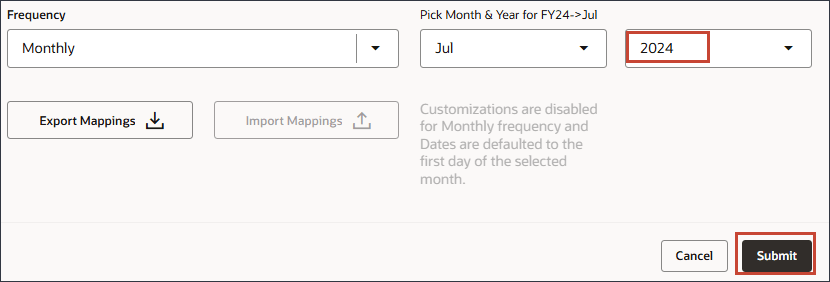
[빈도]에서 월별이 선택되었는지 확인합니다.
빈도 및 날짜 형식을 정의하는 날짜 매핑은 데이터 과학 엔진에 기간 데이터를 전송하는 중요한 단계입니다.
FY24 -> 7월의 피킹 월 및 연도에서 월이 선택되어 있는지 확인하고 월의 경우 7월을 선택합니다.
연도를 누르고 연도에 대해 2024를 선택한 다음 제출을 누릅니다.
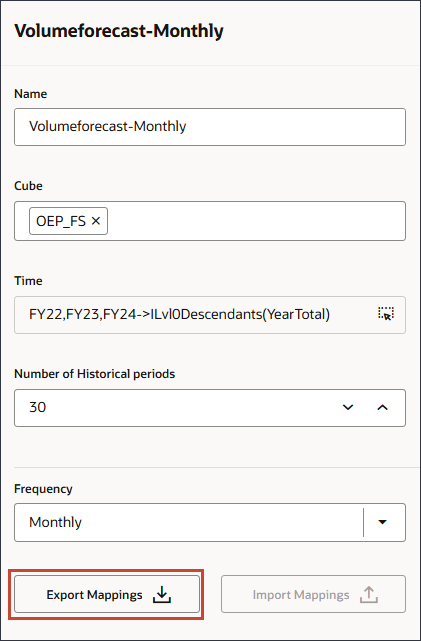
매핑을 검토하려면 VolumeForecast-Monthly 달력에 대해 (작업)을 누르고 편집을 선택합니다.
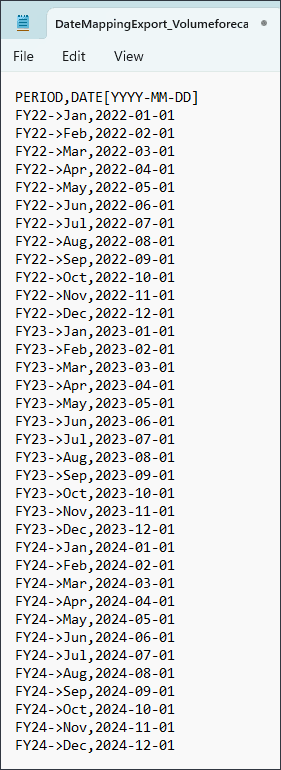
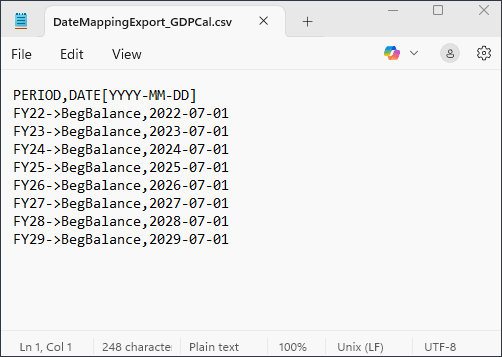
매핑 익스포트를 누릅니다.
파일을 열고 매핑을 검토할 수 있습니다. 메모장에서 .csv 파일을 열어야 합니다.
메모장 파일을 닫고 취소를 누릅니다.
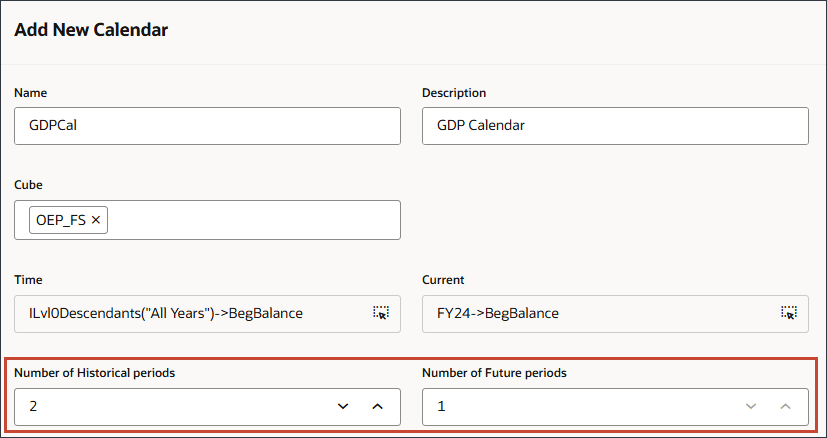
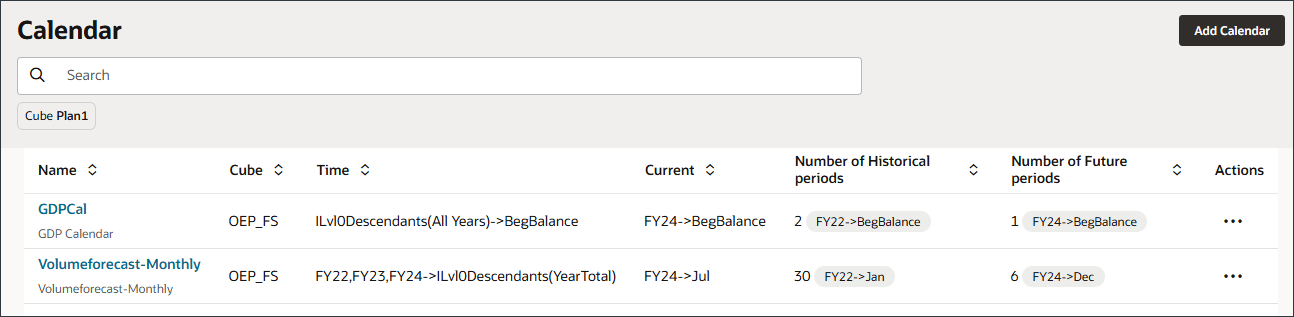
사용자정의 캘린더 생성
GDP 성장률은 FY22, FY23 및 FY24에 대해 BegBalance에 저장되므로 고급 예측에 BegBalance 기간의 입력이 포함될 수 있도록 사용자정의 캘린더를 생성합니다.
멤버 선택에서 연도에 대해 모든 연도에 대해 (함수 선택기)을 누르고 Level0Descendants를 선택합니다.
시간의 경우 예측에 필요한 과거 및 미래 기간의 전체 범위를 포함합니다.
기간을 누릅니다.
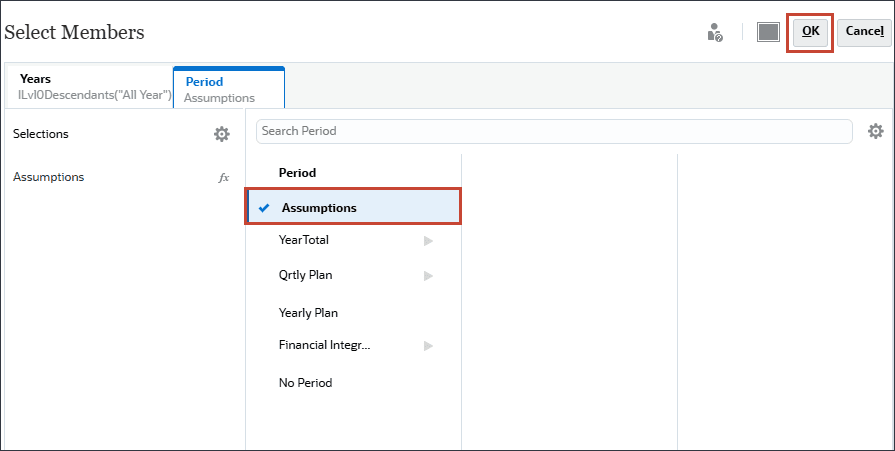
기간에 대해 가정을 선택하고 확인을 누릅니다.
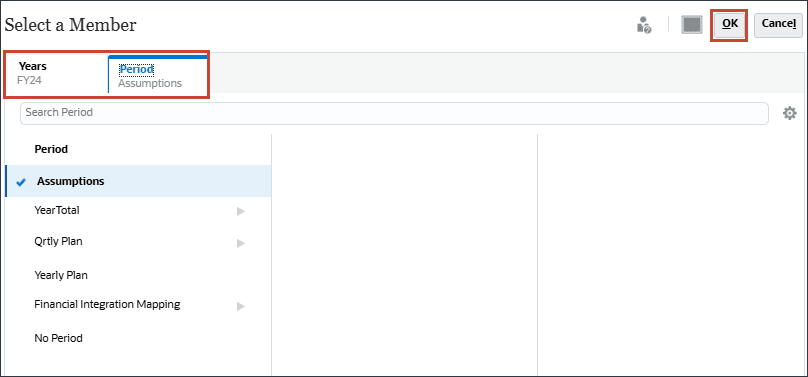
현재에서 (현재 날짜 선택)을 누릅니다.
현재 날짜의 경우 연도에 대해 FY24을 선택하고 기간에 대해 가정을 선택한 다음 확인을 누릅니다.
과거 기간 수에 2를 입력하고 미래 기간 수에 1을 입력한 다음 제출을 누릅니다.
확인 메시지가 표시됩니다.
확인 메시지를 닫을 수 있습니다.
주의:
제출을 눌러 일자 매핑을 설정하기 전에 GDPCal을 저장해야 합니다.
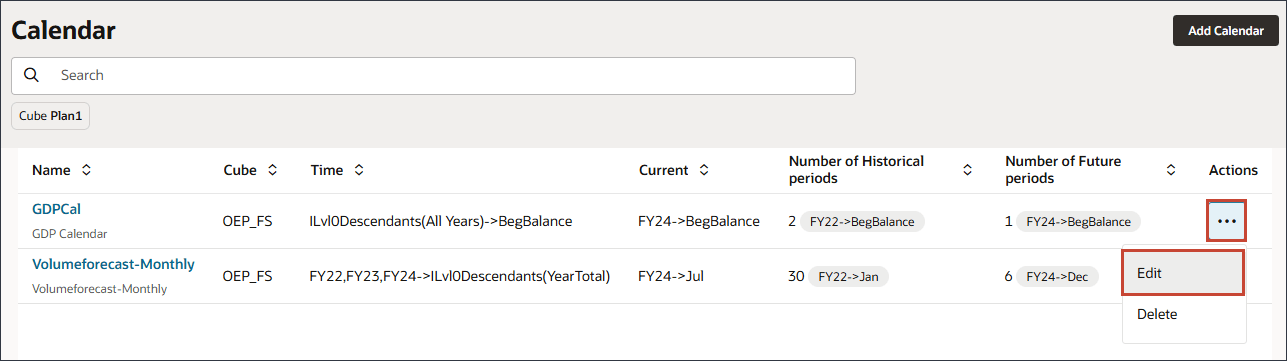
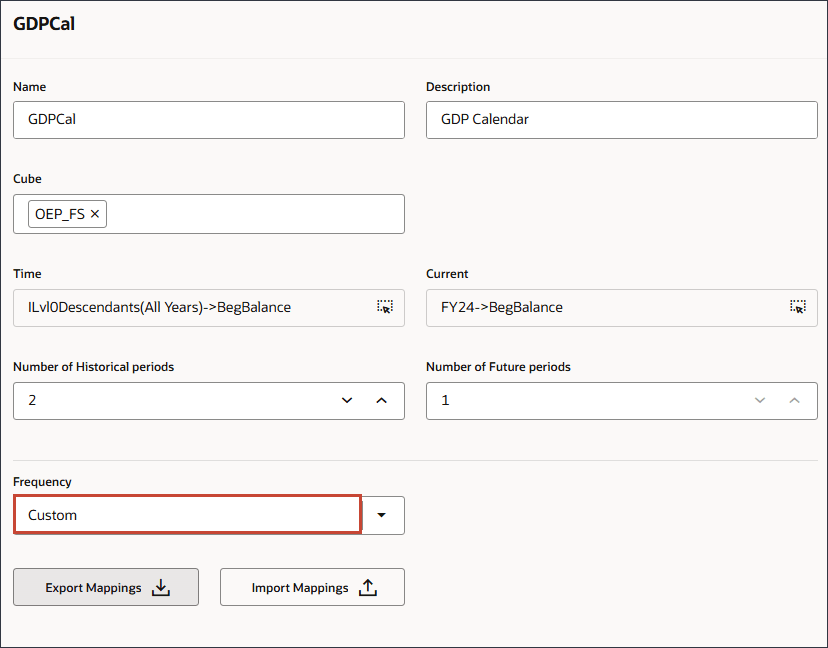
GDPCal 행에서 (작업)을 누르고 편집을 선택합니다.
빈도에서 사용자정의를 선택합니다.
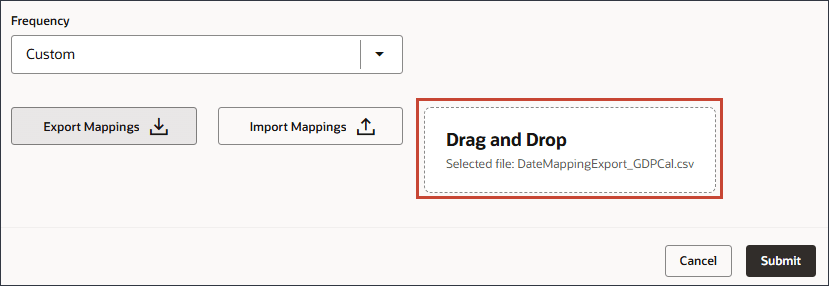
매핑 임포트를 누릅니다.
DateMappingExport_GDPCal.csv를 찾아 선택한 다음 열기를 누릅니다.
제출을 누릅니다.
GDP 달력이 추가됩니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
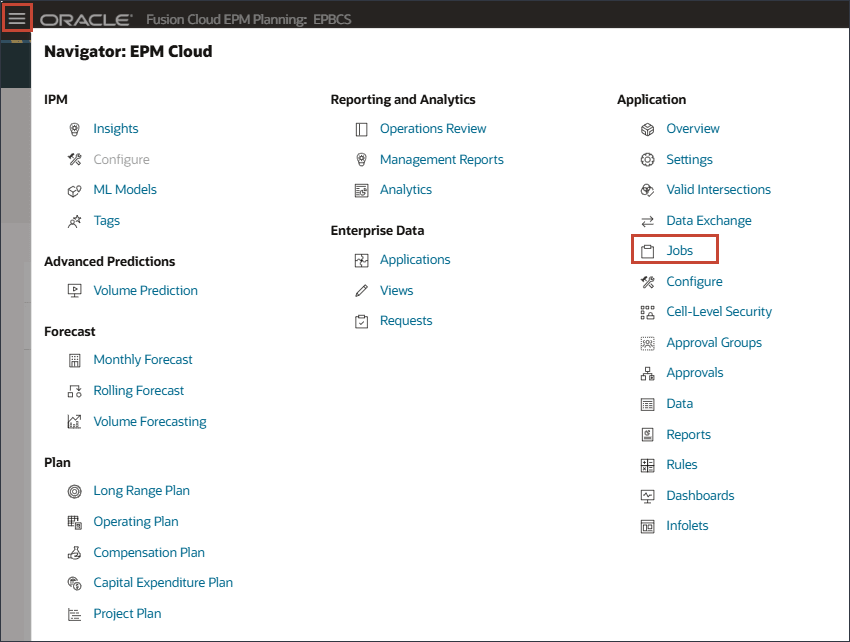
IPM 작업에서 고급 예측 구성
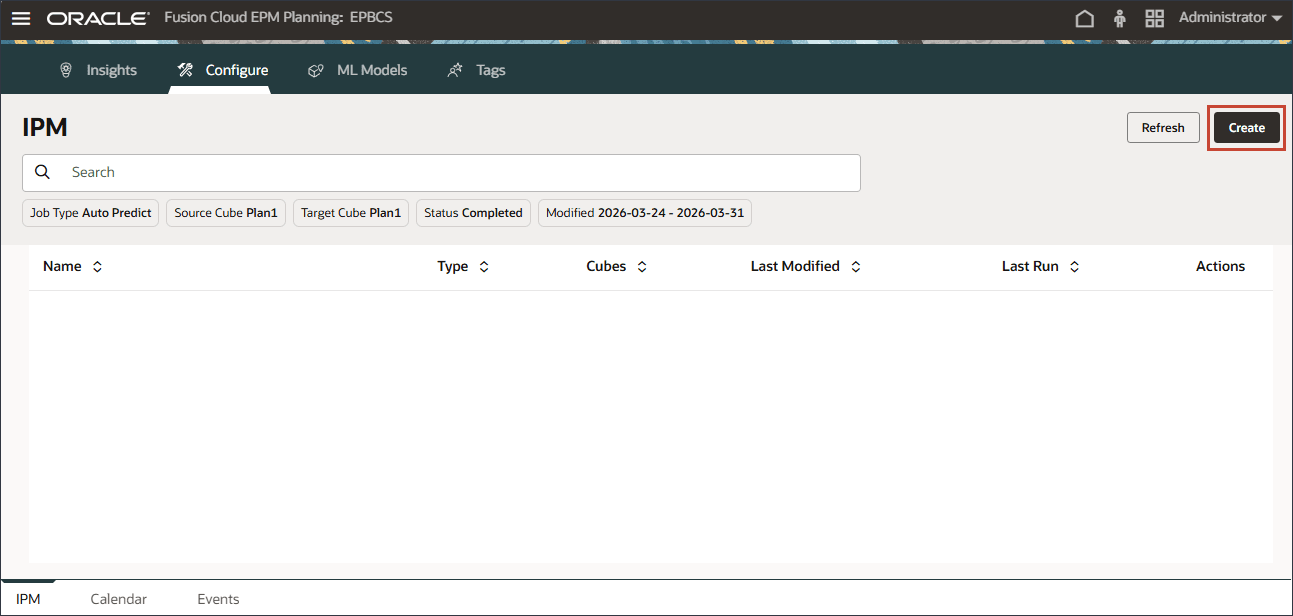
홈 페이지에서 IPM, 구성 순으로 누릅니다.
IPM 탭을 누릅니다.
IPM 페이지에서 생성을 누릅니다.
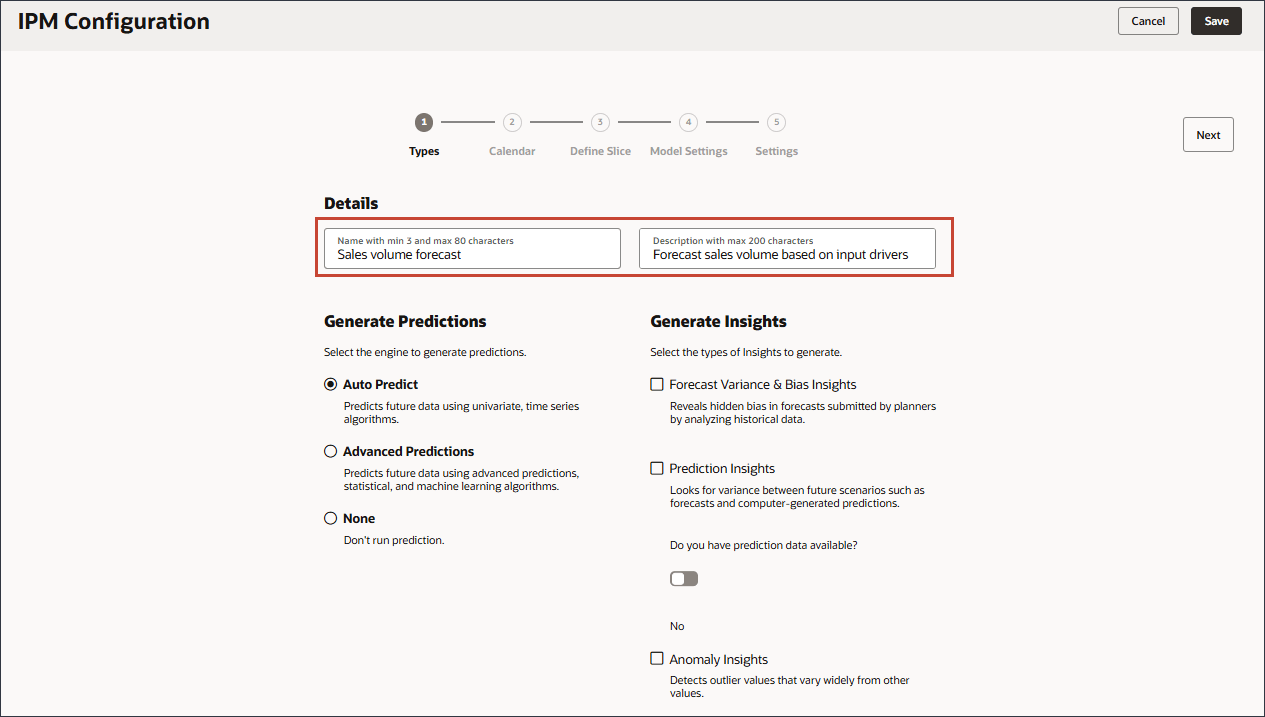
[세부정보]의 [이름]에 판매량 예측을 입력하고 [설명]에 입력 동인을 기준으로 판매량 예측을 입력합니다.
다변량 통계 및 머신 러닝 알고리즘을 사용하여 미래 데이터를 예측하려면 고급 예측을 선택한 후 다음을 누릅니다.
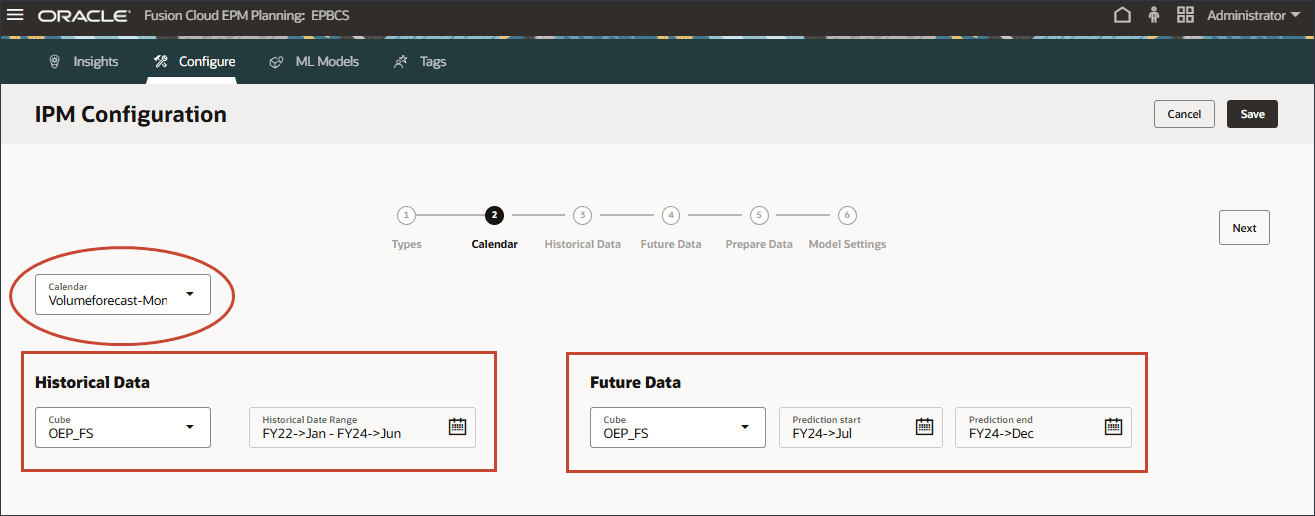
일정 선택
캘린더를 선택하거나 기간 범위를 수동으로 제공하여 과거 및 미래 기간의 시간 범위를 정의할 수 있습니다.
달력을 선택하려면 달력을 누르고 분량 예측-월별을 선택합니다.
달력을 선택하면 과거 및 미래 기간 범위가 자동으로 채워집니다.
큐브 선택은 달력 정의에서 자동으로 채워집니다.
달력을 선택한 경우 기간 범위 정의가 달력 정의에서 채워지므로 기간 범위를 변경할 수 없습니다. 기간을 변경하려면 캘린더 설정으로 돌아가서 변경해야 합니다.
주:
고급 예측의 경우 IPM 구성에서 과거 데이터 또는 미래 데이터를 수동으로 선택할 수 없습니다. 캘린더를 사전 정의해야 합니다.
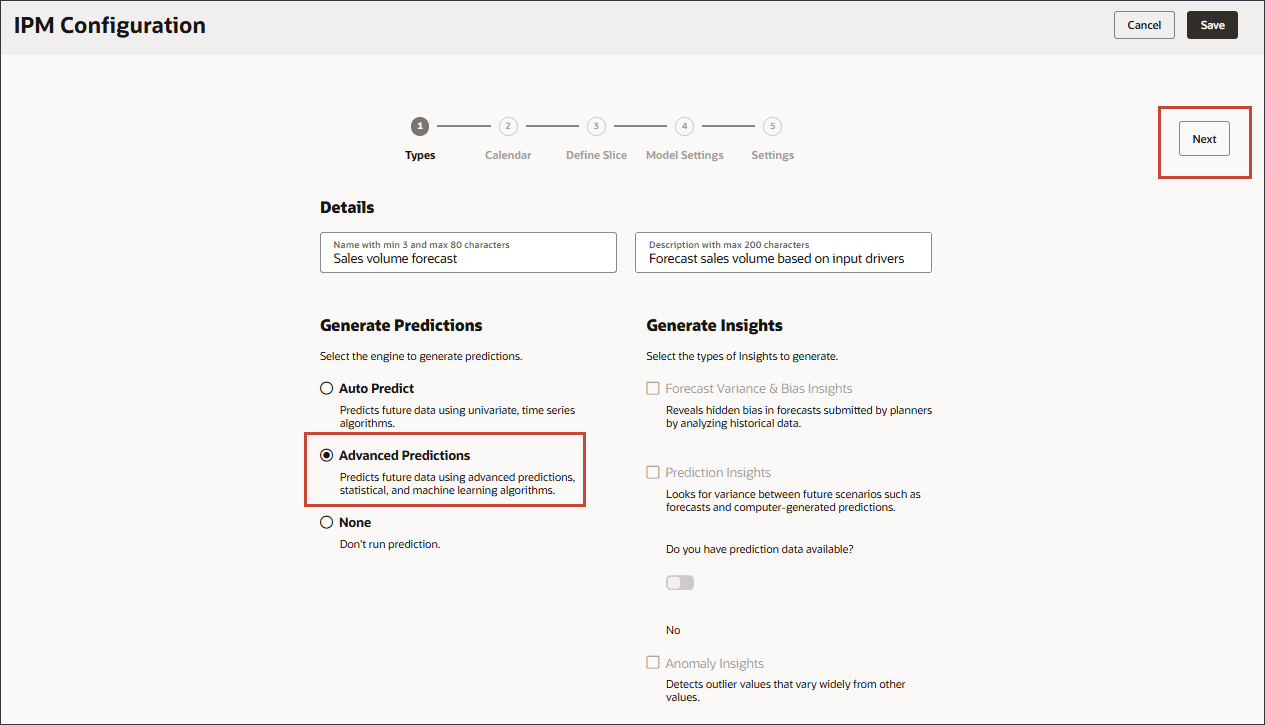
다음을 누릅니다.
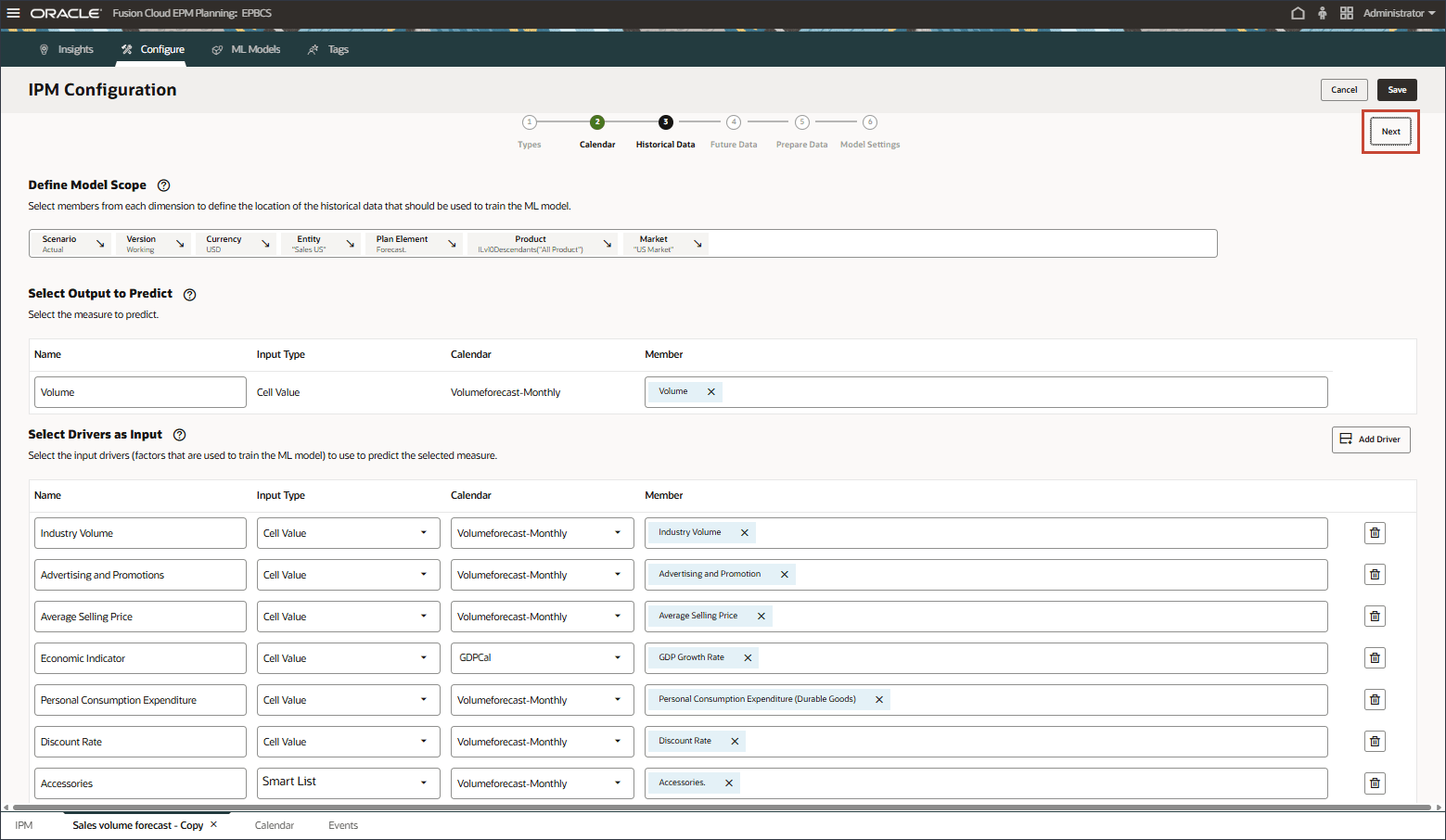
기록 데이터에 대한 슬라이스 정의 선택
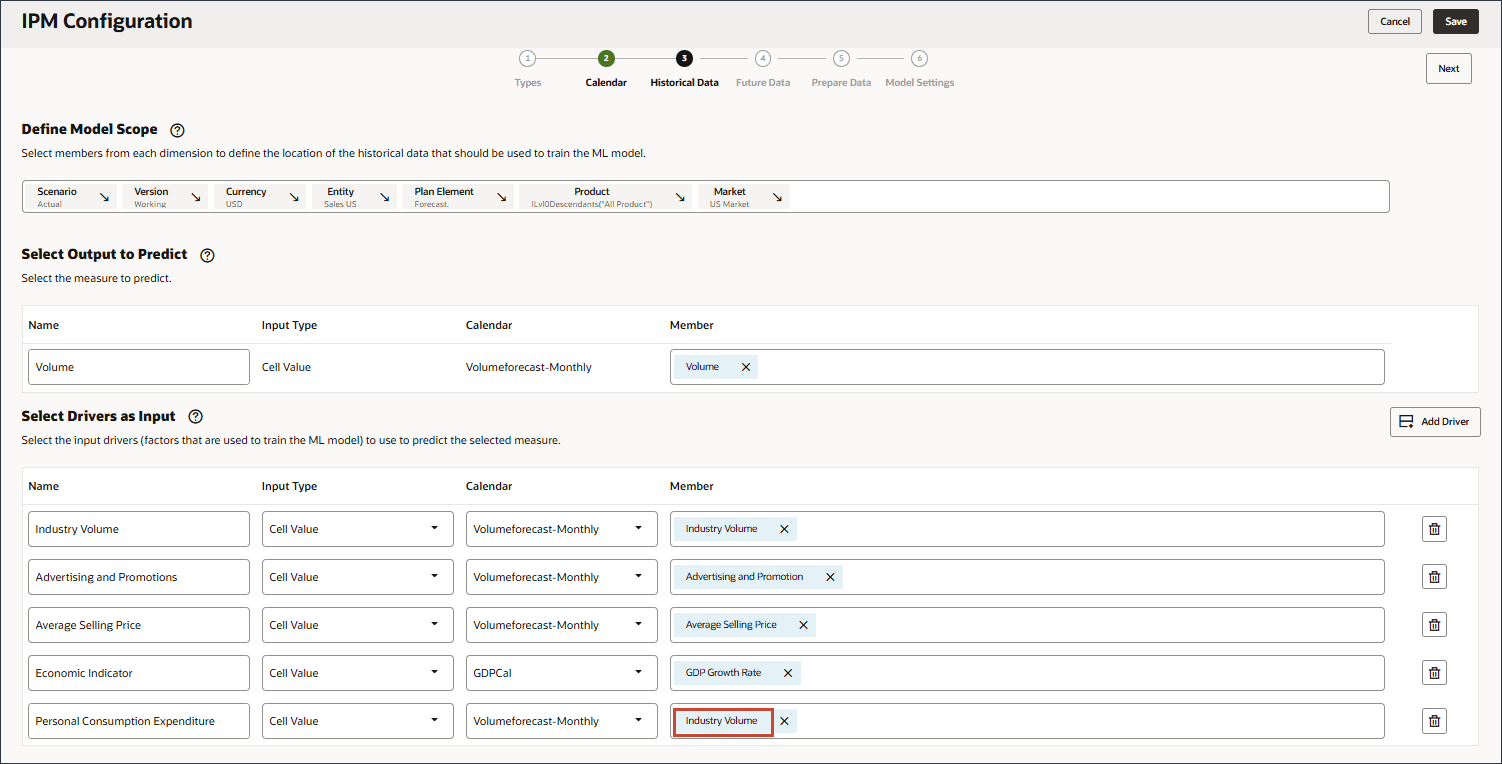
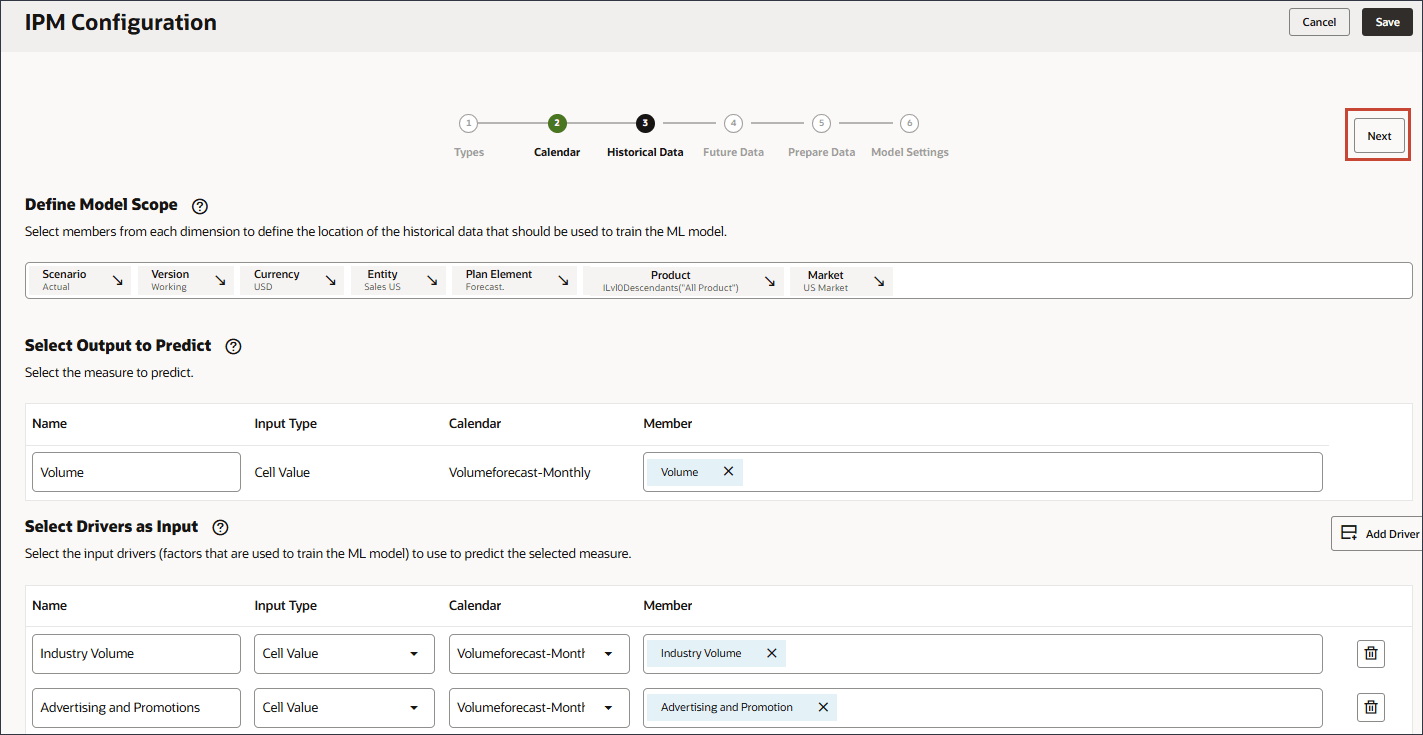
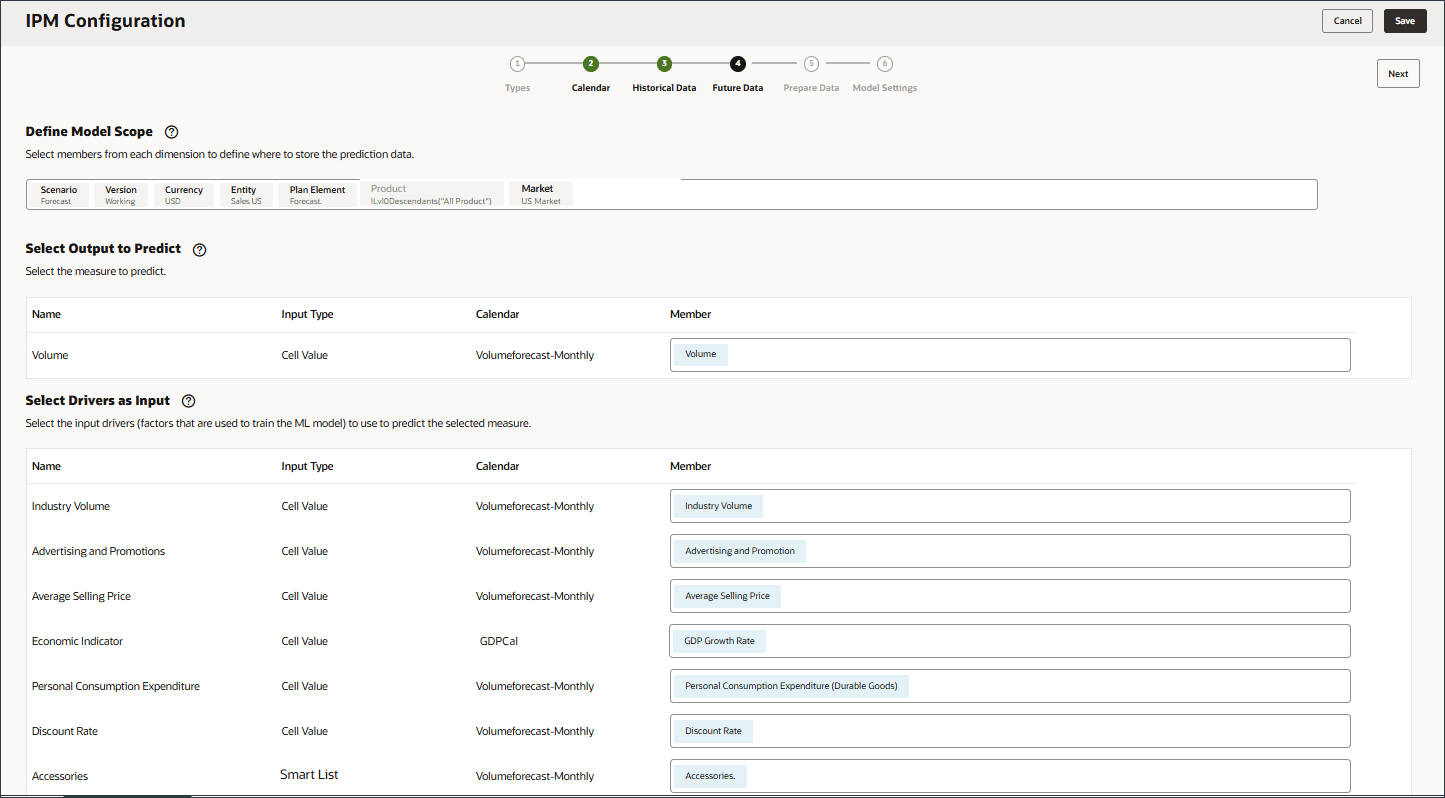
이 섹션에서는 예측할 항목과 사용할 입력 드라이버를 정의합니다. 입력 드라이버를 정의하고 큐브의 데이터에 매핑합니다. 이러한 출력 측정항목 및 입력 드라이버가 EPM 큐브에 이미 정의되어 있어야 합니다. 자습서 앞부분에서 검토했듯이 대상 및 입력 드라이버의 다양한 계정에 필요한 계정 멤버와 데이터가 있습니다.
