Oracle Autonomous Database 및 속성 그래프 쿼리 언어로 지식 그래프 생성
소개
이 사용지침서에서는 그래프 이론, 지식 그래프 및 Oracle Autonomous Database with Property Graph Query Language(PGQL)를 사용하여 그래프 이론의 개념과 지식 그래프를 구현하는 방법을 살펴봅니다. 또한 LLM을 사용하여 문서에서 관계를 추출하고 Oracle에 그래프 구조로 저장하는 데 사용되는 Python 구현에 대해서도 설명합니다.
Graph란?
그래프는 객체 간의 모델링 관계에 초점을 맞춘 수학 및 컴퓨터 과학 분야입니다. 그래프는 다음으로 구성됩니다.
-
정점(노드): 엔티티를 나타냅니다.
-
모서리(링크): 엔티티 간의 관계를 나타냅니다.
그래프는 소셜 네트워크, 시맨틱 네트워크, 지식 그래프 등의 데이터 구조를 나타내는 데 널리 사용됩니다.
지식 그래프란?
지식 그래프는 다음과 같은 실제 지식을 그래프 기반으로 표현한 것입니다.
-
노드는 사람, 장소, 제품 등과 같은 엔티티를 나타냅니다.
-
모서리는 의미 관계를 나타냅니다. 예를 들어, 작업 위치, 일부 및 기타가 있습니다.
지식 그래프는 의미 검색, 추천 시스템 및 질문 답변 애플리케이션을 향상시킵니다.
PGQL과 함께 Oracle Autonomous Database를 사용해야 하는 이유
Oracle은 속성 그래프를 저장하고 질의할 수 있는 완전 관리형 환경을 제공합니다.
-
PGQL은 SQL과 유사하며 복잡한 그래프 패턴을 쿼리하도록 설계되었습니다.
-
Oracle Autonomous Database를 사용하면 생성, 쿼리 및 시각화를 포함한 속성 그래프 기능을 통해 기본적으로 그래프 쿼리를 실행할 수 있습니다.
-
LLM과의 통합을 통해 비정형 데이터(예: PDF)에서 그래프 구조를 자동으로 추출할 수 있습니다.
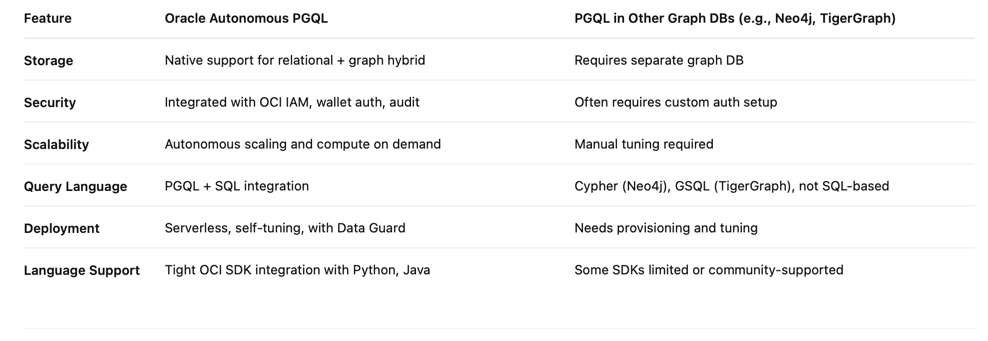
기타 그래프 질의 언어와 비교

기존 그래프 데이터베이스 대비 PGQL을 사용하는 Oracle Autonomous Database의 이점
목표
- Oracle Autonomous Database 및 PGQL을 사용하여 지식 그래프를 생성합니다.
필수 조건
- Python
version 3.10이상을 설치하고 OCI CLI(Oracle Cloud Infrastructure Command Line Interface)를 설치합니다.
