OKE를 사용하여 Cassandra 및 Spark 작업에 대한 데이터 위치 개선
소개
Apache Cassandra는 각 노드가 토큰 범위를 소유하는 분산된 마스터리스 데이터베이스입니다. Apache Spark는 Spark–Cassandra 커넥터를 사용하여 Cassandra 복제본에서 읽을 수 있는 분산형 컴퓨팅 엔진입니다. Kubernetes에서는 데이터가 어디에 보관되는지에 대한 지식 없이 Pod 일정이 잡혀 있으므로 데이터 지역성이 보장되지 않습니다.
이 사용지침서에서는 OKE가 Kubernetes 프리미티브를 사용하여 지역성을 향상시킬 수 있는 방법을 보여줍니다. StatefulSets(Cassandra의 안정적인 ID), 노드 레이블 및 유사성/반친화력(anti-affinity)을 통해 Cassandra 포드와 Spark 실행기를 함께 배치합니다. 따라서 동일한 노드(이상적인 노드)에서 읽기가 제공되거나, 최악의 경우 코로케이션된 복제본에서 읽기가 수행됩니다.
목표
- 3노드 OKE 클러스터 및 배스천(ORM 또는 Terraform)을 배치합니다.
- 레이블 + 유사성을 가진 두 노드에서 Cassandra 및 Spark를 함께 배치합니다.
- Cassandra에 대해 Spark 읽기 작업을 실행하고 확인합니다.
- VCN 흐름 로그로 노드 간 트래픽을 관찰합니다.
필수 조건
- VCN, OKE, 컴퓨트, 로깅(플로우 로그), 선택적 모니터링에 대한 권한이 있는 OCI 테넌시입니다.
- 배스천 액세스를 위한 SSH 키 쌍입니다.
- 기본 Kubernetes에 대한 친숙도(노드, 레이블, 포드 등)
작업 1: OCI ORM(Resource Manager)을 사용하여 환경을 배치합니다(권장).
-
OCI 콘솔에서 스택을 열려면 아래를 누르십시오.

-
안내식 플로우를 따라 다음 작업을 수행합니다.
-
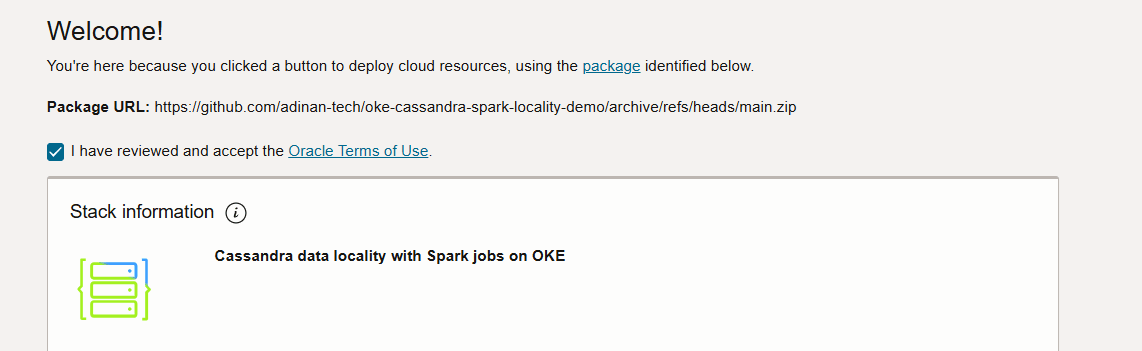
이용약관에 동의합니다.
