22 Oracle CQL Statements
This chapter describes data definition language (DDL) statements in Oracle Continuous Query Language (Oracle CQL).
This chapter includes the following section:
22.1 Introduction to Oracle CQL Statements
Oracle CQL supports the following DDL statements:
Note:
In stream input examples, lines beginning withh (such as h 3800) are heartbeat input tuples. These inform Oracle Event Processing that no further input will have a timestamp lesser than the heartbeat value.For more information, see:
Query
Use the query statement to define a Oracle CQL query that you reference by identifier in subsequent Oracle CQL statements.
If your query references a stream or view, then the stream or view must already exist.
If the query already exists, Oracle Event Processing server throws an exception.
For more information, see:
You express a query in a <query></query> element as Example 22-1 shows.
The query element has one attribute:
-
id: Specify theidentifieras thequeryelementidattribute.The
idvalue must conform with the specification given by identifier::=.
Example 22-1 Query in a <query></query> Element
<query id="q0"><![CDATA[
select * from OrderStream where orderAmount > 10000.0
]]></query>
query::=
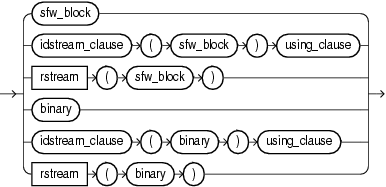
(sfw_block::=, idstream_clause::=, binary::=, using_clause::=)
sfw_block::=
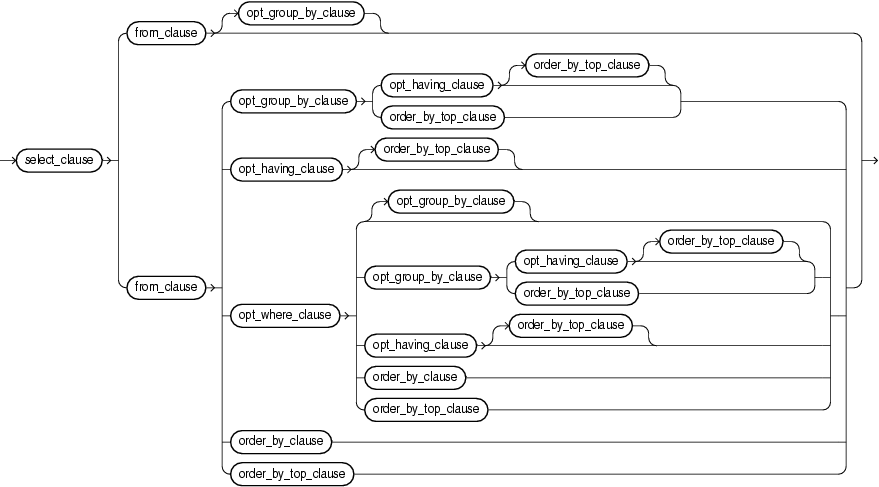
(select_clause::=, from_clause::=, opt_where_clause::=, opt_group_by_clause::=, order_by_clause::=, order_by_top_clause::=, opt_having_clause::=)
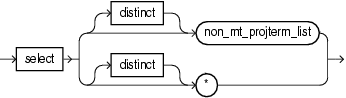
projterm::=
from_clause::=

(non_mt_relation_list::=, relation_variable::=, non_mt_cond_list::=)
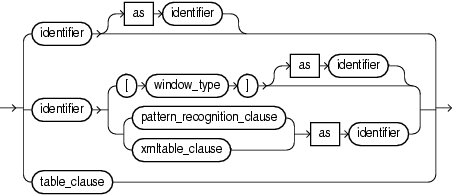
(identifier::=, window_type::=, pattern_recognition_clause::=, xmltable_clause::=, object_expr::=, datatype::=, table_clause::=)
window_type::=
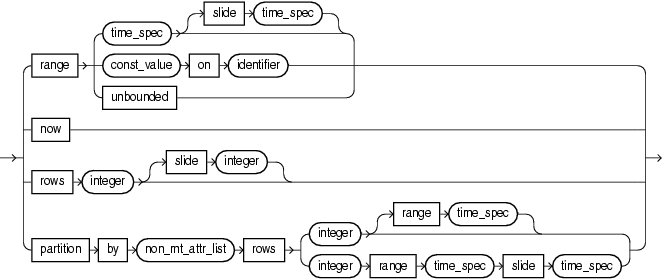
(identifier::=, non_mt_attr_list::=, time_spec::=)
table_clause::=
(object_expr::=, identifier::=, datatype::=)

(pattern_partition_clause::=, order_by_list::=)
orderterm::=
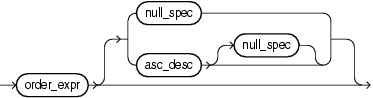
(order_expr::=, null_spec::=, asc_desc::=)
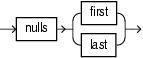
null_spec::=
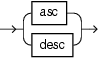
asc_desc::=
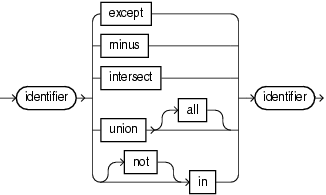
binary::=

using_clause::=
usinglist::=
(xmlnamespace_clause::=, const_string::=, xqryargs_list::=, xtbl_cols_list::=)

Specify the Oracle CQL query statement itself (see "query").
