3 Understanding the Persistence Unit
This chapter describes details about the persistence unit and the persistence layer.
This chapter includes the following sections:
3.1 About the Persistence Unit
A persistence unit defines the details that are required when you acquire an entity manager. To package your EclipseLink JPA application, you must configure the persistence unit during the creation of the persistence.xml file. Define each persistence unit in a persistence-unit element in the persistence.xml file.
Use the persistence.xml file to package your entities. Once you choose a packaging strategy, place the persistence.xml file in the META-INF directory of the archive of your choice. The following sections provide more detail on how to specify the persistence unit. For more information and examples, see "persistence.xml file" in the JPA Specification. For information on EclipseLink extensions to the persistence.xml file, see "Persistence Property Extensions Reference" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
3.1.1 About the Persistence Unit Name
If you are developing your application in a Java EE environment, ensure that the persistence unit name is unique within each module. For example, you can define only one persistence unit with the name EmployeeService in an emp_ejb.jar file.
For more information, see "name" in the JPA Specification.
3.1.2 About the Persistence Provider
The persistence provider defines the implementation of JPA. It is defined in the provider element of the persistence.xml file. Persistence providers are vendor-specific. The persistence provider for EclipseLink is org.eclipse.persistence.jpa.PersistenceProvider.
3.1.3 About the Transaction Type Data Source
If you are developing your application in a Java EE environment, use the default transaction type: JTA (for Java Transaction API) and specify the data source in a jta-data-source element.
If you are using a data source that does not conform to the JTA, then set the transaction-type element to RESOURCE_LOCAL and specify a value for the non-jta-data-source element.
If you are using the default persistence provider, org.eclipse.persistence.jpa.PersistenceProvider, then the provider attempts to automatically detect the database type based on the connection metadata. This database type is used to issue SQL statements specific to the detected database type. You can specify the optional eclipselink.target-database property to guarantee that the database type is correct.
For more information, see "transaction-type" and "provider" in the JPA Specification.
3.1.4 About Logging
EclipseLink provides a logging utility even though logging is not part of the JPA specification. Hence, the information provided by the log is EclipseLink JPA-specific. With EclipseLink, you can enable logging to view the following information:
-
Configuration details
-
Information to facilitate debugging
-
The SQL that is being sent to the database
You can specify logging in the persistence.xml file. EclipseLink logging properties let you specify the level of logging and whether the log output goes to a file or standard output. Because the logging utility is based on java.util.logging, you can specify a logging level to use.
The logging utility provides nine levels of logging control over the amount and detail of the log output. Use eclipselink.logging.level to set the logging level, for example:
<property name="eclipselink.logging.level" value="FINE"/>
By default, the log output goes to System.out or to the console. To configure the output to be logged to a file, set the property eclipselink.logging.file, for example:
<property name="eclipselink.logging.file" value="output.log"/>
EclipseLink's logging utility is pluggable, and several different logging integrations are supported, including java.util.logging. To enable java.util.logging, set the property eclipselink.logging.logger, for example:
<property name="eclipselink.logging.logger" value="JavaLogger"/>
For more information about EclipseLink logging and the levels of logging available in the logging utility, see "Persistence Property Extensions Reference" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
3.1.5 About Vendor Properties
The last section in the persistence.xml file is the properties section. The properties element gives you the chance to supply EclipseLink persistence provider-specific settings for the persistence unit. See "properties" in the JPA Specification. see also "Persistence Property Extensions Reference" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
3.1.6 About Mapping Files
Apply the metadata to the persistence unit. This metadata is a union of all the mapping files and the annotations (if there is no xml-mapping-metadata-complete element). If you use one mapping orm.xml file for your metadata, and place this file in a META-INF directory on the classpath, then you do not need to explicitly list it. The EclipseLink persistence provider will automatically search for this file and use it. If you named your mapping files differently or placed them in a different location, then you must list them in the mapping-file elements in the persistence.xml file.
For more information, see "mapping-file, jar-file, class, exclude-unlisted-classes" in the JPA Specification.
3.1.7 About Managed Classes
Typically, you put all of the entities and other managed classes in a single JAR file, along with the persistence.xml file in the META-INF directory, and one or more mapping files (when you store metadata in XML).
At the time the EclipseLink persistence provider processes the persistence unit, it determines which set of entities, mapped superclasses, and embedded objects each particular persistence unit will manage.
At deployment time, the EclipseLink persistence provider may obtain managed classes from any of the following sources. A managed class will be included if it is one of the following:
-
Local classes: the classes annotated with
@Entity,@MappedSuperclassor@Embeddablein the deployment unit in which itspersistence.xmlfile was packaged. For more information, see "Entity" in the JPA Specification.Note:
If you are deploying your application in the Java EE environment, the application server itself, not the EclipseLink persistence provider, will discover local classes. In the Java SE environment, you can use theexclude-unlisted-classeselement tofalseto enable this functionality—EclipseLink persistence provider will attempt to find local classes if you set this element to false. See "mapping-file, jar-file, class, exclude-unlisted-classes" in the JPA Specification. -
Classes in mapping files: the classes that have mapping entries, such as entity (see "entity" in the JPA Specification), mapped-superclass or embeddable, in an XML mapping file. For more information, see "mapped-superclass" and "embeddable" in the JPA Specification.
If these classes are in the deployed component archive, then they will already be on the classpath. If they are not, you must explicitly include them in the classpath.
-
Explicitly listed classes: the classes that are listed as class elements in the
persistence.xmlfile.Consider listing classes explicitly if one of the following applies:
-
there are additional classes that are not local to the deployment unit JAR. For example, there is an embedded object class in a different JAR that you want to use in an entity in your persistence unit. You would list the fully qualified class in the class element in the
persitence.xmlfile. You would also need to ensure that the JAR or directory that contains the class is on the classpath of the deployed component (by adding it to the manifest classpath of the deployment JAR, for example); -
you want to exclude one or more classes that may be annotated as an entity. Even though the class may be annotated with the
@Entityannotation, you do not want it treated as an entity in this particular deployed context. For example, you may want to use this entity as a transfer object and it needs to be part of the deployment unit. In this case, in the Java EE environment, you have to use theexclude-unlisted-classeselement of thepersistence.xmlfile—the use of the default setting of this element prevents local classes from being added to the persistence unit. For more information, see "mapping-file, jar-file, class, exclude-unlisted-classes" of the JPA Specification. -
you plan to run your application in the Java SE environment, and you list your classes explicitly because that is the only portable way to do so in Java SE.
-
-
Additional JAR files of managed classes: the annotated classes in a named JAR file listed in a
jar-fileelement in thepersistence.xmlfile. For more information, see "mapping-file, jar-file, class, exclude-unlisted-classes" in the JPA Specification.You have to ensure that any JAR file listed in the
jar-fileelement is on the classpath of the deployment unit. Do so by manually adding the JAR file to the manifest classpath of the deployment unit.Note that you must list the JAR file in the
jar-fileelement relative to the parent of the JAR file in which thepersistence.xmlfile is located. This matches what you would put in the classpath entry in the manifest file.
3.1.8 About the Deployment Classpath
To be accessible to the EJB JAR, WAR, or EAR file, a class or a JAR file must be on the deployment classpath. You can achieve this in one of the following ways:
-
Put the JAR file in the manifest classpath of the EJB JAR or WAR file.
To do this, add a classpath entry to the
META-INF/MANIFEST.MFfile in the JAR or WAR file. You can specify one or more directories or JAR files, separating them by spaces. -
Place the JAR file in the library directory of the EAR file.
This will make the JAR file available on the application classpath and accessible by all of the modules deployed within the EAR file. By default, this would be the
libdirectory of the EAR file, although you may configure it to be any directory in the EAR file using thelibrary-directoryelement in theapplication.xmldeployment descriptor.
3.1.9 About Persistence Unit Packaging Options
Java EE allows for persistence support in a variety of packaging configurations. You can deploy your application to the following module types:
-
EJB modules: you can package your entities in an EJB JAR. When defining a persistence unit in an EJB JAR, the
persistence.xmlfile is not optional–you must create and place it in theMETA-INFdirectory of the JAR alongside the deployment descriptor, if it exists. -
Web modules: you can use a WAR file to package your entities. In this case, place the
persistence.xmlfile in theWEB-INF/classes/META-INFdirectory. Since theWEB-INF/classesdirectory is automatically on the classpath of the WAR, specify the mapping file relative to that directory. -
Persistence archives: a persistence archive is a JAR that contains a
persistence.xmlfile in itsMETA-INFdirectory and the managed classes for the persistence unit defined by thepersistence.xmlfile. Use a persistence archive if you want to allow multiple components in different Java EE modules to share or access a persistence unit.Once you create a persistence archive, you can place it in either the root or the application library directory of the EAR. Alternatively, you can place the persistence archive in the
WEB-INF/libdirectory of a WAR. This will make the persistence unit accessible only to the classes inside the WAR, but it enables the decoupling of the definition of the persistence unit from the web archive itself.
For more information, see "Persistence Unit Packaging" in the JPA Specification.
3.1.10 About the Persistence Unit Scope
You can define any number of persistence units in single persistence.xml file. The following are the rules for using defined and packaged persistence units:
-
Persistence units are accessible only within the scope of their definition.
-
Persistence units names must be unique within their scope.
For more information, see "Persistence Unit Scope" in the JPA Specification.
3.1.11 About Composite Persistence Units
You can expose multiple persistence units (each with unique sets of entity types) as a single persistence context by using a composite persistence unit. Individual persistence units that are part of this composite persistence unit are called composite member persistence units.
With a composite persistence unit, you can:
-
Map relationships among any of the entities in multiple persistence units
-
Access entities stored in multiple databases and different data sources
-
Easily perform queries and transactions across the complete set of entities
Figure 3-1 illustrates a simple composite persistence unit. EclipseLink processes the persistence.xml file and detects the composite persistence unit, which contains two composite member persistence units:
-
Class A is mapped by a persistence unit named memberPu1 located in the
member1.jarfile. -
Class B is mapped by a persistence unit named memberPu2 located in the
member2.jarfile.
Figure 3-1 A Simple Composite Persistence Unit
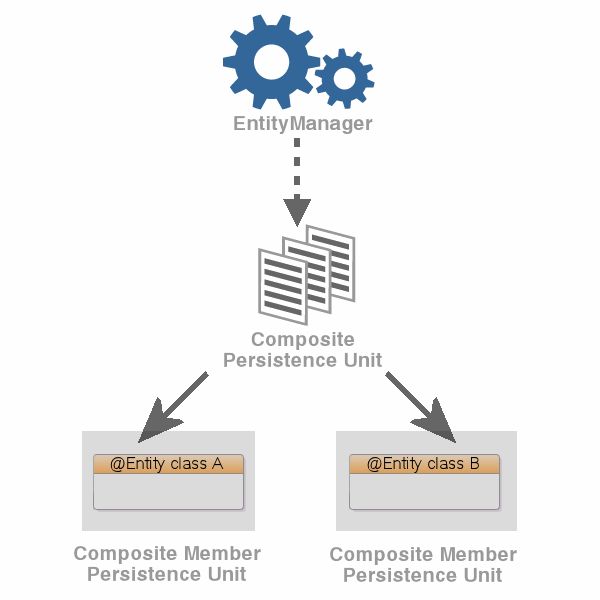
Description of ''Figure 3-1 A Simple Composite Persistence Unit''
For more information, see "Using Multiple Databases with a Composite Persistence Unit" in Solutions Guide for Oracle TopLink.