-
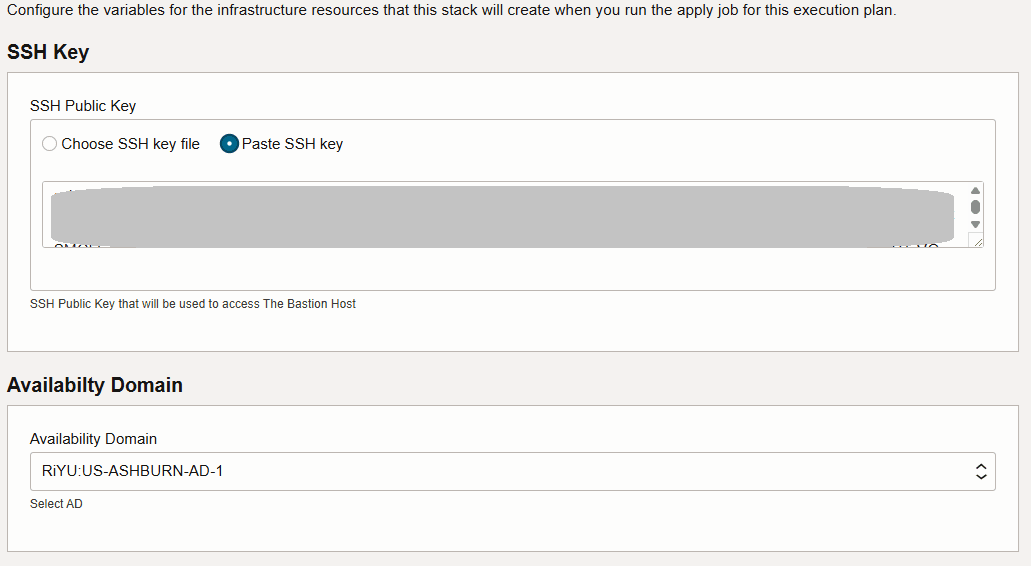
SSH 키를 삽입하고 가용성 도메인을 선택합니다.
-
VCN, OKE 클러스터 및 배스천을 배치하기 위해 나머지 값을 기본값으로 유지할 수 있습니다.
-
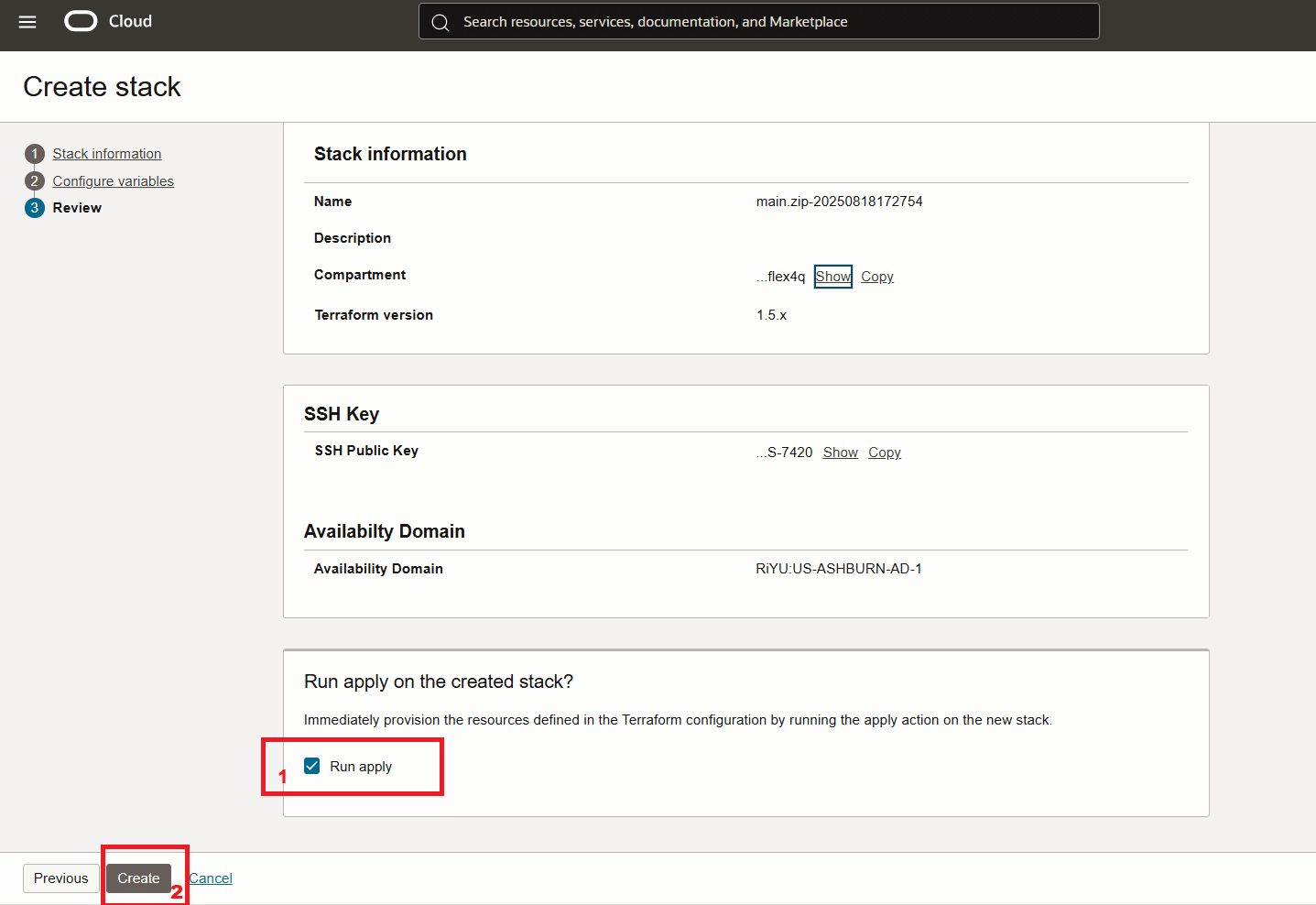
스택을 실행합니다.
-
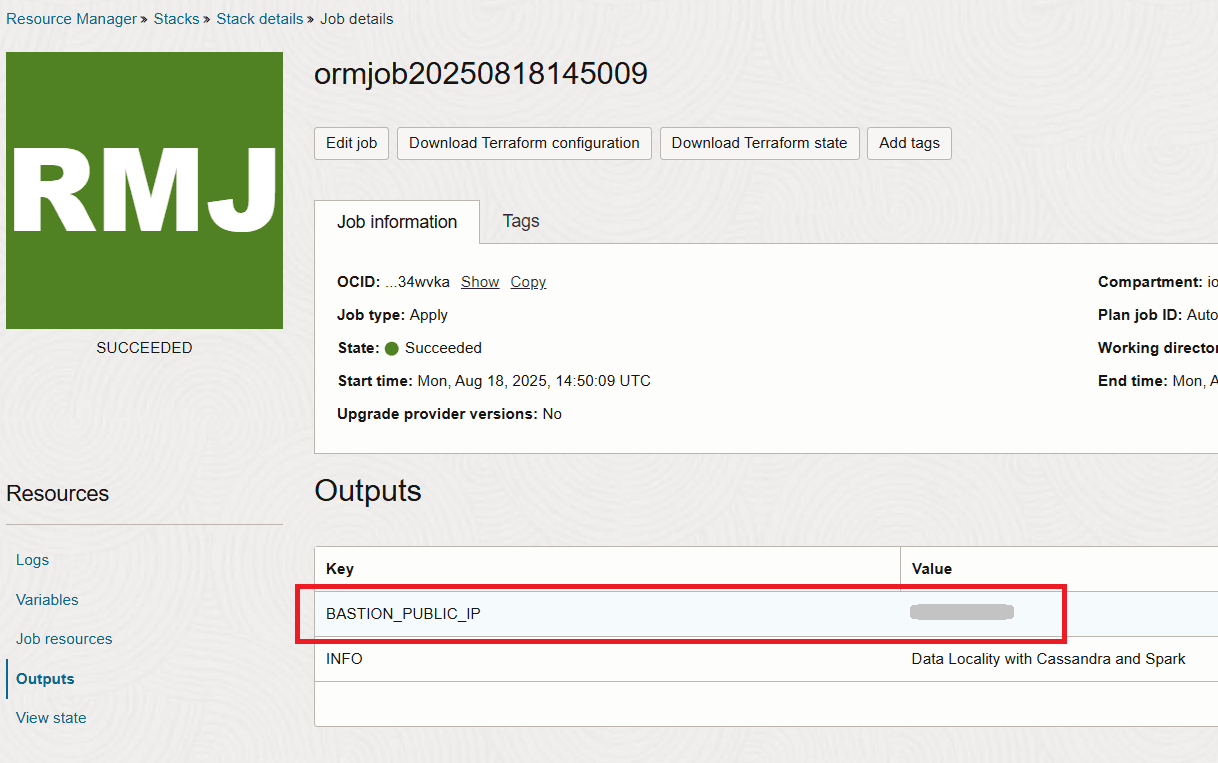
스택이 완료되면 출력 섹션에서 배스천의 IP를 가져옵니다.
작업 2: 배스천에 접속하고 배치 확인
초기 인프라 프로비저닝은 약 15분 이내에 완료되지만 전체 설정(배스천의 cloud-init를 통해)은 Helm을 설치하고 Cassandra 및 Spark를 배포하며 읽기 작업을 실행하는 데 약 20분 더 걸립니다.
-
프로세스를 모니터하려면 배스천으로 SSH를 실행합니다.
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
아래 명령을 실행하여 cloudinit 스크립트의 진행률을 모니터합니다.
tail -f /var/log/oke-automation.log -
3개의 시드 Cassandra 값을 읽고 Cloud-init complete 메시지가 표시되면 스택이 완료됩니다.
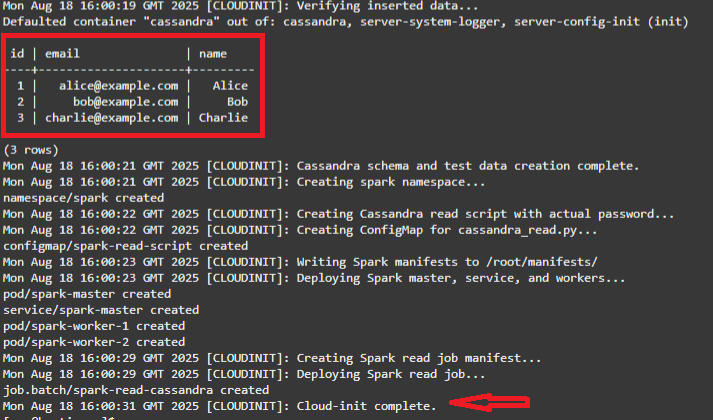
주: cloudinit 스크립트가 수행한 작업은 다음과 같습니다.
- kubectl, Helm, OCI CLI(인스턴스 주체)를 설치하고, kubeconfig를 인출합니다.
- 근로자 대기
- 레이블을 처음 두 노드로 지정합니다.
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - cert-manager 및 k8ssandra-operator(CRD) 설치
- K8ssandraCluster 적용
- Cassandra 대기
- testks.users를 생성하고 3개의 행을 삽입합니다.
- spark 네임스페이스 생성, /scripts/cassandra_read.py로 ConfigMap 빌드(testks.users 읽기)
- Spark 마스터, 서비스 및 두 명의 워커 배포(nodeSelector 스파크 지역: "true", 워커 반친화력)
- 작업 spark-read-cassandra 제출
-
배스천 VM에서 기존 노드를 확인합니다.
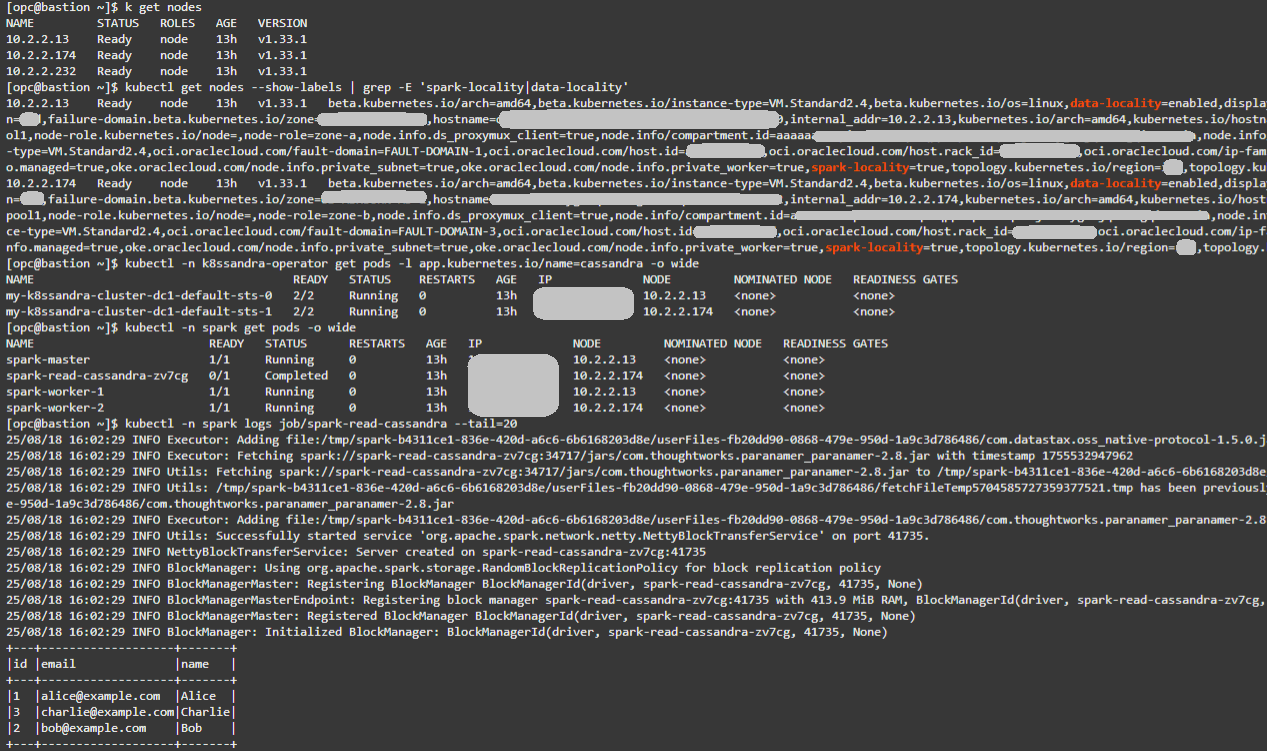
kubectl get nodes -
지역 레이블을 확인합니다. spark-locality=true 및 data-locality=enabled인 두 노드가 필요합니다.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Cassandra 배치 확인:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Spark 배치 확인:
kubectl -n spark get pods -o wide -
Spark 읽기 작업 로그를 확인합니다. testks.users의 세 레코드와 성공적인 실행이 표시됩니다.
kubectl -n spark logs job/spark-read-cassandra --tail=20
팁: Cassandra 및 Spark POD에서 NODE 값을 일치시키면 코로케이션과 지역성에 대한 이상적인 조건이 확인됩니다. 자세한 플로우 로그 결과를 보려면 cqlsh를 사용하여 testks.users에 추가 행을 삽입하십시오. 큰 데이터 세트는 더 많은 읽기 트래픽을 생성하므로 지역성 대 비지역성 효과를 관찰하기가 더 쉽습니다.
다음은 위의 명령에 대한 예제 출력입니다.
작업 3: VCN 흐름 로그로 네트워크 효과 관찰
VCN 플로우 로그를 사용하여 Spark 읽기 중 Cassandra 트래픽 플로우를 파악할 수 있습니다. 현재 자동화는 플로우 로그에서 볼 수 있는 항목에 영향을 주는 Flannel(VXLAN)을 사용합니다.
CNI의 변화
- Flannel (VXLAN, 이 실험실):
- 동일 노드 POD 트래픽은 호스트 브리지에서 유지되지만 VCN 플로우 로그 항목은 없습니다.
- 노드 간 Pod 트래픽은 UDP
(VXLAN)로 캡슐화됩니다. 기본적으로 Flannel은 포트 8472를 사용하지만, 해당 포트를 사용할 수 없는 경우 다른 높은 UDP 포트를 선택할 수 있습니다. 정확한 포트는 배포마다 다를 수 있습니다.
- VCN-고유 POD 네트워킹(NPN):
- 파드는 VCN IP를 가져오고 트래픽은 오버레이 없이 L3로 라우팅됩니다.
- 플로우 로그에는 실제 응용 프로그램 포트가 표시됩니다(Cassandra: TCP 9042의 경우).
-
워커 서브넷에서 플로우 로그를 사용으로 설정합니다.
OCI 콘솔에서 OKE 작업자 서브넷에 대한 플로우 로그를 사용으로 설정합니다. 트래픽을 생성하기 위해 Spark 읽기 작업을 다시 실행하거나 기다립니다.
-
질의 플로우 로그(클러스터와 일치하는 경로 선택)
이 자동화(Flannel/VXLAN)를 사용하는 경우: 다음과 유사한 고급 쿼리를 사용합니다.
