1 Introduction to Knowledge Modules
This chapter provides an introduction to Knowledge Modules (KM). It explains what is a knowledge module, and describes the different types of KMs.
This chapter includes the following sections:
1.1 What is a Knowledge Module?
Knowledge Modules (KMs) are code templates. Each KM is dedicated to an individual task in the overall data integration process. The code in the KMs appears in nearly the form that it will be executed except that it includes Oracle Data Integrator (ODI) substitution methods enabling it to be used generically by many different integration jobs. The code that is generated and executed is derived from the declarative rules and metadata defined in the ODI Designer module.
-
A KM will be reused across several mappings or models. To modify the behavior of hundreds of jobs using hand-coded scripts and procedures, developers would need to modify each script or procedure. In contrast, the benefit of Knowledge Modules is that you make a change once and it is instantly propagated to hundreds of transformations. KMs are based on logical tasks that will be performed. They don't contain references to physical objects (datastores, attributes, physical paths, etc.)
-
KMs can be analyzed for impact analysis.
-
KMs can't be executed standalone. They require metadata from mappings, datastores and models.
KMs fall into 6 different categories as summarized in the table below:
| Knowledge Module | Description | Usage |
|---|---|---|
| Reverse-engineering KM | Retrieves metadata to the Oracle Data Integrator work repository | Used in models to perform a customized reverse-engineering |
| Check KM | Checks consistency of data against constraints |
|
| Loading KM | Loads heterogeneous data to a staging area | Used in mappings with heterogeneous sources |
| Integration KM | Integrates data from the staging area to a target | Used in mappings |
| Journalizing KM | Creates the Change Data Capture framework objects in the source staging area | Used in models, sub models and datastores to create, start and stop journals and to register subscribers. |
| Service KM | Generates data manipulation web services | Used in models and datastores |
KMs have two different types of implementation styles: Template-style and component-style. Template-style KMs can be created and edited by users. Component-style KMs are built-in KMs that can be configured through options, but not be created or modified by users. The currently available component-style KMs are Loading KMs and Integration KMs. The style of a KM can be seen in the physical view properties of the Mapping Editor.
The following sections describe each type of Knowledge Module.
1.2 Reverse-Engineering Knowledge Modules (RKM)
The RKM role is to perform customized reverse engineering for a model. The RKM is in charge of connecting to the application or metadata provider then transforming and writing the resulting metadata into Oracle Data Integrator's repository. The metadata is written temporarily into the SNP_REV_xx tables. The RKM then calls the Oracle Data Integrator API to read from these tables and write to Oracle Data Integrator's metadata tables of the work repository in incremental update mode. This is illustrated below:
Figure 1-1 Reverse-engineering Knowledge Modules
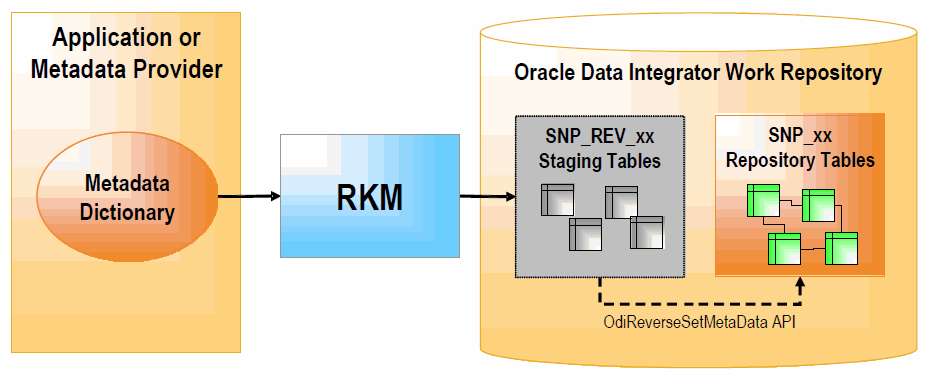
Description of ''Figure 1-1 Reverse-engineering Knowledge Modules''
A typical RKM follows these steps:
-
Cleans up the SNP_REV_xx tables from previous executions using the OdiReverseResetTable tool.