3.2 Building and Using the Persistence Layer
EclipseLink requires that classes must meet certain minimum requirements before they can become persistent. EclipseLink also provides alternatives to most requirements. EclipseLink uses a nonintrusive approach by employing a metadata architecture that allows for minimal object model intrusions.
This section includes the following information:
3.2.1 Implementation Options
When implementing your persistence layer using EclipseLink, consider the following options:
3.2.1.1 Using EclipseLink JPA Metatdata, Annotations, and XML
When using JPA, you can specify persistence layer components using any combination of standard JPA annotations and persistence.xml, EclipseLink JPA annotation extensions, and EclipseLink JPA persistence.xml extensions.
For more information, see Section 2.2.3, "About Configuration Basics".
3.2.1.2 Using EclipseLink Metadata Java API
Persistence layer components can be coded or generated as Java. To use Java code, you must manually write code for each element of the project including: project, login, platform, descriptors, and mappings. This may be more efficient if your application is model-based and relies heavily on code generation.
3.2.1.3 Using Method and Direct Field Access
You can access the fields (data members) of a class by using a getter/setter method (also known as property access) or by accessing the field itself directly.
When to use method or direct field access depends on your application design. Consider the following guidelines:
-
Use method access outside of a class.
This is the natural public API of the class. The getter/setter methods handle any necessary side-effects and the client need not know anything about those details.
-
Use direct field access within a class to improve performance.
In this case, you are responsible for taking into consideration any side-effects not invoked by bypassing the getter/setter methods.
When considering using method or direct field access, consider the following limitations.
If you enable change tracking on a getter/setter method (for example, you decorate method setPhone with @ChangeTracking), then EclipseLink tracks changes accordingly when a client modifies the field (phone) using the getter/setter methods.
Similarly, if you enable change tracking on a field (for example, you decorate field phone with @ChangeTracking), then EclipseLink tracks changes accordingly when a client modifies the field (phone) directly.
However, if you enable change tracking on a getter/setter method (for example, you decorate method setPhone with @ChangeTracking) and a client accesses the field (phone) directly, EclipseLink does not detect the change. If you choose to code in this style of field access within a class for performance and method access outside of a class, then be aware of this limitation.
For more information, see the description of the @ChangeTracking annotation in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
3.2.1.4 Using Java Byte-code Weaving
Weaving is a technique of manipulating the byte-code of compiled Java classes.
Weaving is used to enhance both JPA entities and Plain Old Java Object (POJO) classes for such things as lazy loading, change tracking, fetch groups, and internal optimizations.
For more information, see Section 3.5, "About Weaving".
3.2.2 Persistent Class Requirements
When you create persistent Java objects, use direct access on private or protected attributes.
If you are using weaving, the ValueHolderInterface is not required. For more information, see Section 3.5, "About Weaving." See Section 6.2.1, "Indirection (Lazy Loading)" for more information on indirection and transparent indirection.
3.2.3 Persistence Layer Components
The purpose of your application's persistence layer is to use a session at run time to associate mapping metadata and a data source (see Chapter 7, "Understanding Data Access") to create, read, update, and delete persistent objects using the EclipseLink cache, queries and expressions, and transactions.
Typically, the EclipseLink persistence layer contains the following components:
3.2.3.1 Mapping Metadata
The EclipseLink application metadata model is based on the project. The project includes descriptors, mappings, and various policies that customize the run-time capabilities. You associate this mapping and configuration information with a particular data source and application by referencing the project from a session.
For more information, see the following:
3.2.3.2 Cache
By default, EclipseLink sessions provide an object-level cache that guarantees object identity and enhances performance by reducing the number of times the application needs to access the data source. EclipseLink provides a variety of cache options, including locking, refresh, invalidation, isolation, and coordination. Using cache coordination, you can configure EclipseLink to synchronize changes with other instances of the deployed application. You configure most cache options at the persistence unit or entity level. You can also configure cache options on a per-query basis or on a descriptor to apply to all queries on the reference class.