For syntax, see "Query".
You can create an Oracle CQL query from any of the following clauses:
-
sfw_block: a select, from, and other optional clauses (see "sfw_block"). -
binary: an optional clause, often a set operation (see "binary"). -
xstream_clause: apply an optional relation-to-stream operator to yoursfw_blockorbinaryclause to control how the query returns its results (see "idstream_clause").
For syntax, see query::=.
Specify the select, from, and other optional clauses of the Oracle CQL query. You can specify any of the following clauses:
-
select_clause: the stream elements to select from the stream or view you specify (see "select_clause"). -
from_clause: the stream or view from which your query selects (see "from_clause"). -
opt_where_clause: optional conditions your query applies to its selection (see "opt_where_clause") -
opt_group_by_clause: optional grouping conditions your query applies to its results (see "opt_group_by_clause") -
order_by_clause: optional ordering conditions your query applies to its results (see "order_by_clause") -
order_by_top_clause: optional ordering conditions your query applies to the top-nelements in its results (see "order_by_top_clause") -
opt_having_clause: optional clause your query uses to restrict the groups of returned stream elements to those groups for which the specifiedconditionisTRUE(see "opt_having_clause")
For syntax, see sfw_block::= (parent: query::=).
Specify the select clause of the Oracle CQL query statement.
If you specify the asterisk (*), then this clause returns all tuples, including duplicates and nulls.
Otherwise, specify the individual stream elements you want (see "non_mt_projterm_list").
Optionally, specify distinct if you want Oracle Event Processing to return only one copy of each set of duplicate tuples selected. Duplicate tuples are those with matching values for each expression in the select list. For an example, see "Select and Distinct Examples".
For syntax, see select_clause::= (parent: sfw_block::=).
Specify the projection term ("projterm") or comma separated list of projection terms in the select clause of the Oracle CQL query statement.
For syntax, see non_mt_projterm_list::= (parent: select_clause::=).
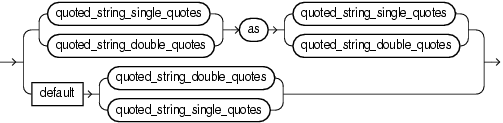
Specify a projection term in the select clause of the Oracle CQL query statement. You can select any element from any of stream or view in the from_clause (see "from_clause") using the identifier of the element.
Optionally, you can specify an arithmetic expression on the projection term.
Optionally, use the AS keyword to specify an alias for the projection term instead of using the stream element name as is.
For syntax, see projterm::= (parent: non_mt_projterm_list::=).
Specify the from clause of the Oracle CQL query statement by specifying the individual streams or views from which your query selects (see "non_mt_relation_list").
To perform an outer join, use the LEFT or RIGHT OUTER JOIN ... ON syntax. To perform an inner join, use the WHERE clause.
For more information, see:
For syntax, see from_clause::= (parent: sfw_block::=).
Specify the stream or view ("relation_variable") or comma separated list of streams or views in the from clause of the Oracle CQL query statement.
For syntax, see non_mt_relation_list::= (parent: from_clause::=).
Use the relation_variable statement to specify a stream or view from which the Oracle CQL query statement selects.
You can specify a previously registered or created stream or view directly by its identifier you used when you registered or created the stream or view. Optionally, use the AS keyword to specify an alias for the stream or view instead of using its name as is.
To specify a built-in stream-to-relation operator, use a window_type clause (see "window_type"). Optionally, use the AS keyword to specify an alias for the stream or view instead of using its name as is.
To apply advanced comparisons optimized for data streams to the stream or view, use a pattern_recognition_clause (see "pattern_recognition_clause"). Optionally, use the AS keyword to specify an alias for the stream or view instead of using its name as is.
To process xmltype stream elements using XPath and XQuery, use an xmltable_clause (see "xmltable_clause"). Optionally, use the AS keyword to specify an alias for the stream or view instead of using its name as is.
To access, as a relation, the multiple rows returned by a data cartridge function in the FROM clause of an Oracle CQL query, use a table_clause (see "table_clause").
For more information, see:
For syntax, see relation_variable::= (parent: non_mt_relation_list::=).
Specify a built-in stream-to-relation operator.
For more information, see Section 1.1.3, "Stream-to-Relation Operators (Windows)".
For syntax, see window_type::= (parent: relation_variable::=).
Use the data cartridge TABLE clause to access the multiple rows returned by a data cartridge function in the FROM clause of an Oracle CQL query.
The TABLE clause converts the set of returned rows into an Oracle CQL relation. Because this is an external relation, you must join the TABLE function clause with a stream. Oracle Event Processing invokes the data cartridge method only on the arrival of elements on the joined stream.
Use the optional OF keyword to specify the type contained by the returned array type or Collection type.
Use the AS keyword to specify an alias for the object_expr and for the returned relation.
Note the following:
-
The data cartridge method must return an array type or
Collectiontype. -
You must join the
TABLEfunction clause with a stream.
For examples, see:
For more information, see:
For syntax, see table_clause::= (parent: relation_variable::=).