이 구성에서 계정 차원에는 출력 및 입력 드라이버에 필요한 측정 단위와 계정이 포함되어 있으므로 계정 차원을 구성 정의 행에 포함해야 합니다.
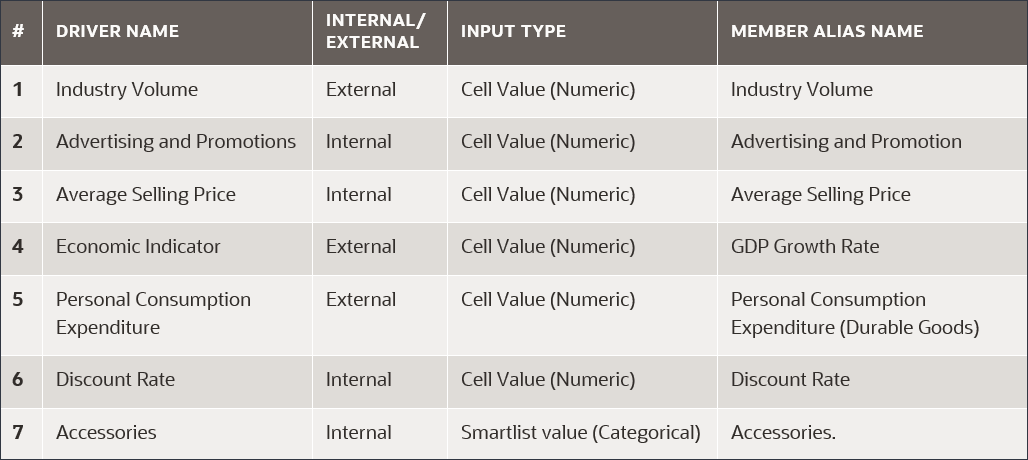
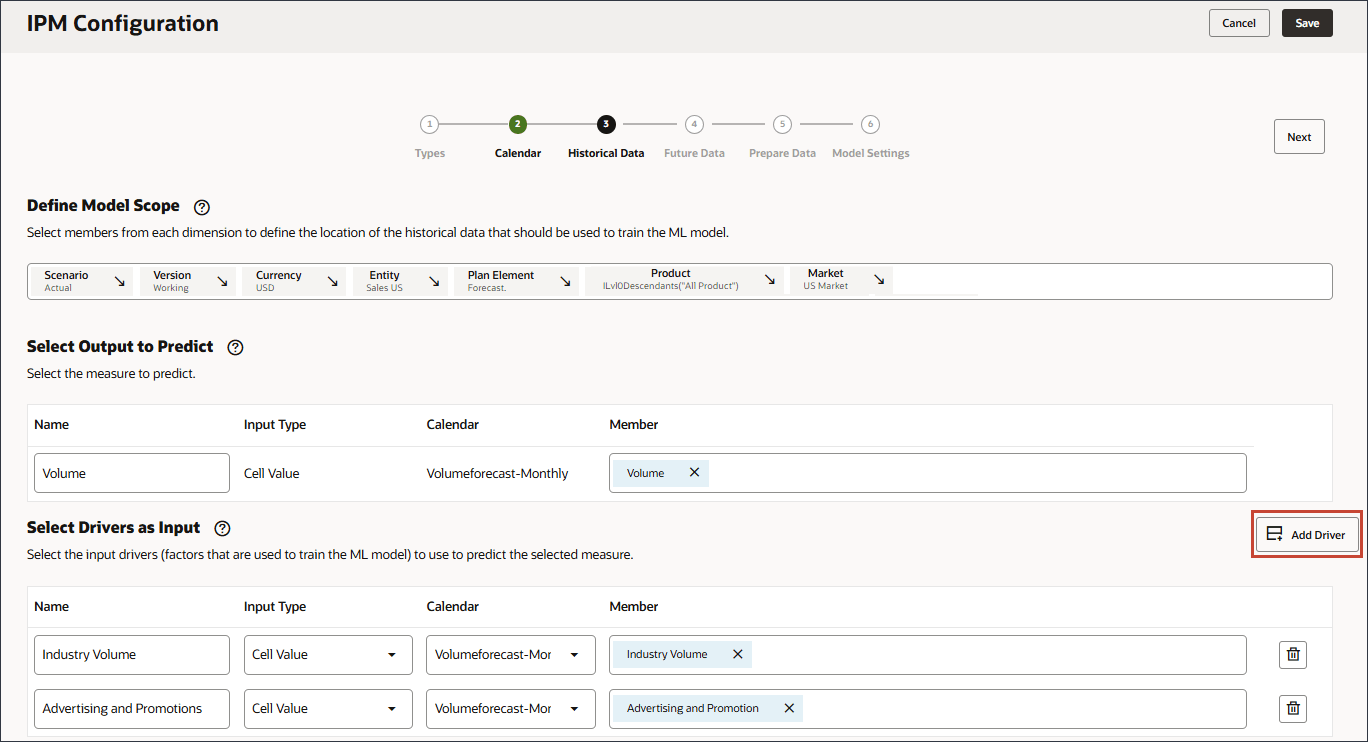
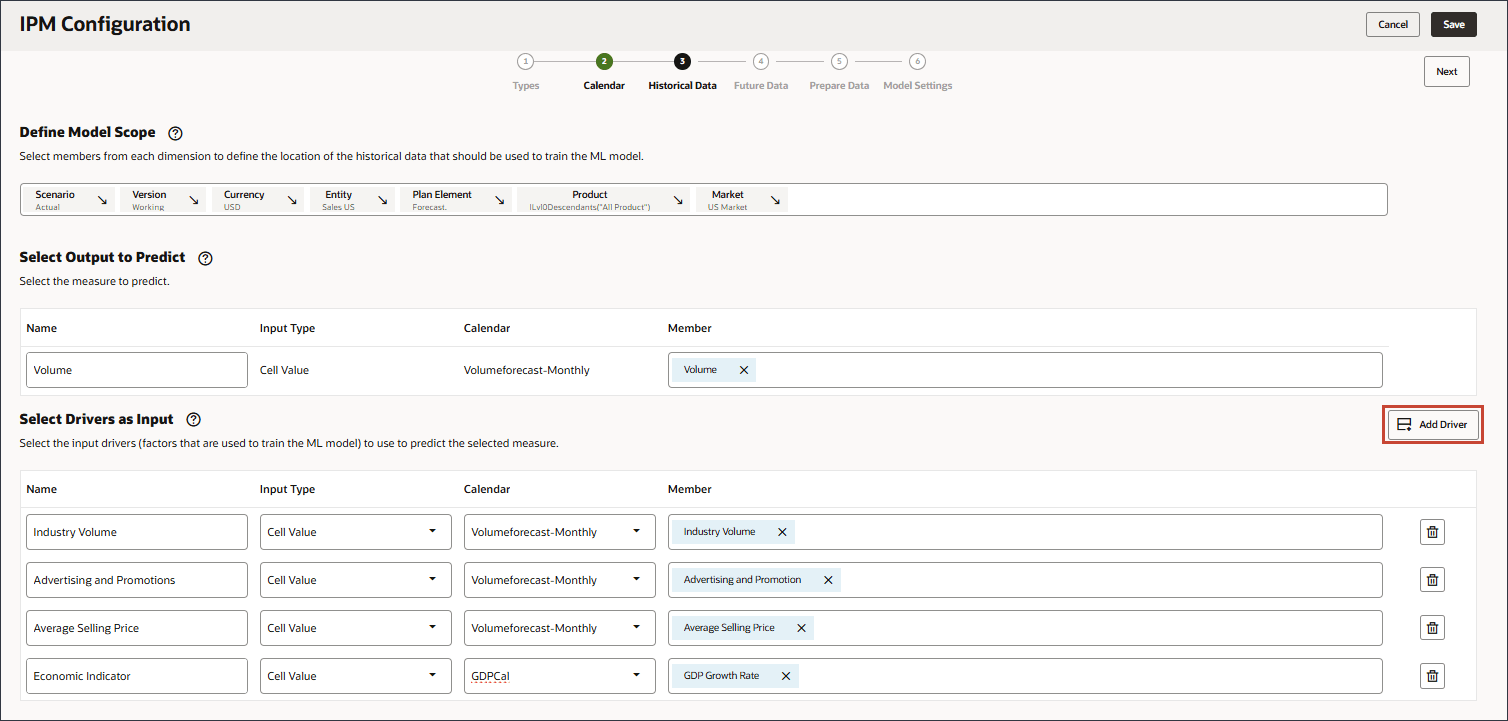
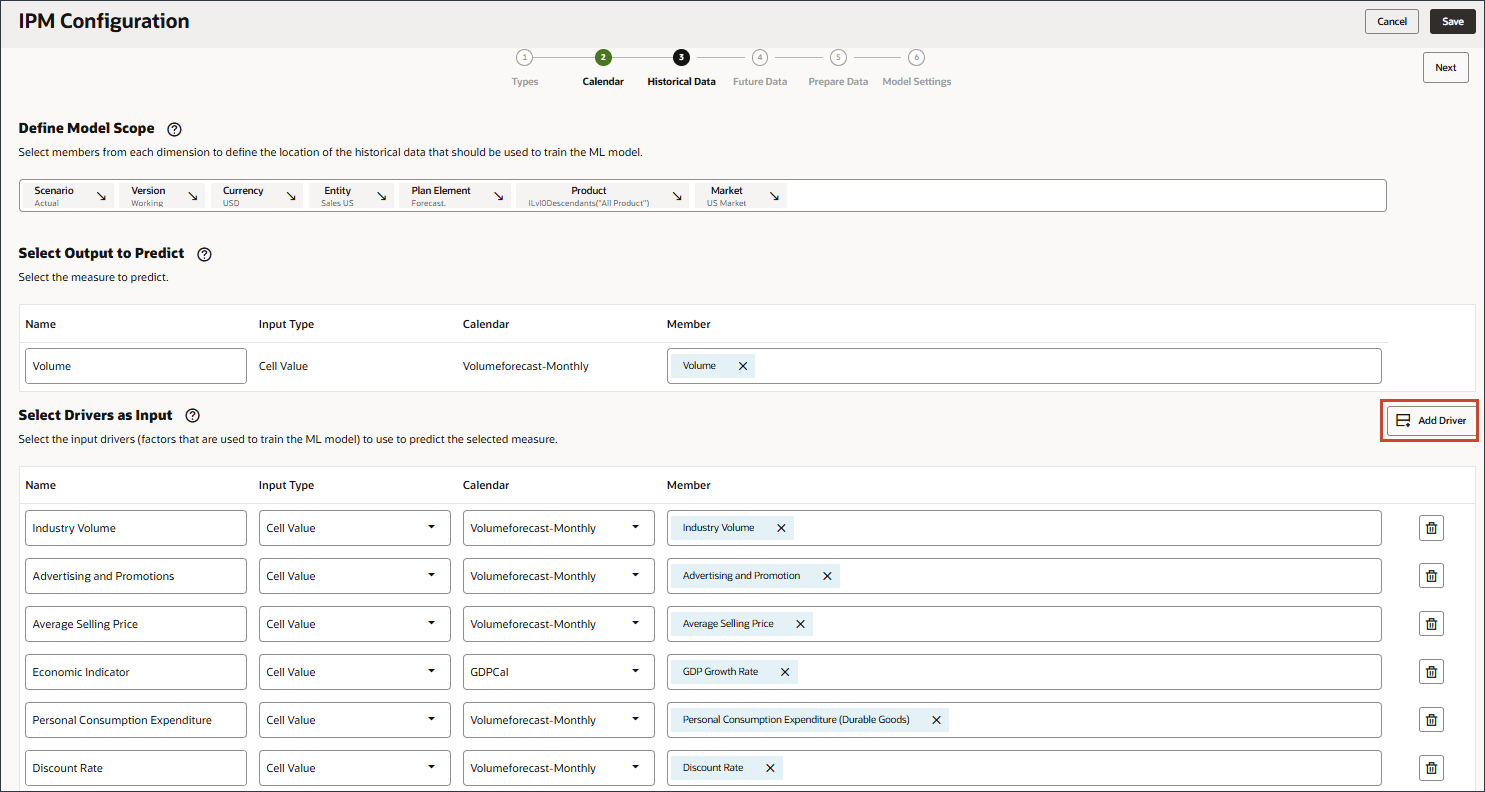
선택한 측정을 예측하기 위해 예측 모델을 교육하는 데 사용되는 요소인 입력 동인을 정의합니다. 7개의 입력 드라이버가 있습니다.
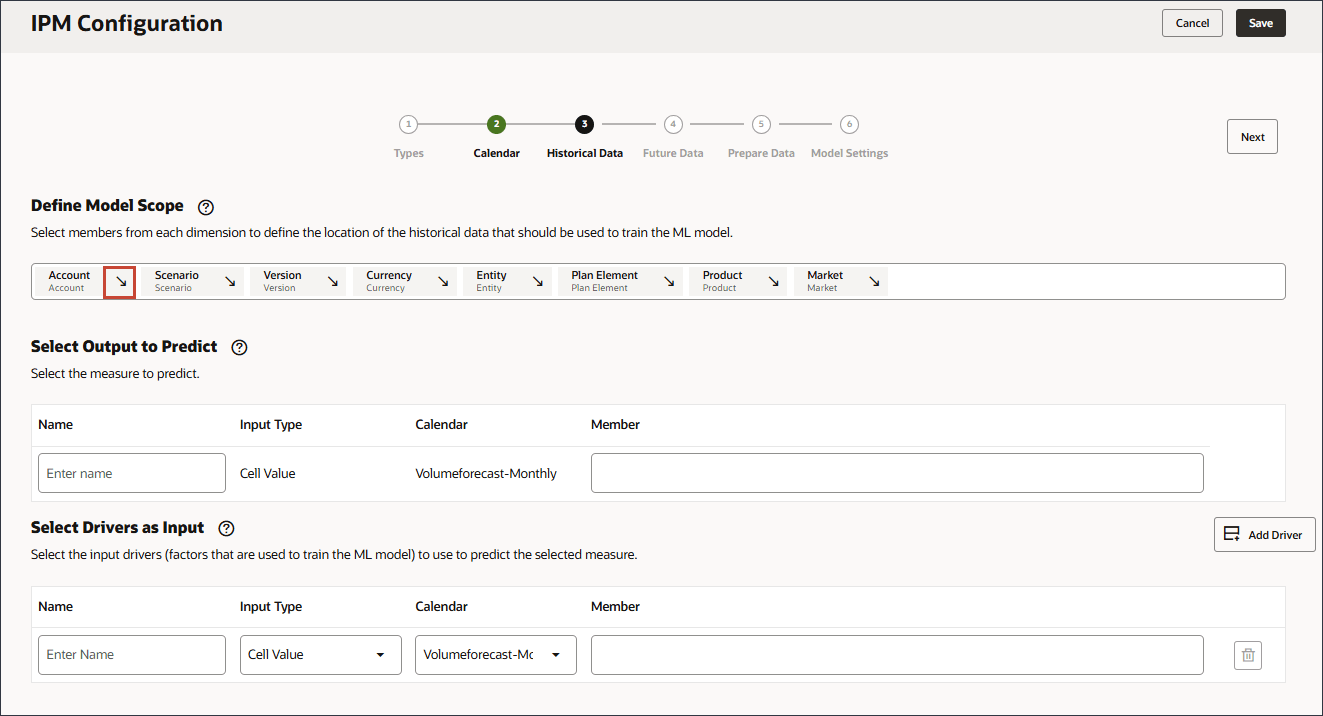
고객사 오른쪽에 있는 화살표를 클릭합니다.
계정이 행에 추가되었습니다.
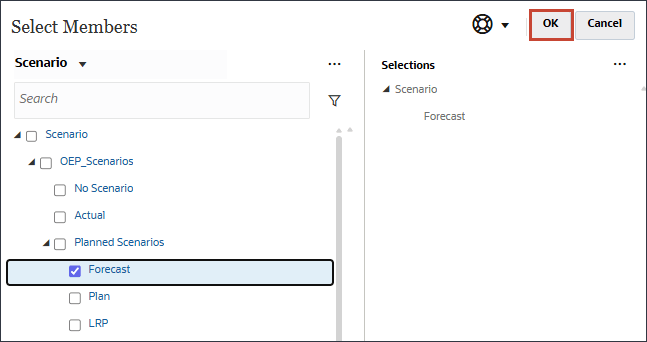
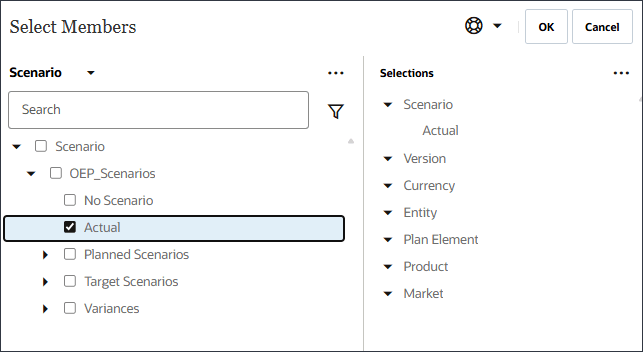
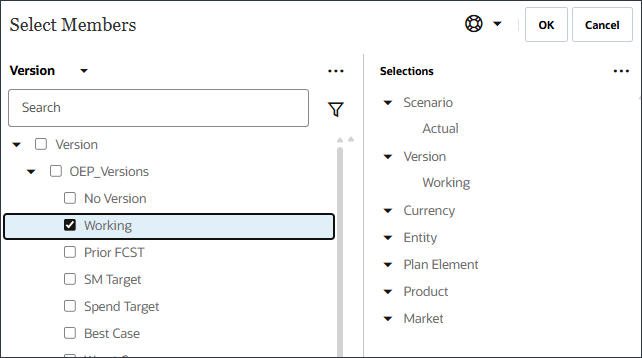
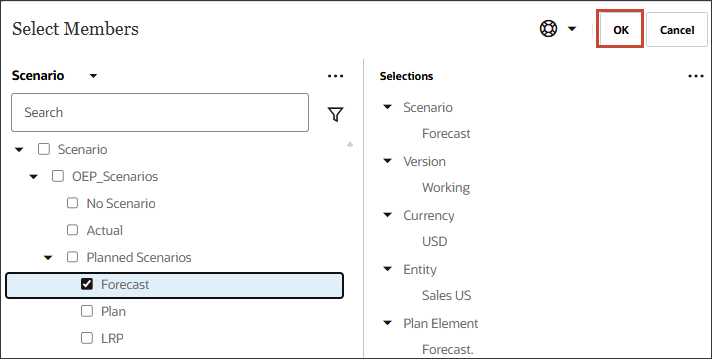
시나리오의 경우 시나리오를 눌러 멤버 선택기를 엽니다.
OEP_Scenarios을 확장하고 실제를 선택합니다.
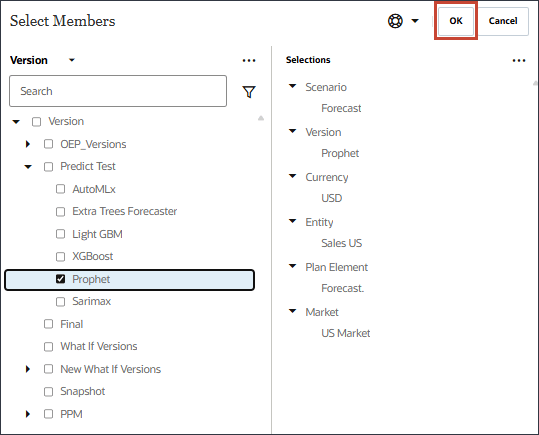
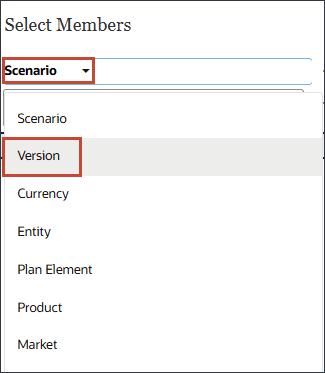
시나리오를 누르고 버전을 선택합니다.
OEP_Versions을 확장하고 작업 중을 선택합니다.
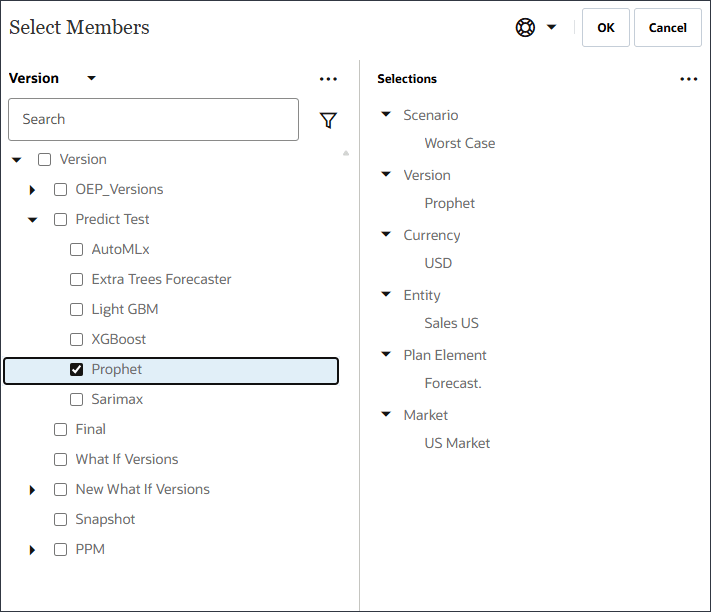
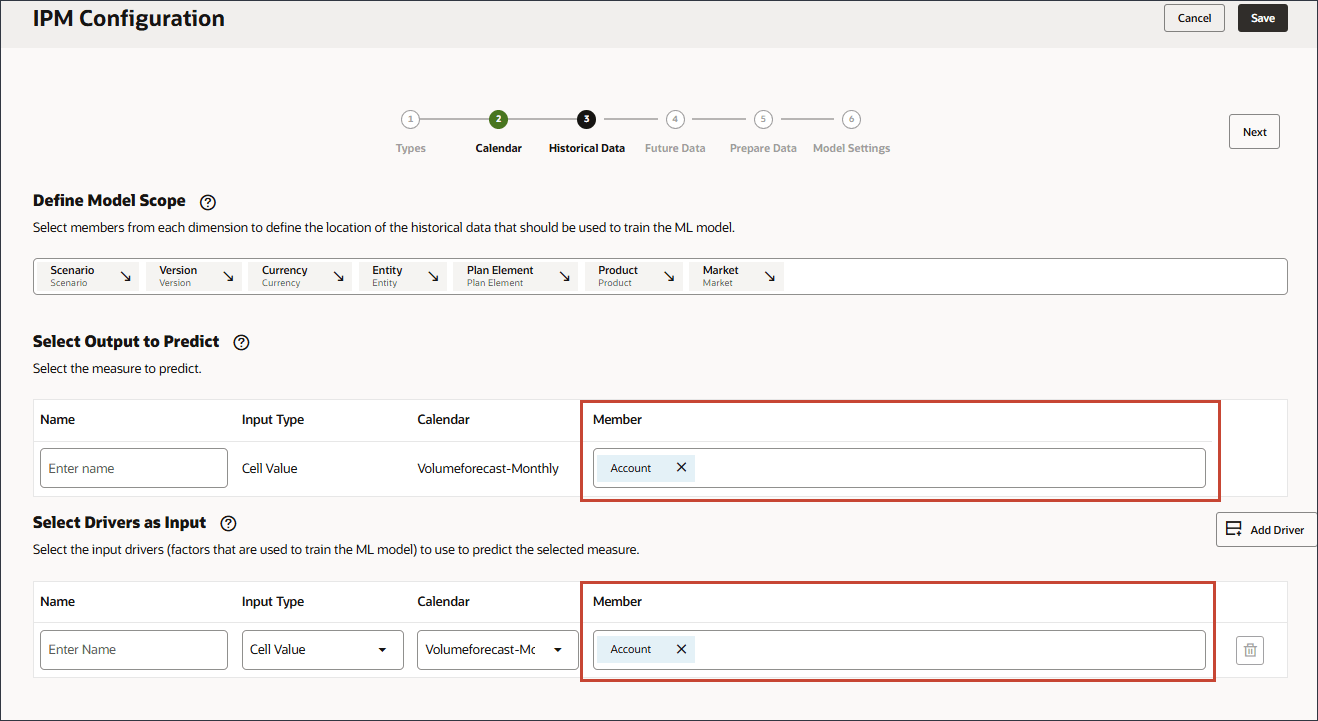
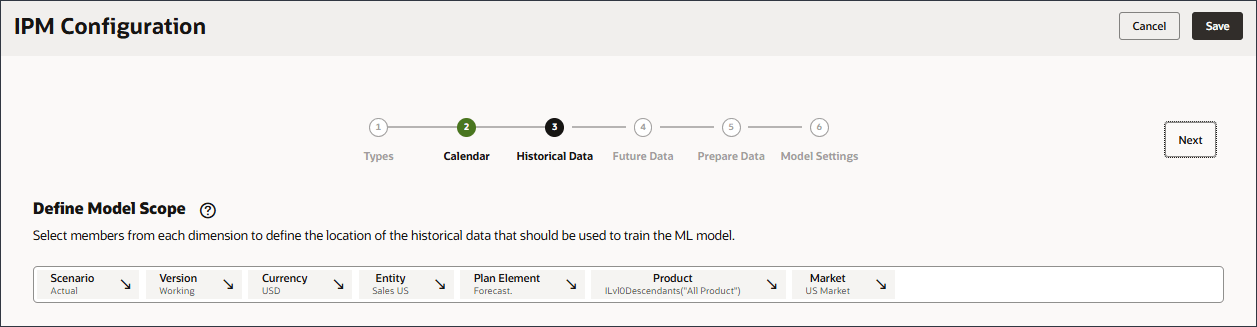
멤버 선택기를 사용하고 다음 POV 차원 멤버를 선택하여 모델 범위를 정의합니다. 모든 멤버를 선택한 후 확인을 누릅니다.
참고:
POV(모델 범위)를 정의하려면 각 차원을 선택한 다음 [멤버 선택] 대화상자에서 함수를 포함한 멤버를 선택합니다. 멤버 검색 가능.
차원
멤버
Scenario
실제
Version
작업 중
통화
USD
엔티티
미국 판매
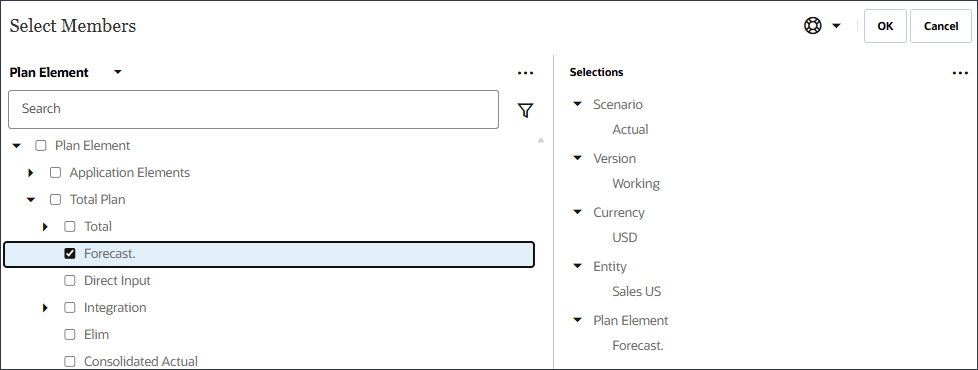
계획 요소
예측.
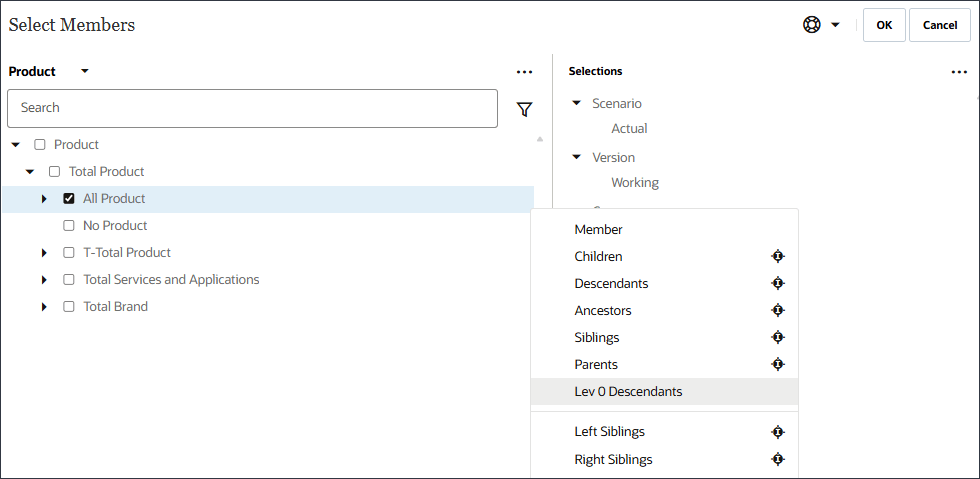
제품
Ilvl0Descendants("모든 제품")
Market
미국 시장
참고:
계획 요소의 경우 계획 요소 및 총 계획 아래에 있는 "예측"을 선택합니다. "예측"은 OFS_Load 멤버의 별칭입니다. 별칭 "예측"에는 이름에 마침표가 포함되어 있습니다.
참고:
프로덕트의 경우 모든 프로덕트의 레브 0 종속 항목을 선택합니다.
고급 예측 모델을 학습시키는 데 사용할 역사적 데이터의 위치를 정의하려면 각 차원에서 POV 멤버를 선택합니다. 예를 들어, Ilvl0Descendants("모든 제품")의 모든 멤버에 대한 볼륨을 예측하도록 고급 예측 모델을 교육하고, 실제 시나리오 및 작업 버전의 과거 데이터를 사용하고, USD 통화를 사용하고, 미국 판매 엔티티를 사용하는 등의 작업을 수행합니다.
선택 사항을 확인합니다.