For more information, see Chapter 8, "Understanding Caching."
3.2.3.3 Queries and Expressions
For Object-relational architectures, EclipseLink provides several object and data query types, and offers flexible options for query selection criteria, including the following:
-
EclipseLink expressions
-
JPQL (Java Persistence Query Language)
-
SQL
-
Stored procedures
-
Query by example
With these options, you can build any type of query. Oracle recommends using named queries to define application queries. Named queries are held in the project metadata and referenced by name. This simplifies application development and encapsulates the queries to reduce maintenance costs.
For Object-relational architectures, you are free to use any of the query options regardless of the persistent entity type. Alternatively, you can build queries in code, using the EclipseLink API.
Note:
These query techniques cannot be used with MOXy (OXM, JAXB) mapping. However you can perform queries when using legacy EIS XML projects.For more information, see Chapter 9, "Understanding Queries" and Chapter 10, "Understanding EclipseLink Expressions."
3.3 About Persisting Objects
This section includes a brief description of relational mapping and provides information and restrictions to guide object and relational modeling. This information is useful when building applications.
This section includes information on the following:
3.3.1 Application Object Model
Object modeling refers to the design of the Java classes that represent your application objects. You can use your favorite integrated development environment (IDE) or Unified Modeling Language (UML) modeling tool to define and create your application object model.
Any class that registers a descriptor with EclipseLink database sessions is called a persistent class. EclipseLink does not require that persistent classes provide public accessor methods for any private or protected attributes stored in the database. Refer to Section 3.2.2, "Persistent Class Requirements" for more information.
3.3.2 Data Storage Schema
Your data storage schema refers to the design that you implement to organize the persistent data in your application. This schema refers to the data itself—not the actual data source (such as a relational database or nonrelational legacy system).
During the design phase of the application development process, you should decide how to implement the classes in the data source. When integrating existing data source information, you must determine how the classes relate to the existing data. If no legacy information exists to integrate, decide how you will store each class, then create the necessary schema.
3.3.3 Primary Keys and Object Identity
When making objects persistent, each object requires an identity to uniquely identify it for storage and retrieval. Object identity is typically implemented using a unique primary key. This key is used internally by EclipseLink to identify each object, and to create and manage references. Violating object identity can corrupt the object model.
In a Java application, object identity is preserved if each object in memory is represented by one, and only one, object instance. Multiple retrievals of the same object return references to the same object instance—not multiple copies of the same object.
EclipseLink supports multiple identity maps to maintain object identity (including composite primary keys). See Section 8.2, "About Cache Type and Size" for additional information.
3.3.4 Mappings
EclipseLink uses metadata to describe how objects and beans map to the data source. This approach isolates persistence information from the object model—you are free to design their ideal object model, and DBAs are free to design their ideal schema. For more information, see Section 2.1, "About Metadata".
At run time, EclipseLink uses the metadata to seamlessly and dynamically interact with the data source, as required by the application.
EclipseLink provides an extensive mapping hierarchy that supports the wide variety of data types and references that an object model might contain. For more information, see Chapter 6, "Understanding Mappings."
3.3.5 Foreign Keys and Object Relationships
A foreign key can be one or more columns that reference a unique key, usually the primary key, in another table. Foreign keys can be any number of fields (similar to primary key), all of which are treated as a unit. A foreign key and the primary parent key it references must have the same number and type of fields.
Foreign keys represents relationships from a column or columns in one table to a column or columns in another table. For example, if every Employee has an attribute address that contains an instance of Address (which has its own descriptor and table), the one-to-one mapping for the address attribute would specify foreign key information to find an address for a particular Employee.
3.3.6 Inheritance
Object-oriented systems allow classes to be defined in terms of other classes. For example: motorcycles, sedans, and vans are all kinds of vehicles. Each of the vehicle types is a subclass of the Vehicle class. Similarly, the Vehicle class is the superclass of each specific vehicle type. Each subclass inherits attributes and methods from its superclass (in addition to having its own attributes and methods).
