7 Setting Up Database Objects and Connection Pools
This chapter describes the properties of the database and connection pool objects in the Physical layer.
Properties for database objects and connection pools are typically set automatically when you import metadata from your data sources. However, in some cases you may want to adjust database or connection pool settings, or create a database object or connection pool manually.
This chapter contains the following sections:
Setting Up Database Objects
Importing metadata from a data source automatically creates a database object for the schema, but you may need to adjust or view the database properties.
In addition, you sometimes need to manually create a database object and connection pool for certain situations like configuring usage tracking, setting up Oracle Scorecard and Strategy Management, or configuring aggregate persistence targets.
See "System Requirements and Certification" for information about supported data sources.
The following sections provide information about how to create, edit, or view properties for database objects in the Physical layer:
About Database Types in the Physical Layer
If you import the physical schema into the Physical layer, the Administration tool usually assigns database type automatically.
The following list contains additional information about automatic assignment of database types:
-
Relational data sources. During the import process, some ODBC drivers provide the Oracle BI Server with the database type. However, if the server cannot determine the database type, an approximate ODBC type is assigned to the database object. Replace the ODBC type with the closest matching entry from the Database list.
-
Multidimensional data sources. Microsoft Analysis Services and SAP/BW are the only supported XMLA-compliant data sources currently available. After you import metadata from a multidimensional data source, check the database object and update the appropriate database type and version if necessary.
Creating a Database Object Manually in the Physical Layer
If you create a database object manually, you also need to manually set up an associated connection pool.
For multidimensional data sources, if you create the physical schema in the Physical layer of the repository, you need to create one database in the physical layer for each cube, or set of cubes, that belong to the same catalog (database) in the data source. A physical database can have more than one cube. However, all of these cubes must be in the same catalog in the data source.
Caution:
It is strongly recommended that you import your physical schema.To create a database object:
-
In the Administration Tool, in the Physical layer, right-click and select New Database.
Make sure that no object is selected when you right-click.
-
In the Database dialog, in the General tab, complete the fields using Table 7-1 as a guide.
Table 7-1 Options in the General Tab of the Database Dialog
| Option | Description |
|---|---|
|
Data source definition: Database |
The database type for your database. See "Specifying SQL Features Supported by a Data Source" for more information about using the Features tab to examine the SQL features supported by the specified database type. |
|
Data source definition: CRM metadata tables |
This property is only available for relational data sources and is for legacy Siebel Systems sources only. When selected, indicates that the definition of physical tables and columns for Siebel CRM tables was derived from the Siebel metadata dictionary. |
|
Data source definition: Virtual Private Database |
Identifies the physical database source as a virtual private database (VPD). When a VPD is used, returned data results are contingent on the user's authorization credentials. Therefore, it is important to identify these sources. These data results affect the validity of the query result set that is used with caching. See "Managing Performance Tuning and Query Caching" in Oracle Fusion Middleware System Administrator's Guide for Oracle Business Intelligence Enterprise Edition. Always select this option for Essbase, Hyperion Financial Management, and Hyperion Planning data sources that are configured for SSO in the corresponding connection pool. Note: If you select this option, you also should select the Security Sensitive option in the Session Variable dialog. See "Creating Session Variables" for more information. |
|
Persist connection pool |
To use a persistent connection pool, you must set up a temporary table first. See "Setting Up Persist Connection Pools" for more information. |
|
Allow populate queries by default |
When selected, allows everyone to execute |
|
Allow direct database requests by default |
When selected, allows all users to execute physical queries. The Oracle BI Server sends unprocessed, user-entered, physical SQL directly to an underlying database. The returned results set can be rendered in Oracle BI Presentation Services, and then charted, rendered in a dashboard, and treated as an Oracle BI request. If you want most, but not all, users to be able to execute physical queries, select this option and then limit queries for specific users or groups. See "Setting Query Limits" for more information. Caution: If configured incorrectly, this option can expose sensitive data to an unintended audience. See "When to Allow Direct Database Requests by Default" for more information. For more information about executing physical SQL, see "Working with Direct Database Requests" in Oracle Fusion Middleware User's Guide for Oracle Business Intelligence Enterprise Edition. |
When to Allow Direct Database Requests by Default
The property Allow direct database requests by default lets all users execute physical queries. If configured incorrectly, it can expose sensitive data to an unintended audience.
Use the following recommended guidelines when setting this database property:
-
The Oracle BI Server should be configured to accept connection requests only from a computer on which the Oracle BI Server, Oracle BI Presentation Services, or Oracle BI Scheduler are running. This restriction should be established at the TCP/IP level using the Oracle BI Presentation Services IP address. This allows only a TCP/IP connection from the IP address of Oracle BI Presentation Services.
-
To prevent users from running
nqcmd(a utility that executes SQL scripts) by logging in remotely to this computer, you should disallow access by the following to the computer on which you installed Oracle BI Presentation Services:-
TELNET
-
Remote shells
-
Remote desktops
-
Teleconferencing software (such as Windows NetMeeting)
If necessary, you might want to make an exception for users with administrator permissions.
-
-
Only users with administrator permissions should be allowed to perform the following tasks:
-
TELNET into the Oracle BI Server and Oracle BI Presentation Services computers to perform tasks such as running
nqcmdfor cache seeding. -
Access the advanced SQL page of Answers to create requests. For more information, see Oracle Fusion Middleware User's Guide for Oracle Business Intelligence Enterprise Edition.
-
-
Set up group/user-based permissions on Oracle BI Presentation Services to control access to editing (preconfigured to allow access by Oracle BI Presentation Services administrators) and executing (preconfigured to not allow access by anyone) direct database requests. For more information, see Oracle Fusion Middleware Security Guide for Oracle Business Intelligence Enterprise Edition.
Specifying SQL Features Supported by a Data Source
When you import metadata or specify a database type in the General tab of the Database dialog, the set of SQL features for that database object is automatically populated with default values appropriate for the database type. The Oracle BI Server uses these SQL features with this data source.
When a feature is marked as supported (checked) in the Features tab of the Database dialog, the Oracle BI Server typically pushes the function or calculation down to the data source for improved performance. When a function or feature is not supported in the data source, the calculation or processing is performed in the Oracle BI Server.
The supported features list in the Features tab uses the feature defaults defined in the DBFeatures.INI file, located in ORACLE_INSTANCE\config\OracleBIServerComponent\coreapplication_obisn. Although you should not modify this file directly, it can be useful to look at this file to compare the features supported by different data source types.