작업 1: Python 패키지 설치
Python 코드에는 Oracle Cloud Infrastructure(OCI) Generative AI를 사용하기 위한 특정 라이브러리가 필요합니다. 필요한 Python 패키지를 설치하려면 다음 명령을 실행하십시오. requirements.txt에서 파일을 다운로드할 수 있습니다.
pip install -r requirements.txt
작업 2: Oracle Database 23ai 생성(항상 무료)
이 작업에서는 항상 무료 모드로 Oracle Database 23ai를 프로비전하는 방법에 대해 알아봅니다. 이 버전은 추가 비용 없이 개발, 테스트 및 학습에 이상적인 완전 관리형 환경을 제공합니다.
-
OCI 콘솔에 로그인하고 Oracle Database, Autonomous Database로 이동한 다음 Autonomous Database 인스턴스 생성을 누릅니다.
-
다음 정보를 입력합니다.
- 데이터베이스 이름: 인스턴스에 대한 식별 이름을 입력합니다.
- 작업 로드 유형: 필요에 따라 데이터 웨어하우스 또는 트랜잭션 처리를 선택합니다.
- 컴파트먼트: 리소스를 구성할 적절한 컴파트먼트를 선택합니다.
-
인스턴스가 무료로 프로비전되도록 하려면 항상 무료를 선택합니다.
-
ADMIN유저에 대해 데이터베이스 액세스에 사용할 보안 암호를 생성합니다. -
설정을 검토한 후 Autonomous Database 생성을 누릅니다. 인스턴스가 프로비전되어 사용할 수 있을 때까지 몇 분 정도 기다립니다.
Oracle Autonomous Database 연결 프로세스에 익숙하지 않은 경우 다음 링크를 따라 코드를 이해하고 적절하게 구성합니다.
주: Wallet 메소드를 사용하여 Python 코드 내부의 데이터베이스에 접속해야 합니다.
작업 3: 코드 다운로드 및 이해
그래프의 일반적인 사용 사례는 LLM과 함께 작동하는 구성요소 및 PDF 파일과 같은 지식 기반 중 하나로 사용하는 것입니다.
이 자습서에서는 언급된 모든 구성요소를 사용하는 OCI Generative AI를 사용하여 자연어로 PDF 문서 분석을 기반으로 사용합니다. 그러나 이 문서에서는 Oracle Database 23ai를 Graph와 함께 사용하는 데 중점을 둡니다. 기본적으로 기본 자료의 Python 코드(main.py)는 Oracle Database 23ai를 사용하는 부분에서만 수정됩니다.
이 서비스에서 실행되는 프로세스는 다음과 같습니다.
-
그래프 스키마를 생성합니다.
-
LLM을 사용하여 개체 및 관계를 추출합니다.
-
Oracle에 데이터를 삽입합니다.
-
속성 그래프를 작성합니다.
Oracle Database 23ai와 호환되는 업데이트된 Python 그래프 코드(main.py)를 다운로드하세요.