Specify the time over which a range or partitioned range sliding window should slide.
Default: if units are not specified, Oracle Event Processing assumes [second|seconds].
For more information, see "Range-Based Stream-to-Relation Window Operators" and "Partitioned Stream-to-Relation Window Operators".
For syntax, see time_spec::= (parent: window_type::=).
Specify the (optional) where clause of the Oracle CQL query statement.
Because Oracle CQL applies the WHERE clause before GROUP BY or HAVING, if you specify an aggregate function in the SELECT clause, you must test the aggregate function result in a HAVING clause, not the WHERE clause.
In Oracle CQL (as in SQL), the FROM clause is evaluated before the WHERE clause. Consider the following Oracle CQL query:
SELECT ... FROM S MATCH_RECOGNIZE ( .... ) as T WHERE ...
In this query, the S MATCH_RECOGNIZE ( .... ) as T is like a subquery in the FROM clause and is evaluated first, before the WHERE clause. Consequently, you rarely use both a MATCH_RECOGNIZE clause and a WHERE clause in the same Oracle CQL query. Instead, you typically use views to apply the required WHERE clause to a stream and then select from the views in a query that applies the MATCH_RECOGNIZE clause.
For more information, see:
-
Section 9.1.1, "Built-In Aggregate Functions and the Where, Group By, and Having Clauses"
-
Section 11.1.2, "Colt Aggregate Functions and the Where, Group By, and Having Clauses"
For syntax, see opt_where_clause::= (parent: sfw_block::=).
Specify the (optional) GROUP BY clause of the Oracle CQL query statement. Use the GROUP BY clause if you want Oracle Event Processing to group the selected stream elements based on the value of expr(s) and return a single (aggregate) summary result for each group.
Expressions in the GROUP BY clause can contain any stream elements or views in the FROM clause, regardless of whether the stream elements appear in the select list.
The GROUP BY clause groups stream elements but does not guarantee the order of the result set. To order the groupings, use the ORDER BY clause.
Because Oracle CQL applies the WHERE clause before GROUP BY or HAVING, if you specify an aggregate function in the SELECT clause, you must test the aggregate function result in a HAVING clause, not the WHERE clause.
For more information, see:
-
Section 9.1.1, "Built-In Aggregate Functions and the Where, Group By, and Having Clauses"
-
Section 11.1.2, "Colt Aggregate Functions and the Where, Group By, and Having Clauses"
For syntax, see opt_group_by_clause::= (parent: sfw_block::=).
Specify the ORDER BY clause of the Oracle CQL query statement as a comma-delimited list ("order_by_list") of one or more order terms (see "orderterm"). Use the ORDER BY clause to specify the order in which stream elements on the left-hand side of the rule are to be evaluated. The expr must resolve to a dimension or measure column. This clause returns a stream.
Both ORDER BY and ORDER BY ROWS support specifying the direction of sort as ascending or descending by using the ASC or DESC keywords. They also support specifying whether null items should be listed first or last when sorting by using NULLS FIRST or NULLS LAST.
For more information, see:
For syntax, see order_by_clause::= (parent: sfw_block::=).
Specify the ORDER BY clause of the Oracle CQL query statement as a comma-delimited list ("order_by_list") of one or more order terms (see "orderterm") followed by a ROWS keyword and integer number (n) of elements. Use this form of the ORDER BY clause to select the top-n elements over a stream or relation. This clause returns a relation.
Consider the following example queries:
-
At any point of time, the output of the following example query will be a relation having top 10 stock symbols throughout the stream.
select stock_symbols from StockQuotes order by stock_price rows 10
-
At any point of time, the output of the following example query will be a relation having top 10 stock symbols from last 1 hour of data.
select stock_symbols from StockQuotes[range 1 hour] order by stock_price rows 10
See "order_by_clause::=" for more about what is supported by ORDER BY.
For more information, see:
For syntax, see order_by_top_clause::= (parent: sfw_block::=).
Specify a comma-delimited list of one ore more order terms (see "orderterm") in an (optional) ORDER BY clause.
For syntax, see order_by_list::= (parent: order_by_clause::=).
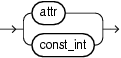
A stream element (attr::=) or positional index (constant int) to a stream element. Optionally, you can configure whether or not nulls are ordered first or last using the NULLS keyword (see "null_spec").
order_expr (order_expr::=) can be an attr or constant_int. The attr (attr::=) can be any stream element or pseudo column.
For syntax, see orderterm::= (parent: order_by_list::=).
Specify whether or not nulls are ordered first (NULLS FIRST) or last (NULLS LAST) for a given order term (see "orderterm").
For syntax, see null_spec::= (parent: orderterm::=).
Specify whether an order term is ordered in ascending (ASC) or descending (DESC) order.
For syntax, see asc_desc::= (parent: orderterm::=).
Use the HAVING clause to restrict the groups of returned stream elements to those groups for which the specified condition is TRUE. If you omit this clause, then Oracle Event Processing returns summary results for all groups.
Specify GROUP BY and HAVING after the opt_where_clause. If you specify both GROUP BY and HAVING, then they can appear in either order.
Because Oracle CQL applies the WHERE clause before GROUP BY or HAVING, if you specify an aggregate function in the SELECT clause, you must test the aggregate function result in a HAVING clause, not the WHERE clause.