Inheritance provides several application benefits, including the following:
-
Using subclasses to provide specialized behaviors from the basis of common elements provided by the superclass. By using inheritance, you can reuse the code in the superclass many times.
-
Implementing abstract superclasses that define generic behaviors. This abstract superclass may define and partially implement behavior, while allowing you to complete the details with specialized subclasses.
3.3.7 Concurrency
To have concurrent clients logged in at the same time, the server must spawn a dedicated thread of execution for each client. Java EE application servers do this automatically. Dedicated threads enable each client to work without having to wait for the completion of other clients. EclipseLink ensures that these threads do not interfere with each other when they make changes to the identity map or perform database transactions. Your client can make transactional changes in an isolated and thread safe manner. EclipseLink manages clones for the objects you modify to isolate each client's work from other concurrent clients and threads. This is essentially an object-level transaction mechanism that maintains all of the ACID (Atomicity, Consistency, Isolation, Durability) transaction principles as a database transaction.
EclipseLink supports configurable optimistic and pessimistic locking strategies to let you customize the type of locking that the EclipseLink concurrency manager uses. For more information, see Section 5.2.4, "Descriptors and Locking."
3.3.8 Caching
EclipseLink caching improves application performance by automatically storing data returned as objects from the database for future use. This caching provides several advantages:
-
Reusing Java objects that have been previously read from the database minimizes database access
-
Minimizing SQL calls to the database when objects already exist in the cache
-
Minimizing network access to the database
-
Setting caching policies a class-by-class and bean-by-bean basis
-
Basing caching options and behavior on Java garbage collection
EclipseLink supports several caching polices to provide extensive flexibility. You can fine-tune the cache for maximum performance, based on individual application performance. Refer to Chapter 8, "Understanding Caching" for more information.
3.3.9 Nonintrusive Persistence
The EclipseLink nonintrusive approach of achieving persistence through a metadata architecture means that there are almost no object model intrusions.
To persist Java objects, EclipseLink does not require any of the following:
-
Persistent superclass or implementation of persistent interfaces
-
Store, delete, or load methods required in the object model
-
Special persistence methods
-
Generating source code into or wrapping the object model
See Section 3.2, "Building and Using the Persistence Layer" for additional information on this nonintrusive approach. See also Section 2.1, "About Metadata."
3.3.10 Indirection
An indirection object takes the place of an application object so the application object is not read from the database until it is needed. Using indirection, or lazy loading in JPA, allows EclipseLink to create stand-ins for related objects. This results in significant performance improvements, especially when the application requires the contents of only the retrieved object rather than all related objects.
Without indirection, each time the application retrieves a persistent object, it also retrieves all the objects referenced by that object. This may result in lower performance for some applications.
Note:
Oracle strongly recommends that you always use indirection.EclipseLink provides several indirection models, such as proxy indirection, transparent indirection, and value holder indirection.
See Section 6.2.7.3.5, "Using Indirection with Collections" and Section 6.2.1, "Indirection (Lazy Loading)" for more information.
3.3.11 Mutability
Mutability is a property of a complex field that specifies whether the field value may be changed or not changed as opposed to replaced.
An immutable mapping is one in which the mapped object value cannot change unless the object ID of the object changes: that is, unless the object value is replaced by another object value altogether.
A mutable mapping is one in which the mapped object value can change without changing the object ID of the object.
By default, EclipseLink assumes the following:
-
all
TransformationMappinginstances are mutable -
all JPA
@Basicmapping types, exceptSerializabletypes, are immutable (includingDateandCalendartypes) -
all JPA
@BasicmappingSerializabletypes are mutable
Whether a value is immutable or mutable largely depends on how your application uses your persistent classes. For example, by default, EclipseLink assumes that a persistent field of type Date is immutable: this means that as long as the value of the field has the same object ID, EclipseLink assumes that the value has not changed. If your application uses the set methods of the Date class, you can change the state of the Date object value without changing its object ID. This prevents EclipseLink from detecting the change. To avoid this, you can configure a mapping as mutable: this tells EclipseLink to examine the state of the persistent value, not just its object ID.
