9 Performance Best Practices
Unnecessarily complex data sets can result in poor performance of data model execution. This chapter provides tips for creating more efficient data models.
9.1 Know Oracle WebLogic Server Default Time Out Setting
WebLogic Server has a default time out of 600 seconds for each thread that spans for a request. When the time exceeds 600 seconds, WebLogic Server marks the thread as "Stuck". When the number of Stuck threads reaches 25, the server shuts down.
To avoid this problem, ensure that your SQL execution time does not exceed the WebLogic Server setting.
9.2 Best Practices for SQL Data Sets
Consider the following tips to help you create more efficient SQL data sets:
9.2.1 Only Return the Data You Need
Ensure that your query returns only the data you need for your reports. Returning excessive data risks OutOfMemory exceptions.
For example, never simply return all columns as in:
SELECT * FROM EMPLOYEES;
Always avoid the use of *.
Two best practices for restricting the data returned are:
-
Always select only the columns you need
For example:
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES;
-
Use a WHERE clause and bind parameters whenever possible to restrict the returned data more precisely.
This example selects only the columns needed and only those that match the value of the parameter:
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
9.2.2 Use Column Aliases to Shorten XML File Length
The shorter the column name, the smaller the resulting XML file; the smaller the XML file the faster the system parses it. Shorten your column names using aliases to shorten I/O processing time and enhance report efficiency.
In this example, DEPARTMENT_ID is shortened to "id" and DEPARTMENT_NAME is shortened to "name":
SELECT DEPARTMENT_ID id, DEPARTMENT_NAME nameFROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
9.2.3 Avoid Using Group Filters by Enhancing Your Query
Although the Data Model Group Filter feature enables you to remove records retrieved by your query, this process takes place in the middle tier, which is much less efficient than the database tier.
It is a better practice to remove unneeded records through your query using WHERE clause conditions instead.
9.2.4 Avoid PL/SQL Calls in WHERE Clauses
PL/SQL function calls in the WHERE clause of the query can result in multiple executions. These function calls execute for each row found in the database that matches. Moreover, this construction requires PL/SQL to SQL context switching, which is inefficient.
As a best practice, avoid PL/SQL calls in the WHERE clause; instead, join the base tables and add filters.
9.2.5 Avoid Use of the System Dual Table
Use of the system DUAL table for returning the sysdate or other constants is inefficient and should be avoided when not required.
For example, instead of:
SELECT DEPARTMENT_ID ID, (SELECT SYSDATE FROM DUAL) TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
Consider:
SELECT DEPARTMENT_ID ID, SYSDATE TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
Note that in the first example, DUAL is not required. You can access SYSDATE directly.
9.2.6 Avoid PL/SQL Calls at the Element Level
Package function calls at the element (within the group) or row level are not allowed; however you can include package function calls at the global element level because these functions are executed only once per data model execution request.
Example:
<dataStructure>
<group name="G_order_short_text" dataType="xsd:string" source="Q_ORDER_ATTACH">
<element name="order_attach_desc" dataType="xsd:string" value="ORDER_ATTACH_DESC"/>
<element name="order_attach_pk" dataType="xsd:string" value="ORDER_ATTACH_PK"/>
<element name="ORDER_TOTAL _FORMAT" dataType="xsd:string" value=" WSH_WSHRDPIK_XMLP_PKG.ORDER_TOTAL _FORMAT "/> <!-- This is wrong should not be called within group.-->
</group>
<element name="S_BATCH_COUNT" function="sum" dataType="xsd:double" value="G_mo_number.pick_slip_number"/>
</dataStructure>
9.2.7 Avoid Including Multiple Data Sets
It can seem desirable to create one data model with multiple data sets to serve multiple reports, but this practice results in very poor performance. When a report runs, the data processor executes all data sets irrespective of whether the data is used in the final output.
For better report performance and memory efficiency, consider carefully before using a single data model to support multiple reports.
9.2.8 Avoid Nested Data Sets
The data model provides a mechanism to create parent-child hierarchy by linking elements from one data set to another. At run time, the data processor executes the parent query and for each row in the parent executes the child query. When a data model has many nested parent-child relationships slow processing can result.
