Criando uma Tabela no Serviço Oracle NoSQL Database Cloud
Saiba como projetar e configurar tabelas no Oracle NoSQL Database Cloud Service.
Este artigo tem os seguintes tópicos:
Campos da Tabela
Saiba como criar e configurar dados usando campos da tabela.
Um aplicativo poderá optar pelo uso de tabelas que não contêm esquema, onde uma linha consiste em campos-chave e um único campo de dados JSON. Uma tabela sem esquema oferece flexibilidade no que pode ser armazenado em uma linha.
Como alternativa, o aplicativo pode optar por usar tabelas de esquema fixo, em que todos os campos da tabela são definidos como tipos específicos.
As tabelas de esquema fixo com dados tipados são mais seguras para uso com base em um ponto de vista de aplicação de regras e de eficiência do armazenamento. Embora o esquema de tabelas de esquema fixo possa ser modificado, não é possível modificar a estrutura da tabela facilmente. Uma tabela sem esquema é flexível e a estrutura da tabela pode ser modificada facilmente.
Por fim, um aplicativo também pode usar uma abordagem de modelo de dados híbridos em que uma tabela pode ter campos de dados tipados e JSON.
Os exemplos a seguir demonstram como projetar e configurar dados para todas as três abordagens.
Exemplo 1: Criando uma Tabela Sem Esquema
Você tem várias opções para armazenar informações sobre padrões de navegação na tabela. Uma opção é definir uma tabela que usa um ID de cookie como uma chave e mantém os dados de segmentação do público-alvo como um único campo JSON.
// schema less, data is stored in a JSON field
CREATE TABLE audience_info (
cookie_id LONG,
audience_data JSON,
PRIMARY KEY(cookie_id))Nesse caso, a tabela audience_info pode conter um objeto JSON como:
{
"cookie_id": "",
"audience_data": {
"ipaddr" : "
10.0.00.xxx",
"audience_segment: {
"sports_lover" : "2018-11-30",
"book_reader" : "2018-12-01"
}
}
}Seu aplicativo terá um campo-chave e um campo de dados para essa tabela. Você tem flexibilidade no que optou por armazenar informações no campo audience_data. Portanto, você pode alterar facilmente os tipos de informações disponíveis.
Exemplo 2: Criando uma Tabela de Esquema Fixo
Você pode armazenar informações sobre padrões de navegação criando sua tabela com campos mais declarados explicitamente:
// fixed schema, data is stored in typed fields.
CREATE TABLE audience_info(
cookie_id LONG,
ipaddr STRING,
audience_segment RECORD(sports_lover TIMESTAMP(9),
book_reader TIMESTAMP(9)),
PRIMARY KEY(cookie_id))Neste exemplo, sua tabela tem um campo-chave e dois campos de dados. Seus dados são mais compactos e você pode garantir que todos os campos de dados sejam precisos.
Exemplo 3: Criando uma Tabela Híbrida
Você pode armazenar informações sobre padrões de navegação usando campos de dados tipados e JSON em sua tabela.
// mixed, data is stored in both typed and JSON fields.
CREATE TABLE audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Chaves Primárias e Chaves de Partição
Conheça a finalidade das chaves primárias e das chaves de partição durante o projeto do seu aplicativo.
As chaves primárias e as chaves de partição são elementos importantes no seu esquema e ajudam você a acessar e distribuir dados de forma eficiente. Você só cria chaves primárias e de partição quando cria uma tabela. Eles permanecem no local durante a vida útil da tabela e não podem ser alterados ou descartados.
Chaves Primárias
Você deve designar uma ou mais colunas de chave primária ao criar a tabela. Uma chave primária identifica exclusivamente cada linha da tabela. Para operações CRUD simples, o Oracle NoSQL Database Cloud Service usa a chave primária para recuperar uma linha específica para leitura ou modificação. Por exemplo, considere que uma tabela tenha os seguintes campos:
-
productName -
productType -
productLine
Com base na sua experiência, você sabe que o nome do produto é importante, bem como exclusivo, para cada linha. Portanto, defina productName como a chave primária. Logo, você recupera linhas de interesse com base no productName. Nesse caso, use uma instrução como essa para definir a tabela.
/* Create a new table called users. */
CREATE TABLE if not exists myProducts
(
productName STRING,
productType STRING,
productLine INTEGER,
PRIMARY KEY (productName)
)"Chaves de Shard
A principal finalidade das chaves do shard é distribuir dados pelo cluster do Oracle NoSQL Database Cloud Service para maior eficiência e posicionar registros que compartilham a chave do shard localmente para facilitar a referência e o acesso. Os registros que compartilham a chave de shard são armazenados no mesmo local físico e podem ser acessados de maneira atômica e eficiente.
Seu projeto de chave Principal e shard tem implicações no dimensionamento e obtenção de throughput provisionado. Por exemplo, quando os registros compartilham as chaves de partição, você pode excluir várias linhas de tabela em uma operação atômica ou recuperar um subconjunto de linhas de sua tabela em uma única operação atômica. Além de permitir a escalabilidade, as chaves de partição bem projetadas podem melhorar o desempenho, exigindo menos ciclos para inserir dados ou obter dados de um único shard.
Por exemplo, suponha que você designe três campos de chave primária:
PRIMARY KEY (productName, productType, productLine)Como você sabe que seu aplicativo faz consultas com frequência usando as colunas productName e productType, é apropriado especificar esses campos como chaves de shard. A designação de chave de partição garante que todas as linhas dessas duas colunas sejam armazenadas no mesmo shard. Se esses dois campos não forem chaves do shard, as colunas mais consultadas poderão ser armazenadas em qualquer shard. Logo, a localização de todas as linhas de ambos os campos requer a varredura de todo o armazenamento de dados, em vez de um shard.
As chaves de partição designam armazenamento no mesmo shard para facilitar consultas eficientes de valores de chave. No entanto, como você deseja que seus dados sejam distribuídos entre os shards para melhor desempenho, é necessário evitar chaves de partição que tenham poucos valores exclusivos.
Observação: Se você não designar chaves para shard ao criar uma tabela, o Oracle NoSQL Database Cloud Service usará as chaves primárias da organização de shard.
Fatores importantes a serem considerados ao escolher uma chave de partição
-
Cardinalidade: campos de cardinalidade baixa, como um país de origem de usuário, agrupam registros em alguns shards. Por sua vez, esses shards exigem rebalanceamento frequente de dados, aumentando a probabilidade de problemas de hot shard. Em vez disso, cada chave de partição deve ter uma cardinalidade alta, em que a chave de partição pode expressar uma fatia uniforme de registros no conjunto de dados. Por exemplo, os números de identidade como
customerID,userIDouproductIDsão bons candidatos para uma chave de partição. -
Atomicidade: Somente objetos que compartilham a chave do shard podem participar de uma transação. Se você precisar de transações de ACID que abrangem vários registros, escolha uma chave de partição que permita atender a essa necessidade.
Quais são as melhores práticas a serem seguidas?
-
Distribuição Uniforme de Chaves de Fragmento: Quando as Chaves de Fragmento são distribuídas uniformemente, nenhum fragmento único limita a capacidade do sistema.
-
Isolamento de Consultas: As consultas devem ser direcionadas a um shard específico para maximizar a eficiência e desempenho. Se as consultas não estiverem isoladas em um único shard, a consulta será aplicada a todos os shards, o que é menos eficiente e aumenta a latência da consulta.
Consulte Criando Tabelas para saber como designar chaves primárias e shard usando o objeto TableRequest.
Tempo de Vida
Saiba como especificar tempos de expiração para tabelas e linhas usando o recurso TTL (Tempo de Vida).
Muitos aplicativos tratam dados que têm um tempo de vida útil limitado. O Tempo de Vida (TTL) é um mecanismo que permite definir um período nas linhas da tabela, após o qual as linhas expiram automaticamente e não ficam mais disponíveis. É a quantidade de tempo que dados pode permanecer no Oracle NoSQL Database Cloud Service. Os dados que atingem o tempo de expiração não podem mais ser recuperados e não aparecem em estatísticas de armazenamento.
Por padrão, cada tabela que você criar tem um valor de TTL zero, indicando que não há tempo de expiração. Você pode declarar um valor de TTL quando criar uma tabela, especificando o TTL com um número, seguido por HOURS ou DAYS. As linhas de tabela herdam o valor de TTL da mesa em que residem, a não ser que você defina explicitamente um valor de TTL para as linhas de tabela. A definição do valor TTL de uma linha substitui o valor TTL da tabela. Se você alterar o valor do TTL da mesa depois que a linha tiver um valor do TTL, o valor do TTL da fila continuará.