You can configure the mutability of the following:
-
TransformationMappinginstances; -
any JPA
@Basicmapping type (includingDateandCalendartypes) individually; -
all
DateandCalendartypes.
Mutability can affect change tracking performance. For example, if a transformation mapping maps a mutable value, EclipseLink must clone and compare the value. If the mapping maps a simple immutable value, you can improve performance by configuring the mapping as immutable.
Mutability also affects weaving. EclipseLink can only weave an attribute change tracking policy for immutable mappings.
For more information, see Section 3.5, "About Weaving". See also the description of the @Mutable annotation in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
3.4 Migrating Applications to the EclipseLink Persistence Manager
You can configure an application server to use EclipseLink as the persistence manager. You can use only one persistence manager for all of the entities with container-managed persistence in a JAR file.
EclipseLink provides automated support for migrating an existing Java EE application to use EclipseLink as the persistence manager. For more information, see "Migrating from Apache OpenJPA to TopLink" in Solutions Guide for Oracle TopLink.
3.5 About Weaving
Weaving is a technique of manipulating the byte-code of compiled Java classes. The EclipseLink JPA persistence provider uses weaving to enhance both JPA entities and Plain Old Java Object (POJO) classes for such things as lazy loading, change tracking, fetch groups, and internal optimizations.
Weaving can be performed either dynamically at runtime, when entities are loaded, or statically at compile time by post-processing the entity .class files. By default, EclipseLink uses dynamic weaving whenever possible, including inside a Java EE application server and in Java SE when the EclipseLink agent is configured. Dynamic weaving is recommended as it is easy to configure and does not require any changes to a project's build process.
This section describes the following:
3.5.1 Using Dynamic Weaving
Use dynamic weaving to weave application class files one at a time, as they are loaded at run time. Consider this option when the number of classes to weave is few or when the time taken to weave the classes is short.
If the number of classes to weave is large or the time required to weave the classes is long, consider using static weaving.
3.5.2 Using Static Weaving
Use static weaving to weave all application class files at build time so that you can deliver prewoven class files. Consider this option to weave all applicable class files at build time so that you can deliver prewoven class files. By doing so, you can improve application performance by eliminating the runtime weaving step required by dynamic weaving.
In addition, consider using static weaving to weave in Java environments where you cannot configure an agent.
3.5.3 Weaving POJO Classes
EclipseLink uses weaving to enable the following for POJO classes:
-
Lazy loading
-
Change tracking
-
Fetch groups
EclipseLink weaves all the POJO classes in the JAR you create when you package a POJO application for weaving.
EclipseLink weaves all the classes defined in the persistence.xml file, that is:
-
All the classes you list in the
persistence.xmlfile. -
All classes relative to the JAR containing the
persistence.xmlfile if element<exclude-unlisted-classes>is false.
3.5.4 Weaving and Java EE Application Servers
The default EclipseLink weaving behavior applies in any Java EE JPA-compliant application server using the EclipseLink JPA persistence provider. To change this behavior, modify your persistence.xml file (for your JPA entities or POJO classes) to use EclipseLink JPA properties, EclipseLink JPA annotations, or both.
3.5.5 Disabling Weaving with Persistence Unit Properties
To disable weaving using EclipseLink persistence unit properties, configure your persistence.xml file with one or more of the following properties set to false:
-
eclipse.weaving; disables all weaving -
eclipselink.weaving.lazy; disables weaving for lazy loading (indirection) -
eclipselink.weaving.changetracking; disables weaving for change tracking -
eclipselink.weaving.fetchgroups; disables weaving for fetch groups -
eclipselink.weaving.internal; disables weaving for internal optimization -
eclipselink.weaving.eager; disables weaving for indirection on eager relationships
See