-
create_knowledge_graph:def create_knowledge_graph(chunks): cursor = oracle_conn.cursor() # Creates graph if it does not exist try: cursor.execute(f""" BEGIN EXECUTE IMMEDIATE ' CREATE PROPERTY GRAPH {GRAPH_NAME} VERTEX TABLES (ENTITIES KEY (ID) LABEL ENTITIES PROPERTIES (NAME)) EDGE TABLES (RELATIONS KEY (ID) SOURCE KEY (SOURCE_ID) REFERENCES ENTITIES(ID) DESTINATION KEY (TARGET_ID) REFERENCES ENTITIES(ID) LABEL RELATIONS PROPERTIES (RELATION_TYPE, SOURCE_TEXT)) '; EXCEPTION WHEN OTHERS THEN IF SQLCODE != -55358 THEN -- ORA-55358: Graph already exists RAISE; END IF; END; """) print(f"🧠 Graph '{GRAPH_NAME}' created or already exists.") except Exception as e: print(f"[GRAPH ERROR] Failed to create graph: {e}") # Inserting vertices and edges into the tables for doc in chunks: text = doc.page_content source = doc.metadata.get("source", "unknown") if not text.strip(): continue prompt = f""" You are an expert in knowledge extraction. Given the following technical text: {text} Extract key entities and relationships in the format: - Entity1 -[RELATION]-> Entity2 Use UPPERCASE for RELATION types. Return 'NONE' if nothing found. """ try: response = llm_for_rag.invoke(prompt) result = response.content.strip() except Exception as e: print(f"[ERROR] Gen AI call error: {e}") continue if result.upper() == "NONE": continue triples = result.splitlines() for triple in triples: parts = triple.split("-[") if len(parts) != 2: continue right_part = parts[1].split("]->") if len(right_part) != 2: continue raw_relation, entity2 = right_part relation = re.sub(r'\W+', '_', raw_relation.strip().upper()) entity1 = parts[0].strip() entity2 = entity2.strip() try: # Insertion of entities (with existence check) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity1, entity1]) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity2, entity2]) # Retrieve the IDs cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity1]) source_id = cursor.fetchone()[0] cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity2]) target_id = cursor.fetchone()[0] # Create relations cursor.execute(""" INSERT INTO RELATIONS (SOURCE_ID, TARGET_ID, RELATION_TYPE, SOURCE_TEXT) VALUES (:src, :tgt, :rel, :txt) """, [source_id, target_id, relation, source]) print(f"✅ {entity1} -[{relation}]-> {entity2}") except Exception as e: print(f"[INSERT ERROR] {e}") oracle_conn.commit() cursor.close() print("💾 Knowledge graph updated.")-
그래프 스키마는
ENTITIES(정점) 및RELATIONS(가장자리)를 링크하는CREATE PROPERTY GRAPH로 생성됩니다. -
MERGE INTO를 사용하여 새 엔티티가 없는 경우에만 삽입합니다(고유성 보장). -
LLM(Oracle Generative AI)은
Entity1 -[RELATION]-> Entity2.형식의 3배를 추출하는 데 사용됩니다. -
Oracle과의 모든 상호 작용은
oracledb및 PL/SQL 익명 블록을 통해 수행됩니다.
이제 다음을 수행할 수 있습니다.
-
PGQL을 사용하여 그래프 관계를 탐색하고 쿼리합니다.
-
시각화를 위해 Graph Studio에 연결합니다.
-
API REST 또는 LangChain 에이전트를 통해 그래프를 표시합니다.
-
-
그래프 질의 지원 기능
지식 그래프에 대한 의미 검색 및 추론을 가능하게 하는 두 가지 필수 함수는
extract_graph_keywords및query_knowledge_graph입니다. 이러한 구성요소를 사용하면 Oracle Autonomous Database에서 PGQL을 사용하여 질문을 의미 있는 그래프 쿼리로 해석할 수 있습니다.-
extract_graph_keywords:def extract_graph_keywords(question: str) -> str: prompt = f""" Based on the question below, extract relevant keywords (1 to 2 words per term) that can be used to search for entities and relationships in a technical knowledge graph. Question: "{question}" Rules: - Split compound terms (e.g., "API Gateway" → "API", "Gateway") - Remove duplicates - Do not include generic words such as: "what", "how", "the", "of", "in the document", etc. - Return only the keywords, separated by commas. No explanations. Result: """ try: resp = llm_for_rag.invoke(prompt) keywords_raw = resp.content.strip() # Additional post-processing: remove duplicates, normalize keywords = {kw.strip().lower() for kw in re.split(r'[,\n]+', keywords_raw)} keywords = [kw for kw in keywords if kw] # remove empty strings return ", ".join(sorted(keywords)) except Exception as e: print(f"[KEYWORD EXTRACTION ERROR] {e}") return ""동작:
-
LLM(
llm_for_rag)을 사용하여 자연어 질문을 그래프 친화적 키워드 목록으로 변환합니다. -
프롬프트는 그래프 검색과 관련된 엔티티 및 용어를 완전히 추출하도록 설계되었습니다.
중요한 이유는 다음과 같습니다.
