9 Creating and Using Dimensions and Cubes
This chapter describes how to create and use dimensional objects in ODI. Dimensional objects are logical structures to help identify and categorize data. Oracle Data Integrator enables you to design, create, edit and load two types of dimensional objects - dimensions and cubes.
Note:
The Dimensions and Cubes feature only support Oracle Technology.This chapter includes the following topics in detail:
Overview of Dimensional Objects
Dimensional objects are logical construct that are used to create a model representing the logical design of a data warehouse. The physical design and implementation of the dimensional model will translate the logical design into database via SQL statements. This section provides a general overview on dimension and cube objects along with their physical implementation.
For more information on Data Warehousing, refer to https://docs.oracle.com/database/121/DWHSG/toc.htm
Overview of Dimensions
A dimension is a structure that organizes data. For example, a products dimension organizes data about products including product information, product categories and its sub-categories. A dimension consists of a set of levels and a set of hierarchies defined over these levels.
To create a dimension, you must define the following:
-
Levels
-
Level Attributes
-
Hierarchies
For example, the products dimension can have levels category and subcategory. It can have hierarchies to help drill from product to sub-category or to category.
Using dimensions improves query performance as users often analyze data by drilling down on known hierarchies. An example of a hierarchy is the Time hierarchy of year, quarter, month, day.
-
Level
Level represents a collection of dimension values that share similar characteristics. For example, there can be a State level that has state name, state population and state capital.
-
Level Attribute
Level Attribute includes one surrogate and business identifiers for levels. A level attribute is a descriptive characteristic of a level value. For example, an ITEM level can have an attribute called COLOR. For example, item1 has value green as COLOR and item2 has value blue as COLOR. Attributes represent logical groupings that enable end users to select data based on like characteristics.
Some level attributes are natural keys or surrogate identifiers.A Natural key uniquely identifies the record from the source system. It can be composed of composite keys.
A surrogate identifier uniquely identifies each level record across all the levels of the dimension. It must be composed of a single attribute. Surrogate identifiers enable you to hook facts to any dimension level as opposed to the lowest dimension level only. You must use a surrogate key if:
-
your dimension is a Type 2 slowly changing dimension (SCD). In these cases, you can have multiple dimension records loaded for each Natural key value, so you need an extra unique key to track these records
-
your dimension contains more that one level and is implemented using a star schema. Thus, any cube that references such a dimension references multiple dimension level.
If no surrogate key is defined, then only the leaf-level dimension records are saved in the dimension table, the parent level information is stored in extra columns in the leaf-level records. But there is no unique way to reference the upper level in that case.
You do not need a surrogate key for any Type 1 dimensions, implemented by star, where only the leaf level(s) are referenced by a cube.
-
-
Hierarchy
A structure that uses ordered levels as a means of organizing data. A level hierarchy defines hierarchical relationships between adjacent levels. A hierarchical relationship is a functional dependency from one level of a hierarchy to a more abstract level in the hierarchy.
A hierarchy can be used to define data aggregation; for example in a time dimension. A hierarchy might be used to aggregate data from the "Months" level to the "Quarter" level to the "Year" level.
-
Dimension Role
A dimension can perform multiple dimension roles in a data warehouse.
Within a data warehouse, a cube can refer to the same dimension multiple times. For each such reference, the dimension performs a different dimension role in the cube.
For example, in a wholesale company, each sales record can have three time values:
-
First time value records when the order is received
-
Second time value records when the product is shipped
-
Third time value records when the payment is received.
Different departments in the wholesales company are interested to summarize the sales data in different ways:- by order time, by product shipment time and by product payment time.
To model such scenario, the warehouse designer has the following choices:
-
Model and populate three time dimensions separately and let the wholesales cube refer to each time dimension.
-
Model one time dimension. Create three roles for the time dimension. First one is "order time". Second one is "ship time". Third one is "payment time". Let the sales cube refer to "order time", "ship time" and "payment time".
The second choice has the advantage of storing the time data only once.
-
-
Overview of Slowly Changing Dimensions
During loading of a dimension, you may require to preserve existing data when new data comes in. For example, let's say that the warehouse records initially that a city has population 5000. Now new data comes in which indicate the city has a new population of 6000. Instead of simply overriding the old population with the new number, you may need to retain the old population somewhere in the warehouse so that you can compare the two populations at some point of time.
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data warehouse. The strategy of how to keep historical data is called slowly changing dimension strategy. In data warehousing, there are three commonly recognized types of SCDs. They are: Type 1, Type 2, and Type 3.
Types of Slow Changing Dimensions
-
Type I slowly changing dimension doesn't store any history. In a Type 1 Slowly Changing Dimension (SCD), the new data overwrites the existing data. Typically, this type is not considered an SCD and most dimensions are of this type. Thus the historic data is lost as it is not stored else where. This is the default type of dimension you create. You need not specify any additional information to create a Type 1 SCD, unless there are specific business reasons, you must assume that a Type 1 SCD is sufficient.