-
Retrieves sub models, datastores, attributes, unique keys, foreign keys, conditions from the metadata provider to SNP_REV_SUB_MODEL, SNP_REV_TABLE, SNP_REV_COL, SNP_REV_KEY, SNP_REV_KEY_COL, SNP_REV_JOIN, SNP_REV_JOIN_COL, SNP_REV_COND tables.
-
Updates the model in the work repository by calling the OdiReverseSetMetaData tool.
1.3 Check Knowledge Modules (CKM)
The CKM is in charge of checking that records of a data set are consistent with defined constraints. The CKM is used to maintain data integrity and participates in the overall data quality initiative. The CKM can be used in 2 ways:
-
To check the consistency of existing data. This can be done on any datastore or within mappings, by setting the STATIC_CONTROL option to "Yes". In the first case, the data checked is the data currently in the datastore. In the second case, data in the target datastore is checked after it is loaded.
-
To check consistency of the incoming data before loading the records to a target datastore. This is done by using the FLOW_CONTROL option. In this case, the CKM simulates the constraints of the target datastore on the resulting flow prior to writing to the target.
In summary: the CKM can check either an existing table or the temporary "I$" table created by an IKM.
The CKM accepts a set of constraints and the name of the table to check. It creates an "E$" error table which it writes all the rejected records to. The CKM can also remove the erroneous records from the checked result set.
The following figures show how a CKM operates in both STATIC_CONTROL and FLOW_CONTROL modes.
Figure 1-2 Check Knowledge Module (STATIC_CONTROL)
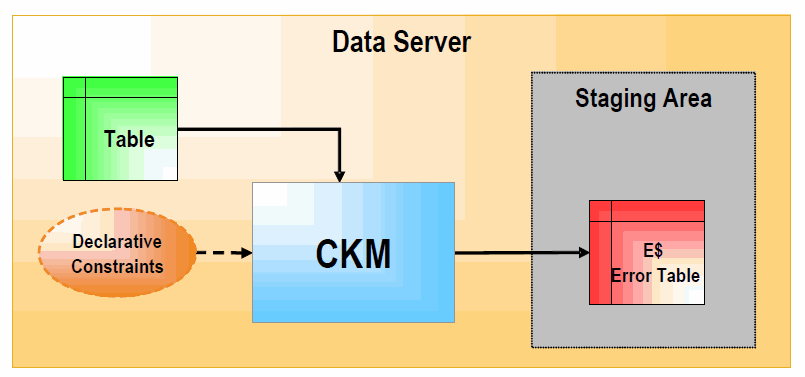
Description of ''Figure 1-2 Check Knowledge Module (STATIC_CONTROL)''
In STATIC_CONTROL mode, the CKM reads the constraints of the table and checks them against the data of the table. Records that don't match the constraints are written to the "E$" error table in the staging area.
Figure 1-3 Check Knowledge Module (FLOW_CONTROL)
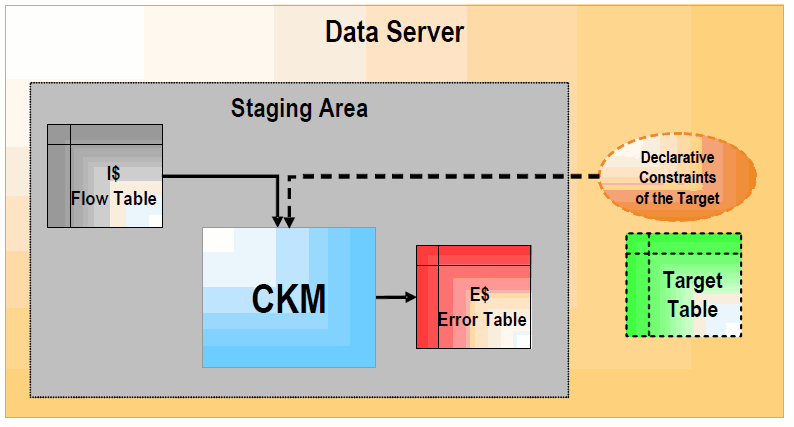
Description of ''Figure 1-3 Check Knowledge Module (FLOW_CONTROL)''
In FLOW_CONTROL mode, the CKM reads the constraints of the target table of the Mapping. It checks these constraints against the data contained in the "I$" flow table of the staging area. Records that violate these constraints are written to the "E$" table of the staging area.