You can tailor the query features for a data source. For example, a new version of a data source may be released with updated feature support that is not reflected in the Oracle BI Server defaults. In this case, you can update the settings in the Features tab to reflect the actual features supported by the new version of the data source. Or, if a data source supports a particular feature (such as left outer join queries) but you want to prohibit the Oracle BI Server from sending such queries to a particular data source, you can change this default setting in the Features tab. A third situation is when you have federated data sources that execute functions differently. To ensure query results are consistent, you can disable the appropriate functions so that the calculations are performed in a consistent manner in the Oracle BI Server.
Caution:
Be very careful when modifying the set of supported features in the Features tab. If you enable SQL features that the data source does not support, your query may return errors and unexpected results. If you disable supported SQL features, the server could issue less efficient SQL to the data source.In most cases, you should keep the default values. If you do change the defaults to mark a feature as supported in the Features tab, make sure that the feature is actually supported by the data source.
To specify SQL features supported by a data source:
-
In the Administration Tool, in the Physical layer, double-click the database for which you want to specify SQL features.
-
In the Database dialog, click the Features tab.
-
In the Features tab, use the information in Table 7-2 to help you specify properties for each SQL feature.
Table 7-2 Options in the Features Tab of the Database Dialog
| Option | Description |
|---|---|
|
Feature |
The name of the database feature, such as |
|
Value |
Shows the current value for the given feature. Selected indicates that the feature is supported in the data source, and that the function or feature should be performed in the data source rather than in the Oracle BI Server. Some features show a default value in the Value column rather than selected/not selected, such as 10 for It is strongly recommended that you keep the default selections and default values. |
|
Default |
Shows the default value for the given feature. The defaults listed in this column are specified in the file DBFeatures.INI. |
|
Find |
Lets you type a string to help you locate a feature in the list. |
|
Find Again |
This option becomes available after you click Find. It lets you perform multiple searches for the same string. |
|
Query DBMS |
This button is only used if you are installing and querying a data source that has no set of feature defaults in the Oracle BI Server. It lets you query this type of data source for Feature table entries so that you can find out which SQL features it supports. You can then change the entries that appear in the Features tab based on your query results. This button is not available if you are using an XML or a multidimensional data source. Caution: Be very careful when using the Query DBMS feature. The results of the features query are not always an accurate reflection of the SQL features actually supported by the data source. When using this feature, you should verify that the list of supported features in the Features tab matches the actual features supported by your data source. Refer to the documentation for your data source for details. |
|
Reset to defaults |
This button restores the default values for this data source type from the file DBFeatures.INI. |
Note:
Do not change theOPTIMIZE_MDX_FILTER_QUALIFICATION feature. This parameter is reserved for a future release.Viewing Database Properties
The Database Properties tab is used for some data sources as a generic mechanism for extending the Physical layer metadata.
For example, for Oracle ADF data sources, you can view custom database properties that are passed to the Administration Tool from Oracle ADF BI view objects. Click the Database Properties tab to view the custom properties. You do not typically need to create or edit these properties.
Table 7-3 shows examples of custom properties.
Table 7-3 Examples of Custom Properties in the Database Properties Tab
| Category | Key Name | Value | Description |
|---|---|---|---|
|
FscmTopModelAM.AccountBIAM |
BIObject_FLEX_TREE_VS_COST_CENTER_LABEL_VI |
Dim - Cost Center |
FLEX_TREE_VS_COST_CENTER_LABEL_VI view object needs to map to the Dim - Cost Center logical dimension |
|
FscmTopModelAM.AccountBIAM |
BIFlexfieldViewUsage |
FLEX_BI_AcctKff_VI |
FLEX_BI_AcctKff_VI is the CCID view object for FscmTopModelAM.AccountBIAM |
|
FscmTopModelAM.AccountBIAM |
EnforceCustomDataType_FscmTopModelAM.AccountBIAM |
"Segment 1":"VARCHAR"; "Segment ID":"DOUBLE" |
For FscmTopModelAM.AccountBIAM view objects, the data type of some physical columns needs to be overridden with the values passed in the property |
About Connection Pools
The connection pool is an object in the Physical layer that describes access to the data source. It contains information about the connection between the Oracle BI Server and that data source.
The Physical layer in the Administration Tool contains at least one connection pool for each database. When you create the Physical layer by importing a schema for a data source, the connection pool is created automatically. You can configure multiple connection pools for a database. Connection pools allow multiple concurrent data source requests (queries) to share a single database connection, reducing the overhead of connecting to a database.
Note:
It is recommended that you create a dedicated connection pool for initialization blocks. See "About Connection Pools for Initialization Blocks" for more information.For each connection pool, you must specify the maximum number of concurrent connections allowed. After this limit is reached, the connection request waits until a connection becomes available.
Increasing the allowed number of concurrent connections can potentially increase the load on the underlying database accessed by the connection pool. Test and consult with your DBA to make sure the data source can handle the number of connections specified in the connection pool. Also, if the data sources have a charge back system based on the number of connections, you might want to limit the number of concurrent connections to keep the charge-back costs down.
In addition to the potential load and costs associated with the database resources, the Oracle BI Server allocates shared memory for each connection upon server startup. This raises the number of connections and increases Oracle BI Server memory usage.
About Connection Pools for Initialization Blocks
It is recommended that you create a dedicated connection pool for initialization blocks. This connection pool should not be used for queries.
Additionally, it is recommended that you isolate the connections pools for different types of initialization blocks. This also makes sure that authentication and login-specific initialization blocks do not slow down the login process. The following types should have separate connection pools:
-
All authentication and login-specific initialization blocks such as language, externalized strings, and group assignments.
-
All initialization blocks that set session variables.
-
All initialization blocks that set repository variables. These initialization blocks should always be run using credentials with administrator privileges.
Be aware of the number of these initialization blocks, their scheduled refresh rate, and when they are scheduled to run. Typically, it would take an extreme case for this scenario to affect resources. For example, refresh rates set in minutes, greater than 15 initialization blocks that refresh concurrently, and a situation in which either of these scenarios could occur during prime user access time frames.
Initialization blocks should be designed so that the maximum number of Oracle BI Server variables may be assigned by each block. For example, if you have five variables, it is more efficient and less resource intensive to construct a single initialization block containing all five variables. When using one initialization block, the values are resolved with one call to the back end tables using the initialization string. Constructing five initialization blocks, one for each variable, would result in five calls to the back end tables for assignment.
