Consultar Dados Externos com o Serviço Data Catalog
O Oracle Cloud Infrastructure Data Catalog é o serviço de gerenciamento de metadados do Oracle Cloud que ajuda você a descobrir dados e oferecer suporte à governança de dados. Ele fornece um inventário de ativos, um glossário de negócios e um metastore comum para data lakes.
O Autonomous AI Database pode aproveitar esses metadados para simplificar drasticamente o gerenciamento do acesso ao armazenamento de objetos do seu data lake. Em vez de definir manualmente tabelas externas para acessar o data lake, use as tabelas externas que são definidas e gerenciadas automaticamente. Essas tabelas serão encontradas em esquemas protegidos pelo Autonomous AI Database que são mantidos atualizados com alterações no serviço Data Catalog.
Sobre Consultar com o Serviço Data Catalog
Ao sincronizar com metadados do serviço Data Catalog, o Autonomous AI Database cria automaticamente tabelas externas para cada entidade lógica coletada pelo serviço Data Catalog. Essas tabelas externas são definidas em esquemas de banco de dados que são totalmente gerenciados pelo processo de sincronização de metadados. Os usuários podem consultar dados imediatamente sem precisar derivar manualmente o esquema (colunas e tipos de dados) para origens de dados externas e criar tabelas externas manualmente.
A sincronização é dinâmica, mantendo o Autonomous AI Database atualizado em relação às alterações nos dados subjacentes, reduzindo o custo de administração, pois ele mantém automaticamente centenas a milhares de tabelas. Ele também permite que várias instâncias do Autonomous AI Database compartilhem o mesmo Data Catalog, reduzindo ainda mais os custos de gerenciamento e fornecendo um conjunto comum de definições de negócios.
As pastas/buckets do serviço Data Catalog são contêineres que sincronizam com esquemas do Autonomous Database. Entidades lógicas dentro dessas pastas/buckets são mapeadas para tabelas externas do Autonomous Database. Esses esquemas e tabelas externas são gerados e mantidos automaticamente por meio do processo de sincronização:
-
Pastas/Buckets mapeiam para esquemas de banco de dados que são apenas para fins organizacionais.
-
A organização deve ser consistente com o data lake e minimizar a confusão ao acessar dados por diferentes caminhos.
-
O serviço Data Catalog é a origem da verdade para as tabelas contidas nos esquemas. As alterações feitas no serviço Data Catalog atualizam as tabelas do esquema durante uma sincronização subsequente.
Para usar esse recurso, um Administrador do Serviço Database Data Catalog inicia uma conexão com uma instância do serviço Data Catalog, seleciona quais ativos de dados e entidades lógicas serão sincronizados e executa a sincronização. O processo de sincronização cria esquemas e tabelas externas com base nos ativos de dados coletados e nas entidades lógicas do serviço Data Catalog selecionado. Assim que as tabelas externas são criadas, os Analistas de Dados podem começar a consultar seus dados sem precisar derivar manualmente o esquema para origens de dados externas e criar tabelas externas.
Observação: O Pacote DBMS_DCAT está disponível para executar as tarefas necessárias para consultar ativos de dados do armazenamento de objetos do serviço Data Catalog. Consulte Pacote DBMS_DCAT.
Conceitos Relacionados à Consulta com o Serviço Data Catalog
É necessária uma compreensão dos conceitos a seguir para consulta com o serviço Data Catalog.
Data Catalog: O serviço Data Catalog coleta ativos de dados que apontam para as origens de dados de armazenamento de objetos que você deseja consultar com o Autonomous AI Database. No serviço Data Catalog, você pode especificar como os dados são organizados durante a coleta, suportando diferentes padrões de organização de arquivos. Como parte do processo de coleta do serviço Data Catalog, você pode selecionar os buckets e arquivos que deseja gerenciar no ativo. Para obter mais informações, consulte Visão Geral do Serviço Data Catalog.
Armazenamentos de Objetos: Os Armazenamentos de Objetos têm buckets que contêm uma variedade de objetos. Alguns tipos comuns de objetos encontrados nesses buckets incluem: arquivos CSV, parquet, avro, json e ORC. Os buckets geralmente têm uma estrutura ou um padrão de design para os objetos que eles contêm. Há muitas maneiras diferentes de estruturar dados e muitas maneiras diferentes de interpretar esses padrões.