For more information, see:
-
Section 9.1.1, "Built-In Aggregate Functions and the Where, Group By, and Having Clauses"
-
Section 11.1.2, "Colt Aggregate Functions and the Where, Group By, and Having Clauses"
For an example, see "HAVING Example".
For syntax, see opt_having_clause::= (parent: sfw_block::=).
Use the binary clause to perform operations on the tuples that two streams or views return. Most of these perform set operations, receiving two relations as operands. However, the UNION ALL operator can instead receive two streams, which are by nature unbounded.
For examples, see:
For syntax, see binary::= (parent: query::=).
Use an idstream_clause to specify an IStream or DStream relation-to-stream operator that applies to the query.
For more information, see Section 1.1.4, "Relation-to-Stream Operators".
For syntax, see idstream_clause::= (parent: query::=).
Use a DIFFERENCE USING clause to succinctly detect differences in the IStream or DStream of a query.
For more information, see Section 20.2.10, "Detecting Differences in Query Results".
For syntax, see using_clause::= (parent: query::=).
Use a usinglist clause to specify the columns to use to detect differences in the IStream or DStream of a query. You may specify columns by:
-
attribute name: use this option when you are selecting by attribute name.
Example 22-2 shows attribute name
c1in theDIFFERENCE USINGclauseusinglist. -
alias: use this option when you want to include the results of an expression where an alias is specified.
Example 22-2 shows alias
logvalin theDIFFERENCE USINGclauseusinglist. -
position: use this option when you want to include the results of an expression where no alias is specified.
Specify position as a constant, positive integer starting at 1, reading from left to right.
Example 22-2 specifies the result of expression
funct(c2, c3)by its position (3) in theDIFFERENCE USINGclauseusinglist.
Example 22-2 Specifying the usinglist in a DIFFERENCE USING Clause
<query id="q1">
ISTREAM (
SELECT c1, log(c4) as logval, funct(c2, c3) FROM S [RANGE 1 NANOSECONDS]
) DIFFERENCE USING (c1, logval, 3)
</query>
For more information, see Section 20.2.10, "Detecting Differences in Query Results".
For syntax, see usinglist::= (parent: using_clause::=).
Use an xmltable_clause to process xmltype stream elements using XPath and XQuery. You can specify a comma separated list (see xtbl_cols_list::=) of one or more XML table columns (see xtbl_col::=), with or without an XML namespace.
For examples, see:
For syntax, see xmltable_clause::= (parent: relation_variable::=).
Use a pattern_recognition_clause to perform advanced comparisons optimized for data streams.
For more information and examples, see Chapter 21, "Pattern Recognition With MATCH_RECOGNIZE".
For syntax, see pattern_recognition_clause::= (parent: relation_variable::=).
The following examples illustrate the various semantics that this statement supports:
For more examples, see Chapter 20, "Oracle CQL Queries, Views, and Joins".
Example 22-3 shows how to register a simple query q0 that selects all (*) tuples from stream OrderStream where stream element orderAmount is greater than 10000.
<query id="q0"><![CDATA[
select * from OrderStream where orderAmount > 10000.0
]]></query>
Consider the query q4 in Example 22-4 and the data stream S2 in Example 22-5. Stream S2 has schema (c1 integer, c2 integer). The query returns the relation in Example 22-6.
<query id="q4"><![CDATA[
select
c1,
sum(c1)
from
S2[range 10]
group by
c1
having
c1 > 0 and sum(c1) > 1
]]></query>
Example 22-5 HAVING Stream Input
Timestamp Tuple 1000 ,2 2000 ,4 3000 1,4 5000 1, 6000 1,6 7000 ,9 8000 ,
BINARY Example: UNION and UNION ALL
The UNION and UNION ALL operators both take two operands and combine their elements. The result of the UNION ALL operator includes all of the elements from the two operands, including duplicates. The result of the UNION operator omits duplicates.
The UNION operator accepts only two relations and produces a relation as its output. This operator cannot accept streams because in order to remove duplicates, the Oracle CQL engine must keep track of all of the elements contained in both operands. This is not possible with streams, which are by nature unbounded.
The UNION ALL operator accepts either two streams (and producing a stream) or two relations (producing a relation) as its operands. Using one stream and one relation as operands is invalid for both operators.
Given the relations R1 and R2 in Example 22-8 and Example 22-9, respectively, the UNION query q1 in Example 22-7 returns the relation in Example 22-10 and the UNION ALL query q2 in Example 22-7 returns the relation in Example 22-11.
See Example 22-12, Example 22-13, and Example 22-14 for an example of UNION ALL with streams instead of relations.