If an initialization block fails for a particular connection pool during Oracle BI Server start-up, no more initialization blocks using that connection pool are processed. Instead, the connection pool is blacklisted and subsequent initialization blocks for that connection pool are skipped. This behavior ensures that the Oracle BI Server starts in a timely manner, even when a connection pool has a large number of associated initialization blocks or variables.
If this occurs, a message similar to the following appears in the server log:
[OracleBIServerComponent] [ERROR:1] [43143] Blacklisted connection pool
name_of_connection_pool
If you see this error, check the initialization blocks for the given connection pool to ensure they are correct.
See "Working with Initialization Blocks" for more information about these objects.
Creating or Changing Connection Pools
Typically, database objects and connection pools are created automatically when you import physical schemas, for both relational and multidimensional data sources. If you did not import physical schemas, you must create a database object before you create a connection pool.
You create or change a connection pool in the Physical layer of the Administration Tool.
To modify more than one connection pool, use the "List Connection Pool Command" and the "Update Connection Pool Command."
If you have already defined an existing database and connection pool, you can right-click the connection pool in the Physical layer and select Import Metadata to import metadata for this data source. The Import Metadata Wizard appears with the information on the Select Data Source screen pre-filled. See Chapter 5, "Importing Metadata and Working with Data Sources" for information about the Import Wizard.
To automate connection pool changes for use in a process such as production migration, consider using the Oracle BI Server XML API. See "About the Oracle BI Server XML API" in Oracle Fusion Middleware XML Schema Reference for Oracle Business Intelligence Enterprise Edition for more information.
To create or change a connection pool:
-
In the Physical layer of the Administration Tool, right-click a database and select New Object, then select Connection Pool. Or, double-click an existing connection pool.
-
Specify or adjust the properties as needed, then click OK.
The following sections describe how to set properties in the various tabs of the Connection Pool dialog:
Setting Connection Pool Properties in the General Tab
This section describes the properties in the General tab of the Connection Pool dialog. The General tab is available for all data sources.
To set general properties for connection pools:
-
In the Connection Pool dialog, click the General tab, and then complete the fields using the information in Table 7-4 and Table 7-5.
The properties listed in the General tab vary according to the data source type. For example, XMLA data sources have a connection pool property for URL, while relational and XML data sources have the option Require fully qualified table names.
This section contains the following topics:
Common Connection Pool Properties in the General Tab
This section describes connection pool properties in the General tab that are common among most data source types.
Figure 7-1 shows the General tab of the Connection Pool dialog, for an OCI data source.
Figure 7-1 General Tab of the Connection Pool Dialog: OCI Data Source
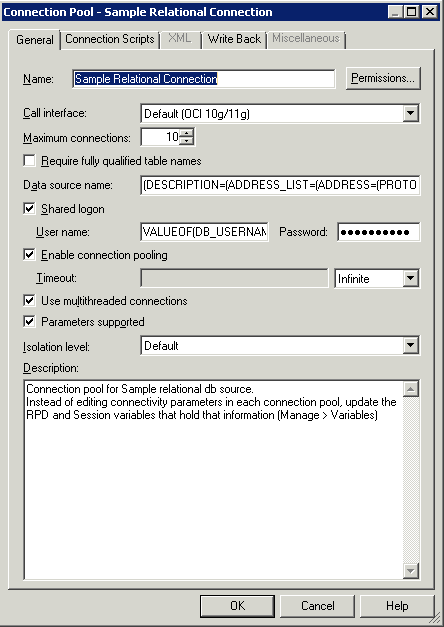
Description of ''Figure 7-1 General Tab of the Connection Pool Dialog: OCI Data Source''
Table 7-4 describes the properties in the General tab of the Connection Pool dialog that are common for different data source types.
Table 7-4 Connection Pool Properties in the General Tab: Common Properties
| Property | Description |
|---|---|
|
Name |
The name for the connection pool. A name is assigned automatically for connection pools created upon import. |
|
Permissions |
Use this option to assign permissions for individual users or application roles to access the connection pool. For example, you can set up a privileged group of users to have its own connection pool. This feature is not intended to be used for data access security. For example, connection pool permissions do not protect cache entries. Refer to Chapter 14 for complete information on data access security in Oracle Business Intelligence. |
|
Call interface |
Identifies the application programming interface (API) with which to access the data source. Some databases can be accessed using native APIs, some use ODBC, and some work both ways. Java data sources are accessed using JDBC/JNDI. If the call interface is XML, the XML tab is available but options that do not apply to XML data sources are not available. |
|
Maximum connections |
The maximum number of connections allowed for this connection pool. The default is 10. This value should be determined by the database make and model and the configuration of the hardware for the computer on which the database runs, as well as the number of concurrent users who require access. For Microsoft Analysis Services data sources, you might encounter 503 Service Not Available errors if the Max Connections setting in the connection pool (default 10) is greater than the XMLA MaxThreadsPerClient setting configured in Analysis Services (default 4). To avoid these errors, increase the MaxThreadsPerClient setting in the msmdpump.ini file, or reduce the Max Connections setting in the repository connection pool. See also "Improving Use of System Memory Resources with TimesTen Data Sources" for related information. Note: For deployments with Oracle BI Interactive Dashboards pages, consider estimating this value at 10% to 20% of the number of simultaneous users multiplied by the number of requests on a dashboard. This number can be adjusted based on usage. The total number of all connections in the repository should be less than 800. To estimate the maximum connections needed for a connection pool dedicated to an initialization block, you might use the number of users concurrently logged on during initialization block execution. |
|
Require fully qualified table names |