An attribute can play only one of these roles. For example, an attribute cannot be a regular attribute and an effective date attribute.
-
Type II slowly changing dimension stores all versions of histories. They store the entire history of values of every attribute and every parent level relationship that is marked as SCD2 Trigger. In the population example, a type two slowly changing dimension stores all population numbers that each city can ever hold.
Define the following parameters, to define a type two SCD:
-
For the level attribute that will trigger the SCD type 2, you have to select the settings as Trigger History. You can choose one or more level attributes so that changes in the value of chosen attributes will trigger a version of history to be saved.
-
To use SCD Type 2, Surrogate Keys attributes should be created for all the levels. Surrogate Key attribute should not be set as SCD2 Trigger History.
-
Level that has any of attributes defined as Type 2 Trigger History must have date/timestamp level attribute set as Type 2 Setting Start Date.
-
Level that has any of attributes defined as Type 2 Trigger History must have date/timestamp level attribute set as Type 2 Setting End Date.
-
A SCD type 2 can also be triggered by the Parent Level reference member, if it has been set to Trigger History.
To create a Type 2 SCD or a Type 3 SCD, in addition to the regular dimension attributes, you need additional attributes that perform the following roles:
-
Trigger History: These are attributes for which historical values must be stored. For example, in the PRODUCTS dimension, the attribute PACKAGE_TYPE of the Product level can be a triggering attribute. When the value of the attribute changes, the old value must be stored.
-
Start Date: This attribute stores the start date of the record's life span.
-
End Date: This attribute stores the end date of the record's life span.
-
Previous Attribute: For Type 3 SCDs only, this attribute stores the previous value of a attribute, that has a version.
-
-
Type III slowly changing dimension store two versions of values for the chosen level of attributes, that is the current value and the previous value. In the population example, a type three slowly changing dimension will keep the current population of each city as well as the previous population.
Define the following parameters, to define a type three SCD:
-
For each level attribute, that you want to store previous value, you need to create and assign another level attribute as Type 3 Previous Attribute. Also, date/timestamp level attribute must be created and assigned to level attribute as Type 3 Start Date.
-
There are two restrictions on which attribute can have a previous value. They are:
-
-
Previous value attribute cannot have further previous values. For example, once you indicate an attribute as "old_email" as the previous value of "email", they cannot choose yet another attribute "previous-previous email" to be used as the previous value of "old_email".
-
The Surrogate Key attribute cannot have previous values.
-
-
Dimension Implementation
Along with defining logical structure of dimension, such as its levels, attributes and hierarchies, you need to specify how the dimension data is physically stored.
Note:
ODI supports only Star schema for the current release.In a star schema, the data of each dimension is stored on a single datastore.
We call this specification of data storage of dimension as dimension implementation.
Overview of Cubes
A cube is a set of measures grouped together that have similar dimensionality. The axes of the cube contain dimension values and the body of the cube contains measure values.
For example, sales data can be organized into a cube, whose edges contain values from the Time, Product, and Customer dimensions and whose body contains values from the Volume Sales, and Dollar Sales measures.
Each cube must hold data related to one or more dimensions. Dimensions can be shared across cubes. The same dimension may be reused under different dimension roles by the same cube. Each cube must have a fact table.
Understanding Measure (Fact)
A measure is data, usually numeric and additive, that can be examined and analyzed. Examples include Sales, Cost and Profit. Fact and measure are synonymous; Fact is more commonly used with relational environments whereas Measure is more commonly used with multidimensional environments.
Cube Implementation
After specifying the logical structure of a cube, such as measures and dimension references, it is necessary for users to specify how the cube will be physically stored. Typically a cube is stored on a single table called fact table. Each measure usually corresponds to one column and each dimension reference corresponds to a column on the fact table and optionally a foreign key from fact table to dimension table.
Creating Dimensional Objects through ODI
In ODI, a new type of model called Dimension and Cube Model is added to support creation of dimension and cube objects. The dimensional objects can be used in mapping for creating the physical data warehouse.
This section elaborates on the following:
Dimension and Cube Accordion
Dimensional objects are added as a separate accordion in the Navigator tab. A dimension model serves as a folder to contain dimension and cube objects as shown below:
Using Dimensions in ODI
This section elaborates on the following:
Generic Properties
-
Dimension is modeled separately from the underlying datastore objects.
-
It supports type one, type two and type three slowly changing dimensions
-
It supports dimension roles
-
Supports multiple hierarchies
To define a dimension, you need to specify its levels and hierarchies.
-
Level
-
A level may determine one or more dependent attributes.
-
All columns of a level must come from the same table.
-
Levels could be shared across hierarchies.
-
Levels must be ordered within a hierarchy
-
A level can uniquely determine some attributes. These attribute columns must come from the same table as level columns.
-
The columns of a hierarchy level may not be associated with more than one dimension.