In both cases, a CKM usually performs the following tasks:
-
Create the "E$" error table on the staging area. The error table should contain the same columns as the attributes in the datastore as well as additional columns to trace error messages, check origin, check date etc.
-
Isolate the erroneous records in the "E$" table for each primary key, alternate key, foreign key, condition, mandatory column that needs to be checked.
-
If required, remove erroneous records from the table that has been checked.
1.4 Loading Knowledge Modules (LKM)
An LKM is in charge of loading source data from a remote server to the staging area. It is used by mappings when some of the source datastores are not on the same data server as the staging area. The LKM implements the declarative rules that need to be executed on the source server and retrieves a single result set that it stores in a "C$" table in the staging area, as illustrated below.
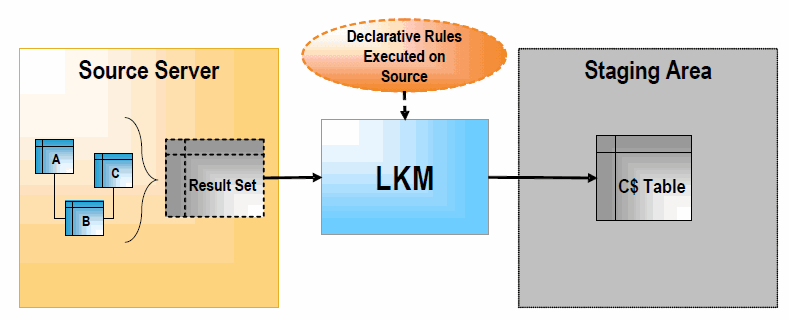
-
The LKM creates the "C$" temporary table in the staging area. This table will hold records loaded from the source server.
-
The LKM obtains a set of pre-transformed records from the source server by executing the appropriate transformations on the source. Usually, this is done by a single SQL SELECT query when the source server is an RDBMS. When the source doesn't have SQL capacities (such as flat files or applications), the LKM simply reads the source data with the appropriate method (read file or execute API).
-
The LKM loads the records into the "C$" table of the staging area.
A mapping may require several LKMs when it uses datastores from different sources. When all source datastores are on the same data server as the staging area, no LKM is required.