Por exemplo, um padrão de design típico usa pastas de nível superior que representam tabelas. Os arquivos dentro de uma determinada pasta compartilham o mesmo esquema e contêm dados para essa tabela. As subpastas são frequentemente usadas para representar partições de tabela (por exemplo, uma subpasta para cada dia). O serviço Data Catalog se refere a cada pasta de nível superior como uma entidade lógica, e essa entidade lógica é mapeada para uma tabela externa do Autonomous AI Database.
Conexão: Uma conexão é uma conexão do Autonomous AI Database com uma instância do serviço Data Catalog. Para cada instância do Autonomous AI Database, pode haver conexões com várias instâncias do serviço Data Catalog. A credencial do Autonomous AI Database deve ter direitos para acessar ativos do serviço Data Catalog que foram coletados do armazenamento de objetos.
Coleta: Um processo do serviço Data Catalog que verifica o armazenamento de objetos e gera as entidades lógicas de seus conjuntos de dados.
Ativo de Dados: Um ativo de dados no serviço Data Catalog representa uma origem de dados, que inclui bancos de dados, Oracle Object Storage, Kafka e muito mais. O Autonomous AI Database utiliza os ativos do Oracle Object Storage para sincronização de metadados.
Entidade de Dados: Uma entidade do serviço Data Catalog é uma coleção de dados, como uma tabela ou view do banco de Dados, ou um único arquivo, e normalmente tem muitos atributos que descrevem seus dados.
Entidade Lógica: Em Data Lakes, vários arquivos geralmente compreendem uma única entidade lógica. Por exemplo, você pode ter arquivos de sequência de cliques diários e esses arquivos compartilham o mesmo esquema e tipo de arquivo.
Uma entidade lógica do serviço Data Catalog é um grupo de arquivos do Object Storage que são derivados durante a coleta aplicando padrões de nome de arquivo que foram criados e designados a um ativo de dados.
Objeto de Dados: Um objeto de dados no Serviço Data Catalog refere-se a ativos e entidades de dados.
Padrão de Nome de Arquivo: Em um data lake, os dados podem ser organizados de diferentes maneiras. Normalmente, as pastas capturam arquivos do mesmo esquema e tipo. Você deve se registrar no serviço Data Catalog como seus dados são organizados. Os padrões de nome de arquivo são usados para identificar como seus dados são organizados. No serviço Data Catalog, você pode definir padrões de nome de arquivo usando expressões regulares. Quando o serviço Data Catalog coleta um ativo de dados com um padrão de nome de arquivo designado, as entidades lógicas são criadas com base no padrão de nome de arquivo. Ao definir e designar esses padrões a ativos de dados, vários arquivos podem ser agrupados como entidades lógicas com base no padrão de nome de arquivo.
Sincronizar (Sincronizar): O Autonomous AI Database executa sincronizações com o serviço Data Catalog para manter automaticamente seu banco de dados atualizado em relação às alterações nos dados subjacentes. A sincronização pode ser realizada manualmente ou em uma programação.
O processo de sincronização cria esquemas e tabelas externas com base nos ativos de dados e entidades lógicas do serviço Data Catalog. Esses esquemas são protegidos, o que significa que seus metadados são gerenciados pelo serviço Data Catalog. Se quiser alterar os metadados, você deverá fazer as alterações no serviço Data Catalog. Os esquemas do Autonomous AI Database refletirão quaisquer alterações após a próxima sincronização ser executada. Para obter mais detalhes, consulte Mapeamento de Sincronização.
Mapeamento de Sincronização
O processo de sincronização cria e atualiza esquemas do Autonomous AI Database e tabelas externas com base em ativos de dados, pastas, entidades lógicas, atributos e substituições personalizadas relevantes do serviço Data Catalog.
| Data Catalog | Autonomous AI Database | Descrição do Mapeamento |
|---|---|---|
| Ativo de dados e pasta (bucket de armazenamento de objetos) | Nome do esquema | Valores padrão: Por padrão, o nome do esquema gerado no Autonomous AI Database tem o seguinte formato:
Personalizações: Odata-asset-name e o folder-name padrão podem ser personalizados definindo propriedades personalizadas, nomes de negócios e nomes de exibição para substituir esses nomes padrão.