-
No two levels may have an identical set of columns. The columns of each hierarchy level are not null.
-
Each level may appear in a hierarchy at most once.
-
-
Hierarchy
-
A dimension must have one or more hierarchies.
-
Each hierarchy must have one or more levels.
-
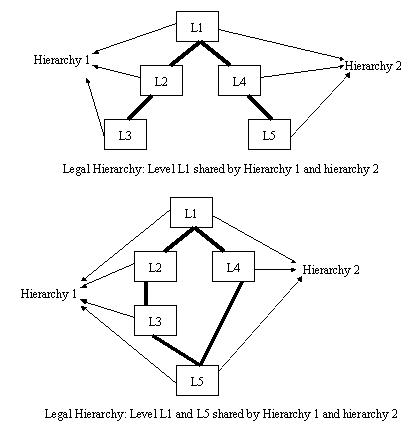
Levels of a dimension may be shared across hierarchies. The hierarchies of a dimension may overlap or be disconnected from each other. The following diagrams illustrate the kind of hierarchies ODI will be able to support.
-
All hierarchies must strictly have1:n relationships. Considering two adjacent levels in a hierarchy, one record in a parent level corresponds to multiple records in a child level within a hierarchy. Further, a record in a child level can correspond to only one parent record within a hierarchy.
-
Ability to skip levels within a hierarchy.
-
It supports the selection of a default hierarchy.
-
No support for inverted hierarchy.
Table 9-1 Examples of Inverted Hierarchy
Hierarchy One Hierarchy Two Total US
Total US
Region
District
District
Region
Account
Account
In hierarchy one, Districts roll into regions, and in hierarchy two regions roll into Districts.
-
Using Cubes in ODI
This section elaborates on the following:
Generic Properties
-
Each cube must have one and only one fact table. A cube contains a list of measures.
-
The fact table contains measure columns.
-
Each cube must be defined by a set of dimensions.
-
A cube may reuse the same dimension multiple times under different aliases.
-
A cube can refer to a non-lowest level in a dimension.
-
A fact table may contain multiple measures.
-
The 1:n relationships from the fact tables to the dimension tables must be enforced.
Creating New Dimensional Models
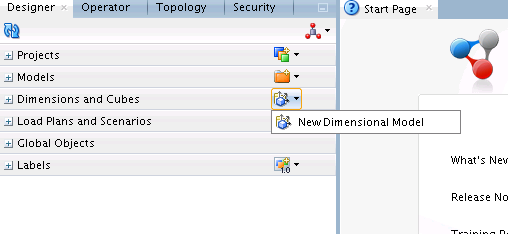
To create a new dimensional model,
-
In the Designer tab, click the New Dimensional Model icon, present beside the Dimensions and Cubes node, as show below:
Definition tab appears, allowing you to configure the following details of the newly created dimensional model:
-
Name - Enter the name of the newly created dimensional model
-
Code- Enter the code of the newly created dimensional model
-
Description - Enter a description for the newly created dimensional model
Click the Save icon.
A new dimensional model folder with the specified name is created with two nodes - Dimensions and Cubes, as shown below:
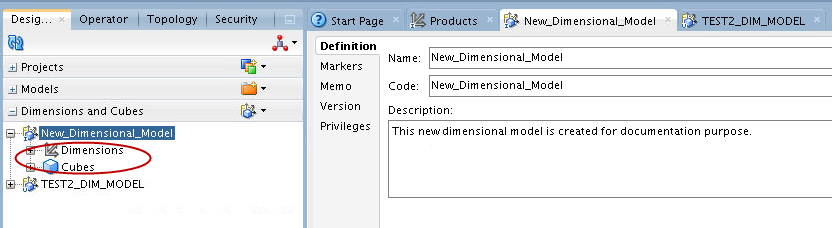
Creating and Editing Dimensional Objects using the Editor
To create new dimensional objects,
-
Right-click the Dimensions node and select New Dimension option, to create a new dimension object
-
Right-click the Cubes node and select New Cube option, to create a new cube object
New dimensional objects are created.
To edit the properties of existing dimensional objects,
-
Double click the required dimension or cube object that you wish to edit
or else right-click and select Open.
The selected dimensional object opens in the Dimension or Cube editor. The Dimension or Cube Editor gives you full control over all the aspects of dimension or cube definition and implementation. This provides maximum flexibility to perform various operations related to the created dimensional objects.
Using Dimension Editor
Dimension Editor has three essential tabs for easy and effective administration of a dimension object. They are:
Definition Tab
Definition tab of the Dimension Editor allows you to define the following properties of a newly created or existing dimension:
-
Name- It represents the name of the created dimension.
In the Name text box, enter the required name of the created dimension.
-
Description- It represents a short description of the created dimension.
In the Description text box, enter a short description for the created dimension.
-
Pattern Name - It denotes the type of pattern that has to be applied to the created dimension.