-
비정형 질문과 정형 쿼리 간의 격차를 해소합니다.
-
특정 도메인 관련 용어만 PGQL 쿼리의 일치에 사용되도록 합니다.
LLM 강화 동작:
-
복합 기술 용어를 위반합니다.
-
중지 단어(예: 무엇, 방법 등)를 제거합니다.
-
용어의 대소문자를 줄이고 중복을 제거하여 텍스트를 정규화합니다.
예제:
-
입력:
"What are the main components of an API Gateway architecture?" -
출력 키워드:
api, gateway, architecture, components
-
-
query_knowledge_graph:def query_knowledge_graph(query_text): cursor = oracle_conn.cursor() sanitized_text = query_text.lower() pgql = f""" SELECT from_entity, relation_type, to_entity FROM GRAPH_TABLE( {GRAPH_NAME} MATCH (e1 is ENTITIES)-[r is RELATIONS]->(e2 is ENTITIES) WHERE CONTAINS(e1.name, '{sanitized_text}') > 0 OR CONTAINS(e2.name, '{sanitized_text}') > 0 OR CONTAINS(r.RELATION_TYPE, '{sanitized_text}') > 0 COLUMNS ( e1.name AS from_entity, r.RELATION_TYPE AS relation_type, e2.name AS to_entity ) ) FETCH FIRST 20 ROWS ONLY """ print(pgql) try: cursor.execute(pgql) rows = cursor.fetchall() if not rows: return "⚠️ No relationships found in the graph." return "\n".join(f"{r[0]} -[{r[1]}]-> {r[2]}" for r in rows) except Exception as e: return f"[PGQL ERROR] {e}" finally: cursor.close()동작:
- 키워드 기반 문자열(대개
extract_graph_keywords에서 생성됨)을 수락하고 지식 그래프에서 관계를 검색하는 PGQL 질의를 생성합니다.
주요 역학:
-
GRAPH_TABLE절은MATCH를 사용하여 그래프를 소스에서 대상 노드로 순회합니다. -
CONTAINS()를 사용하여 노드/에지 속성(e1.name,e2.name,r.RELATION_TYPE)에서 부분 및 퍼지 검색을 허용합니다. -
결과를 20으로 제한하여 출력이 과도하게 발생하는 것을 방지합니다.
PGQL을 사용하는 이유:
-
PGQL은 SQL과 유사하지만 그래프 순회용으로 설계되었습니다.
-
Oracle Autonomous Database는 속성 그래프를 지원하므로 관계형 세계와 그래프 세계 간의 원활한 통합이 가능합니다.
-
엔터프라이즈급 인덱스화, 최적화 및 기본 그래프 검색 기능을 제공합니다.
Oracle 관련 참고 사항:
-
GRAPH_TABLE()는 Oracle PGQL에 고유하며 관계형 테이블을 통해 정의된 그래프의 논리적 뷰에 대한 질의를 허용합니다. -
Cypher(Neo4j)와 달리 PGQL은 SQL 확장을 사용하여 구조화된 데이터를 통해 실행되므로 RDBMS가 많은 환경에서 더 친숙해집니다.
- 키워드 기반 문자열(대개
-
작업 4: 챗봇 실행
챗봇을 실행하려면 다음 명령을 실행합니다.
python main.py
관련 링크
승인
- 작성자 - Cristiano Hoshikawa(Oracle LAD A, 팀 솔루션 엔지니어)
추가 학습 자원
docs.oracle.com/learn에서 다른 랩을 탐색하거나 Oracle Learning YouTube 채널에서 더 많은 무료 학습 콘텐츠에 액세스하세요. 또한 education.oracle.com/learning-explorer를 방문하여 Oracle Learning Explorer가 되십시오.
제품 설명서는 Oracle Help Center를 참조하십시오.
Create a Knowledge Graph with Oracle Autonomous Database and Property Graph Query Language
G38837-02
Copyright ©2025, Oracle and/or its affiliates.