Select this option if the database or database configuration requires fully qualified table names. This option is not available for some data source types. When this option is selected, all requests sent from the connection pool use fully qualified names to query the underlying database. The fully qualified names are based on the physical object names in the repository. If you are querying the same tables from which the Physical layer metadata was imported, you can safely select this option. If you have migrated your repository from one physical database to another physical database that has different database and schema names, the fully qualified names would be invalid in the newly migrated database. In this case, if you do not select this option, the queries will succeed against the new database objects. For some data sources, fully qualified names might be safer because they guarantee that the queries are directed to the desired tables in the desired database. For example, if the RDBMS supports a master database concept, a query against a table named Customer first looks for that table in the master database, and then looks for it in the specified database. If the table named Customer exists in the master database, that table is queried, not the table named Customer in the specified database. It is sometimes necessary to select this option when you are using an Oracle Database, and you are accessing the database with a user that is not the owner of the schema containing the tables. When the Oracle Database interprets table names in SQL, it assumes that the user that made the query is the owner if the table name is not fully qualified in the query. This can result in an incorrect qualified name. For example, if the user SAMPLE creates a table called CUSTOMER, the fully qualified table name is SAMPLE.CUSTOMER. When the SAMPLE user references the CUSTOMER table in a query, the Oracle Database assumes the fully qualified table name is SAMPLE.CUSTOMER, and the access is successful. However, if the JANEDOE user references the CUSTOMER table in a query, the Oracle Database assumes the fully qualified table name is JANEDOE.CUSTOMER, and a "Table or view not found" error can result. To enable access for JANEDOE, you must select Require fully qualified table names in the connection pool so that the Oracle BI Server specifies SAMPLE.CUSTOMER in all queries. |
|
Data source name |
The name of the data source to which you want this connection pool to connect and send physical queries. The value you enter in this field depends on the selected call interface:
If you are using Microsoft SQL Server, then enter an ODBC data source name or a full connect string. The following is the syntax for the full connect string:
Driver={Driver Name};Address=Host Name;Database=Database Name
Where Driver Name refers to the Microsoft SQL Server ODBC driver name. This driver name must exist in odbcinst.ini, and the environment variable ODBCINST should be set to point to odbcinst.ini. |
|
Shared logon |
Select this option if you want all users whose queries use the connection pool to access the underlying database using the same user name and password. If this option is selected, then all connections to the database that use the connection pool use the user name and password specified in the connection pool, even if the user has specified a database user name and password in the DSN (or in user configuration). If this option is not selected, connections through the connection pool use the database user ID and password specified in the DSN or in the user profile. |
|
Enable connection pooling |
When selected, allows a single database connection to remain open for the specified time for use by future query requests. Connection pooling saves the overhead of opening and closing a new connection for every query. If you do not select this option, each query sent to the database opens a new connection. |
|
Timeout |
Specify the amount of time and in what increment (such as minutes) that a connection to the data source remains open after a request completes. During this time, new requests use this connection rather than open a new one (up to the number specified for the maximum connections). The time is reset after each completed connection request. If you are using an ADF data source and the call interface is OracleADF_HTTP and the query mode is SQLBypass, then Timeout specifies the maximum execution time before the connection is canceled. |
|
Use multithreaded connections |
When this option is selected, the Oracle BI Server terminates idle physical queries (threads). When not selected, one thread is tied to one database connection (number of threads = maximum connections). Even if threads are idle, they consume memory. The parameter |
|
Parameters supported |
If this option is not selected, and the database features table supports parameters, special code executes that allows the Oracle BI Server to push filters (or calculations) with parameters to the database. The Oracle BI Server does this by simulating parameter support within the gateway/adapter layer by sending extra SQLPrepare calls to the database. |
|
Isolation level |
For ODBC and DB2 gateways only. The value sets the transaction isolation level on each connection to the back-end database. The isolation level setting controls the default transaction locking behavior for all statements issued by a connection. Only one option can be set at a time. It remains set for that connection until it is explicitly changed. The following options are available: Dirty read. Implements dirty read (isolation level 0 locking). This is the least restrictive isolation level. When this option is set, it is possible to read uncommitted or dirty data, change values in the data, and have rows appear or disappear in the data set before the end of the transaction. Dirty data is data that needs to be cleaned before being queried to obtain correct results (for example, duplicate records, records with inconsistent naming conventions, or records with incompatible data types). Committed read. Specifies that shared locks are held while the data is read to avoid dirty reads. However, the data can be changed before the end of the transaction, resulting in non repeatable reads or phantom data. Repeatable read. Places locks on all data that is used in a query, preventing other users from updating the data. However, new phantom rows can be inserted into the data set by another user and are included in later reads in the current transaction. Serializable. Places a range lock on the data set, preventing other users from updating or inserting rows into the data set until the transaction is complete. This is the most restrictive of the four isolation levels. Because concurrency is lower, use this option only if necessary. |
Multidimensional Connection Pool Properties in the General Tab
This section describes connection pool properties in the General tab that are specific to multidimensional data sources.
Figure 7-2 shows the General tab of the Connection Pool dialog, for an Essbase data source.
Figure 7-2 General Tab of the Connection Pool Dialog: Essbase Data Source
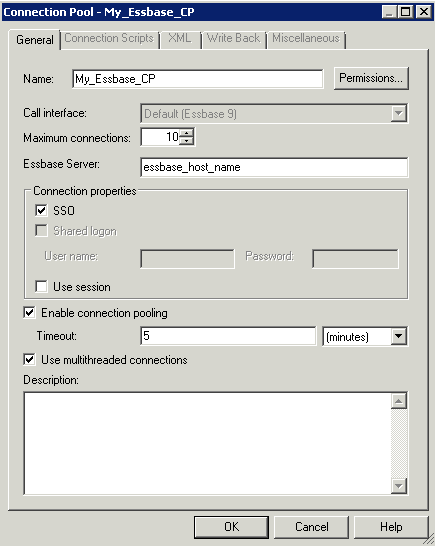
Description of ''Figure 7-2 General Tab of the Connection Pool Dialog: Essbase Data Source''
Table 7-5 describes the properties in the General tab of the Connection Pool dialog that are specific to multidimensional data sources. Note that some properties only appear for certain types of multidimensional data sources.