Note:
ODI has a default built-in pattern called Dimension Pattern. -
Binding Datastore - It denotes the datastores to which the created dimension is bound to.
-
Surrogate Key Sequence - represents a sequence from a project tree (where dimension mappings are created), that is used to generate surrogate keys for the dimension if Surrogate Keys are used.
Note:
Project ODI Sequence of type Native Sequence must be created in the same logical schema where dimension datastore is present.Levels Tab
Levels tab of the Dimension Editor allows you to define the levels and level attributes for each level of a newly created or existing dimension. It contains the following tables:
-
Levels table
-
Levels Attributes table
-
Parent Level References
-
Levels table
The list of levels available for a dimension are displayed in the Levels table, present at the top of the Levels tab. You can create levels from top to bottom and by this it becomes easier to define level relationships.
For creating or removing levels click the Add + or cross x icons present in the header of the Levels table.
This Levels table contains the following parameters:
-
Name - It represents the name of the created level.
In the Name text box, enter the name of the newly created level.
-
Description - It represents a short description for the level creation.
In the Description text box, enter a short description for the newly created level.
-
Binding Datastore - It represents the datastore that is used to store the dimension data.
-
Staging Datastore - It represents the datastore that is used to stage the incoming data for this level before loading them into the actual binding datastore.
Please note, Binding and Staging Datastores need to already exist and they should be present in the same data model. Along with these, the bound datastore must also be created in the database. The staging tables are created and truncated during the execution of mapping in which the dimensions are used. These datastores should have all the attributes to bind to Levels attributes, Natural Key Members attributes and Parent Level reference attributes for all levels.
-
-
Level Attributes Table
This table displays all the level attributes of the level that is selected in the Levels table.
For creating or removing level attributes click the Add + or cross x icons and to reorder the level, click the up or down arrow icons, present in the header of the Level Attributes table.
This Levels table contains the following parameters:
-
Name - It represents the name of the created level attribute.
In the Name text box, enter the name of the created level attribute.
-
Is Surrogate Key - It represents the nature of the selected attribute i.e.whether it can be treated as the surrogate key or not.
Click the Is Surrogate Key check box, to use the selected attribute as a surrogate key.
-
Description - It represents a short description for the newly created level attribute.
In the Description text box, enter a short description for the newly created level attribute.
-
Data Type - It represents the data type of the newly created level attribute.
From the Data Type drop-down box, select the required data type for the newly created level attribute. The values of the Data Type drop-down box are the data types in the "Generic SQL" technology defined in ODI repository.
-
SCD2 Setting - It contains the following values:
-
None - Select this option, if you do not wish to select any of the below listed attributes.
-
Start Date - This attribute stores the start date of the record's life span.
-
End Date - This attribute stores the end date of the record's life span.
-
Trigger History - These are attributes for which historical values must be stored. For example, in the PRODUCTS dimension, the attribute PACKAGE_TYPE of the Product level can be a triggering attribute. When the value of the attribute changes, the old value must be stored. Select this option for an attribute, if the attribute should be versioned.
From the SCD2 Setting drop-down box, select the required value.
-
-
SCD 3 Previous Attribute -It represents the list of level attributes for the current level. If this parameter is set, then SCD3 enabled is for the newly created level attribute. When the incoming data contains any change to this attribute, its value is first moved to the SCD3 previous attribute before being overridden by the incoming data.
-
SCD 3 Effective Date - This drop-down box lists all the level attributes of the current level. When SCD3 is enabled for the newly created level attribute, the timestamp with which the previous value is set will be stored in the level attribute designated as SCD 3 effective date.
-
Attribute - You can select the datastore attribute that is used to store the data for the newly created level attribute from the binding attribute drop-down box. The valid values of the binding attributes constitute the attributes of the dimension table (for star dimension implementation).
-
Staging Attribute - You can select the datastore attribute that is used to store the data for this level attribute from the drop-down box. The valid values of the staging attribute constitutes the attributes of the staging datastore selected as the binding for the current level.
Note:
Within the same level, only one level attribute can act as either Surrogate Key or SCD2 Start Date or SCD2 End Date or SCD3 Previous Attribute or SCD3 Start Date. You will get an error message, when you try to set multiple level attributes with a particular role. -
Natural Key Members - Natural Key Members table displays the key members for the Natural key of the level that is selected in the Levels table. The Natural key is also commonly known as "Business Key" or "Application Key", which is usually used to store the key value(s) that can uniquely identify a particular record in the source systems.
For creating or removing natural key members, click the Add + or cross x icons and to reorder the level, click the up or down arrow icons, present in the header of the Natural Key Members table. This table contains the Level Attribute column. The level attribute constitutes the natural key of the selected level. The valid values of this column are the list of level attributes of the current level are listed in this column.
-
-
Parent Level References Table - This table defines the list of references from the selected level in the Level table to some other parent level. This table is driven from the Level table
For creating or removing parent level references, click the Add + or cross x icons, present in the header of the Parent Level Attributes table.