A better approach to avoid nested data sets is to combine multiple data set queries into a single query using the WITH clause.
Following are some general tips about when to combine multiple data sets into one data set:
-
When the parent and child have a 1-to-1 relationship; that is, each parent row has exactly one child row, then merge the parent and child data sets into a single query.
-
When the parent query has many more rows compared to the child query. For example, an invoice distribution table linked to an invoice table where the distribution table has millions of rows compared to the invoice table. Although the execution of each child query takes less than a second, for each distribution hitting the child query can result in STUCK threads.
Example of when to use a WITH clause:
Query Q1: SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMMFROM EMPLOYEES Query Q2: SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOCFROM DEPARTMENTS
Combine the these queries into one using WITH clause as follows:
WITH Q1 as (SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOC FROM DEPARTMENTS), Q2 as (SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMM FROM EMPLOYEES) SELECT Q1.*, Q2.* FROM Q1 LEFT JOIN Q2 ON Q1.DID=Q2.EDID
9.2.9 Avoid In-Line Queries (as summary columns)
In-line queries execute for each column for each row. For example, if a main query has 100 columns, and brings 1000 rows, then each column query executes 1000 times. Altogether, it is 100 multiplied by 1000 times.This is not scalable and cannot perform well. Avoid using in-line sub queries whenever possible.
Avoid the following use of in-line queries. If this query returns only a few rows this approach may work satisfactorily; however, if the query returns 10000 rows, then each sub or inline query executes 10000 times and the query would likely result in Stuck threads.
SELECT NATIONAL_IDENTIFIERS,NATIONAL_IDENTIFIER, PERSON_NUMBER, PERSON_ID, STATE_CODE FROM (select pprd.person_id,(select REPLACE(national_identifier_number,'-') from per_ national_identifiers pni where pni.person_id = pprd.person_id and rownum<2) national_identifiers,(select national_identifier_number from per_national identifiers pni where pni.person_id = pprd.person_id and rownum<2) national_ identifier,(select person_number from per_all_people_f ppf where ppf.person_id = pprd.person_id and :p_effective_start_date between ppf.effective_start_date and ppf.effective_ end_date) PERSON_NUMBER (Select hg.geography_code from hz_geographies hg where hg.GEOGRAPHY_NAME = paddr.region_2 and hg.geography_type = 'STATE') state_code
9.2.10 Avoid Excessive Parameter Bind Values
Oracle database allows bind maximum of 1000 values per parameter. Binding a large number of parameter values is inefficient. Avoid binding more than 100 values to a parameter.
When you create a Menu type parameter, if your list of values may contain many values, ensure that if you enable both the "Multiple Selection" and "Can Select All" options, then also select NULL value passed to ensure too many values are not passed.
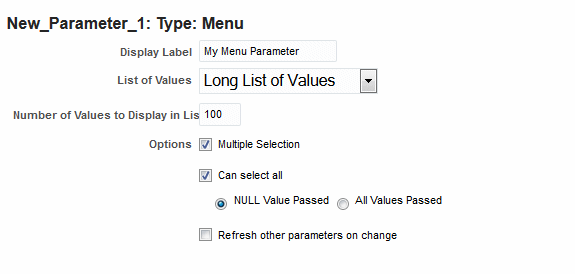
9.2.11 Tips for Multi-value Parameters
Often report consumers must run reports that support the following conditions:
-
If no parameter is selected (null), then return all.
-
Allow selection of multiple parameter values
In these cases the use of NVL() does not work, you should therefore use
-
COALESCE() for queries against Oracle Database
-
CASE / WHEN for Oracle BI EE (logical) queries
Example:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEES WHERE DEPARTMENT_ID = NVL(:P_DEPT_ID, DEPARTMENT_ID
The preceding query syntax is correct only when the value of P_DEPT_ID is a single value or null. This syntax does not work when you pass more than a single value.
To support multiple values, use the following syntax:
For Oracle Database:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEES WHERE (DEPARTMENT_ID IN (:P_DEPT_ID) OR COALESCE (:P_DEPT_ID, null) is NULL)
For Oracle BI EE data source:
(CASE WHEN ('null') in (:P_YEAR) THEN 1 END =1 OR "Time"."Per Name Year" in (:P_YEAR))
For Oracle BI EE the parameter data type must be string. Number and date data types are not supported.