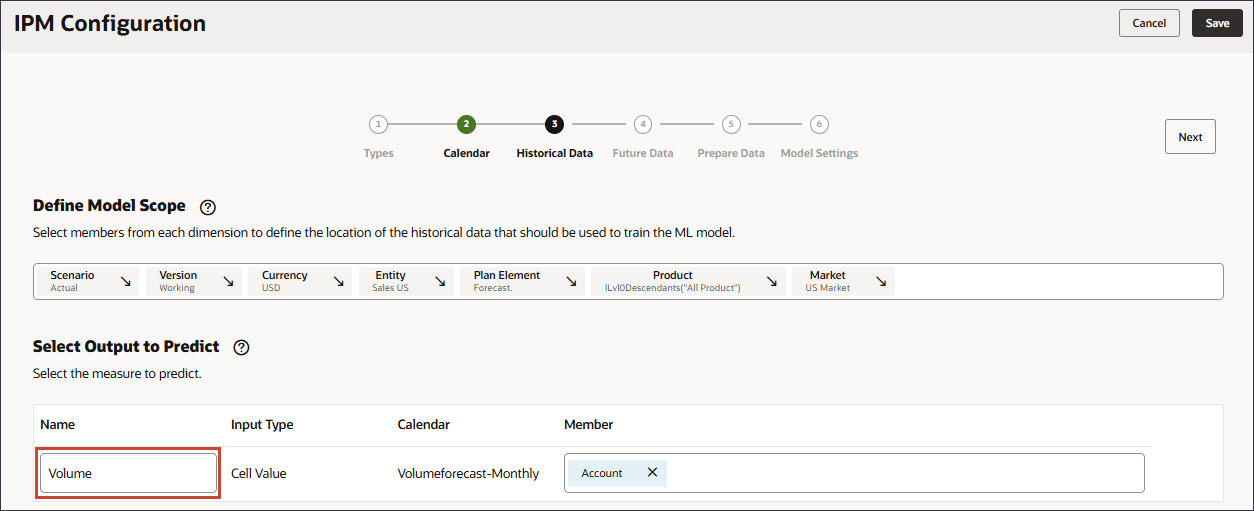
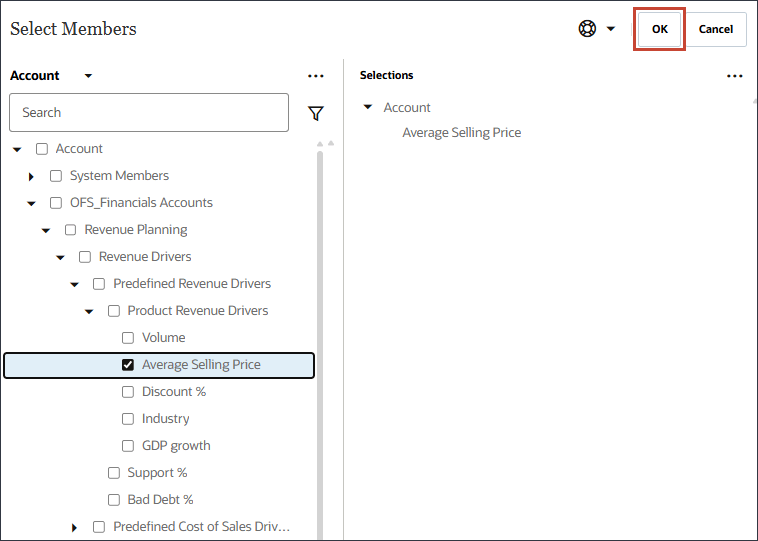
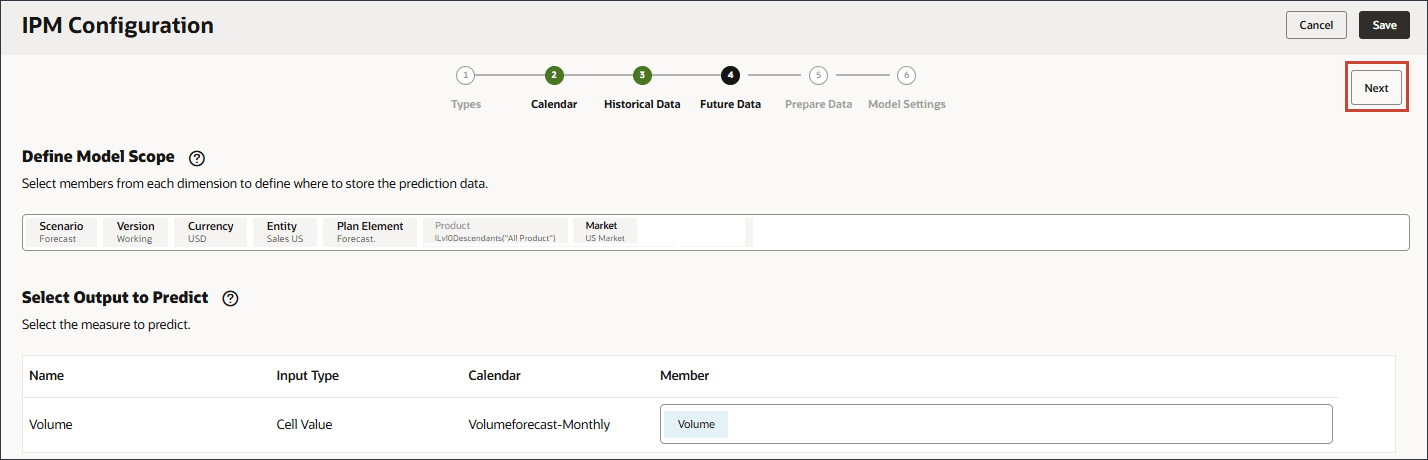
예측할 출력 선택에서 이름에 볼륨을 입력합니다.
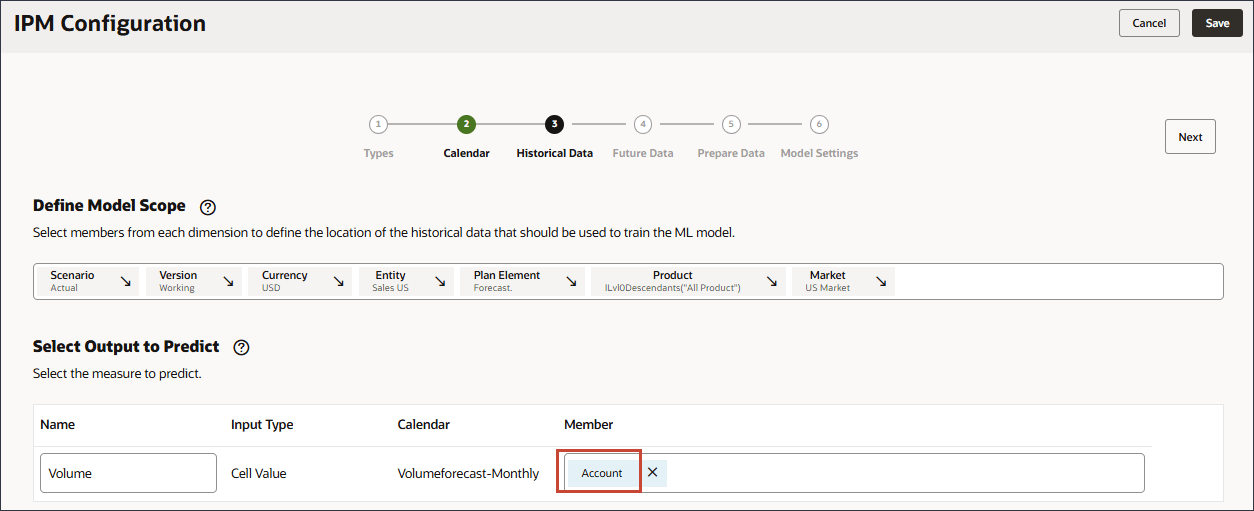
예측할 출력 선택에서 계정을 누릅니다.
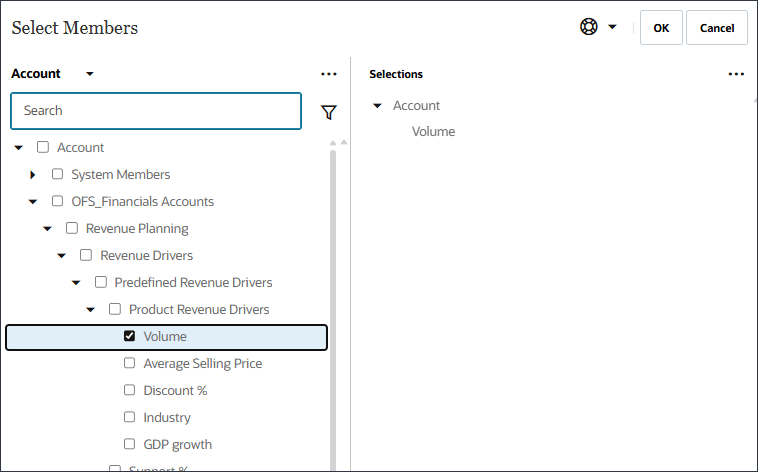
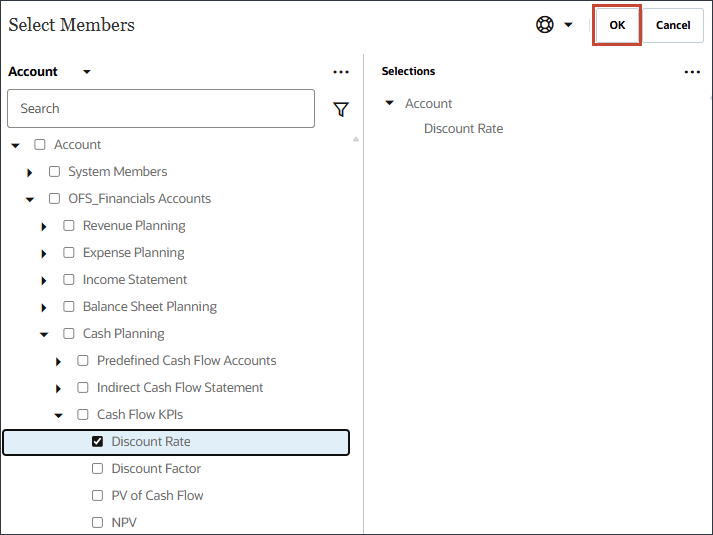
멤버 선택기를 사용하여 볼륨을 선택하고 확인을 누릅니다.
주의:
올바른 볼륨 계정을 선택했는지 확인합니다. 별칭이 볼륨인 경우 이 계정의 멤버 이름은 OFS_Volume입니다.
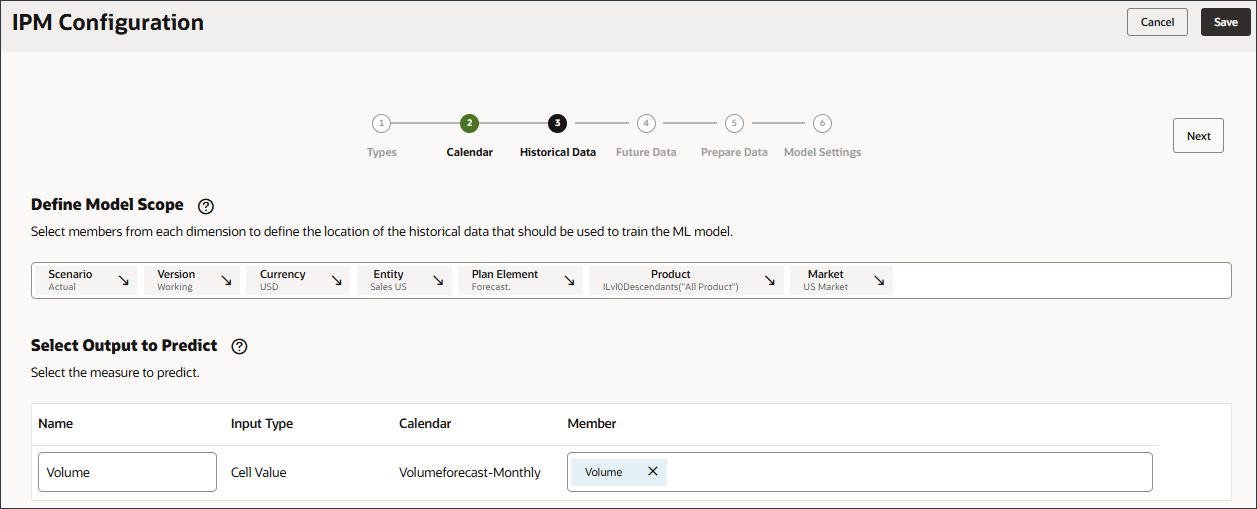
볼륨이 선택되었습니다.
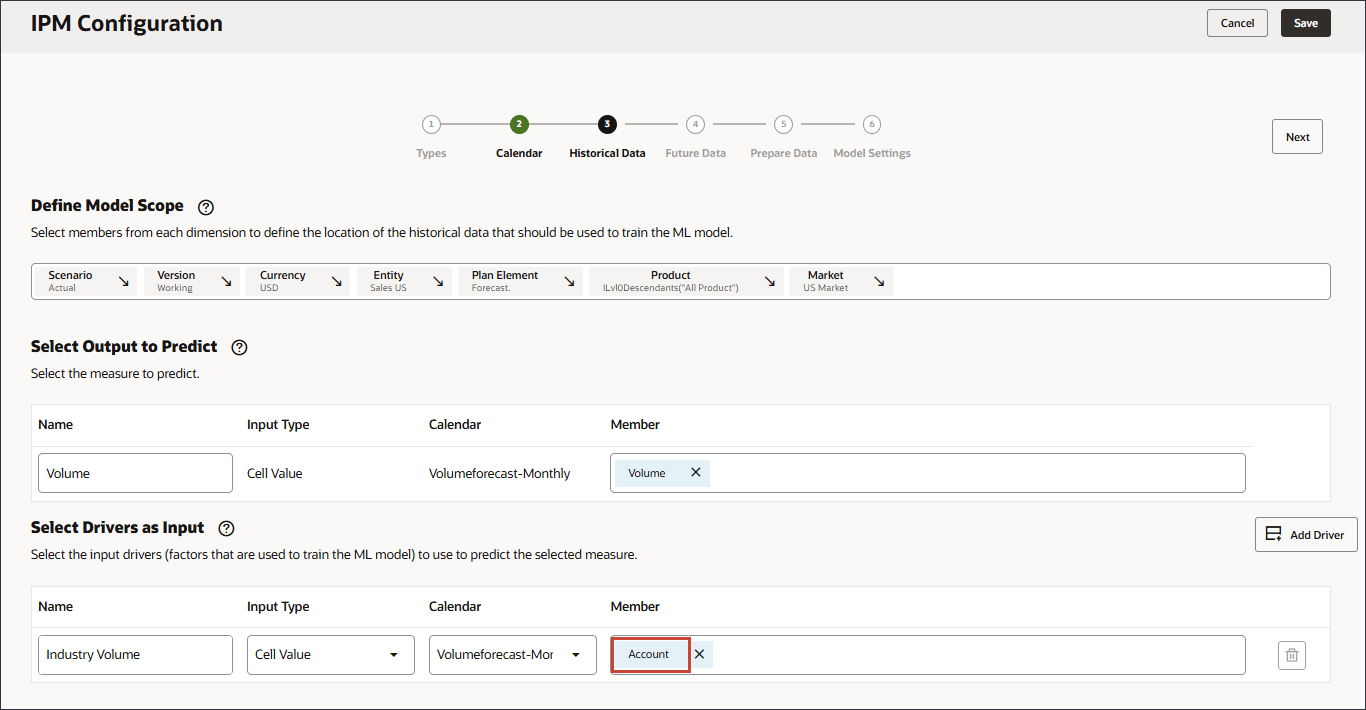
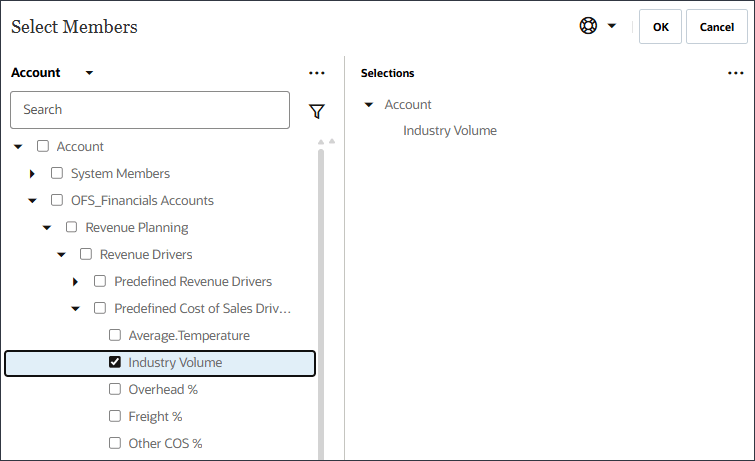
입력으로 드라이버 선택에서 이름에 산업 거래량을 입력하고 계정을 누릅니다.
산업 볼륨을 선택하고 확인을 누릅니다.
주의:
계층에서 사전 정의된 판매 비용 동인 아래에 있는 올바른 산업 거래량 계정을 선택해야 합니다.
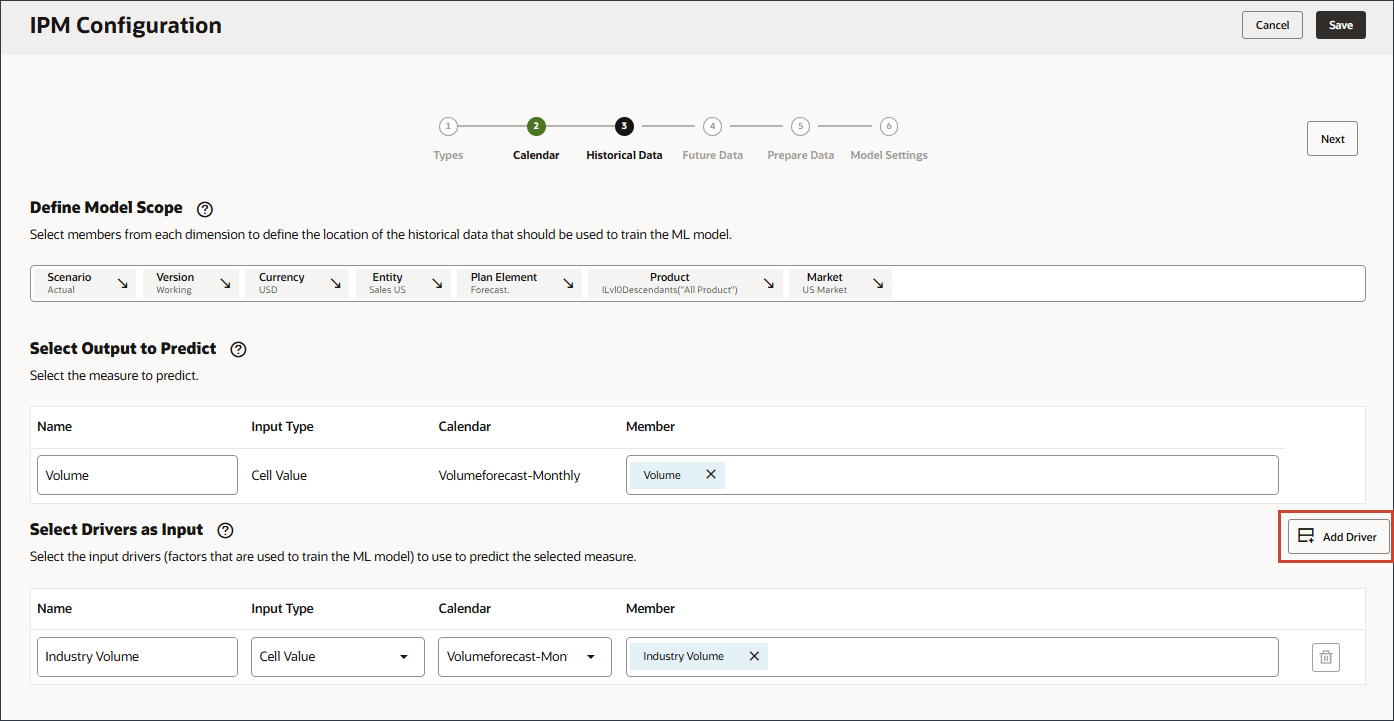
드라이버 추가를 누릅니다.
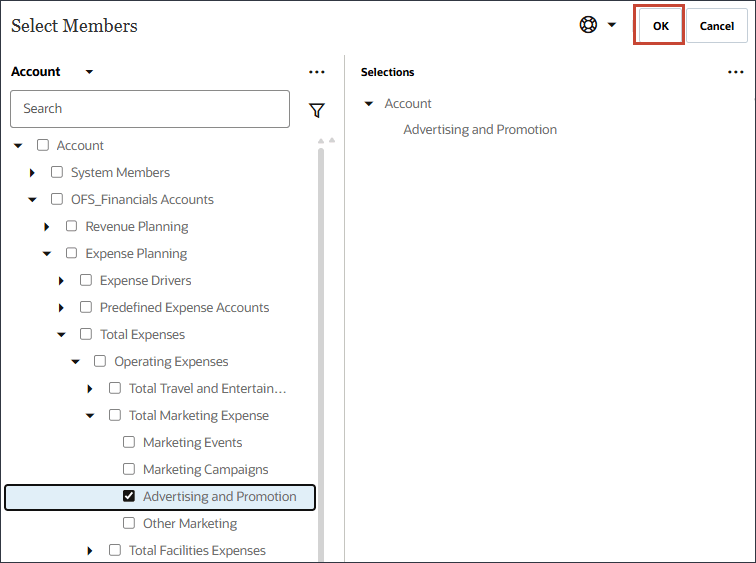
이름에서 광고 및 판촉을 입력하고 광고 및 판촉의 경우 멤버에서 산업 거래량을 누릅니다.
광고 및 판촉을 선택하고 확인을 누릅니다.
참고:
멤버 이름이 "OFS_Advertising and Promotion"인 멤버를 선택해야 합니다. 별칭은 광고 및 판촉입니다.
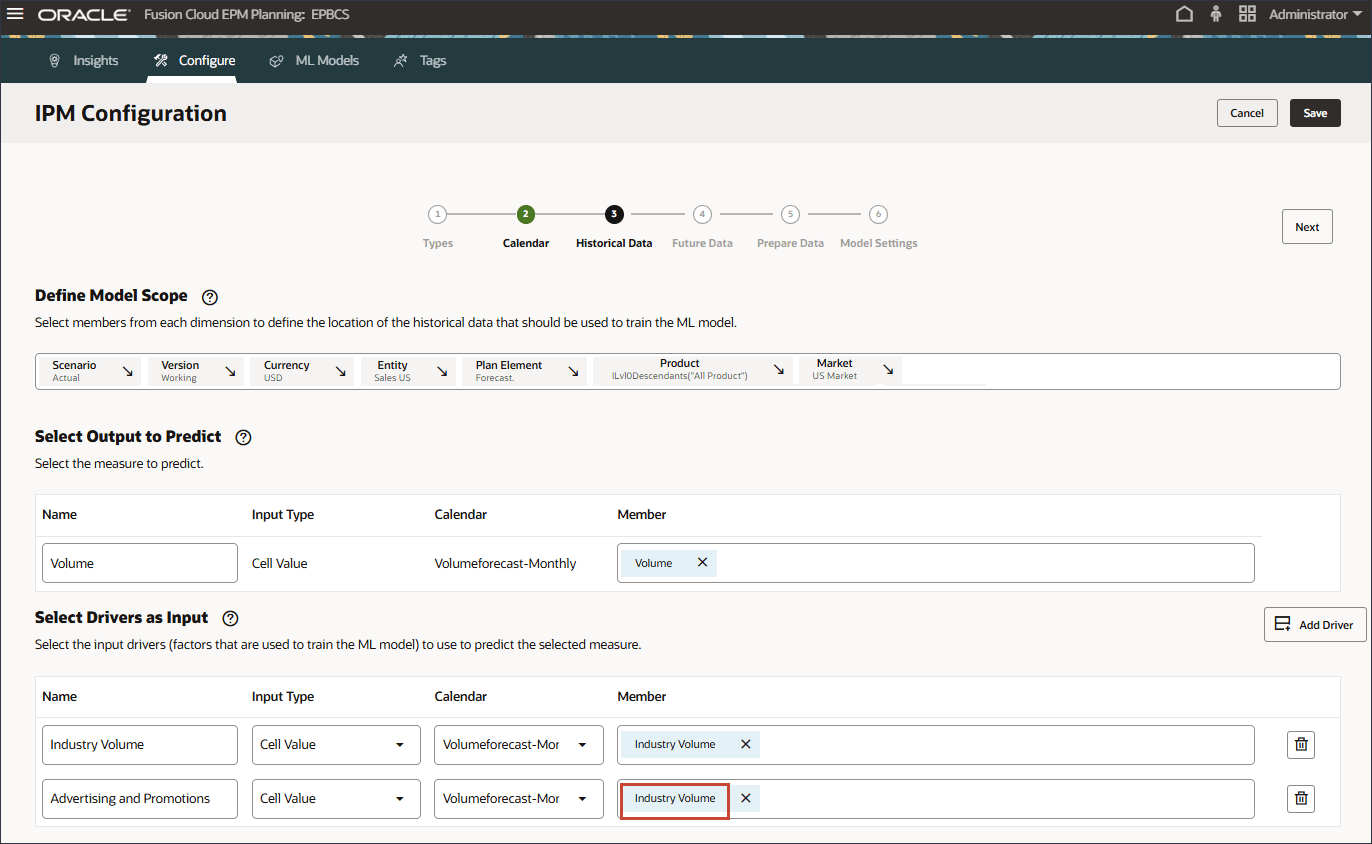
드라이버 추가를 누릅니다.
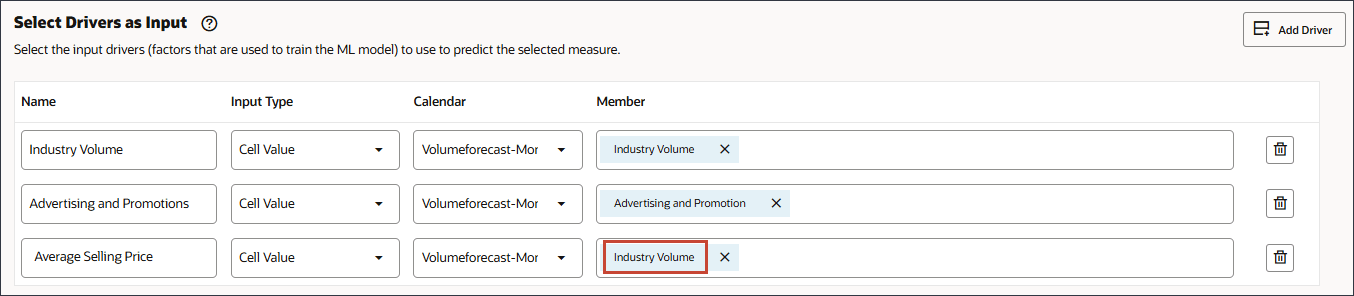
이름에서 평균 판매 가격을 입력하고 평균 판매 가격에 대해 멤버에서 산업 거래량을 누릅니다.
평균 판매 가격을 선택하고 확인을 누릅니다.
참고:
멤버 이름이 "OFS_Ave 판매 가격"인 멤버를 선택해야 합니다. 별칭은 평균 판매 가격입니다.
드라이버 추가를 누릅니다.
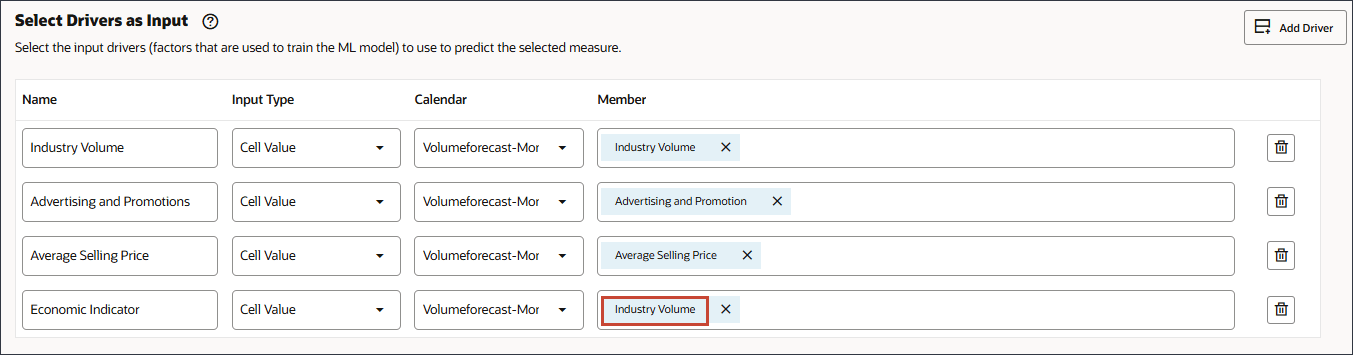
이름에서 경제 지표를 입력하고 경제 지표의 경우 멤버에서 산업 거래량을 누릅니다.
GDP 증가율을 선택하고 확인을 누릅니다.
주의:
올바른 계정을 선택했는지 확인합니다. 별칭이 GDP 성장률인 경우 이 계정의 멤버 이름은 경제 지표입니다.
회원 경제 지표는 GDP 성장률에 매핑됩니다.
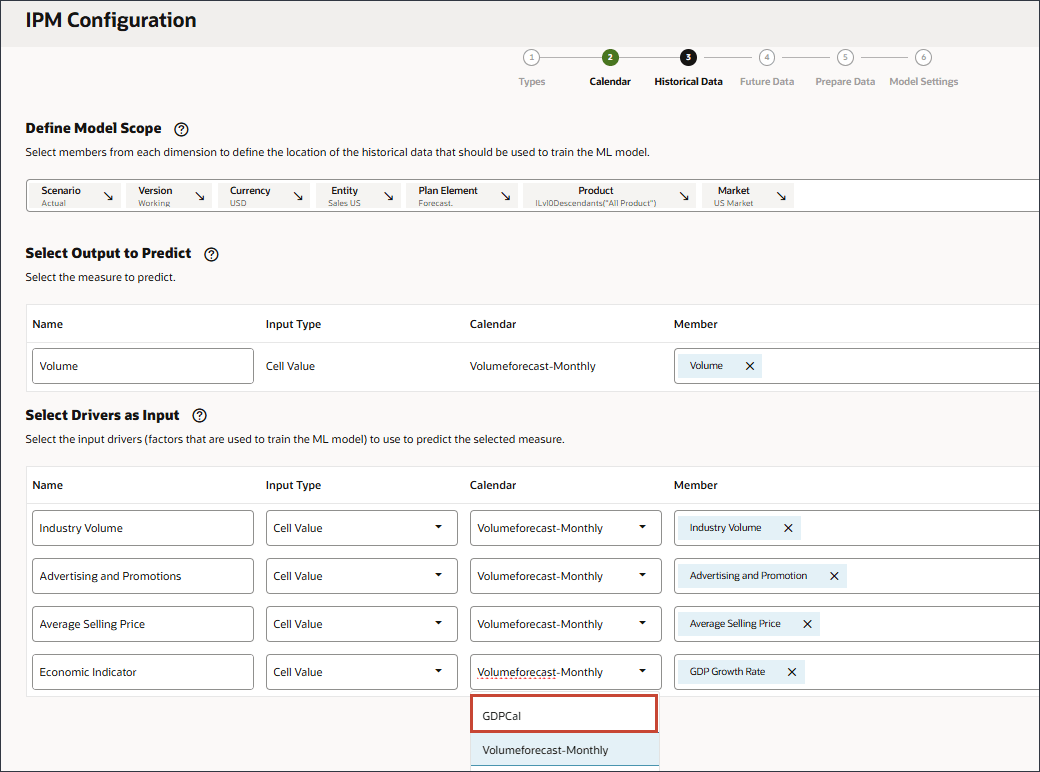
경제 지표의 경우 달력에 대해 Volumeforecast-Monthly를 누르고 GDPCal를 선택합니다.
드라이버 추가를 누릅니다.
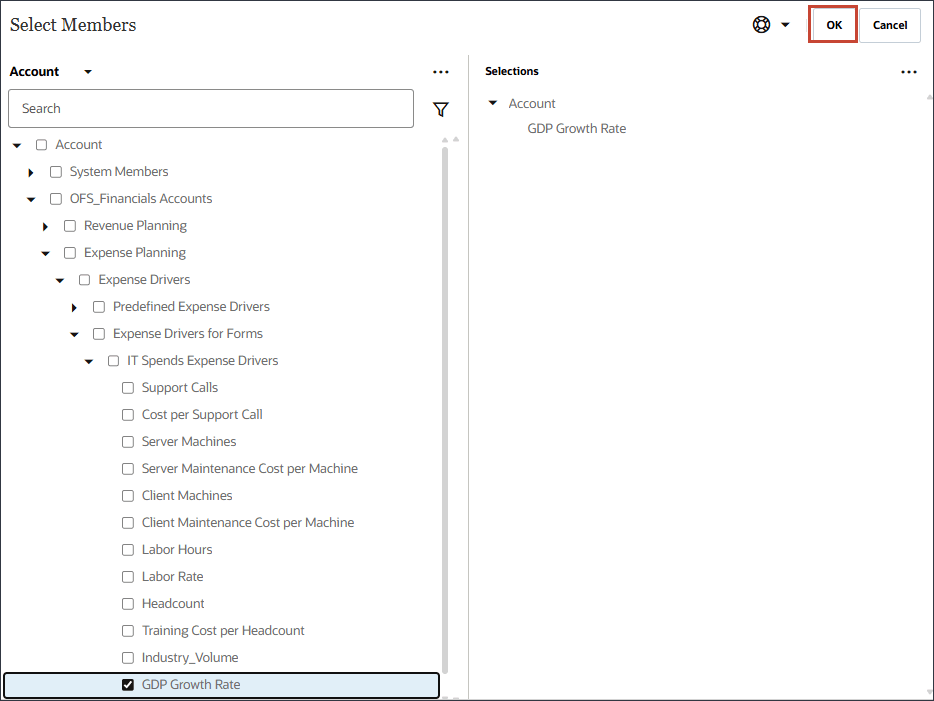
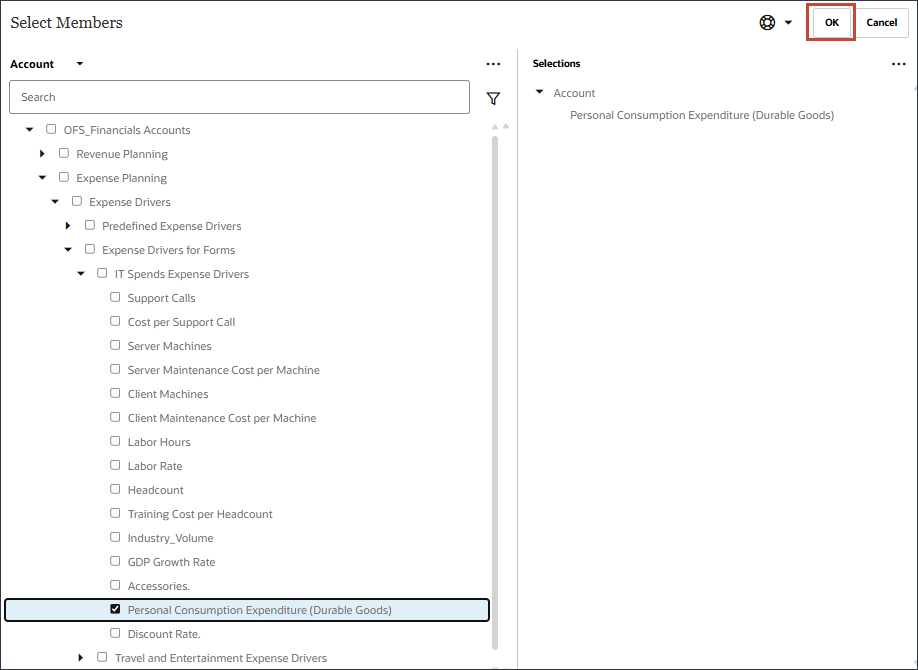
이름에서 개인 소비 지출을 입력하고 개인 소비 지출의 경우 멤버에서 산업 거래량을 누릅니다.
개인 소비 비용(내구재)을 선택하고 확인을 누릅니다.
참고:
멤버 이름이 "개인 소비 지출(내구재)"인 멤버를 선택해야 합니다. 이 구성원의 별칭은 "개인 소비 지출(내구재)"입니다.