Table 7-5 Connection Pool Properties in the General Tab: Multidimensional Data Source Properties
| Property | Description |
|---|---|
|
URL |
This property is only displayed for XMLA data sources. Specify the URL to connect to the XMLA provider. This URL points to the XMLA virtual directory of the computer hosting the cube. This virtual directory must be associated with msxisapi.dll (part of the Microsoft XML for Analysis SDK installation). For example, the URL might look like the following: http://SDCDL360i101/xmla/msxisap.dll |
|
Essbase Server |
This property is only displayed for Essbase data sources. Specify the host name of the computer where the Essbase Server is running. If the Essbase Server is running on a non-default port, or if it is part of an Essbase Cluster, you must include the port number in the Essbase Server field, in the format Note: You can import metadata from an Essbase Cluster, but you must still specify an individual Essbase Server host name and port number in the Essbase Server field. |
|
SSO |
This property is only displayed for Essbase, Hyperion Financial Management, and Hyperion Planning data sources. For Essbase, select this option if you want Essbase to be able to enforce security policies that provide different cube access or member-level access to different users. If you select this option then you must also select the Shared logon option. Do not select this option if all users are expected to have the same access to the Essbase cube. In this case all the users will have the same access to the cube based on the shared credentials specified in the connection pool. If you do not select this option then you must also select the Shared logon option. For Hyperion Financial Management or Hyperion Planning, select this option and be sure that the Shared logon option is unchecked to authenticate against Hyperion Financial Management or Hyperion Planning using a shared token, rather than using a set of shared credentials in the connection pool. If you select this option, you should also select Virtual Private Database in the corresponding database object to protect cache entries. See Table 7-1 for more information. |
|
Shared logon |
This property is only displayed for Essbase, Hyperion Financial Management, and Hyperion Planning data sources. For all Essbase data sources, it is required that you select this option. See "Configuring Essbase to Use a Shared Logon" for more information about using this option in Essbase Connection Pools. For Hyperion Financial Management or Hyperion Planning, you will set this option based on how you set the SSO property.
|
|
Data Source Information: Data Source |
Specify the vendor-specific information used to connect to the multidimensional data source. Consult your multidimensional data source administrator for setup instructions because specifications can change. For example, if you use v1.0 of the XML for Analysis SDK, then the value should be |
|
Data Source Information: Catalog |
Specify the list of catalogs available, if you imported data from your data source. The cube tables correspond to the catalog you use in the connection pool. |
|
System IP or Hostname |
This property is only displayed for SAP/BW data sources. Provide the host name or IP address of the SAP data server. This field corresponds to the parameter |
|
System Number |
This property is only displayed for SAP/BW data sources. Provide the SAP system number. This is a two-digit number assigned to an SAP instance, also called Web Application Server, or WAS. This field corresponds to the parameter |
|
Client Number |
This property is only displayed for SAP/BW data sources. Provide the SAP client number. This is a three-digit number assigned to the self-contained unit called Client in SAP. A Client can be a training, development, testing, or production client, or it can represent different divisions in a large company. This field corresponds to the parameter |
|
Language |
This property is only displayed for SAP/BW data sources. Provide the SAP language code used when logging in to the data source (for example, EN for English or DE for German). This field corresponds to the parameter |
|
Additional Parameters |
This property is only displayed for SAP/BW data sources. Optionally, provide additional connection string parameters in the format param=value. Delimit multiple parameters with a colon. |
|
Use session |
An option that controls whether queries go through a common session. Consult your multidimensional data source administrator to determine whether this option should be enabled. Default is Off (not selected). |
Setting Connection Pool Properties in the Connection Scripts Tab
You can create connection scripts and set them to be run before the connection is established, before a query is run, after a query is run, or after the connection is disconnected. For example, you can create a connection script that, on connect, inserts the name of the user and the connection time into a table.
This topic describes the properties in the Connection Scripts tab of the Connection Pool dialog. The Connection Scripts tab is available for ODBC, OCI, Oracle OLAP, ADF, and DB2 data sources.
Connection scripts can contain any commands accepted by the database, such as a command to turn on quoted identifiers. In a mainframe environment, a script could be used to set the secondary authorization ID when connecting to DB2 to force a security exit to a mainframe security package such as RACF. This enables mainframe environments to maintain security in one central location.
Because the connection script is sent directly to the data source, the script should use native SQL or another language understood by the data source, not Oracle BI Server Logical SQL.
To create connection scripts for data sources:
-
In the Connection Pool dialog, click the Connection Scripts tab, and then complete the fields using the information in Table 7-6.
To enter a new connection script, click New next to the appropriate script type. Then, enter or paste the SQL statements for the script and click OK.
You can edit existing scripts by clicking the ellipsis button to launch the Physical SQL window. Use the Up Arrow and Down Arrow buttons to reorder existing scripts.
Click Delete to remove a script.
Figure 7-3 shows the Connection Scripts tab of the Connection Pool dialog.
Figure 7-3 Connection Scripts Tab of the Connection Pool Dialog
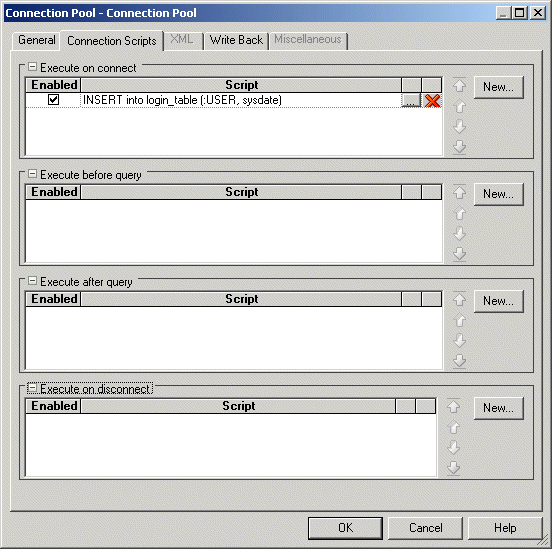
Description of ''Figure 7-3 Connection Scripts Tab of the Connection Pool Dialog''
Table 7-6 describes the properties in the Connection Scripts tab of the Connection Pool dialog.
Table 7-6 Connection Pool Properties in the Connection Scripts Tab
| Property | Description |
|---|---|
|
Execute on connect |
Contains SQL queries that are executed before the connection is established. |
|
Execute before query |
Contains SQL queries that are executed before the query is run. |
|
Execute after query |
Contains SQL queries that are executed after the query is run. |
|
Execute on disconnect |
Contains SQL queries that are executed after the connection is closed. |
Setting Connection Pool Properties in the XML Tab
Use the Connection Pool Properties in the XML tab to set properties for XML and XML Server data sources.
Caution:
The XML tab of the Connection Pool dialog provides the same functionality as the XML tab of the Physical Table dialog. However, the properties in the XML tab of the Physical Table dialog override the corresponding settings in the Connection Pool dialog.To set connection pool properties for XML data sources:
-
In the Connection Pool dialog, click the XML tab, and then complete the fields using the information in Table 7-7.
Figure 7-4 shows the XML tab of the Connection Pool dialog.