9.2.12 Group Break and Sorting Data
The data model provides a feature to group breaks and sort data. Sorting is supported for parent group break columns only. For example, if a data set of employees is grouped by department and manager, you can sort the XML data by department. If you know how the data should be sorted in the final report or template, you specify sorting at data generation time to optimize document generation.The column order specified in the SELECT clause must exactly match the element orders in the data structure. Otherwise group break and sort may not work. Due to complexity, multiple grouping with multiple sorts at different group levels is not allowed.
Example: In the example shown below, sort and group break are applied to the parent group only, that is, G_1. Notice the column order in the query, data set dialog, and data structure. The SQL column order must exactly match the data structure element field order; otherwise, it may result in data corruption.
Example:
SELECT d.DEPARTMENT_ID DEPT_ID, d.DEPARTMENT_NAME DNAME,
E.FIRST_NAME FNAME,E.LAST_NAME LNAME,E.JOB_ID JOB,E.MANAGER_ID
FROM EMPLOYEES E,DEPARTMENTS D
WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID
ORDER BY d.DEPARTMENT_ID, d.DEPARTMENT_NAME
Once you define the query, you can use the data model designer to select data elements and create group breaks as shown:
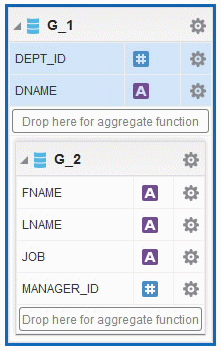
The Data Structure with breaks is:
<output rootName="DATA_DS" uniqueRowName="false"> <nodeList name="data-structure"> <dataStructure tagName="DATA_DS"> <group name="G_1" label="G_1" source="q1"> <element name="DEPT_ID" value="DEPT_ID" label="DEPT_ID" fieldOrder="1"/> <element name="DNAME" value="DNAME" label="DNAME" fieldOrder="2"/> <group name="G_2" label="G_2" source="q1"> <element name="FNAME" value="FNAME" label="FNAME" fieldOrder="3"/> <element name="LNAME" value="LNAME" label="LNAME" fieldOrder="4"/> <element name="JOB" value="JOB" label="JOB" fieldOrder="5"/> <element name="MANAGER_ID" value="MANAGER_ID" label="MANAGER_ID" fieldOrder="6"/> </group> </group> </dataStructure> </nodeList> </output>
9.3 Lists of Values
Lists of values based on SQL queries must be limited to 1000 rows. Adding blind runaway queries in a list of values can cause OutOfMemory exceptions. Consider that the number of rows returned by an LOV is stored in memory, therefore the higher the number of rows the more memory usage.
9.4 Working with Lexicals/Flexfields
Oracle BI Publisher supports lexical parameters for Oracle Fusion Applications and Oracle E-Business Suite. Lexical parameters enable you to create dynamic queries.
In BI Publisher, lexical parameters are defined as:
Lexical - a PL/SQL packaged variable defined as a data model parameter.
Key Flexfield (KFF) – a lexical token in a data set query. KFF creates a "code" made up of meaningful segment values and stores a single value as a code combination id. Key Flexfields always return as a single column when used in SELECT / SEGMENT METADATA type or condition when used in WHERE clause. Key Flexfields execute at run time to extract the lexical definition and then are substituted in the SQL query.
Descriptive Flexfields (DFF) - provide a customizable expansion space to track additional information that is important and unique to the business. DFFs can be context sensitive, where the information stored in the application depends on the other values of the user input. Unlike Key Flexfields, Descriptive Flexfields can have multiple context-sensitive segments.
Usage: When you define any lexical, name the lexical to match the usage so that when the editor dialog pops up it will be easier to enter the default values for the SQL query. For example, if you are using a lexical in a SELECT clause, use "_select" as a suffix. The default values must be valid to get metadata.
