4 High Availability for Oracle Data Integrator
This chapter provides a description of Oracle Data Integrator components from a high availability perspective and a roadmap for setting up a high availability topology. The sections in this chapter outline the single instance concepts that are important for designing high availability deployment.
This chapter includes the following topics:
Note:
For more information regarding High Availability concepts and procedures, see High Availability Guide.4.1 Oracle Data Integrator Single Instance Characteristics
Oracle Data Integrator run-time agents manage integration processes. Oracle Data Integrator agents are components that run the integration jobs deployed in a production configuration as scenarios stored in a repository.
Oracle Data Integrator agents process each scenario execution instance as a session. Each session exists in the agent as a separate thread of the agent Java process.
Agents store very basic information about the session they run. Most of the session data is stored in the repository. When a scenario is executed on an agent, the agent creates a session in the repository that corresponds to this scenario's instance. The agent reads each task of this session from the repository, processes it, and writes the result - the return code, message and tasks metrics such as the duration or number of rows processed - into the repository.
The repository consists of two database schemas, one containing the master repository, and one containing the work repository. The master repository contains all topology and security related information (such as the source data server definition, target data server definition, and user credential). The work repository contains development and run-time data (such as sessions and scenarios). The master repository also contains the connection information to the work repository. To connect to a work repository, an agent first connects to the master repository, checks the Oracle Data Integrator user's credentials, reads the work repository connection information, and then connects to the work repository. A typical topology includes one master repository and possibly several work repositories (for example, for test and production).
Sessions can be initiated on the agent:
-
From another Oracle Data Integrator component (such as the agent or Oracle Data Integrator Studio) over HTTP.
-
Via the agent's web service interface.
-
From an external scheduler or from a command line.
-
From a Java program using the Agent Invocation SDK
The agent is always attached to a master repository. It connects to this master repository at startup and is able to start sessions on any of the work repositories attached to this master. It also acts as a scheduler. On startup, the agent reads from the different work repositories the schedules defined for the agent, and stores this scheduling information. The agent is able to initiate sessions from this in-memory schedule on the appropriate work repositories.
Agents can interact with one another through remote scenario startup (over HTTP) or via the load balancing feature. Load balancing allows defining hierarchies of parent/child agents. In this hierarchy, parent agents can delegate the processing of their sessions to their child agents.
The agent is a Java program that is provided as a Java EE agent and as a standalone agent. The Java EE agent is a web application that can be deployed in a Java EE application server, along with other web applications within the same JVM. This agent can use this server's data sources to connect the source, target and repository databases.
The standalone agent is provided as a standalone Java process started from a command line interface. This standalone agent is similar to the Java EE agent, but is embedded in a lightweight container. The main difference is that unlike the Java EE agent, the standalone agent can connect the source and target data servers using only direct JDBC connection.
4.1.1 Oracle Data Integrator Sessions Lifecycle and Recovery
When an execution request arrives to a run-time agent, the agent connects the master repository to check the user credentials and then the work repository to create the session and all its tasks, and marks them as "waiting." Then it creates the connections to all the data servers that will be used during this session.
When execution starts, the agent reads the first task in the work repository to be executed, and marks both the session and this task as "running." This task can start an operation on the data servers or on the operating system. When the task is complete, the agent writes into the work repository the execution result for this task, moves it to a finished state ("Done", "Warning" or "Error") and proceeds to the next task in the session. Note that errors cases can be handled in the ODI packages, and an error does not necessarily halt a session. When the session completes (either because of an unmanaged error, or by reaching a final step), the agent moves the session to a finished state ("Done", "Warning" or "Error") and releases all the connections. At this point, the session is finished.
4.1.1.1 Sessions Interruption
Sessions can be interrupted when:
-
A user requests the agent to stop the session.
-
An agent is stopped by the administrator. All sessions for this agent are stopped, depending on the agent stop mode selected.
-
A critical event occurs on the agent or the repository.
Any session that is stopped due to user or administrator action is moved to an error state and marked as "Stopped."