Exemplos de:
|
| Entidade lógica | Tabela externa | As entidades lógicas são mapeadas para tabelas externas. Se a entidade lógica tiver um atributo particionado, ele será mapeado para uma tabela externa particionada. O nome da tabela externa é derivado do Nome para Exibição ou do Nome da Empresa da entidade lógica correspondente. Se Por exemplo, se |
| Atributos da entidade lógica | Colunas da tabela externa | Nomes de coluna: Os nomes de coluna de tabela externa são derivados dos nomes de exibição de atributo ou nomes comerciais da entidade lógica correspondente. Para entidades lógicas derivadas de arquivos Parquet, Avro e ORC, o nome da coluna é sempre o nome de exibição do atributo, pois representa o nome do campo derivado dos arquivos de origem. Para atributos correspondentes a uma entidade lógica derivada de arquivos CSV, os seguintes campos de atributo são usados na ordem de precedência para gerar o nome da coluna:
Tipo de coluna: A propriedade personalizada Para atributos correspondentes a uma entidade lógica derivada de arquivos Avro com tipos de dados Tamanho da coluna: A propriedade personalizada Precisão da coluna: A propriedade personalizada Para atributos correspondentes a uma entidade lógica derivada de arquivos Avro com tipos de dados Escala de coluna: A propriedade personalizada |
Workflow Típico com o Serviço Data Catalog
Há um workflow típico de ações executadas por usuários que desejam consultar o serviço Data Catalog.
O Administrador do serviço Database Data Catalog cria uma conexão entre a instância do Autonomous AI Database e uma instância do serviço Data Catalog e, em seguida, configura e executa uma sincronização (sincronização) entre o serviço Data Catalog e o Autonomous AI Database. A sincronização cria tabelas e esquemas externos na instância do Autonomous AI Database com base no conteúdo sincronizado do Data Catalog.
O Administrador de Consulta do Catálogo de Dados do Banco de Dados ou o Administrador do Banco de Dados concede acesso READ às tabelas externas geradas para que os Analistas de Dados e outros usuários do banco de dados possam procurar e consultar as tabelas externas.
A tabela abaixo descreve cada ação em detalhes. Para obter uma descrição dos diferentes tipos de usuário incluídos nesta tabela, consulte Usuários e Atribuições do Serviço Data Catalog.
Observação: O Pacote DBMS_DCAT está disponível para executar as tarefas necessárias para consultar ativos de dados do armazenamento de objetos do serviço Data Catalog. Consulte Pacote DBMS_DCAT.
| Ação | Quem é o usuário | Descrição |
|---|---|---|
| Criar políticas | Administrador do Data Catalog do Banco de Dados | A credencial de usuário do Autonomous AI Database deve ter as permissões apropriadas para gerenciar o serviço Data Catalog e para ler no armazenamento de objetos. Mais informações: Credenciais Obrigatórias e Políticas do Serviço IAM. |
| Criar credenciais | Administrador do Data Catalog do Banco de Dados | Certifique-se de que as credenciais do banco de dados estejam em vigor para acessar o serviço Data Catalog e consultar o armazenamento de objetos. O usuário chama Mais informações: Procedimento DBMS_CLOUD CREATE_CREDENTIAL. |
| Criar conexões com o serviço Data Catalog | Administrador do Data Catalog do Banco de Dados | Para iniciar uma conexão entre uma instância do Autonomous AI Database e uma instância do serviço Data Catalog, o usuário chama A conexão com a instância do serviço Data Catalog deve usar uma credencial de usuário com privilégios suficientes do OCI (Oracle Cloud Infrastructure). Depois que a conexão for estabelecida, a instância do serviço Data Catalog será atualizada com o namespace Mais informações: Procedimento SET_DATA_CATALOG_CONN, Procedimento UNSET_DATA_CATALOG_CONN. |
