3 High Availability for EDQ
EDQ can be deployed in a number of ways to support High Availability requirements. The most common and recommended way, is to use WebLogic Clustering to support a highly available EDQ system. WebLogic Clustering allows multiple EDQ servers to share the same installation and configuration and these can be managed and operated as a single system with built-in redundancy. Simple High Availability of EDQ real-time services, however, can be achieved simply by configuring multiple servers with identical configuration, supporting real-time services and load balancing requests between them. In both cases, Oracle Real Application Clustering (RAC) is recommended to ensure high availability of the database tier, though it may be noted that most EDQ real-time services do not require database availability once they are running.
This chapter describes how EDQ operates when deployed to a WebLogic cluster and includes the following sections:
3.1 Technology Requirements
EDQ Clustering is based on WebLogic and Coherence technology, and requires an appropriate license that allows WebLogic and Coherence clustering to be used.High Availability of the Database tier uses Oracle Real Application Clustering (RAC) and requires an appropriate license that allows RAC to be used.
3.2 EDQ in a WebLogic Cluster
EDQ fully supports operation in a WebLogic Cluster. For information on installing EDQ in a cluster, see the "Configuring Enterprise Data Quality with Oracle WebLogic Server chapter in Oracle Fusion Middleware Installing and Configuring Enterprise Data Quality.
For information on configuring and managing a WebLogic Cluster, see the High Availability Guide.
Figure 3-1 shows EDQ in a WebLogic Cluster:
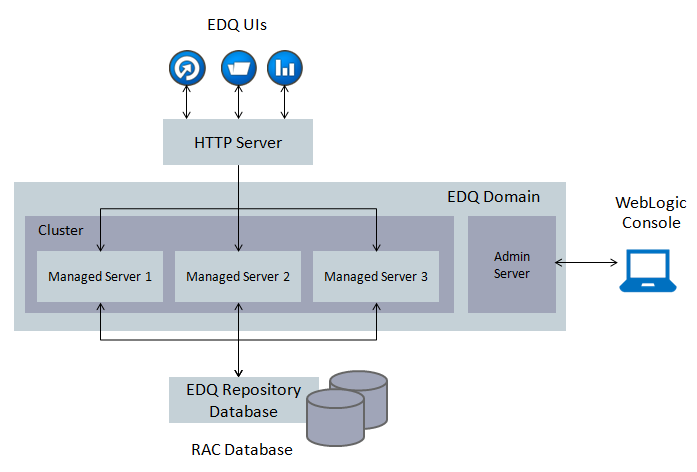
3.2.1 Characteristics of EDQ in a WebLogic Cluster
When deployed in a cluster, EDQ exhibits the following general characteristics:
-
All servers in the cluster share the same schemas in the repository database (EDQ Config and EDQ Results and EDQ Staging). Connections to those schemas are defined as JNDI Data Sources in WebLogic. These data sources may be configured for Oracle RAC to allow the use of multiple database nodes and to load balance connections, and this is recommended for High Availability.
-
Stateless real-time jobs run on ALL managed servers in the cluster. See "Job Definitions When Running in a Cluster" for more information on how the system detects a stateless real-time job.
-
A batch job runs on one of the managed servers in the cluster, normally the least busy server. For example, in a cluster of two servers, if server A is currently running a batch job and another is submitted, the new batch job will run on server B.
-
Where Oracle RAC is used and one of the nodes is stopped or fails:
-
Running real-time jobs usually continue processing as normal.
-
Running batch jobs using connections to a failed node will fail, however, can be restarted as the newly submitted batch job will request new connections to an active node.
-
If the system is idle, there is no impact.
-
-
Where Oracle RAC is not used and the database is not available:
-
Running real-time jobs usually continue processing as normal.
-
Running batch jobs fail and cannot be restarted successfully until the database is made available again.
-
If the system is idle, there is no impact.
-
The EDQ application server does not require a restart, provided the JNDI connection pool is unsuspended once the database is available again.
-
-
When a managed server in the cluster fails, it can be detected by the load balancer and the request router (such as Oracle HTTP Server) no longer routes requests to this managed server. Batch jobs are processed by one of the live servers.
3.2.2 Job Definitions When Running in a Cluster
EDQ automatically detects if a job is a stateless real-time production job that can run on all servers in a cluster, or if it includes either batch processing or results writing, and therefore should run on a single server in the cluster.
To be detected as a real-time job that runs on all servers in a cluster, a job must have the following properties:
-
It must have a single phase only.
-
All process chains must be connected to a real-time reader or a Data Interface reader that is configured to use a real-time mapping.
-
It must not write to staged data or reference data.
Note:
Jobs which only write to the landing area are not treated as writing staged data assuming they export data via a Data Interface. The job may contain such writers, as long as they are disabled when running the job, for example, in the job definition or Run Profile. -
It must not publish results to staged data.