In the case of an agent or repository crash, a session that cannot be stopped properly still appears in a running state in the repository. These sessions are called stale sessions, because they are marked as running, but are no longer handled by any agent. Stale sessions are automatically moved to an error state when an agent restarts and detects that these sessions are incorrectly marked in the repository as being executed by this agent.
4.1.1.2 Recovering Sessions
Oracle Data Integrator uses JDBC transactions when interacting with source and target data servers, and any open transaction state is not persisted when a session finishes in error state. The appropriate restart point is the task that started the unfinished transaction(s). If such a restart point is not identifiable, it is recommended that you start a fresh session by executing the scenario instead of restarting existing sessions that are in error state.
By default, a session restarts from the last task that failed to execute (typically a task in error or in waiting state). A session may need to be restarted in order to proceed with existing staging tables and avoid re-running long loading phases. In that case the user should take into consideration transaction management, which is KM specific. A general guideline is: If a crash occurs during a loading task, you can restart from the loading task that failed. If a crash occurs during an integration phase, restart from the first integration task, because integration into the target is within a transaction. This guideline applies only to one interface at a time. If several interfaces are chained and only the last one performs the commit, then they should all be restarted because the transaction runs over several interfaces.
To restart from a specific task or step:
-
In Operator Navigator, navigate to this task or step, edit it and switch it to Waiting state.
-
Set all tasks and steps after this one in the Operator tree view to Waiting state.
-
Right-click the session and click Restart.
The session restarts from the first task in waiting state.
4.1.2 Agent Startup and Shutdown Cycle
Figure 4-1 shows the agent startup cycle.
Figure 4-1 Oracle Data Integrator Agent Startup Cycle
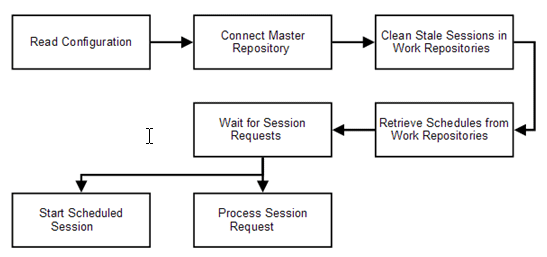
Description of ''Figure 4-1 Oracle Data Integrator Agent Startup Cycle''
When the Oracle Data Integrator agent starts, it first reads its configuration, which includes master repository connection information. Then the agent connects to each of the work repositories attached to this master repository and removes stale sessions. Stale sessions are sessions that are incorrectly indicated in the work repository as running on this given agent. Stale sessions may result from an agent being stopped without being able to stop these sessions gracefully. As the agent restarts, it identifies the stale sessions and moves them to an error state.
From that point, the agent can retrieve and compute the schedules available for it in each work repository. Once this phase is complete, the agent waits for incoming sessions requests to start their processing, and is also able to start sessions based on its schedules.
4.1.3 Oracle Data Integrator External Dependencies
Oracle Data Integrator depends on the Oracle Data Integrator master repository and work repository database schemas.
If advanced features are being used, these other dependencies may exist:
-
Other Oracle Data Integrator agents: If the load balancing feature is configured and the agent needs to delegate the execution of sessions to its child agents.
-
If External Password Storage is enabled for this agent's master repository, the agent depends on the credential store for retrieving the source and target data servers' passwords to connect these data servers during session execution.
-
If External Authentication is enabled for this agent's master repository, the run-time agents as well as Oracle Data Integrator Console depend on the Identity Store service that stores the Oracle Data Integrator user accounts.
These components must be available for the Oracle Data Integrator system to start and run properly.
4.1.4 Oracle Data Integrator Startup and Shutdown Process
For information on the startup and shutdown process, see the following sections in Installing and Configuring Oracle Data Integrator.
-
Java EE Agent: "Configuring the Domain for the Java EE Agent"
-
Standalone Agent: "Configuring the Domain for the Standalone Agent"
-
Standalone Colocated Agent: "Configuring the Domain for the Standalone Colocated Agent"
4.1.5 Oracle Data Integrator Configuration Artifacts
This section describes Oracle Data Integrator configuration artifacts.
4.1.5.1 Agent Configuration
For information on configuring the Java EE Agent, Standalone Agent, Standalone Colocated Agent, see Installing and Configuring Oracle Data Integrator.