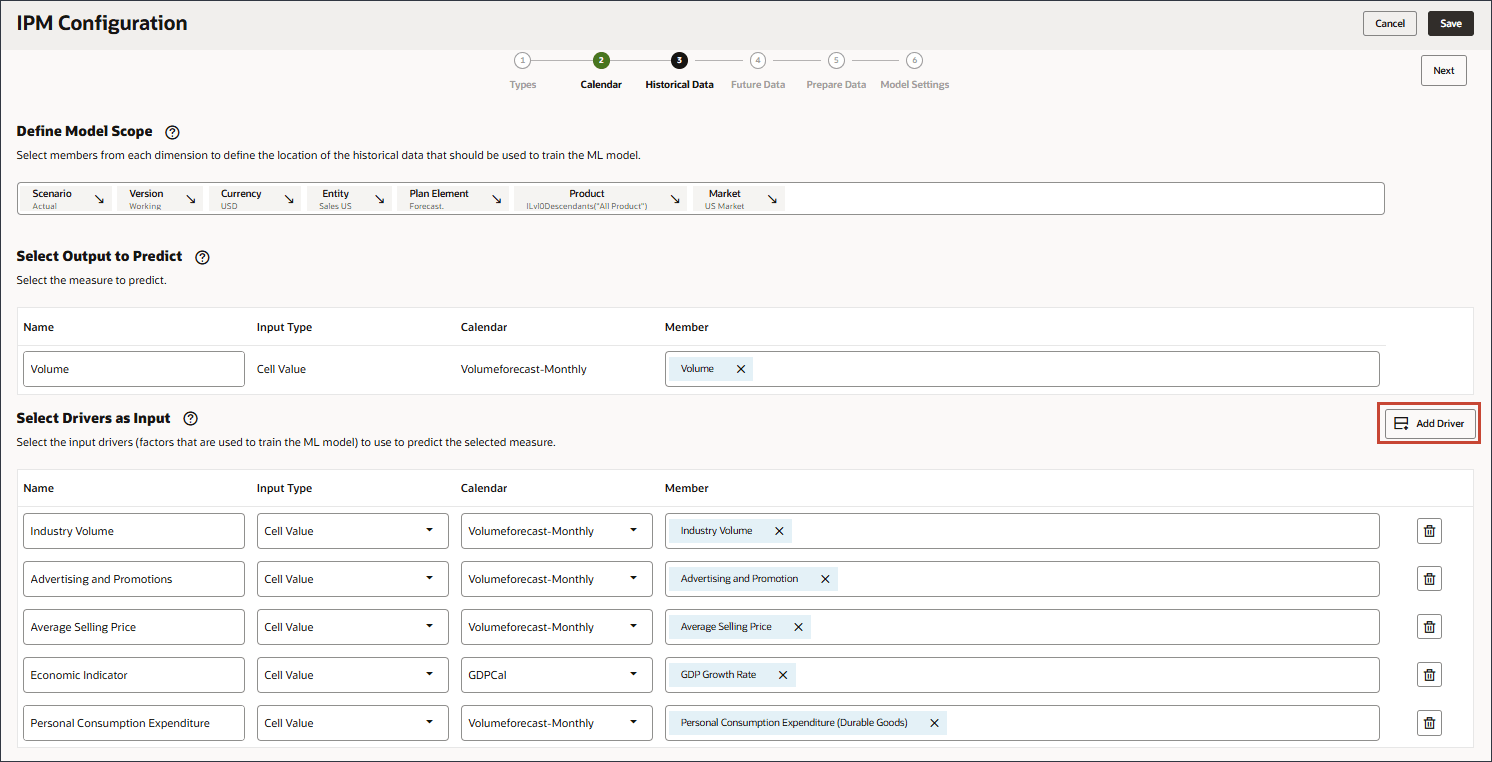
드라이버 추가를 누릅니다.
이름에 할인율을 입력하고 할인율의 경우 멤버에서 산업 거래량을 누릅니다.
할인율을 선택하고 확인을 누릅니다.
참고:
멤버 이름이 "OFS_Discount Rate"인 멤버를 선택해야 합니다. 이 멤버의 별칭은 이름에 마침표가 없는 "할인율"입니다.
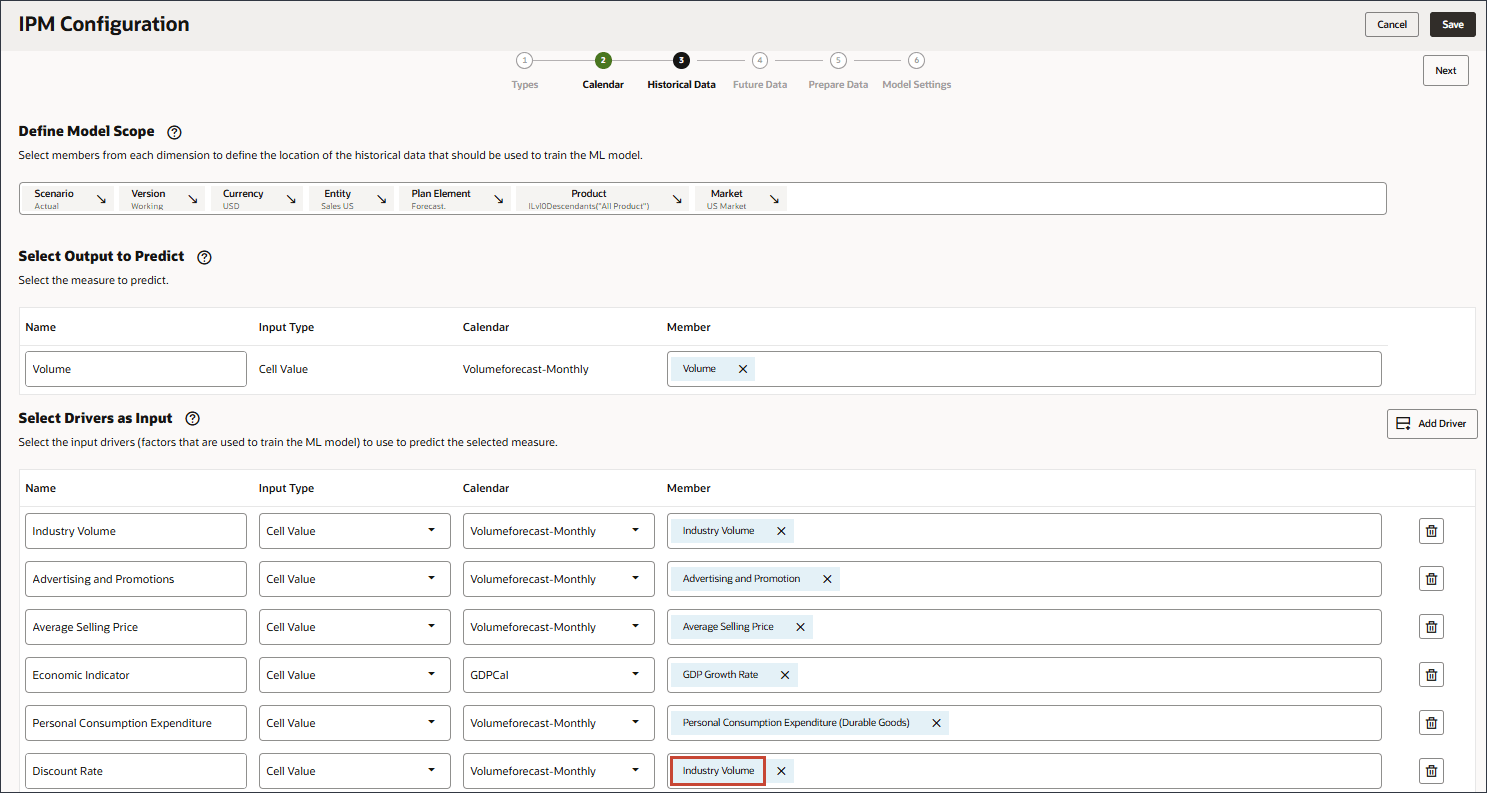
드라이버 추가를 누릅니다.
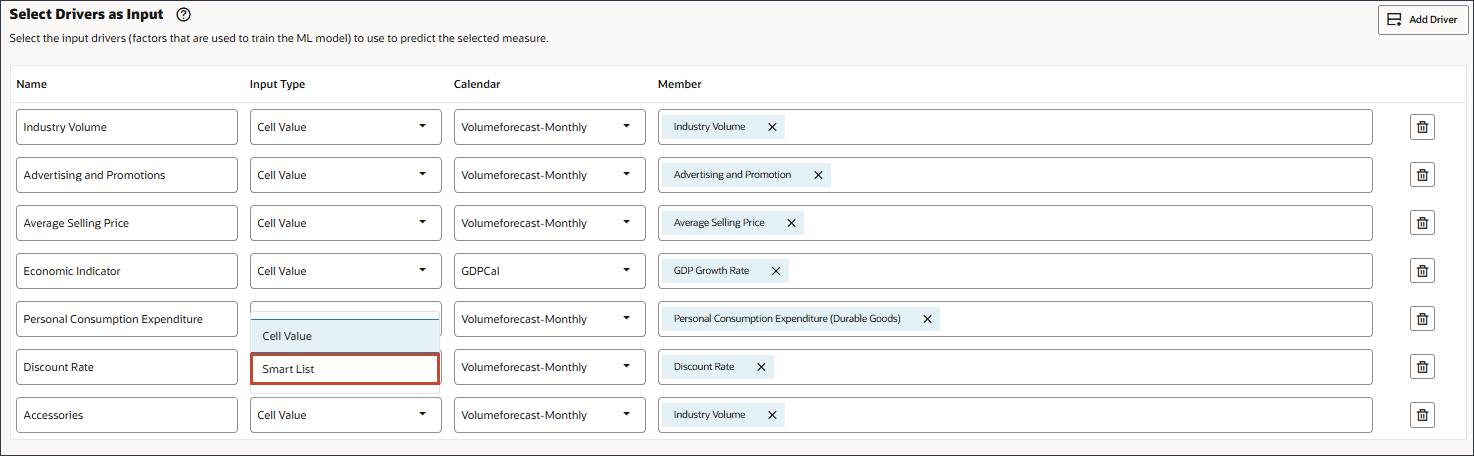
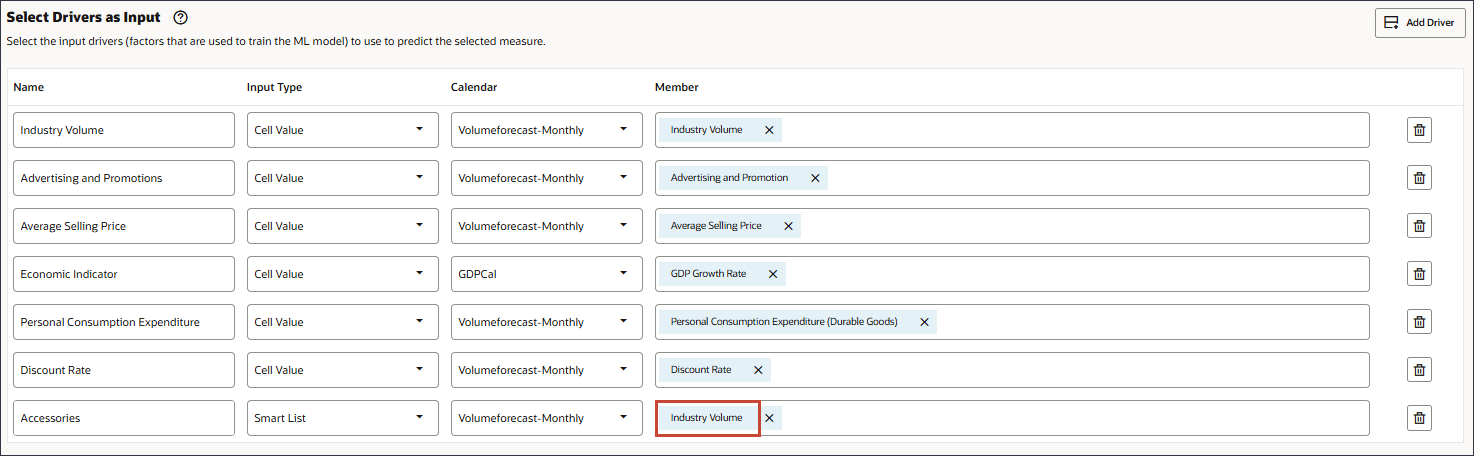
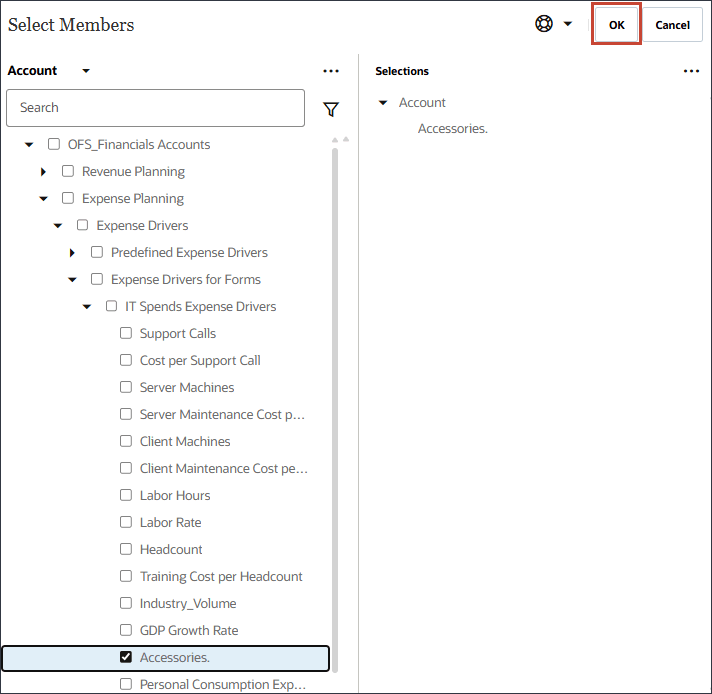
이름에 부속품을 입력하고 입력 유형에 대해 셀 값을 누른 다음 스마트 목록을 선택합니다.
액세서리의 경우 멤버에서 산업 볼륨을 누릅니다.
액세서리를 선택하고 확인을 누릅니다.
참고:
멤버 이름이 "액세서리"인 멤버를 선택해야 합니다. 멤버 이름과 별칭은 모두 동일하며 두 이름 모두에 마침표가 포함됩니다.
위로 스크롤하여 다음을 누릅니다.
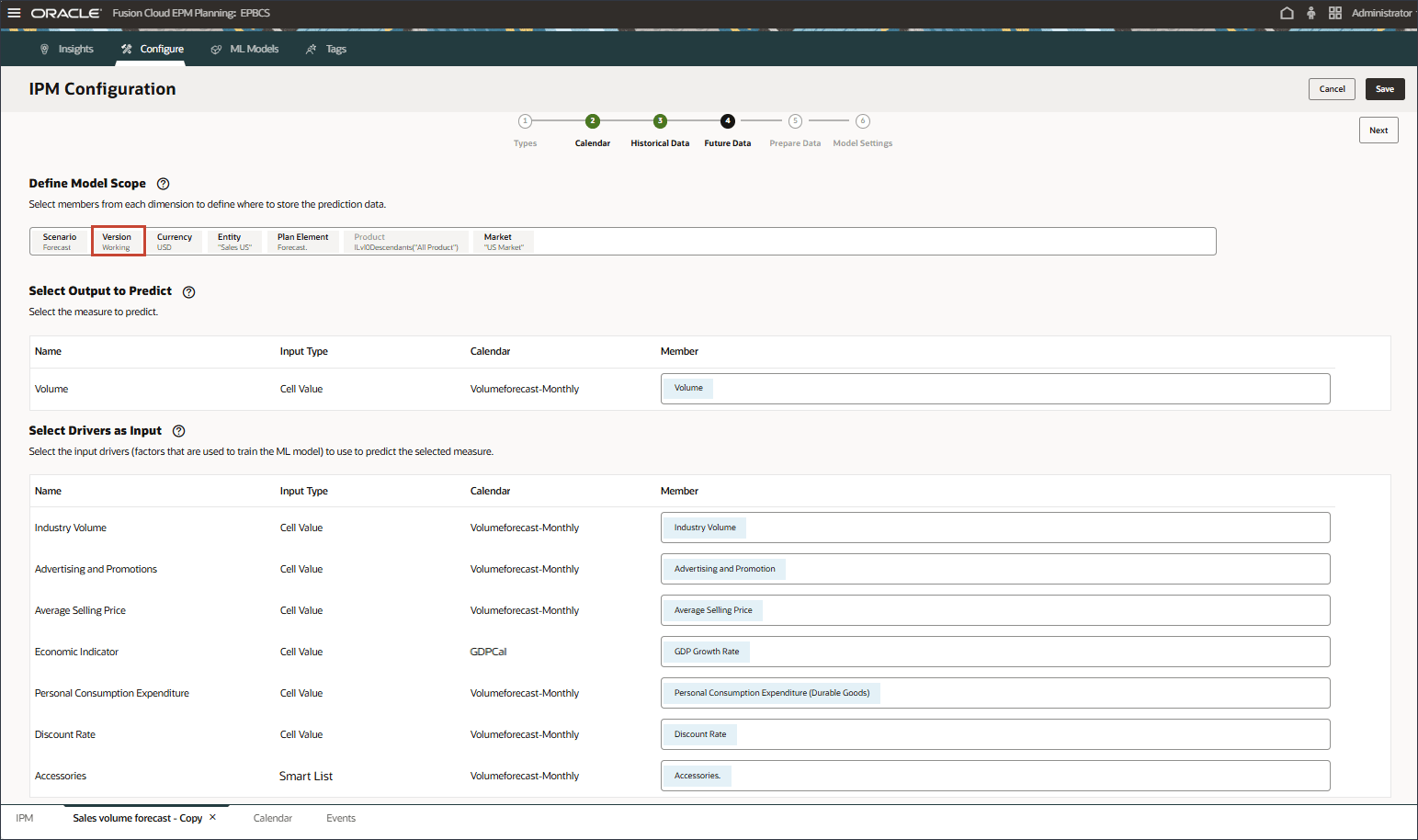
이후 데이터에 대한 슬라이스 정의 선택
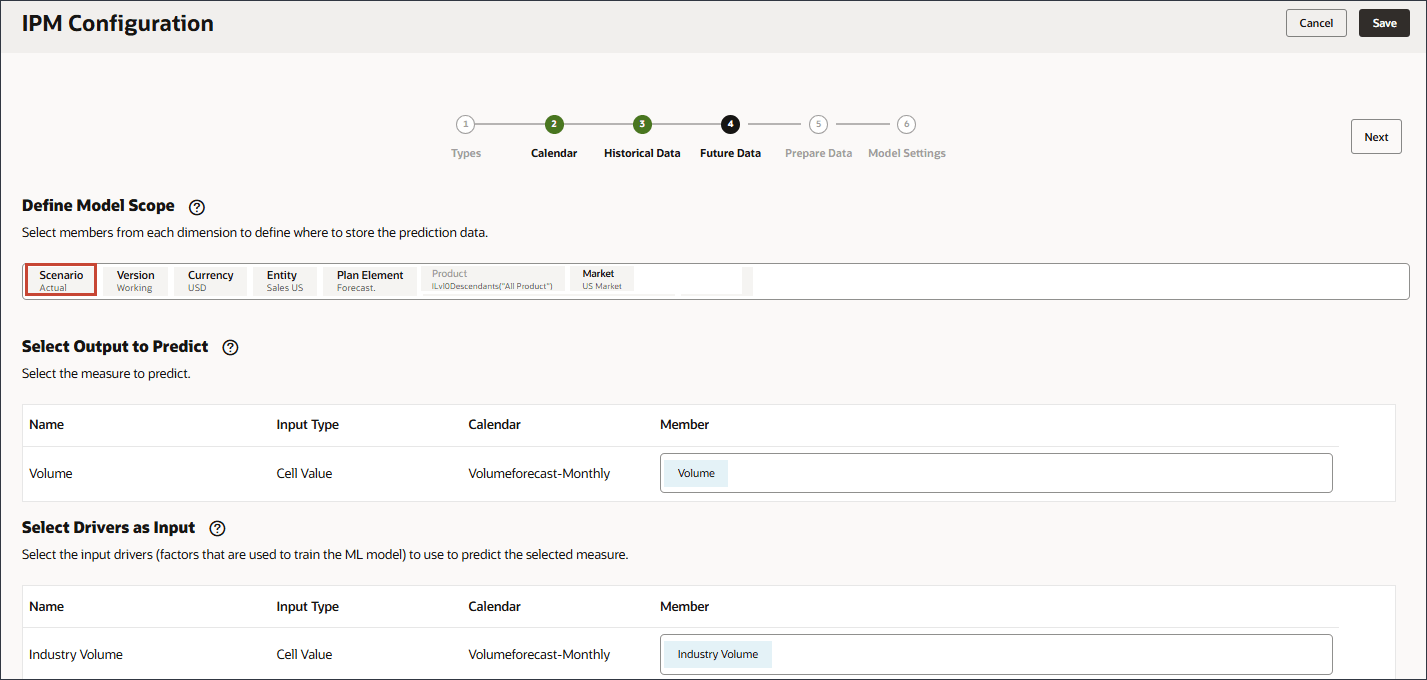
이 섹션에서는 예측의 출력을 저장할 슬라이스 정의를 선택합니다. 기본적으로 과거 데이터에 대해 설정한 구성이 미래 데이터 페이지로 전달됩니다. 특정 멤버를 수정하여 미래 데이터가 있는 위치와 예측이 저장되는 위치를 정의할 수 있습니다.
POV에서 시나리오를 누릅니다.
예측을 선택하고 확인을 누릅니다.
다른 변경 사항은 필요하지 않습니다. 입력 및 출력 드라이버가 동일합니다.
예측 결과는 예측 시나리오 또는 예측을 저장할 시나리오로 이동할 수 있습니다.
다음을 누릅니다.
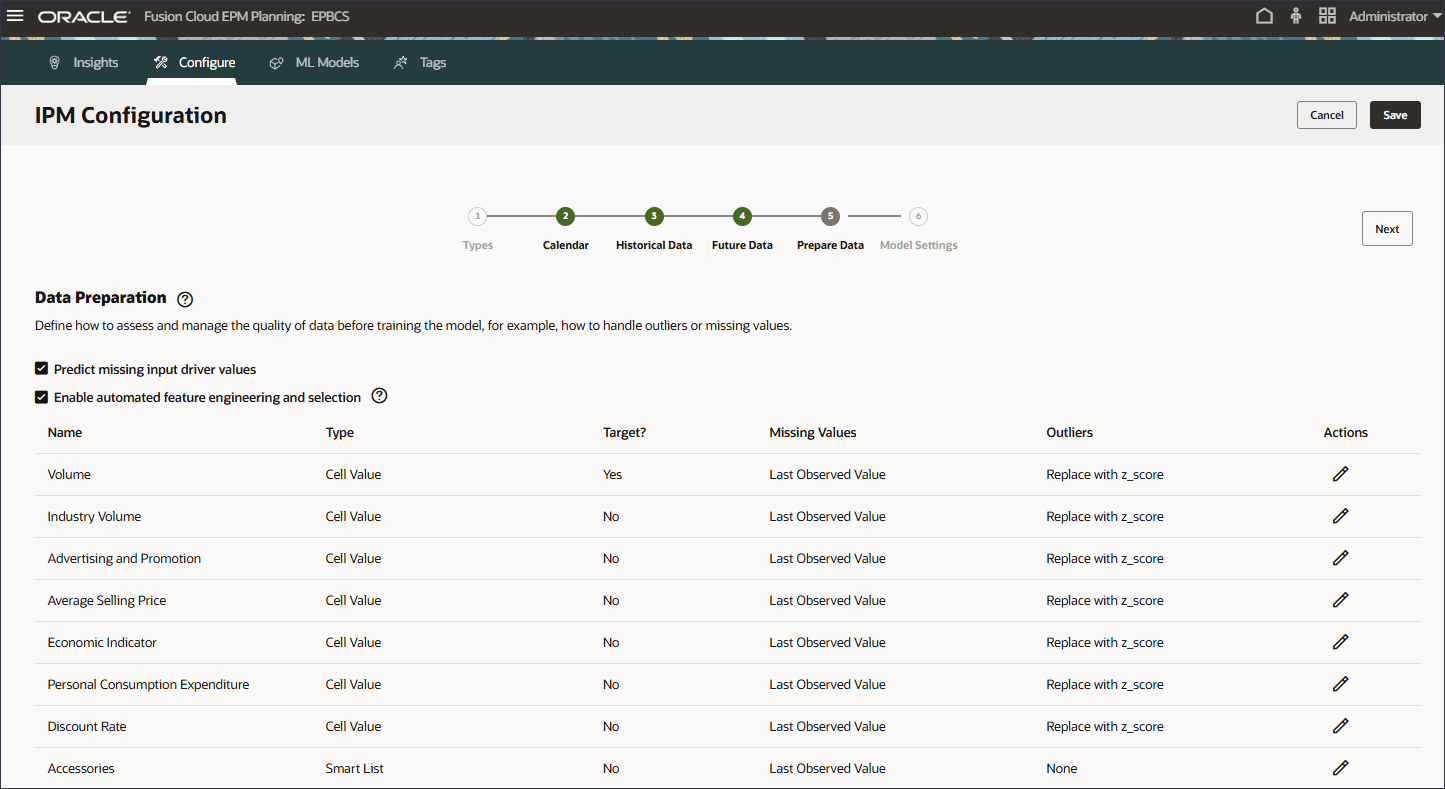
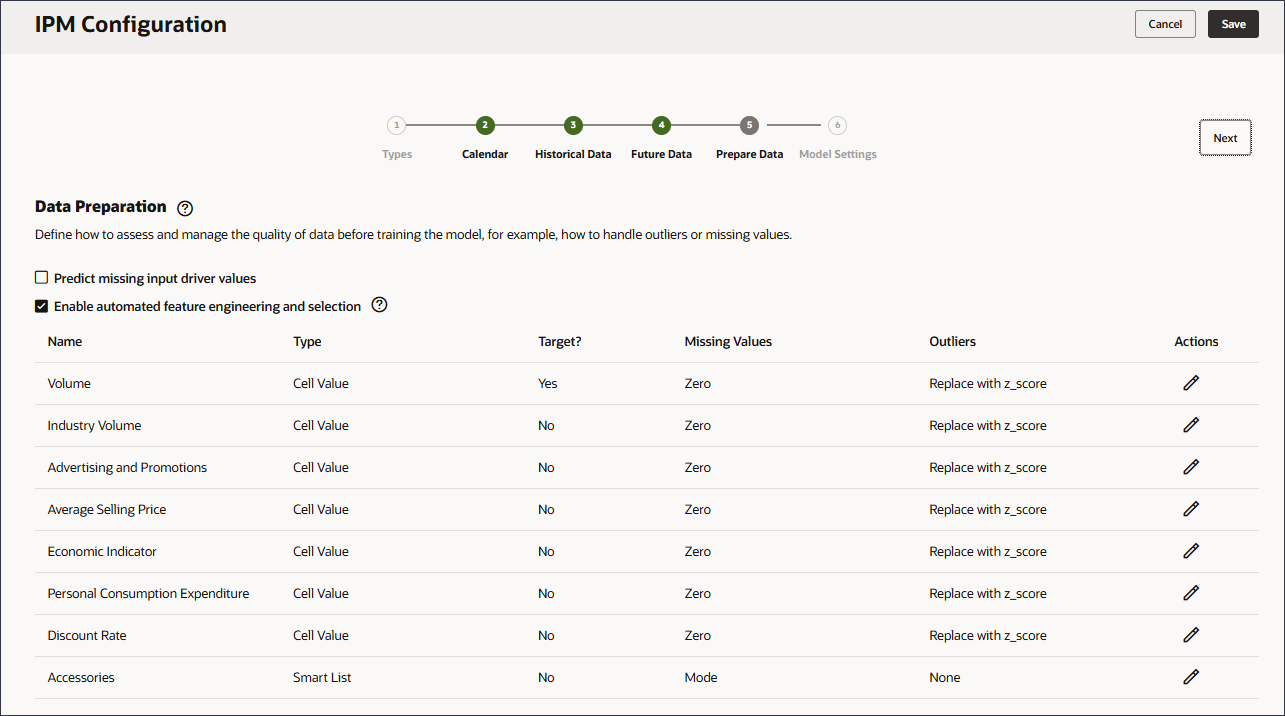
데이터 품질 문제 처리 방법 정의
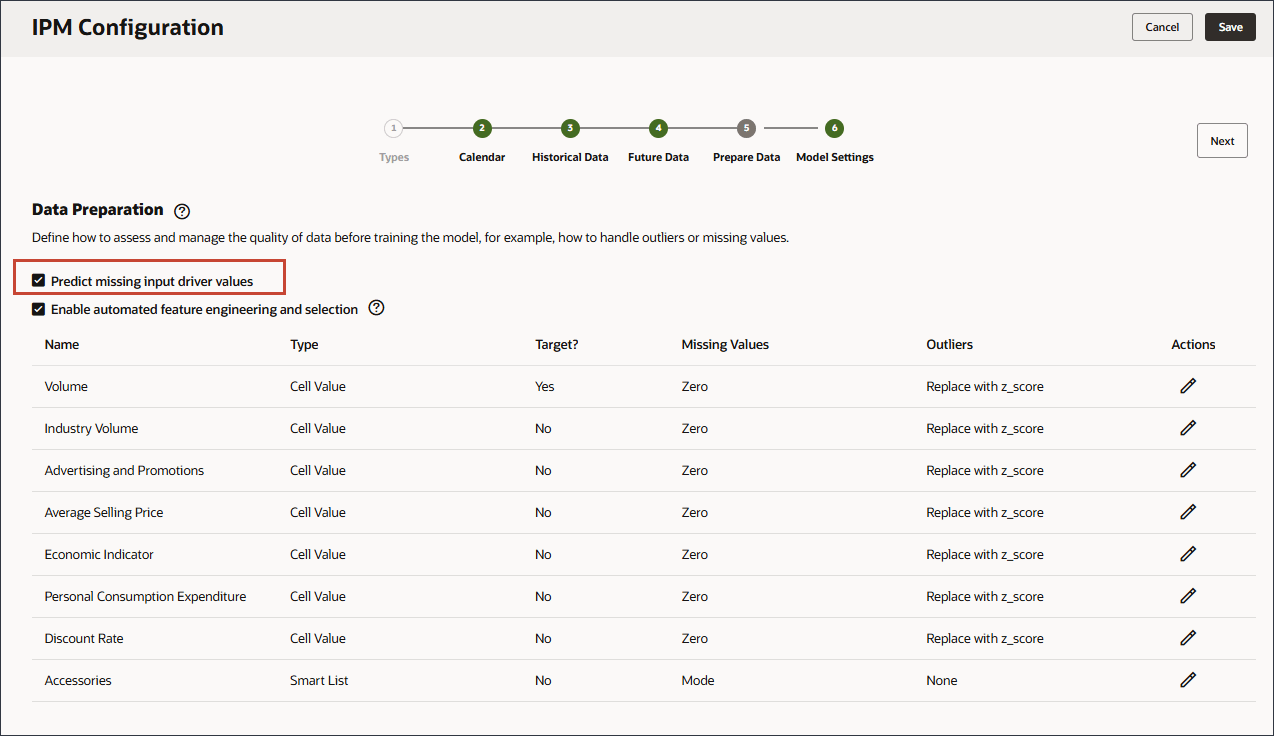
데이터 준비 단계에서 누락된 입력 드라이버 값을 처리하는 방법을 선택할 수 있습니다. 앞서 입력 드라이버를 검토했으며 'eReader' 제품에 대한 이후 드라이버 데이터 값이 없음을 확인했습니다.
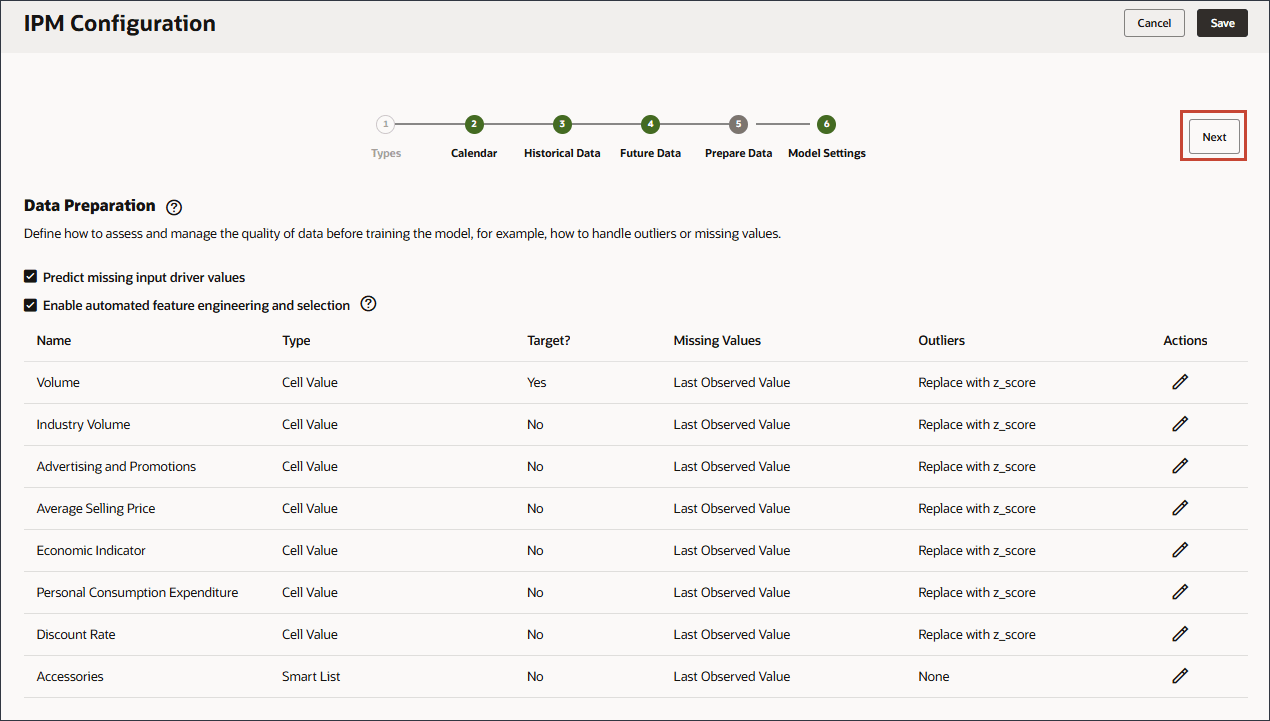
데이터 준비에는 드라이버 이름, 유형, 대상, 누락된 값, 이상값 및 작업에 대한 열이 포함됩니다.
모델을 학습하기 전에 데이터 품질을 평가하고 관리하는 방법(예: 이상치나 누락된 값을 처리하는 방법)을 정의합니다.
값이 누락되도록 예측하는 데 사용되는 기록 데이터에는 매우 일반적입니다. 측정 실패, 형식 지정 문제, 인적 오류 또는 기록할 정보 부족 등 몇 가지 이유로 데이터에 값이 누락되었을 수 있습니다. 대상 예측 및 관련 데이터 세트에서 누락된 값을 처리하기 위해 제공된 채우기 옵션이 서로 다릅니다. 채우기는 데이터 세트의 누락된 항목에 표준화된 값을 추가하는 프로세스입니다.
다음 옵션 중에서 선택하여 누락된 값을 바꿀 수 있습니다.
없음: 수행할 작업이 없습니다(데이터를 있는 그대로 전송).
0: 열에 대해 누락된 값을 0으로 바꿉니다.
평균(숫자 데이터)으로 바꾸기: 과거 계열에서 평균으로 바꿉니다.
중간값(숫자 데이터)으로 바꾸기: 과거 계열의 중앙값 지점으로 바꿉니다.
모드로 바꾸기(숫자 및 범주별 데이터): 과거 데이터에서 가장 일반적인 값으로 바꿉니다.
다음 관찰된 값으로 바꾸기: 누락된 값을 다음 기간에 관찰/표시된 값으로 바꿉니다.
마지막 관찰된 값으로 바꾸기: 누락된 값을 이전 기간에 관찰된 값으로 바꿉니다.
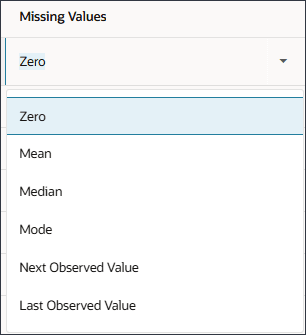
이상값의 경우 시스템에서 0, 평균, z-점수 또는 없음으로 대체할지 여부를 정의합니다.
다음 옵션을 선택하여 이상치를 바꿀 수 있습니다.
없음: 수행할 이상치 처리가 없습니다.
0으로 대체: 0으로 대체합니다.
평균으로 바꾸기: 가장 가까운 K 값의 평균으로 바꿉니다.
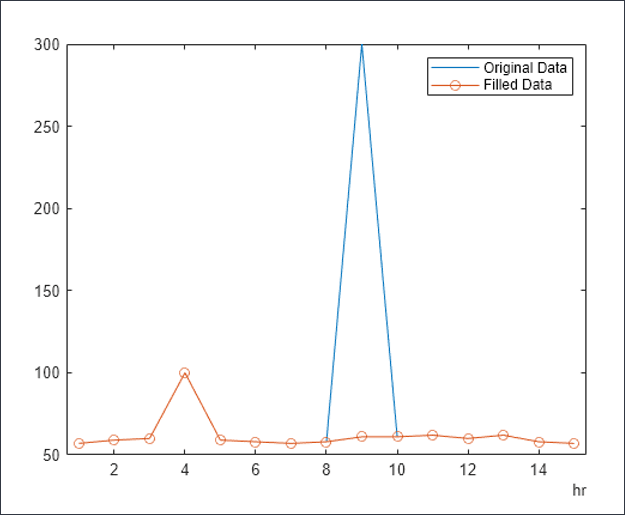
Z 점수로 대체: 숫자 열의 경우 평균 +/- 3*표준 편차(표준 편차)에서 벗어나는 값은 이상값으로 처리됩니다. '평균 - 3*std dev'보다 작은 값은 '평균 -3*std dev'로 바뀝니다. 마찬가지로 'mean + 3*std dev'보다 큰 값은 'mean + 3*std dev'로 대체됩니다.
