A User Interface
The Oracle Content Server interface includes various pages that you can use to manage the publishing process of your Oracle Site Studio web sites:
A.1 Oracle Site Studio Publisher Tasks
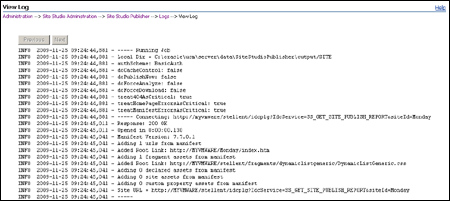
This screen lists the publishing tasks that have been defined, and details about their operation.
| Element | Description |
|---|---|
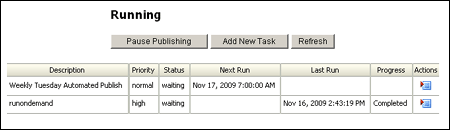
| Pause Publishing | Click to stop the scheduling process from starting new tasks. This will pause scheduling new tasks, but will not pause tasks that are currently running.
This button only appears when tasks are not paused. |
| Resume Publishing | Click to allow the scheduling process to start new tasks.
This button only appears when tasks are paused. |
| Add New Task | Opens the Add New Task screen (see Section A.2, "Add New Task/Edit Task") to enter a task for publishing. |
| Refresh | Refreshes the list of tasks. |
| Description | The name of the task. |
| Priority | Shows if the task runs as a high priority or normal priority. |
| Status | Shows if the task is Waiting, Pending, Running, Finished, or Expired. |
| Next Run | Scheduled date and time that the task will run. |
| Last Run | Date and time of the completion (or failure) of the most recent run of the task.
If this field is blank, the task has not been run since the last time the server was restarted. |
| Progress | Current progress status of the task. |
| Actions | Click to open a menu and select an action for the task.
Edit: opens the Edit Task screen (see Section A.2, "Add New Task/Edit Task") to make changes to the task. Run: puts the task in the queue to run, and will continue to run according to the schedule set for the task. This is the only method to run manual tasks. Stop: available only while a task is running. Stops the task. Delete: deletes the task. View Info: opens a screen to view the information about previous times the task has run. This is disabled on tasks that have never run. View Logs: opens the screen to view the logs for the task. |
A.2 Add New Task/Edit Task
The page used for adding and editing tasks to run with publisher has many parts to it. It is here that you can specify how often you publish a site, what site to publish, and even which sections of the site to include or exclude as well as other filters. Triggers can be set as well.
This section covers the following topics:
A.2.1 Publisher Settings
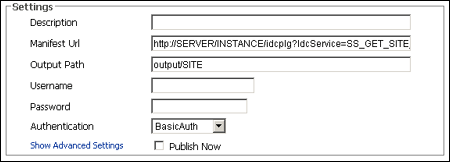
The Publisher Settings section is used to set the basic information of the task. The location of the site to publish, the location of the output, the username and password, and so forth.
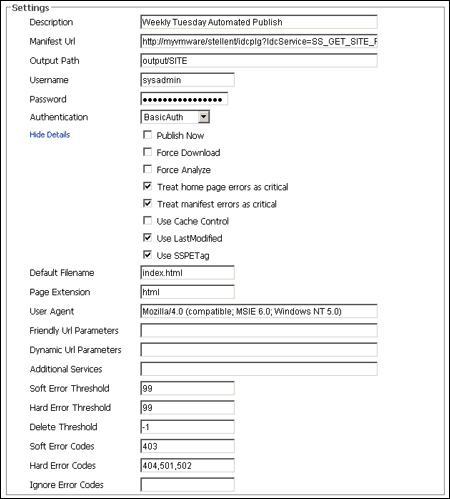
The Settings section has advanced settings, which can easily be seen when you click Show Advanced Settings. The advanced settings expand and display in the same section.