-
It must be run with a Run Label.
Note:
Jobs that use Interval mode to write results data, write results for review in Match Review, or publish to the Dashboard cannot run on all servers.
The following types of jobs are theoretically possible. These attempt to run on all servers but do not run successfully on all servers:
-
A real-time job with a 'before' phase trigger that runs a batch job. This type of job should be reconfigured such that the real-time job is triggered at the end of the batch job.
-
A real-time job that writes to reference data or staged data. This type of job runs successfully on one server only, but fails on other servers with an 'already locked' message. This type of job should not be used in production. It should be run on a single server by not running it with a run label so that results and written data can be reviewed. If there is a need to write out data from a production stateless real-time job that runs on all servers, this should be done using a Writer that writes through a Data Interface to an Export running in Append mode.
-
A real-time job that is run more than once at the same time. The first instance of the job runs on all servers, however, subsequent attempts will fail.
All other types of job, such as batch jobs and real-time jobs that write results or are without a run label, run on the least busy managed server in the cluster. This means that some types of jobs that were created in versions of EDQ before 12.2.1 and that are currently considered as real-time jobs will not be considered as jobs that can run on all servers. This is particularly true of jobs that have an initial phase that prepares data (for example, reference data for a real-time match process) in batch, and a later phase that performs real-time processing. If there is a requirement to run the real-time phase of such jobs on all servers, the job should be split into two jobs - a batch job that prepares the reference data and a real-time job that meets the requirements above. The batch job should have an end of final phase trigger that starts the real-time job. This will then mean that the batch job will run on a single server and the real-time job will run on all servers.
3.2.3 Monitoring EDQ Web Services
Most load balancers are aware of whether managed servers are running or not, but are not necessarily aware of whether this actually means that the application's services are 'ready'. EDQ real-time jobs supporting web services are normally intended to be running whenever the managed server is running, and therefore scheduled to start on server start-up. This can be achieved using an "Autorun" chore. A clustered environment provides advantages here. Since stateless real-time jobs run on all servers in a cluster, any running real-time jobs will automatically start up on a new managed server that is added to the cluster with no need for manual intervention.
In addition, EDQ integrates with the Fusion Middleware 'Ready App' feature, which allows a URL to be checked to determine if an application is ready to receive web service requests or not.
The URL to check for readiness is [http://server:port/weblogic/ready], so for example it might be [http://host234:8001/weblogic/ready]for an EDQ managed server.
When a server is ready to service requests the URL returns a status of 200. If the server is not ready it will return 503. This then provides an easy way for load balancers to detect service availability.
When an EDQ server starts up, it assumes the use of Autorun or a schedule to immediately start the required real-time jobs. However, if those jobs are stopped or fail for any reason (and the managed server is still running), the EDQ server can declare itself 'not ready' by use of a trigger. EDQ's default implementation of the Ready App integration is set up to monitor the availability of all the Customer Data Services Pack real-time services, but can be modified to monitor the real-time services of your choice. It is implemented using an EDQ trigger in the EDQ 'home' configuration directory:
[domain home]/edq/config/fmwconfig/edq/oedq.home/triggers/readyappjobfail.groovy
To modify this, such that the failure of a different set of named jobs will result in an EDQ server declaring itself 'not ready', copy the file to the triggers directory in the [oedq.local.home] directory and modify the projects and missions lists to correspond with the EDQ projects and jobs that you want to monitor.
3.2.4 UI Behavior
If EDQ is deployed in a cluster, it is possible to use a front-end load balancer, such as Oracle HTTP Server, and load balance user sessions across the cluster. In this scenario, a user accessing the system using a load-balanced URL is connected to one of the managed servers, and all subsequent actions will be on that server. In most aspects, it is immaterial to users which server they are connected to, as the configuration and results databases are the same. Jobs and tasks that are active on the cluster are displayed to Director and Server Console users regardless of which of the managed servers they are connected to. The server that is running each job is displayed in the UI.
To customize the EDQ web pages, such as the Launchpad, to display the name of the managed server to which the user session is connected in the header, add the following line to director.properties in the EDQ Local Home directory:
[expr]adf.headerextra = ': ' || weblogic.Name
UI sessions, in both the WebStart applications and the EDQ Launchpad, are not automatically failed over. In the event of managed server failure, users connected to that managed server need to log in again. Provided at least one other managed server is available, the log in attempt should be successful as the user is then connected to an active managed server.
3.2.5 Tuning
As EDQ Clustering uses Coherence, it may be necessary to tune certain aspects of the system by adjusting Coherence parameters. For information, see the "Performance Tuning" section in Developing Applications with Oracle Coherence.