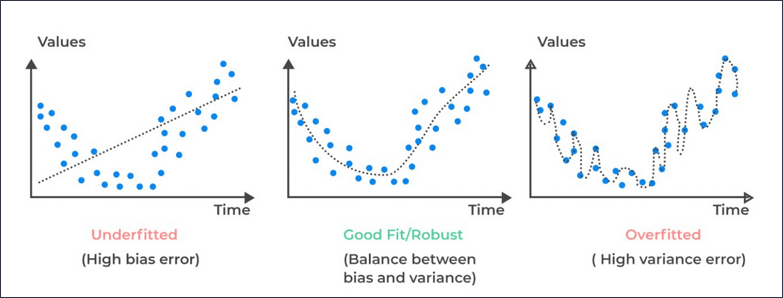
아래 그래프에서는 식별되고 정규화된 값으로 대체되는 이상값의 예입니다.
누락된 입력 동인 값 예측을 사용으로 설정합니다.
누락된 입력 동인 값 예측을 사용으로 설정하면 통계 예측, 즉 해당 측정에 대한 데이터가 없는 경우 단변량 예측을 사용하여 값을 예측할 수 있습니다.
누락된 값의 경우 옵션 목록을 확인합니다.
누락된 값의 선택을 수정하려면 드라이버 행의 작업 열에서 (작업)을 누릅니다.
각 드라이버 행에 대해 [작업]에서 (작업)을 누르고 옵션 목록에서 마지막 관찰된 값을 선택합니다.
참고:
각 행의 [값 누락] 옵션을 변경한 후 (저장)을 누를 수 있습니다.
모든 드라이버에 대해 누락된 값이 마지막 관찰 값으로 설정됩니다.
이상값의 경우 옵션 목록을 확인합니다.
이상값에 대한 선택을 수정하려면 드라이버 행의 작업 열에서 (작업)을 누릅니다.
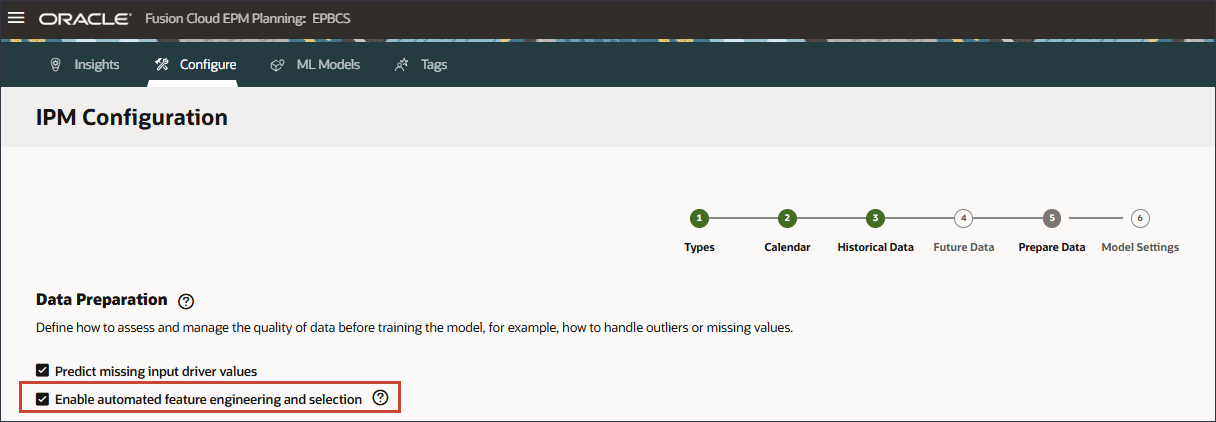
기능 엔지니어링 활성화
이 섹션에서는 피쳐 엔지니어링이 활성화되어 있는지 확인합니다.
고급 예측에서 기능 엔지니어링을 사용하여 입력 드라이버와 예측 출력 간의 숨겨진 관계를 찾습니다. 예측 작업에 의해 자동으로 생성된 잘 엔지니어링된 기능을 통해 모델이 보다 관련성 높은 정보를 캡처할 수 있어 모델 성능이 향상되고 예측이 향상됩니다.
기능 엔지니어링은 기존 기능을 변환하거나 모델 성능을 개선하기 위해 새 기능을 생성하여 머신 러닝을 위한 데이터를 준비하는 프로세스입니다.
지능형 기능 엔지니어링은 정의된 드라이버를 기반으로 기능을 생성합니다.
피쳐 엔지니어링을 사용하면 추가 정보가 파생되어 보다 정확한 예측이 가능합니다.
적용된 변형은 다음과 같습니다.
시간 기반 기능입니다. 특정 요일이 더 많은 영향을 줍니까?
지연 효과. 5월 마케팅 지출이 7월 판매량에 미치는 영향과 같이 비즈니스 동인이 목표에 미치는 지연 효과는 무엇입니까?
변환을 집계합니다. 예를 들어, 롤링 평균 값이 단일 데이터 지점이 아닌 비즈니스 동인에 미치는 영향은 무엇입니까?
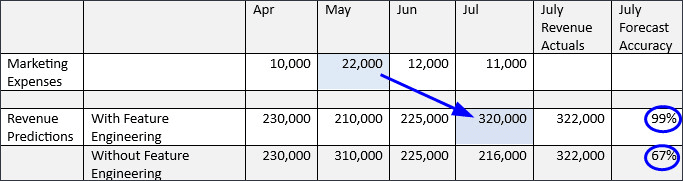
아래 예제에서는 비즈니스 드라이버가 대상에 미치는 지연 효과를 확인할 수 있습니다. 5월의 마케팅 지출은 7월의 판매량에 영향을 줍니다. 기능 엔지니어링이 없으면 7월 수익 예측은 정확도가 67%이지만 기능 엔지니어링을 사용하면 7월 수익은 99% 정확도로 예측됩니다.
지연 효과
기능 엔지니어링은 기본적으로 사용으로 설정됩니다.
기능 엔지니어링이 사용으로 설정되었는지 확인합니다.
다음을 누릅니다.
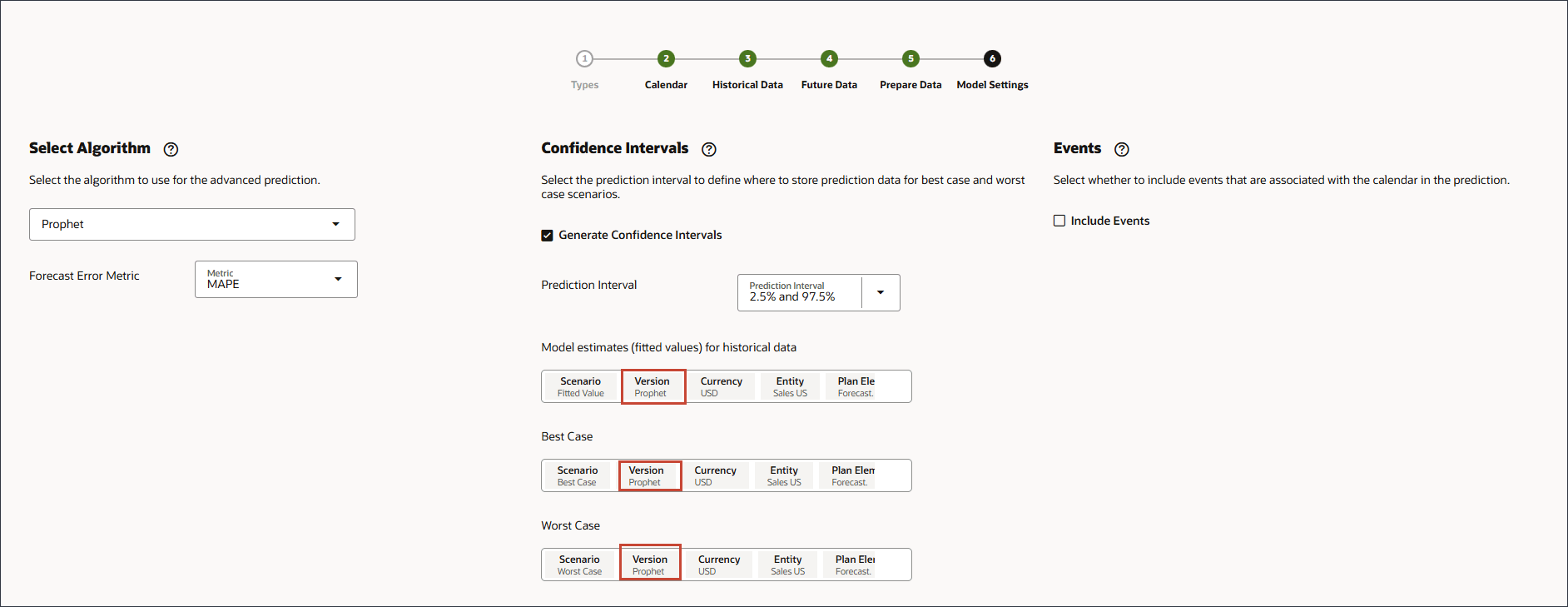
모델 설정에 대한 알고리즘 선택
이 섹션에서는 모델 설정에 대한 알고리즘을 선택합니다.
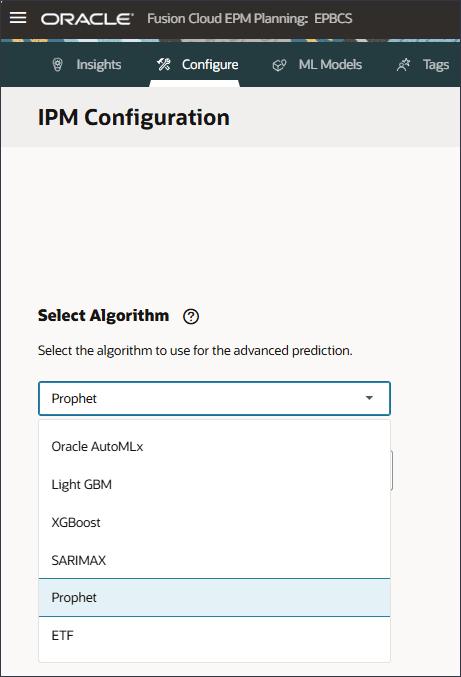
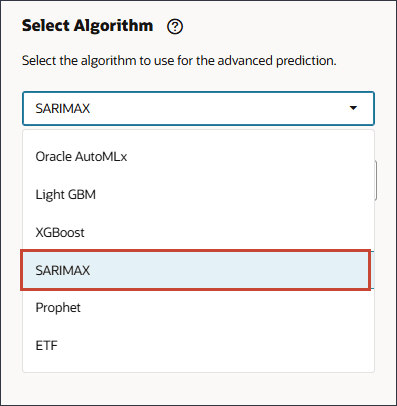
Oracle AutoML 또는 Light GBM, XGBoost, Prophet 또는 SARIMAX와 같은 특정 알고리즘을 선택할 수 있습니다.
Oracle AutoMLx는 다음을 수행하는 독점적 프레임워크입니다.
데이터에서 다양한 통계 모델 및 머신 러닝 알고리즘 실행
모델 튜닝 및 검증
데이터에 가장 적합한 모델 찾기
최고의 모델에 맞는 데이터
Oracle AutoMLx, Light GBM, XGBoost, Prophet 및 SARIMAX와 같은 다양한 알고리즘 중 하나를 선택할 수 있습니다. 이는 모델 교육에 대해 전 세계적으로 사용 가능한 고급 예측 알고리즘의 모범 사례입니다. AutoMLx 알고리즘에는 아래 세부정보에 따라 다중 알고리즘이 있습니다.
AutoMLx python 패키지는 머신 러닝 파이프라인 및 모델을 자동으로 생성, 최적화 및 설명합니다. AutoML 파이프라인은 주어진 학습 데이터 세트 및 현재 진행 중인 예측 작업에 가장 적합한 모델을 찾는 조정된 ML 파이프라인을 제공합니다. AutoML에는 정확하게 튜닝된 모델로 데이터 과학 프로세스를 빠르게 시작하는 간단한 파이프라인 레벨의 Python API가 있습니다. AutoML은 다음 작업을 지원합니다.
AutoClassifier: 표 형식 데이터 세트가 있는 감독된 분류 또는 회귀 예측으로, 대상은 각각 단순 바이너리, 다중 클래스 값 또는 테이블의 실제 값 열일 수 있습니다.
AutoRegressor: 이미지 및 텍스트 데이터 세트에 대한 감독된 분류입니다.
AutoAnomalyDetector: 대상 또는 레이블이 제공되지 않는 감독되지 않은 변형 감지입니다.
AutoForecaster: 단변량 및 다변량 시계열 예측 작업.
AutoML 파이프라인은 선행 처리, 알고리즘 선택, 적응형 샘플링, 기능 선택, 모델 튜닝의 다섯 가지 주요 ML 파이프라인 단계로 구성됩니다. 이러한 조각은 간단한 AutoML 파이프라인으로 쉽게 결합되어 제한된 사용자 입력/상호 작용으로 전체 파이프라인을 자동으로 최적화합니다.
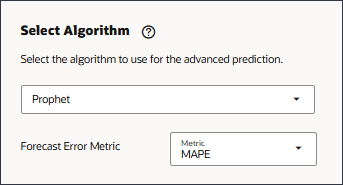
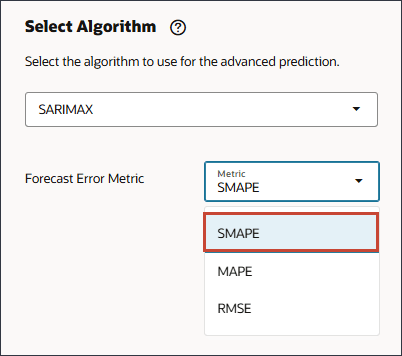
[알고리즘 선택]에서 드롭다운 목록을 눌러 선택사항을 확인한 다음 SARIMAX를 선택합니다.
예측 오류 측정항목의 경우 측정항목에 대해 SMAPE를 선택합니다.
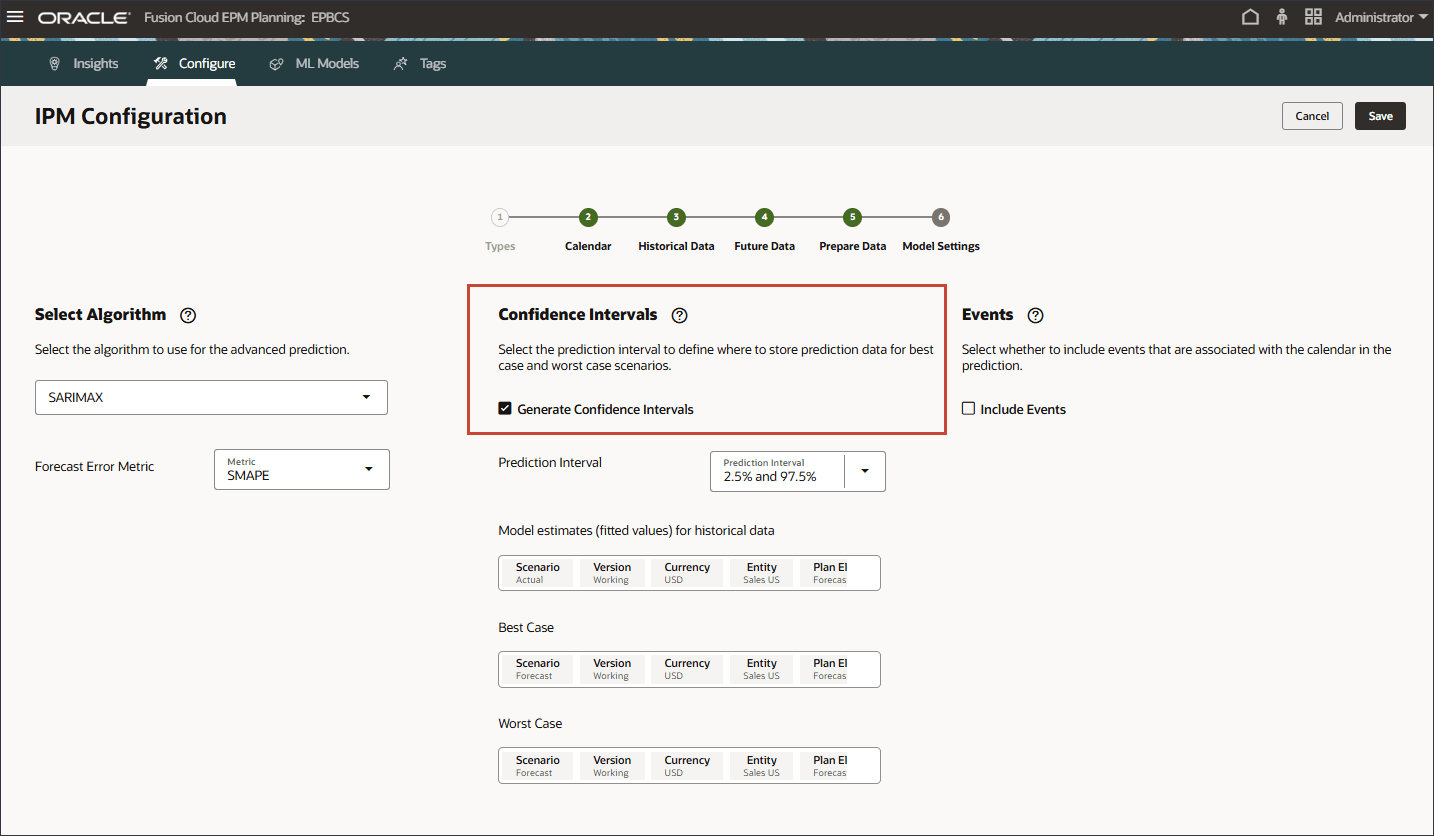
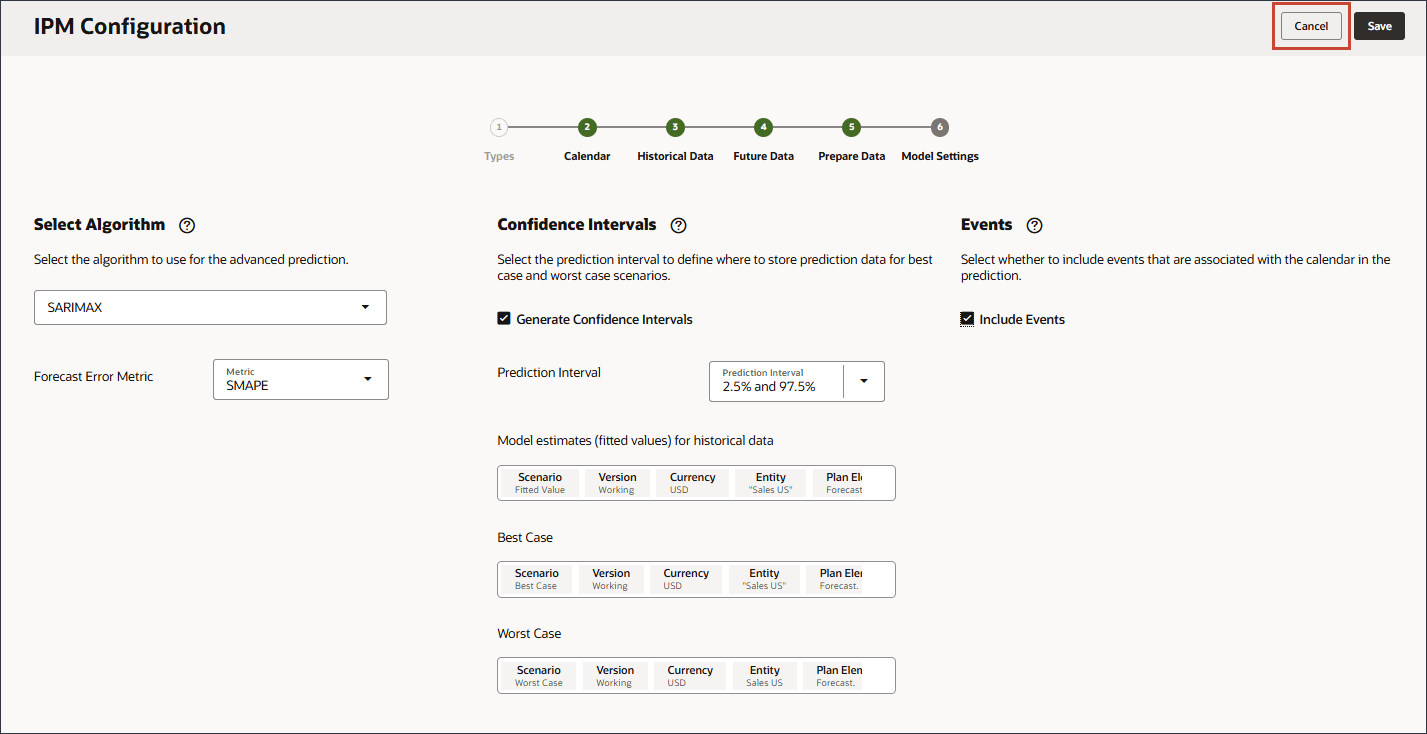
모델 설정에 대한 신뢰 구간 선택
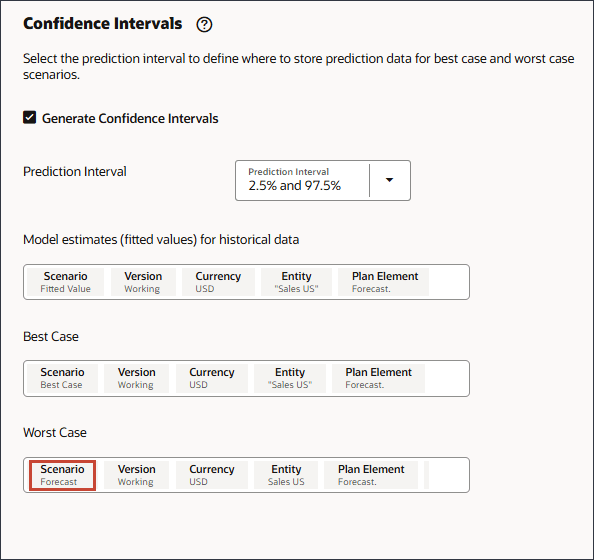
이 섹션에서는 최적화할 신뢰 구간 및 척도를 선택합니다.
신뢰 구간 설정에 따라 시스템은 고급 예측의 여러 시나리오를 생성하고 이 모델 설정 설정에서 제공된 시나리오에 따라 결과를 저장합니다.
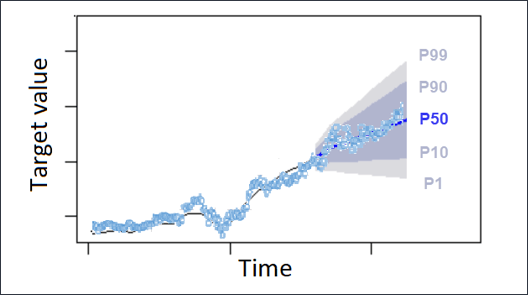
예측의 신뢰 구간은 예측 출력 값에 대한 상한 및 하한을 제공할 수 있습니다.
예를 들어, 신뢰 구간 10%(P10) 및 90%(P90)를 사용하면 신뢰 구간 80%로 알려진 값 범위를 제공합니다. 관찰된 값은 시간의 P10 값 10%보다 낮을 것으로 예상되며, P90 값은 시간의 관찰된 값 90%보다 높을 것으로 예상됩니다.
P10 및 P90에서 예측을 생성하면 실제 값이 시간의 80% 범위 사이에 있을 것으로 예상할 수 있습니다. 이 값 범위는 표시된 그림에서 P10와 P90 사이의 음영 처리된 영역으로 표시됩니다.
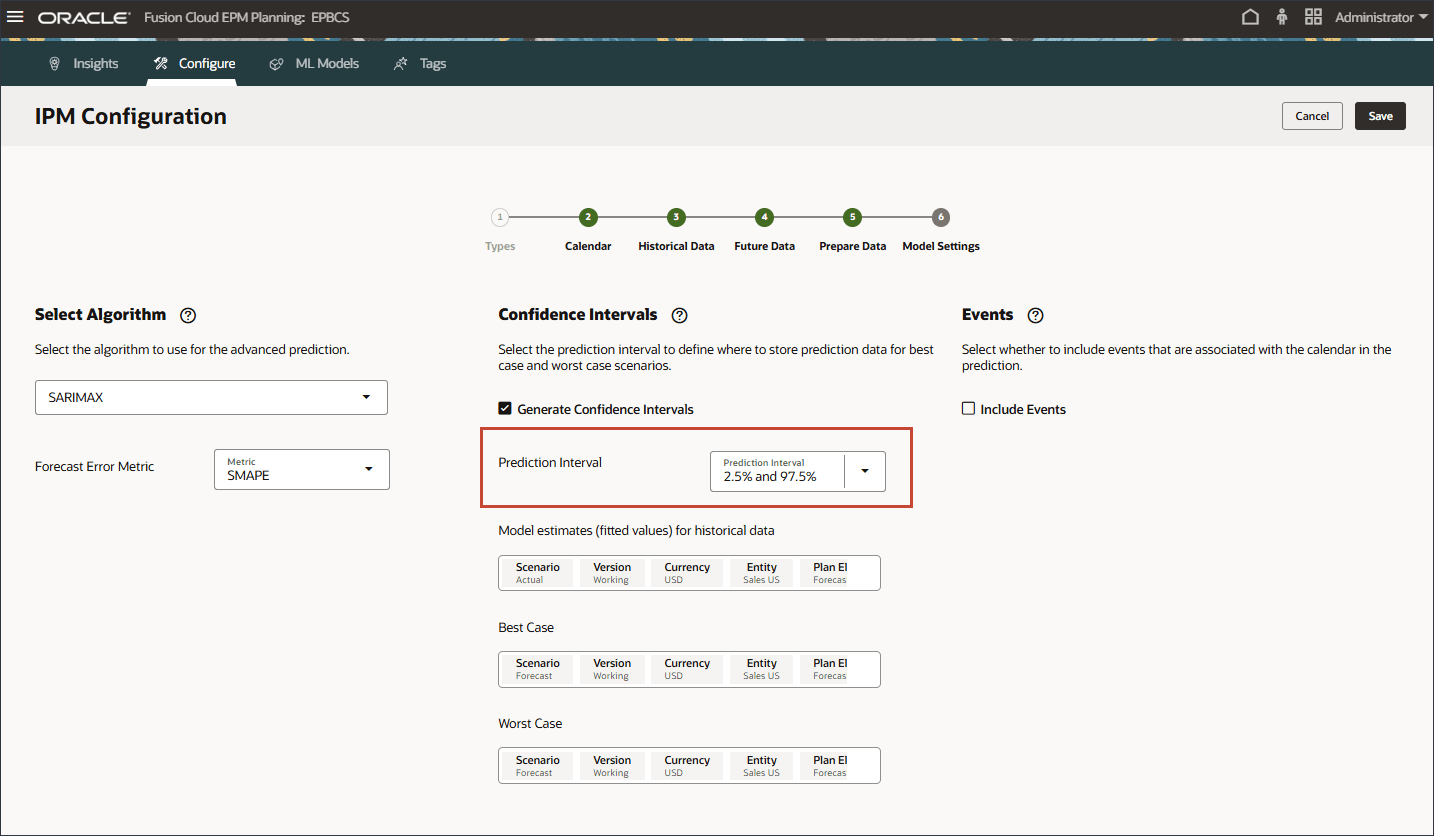
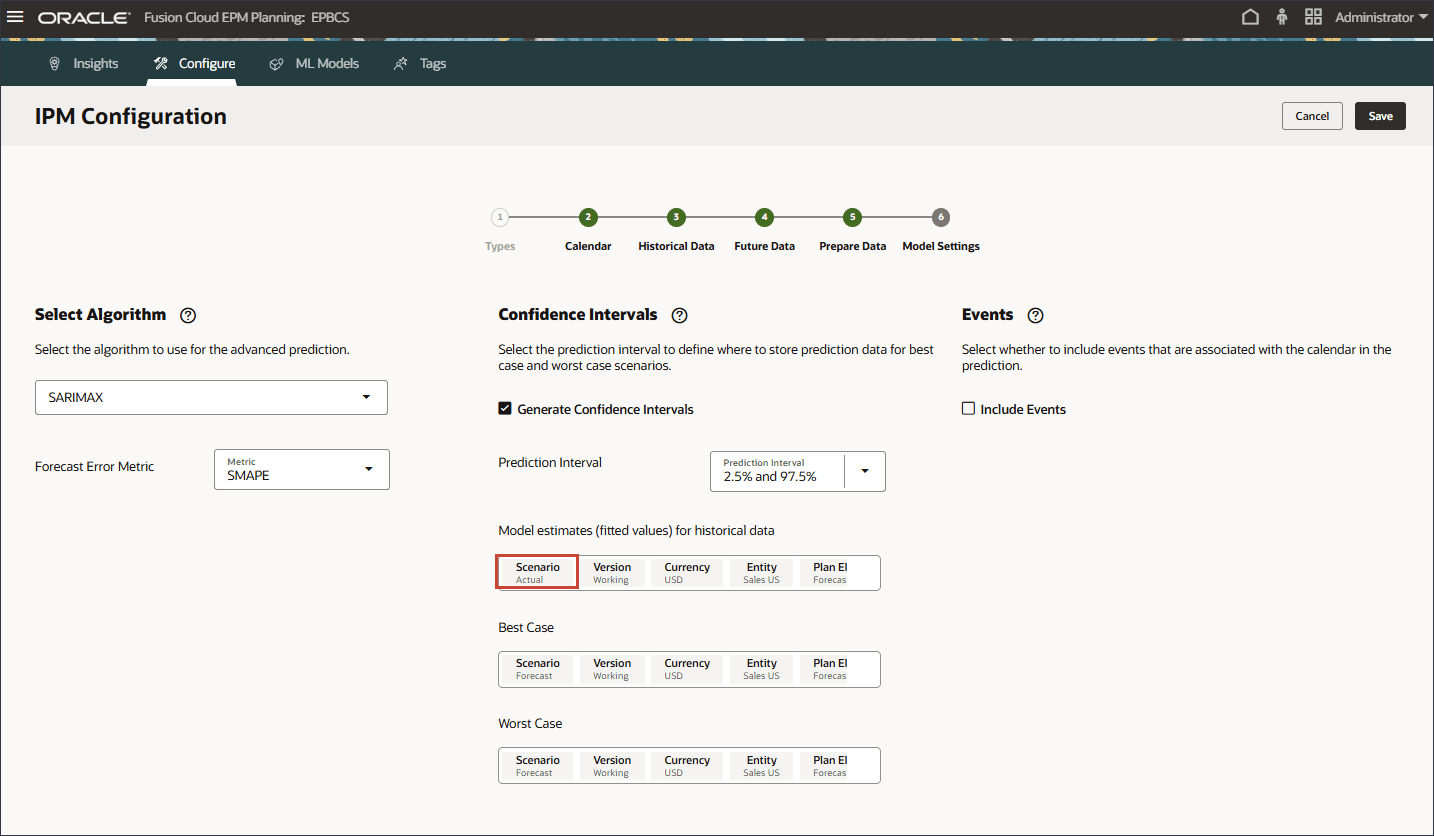
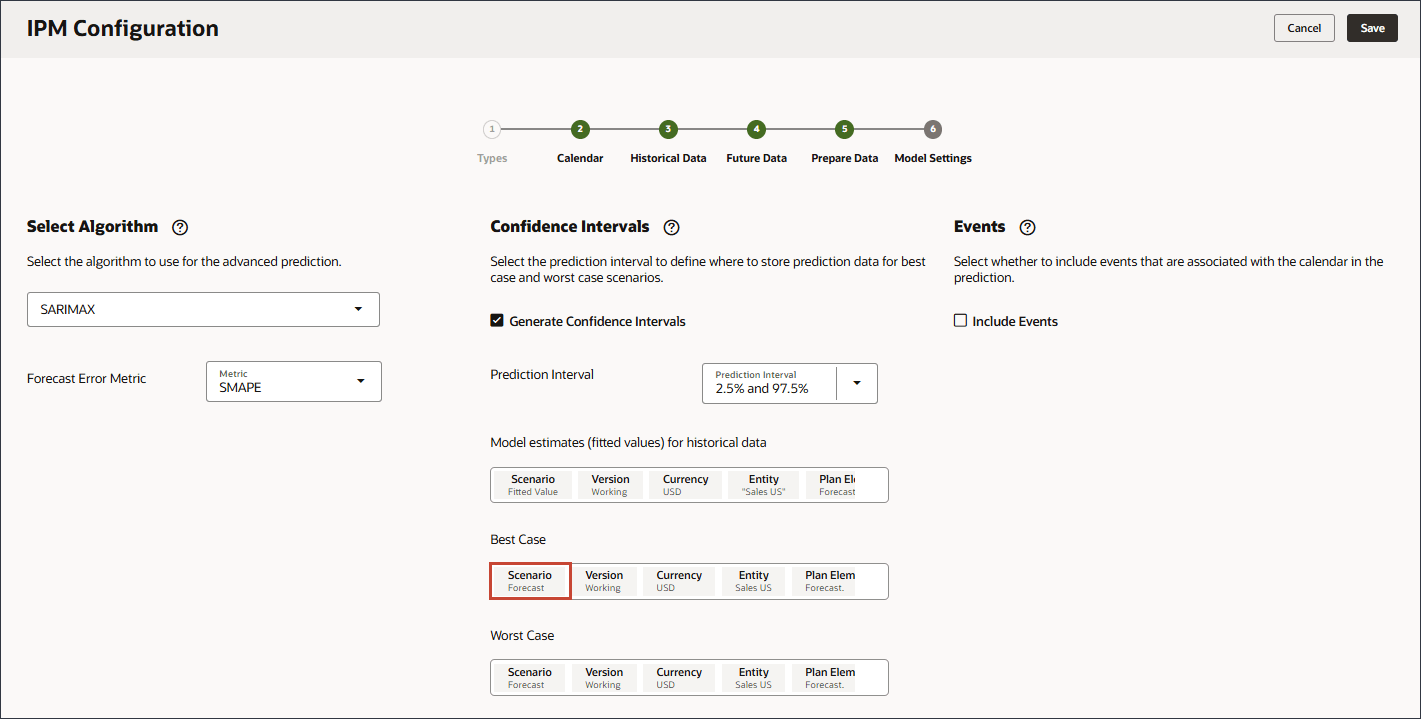
모델 설정 페이지의 신뢰 구간에서 신뢰 구간 생성을 선택합니다.
예측 간격의 경우 최선의 경우, 최악의 경우 및 적합 값 예측에 대한 기본 설정을 유지합니다.
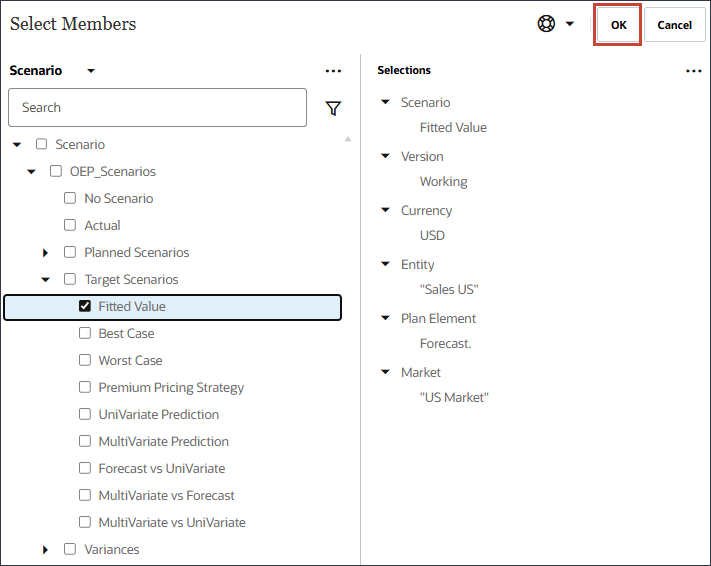
과거 데이터에 대한 모델 추정치(적정 값)에서 시나리오를 누릅니다.
시나리오의 경우 적합한 값을 선택하고 확인을 누릅니다.