Functionally, a parent level reference defines how to retrieve the parent level record from the current record. One or more attributes in the current record are used as a foreign key to match the corresponding natural key attributes in the parent level. The Parent Level References table contains following columns:
-
Name - It represents the name of the created parent level reference.
In the Name text box, enter the name of the newly created parent level reference.
-
Description - It represents a short description for the newly created parent level reference. In the Description text box, enter a short description for the newly created parent level reference.
-
Parent Level - Select the required parent level that this reference is pointing to, from the parent level drop-down box. The valid values of the parent level column constitute the list of levels in the dimension that is higher than the currently selected level.
Note:
You can select the same parent level in multiple parent level references. It means that there are multiple paths from the current record to that parent level. -
SCD 2 Setting - This parameter has two values - None or Trigger History. If you select trigger history as SCD 2 setting, a new row is created during dimension loading if any one of the parent level reference key member columns is not the same as the incoming data.
-
Parent Level Reference Key Members table is driven from the parent level reference that is selected in the Parent Level References table. If the parent level has a surrogate key then the key member is surrogate key, if not it is a natural key. Rows in this table are automatically populated with the key members of the parent level. This table contains the following columns:
-
Parent Key Attribute - The level attribute that is part of the natural key of the parent level. The Dimension component is used in a mapping to load data into dimensions defined in ODI.
-
Foreign Key Attribute - This parameter represents the datastore column of the current level that is used to match the corresponding natural key member of the parent level. The valid values of the foreign key attribute drop-down box are all the columns of the datastore of the currently selected level.
-
Foreign Key Staging Attribute - This parameter represents the datastore column of the current level that is used to match the corresponding natural key member of the parent level. The valid values of the foreign key staging attribute drop-down box are all the columns of the staging datastore of the currently selected level.
Note:
For a star dimension, you need not specify the key members of a parent level reference, as a dimension record is stored in the same database row, which includes all information of the parent level.
Hierarchies Tab
The Hierarchies tab displays the list of hierarchies that are defined for the newly created dimension. Hierarchy defines how dimension data is summarized and rolled up in BI reporting tools.
For creating or removing hierarchies click the Add + or cross x icons and to reorder the level, click the up or down arrow icons, present in the header of the Hierarchies table. The Hierarchies table contains the following columns:
-
Name - It represents the name of the created hierarchy.
In the Name text box, enter the name of the newly created hierarchy.
-
Description - It represents a short description for the newly created hierarchy.
In the Description text box, enter a short description for the newly created hierarchy.
-
Default - When a dimension has multiple hierarchy, query tools show the default hierarchy. Only one hierarchy can be defined as default.
The Hierarchy Members table displays the list of level members in the hierarchy selected in the Hierarchies table. For adding or removing hierarchy Members click the Add + or cross x icons and to reorder the level, click the up or down arrow icons present in the header of the Hierarchies table. The hierarchy members are sorted based on the natural order of the levels in the dimension. This table contains the following columns:
-
Level - Select the required level for the newly created hierarchy from the Level drop-down box. The valid values listed in the drop-down box are the list of levels in the dimension that are not a member of the currently selected hierarchy which are of lower level than any preceding hierarchy members.
For example, if we have a dimension with three levels - Brand, Category and Product, if the first hierarchy member is Brand, then the valid levels of the second hierarchy members are Category and Product.
-
Parent Level Reference - The parent level reference that is used to navigate from the selected level to the level of the immediately preceding hierarchy members. The column is a drop-down box and its valid values are the parent level references between the current level and the level of the immediately preceding hierarchy member.
Skip Level Members table displays the list of skip level members in the hierarchy member selected in the Hierarchy Members table. This allows the data present in the level, to have multiple paths to roll up to different parent levels, wherein some paths may skip one or more parent levels in the same hierarchy.
For example, assume that we have a hierarchy Store in the order- City -> Region -> State -> County in a dimension called Store of a retail company. In this company, some stores are more important and they report directly to the regional office. As a result, a store can have two parent levels, city and region, where City is optional. To describe this hierarchy, we have a hierarchy member for Store level and its parent level is City. This hierarchy member also has a skip level and its parent level reference is pointing to Region level.
Since parent levels can skip multiple paths, click + or cross x buttons to describe these different roll up paths. The Skip Levels table contains the following columns:
Parent Level Reference: The parent level reference that is used to skip to some preceding level in the hierarchy. This column is a drop-down box and its valid values are the parent level references defined for the level of the currently selected hierarchy member, and including those parent level references that do not point to the immediately preceding level.
Using the Cube Editor
Cube Editor has two essential tabs for easy and effective administration of a cube object. They are:
Definition Tab
Definition tab of the Cube Editor allows you to define the following properties of a newly created or existing cube objects:
-
Name - It represents the name of the created cube object.