Figure 7-4 XML Tab of the Connection Pool Dialog
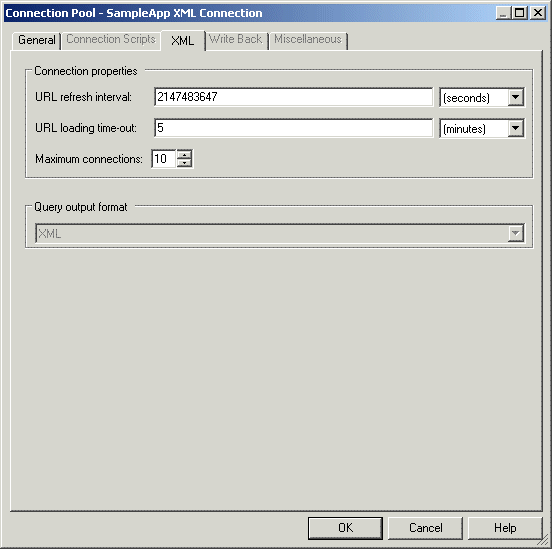
Description of ''Figure 7-4 XML Tab of the Connection Pool Dialog''
Table 7-7 describes the properties in the XML tab of the Connection Pool dialog.
Table 7-7 Connection Pool Properties in the XML Tab
| Property | Description |
|---|---|
|
Connection method: Search script |
This property is only displayed for XML Server data sources. Click Browse to locate the appropriate search script. |
|
Connection properties: URL refresh interval |
This property is used for XML data sources and is not available for XML Server data sources. The refresh interval is analogous to setting cache persistence for database tables. The URL refresh interval is the time interval after which the XML data source is queried again directly rather than using results in cache. The default setting is infinite, meaning the XML data source is never refreshed. If you specified a URL to access the data source, set the URL refresh interval.
|
|
Connection properties: URL loading time-out |
The timeout interval for queries. The default is 15 minutes. If you specified a URL to access the data source, set the URL loading time-out as follows:
|
|
Connection properties: Maximum connections |
The maximum number of connections. The default is 10. |
|
Query input supplements: Header file/Trailer file |
This property is only displayed for XML Server data sources. Click Browse to locate the header and trailer files. |
|
Query output format |
For XML data sources, choose only XML. Other output formats are available for XML Server data sources. |
Setting Connection Pool Properties in the Write Back Tab
Use the Write Back tab to set write back properties for ODBC, OCI, Oracle OLAP, ADF, and DB2 data sources.
To set write-back properties for data sources:
-
In the Connection Pool dialog, click the Write Back tab, and then complete the fields using the information in Table 7-8.
Figure 7-3 shows the Write Back tab of the Connection Pool dialog.
Figure 7-5 Write Back Tab of the Connection Pool Dialog
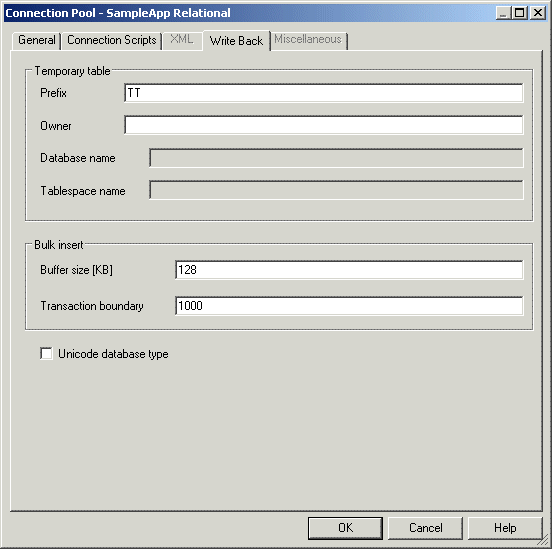
Description of ''Figure 7-5 Write Back Tab of the Connection Pool Dialog''
Table 7-8 describes the properties in the Write Back tab of the Connection Pool dialog.
Table 7-8 Connection Pool Properties in the Write Back Tab
| Property | Description |
|---|---|
|
Temporary table: Prefix |
When the Oracle BI Server creates a temporary table, these are the first two characters in the temporary table name. The default value is |
|
Temporary table: Owner |
Table owner name used to qualify a temporary table name in a SQL statement, for example to create the table |
|
Temporary table: Database name |
Database where the temporary table will be created. This property applies only to IBM OS/390 because IBM OS/390 requires database name qualifier to be part of the |
|
Temporary table: Tablespace name |
Tablespace where the temporary table will be created. This property applies to OS/390 only as OS/390 requires tablespace name qualifier to be part of the |
|
Bulk insert: Buffer size (KB) |
Used for limiting the number of bytes each time data is inserted in a database table. For optimum performance, consider setting this parameter to 128. See "About Setting the Buffer Size and Transaction Boundary" for additional information. |
|
Bulk insert: Transaction boundary |
Controls the batch size for an insert in a database table. For optimum performance, consider setting this parameter to 1000. See "About Setting the Buffer Size and Transaction Boundary" for additional information. |
|
Unicode database type |
Select this option when working with columns of an explicit Unicode data type, such as
Note: Unicode and non-Unicode data types cannot coexist in a single non-Unicode database. For example, mixing the |
Setting Connection Pool Properties in the Miscellaneous Tab
Use the Miscellaneous tab of the Connection Pool dialog to set application properties for ADF, JDBC, and JNDI data sources.
This section contains the following topics:
Application Properties for ADF Data Sources
To set application properties for ADF data sources, in the Connection Pool dialog, click the Miscellaneous tab, and then complete the fields using the information in Table 7-9.
Figure 7-6 shows the Miscellaneous tab of the Connection Pool dialog.
Figure 7-6 Miscellaneous Tab of the Connection Pool Dialog
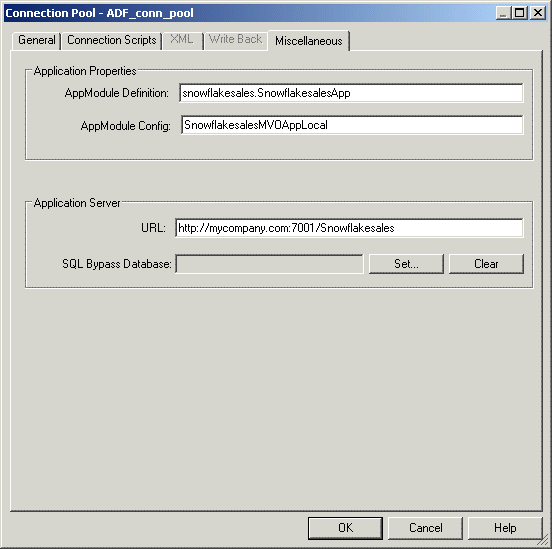
Description of ''Figure 7-6 Miscellaneous Tab of the Connection Pool Dialog''
Table 7-9 describes the properties in the Miscellaneous tab of the Connection Pool dialog.