| Element | Description |
|---|---|
| Description | Enter a name of the task. |
| Manifest Url | Enter the URL for Oracle Site Studio Publisher to crawl. This is a specially formatted url that gets information about the web site to initiate the crawl. |
| Output Path | Enter the path to the local directory where content is downloaded. This is relative to the SSPHome location. |
| Username | Enter the user ID for password-protected sites |
| Password | Enter the encoded password for password-protected sites. |
| Authentication | Select the type of authentication for the site.
|
| Publish Now | Select to compare and publish only the marked, changed pages. If the altered content includes new links, Oracle Site Studio Publisher also publishes those links. |
| Show Advanced Settings | Click to display the Advanced Settings. |
| Hide Details | Click to collapse the Advanced Settings. |
| Force Download | Select to force a download of the Web page whether there are found changes or not. |
| Force Analyze | Select to force the analysis pass of the files listed in the filter parameters. If no files are listed in the filter, then all pages are analyzed.
This is used only with filters. |
| Treat home page errors as critical | Select to specify if any error retrieving the home page aborts the job. |
| Treat manifest errors as critical | Select to specify if any error retrieving any of the page urls listed in the site manifest aborts the job. |
| Use Cache Control | Select to compare the Max Age section property. Oracle Site Studio Publisher only selects and crawls those pages where the max-age value has not expired. |
| Use Last Modified | Select to use the value of the http header Last-Modified returned from the web server.
The web server normally returns this header for all resources accessed with a weblayout URL. (This response header is not provided for a dynamic Oracle Site Studio page.) If useLastModified is checked, the Last-Modified value is re-submitted in an If-Modified-Since request header the next time that resource is retrieved. That then allows the web server to return a 304 - Not Modified response if the resource is unchanged. If this is not checked, the resource is downloaded and compared with the previously retrieved content. You would only choose to do this if you found that your web server was returning unreliable results for Last-Modified. |
| Use SSPETag | This option controls a proprietary mechanism used to identify changes to files retrieved by the GET_FILE service.
Without this mechanism, file content is retrieved and compared with the previous version. Use of this mechanism allows the content server to return a 304 - Not Modified response and so avoid unnecessary downloads. |
| Default Filename | Specify the filename to be used for URLs where there is no filename explicitly specified. |
| Page Extension | The extension that is added to page urls that do not otherwise specify an extension. For example, a typical reference to a document in the dynamic site might look like:
Where |
| User Agent | Enables you to specify a value for the User-Agent http request header used by Oracle Site Studio Publisher when crawling the site. |
| Friendly Url Parameters | Specify a comma separated list of additional parameter names to honor.
Oracle Site Studio Publisher supports a few built-in values. Friendly Urls already honor parameters ending in NextRow or _dcPageNum and use the parameter name and value to construct the filename for the crawled page. If a URL Parameter affects the appearance of the page, then you need to capture a different copy of the page for each combination of parameter values. |
| Dynamic Url Parameters | Specify a comma separated list of additional parameter names to honor.
Dynamic Urls using the GET_PAGE service already honor dID, dDocName, RevisionSelectionMethod, and Rendition. If a URL Parameter affects the appearance of the page, then you need to capture a different copy of the page for each combination of parameter values. |
| Additional Services | Select to allow additional services to be crawled.
This element enables you to control the service calls that Oracle Site Studio Publisher attempts to crawl. There is built-in support for those services that are expected to generate meaningful static content: SS_GET_PAGE, GET_FILE, and GET_DYNAMIC_CONVERSION. |
| Soft Error Threshold | The number of soft errors allowed. If the defined number is exceeded, publishing fails. |
| Hard Error Threshold | The number of hard errors allowed. If the defined number is exceeded, publishing fails. |
| Delete Threshold | The number of objects that can be missing before the crawl is failed. If this number is exceeded, publishing fails. |
| Soft Error Codes | Enter a list of codes to specify individual error codes that are treated as soft errors.