In the Name text box, enter the required name of the created cube object.
-
Description - It represents a short description of the created cube object.
In the Description text box, enter a short description for the created cube object.
-
Binding Datastore- The datastore that is used to store the cube data can be selected using the wheel. It displays all the datastores present in all the models of ODI repository. Click the Search icon, present beside the Cube Table text box, to select the required cube table.
Details Tab
Details tab of the Cube Editor allows you to define the following properties of a newly created or existing cube objects:
Note:
ODI supports only single datastore to store cube information.-
Dimensions Table - The Dimensions table displays the list of dimensions being used by the cube. You can add or delete a dimension using the Add "+" or Cross "X" buttons present in the header of the Dimensions Table. The Dimensions Table has the following columns:
-
Level - It denotes the level of the dimension that is referenced to the cube. When you click the browse icon, present beside any Level parameter in the table, it displays all the levels present in all the dimensions of ODI repository. When you select the level, the qualified name of the level (in the form of <dimension_name>.<level_name>) is displayed in the column.
-
Role - If you plan to use the same dimension multiple times in a cube then you have to specify an alternate name to uniquely identify the same dimension. This can be done by using the role column.
-
-
Key Binding Table -The Key binding table is driven by the dimension table. It has the following columns:
-
Dimension Key - If any dimension is selected in the Dimension Table then the Key binding datastore displays the keys present in the Dimension Key column. If the dimension uses a surrogate key then the respective surrogate key is displayed, if surrogate keys are not used then Natural Keys are displayed.
-
Binding Attribute - This parameter displays all the attributes present in the cube binding datastore. If any attribute is already bound to a Dimension key or a measure then those attributes are not listed.
-
-
Measure Tables - Measure Tables are used to add or delete new measures. Measure Table comprises of the following columns:
-
Name - It denotes the name of the created measure.
In the Name column, enter the name of the newly added measure.
-
Description - It denotes a short description of the measure creation.
In the Description column, enter a short description of then newly created measure.
-
Data Type - You can select the data type of the level attribute from the Data Type drop-down box. The valid values of the column are all the data types in the "Generic SQL" technology defined in ODI repository.
-
Size - It denotes the length or precision of the measure.
-
Scale - It denotes the scale of this measure (for numeric data type).
-
Binding Column - This column denotes the datastore that is used to store the data for a measure. The valid values of this binding column are the columns of the cube table. If any attribute is already bound to a dimension key or a measure then those attributes are not listed in this column.
-
Using Dimensional Components in Mappings
Dimensional Objects can be used extensively in mappings.
Using Dimension Component in Mapping
The Dimension component is used in a mapping to load data into dimensions and slowly changing dimensions.
The Dimension component contains one group for each level in the dimension. The groups use the same name as the dimension levels. The level attributes of each level are listed under the group that represents the level.
You cannot map a data flow to the surrogate key attribute or the parent reference key attribute of any dimension level.
To use a dimension in a Mapping, drag the dimension from the Dimensions and Cubes Model and drop it in the Mapping Editor Canvas, as shown below:
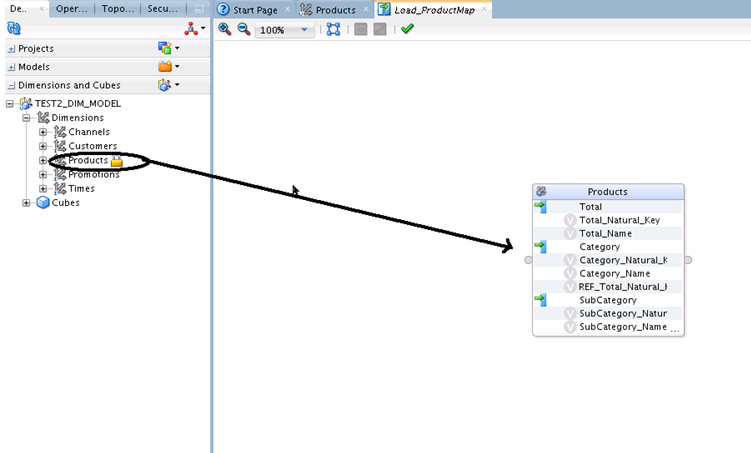
Dimension Component Properties Editor
The Dimension component has the following properties:
Attributes
Attributes are fixed and provided by the base dimension. It is a data field within a level.
General Properties
The general properties of the dimension component includes:
-
Name- It denotes the name of the created dimension component
-
Description - It denotes a short description provided during dimension component creation
-
Dimension - It is a read only property which provides information on which base dimension it is related to.
-
Datastore - It is a read only property, and this value is derived from the base dimension and it is the name of the datastore to which the base dimension is bound to.
-
Sequence - It refers to the sequence that is used by the base dimension.
-
Storage Type - The default value for storage type is Star.
-
Component Type - The default value for component type is Dimension.