| Criar uma sincronização seletiva | Administrador do Data Catalog do Banco de Dados | Crie um job de sincronização selecionando os objetos do serviço Data Catalog a serem sincronizados. O usuário pode:
Mais informações: Consulte Procedimento CREATE_SYNC_JOB, Procedimento DROP_SYNC_JOB, Mapeamento de Sincronização |
| Sincronizar com o Serviço Data Catalog | Administrador do Data Catalog do Banco de Dados | O usuário inicia uma operação de sincronização. A sincronização é iniciada manualmente por meio da chamada de procedimento A operação de sincronização cria, modifica e elimina tabelas e esquemas externos de acordo com o conteúdo do serviço Data Catalog e as seleções de sincronização. A configuração manual é aplicada usando Propriedades Personalizadas do Serviço Data Catalog. Mais informações: Consulte Procedimento DBMS_DCAT RUN_SYNC, Procedimento CREATE_SYNC_JOB, Mapeamento de Sincronização |
| Monitorar sincronização e exibir logs | Administrador do Data Catalog do Banco de Dados | O usuário pode exibir o status de sincronização consultando a view USER_LOAD_OPERATIONS. Após a conclusão do processo de sincronização, o usuário poderá exibir um log dos resultados da sincronização, incluindo detalhes sobre os mapeamentos de entidades lógicas para tabelas externas. |
| Conceder privilégios | Administrador de Consulta do Catálogo de Dados do Banco de Dados, Administrador do Banco de Dados | O Administrador de Consulta do Catálogo de Dados ou o Administrador do banco de dados deve conceder READ em tabelas externas geradas aos usuários do analista de dados. Isso permite que os analistas de dados consultem as tabelas externas geradas. |
| Procurar e consultar tabelas externas | Analista de Dados | Os analistas de dados podem consultar as tabelas externas por meio de qualquer ferramenta ou aplicativo compatível com o Oracle SQL. Os Analistas de Dados podem revisar os esquemas e tabelas sincronizados nos esquemas DCAT$\* e consultar as tabelas usando o Oracle SQL. Mais informações: Mapeamento de Sincronização |
| Encerrar conexões com o serviço Data Catalog | Administrador do Data Catalog do Banco de Dados | Para remover uma associação existente do serviço Data Catalog, o usuário chama o procedimento Essa ação só é feita quando você não planeja mais usar o serviço Data Catalog e as tabelas externas derivadas do catálogo. Esta ação exclui metadados do serviço Data Catalog e elimina tabelas externas sincronizadas da instância do Autonomous AI Database. As propriedades personalizadas no serviço Data Catalog e nas políticas do OCI não são afetadas. Mais informações: Procedimento UNSET_DATA_CATALOG_CONN |
Exemplo: Cenário MovieStream
Nesse cenário, o Moviestream está capturando dados em uma zona de destino no armazenamento de objetos. Grande parte desses dados, mas não necessariamente todos, é usada para alimentar um Autonomous AI Database. Antes de alimentar o Autonomous AI Database, os dados são transformados, limpos e subsequentemente armazenados na área "ouro".
O serviço Data Catalog é usado para coletar essas origens e, em seguida, fornecer um contexto de negócios aos dados. Os metadados do serviço Data Catalog são compartilhados com o Autonomous AI Database, permitindo que os usuários do Autonomous AI Database consultem essas origens de dados usando o Oracle SQL. Esses dados podem ser carregados no Autonomous AI Database ou consultados dinamicamente usando tabelas externas.
Para obter mais informações sobre como usar o serviço Data Catalog, consulte Documentação do Serviço Data Catalog.
-
Object Store - Revisar buckets, pastas e arquivos
-
Revise os buckets no seu armazenamento de objetos.
Por exemplo, abaixo estão os buckets de destino (
moviestream_landing) e de zona ouro (moviestream_gold) no armazenamento de objetos: -
Verifique as pastas e os arquivos nos buckets do armazenamento de objetos.