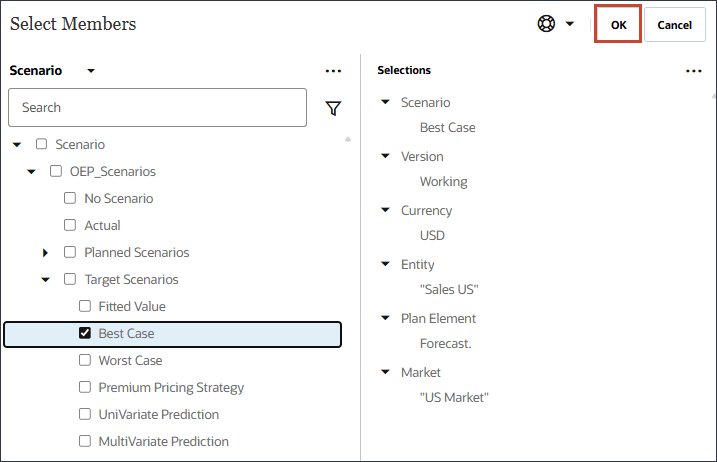
최선의 경우 시나리오를 누릅니다.
시나리오의 경우 최적 사례를 선택하고 확인을 누릅니다.
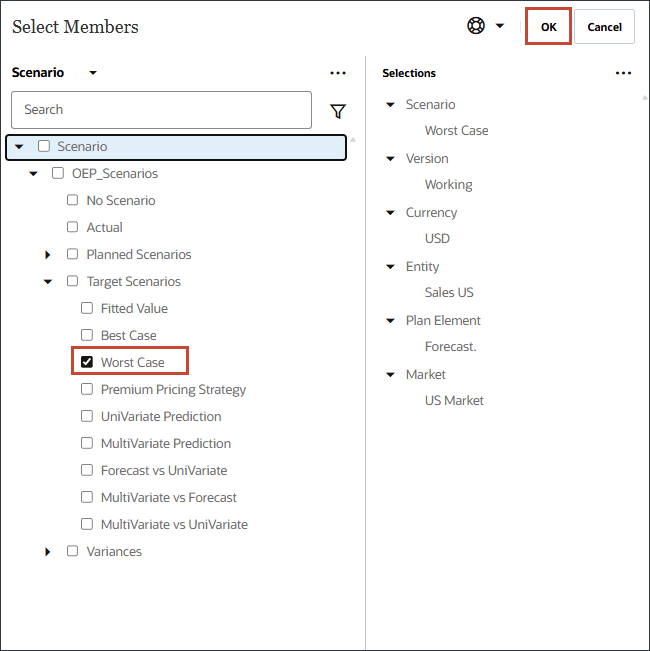
최악의 경우 시나리오를 누릅니다.
시나리오의 경우 최악의 사례를 선택하고 확인을 누릅니다.
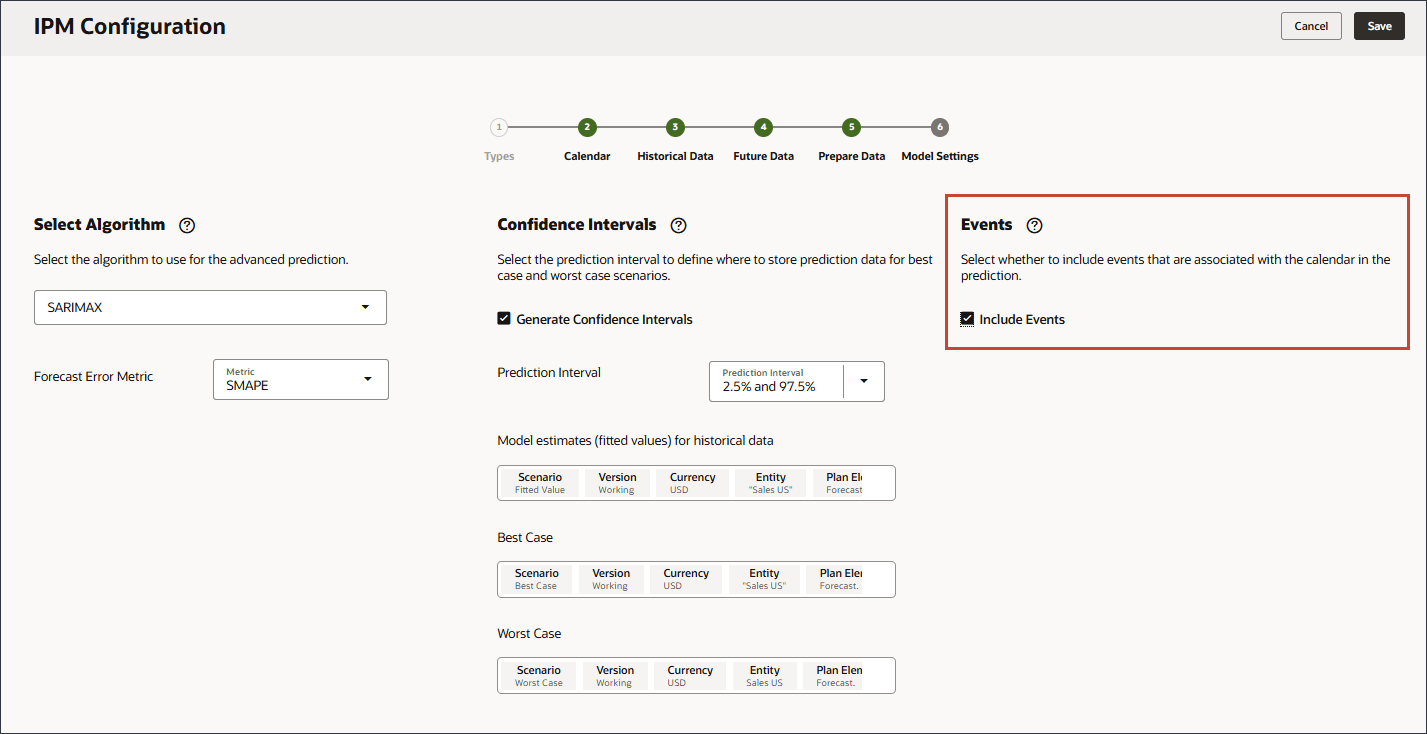
이벤트 선택하는 중
이 섹션에서는 예측에 이벤트를 포함할지 여부를 선택합니다.
예측에 이벤트를 포함할 수 있습니다. 이벤트는 고급 튜닝에 사용할 수 있으며, 발생하고 과거 데이터에 영향을 미치는 특정 이벤트가 예측에 고려되도록 하려면 정확성을 높일 수 있습니다. 이러한 이벤트에는 다음이 포함될 수 있습니다.
크리스마스와 같은 동일한 기간의 반복 이벤트
라마단과 같은 다양한 기간의 반복 이벤트
허리케인과 같은 일회성 행사
팬데믹과 같은 이벤트 건너뛰기
오른쪽의 이벤트에서 이벤트 포함을 선택합니다.
저장을 누릅니다.
정보 메시지가 표시됩니다.
취소를 누릅니다.
새 고급 예측 작업이 표시됩니다.
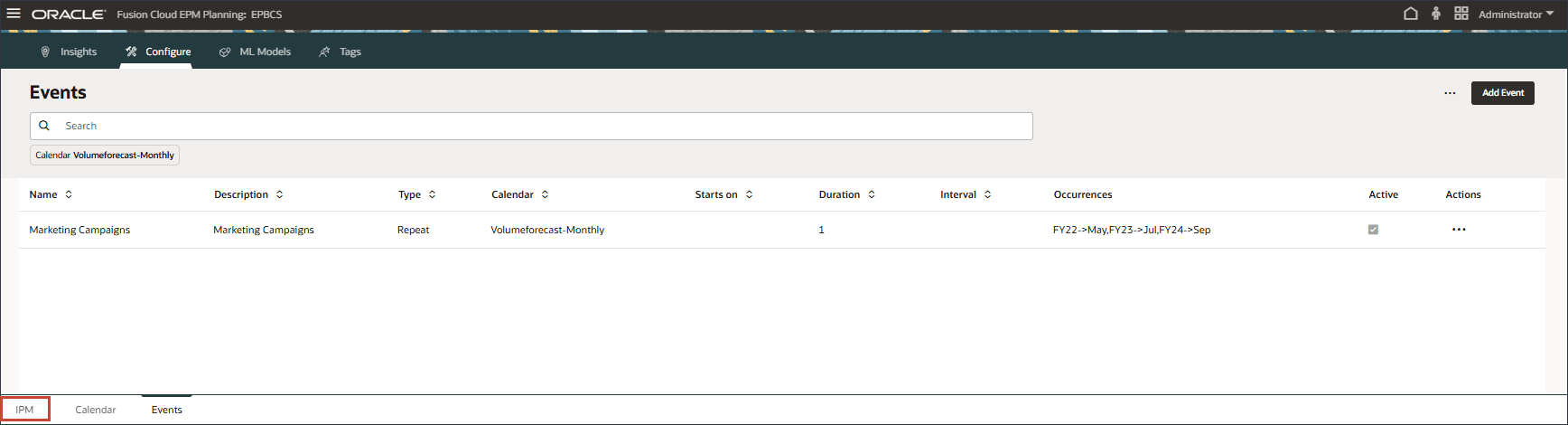
이벤트 추가
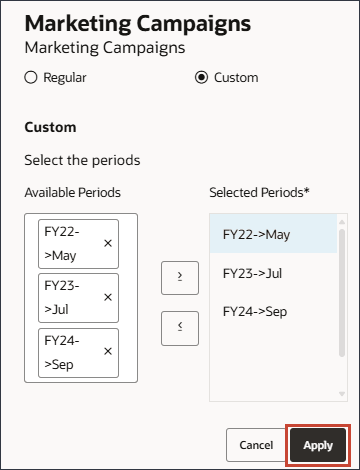
이 섹션에서는 5월 22일, 7월 23일 및 9월 24일 기간에 대한 새 마케팅 캠페인 이벤트를 추가합니다. 5월 22일과 7월 23일은 실제 기간이지만, 9월 24일은 마케팅 캠페인이 예정된 미래 예측 기간입니다. 이 이벤트는 기본적으로 이전 연도 5월과 7월에 발생한 동일한 이벤트도 향후 9월에 발생할 계획임을 나타냅니다.
이벤트 탭을 누릅니다.
이벤트 추가()를 누릅니다.
새 이벤트에 대해 다음 정보를 입력 또는 선택합니다.
열
값
이름
마케팅 캠페인을 실행합니다.
설명
마케팅 캠페인을 실행합니다.
유형
반복
달력
수량 예측-월별
기간
1
마케팅 캠페인 이벤트는 [반복] 유형이며 [볼륨 예측-월별] 일정을 기반으로 합니다.
발생에 대해 (이벤트 발생)을 누릅니다.
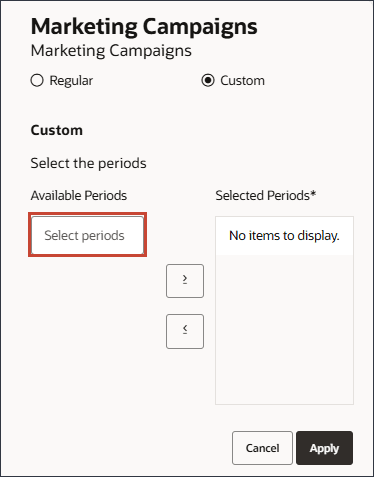
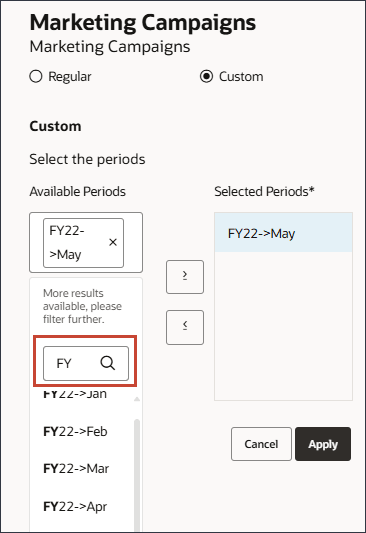
사용자정의를 선택하고 기간 선택을 누릅니다.
기간의 경우 5월 FY22을 선택하고 선택한 기간으로 이동합니다.
왼쪽에서 기간 영역을 누르고 FY23를 입력합니다.
검색 상자가 표시됩니다.
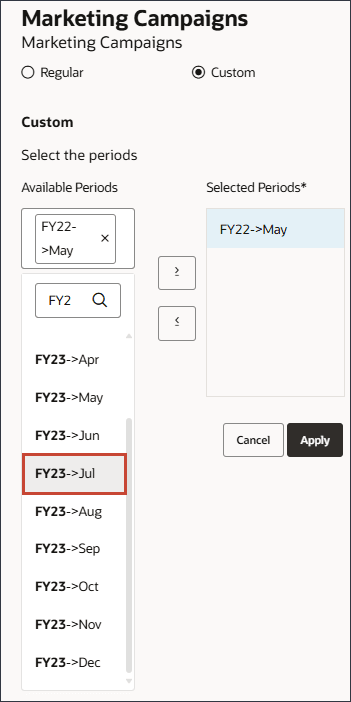
7월 FY23을 선택합니다.
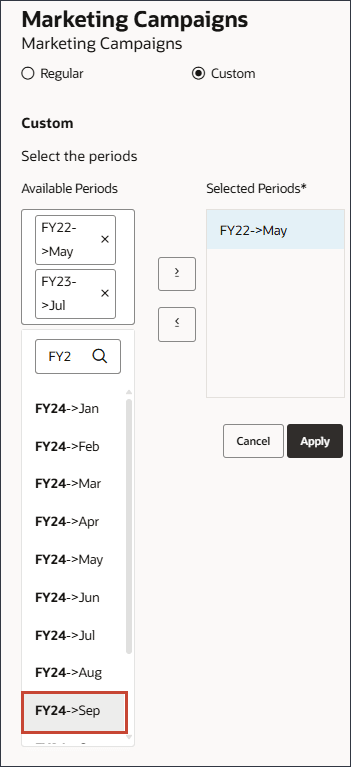
[사용 가능한 기간] 영역을 누르고 FY24를 입력한 다음 FY24 9월을 선택합니다.
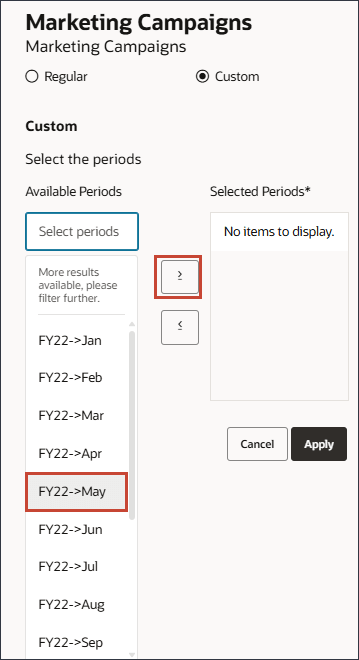
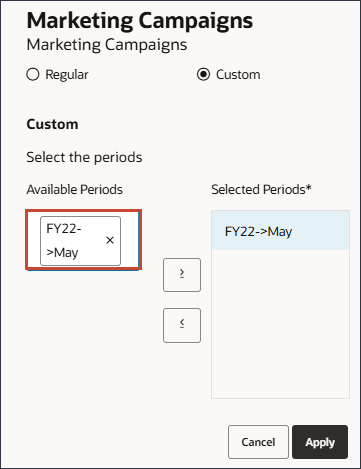
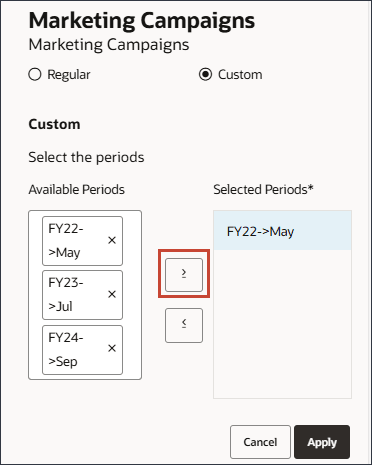
모든 기간을 선택한 기간으로 이동합니다.
적용을 누릅니다.
새 이벤트 행의 오른쪽에서 (저장)을 누릅니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
광고 및 판촉 비용 및 판매량 검토
이 섹션에서는 2022년 5월 및 2023년 7월의 광고 및 프로모션 비용과 판매량에 대한 실제 데이터를 검토하여 드라이버와 출력 간의 상관 관계를 파악합니다. 또한 향후 2024년 9월 드라이버 데이터를 검토합니다.
홈 페이지에서 고급 예측, 볼륨 예측 순으로 누릅니다.
입력 드라이버 탭을 선택합니다.
POV에서 계정을 누르고 광고 및 프로모션을 선택합니다.
5월 22일과 7월 23일의 경우 해당 월 동안 데이터가 범프됩니다.
이후 2024년 9월 데이터의 경우 구성 작업에서 이벤트가 사용으로 설정되었으므로 시스템에서 예측 결과를 자동으로 범프해야 합니다.
페이지 하단에서 볼륨 분석 탭을 누릅니다.
거래량 분석 차트는 마케팅 캠페인 이벤트로 인해 2023년 7월 거래량 데이터가 범프되었음을 보여줍니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
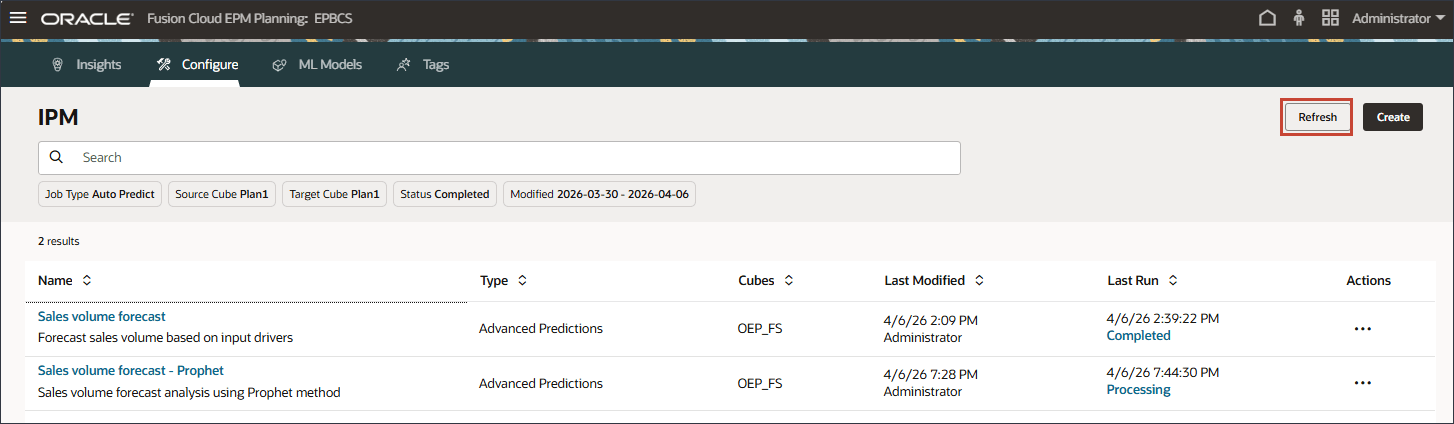
고급 예측 작업 실행
이 섹션에서는 고급 예측 작업을 실행하여 예측을 생성합니다.
홈 페이지에서 IPM을 누르고 구성을 선택합니다.
아래쪽에서 IPM 탭을 선택합니다.
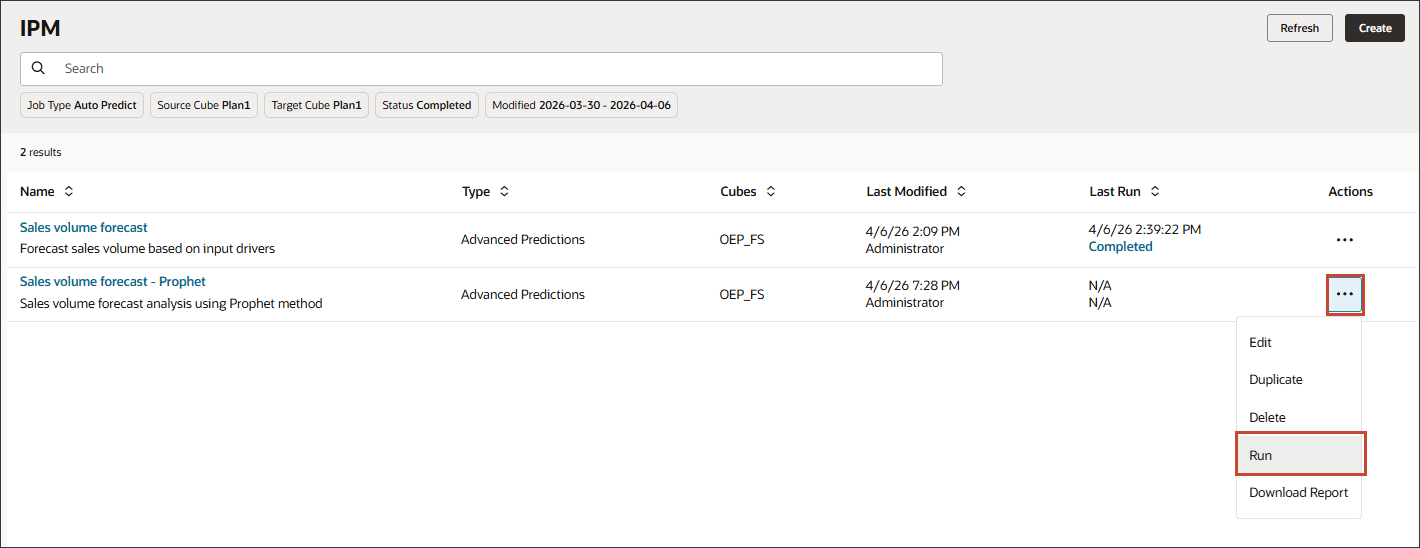
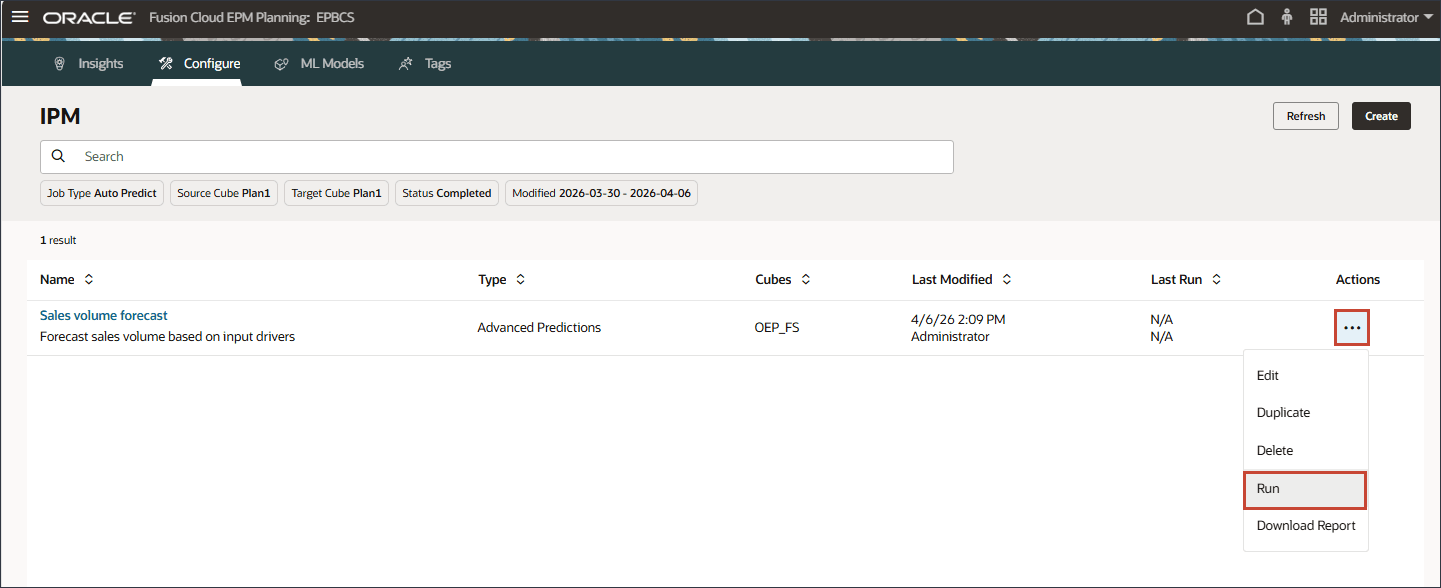
판매량 예측의 경우 오른쪽에서 (작업)을 누르고 실행을 선택합니다.
IPM 페이지에서는 고급 예측 작업을 실행하고, 작업 상태를 모니터하고, 오류 로그를 검토하고, 필요에 따라 구성을 변경할 수 있습니다.
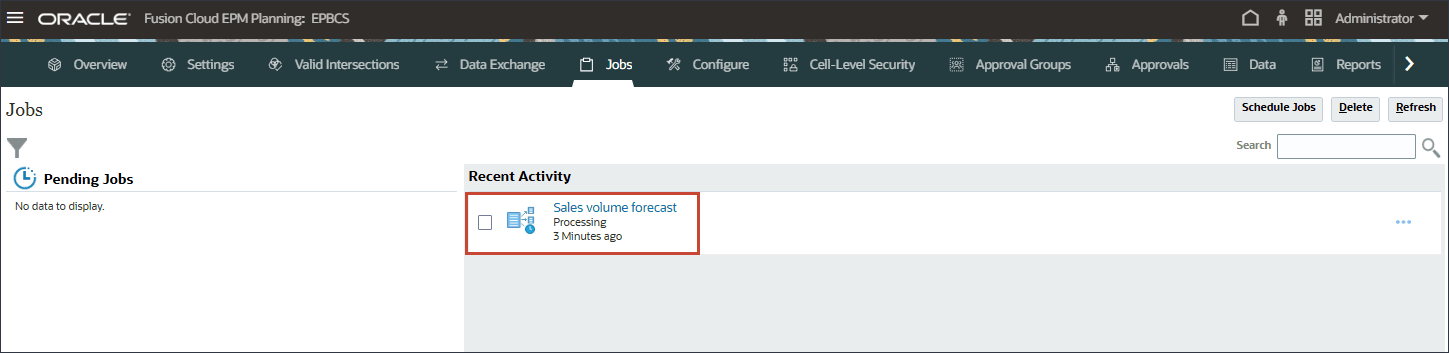
작업을 실행한 후 작업이 성공적으로 시작되었음을 알리는 정보 메시지가 표시됩니다.
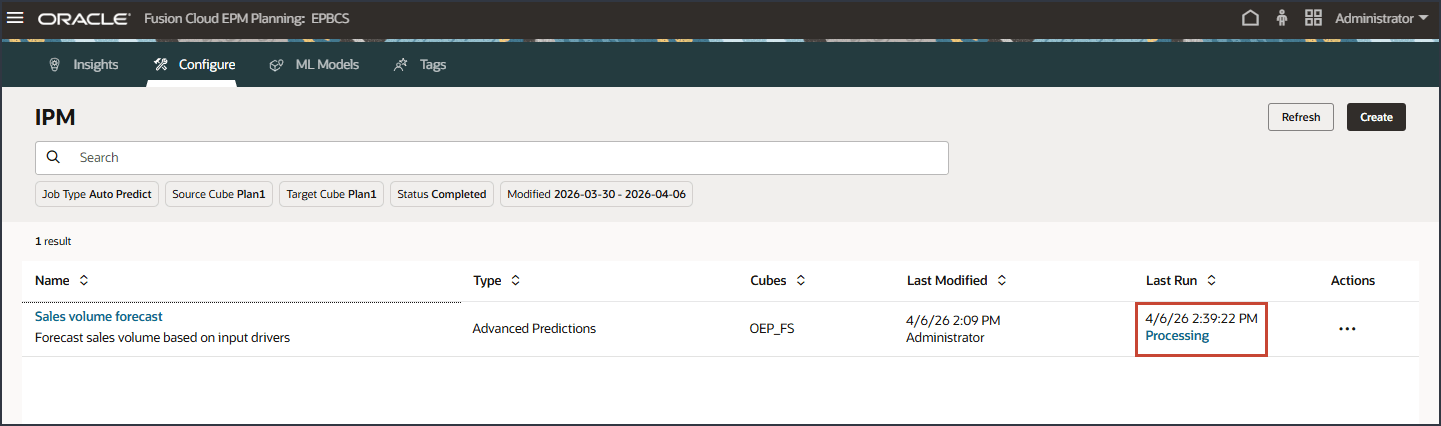
날짜 및 시간이 있는 [마지막 실행] 열에서 현재 상태를 볼 수 있습니다. 작업을 제출한 후 표시되는 상태가 "처리 중"입니다.
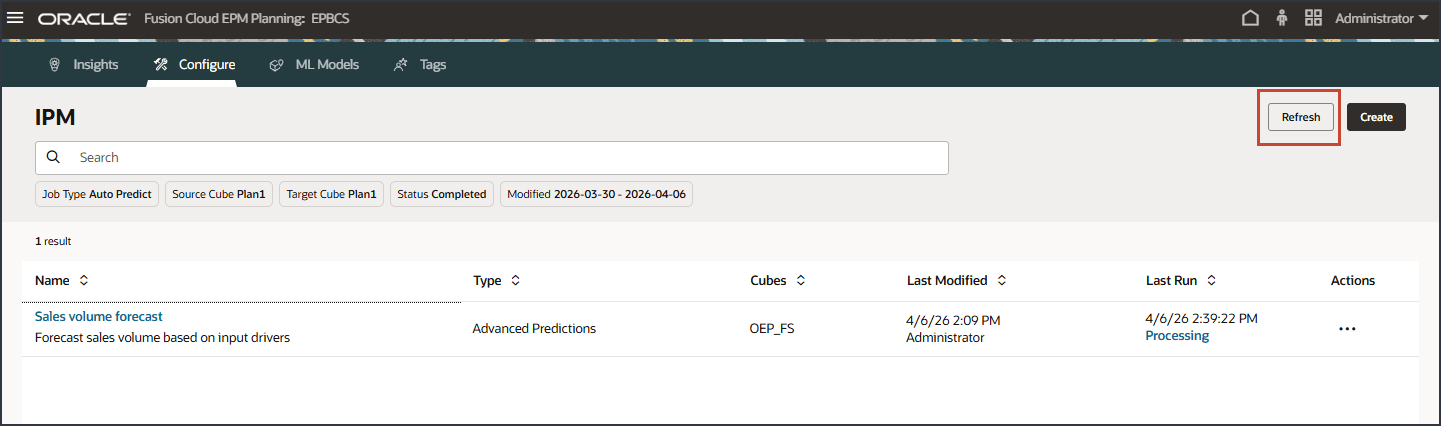
IPM 페이지에서 새로고침을 눌러 작업 상태를 업데이트합니다.
주:
작업을 완료하는 데 몇 분 정도 걸립니다.
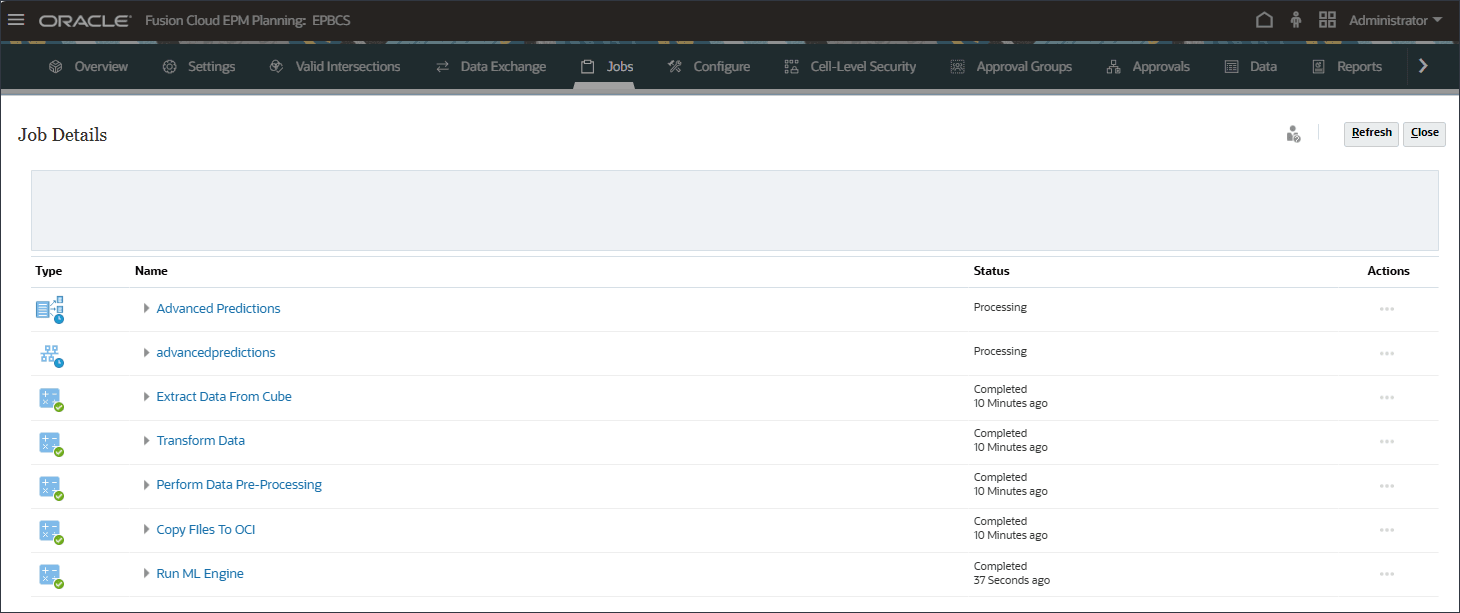
(네비게이터)을 누르고 [애플리케이션]에서 작업을 누릅니다.
작업 페이지에서 판매 볼륨 예측을 누릅니다.
예측을 생성하기 위해 여러 작업이 내부적으로 트리거되었습니다.
시스템은 한 번의 클릭만으로 지수 평활, ARIMA 및 회귀 모델을 포함한 여러 알고리즘을 테스트한 다음 가장 통계적으로 정확한 예측을 표시합니다. 이를 통해 계획자는 몇 초 내에 데이터 기반 예측을 생성하여 수동 분석 시간을 대체할 수 있습니다.
주:
작업을 완료하는 데 몇 분 정도 걸립니다.
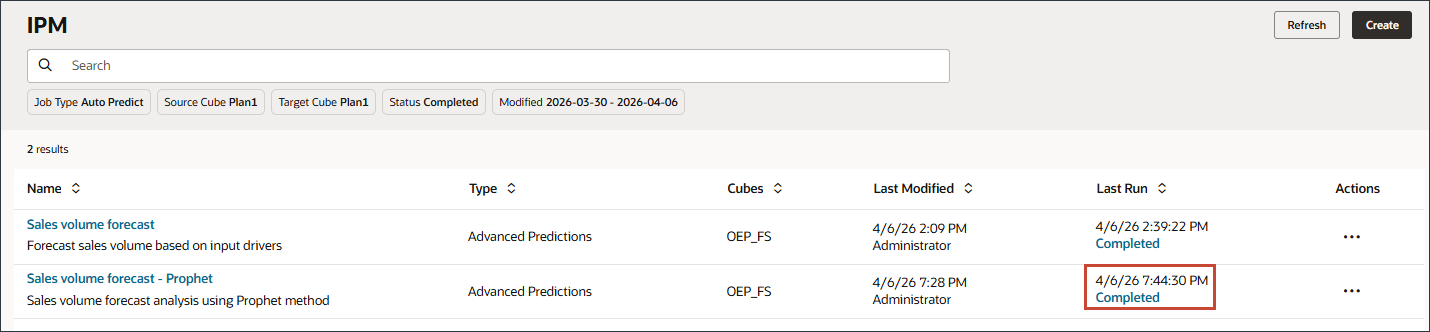
모든 고급 예측 작업이 성공적으로 완료될 때까지 기다린 후 닫기를 누릅니다.
새로 고침을 누르십시오.
주 작업이 성공적으로 완료되었습니다.
(네비게이터)을 누르고 IPM에서 구성을 누릅니다.