1.5 Integration Knowledge Modules (IKM)
The IKM is in charge of writing the final, transformed data to the target table. Every mapping uses a single IKM. When the IKM is started, it assumes that all loading phases for the remote servers have already carried out their tasks. This means that all remote source data sets have been loaded by LKMs into "C$" temporary tables in the staging area, or the source datastores are on the same data server as the staging area. Therefore, the IKM simply needs to execute the "Staging and Target" transformations, joins and filters on the "C$" tables, and tables located on the same data server as the staging area. The resulting set is usually processed by the IKM and written into the "I$" temporary table before loading it to the target. These final transformed records can be written in several ways depending on the IKM selected in your mapping. They may be simply appended to the target, or compared for incremental updates or for slowly changing dimensions. There are 2 types of IKMs: those that assume that the staging area is on the same server as the target datastore, and those that can be used when it is not. These are illustrated below:
Figure 1-5 Integration Knowledge Module (Staging Area on Target)
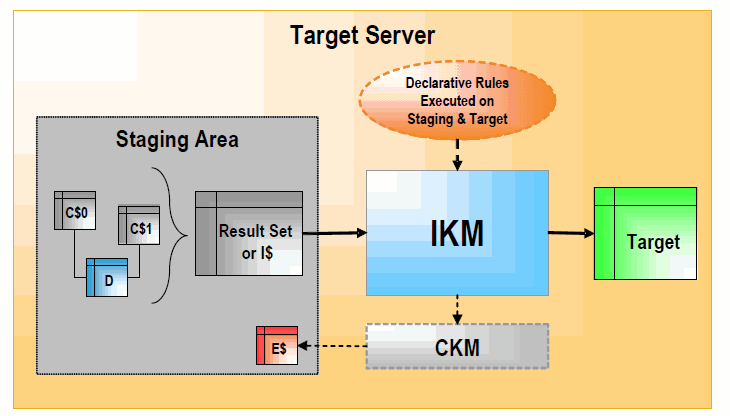
Description of ''Figure 1-5 Integration Knowledge Module (Staging Area on Target)''
When the staging area is on the target server, the IKM usually follows these steps:
-
The IKM executes a single set-oriented SELECT statement to carry out staging area and target declarative rules on all "C$" tables and local tables (such as D in the figure). This generates a result set.
-
Simple "append" IKMs directly write this result set into the target table. More complex IKMs create an "I$" table to store this result set.
-
If the data flow needs to be checked against target constraints, the IKM calls a CKM to isolate erroneous records and cleanse the "I$" table.
-
The IKM writes records from the "I$" table to the target following the defined strategy (incremental update, slowly changing dimension, etc.).
-
The IKM drops the "I$" temporary table.
-
Optionally, the IKM can call the CKM again to check the consistency of the target datastore.
These types of KMs do not manipulate data outside of the target server. Data processing is set-oriented for maximum efficiency when performing jobs on large volumes.
Figure 1-6 Integration Knowledge Module (Staging Area Different from Target)
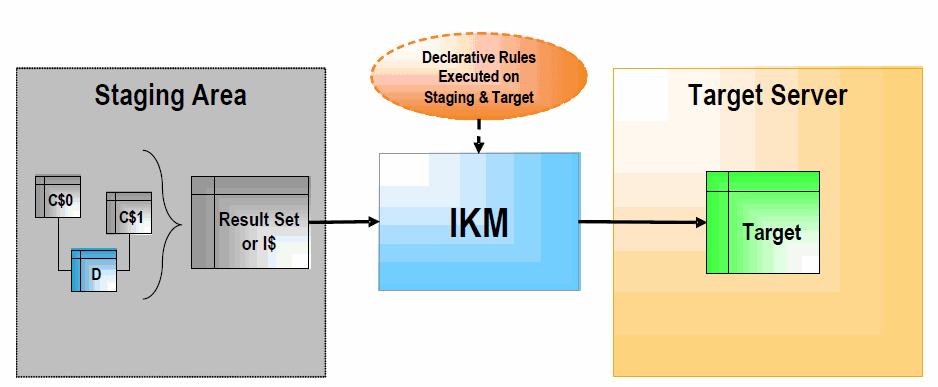
Description of ''Figure 1-6 Integration Knowledge Module (Staging Area Different from Target)''
When the staging area is different from the target server, as shown in Figure 1-6, the IKM usually follows these steps:
-
The IKM executes a single set-oriented SELECT statement to carry out declarative rules on all "C$" tables and tables located on the staging area (such as D in the figure). This generates a result set.
-
The IKM loads this result set into the target datastore, following the defined strategy (append or incremental update).
This architecture has certain limitations, such as:
-
A CKM cannot be used to perform a data integrity audit on the data being processed.
-
Data needs to be extracted from the staging area before being loaded to the target, which may lead to performance issues.