Por exemplo, abaixo estão as pastas no bucket de destino (
moviestream_landing) no armazenamento de objetos:
-
-
Catálogo de Dados - Criar padrões de nome de arquivo
-
Informe ao serviço Data Catalog como seus dados são organizados usando padrões de nome de arquivo. Estas são expressões regulares usadas para categorizar arquivos. Os padrões de nome de arquivo são usados pelo coletor do serviço Data Catalog para derivar entidades lógicas. Os dois padrões de nome de arquivo a seguir são usados para coletar os buckets no exemplo MovieStream. Consulte Coletando Arquivos do Serviço Object Storage como Entidades de Dados Lógicas para obter mais detalhes sobre a criação de padrões de nome de arquivo.
Estilo Hive Estilo de pasta {bucketName:.*}/{logicalEntity:[^/]+}.db/{logicalEntity:[^/]+}/.*{bucketName:[\w]+}/{logicalEntity:[^/]+}(?<!.db)/.*$- Cria entidades lógicas para origens que contêm ".db" como a primeira parte do nome do objeto.
- Para garantir a exclusividade dentro do bucket, o nome resultante é (db-name).(nome da pasta)
- Cria uma entidade lógica com base no nome da pasta fora da raiz
- Para evitar a duplicação com o Hive, os nomes de objetos que têm ".db" são ignorados.
-
Para criar padrões de nome de arquivo, vá para a guia Padrões de Nome de Arquivo do seu serviço Data Catalog e clique em Criar Padrão de Nome de Arquivo. Por exemplo, a seguir está a guia Criar Padrão de Nome de Arquivo do serviço Data Catalog
moviestream:
-
-
Catálogo de Dados - Criação de Ativo de Dados
-
Crie um ativo de dados que seja usado para coletar dados do seu armazenamento de objetos.
Por exemplo, um ativo de dados chamado
phoenixObjStoreé criado no serviço Data Catalogmoviestream: -
Adicionar uma conexão ao seu ativo de dados.
Neste exemplo, o ativo de dados se conecta ao compartimento do recurso de armazenamento de objetos
moviestream. -
Agora, associe seus padrões de nome de arquivo ao seu ativo de dados. Selecione Designar Padrões de Nome de Arquivo, marque os padrões desejados e clique em Designar.
Por exemplo, aqui estão os padrões designados ao ativo de dados
phoenixObjStore: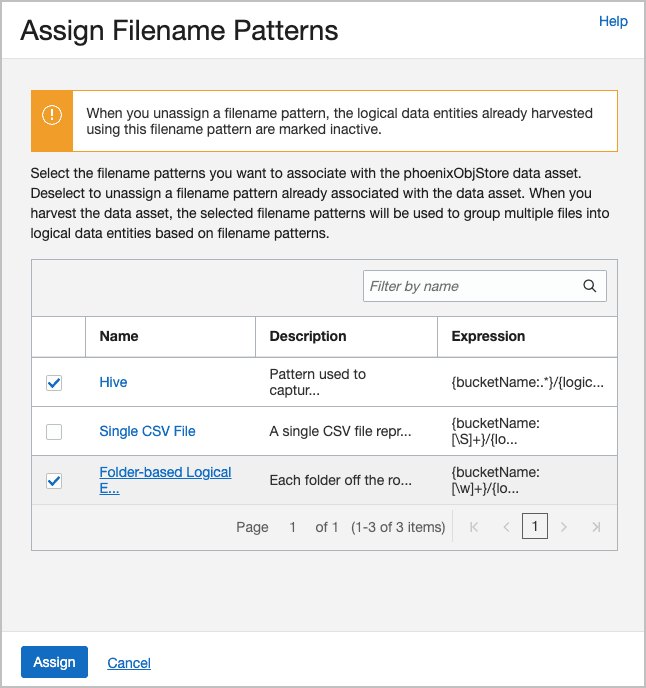
-
Catálogo de Dados - Coletar dados do armazenamento de objetos
a. Coletar o ativo de dados do serviço Data Catalog. Selecione os buckets do armazenamento de objetos que contêm os dados de origem.
Neste exemplo, os buckets
moviestream_golde ` moviestream_landing` do armazenamento de objetos são selecionados para coleta.b. Depois de executar o job, você verá as entidades lógicas. Use a opção Procurar Ativos de Dados para revisá-los.