Você pode atualizar o valor de TTL de uma linha da tabela a qualquer momento antes que a linha atinja o tempo de expiração. Os dados expirados não podem mais ser acessados. Portanto, o uso de valores de TTL é mais eficiente do que excluir linhas manualmente, porque o overhead de gravar uma entrada de log do banco de dados para a exclusão de dados é evitado. Os dados expirados são expurgados do disco após a data de expiração.
Estados da Tabela e Ciclos da Vida
Saiba mais sobre os diferentes estados de tabela e seu significado (processo de ciclo de vida de tabela).
Cada tabela passa por uma série de diferentes estados, desde a criação da tabela até a exclusão (eliminação). Por exemplo, uma tabela no estado DROPPING não pode prosseguir para o estado ACTIVE, ao passo que uma tabela no estado ACTIVE pode passar para o estado UPDATING. Você pode rastrear os diferentes estados da tabela monitorando o ciclo de vida da tabela. Esta seção descreve os vários estados de tabela.
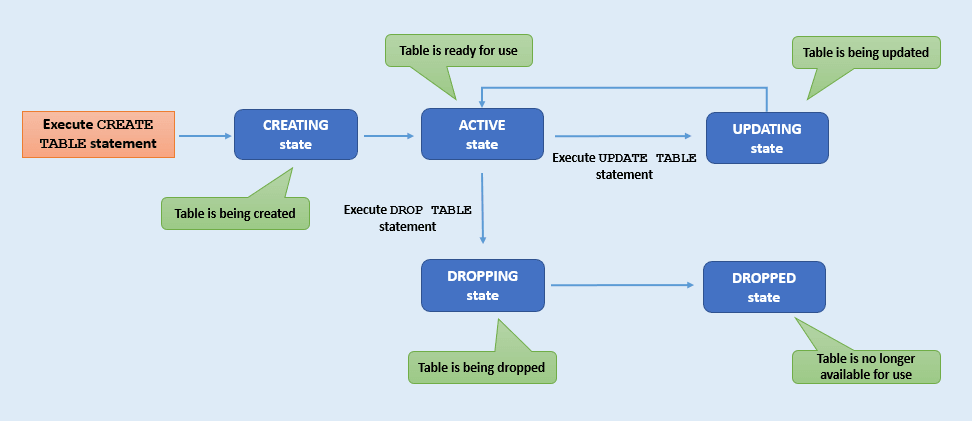
Descrição da ilustração table-state.png
| Estado da Tabela | Descrição |
|---|---|
CREATING |
A tabela está em processo de criação. Não está pronto para uso. |
UPDATING |
A atualização da tabela está em andamento. Não é possível fazer mais modificações na tabela nesse estado. Uma tabela permanece no estado
|
ACTIVE |
A tabela pode ser usada no estado atual. A tabela pode ter sido criada ou modificada recentemente, mas o estado da tabela agora é estável. |
DROPPING |
A tabela está sendo eliminada e não pode ser acessada para nenhuma finalidade. |
DROPPED |
A tabela foi eliminada e não existe mais para atividades de leitura, gravação ou consulta. Observação: uma vez eliminada, uma tabela com o mesmo nome poderá ser criada novamente. |
Hierarquias de Tabelas
O Oracle NoSQL Database permite que tabelas existam em um relacionamento pai-filho. Isto é conhecido como hierarquias de tabela.
A instrução create table permite a criação de uma tabela como filha de outra tabela, a qual se torna pai da nova tabela. Isso é feito usando um nome composto (name_path) para a tabela filho. Um nome composto consiste em um número N (N > 1) de identificadores separados por pontos. O último identificador é o nome local da tabela filho e os primeiros identificadores N-1 apontam para o nome do pai.
Características das tabelas pai-filho:
-
Uma tabela filho herda as colunas de chave primária de sua tabela pai.
-
Todas as tabelas na hierarquia têm as mesmas colunas de chave de partição, que são especificadas na instrução de criação de tabela da tabela raiz.
-
Não é possível eliminar uma tabela pai antes de seus filhos.
-
Uma restrição de integridade referencial não é imposta em uma tabela pai-filho.
Você deve considerar o uso de tabelas filho quando alguma forma de normalização de dados for necessária. As tabelas filho também podem ser uma boa escolha ao modelar relacionamentos de 1 a N e também fornecer semântica de transação ACID ao gravar vários registros em uma hierarquia pai-filho.