4.1.5.2 Oracle Data Integrator Console Configuration
Oracle Data Integrator Console configuration consists of connection definitions to the master and work repositories that can be browsed using this web application.
The list of connections is stored in the repositories.xml file in the following directory:
user_projects/domains/domainName/config/oracledi
Connections can be added, edited, or deleted from the Oracle Data Integrator Console management pages.
Note:
Oracle Data Integrator Console is used as the entry point for Enterprise Manager to discover Oracle Data Integrator targets in a domain. The discovery process works in the following way: Enterprise Manager identifies Oracle Data Integrator Console. Using the Oracle Data Integrator Console configuration, Enterprise Manager identifies the master and work repositories as well as the run-time agents in the domain. For more information, see Using Oracle Data Integrator Console.4.1.5.3 Oracle Data Integrator Log Locations and Configuration
This section provides information about Oracle Data Integrator log locations and configuration.
4.1.5.3.1 Oracle Data Integrator Session Logs
Oracle Data Integrator session execution logs are stored in the work repositories against which the sessions are started. This session shows Oracle Data Integrator session details, such as the executed code and the number of processed rows. This log can be displayed from the Oracle Data Integrator Studio's Operator Navigator, in the Session List accordion, or from Oracle Data Integrator Console's Browse tab, under Run-Time > Sessions.
4.1.5.3.2 Java EE Agent Log Files
The operations performed by the Oracle Data Integrator Java EE agent are logged by Oracle WebLogic Managed Server where the agent application is running. You can find these logs at the following location:
DOMAIN_HOME/servers/WLS_ServerName/logs/oracledi/odiagent.log
The log files for the different Oracle WebLogic Server Managed Servers are also available from Oracle WebLogic Server Administration Console. To verify the logs, access Oracle WebLogic Server Administration Console using the following URL: admin_server_host:port/console. Click Diagnostics-Log Files.
It is also important to verify the output of the Oracle WebLogic Managed Server where Oracle Data Integrator is running. This information is stored at the following location:
DOMAIN_HOME/servers/WLS_ServerName/logs/WLS_ServerName.out
Additionally, a diagnostic log is produced in the log directory for the managed server. This log's granularity and logging properties can be changed through the following file:
DOMAIN_HOME/config/fmwconfig/logging/oraclediagent-logging.xml
4.1.5.3.3 Standalone and Standalone Colocated Agent Log Files
The operations performed by the Oracle Data Integrator standalone and standalone colocated agent are logged by the lightweight container running the agent. By default, logs are traced on the console and in the <DOMAIN_HOME>/system_components/ODI/<AgentName>/logs/ folder.
The logging method and the logging level can be configured by editing the <DOMAIN_HOME>/config/fmwconfig/components/ODI/<AgentName>/ODI-logging-config.xml file.
4.1.5.3.4 Oracle Data Integrator Console Log Files
Oracle Data Integrator Console logging operations are logged by Oracle WebLogic Managed Server where the agent application is running, like the Java EE agent log files described in Section 4.1.5.3.2, "Java EE Agent Log Files."
4.2 Oracle Data Integrator High Availability and Failover Considerations
This section describes Oracle Data Integrator high availability and failover considerations.
4.2.1 Oracle Data Integrator Clustered Deployment
Figure 4-2 shows a two-node Oracle Data Integrator cluster running on two Oracle WebLogic servers. Oracle WebLogic Servers are front ended by Oracle HTTP Servers, which load balance incoming requests to them.