There are no wildcards allowed in this list, you must list each error code explicitly (separated by a comma). |
| Hard Error Codes | Enter a list of codes to specify individual error codes that are treated as hard errors.
There are no wildcards allowed in this list, you must list each error code explicitly (separated by a comma). |
| Ignore Error Codes | Enter a list of codes to specify individual error codes that are ignored. These codes will not affect the Oracle Site Studio Publisher crawl.
There are no wildcards allowed in this list, you must list each error code explicitly (separated by a comma). |
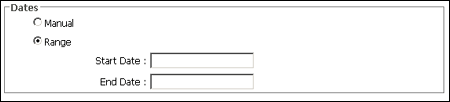
A.2.2 Dates
The Dates section is used to specify a range of dates that the task will run.
If you select Manual, then the Days section options (see Section A.2.3, "Days") and the Run Time section options (see Section A.2.4, "Run Times") are grayed out. This is because selecting Manual will mean that the task is a task with will run only on-demand.
| Element | Description |
|---|---|
| Manual / Range | Select to either have a task that runs only when commanded (manual) or to run at regular intervals at least once within a certain range of dates. |
| Start Date | The first date of a range that the task will run. |
| End Date | The final date of a range that the task will be run. |
A.2.3 Days
The Days section is used to select if the task will run on certain days of the week, or on certain days of the month.
The options in this section will be available only if Range was selected in the Dates section (see Section A.2.2, "Dates").

| Element | Description |
|---|---|
| Days of Week | Select to run the task on the selected days of the week. The task will run on the days selected that are within the range selected in the Dates section (see Section A.2.2, "Dates"). |
| Days of Month | Select to run the task on particular days of the month. Days can be listed individually, by a range, or in a combination of both, for example: 1,2,7-13,25.
The word |
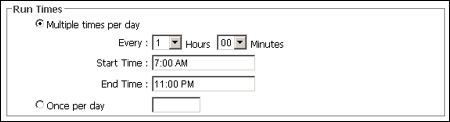
A.2.4 Run Times
The Run Times section is used to specify how often the task runs each day.
The options in this section will be available only if Range was selected in the Dates section (see Section A.2.2, "Dates").
| Element | Description |
|---|---|
| Multiple Times Per Day | Select to have a task that runs either at regular intervals each day. |
| Once per Day | Select to have a task that runs only once per day.
Enter a time in the box. |
| Hours Minutes | Select how often the task should run between the Start Time and the End Time. |
| Start Time | The time of day the task will start running. |
| End Time | The time of day the task will stop running. |
A.2.5 Options
The Options section is where you set the priority and log levels of the task. You can also set an email address to receive notification after the task runs.

| Element | Description |
|---|---|
| Priority | Select to mark this task as a priority task. This is used to ensure that the more vital tasks are run at a priority over the other tasks. |
| Log Level | Select the level of log information to write to the logs.
Each item in the drop-down list includes the logging levels above it. For example, selecting INFO includes logs of not only INFO items but also WARN and ERROR. |
| Email Notification | Enter an email address to send notification of the task completion (or error) to. |
A.2.6 Include List
The Include List section is used to specify which parts of the site (by URL) should be included in publishing.
If you list a URL for inclusion in this section, and it appears in a listed FilterSet type 'exclude' , then it will not be included in the publishing.

| Element | Description |
|---|---|
| Hide Include List | Click to minimize the Include List section. |
| URL | Enter a URL to place on the Include List for Oracle Site Studio Publisher to crawl. This can be a regular expression. |
| Remove | Click to remove the URL from the list. |
| Add New Item | Click to add another field to enter an additional URL for the Include List. |
A.2.7 Exclude List
The Exclude List is used to specify which parts of the site (by URL) should be excluded from publishing.