1.6 Journalizing Knowledge Modules (JKM)
JKMs create the infrastructure for Change Data Capture on a model, a sub model or a datastore. JKMs are not used in mappings, but rather within a model to define how the CDC infrastructure is initialized. This infrastructure is composed of a subscribers table, a table of changes, views on this table and one or more triggers or log capture programs as illustrated below.
Figure 1-7 Journalizing Knowledge Module
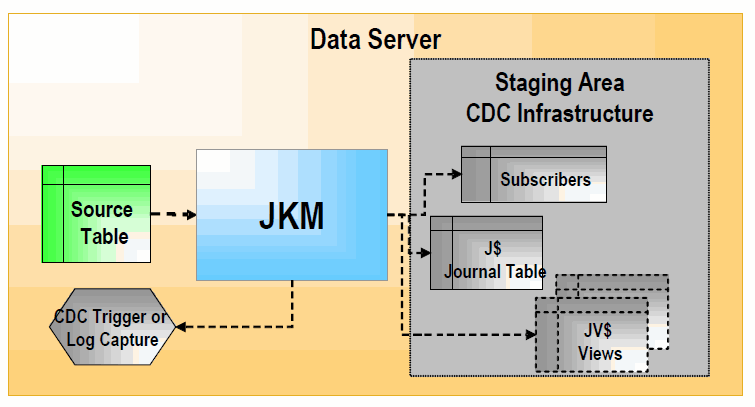
Description of ''Figure 1-7 Journalizing Knowledge Module''
1.7 Service Knowledge Modules (SKM)
SKMs are in charge of creating and deploying data manipulation Web Services to your Service Oriented Architecture (SOA) infrastructure. SKMs are set on a Model. They define the different operations to generate for each datastore's web service. Unlike other KMs, SKMs do no generate an executable code but rather the Web Services deployment archive files. SKMs are designed to generate Java code using Oracle Data Integrator's framework for Web Services. The code is then compiled and eventually deployed on the Application Server's containers.
1.8 Guidelines for Knowledge Module Developers
The first guideline when developing your own KM is to never start from a blank page.
Oracle Data Integrator provides a large number of knowledge modules out-of-the-box. It is recommended that you start by reviewing the existing KMs and start from an existing KM that is close to your use case. Duplicate this KM and customize it by editing the code.
When developing your own KM, keep in mind that it is targeted to a particular stage of the integration process. As a reminder:
-
LKMs are designed to load remote source data sets to the staging area into Loading ("C$") tables.
-
IKMs apply the source flow from the staging area to the target. They start from the Loading tables, may transform and join them into a single integration table ("I$") table, may call a CKM to perform data quality checks on this integration table, and finally write the flow data to the target
-
CKMs check data quality in a datastore or a integration table ("I$") against data quality rules expressed as constraints. The rejected records are stored in the error table ("E$")
-
RKMs are in charge of extracting metadata from a metadata provider to the Oracle Data Integrator repository by using the SNP_REV_xx temporary tables.
-
JKMs are in charge of creating and managing the Change Data Capture infrastructure.
Be also aware of these common pitfalls:
-
Avoid creating too many KMs: A typical project requires less than 5 KMs! Do not confuse KMs and procedures, and do not create one KM for each specific use case. Similar KMs can be merged into a single one and parameterized using options.
-
Avoid hard-coded values, including catalog or schema names in KMs: You should instead use the substitution methods getTable(), getTargetTable(), getObjectName(), knowledge module options or others as appropriate.
-
Avoid using variables in KMs: You should instead use options or flex fields to gather information from the designer.
-
Writing the KM entirely in Jython, Groovy or Java: You should do that if it is the appropriate solution (for example, when sourcing from a technology that only has a Java API). SQL is easier to read, maintain and debug than Java, Groovy or Jython code.
-
Using <%if%> statements rather than a check box option to make code generation conditional.
Other common code writing recommendations that apply to KMs:
-
The code should be correctly indented.
-
The generated code should also be indented in order to be readable.
-
SQL keywords such as "select", "insert", etc. should be in lowercase for better readability.