Neste exemplo, você está examinando a entidade lógica
customer-extensione seus atributos.Se você tiver um glossário, o serviço Data Catalog recomenda categorias e termos para associar à entidade e seus atributos. Isso fornece um contexto de negócios para os itens. Esquemas, tabelas e colunas muitas vezes não são autoexplicativos.
Em nosso exemplo, queremos diferenciar entre os diferentes tipos de buckets e o significado de seu conteúdo:
-
O que é uma zona de pouso?
-
Qual é a precisão dos dados?
-
Quando foi a última atualização?
-
qual é a definição de uma entidade lógica ou seu atributo
-
-
Autonomous AI Database - Estabelecer Conexão com o Serviço Data Catalog
Conecte o Autonomous AI Database ao serviço Data Catalog. Você precisa garantir que a credencial usada para fazer essa conexão esteja usando um principal do OCI autorizado a acessar o ativo do serviço Data Catalog. Para obter mais informações, consulte Políticas do Serviço Data Catalog.
a. Estabelecer Conexão com o Serviço Data Catalog
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.iad.aaaaaaaardp66bg....twiq' define dcat_region='us-ashburn-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections;b. Sincronize o Data Catalog com o Autonomous AI Database. Aqui, sincronizaremos todos os ativos de armazenamento de objetos:
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes;c. Autonomous AI Database - Agora comece a executar consultas no armazenamento de objetos.
-- Query the Data ! select *from dcat$phoenixobjstore_moviestream_gold.genre; -
Alterar esquemas para objetos
Os nomes de esquema padrão são bastante complicados. Vamos simplificá-los especificando o atributo personalizado
Oracle-Db-Schemado ativo e da pasta no serviço Data Catalog. Altere o ativo de dados paraPHXe as pastas paralandingegold, respectivamente. O esquema é uma concatenação dos dois.a. No serviço Data Catalog, navegue até o bucket
moviestream_landinge altere o ativo paralandingegold, respectivamente.Antes da alteração:
Após a alteração:
b. Execute outra sincronização.
-
Exemplo: Cenário de Dados Particionados
Este cenário ilustra como criar tabelas externas no Autonomous AI Database baseadas em entidades lógicas do serviço Data Catalog coletadas de dados particionados no Object Store.
O exemplo a seguir é baseado em Exemplo: Cenário MovieStream e foi adaptado para demonstrar a integração com dados particionados. O serviço Data Catalog é usado para coletar essas origens e, em seguida, fornecer um contexto de negócios aos dados. Para obter mais detalhes sobre este exemplo, consulte Exemplo: Cenário MovieStream.
Para obter mais informações sobre como usar o serviço Data Catalog, consulte Documentação do Serviço Data Catalog.
-
Object Store - Revisar buckets, pastas e arquivos
-
Revise os buckets no seu armazenamento de objetos.
Por exemplo, abaixo estão os buckets de destino (
moviestream_landing) e de zona ouro (moviestream_gold) no armazenamento de objetos: -
Verifique as pastas e os arquivos nos buckets do armazenamento de objetos.
Por exemplo, abaixo estão as pastas no bucket de destino (
moviestream_landing) no armazenamento de objetos:
-
-
Catálogo de Dados - Criar padrões de nome de arquivo
-
Informe ao serviço Data Catalog como seus dados são organizados usando padrões de nome de arquivo. Estes são prefixos de pasta ou expressões regulares usadas para categorizar arquivos. Os padrões de nome de arquivo são usados pelo coletor do serviço Data Catalog para derivar entidades lógicas. Quando um prefixo de pasta é especificado, o serviço Data Catalog gera automaticamente entidades lógicas com base no prefixo de pasta especificado no armazenamento de objetos. O padrão de nome de arquivo a seguir é usado para coletar os buckets no exemplo MovieStream. Consulte Coletando Arquivos do Serviço Object Storage como Entidades de Dados Lógicas para obter mais detalhes sobre a criação de padrões de nome de arquivo.
Prefixo de pasta Descrição workshop.db/Cria entidades lógicas para origens que contêm o caminho "workshop.db" no armazenamento de objetos. -
Para criar padrões de nome de arquivo, vá para a guia Padrões de Nome de Arquivo do seu serviço Data Catalog e clique em Criar Padrão de Nome de Arquivo. Por exemplo, a seguir está a guia Criar Padrão de Nome de Arquivo do serviço Data Catalog
moviestream:
-
-
Catálogo de Dados - Criação de Ativo de Dados
-
Crie um ativo de dados que seja usado para coletar dados do seu armazenamento de objetos.
Por exemplo, um ativo de dados chamado
amsterdamObjStoreé criado no serviço Data Catalogmoviestream: -
Adicionar uma conexão ao seu ativo de dados.
Neste exemplo, o ativo de dados se conecta ao compartimento do recurso de armazenamento de objetos
moviestream. -
Agora, associe seus padrões de nome de arquivo ao seu ativo de dados. Selecione Designar Padrões de Nome de Arquivo, marque os padrões desejados e clique em Designar.
Por exemplo, aqui estão os padrões designados ao ativo de dados
amsterdamObjStore:
-
-
Catálogo de Dados - Coletar dados do armazenamento de objetos
-
Colete o ativo de dados do serviço Data Catalog. Selecione os buckets do armazenamento de objetos que contêm os dados de origem.
Neste exemplo, os buckets
moviestream_golde ` moviestream_landing` do armazenamento de objetos são selecionados para coleta. -
Depois de executar o job, você verá as entidades lógicas. Use a opção Procurar Ativos de Dados para revisá-los.
Neste exemplo, você está examinando a entidade lógica
sales_sample_parquete seus atributos. Observe que o serviço Data Catalog identificou o atributomonthcomo particionado.
-
-
Autonomous AI Database - Estabelecer Conexão com o Serviço Data Catalog
Conecte o Autonomous AI Database ao serviço Data Catalog. Você precisa garantir que a credencial usada para fazer essa conexão esteja usando um principal do OCI autorizado a acessar o ativo do serviço Data Catalog. Para obter mais informações, consulte Políticas do Serviço Data Catalog.
-
Estabelecer Conexão com o Serviço Data Catalog
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.eu-amsterdam-1....leguurn3dmqa' define dcat_region='eu-amsterdam-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections; -
Sincronize o Data Catalog com o Autonomous AI Database. Aqui, sincronizaremos todos os ativos de armazenamento de objetos:
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes; -
Autonomous AI Database - Agora comece a executar consultas no armazenamento de objetos.
-- Query the Data ! select count(*) from DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING.SALES_SAMPLE_PARQUET; -- Examine the generated partitioned table select dbms_metadata.get_ddl('TABLE','SALES_SAMPLE_PARQUET','DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING') from dual; CREATE TABLE "DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING"."SALES_SAMPLE_PARQUET" ( "MONTH" VARCHAR2(4000) COLLATE "USING_NLS_COMP", "DAY_ID" TIMESTAMP (6), "GENRE_ID" NUMBER(20,0), "MOVIE_ID" NUMBER(20,0), "CUST_ID" NUMBER(20,0), ... ) DEFAULT COLLATION "USING_NLS_COMP" ORGANIZATION EXTERNAL ( TYPE ORACLE_BIGDATA ACCESS PARAMETERS ( com.oracle.bigdata.fileformat=parquet com.oracle.bigdata.filename.columns=["MONTH"] com.oracle.bigdata.file_uri_list="https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/*" ... ) ) REJECT LIMIT 0 PARTITION BY LIST ("MONTH") (PARTITION "P1" VALUES (('2019-01')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-01/*'), PARTITION "P2" VALUES (('2019-02')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-02/*'), ...PARTITION "P24" VALUES (('2020-12')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2020-12/*')) PARALLEL
-
-
Alterar esquemas para objetos
Os nomes de esquema padrão são bastante complicados. Vamos simplificá-los especificando o atributo personalizado
Oracle-Db-Schemado ativo e da pasta no serviço Data Catalog. Altere o ativo de dados paraPHXe as pastas paralandingegold, respectivamente. O esquema é uma concatenação dos dois.-
No serviço Data Catalog, navegue até o bucket
moviestream_landinge altere o ativo paralandingegold, respectivamente.Antes da alteração:
Após a alteração:
-
Execute outra sincronização.
-