Table 7-9 Connection Pool Properties in the Miscellaneous Tab
| Property | Description |
|---|---|
|
AppModule Definition |
The fully qualified Java package name of the Root Application Module to which you want to connect, such as |
|
AppModule Config |
Determines which application configuration is used in the connection, such as |
|
URL |
The URL to the Oracle Business Intelligence broker servlet, in the format: http://host:port/APP_DEPLOYMENT_NAME/obieebroker For example: http://localhost:7001/SnowflakeSalesApp/obieebroker The URL is case-sensitive. |
|
SQL Bypass Database |
(Optional) The name of the SQL Bypass database. The SQL Bypass database must be a physical database in the Physical layer of the repository. The database object for the SQL Bypass database must have a valid connection pool, with connection information that points to the same database that is being used by the JDBC Data source defined in the WebLogic Server. The SQL Bypass database does not need to have any tables under it. After a valid database name is supplied, the SQL Bypass feature is enabled for all queries. The SQL Bypass feature directly queries the database so that aggregations and other transformations are pushed down where possible, reducing the amount of data streamed and worked on in Oracle Business Intelligence. See "About Specifying a SQL Bypass Database" for more information. |
Application Properties for JDBC (Direct Driver) or JDBC (JNDI) Data Sources
To set application properties for JDBC (Direct Driver) or JDBC (JNDI) data sources, in the Connection Pool dialog, click the Miscellaneous tab, and then complete the fields using the following information:
-
Required Cartridge Version - This value defaults to 12.1.
-
Use SQL Over HTTP - For JDBC (JNDI) call interface, only. If you are using Oracle BI Cloud Service, set this field to false to use HTTP to communicate between networks. For example, set this field to false if the BI Server and the data source you are accessing reside on different Oracle clouds.
-
Javads Server URL - For JDBC (Direct Driver) call interface, only. The hostname and port that was specified in the Connect to Java Datasource Server dialog defaults into this field. This is the URL for the Java Datasource server, which supplies the Java metadata into the Physical layer.
-
Driver Class - For JDBC (Direct Driver) call interface, only. Specify the driver to connect to the database. For example, the DB2 JDBC driver. The driver that you specify must be deployed in Oracle Weblogic Server.
By default the Oracle JDBC driver (oracle.jdbc.OracleDriver) is available in Oracle Weblogic Server.
Setting Up Persist Connection Pools
A persist connection pool is a database property that is used for specific types of queries (typically used to support Marketing queries). In some queries, all of the logical query cannot be sent to the transactional database because that database might not support all of the functions in the query. This issue might be solved by temporarily constructing a physical table in the database and rewriting the Oracle BI Server query to reference the new temporary physical table.
You can use the persist connection pool in the following situations:
-
Populate stored procedures. Use to rewrite the Logical SQL result set to a managed table. Typically used by Oracle's Siebel Marketing Server to write segmentation cache result sets.
-
Perform a generalized subquery. Stores a nonfunction subquery in a temporary table, and then rewrites the original subquery result against this table. Reduces data movement between the Oracle BI Server and the database, supports unlimited IN list values, and might result in improved performance.
In these situations, the user issuing the Logical SQL query must have been granted the Populate privilege on the target database.
The persist connection pool functionality designates a connection pool with write-back capabilities for processing this type of query. You can assign one connection pool in a single database as a persist connection pool. If this functionality is enabled, the user name specified in the connection pool must have the privileges to create DDL (Data Definition Language) and DML (Data Manipulation Language) in the database.
To assign a persist connection pool:
-
In the Physical layer of the Administration Tool, double-click the database object for which you want to assign a persist connection pool.
-
In the Database dialog, click the General tab.
-
In the Persist connection pool area, click Set.
If there is only one connection pool, it appears in the Persist connection pool field.
-
If there are multiple connection pools, in the Browse dialog, select the appropriate connection pool, and then click OK.
The selected connection pool name appears in the Persist connection pool field.
-
(Optional) To set write-back properties, click the Connection Pools tab.
-
In the connection pool list, double-click the connection pool.
-
In the Connection Pool dialog, click the Write Back tab.
-
Complete the fields using Table 7-8 as a guide. See also "About Setting the Buffer Size and Transaction Boundary" for additional information.
-
Click OK, then click OK again to save the persist connection pool.
To remove a persist connection pool:
-
In the Physical layer of the Administration Tool, double-click the database object that contains the persist connection pool you want to remove.
-
In the Database dialog, click the General tab.
-
In the Persist connection pool area, click Clear.
The database name is replaced by
not assignedin the Persist connection pool field. -
Click OK.
About Setting the Buffer Size and Transaction Boundary
If each row size in a result set is 1 KB and the buffer size is 20 KB, then the maximum array size is 20 KB. If there are 120 rows, there are 6 batches with each batch size limited to 20 rows.
If you set Transaction boundary to 3, the server commits twice. The first time, the server commits after row 60 (3 * 20). The second time, the server commits after row 120. If there is a failure when the server commits, the server only rolls back the current transaction. For example, if there are two commits and the first commit succeeds but the second commit fails, the server only rolls back the second commit.
For optimum performance, consider setting the buffer size to 128 and the transaction boundary to 1000.
List Connection Pool Command
Use the list connection pool command listConnectionpool to create a list of connection pools in JSON format for a specific service instance. Use this and the updateConnectionpool utility when you need to update more than one connection pool.
You execute the utility through a launcher script, data-model-cmd.sh on UNIX and data-model-cmd.cmd on Windows. You can find the launcher script at the following location:
Oracle_Home/user_projects/domains/bi/bitools/bin
See "What You Need to Know Before Using the Command" for more information.
The listConnectionpool command takes the following parameters:
listConnectionpool -SI <service_instance> -U <cred_username> [-P <cred_password>] [-S <hostname>] [-N <port_number>] [-V <true/false>] [-O <outputFile.json>] [-SSL] [-H]
SI specifies the name of the service instance.
U specifies a valid user's name to be used for Oracle BI EE authentication.
P specifies the password corresponding to the user's name that you specified for U. If you do not supply the password, then you will be prompted for the password when the command is run. For security purposes, Oracle recommends that you include a password in the command only if you are using automated scripting to run the command.
S specifies the Oracle BI EE host name. Only include this option when you are running the command from a client installation.
N specifies the Oracle BI EE port number. Only include this option when you are running the command from a client installation.
V specifies whether to include repository variables used in the connection pool. Note that the default is false.
O specifies the output file name with the .json suffix.
SSL specifies to use SSL to connect to the WebLogic Server to run the command. Only include this option when you are running the command from a client installation.
H displays the usage information and exits the command.
data-model-cmd.sh listConnectionpool -SI bi -U weblogic -P password -S server1.example.com -N 7777 -SSL -V true -O output.json
Sample JSON List Connection Pool Output
{ "Title":"List Connection Pools",
"Conn-Pool-Info":[
{
"uid":"80ca62c5-0bd5-0000-714b-e31d00000000",
"connPool":"SampleApp_Lite_Xml",
"parentName":"\"Sample App Lite Data\"",
"user":"VALUEOF(REPO_STATIC_VAR)_Tushar",
"password":"B25F85BC2A170AD4349DEF26E4D1295D 7C2E35213306F12832914CBE7A9DD95561D771DED06484112B1FC6F27B6D0D58",
"dataSource":"VALUEOF(NQ_SESSION.SERVICEINSTANCEROOT)/data/SampleAppLite"
}
],
"Variables-In-Conn-Pool":[
{
"uid":"40000000-3c25-155b-991a-0af2537d0000",
"variable":"REPO_STATIC_VAR",
"value":"'RepoStaticVariable'"
}
]}
Update Connection Pool Command
Use the update connection pool command updateConnectionpool to upload a modified JSON file containing updated connection pool values to a specific server instance. Use this and the listConnectionpool utility when you need to update more than one connection pool.
Use the listConnectionpool command to create a JSON file containing a list of connection pools for a specific service instance. Modify the connection pool information in this file and then upload it to the service instance using the updateConnectionpool command. Note that you must not modify the uid and connPool values in the file. See "List Connection Pool Command" for more information.
You execute the utility through a launcher script, data-model-cmd.sh on UNIX and data-model-cmd.cmd on Windows. You can find the launcher script at the following location:
Oracle_Home/user_projects/domains/bi/bitools/bin
See "What You Need to Know Before Using the Command" for more information.
The updateConnectionpool command takes the following parameters:
updateConnectionpool -C <connectionpoolList.json> -SI <service_instance> -U <cred_username> [-P <cred_password>] [-S <hostname>] [-N <port_number>] [-SSL] [-H]
C specifies the name of the modified JSON file that you want to upload. Note this file must not contain modified uid and connPool values. See "Sample JSON List Connection Pool Output" for information about the correct syntax for the update connection pool input file.
SI specifies the name of the service instance.
U specifies a valid user's name to be used for Oracle BI EE authentication.
P specifies the password corresponding to the user's name that you specified for U. If you do not supply the password, then you will be prompted for the password when the command is run. For security purposes, Oracle recommends that you include a password in the command only if you are using automated scripting to run the command.
S specifies the Oracle BI EE host name. Only include this option when you are running the command from a client installation.
N specifies the Oracle BI EE port number. Only include this option when you are running the command from a client installation.
SSL specifies to use SSL to connect to the WebLogic Server to run the command. Only include this option when you are running the command from a client installation.
H displays the usage information and exits the command.
data-model-cmd.sh updateConnectionpool -C connpool.json -SI bi -U weblogic -P password -S server1.example.com -N 7777 -SSL
Using the BIServerT2PProvisioner.jar Utility to Change Connection Pool Passwords
When moving your Oracle BI repository from one environment to another, you often need to change connection pool information for data sources, because the connection information in one environments is typically different from the connection information in another environments.
Note:
Although you can use BIServerT2PProvisioner.jar to update connection pool passwords, Oracle's preferred method is the updateConnectionpool command. See "Update Connection Pool Command"for information.Connection pool passwords are encrypted and stored inside the encrypted repository file. Because of this, plain-text passwords must first be encrypted before they can be applied to an Oracle BI repository.
You can use the BIServerT2PProvisioner.jar utility to programmatically change and encrypt connection pool passwords in a repository. Note that the utility only works with repositories in RPD format; you cannot use the utility with MDS XML-format repositories. In addition, the utility requires JDK 1.6.
To use the BIServerT2PProvisioner.jar utility to change connection pool passwords:
The location of BIServerT2PProvisioner.jar is:
Oracle_Home/bi/bifoundation/server
-
Run BIServerT2PProvisioner.jar using the
-generateoption to generate a template file where you can input the new passwords, as follows:java -jar ORACLE_HOME/bifoundation/server/bin/BIServerT2PProvisioner.jar -generate repository_name -output password_file
Where:
repository_nameis the name and path of the Oracle BI repository that contains the connection pools for which you want to change passwords.password_fileis the name and path of the output password text file. This file will contain the connection pool names from the specified repository.Then, enter the repository password when prompted.
For example:
java -jar BIServerT2PProvisioner.jar -generate original.rpd –output inputpasswords.txt Enter the repository password: My_Password
-
Edit the password file to replace
<Change Password>with the updated password for each connection pool. A sample password file might appear as follows:"SQLDB_UsageTracking"."UTCP" = <Change Password> "SQLDB_Data"."Db Authentication Pool" = <Change Password>
Tip: Make sure to only edit the text to the right of the equals sign. If you change the text to the left of the equals sign, then the syntax for the connection pool names will be incorrect.
Save and close the password file when your edits are complete.
-
Run BIServerT2PProvisioner.jar again with the
-passwordsoption, as follows:java -jar BIServerT2PProvisioner.jar -passwords password_file -input input_repository -output output_repository
Where:
password_fileis the name and path of the text file that specifies the connection pools and their corresponding changed passwords.input_repositoryis the name and path of the Oracle BI repository where you want to apply the changed passwords.output_repositoryis the name and path of the output repository that contains the updated passwords.Then, enter the repository password when prompted.
For example:
java -jar BIServerT2PProvisioner.jar -passwords inputpasswords.txt -input original.rpd -output updated.rpd Enter the repository password: My_Password
-
Oracle does not recommend leaving clear-text passwords available on the system. Instead, either delete the input password file completely, or encrypt it so that it cannot be viewed.