The following example demonstrates the usage of a lexical:
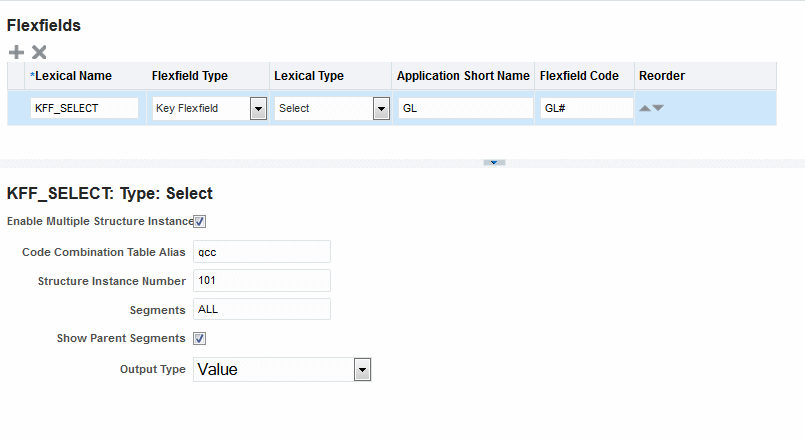
When you create the data set query for the select columns, specify column alias,
SELECT gcc.CODE_COMBINATION_ID, GCC.ATTRIBUTE_CATEGORY, gcc.segment1 seg1, gcc.segment2 seg2, gcc.segment3 seg3, gcc.segment4 seg4, gcc.segment5 seg5, &KFF_SELECT account FROM GL_CODE_COMBINATIONS GCC WHERE gcc.CHART_OF_ACCOUNTS_ID = 101 AND &KFF_WHERE
When you save the query, a pop-up dialog prompts you for the default values. To get SQL metadata at design time you must specify the default values that can form a valid SQL query. For example,
-
if the lexical usage is a SELECT clause then you could enter null
-
if the lexical usage is a WHERE clause then you could enter 1 = 1 or 1 =2
-
if the lexical usage is ORDER BY clause then you could enter 1

9.5 Working with Date Parameters
Oracle BI Publisher always binds date column or date parameter as a timestamp object. To avoid timestamp conversion, define the parameter as a string and pass the value with formatting as 'DD-MON-YYYY' to match the RDBMS date format.
9.6 Run Report Online/Offline (Schedule)
Running reports in interactive/online mode uses in-memory processing. Use the following guidelines for deciding when a report is appropriate for running online.
For Online / Interactive mode:
-
When report output size is less than 50MB
Browsers do not scale when loading large volumes of data. Loading more than 50MB in the browser will slow down or possibly crash your session.
-
Data model SQL Query time out is less than 600 seconds
Any SQL query execution that takes more than 600 seconds results in Stuck WebLogic Server threads. To avoid this condition schedule long-running queries. The Scheduler process uses its own JVM threads instead of Weblogic server threads. It is more efficient to schedule reports than run reports online.
-
Total number of elements in the data structure is less than 500
When the data model data structure contains many data elements, the data processor must maintain the element values in memory; which may result in OutOfMemory exceptions. To avoid this condition, schedule these reports. For scheduled reports, the data processor uses temporary file system to store and process data.
-
No CLOB or BLOB columns
Online processing holds the entire CLOB or BLOB columns in memory. You should schedule reports that include CLOB or BLOB columns.
9.7 Setting Data Model Properties to Prevent Memory Errors
You can use the following properties to help prevent memory errors in your system:
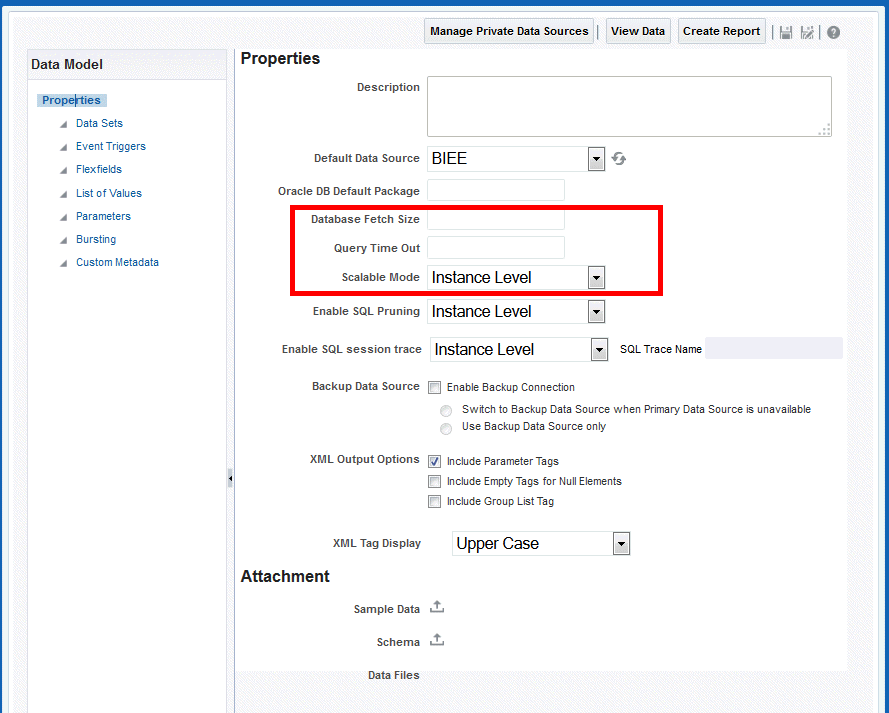
9.7.1 Query Time Out
The Query Time out property specifies the time limit in seconds within which the database must execute SQL statements. BI Publisher provides a mechanism to set user preferred query time out at the data model level. The default value is 600 seconds.
Queries that cannot execute under 600 seconds are not well-optimized. Your DBA or a performance expert should analyze the query for further tuning.
Increasing the time out value risks Stuck WebLogic Server threads. Do not raise the value unless all other optimizations and alternatives have been utilized.
9.7.2 DB Fetch Size
This property specifies the number of rows that are fetched from the database at a time. This setting can be overridden at the data model level by setting the Database Fetch Size in the general properties of the data model.
Setting the value higher reduces the number of round trips to the database but consumes more memory. Consider the number of elements in the data model before changing this property.
BI Publisher recommends setting the property Auto DB fetch size to "true" so that the system calculates the fetch size at run time.
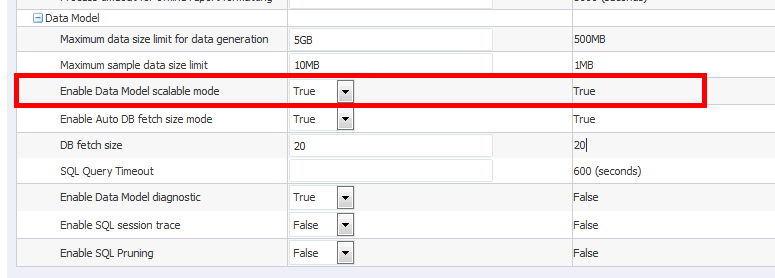
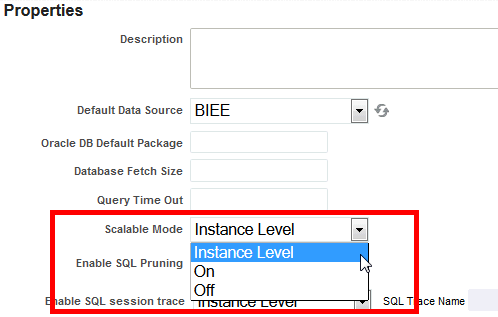
9.7.3 Scalable Mode
When the Scalable mode property is on, BI Publisher uses the temp file system to generate data. Data processor uses the least amount of memory. This scalable mode property can be set at the data model level and the instance level. Data model setting overrides the instance value.
Set the Instance value from Administrator > Runtime Properties > Data Model:
The instance value can be overridden by Data model setting shown here:
The following table details the expected results for the possible on/off settings at each level:
| Scalable Mode Instance Value | Scalable Mode Data Model Value | Expected Result |
|---|---|---|
| On | Instance | On |
| Off | Instance | Off |
| On | On | On |
| On | Off | Off |
| Off | On | On |
| Off | Off | Off |
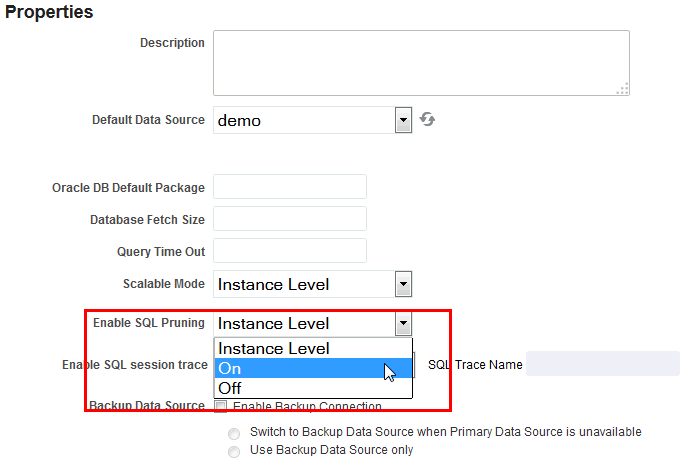
9.7.4 SQL Pruning
SQL pruning enhances performance by fetching only the columns that are used in the report layout/template. Columns that are defined in the query but are not used in the report are not fetched. This improves query fetch size and reduces JDBC rowset memory.
Note that this feature does not alter the where clause but instead wraps the entire SQL with the columns specified in the layout.
To enable SQL pruning – On the Data Model Properties page, select On for the Enable SQL Pruning property.
9.8 SQL Query Tuning
Query tuning is the most important step to improve performance of any report. Explain plan, SQL Monitoring, SQL Trace facility with TKPROF are the most basic performance diagnostic tools that can help to tune SQL statements in applications running against the Oracle Database.
Oracle BI Publisher provides a mechanism to generate the explain plan and SQL monitoring reports and to enable SQL session trace. This functionality is applicable to SQL statements executing against Oracle Database only. Logical queries against BI Server or any other type of database are not supported.
9.8.1 Generate Explain Plan
You can generate an Explain plan at the data set level for a single query or at the report level for all queries in a report. For more information about interpreting the explain plan, see the Oracle Database SQL Tuning Guide.
9.8.1.1 Explain Plan for a Single Query
From the SQL data set Edit dialog you can generate an explain plan before actually executing the query. This will provide a best guess estimation of plan. The query will be executed binding with null values.
Click Generate Explain Plan on the Edit SQL Query dialog. Open the gnerated document in a text editor like Notepad or WordPad.
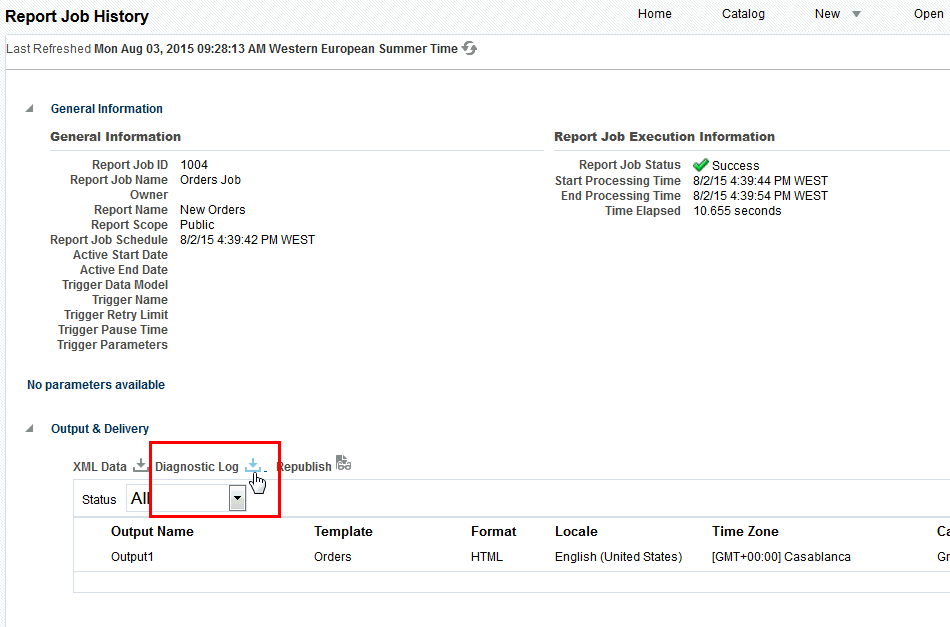
9.8.1.2 Explain Plan for Reports
To generate an explain for a report, run the report through the Scheduler:
-
On the New menu, select Report Job.
-
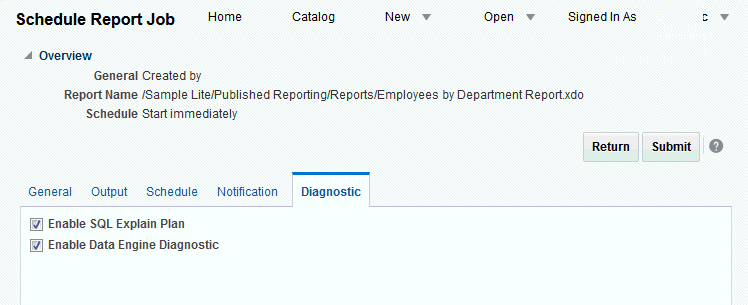
Select the report to schedule then click the Diagnostics tab.
Note: You must have BI Administator or BI Data Model Developer privileges to access the Diagnostics tab.
-
Select Enable SQL Explain Plan and Enable Data Engine Diagnostic.
-
Submit the report.
-
When the report finishes, go to the Report History page.
(From the Home page, under Browse/Manage, select Report Job History.)
-
Select your report to view the details. Under Output & Delivery click Diagnostic Log to download the explain plan output.
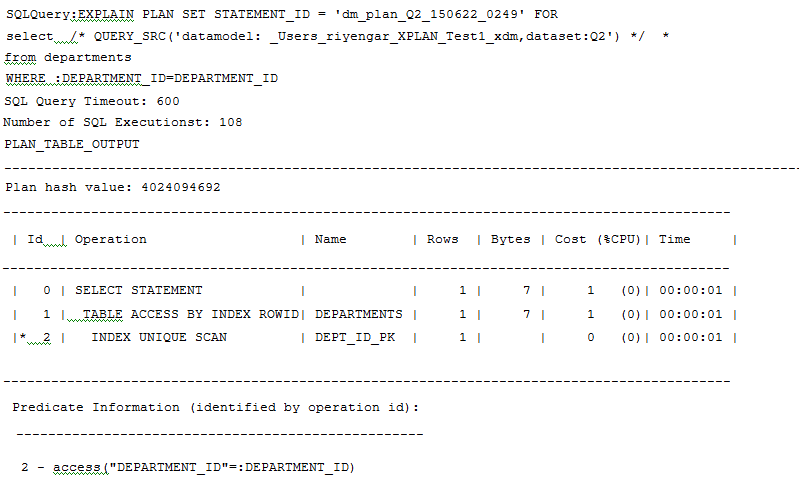
Sample Explain plan:
9.8.1.3 Guidelines for Tuning Queries
-
Analyze the explain plan and identify high impact SQL statements.
-
Add required filter conditions and remove unwanted joins.
-
Avoid and remove FTS (full table scans) on large tables. Note that in some cases, full table scans on small tables are faster and improve query fetch. Ensure that you use caching for small tables.
-
Use SQL hints to force use of proper indexes.
-
Avoid complex sub-queries and use Global Temporary Tables where necessary.
-
Use Oracle SQL Analytical functions for multiple aggregation.
-
Avoid too many sub-queries in where clauses if possible. Instead rewrite queries with outer joins.
-
Avoid group functions like HAVING and IN / NOT IN where clause conditions.
-
Use CASE statements and DECODE functions for complex aggregate functions.
9.8.1.4 Tips for Database Tuning
-
Work with your Database Administrator to gather statistics on the tables.
-
If the server is very slow, analyze network / IO / Disk issues and optimize the server parameters.
-
In some scenarios when you cannot avoid a large data fetch you may encounter PGA Heap size errors in the database. To resolve these issues, increase PGA heap size as a last resort. Use the following statement to increase heap size:
alter session set events '10261 trace name context forever, level 2097152'