-
Pattern - The default value for pattern is Dimension Pattern and if you create your own pattern they get listed here, thereby enabling you to select the required pattern.
Connector Points
Connector points define the connections between components inside a mapping. The Dimension Component has only input connector points. The output connector points are invalid. The properties of input connector points are:
Table 9-2 Properties of Input Connector Points
| Property | Descriptio |
|---|---|
|
Name |
It denotes the name of the connector point. This field can be edited. |
|
Description |
It denotes the description of the connector point. |
|
Bound Object |
It denotes the name of the object to which the connector point is bound to. This field remains blank, if the component type does not support connector point binding. |
|
Connected From |
It denotes the name of the preceding components to which this component connects from. |
History Properties
The History properties of the dimension component includes the following:
Note:
These properties are applicable only for Type 2 SCDs.-
Default Effective Time of Initial Record- It represents the default value assigned as the effective time for the initial load of a particular dimension record.
-
Default Effective Time of Open Record - It represents the default value set for the effective time of the open records, after the initial record. This value should not be modified.
-
Default Expiration Time of Open Record - It represents a date value that is used as the expiration time of a newly created open record for all the levels in the dimension.
-
Slowly Changing Type- This is a read only property and this value is set based on the type of SCD settings.
-
Type 2 Gap - It represents the time interval between the expiration time of an old record that is versioned and the start time of the current record that has just been versioned.
When the value of a triggering attribute is updated, the current record is closed and a new record is created with the updated values. Because the closing of the old record and opening of the current record occur simultaneously, it is useful to have a time interval between the end time of the old record and the start time of the open record, instead of using the same value for both.
-
Type 2 Gap Unit - It represents the unit of time used to measure the gap interval represented in the Type2 Gap property. Available options are: Seconds, Minutes, Hours, Days, and Weeks. The default value is Seconds.
Using Cube Component in Mappings
The cube component is based on a cube object and has a set of attributes according to the base cube.
When you drag and drop a cube object onto to a mapping editor, a cube component gets created based on that cube.
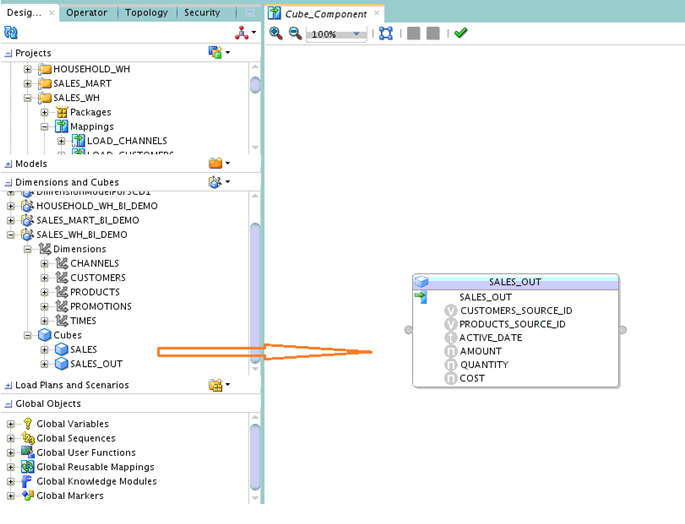
Note:
The cube component can be used only as a target and cannot be used as a source for any other component.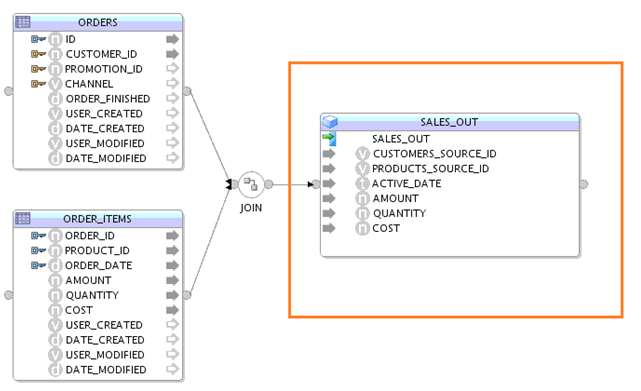
Cube Component Properties Editor
The Cube component has the following properties:
Attributes
Cube component has a set of input map attributes derived from the base cube. They are:
-
Measure Attributes - Each measure in base cube of the cube component has a corresponding map attribute in cube component. The map attribute is bound to the cube measure. The measure name is used as the map attribute name.
-
Dimension Natural key Attributes - Each natural key attribute of the referenced level has a corresponding map attribute in cube component. The map attribute is bound to the natural key level attribute of the referenced level.
-
If the dimension reference of the cube has role qualifier set, then the map attribute name is in the form of <dimension name>_<role name>_<attribute name>.
-
If the dimension reference of the cube has no role qualifier, then the map attribute name is in the form of <dimension name>_<attribute name>.
-
-
Active Date - It is a special map attribute which is created in the case that the base cube of the cube component references at least one SCD2 dimension.