Example 22-7 UNION and UNION ALL Queries
<query id="q1"><![CDATA[
R1 UNION R2
]]></query>
<query id="q2"><![CDATA[
R1 UNION ALL R2
]]></query>
Example 22-8 UNION Relation Input R1
Timestamp Tuple Kind Tuple 200000: + 20,0.2 201000: - 20,0.2 400000: + 30,0.3 401000: - 30,0.3 100000000: + 40,4.04 100001000: - 40,4.04
Example 22-9 UNION Relation Input R2
Timestamp Tuple Kind Tuple
1002: + 15,0.14
2002: - 15,0.14
200000: + 20,0.2
201000: - 20,0.2
400000: + 30,0.3
401000: - 30,0.3
100000000: + 40,4.04
100001000: - 40,4.04
Example 22-10 UNION Relation Output
Timestamp Tuple Kind Tuple
1002: + 15,0.14
2002: - 15,0.14
200000: + 20,0.2
201000: - 20,0.2
400000: + 30,0.3
401000: - 30,0.3
100000000: + 40,4.04
100001000: - 40,4.04
Example 22-11 UNION ALL Output from Relation Input
The following output is from using UNION ALL with two relations as operands.
Timestamp Tuple Kind Tuple
1002: + 15,0.14
2002: - 15,0.14
200000: + 20,0.2
200000: + 20,0.2
20100: - 20,0.2
201000: - 20,0.2
400000: + 30,0.3
400000: + 30,0.3
401000: - 30,0.3
401000: - 30,0.3
100000000: + 40,4.04
100000000: + 40,4.04
10001000: - 40,4.04
100001000: - 40,4.04
Example 22-12 UNION ALL Stream Input S1
Timestamp Tuple 100000: 20,0.1 150000: 15,0.1 200000: 5,0.2 400000: 30,0.3 100000000: 8,4.04
Example 22-13 UNION ALL Stream Input S2
Timestamp Tuple
1001: 10,0.1
1002: 15,0.14
200000: 20,0.2
400000: 30,0.3
100000000: 40,4.04
Example 22-14 UNION ALL Output from Stream Input
The following output is from using UNION ALL with the two preceding streams as operands. Note that all of the elements are inserted events.
Timestamp Tuple Kind Tuple
1001: + 10,0.1
1002: + 15,0.14
100000: + 20,0.1
150000: + 15,0.14
200000: + 20,0.2
200000: + 5,0.2
400000: + 30,0.3
400000: + 30,0.3
100000000: + 40,4.04
100000000: + 8,4.04
The INTERSECT operator returns a relation (with duplicates removed) with only those elements that appear in both of its operand relations.
Given the relations R1 and R2 in Example 22-16 and Example 22-17, respectively, the INTERSECT query q1 in Example 22-15 returns the relation in Example 22-18.
Example 22-16 INTERSECT Relation Input R1
Timestamp Tuple Kind Tuple 1000: + 10,30 1000: + 10,40 2000: + 11,20 3000: - 10,30 3000: - 10,40
Example 22-17 INTERSECT Relation Input R2
Timestamp Tuple Kind Tuple 1000: + 10,40 2000: + 10,30 2000: - 10,40 3000: - 10,30
Example 22-18 INTERSECT Relation Output
Timestamp Tuple Kind Tuple 1000: + 10,40 2000: + 10,30 2000: - 10,40 3000: - 10,30
BINARY Example: EXCEPT and MINUS
As in database programming, the EXCEPT and MINUS operators are very similar. They both take relations as their two operands. Both result in a relation that is essentially elements of the first operand relation that are not also in the second operand relation.
An important difference between EXCEPT and MINUS is in how they handle duplicate occurrences between the first and second relation operands, as follows:
-
The EXCEPT operator results in a relation made up of elements from the first relation, removing elements that were also found in the second relation up to the number of duplicate elements found in the second relation. In other words, if an element occurs m times in the first relation and n times in the second, the number of that element in the result will be n subtracted from m, or 0 if there were fewer in m than n.
-
The MINUS operator results in a relation made up of elements in the first relation minus those elements that were also found in the second relation, regardless of how many of those elements were found in each. The MINUS operator also removes duplicate elements found in the first relation, so that each duplicate item is unique in the result.
The following examples illustrate the MINUS operator. Given the relations R1 and R2 in Example 22-20 and Example 22-21, respectively, the MINUS query q1 in Example 22-19 returns the relation in Example 22-22.
Example 22-20 MINUS Relation Input R1
Timestamp Tuple Kind Tuple 1500: + 10,40 1800: + 10,30 2000: + 10,40 2000: + 10,40 2100: - 10,40 3000: - 10,30
Example 22-21 MINUS Relation Input R2
Timestamp Tuple Kind Tuple 1000: + 11,20 2000: + 10,40 3000: - 10,30
Example 22-22 MINUS Relation Output
Timestamp Tuple Kind Tuple 1500: + 10,40 1800: + 10,30 2100: - 10,40
The following examples illustrate the EXCEPT operator. Given the relations R1 and R2 in Example 22-24 and Example 22-25, respectively, the EXCEPT query q1 in Example 22-23 returns the relation in Example 22-26.
Example 22-24 EXCEPT Relation Input R1
Timestamp Tuple Kind Tuple 1500: + 10,40 1800: + 10,30 2000: + 10,40 2000: + 10,40 2100: - 10,40 3000: - 10,30
Example 22-25 EXCEPT Relation Input R2
Timestamp Tuple Kind Tuple 1000: + 11,20 2000: + 10,40 3000: - 10,30
Example 22-26 EXCEPT Relation Output
Timestamp Tuple Kind Tuple 1500: + 10,40 1800: + 10,30 2000: + 10,40 2100: - 10,40
In this usage, the query will be a binary query.
Note:
You cannot combine this usage within_condition_membership as Section 6.8.2, "Using IN and NOT IN as a Membership Condition" describes.Consider the views V3 and V4 and the query Q1 in Example 22-27 and the data streams S3 in Example 22-28 (with schema (c1 integer, c2 integer)) and S4 in Example 22-29 (with schema (c1 integer, c2 integer)). In this condition test, the numbers and data types of attributes in left relation should be same as number and types of attributes of the right relation. Example 22-30 shows the relation that the query returns.
Example 22-27 IN and NOT IN as a Set Operation: Query
<view id="V3" schema="c1 c2"><![CDATA[
select * from S3[range 2]
]]></query>
<view id="V4" schema="c1 d1"><![CDATA[
select * from S4[range 1]
]]></query>
<query id="Q1"><![CDATA[
v3 not in v4
]]></query>
Example 22-28 IN and NOT IN as a Set Operation: Stream S3 Input
Timestamp Tuple 1000 10, 30 1000 10, 40 2000 11, 20 3000 12, 40 3000 12, 30 3000 15, 50 h 2000000
Example 22-29 IN and NOT IN as a Set Operation: Stream S4 Input
Timestamp Tuple 1000 10, 40 2000 10, 30 2000 12, 40 h 2000000
Example 22-30 IN and NOT IN as a Set Operation: Relation Output
Timestamp Tuple Kind Tuple 1000: + 10,30 1000: + 10,40 1000: - 10,30 1000: - 10,40 2000: + 11,20 2000: + 10,30 2000: + 10,40 2000: - 10,30 2000: - 10,40 3000: + 15,50 3000: + 12,40 3000: + 12,30 4000: - 11,20 5000: - 12,40 5000: - 12,30 5000: - 15,50
Consider the query q1 in Example 22-31. Given the data stream S in Example 22-32, the query returns the relation in Example 22-33.
Example 22-31 Select DISTINCT Query
<query id="q1"><![CDATA[
SELECT DISTINCT FROM S WHERE c1 > 10
]]></query>
Example 22-32 Select DISTINCT Stream Input
Timestamp Tuple 1000 23 2000 14 3000 13 5000 22 6000 11 7000 10 8000 9 10000 8 11000 7 12000 13 13000 14
Consider the query q1 in Example 22-34 and the data stream S in Example 22-35. Stream S has schema (c1 xmltype). The query returns the relation in Example 22-36.
For a more complete description of XMLTABLE, see Section 20.2.6, "XMLTABLE Query".
<query id="q1"><![CDATA[
SELECT
X.Name,
X.Quantity
FROM S1,
XMLTABLE (
"//item" PASSING BY VALUE S1.c2 as "."
COLUMNS
Name CHAR(16) PATH "/item/productName",
Quantity INTEGER PATH "/item/quantity"
) AS X
]]></query>
Example 22-35 XMLTABLE Stream Input
Timestamp Tuple 3000 "<purchaseOrder><shipTo><name>Alice Smith</name><street>123 Maple Street</street><city>Mill Valley</city><state>CA</state><zip>90952</zip> </shipTo><billTo><name>Robert Smith</name><street>8 Oak Avenue</street><city>Old Town</city><state>PA</state> <zip>95819</zip> </billTo><comment>Hurry, my lawn is going wild!</comment><items> <item><productName>Lawnmower </productName><quantity>1</quantity><USPrice>148.95</USPrice><comment>Confirm this is electric</comment></item><item> <productName>Baby Monitor</productName><quantity>1</quantity> <USPrice>39.98</USPrice> <shipDate>1999-05-21</shipDate></item></items> </purchaseOrder>" 4000 "<a>hello</a>"
Example 22-36 XMLTABLE Relation Output
Timestamp Tuple Kind Tuple 3000: + <productName>Lawnmower</productName>,<quantity>1</quantity> 3000: + <productName>Baby Monitor</productName>,<quantity>1</quantity>
XMLTABLE With XML Namespaces Query Example
Consider the query q1 in Example 22-37 and the data stream S1 in Example 22-38. Stream S1 has schema (c1 xmltype). The query returns the relation in Example 22-39.
For a more complete description of XMLTABLE, see Section 20.2.6, "XMLTABLE Query".
Example 22-37 XMLTABLE With XML Namespaces Query
<query id="q1"><![CDATA[
SELECT *
FROM S1,
XMLTABLE (
XMLNAMESPACES('http://example.com' as 'e'),
'for $i in //e:emps return $i/e:emp' PASSING BY VALUE S1.c1 as "."
COLUMNS
empName char(16) PATH 'fn:data(@ename)',
empId integer PATH 'fn:data(@empno)'
) AS X
]]></query>
Example 22-38 XMLTABLE With XML Namespaces Stream Input
Timestamp Tuple 3000 "<emps xmlns=\"http://example.com\"><emp empno=\"1\" deptno=\"10\" ename=\"John\" salary=\"21000\"/><emp empno=\"2\" deptno=\"10\" ename=\"Jack\" salary=\"310000\"/><emp empno=\"3\" deptno=\"20\" ename=\"Jill\" salary=\"100001\"/></emps>" h 4000
Example 22-39 XMLTABLE With XML Namespaces Relation Output
Timestamp Tuple Kind Tuple 3000: + John,1 3000: + Jack,2 3000: + Jill,3
Data Cartridge TABLE Query Example: Iterator
Consider a data cartridge (MyCartridge) with method getIterator as Example 22-40 shows.
Example 22-40 MyCartridge Method getIterator
...
public static Iterator<Integer> getIterator() {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
return list.iterator();
}
...
Consider the query q1 in Example 22-41. Given the data stream S0 in Example 22-42, the query returns the relation in Example 22-43.
Example 22-41 TABLE Query: Iterator
<query id="q1"><![CDATA[
select S1.c1, S1.c2, S2.c1
from
S0[now] as S1,
table (com.acme.MyCartridge.getIterator() as c1) of integer as S2
]]></query>
Example 22-42 TABLE Query Stream Input: Iterator
Timestamp Tuple 1 1, abc 2 2, ab 3 3, abc 4 4, a h 200000000
Example 22-43 TABLE Query Output: Iterator
Timestamp Tuple Kind Tuple 1: + 1,abc,1 1: + 1,abc,2 1: - 1,abc,1 1: - 1,abc,2 2: + 2,ab,1 2: + 2,ab,2 2: - 2,ab,1 2: - 2,ab,2 3: + 3,abc,1 3: + 3,abc,2 3: - 3,abc,1 3: - 3,abc,2 4: + 4,a,1 4: + 4,a,2 4: - 4,a,1 4: - 4,a,2
Data Cartridge TABLE Query Example: Array
Consider a data cartridge (MyCartridge) with method getArray as Example 22-44 shows.
Example 22-44 MyCartridge Method getArray
...
public static Integer[] getArray(int c1) {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
return list.toArray(new Integer[2]);;
}
...
Consider the query q1 in Example 22-45. Given the data stream S0 in Example 22-46, the query returns the relation in Example 22-47.
Example 22-45 TABLE Query: Array
<query id="q1"><![CDATA[
select S1.c1, S1.c2, S2.c1
from
S0[now] as S1,
table (com.acme.MyCartridge.getArrayS1.c1) as c1) of integer as S2
]]></query>
Example 22-46 TABLE Query Stream Input: Array
Timestamp Tuple 1 1, abc 2 2, ab 3 3, abc 4 4, a h 200000000
Example 22-47 TABLE Query Output: Array
Timestamp Tuple Kind Tuple 1: + 1,abc,1 1: + 1,abc,2 1: - 1,abc,1 1: - 1,abc,2 2: + 2,ab,2 2: + 2,ab,4 2: - 2,ab,2 2: - 2,ab,4 3: + 3,abc,3 3: + 3,abc,6 3: - 3,abc,3 3: - 3,abc,6 4: + 4,a,4 4: + 4,a,8 4: - 4,a,4 4: - 4,a,8
Data Cartridge TABLE Query Example: Collection
Consider a data cartridge (MyCartridge) with method getCollection as Example 22-48 shows.
Example 22-48 MyCartridge Method getCollection
...
public HashMap<Integer,String> developers;
developers = new HashMap<Integer,String>();
developers.put(2, "Mohit");
developers.put(4, "Unmesh");
developers.put(3, "Sandeep");
developers.put(1, "Swagat");
public HashMap<Integer,String> qaengineers;
qaengineers = new HashMap<Integer,String>();
qaengineers.put(4, "Terry");
qaengineers.put(5, "Tony");
qaengineers.put(3, "Junger");
qaengineers.put(1, "Arthur");
...
public Collection<String> getEmployees(int exp_yrs) {
LinkedList<String> employees = new LinkedList<String>();
employees.add(developers.get(exp_yrs));
employees.add(qaengineers.get(exp_yrs));
return employees;
}
...
Consider the query q1 in Example 22-49. Given the data stream S0 in Example 22-50, the query returns the relation in Example 22-51.
Example 22-49 TABLE Query: Collection
<query id="q1"><![CDATA[
RStream(
select S1.c1, S2.c1
from
S0[now] as S1,
table(S1.c2.getEmployees(S1.c1) as c1) of char as S2
)
]]></query>
Example 22-50 TABLE Query Stream Input: Collection
Timestamp Tuple 1 1, abc 2 2, ab 3 3, abc 4 4, a h 200000000
Example 22-51 TABLE Query Output: Collection
Timestamp Tuple Kind Tuple 1: + 1,Swagat 1: + 1,Arthur 2: + 2,Mohit 3: + 3,Sandeep 3: + 3,Junger 4: + 4,Unmesh 4: + 4,Terry
Use the ORDER BY clause with stream input to sort events that have duplicate timestamps. ORDER BY is only valid when the input is a stream and only sorts among events of the same timestamp. Its output is a stream with the sorted events.
For more information, see "order_by_clause::=".
Consider the query q1 in Example 22-55. Given the data stream S0 in Example 22-56, the query returns the relation in Example 22-57. The query sorts events of duplicate timestamps in ascending order by tuple values.