| Element | Description |
|---|---|
| Hide Exclude List | Click to minimize the Exclude List section. |
| URL | Enter a URL to place on the Exclude List for Oracle Site Studio Publisher to avoid. This can be a regular expression. |
| Remove | Click to remove the URL from the list. |
| Add New Item | Click to add another field to enter an additional URL for the Exclude List. |
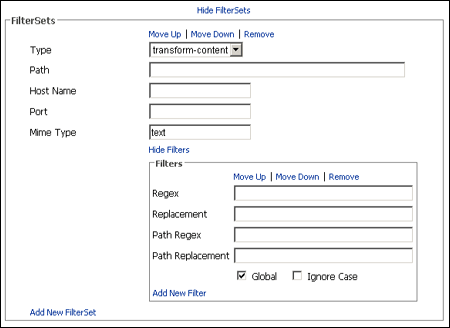
A.2.8 FilterSets
Filtersets are controls used to transform content once it is downloaded from crawling, before it is published. Filters are applied in the order that they appear in the Filterset.
| Element | Description |
|---|---|
| Add New Filterset | Expands to display an additional set of fields to enter information for another filterset. |
| Move Up | Move Down | Remove | Select to move the filterset up or down in the list relative to other filtersets, or to remove it completely. |
| Type | This attribute specifies the context in which the filterset should be invoked. The types available are:
transform-content: for URLs that match this filterset, the child filter elements are applied during download, transforming the content in the manner specified by these filters. transform-link: for URLs that match this filterset, the child filter elements are applied during download. In this case, the filter elements are only applied to links found in the current downloaded file, not to the entire content. exclude: for URLs that would normally be included, match this filterset, and the URL matches, content is not downloaded. |
| Path | The path attribute is a wildcard pattern to match the file path of the URL (the part following the URL's host name) currently being downloaded.
A Java regular expression syntax is used for pattern matching. Use the following reference:
|
| Hostname | Enter a value to match the URL's host name (the domain name part of the URL) with the specified host name. |
| Port | Enter a value to match a URL's port number. |
| Mime Type | Enter a value to match the URL's MIME-type. The value that starts with the value specified by this type is considered a match; therefore, text matches both text/html and text/xml. |
| Show Filters | Expands to display the filters specified in the FilterSet.
When opened, the link becomes Hide Filters, to close the list of individual filters. |
| Add New Filter | Adds an additional set of fields to enter a new filter. |
| Move Up | Move Down | Remove | Click to move the filter up or down in the list relative to other filters, or to remove it completely. |
| Regex | A java regular expression used to identify text to be replaced in the content of the current file or in the link. |
| Replacement | The value replacing the text identified by the regex attribute. |
| Path Regex | A Java regular expression used to identify a path and file to replace in the context of the current file. This value is only meaningful within an enclosing transform-content filterset. |
| Path Replacement | The replacement value used to change the filename. |
| Global | Controls the behavior of the substitution. If Global is checked, every match for the regex expression is replaced. If unchecked, only the first occurrence is replaced. |
| Ignore Case | Controls the behavior of the regex expression. If Ignore Case is selected, then the case of the expression is ignored when comparing the regex. |
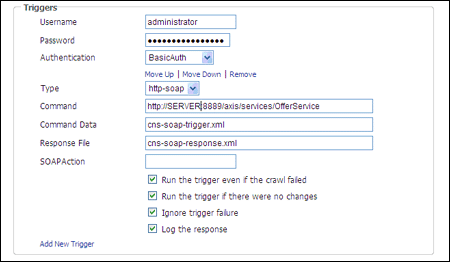
A.2.9 Triggers
Triggers enable the replication engine to run commands either before a package is downloaded or after the download is complete. The types of triggers available are cmd, http-post, http-get, and http-soap.