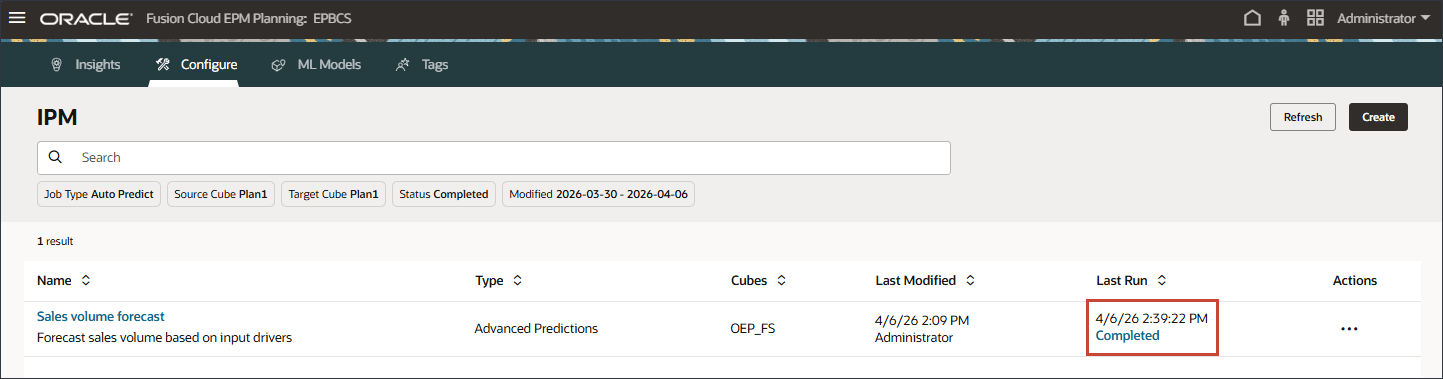
판매량 예측이 성공적으로 완료되었습니다.
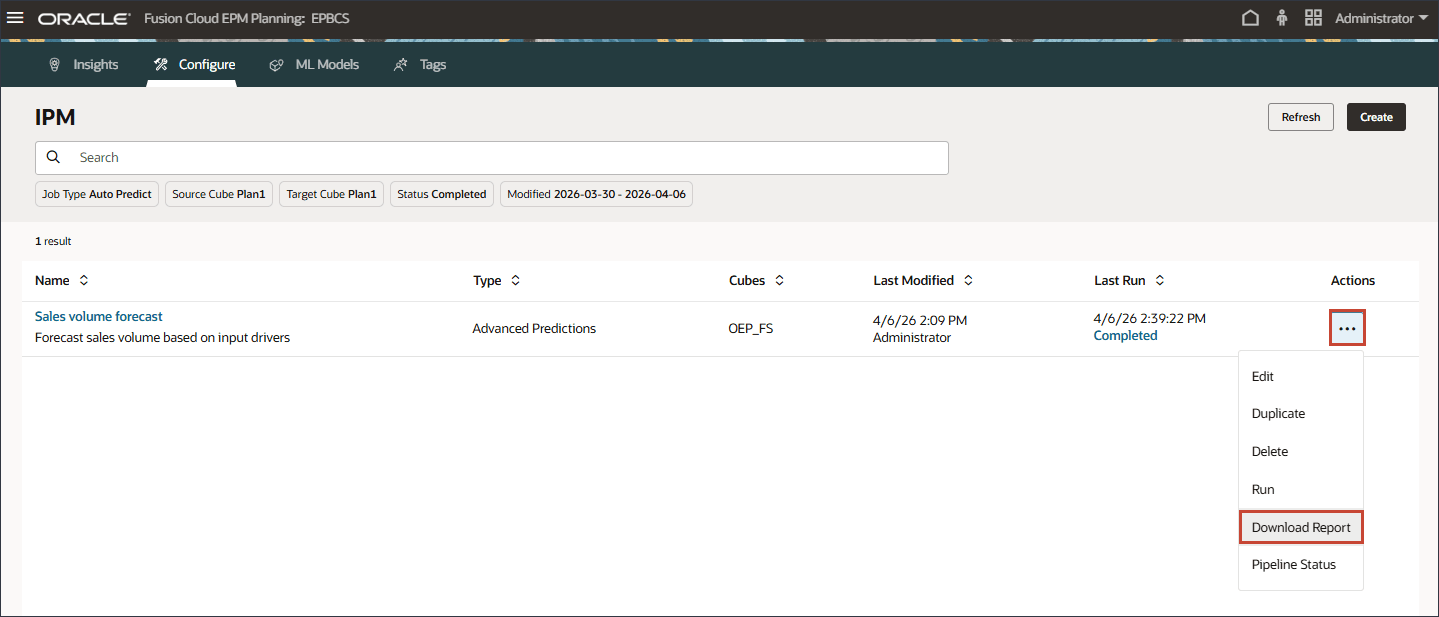
작업이 성공적으로 완료된 후 보고서를 다운로드하고 예측 결과를 검토할 수 있습니다. 판매량 예측의 경우 오른쪽에서 (작업)을 누르고 보고서 다운로드를 선택합니다.
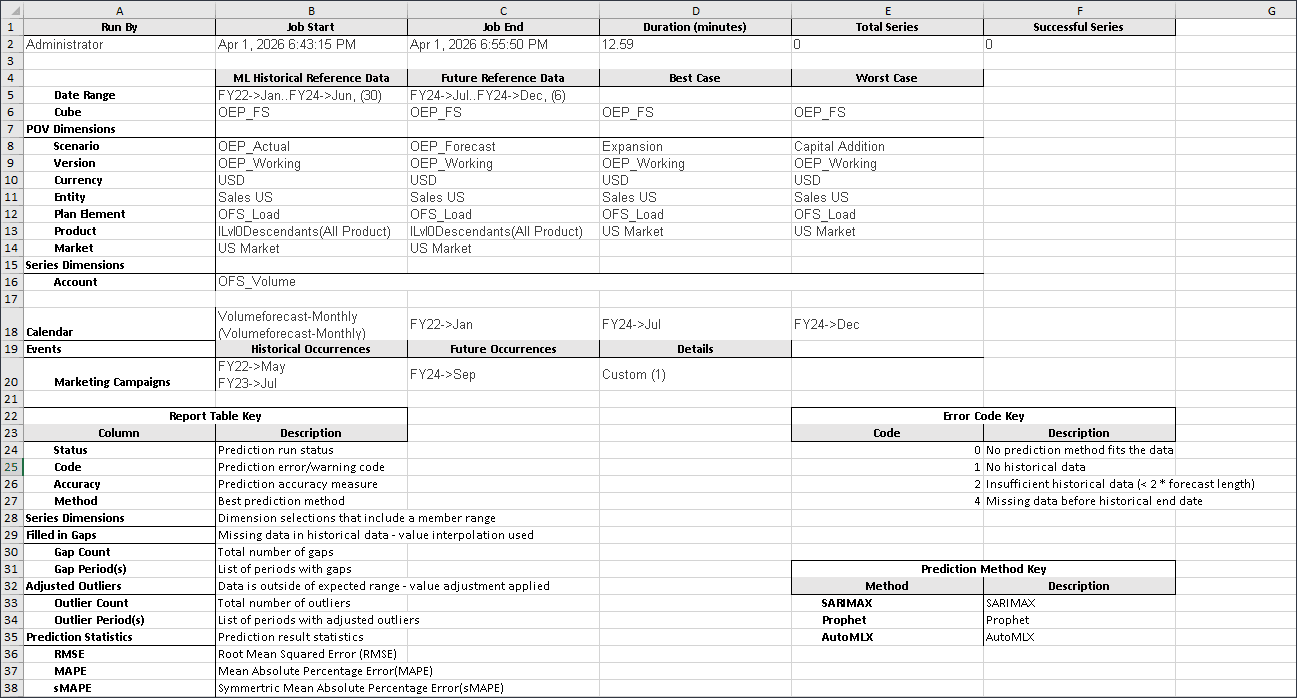
다운로드 보고서는 고급 예측 작업과 관련된 모든 세부정보가 포함된 .csv 파일을 포함하는 zip 파일입니다. 이 샘플 판매량 예측 보고서를 검토할 수 있습니다.
아래는 보고서의 샘플입니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
고급 예측 결과 검토
거래량 예측 결과 검토
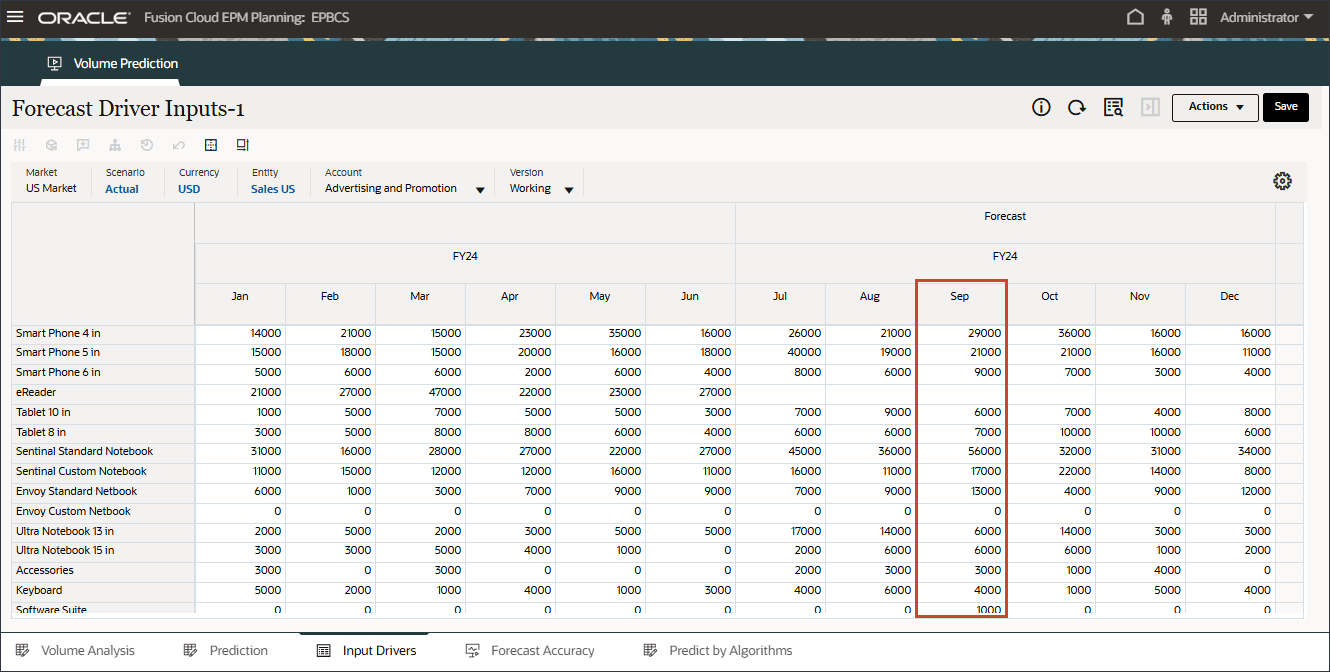
이 섹션에서는 거래량 예측 결과를 검토합니다. 모든 입력 드라이버 계정에 대해 "누락된 입력 드라이버 값 예측" Imputation 기능을 사용하여 eReader 제품 범주의 미래 값이 예측되었는지 확인하려고 합니다.
홈 페이지에서 고급 예측을 누르고 볼륨 예측을 선택합니다.
아래쪽에서 입력 드라이버 탭을 누릅니다.
POV의 계정에서 산업 거래량을 선택합니다.
오른쪽으로 스크롤.
고급 예측 작업에서 계산 기능("누락된 입력 드라이버 값 예측")을 사용하여 산업 볼륨 미래 데이터(7월 ~ 12월, FY24)가 예측되었습니다.
POV의 계정에서 광고 및 프로모션을 선택합니다.
광고 및 판촉 데이터(7월 ~ 12월, FY24)는 고급 예측 작업에서 인정 기능("누락된 입력 드라이버 값 예측")을 사용하여 예측되었습니다.
POV에서 계정에 대해 평균 판매 가격을 선택합니다.
고급 예측 작업에서 평균 판매 가격(7월 ~ 12월, FY24)이 계산 기능("누락된 입력 드라이버 값 예측")을 사용하여 예측되었습니다.
POV에서 계정에 대해 개인 소비 지출(내구재)을 선택합니다.
개인 소비 지출(내구재)(7월 ~ 12월, FY24)은 고급 예측 작업에서 인정 기능("누락된 입력 드라이버 값 예측")을 사용하여 예측되었습니다.
POV에서 계정에 대해 할인율을 선택합니다.
고급 예측 작업에서 계산 기능("누락된 입력 드라이버 값 예측")을 사용하여 할인율(7월 ~ 12월, FY24)이 예측되었습니다.
POV에서 계정에 대해 액세서리를 선택합니다.
고급 예측 작업에서 부속품(7월 ~ 12월, FY24)이 계산 기능("누락된 입력 드라이버 값 예측")을 사용하여 예측되었습니다.
대상 변수에 대한 예측 결과 검토
이 섹션에서는 Product Sales 볼륨인 대상 변수의 예측 결과를 검토합니다. 또한 설명 가능성을 검토하고 기능 중요성을 검토합니다.
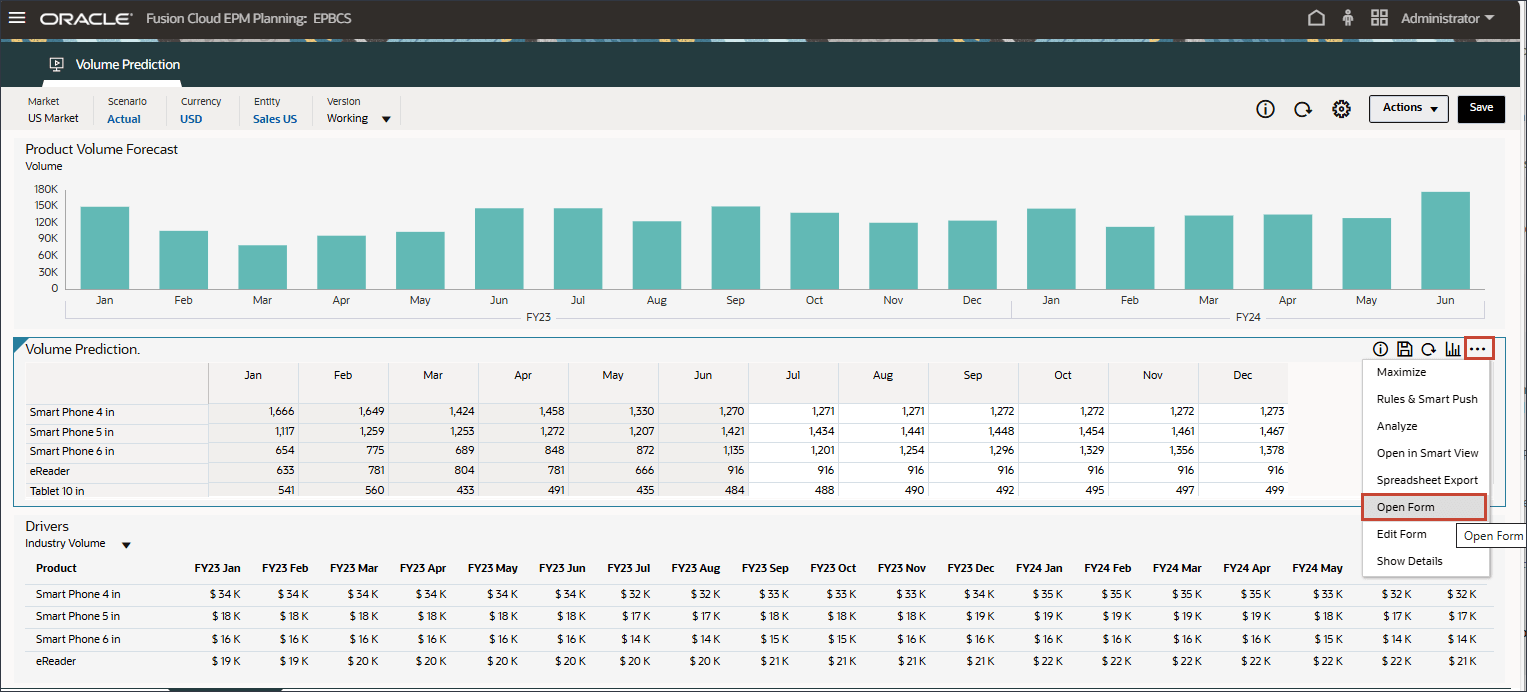
하단에서 예측 탭을 누릅니다.
볼륨 예측 대시보드가 표시됩니다.
볼륨 예측 양식의 중간에서 (작업)을 누르고 양식 열기를 선택합니다.
고급 예측 결과는 IPM 작업에 구성된 SARIMAX 알고리즘을 사용하여 7월부터 12월까지 FY24에 생성됩니다.
POV에서 실제를 누릅니다.
OEP_Scenarios 및 계획된 시나리오에서 예측을 선택하고 확인을 누릅니다.
예측 데이터가 표시됩니다.
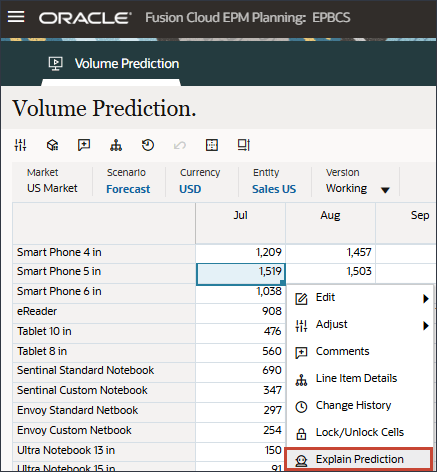
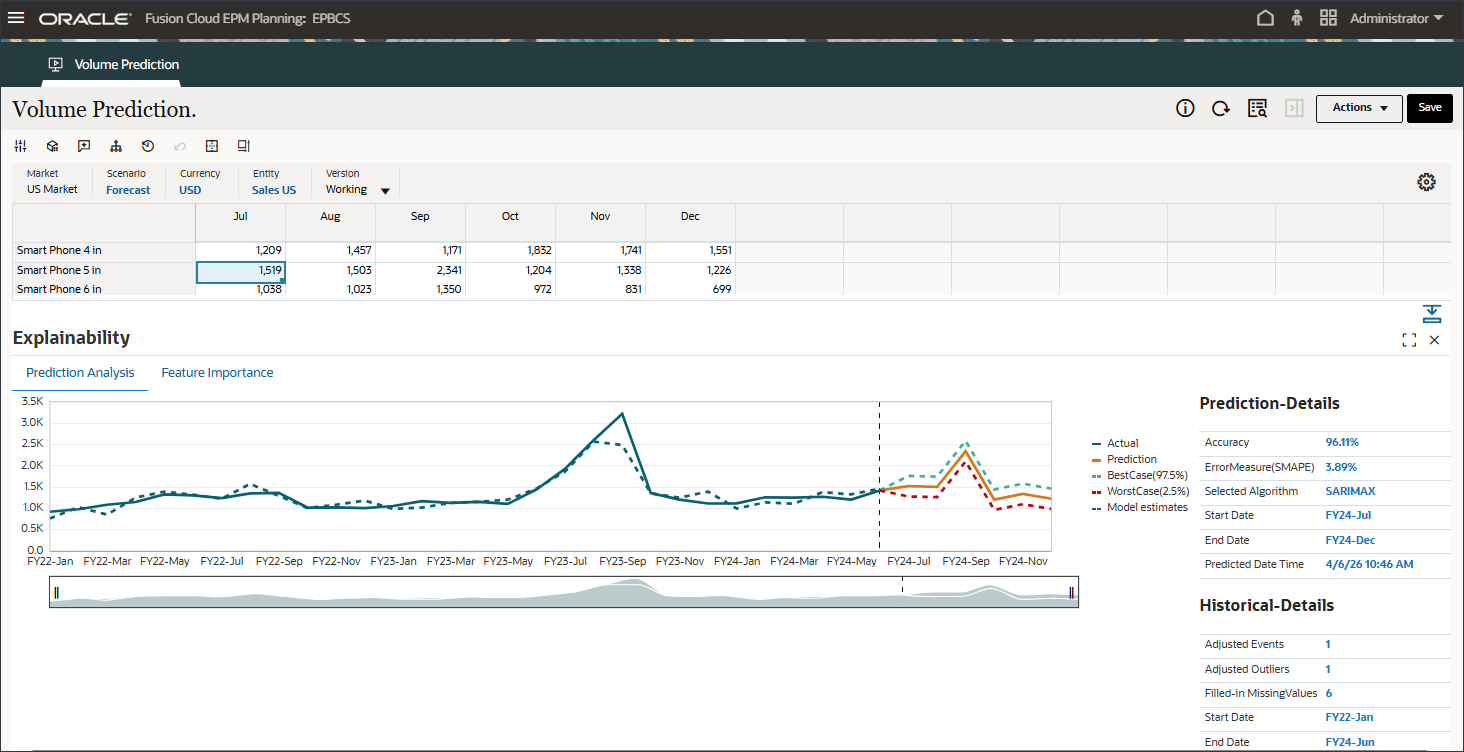
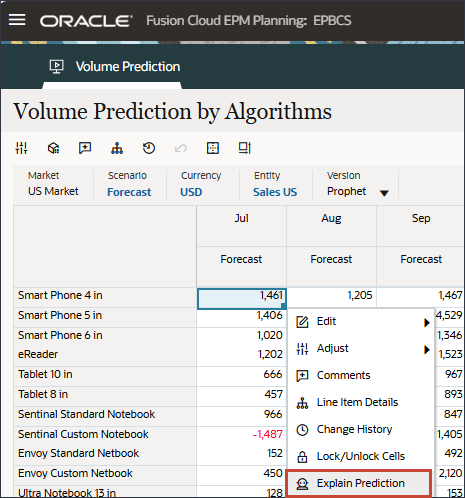
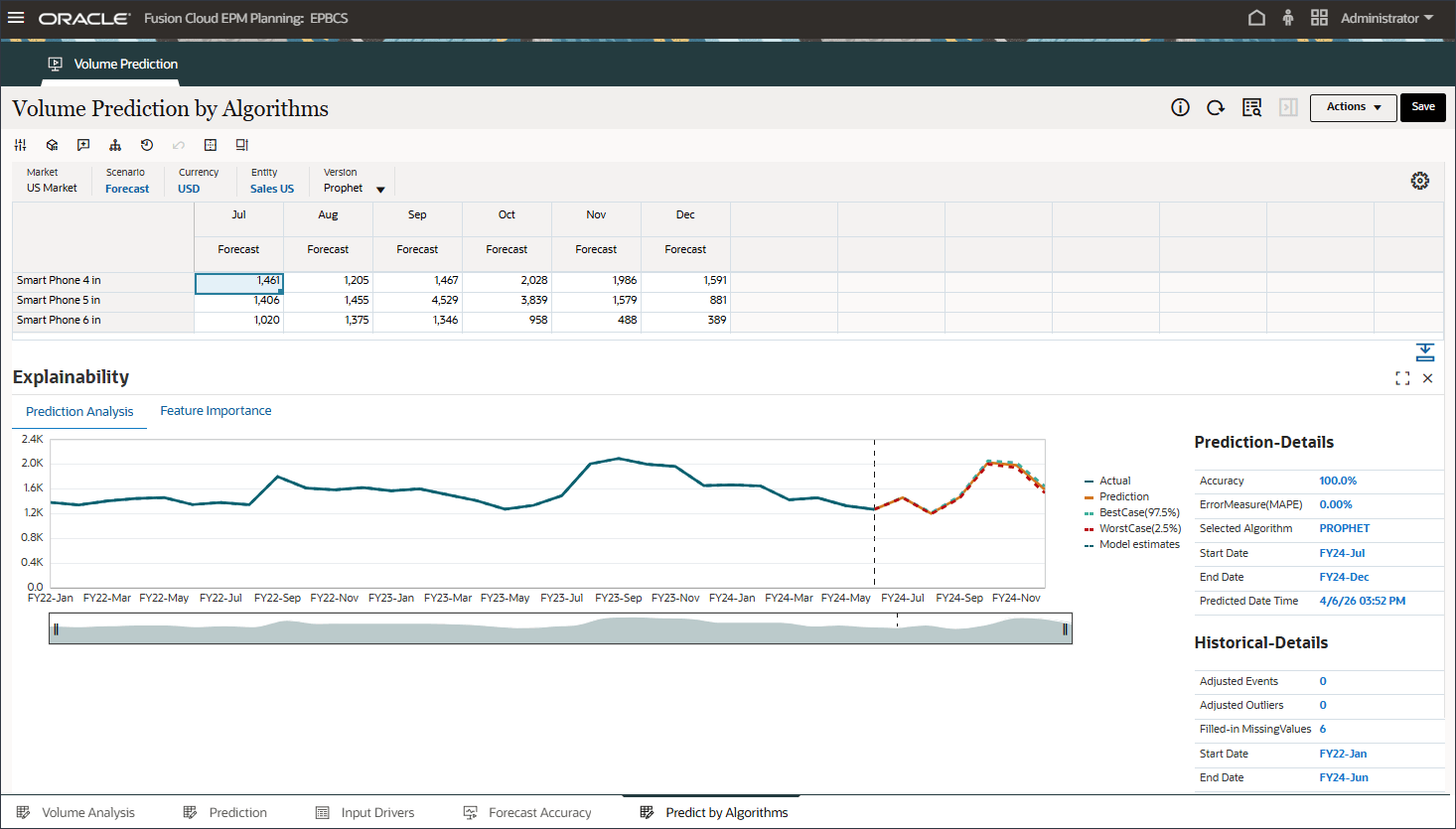
자세한 내용을 검토하고 예측 결과에 대한 설명을 보려면 스마트 폰 5의 7월과 같은 기간을 마우스 오른쪽 단추로 누르고 예측 설명을 선택합니다.
예측 설명을 선택하면 두 탭에 정보가 있는 설명 가능성을 검토할 수 있습니다.
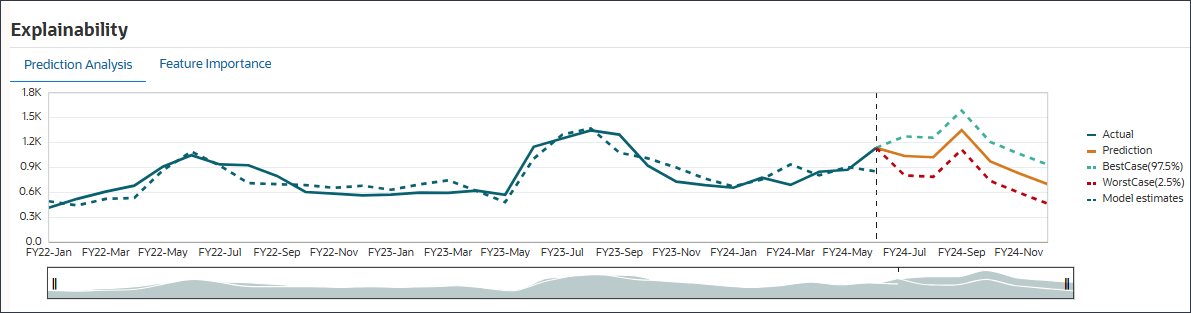
예측 분석 탭에는 최선의 경우, 최악의 경우, 가장 가능성이 높은 시나리오를 고려하여 과거 추세 및 예측 결과가 포함된 꺾은선형 차트가 표시됩니다. 정확도, 오류 측정(SMAPE), 예측 결과 생성에 사용되는 알고리즘, 예측 시작 및 종료 일자와 같은 추가 예측 세부정보도 제공됩니다.
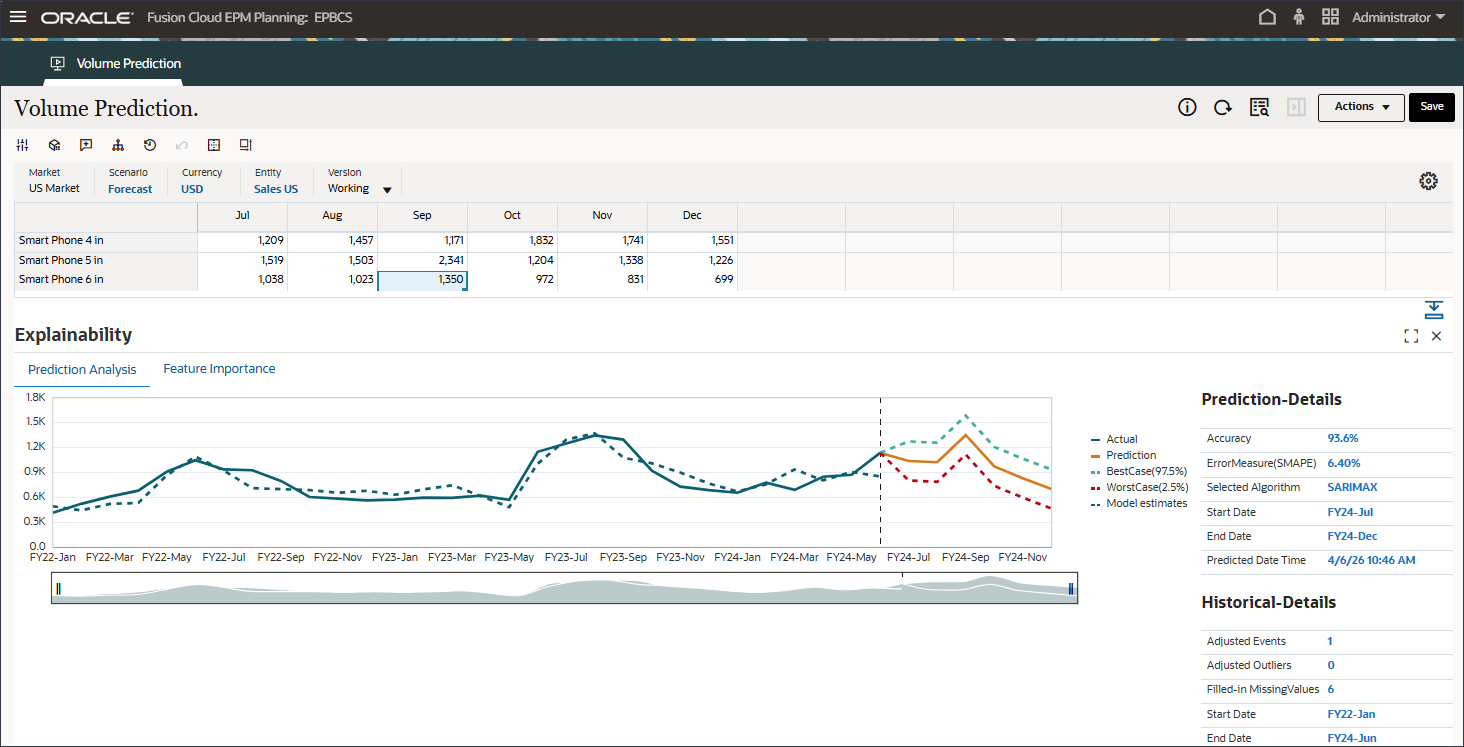
스마트 폰 6의 경우 9월과 같이 다른 항목을 선택합니다.
FY22-5월, FY23-7 및 FY24-Sep 예측 결과에 나타나는 이벤트의 영향을 확인합니다.
적합 값을 과거 실제 데이터와 비교하여 예측 모델이 제공된 데이터의 변형을 얼마나 잘 캡처할 수 있었는지 확인할 수 있습니다. 예측은 과거 데이터의 적합 값을 사용하여 미래의 추세를 사용하여 이루어졌습니다.
점선/곡선은 기본 논리/추세 학습을 기반으로 하는 과거 데이터에 대한 모델의 추정과 같은 적합한 선을 나타냅니다. 적합 값을 과거 실제 데이터와 비교하면 모델이 제공된 데이터의 변형을 캡처할 수 있었던 정도를 확인할 수 있습니다.
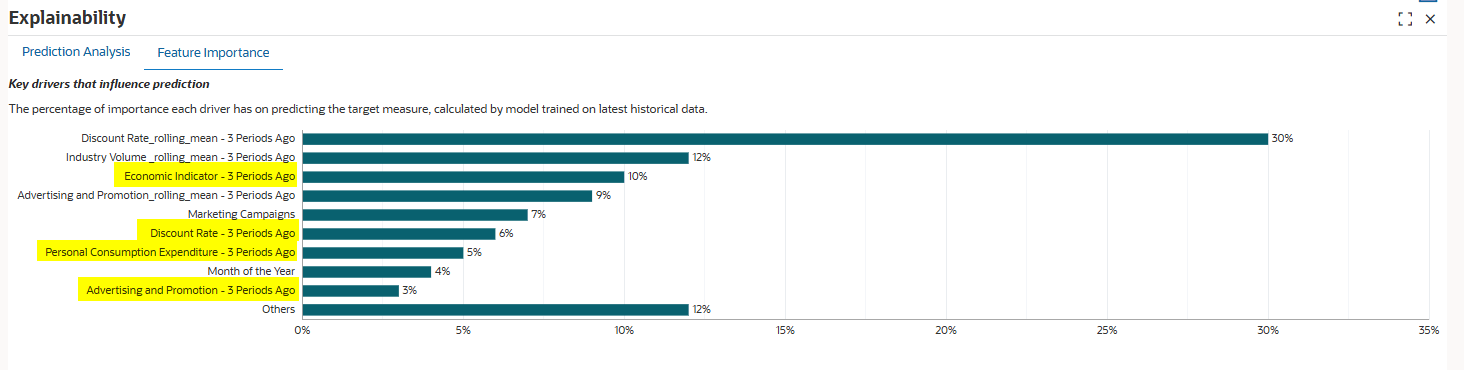
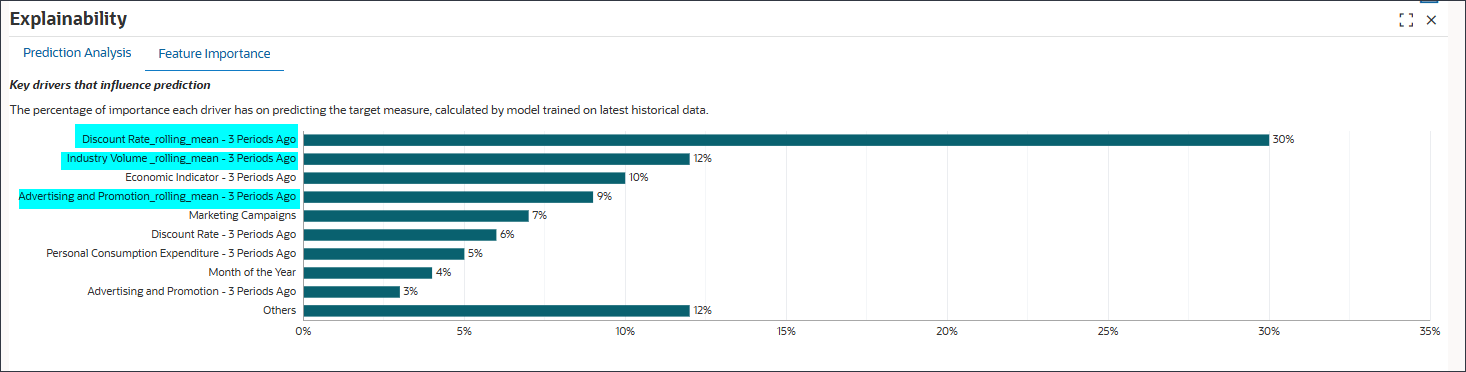
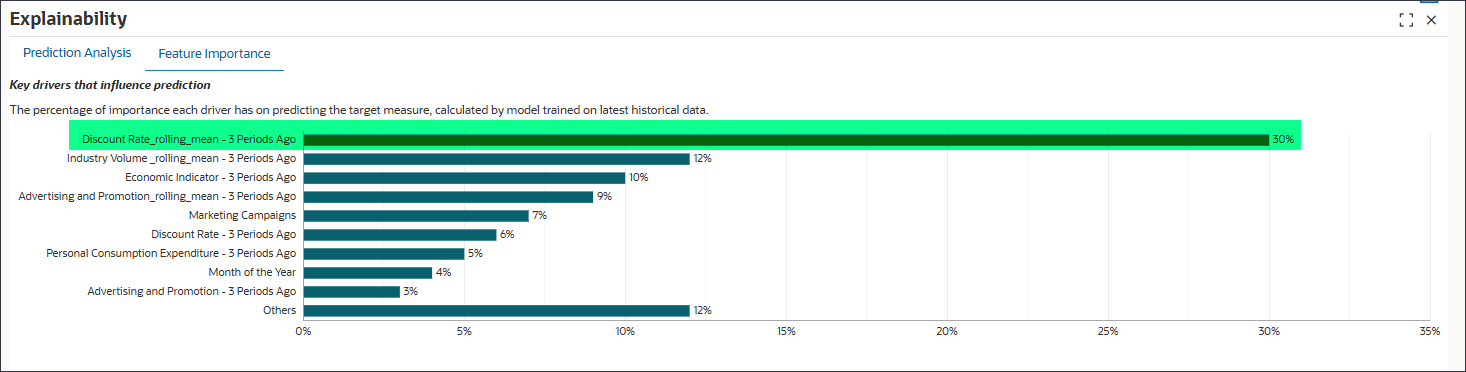
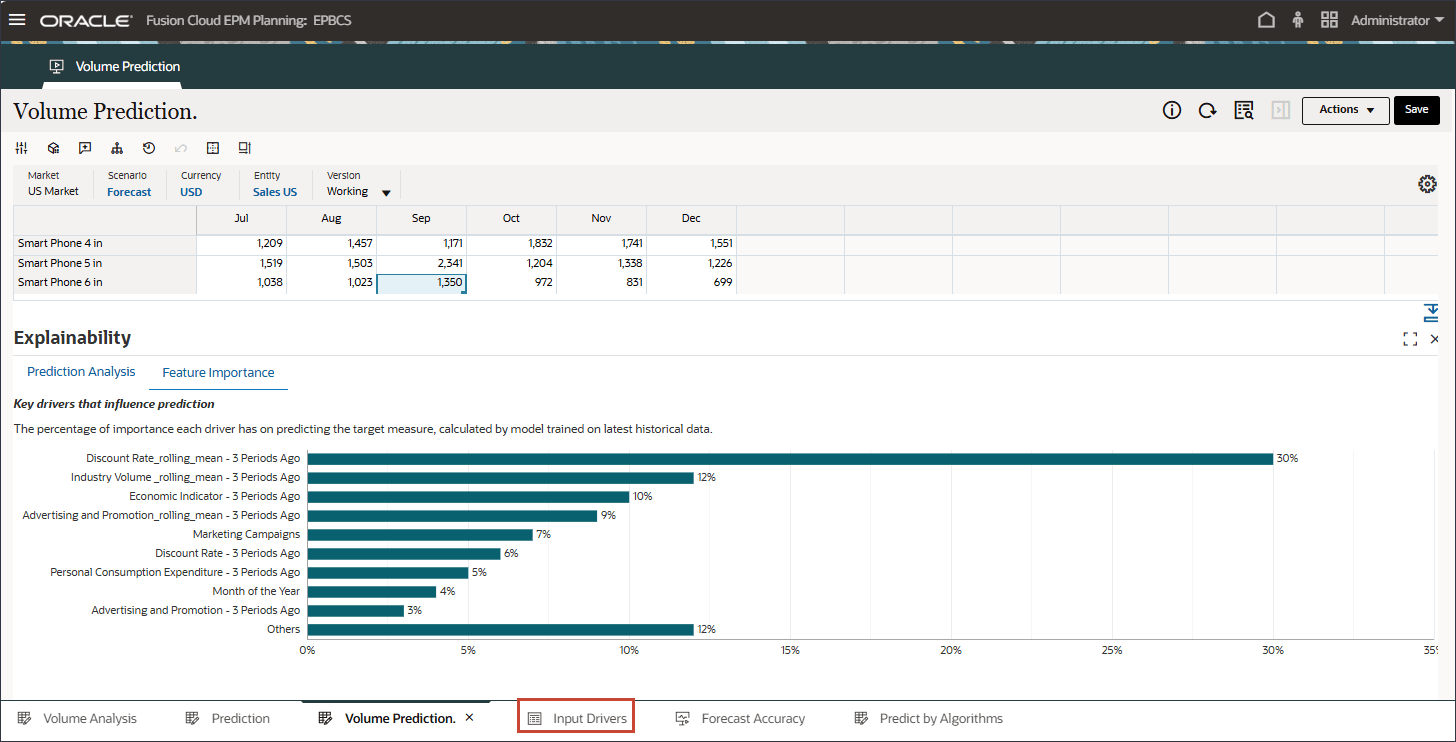
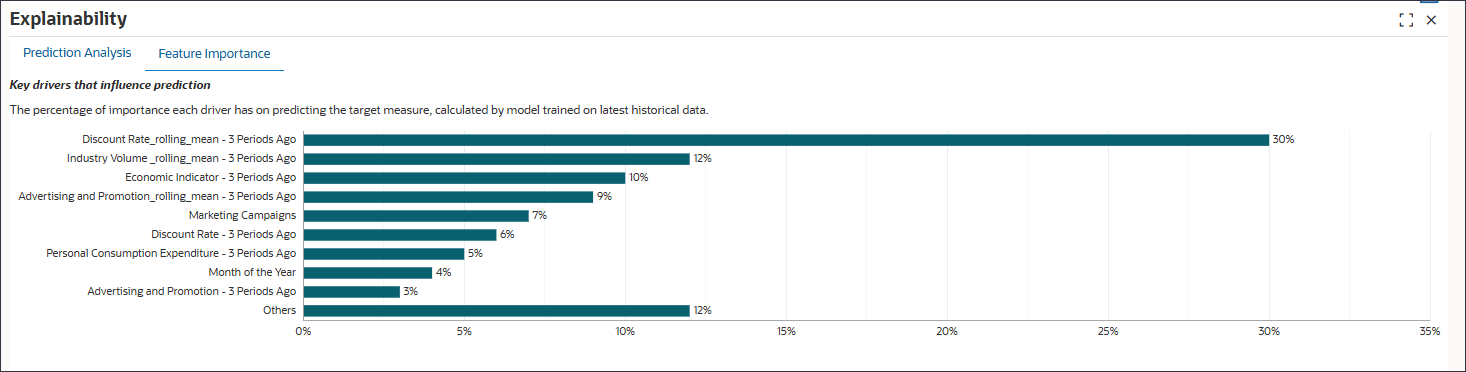
기능 중요도 탭을 선택합니다.