Figure 4-2 Oracle Data Integrator High Availability Architecture
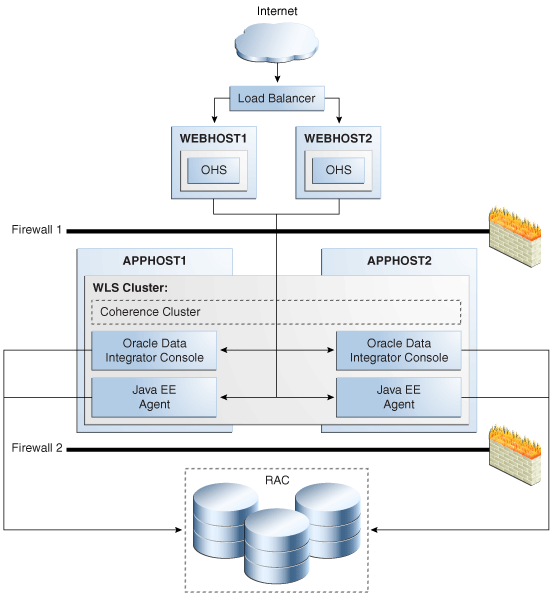
Description of ''Figure 4-2 Oracle Data Integrator High Availability Architecture''
The main characteristics of this configuration are:
-
Oracle Data Integrator applications run on two clustered WebLogic Server managed servers. The WebLogic Server cluster synchronizes configuration for common artifacts of WebLogic Server used by Oracle Data Integrator, such as data sources.
-
To avoid duplicate schedule processing, only one of these agents behaves like a scheduler. A Coherence cache is used to handle scheduler service uniqueness and migration.
The agent provides failover scheduling capabilities. For example, if a schedule is supposed to start at 9 AM, and the cycle is to run job X every hour for four hours, and the agent fails at 9:55 AM, it should compute where it was in the cycle and continue. However, if a single job is scheduled to start at 9 AM, and the agent fails at 8:59 AM, and then recovers at 9:01 AM, then it will not run the job that was scheduled at 9 AM.
-
Requests to the Oracle Data Integrator agent in a cluster must be routed via a load balancer or via an HTTP proxy server. The address of this fronting server is used by clients to connect transparently to any of the Oracle Data Integrator servers in the cluster. This address must be specified in the agent definition in the master repository. The scheduler singleton also routes all scheduled sessions startup requests to this address so that they are load balanced over the cluster.
-
Oracle Data Integrator's master and work repositories database is configured with Oracle Real Application Clusters (Oracle RAC) to protect from database failures. Oracle Data Integrator components perform the appropriate reconnection and operations retries if database instance failure occurs.
4.2.2 Oracle Data Integrator Protection from Failure and Expected Behavior
This section describes how an Oracle Data Integrator high availability cluster deployment and Node Manager protects components from failure. This section also describes expected behavior in the event of component failure.
4.2.2.1 WebLogic Server or Standalone Agent Crash
If a WebLogic Server crashes, Node Manager attempts to restart it locally. If repeated restarts fail, the WebLogic Server infrastructure attempts to perform a server migration of the server to the other node in the cluster. While the failover takes place, the other WebLogic instance becomes the scheduler and is able to read, compute, and execute the schedule for all work repositories. A Coherence cache is used to handle the scheduler lifecycle. Locking guarantees the uniqueness of the scheduler, and event notification provides scheduler migration. Note that when an agent restarts and computes its schedule, it takes into account schedules in progress (those in the middle of an execution cycle). These are automatically continued in their execution cycle beyond the server startup time. New sessions will be triggered as if the scheduler was never stopped.
Stale sessions are moved to an error state and are treated as such when restarted. This session recovery/restart is described in Section 4.1.1.1, "Sessions Interruption" and Section 4.1.1.2, "Recovering Sessions."
Oracle Data Integrator agents may be down due to failure in accessing resources, or other issues unrelated to whether the managed server is running. Therefore, Oracle recommends that administrators monitor the managed server logs for cluster errors caused by the application. For information about log file locations, see Section 4.1.5.3, "Oracle Data Integrator Log Locations and Configuration."
The Oracle Data Integrator Console does not support HTTP session failover. The user must log into the Oracle Data Integrator Console again after a failure.
4.2.2.2 Repository Database Failure
The Oracle Data Integrator repositories are protected against failures in the database by using multi data sources. These multi data sources are typically configured during the initial set up of the system (Oracle Fusion Middleware Configuration Wizard allows you to define these multi-pools directly at installation time) and guarantee that when an Oracle RAC database instance that hosts a repository fails, the connections are re-established with available database instances. The multi data source allows you to configure connections to multiple instances in an Oracle RAC database.