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
- Pod-to-Pod 트래픽은
Cassandra 포트 9042 대신 작업자 노드 IP 간에 UDP로 캡슐화됩니다. - 동일 노드 읽기: VCN 플로우 로그 항목이 없습니다(트래픽은 로컬에 유지됨).
- 노드 간 읽기: 아래 그림에서 작업자 노드 IP 간 UDP 14789 흐름으로 표시됩니다.
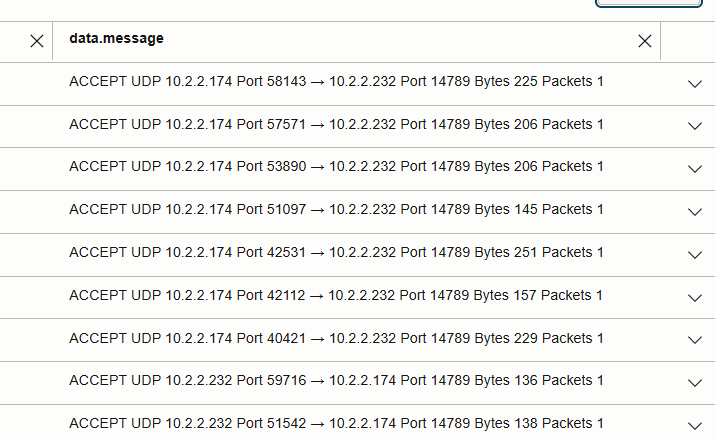
- UDP 14789에서 패킷 수를 비교하면 데이터 지역성 대 비지역성의 효과가 강조 표시됩니다.
클러스터에서 NPN을 사용하는 경우:
- 포드/작업자 IP 간 TCP dstPort = 9042에 대해 직접 필터링합니다.
- Cassandra CQL이 9042 흐름으로 읽거나 쓰는 것을 볼 수 있습니다. (이상적으로 거의 없음)
참고: 플로우 로그는 새 항목을 수집하는 데 몇 분 정도 걸릴 수 있습니다.
주요 고려 사항
-
노드가 3개 이상인 클러스터:
클러스터 크기가 증가함에 따라 지역성이 더욱 중요합니다. 배치 규칙이 없으면 로컬 복제본이 없는 노드에서 Spark 실행기가 실행되어 많은 원격 읽기가 발생할 수 있습니다. 코로케이션은 읽기가 로컬이거나 최악의 경우 다른 복제본에 대한 단일 홉인지 확인합니다.
- 코로케이션을 통한 성능 향상:
- 제로 홉 로컬 읽기 → 최저 대기 시간.
- 노드 간 읽기 횟수 감소 → 대역폭 사용 감소 및 경합 감소
- Cassandra를 병렬로 읽는 Spark 작업에 대한 처리량이 높아집니다.
- 이 자동화에 사용되는 방식:
- StatefulSets → 안정적인 Cassandra Pod ID입니다.
- 노드 레이블(
spark-locality,data-locality) → 코로케이션에 대한 노드를 지정합니다. - Pod affinity/anti-affinity → Cassandra 노드에 예약된 Spark 실행기가 서로 균형을 이룹니다.
- K8ssandra 운영자 → 선언적 Cassandra 배치 및 관리.
- ConfigMap + Spark 작업 → Cassandra 읽기 검증 및 트래픽 생성
- VCN 흐름 로그 → 지역성 효과를 관찰하고 확인합니다.
- OKE의 범위를 벗어남(응용 프로그램 레벨 요소):
- Spark 작업 예약 및 분할 영역 지정입니다.
- Cassandra 복제 계수 및 일관성 레벨입니다.
- 복제본 선택을 위한 Spark–Cassandra 커넥터 논리입니다.
관련 링크
추가 리소스에 대한 링크를 제공합니다. 이 섹션은 선택 사항입니다. 필요하지 않은 경우 삭제합니다.
승인
- Authors - Adina Nicolescu(Principal Cloud Architect)
추가 학습 자원
docs.oracle.com/learn에서 다른 랩을 탐색하거나 Oracle Learning YouTube 채널에서 더 많은 무료 학습 콘텐츠에 액세스하세요. 또한 education.oracle.com/learning-explorer를 방문하여 Oracle Learning Explorer가 되십시오.
제품 설명서는 Oracle Help Center를 참조하십시오.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53302-01