기능 선택은 예측 정확도에 영향을 미치는 가장 관련성이 높은 비즈니스 동인을 식별하고 과다 적합을 방지하기 위해 "시끄러운" 또는 영향이 낮은 변수를 필터링합니다. 또한 복잡성과 처리 시간을 줄여 성능을 향상시킵니다. 예측 능력을 기반으로 기능의 순위를 지정하여 설명 가능성을 지원합니다.
이 차트는 상위 9개 기능을 보여줍니다. 나머지 기능은 백분율 값으로 집계되고 Others 머리글 아래에 그룹화됩니다.
래깅 기능을 식별합니다.
래깅 기능:
경제 지표 - 3년 전, 할인율 - 3년 전, 개인 소비 지출 - 3년 전, 광고 및 프로모션 - 3년 전의 기간이 지연되는 기능입니다.
이 예에서는 할인율 - 이전 3개 기간이 중요한 기능으로 차트 맨 위에 표시됩니다. 이는 3개월 전의 가격 결정이 지연되었지만 볼륨에 상당한 영향을 미쳤음을 시사합니다. 이것은 기능 엔지니어링이 자동으로 발견한 비즈니스 통찰력입니다. 기능 엔지니어링이 없으면 현재 기간의 할인율만 고려됩니다.
롤링 평균:
할인 Rate_rolling_mean - 3년 전, 산업 Volume_rolling_mean - 3년 전, 광고 및 Promotions_rolling_mean 3년 전의 기간은 롤링 평균입니다.
롤링은 여러 기간 동안 드라이버 값의 평균을 계산하여 단기 변동을 완화시킵니다. 예를 들어, 할인 Rate_rolling_mean - 3 이전 기간에는 지난 기간 동안의 평균 할인율이 반영되어 단일 월 값보다 기본 추세를 더 많이 나타낼 수 있습니다.
기능 중요도 검사
30%에서 Rate_rolling_mean - 3개월 전의 할인율은 목표 측정을 예측하는 데 가장 중요합니다. 산업 Volume_rolling_mean - 3년 전의 기간은 12%이고 경제 지표 - 3년 전의 기간은 10%입니다.
입력 드라이버를 세분화하고 고급 예측 작업을 다시 실행하려는 경우 [입력 드라이버] 탭으로 이동하여 드라이버 값을 편집할 수 있습니다.
계정을 누르고 광고 및 프로모션과 같은 드라이버를 선택합니다. 그런 다음 고급 예측 작업을 다시 실행하기 전에 업데이트된 값을 입력하고 저장합니다.
고급 예측 작업을 실행하려면 이 자습서의 고급 예측 작업 실행 섹션의 단계를 따릅니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
예측 알고리즘 변경
이 섹션에서는 예측 생성에 사용되는 알고리즘을 변경합니다. 고급 예측 작업의 복사본을 만들고 세부정보를 수정하여 다른 예측 방법을 선택합니다.
홈 페이지에서 IPM, 구성 순으로 누릅니다.
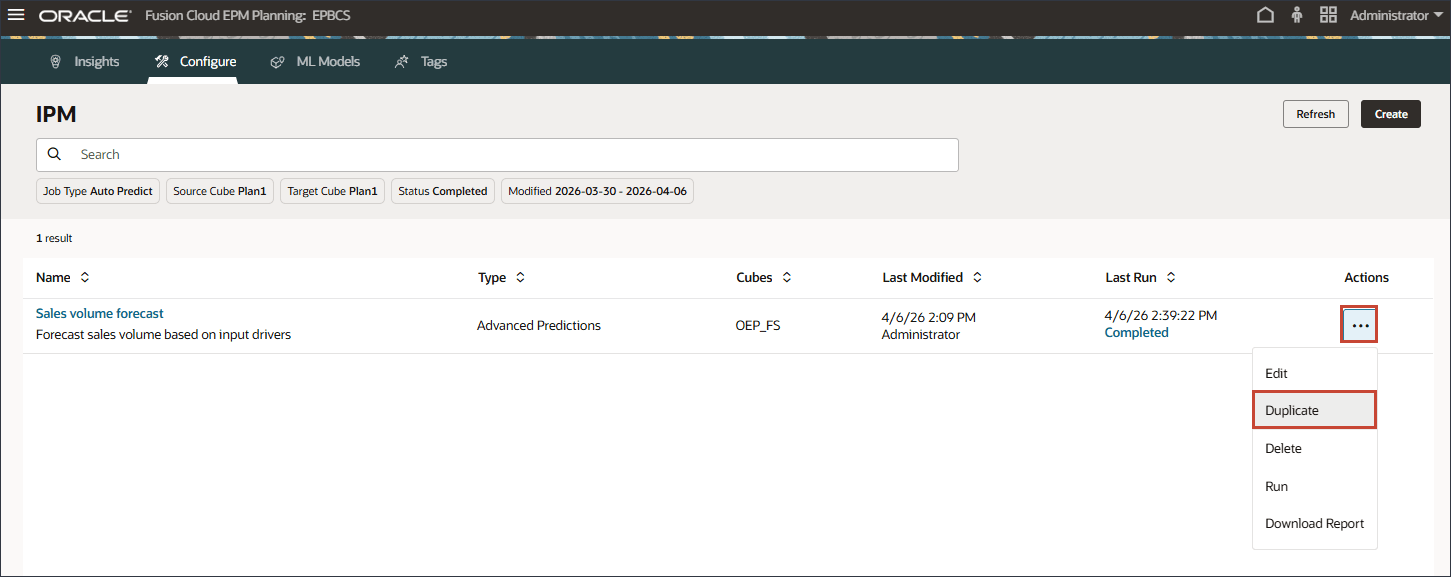
판매량 예측 행에서 (작업)을 누르고 복제를 선택합니다.
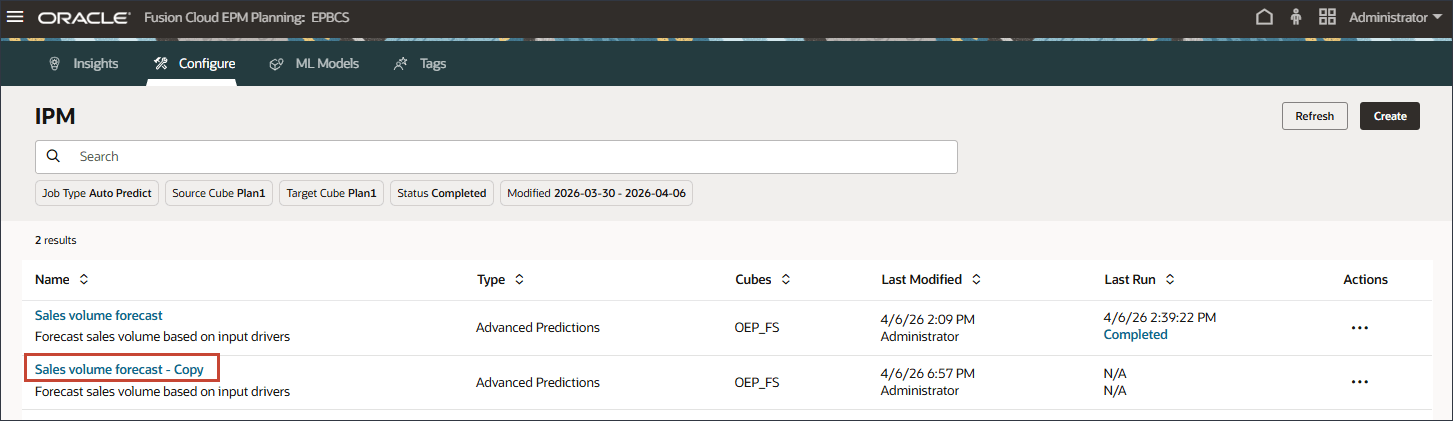
중복 작업의 설정을 수정하려면 판매 볼륨 예측 - 복사를 누릅니다.
세부정보에서 이름을 판매 볼륨 예측 - 예언자로 업데이트하고 설명을 선언자 메소드를 사용하여 판매 볼륨 예측 분석으로 업데이트한 후 다음을 누릅니다.
캘린더를 동일하게 유지하고 다음을 누릅니다.
과거 데이터 슬라이스를 동일하게 유지하고 다음을 누릅니다.
미래 데이터의 경우 모델 범위 정의에서 버전을 누릅니다.
선지자를 선택하고 확인을 누릅니다.
업데이트된 모델 범위를 확인하고 다음을 누릅니다.
데이터 준비 단계의 경우 변경할 필요가 없습니다. 다음을 누릅니다.
모델 설정 단계의 알고리즘 선택에서 선지자를 선택합니다.
예측 오류 측정항목의 경우 MAPE를 선택합니다.
모델 예측, 최선의 경우 및 최악의 경우 버전을 선언자로 변경합니다.
모델 예측, 최선의 경우 및 최악의 경우의 버전은 예언자로 변경됩니다.
이벤트에서 이벤트 포함이 선택되어 있는지 확인하고 저장을 누릅니다.
취소를 누릅니다.
판매량 예측 - 예언자 작업의 경우 (작업)을 누르고 실행을 선택합니다.
작업이 완료되었다고 표시될 때까지 새로고침을 누릅니다.
주:
작업을 완료하는 데 몇 분 정도 걸립니다.
작업이 완료되었습니다.
홈 페이지로 돌아가려면 (홈)을 누르십시오.
홈 페이지에서 고급 예측, 볼륨 예측 순으로 누릅니다.
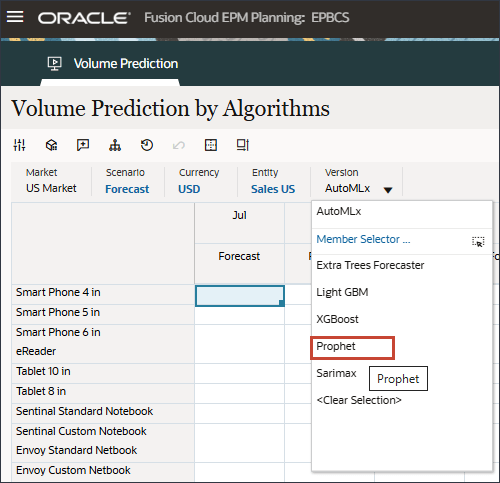
아래쪽에서 알고리즘별 예측 탭을 선택합니다.
버전에 대해 선지자를 선택합니다.
Explain Prediction을 눌러 예측을 검토합니다. Smart Phone 4 in의 Jul과 같은 값을 마우스 오른쪽 단추로 누르고 예측 설명을 선택합니다.
설명 가능성을 검토합니다. 일부 제품 시리즈의 경우 예언자는 더 나은 정확성을 가지고 있습니다.
예측 값 추가
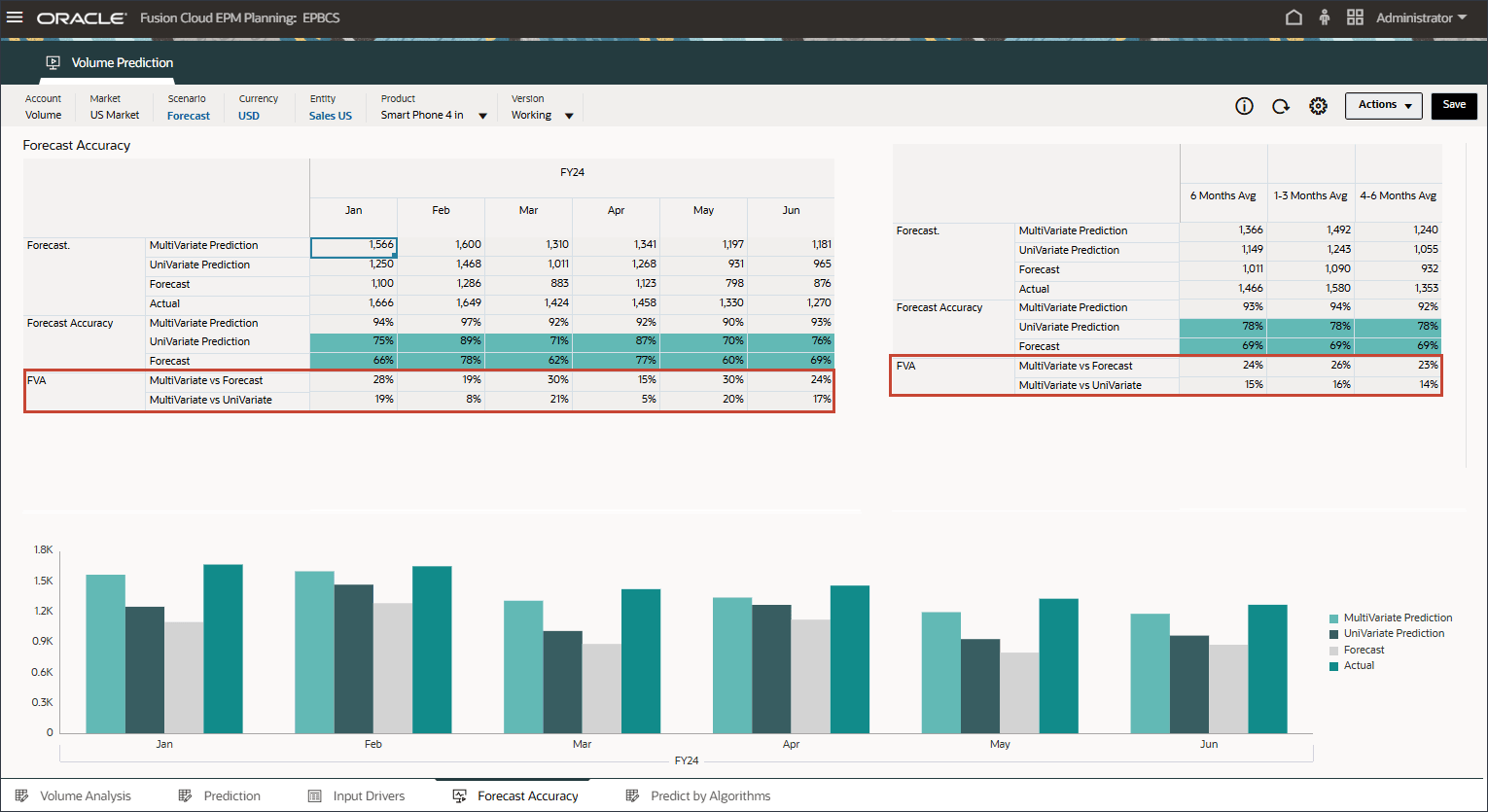
예측 값 추가(FVA)는 예측 방법의 변경으로 인한 정확도 향상(또는 감소)을 측정하여 예측 프로세스의 효율성을 평가하는 데 사용되는 척도입니다. FVA는 예측 프로세스의 각 단계가 순진한 예측 또는 이전 예측 버전과 같은 기준 대비 값을 추가하는지 여부를 결정하는 데 도움이 됩니다.
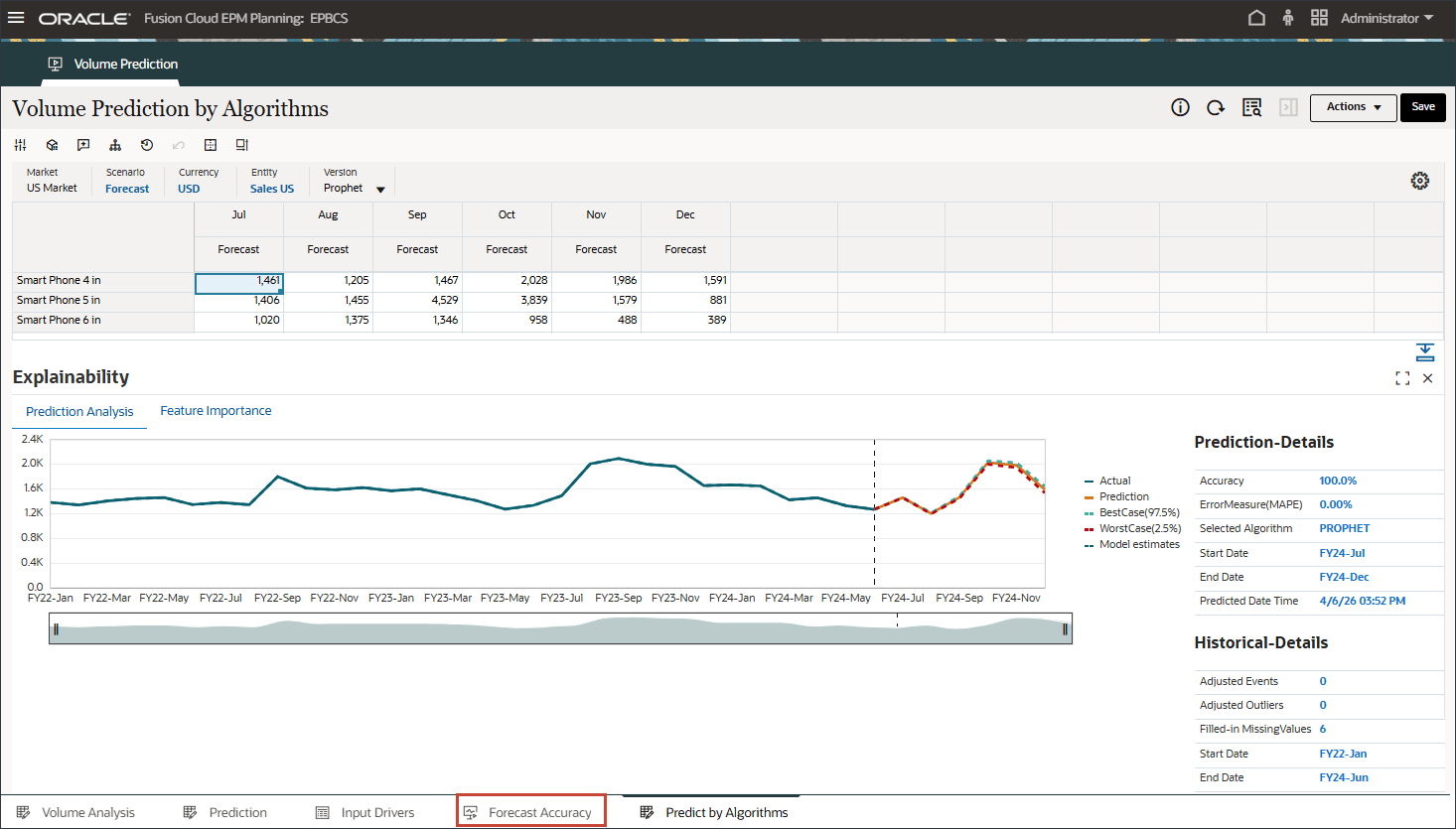
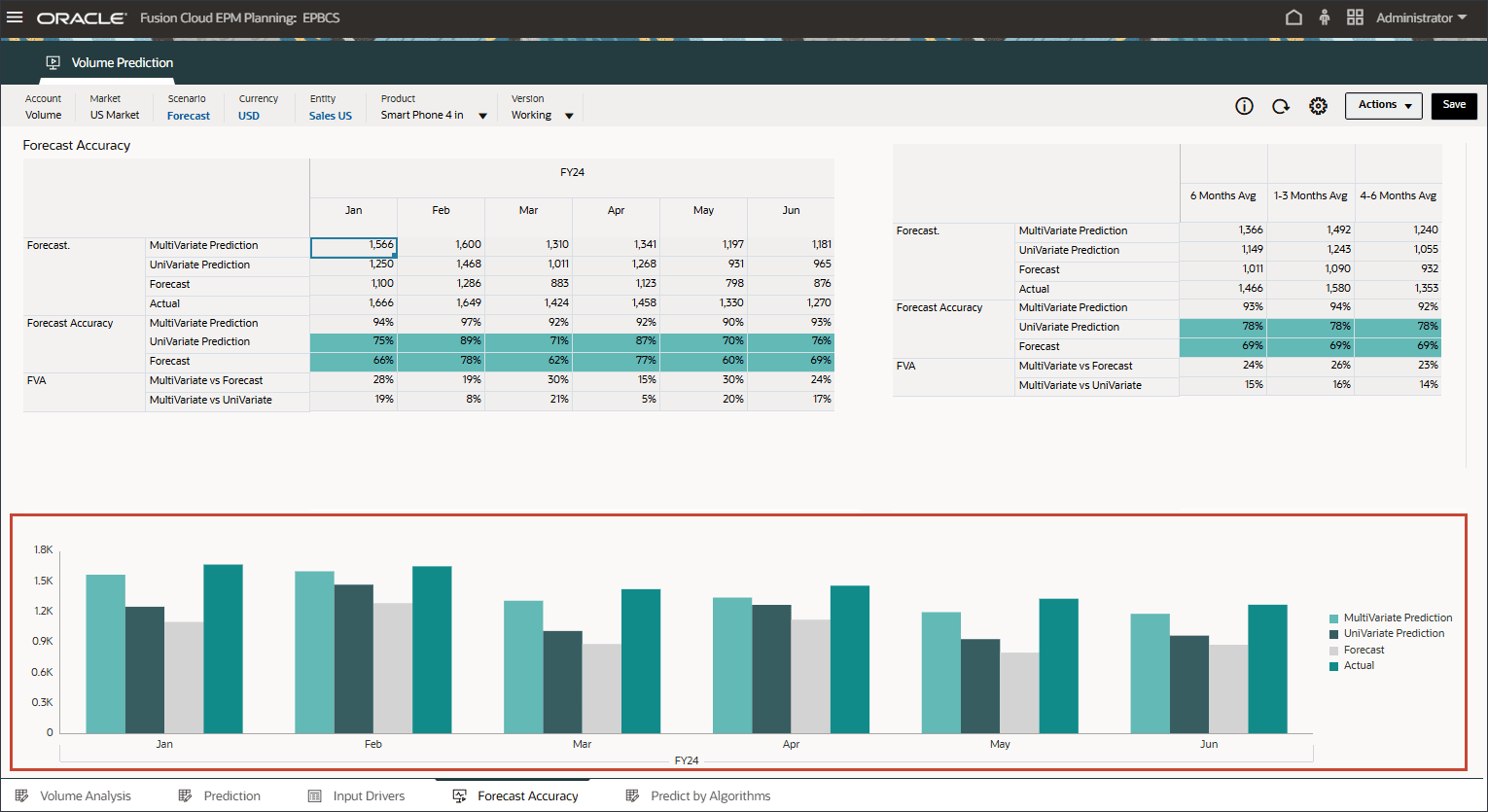
아래쪽에서 예측 정확도 탭을 누릅니다.
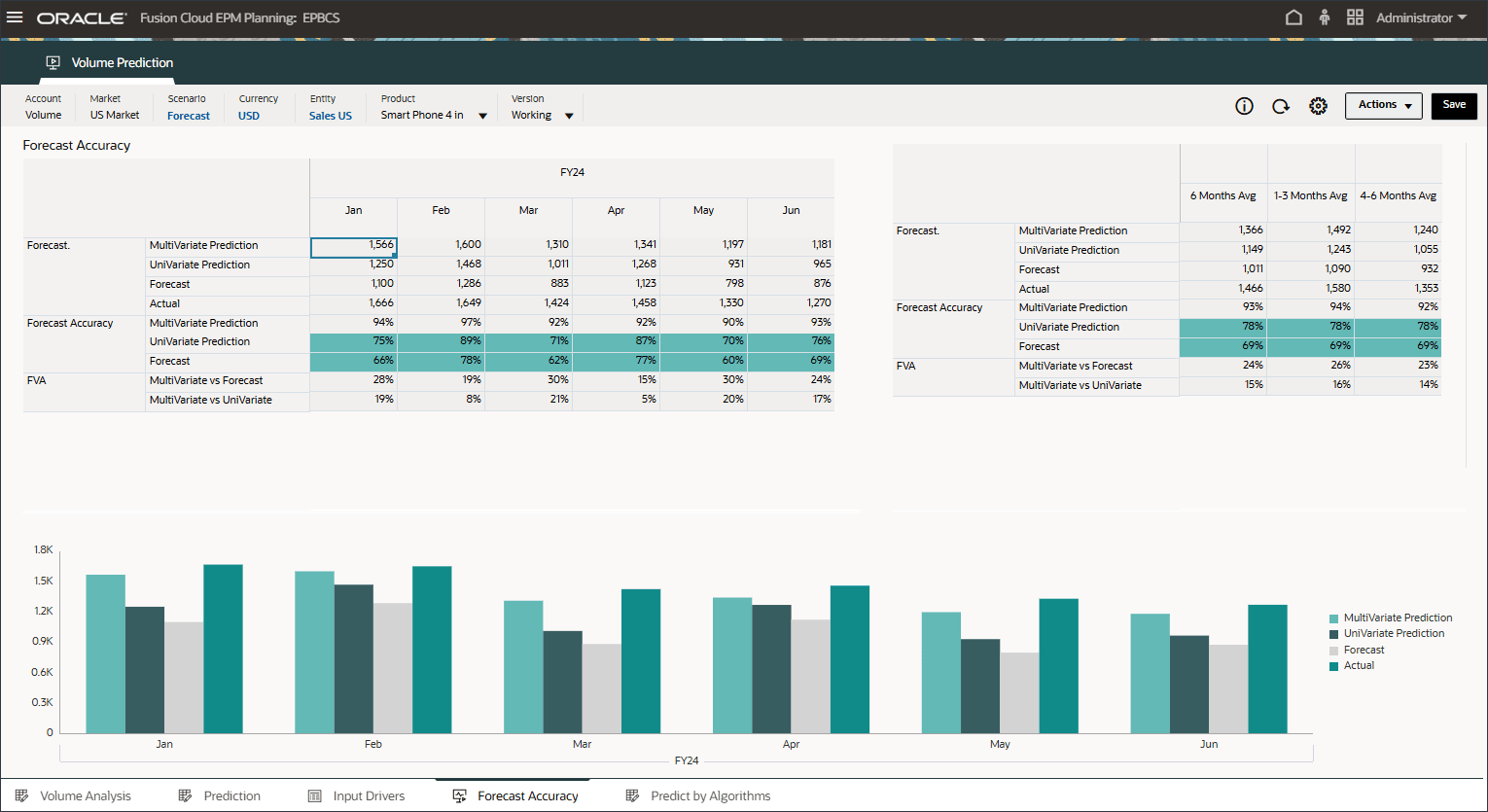
실제 데이터를 이미 사용할 수 있는 1월 24일부터 6월 24일까지의 기간 동안 예측 정확도를 측정하기 위해 테스트가 수행됩니다. 고급 예측 결과(다변량 예측), 단변량 예측 및 예측과 실제 값을 비교하여 예측의 정확도를 측정할 수 있습니다.
FVA를 계산하기 위해 조정된 예측의 정확도를 기준의 정확도와 비교합니다. 조정된 예측이 기준과 비교하여 오류를 줄이면 FVA가 양수이고 오류가 증가하면 FVA가 음수입니다. 이 척도는 예측 담당자가 예측 프로세스에서 정확도를 개선하고 부가가치가 없는 활동을 제거하는 단계에 집중할 수 있도록 지원합니다.
고급 예측(ML)에 대한 예측 값 추가를 검토하여 예측 및 단변량 예측 결과에 비해 훨씬 더 나은지 확인합니다.
고급 예측 결과와 단변량 예측 및 예측 시나리오를 비교하는 막대 차트를 검토합니다.
ML을 사용한 고급 예측은 실제 결과에 더 가까워지므로 계획자가 향후 계획 및 예측을 위해 고급 예측 방법을 사용할 수 있는 신뢰 수준이 높아집니다.



 (홈)을 누르십시오.
(홈)을 누르십시오.
 (검색)을 누릅니다.
(검색)을 누릅니다.
 (모두 이동)을 누릅니다.
(모두 이동)을 누릅니다. 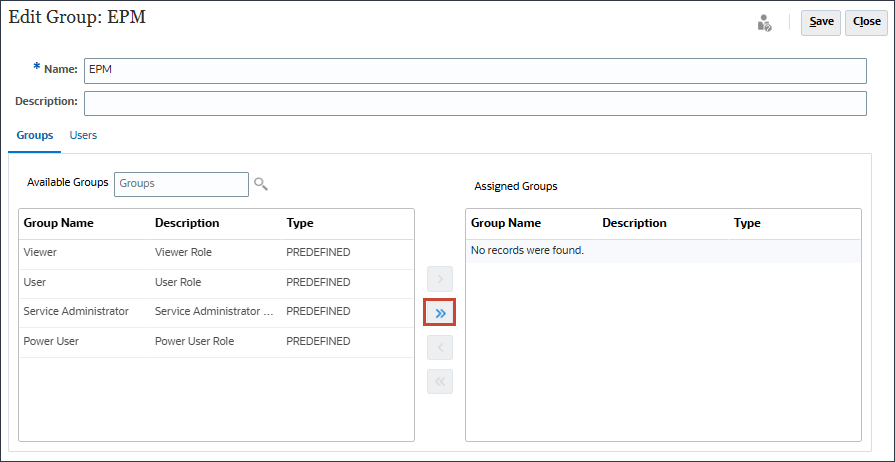

 (기본값)을 누르고 EPM Cloud를 선택합니다.
(기본값)을 누르고 EPM Cloud를 선택합니다. 

 (작업)을 누르고 최대화를 선택합니다.
(작업)을 누르고 최대화를 선택합니다. 
 (시간 선택)을 누릅니다.
(시간 선택)을 누릅니다. 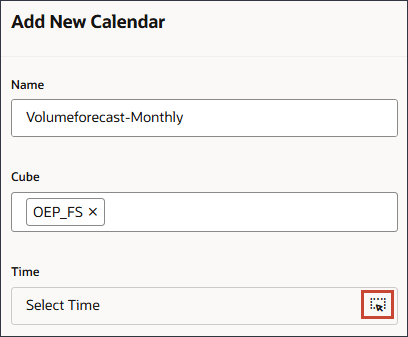
 (함수 선택기)을 선택하고 레벨 0 하위 멤버를 선택합니다.
(함수 선택기)을 선택하고 레벨 0 하위 멤버를 선택합니다. 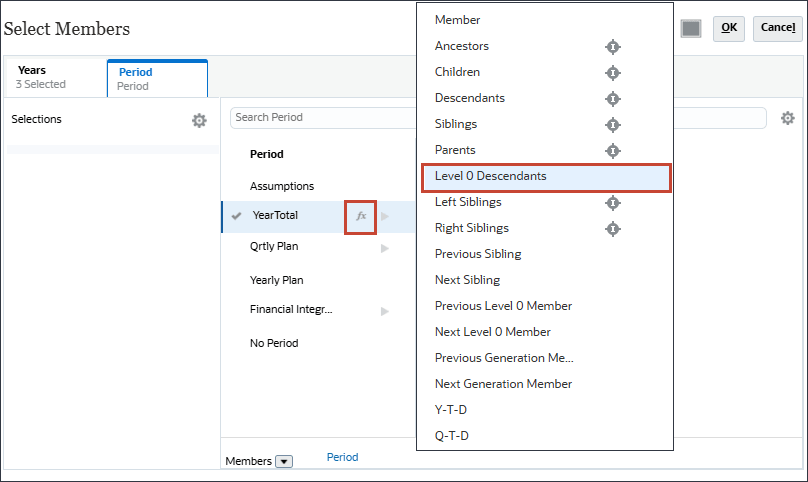








 (작업)을 누릅니다.
(작업)을 누릅니다. 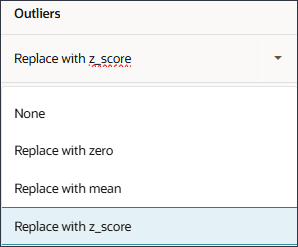



 (이벤트 발생)을 누릅니다.
(이벤트 발생)을 누릅니다. 
 (저장)을 누릅니다.
(저장)을 누릅니다. 

 (네비게이터)을 누르고 [애플리케이션]에서 작업을 누릅니다.
(네비게이터)을 누르고 [애플리케이션]에서 작업을 누릅니다.