The Java EE agent uses WebLogic multi data sources that are configured during initial setup. The Standalone and Standalone Colocated agents use the Oracle RAC JDBC connection string specified when deploying the ODI Agent templates.
For additional information about multi data source configuration with Oracle RAC, see "Using Multi Data Sources with Oracle RAC" in Oracle Fusion Middleware Configuring and Managing JDBC Data Sources for Oracle WebLogic Server.
Oracle Data Integrator implements a retry logic that allows in-flight sessions to proceed if a repository instance becomes unavailable and is restored at a later time. In an Oracle RAC enabled configuration, both in-flight and incoming session execution requests are served as long as an Oracle RAC node is available. This is supported in both the standalone and Java EE agents using the Retry Connection Count number and Connection Retry Delay time parameters. Users can configure these parameters when generating the WebLogic Server template for the Java EE agent. For the Standalone and Standalone Colocated agents, the retry parameters can be configured in <DOMAIN_HOME>/config/fmwconfig/components/ODI/<AGENT_NAME>/instance.properties.
If Oracle Data Integrator Studio loses its connection to an Oracle RAC database, you will lose any Oracle Data Integrator Studio work performed since the last save operation. As a general practice, save your work on a regular basis when you use Oracle Data Integrator Studio.
4.2.2.3 Scheduler Node Failure
In an Oracle Data Integrator agent cluster, when the agent node that is the scheduler node crashes, another node in the WebLogic Server cluster takes over as the scheduler node. The new scheduler node reinitializes all the schedules from that point and continues executing the scheduled scenarios from that point forward.
However, an issue arises in this situation if a scheduled scenario with a repeatable execution cycle was running on the first scheduler node when that node crashed. When the new scheduler node takes over, the scheduler scenario that was running on the first scheduler node will not continue its iterations on the new scheduler node from the point at which the first scheduler node crashed.
For example, if the scheduled scenario is configured to repeat the execution ten times after an interval of two minutes, and the first scheduler node crashes in the middle of the third execution, the new scheduler node should continue the execution of the scenario for the next eight executions. However, the new scheduler node does not continue the remaining executions of the scenario.
4.3 Roadmap for Setting Up a High Availability Topology
This section provides the high level steps you need to perform to set up a high availability topology.
Table 4-1 Roadmap for Setting Up a High Availability Topology
| Task | Documentation |
|---|---|
|
1. Install Real Application Clusters |
See Oracle Real Application Clusters Administration and Deployment Guide. |
|
2. Install middleware components |
See Installing and Configuring the Oracle Fusion Middleware Infrastructure. |
|
3. Configure Repository Connections to Oracle RAC |
See "Configuring Repository Connections to Oracle RAC" in High Availability Guide. |
|
4. Install Oracle HTTP Server |
|
|
5. Configure a load balancer |
See "Configuring the Load Balancer" and "Server Load Balancing in a High Availability Environment" in High Availability Guide. |
|
6. Scale out the topology (machine scale out) |
See "Scaling Out a Topology (Machine Scale Out)" in High Availability Guide. |
|
7. Create the high availability domain |
See "Configuring Active GridLink Data Sources with Oracle RAC" in High Availability Guide. |
|
8. Configure high availability for the Administration Server |
See "Administration Server High Availability" in High Availability Guide. |
|
9. Reconfigure agents |
See "Reconfigure Agents". |
4.3.1 Reconfigure Agents
Agent definitions should point to the load balancer address instead of the individual server addresses. Connect to Oracle Data Integrator Studio and edit the Load Balancer Host and Port properties, as shown below:
-
Start Oracle Data Integrator Studio at ODI_HOME
/oracledi/client/odi.sh. -
After Oracle Data Integrator Studio comes up, click on Connect to Repository on the left-hand pane.
-
When the Login window appears, click OK to log on.
-
When you are connected, open the Physical Architecture section on the left-hand pane.
-
Select Agents and then select OracleDIAgent.
-
Edit the following properties:
- Host: The load balancer virtual server address.
- Port: The load balancer virtual address listening port.
-
Click Test to test the agent connection.
-
Save and exit Oracle Data Integrator Studio.