| Element | Description |
|---|---|
| Show Triggers | Opens the fields required to enter the most basic information for a trigger. |
| Add New Trigger | Opens additional information to add multiple types of triggers. |
| Username | The username used for authentication. You cannot specify different authentications for each trigger. All triggers in a task must have the same credentials and authentication method. |
| Password | The password used for authentication. You cannot specify different authentications for each trigger. All triggers in a task must have the same credentials and authentication method. |
| Authentication | Select to authenticate the user either with basic authentication or with a custom form. |
| Move Up | Move Down | Remove | Click to move the trigger up or down in the list relative to other triggers, or to remove it completely. |
| Type | Specifies the type of trigger. |
| Command | Command line arguments to pass through the trigger. Only used if the type is set to cmd. |
| Command Data | The path, relative to the task's output path, of the file to be uploaded. Only used if the type is set to http-post or http-soap. |
| Response File | Specifies the full path to a file to capture the response. |
| SOAPAction | Sets the value for the SOAPAction HTTP request header field. Only used if the type is set to http-soap. |
| Run the trigger even if the crawl failed | Specifies whether the command should be run, even if the job encountered errors. |
| Run the trigger if there were no changes | If checked, the trigger will run even if there has been no change in content. |
| Ignore trigger failure | Specifies whether further trigger execution will happen.
If checked, further triggers will run, even if the current trigger fails. |
| Log the response | Specifies whether to write the response to the log. |
A.3 Task Info
The Task Info screen is used to view information about the most recent task initiating the specified Oracle Site Studio Publisher crawl.
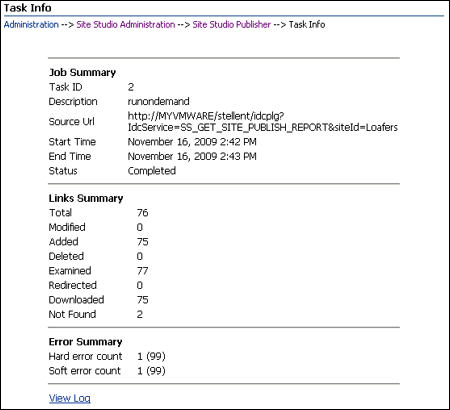
| Element | Description |
|---|---|
| Task ID | The ID number of the task. |
| Description | The description of the task. |
| Source Url | The source URL of the site being published. |
| Start Time | The time the task started. |
| End Time | The time the task completed. |
| Status | The completion status of the task. |
| Total | Total number of URLs (including files such as CSS, JavaScript, and so forth) that make up the crawled site. |
| Modified | Number of URLs that were modified since the most recent crawl of the site. |
| Added | Number of URLs added since the most recent crawl of the site. |
| Deleted | Number of URLs deleted since the most recent crawl of the site. |
| Examined | The number of URLs followed while crawling the site. |
| Redirected | The number of URLs redirected while crawling the site. |
| Downloaded | The number of examined links that were actually downloaded. |
| Not found | The number of links followed that received an error. |
| Hard Error Count | Total number of "hard" errors found. The number in parenthesis is the maximum allowed. |
| Soft Error Count | Total number of "soft" errors found. The number in parenthesis is the maximum allowed. |
| View Log | Opens the log file for the task in the View Log screen (see Section A.5, "View Log"). |
A.4 Logs
Lists the job summary and different log files generated for the specific task.
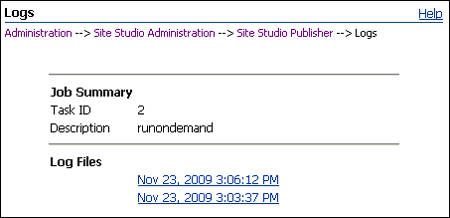
| Element | Description |
|---|---|
| Task ID | The ID number of the task. |
| Description | The description of the task, as entered in the Publisher Settings section on the Add/Edit Task page (see Section A.2.1, "Publisher Settings"). |
| Log Files | A link for each date and time that the task was run. Each link opens the log file for that specific run on the View Log page (see Section A.5, "View Log").
If the log file is very long, it will be split across multiple files, and each file will have a link with the same timestamp. |