To avoid potential issues when restarting a previously failed server in a cluster that can cause client disconnection issues (to other managed servers), Oracle recommends setting the Member Warmup Timeout property of the Cluster to 30 (seconds) using the WebLogic Console (as opposed to the default value of 0). This setting is found under the General settings for the cluster.
3.2.6 Use of Oracle Web Services Manager
If there are other managed servers in the domain using the Oracle Web Services Manager Policy Manager ('wsm-pm'), then all EDQ managed servers need to be created referencing the WSMPM-MAN-SVR server startup group in the WebLogic Domain Configuration Wizard, in addition to the EDQ managed server startup group that is created by default.
3.2.7 Management Ports
If you are running EDQ as a single managed server and not using a WebLogic cluster, the default management port is 8090. If you are running EDQ in a WebLogic cluster, EDQ uses random ports which are allocated on server start. You can examine the Server Access MBean to find the current ports, but note that these will change when the EDQ servers are restarted.
The standard EDQ JMX client has been updated to query these server access beans automatically, using the MBean server in the Administration server. Specify the host name and port for the Administration server and, the connector code will redirect the request to one of the managed servers on the correct port.
$ java -jar jmxtools.jar runjob ... adminhost:7001
The username and password with jmxtools must be valid in WebLogic and EDQ. Use a user from the authentication provider setup in OPSS. If you are using a single EDQ server, there is no advantage in running this in a cluster. Remove the server from the cluster and, the default port 8090 will be used.
It is possible to configure different, fixed, management port for each server in a cluster. (If the servers are running on different machines, they can use the same port). Edit the oedq.local.home version of director.properties and replace the current management port setting with:
[expr]management.port = 8090 + servernum - 1
Here servernum is a precomputed value which is 1 for edq_server1, 2 for edq_server2 and so on. Using this example the management port for edq_server1 will be 8090, the port for edq_server2 will be 8091, so on.
The Siebel configuration in dnd.properties will be required to use the port for a specific managed server. If you are running EDQ as a single managed server and not using a WebLogic cluster, the default management port is 8090.
To discover the management (JMX) ports for any managed server, use Enterprise Manager Fusion Middleware Control as follows:
-
Click on the domain to bring up the drop-down list of options and select the System MBean Browser.
-
Navigate to Application Defined Mbeans > edq > Server: servername > ServerAccess > ServerAccess.
3.2.8 Assumptions
EDQ uses a number of files in the filing system of a given server. In most cases, for example for most of the files in the EDQ configuration directories, these files are accessed in a read-only fashion and do not change. It is therefore possible to pack and unpack the WebLogic domain onto several machines.
However, some types of EDQ jobs, especially batch jobs, require access to the EDQ file landing area in order to run. For correct operation of a clustered system, this file landing area should be mounted on shared file storage (for example, NFS) so that managed servers on different machines can access it. This then means that if a job is triggered by the presence of a file in the landing area, it can still run on any managed server on any machine, or if one EDQ job writes a file to the landing area that is then consumed by another job, both jobs could run on any machine as they have shared access to the landing area.
Note that a Best Practice for Fusion Middleware High Availability is to mount the whole domain on shared file storage, which ensures this requirement is met without the need to move the landing area specifically. For information, see Oracle Best Practices for High Availability.
If the landing area is specifically moved to shared storage, the operating system user account that runs the EDQ application server must have read and write access to it, and director.properties in the EDQ local home directory must be updated to add the following property to point to it:
landingarea=[path]
3.2.9 Limitations and Exclusions
As noted above, in normal operation and in most use cases, EDQ real-time jobs continue to work in the event of any disruption in repository database availability. This is true for all real-time jobs that are provided in the Customer Data Services Pack, and for most custom-configured real-time jobs.
However, the following limitations must be noted:
-
If a real-time job performs Reference Data Matching using one or match processors with staged or reference data input into its Reference Data port, any match processors in the processes used must be configured to cache the prepared reference data into memory. This is enabled using a simple tick-box option in the Advanced Options of the match processor.
-
If a real-time job publishes data to Case Management, it fails messages until the database is available again. The real-time job itself continues running.
-
If a real-time job uses an External Lookup that directly looks up into an external database, rather than Staged Data or Reference Data, which is normally cached in memory, the lookup may fail and this may fail messages until the database being looked up is available again.
-
Similarly, if a real-time job uses a large Reference Data set using Staged or Reference Data, but over the configurable cache limit, which cannot be cached in memory, the lookup will fail and this will fail any messages until the database is available again. Note that the default maximum row limit for caching a Reference Data set is 100,000 rows, but this can be modified by adding the following line in
director.propertiesin the EDQ Local Home:resource.cache.maxrows = [rowlimit]
where
[rowlimit]is the maximum number of rows, for example 100000. -
If a real-time job uses a user account in an external realm, it is dependent on the LDAP server being contactable to lookup user details.