<query id="q1"><![CDATA[
SELECT *
FROM S0
ORDER BY c1,c2 ASC
]]></query>
Example 22-53 ORDER BY Stream Input
Timestamp Tuple 1000 7, 15 2000 7, 14 2000 5, 23 2000 5, 15 2000 5, 15 2000 5, 25 3000 3, 12 3000 2, 13 4000 4, 17 5000 1, 9 h 1000000000
Example 22-54 ORDER BY Stream Output
Timestamp Tuple Kind Tuple 1000: + 7,15 2000: + 5,15 2000: + 5,15 2000: + 5,23 2000: + 5,25 3000: + 2,13 3000: + 3,19 4000: + 4,17 5000: + 1,9
Use the ORDER BY clause with the ROWS keyword to use ordering criteria to determine whether an event received by the query should be included in output. ORDER BY ROWS accepts either stream or relation input and outputs a relation.
The ORDER BY ROWS clause maintains a set of events whose maximum size is the number specified by the ROWS keyword. As new events are received, they are evaluated, based on thr order criteria and the ROWS limit, to determine whether they will be added to the output.
Note that the output of ORDER BY ROWS is not arranged based on the ordering criteria, as is the output of the ORDER BY clause. Instead, ORDER BY ROWS uses the ordering criteria and specified number of rows to determine whether to admit events into the output as they are received.
For more information, see "order_by_top_clause::=".
Consider the query q1 in Example 22-55. Given the data stream S0 in Example 22-56, the query returns the relation in Example 22-57.
Example 22-55 ORDER BY ROWS Query
<query id="q1"><![CDATA[
SELECT c1 ,c2
FROM S0
ORDER BY c1,c2 ROWS 5
]]></query>
Example 22-56 ORDER BY ROWS Stream Input
Timestamp Tuple 1000 7, 15 2000 7, 14 2000 5, 23 2000 5, 15 2000 5, 15 2000 5, 25 3000 2, 13 3000 3, 19 4000 4, 17 5000 1, 9 h 1000000000
Example 22-57 ORDER BY ROWS Output
Timestamp Tuple Kind Tuple 1000: + 7,15 2000: + 7,14 2000: + 5,23 2000: + 5,15 2000: + 5,15 2000: - 7,15 2000: + 5,25 3000: - 7,14 3000: + 2,13 3000: - 5,25 3000: + 3,19 4000: - 5,23 4000: + 4,17 5000: - 5,15 5000: + 1,9
In the following example, the query uses the PARTITION keyword to specify the tuple property within which to sort events and constrain output size. Here, the PARTITION keyword specifies that events in the input should be evaluated based on their symbol value.
In other words, when determining whether to include an event in the output, the query looks at the existing set of events in output that have the same symbol. The ROWS limit is two, meaning that the query will maintain a set of sorted events that has no more than two events in it. For example, if there are already two events with the ORCL symbol, adding another ORCL event to the output will require deleting the oldest element in output having the ORCL symbol.
Also, the query is ordering events by the value property, so that is also considered when a new event is being considered for output. Here, the DESC keyword specifies that event be ordered in descending order. A new event that does not come after events already in the output set will not be included in output.
Example 22-58 ORDER BY ROWS with PARTITION Query
<query id="q1"><![CDATA[
SELECT symbol, value
FROM S0
ORDER BY value DESC ROWS 2
PARTITION BY symbol
]]></query>
Example 22-59 ORDER BY ROWS with PARTITION Input
Timestamp Tuple 1000 ORCL, 500 1100 MSFT, 400 1200 INFY, 200 1300 ORCL, 503 1400 ORCL, 509 1500 ORCL, 502 1600 MSFT, 405 1700 INFY, 212 1800 INFY, 209 1900 ORCL, 512 2000 ORCL, 499 2100 MSFT, 404 2200 MSFT, 403 2300 INFY, 215 2400 MSFT, 415 2500 ORCL, 499 2600 INFY, 211
Example 22-60 ORDER BY ROWS with PARTITION Output
Timestamp Tuple Kind Tuple 1000 + ORCL,500 1100 + MSFT,400 1200 + INFY,200 1300 + ORCL,503 1400 - ORCL,500 1400 + ORCL,509 1600 + MSFT,405 1700 + INFY,212 1800 - INFY,200 1800 + INFY,209 1900 - ORCL,503 1900 + ORCL,512 2100 - MSFT,400 2100 + MSFT,404 2300 - INFY,209 2300 + INFY,215 2400 - MSFT,404 2400 + MSFT,415
View
Use view statement to create a view over a base stream or relation that you reference by identifier in subsequent Oracle CQL statements.
For more information, see:
You express the a view in a <view></view> element as Example 22-61 shows.
The view element has two attributes:
-
id: Specify theidentifieras theviewelementidattribute.The
idvalue must conform with the specification given by identifier::=. -
schema: Optionally, specify the schema of the view as a space delimited list of attribute names.Oracle Event Processing server infers the types.
Example 22-61 View in a <view></view> Element
<view id="v2" schema="cusip bid ask"><![CDATA[
IStream(select * from S1[range 10 slide 10])
]]></view>
The body of the view has the same syntax as a query. For more information, see "Query".
The following examples illustrate the various semantics that this statement supports. For more examples, see Chapter 20, "Oracle CQL Queries, Views, and Joins".
Example 22-62 shows how to register view v2.