If the map attribute in cube component is represented as a natural key identifier of the referenced dimension, it has the following properties:
-
Target
-
Expression
-
Execute on Hint
-
Fixed Execution Location
-
-
General
-
Name
-
Description
-
Data Type
-
Size
-
Scale
-
Attribute Role - It is a read-only property, which indicates the attribute, represented as a natural key identifier.
-
Bound Object - It is a read-only property. The attribute is bound to a natural key level attribute
-
If the map attribute in cube component is represented as a cube measure, it has the following properties.
-
Target
-
Expression
-
Execute on Hint
-
Fixed Execution Location
-
-
General
-
Name
-
Description
-
Data Type
-
Size
-
Scale
-
Attribute Role - It is a read-only property, which indicates the attribute, represented as a cube measure.
-
Bound Object - It is a read-only property. The attribute is bound to a cube measure.
-
Source Aggregation Function - It denotes the source loading aggregation function for the measure. This property is worked together with property "Enable Source Aggregation" on cube component. In the user interface, a combo box lists all the aggregate functions of the generic technology.
-
The active date attribute in cube component has following properties:
-
Target
-
Expression
-
Execute on Hint
-
Fixed Execution Location
-
-
General
-
Name
-
Description
-
Data Type - It denotes the default data type for Active Date attribute - "TIMESTAMP".
-
Size
-
Scale
-
Attribute Role - It is a read-only property, which is set to Active Date. Active Date attribute has a default expression which is set to "FUNC_SYSDATE". "FUNC_SYSDATE" is a global user function. This function is also used in Dimension Component.
-
General Properties
Cube component has the following general properties:
-
Name - It denotes the name of the cube component.
-
Description - It denotes a short description of the mapping.
-
Cube - It is a read-only property that provides the base cube of the cube component.
-
Datastore - It is a read-only property and this value is derived from the base cube. It is the bound datastore of the base cube of this component.
-
Component Type - It is a ready only property and its value is Cube, by default.
-
Pattern - At present, you can select only pattern - Cube Pattern.
Target Properties
Cube component has following target properties:
-
Integration Type - Integration Type is of three types. They are:
-
None
-
Incremental Update
-
Control Append
The default value is Incremental Update. The integration type ultimately helps to determine the default IKM and limit the set of IKM choices.
-
-
Enable Source Aggregation - If this property is enabled, an aggregate component is added in the expanded map of the cube component before loading the fact table. The source row set is grouped by the dimension reference attributes. Measure aggregation functions are determined by the SOURCE_AGGREGATION_FUNCTION attribute properties.
Expanding Dimensional Components
This section explains briefly about expanding the dimension and cube components.
Expanding Dimension Component
Dimension component is an expandable component and it can be expanded like a reusable Mapping.
To expand a dimension component, right-click the dimension component and from the pop-up menu select Open.
It switches to the expanded mapping of the dimension component. The expanded mapping is determined by the selected pattern.
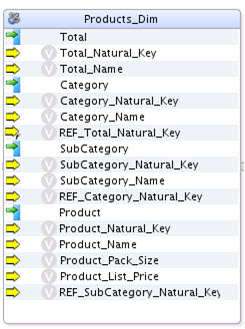
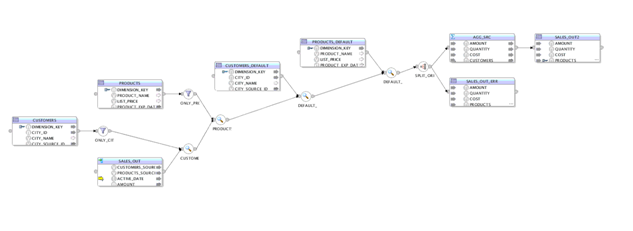
A typical expanded mapping of a dimension component looks like:
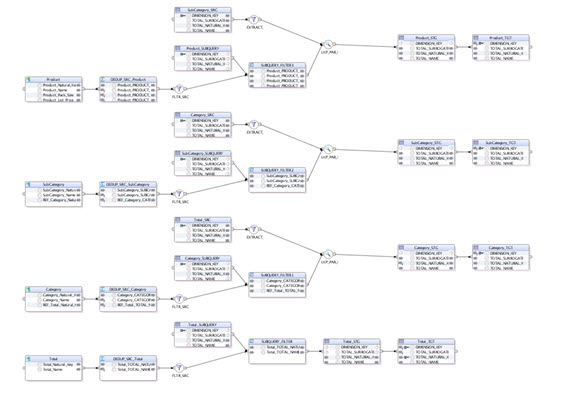
Expanding Cube Component
Cube component is an expandable component and it can be expanded like a reusable Mapping.
To expand a cube component, right-click the cube component and from the pop-up menu select Open.
It switches to the expanded mapping of the cube component. The expanded mapping is determined by the selected pattern.
A typical expanded mapping of a cube component looks like: